量化图嵌入中的隐私泄漏
摘要。
已经提出图嵌入将图数据映射到低维空间以进行下游处理(例如,节点分类或链接预测)。 随着个人数据收集的增加,可以针对私人数据和敏感数据来训练图嵌入。 我们首次通过针对图神经网络的三种推理攻击来量化图嵌入中的隐私泄漏。 我们的成员推理攻击旨在推断与单个用户数据对应的图节点是否是模型私有训练数据的成员。 我们考虑一个黑盒设置,其中对手利用输出预测分数,以及一个白盒设置,其中对手还可以访问已发布的节点嵌入。 通过利用图嵌入留下的训练和测试数据记录之间的可区分足迹,我们的攻击提供了超出随机猜测的高达 28%(黑盒)和 36%(白盒)的准确度。 在我们的图重建攻击中,对手的目标是在给定相应的图嵌入的情况下重建目标图。 在这里,攻击者可以以超过 80% 的准确度重建图,并以比随机猜测高 30% 的准确度推断两个节点之间的链接。 最后,我们提出了一种属性推断攻击,其中攻击者旨在推断与单个用户相对应的敏感节点属性。 我们表明,图嵌入和节点属性之间的强相关性允许对手推断敏感信息(例如性别或位置)。
1. 介绍
大规模现实世界系统通常以图的形式建模:移动性、网络基础设施、在线社交网络、万维网、引文网络和生物医学数据集,它们将实体表示为节点及其与边的关系(Zhou等人,2018)。 传统的深度神经网络无法捕捉结构化数据的细微差别,但一类特定的算法,即图神经网络(GNN)已经在如此复杂的图数据上显示出最先进的性能,用于节点分类,链接预测等。在机器学习中使用图数据的一个重要的预处理步骤是将高维图数据嵌入到低维表示中,以便于机器学习算法的处理。 然而,在许多应用中,此类嵌入被释放以进行进一步处理以节省存储成本,但没有考虑隐私影响。 如此大的图形数据集引发了底层训练数据的隐私问题,特别是如果算法是使用私有数据和潜在敏感数据进行训练的。
在机器学习 (ML) 的背景下,当对手推断出训练数据集中特定用户的数据记录的某些内容时,就会发生隐私侵犯,而这些数据记录无法从在类似数据分布上训练的其他模型中推断出来(Shokri 等人,2017;Nasr 等人,2019)。 这种信息泄漏是通过各种推理攻击的成功来量化的。 在属性推断攻击中,攻击者推断模型中使用的个人数据记录的敏感特征。 属性推断的更强有力的情况是攻击者训练重建一部分私有数据,即数据重建攻击。 在成员资格推断攻击中,对手训练推断私人数据中特定个人记录的成员资格。 先前有关隐私攻击的文献主要关注在文本、图像和语音等非图数据上训练的模型,以研究成员推理的脆弱性(Salem 等人,2019;Shokri 等人,2017),属性推理(Gong and Liu, 2016a; Ateniese 等人, 2015; Bouetet 等人, 2021)、属性推理(Ganju 等人, 2018)、模型反演(Fredrikson等人, 2015)攻击以及模型参数和超参数窃取攻击(Duddu等人, 2018; Duddu和Rao, 2019; Wang和Gong, 2018)。 虽然传统机器学习得到了充分研究,但对抗性环境下基于图的机器学习模型的隐私风险尚未得到充分探索和量化。
考虑一个捕获疾病爆发的图表,其中节点代表用户,节点特征指示医疗症状,边缘指示疾病传播。 通常,在此类数据集中,GNN 提供最先进的性能,用于预测图中任意用户的疾病(通过节点分类)并确定未来的爆发(通过链接预测)。 然而,当这种嵌入模型不考虑隐私时,对手可以通过识别用户是否是训练数据的一部分来推断特定用户的健康状况。 此外,攻击者有可能从低维嵌入重建敏感输入图。 最后,图嵌入从输入图中捕获重要语义,同时以优先连接的形式维护上下文信息,可用于推断有关个人的敏感属性。 这三种隐私攻击,即成员资格推断、图重建和属性推断,是直接侵犯用户隐私的例子,并且可以在未经用户同意的情况下进一步使用。 此外,公司花费大量资源来注释训练数据集,以实现最先进的性能,而此类推断训练数据(图)的攻击也侵犯了知识产权。
在这项工作中,我们提出了在不同威胁模型和对手假设下的图嵌入算法的首次全面隐私分析。 我们专注于公开发布的图嵌入的隐私分析,这些图嵌入使用私有图数据进行训练并用于不同的下游任务。 对于隐私分析,我们使用了各种侵犯用户隐私的攻击:成员资格推断、图重建和属性推断。 首先,我们使用成员推理攻击来评估隐私泄露,其中对手可以访问 (a) GNN 的输出预测(黑盒设置)和 (b) 图嵌入(白盒设置)。 黑盒设置考虑了神经网络基于卷积核的图嵌入的下游节点分类任务的具体情况。 我们提出了两种黑盒成员推理攻击:具有数据分布的辅助知识,称为影子模型攻击,和没有辅助知识,称为置信度攻击。 在这里,我们表明,对于三个不同的数据集(即 Cora),所提出的攻击对于置信度得分攻击的推理准确度分别为 78%、63% 和 60%,对于影子模型攻击的推理准确度分别为 62%、60% 和 55% 、Citesser 和 Pubmed 数据集。 对于白盒设置,我们针对更一般的情况提出了一种无监督攻击,即仅使用图嵌入来区分给定节点是否是训练图的一部分。 我们表明,在这种情况下,对手可以高精度地预测训练数据(三个数据集的平均预测率为 70%)。
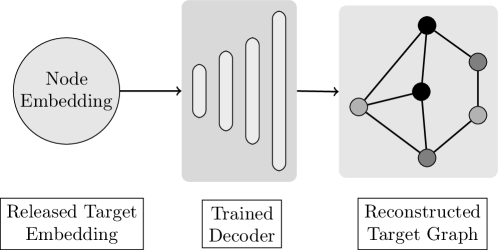
其次,我们提出了一种新颖的图重建攻击,其中对手可以访问子图的节点嵌入,训练编码器-解码器模型以从其公开发布的嵌入重建目标图。 这种攻击具有严重的隐私影响,因为对手重建了可能敏感的输入图。 这种攻击具有很高的精度:Cora 为 0.722,Citeseer 为 0.778,Pubmed 数据集为 0.95。 此外,随着对手先验知识的增加,攻击性能显着提高。 一个重要的隐私含义是链接推断,其中攻击者预测图中任意两个目标节点之间的链接。 通过这种攻击,攻击者推断目标节点之间的链接的平均准确度为 80%,而基线随机猜测准确度为 50%。
最后,我们提出了一种属性推断攻击,其中对手尝试使用已发布的图嵌入来推断图中用户节点的敏感属性。 我们考虑在两个现实世界的社交网络数据集:Facebook 和 LastFM 上使用两种最先进的基于无监督随机游走的嵌入 Node2Vec 和 DeepWalk,其中对手的目的分别是推断用户性别和位置。 考虑到子图的嵌入和相应的敏感属性,我们将属性推断建模为监督学习问题。 对手训练一个监督攻击模型,根据公开发布的目标嵌入来预测目标用户的敏感、隐藏属性。 在这里,LastFM (Facebook) 数据集的攻击 F1 得分(捕捉精确度和召回率之间的平衡)对于 DeepWalk 高达 0.65 (0.59),对于 Node2Vec 高达 0.83 (0.61)。 我们的工作强调了图数据处理算法中严重的数据隐私风险,并呼吁进一步研究为图数据设计隐私保护嵌入算法。 使用我们的代码可以轻松重现我们的结果111https://github.com/vasishtduddu/GraphLeaks。
2. 背景
大量现实世界的应用需要处理包含不同实体之间丰富关系信息的图数据(例如在线社交媒体、疾病爆发、推荐引擎、知识图谱和导航系统)(周等人,2018). 深度学习,更准确地说,卷积神经网络通过捕获图像像素之间的空间关系并提取多层特征,在非图数据(例如图像分类)上表现出了巨大的性能。 然而,这些机器学习算法对于图数据的学习效果不佳(周等人,2018)。 事实上,即使节点之间没有固定的顺序,模型也必须捕获图数据中的连接,同时确保图数据表示的不变性。 换句话说,表示节点之间连接的邻接矩阵有所不同,但仍然产生相同的图。 为了克服这一限制,图数据通过嵌入算法传递,该算法将大图映射到较低维度,然后用于 GNN 的下游处理。 图嵌入算法使在低维欧几里得数据集(例如图像)上运行的模型能够通过将数据映射到低维嵌入来绘制数据图。 我们将图表示为 ,其中 表示由节点 {} 组成的顶点集, 表示节点之间的边。 表示为对称的稀疏邻接矩阵 其中 表示之间的边权重节点 和 以及 表示缺失的边。
2.1. 图嵌入算法
为了减轻下游图处理的空间和计算开销,图嵌入算法提供了一种有效的方法来以低维嵌入表示图数据(Chen等人,2018)。 具体来说,嵌入算法,其中节点 ,将节点作为其输入并输出一个 维向量,该向量捕获原始图的属性,例如 与 中其他节点的距离。人们对嵌入整个图和节点的不同图嵌入算法进行了深入研究(Cai等人,2018)。 基于随机游走的节点嵌入算法遍历图来采样随机游走,然后将其作为句子传递给 SkipGram 算法以获得相应的节点特征(Grover 和 Leskovec,2016;Perozzi 等人,2014)。 在基于深度学习的图嵌入中,特征和邻接矩阵都可以用于为每个节点生成低维嵌入。 为了生成这些嵌入,更新嵌入函数的参数以改进图节点的表示,同时保持原始属性。 这些通常使用 GNN 和图卷积网络进行建模。 在这项工作中,我们关注节点嵌入并将其称为图嵌入。 我们考虑使用基于随机游走的嵌入来进行属性推断,以及使用基于深度学习的嵌入来进行节点推断和图重建攻击。
2.2. 图神经网络
GNN 的初始层用于生成输入图的嵌入,可以通过附加分类器网络作为 GNN 来扩展节点分类和链接预测任务。 嵌入形式的预处理图以及节点特征被表示为用于计算的矩阵。 GNN 的训练依赖于消息传递算法,该算法是相邻节点 特征的加权聚合,以计算特定节点 的特征。给定单个节点 的特征 ,GNN 生成输出标签 ,它捕获具有特征 然后反向传播节点 的结果分类的损失,以更新聚合的模型权重。 考虑一个 特征矩阵 ,其中 是节点数, 是节点特征数。 考虑一个邻接矩阵 ,它以矩阵形式捕获图结构的表示。 具有 特征的层的输出将特征矩阵和邻接矩阵作为输入,以生成 矩阵作为输出。 计算由 和 和 给出, 是层数, 是中间激活。 基于不同的聚合函数,我们得到不同的GNN算法,例如图卷积网络(GCN)(Kipf and Welling,2017),GraphSAGE (Hamilton等人,2017),图注意力网络(GAT)(Veličković等人,2018)和拓扑自适应GCN(TAGCN)(Du等人,2018)。
3. 威胁模型
在本节中,我们描述了我们研究的各种攻击的威胁模型、攻击方法和对手假设。
3.1. 成员资格推断攻击
成员推理攻击允许 GNN 中的个人信息泄露。具体来说,攻击者的目标是识别用户节点 是否是用于训练目标模型的图 的一部分。 这是一个二元分类问题,对手学习阈值来预测用户节点的成员资格。 根据对手对 的了解,我们考虑两种设置:黑盒(有或没有辅助知识)和白盒。 如图1所示,为了区分训练图的成员和非成员,黑盒攻击利用输出预测的统计差异,而白盒攻击则利用中间低维嵌入。
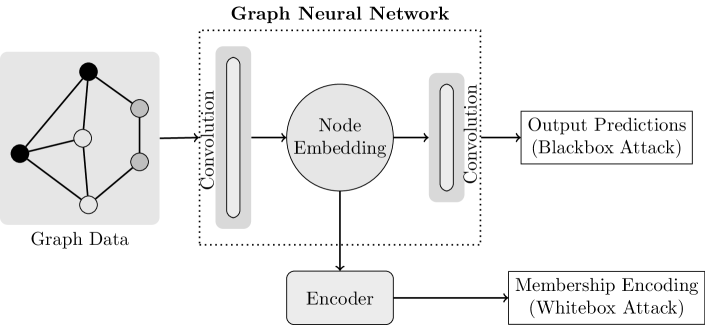
3.1.1. Blackbox:使用输出预测进行推理
在这种情况下,我们将目标模型视为经过训练的用于节点分类任务的 GNN。 攻击者的目的是推断图中用户的节点是否在训练目标模型 中使用。 在黑盒设置中,对手只能访问给定输入 的模型输出 。 攻击者无法访问训练模型的参数以及中间计算。 这是一种实用的设置,通常出现在机器学习即服务的情况下,其中训练有素的模型部署在云中,攻击者通过 API 查询模型并接收相应的预测。
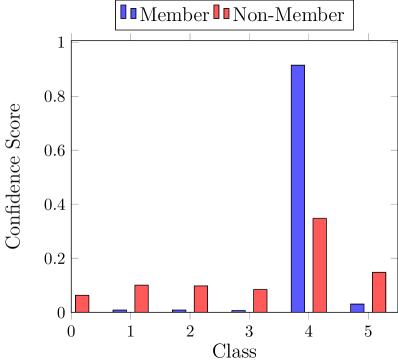
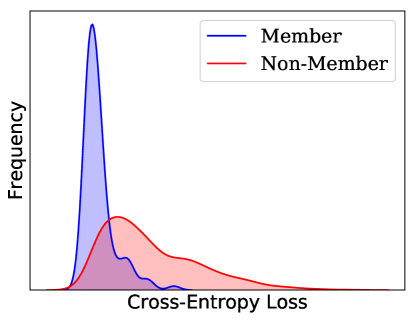
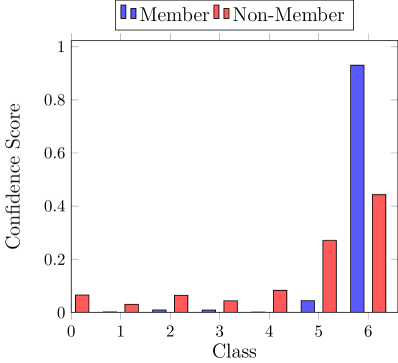
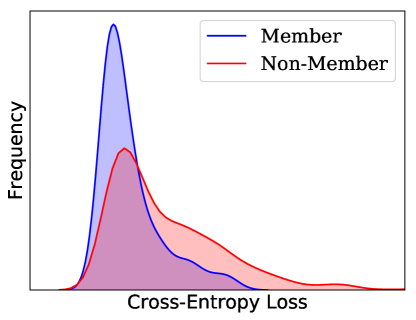
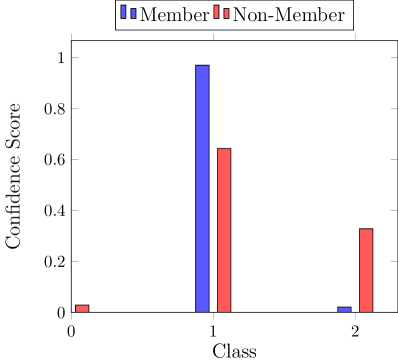
黑盒对手利用训练预测置信度和测试数据之间的统计差异(Shokri等人,2017)。 图2(左)说明了这种差异,其中一个类别的预测置信度对于数据点而言要高得多。 与未见的测试节点相比,对已见 节点进行更高置信度的预测称为过度拟合。 输出预测置信度的差异直接源于训练数据和测试数据之间可区分的输出分布,由分布之间的非重叠区域指示(图2,右)。
我们考虑黑盒设置中的两种攻击:(a)影子模型攻击和(b)置信度得分攻击。


暗影攻击: 影子攻击依靠对手训练一个与目标模型功能相似的本地替代模型来识别成员和非成员的特征。
对手了解目标 GNN 架构和辅助图数据集 ,这些数据集是从与 相同的底层数据分布中采样的,这与先前的攻击设置 一致(Shokri 等人, 2017;Gong and Liu,2016a;Ateniese 等人,2015;Hayes 等人,2019),但攻击可以在不同模型之间转移(Salem 等人,2019)。
这是一个实际的假设,其中社交网络具有公开可用的 API,使攻击者能够获取原始社交网络图的子图。
为了进行攻击,对手使用先验知识将目标模型的预测映射到成员值,从而监督攻击。
对于目标模型 ,攻击者在从与 相同的分布中提取的辅助图数据 () 上训练替代模型 >。
假设数据集不重叠,即 ,这使得攻击更加实用。
我们的目标是训练 以模仿 的行为,即对于相同的输入用户节点 ,但由于在不同的数据上训练了不同的参数 和 ,输出预测结果应彼此相似 。
给定替代模型,攻击者创建一个包含二进制类的合成数据集,用于区分 的训练数据 的成员和非成员(编码为类 1 和类 0),同时使用输出预测作为输入特征。
也就是说,合成数据集的输入为 对用户节点 的预测,如果 和“非成员”则分类为“成员”否则。
因此,被用作的代理来学习的输出预测和成员信息之间的映射。
攻击者在合成数据集上训练二元攻击分类器 ,用于预测新用户节点是否是 的成员。
信心攻击: 在这种特殊情况下,我们减轻了对手对数据分布和目标模型架构的了解的假设,作为影子模型的一部分,使攻击适用于广泛的实际场景。 由于攻击者没有先验知识来映射目标模型的输出预测来对成员进行分类,因此攻击是在无监督的环境中进行的。 为了进行攻击,攻击者利用了具有较高输出置信度预测的图节点可能是 的成员这一事实。 在这里,攻击者找到具有最高置信度的输出预测,并比较它是否高于某个阈值,以决定相应的图节点是否在模型的训练图 中。 大的输出置信度表明数据点在训练数据中的成员资格。 攻击者会扫描不同的值来选择最适合应用程序的阈值。 传统机器学习的先前工作表明,置信攻击比影子模型攻击要好得多,这在我们的实验中得到了验证(Song 和 Mittal,2020)。 用于区分成员和非成员的置信度得分攻击的信号直接来自目标模型,其中影子模型很微妙,并使用替代模型的输出作为信号。 这种情况下的攻击成功取决于训练本地替代模型的辅助数据的质量及其与目标模型的功能相似性。
3.1.2. 白盒:使用图嵌入进行推理
白盒设置中的对手可以访问中间层的模型输出,在我们的例子中,中间层对应于每个节点的嵌入作为图卷积层的输出。 这是联邦学习情况下的实际对手假设,可以观察到中间计算(Nasr 等人,2019;Melis 等人,2019)。
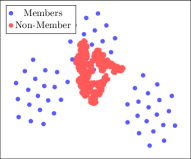
如第 2 节所述,GNN 计算输入图数据的低维嵌入。 GNN 的参数在训练的每次迭代中都会更新,并专门针对训练数据的高性能进行调整,从而在训练数据点和测试数据点的嵌入之间形成可区分的足迹。 图 3 通过绘制使用 2D-TSNE 算法降维后训练和测试图节点的嵌入来说明这一基本原理(van der Maaten 和 Hinton,2008)。
攻击方法是无监督的,对手没有监督标签来将中间嵌入映射到成员资格值。 对手以无监督的方式训练编码器-解码器网络,以将中间嵌入映射到单个成员值。 对于输入图节点的嵌入,编码器生成一个标量隶属度值,该值传递给解码器以通过最小化获得重建损失:。 给定不同训练和测试数据点的隶属度值,K-Means 聚类用于将节点分为两类(成员和非成员)。 为了区分集群,对手需要知道少量成员和非成员的先验映射。 对于任何新的用户节点,攻击者会将它们聚集为训练数据的成员或非成员。
3.2. 图重建攻击
鉴于公开发布的敏感目标图数据()的嵌入,攻击者在这次攻击中的目标是重建以及不同节点之间的相应连接。 具体来说,对手的目标是重建图的邻接矩阵 ,如果节点 和 之间存在边,则邻接矩阵 为二进制,否则为零。 虽然节点成员资格推断是对用户数据的一种微妙的隐私侵犯,但这是一种更强的攻击,对手会重建整个敏感图数据。
图嵌入经过专门计算,以确保底层图属性不会改变。 换句话说,嵌入捕获了有关图的丰富语义、不变性和结构信息,例如,通过保留与相邻节点的接近度。 因此,发布的图嵌入与实际图之间存在很强的相关性,可用于重建图数据。
假设对手知道辅助子图 ,它是从与目标图 相同的分布中采样的。
根据经验,这是通过从完整图数据集中采样两个不重叠的子图来获得的。
对手分两个阶段执行图重建(图4)。
在第一阶段,攻击者在 上训练图编码器-解码器攻击模型。
图编码器 将 的邻接矩阵映射到表示为邻接的相应节点嵌入 矩阵。
解码器重建邻接矩阵,同时使用反向传播训练两个模型以最小化重建损失:。
对于攻击模型,我们考虑采用图卷积作为编码器和解码器的架构,该解码器计算嵌入向量 与其转置 之间的点积(Kipf 和 Welling ,2017)。
攻击模型在上进行训练,并在与目标图对应的目标嵌入上进行测试,以重建图数据。
给定目标发布的嵌入,攻击者然后使用经过训练的解码器攻击模型将发布的嵌入映射到目标邻接矩阵 。

链接推断: 链接推断是图重建攻击的直接结果,攻击者可以使用重建图的邻接矩阵检查两个用户之间的边缘。 此推理是一个二元分类问题,对手的目的是推断图中两个节点之间是否存在链接。 这一推论代表了两个人在在线社交网络中彼此认识的知识,例如导致识别用户的朋友圈,这是对个人隐私的侵犯。 更正式地说,给定两个用户节点和,攻击者查询重建的邻接矩阵以推断之间是否存在链接t3>(如果)或不(如果)。 链接推理攻击的成功与否很大程度上取决于目标邻接矩阵重构的成功与否。
3.3. 属性推断攻击
之前的攻击主要针对敏感图数据和利用不同节点之间的连接的推理攻击,而属性推理攻击则利用用户节点的敏感特征。 特别是,给定子图节点的嵌入和相应的敏感属性( ),攻击者的目标是推断与公开发布的目标相对应的敏感属性嵌入 。 这是一个实际的假设,因为一小部分用户确实在其个人资料中公开了他们的信息,而其他用户则更愿意将此类信息(例如性别和位置)保密。
对于大多数实际的现实应用程序,图中的节点遵循优先连接,即彼此相似的节点彼此连接。 在社交网络中尤其如此,其中具有相似喜好和偏好的用户(表示为图中节点的特征)连接在一起(Gong 和 Liu,2016b;Jia 等人,2017)。 图中的这种特征相似性和优先连接由图嵌入捕获以保留图属性。 因此,嵌入与节点特征密切相关,可用于推断敏感属性。
对手可以从对手已知的辅助子图中访问节点嵌入和相应节点的敏感属性( 。 对手使用这些先验知识来训练监督攻击分类器 ,它将嵌入映射到敏感属性,即 。 使用这个经过训练的攻击模型,攻击者推断出与目标嵌入 相对应的敏感属性 ,其中 。
4. 实验设置
在本节中,我们将介绍所考虑的数据集、嵌入算法、评估指标和方法。
4.1. 数据集
对于成员推理和图重建攻击,我们考虑三个标准基准测试数据集:Pubmed、Citeseer 和 Cora。 对于属性推断攻击,我们依次考虑两个具有匿名敏感属性的社交网络数据集:Facebook222http://snap.stanford.edu/data/ego-Facebook.html 和 LastFM333http://snap.stanford.edu/data/feather-lastfm-social.html。
Pubmed。 Pubmed 糖尿病数据集包含 PubMed 数据库中与糖尿病相关的 19,717 篇科学出版物,分为三类之一。 引文网络由 44,338 个链接组成。 数据集中的每个出版物都由来自字典的 TF/IDF 加权词向量进行描述,该词典由 500 个唯一单词组成。 我们使用 60 个训练样本、500 个验证样本和 1,000 个测试样本。
Citeseer。 CiteSeer 数据集包含 3,312 份科学出版物,分为六类之一。 引文网络由 4,732 个链接组成。 每个出版物都由 0/1 值的单词向量来描述,该向量指示字典中相应单词的不存在/存在。 该词典由 3,703 个独特单词组成。 训练样本数量为120个,验证样本500个,测试样本1000个。
科拉。 Cora 数据集包含 2,708 份科学出版物,分为七类之一。 引文网络由 5,429 个链接组成。 每个出版物都由 0/1 值的单词向量来描述,该向量指示字典中相应单词的不存在/存在。 该词典由 1,433 个独特单词组成。 训练中使用了 140 个样本、300 个验证样本和 1,000 个测试样本。
脸书。 该数据集由代表社交网络上不同用户帐户的 4,039 个节点组成,通过 88,234 条边相互连接。 每个用户节点都有不同的特征,包括性别、学历、家乡等。 用户信息已通过假名进行匿名化,并且特征的解释已被模糊化(即属性“男性”和“女性”已分别替换为“性别 1”和“性别 2”)。
最后FM。 该数据集是使用专门为亚洲国家用户创建的社交网络提供的公共 API 于 2020 年 3 月收集的。 该数据集有 7,624 个节点,以及基于相互关注关系的 27,806 条边连接在一起。 每个用户都有属性,例如他们喜欢的音乐和艺术家、位置等。
4.2. 嵌入算法
出于实验目的,我们考虑两类嵌入算法:GNN 和基于随机游走的算法。 我们考虑以下基于 GNN 的嵌入技术:
图卷积网络(GCN)(Kipf 和 Welling,2017)。 GCN 使用矩阵分解计算相邻节点的目标节点特征,将邻接矩阵 归一化为 ,其中 是对角节点度矩阵并求平均值相邻节点的特征。 另一个技巧是使用对称归一化作为 。
GraphSAGE (Hamilton 等人, 2017)。 GraphSAGE 将 GCN 中的操作扩展为更通用的函数,用于节点特征的转换和聚合。 GCN 中图数据的嵌入依赖于矩阵分解,而 GraphSAGE 使用均值、LSTM 和池化的节点特征聚合来学习嵌入函数。
图注意力网络(GAT)(Veličković 等人,2018)。 与聚合过程中的特征相关的权重是在训练过程中明确定义和学习的。 GAT 使用节点特征的自注意力机制隐式定义权重。
拓扑自适应 GCN (TAGCN) (Du 等人, 2018)。 TAGCN 提出在顶点域中使用通用 K 局部滤波器卷积,而不是使用谱卷积来学习非线性图数据。 它取代了传统光谱 GCN 中用于网格结构输入数据量的固定方形滤波器。
对于成员推理,我们考虑白盒设置中所有上述四种架构的嵌入,而对于黑盒设置,我们仅考虑 GraphSAGE 算法,因为归纳训练图模型具有挑战性,而 GraphSAGE 架构专门设计用于在此类训练设置中工作 (汉密尔顿等人,2017)。 在图重建攻击的情况下,我们考虑通用 GCN 模型作为攻击模型的编码器。 在属性推断攻击的情况下,我们考虑两种基于随机游走的最先进的无监督图嵌入算法,即 Node2Vec (Grover 和 Leskovec,2016) 和 DeepWalk (Perozzi 等人, 2014)。
DeepWalk (Perozzi 等人, 2014)。 该算法从图中创建一个转移矩阵,并从该矩阵中对随机游走进行采样。 节点被视为单词,随机游走被视为句子,并将生成的序列传递给 Word2Vec 和 SkipGram (Mikolov 等人, 2013) 以获得节点嵌入。
Node2Vec (Grover 和 Leskovec,2016)。 这是 DeepWalk 的扩展,它结合了图上的广度优先和深度优先搜索探索来创建有偏差的随机游走。 如上所述,嵌入是使用 Word2Vec 算法计算的。
4.3. 指标
为了估计成员资格和链接推理的攻击成功率,我们考虑推理准确性。
推理准确性。 隶属度和链接推断是二元分类问题:节点是否是训练数据的一部分(隶属度推断)以及任意两个节点之间是否存在链接(链接推断)。 因此,随机猜测训练的准确性为 50%,任何更高的准确性都表明模型敏感数据的隐私泄露。 为了计算对手通过随机猜测执行攻击所获得的额外收益,我们将“对手优势”命名为计算如下的度量:。 与随机猜测相比,该指标估计模型的信息泄漏。
为了评估图重建攻击的性能,我们使用两个主要指标:精度和 roc 分数。
精度。 真阳性的比率由精度给出,并估计目标图中实际存在的预测样本的百分比。
ROC-AUC 评分。 ROC 曲线在 y 轴上绘制真阳性率,在 x 轴上绘制假阳性率。 AUC 分数计算 ROC 曲线下的面积,以获得模型区分不同类别的能力。 对于图重建以获得二元邻接矩阵的二元分类问题,随机猜测精度为 50%,任何更高的精度都表明对手在重建目标图方面具有优势。
在属性推断攻击的情况下,我们使用 F1 分数进行评估以平衡召回率和精度。
F1-分数。 该指标计算精度和召回率之间的调和平均值,从而估计目标图中预测的样本的百分比。
4.4. 方法
在这项工作中,我们特别关注 GNN 的归纳训练,其中模型在训练期间不会看到测试节点,这与整个图和特征都是先验可用的转导学习不同。 给定完整的图 ,我们对子图 进行采样,该子图用于训练模型并评估所提供的图 上的模型性能。 这种归纳设置使对手能够了解有关目标模型训练图的新信息,从而导致隐私泄露。
值得注意的是,没有一个模型是故意过度拟合的。 我们考虑最先进的架构,并使用最先进的库或使用原始论文中提到的训练细节来训练它们。 因此,模型中的过度拟合是自然的而不是被迫的。 换句话说,这些攻击对所有图模型都有效,包括可能为不同服务部署的最先进模型。
5. 评估
在本节中,我们评估攻击造成的隐私泄露。
5.1. 来自输出预测的成员推理攻击
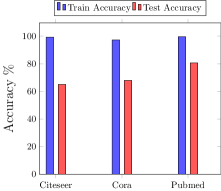
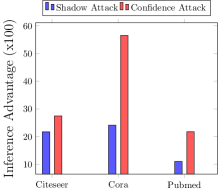
图5(a)给出了在三个数据集上训练的GraphSage架构的过度拟合。 我们利用模型的输出预测来评估两种黑盒推理攻击:使用数据分布辅助知识的影子推理和不使用辅助知识的置信推理。 图5(b)所示的结果表明,在置信推理攻击下,推理准确率分别为78.28%(相当于对手的优势为27.48%)、63.75%(相当于对手的优势为56.56%)和Cora、Citeseer 和 Pubmed 数据集分别为 60.89%(优势为 21.78%)。 在影子模型攻击的情况下,Cora 的推理准确率为 62.06%(对手优势为 21.74%),Citeseer 的推理准确率为 60.87%(对手优势为 24.12%),Pubmed 数据集的推理准确率为 55.51%(对手优势为 11.02%) )。 因此,与影子模型攻击(即有辅助知识)相比,置信攻击(即没有辅助知识)中的成员泄漏更高。 虽然违反直觉,但这一结果与传统机器学习模型的类似攻击方法一致(Song 和 Mittal,2020)。 影子模型攻击的成功取决于辅助数据集的质量以及影子模型与目标模型的接近程度。 对于图模型,由于数据量有限,我们只考虑一种影子模型,但攻击性能可以以在更多数据上训练多个影子模型为代价来提高(Shokri等人,2017)。
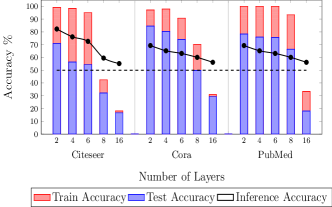
层数增加的影响。 我们评估了增加用于聚合特征的邻域节点范围的置信度攻击的性能(图6)。 为此,我们通过增加 GNN 的层数来扩展消息传递算法的范围(Klicpera 等人,2019;Li 等人,2018)。 当层数从 2 增加到 6 时,GCN 的推理精度下降了 8%。 有趣的是,对于 Cora、Citeseer 和 Pubmed 数据集,泛化误差增加(训练精度保持不变,但测试精度下降),但推理精度持续下降,这表明图中不同节点之间的优先连接的影响起着显着的作用影响推理准确性的作用。 对于 GNN 中的大量层( 8 层),对于所有数据集和架构,模型完全失去了预测能力。 一般来说,随着消息传递算法的层数从 2 层增加到 16 层,推理精度和预测精度都会降低。 这意味着会员隐私泄露受到不同节点之间具有优先连接的结构化图数据的影响。 具体来说,聚合来自更多节点的特征会导致更高的平均,当模型收敛到随机游走的极限分布时,会降低可区分性(特征的过度平滑)(Klicpera 等人,2019;Li 等人,2018) 这对于推理攻击至关重要(Shokri 等人,2017;Salem 等人,2019)。
5.2. 图嵌入的成员推理攻击
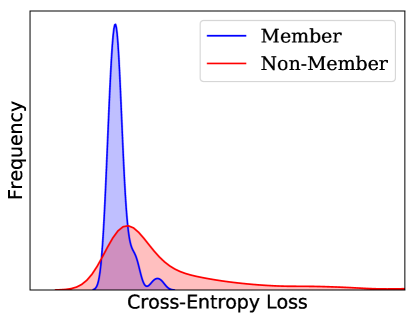
我们利用训练和测试数据的中间特征表示的差异在白盒设置中执行成员推理攻击。 结果表明,在 PubMed 数据集上训练的不同模型泄漏的信息比随机猜测的准确率高出 20% 到 36%。 另一方面,在 Citeseer 数据集上训练的模型为对手提供了比随机猜测高 7% 到 17% 的优势,而在 Cora 数据集上则为 4% 到 7% 之间。 PubMed 数据集的训练和测试数据点的嵌入显着不同,如图 7 所示,与 Cora 和 Citeseer 数据集相比,这会导致更高的白盒成员资格推断准确性。 Pubmed 数据集的较高准确度可归因于特征的显着可区分性,如图 3 中目视检查所见。
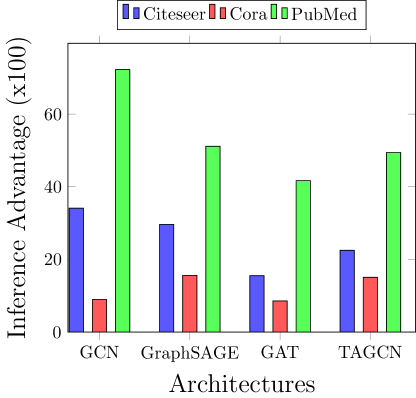
无监督白盒攻击的成功归功于消息传递,该消息传递更新了参数(权重),以确保不同类的数据点之间具有更高的可区分性,从而在训练数据集上实现高精度。 事实上,参数经过专门更新以适应训练数据集,从而导致特征嵌入和测试数据记录之间具有很高的可区分性。 此外,初始层的特征嵌入很有用,因为对于后面的层,特征被过度平滑,这也降低了准确性(如增加消息传递算法的节点范围所示)。
5.3. 图重建攻击
图重建的成功与否是在看不见的目标图上评估的,而模型是在训练图(对手的)上进行训练的。 Cora 数据集的测试 AUC 得分为 0.65,平均精度为 0.722,而 Citeseer 数据集的测试 AUC 得分为 0.65,平均精度为 0.778。 对于 Pubmed 数据集,我们在测试集上得到的平均精度为 0.95,在重建目标测试图时 ROC 为 0.94。 图8给出了验证子图上三个数据集的AUC分数变化曲线和平均精度。
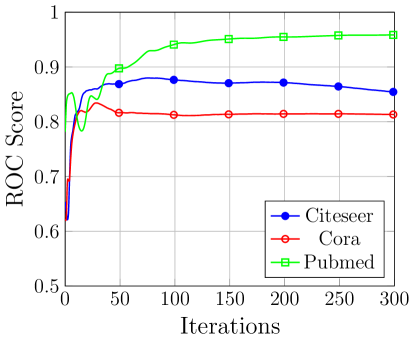
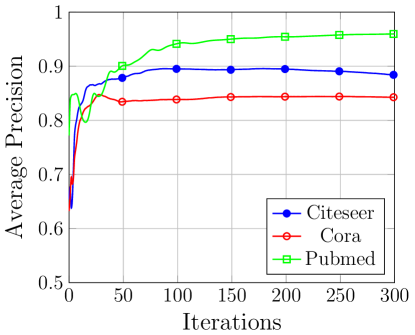
对手知识的影响。 当对手的知识增加到目标图的 50% 时,我们观察到攻击性能有所提高。 具体来说,Cora 的 AUC 分数从 0.65 增加到 0.76,而平均精度从 0.722 增加到 0.81。 在 Citeseer 数据集中,AUC 分数从 0.65 增加到 0.779,平均精度从 0.778 增加到 0.828。 最后,Pubmed 数据集显示 AUC 分数从 0.94 增加到 0.95,平均精度从 0.95 增加到 0.96。
5.4. 链接推理攻击
图重建攻击的直接含义是通过查询重建的邻接矩阵来推断网络中两个节点之间是否存在链接。 这是一个二元分类问题。
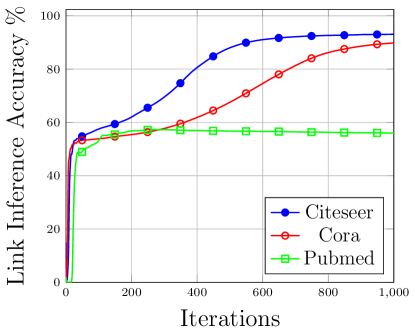
图 9 描述了针对三个数据集的攻击结果。 对于 Citeseer 数据集,推理精度约为 93.39%,而对于 Cora 数据集,推理精度为 90.73%,对于 Pubmed 数据集,推理精度为 57.28%。 这表明对手优势为 86.78% (Citeseer)、81.06% (Cora) 和 14.56% (Pubmed)。 三个数据集使用相同的训练-测试-验证分布,其中 30% 是训练记录,60% 是测试记录,其余 10% 作为验证记录。
5.5. 属性推断攻击
在属性推断攻击的情况下,我们使用三种攻击模型:神经网络(NN)、随机森林(RF)和支持向量机(SVM)来评估两种最先进的嵌入模型:Node2Vec 和 DeepWalk。 我们使用 Facebook 和 LastFM 数据集上的两种算法生成嵌入,其中分别包含性别和位置作为敏感属性。 也就是说,攻击者将用户性别推断为 Facebook 数据集中的目标敏感属性,分为三类之一:男性、女性和其他。 LastFM 数据集的位置目标属性针对网络中的用户分为 18 个位置。
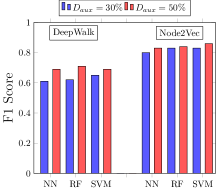
推理攻击性能由 F1 分数给出(图10)。 对于 Facebook,使用 DeepWalk 进行图嵌入导致 NN 的 F1 分数为 0.57,RF 的 F1 分数为 0.58,SVM 分类器的 F1 分数为 0.59。 另一方面,Facebook 的 Node2Vec 嵌入的 NN、Rf 和 SVM 攻击分类器的 F1 分数分别为 0.59、0.57 和 0.61。 对于 LastFM,我们发现 Node2Vec 的攻击 F1 分数高于 DeepWalk 嵌入。 对应于 NN、RF 和 SVM 攻击分类器的 DeepWalk 的 F1 得分为 0.61、0.62 和 0.65,而对于 NN、RF 和 SVM,使用 Node2Vec 嵌入的 F1 得分为 0.80、0.83 和 0.83。
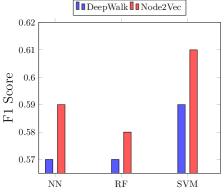
对手知识的影响。 Facebook数据集的攻击模型的性能并没有提高太多。 将对手辅助数据集的知识从 30% 增加到 50% 后,攻击 LastFM 数据集的置信度就会增加。 对于 DeepWalk 算法,攻击 F1 分数从 NN 的 0.61 增加到 0.69,RF 的攻击 F1 分数从 0.62 增加到 0.71,SVM 攻击分类器的攻击 F1 分数从 0.65 增加到 0.69。 另一方面,对于 Node2Vec,攻击模型 F1 分数从 NN 的 0.80 增加到 0.83,RF 的攻击模型 F1 分数从 0.83 增加到 0.84,SVM 的攻击模型 F1 分数从 0.83 增加到 0.86。
6. 相关工作
位置和移动数据的广泛可用性伴随着机器学习算法的发展,以预测兴趣、协同定位或其他敏感用户信息(Noulas 等人,2009)。 传统方法定义特征来表征用户数据,并将这些特征用于各种预测任务。 但是,在机器学习中使用图数据的一个重要预处理步骤是将高维图数据嵌入到低维表示中,以便于机器学习算法(Yang等人,2019)进行处理。 在此背景下,GNN (Zhou 等人,2018) 在复杂图数据上具有最先进的性能,适用于节点分类和链接预测等任务。 然而,使用此类嵌入的隐私影响尚未得到充分考虑。
侵犯数据隐私的推理攻击已经在传统机器学习模型的背景下进行了探索。 成员推理攻击可以部署在传统机器学习算法中的白盒(Nasr等人,2019)和黑盒(Shokri等人,2017)设置中。 这些攻击进一步扩展到协作学习(Melis等人,2019;Nasr等人,2019)和生成模型(Hayes等人,2019)。 另一方面,重建攻击推断了传递给模型的输入的私有属性(Gong and Liu, 2016a; Ateniese 等人, 2015; Ganju 等人, 2018; Fredrikson 等人, 2015)。 其他隐私攻击旨在提取超参数(Wang和Gong,2018),使用侧通道(Duddu等人,2018)或输出预测对模型架构和参数进行逆向工程(Duddu 和 Rao,2019)。 神经网络对数据的记忆被认为是隐私泄露的主要原因(Song等人,2017;Carlini等人,2019;Song和Shmatikov,2020)。 此外,最近的工作表明图神经网络中存在隐私风险,其中对手可以使用两个节点特征之间的距离之间的手动阈值来推断两个节点之间存在链接(He等人,2021)。 然而,这种攻击包含在我们更通用的攻击方法中,我们提取整个邻接矩阵,可用于推断链接的存在。 文本模型已被证明可以通过属性推断和反转攻击泄露用户数据(Song 和 Raghunathan,2020;Pan 等人,2020)。 然而,在高维图的情况下直接应用这些攻击是不可能的,并且需要额外考虑网络结构,这使得我们的问题具有挑战性。 除了隐私攻击之外,还探索了针对 GNN 的对抗性攻击(Zügner 等人,2018;Bojchevski 和 Günnemann,2019)以及训练算法来增强针对此类攻击的鲁棒性(Zügner 等人,2019)(Zügner 等人,2019) Günnemann,2019;朱等人,2019)。
为了减轻成员资格和属性推断攻击,Memguard (Jia 等人,2019) 和 AttriGuard (Jia 等人,2018) 在最终输出预测中添加精心设计的噪声以错误分类影子模型攻击。 会员隐私蒸馏(Shejwalkar 和 Houmansadr,2021) 是最先进的防御,它通过仔细生成用于知识转移的转移集,使用知识转移来规范其模型。 使用极小极大优化的对抗正则化可以对模型进行正则化,以减轻推理攻击(Nasr 等人,2018)。 (Salem 等人, 2019) 研究使用集成训练、dropout 和 L2 正则化的基于正则化的防御。 差分隐私通过向梯度添加噪声,在理论上保证减轻了此类隐私攻击,但面临着不平衡的隐私准确性权衡(Abadi等人,2016)。 这种差异化隐私框架也在图和文本嵌入的背景下进行了探索(Xuan-Son Vu,2019;Xu等人,2018),但它们在降低拟议攻击带来的隐私风险方面的功效尚不清楚有待探索。
7. 讨论与结论
这项工作提供了第一个与在敏感图数据上训练的图嵌入算法相关的全面隐私风险分析。 具体来说,本文在实际对手假设和威胁模型下量化了三类主要隐私攻击的隐私泄露,即成员推理、图重建和属性推理。 首先,对手进行成员推理训练攻击,旨在推断给定用户的节点是否在图数据集中使用。 其次,可以反转公开发布的嵌入以获得输入图数据,从而使对手能够对敏感图数据执行图重建攻击。 这进一步使得攻击者能够执行链路推断攻击,以推断网络中两个节点之间是否存在链路。 最后,我们表明对手可以从图嵌入中推断出用户的敏感隐藏属性,例如性别和位置。 我们的结果强调了图嵌入中的许多隐私风险,并呼吁进一步研究以减轻这些隐私威胁。
可以考虑降低隐私风险的潜在缓解策略。 例如,通过舍入降低每个节点的嵌入向量的精度有助于减少攻击模型学习输入的丰富特征(Shokri等人,2017;Pan等人,2020)。 在所提出的攻击中,攻击者模型是一种机器学习算法,容易受到对抗性示例的影响,即在输出预测中添加难以察觉的噪声,以迫使目标模型错误分类。 嵌入可以用额外的对抗性噪声来释放,以对目标模型进行错误分类,同时额外确保实用性(Jia和Gong,2018;Jia等人,2019)。 此外,推理攻击可以在训练过程中建模为具有联合优化的最小最大对抗训练,以使用图嵌入(例如 GNN)最小化模型损失,同时最大化对手在推断敏感输入 (Nasr 等)时的损失人,2018;宋和拉古纳坦,2020)。 最后,差异隐私可以为个人数据点 上嵌入的下游处理中的总隐私泄漏提供理论界限(Xuan-Son Vu,2019;Xu 等人,2018)。 然而,这些潜在缓解措施的功效有待未来的研究。
参考
- (1)
- Abadi et al. (2016) Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. In CCS. 308––318.
- Ateniese et al. (2015) Giuseppe Ateniese, Luigi V. Mancini, Angelo Spognardi, Antonio Villani, Domenico Vitali, and Giovanni Felici. 2015. Hacking Smart Machines with Smarter Ones: How to Extract Meaningful Data from Machine Learning Classifiers. Int. J. Secur. Netw. 10, 3 (2015), 137–150.
- Bojchevski and Günnemann (2019) Aleksandar Bojchevski and Stephan Günnemann. 2019. Adversarial Attacks on Node Embeddings via Graph Poisoning. In ICML.
- Boutet et al. (2021) Antoine Boutet, Carole Frindel, Sébastien Gambs, Théo Jourdan, and Claude Rosin Ngueveu. 2021. DYSAN: Dynamically sanitizing motion sensor data against sensitive inferences through adversarial networks. In ASIACCS.
- Cai et al. (2018) H. Cai, V. W. Zheng, and K. C. Chang. 2018. A Comprehensive Survey of Graph Embedding: Problems, Techniques, and Applications. IEEE Transactions on Knowledge and Data Engineering 30, 9 (2018), 1616–1637.
- Carlini et al. (2019) Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks. In USENIX Security. 267–284.
- Chen et al. (2018) Haochen Chen, Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2018. A Tutorial on Network Embeddings. arXiv:1808.02590 (2018).
- Du et al. (2018) Jian Du, Shanghang Zhang, Guanhang Wu, José M. F. Moura, and Soummya Kar. 2018. Topology Adaptive Graph Convolutional Networks. arXiv:1710.10370 (2018).
- Duddu and Rao (2019) Vasisht Duddu and D Vijay Rao. 2019. Quantifying (Hyper) Parameter Leakage in Machine Learning. arXiv:1910.14409 (2019).
- Duddu et al. (2018) Vasisht Duddu, Debasis Samanta, D Vijay Rao, and Valentina E. Balas. 2018. Stealing Neural Networks via Timing Side Channels. arxiv:1812.11720 (2018).
- Fredrikson et al. (2015) Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. 2015. Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures. In CCS. 1322––1333.
- Ganju et al. (2018) Karan Ganju, Qi Wang, Wei Yang, Carl A. Gunter, and Nikita Borisov. 2018. Property Inference Attacks on Fully Connected Neural Networks Using Permutation Invariant Representations. In CCS. 619–633.
- Gong and Liu (2016a) N.Z. Gong and B. Liu. 2016a. You Are Who You Know and How You Behave: Attribute Inference Attacks via Users’ Social Friends and Behaviors. In USENIX Security. 979–995.
- Gong and Liu (2016b) Neil Zhenqiang Gong and Bin Liu. 2016b. You Are Who You Know and How You Behave: Attribute Inference Attacks via Users’ Social Friends and Behaviors. In USENIX Security. 979–995.
- Grover and Leskovec (2016) Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable Feature Learning for Networks. In KDD.
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In NeurIPS, I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.). 1024–1034.
- Hayes et al. (2019) Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. 2019. LOGAN: Membership Inference Attacks Against Generative Models. PETS 1 (2019), 133 – 152.
- He et al. (2021) Xinlei He, Jinyuan Jia, Michael Backes, Neil Zhenqiang Gong, and Yang Zhang. 2021. Stealing Links from Graph Neural Networks. In USENIX Security.
- Jia and Gong (2018) Jinyuan Jia and Neil Zhenqiang Gong. 2018. Attriguard: A Practical Defense against Attribute Inference Attacks via Adversarial Machine Learning. In USENIX Security. 513––529.
- Jia et al. (2019) Jinyuan Jia, Ahmed Salem, Michael Backes, Yang Zhang, and Neil Zhenqiang Gong. 2019. MemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples. In CCS. 259–274.
- Jia et al. (2017) Jinyuan Jia, Binghui Wang, Le Zhang, and Neil Zhenqiang Gong. 2017. AttriInfer: Inferring User Attributes in Online Social Networks Using Markov Random Fields. In WWW. 1561–1569.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR.
- Klicpera et al. (2019) Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. 2019. Combining Neural Networks with Personalized PageRank for Classification on Graphs. In ICLR.
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-Ming Wu. 2018. Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning. In AAAI.
- Melis et al. (2019) Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. 2019. Exploiting Unintended Feature Leakage in Collaborative Learning. In SP. 691–706.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and Their Compositionality. In NIPS. 3111––3119.
- Nasr et al. (2018) Milad Nasr, Reza Shokri, and Amir Houmansadr. 2018. Machine Learning with Membership Privacy Using Adversarial Regularization. In CCS. 634–646.
- Nasr et al. (2019) M. Nasr, R. Shokri, and A. Houmansadr. 2019. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In SP. 739–753.
- Noulas et al. (2009) Anastasios Noulas, Mirco Musolesi, Massimiliano Pontil, and Cecilia Mascolo. 2009. Inferring interests from mobility and social interactions. In NIPS Workshop. 2–88.
- Pan et al. (2020) X. Pan, M. Zhang, S. Ji, and M. Yang. 2020. Privacy Risks of General-Purpose Language Models. In SP.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. DeepWalk: Online Learning of Social Representations. In KDD. 701–710.
- Salem et al. (2019) Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. 2019. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In NDSS.
- Shejwalkar and Houmansadr (2021) Virat Shejwalkar and Amir Houmansadr. 2021. Membership Privacy for Machine Learning Models Through Knowledge Transfer. In AAAI.
- Shokri et al. (2017) R. Shokri, M. Stronati, C. Song, and V. Shmatikov. 2017. Membership Inference Attacks Against Machine Learning Models. In SP. 3–18.
- Song and Raghunathan (2020) Congzheng Song and Ananth Raghunathan. 2020. Information Leakage in Embedding Models. (2020). arXiv:2004.00053
- Song et al. (2017) Congzheng Song, Thomas Ristenpart, and Vitaly Shmatikov. 2017. Machine Learning Models That Remember Too Much. In CCS. 587––601.
- Song and Shmatikov (2020) Congzheng Song and Vitaly Shmatikov. 2020. Overlearning Reveals Sensitive Attributes. In ICLR.
- Song and Mittal (2020) Liwei Song and Prateek Mittal. 2020. Systematic Evaluation of Privacy Risks of Machine Learning Models. arXiv:2003.10595 (2020).
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing Data using t-SNE. Journal of Machine Learning Research (2008), 2579–2605.
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. In ICLR.
- Wang and Gong (2018) B. Wang and N. Z. Gong. 2018. Stealing Hyperparameters in Machine Learning. In SP. 36–52.
- Xu et al. (2018) Depeng Xu, Shuhan Yuan, Xintao Wu, and HaiNhat Phan. 2018. DPNE: Differentially Private Network Embedding. 235–246.
- Xuan-Son Vu (2019) Lili Jiang Xuan-Son Vu, Son N. Tran. 2019. dpUGC: Learn Differentially Private Representation for User Generated Contents. In CICLing.
- Yang et al. (2019) Dingqi Yang, Bingqing Qu, Jie Yang, and Philippe Cudre-Mauroux. 2019. Revisiting user mobility and social relationships in lbsns: a hypergraph embedding approach. In WWW. 2147–2157.
- Zhou et al. (2018) Jie Zhou, Ganqu Cui, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. 2018. Graph neural networks: A review of methods and applications. arXiv:1812.08434 (2018).
- Zhu et al. (2019) Dingyuan Zhu, Ziwei Zhang, Peng Cui, and Wenwu Zhu. 2019. Robust Graph Convolutional Networks Against Adversarial Attacks. In KDD. 1399––1407.
- Zügner et al. (2018) Daniel Zügner, Amir Akbarnejad, and Stephan Günnemann. 2018. Adversarial Attacks on Neural Networks for Graph Data. In KDD. 2847––2856.
- Zügner and Günnemann (2019) Daniel Zügner and Stephan Günnemann. 2019. Certifiable Robustness and Robust Training for Graph Convolutional Networks. In KDD. 246––256.