无标签数据深度网络自训练的理论分析
摘要
自训练算法训练模型以适应另一个先前学习的模型预测的伪标签,在使用神经网络学习未标记数据方面非常成功。 然而,目前对自训练的理论理解仅适用于线性模型。 这项工作为半监督学习、无监督领域适应和无监督学习的深度网络自训练提供了统一的理论分析。 我们分析的核心是一个简单但现实的“扩展”假设,它指出数据的低概率子集必须扩展到相对于该子集具有大概率的邻域。 我们还假设不同类中的示例邻域具有最小的重叠。 我们证明,在这些假设下,基于自我训练和输入一致性正则化的人口目标最小化将在地面实况标签方面实现高精度。 通过使用现成的泛化边界,我们立即将此结果转换为神经网络的样本复杂性保证,该神经网络的边际和 Lipschitzness 为多项式。 我们的结果有助于解释最近提出的使用输入一致性正则化的自训练算法的经验成功。
1简介
尽管神经网络的监督学习已成为标准且可靠,但它仍然经常需要大量标记数据集。 由于标签可能昂贵或难以获得,因此在深度学习中利用未标记数据已成为一个活跃的研究领域。 半监督学习近期研究成果(Chapelle 等人, 2010; Kingma 等人, 2014; Kipf & Welling, 2016; Laine & Aila, 2016; Sohn 等人, 2020; Xie 等人, 2020) 和无监督域适应 (Ben-David 等人, 2010; Ganin & Lempitsky, 2015; Ganin 等人, 2016; Tzeng 等人, 2017; Hoffman 等人, 2018; Shu 等人, 2018; Zhang 等人,2019) 利用大量未标记数据以及来自相同分布或相关分布的标记数据。 无监督学习或表征学习的最新进展(Hinton 等人, 1999; Doersch 等人, 2015; Gidaris 等人, 2018; Misra & Maaten, 2020; Chen 等人, 2020a, b; Grill 等人, 2020) 在不使用任何标签的情况下学习高质量的表示。
自训练是一种常见的算法范例,用于利用深度网络的未标记数据。 自训练方法训练一个模型来拟合伪标签,即通过先前学习的模型对未标记数据进行预测(Yarowsky,1995;Grandvalet & Bengio,2005;Lee,2013)。 最近的工作还扩展了这些方法,以增强输入转换下预测的稳定性,例如对抗性扰动(Miyato等人,2018)和数据增强(Xie等人,2019)。 这些被称为输入一致性正则化的方法已在半监督学习(Sohn等人,2020;Xie等人,2020)、无监督域适应(French等人,2017)方面取得了成功; Shu 等人, 2018),以及无监督学习(Hu 等人, 2017; Grill 等人, 2020)。
尽管取得了实证上的成功,但理解如何使用未标记数据的理论进展仍然滞后。 尽管监督学习相对容易理解,但用于推理未标记数据的统计工具却并不容易获得。 大约 25 年前,Vapnik (1995)提出了针对无标签数据的转导 SVM,这可以被视为自我训练的早期版本,但很少有工作表明该方法提高了样本复杂度(Derbeko等人,2004)。 使用未标记的数据需要对输入分布进行适当的假设(Ben-David 等人,2008)。 最近的论文(Carmon 等人,2019;Raghunathan 等人,2020;Chen 等人,2020c;Kumar 等人,2020;Oymak & Gulcu,2020)分析了各种环境下的自我训练,但主要是对于线性模型,通常要求数据是高斯或接近高斯的。 Kumar 等人 (2020) 还分析了在多个时间步上发生逐渐域转移的情况下的自我训练,但假设连续时间步之间的转移有一个小的 Wasserstein 距离界限。 另一种研究方法是使用非参数方法利用无标记数据,要求无标记样本的复杂度为指数维度(Rigollet,2007 年;Singh 等人,2009 年;Urner & Ben-David,2013 年)。
本文为半监督学习、无监督领域适应和无监督学习的深度网络自训练提供了统一的理论分析。 在数据分布的简单而现实的扩展假设下,我们表明,使用深度网络进行输入一致性正则化的自我训练可以在真实标签上实现高精度,使用未标记的样本大小(模型的边际和 Lipschitzness 为多项式)。 我们的分析为最近经验上成功的依赖输入一致性正则化的自训练算法提供了理论直觉(Berthelot 等人,2019;Sohn 等人,2020;Xie 等人,2020)。
我们的扩展假设直观地表明数据分布在每个类内具有良好的连续性。 具体来说,令 为以类 为条件的数据分布,扩展表明对于类 的示例的小子集 ,
| (1.1) |
其中 是扩展因子。 邻域将被定义为包含数据增强,但目前可以将其视为与 距离较小的 点的集合。这个概念是 Cheeger 常数(或等周或膨胀常数)的扩展(Cheeger,1969),它在图论中得到了广泛的研究(Chung & Graham,1997) 、组合优化(Mohar & Poljak, 1993; Raghavendra & Steurer, 2010)、抽样(Kannan 等人, 1995; Lovász & Vempala, 2007; 张等人, 2017),甚至在早期版本的自我训练中(Balcan等人,2005)用于协同训练设置(Blum&Mitchell,1998)。 扩展表示每个类的流形具有足够的连通性,因为每个子集 都有一个大于 的邻域。我们在3.1节中给出了满足扩展的分布的示例。 我们还需要一个分离条件,表明来自不同类别的相邻对很少。
我们的算法通过使用输入一致性正则化(Miyato等人,2018;Xie等人,2019)来利用扩展来鼓励分类器的预测与相邻示例保持一致:
| (1.2) |
对于无监督域适应和半监督学习,我们分析了一种算法,该算法使 适合未标记数据上的伪标签,同时规范输入一致性。 假设扩展和分离,我们证明拟合模型将对伪标签进行去噪,并在真实标签上实现高精度(定理4.3)。 这解释了这样的经验现象:尽管无法获得真实标签,但对伪标签的自我训练通常会比伪标签器有所改进。
对于无监督学习,我们考虑找到一个分类器,该分类器可以最小化输入一致性正则化器,并限制为每个标签分配足够的示例。 在定理 3.6 中,我们表明,假设扩展和分离,学习的分类器在预测真实类别方面将具有很高的准确性,直到标签的排列(没有真实标签就无法恢复)。
定理的主要直觉如下:输入一致性正则化确保模型局部一致,扩展性质将局部一致性放大为同一类内的全局一致性。 在无监督域适应设置中,如图1(右)所示,错误伪标记的示例(红色区域)逐渐被正确伪标记的邻居(绿色区域)去噪,其概率质量为不平凡(至少 倍于扩展错误集的质量)。 我们注意到,仅需要对总体分布进行扩展,但对经验样本进行了自我训练。 由于参数方法的外推能力,扩张的局部到全局一致性效应隐含地发生在总体上。 相比之下,最近邻方法需要在经验样本上显式进行扩展,从而遭受维数灾难。 我们在下面提供更多详细信息,并在图 1(左)中可视化此效果。

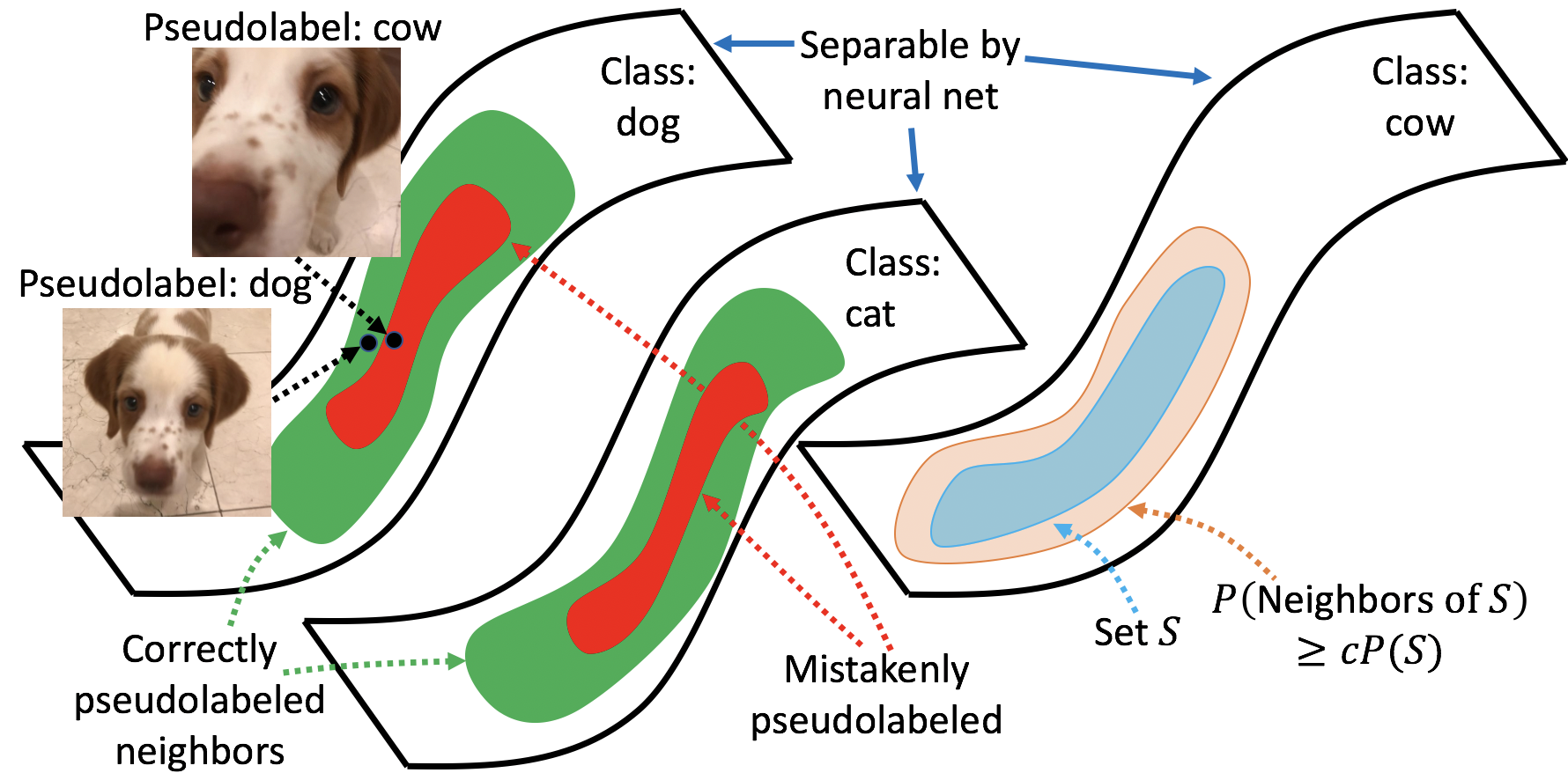
据我们所知,本文首次对用于无监督学习、半监督学习和无监督域适应的深度神经网络模型进行了多项式样本复杂性保证的分析。 之前的工作(Rigollet,2007;Singh 等人,2009;Urner & Ben-David,2013)分析了非参数方法,这些方法基本上用未标记的数据精确地恢复了数据分布,但要求样本复杂度在维度上呈指数级。 我们的方法优化了参数损失函数和正则化器,因此涉及总体损失的保证可以使用现成的泛化界限转换为有限样本结果(定理3.7)。 当神经网络能够以较大余量分离真实类别时,这些边界的样本复杂度可以很小,即维度为多项式。
最后,我们注意到我们的正则化器 对应于强制一致性。 对抗性示例,经证明对半监督学习 (Miyato 等人,2018;Qiao 等人,2018) 和无监督领域适应 (Shu 等人,2018). 此外,我们可以扩展(1.1)中的邻域概念以包括示例的数据增强,这将增加邻域大小,从而改善扩展。 因此,我们的理论可以帮助解释经验观察,即基于积极数据增强或对抗性训练的一致性正则化可以提高未标记数据的性能(Shu 等人,2018;Xie 等人,2019;Berthelot 等人,2019;Sohn 等人,2020;谢等人,2020;陈等人,2020a)。
总之,我们的贡献包括:1)我们提出了一个简单而现实的扩展假设,该假设表明数据分布在真实类别的流形内具有连通性2)使用此扩展假设,我们为 self 提供真实准确度保证-训练算法对未标记数据的输入一致性进行正则化,3)我们的分析可以通过现成的泛化边界轻松应用于具有多项式未标记样本的深度网络。
1.1 其他相关工作
通过伪标签(Lee,2013)或最小熵目标(Grandvalet & Bengio,2005)进行自我训练已广泛应用于半监督学习( Laine & Aila, 2016; Iscen 等人, 2019; Berthelot 等人, 2020) 和无监督域适应(Long 等人,2013;French 等人,2017;Saito 等人,2017;Shu 等人,2018;Zou 等人,2019)。 我们的论文研究了输入一致性正则化,它增强了未标记数据的预测的稳定性。 在实践中,这些转换包括对抗性扰动,被提议为增值税目标(Miyato等人,2018),以及数据增强(Xie等人,2019) 。
对于无监督学习,我们的自我训练目标与 BYOL (Grill 等人,2020) 密切相关,这是一种最近最先进的方法,可训练学生模型以匹配由基于输入的强增强版本的教师模型。 对比学习是另一种流行的无监督表示学习方法,它鼓励“正对”的表示(理想情况下由同一类的示例组成)接近,同时将负对推得较远(Mikolov 等人,2013;Oord 等人,2018;阿罗拉等人,2019)。 最近的对比学习工作通过使用强大的数据增强形成正对(Chen 等人,2020a,b)来实现最先进的表示质量。 数据增强在这里的作用在本质上类似于我们使用输入一致性正则化。 与我们的设置不太相关的是通过解决自监督借口任务来学习表示的算法,例如修复和预测旋转(Pathak等人,2016;Noroozi&Favaro,2016;Gidaris等人,2018) 。 Lee 等人 (2020) 从理论上分析了自监督学习,但他们的分析适用于与我们不同类别的算法。
先前的理论工作通过假设访问根据特定主题建模设置(Tosh等人,2020)或同一类中的独立样本对(Arora等人)分布的文档数据来分析对比学习,2019)。 然而,这些分析所需的假设并不一定适用于视觉,其中正对对同一图像应用不同的数据增强,因此具有很强的相关性。 其他论文分析了表征学习的信息论特性(Tian 等人,2020;Tsai 等人,2020)。
先前的工作分析了半监督学习的连续性或“集群”假设,这与我们的扩展概念相关(Seeger,2000;Rigollet,2007;Singh 等人,2009;Urner & Ben-David,2013). 然而,这些论文使用非参数方法利用未标记的数据,需要在维度上呈指数级的未标记样本复杂性。 另一方面,我们的分析是针对参数方法的,因此当神经网络可以大范围地分离真实类别时,未标记样本的复杂性可能会很低。
协同训练是自我训练的经典版本,需要两个不同的数据“视图”(即特征子集),每个视图都可以用于预测其自身的真实标签 (Blum 和 Mitchell, 1998;达斯古普塔等人,2002;巴尔坎等人,2005)。 例如,为了预测网页的主题,一个视图可以是传入链接,另一个视图可以是页面中的单词。 最初的协同训练算法(Blum&Mitchell,1998;Dasgupta等人,2002)假设两个视图在真实标签上是独立的,并利用这种独立性来获得未标记数据的准确伪标签。 相比之下,如果我们通过将示例和随机采样的邻居视为数据的两个视图来将我们的设置放入协同训练框架中,则这两个视图是高度相关的。 Balcan 等人 (2005) 放宽了对协同训练的独立观点的要求,同样通过使用“扩展”假设。 我们的假设与他们的假设密切相关,并且如果我们通过将相邻示例视为两种视图来将我们的设置放入协同训练框架中,那么在概念上是等效的。 然而,他们的分析要求可信的伪标签都是准确的,并且没有严格考虑其算法中潜在的错误传播。 相反,我们的贡献是提出并分析一个涉及输入一致性正则化的目标函数,其最小化去噪来自潜在不正确伪标签的错误。 我们还为神经网络假设类提供有限样本复杂性界限并分析无监督学习算法。
无监督域适应的替代理论分析假设源域和目标域之间的差异有界测量(Ben-David 等人,2010;Zhang 等人,2019)。 Balcan & Blum (2010) 提出了一种用于分析半监督学习的 PAC 式框架,但其界限要求用户指定包含数据先验知识的兼容性概念,并且不适用到域适应。 Globerson 等人 (2017) 证明半监督学习在标记样本复杂性方面可以优于监督学习,但假设完全了解未标记分布。 (Mobahi 等人, 2020) 表明,对于核方法,自蒸馏(自训练的一种变体)可以有效地放大正则化。 他们的分析适用于核方法,而我们的分析适用于数据假设下的深层网络。
2 预备知识和符号
我们让 表示输入空间 上未标记示例的分布。 对于无监督学习, 是唯一相关的分布。 对于无监督域适应,我们还定义了源分布 并让 表示在从 采样的标记数据集上训练的源分类器。 为了将这些定义转化为半监督学习,我们将 和 设置为相同,但 允许访问标签。 我们分析仅依赖于到的算法。
我们考虑分类,并假设数据被划分为 类,其中 的类由 的地面实况 给出。 我们让 表示以 为条件的 的类条件分布。 我们假设每个示例 都有一个唯一的标签,因此 、 对 具有不相交的支持。 让 表示 i.i.d. 来自 的未标记训练示例。我们还使用 来指代这些示例的均匀分布。 我们让表示学习的评分函数(例如神经网络输出的连续logits),表示由引起的离散标签:(按字典顺序断开关系)。
伪标签。 伪标签方法是半监督学习和领域适应的一种自我训练形式,其中源分类器 用于预测未标记目标数据上的伪标签 (Lee,2013) 。 然后,这些方法训练一个新的分类器来适应这些伪标签,例如,使用标准交叉熵损失:。 我们的理论分析适用于基于伪标签的目标。 其他形式的自我训练包括熵最小化,它是密切相关的,并且在某些设置中相当于伪标签,其中伪标签每次迭代都会更新(Lee,2013;Chen等人,2020c)。
3 无监督学习的扩展属性和保证
在本节中,我们将首先介绍关于扩展的关键假设。 然后我们研究扩展对无监督学习的影响。 我们证明,如果分类器与 w.r.t 一致。 输入转换并以适当的概率预测每个类,学习到的标签将与真实类对齐,直到类索引的排列(定理3.6)。
3.1 扩展属性
我们引入了扩展的概念。 当我们的理论研究强制输入转换稳定性的目标时,我们将首先通过下面定义的集合 对输入 的允许转换进行建模。 我们让 表示通过数据增强获得的某个 Transformer 集合,并定义 为与 的某个数据增强的距离为 的点集合。 我们可以将 视为比 的典型范数小得多的值,因此 的概率在维度上呈指数级小。 我们的理论很容易适用于 的其他选择,尽管为了简单起见我们将此定义设置为默认值。 现在我们定义的邻域,用表示,作为其变换集与的变换集重叠的点的集合:
| (3.1) |
对于,我们将的邻域定义为其元素的邻域的并集:。 我们现在定义分布 的扩展属性,它降低了低概率集的邻域大小并捕获输入空间中分布的连通性。
Definition 3.1 (-扩展)。
如果对于具有 的所有 来说,以下条件成立,我们就说类条件分布 满足 展开:
| (3.2) |
如果满足所有的扩展,那么我们说满足扩展。
我们注意到,这个定义考虑了总体分布,并且扩展预计不会在训练集上成立,因为所有经验示例彼此相距很远,因此训练示例的邻域不会重叠。 这个概念与Cheeger常数密切相关,它用于限制连续分布采样的混合时间和命中时间(Lovász & Vempala, 2007;Zhang 等人, 2017) 和小集扩展,量化图的连通性(Hoory 等人,2006;Raghavendra & Steurer,2010)。 特别是,当邻域被定义为与集合的 距离至多 的点的集合时,则扩展因子 的界限如下通过 ,其中 是 Cheeger 常数 (Zhang 等人, 2017)。 在D.1节中,我们使用GAN来证明扩展是视觉中的现实属性。 对于无监督学习,我们需要使用 和 进行扩展:
Assumption 3.2 (无监督学习的扩展要求)。
我们假设 满足 对 的展开,而 满足 对 的展开。
我们还假设真实类别在输入空间中是分离的。 我们将总体一致性损失 定义为 对输入转换不稳健的示例的分数:
| (3.3) |
我们假设地面真值类远离输入空间:
Assumption 3.3 (分离).
我们假设 被 - 由真实分类器 以概率 分隔,如下所示: 。
我们在定理 4.3 和 3.6 中的准确性保证将取决于 。 我们期望 很小或可以忽略不计(例如维度的逆多项式)。 分离要求要求两个类之间的距离大于,即定义中的半径。 然而,可能比典型示例的范数小得多,因此我们的扩展要求可能比典型的“聚类”概念弱,后者要求类内距离小于类间距离。 我们从高斯的混合开始定量地证明了这一点。
Example 3.4 (各向同性高斯的混合).
假设是具有各向同性协方差的高斯和的混合,对应于单独的类。111这些类并不是不相交的,正如我们的理论为简单起见所假设的那样。 然而,它们几乎是不相交的,并且很容易修改我们的分析以适应这一点。 我们在部分中提供详细信息 B.2. 假设变换集是一个球,半径为,围绕,因此没有数据增强,并且。 那么满足扩展。 此外,如果均值之间的最小距离满足,则以概率分隔。
在上面的例子中,人口分布满足展开,但经验分布不满足。 任意两个经验例子之间的最小距离为的概率很高,因此当时它们不能是彼此的邻居。 此外,类内距离 远大于均值之间的距离(假设为 )。 因此,基于经验样本的简单的基于距离的聚类算法不适用。 3.2节中的无监督学习算法可以近似地恢复具有多项式样本的混合分量,误差高达。 此外,这几乎是信息理论上最优的:通过总变化距离,需要均值之间的 距离来恢复混合分量。
该示例通过更一般的等周不等式扩展到对数凹分布(Bobkov 等人,1999)。 因此,我们的分析适用于先前工作(Chen等人,2020c)的设置,该工作研究了高斯或对数凹分布混合的线性模型的自我训练。
然而,我们分析的主要好处是,与之前仅考虑高斯或近高斯分布的自我训练工作相比,它适用于比高斯分布更丰富的分布族(Raghunathan 等人,2020;Chen等人,2020c;库马尔等人,2020)。 我们在以下流形混合示例中演示了这一点:
Example 3.5 (流形混合).
假设环境空间 上的每个类条件分布 (其中 )由某个 -bi-Lipschitz 生成222A -bi-Lipschitz函数 满足 。 潜在变量 上的生成器 :
我们将变换集设置为球,半径为,围绕,因此没有数据增强并且。 那么,满足扩展。
3.2无监督学习的群体保证
我们设计了一个利用扩展和分离特性的无监督学习目标。 我们的目标是总体分布,但它是参数化的,因此我们可以将其扩展到第 3.3 节中的有限样本情况。 我们希望仅使用未标记的数据来学习分类器 ,以便预测的类别与真实类别保持一致。 请注意,在不观察任何标签的情况下,我们只能学习基本事实类直至排列,从而导致为分类器 定义以下排列不变错误:
我们研究了分类器 上的以下无监督总体目标,它鼓励输入一致性,同时确保预测的类别具有足够的概率。
| (3.4) |
这里是假设3.2中的膨胀系数。 该约束确保任何预测类别的概率大于输入一致性损失。 让 表示最小真实类别的概率。 下面的定理表明,当满足扩展和分离时,目标的全局极小值(3.4)将具有较低的误差。
在B节中,我们提供了定理3.6的证明以及该定理的一个变体,该变体适用于较弱的可加性展开概念。 通过应用 3.3 节的泛化界限,我们可以将定理 3.6 转换为有限样本保证,该保证是模型的边际和 Lipschitzness 的多项式(参见定理 C.1)。
我们的目标让人想起最近在无监督表示学习中取得最先进结果的方法:SimCLR (Chen 等人, 2020a)、MoCov2 (He 等人, 2020; Chen等人,2020b),以及 BYOL (Grill 等人,2020)。 与我们的算法不同的是,这些方法并不预测离散标签,而是直接预测在输入 Transformer 条件下保持一致的表征。不过,我们的分析仍然可以解释为什么输入一致性正则化对这些方法如此重要:假设数据满足扩展性,它将鼓励表征在 整个类中具有相似性,因此表征将捕捉到地面实况的类结构。
Chen 等人 (2020a) 还观察到,使用更积极的数据增强来规范输入稳定性可以显着提高表示质量。 我们指出,我们的理论提供了一个潜在的解释:在我们的框架中,加强增强会增加邻域的大小,从而产生更大的扩展因子 并提高准确度范围 (3.5 )。
3.3深度学习模型的有限样本保证
在本节中,我们表明,如果真实类别可以通过具有大鲁棒余量的神经网络进行分离,那么泛化效果会很好。 与之前的工作相比,定理 3.6 和定理 4.3 的主要优点是它们分析参数目标,因此有限样本保证通过现成的泛化边界立即成立。 先前关于与扩展相关的连续性或“集群”假设的工作需要非参数技术,其样本复杂度在维度 上呈指数增长(Seeger, 2000; Rigollet, 2007; Singh 等人, 2009; Urner & Ben-David, 2013) 。
我们基于全层裕度的概念应用(Wei & Ma,2019b)的泛化界限,尽管任何其他界限都可以。 全层裕度衡量神经网络对每个隐藏层同时扰动的稳定性。 正式地,假设 是某个前馈神经网络 的预测,该网络计算以下函数:带有权重矩阵 的 。 让 表示任何隐藏层的最大尺寸。 让 表示示例 中标签 的所有层边距,在 C.2 节中正式定义。 现在,我们只需注意 具有以下属性:如果 ,则 ,因此我们可以通过对所有阈值进行阈值化来限制 0-1 损失的上限-层边距: 对于任何。 我们还可以定义一个测量输入转换稳健性的变体:。 以下结果表明,大的全层裕度意味着输入一致性损失具有良好的泛化性,这出现在目标 (3.4) 中。
Theorem 3.7 (定理3.1的扩展(Wei & Ma, 2019b))。
训练集 的抽取概率为 ,所有 形式的神经网络 将满足
| (3.6) |
对于所有 的选择,其中 是低阶项,而 隐藏了 和 中的多对数因子。
4 用于半监督学习和领域适应的去噪伪标签
我们研究半监督学习和无监督领域适应设置,在这些设置中我们可以访问未标记的数据和伪标记器 。 这种设置需要比无监督学习设置更复杂的分析,因为伪标签可能不准确,并且学生分类器可能会放大这些错误。 我们设计了一个总体目标来衡量输入转换的一致性和伪标签的准确性。 假设扩展和分离,我们表明该目标的最小化器在ground-truth标签上将具有高精度。
我们假设可以访问伪标签,它是通过域适应设置中的标记源数据或半监督设置中的标记数据上的分类器获得的。 通过访问伪标签,我们可以准确地恢复真实标签,而不是像 3.2 节中那样进行排列。 对于,将定义为和之间的不一致。 错误度量是真实标签上的标准 0-1 损失:。 让 表示一组错误的伪标签示例。 我们需要对扩展做出以下假设,直观地表明 的每个子集都有足够大的邻域。
Assumption 4.1 ( 在小于 的集合上展开)。
将 定义为任何类中错误伪标签示例的最大比例。 我们假设 和 满足 的 展开。 我们用 来表达我们的界限。
请注意,上述要求比无监督学习设置中所需的条件要求更高(假设3.2)。 较大的 说明伪标签中的错误可能会以最坏情况的方式对学习的分类器产生不利影响。 这种担忧不适用于无监督学习,因为不使用伪标签。 对于示例 3.4 和 3.5 中的玩具分布,我们可以将邻域半径增加 3 倍以获得 (0.16, 6) 扩展,这已经足够了满足假设4.1中的要求。
另一方面,假设4.1比假设3.2严格,因为仅对于质量小于的小集合才需要扩展,伪标记器在类上的最坏情况错误,该错误可能比假设 3.2 中所需的 小得多。 此外,无监督目标(3.4)具有输入一致性正则化器不能太大的约束,而此设置不需要这样的约束。 我们注意到,假设 4.1 也可以放宽,直接考虑错误伪标签示例子集的扩展,同时对扩展因子 的要求更宽松(参见第 A.1)。 我们在分类器 上设计了以下目标,它使分类器适合伪标签,同时规范输入一致性:
| (4.1) |
该目标优化了输入一致性正则化器和拟合伪标签的损失的加权组合,并且与最近成功的半监督学习算法相关(孙等人,2020;谢等人,2020)。 我们可以证明 始终成立。 以下引理根据目标值限制 的误差。
Lemma 4.2.
假设假设4.1成立。 那么分类器 的错误在一致性方面受到限制。 伪标签的输入转换和准确性:。
当扩展和分离同时成立时,我们表明最小化 (4.1) 会导致分类器能够对伪标签进行去噪并提高其真实准确度。
我们在第 4.1 节中提供了证明草图,并在第 A.1 节中提供了完整证明。 我们的结果解释了一个可能令人惊讶的事实,即即使没有提供有关真实标签的附加信息,使用伪标签的自我训练通常也会比伪标签器有所改进。 在定理C.2中,我们使用3.3节中的泛化界限将定理4.3转化为有限样本保证。
乍一看,定理 4.3 中的误差界似乎比定理 3.6 弱,因为对 的额外依赖。 这种差异是由于对扩展和输入一致性正则器的值的要求较弱。 首先,3.2节要求对所有概率小于的集合进行扩展,而假设4.1只要求对概率小于,它可以比小得多。 其次,3.2 节中的误差范围仅适用于 值较小的分类器,如 (3.4) 中所示。 另一方面,引理4.2给出了所有分类器的错误界限,无论如何。 事实上,加强对3.2节的扩展要求将使我们能够获得类似于定理3.6的精度保证,用于具有低输入一致性正则化值的伪标签训练分类器。
4.1 定理证明草图4.3
我们为所有示例的输入一致性正则化器均为 0 的极端情况提供了引理 4.2 的证明草图,即 ,因此 。 对于这个证明草图,我们还对 时的情况做了额外的限制。
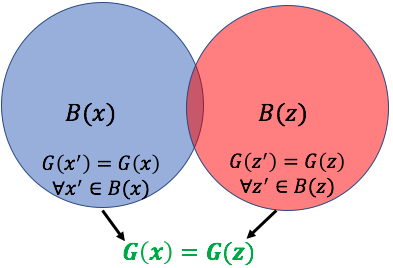
我们首先介绍一些一般符号。 对于集合,我们使用表示,使用分别表示集合交集和并集。 让 表示 的补集。
让 表示带有真实标签 的示例集。 对于 ,我们将 定义为 的邻域,其邻居仅限于同一类:。 以下关键声明将考虑两个集合:分类器出错的正确伪标记示例集 ,以及分类器和伪标记器都不符合基本事实的示例集 . 下面的权利要求使用扩展属性来表明
Claim 4.5。
假设所有示例的输入一致性正则化器均为 0,即 ,则它保持 。 那么接下来就是
用于简化设置的引理4.2的证明草图。
5实验
6结论
在这项工作中,我们提出了一个数据扩展假设,允许对半监督和无监督学习的自我训练进行统一的理论分析。 我们的假设对于现实世界的数据集是现实的,特别是在视觉方面。 我们的分析适用于深度神经网络,并且可以解释为什么基于自训练和输入一致性正则化的算法可以在未标记的数据上表现得如此出色。 我们希望这一假设能够促进未来的理论分析,并启发半监督和无监督学习的理论原理算法。 例如,未来工作的一个有趣问题是扩展我们的假设,以分析基于对齐源和目标的域适应算法(Hoffman等人,2018)。
致谢
我们要感谢 Ananya Kumar 提供的有益评论和讨论。 CW 感谢 NSF 研究生研究奖学金的支持。 TM 还得到了 Google 教师奖、斯坦福数据科学计划和斯坦福人工智能实验室的部分支持。 作者还要感谢斯坦福研究生奖学金计划的资助。
参考
- Arora et al. (2018) Sanjeev Arora, Rong Ge, Behnam Neyshabur, and Yi Zhang. Stronger generalization bounds for deep nets via a compression approach. arXiv preprint arXiv:1802.05296, 2018.
- Arora et al. (2019) Sanjeev Arora, Hrishikesh Khandeparkar, Mikhail Khodak, Orestis Plevrakis, and Nikunj Saunshi. A theoretical analysis of contrastive unsupervised representation learning. arXiv preprint arXiv:1902.09229, 2019.
- Balcan & Blum (2010) Maria-Florina Balcan and Avrim Blum. A discriminative model for semi-supervised learning. Journal of the ACM (JACM), 57(3):1–46, 2010.
- Balcan et al. (2005) Maria-Florina Balcan, Avrim Blum, and Ke Yang. Co-training and expansion: Towards bridging theory and practice. In Advances in neural information processing systems, pp. 89–96, 2005.
- Ben-David et al. (2008) Shai Ben-David, Tyler Lu, and Dávid Pál. Does unlabeled data provably help? worst-case analysis of the sample complexity of semi-supervised learning. 2008.
- Ben-David et al. (2010) Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains. Machine learning, 79(1-2):151–175, 2010.
- Berthelot et al. (2019) David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems, pp. 5049–5059, 2019.
- Blum & Mitchell (1998) Avrim Blum and Tom Mitchell. Combining labeled and unlabeled data with co-training. In Proceedings of the eleventh annual conference on Computational learning theory, pp. 92–100, 1998.
- Bobkov et al. (1997) Sergey G Bobkov et al. An isoperimetric inequality on the discrete cube, and an elementary proof of the isoperimetric inequality in gauss space. The Annals of Probability, 25(1):206–214, 1997.
- Bobkov et al. (1999) Sergey G Bobkov et al. Isoperimetric and analytic inequalities for log-concave probability measures. The Annals of Probability, 27(4):1903–1921, 1999.
- Brock et al. (2018) Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
- Carmon et al. (2019) Yair Carmon, Aditi Raghunathan, Ludwig Schmidt, John C Duchi, and Percy S Liang. Unlabeled data improves adversarial robustness. In Advances in Neural Information Processing Systems, pp. 11192–11203, 2019.
- Chapelle et al. (2010) Olivier Chapelle, Bernhard Schlkopf, and Alexander Zien. Semi-Supervised Learning. The MIT Press, 1st edition, 2010. ISBN 0262514125.
- Cheeger (1969) Jeff Cheeger. A lower bound for the smallest eigenvalue of the laplacian. In Proceedings of the Princeton conference in honor of Professor S. Bochner, pp. 195–199, 1969.
- Chen et al. (2020a) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020a.
- Chen et al. (2020b) Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020b.
- Chen et al. (2020c) Yining Chen, Colin Wei, Ananya Kumar, and Tengyu Ma. Self-training avoids using spurious features under domain shift. arXiv preprint arXiv:2006.10032, 2020c.
- Chung & Graham (1997) Fan RK Chung and Fan Chung Graham. Spectral graph theory. Number 92. American Mathematical Soc., 1997.
- Dasgupta et al. (2002) Sanjoy Dasgupta, Michael L Littman, and David A McAllester. Pac generalization bounds for co-training. In Advances in neural information processing systems, pp. 375–382, 2002.
- Derbeko et al. (2004) Philip Derbeko, Ran El-Yaniv, and Ron Meir. Error bounds for transductive learning via compression and clustering. In Advances in Neural Information Processing Systems, pp. 1085–1092, 2004.
- Doersch et al. (2015) Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE international conference on computer vision, pp. 1422–1430, 2015.
- Engstrom et al. (2019) Logan Engstrom, Andrew Ilyas, Hadi Salman, Shibani Santurkar, and Dimitris Tsipras. Robustness (python library), 2019. URL https://github.com/MadryLab/robustness.
- French et al. (2017) Geoffrey French, Michal Mackiewicz, and Mark Fisher. Self-ensembling for visual domain adaptation. arXiv preprint arXiv:1706.05208, 2017.
- Ganin & Lempitsky (2015) Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. In International conference on machine learning, pp. 1180–1189. PMLR, 2015.
- Ganin et al. (2016) Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. The Journal of Machine Learning Research, 17(1):2096–2030, 2016.
- Gidaris et al. (2018) Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728, 2018.
- Globerson et al. (2017) Amir Globerson, Roi Livni, and Shai Shalev-Shwartz. Effective semisupervised learning on manifolds. In Conference on Learning Theory, pp. 978–1003, 2017.
- Grandvalet & Bengio (2005) Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in neural information processing systems, pp. 529–536, 2005.
- Grill et al. (2020) Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprint arXiv:2006.07733, 2020.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738, 2020.
- Hinton et al. (1999) Geoffrey E Hinton, Terrence Joseph Sejnowski, Tomaso A Poggio, et al. Unsupervised learning: foundations of neural computation. MIT press, 1999.
- Hoffman et al. (2018) Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In International conference on machine learning, pp. 1989–1998. PMLR, 2018.
- Hoory et al. (2006) Shlomo Hoory, Nathan Linial, and Avi Wigderson. Expander graphs and their applications. Bulletin of the American Mathematical Society, 43(4):439–561, 2006.
- Hu et al. (2017) Weihua Hu, Takeru Miyato, Seiya Tokui, Eiichi Matsumoto, and Masashi Sugiyama. Learning discrete representations via information maximizing self-augmented training. arXiv preprint arXiv:1702.08720, 2017.
- Iscen et al. (2019) Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, and Ondrej Chum. Label propagation for deep semi-supervised learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5070–5079, 2019.
- Kannan et al. (1995) Ravi Kannan, László Lovász, and Miklós Simonovits. Isoperimetric problems for convex bodies and a localization lemma. Discrete & Computational Geometry, 13(3-4):541–559, 1995.
- Kingma et al. (2014) Durk P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In Advances in neural information processing systems, pp. 3581–3589, 2014.
- Kipf & Welling (2016) Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- Kumar et al. (2020) Ananya Kumar, Tengyu Ma, and Percy Liang. Understanding self-training for gradual domain adaptation. arXiv preprint arXiv:2002.11361, 2020.
- Laine & Aila (2016) Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. arXiv preprint arXiv:1610.02242, 2016.
- Lee (2013) Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. 2013.
- Lee et al. (2020) Jason D Lee, Qi Lei, Nikunj Saunshi, and Jiacheng Zhuo. Predicting what you already know helps: Provable self-supervised learning. arXiv preprint arXiv:2008.01064, 2020.
- Long et al. (2013) Mingsheng Long, Jianmin Wang, Guiguang Ding, Jiaguang Sun, and Philip S Yu. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE international conference on computer vision, pp. 2200–2207, 2013.
- Lovász & Vempala (2007) László Lovász and Santosh Vempala. The geometry of logconcave functions and sampling algorithms. Random Structures & Algorithms, 30(3):307–358, 2007.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119, 2013.
- Misra & Maaten (2020) Ishan Misra and Laurens van der Maaten. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6707–6717, 2020.
- Miyato et al. (2018) Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 41(8):1979–1993, 2018.
- Mobahi et al. (2020) Hossein Mobahi, Mehrdad Farajtabar, and Peter L Bartlett. Self-distillation amplifies regularization in hilbert space. arXiv preprint arXiv:2002.05715, 2020.
- Mohar & Poljak (1993) Bojan Mohar and Svatopluk Poljak. Eigenvalues in combinatorial optimization. In Combinatorial and graph-theoretical problems in linear algebra, pp. 107–151. Springer, 1993.
- Nagarajan & Kolter (2019) Vaishnavh Nagarajan and J Zico Kolter. Deterministic pac-bayesian generalization bounds for deep networks via generalizing noise-resilience. arXiv preprint arXiv:1905.13344, 2019.
- Noroozi & Favaro (2016) Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision, pp. 69–84. Springer, 2016.
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Oymak & Gulcu (2020) Samet Oymak and Talha Cihad Gulcu. Statistical and algorithmic insights for semi-supervised learning with self-training. ArXiv, abs/2006.11006, 2020.
- Pathak et al. (2016) Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2536–2544, 2016.
- Qiao et al. (2018) Siyuan Qiao, Wei Shen, Zhishuai Zhang, Bo Wang, and Alan Yuille. Deep co-training for semi-supervised image recognition. In Proceedings of the european conference on computer vision (eccv), pp. 135–152, 2018.
- Raghavendra & Steurer (2010) Prasad Raghavendra and David Steurer. Graph expansion and the unique games conjecture. In Proceedings of the forty-second ACM symposium on Theory of computing, pp. 755–764, 2010.
- Raghunathan et al. (2020) Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John Duchi, and Percy Liang. Understanding and mitigating the tradeoff between robustness and accuracy. arXiv preprint arXiv:2002.10716, 2020.
- Rigollet (2007) Philippe Rigollet. Generalization error bounds in semi-supervised classification under the cluster assumption. Journal of Machine Learning Research, 8(Jul):1369–1392, 2007.
- Saito et al. (2017) Kuniaki Saito, Yoshitaka Ushiku, and Tatsuya Harada. Asymmetric tri-training for unsupervised domain adaptation. arXiv preprint arXiv:1702.08400, 2017.
- Seeger (2000) Matthias Seeger. Learning with labeled and unlabeled data. Technical report, 2000.
- Shu et al. (2018) Rui Shu, Hung H Bui, Hirokazu Narui, and Stefano Ermon. A dirt-t approach to unsupervised domain adaptation. arXiv preprint arXiv:1802.08735, 2018.
- Singh et al. (2009) Aarti Singh, Robert Nowak, and Jerry Zhu. Unlabeled data: Now it helps, now it doesn’t. In Advances in neural information processing systems, pp. 1513–1520, 2009.
- Sohn et al. (2020) Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv preprint arXiv:2001.07685, 2020.
- Tarvainen & Valpola (2017) Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, pp. 1195–1204, 2017.
- Tian et al. (2020) Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. What makes for good views for contrastive learning. arXiv preprint arXiv:2005.10243, 2020.
- Tosh et al. (2020) Christopher Tosh, Akshay Krishnamurthy, and Daniel Hsu. Contrastive estimation reveals topic posterior information to linear models. arXiv preprint arXiv:2003.02234, 2020.
- Tsai et al. (2020) Yao-Hung Hubert Tsai, Yue Wu, Ruslan Salakhutdinov, and Louis-Philippe Morency. Demystifying self-supervised learning: An information-theoretical framework. arXiv preprint arXiv:2006.05576, 2020.
- Tzeng et al. (2014) Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474, 2014.
- Tzeng et al. (2017) Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7167–7176, 2017.
- Urner & Ben-David (2013) Ruth Urner and Shai Ben-David. Probabilistic lipschitzness: A niceness assumption for deterministic labels. 2013.
- Vapnik (1995) Vladimir Vapnik. The nature of statistical learning theory. Springer science & business media, 1995.
- Wei & Ma (2019a) Colin Wei and Tengyu Ma. Data-dependent sample complexity of deep neural networks via lipschitz augmentation. In Advances in Neural Information Processing Systems, pp. 9725–9736, 2019a.
- Wei & Ma (2019b) Colin Wei and Tengyu Ma. Improved sample complexities for deep networks and robust classification via an all-layer margin. arXiv preprint arXiv:1910.04284, 2019b.
- Xie et al. (2019) Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V Le. Unsupervised data augmentation for consistency training. arXiv preprint arXiv:1904.12848, 2019.
- Xie et al. (2020) Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698, 2020.
- Yalniz et al. (2019) I Zeki Yalniz, Hervé Jégou, Kan Chen, Manohar Paluri, and Dhruv Mahajan. Billion-scale semi-supervised learning for image classification. arXiv preprint arXiv:1905.00546, 2019.
- Yarowsky (1995) David Yarowsky. Unsupervised word sense disambiguation rivaling supervised methods. In 33rd annual meeting of the association for computational linguistics, pp. 189–196, 1995.
- Zhang et al. (2017) Yuchen Zhang, Percy Liang, and Moses Charikar. A hitting time analysis of stochastic gradient langevin dynamics. In Conference on Learning Theory, pp. 1980–2022, 2017.
- Zhang et al. (2019) Yuchen Zhang, Tianle Liu, Mingsheng Long, and Michael I Jordan. Bridging theory and algorithm for domain adaptation. arXiv preprint arXiv:1904.05801, 2019.
- Zou et al. (2019) Yang Zou, Zhiding Yu, Xiaofeng Liu, BVK Kumar, and Jinsong Wang. Confidence regularized self-training. In Proceedings of the IEEE International Conference on Computer Vision, pp. 5982–5991, 2019.
附录A伪标签去噪证明
A.1 放宽伪标签的扩展假设
在本节中,我们提供了定理 4.3 的宽松版本的证明。 然后,我们将在 A.2 节中将定理 4.3 简化为这个宽松版本。 将邻域概念限制为仅同一真实类中的示例将很有帮助:定义 和 。 请注意, 和 之间通常存在以下关系:
我们将在下面定义 子集的扩展的加法概念。
Definition A.1 (-集合 上的加法扩展)。
如果对于包含 的所有 都成立,我们就说 满足 在 上的正扩展:
现在,对于给定的分类器,定义 、 的稳健集,作为 在 下稳健的输入集t3>-转换:
以下定理表明,如果分类器 具有 鲁棒性并且足够好地拟合伪标签,则在 true 标签上的分类精度将会很高。
Theorem A.2.
对于给定的伪标签 ,假设 对于某些 在 上具有 -additive-expansion 。 假设 以足够的准确性和稳健性拟合伪标签:
| (A.1) |
那么 满足以下错误界限:
为了解释这个陈述,假设 拟合伪标签,错误率最多为 并且 (A.1) 成立。 然后是,因此如果对对总体分布的扰动具有鲁棒性,则
Lemma A.3.
在定理A.2的设定下,我们有。 结果,由于它包含 ,因此它紧随 之后。
证明依赖于以下思想:我们证明如果具有大概率,那么通过扩展假设,集合也将具有大概率(声明A.4 然而,我们还将证明 中的示例必须满足 (主张 A.5),这意味着伪标签损失会对此类示例造成惩罚。 因此, 不能太大(A.1),这意味着 也不能太大。
Claim A.4。
在定理A.2的设置中,定义。 如果,那么
证明。
定义。 假设满足-additive-expansion,如果成立,则成立。 此外,根据 和 的定义,我们将 定义为 ,等等 。 因此,我们得到
现在我们利用包含排除原理来计算
代入上式,我们得到
我们在其中获得了最后一行,因为 。 ∎
Claim A.5。
在定理4.3的设置中,定义。 对于任何,它都保持和。
证明。
对于任何,存在,使得根据的定义,和。 选择。 正如一样,根据的定义,我们也必须有。 此外,如、。 从开始,就得出。
正如 定义的 一样, 与 上的真实分类器非常匹配,因此 。 根据需要,可以得出 。 ∎
引理A.3的证明。
接下来,我们声明。 要查看这一点,请注意 、 和 。 因此, 和 意味着 。
下一个引理限制。
Lemma A.6.
在定理A.2的设置下,以下界限成立:
证明。
A.2 定理证明4.3
在本节中,我们通过将引理4.2简化为定理A.2来完成定理4.3的证明。 这需要将乘法扩展转换为 -additive-expansion,这是在以下引理中完成的。 让 表示带有真实类 的错误伪标签示例。
证明。
现在我们将完成引理4.2的证明。 Note that given Lemma 4.2, Theorem 4.3 follows immediately by noting that satisfies and by Assumption 3.3.
我们首先定义类条件伪标签和鲁棒性损失:和。 我们还将类条件错误定义如下:。 我们在下面证明引理 4.2 的类条件变体。
证明。
附录B无监督学习的证明
Definition B.1 (-constant-expansion).
如果对于满足 和 的所有 的所有 来说,以下条件成立,我们就说分布 满足 实体扩展:
如前所述, 由 定义。 我们将在本小节中使用上述扩展概念。 我们首先展示了一个为每个类别分配足够概率的鲁棒标记函数,该函数将与真实类别保持一致。
Theorem B.2.
假设 满足某个 的 -stant-expansion 条件。 如果它成立 并且
存在满足以下条件的排列 :
| (B.1) |
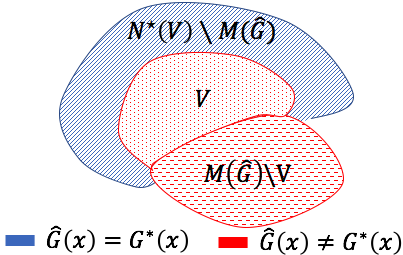
将定义为由:引起的分区。 以下引理显示 的某些子集的邻域未由 稳健地标记,其中 是 的某些子集。
Lemma B.3.
在定理B.2的设置中,考虑形式的任何集合,其中是的任意子集。 然后。
证明。
考虑任何。 有两种情况。 首先,如果,则根据的定义,。 然而,,它一定暗示着。 其次,如果,根据的定义,存在使得。 对于, 也是如此。 因此,由于,所以。 因此,可以得出。 ∎
接下来,我们展示 找到的每个簇将占据某些真实类别的大部分标签。
Lemma B.4.
在定理B.2的设定下,对于所有,存在使得。
证明。
为了矛盾起见,假设存在,使得对于所有,。 定义集合和。 请注意, 形成 的分区,因为 本身彼此不相交。 此外,我们可以将引理B.3与一起应用以获得。
现在我们观察到。 使用定理条件,可以得出
此外,对于所有 我们注意到
| (B.2) |
因此,。 因此,通过 -constant-expansion 我们有
作为,这意味着,一个矛盾。 ∎
前面的引理将用于构造由 预测的自然排列映射类到真实类。
证明。
根据引理 B.4 的结论,这种 的存在可能不成立的唯一方式是,如果存在某个 ,其中 代表 ,其中 。 在这种情况下,根据鸽子洞原理,由于 Lemma B.4 的结论适用于所有 ,并且 有 种可能的选择,因此一定存在 其中 对于 ,其中 。 那么,这是一个矛盾。
最后,要看到 是一个排列,请注意,如果 为 ,这将导致与上面相同的矛盾。 ∎
定理证明B.2。
首先,我们声明。 要看到这一点,请考虑任何 。 根据定义, 使得 和 或 。 因此,可以得出 ,其中最后一个相等是由于 和 对于 来说是不相交的事实。 现在我们将引理 B.3 应用于每个 来得出 的结论。
最后,我们观察到
| (B.3) |
根据引理 B.5 中 的定义。 现在我们再次应用 -constant-expansion 属性,正如我们假设的 一样,获得
然而,正如我们展示的,我们也有。 这与 和 矛盾,因此与 矛盾。
最后,我们注意到。 这样,我们最终得到
∎
B.1 定理证明3.6
Lemma B.6.
假设 满足 上的 乘法展开(定义 3.1)。 那么,对于任何 的选择, 都满足 恒定扩展。
证明。
考虑任何,使得适用于所有和。 定义。 首先,在 的情况下,我们通过乘法展开
| (because and ) |
这样,我们立即获得了不断的扩张。
现在我们考虑的情况。 通过乘法展开,我们必须有
| (because and ) | ||||
∎
以下引理说明了乘法展开设置的准确性保证。
Lemma B.7.
B.2 示例3.4和3.5的理由
为了避免示例 3.4 的不相交问题,我们可以将真实类 重新定义为 处最有可能的标签。 这也会导致截断的类条件分布 、,其中重叠被删除。 我们可以将理论分析应用于 、,然后将结果转换回 ,仅在重叠最小时稍微改变边界。
为了证明例 3.4,我们使用了高斯等周不等式 (Bobkov 等人,1997 年),该不等式指出,对于任何固定的 ,其中 为 ,选择 使 最小化的半空间给出:为矢量 与 。 然后是设置、,以及。 由于 在 中对于 正在减少,因此我们关于扩展的主张如下。 要查看我们关于分离的声明,请考虑集合 ,其中 。 我们注意到这些集合是 相互分离的,此外,对于示例中 的下限,我们注意到 在 下的概率为 。
对于示例3.5,我们注意到对于,。 因此,我们关于扩张的主张简化为高斯情况。
附录C全层边距泛化边界
C.1 端到端保证
在本节中,我们为有限训练集的无监督学习、半监督学习和无监督域适应提供端到端保证。 对于以下两个定理,我们将符号 作为某些乘法量的占位符,该乘法量是 中的多对数。 我们首先为无监督学习提供有限样本保证。
Theorem C.1.
以下定理为无监督域适应和半监督学习提供了有限样本保证。
C.2 第3.3节的证明
在本节中,我们提供定理3.7的证明草图。 该证明非常密切地遵循(Wei & Ma,2019b)的分析,但由于存在一些细微的差异,为了完整性,我们将其包含在此处。 我们首先声明目标中其他量的附加界限,其证明方式与定理 3.7 相同。
Theorem C.3.
训练样本 的抽取概率为 ,所有 形式的神经网络 将满足
对于所有 的选择,其中 是低阶项,而 隐藏了 和 中的多对数因子。
Theorem C.4.
训练样本 的抽取概率为 ,所有 形式的神经网络 将满足
对于所有 、 的选择,其中 为低阶项, 隐藏了 和 中的多对数因子。
现在我们概述定理3.7的证明,因为定理C.3和C.4的证明是相同的。 我们首先正式定义在带有标签 的示例 上评估的神经网络 的全层边距 。 我们记得 计算函数 。 我们对的图层进行索引,如下:定义,为定义,这样 。 令表示每一层的扰动,我们将扰动输出定义如下:
现在所有层边距 定义为
正如泛化界限证明中的典型情况一样,我们定义一类固定的神经网络函数来分析,表示为
其中 是第 权重矩阵的某种可能实例化。 我们还重载符号,让 表示与矩阵乘以 中的权重相对应的函数类。 让 表示矩阵运算符范数。 对于函数类,我们让表示规范中的覆盖数。 以下条件对于分析很有用:
Condition C.5 (条件 A.1 来自 (Wei & Ma,2019b))。
我们说函数类 满足关于范数 的 覆盖条件,复杂度为 如果对于所有 ,
Lemma C.6 (定理A.1的改编(Wei & Ma, 2019b))。
引理C.6的证明反映了定理A.1的证明(Wei & Ma, 2019b)。 主要区别在于,因为我们寻求边际阈值的界限,而(Wei & Ma,2019b)证明了取决于平均边际的界限,所以我们必须分析稍微修改的泛化损失。 为了证明引理C.6,我们首先定义扰动的和。 我们证明 是 中的 Lipschitz,相对于 固定 。
Claim C.7。
选择。 那么对于任何,
如果我们用 替换 ,同样的结论成立。
证明。
我们考虑两种情况:
情况 1:。 让 表示公共值。 在这种情况下,期望的结果立即从的权利要求E.1得出(Wei & Ma, 2019b)。
情况 2:。 在这种情况下,(Wei & Ma, 2019b)中权利要求A.1的解释意味着。 (本质上,我们选择 和 ,这样 。) 同样,。 因此,它必须遵循 。 ∎
对于 ,定义斜坡损失 如下:
我们现在定义假设类。 现在我们限制该假设类的 Rademacher 复杂度:
由于权利要求C.8的证明是标准的,我们提供了其证明的草图。
权利要求C.8的证明草图。
首先,通过(Wei & Ma, 2019b)的引理A.3,我们得到满足条件C.5且范数 和复杂性。 现在让 成为 中 的 覆盖。 我们定义函数 的 -范数如下:
然后标准表明
是 在 准则中的 覆盖,因为对于任意固定的 , 是 利普希兹,而 在 准则 中是 利普希兹。 由此可见。 现在我们应用达德利定理:
可以使用标准计算来限制右侧的数量,从而给出所需的结果。 ∎
引理C.6的证明。
首先,根据 Rademacher 复杂度和泛化之间的标准关系,声明 C.8 让我们得出结论:以概率 ,对于任何 固定 ,所有满足:
我们还注意到 当 时,因为在这种情况下 。 由此可见。 因此,我们得到
| (C.2) |
仍有待证明 (C.1) 对于所有 成立。现在,以 形式对 的选择执行联合绑定已成为标准,其中 和 ,因此我们只在这里勾画一下论证。 我们将 与失败概率 联合绑定到 (C.2),因此 (C.2) 将成立对于所有,概率为。 对于 的任何选择,都会有 使得 或 (C.1) 必定成立。 (有关更详细的论证,请参阅(Wei & Ma,2019b)的定理 C.1。) 因此,将存在一些 ,使得 (C.2) 的右侧被 (C.1),根据需要。 ∎
C.3 全层边距的数据相关下限
现在,当激活 具有 -Lipschitz 导数时,我们将提供定理 3.7 中使用的所有层边距的下界。 在本节中,可以方便地修改索引以将激活计为自己的层,因此总共有 层。 令 表示第 矩阵乘法之前层的 范数,其中下标中的括号区分权重索引和层索引(其中还包括激活层)。 将 定义为第 层相对于在 处评估的第 层的雅可比行列式。 定义。 我们使用以下量来测量 之后层的稳定性:
对于次要项 给出的
现在,我们对 和 有以下下限:
Proposition C.9 (来自的引理C.1(Wei & Ma,2019b))。
在上面的设置中,如果,我们有
此外,如果 对于所有 ,则
附录D实验
D.1 使用 GAN 对扩展属性的经验支持
在本节中,我们提供有关图 1(左)中所示的 GAN 验证的更多详细信息。 我们使用从预训练的 BigGAN (Brock 等人,2018) 中采样的 128 x 128 图像。 我们将图像分类为 Engstrom 等人 (2019) 鲁棒性库中选择的 10 个超类:狗、鸟、昆虫、猴子、汽车、猫、卡车、水果、真菌、船。 这些超类由属于超类类别的所有 ImageNet 类组成。 为了从超类中采样图像,我们从超类中统一采样 ImageNet 类,然后从以该类为条件的 GAN 中采样。 我们对每个超类采样 1000 张图像,并训练 ResNet-56 (He 等人, 2016) 来预测超类,实现了 93.74% 的验证准确率。
接下来,我们将 GAN 图像近似投影到经过训练的分类器的错误标记集上。 我们近似投影如下:我们优化一个目标,该目标由距原始图像的 距离和预训练分类器与超类标签的负交叉熵损失组成。 令表示GAN映射,表示原始图像,表示标签,表示预训练分类器,目标如下:
我们使用 和学习率 优化 2000 个梯度下降步骤的 ,使用与生成 生成的 是集合 中 的邻居,这是错误标记的 集合。
对从每个类中采样的 200 个 GAN 图像执行此过程后,我们发现这些图像中有 20% 的邻居 具有 。 请注意,这相当于将 [0, 1] 中的像素值平均修改每个像素 0.024。 我们使用 来表示通过这种方式找到的一组错误标记的邻居。 通过目视检查,我们发现邻居在视觉上与原始图像非常相似,这表明将这些图像视为“邻居”是合适的。 在图 1 中,我们可视化了此过程找到的邻居的典型示例。 因此,设置,概率为0.0626的集合具有由概率为0.2的引起的相对较大的邻域。 这支持了我们的扩展假设,尤其是 A 节中的加性概念。
接下来,我们使用相同的分类器作为伪标记器,对每个超类包含 10000 个额外未标记图像的数据集执行自训练,其中这些图像是独立于上一步中的 200 个 GAN 图像进行采样的。 我们使用 VAT (Miyato 等人,2018)将输入一致性正则化添加到自训练过程中。 经过自训练,新分类器的验证准确率提高到95.69%。
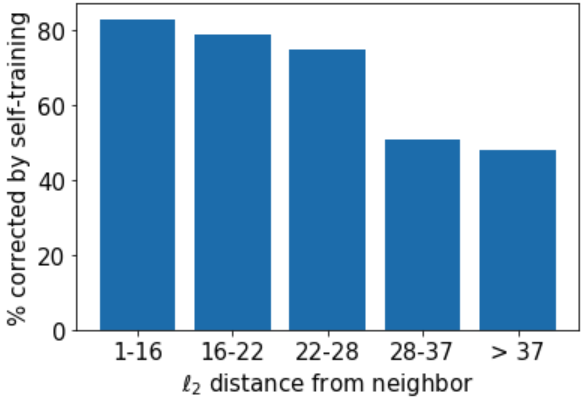
此外,我们还评估了自训练分类器 在 子集上的性能,其中与邻居的距离大于 1。 我们让 表示这个子集。 我们选择以这种方式过滤,以排除原始邻居已经被错误分类的情况。 我们发现 在 的示例中达到了 67.27% 的准确率。
此外,图 3 表明 在来自 的示例中更加准确,这些示例更接近用于初始化投影的原始邻居。 这提供了证据,表明输入一致性正则化自训练确实通过依赖正确伪标记的邻居进行去噪来纠正伪标记器的错误,因为图3显示与邻居更接近的示例是更有可能被去噪。 最后,我们还指出,图 3 提供了证据,表明去噪机制确实从自训练数据集推广到总体,因为 中的示例及其原始邻居都没有出现在自训练数据集中。
D.2 伪标记实验
在本节中,我们验证 (4.1) 中的理论目标是否按预期工作。 我们考虑一个无监督的域适应设置,我们使用源分类器中的伪标签进行自我训练。 我们评估了以下优化理想目标 (4.1) 的渐进步骤,目的是展示添加我们理论的每个组件所带来的改进:
来源:我们在标记的源数据集上训练模型,并直接在目标验证集上对其进行评估。
PL:使用上面获得的分类器,我们在目标训练集上生成伪标签,并训练一个新的分类器来适应这些伪标签。
PL+VAT:我们考虑理论中的扰动集由周围的球给出的情况。 我们训练一个分类器来拟合伪标签,同时使用 (Miyato 等人,2018) 的增值税损失对目标域上的对抗鲁棒性进行正则化,获得分类器 的以下损失:
请注意,此损失仅在 正确预测 的示例中强制执行真正的稳定性。 对于不符合 的伪标签,交叉熵损失会降低模型的置信度,因此离散标签仍然可能在此类示例的输入转换下轻松翻转。
PL+VAT+AMO:由于定理4.3中的理论保证是针对群体损失的,因此我们应用的AMO算法(Wei & Ma, 2019b) 在增值税损失项中,以规范稳健的全层利润(参见第 3.3 节)。 这鼓励了训练集的鲁棒性,以更好地泛化。
PL+VAT+AMO+MinEnt:请注意,PL+VAT 仅鼓励适合伪标签的示例的鲁棒性,但理想的分类器不应适合与真实情况不一致的伪标签。 由于定理 4.3 中的界限随着 的鲁棒性而提高,我们的目标是鼓励 与 。 为此,我们修改损失以允许分类器忽略伪标签的 部分并优化这些示例的最小熵损失。 我们在下面提供了有关如何选择要忽略的伪标签的更多详细信息。
MinEnt+VAT+AMO:我们通过从目标中删除伪标签来研究它们的影响。 相反,我们依赖于以下损失,它只是在拟合源数据集时对目标执行熵最小化:
我们考虑了训练稳定性的源损失。 和之前一样,我们在增值税损失项中应用 AMO 算法,以鼓励分类器泛化的鲁棒性。
表 1 显示了这些方法在六个无监督域适应基准上的性能。 我们看到,当我们向目标添加额外的组件以匹配理论时,性能会提高。 我们注意到,这些实验的目标是验证我们的理论,而不是推动这些数据集的最新技术,这通常依赖于领域混淆(Tzeng 等人,2014;Ganin 等人,2016; Tzeng 等人, 2017),这超出了我们的理论范围。 例如,Shu 等人 (2018) 通过使用域混淆技术,同时在目标上优化增值税损失和熵最小化,同时在标记源数据上进行训练,在这些基准上取得了出色的结果。 我们的 MinEnt+VAT+AMO 结果表明,当域混淆被消除时,性能会受到影响,并且实际上比仅在除 STL-10 到 CIFAR-10 之外的所有数据集上的源训练更差。 我们在下面提供了更多的实验细节。 我们对每个数据集使用与(Shu等人,2018)相同的数据集设置和模型架构。 所有分类器均使用 SGD 进行优化,余弦学习率和权重衰减为 5e-4,目标批量大小为 128。 学习率的值根据每个数据集和方法的验证集在值范围 内进行调整。 我们通过在范围内以相同方式进行调整来选择,即增值税损失系数。 对于 MinEnt+VAT+AMO,我们修复 PL+VAT+AMO+MinEnt 的最佳超参数并调整 并修复 。 我们还调整了 中源损失的批量大小。 表 1 描述了目标验证集的准确性。 我们使用提前停止并显示训练期间达到的最佳准确性。 所有显示的准确度均基于算法的一次运行,但 (+MinEnt) 方法除外,我们使用相同的超参数对 3 次独立运行进行平均。
为了计算增值税损失(Miyato等人,2018),我们在图像空间中采取一步梯度下降,以最大化扰动图像与原始图像之间的KL散度。 然后我们将此梯度归一化为 范数 1 并将其添加到图像中以获得扰动版本。 为了结合(Wei & Ma,2019a)的AMO算法,我们还优化了DIRT-T架构中池化层之前的三个隐藏层的对抗性扰动。 扰动的初始值设置为 0,我们使用学习率为 1 的一步梯度上升,将它们与对输入的扰动联合优化。
最后,我们提供了有关如何选择要忽略 PL+VAT+AMO+MinEnt 目标的伪标签的详细信息。 在此步骤中需要小心,以防止优化目标陷入不良的局部最小值。 我们将维护一个模型,其权重是过去模型权重的指数移动平均值。 每次梯度更新,的权重都会更新,其中是梯度更新后的当前模型权重。 我们的目标是丢弃 - 最大化 的伪标签部分,其中 是伪标签,例如 ,而 索引当前迭代。 在训练过程中,我们会将 从 0 线性增加到最终值 。 为了实现这一目标,我们维护损失的 分位数的指数移动平均值,并使用损失 的 分位数在每次迭代中进行更新> 根据当前批次计算。 我们忽略损失值高于第 个损失分位数的指数移动平均值的伪标签。
| Source | MNIST | MNIST | SVHN | SynDigits | SynSigns | STL-10 |
|---|---|---|---|---|---|---|
| Target | SVHN | MNIST-M | MNIST | SVHN | GTSRB | CIFAR-10 |
| Source Only | 35.8% | 57.3% | 85.4% | 86.3% | 77.8% | 58.7% |
| MinEnt + VAT + AMO | 20.6% | 28.9% | 83.2% | 83.6% | 42.8% | 67.6% |
| PL Only | 38.3% | 60.7% | 92.3% | 90.6% | 85.7% | 62.0% |
| + VAT | 41.7% | 79.8% | 97.6% | 93.4% | 90.5% | 62.3% |
| + AMO | 42.5% | 81.4% | 97.9% | 93.8% | 93.0% | 63.9% |
| + MinEnt | 46.8% | 93.8% | 98.9% | 94.8% | 95.4% | 67.0% |