深入挖掘中文文本图像识别中的CRNN模型
摘要
自动文本图像识别是计算机视觉领域的普遍应用。 一种有效的方法是使用卷积循环神经网络(CRNN)以端到端(End2End)的方式完成任务。 然而,众所周知,CRNN 无法检测多行图像和类 Excel 图像。 在本文中,我们提出了一种替代方案,首先识别单行图像,然后使用所提出的多种方法扩展相同的架构来识别多行图像。 为了识别包含方框线的类 Excel 图像,我们提出了线深度去噪卷积自动编码器(Line-DDeCAE)来恢复方框线。 最后,我们提出了一种知识蒸馏(KD)方法来压缩原始 CRNN 模型而不失通用性。 为了进行实验,我们首先从一本中文小说中生成人工样本,然后进行各种实验来验证我们的方法。
1简介
光学字符识别(OCR)在现实世界中有着广泛的应用。 目前的方法倾向于使用深度神经网络(DNN)来接收简单的预处理图像作为输入,然后提取有用的特征来进行最终预测(Girshick 等人(2014);Wang 等人(2012);Bissacco 等人(2013) ); Jaderberg 等人 (2016); Graves 等人 (2008))。 这种简单的过程已经成为这项任务的标准方法,现在更多的研究重点关注如何发明聪明的技巧来提高整体架构的性能。
卷积循环神经网络(CRNN)(Shi 等人 (2016))是第一个成功的端到端(End2End)文本图像识别模型。 随后提出了多种基于 CRNN 模型来提高准确性的新想法。 CRNN由三个相互依赖的模块组成:卷积神经网络(CNN)、循环神经网络(RNN)、联结时间分类(CTC)。 CNN 接收图像来提取特征,RNN(特别是双向 LSTM/BiLSTM)循环所有特征来计算 CTC 损失。 为了更新模型中的参数,CRNN 反向传播整个模型以获得梯度。
当输入图像只有一行文本时,CRNN 表现良好。 直观上,CNN 使用宽度大于高度的内核尺寸,因此,提取的特征可以作为嵌入输入到 BiLSTM 中以计算 CTC 损失。 为了识别多行图像,现有方法倾向于使用目标检测算法首先获得文本区域,然后将其放入CRNN中。 当有大量训练数据集可用时,这种两阶段过程效果很好,但是模型容量和计算效率严重限制了部署。
此外,根据我们的实验结果,我们得出结论,当图像采用类似 Excel 的形式时,CRNN 的表现不太准确。 现有方法利用简单的传统计算机视觉算法来消除前方图像中的框线。 然而,该方法对于各种情况下的不同图像风格并不鲁棒。
在本文中,我们提出了多种方法来克服简单 End2End CRNN 模型中的上述困难。 为了识别单行图像,原始 CRNN 应用 VGG16 模型(Simonyan & Zisserman (2014))作为主干,并在 CNN 块中修改内核大小和步幅,以导出 特征图最后的conv层。 为了避免精心设计的超参数,我们使用标准的VGG16模型(根据样本复杂度剪掉几层),为了获得最终的嵌入到BiLSTM中,我们设计了列平均池化来自适应地得到 特征图。
为了识别多行图像,我们提出了两种简单而有效的方法。 第一个是在 CNN 的最后一层,对于每个输出特征图,我们只需将其拉伸为一行特征。 所有特征图都可以并行执行。 根据我们的实现,我们惊讶地发现这种方法可以很好地识别多行图像。 另一种是我们在CNN的最后一个特征图中使用注意力机制,对于每个特征图,我们将其重塑为二维矩阵,第一维为高度,第二维为宽度和通道数的乘积,然后我们使用两个在第一维上将独立的 Conv1d 层连接到 conv 以获得新的特征图和注意力掩模,我们引用注意力是因为我们采用了 ECANet 中的类似想法(Wang 等)人(2020))。
我们的下一个任务是根据需要消除图像中的框线。 我们提出了一种深度去噪卷积自动编码器 (DDeCAE) (Gondara (2016)) 变体 Line-DDeCAE,将文本视为尝试重建框线的噪声。 受去噪自动编码器的启发,我们在数据集的高维空间中查看比文本更低的流形中的框线,因此很容易恢复它们,最后,添加原始输入数据给我们提供了没有框线的干净图像。
为了将我们的模型部署到便携式设备中,我们选择将大型模型压缩为轻型模型。 已经制定了不同的策略。 剪枝(Han 等人 (2015b); Luo 等人 (2017); Molchanov 等人 (2016); Li 等人 (2016))削减网络中的大量权重,并简化整个模型超过;二值化网络(Dean 等人 (2012); Rastegari 等人 (2016); Hubara 等人 (2016))将权重处理为 -1 或 1,以减少模型的存储空间等。以上全部作品倾向于通过或多或少的学习信息损失来获得小型架构。 知识蒸馏(KD)(Hinton 等人(2015))是一种有前景的方法,通过模仿大型(教师)模型到小型(学生)模型之间的逻辑关系,将学到的知识转移到小型(学生)模型中。 为了有效地缩小模型尺寸,我们在三个方面采用了KD方法。 首先,我们应用标准 KD 来匹配软逻辑,然后借鉴 FitNets (Romero 等人 (2014)) 的思想来匹配 CNN 中的中间层,最后,我们还将隐藏状态和单元状态推送到BiLSTM 进行匹配。
总而言之,我们在本文中的贡献是:
1. 对于单行图像,我们建议使用简单的列平均池化而不是精心设计的超参数来获得CNN最后一层的特征图。
2. 对于多行图像,我们提出了两种简单而有效的方法来提高性能。
3. 对于带有框线的图像,我们提出 Line-DDeCAE 来恢复图像中的线条,然后我们可以通过与输入求和来获得干净的文本图像。
4. 为了将我们的模型部署到便携式设备中,我们提出了一种 CRNN 的 KD 方法,它将大型模型压缩为轻量级模型。
5. 我们生成了一个人工中文数据集进行验证,大量实验揭示了我们方法的效率。
2相关工作
我们简单回顾一下 CRNN、attention、AutoEncoder 和 KD 的相关工作。
CRNN。 CRNN模型在文本图像识别中受到广泛关注。 CRNN 以 End2End 训练和推理方式而闻名,它放弃了图像预处理、文本检测和文本分割以及最终识别的复杂程序。 CRNN只是简单地应用VGG16作为backbone从图像中提取特征来自动完成文本检测。 为了实现文本分割和识别,CRNN 利用 BiLSTM 和 CTC 损失来包裹整个预测过程。 CRNN 是当今研究领域的默认架构之一。 还提出了一些其他类似 CRNN 的模型(Kapka & Lewandowski (2019);Kao 等人 (2018))。 然而,CRNN 对于多行图像和类似 excel 的图像并不鲁棒。 要识别多行图像,一种简单的方法是首先使用目标检测算法(PSENet、YOLO等)(Li 等人 (2018); Redmon 等人 (2016); Ren 等人 (2015))来检测文本区域,然后提取的原始图像可以放入CRNN模型中进行训练,这个过程很难以End2End方式执行,因此,两阶段过程可以切断它们之间的连接。 此外,类似 Excel 的图像包含方框线,我们的实验结果表明 CRNN 对此类数据不友好。 最后,由于使用了大型模型主干,CRNN 无法满足低延迟实现。 在本文中,我们重点关注基线 CRNN 模型,并提出了多种简单而有效的方法来解决上述问题。
注意。 注意力机制(Bahdanau 等人 (2014))如今已渗透到机器学习的更广泛领域。 在自然语言处理(NLP)领域,人们的关注已经获得了足够的动力。 最近,Transformer (Vaswani 等人 (2017)) 模型应用纯注意力机制击败了传统语言模型。 BERT (Devlin 等人 (2018)) 学习上下文词嵌入,这已在许多下游 NLP 任务中得到有效证明。 越来越多的 NLP 模型超越人类水平的性能也封装了注意力,如 GPT (Khandelwal 等人 (2019))、T5 (Raffel 等人 (2019)) 等.. 在计算机视觉(CV)中,注意力被广泛应用于物体识别任务(Fu 等人 (2017))。 其他一些注意力机制也是可用的,SENet (Hu 等人 (2018)) 首先通过计算每个通道的全局平均池激活的 sigmoidal 注意力值来引入通道注意力。 更多基于SENet注意力的方法被提出(Wang等人(2020); Li等人(2019))。 在本文中,我们应用了 ECANet (Wang 等人 (2020)) 中的相同思想,其中注意力被 Conv1d 层取代,而不是原始 SENet 中的全连接层。
自动编码器。 受 PCA 的启发,AutoEncoder(AE)被提出用于在大型训练数据集不可用时对大型神经网络进行预训练(Ng 等人 (2011); Gondara (2016); Rifai 等人 ( 2011))。 AE 由编码器和解码器组成,编码器用于将输入压缩为密集特征,解码器将密集特征映射回输入空间,希望输出与输入相似。 AE 可以以贪婪逐层方式(输入逐层重建)进行训练,也可以以端到端方式(所有层可以同时训练)进行训练,即深度 AE 或堆叠 AE。 此外,AE 可以被视为生成模型,从压缩的隐藏特征生成新的示例。 变分AE(VAE)(Kingma & Welling (2013))首先将输入映射到压缩层中的高斯分布,然后将采样的压缩(隐藏)特征映射到各种输出。 在本文中,我们使用一种变体深度 AE,其中编码器由卷积层和池化层组成,解码器由上采样层和转置卷积层组成。
知识蒸馏。 有多种方法可以实现模型压缩。 剪枝 (Han 等人 (2015b); Luo 等人 (2017); Molchanov 等人 (2016); Li 等人 (2016)) 在训练过程中删除不重要的权重,并且对整个模型进行修剪超过。 量化(Wu 等人 (2016); Han 等人 (2015a))旨在与相似范围内的权重共享相同的值。 二值化网络 (Dean 等人 (2012); Rastegari 等人 (2016); Hubara 等人 (2016)) 尝试满足所有权重为 -1 或 1。 此外,还提供了一些灯光模型设计,请读者参考(Sandler 等人 (2018); Iandola 等人 (2016); Zhuang 等人 (2018a))。 知识蒸馏(KD)(Hinton 等人 (2015))是将知识从大型(教师)模型转移到小型(学生)模型的一种非常有前景的方法。 标准 KD 方法建议学生模型学习“硬”标签和教师输出的“软”标签,而不是直接从数据“硬”标签中学习,这些标签似乎是具有温度超参数的 softmax 概率分布。 已经发布了大量 KD 算法来解决标准 KD 的缺点。 FitNets (Romero 等人 (2014)) 是第一个尝试让学生模型模仿教师模型中的中间层的 KD 方法。 在FSP(Yim等人(2017))中,学生在模型的大部分内容中学习老师的Gram矩阵。 注意力 KD(Zagoruyko & Komodakis (2016))尝试学习学生和教师之间中间层的注意力值。 在通道方面的蒸馏中,Zhou 等人 (2020) 尝试匹配教师和学生模型之间的 SE 注意力。 上述工作都是假设有一个固定的预训练教师模型,因此,必须存储教师模型的输出以供下游学生训练,这是效率不高的。 为了解决这个问题,在线蒸馏的工作出现了。 DML (Zhang 等人 (2018b)) 倾向于让教师通过标准 KD 方法向学生学习,但他们都是同时学习。 Be-your-own-teacher (Zhang 等人 (2019)) 从自身架构中学习学生。 Chen等人(2017)发明了教师和学生模型共同学习的简单有效的目标检测蒸馏方法。 现在更多的作品主要关注如何同时学习教师和学生。 在本文中,我们也采用这种思想来一起学习大型 CRNN 和小型 CRNN 模型,而不需要存储预先训练的教师统计数据,从而产生很高的效率。
3方法
3.1 列平均池化
传统的CRNN重新设计CNN模块中的超参数以满足最后一层特征图的大小。 然而,我们发现,如果不仔细调整超参数,列平均池化(CAP)可能会导致类似的结果,如图1所示。
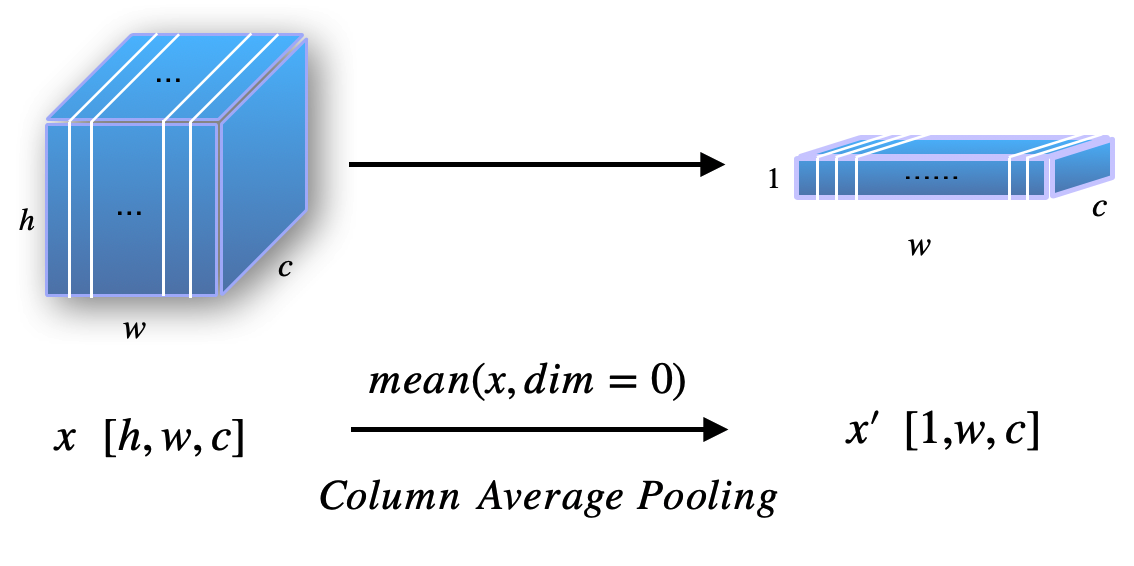
假设最后一层的特征图的大小具有形状:,其中分别是高度、宽度和通道数。 这里,我们省略了批次维度。 CAP其实很简单,让为CAP的输出,然后
| (1) |
3.2 多行拉伸
为了处理多行图像,我们首先使用一种简单的方法将最后一层的特征图拉伸到一行。 受物体检测中FCN(Dai等人(2016))的启发,每个滑动窗口可以使用conv操作并行处理,因此可以分解最终层的特征图分成对应于每个窗口的不同部分。 对于多行图像,每一行也可以并行操作,因此,我们采用与FCN相同的思想,使用相同的架构来识别单行图像,我们可以在最后一层中导出多行特征图如图2所示,因此我们在MultiRow Stretching方法中将其重塑为单行特征图。
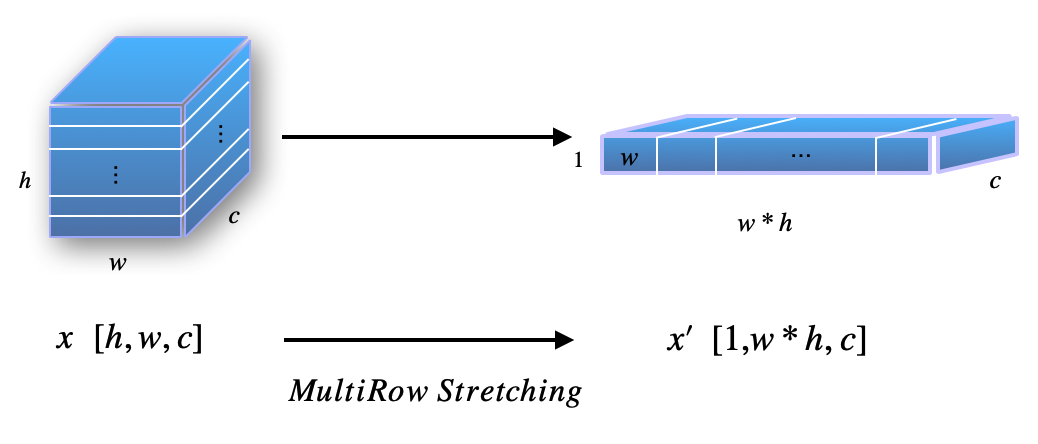
直观上,我们通过将一张图像中的所有句子以行的方式连接在一起,将它们视为一个句子。 具体来说,重用上面部分的符号,为了最终计算 CTC 损失,我们以 PyTorch 方式使用标签 执行以下操作:
| (2) | ||||
| (3) |
3.3注意
多行拉伸可以解决字符较少的图像,如果拉伸的特征很长,可能会出现梯度消失或爆炸问题。 此外,如果原始输入图像中的每一行之间没有明显的关系,那么该方法可能会收敛到次优结果。 因此,我们使用 ECANet (Wang 等人 (2020)) 中类似的注意力方法来导出具有固定行的图像的最终特征图。 图 3 说明了此过程。
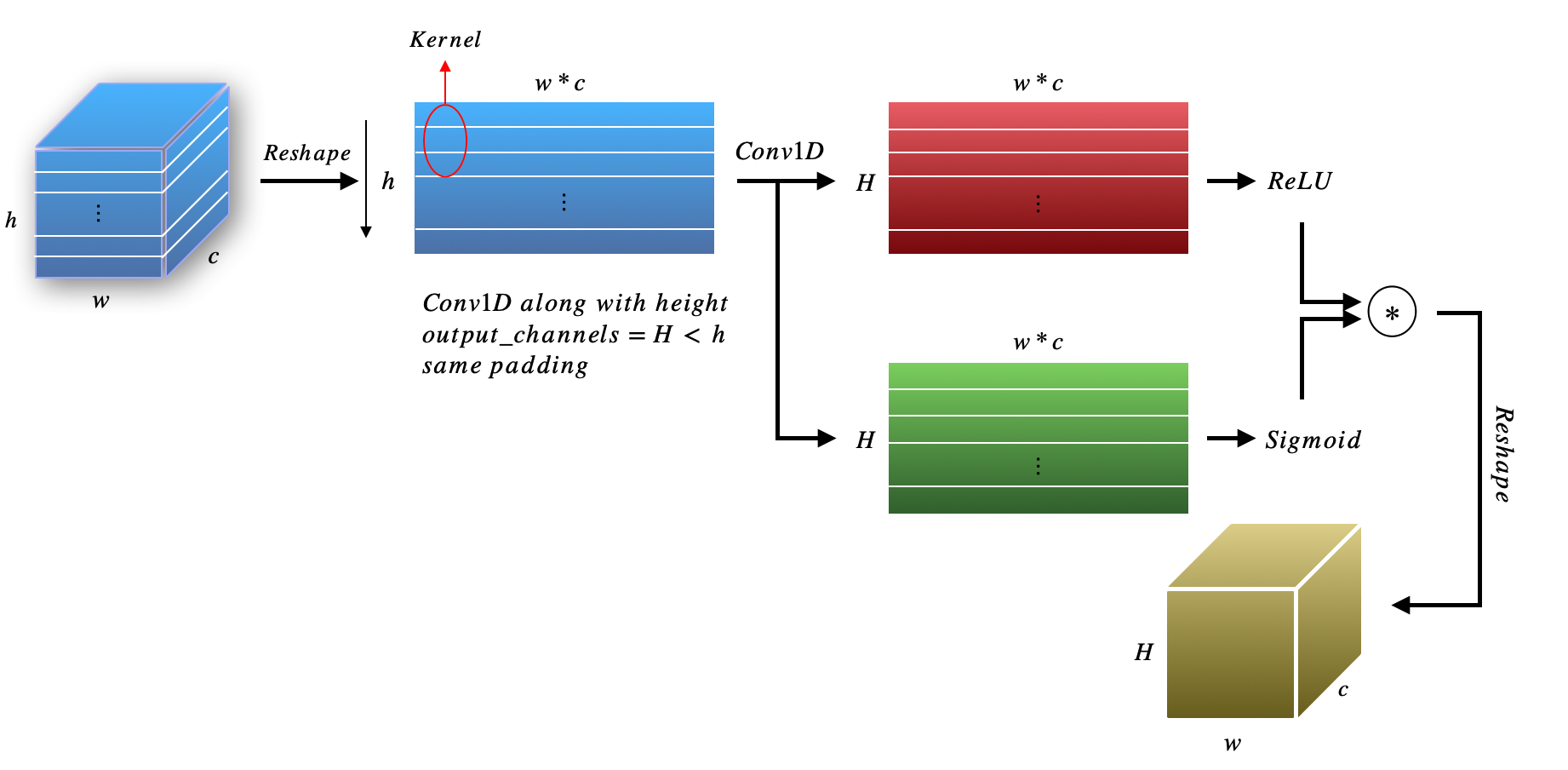
按照上述符号,我们首先将 3D 张量 重塑为 2D 张量 。 对于每一行特征,我们将其视为最终特征图的一个元素。 直观地,假设每个图像的行是,所以我们关注中的每一行来导出特征图和S形注意掩模。 就像在 ECANet 中一样,我们使用 Conv1D 在特征图的高度上进行 conv 。 最终结果可以通过参与特征图和注意力掩模的乘积得出。 总结一下上面的说法,我们有以下操作:
| (4) | ||||
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) | ||||
| (9) |
对于最终的,我们将其逐行分成独立的部分。 然后我们将它们输入 BiLSTM 来计算单个 CTC 损失。 给定批量大小,优化的CTC损失为:
| (10) |
其中是特征图部分的示例,是相应的标签。
3.4线深度去噪卷积自动编码器
在本节中,我们提出了一种深度去噪卷积自动编码器 (DDeCAE) (Gondara (2016)) 变体,称为图 4 中的 Line-DDeCAE,以去除原始图像。 类似 Excel 形式的原始图像更难识别。 因此,在这项工作中,我们倾向于首先获得没有框线的干净图像,然后将它们发送到 CRNN 中进行识别任务。
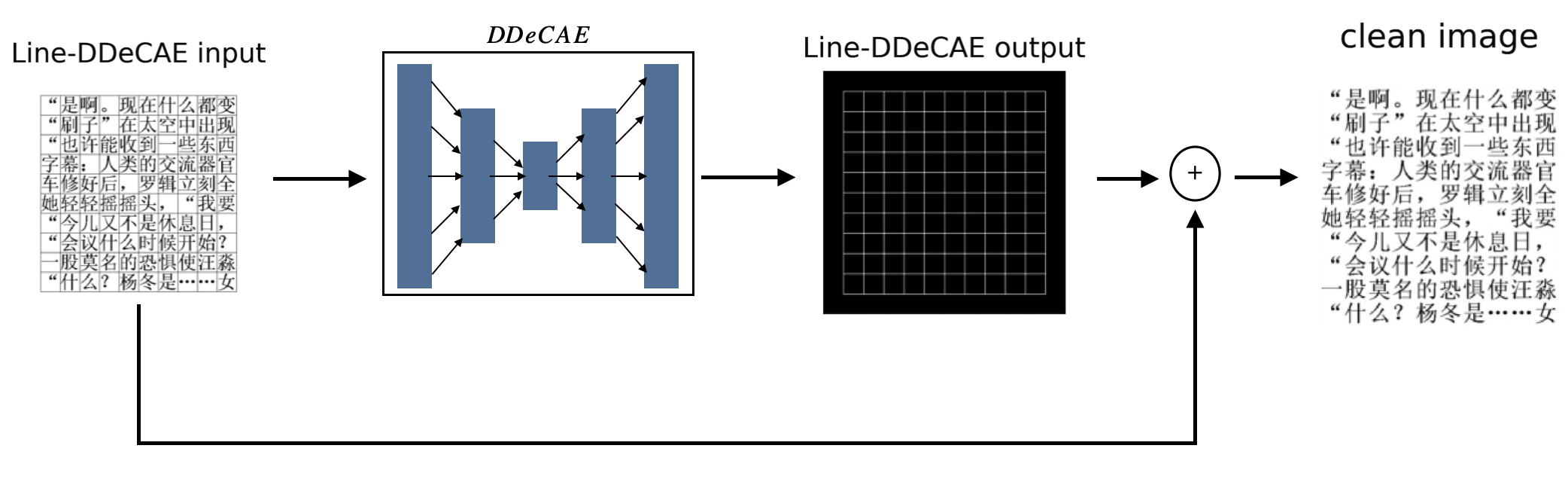
受去噪自动编码器(DeAE)的启发,原始输入被小的随机噪声扭曲,被压缩为紧密的特征并重建原始输入。 直观地说,添加噪声会让原始数据分布稍微消失,从而产生更强大的压缩特征。 在这项工作中,我们要么将图像中的文本视为尝试恢复框线的噪声,要么将图像中的框线视为尝试恢复文本的噪声(这就是 DDeCAE 所做的)。 我们在 DCGAN (Radford 等人 (2015)) 的判别器和生成器中使用相同的架构,分别构建 Line-DDeCAE 的编码器和解码器,只需进行少量修改。
在实验中,我们发现当我们将框线视为噪声并恢复文本时,结果确实很嘈杂。 由于文本位于比框线更复杂的高维流形中,因此剥离框线是一项更容易的任务,而恢复文本则更困难。 因此,我们尝试恢复文本为噪声的框线。 回想一下最初的 DeAE,作者建议噪声输入不应偏离原始数据分布太多。 在 Line-DDeCAE 中,我们显然让噪声与原始流形完全不同。 然而,在实验中,我们发现这种方法效果很好。 我们假设虽然噪声(文本)远离原始流形(盒子线),但盒子线位于更紧凑的流形中,并且从更高的流形中恢复它相对容易。 最后,我们将原始输入图像与 Line-DDeCAE 的输出相加,以获得没有框线的干净图像。
总之,假设带框线的原始输入是,Line-DDeCAE的输出是,那么干净的图像是,上面的过程可以是总结为以下操作:
| (11) | ||||
| (12) |
3.5知识蒸馏
在本节中,我们介绍一种简单的 KD 方法,用于将大型(教师)CRNN 模型压缩为小型(学生)模型。
标准KD利用KL散度通过温度超参数来推动学生的softmax接近教师的softmax,这称为软目标。 具体来说,标准KD应用了将软目标与原始目标(硬标签)相结合的损失函数。 假设教师模型的logit为,学生模型的logit为,是对应的ground-truth标签,示例的学生模型的softmax输出为,教师模型的softmax输出为,学生模型的标准KD的损失为:
| (13) |
其中 是权衡硬目标交叉熵损失和软目标 KL 散度的超参数。
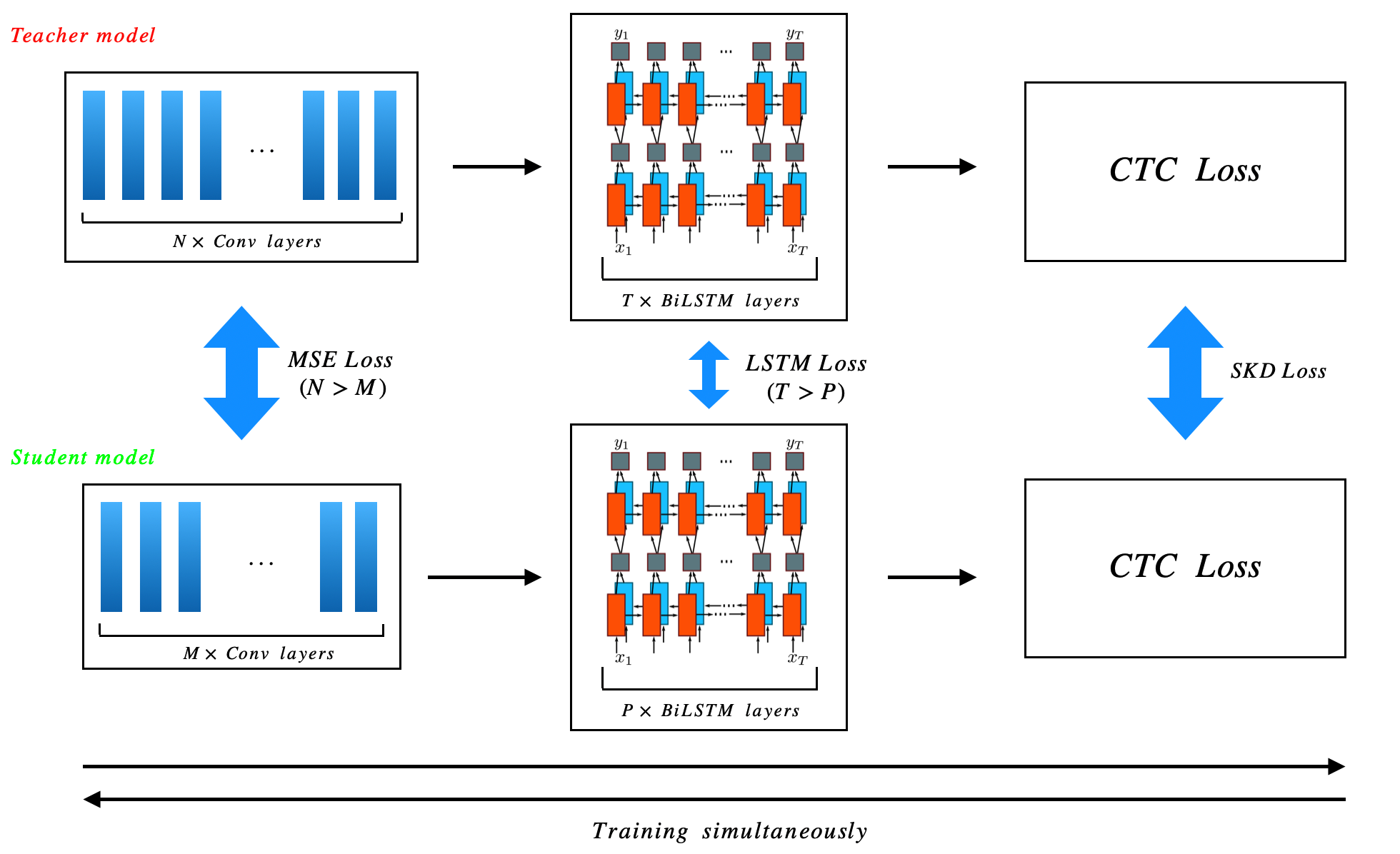
除了标准的 KD 之外,在 CNN 中我们还采用了 FitNets (Romero 等人 (2014)) 的思想来比较教师模型和学生模型之间的中间层激活。 为了匹配维度,我们使用卷积层作为回归层。 假设我们比较层,对于层,学生模型的激活是,教师模型的激活是,那么所有层MSE损失是:
| (14) |
最后,为了从 BiLSTM 中提取知识,我们建议比较学生模型和教师模型之间的 值和 值的最后一个时间步,因为 BiLSTM 中隐藏值的最后一步可能会积累足够的信息来提炼。 按照上面相同的符号,将教师模型中的最后一个 表示为 ,将学生模型中的最后一个 表示为 ,将学生模型中的最后一个 表示为 ,我们可以将 写为:
| (15) |
我们在教师模型和学生模型中使用相同的隐藏维度。
总而言之,我们在优化中使用以下损失函数:
| (16) |
需要注意的是,我们同时优化整个学生模型和教师模型,为了克服模型崩溃问题 (Miyato 等人 (2018)),我们将教师模型的值从 PyTorch 张量中分离出来,仅鼓励学生模型朝着精炼的方式进行优化。 因此,整个优化损失函数为:
| (17) |
本文提出的KD算法整体如图5所示。
4实验
4.1 数据集
在本文中,我们从中国小说《三体》中生成简单的合成数据集。 我们按照本书的顺序生成所有示例。 每个图像包括 1 行或 7 行或 10 行和类似的列,以使每个图像除了单行图像外都接近正方形。 我们创建单行图像数据集,称为 用于 CAP 验证。 对于多行拉伸和注意力方法,我们生成没有框线的(每个图像包含7行),并且我们还创建带有框线数据集的多行图像(每个图像包含 10 行)来验证 Line-DDeCAE 方法。 对于 KD,我们运行 的扩展版本,即 和 进行蒸馏。
对于每种方法,我们将相应的数据集分为 80% 用于训练,20% 用于测试。 由于 CAP 算法的简单性,我们只生成 5,000 个示例用于训练和测试。 对于多行拉伸和注意力方法,我们总共生成了 30,000 个示例。 在 KD 中,因为我们需要同时训练教师和学生模型,所以我们应该将 扩大到 10,000 个示例 ,每张图像中包含更多字符。 表1总结了不同方法的数据集统计数据,图6给出了数据集中的采样示例以说明数据集样式。
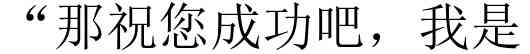

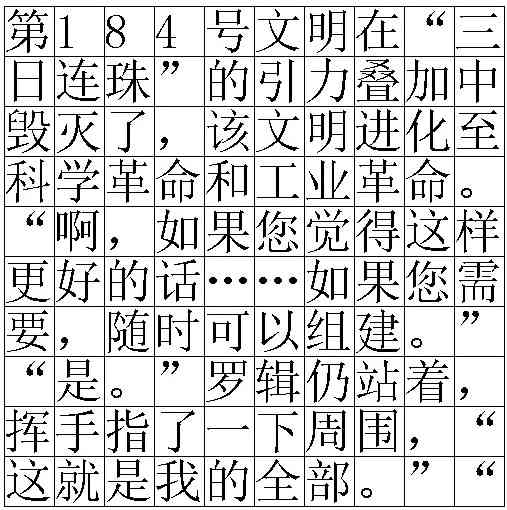
| data set | verified methods | # examples | # train | # test | # rows |
|---|---|---|---|---|---|
| CAP | 5,000 | 4,000 | 1,000 | 1 | |
| KD | 10,000 | 8,000 | 2,000 | 1 | |
| MultiRow Stretching/Attention/KD | 30,000 | 24,000 | 6,000 | 7 | |
| Line-DDeCAE | 30,000 | 24,000 | 6,000 | 10 |
4.2实施
在训练过程中,我们将输入图像的大小调整为单行图像的 和多行图像的 ,我们还将所有 RGB 图像转换为灰度。 在 CNN 模块中,我们遵循原始 VGG16 模型中相同的超参数设置,但剪掉了一些层以避免过度拟合,除了最后一个池化层,我们对单行图像使用池大小 (2, 3)。 在 BiLSTM 模块中,我们将隐藏大小设置为 256 并堆叠 2 个 BiLSTM 层。 在训练过程中,对于大多数实验,我们将训练纪元设置为 200,批量大小为 16,我们尝试使用 Nesterov 模式的 SGD 优化器,动量为 0.9,我们还尝试使用 AMSGrad 模式的 Adam,动量为 0.9,RMSProp 0.99,但我们只报告优越SGD 产生单行图像,而高级 Adam 产生多行图像。 初始学习率设置为,每 60 个时期的衰减率为 2。 我们还将权重衰减参数设置为。 在KD中,参数为0.5的和参数为0.2的,我们将温度设置为1.5,通过将训练数据分割为90%的训练和网格搜索,我们获得上述超参数10% 验证。 对于学生模型,我们砍掉了 CNN 模块中的几层,只使用一层 BiLSTM。 有关超参数的更多详细信息,请参阅附录A.1。
4.3指标
在本文中,我们使用两个指标:字符级精度(CLP)和图像级精度(ILP)。 在 CLP 中,我们将每张图像中的预测字符与所有字符进行计数,在 ILP 中,如果每张图像中的所有字符都被正确预测,我们会得到一个正确的结果。 具体来说,
| (18) | |||
| (19) |
其中 是示例数, 是 示例中的字符数, 是真实情况,是对应的预测,是指示函数。
4.4结果
我们报告测试集的所有平均结果,每次运行三次。
4.4.1 CAP
在这一部分中,我们使用来比较CAP和原始CRNN模型。 在表2中,作为比较,我们使用CRNN模型中的默认设置。 请注意,CAP 在 CLP(-0.09%)和 ILP(-0.08%)方面的表现几乎与原始 CRNN 模型相同。 我们认为 CAP 也可以在不手动调整 CNN 模块中的超参数的情况下获得类似的结果。
| methods | CLP | ILP |
|---|---|---|
| CRNN | 97.31 | 91.33 |
| CAP | 97.20 | 91.25 |
4.4.2 多行拉伸和注意力
我们使用不带框线的 来验证 MultiRow Stretching 和 Attention 方法。 最终结果见表3。 原始 CRNN 无法处理多行图像,因此我们只报告两种提出的方法。 请注意,与 CLP 中的 Attention 方法相比,MultiRow Stretching 的最终结果非常好(+0.76%),我们认为数据集仅包含 7 行图像,我们声称如果每个图像包含更多行,则此性能可能会下降。
| methods | CLP | ILP |
|---|---|---|
| MultiRow Stretching | 80.52 | 60.17 |
| Attention | 81.31 | 60.04 |
4.4.3行-DDeCAE
接下来,我们使用 训练 Line-DDeCAE 模型。 采样图像如图7所示,更多示例请参见附录A.3。 我们还与简单的 DDeCAE 模型进行了比较。 Line-DDeCAE 和 DDeCAE 共享相同的模型结构。 请注意,DDeCAE 模型无法很好地恢复文本,但是 Line-DDeCAE 几乎完美地恢复框线。 我们还得出结论,Line-DDeCAE 也比 DDeCAE 收敛得更快更好,训练程序可以在附录A.2中找到。 然后,为了验证更多 Line-DDeCAE 模型,我们将 数据输入到预训练的 Line-DDeCAE 模型中,并将输出注入 CRNN 模型中以训练 MultiRow Stretching 算法。 所有结果均在表4中。 与DDeCAE相比,我们注意到,使用Line-DDeCAE可以在CLP(+5.09%)和ILP(+9.51%)中获得较高的性能。 另请注意,如果我们直接将 输入到 CRNN 中,模型无法在某个级别收敛。

| methods | CLP | ILP |
|---|---|---|
| CRNN | 50.77 | 35.98 |
| DDeCAE+CRNN | 70.38 | 50.14 |
| Line-DDeCAE+CRNN | 75.47 | 59.65 |
4.4.4KD
最后,我们使用 和 将先前教师 CRNN 模型中的知识提炼为 半尺寸 学生 CRNN 模型。 为了有效地从教师模型中提取知识,我们同时训练教师和学生模型。 然而,我们将值从教师模型的张量中分离出来,以避免模型崩溃问题(Miyato 等人(2018))。 最终结果见表5。 在单行图像中,蒸馏模型的性能提高了巨大差距(CLP +2.45%,ILP +7.03%),而在多行图像中,我们运行 MultiRow Stretching 方法,蒸馏模型仍然优于教师模型( CLP +0.22%,ILP +0.23%)。 综上所述,几乎减少了一半的参数,但保留甚至提高了类似的精度,这是一个非常有希望的结果。
| data sets | methods | CLP | ILP |
|---|---|---|---|
| CRNN | 89.29 | 71.17 | |
| Distilled CRNN | 91.74 | 78.20 | |
| CRNN(MultiRow Stretching) | 80.52 | 60.17 | |
| Distilled CRNN | 80.74 | 60.40 |
5结论
在本文中,我们提出了多种简单而有效的方法来通过实现中文文本图像识别任务来提高 CRNN 性能。 特别是,我们提倡使用CAP来代替单行图像的详尽的超参数微调;我们还提出了两种处理多行图像的方法;原始的CRNN不能很好地识别类似excel的图像,因此我们提出了Line-DDeCAE来首先恢复框线,我们发现这是一个简单的任务,然后添加原始输入图像以获得干净的图像;最后,我们提出了高效的在线 KD 方法,将教师模型提炼为一半大小的学生模型,而不失通用性。 生成的合成数据集的实验结果表明我们的方法是高效的。
参考
- Bahdanau et al. (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- Bissacco et al. (2013) Alessandro Bissacco, Mark Cummins, Yuval Netzer, and Hartmut Neven. Photoocr: Reading text in uncontrolled conditions. In Proceedings of the IEEE International Conference on Computer Vision, pp. 785–792, 2013.
- Chen et al. (2017) Guobin Chen, Wongun Choi, Xiang Yu, Tony Han, and Manmohan Chandraker. Learning efficient object detection models with knowledge distillation. In Advances in Neural Information Processing Systems, pp. 742–751, 2017.
- Dai et al. (2016) Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-fcn: Object detection via region-based fully convolutional networks. In Advances in neural information processing systems, pp. 379–387, 2016.
- Dean et al. (2012) Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc’aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, et al. Large scale distributed deep networks. In Advances in neural information processing systems, pp. 1223–1231, 2012.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Fu et al. (2017) Jianlong Fu, Heliang Zheng, and Tao Mei. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4438–4446, 2017.
- Girshick et al. (2014) Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 580–587, 2014.
- Gondara (2016) Lovedeep Gondara. Medical image denoising using convolutional denoising autoencoders. In 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), pp. 241–246. IEEE, 2016.
- Graves et al. (2008) Alex Graves, Marcus Liwicki, Santiago Fernández, Roman Bertolami, Horst Bunke, and Jürgen Schmidhuber. A novel connectionist system for unconstrained handwriting recognition. IEEE transactions on pattern analysis and machine intelligence, 31(5):855–868, 2008.
- Han et al. (2015a) Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015a.
- Han et al. (2015b) Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network. In Advances in neural information processing systems, pp. 1135–1143, 2015b.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Hu et al. (2018) Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7132–7141, 2018.
- Hubara et al. (2016) Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks. In Advances in neural information processing systems, pp. 4107–4115, 2016.
- Iandola et al. (2016) Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size. arXiv preprint arXiv:1602.07360, 2016.
- Jaderberg et al. (2016) Max Jaderberg, Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Reading text in the wild with convolutional neural networks. International journal of computer vision, 116(1):1–20, 2016.
- Kao et al. (2018) Chieh-Chi Kao, Weiran Wang, Ming Sun, and Chao Wang. R-crnn: Region-based convolutional recurrent neural network for audio event detection. arXiv preprint arXiv:1808.06627, 2018.
- Kapka & Lewandowski (2019) Sławomir Kapka and Mateusz Lewandowski. Sound source detection, localization and classification using consecutive ensemble of crnn models. arXiv preprint arXiv:1908.00766, 2019.
- Khandelwal et al. (2019) Urvashi Khandelwal, Kevin Clark, Dan Jurafsky, and Lukasz Kaiser. Sample efficient text summarization using a single pre-trained transformer. arXiv preprint arXiv:1905.08836, 2019.
- Kingma & Welling (2013) Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Li et al. (2016) Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016.
- Li et al. (2018) Xiang Li, Wenhai Wang, Wenbo Hou, Ruo-Ze Liu, Tong Lu, and Jian Yang. Shape robust text detection with progressive scale expansion network. arXiv preprint arXiv:1806.02559, 2018.
- Li et al. (2019) Xiang Li, Wenhai Wang, Xiaolin Hu, and Jian Yang. Selective kernel networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 510–519, 2019.
- Luo et al. (2017) Jian-Hao Luo, Jianxin Wu, and Weiyao Lin. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE international conference on computer vision, pp. 5058–5066, 2017.
- Miyato et al. (2018) Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 41(8):1979–1993, 2018.
- Molchanov et al. (2016) Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. Pruning convolutional neural networks for resource efficient inference. arXiv preprint arXiv:1611.06440, 2016.
- Ng et al. (2011) Andrew Ng et al. Sparse autoencoder. CS294A Lecture notes, 72(2011):1–19, 2011.
- Radford et al. (2015) Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
- Rastegari et al. (2016) Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. In European conference on computer vision, pp. 525–542. Springer, 2016.
- Redmon et al. (2016) Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 779–788, 2016.
- Ren et al. (2015) Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pp. 91–99, 2015.
- Rifai et al. (2011) Salah Rifai, Pascal Vincent, Xavier Muller, Xavier Glorot, and Yoshua Bengio. Contractive auto-encoders: Explicit invariance during feature extraction. In Icml, 2011.
- Romero et al. (2014) Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550, 2014.
- Sandler et al. (2018) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510–4520, 2018.
- Shi et al. (2016) Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE transactions on pattern analysis and machine intelligence, 39(11):2298–2304, 2016.
- Simonyan & Zisserman (2014) Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
- Wang et al. (2020) Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo, and Qinghua Hu. Eca-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11534–11542, 2020.
- Wang et al. (2012) Tao Wang, David J Wu, Adam Coates, and Andrew Y Ng. End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st international conference on pattern recognition (ICPR2012), pp. 3304–3308. IEEE, 2012.
- Wu et al. (2016) Jiaxiang Wu, Cong Leng, Yuhang Wang, Qinghao Hu, and Jian Cheng. Quantized convolutional neural networks for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4820–4828, 2016.
- Yim et al. (2017) Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4133–4141, 2017.
- Zagoruyko & Komodakis (2016) Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928, 2016.
- Zhang et al. (2019) Linfeng Zhang, Jiebo Song, Anni Gao, Jingwei Chen, Chenglong Bao, and Kaisheng Ma. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE International Conference on Computer Vision, pp. 3713–3722, 2019.
- Zhang et al. (2018a) Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6848–6856, 2018a.
- Zhang et al. (2018b) Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4320–4328, 2018b.
- Zhou et al. (2020) Zaida Zhou, Chaoran Zhuge, Xinwei Guan, and Wen Liu. Channel distillation: Channel-wise attention for knowledge distillation. arXiv preprint arXiv:2006.01683, 2020.
附录A附录
A.1 训练超参数
在本节中,我们在表6中列出了所有实验中的所有超参数。
| methods | hyperparameters | ||||
| image size | epochs | batch size | optimizer | init_lr | |
| CRNN | (224, 224)/(64, 128) | 200 | 20 | AMSGrad/Nesterov | 1e-4 |
| CAP | (64, 128) | 200 | 20 | Nesterov | 1e-4 |
| MultiRow Stretching | (224, 224) | 200 | 20 | AMSGrad | 1e-4 |
| Attention | (224, 224) | 200 | 20 | AMSGrad | 1e-4 |
| DDeCAE | (224, 224) | 100 | 64 | Adam | 1e-3 |
| Line-DDeCAE | (224, 224) | 100 | 64 | Adam | 1e-3 |
| DDeCAE + CRNN | (224, 224) | 200 | 16 | AMSGrad | 1e-4 |
| Line-DDeCAE + CRNN | (224, 224) | 200 | 16 | AMSGrad | 1e-4 |
| KD with single-row | (64, 128) | 300 | 16 | Nesterov | 1e-4 |
| KD with multi-row | (224, 224) | 300 | 16 | AMSGrad | 1e-4 |
| lr_decay rate | weight decay | temperature | |||
| CRNN | 2 | 1e-6 | N/A | N/A | N/A |
| CAP | 2 | 1e-6 | N/A | N/A | N/A |
| MultiRow Stretching | 2 | 1e-6 | N/A | N/A | N/A |
| Attention | 2 | 1e-6 | N/A | N/A | N/A |
| DDeCAE | 5 | 0 | N/A | N/A | N/A |
| Line-DDeCAE | 5 | 0 | N/A | N/A | N/A |
| DDeCAE + CRNN | 2 | 1e-6 | N/A | N/A | N/A |
| Line-DDeCAE + CRNN | 2 | 1e-6 | N/A | N/A | N/A |
| KD with single-row | 2 | 1e-6 | 0.5 | 0.2 | 1.5 |
| KD with multi-row | 2 | 1e-6 | 0.5 | 0.2 | 1.5 |
表中,init_lr表示初始学习率,lr_rate表示学习率衰减率,和是在和
A.2 Line-DDeCAE 和 DDeCAE 中的培训程序
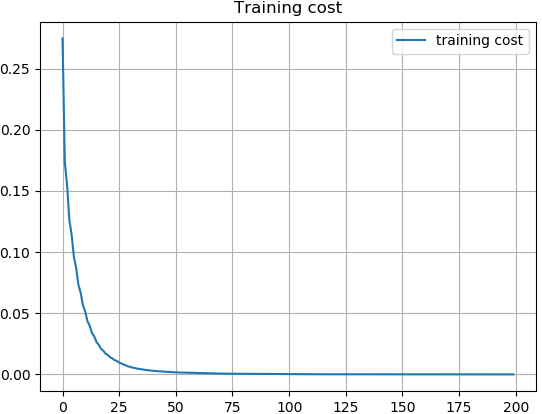
图8揭示了Line-DDeCAE和DDeCAE中的训练损失如何变化,我们可以看到Line-DDeCAE比DDeCAE收敛得稍快且好得多,我们认为由于盒子线很容易在高维度空间比文本大,因此,Line-DDeCAE 在这种情况下是一个合理的替代方案。
A.3 来自 Line-DDeCAE 和 DDeCAE 的更多示例









根据图中,我们得出结论,Line-DDeCAE 明确地完美地恢复了框线,而 DDeCAE 更努力地恢复了不理想的文本。