对比行为相似性
嵌入,用于
强化学习中的泛化
摘要
在少数环境中训练的强化学习方法很少能学到泛化到未见过的环境的策略。 为了提高泛化能力,我们将强化学习中固有的顺序结构纳入表示学习过程中。 这种方法与最近的方法正交,后者很少明确地利用这种结构。 具体来说,我们引入了一种具有理论动机的策略相似性度量(PSM),用于测量状态之间的行为相似性。 PSM 为这些状态以及未来状态的最优策略相似的状态分配高度相似性。 我们还提出了一种对比表示学习过程来嵌入任何状态相似性度量,我们用 PSM 实例化该度量以获得策略相似性嵌入(PSE)111发音为“双鱼座”。)。 我们证明 PSE 可以提高各种基准的泛化能力,包括具有虚假相关性的 LQR、像素跳跃任务以及 Distracting DM Control Suite。 源代码可在 agarwl.github.io/pse 获取。
1简介
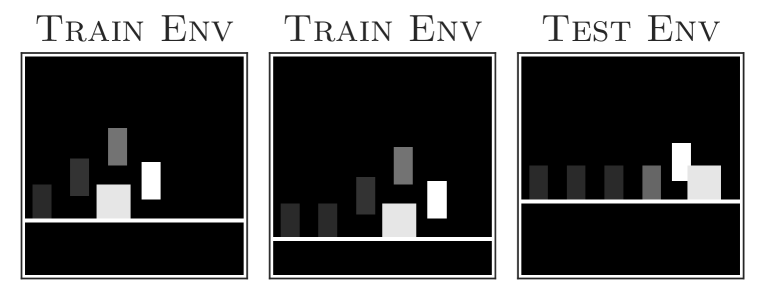
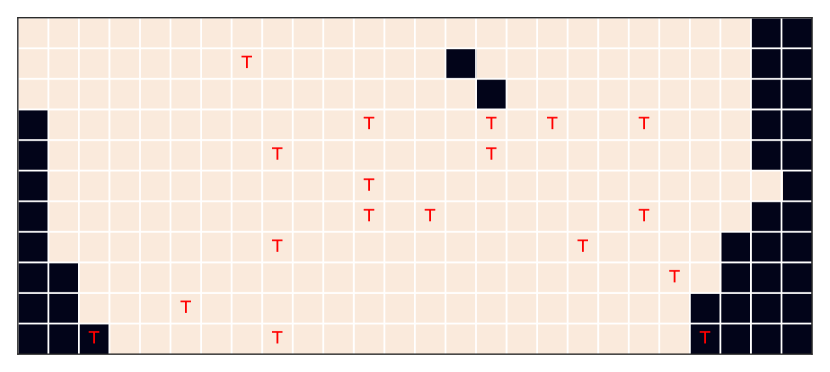
当前的强化学习(RL)方法通常学习的策略不能泛化到与代理训练时不同的环境,即使这些环境在语义上是等效的(Tachet des Combes 等人,2018;Song 等人,2019; Cobbe 等人,2019)。 例如,考虑一个跳跃任务,其中代理从像素学习,需要跳过障碍物(图1)。 经过一些具有不同障碍物位置的跳跃任务训练的深度强化学习代理很难在障碍物位于以前看不见的位置的测试任务中成功跳跃。
最近规避 RL 泛化能力差的解决方案改编自监督学习,因此在很大程度上忽略了 RL 的顺序方面。 这些解决方案大多数围绕着增强学习过程,包括数据增强(例如,Kostrikov 等人,2020;Lee 等人,2020a)、正则化(Cobbe 等人,2019;Farebrother 等)人, 2018),噪声注入(Igl 等人, 2019),以及多样化的训练条件(Tobin 等人, 2017);他们很少利用顺序决策问题的特性,例如跨时间观察的动作的相似性。
相反,我们通过将强化学习问题的属性纳入表示学习过程来解决泛化问题。 我们的方法利用了这样一个事实:代理在具有相似底层机制的环境中运行时,至少会表现出在这些环境中相似的短行为序列。 具体来说,当代理在这些状态和未来状态中的最优策略相似时,代理被优化以学习状态接近的嵌入。 这种接近度的概念是通用的,它适用于来自不同环境的观察。
具体来说,受互模拟指标(Castro,2020;Ferns等人,2004)的启发,我们提出了一种新颖的策略相似性指标(PSM)。 PSM(第 3 节)通过这些状态的长期最佳行为的接近度来定义源自不同环境的状态之间的相似性概念。 PSM 与奖励无关,因此与依赖奖励信息的方法相比,它的泛化能力更强。 我们证明 PSM 产生从一种环境转移到另一种环境的策略次优性的上限(定理 1),这是互模拟无法实现的。
我们采用 PSM 进行表示学习,并为深度强化学习引入策略相似性嵌入 (PSE)。 为此,我们提出了一个通用的对比过程(第 4 节)来学习基于任何状态相似性度量的嵌入。 PSE 是该过程与 PSM 的实例化。 PSE 呼吁泛化,因为它们通过将行为等效的状态放在一起来编码与任务相关的不变性。 这与之前的方法不同,之前的方法依赖于捕获此类不变性,而没有经过明确训练来实现这一点,例如,通过状态之间的价值函数相似性(例如,Castro & Precup,2010),或者对观察空间的固定变换具有鲁棒性(例如,Kostrikov 等人,2020;Laskin 等人,2020a)。
PSE 可以带来更好的泛化,同时与大多数领域处理泛化的方式正交。 我们在三个现有基准上展示了我们的方法的有效性和广泛适用性专门用于测试泛化:(i)从像素跳跃任务(Tachet des Combes等人,2018) (第5节),(ii)具有虚假相关性的LQR(宋等人,2019)(第6.1节),以及(iii)分散注意力DM 控制套件 (Stone 等人,2021)(第 6.2 节)。 与多种方法相比,我们的方法提高了泛化能力,包括标准正则化(Farebrother等人,2018;Cobbe等人,2019)、互模拟(Castro & Precup,2010;Castro,2020;张等人, 2021),分布外泛化 (Arjovsky 等人, 2019) 和最先进的数据增强 (Kostrikov 等人, 2020 ;拉斯金等人,2020a;李等人,2020a)。
2 预赛
我们将环境描述为马尔可夫决策过程 (MDP) (Puterman, 1994) ,具有状态空间 、动作空间 、奖励函数、转换动态和折扣因子。 策略 将状态 映射到操作的分布。 只要方便,我们就会滥用符号并写成 来描述概率分布 ,将 视为向量。 在强化学习中,目标是找到一个最优策略 ,从初始状态 开始最大化累积预期回报 。
我们有兴趣学习一种可以在相关环境中推广的策略。 我们通过考虑 MDP 的集合 来形式化这一点,共享操作空间 但具有不相交的状态空间。 我们用和来表示特定环境的状态空间,用,来表示特定环境的奖励和转移函数状态空间为 的 MDP,其最优策略为 ,我们假设它是唯一的而不失一般性。 对于给定的策略 ,我们进一步将它们专门化为 和 ,即由以下
我们将 写为 中 MDP 状态空间的并集。 具体来说,不同的MDP对应于一个问题类中的特定场景(图1),而是所有可能配置的空间。 如果不使用下标,、 和 指的是该“联盟 MDP”的奖励和转换函数,以及在 ;这个符号简化了说明。 我们使用伪计量学来测量跨环境中的状态之间的距离222伪计量学是度量的概括,其中两个不同状态之间的距离可以为零。 在 上;所有此类伪度量的集合是,是上概率分布的度量集合。
在我们的设置中,学习者可以访问来自 的训练 MDP 集合。 与这些环境交互后,学习者必须在整个状态空间 上生成策略 ,然后在来自 的未见 MDP 上对其进行评估。 与迁移学习的设置(Taylor & Stone,2009)的精神类似,这里我们评估该策略在上的零样本性能。
我们的政策相似性指标(第3节)建立在-双向模拟(Castro,2020)的概念之上。 在-bisimulation指标下,两个状态和之间的距离是根据遵循策略时获得的预期奖励之间的差异来定义的。 -双模拟度量满足基于1-Wasserstein度量的递归方程,其中是最小成本在基本度量 下将概率质量从 传输到 ( 上的两个概率分布)(Villani,2008 )。 递归是
| (1) |
为了实现良好的泛化特性,我们学习了一个嵌入函数,它反映了策略相似性度量中编码的信息;这会产生策略相似性嵌入(第 4 节)。 我们使用对比方法(Hadsell 等人, 2006; Oord 等人, 2018),其在表示学习方面的跟踪记录是完善的。 我们采用 SimCLR (Chen 等人, 2020),这是一种流行的对比方法,用于学习图像输入的嵌入。 给定两个输入和,它们的嵌入相似度为,其中表示余弦相似度功能。 SimCLR 的目标是最大化增强版图像(例如,裁剪、颜色变化)之间的相似性,同时最小化与其他图像的相似性。 SimCLR 对于图像的两个版本 以及包含其他图像的集合 使用的损失为:
| (2) |
其中 是反温度超参数。 当 、 和 从某些增强训练分布中得出时,整体 SimCLR 损失就是 的预期值。
3 策略相似度指标
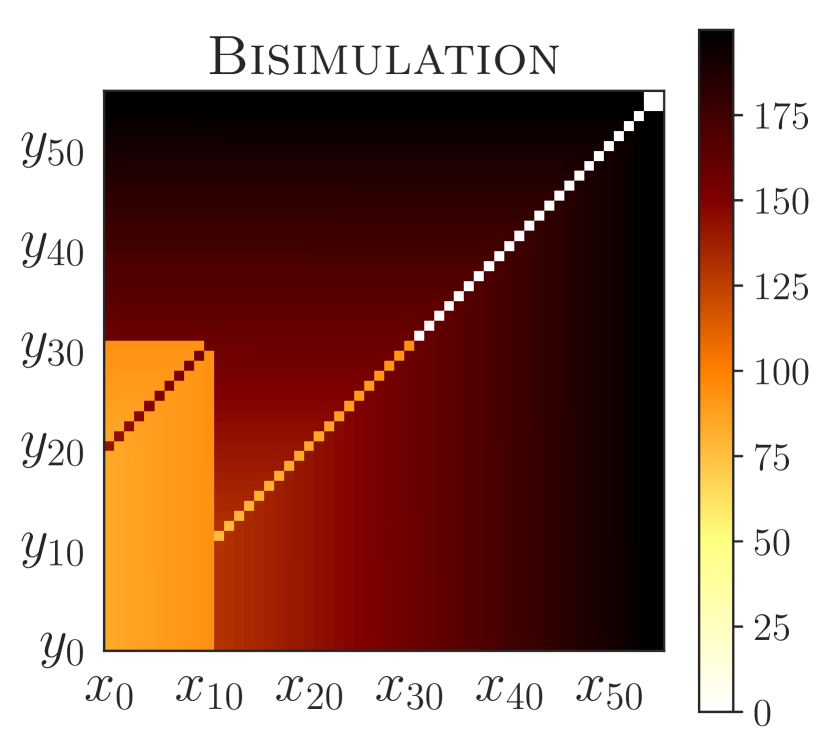
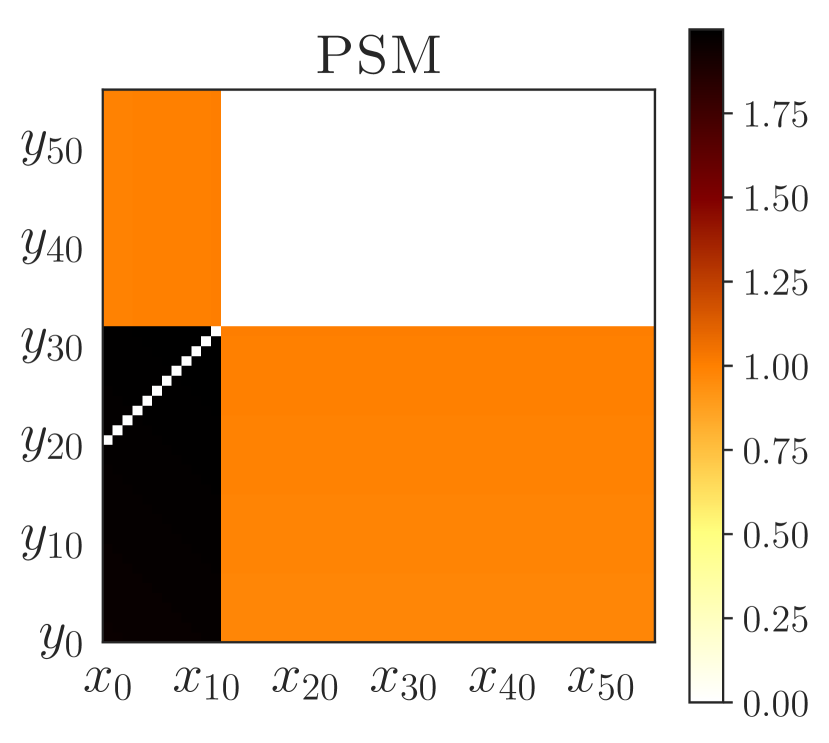
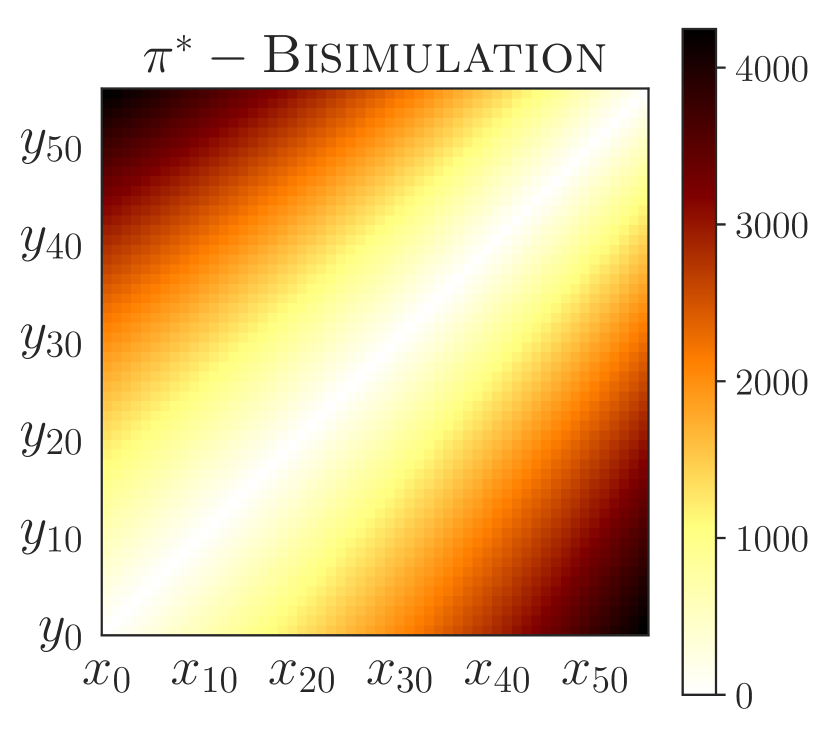
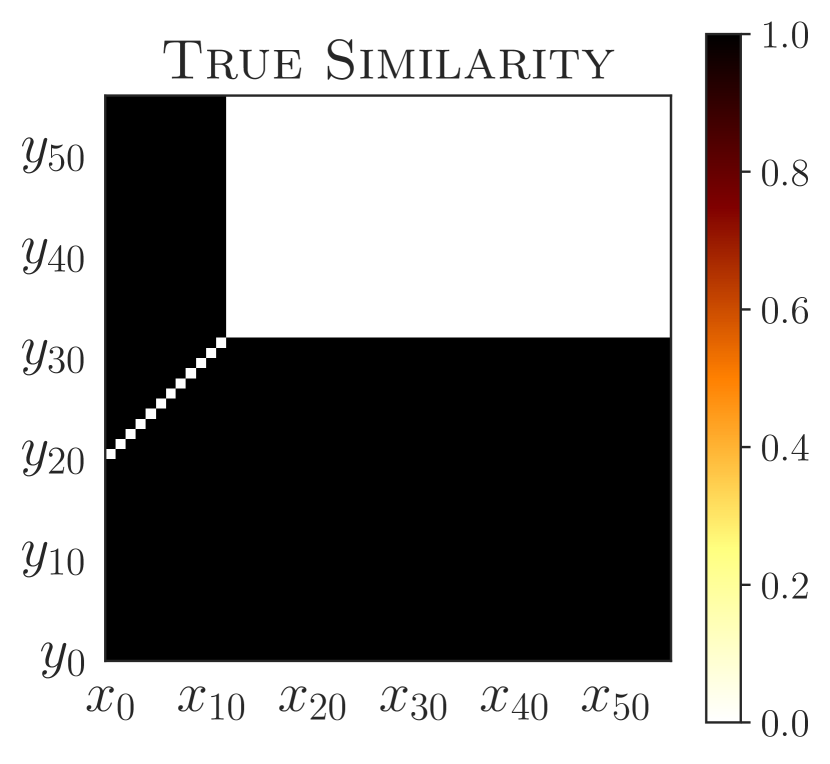
学习泛化策略的一个有用工具是了解哪些状态会导致类似的行为,哪些不会。 为了达到最大效果,这种相似性应该超越立即选择的行动并考虑长期行为。 在这方面,-互模拟指标很有趣,因为它们基于从不同状态收到的未来奖励的完整序列。 然而,考虑奖励可能会过于严格(当政策相同,但获得的奖励不同;见图2)或过于宽松(当政策不同,但获得的奖励不同)。不;参见图5(a))。 事实上,-互模拟指标实际上导致我们的实验中泛化能力较差(5.1 和 5.2 节)。
为了解决这个问题,我们转而考虑政策本身之间的相似性。 我们用策略之间的概率伪度量代替绝对奖励差异,表示为Dist。 此外,由于我们希望在看不见的环境中表现良好,因此我们对最佳行为的相似性感兴趣。 因此,我们使用 作为基础策略。 这会产生策略相似性度量 (PSM),当这些状态和未来状态中的最优策略相似时,状态就接近。 对于给定的Dist,PSM 满足递归方程
| (3) |
Dist 项捕获局部最优行为的差异 (A),而 捕获长期最优行为差异 (B);分配给两者的确切权重由折扣因子给出。 此外,当Dist有界时,保证是有限的。 虽然从技术上讲存在多个 PSM(每个 Dist 一个),但只要上下文清楚,我们就会忽略这一区别。 命题A.1给出了唯一性的证明。
我们 PSM 的主要用途是比较跨环境的状态。 在这种情况下,为了清楚起见,我们在特定环境中识别方程 3 中的术语并编写(尽管其技术不准确)
PSM 适用于离散和连续动作空间。 在我们的实验中,Dist是当是离散时的总变化距离(),并且我们使用之间的距离当连续时两个策略的平均动作。 PSM 可以使用动态规划迭代计算(Ferns 等人,2011)(更多详细信息请参见第 C.1 节)。 此外,当在训练环境中不可用时,我们将其替换为近似以获得近似PSM,接近于精确PSM,具体取决于(命题C.3)。
尽管在形式上类似于-互模拟度量,PSM 具有不同的特征,更适合泛化学习策略的问题。 为了说明这一点,请考虑以下简单的最近邻方案:给定一个状态 ,用 表示其在 中最接近的匹配。 假设我们使用此方案将 传输到 ,从某种意义上说,我们根据策略 进行操作。 然后,我们可以限制 和 之间的差异,如果将 替换为 -bisimulation 指标,则这是不可能的。
Theorem 1。
[绑定策略转移] 对于任何 ,让 定义从 开始并遵循策略 遇到的随机状态序列。 我们有:
4 学习对比度量嵌入
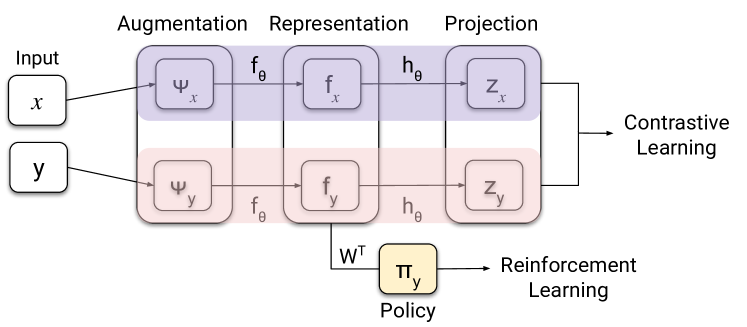
为了将学习到的策略推广到新环境,我们以对比表示的成功为基础(第 2 节)。 给定状态相似性度量,我们开发了一个通用程序(算法1)来学习的对比度量嵌入(CME)。我们利用度量来定义正负对的集合,并为对比损失中的这些对分配重要性权重(方程)。
我们首先应用转换将 转换为相似性度量 ,以 [0, 1] 为界,表示“软”相似性。 在这项工作中,我们使用具有正尺度参数的高斯核来变换,即。 控制相似性度量对 的敏感度。
其次,我们分别从 MDP 中选择给定一组状态 和 的正负对。 对于每个锚状态,我们基于相似性度量使用其在中的最近邻居来定义正对,其中。 中的其余状态与 配对,用作负对。 这种对的选择是由定理 1 驱动的,该定理表明,如果我们将 中的最优策略转移到使用 PSM 定义的最近邻居,则其在 中的性能t3> 具有受 PSM 限制的次优性。
接下来,我们定义 SimCLR 对比损失的软版本(方程 2),用于学习函数 ,该函数将状态(通常是高维)映射到嵌入。 给定正状态对 、集合 和相似性度量 ,损失(I.2
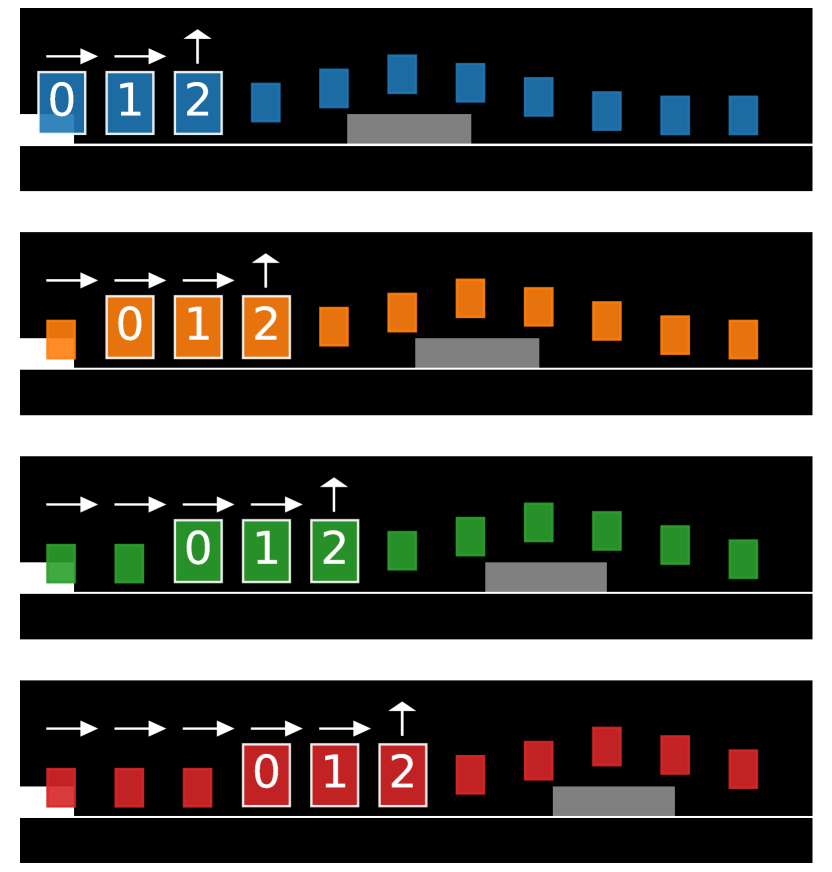
其中我们使用与公式 2 中相同的符号。 按照 SimCLR,我们使用表示形式的非线性投影 (图 3)。 代理的策略是表示的仿射函数。
和 的总对比损失利用最佳轨迹 和 ,其中 和 。 我们设置并定义
我们将通过策略相似性度量学习的 CME 称为策略相似性嵌入(PSE)。 通过在计算状态嵌入时使用增强状态,PSE 可以轻松地与数据增强相结合。 我们通过在训练期间添加 (算法 1)作为辅助目标,与 RL 代理同时学习 PSE。 接下来,我们将说明这个辅助目标的好处。
5 像素跳跃任务:案例研究
任务描述。 跳跃任务(Tachet des Combes等人,2018)(图1) 使用明确定义的变化因素来捕获代理是否可以直接从图像输入中学习泛化所需的正确不变性。 该任务包括代理尝试跳过障碍物。 代理可以执行两个操作:右和跳跃。 智能体需要在距障碍物特定距离处精确计算跳跃时间,否则最终会撞到障碍物。 不同的任务包括改变地板高度和/或障碍物位置。 概括来说,智能体在根据障碍物位置跳跃时需要保持楼层高度不变。 障碍物可以位于 26 个不同的位置,而地板有 11 个不同的高度,总共 286 个任务。
问题设置。 我们将问题分为 18 个已见(训练)和 268 个未见(测试)任务,以使用在期间看到的变化的潜在因素中的一些变化来对泛化进行压力测试。 正面例子数量较少333我们有 18 种不同的轨迹,其中包含多个动作示例向右,但只有一个实例每个轨迹的 跳跃 动作,导致总共只有 18 个动作实例跳跃。 导致数据量低的高度不平衡的分类问题,使得在没有额外归纳偏差的情况下变得具有挑战性。 因此,我们评估有和没有数据增强的情况下的泛化. 不同的网格配置(图4)捕获不同类型的泛化:“宽”网格通过“插值”测试泛化,“窄”网格通过“外推”测试分布外泛化,随机网格实例评估类似于监督学习的泛化能力,其中训练和测试样本是独立同分布的。 来自相同的分布。
我们使用了 RandConv (Lee 等人, 2020a),这是一种用于泛化的最先进的数据增强。 对于超参数选择,我们在包含“宽”网格中 54 个未见任务的验证集上评估所有代理(图4(a)),并选择具有最佳验证性能的参数。 我们对所有网格配置使用这些固定参数,以显示 PSE 对超参数调整的鲁棒性。 我们首先计算训练任务中的最佳轨迹。 使用这些轨迹,我们使用动态规划计算 PSM(C.1 节)。 我们通过模仿学习来训练智能体,并结合 PSE 的辅助损失(第 4 节)。 更多详细信息请参见 F 节。
| Data Augmentation | Method | Grid Configuration (%) | ||
|---|---|---|---|---|
| “Wide” | “Narrow” | Random | ||
| ✗ | Dropout and reg. | 17.8 (2.2) | 10.2 (4.6) | 9.3 (5.4) |
| Bisimulation Transfer4 | 17.9 (0.0) | 17.9 (0.0) | 30.9 (4.2) | |
| PSEs | 33.6 (10.0) | 9.3 (5.3) | 37.7 (10.4) | |
| ✓ | RandConv | 50.7 (24.2) | 33.7 (11.8) | 71.3 (15.6) |
| RandConv + -bisimulation | 41.4 (17.6) | 17.4 (6.7) | 33.4 (15.6) | |
| RandConv + PSEs | 87.0 (10.1) | 52.4 (5.8) | 83.4 (10.1) | |
5.1 评估跳跃任务的泛化能力
我们展示了 PSE 与常见泛化方法(例如正则化 (例如,Cobbe 等人,2019;Farebrother 等人,2018) 和数据增强 (例如,Lee 等人, 2020a;Laskin 等人,2020a),这对于基于像素的 RL 任务非常有效。 我们还将 PSE 与互模拟传输进行了对比(Castro & Precup,2010),这是一种基于互模拟指标基于表格状态的传输方法不进行任何学习 和保留表示的互模拟(Zhang 等人, 2021),显示了 PSM 相对于流行的状态相似性度量的优势。
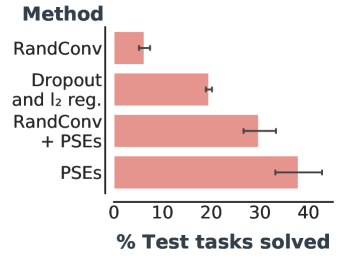
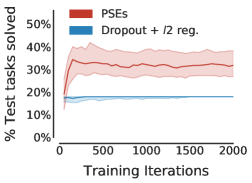
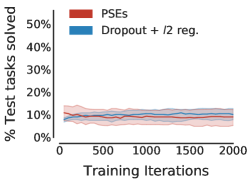
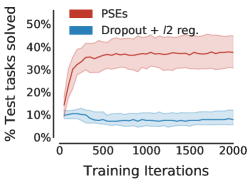
我们首先研究了 PSE 在没有纳入额外领域知识的情况下对现有训练方法的泛化程度。 表 1 总结了在没有数据增强的情况下,这些方法在不同训练/测试分组中的性能 (c.f. 详细说明见图4)。 PSE 仅包含 18 个示例,已带来比标准正则化更好的性能。
PSE 在“宽”和随机网格中的性能也优于互模拟传输。 虽然互模拟传递是 不切实际的444互模拟传输假设预言机可以访问未见过的环境以及表格状态空间的动态和奖励,以计算精确的互模拟指标(B 节)。 在评估零样本泛化时,我们仍然进行了这种对 PSE 不公平的比较,以突显其功效。 PSE 表现更好,因为与互模拟相比,PSM 与奖励无关(c.f. 命题 C.1) – 跳跃动作的预期返回根据障碍物位置的不同而有很大不同 (c.f. 图F.2 PSM 和互模拟的视觉并置)。 总的来说,这些结果是有希望的,因为它们将 PSE 视为一种不依赖于数据增强的有效泛化方法。
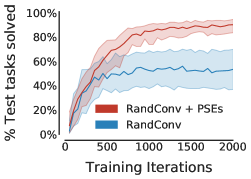
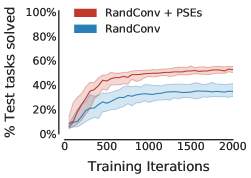
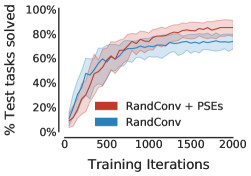
尽管如此,PSE 是对数据增强的补充,数据增强不断提高深度强化学习的泛化能力。 我们将 RandConv 与 PSE 结合使用与仅使用 RandConv 进行了比较。 特定领域的增强在跳跃任务中也取得了成功。 因此,与没有增强的技术相比,RandConv 如此有效也就不足为奇了。 表 1( 行)显示 PSE 显着提高了所有网格配置中 RandConv 的性能。 此外,表1(行)表明,当与RandConv结合使用时,保留表示的互模拟(Zhang等人,2021)将泛化能力降低了 相对于 PSE。
值得注意的是,表1(行)表明基于学习的方法在没有数据增强的“窄”网格上无效。 也就是说,PSE 与 RandConv 结合使用时效果非常好。 然而,即使有了数据增强,“窄”网格中的泛化也仅发生在训练任务附近,这表明该网格给基于学习的方法带来了挑战。 我们认为这是由于神经网络的外推能力较差(例如,Haley & Soloway,1992;Xu 等人,2020),在没有数据增强的先验归纳偏差的情况下,这种外推能力更容易被察觉。
5.2 了解 PSE 的收益:消融和可视化


| Metric / Embedding | -embeddings | CMEs |
|---|---|---|
| -bisimulation | 41.4 (17.6) | 23.1 (7.6) |
| PSM | 17.5 (8.4) | 87.0 (10.1) |
PSE 是通过 PSM 学习的对比度量嵌入 (CME)。 我们通过消除 CME(第 4 节)和 PSM(第 3 节)来研究它们的收益。 CME 可以通过任何状态相似性度量来学习 - 我们使用 -bisimulation (Castro, 2020) 作为替代方案。 同样,PSM 可以与任何度量嵌入一起使用 - 我们使用 -embeddings(第 D 节)作为替代方案,其中 Zhang 等人 (2021) 与-bisimulation 一起使用,用于在单任务强化学习设置中学习表示。 为了公平比较,我们为表 2 中每个消融条目的 128 次试验调整超参数。
表 2 显示 PSE( PSM + CME)的泛化能力明显优于 -与 CME 的互模拟或 -嵌入,两者都会显着降低性能(分别为 和 )。 这是预期的,因为-互模拟对跳跃任务施加了不正确的不变性(c.f. 图2(a)和2(d))。 此外,从表 2 的行来看,对于 PSM,CME 优于 -嵌入,而对于 -bisimulation 则较差。 这一结果符合这样的假设:与 -embeddings 相比,CME 更好地强化了由相似性度量编码的不变性(c.f. 图5(b)和5(c))。
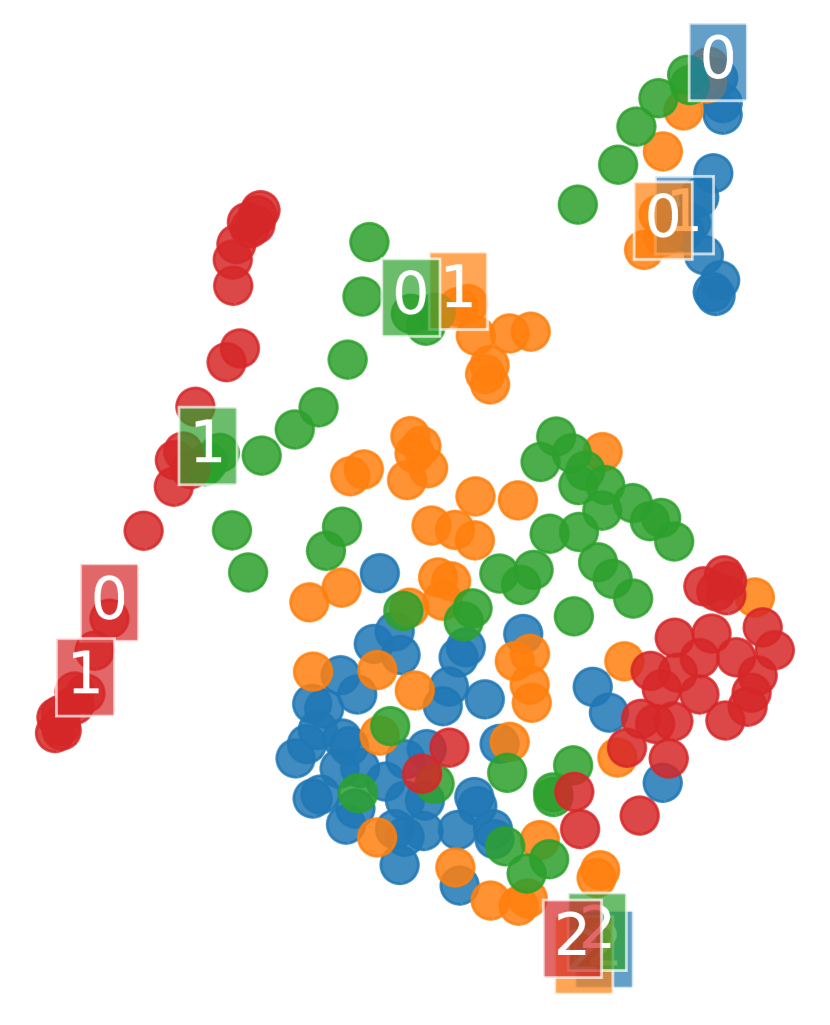
可视化学习到的表示。 我们通过使用 UMAP (McInnes 等人,2018) 将上面的消融中的度量嵌入投影到二维来可视化,UMAP 是一种流行的高维数据可视化技术,与其他技术相比,它可以更好地保留数据的全局结构t-SNE 等方法(Coenen & Pearce,2019)。
图 5 显示 PSE 将状态分为两组:(1) 单个次优操作导致失败的状态(jump 之前的所有状态)和 (2) 其中动作不会影响最终结果(jump之后的状态)。 此外,PSE 会对齐第一组中的标记状态,其 PSM 距离为零。 这些对齐的状态与障碍物的距离相同,这是跨任务通用的不变特征。 另一方面,带有 PSM 的 -embeddings (Zhang 等人, 2021) 不会将状态与零 PSM 对齐,除了具有跳跃动作的状态 - 正如所观察到的,泛化性很差从经验上看,这可能是由于具有相同最佳行为的状态最终导致了遥远的嵌入。 具有 -bisimulation 的 CME 将状态与 -bisimulation 距离为零 – 这些状态与开始状态等距,并且对于具有不同障碍物位置的任何任务对具有不同的最佳行为(图2(c))。
5.3 政策次优对私营企业的影响
为了了解学习有效 PSE 对策略质量的敏感性,我们在跳跃任务上使用 次优策略来计算 PSE,该策略以概率 采取最优动作,并且次优行动的概率为 。
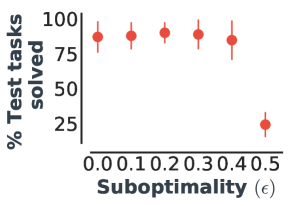
我们针对日益次优的策略评估 PSE 的泛化性能,范围从最优策略 () 到统一随机策略 ()。 为了隔离次优对 PSE 的影响,智能体仍然在训练期间对所有 模仿最优动作。
5.4 用颜色跳跃任务:任务相关的不变性很重要
PSE 捕获的任务相关的不变性通常与数据增强的任务无关的不变性正交。 这种差异很重要,因为对于某些 RL 任务,数据增强可能会错误地将状态与不同的最佳行为混为一谈。 通常需要领域知识来选择适当的增强,否则增强甚至会损害泛化。 相比之下,PSE 不需要任何领域知识,而是利用 RL 任务的固有结构。
为了演示 PSE 和数据增强之间的差异,我们只需在跳跃任务中添加彩色障碍物(见图 F.5)。 在这个修改后的任务中,智能体的最佳行为取决于障碍物颜色:智能体需要跳过红色障碍物但撞击绿色障碍物以获得高回报。 红色障碍物任务与原来的跳跃任务难度相同,而绿色障碍物任务则更容易。 我们在“宽”网格上针对两种障碍物颜色,分别对智能体进行 18 个训练任务的联合训练,并评估对未见过的红色任务的泛化能力。
6 额外的实证评估
在本节中,我们展示了 PSM 使用具有非图像输入的 LQR 任务 (Song 等人,2019) 忽略了泛化的虚假信息。 然后,我们使用 Distracting DM Control Suite (Stone 等人,2021) 展示了 PSE 的可扩展性,无需在具有连续操作的 RL 设置中显式访问最优策略。
6.1 具有虚假相关性的 LQR
我们展示了当面对语义等效的环境时,使用 PSM 学习的表示如何能够学习变化的主要因素并忽略阻碍的虚假相关性
概括。 我们使用带有干扰项的 LQR (Song 等人,2019;Sonar 等人,2020) 通过线性函数近似来评估基于特征的 RL 设置中的泛化能力。 干扰因素是与最佳动作虚假相关的输入特征,可用于在训练期间预测这些动作,但会损害泛化能力。 代理使用 2 个具有固定干扰因素的环境来学习线性策略。 该策略是在具有看不见的干扰因素的环境中进行评估的。
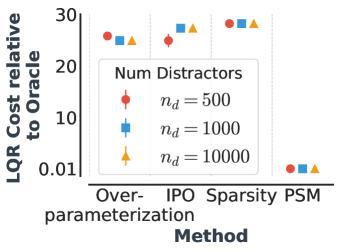
我们在 PSM 接近于零的训练环境中聚合状态对。 我们将这种方法与 (i) IPO (Sonar 等人, 2020) 进行对比,这是一种基于 IRM (Arjovsky 等人, 2019) 的策略优化方法,适用于非分布泛化,(ii) 过参数化,通过隐式正则化实现更好的泛化(宋等人,2019),以及 (iii) 自策略以来使用 正则化实现权重稀疏在此任务中泛化的权重是稀疏的。
6.2分散注意力的 DM 控制套件

最后,我们在 Distracting DM Control Suite (DCS) (Stone 等人,2021) 上展示了 PSE 的可扩展性,测试智能体是否可以忽略与 RL 任务无关的高维视觉干扰因素。 由于我们无法获得最佳训练策略,因此我们使用学习策略作为 的代理来计算 PSM 并收集数据以优化 PSE。 即使采用这种近似值,PSE 的性能也优于最先进的数据增强。
DCS 通过视觉干扰扩展了 DM 控制(Tassa 等人,2020)。 我们使用动态背景干扰(Stone 等人,2021;Zhang 等人,2018b),其中视频在特定帧的背景中播放。 每个新剧集都会对视频和帧进行随机采样。 我们在训练期间使用 2 个视频(图 9),并评估 30 个未见过的视频的泛化能力(图 H.1)。
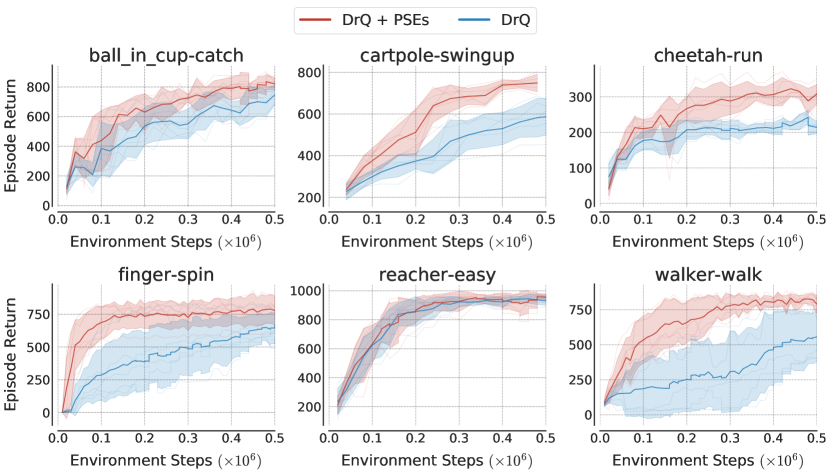
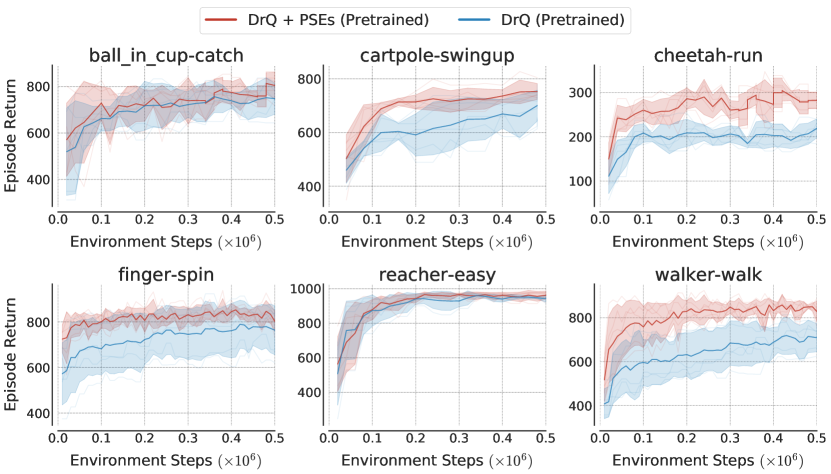
所有代理均建立在 SAC (Haarnoja 等人,2018) 之上,并结合 DrQ (Kostrikov 等人,2020),这是一种具有最新技术的增强方法DM控制上的艺术表演。 如果没有对 DM 控制进行数据增强,SAC 的表现很差,即使在训练(Kostrikov 等人,2020)期间也是如此。 我们通过学习 PSE 的辅助损失来增强 DrQ,并将其与 DrQ 进行比较(表 3)。 与 DrQ 正交,PSE 基于 PSM 跨环境对齐不同状态的表示(c.f. 图3). 所有代理都经过 500K 环境步骤的随机作物增强训练。 为了计算 PSM,我们使用 DrQ 在训练环境中预训练 500K 步学习的策略。
| Initialization | Method | BiC-catch | C-swingup | C-run | F-spin | R-easy | W-walk |
|---|---|---|---|---|---|---|---|
| Random | DrQ | 74728 | 58242 | 22012 | 64654 | 93114 | 54983 |
| DrQ + PSEs | 82117 | 74919 | 30812 | 77949 | 95510 | 78928 | |
| Pretrained | DrQ | 74830 | 68922 | 21910 | 76448 | 94310 | 70929 |
| DrQ + PSEs | 80525 | 75313 | 2828 | 80319 | 96211 | 82921 |
首先,假设预先向代理提供了 PSM,我们研究 PSE 相对于 DrQ 的泛化能力有多好。 代理的策略是随机初始化的,因此相对于 DrQ 的额外收益可以归因于 PSM 的辅助信息。 表 3 中的显着收益表明 PSE 在编码干扰项不变性方面比 DrQ 更有效。
7相关工作
PSM(3 节)受到互模拟指标(B 节)的启发。 然而,与传统的互模拟(例如,Larsen & Skou,1991;Givan 等人,2003;Ferns 等人,2011)不同,PSM 更容易处理,因为它是针对类似于以下的单一策略进行定义的:最近提出的-bisimulation(Castro,2020;Zhang等人,2021)。 然而,与 PSM 相比,互模拟指标依赖于奖励信息,并且可能无法在某些环境中提供有意义的行为相似性概念(第 5 节)。 例如,PSM 下相似的状态将具有相似的最优政策,但它们之间可以具有任意大的-互模拟距离(命题C.1)。
PSE(4 节)使用对比学习来编码跨 MDP 的行为相似性(3 节)。 此前,对比学习已应用于强加状态自一致性(Laskin等人,2020b),捕获预测信息(Oord等人,2018;Mazoure等人,2020;Lee等人, 2020b) 或在 MDP 内编码过渡动态 (van der Pol 等人, 2020; Stooke 等人, 2020; Schwarzer 等人, 2020) 。 这些方法可以与 PSE 集成以编码额外的不变性。 有趣的是,本着与 PSE 类似的精神,Pacchiano 等人 (2020); Moskovitz 等人 (2021) 探索比较策略之间的行为相似性,以指导 MDP 内的策略优化。
8结论
本文通过两个贡献推进了 RL 中的泛化:(1) 政策相似度量 (PSM),它提供了基于行为邻近性的状态相似性新概念;(2) 对比度量嵌入,它利用对比学习的优势,基于相似度量进行表征。 PSE 将这两种想法结合起来以提高泛化能力。 总的来说,本文展示了利用强化学习的固有结构来学习有效表示的好处。
参考
- Agarwal et al. (2019) Rishabh Agarwal, Chen Liang, Dale Schuurmans, and Mohammad Norouzi. Learning to generalize from sparse and underspecified rewards. In ICML, 2019.
- Arjovsky et al. (2019) Martín Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. CoRR, abs/1907.02893, 2019.
- Arora et al. (2019) Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. Implicit regularization in deep matrix factorization. In Advances in Neural Information Processing Systems, pp. 7413–7424, 2019.
- Balaji et al. (2018) Yogesh Balaji, Swami Sankaranarayanan, and Rama Chellappa. Metareg: Towards domain generalization using meta-regularization. In Advances in Neural Information Processing Systems, pp. 998–1008, 2018.
- Castro (2020) Pablo Samuel Castro. Scalable methods for computing state similarity in deterministic Markov decision processes. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- Castro & Precup (2010) Pablo Samuel Castro and Doina Precup. Using bisimulation for policy transfer in MDPs. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2010.
- Chen et al. (2020) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. CoRR, abs/2002.05709, 2020.
- Cobbe et al. (2019) Karl Cobbe, Oleg Klimov, Christopher Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), 2019.
- Coenen & Pearce (2019) Andy Coenen and Adam Pearce. Understanding umap, 2019. URL https://pair-code.github.io/understanding-umap/.
- Farebrother et al. (2018) Jesse Farebrother, Marlos C. Machado, and Michael Bowling. Generalization and regularization in DQN. In NeurIPS Deep Reinforcement Learning Workshop, 2018.
- Ferns et al. (2004) Norm Ferns, Prakash Panangaden, and Doina Precup. Metrics for finite Markov decision processes. In Proceedings of the Conference in Uncertainty in Artificial Intelligence (UAI), 2004.
- Ferns et al. (2006) Norm Ferns, Pablo Samuel Castro, Doina Precup, and Prakash Panangaden. Methods for computing state similarity in Markov decision processes. In Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence, UAI ’06. AUAI Press, 2006.
- Ferns et al. (2011) Norm Ferns, Prakash Panangaden, and Doina Precup. Bisimulation metrics for continuous markov decision processes. SIAM Journal on Computing, 40(6):1662–1714, 2011.
- Ferns & Precup (2014) Norman Ferns and Doina Precup. Bisimulation metrics are optimal value functions. In The 30th Conference on Uncertainty in Artificial Intelligence, pp. 10, 2014.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning (ICML), 2017.
- Givan et al. (2003) Robert Givan, Thomas Dean, and Matthew Greig. Equivalence notions and model minimization in markov decision processes. Artificial Intelligence, 147(1-2):163–223, 2003.
- Golovin et al. (2017) Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, and D Sculley. Google vizier: A service for black-box optimization. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1487–1495, 2017.
- Gunasekar et al. (2017) Suriya Gunasekar, Blake E Woodworth, Srinadh Bhojanapalli, Behnam Neyshabur, and Nati Srebro. Implicit regularization in matrix factorization. In Advances in Neural Information Processing Systems, pp. 6151–6159, 2017.
- Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290, 2018.
- Hadsell et al. (2006) Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pp. 1735–1742. IEEE, 2006.
- Haley & Soloway (1992) Pamela J Haley and DONALD Soloway. Extrapolation limitations of multilayer feedforward neural networks. In [Proceedings 1992] IJCNN International Joint Conference on Neural Networks, volume 4, pp. 25–30. IEEE, 1992.
- Igl et al. (2019) Maximilian Igl, Kamil Ciosek, Yingzhen Li, Sebastian Tschiatschek, Cheng Zhang, Sam Devlin, and Katja Hofmann. Generalization in reinforcement learning with selective noise injection and information bottleneck. In Advances in Neural Information Processing Systems, pp. 13978–13990, 2019.
- Jin et al. (2020) Wengong Jin, Regina Barzilay, and Tommi Jaakkola. Domain extrapolation via regret minimization. arXiv preprint arXiv:2006.03908, 2020.
- Juliani et al. (2019) Arthur Juliani, Ahmed Khalifa, Vincent-Pierre Berges, Jonathan Harper, Ervin Teng, Hunter Henry, Adam Crespi, Julian Togelius, and Danny Lange. Obstacle Tower: A generalization challenge in vision, control, and planning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2019.
- Justesen et al. (2018) Niels Justesen, Ruben Rodriguez Torrado, Philip Bontrager, Ahmed Khalifa, Julian Togelius, and Sebastian Risi. Illuminating generalization in deep reinforcement learning through procedural level generation. arXiv preprint arXiv:1806.10729, 2018.
- Killian et al. (2017) Taylor W. Killian, George Dimitri Konidaris, and Finale Doshi-Velez. Robust and efficient transfer learning with hidden parameter Markov decision processes. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp. 4949–4950, 2017.
- Kostrikov et al. (2020) Ilya Kostrikov, Denis Yarats, and Rob Fergus. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. CoRR, abs/2004.13649, 2020.
- Larsen & Skou (1991) Kim G Larsen and Arne Skou. Bisimulation through probabilistic testing. Information and computation, 94(1):1–28, 1991.
- Laskin et al. (2020a) Michael Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, and Aravind Srinivas. Reinforcement learning with augmented data. CoRR, abs/2004.14990, 2020a.
- Laskin et al. (2020b) Michael Laskin, Aravind Srinivas, and Pieter Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, PMLR 119, 2020b. arXiv:2003.06417.
- Lee et al. (2020a) Kimin Lee, Kibok Lee, Jinwoo Shin, and Honglak Lee. Network randomization: A simple technique for generalization in deep reinforcement learning. In The International Conference on Learning Representations (ICLR), 2020a.
- Lee et al. (2020b) Kuang-Huei Lee, Ian Fischer, Anthony Liu, Yijie Guo, Honglak Lee, John Canny, and Sergio Guadarrama. Predictive information accelerates learning in rl. arXiv preprint arXiv:2007.12401, 2020b.
- Li et al. (2018) Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M. Hospedales. Learning to generalize: Meta-learning for domain generalization. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2018.
- Mazoure et al. (2020) Bogdan Mazoure, Remi Tachet des Combes, Thang Long DOAN, Philip Bachman, and R Devon Hjelm. Deep reinforcement and infomax learning. Advances in Neural Information Processing Systems, 33, 2020.
- McInnes et al. (2018) L. McInnes, J. Healy, and J. Melville. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. ArXiv e-prints, February 2018.
- Moskovitz et al. (2021) Ted Moskovitz, Michael Arbel, Ferenc Huszar, and Arthur Gretton. Efficient wasserstein natural gradients for reinforcement learning. In International Conference on Learning Representations, 2021.
- Oh et al. (2017) Junhyuk Oh, Satinder P. Singh, Honglak Lee, and Pushmeet Kohli. Zero-shot task generalization with multi-task deep reinforcement learning. In Proceedings of the International Conference on Machine Learning (ICML), 2017.
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Pacchiano et al. (2020) Aldo Pacchiano, Jack Parker-Holder, Yunhao Tang, Krzysztof Choromanski, Anna Choromanska, and Michael Jordan. Learning to score behaviors for guided policy optimization. In International Conference on Machine Learning, 2020.
- Packer et al. (2018) Charles Packer, Katelyn Gao, Jernej Kos, Philipp Krähenbühl, Vladlen Koltun, and Dawn Song. Assessing generalization in deep reinforcement learning. arXiv preprint arXiv:1810.12282, 2018.
- Perez et al. (2020) Christian F. Perez, Felipe Petroski Such, and Theofanis Karaletsos. Generalized hidden parameter mdps transferable model-based rl in a handful of trials. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- Pont-Tuset et al. (2017) Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675, 2017.
- Puterman (1994) Martin L Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., 1994.
- Raileanu et al. (2020) Roberta Raileanu, Max Goldstein, Denis Yarats, Ilya Kostrikov, and Rob Fergus. Automatic data augmentation for generalization in deep reinforcement learning. arXiv preprint arXiv:2006.12862, 2020.
- Rajeswaran et al. (2017) Aravind Rajeswaran, Kendall Lowrey, Emanuel Todorov, and Sham M. Kakade. Towards generalization and simplicity in continuous control. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
- Recht (2019) Benjamin Recht. A tour of reinforcement learning: The view from continuous control. Annual Review of Control, Robotics, and Autonomous Systems, 2019.
- Schwarzer et al. (2020) Max Schwarzer, Ankesh Anand, Rishab Goel, R Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with momentum predictive representations. arXiv preprint arXiv:2007.05929, 2020.
- Sonar et al. (2020) Anoopkumar Sonar, Vincent Pacelli, and Anirudha Majumdar. Invariant policy optimization: Towards stronger generalization in reinforcement learning. arXiv preprint arXiv:2006.01096, 2020.
- Song et al. (2019) Xingyou Song, Yiding Jiang, Yilun Du, and Behnam Neyshabur. Observational overfitting in reinforcement learning. In The International Conference on Learning Representations (ICLR), 2019.
- Stone et al. (2021) Austin Stone, Oscar Ramirez, Kurt Konolige, and Rico Jonschkowski. The distracting control suite – a challenging benchmark for reinforcement learning from pixels. arXiv preprint arXiv:2101.02722, 2021.
- Stooke et al. (2020) Adam Stooke, Kimin Lee, Pieter Abbeel, and Michael Laskin. Decoupling representation learning from reinforcement learning. arXiv preprint arXiv:2009.08319, 2020.
- Tachet des Combes et al. (2018) Remi Tachet des Combes, Philip Bachman, and Harm van Seijen. Learning invariances for policy generalization. In Workshop track at the International Conference on Learning Representations (ICLR), 2018.
- Tang et al. (2020) Yujin Tang, Duong Nguyen, and David Ha. Neuroevolution of self-interpretable agents. arXiv preprint arXiv:2003.08165, 2020.
- Tassa et al. (2020) Yuval Tassa, Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, and Nicolas Heess. dm_control: Software and tasks for continuous control. arXiv preprint arXiv:2006.12983, 2020.
- Taylor & Stone (2009) Matthew E. Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research, 10:1633–1685, 2009.
- Tobin et al. (2017) Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 23–30. IEEE, 2017.
- van der Pol et al. (2020) Elise van der Pol, Thomas Kipf, Frans A Oliehoek, and Max Welling. Plannable approximations to mdp homomorphisms: Equivariance under actions. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pp. 1431–1439, 2020.
- Villani (2008) Cédric Villani. Optimal transport: old and new. Springer, 2008.
- Witty et al. (2018) Sam Witty, Jun Ki Lee, Emma Tosch, Akanksha Atrey, Michael Littman, and David Jensen. Measuring and characterizing generalization in deep reinforcement learning. In NeurIPS Critiquing and Correcting Trends in Machine Learning Workshop, 2018.
- Xu et al. (2020) Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S Du, Ken-ichi Kawarabayashi, and Stefanie Jegelka. How neural networks extrapolate: From feedforward to graph neural networks. arXiv preprint arXiv:2009.11848, 2020.
- Ye et al. (2020) Chang Ye, Ahmed Khalifa, Philip Bontrager, and Julian Togelius. Rotation, translation, and cropping for zero-shot generalization. CoRR, abs/2001.09908, 2020.
- Zhang et al. (2018a) Amy Zhang, Nicolas Ballas, and Joelle Pineau. A Dissection of Overfitting and Generalization in Continuous Reinforcement Learning. CoRR, abs/1806.07937, 2018a.
- Zhang et al. (2018b) Amy Zhang, Yuxin Wu, and Joelle Pineau. Natural environment benchmarks for reinforcement learning. arXiv preprint arXiv:1811.06032, 2018b.
- Zhang et al. (2020) Amy Zhang, Clare Lyle, Shagun Sodhani, Angelos Filos, Marta Kwiatkowska, Joelle Pineau, Yarin Gal, and Doina Precup. Invariant causal prediction for block mdps. In Proceedings of the International Conference on Machine Learning (ICML), 2020.
- Zhang et al. (2021) Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction. The International Conference on Learning Representations (ICLR), 2021.
- Zhang et al. (2018c) Chiyuan Zhang, Oriol Vinyals, Rémi Munos, and Samy Bengio. A study on overfitting in deep reinforcement learning. CoRR, abs/1804.06893, 2018c.
附录
附录A证明
我们首先定义一些将在这些结果中使用的符号:
-
•
我们表示
-
•
对于任何,设,其中。
-
•
。
我们现在继续讨论主要结果所必需的一些技术引理。
Lemma 1.
给定任意两个伪度量555伪计量学是度量的概括,其中两个不同状态之间的距离可以为零。 和概率分布 ,其中 ,我们有:
证明。
请注意,用于计算 的线性程序的对偶由下式给出
使用受上述约束的对偶公式, 可以写为
∎
Lemma 2.
给定任何 ,我们有:
证明。
∎
Lemma 3.
给定任何,如果,我们有:
证明。
请注意,我们有以下等式,其中 是一个由零组成的向量:
这与 的原始 LP 的形式相同。 根据假设,我们有
这意味着 是 的可行解决方案:
结果如下。 ∎
Proposition A.1.
运算符 给出:
是收缩映射,并且对于有界 具有唯一的固定点。
证明。
我们首先证明是收缩映射。 然后,巴纳赫不动点定理的简单应用断言 具有唯一的不动点。 请注意,对于所有伪计量 和所有状态 、,
因此,,使得是的收缩映射并且具有唯一的固定点。 ∎
请参阅1
证明。
我们将通过归纳法来证明这一点。 假设 的界限成立,我们证明 的界限成立。 的基本情况源自 。 请注意, 因为每个时间步的 距离最多可为 1。
让 表示在遵循政策 并从状态 开始时,经过 步后结束于状态 的概率。 然后我们有:
因此,通过归纳,对于所有 可以得出:
这就完成了证明。 ∎
附录 B 双向模拟指标
符号。 我们使用 2 节中定义的符号。
双向模拟指标(Givan等人,2003;Ferns等人,2011)定义了伪度量,其中是根据即时奖励和奖励之间的距离来定义的。下一个状态分布。 定义 为
| (B.1) |
那么,有一个唯一的固定点,它是互模拟度量。 使用 1-Wasserstein 度量 。 伪测量 下的 1-Wasserstein 距离 可以使用对偶线性程序计算:
由于我们只对计算 和 中的状态之间的耦合感兴趣,因此上述公式假设 对于所有 和所有 的 。 的计算成本很高,并且需要状态的表格表示,这对于大型状态空间来说是不切实际的。 在政策互模拟(Castro,2020)(例如, -互模拟)与特定行为策略相关,并且比互模拟更容易近似。
附录 C策略相似度度量
C.1 计算 PSM
一般来说,跨 MDP 和 的给定 Dist 的 PSM 由下式给出
| (C.1) |
由于我们的主要重点是展示 PSM 在泛化方面的实用性,因此我们仅使用可以使用动态编程计算 PSM 的环境。 使用与 Castro (2020) 类似的观察,我们断言 的递归在确定性环境中采用以下形式:
| (C.2) |
其中 、 分别是从状态 采取操作 、 的下一个状态。 此外,我们假设 和 的终端状态之间的 Dist 为零。 请注意,方程C.2的形式与Q学习中的更新规则非常相似,因此可以使用近似动态规划对样本进行有效计算。 给定最佳轨迹和,其中和,方程C.2可以使用精确的动态规划来求解;我们在I.1节中提供了伪代码。
还有其他方法可以近似互模拟度量中的 Wasserstein 距离(例如 Ferns 等人,2006;2011;Castro,2020;Zhang 等人,2021)。 也就是说,随机环境的近似互模拟(或 PSM)仍然是一个令人兴奋的研究方向(Castro,2020)。 研究 PSM 中长期行为差异的其他距离度量对于未来的工作也很有趣。
C.2 PSM 与数据增强和双向模拟的连接
连接到互模拟。 尽管互模拟指标具有吸引人的特性,例如边界值函数差异(例如, (Ferns & Precup,2014)),但它们依赖于奖励信息,可能无法提供有意义的概念某些环境下的行为相似性。 命题C.1意味着PSM下相似的国家将具有相似的最优政策,但它们之间可以具有任意大的互模拟距离。
Proposition C.1.
存在环境 和 ,使得 其中 、 对于任何给定的 .
例如,考虑图 2 中两个语义等效的环境,其中 和 分别具有不同的奖励 。 每当 时,互模拟指标都会错误地暗示 在行为上与 比 更相似。
连接到数据增强。 数据增强通常假设可以访问最优不变变换,例如基于图像的基准中的随机裁剪或翻转(Laskin 等人,2020a;Kostrikov 等人,2020)。 然而,对于某些 RL 任务,这种增强可能会错误地将状态与不同的最佳行为混淆,并损害泛化能力。 例如,如果在具有左右动作的目标达成任务中翻转图像观察,则最佳动作也将翻转为采取左侧动作而不是右侧动作,反之亦然。 命题C.2指出PSM可以精确地量化这种增强的不变性。
Proposition C.2.
对于 MDP 及其数据增强 的 Transformer 版本 , 表示 对于任意 的最优不变性。
C.3 具有近似最优策略的 PSM
任意策略的广义策略相似性度量。对于给定的 Dist,我们定义一个广义 PSM ,其中 是 上所有策略的集合。 满足递归方程:
| (C.3) |
由于假定 Dist 是伪几何,而 是概率度量,这意味着 是伪几何,因为 (1) 是非负值、即 , (2) 是对称的,即 , 并且 满足三角形不等式,即 .
使用广义 PSM 的概念,我们表明使用次优策略导致的 PSM 近似误差受到策略次优性的限制。 因此,对于次优性降低的策略,PSM 近似变得更加准确,从而提高 PSE。
Proposition C.3。
[PSM 中的近似误差] 令 为使用在 上定义的次优策略 计算的近似 PSM,即 。 我们有:
证明。
附录 D L2 度量嵌入
学习度量嵌入的另一个常见选择(Zhang 等人, 2021) 是使用平方损失(即 -loss)来匹配一对状态的表示之间的欧几里得距离与这些状态之间的度量距离。 具体来说,对于给定的和表示,损失被最小化。 然而,它可能限制性太强,无法匹配精确的度量距离,我们通过将 度量嵌入与 CME 进行比较来实证证明(第 5.2 节)。
附录E扩展相关工作
不同任务之间的泛化过去被描述为迁移学习。 过去,大多数迁移学习方法依赖于固定表示并解决不同的问题表述(例如,假设共享状态空间)。 Taylor & Stone (2009) 对表征学习在强化学习中变得如此流行之前的技术进行了全面的调查。 最近,在不同但相关的任务中表现良好的问题开始被视为泛化问题;社区强调深度强化学习代理往往会过度适应他们所训练的环境(Cobbe 等人,2019;Witty 等人,2018;Farebrother 等人,2018;Juliani 等人,2019;Kostrikov 等人, 2020;宋等人,2019;Justesen 等人,2018;。
先前的泛化方法通常改编自监督学习,包括正则化(Cobbe等人,2019;Farebrother等人,2018)、随机性(Zhang等人,2018c)、噪声注入(Igl等人,2019;Zhang等人,2018a),更多样化的训练条件(Rajeswaran等人,2017;Witty等人,2018)和自注意力架构(唐等人,2020)。 相比之下,PSE 利用行为相似性(第 3 节),这是与 RL 的顺序方面相关的属性。
元学习也与泛化有关。 元学习方法试图找到一种需要少量梯度步骤即可在新任务上取得良好性能的参数化(Finn等人,2017)。 在此背景下,各种能够进行零样本泛化的元学习方法被提出(Li等人,2018;Agarwal等人,2019;Balaji等人,2018)。 这些方法通常包括最小化代理所在环境的损失,同时添加辅助损失以确保代理可用的其他(验证)环境的改进。 然而,Tachet des Combes 等人 (2018) 已经表明,元学习方法在跳跃任务中失败了,我们也根据经验观察到这一点。 其他人也报告了类似的发现(例如,Farebrother 等人,2018)。
还有其他几种方法可以解决强化学习中的零样本泛化问题,但它们通常依赖于特定领域的信息。 一些例子包括关于环境中实体之间的等价性的知识(Oh等人,2017)以及关于代理控制下的内容(Ye等人,2020)。 基于因果关系的方法是解决泛化问题的另一种方法,但当前的解决方案无法扩展到高维观察空间(例如,Killian 等人,2017;Perez 等人,2020;Zhang 等人,2020).
附录F像素跳跃任务


详细任务描述。 跳跃任务包括代理尝试跳过地板上的障碍物。 环境是确定性的,代理在每个时间步都会观察到 的奖励。 如果智能体成功到达屏幕最右侧,它会收到的额外奖励;如果智能体接触到障碍物,则情节终止。 观察空间是环境的像素表示,如图1所示。 代理可以执行两个操作:右和跳跃。 jump 动作使代理垂直和水平向右移动。
架构。 用于跳跃任务实验的神经网络改编自 Nature DQN 架构。 具体来说,该网络由 3 个大小分别为 32、64、64 的卷积层组成,滤波器大小为 、 和 ,步幅为 4、2 和 1 , 分别。 卷积网络的输出被馈送到大小为 256 的单个全连接层,然后是“ReLU”非线性层。 最后,这个 FC 层输出被输入到一个线性层,该线性层计算输出 jump 和 right 动作概率的策略。
总损失。 对于跳跃世界,总损失由 给出,其中 是模仿学习损失, 是学习 PSE 的辅助损失,系数为 。
F.1 颜色跳跃任务
| Method | Red (%) | Green (%) | ||
|---|---|---|---|---|
| RandConv | 6.2 | (0.4) | 99.6 | (0.2) |
| Dropout and reg. | 19.5 | (0.2) | 100.0 | (0.0) |
| RandConv + PSEs | 29.8 | (1.3) | 99.6 | (0.2) |
| PSEs | 37.9 | (1.9) | 100.0 | (0.0) |
F.2 超参数
对于超参数选择,我们在包含“宽”网格中 54 个未见过的任务的验证集上评估所有代理,并选择具有最佳验证性能的参数。 验证集(图F.7)是通过使用地板高度相差1或障碍物位置相差1的环境附近的环境来选择的。
| Hyperparameter | Value |
| Learning rate decay | 0.999 |
| Training epochs | 2000 |
| Optimizer | Adam |
| Batch size (Imitation) | 256 |
| Num training tasks | 18 |
| -scale Parameter () | 0.01 |
| Embedding size () | 64 |
| Batch Size () | 57 |
| 57 |

| Hyperparameter | Dropout and -reg. | PSEs | RandConv | RandConv + PSEs |
| Learning Rate | ||||
| -reg. coefficient | – | – | ||
| Dropout coefficient | – | – | – | |
| Contrastive Temperature () | – | – | ||
| Auxiliary loss coefficient () | – | – |
| Hyperparameter | Dropout and -reg. | PSEs | RandConv | RandConv + PSEs |
| Learning Rate | ||||
| -reg. coefficient | – | – | ||
| Dropout coefficient | – | – | – | |
| Contrastive Temperature () | – | – | ||
| Auxiliary loss coefficient () | – | – |
| Hyperparameter | PSM | -bisimulation | ||
|---|---|---|---|---|
| CMEs | -embeddings | CMEs | -embeddings | |
| Learning Rate | ||||
| Contrastive Temperature () | – | – | ||
| Auxiliary loss coefficient () | ||||
附录 GLQR:其他详细信息
| Method | Number of Distractors () | ||
|---|---|---|---|
| 500 | 1000 | 10000 | |
| Overparametrization (Song et al., 2019) | 25.8 (1.5) | 24.9 (1.1) | 24.9 (0.4) |
| IPO (Sonar et al., 2020) (IRM + Policy opt.) | 32.6 (5.0) | 27.3 (2.8) | 24.8 (0.4) |
| Weight Sparsity (-reg.) | 28.2 (0.0) | 28.2 (0.0) | 28.2 (0.0) |
| PSM (State aggregation) | 0.03 (0.0) | 0.03 (0.0) | 0.02 (0.0) |
具有线性动力学和二次成本的最优控制(通常称为 LQR)已越来越多地用作深度强化学习问题的简化替代方法(Recht,2019)。 继宋等人(2019); Sonar 等人 (2020),我们分析了以下 LQR 问题来评估泛化能力:
| (G.1) |
其中 是初始状态分布, 是时间 t 时的(隐藏)真实状态, 是控制操作,是线性策略矩阵。 代理接收输入观察,它是状态的线性变换。 和 是半正交矩阵,可防止预测最佳动作时的信息损失。 一个环境对应于的特定选择;所有其他系统参数 () 都是跨环境共享且代理未知的固定矩阵。 代理使用基于方程G.1的训练环境来学习策略矩阵。 在测试时,学习的策略在未见过的 环境中进行评估。
此设置中的泛化挑战是忽略干扰项: 表示跨环境不变的状态特征,而 是大小为 的高维干扰项,分别使得。 此外,泛化到所有环境的策略矩阵是,其中对应于可以访问状态的最优LQR解决方案。 然而,对于具有干扰项的单一环境,存在多种解决方案,例如。 请注意,干扰因素比 中的不变特征大一个数量级,并且对它们的依赖可能会导致代理对具有看不见的干扰因素的输入做出不稳定的行为,从而导致泛化能力较差。
我们使用具有两个线性层的过参数化策略,即 ,其中是观察的学习表示。 我们使用梯度下降来学习 ,使用 2 个具有不同数量干扰因素的训练环境的组合成本。 我们通过使用平方损失来匹配观察对的表示,从而聚合具有接近零 PSM 的观察对。 我们使用 Sonar 等人 (2020) 发布的开源代码进行实验。
| Parameter | Setting |
|---|---|
| A | Orthogonal matrix, scaled 0.8 |
| B | |
| 20 | |
| 20 | |
| Q | |
| R | |
| Orthogonal Initialization, scaled 0.001 | |
| Random semi-orthogonal matrix |
IPO 训练对干扰因素的依赖也凸显了 IRM 的局限性:如果模型可以实现零错误的解决方案,那么无论其泛化能力如何,任何此类解决方案都可以被 IRM 接受 - 这是过度参数化深度神经网络的常见场景 (金等人,2020)。
G.1 PSM聚合的接近最优
Conjecture 1.
假设策略相似性度量 (PSM) 的状态聚合误差为零,则使用梯度下降学习的策略矩阵 与干扰项无关。
证明。
对于 LQR 域 ,观察对 (、) 的 PSM 为零,当且仅当底层状态 与对中的观察结果。 这是事实,因为 (a) 两个域具有相同的转换动态,如方程 G.1 所指定,并且 (b) 最优策略是确定性的,并且完全由当前状态 随时。
假设 和 分别为干扰半正交矩阵 和 。 此外,分别由和给出表示。 假设 其中 和 和 。
此外,众所周知,由于隐式正则化,梯度下降往往会找到低秩解(Arora等人,2019;Gunasekar等人,2017),例如,通过足够小的步长和足够接近原点的初始化,矩阵分解的梯度下降收敛到 2 层线性网络的最小核范数解(Gunasekar 等人,2017)。 基于此,我们推测,我们在实践中发现这是正确的。 ∎
附录 H 分散控制套件

我们使用与 Kostrikov 等人 (2020) 相同的设置; Stone 等人 (2021) 了解实施细节和协议。 为了完整起见,我们在下面描述详细信息。
动态背景干扰。 在 Distracting Control Suite (Stone 等人, 2021) 中,随机背景从 DAVIS 2017 数据集 (Pont-Tuset 等人, 2017) 的场景投影到现场。 为了使这些背景对所有任务和视图都可见,地板网格是半透明的,透明度系数为 0.3。 我们选取 DAVIS 2017 训练集中的前 2 个视频,并从每集开头的场景和帧中随机采样。 在动态设置中,视频向前或向后播放,直到到达最后一帧或第一帧,此时视频将向后播放。 这样,背景运动总是平滑且没有“剪切”。
软演员评论家。 Soft Actor-Critic (SAC) (Haarnoja 等人, 2018) 学习状态-动作值函数 、随机策略 和温度 通过优化 折扣最大熵目标来找到 MDP 的最优策略。 一般用于表示模型各部分通过训练更新的参数。 参与者策略 是一个参数 -高斯,给定 样本 ,其中 和 和 是参数平均值和标准差。
策略评估步骤通过优化软贝尔曼残差的单步来学习批评家网络
其中 是转换的重播缓冲区, 是权重的指数移动平均值。 SAC 使用截断双 Q 学习,为了简单起见,我们省略了它,但在实践中使用了它。
然后,策略改进步骤通过优化目标来适应参与者策略 网络
最后,通过损失得知温度
其中 是策略尝试匹配的目标熵超参数,在实践中通常设置为 。
H.1演员和评论家网络
遵循 Kostrikov 等人 (2020),我们对批评者使用裁剪双 Q 学习,其中每个 函数都被参数化为具有 ReLU 的 3 层 MLP 除最后一层之外的每一层之后的激活。 Actor 也是一个带有 ReLU 的 3 层 MLP,输出表示策略的对角高斯的均值和协方差。 评论家和演员的隐藏维度均设置为 。
H.2编码器网络
我们采用 Kostrikov 等人 (2020) 的编码器架构。 该编码器由四个带有 内核和 通道的卷积层组成。 ReLU 激活在每个卷积层之后应用。 除了第一个卷积层具有步幅 之外,我们在任何地方都使用步幅到 。 卷积网络的输出被输入到由 LayerNorm 标准化的单个全连接层中。 最后,我们将 tanh 非线性应用于全连接层的 维输出。 我们使用正交初始化来初始化全连接层和卷积层的权重矩阵,并将偏差设置为零。 演员网络和评论家网络都有单独的编码器,尽管我们共享它们之间的转换层的权重。 此外,只有批判优化器可以更新这些权重(即,我们会在演员的梯度传播到共享卷积层之前将其停止)。
H.3对比度量嵌入损失
对于我们所有的实验,我们使用具有 单元的单个 ReLU 层进行非线性投影以获得嵌入 (图 3)。 我们使用参与者网络中的倒数第二层来计算嵌入。 为了选择超参数,我们使用“Ball In Cup Catch”作为验证环境,使用 3 个温度 和 3 个辅助 损失系数 。 所有其他超参数与之前的工作相同(参见表H.2)。
我们使用训练 DrQ 代理 500K 环境步骤后获得的策略来近似最佳策略。 由于该近似策略中的给定动作序列在不同的训练环境中具有相同的性能,因此我们通过动态编程(请参阅第 I.1 节伪代码)计算跨训练环境的 PSM,使用这样的动作序列。
总损失。 总损失由 给出,其中 是强化学习损失,结合了 、 和 ),而 是学习 PSE 的辅助损失,系数为 。
H.4培训和评估设置
为了进行评估,我们使用 DAVIS 2017 验证数据集中的前 30 个视频(参见图 H.1)。 每个检查点都是通过计算未见过的环境中超过 100 个情节的平均情节返回来评估的。 所有实验均使用每个任务的五个随机种子进行,用于计算其评估的平均值和标准偏差/误差。 我们使用 Kostrikov 等人 (2020) 规定的 作为 DrQ。 继 Kostrikov 等人 (2020) 和 Stone 等人 (2021) 之后,我们为每个任务使用不同的动作重复超参数,我们在表 H.3。 我们将观察输入构建为 连续帧 (Kostrikov 等人,2020) 的堆栈,其中每个帧都是大小为 的 RGB 渲染来自第 个摄像机。 然后,我们将每个像素除以 ,将其缩小到 范围。 对于数据增强,我们通过在连续帧中使用相同的裁剪增强来保持时间一致性。
| Hyperparameter | Setting |
|---|---|
| Contrastive temperature () | 0.1 |
| Auxiliary loss coefficient () | 1.0 |
| -scale parameter () | 0.1 |
| Batch Size () | 128 |
| 1000 // Action Repeat |
| Parameter | Setting |
| Replay buffer capacity | |
| Seed steps | |
| Batch size (DrQ) | |
| Discount | |
| Optimizer | Adam |
| Learning rate | |
| Critic target update frequency | |
| Critic Q-function soft-update rate | |
| Actor update frequency | |
| Actor log stddev bounds | |
| Init temperature |
| Task name | Action repeat |
|---|---|
| Cartpole Swingup | |
| Reacher Easy | |
| Cheetah Run | |
| Finger Spin | |
| Ball In Cup Catch | |
| Walker Walk |
H.5泛化曲线
附录一伪代码
I.1 计算 PSM 的动态规划
I.2 对比损失
a