WeNet:面向生产的流式和非流式端到端语音识别工具包
摘要
在本文中,我们提出了一种名为 WeNet 的开源语音识别工具包,其中实现了一种名为 U2 的新两遍方法,以在单个模型中统一流式和非流式端到端 (E2E) 语音识别。 WeNet 的主要动机是缩小端到端语音识别模型的研究和部署之间的差距。 WeNet提供了一种在现实场景中交付自动语音识别(ASR)应用的有效方法,这是与其他开源端到端语音识别工具包的主要区别和优势。 我们开发了一种混合联结时间分类(CTC)/注意力架构,以 Transformer 或 conformer 作为编码器和注意力解码器来重新评分 CTC 假设。 为了在统一模型中实现流式和非流式,我们使用基于块的动态注意力策略,该策略允许自注意力以随机长度关注正确的上下文。 我们在 AISHELL-1 数据集上的实验表明,与标准非流式 Transformer 相比,我们的模型在非流式 ASR 中实现了 5.03% 的相对字符错误率 (CER) 降低。 模型量化后,我们的模型在运行时实现了合理的 RTF 和延迟。 该工具包可在 https://github.com/mobvoi/wenet 上公开获取。
索引词:WeNet、生产应用导向、U2
1简介
端到端(E2E)自动语音识别(ASR)模型在过去几年中获得了越来越多的关注,例如联结时序分类(CTC)[1, 2]、循环神经网络网络转换器 (RNN-T)、[3, 4, 5, 6] 和基于注意力的编码器-解码器 (AED) [7, 8, 9, 10, 11]。 与传统的混合ASR框架相比,E2E模型最吸引人的优点是训练过程极其简化。
最近的工作[12,13,14]也表明E2E系统在字错误率(WER)标准上已经超越了传统的混合ASR系统。 考虑到上述E2E模型的优点,将新兴的ASR框架部署到现实世界的产品中变得有必要。 然而,部署端到端系统并不容易,有很多实际问题需要解决。
首先,流式问题。 对于许多需要ASR系统快速响应、低延迟的场景来说,流式推理至关重要。 然而,一些E2E模型很难以流式方式运行,例如LAS[8]和Transformer[15]。 要使此类模型以流方式工作[16,17,18],要么需要付出巨大的努力,要么会引入明显的准确性损失。
第二,统一流式和非流式模式。 流式和非流式系统通常是分开开发的。 在单一模型中统一流式传输和非流式传输可以减少开发工作量、训练成本以及部署成本,这也是生产采用的首选[19,20,21,22]。
第三,生产应用问题,这是我们在 WeNet 设计过程中最关心的问题。 将E2E模式推广到真正的生产应用还需要付出很大的努力。 因此,我们必须从模型架构、应用程序和运行平台等方面仔细设计推理工作流程。 由于自回归波束搜索解码的工作方式,大多数E2E模型架构的工作流程极其复杂。 此外,在边缘设备上部署模型时应考虑计算和内存的成本。 至于运行时平台,虽然有多种平台可以用来做神经网络推理,例如ONNX(Open Neural Network Exchange)、Pytorch中的LibTorch、TensorRT[23]、OpenVINO、MNN[24] 和 NCNN 一样,它仍然需要语音处理和高级深度学习优化知识来为特定应用选择最佳的一种。
在这项工作中,我们提出了 WeNet 来解决上述问题。 微网中的“我们”受到“微信”的启发111微信是中国社会最流行的移动设备即时通讯平台。,意思是连接和共享,“Net”源自Espnet[25],因为我们参考了Espnet中很多优秀的设计。 Espnet 是最流行的端到端语音研究开源平台。 它主要关注端到端ASR,采用广泛使用的动态神经网络工具包Chainer和PyTorch作为主要深度学习引擎。 相比之下,WeNet 的主要动机是缩小端到端语音识别模型的研究和生产之间的差距。 在面向生产的原则上,WeNet采用了以下实现方式。 首先,我们提出了一个新的两遍框架,即U2来解决统一的流式和非流式问题。 其次,从模型训练到部署,WeNet 仅依赖于 PyTorch 及其生态系统。 WeNet的主要优势如下。
生产应用优先并准备好生产应用:WeNet 的 Python 代码满足 TorchScript 的要求,因此 WeNet 训练的模型可以直接通过Torch Just In Time(JIT)导出并使用 LibTorch 进行推理。 研究阶段的模型和生产阶段的模型之间不存在差距。
流式和非流式 ASR 统一解决方案:WeNet采用U2框架,实现准确、快速、统一的端到端模型,有利于行业采用。
便携式运行时:提供了多个运行时来展示如何在不同平台上托管 WeNet 训练的模型,包括服务器(x86)和嵌入式(Android 平台中的 ARM)。
轻量:WeNet 专为端到端语音识别而设计,代码干净简单,全部基于 PyTorch 及其生态系统。 因此它不依赖于Kaldi[26],从而简化了安装和使用。
我们的实验表明,WeNet是一个简单易学的语音识别工具包,具有从研究到生产的端到端解决方案。 在本文中,我们将描述模型架构、系统设计和运行时基准,包括实时因素(RTF)和延迟。
2 WeNet
2.1模型架构
由于我们的目标是解决流媒体、统一和生产问题,因此解决方案应该简单、易于构建、方便在运行时应用,同时保持良好的性能。
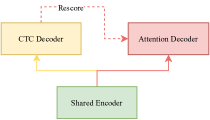
U2这个统一的二通道联合CTC/AED模型很好地解决了这个问题。 如图 1,U2由三部分组成,共享编码器、CTC解码器 和 注意力解码器。 共享编码器 由多个 Transformer [15] 或 Conformer [27] 层组成,仅考虑有限的正确上下文以保持平衡的延迟。 这 CTC 解码器 由一个线性层组成,它将 共享编码器 输出转换为 CTC 激活,而 注意力解码器 由多个 Transformer 解码器层组成。 在解码过程中, CTC 解码器在第一遍中以流模式运行,注意力解码器 在第二遍中使用以给出更准确的结果。
2.1.1训练
CTC 损失和 AED 损失合并在 U2 的训练中:
| (1) |
其中是声学特征,是相应的标签,和分别是CTC和AED损失,而 是一个平衡 CTC 和 AED 损失重要性的超参数。
如前所述,当共享编码器时,我们的U2可以在流模式下工作 不需要全文的信息。 我们采用动态块训练技术来统一非流式和流式模型。 首先,按照固定的块大小将输入分成几个块 具有输入 并且每个块都参与其自身和所有先前的块,因此 CTC解码器 在第一遍中仅取决于块大小。 当chunk大小有限时,以流式方式工作;否则它会以非流的方式工作。 其次,块大小在训练中从 1 到当前训练单词的最大长度动态变化,因此训练后的模型学习以任意块大小进行预测。 根据经验,较大的块大小会带来更好的结果和较高的延迟,因此我们可以通过在运行时调整块大小来轻松平衡准确性和延迟。
2.1.2解码
为了在研究阶段基于Python的解码过程中比较和评估联合CTC/AED模型的不同部分,WeNet支持以下四种解码模式:
-
•
注意力:对模型的 AED 部分应用标准自回归集束搜索。
-
•
ctc_greedy_search:将CTC贪婪搜索应用于模型的CTC部分,CTC贪婪搜索比其他模式超级快。
-
•
ctc_prefix_beam_search:对模型的CTC部分应用CTC前缀波束搜索,可以给出n个最佳候选。
-
•
注意力重新评分:首先在模型的 CTC 部分应用 CTC 前缀波束搜索来生成 n 个最佳候选,然后在 AED 解码器部分上使用相应的编码器输出重新对 n 个最佳候选进行评分。
在开发运行阶段,WeNet仅支持attention_rescoring解码模式,因为它是我们生产的最终解决方案。
2.2系统设计
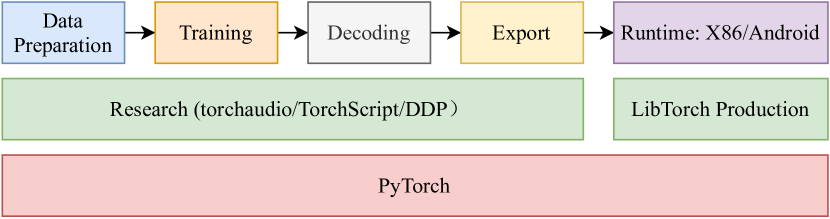
WeNet整体设计栈如图2. 请注意,底层堆栈完全基于 PyTorch 及其生态系统。 中间堆栈由两部分组成。 当我们开发研究模型时,TorchScript用于开发模型,Torchaudio用于即时特征提取,分布式数据并行(DDP)用于分布式训练,torch Just In Time(JIT)用于模型导出,PyTorch量化用于量化模型,LibTorch用于生产运行时。 LibTorch Production 用于托管生产模型,旨在支持各种硬件和平台,如 CPU、GPU (CUDA) Linux、Android 和 iOS。 顶部堆栈显示了 WeNet 中典型的研究到生产流程。 以下小节将详细介绍这些模块的设计。
2.2.1数据准备
在数据准备阶段不需要任何离线特征提取,因为我们在 . WeNet只需要一个Kaldi格式的转录本、一个wave列表文件和一个模型单元字典来创建输入文件。
2.2.2训练
WeNet 的训练阶段具有以下主要特点。
即时特征提取:这是基于 Torchaudio,它可以生成与 Kaldi 相同的 Mel 滤波器组功能。 由于特征是从原始 PCM 数据中即时提取的,因此我们可以在时间和频率级别对原始 PCM 进行数据增强,最后同时在特征级别进行数据增强,从而丰富了数据的多样性。
CTC/AED 联合训练:联合训练加快了训练的收敛速度,提高了训练的稳定性,并给出了更好的识别结果。
分布式训练:WeNet 支持在 PyTorch 中使用 DistributedDataParallel 进行多 GPU 训练,以充分利用多工作器多 GPU 资源,实现更高的线性加速比。
2.2.3 解码
提供了一组 Python 工具来识别波形文件并计算不同解码模式下的准确性。 这些工具可帮助用户在将模型部署到生产环境之前验证和调试模型。 章节中的所有解码算法 2.1.2 都支持。
2.2.4导出
由于WeNet模型是在TorchScript中实现的,因此可以通过torch JIT直接安全地将其导出到生产环境。 然后可以在运行时使用 LibTorch 库托管导出的模型,同时支持 float-32 模型和量化 int-8 模型。 当托管在嵌入式设备(例如基于 ARM 的 Android 和 iOS 平台)上时,使用量化模型可以使推理速度提高一倍甚至更高。
2.2.5运行时
目前,我们支持在两个主流平台上托管WeNet生产模型,即x86作为服务器运行时和Android作为设备上运行时。 提供了适用于两个平台的 C++ API 库和可运行的演示,同时用户还可以使用 C++ 库来实现自己的定制系统。 我们仔细评估了 ASR 系统的三个关键指标,即准确性、实时因素 (RTF) 和延迟。 部分报告的结果 3.2 将表明WeNet适用于许多ASR应用,包括服务API和设备上的语音助手。
3实验
我们在开源中文普通话语音语料库 AISHELL-1 [28] 上进行实验,其中包含 150 小时的训练集、10 小时的开发集和 5 小时的测试集。 测试集总共包含 7,176 个话语。 至于声学特征,80 维对数梅尔滤波器组 (FBANK) 由 Torchaudio 以 25ms 窗口和 10ms 偏移即时计算。 此外,SpecAugment [29] 应用了 2 个频率掩模,其中最大频率掩模为 (),以及2个带最大时间掩码的时间掩码() 来缓解过度拟合。 编码器前面使用了两个内核大小为3*3、步幅为2的卷积子采样层。 对于模型参数,我们使用 12 个 Transformer 层作为编码器,使用 6 个 Transformer 层作为解码器。 Adam 优化器与具有 25,000 个预热步骤的学习率计划一起使用。 此外,我们通过对训练期间开发集上的损失较低的前 K 个最佳模型进行平均来获得最终模型。
3.1统一模型评估
我们首先评估一个非流模型(M1)作为我们的基线,该模型通过完整的注意力进行训练和推理,以及另一个具有动态块策略的统一模型(M2)。 M2 在解码时使用不同的块大小(full/16/8/4)进行推断,其中 full 表示完整注意力非流式情况,16/8/4 表示流式情况。
| decoding method | M1 | M2 | |||
|---|---|---|---|---|---|
| full | 16 | 8 | 4 | ||
| attention | 5.69 | 6.04 | 6.35 | 6.45 | 6.70 |
| ctc_greedy_search | 5.92 | 6.28 | 6.99 | 7.39 | 7.89 |
| ctc_prefix_beam_search | 5.91 | 6.28 | 6.98 | 7.40 | 7.89 |
| attention_rescoring | 5.30 | 5.52 | 6.05 | 6.28 | 6.62 |
如表1,统一模型不仅在完全注意的情况下显示了与非流模型相当的结果,而且在块大小有限的 16/8/4 的流情况下也给出了有希望的结果,这验证了动态块训练策略的有效性。
比较四种不同的解码模式,attention_rescoring 模式在非流模式和统一模式下总能改善 CTC 结果。 ctc_greedy_search 和 ctc_prefix_beam_search 的性能几乎相同,但随着块大小的减小,它们的性能显着下降。 Attention_rescoring 模式减轻了 ctc_prefix_beam_search 结果的性能下降,而 Attention 模式则稍微降低了性能。
Attention_rescoring 模式比attention 模式更快并且具有更好的RTF,因为attention 模式是自回归过程,而attention_rescoring 模式不是。 总体而言,attention_rescoring 模式不仅显示出有希望的结果,而且具有较低的 RTF。 因此,我们的生产选择是基于动态块的具有attention_rescoring解码的统一模型。 所以运行时只支持attention_rescoring模式。
3.2运行时基准
本节将展示上述统一模型 M2 的量化、RTF 和延迟基准。 我们分别在服务器 x86 平台和设备上 ARM Android 平台上完成了基准测试。
对于云x86平台,CPU为4核Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz,总共16G内存。 仅使用一个线程进行 CPU 线程和 TorchScript 推理 222https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inf
erence.html 对于每一句话,因为云服务需要并行处理,单线程避免了并行处理时的性能下降。 对于端侧Android,CPU为4核高通骁龙865,8G内存,单线程用于端侧推理。
3.2.1 量化
这里我们只是比较量化前后的CER。 如表所示 2,CER在量化前后具有可比性。 浮动模型的 CER 与我们在表中列出的略有不同 1因为表1中的结果是通过Python研究工具评估的,而表2 这里是由运行时工具评估的。
| quantization/decoding_chunk | full | 16 | 8 | 4 |
|---|---|---|---|---|
| NO (float32) | 5.58 | 6.03 | 6.27 | 6.60 |
| YES (int8) | 5.59 | 6.06 | 6.28 | 6.64 |
3.2.2RTF
如表3,RTF 随着块大小的减小而增加,因为较小的块需要更多的迭代来进行前向计算。 此外,量化可以在设备上(Android)带来约 2 倍的加速,在服务器(x86)上带来轻微的改进。
| model/decoding_chunk | full | 16 | 8 | 4 |
|---|---|---|---|---|
| server (x86) float32 | 0.079 | 0.095 | 0.128 | 0.186 |
| server (x86) int8 | 0.072 | 0.081 | 0.098 | 0.134 |
| on-device (Android) float32 | 0.164 | 0.251 | 0.350 | 0.505 |
| on-device (Android) int8 | 0.082 | 0.114 | 0.130 | 0.201 |
3.2.3延迟
对于延迟基准测试,我们创建一个 WebSocket 服务器/客户端来模拟真实的流应用程序,因为该基准测试仅在服务器 x86 平台上进行。 我们评估的平均延迟如下所述。 模型延迟 (L1):模型结构引入的等待时间。 对于我们基于块的解码,理论上平均等待时间是块的一半。 我们模型的总模型延迟是 (ms),其中 4 是子采样率,6 是编码器中前两个 CNN 层引入的前瞻,10 是帧移位。 重新评分成本(L2):第二次注意力重新评分的时间成本。 最终延迟(L3):用户(客户端)感知延迟,即用户停止说话到得到识别结果之间的时间差。 当我们的ASR服务器收到语音结束信号时,它首先转发左侧语音进行CTC搜索,然后进行第二遍注意力重新评分,因此重新评分成本是最终延迟的一部分。 对于实际生产,还应该考虑网络延迟,但它可以忽略不计,因为我们在同一台机器上测试服务器/客户端。
| decoding_chunk | L1 (ms) | L2 (ms) | L3 (ms) |
|---|---|---|---|
| 16 | 380 | 115 | 142 |
| 8 | 220 | 115 | 135 |
| 4 | 140 | 114 | 130 |
如表4,对于不同的块大小,重新评分成本几乎相同,这是合理的,因为重新评分计算对于块大小是不变的。 此外,最终延迟由重新评分成本决定,这意味着我们可以通过降低重新评分成本来进一步减少最终延迟。 最后,随着解码块从 4 到 8、从 8 到 16 变化,最终延迟略有增加。
3.315,000小时任务
| test set | Utt Dur (s) | Conformer | U2 | |
|---|---|---|---|---|
| full | 16 | |||
| AISHELL-1 | 5.01 | 3.96 | 3.70 | 4.41 |
| TV | 2.99 | 10.96 | 11.61 | 13.03 |
| Conversation | 2.69 | 12.84 | 13.86 | 15.07 |
我们使用从脱口秀、电视剧、播客和广播广播等各个领域收集的 15,000 小时普通话数据集进一步训练所提出的 U2 模型,以展示我们的模型在行业规模数据集上的能力。 该模型在三个测试集上进行评估。
我们使用 Conformer [27] 作为共享编码器,而解码器是与之前的实验相同的 Transformer。 Conformer在Transformer的基础上增加了卷积模块,因此可以捕获局部和全局上下文,并在不同的ASR任务上获得更好的结果。 特别地,因果卷积用于 Conformer 的块训练,并且我们添加了与 80 维 FBANK 连接的额外 3 维音高特征。 我们保留了之前实验中编码器的主要结构,仅将 Transformer 层更改为具有多头注意力(4 个头)的 12 个一致层。 每个构象层使用 384 个注意力维度和 2048 个前馈维度。 此外,累积梯度也用于稳定训练,我们每 4 步更新一次参数。 此外,我们通过对训练期间评估集损失较低的前 10 个最佳模型进行平均来获得最终模型。 我们使用动态块训练一个完整的上下文一致性 CTC 模型和一个 U2 模型。 使用三个测试集来评估这些模型,包括 AISHELL-1、电视域和会话域。 U2模型工作在attention_rescoring解码模式上,conformer模型工作在attention解码模式上。 如表所示 5,我们可以看到 U2 总体上取得了与 Conformer 基线相当的结果,并且在推理过程中使用充分注意时,在 AISHELL-1 测试集上取得了更好的结果。 当块大小为 16 时,CER 并没有明显变差。
为了分析为什么 U2 模型在 AISHELL-1 任务上表现更好,我们收集了表中所示的每个测试集的平均单词持续时间5. 由于AISHELL-1中的平均单词持续时间比其他两个测试集长得多,因此AISHELL-1任务可能需要更强的全局信息建模能力。 U2模型可以使用注意力解码器对CTC假设进行重新评分,这使得它更有利于AISHELL-1任务。
4结论
我们推出了一个新的开源生产型端到端语音识别工具包WeNet,为流式和非流式应用提供统一的解决方案。 本文介绍了工具包背后的模型结构、系统设计和基准测试。 整个工具包设计精良、轻量级,在开放数据集和内部大型数据集上显示出出色的性能。 Wenet 已经通过采用 n-gram 和 WFST 在运行时支持自定义语言模型。 此外,Wenet还支持基于gRPC的语音识别微服务框架应用。 后续还会更新更多特色功能。 请继续关注并访问我们的网站 https://github.com/wenet-e2e/wenet 以获取更多更新。
参考
- [1] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376.
- [2] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen et al., “Deep speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning, 2016, pp. 173–182.
- [3] A. Graves, “Sequence transduction with recurrent neural networks,” arXiv preprint arXiv:1211.3711, 2012.
- [4] A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,” in IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2013, pp. 6645–6649.
- [5] X. Wang, Z. Yao, X. Shi, and L. Xie, “Cascade RNN-Transducer: Syllable based streaming on-device mandarin speech recognition with a syllable-to-character converter,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 15–21.
- [6] S. Wang, P. Zhou, W. Chen, J. Jia, and L. Xie, “Exploring rnn-transducer for chinese speech recognition,” in 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2019, pp. 1364–1369.
- [7] J. Chorowski, D. Bahdanau, K. Cho, and Y. Bengio, “End-to-end continuous speech recognition using attention-based recurrent nn: First results,” in NIPS 2014 Workshop on Deep Learning, 2014.
- [8] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, attend and spell,” arXiv preprint arXiv:1508.01211, 2015.
- [9] J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-based models for speech recognition,” in Advances in neural information processing systems, 2015, pp. 577–585.
- [10] H. Luo, S. Zhang, M. Lei, and L. Xie, “Simplified self-attention for transformer-based end-to-end speech recognition,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 75–81.
- [11] H. Miao, G. Cheng, C. Gao, P. Zhang, and Y. Yan, “Transformer-based online ctc/attention end-to-end speech recognition architecture,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6084–6088.
- [12] R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly, “A comparison of sequence-to-sequence models for speech recognition.” in Interspeech, 2017, pp. 939–943.
- [13] T. N. Sainath, R. Pang, D. Rybach, Y. He, R. Prabhavalkar, W. Li, M. Visontai, Q. Liang, T. Strohman, Y. Wu et al., “Two-pass end-to-end speech recognition,” 2019, pp. 2773–2777.
- [14] S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” in IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 4835–4839.
- [15] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
- [16] C. Raffel, M.-T. Luong, P. J. Liu, R. J. Weiss, and D. Eck, “Online and linear-time attention by enforcing monotonic alignments,” in International Conference on Machine Learning. PMLR, 2017, pp. 2837–2846.
- [17] C.-C. Chiu and C. Raffel, “Monotonic chunkwise attention,” in International Conference on Learning Representations, 2018.
- [18] H. Inaguma, M. Mimura, and T. Kawahara, “Enhancing monotonic multihead attention for streaming asr,” in Proc. Interspeech, 2020, pp. 2137–2141.
- [19] J. Yu, W. Han, A. Gulati, C.-C. Chiu, B. Li, T. N. Sainath, Y. Wu, and R. Pang, “Universal ASR: Unify and improve streaming asr with full-context modeling,” arXiv preprint arXiv:2010.06030, 2020.
- [20] A. Tripathi, J. Kim, Q. Zhang, H. Lu, and H. Sak, “Transformer transducer: One model unifying streaming and non-streaming speech recognition,” arXiv preprint arXiv:2010.03192, 2020.
- [21] K. Hu, T. N. Sainath, R. Pang, and R. Prabhavalkar, “Deliberation model based two-pass end-to-end speech recognition,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7799–7803.
- [22] K. Hu, R. Pang, T. N. Sainath, and T. Strohman, “Transformer based deliberation for two-pass speech recognition,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 68–74.
- [23] H. Vanholder, “Efficient inference with tensorrt,” 2016.
- [24] X. Jiang, H. Wang, Y. Chen, Z. Wu, L. Wang, B. Zou, Y. Yang, Z. Cui, Y. Cai, T. Yu, C. Lv, and Z. Wu, “MNN: A universal and efficient inference engine,” in Machine Learning and Systems (MLSys), 2020.
- [25] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. E. Y. Soplin, J. Heymann, M. Wiesner, N. Chen et al., “Espnet: End-to-end speech processing toolkit,” arXiv preprint arXiv:1804.00015, 2018.
- [26] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz et al., “The Kaldi speech recognition toolkit,” in IEEE 2011 workshop on automatic speech recognition and understanding. IEEE Signal Processing Society, 2011.
- [27] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al., “Conformer: Convolution-augmented transformer for speech recognition,” in Proc. Interspeech, 2020, pp. 5036–5040.
- [28] H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA). IEEE, 2017, pp. 1–5.
- [29] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” in Proc. Interspeech, 2019, pp. 2613–2617.