软开围栏,分隔符 =;
导言
高斯过程模型
作者
Thomas Beckers
t.beckers@tum.de
摘要
在过去的二十年中,由于一些有利的特性,如偏差方差权衡和与贝叶斯数学的紧密联系,高斯过程回归在建模动态系统中得到越来越广泛的应用。 作为一种数据驱动的方法,高斯过程是一种强大的非线性函数回归工具,无需太多先验知识。 与大多数其他技术相比,高斯过程建模不仅提供平均预测,还提供模型保真度的衡量指标。 在本文中,我们将介绍高斯过程及其在动态系统回归任务中的应用。 自己尝试: gpr.tbeckers.com
原创作品:2020 年 4 月
当前修订:2021 年 2 月 10 日
信息导向控制
慕尼黑工业大学主席
1 引言
高斯过程 (GP) 是一种随机过程,通常是指由时间或空间索引的一组随机变量。 它的特殊属性是,这些变量的任何有限集合都服从多元高斯分布。 因此,GP 是一个对无限多个变量的分布,因此也是一个对具有连续域的函数的分布。 因此,它描述了无限维向量空间上的概率分布。 对于工程应用,GP 作为一种监督机器学习技术,在贝叶斯推理中被用作函数的先验概率分布,因此获得了越来越多的关注。 连续变量的推理导致了高斯过程回归 (GPR),其中先验 GP 模型用训练数据更新,以获得后验 GP 分布。 从历史上看,GPR 用于时间序列预测,最初由 Wiener 和 Kolmogorov 在 1940 年代提出。 之后,它在 1970 年代的地统计学中变得越来越流行,在那里 GPR 被称为 克里金法。 最近,它在机器学习领域卷土重来 [Rad96, WR96],特别是在计算能力快速增长的推动下。
在本文中,我们介绍了关于 GP 和 GPR 的背景信息,主要基于 [Ras06],重点介绍了在控制中的应用。 我们首先介绍 GPs,解释底层内核函数的作用,并展示它与再生核希尔伯特空间的关系。 之后,将介绍动态系统中的嵌入以及模型不确定性作为误差边界的解释。 除了形式化符号之外,还包含了一些例子,以帮助直观理解。
2 高斯过程
设 为一个概率空间,样本空间为 ,相应的 -代数为 ,概率测度为 P。索引集由 给出,其中 为正整数。 那么,一个函数 ,它是 的可测函数,索引为 ,称为随机过程。 如果指定了 ,则函数 是 上的随机变量。 它简化为 。 GP 是一个随机过程,它完全由均值函数 和协方差函数 描述,使得
| (1) | ||||
| (2) | ||||
其中 。 协方差函数是衡量两个状态 之间相关性的指标,与 GPs 结合称为 内核。 尽管 GP 的概率密度函数通常不存在解析描述,但它有一个有趣的性质,即它的任何有限个随机变量集合 都服从 -维多元高斯分布。 由于 GP 定义了函数上的分布,因此每个实现也是索引集 上的函数。 一个时间为 的 GP ,其中
描述了具有标准差为 、均值为 的高斯白噪声的时间依赖性电流信号。
2.1 高斯过程回归
GP 可以用作贝叶斯推理中的先验概率分布,这使得可以执行函数回归。 遵循贝叶斯方法,新信息与现有信息相结合:使用贝叶斯定理,将先验与新数据相结合以获得后验分布。 新信息表示为训练数据集 。 它包含输入值 和输出值 ,其中
| (3) |
对于所有 。 输出数据可能被高斯噪声 损坏。
Remark 1.
请注意,我们始终使用标准符号 来表示输入训练数据,并使用 来表示输出训练数据,在本文档中始终如此。
由于 GP 的任何有限子集都遵循多元高斯分布,因此我们可以写出联合分布
| (4) |
对于任何任意测试点 。 函数 表示均值函数。 矩阵函数 称为协方差或 Gram 矩阵,其中
| (5) |
其中矩阵的每个元素表示训练数据 中两个元素之间的协方差。 表达式 表示 列的 。 为了简化符号,我们在必要时将 简化为 。 矢量值内核函数 计算测试输入 与输入训练数据 之间的协方差,即
| (6) |
为了获得 的后验预测分布,我们根据测试点 和训练数据集 进行条件化,由
| (7) |
因此,条件后验高斯分布由均值和方差定义
| (8) |
基于联合分布 4 的后验均值和方差的详细推导可以在 附录 A 中找到。分析 8 可以得出以下结论:
i) 均值预测可以写成
| (9) |
其中 。 该公式突出了 GPR 的数据驱动特性,因为后验均值是核函数的总和,其数量随着训练数据的数量 而增长。
ii) 方差并不依赖于观测数据,而只依赖于输入,这是高斯分布的特性。 方差是两个项之间的差值:第一项 只是先验协方差,从其中减去一个 (正) 项,表示观测值包含关于函数的信息。 预测的不确定性,以方差表示,只适用于 ,不考虑训练数据中的噪声。 为此,可以在 8 中的方差中添加一个额外的噪声项 。 最后,8清楚地表明了后验均值和方差对核的强烈依赖性,我们将在部分中深入讨论3。
我们假设一个均值为零的 GP,其核函数由
作为先验分布。 假设训练数据集 为
其中输出被标准差为 的高斯噪声所破坏,并且假设测试点为 。 根据 5 到 8,Gram 矩阵 计算为
并且核向量 和 被获得为
最后,用 8,我们计算了 的预测均值和方差
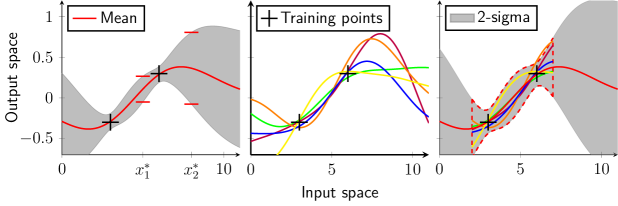
这相当于 标准差为 。 图 1 显示了先验分布(左)、具有两个训练点(黑色十字)的后验分布(中间)以及给定完整训练集 的后验分布(右)。 实线红色线是均值函数,灰色阴影区域表示 标准差。 五个实现(虚线)可视化了函数分布的特征。
![[Uncaptioned image]](x1.png)
2.2 多输出回归
到目前为止,GP 回归允许函数具有标量输出,如 8。 对于扩展到向量值输出,存在多种方法:i) 将内核扩展到多元输出 [ÁRL12],ii) 将输出维度作为训练数据添加 [Ber+17],或 iii) 针对每个输出使用单独的 GPR [Ras06]。 虽然前两种方法对输出维度之间的相关性设定了先验,但后一种方法在不失一般性的情况下忽略了相关性。 遵循方法 iii),训练集 的先前定义被扩展到具有向量值输出,其中
| (10) |
其中 是输出的维度,向量值 GP 由
| (11) | ||||
| (12) |
| (13) |
对于每个输出维度 ,相对于内核 。 变量 表示破坏输出测量 维度的标准差。 components of are combined into a multi-variable Gaussian distribution with
| (14) | ||||
where denotes the posterior variance matrix. This formulation allows to use a GP prior on vector-valued functions to perform predictions for test points . 这种方法单独处理每个输出维度,这基本上是足够的并且易于处理。 An alternative approach is to include the dimension as additional input, e.g., as in [Ber+17], with the benefit of a single GP at the price of loss of interpretability. For highly correlated output data, a multi-output kernel might be beneficial, see [ÁRL12].
Remark 2。
Without specific knowledge about a trend in the data, the prior mean functions are often set to zero, see [Ras06]. 因此,如果没有另外说明,我们将报告其余部分的均值函数设置为零。
2.3 基于内核的视图
In Section 2.1, we target the GPR from a Bayesian perspective. 然而,对于探地雷达的某些应用,不同的观点是有益的;即从内核角度。 接下来,我们从通过核变换扩展的线性回归导出 GPR。 In general, the prediction of parametric models is based on a parameter vector which is typically learned using a set of training data points. 相比之下,非参数模型通常在内存中至少维护训练数据点的子集,以便对新数据点进行预测。 许多线性模型可以转换为对偶表示,其中预测基于核函数的线性组合。 想法是将模型的数据点转换为一个通常是高维的特征空间,其中可以应用线性回归来预测模型输出,如图 图 2 所示。 对于非线性特征映射 ,其中 是一个 维希尔伯特空间,核函数由内积 给出。

因此,内核隐式地编码了数据点如何转换为更高维空间的方式。 在特征空间中作为内积的公式允许扩展许多标准回归方法。 同样,GPR 可以使用标准线性回归模型推导
| (15) |
其中 是输入向量, 是权重向量,其中 和 是未知函数。 输入 的观测值 被高斯噪声 污染,对于所有 都是如此。 该模型的分析类似于标准线性回归,即我们对权重进行先验假设,使得 ,其中 。 基于 收集的训练数据点,如 部分 2.1 中所定义,这导致了著名的线性贝叶斯回归
| (16) |
其中 。 现在,使用特征映射 而不是直接使用 ,会导致 ,其中 。 只要投影是固定函数,即独立于参数 ,模型在参数中仍然是线性的,因此是可解析处理的。 特别是,使用映射 的贝叶斯回归 16 可以写成
| (17) |
其中矩阵 由
| (18) |
此方程可以简化并改写为
| (19) |
其中 等于 8。 事实上,在 19 中,特征图 是不需要的,这被称为 核技巧。 这个技巧也被用在其他基于核的模型中,例如支持向量机 (SVM),更多细节见 [SC08]。
2.4 再现核希尔伯特空间
尽管核既不能唯一定义特征图,也不能唯一定义特征空间,但总能构造一个规范特征空间,即给定某个核的 再现核希尔伯特空间 (RKHS)。 在介绍理论之后,将给出一些说明性示例,以便直观理解。 我们现在将正式介绍这个构造过程,从希尔伯特空间的概念开始,遵循 [BLG16]:一个希尔伯特空间 表示某一类函数的所有可能实现,例如所有连续度为 的函数,用 表示。 此外,希尔伯特空间是一个向量空间,因此任何函数 都必须具有非负范数 ,对于 。 所有函数 还必须在 中配备内积。 简单地说,希尔伯特空间是一个无限维向量空间,其中许多运算的行为与有限情况下的行为类似。 希尔伯特空间的性质已经在文献中被详细探讨过,例如在 [DM+05] 中。 希尔伯特空间一个极其有用的性质是,它们等价于一个相关的核函数 [Aro50]。 这种等价性允许简单地定义一个核,而不是完全定义相关的向量空间。 从形式上说,如果一个希尔伯特空间 是一个 RKHS,它将具有唯一的正定核 ,它跨越空间 。 [Moore-Aronszajn [Aro50]] 每个正定核 都与一个唯一的 RKHS 相关联。 [[Aro50]] 令 为希尔伯特空间, 为一个非空集, 。 那么,内积 是正定的。 重要的是, 中的任何函数 都可以表示为在空间 上评估的此核的加权线性组合,如
| (20) |
其中 对于所有 成立,其中 是特征空间 的维数。 因此,RKHS 配备了内积
| (21) |
其中 。 现在,再生特性表现为
| (22) |
根据 [SHS06],RKHS 定义为
| (23) |
其中 是通过 构造核的特征映射。 我们想找到度为 的多项式核的 RKHS,它由下式给出
对于任何 。 首先,我们必须找到一个特征映射 ,使核对应于内积 。 特征映射的一个可能候选是
我们知道 RKHS 包含所有以下形式的线性组合
其中 。 因此,RKHS 的一个可能候选由下式给出
| (24) |
接下来,必须检查所提出的希尔伯特空间是否与具有度数 的多项式核相关的 RKHS。 这是通过两个步骤来实现的:i) 检查空间是否为希尔伯特空间,以及 ii) 确认再生性。 首先,我们可以很容易地证明这是一个希尔伯特空间,通过使用对称矩阵 重写 ,并使用 是欧几里得空间且与 同构的事实。其次,必须满足 RKHS 的条件,即再生性 。 因为我们可以写成
属性 22 得以满足,因此 是度数为 的多项式核的 RKHS。 请注意,即使映射 对于核 并不唯一,但 与 RKHS 之间的关系是唯一的。 给定一个由 个观测值定义的函数 ,它的 RKHS 范数定义为
| (25) |
其中 和 由 5 给出。 我们也可以使用特征映射,使得
| (26) |
由于 RKHS 和核 之间存在唯一的关联,因此范数 可以等效地写成 。 RKHS 中函数的范数表示函数相对于由核定义的几何结构在 上的变化速度。 从形式上来说,它可以写成
| (27) |
其中距离为 。 具有有限 RKHS 范数的函数也是 RKHS 的元素。 关于 RKHS 和范数的更详细讨论在 [Wah90] 中给出。
我们想要找到函数 的 RKHS 范数,该函数是度数为 的多项式核的 RKHS 的元素,该多项式核由
令函数为
| (28) | ||||
| (29) | ||||
| (30) |
现在,我们有两种方法来计算 RKHS 范数。 首先, 的 RKHS 范数使用 25 通过
带有 。 或者,我们可以使用 26,这将导致 ,其中 由 24 定义。 因此,范数计算为
在此示例中,我们可视化 RKHS 范数的含义。 图 3 显示了具有相同 RKHS 范数(左上角和右上角)、较小 RKHS 范数(左下角)和较大 RKHS 范数(右下角)的不同二次函数。 相同的范数表示函数的相似变化,而更高的范数会导致更变化的函数。
![[Uncaptioned image]](x3.png)
总之,我们研究了内核与其 RKHS 之间的独特关系。 再现属性允许我们将内积写为可处理的函数,该函数隐式地定义了更高(甚至无限)的特征维空间。 函数的 RKHS 范数是基于内核定义的度量的类 Lipschitz 指标。 此 RKHS 视图与机器学习中的内核技巧相关。 在下一节中,将利用 RKHS 范数来确定 GPR 预测值与实际数据生成函数之间的误差。
2.5 模型误差
GPR 最有趣的特性之一是预测方差中编码的不确定性描述。 这种不确定性有利于量化实际潜在数据生成过程与 GPR 之间的误差。 在本节中,我们假设存在一个未知函数 来生成训练数据。 详细来说,数据集 由
| (31) | ||||
其中数据由
| (32) |
对所有 生成。 如果不对 做任何假设,显然不可能量化模型误差。 笼统地说,具有核 的 GPR 的先验分布必须适合学习未知函数。 更技术地说, 必须是 23 中所述的核所跨越的 RKHS 的一个元素。 这导致了以下假设。
Assumption 1.
函数 关于核 具有有限的 RKHS 范数,即 ,其中 是由 跨越的 RKHS。
这听起来很矛盾,因为假设 是未知的。 但是,存在可以任意精确地逼近任何连续函数的核。 因此,对于任何连续函数,任意接近的函数都是通用核的 RKHS 的元素。 更多细节,请参考 第 2.4 节。 关于错误指定的 Gaussian Process 模型的模型误差的更多信息可以在 [BUH18]
中找到。我们把误差量化分为三种不同的方法:i) 鲁棒方法,ii) 场景方法,以及 iii) 信息论方法。 以下介绍了不同的技术,并在 图 4 中进行了可视化。 在本节的剩余部分,我们假设 GPR 使用数据集 31 和 假设 1 进行训练。
2.5.1 鲁棒方法
鲁棒方法利用了 GPR 的预测是高斯分布的事实。 因此,对于任何 ,模型误差由
| (33) |
以高概率限制,其中 调整概率。 但是,对于多个测试点 ,这种方法忽略了 之间的任何相关性。 图 4 显示了如何对于给定的 和 ,方差被用作上限。 因此,任何预测都是独立处理的,这会导致一个非常保守的上限,见 [UBH18]。
2.5.2 场景方法
场景方法不像鲁棒方法那样使用均值和方差,而是直接处理 GPR 的样本。 与其他方法不同的是,场景方法没有直接的模型误差量化,而是基于样本的量化。 其思想是在 个采样点上绘制大量 个样本函数 。 通过从多元高斯分布给出的 中抽取多个实例来执行采样
| (34) |
其中 包含抽样点。 然后,每个样本都可以在应用程序中使用,而不是未知函数。 对于大量的样本,假设未知函数接近这些样本中的一个。 但是,这种方法的关键在于确定给定模型误差 时,所需的样本数 和概率 ,使得
| (35) |
对于所有 。 在 图 4 中,作为示例绘制了 GP 模型的五个不同样本。
2.5.3 信息论方法
或者,[Sri+12] 中的工作推导出一个上限,用于在具有特定概率的紧凑集上的 GPR 样本。 与稳健方法相比,考虑了函数值之间的相关性。 我们在这里重新陈述 [Sri+12] 中的定理。 [[Sri+12]] 给定 假设 1,模型误差
| (36) |
对所有 在紧凑集 上以至少 的概率进行界定
| P | (37) |
其中 定义为
| (38) |
变量 是信息增益的最大值
| (39) |
具有 Gram 矩阵 和输入元素 。 为了计算这个边界,必须知道 的 RKHS 范数。 在应用中,通常情况并非如此。 但是,通常范数可以被上限约束,因此, Section 2.5.3 中的边界可以被上限约束。 为此,RKHS 范数与 27 给出的 Lipschitz 常数之间的关系是有益的,因为 Lipschitz 常数更有可能已知。 一般而言,信息增益的计算是一个非凸优化问题。 然而,对于许多常用的核函数 [Sri+12],信息容量 对训练点的数量具有次线性依赖关系。 因此,即使 随着训练数据的数量而增加,仍然有可能任意精确地学习到真实函数 [Ber+16]。 与其他方法相比,Section 2.5.3 允许对紧凑集中的任何测试点进行误差边界。 在 [BKH19] 中,我们在基于 GP 模型的控制任务中利用了这种方法。 Fig. 4 的右侧插图可视化了信息论边界。
3 模型选择
Equation 8 清楚地表明了核对后验均值和方差的巨大影响。 然而,这并不奇怪,因为核是先验模型的重要组成部分。 对于实际应用,这会导致如何选择核的问题。 此外,大多数内核依赖于必须定义的一组超参数。 因此,为了将 GPR 变成一个强大的实用工具,必须开发解决模型选择问题的方法。 我们将模型选择视为内核及其超参数的确定。 我们只关注定义在 上的内核。 在接下来的两个小节中,我们将介绍不同的内核,并解释超参数及其选择的作用,主要基于 [Ras06]。
Remark 3.
内核函数的选择似乎类似于参数模型的模型选择。 但是,存在两个主要差异:i) 选择完全由贝叶斯方法涵盖,并且 ii) 许多内核允许对各种不同函数进行建模,而参数模型通常仅限于非常特定类型的函数。
3.1 内核函数
内核函数 的值是两个状态 交互的指标。 因此,GPR 的一个重要部分是选择内核函数并估计其自由参数 ,称为超参数。 超参数的数量 取决于内核函数。 内核函数的选择和相应超参数的确定可以看作是回归的自由度。 首先,我们从要被归类为 GPR 内核的函数的一般属性开始。 函数 成为有效内核的必要和充分条件是 Gram 矩阵(参见 5)对于所有可能的输入值 [SC04] 都是半正定的。
Remark 4.
如部分 2.4所示,核函数必须是正定才能跨越唯一的RKHS。 这似乎与 Gram 矩阵所需的 半正定 性矛盾。 解决方法是定义正定核,因为它等同于半正定的 Gram 矩阵。 具体来说,对称函数 是 上的 正定 核,如果
| (40) |
对任何 、 和 成立。 因此,存在一个 半正定 矩阵 ,使得
| (41) |
对任何 和 成立。
满足此条件的函数集 用 表示。 核函数可以分为两类:平稳 核和 非平稳 核。 平稳核是距离 的函数。 因此,它对输入空间中的平移是不变的。 相反,非平稳核直接依赖于 、,并且通常是点积 的函数。 接下来,我们将列出一些常见的核函数及其基本属性。 即使所呈现的核数量有限,新的核也可以很容易地构建,因为 在特定操作(如加法和标量乘法)下是封闭的。 最后,我们在 表 1 中总结了每个核的公式,并提供了一个比较示例。
3.1.1 常数核
常数核的公式如下
| (42) |
此内核主要用于其他内核函数的补充。 它取决于单个超参数 。
3.1.2 线性内核
3.1.3 多项式内核
多项式内核的方程式为
| (44) |
多项式内核有一个额外的参数 ,它决定多项式的次数。 由于包含点积,因此内核也是非平稳的。 对于 ,先验方差快速增长,因此其在某些回归问题中的使用受到限制。 它取决于单个超参数 。
3.1.4 Matérn 内核
Matérn 内核的方程式为
| (45) |
其中 。 Matérn 核是一个非常强大的核,这里给出了最常见的参数化。 从具有 Matérn 核的 GP 模型中提取的函数是次可微的。 这个平稳核的更一般的方程可以在[Bis06]中找到。 这个核是一个通用核,这将在下面解释。 [[SC08, 引理 4.55]] 考虑在任何规定的紧致子集上的通用核的 RKHS。 给定任何正数和任何函数,存在一个函数使得。 直观地说,具有通用核的 GPR 可以任意精确地逼近紧致集上的任何连续函数。 对于,它会导致平方指数核。 两个超参数是和。
3.1.5 平方指数核
平方指数核的方程由下式给出
| (46) |
GPR 最常用的核函数可能是平方指数核,参见[Ras06]。 超参数描述了信号方差,它决定了数据生成函数与其平均值的平均距离。 长度尺度定义了在输入空间中沿着特定轴移动多远才能使函数值变得不相关。 正式地,长度尺度决定了零均值 GP 在单位区间内期望的零电平穿越次数。 平方指数核是无限可微的,这意味着 GPR 表现出平滑的行为。 作为 Matérn 核的极限,它也是一个通用核,参见 [MXZ06]。 图 5 显示了通用核函数的回归能力。 在此示例中,使用具有平方指数核的 GPR 用于不同的训练数据集。 通过似然函数,对每个训练数据集的超参数进行单独优化,参见 第 3.2 节。 注意,所有展示的回归都是基于 相同 的 GP 模型,即相同的核函数,但使用不同的数据集。 这再次突出了 GPR 优越的灵活性。
![[Uncaptioned image]](x5.png)
3.1.6 有理二次核
有理二次核的公式由
| (47) |
该核等效于对具有不同长度尺度的无限多个平方指数核求和。 因此,使用该核的 GP 先验预计会看到在许多长度尺度上平滑变化的函数。 参数 决定了大尺度和小尺度变化的相对权重。 对于 ,有理二次核与平方指数核相同。
3.1.7 平方指数 ARD 核
平方指数 ARD 核的公式由
| (48) |
对平方指数核的自动相关性确定 (ARD) 扩展允许为 设置独立的长度尺度。 当协方差几乎独立于该输入时,不相关维度的单个长度尺度通常较大。 例如,在[Mac97] 和[Bis06] 中可以找到有关不同核的优势的更详细的讨论。 在此示例中,我们使用三组具有相同训练数据的 GPR
| (49) |
但具有不同的核,即平方指数46、线性43 和多项式44 核。 图 6 显示了具有后验均值(红色)、后验方差(灰色阴影)和训练点(黑色)的回归的不同形状。 即使对于这个简单的数据集,平方指数核的灵活性也已显而易见。
![[Uncaptioned image]](x6.png)
| Kernel name | |
|---|---|
| Constant | |
| Linear | |
| Polynomial | |
| Matérn | |
| Squared exponential | |
| Rational quadratic | |
| Squared exponential ARD |
3.2 超参数优化
除了选择核函数外,还必须确定任何超参数的值才能执行回归。 超参数的数量取决于所使用的核函数。 我们将所有超参数连接成一个向量,大小为,其中。 引入超参数集 以涵盖以下定义的各个超参数的不同空间。
Definition 1。
集合 被称为核函数 的超参数集,当且仅当集合 是 的超参数 的域。
通常,信号噪声 ,见 4,也被视为超参数。 为了更好地理解,我们将信号噪声与超参数分开。 存在几种技术允许根据一个最优性准则计算超参数和信号噪声。 从贝叶斯角度来看,我们想要找到超参数向量 ,它在给定输入 和 GP 模型的情况下,最有可能用于输出数据 。 为此,一种方法是优化 GP 的 对数边际似然函数。 另一个想法是将训练集分成两个不相交的集合,一个用于训练,另一个用于验证集,用于监控性能。 这种方法被称为 交叉验证。 下面介绍了这两种选择超参数的技术。
3.2.1 对数边际似然方法
一种非常常见的优化超参数的方法是使用 负对数边际似然函数,通常简称为(负。 对数)似然函数。 它 边际,因为它是在函数 上边缘化得到的。 边际似然是输出数据 符合输入数据 的可能性,使用超参数 。 它由以下给出
| (50) |
详细推导可在 [Ras06] 中找到。 50 中边缘似然的三个项具有以下作用:
-
•
是唯一依赖于输出数据 的项,它表示数据拟合。
-
•
对复杂度进行惩罚,这取决于核函数和输入数据 。
-
•
是一个归一化常数。
Remark 5。
为了符号简洁,我们尽可能地省略对核函数 的超参数的依赖。
在似然意义上,最佳超参数 和信号噪声 是作为负对数边缘似然函数的最小值获得的
| (51) |
由于 50 推导的解析解是不可能的,因此通常使用基于梯度的优化算法来最小化该函数。 然而,负对数似然通常是非凸的,因此无法保证找到最优值 。 事实上,每个局部最小值都对应于对数据的特定解释。 在以下示例中,我们将可视化超参数如何影响回归。 在八个数据点上训练具有平方指数核的 GPR。 信号方差固定为 。 首先,我们可视化长度尺度的影响。 为此,信号噪声固定为 。 图 7 显示了回归的后验均值和负对数似然函数。 log likelihood function. 左侧是三种不同长度尺度的后验均值。 短长度尺度会导致过拟合,而大长度尺度会平滑训练数据(黑色十字)。 虚线红色函数表示使用梯度下降算法针对 51 优化后的长度尺度的均值。 右侧图显示了负对数似然函数。 对数似然函数在信号方差 和长度尺度 上。 最小值位于 。
![[Uncaptioned image]](x7.png)
接下来,通过改变信号噪声 和长度尺度 来可视化数据不同解释的含义。 图 8 的右侧图显示了负对数似然函数的两个最小值。 左下角的最小值位于 和 ,它将数据解释为轻微噪声,从而导致左侧图中的点线红色后验均值。 相反,右上角的最小值位于 和 ,它将数据解释为没有趋势的非常噪声,这表现为左侧图中的青色后验均值。 根据初始值,基于梯度的优化器将终止于这些极小值之一。
![[Uncaptioned image]](x8.png)
3.2.2 交叉验证方法
这种方法将数据集 分成两类:一类用于训练,另一类用于验证。 交叉验证几乎总是用于 -折交叉验证设置中: -折交叉验证数据被分成 个不相交的、大小相等的子集;验证在一个子集上进行,训练使用剩余 个子集的并集进行,整个过程重复 次,每次使用一个不同的子集进行验证。 在这里,不失一般性,我们介绍了留一交叉验证,这意味着 。 遗漏一个训练点 时的预测对数概率由下式给出
| (52) |
其中 和 。 索引表示 和 分别不包含元素 和 。 因此, 52 是在 处输出 的概率,但没有训练点 。 因此,留一交叉验证对数预测概率 为
| (53) |
与对数似然方法 51 相比,交叉验证通常计算量更大,但可能找到数据的更好表示,有关讨论和相关方法,请参见 [GE79]。
4 高斯过程动力学模型
到目前为止,我们考虑在非动态设置中使用 GPR,其中只考虑输入到输出的映射。 然而,高斯过程动力学模型 (GPDMs) 最近已成为系统识别中的一种多功能工具,因为它们具有诸如偏差方差权衡和与贝叶斯数学的紧密联系等有益特性,参见 [FCR14]。 在许多将 GPs 应用于动力学模型的工作中,只使用了过程的均值函数,例如,在 [WHB05] 和 [Cho+13] 中。 这主要是因为 GP 模型通常用于替代确定性参数模型。 然而,GPDMs 包含对底层动力学的更丰富描述,但也包含关于模型本身的不确定性,当考虑完整的概率表示时。 因此,GPDMs 的一个主要方面是区分循环结构和非循环结构。 如果回归向量的一部分取决于模型的输出,则该模型称为循环模型。 尽管循环模型在行为方面变得更加复杂,但它们允许对数据序列进行建模,参见 [Sjö+95]。 如果所有状态都从模型本身反馈回来,那么我们就会得到一个模拟模型,它是循环结构的特例。 这种模型的优点是它独立于实际系统。 因此,它适用于模拟,因为它允许进行多步预测。 在本报告中,我们重点关注两种常用的循环结构:高斯过程状态空间模型 (GP-SSM) 和高斯过程非线性误差输出 (GP-NOE) 模型。
4.1 高斯过程状态空间模型
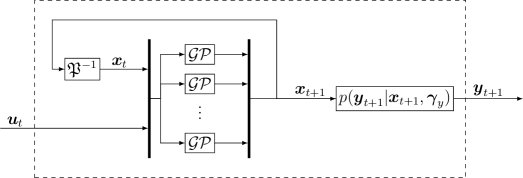
高斯过程状态空间模型被构建为离散时间系统。 在这种情况下,状态是回归量,这在 图 9 中进行了可视化。 这种方法可以提高效率,因为回归量的内部结构不如输入输出模型那样受限。 因此,可能存在一个在回归量数量方面非常有效的模型。 从状态到输出的映射通常被认为是已知的。 输出映射描述已知传感器模型的情况就是这样一个例子。 在 [Fri+13]中提到,对状态映射 和输出映射使用过于灵活的模型会导致不可识别问题。 因此,我们专注于已知的输出映射。 因此,GP-SSM 的数学模型由
| (54) | ||||
其中 是状态向量 和输入 的串联,使得 。 均值函数由连续函数 给出。 输出映射由已知向量 参数化,其中 。 GP-SSM 的系统识别任务主要集中在 上。 它可以被描述为找到基于观察到的训练数据的状态转移概率。
Remark 6.
可以使用已建立的非线性识别技术(如 [KL99] 中介绍的)或利用嵌入式技术(如自动相关性确定 [Koc16])来确定潜在的未知回归器数量。 不匹配会导致与参数化系统识别中类似的问题。
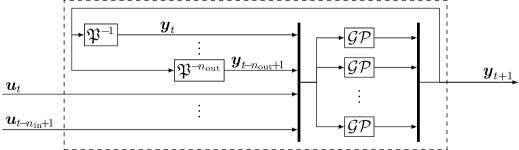
4.2 高斯过程非线性输出误差模型
GP-NOE 模型使用模型的过去 输入值 和过去的 输出值 作为回归器。 图 10 展示了 GP-NOE 的结构,其中输出被反馈。 与 GP-SSM 类似,GP-NOE 的数学模型由
| (55) |
其中 是过去输出 和输入 的串联,使得 。 均值函数由连续函数 给出。 与专注于单步预测的非线性自回归外生模型相反,NOE 模型更适合模拟,因为它考虑了多步预测 [Nel13]。 然而,缺点是由于其递归结构,更复杂的训练过程需要非线性优化方案 [Koc16]。
Remark 7.
始终可以将识别的输入-输出模型转换为状态空间模型,参见 [PL70]。 但是,仅仅关注状态空间模型将阻碍大量有用识别结果的开发。
Remark 8.
GP-SSM 和 GO-NOE 模型的控制相关属性在 [BH16a, BH16, BH20] 中讨论。
5 总结
在本文中,我们介绍了 GP 及其在 GPR 中的应用。 基于以下属性:高斯过程 (GP) 的任何有限子集都遵循多元高斯分布,可以推导出一个封闭形式的公式来预测新测试点的均值和方差。 如果高斯过程 (GP) 的输出数据是高斯分布的,它可以内在地处理噪声输出数据。 由于高斯过程 (GP) 是一种数据驱动的方法,因此回归只需要很少的先验知识。 此外,高斯过程 (GP) 模型的复杂度随着训练点的数量而增加。 模型建模中的一个自由度是选择核函数及其超参数。 我们概述了常见的内核以及成为有效内核函数的必要属性。 对于超参数确定,展示了两种基于数值优化的方法。 高斯过程 (GP) 的核与 RKHS 唯一相关,它决定了高斯过程 (GP) 样本的形状。 基于此,我们比较了不同方法来量化模型误差,这些方法量化了高斯过程 (GP) 与实际数据生成函数之间的误差。 最后,我们介绍了如何在 GP-SSM 和 GP-NOE 模型中将高斯过程 (GP) 模型用作动力系统。
附录 A 条件分布
令 为概率变量,其中 ,它们是多元高斯分布
| (56) |
均值为 ,方差为 。 任务是确定条件概率
| (57) |
联合概率 是一个多元高斯分布,其中
| (58) | ||||
| (59) |
其中 。
| (60) |
将联合分布除以边际分布再次得到一个高斯分布,其中
| (61) |
其中第一部分
| (62) |
因此,条件分布
| (63) |
为了简化 61 的第二部分
| (64) | ||||
| (65) | ||||
其中 因此,我们计算
| (66) | ||||
| (67) | ||||
| (68) |
最后,条件概率由条件均值
| (69) | ||||
| (70) | ||||
参考文献
- [ÁRL12] Mauricio A. Álvarez, Lorenzo Rosasco and Neil D. Lawrence “Kernels for Vector-Valued Functions: A Review” In Foundations and Trends in Machine Learning 4.3, 2012, pp. 195–266 DOI: 10.1561/2200000036
- [Aro50] Nachman Aronszajn “Theory of reproducing kernels” In Transactions of the American mathematical society 68.3, 1950, pp. 337–404 DOI: 10.2307/1990404
- [Ber+16] Felix Berkenkamp, Riccardo Moriconi, Angela P. Schoellig and Andreas Krause “Safe Learning of Regions of Attraction for Uncertain, Nonlinear Systems with Gaussian Processes” In 2016 IEEE 55th Conference on Decision and Control (CDC), 2016, pp. 4661–4666
- [Ber+17] Felix Berkenkamp, Matteo Turchetta, Angela P. Schoellig and Andreas Krause “Safe Model-based Reinforcement Learning with Stability Guarantees” In Advances in Neural Information Processing Systems, 2017, pp. 908–918
- [BH16] Thomas Beckers and Sandra Hirche “Equilibrium distributions and stability analysis of Gaussian Process State Space Models” In 2016 IEEE 55th Conference on Decision and Control (CDC), 2016, pp. 6355–6361 DOI: 10.1109/CDC.2016.7799247
- [BH16a] Thomas Beckers and Sandra Hirche “Stability of Gaussian Process State Space Models” In 2016 European Control Conference (ECC), 2016, pp. 2275–2281 DOI: 10.1109/ECC.2016.7810630
- [BH20] Thomas Beckers and Sandra Hirche “Prediction with Gaussian Process Dynamical Models” In Transaction on Automatic Control, 2020
- [Bis06] Christopher Bishop “Pattern recognition and machine learning” Springer-Verlag New York, 2006
- [BKH19] Thomas Beckers, Dana Kulić and Sandra Hirche “Stable Gaussian Process based Tracking Control of Euler-Lagrange Systems” In Automatica, 2019, pp. 390–397 DOI: 10.1016/j.automatica.2019.01.023
- [BLG16] Yusuf Bhujwalla, Vincent Laurain and Marion Gilson “The impact of smoothness on model class selection in nonlinear system identification: An application of derivatives in the RKHS” In 2016 American Control Conference (ACC), 2016, pp. 1808–1813 DOI: 10.1109/ACC.2016.7525181
- [BUH18] Thomas Beckers, Jonas Umlauft and Sandra Hirche “Mean Square Prediction Error of Misspecified Gaussian Process Models” In 2018 IEEE Conference on Decision and Control (CDC), 2018, pp. 1162–1167 DOI: 10.1109/CDC.2018.8619163
- [Cho+13] Girish Chowdhary, Hassan Kingravi, Jonathan How and Patricio A. Vela “Bayesian nonparametric adaptive control of time-varying systems using Gaussian processes” In 2013 American Control Conference, 2013, pp. 2655–2661 DOI: 10.1109/ACC.2013.6580235
- [DM+05] Lokenath Debnath and Piotr Mikusinski “Introduction to Hilbert spaces with applications” Academic press, 2005
- [FCR14] Roger Frigola, Yutian Chen and Carl E. Rasmussen “Variational Gaussian Process State-Space Models”, 2014 arXiv:1406.4905 [cs.LG]
- [Fri+13] Roger Frigola, Fredrik Lindsten, Thomas B. Schön and Carl E. Rasmussen “Bayesian inference and learning in Gaussian process state-space models with particle MCMC” In Advances in Neural Information Processing Systems, 2013, pp. 3156–3164
- [GE79] Seymour Geisser and William F. Eddy “A Predictive Approach to Model Selection” In Journal of the American Statistical Association 74.365, 1979, pp. 153–160 DOI: 10.1080/01621459.1979.10481632
- [KL99] Robert Keviczky and Haber Laszlo “Nonlinear system identification: input-output modeling approach” Springer Netherlands, 1999
- [Koc16] Juš Kocijan “Modelling and Control of Dynamic Systems Using Gaussian Process Models” Springer International Publishing, 2016 DOI: 10.1007/978-3-319-21021-6
- [Mac97] David J. MacKay “Gaussian Processes - A Replacement for Supervised Neural Networks?”, 1997
- [MXZ06] Charles A. Micchelli, Yuesheng Xu and Haizhang Zhang “Universal kernels” In Journal of Machine Learning Research 7, 2006, pp. 2651–2667
- [Nel13] Oliver Nelles “Nonlinear system identification: from classical approaches to neural networks and fuzzy models” Springer-Verlag Berlin Heidelberg, 2013 DOI: 10.1007/978-3-662-04323-3
- [PL70] M.. Phan and R.. Longman “Relationship between state-space and input-output models via observer Markov parameters” In WIT Transactions on The Built Environment 22 WIT Press, 1970 DOI: 10.2495/DCSS960121
- [Rad96] Neal M. Radford “Bayesian learning for neural networks” Springer-Verlag New York, 1996 DOI: 10.1007/978-1-4612-0745-0
- [Ras06] Carl E. Rasmussen “Gaussian processes for machine learning” The MIT Press, 2006
- [SC04] John Shawe-Taylor and Nello Cristianini “Kernel methods for pattern analysis” Cambridge university press, 2004 DOI: 10.1017/CBO9780511809682
- [SC08] Ingo Steinwart and Andreas Christmann “Support vector machines” Springer Science & Business Media, 2008 DOI: 10.1007/978-0-387-77242-4
- [SHS06] Ingo Steinwart, Don Hush and Clint Scovel “An explicit description of the reproducing kernel Hilbert spaces of Gaussian RBF kernels” In IEEE Transactions on Information Theory 52.10, 2006, pp. 4635–4643 DOI: 10.1109/TIT.2006.881713
- [Sjö+95] Jonas Sjöberg et al. “Nonlinear black-box modeling in system identification: a unified overview” In Automatica 31.12, 1995, pp. 1691–1724 DOI: 10.1016/0005-1098(95)00120-8
- [Sri+12] Niranjan Srinivas, Andreas Krause, Sham M. Kakade and Matthias W. Seeger “Information-theoretic regret bounds for Gaussian process optimization in the bandit setting” In IEEE Transactions on Information Theory 58.5, 2012, pp. 3250–3265 DOI: 10.1109/TIT.2011.2182033
- [UBH18] Jonas Umlauft, Thomas Beckers and Sandra Hirche “A Scenario-based Optimal Control Approach for Gaussian Process State Space Models” In 2018 European Control Conference (ECC), 2018, pp. 1386–1392 DOI: 10.23919/ECC.2018.8550458
- [Wah90] Grace Wahba “Spline models for observational data” SIAM, 1990 DOI: 10.1137/1.9781611970128
- [WHB05] Jack Wang, Aaron Hertzmann and David M. Blei “Gaussian process dynamical models” In Proceedings of the 18th International Conference on Neural Information Processing System, 2005, pp. 1441–1448 DOI: 10.5555/2976248.2976429
- [WR96] Christopher K. Williams and Carl E. Rasmussen “Gaussian processes for regression” In Advances in neural information processing systems, 1996, pp. 514–520