自适应哈密顿神经网络
摘要
利用机器学习来预测混沌系统的研究的快速增长,最近重新燃起了人们对哈密顿神经网络(HNN)的兴趣,其物理约束由汉密尔顿运动方程定义,代表了一类主要的物理增强神经网络。 我们引入了一类能够对非线性物理系统进行适应性训练预测的 HNN:通过基于目标哈密顿系统的少量分岔参数值的时间序列的神经网络,HNN 可以预测其他参数值下的动态状态,其中网络尚未接触到有关这些参数值的系统的任何信息。 HNN 的架构与之前的架构不同,我们加入了一个输入参数通道,使 HNN 参数可识别。 我们证明,使用范例哈密顿系统,使用最少四个参数值的时间序列训练 HNN,赋予神经机在整个参数区间内预测目标系统状态的能力。 利用集合最大 Lyapunov 指数和对齐指数作为指标,我们表明我们的参数认知 HNN 可以成功预测混沌过渡的路线。 物理增强机器学习是研究的前沿领域,我们的适应性强的 HNN 提供了一种理解具有广泛应用的机器学习的方法。
我简介
机器学习中的一个艰巨挑战是缺乏对人工神经网络内部工作原理的理解。 随着机器学习越来越多地融入到支持现代社会运作的许多重要结构和系统中,必须对底层神经网络的内部齿轮有一个普遍的理解。 例如,前馈神经网络或多层感知器构成了现代深度学习机器的基础,在图像、视频和音频处理领域有着广泛的应用LeCun 等人 (2015)。 这样的神经机器通常由输入层、大量隐藏层和输出层组成。 从输入层开始,同一层的节点彼此不交互,但它们通过一组权重和偏差与下一层的节点连接,其值通过训练确定,其中随机梯度的范式方法血统 (SGD) Goodfellow 等人 (2016) 经常使用。 不同层的网络如何协同工作来解决特定问题仍然未知。 在另一项研究中,储层计算是一类循环神经网络Jaeger (2001); Mass 等人 (2002);耶格和哈斯 (2004); Manjunath 和 Jaeger (2013) 自 2017 年以来,作为非线性和混沌动力系统的无模型、完全数据驱动预测的强大范例,获得了相当大的发展势头Haynes 等人 (2015);较大等人 (2017); Pathak 等人 (2017);卢等人 (2017); Duriez 等人 (2017);卢等人 (2018); Pathak 等人 (2018a, b);卡罗尔(2018);中井和齐木 (2018);罗兰和帕利茨(2018);翁等人 (2019);格里菲斯等人 (2019);蒋和赖(2019); Vlachas 等人 (2019);范等人 (2020);张等人(2020)。 储层计算机由输入层、单个隐藏层和输出层组成。 与多层感知器的网络结构不同,水库计算机的隐藏层网络具有复杂的拓扑结构,其中节点按照某种概率分布相互耦合。 另一个区别是,在前馈神经网络中,仅连接隐藏层和输出层神经元的权重和偏差由训练确定,而在水库中计算这些参数以及隐藏层中复杂网络的权重是预先定义的。 训练有素的储层机可以对混沌系统的状态演化进行准确的预测,其持续时间通常比使用非线性时间序列分析中的传统方法可以实现的时间长几倍。 考虑到混沌的特点:对初始条件的敏感依赖,这排除了长期预测,这是值得注意的。 然而,人们对水库计算机的内部网络动态如何表现或“管理”以准确地(在一段时间内)复制真实系统的混沌演化知之甚少。
目前,开发一个通用的可解释框架来涵盖各种类型的机器学习是不可行的。 在这方面,一个有前途的追求方向是所谓的物理增强机器学习,其中神经网络被设计来解决特定的物理问题,目的是通过利用潜在的物理原理或约束来提高学习效率。 这个想法是在大约三十年前De Wilde (1993)提出的,当时哈密尔顿力学的原理被纳入神经网络的设计中,产生了哈密尔顿神经网络(HNN) )最近重新受到关注 Greydanus 等人 (2019);托特等人 (2019); Bertalan 等人 (2019); Choudhary 等人 (2020a); Garg 和 Kagi (2019)。 与传统的神经网络相比,HNN 中的能量是守恒的。 已经证明,HNN 可以被训练为拥有预测目标哈密顿系统在可积和混沌状态下动态演化的能力,前提是该网络使用取自同一组参数值的数据进行训练,其中预测为 Greydanus 等人 (2019);托特等人 (2019); Bertalan 等人 (2019); Choudhary 等人 (2020a); Garg 和 Kagi (2019)。 最近,HNN 的原理已被推广到由拉格朗日运动方程Cranmer 等人 (2020) 和一般类型的常微分描述的系统Chen 等人 (2019)方程 Sanchez-Gonzalez 等人 (2019) 或坐标变换 Dulberg 和 Cohen (2020); Choudhary 等人 (2020b) 在机器人领域的应用 Lutter 等人 (2019); Havoutis 和 Ramamoorthy (2010)。
在本文中,我们解决了哈密顿神经网络的适应性,这是机器学习中的一个基本问题。 更准确地说,我们考虑目标哈密顿系统可能会经历某些参数缓慢漂移或突然变化的情况。 缓慢的环境变化可能导致绝热参数漂移,而外部干扰可能导致参数突然变化。 我们询问是否可以设计 HNN,使用来自目标系统的少量参数值的数据进行训练,以对不在训练集中的参数值具有预测能力。 受到最近基于水库计算预测耗散动力系统关键转变和崩溃的工作的启发 Falahian 等人 (2015);塞斯特尼克和阿贝尔(2019); Kim 等人 (2020); Klos 等人 (2020); Kong等人(2021),我们阐述了一类HNN,其输入层包含一组通道,专门用于输入神经网络感兴趣的不同参数的值。 参数通道的数量等于目标哈密顿系统中自由变化参数的数量。 最简单的情况是目标系统具有单个分叉或控制参数,因此神经网络只需要一个输入参数通道。 我们证明,通过将这样的参数通道合并到前馈类型的 HNN 中,并使用来自少量分岔参数值(例如四个)的时间序列数据进行训练,我们可以有效地使 HNN 适应参数变化。 也就是说,经过如此训练的 HNN 继承了控制目标哈密顿系统动态演化的规则。 当训练参数集中不存在的感兴趣的参数值通过参数通道输入 HNN 时,机器能够生成与目标系统在该特定参数值下的统计匹配的动态行为。 HNN 因此变得具有适应性,因为它从未接触过目标系统在此参数值下的任何信息或数据,但神经机器可以重现动态行为。 使用 Hénon-Heiles 模型作为原型目标哈密顿系统,我们证明了我们的适应性 HNN 可以成功预测任何与训练参数集中的参数值相当接近的参数值的动态行为,无论是可积的还是混沌的。 值得注意的是,通过将一组系统变化的分岔参数值输入参数通道,HNN 可以成功预测目标哈密顿系统中向混沌的转变,我们使用两种度量来表征:系综最大李雅普诺夫指数和对齐指数。 值得强调的是,现有的 HNN 文献中 Greydanus 等人 (2019);托特等人 (2019); Bertalan 等人 (2019); Choudhary 等人 (2020a); Garg 和 Kagi (2019),训练和预测是在目标哈密顿系统的同一组参数值下完成的,但我们的工作不仅如此,还通过增强和扩展的可预测性使 HNN 显着变得更加强大。
我们注意到,在物理学中,机器学习已被用来解决粒子物理学中的难题Guest 等人 (2018); Radovic 等人 (2018)、量子多体系统 Carleo 和 Troyer (2017)、光学系统逆向设计 Peurifoy 等人 (2018),以及量子信息Dunjko 和 Briegel (2018); Carleo 等人 (2019). 然而,底层神经网络的工作机制仍然很大程度上未知Iten等人(2020)。 这里研究的物理增强 HNN 与这些应用不同,因为我们专注于利用物理原理使神经网络在参数变化方面具有前所未有的预测能力。
II 参数认知哈密顿神经网络
物理增强机器学习的中心思想是“迫使”神经网络的动态演化遵循一定的物理规则或约束,例如汉密尔顿运动方程 Greydanus 等人 (2019);托特等人 (2019); Bertalan 等人 (2019); Choudhary 等人 (2020a); Garg 和 Kagi (2019)、拉格朗日方程 Cranmer 等人 (2020),或最小作用原理 Karkar 等人 (2020);杨等人(2020)。 特别是,HNN 的结构使得底层神经动力系统实际上是一个哈密顿系统,在进化过程中能量守恒。 与之前的作品不同Greydanus 等人 (2019);托特等人 (2019); Bertalan 等人 (2019); Choudhary 等人 (2020a); Garg and Kagi (2019),目标哈密顿系统的分岔参数通过额外的输入通道作为神经网络的输入“变量”,使 HNN 学习将输入时间序列与特定值关联起来的分岔参数。 使用少量不同分叉参数值的时间序列来训练 HNN,它可以获得通过分叉参数“感知”目标系统的动态(或动态“气候”)变化的能力。
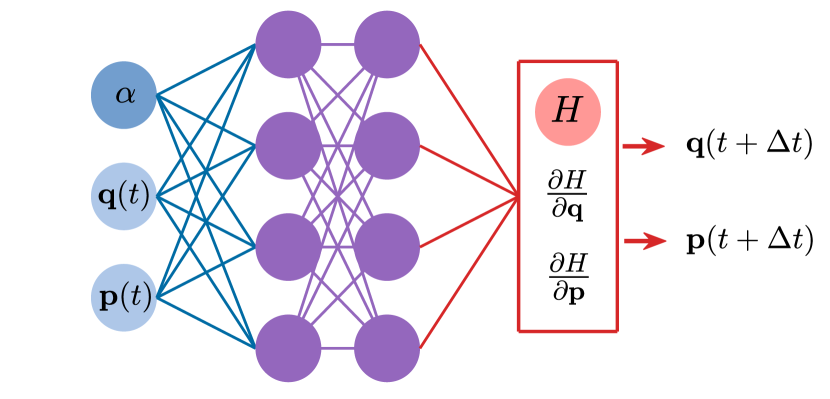
我们的铰接参数认知 HNN 的结构如图 1 所示,其中输入包含三个部分:目标系统的位置和动量变量以及分叉参数。 具体来说,我们使用两个隐藏层,其中每层包含 个人工神经元(节点)。 第三层是输出,其中包含单个节点,其动态状态对应于目标系统的哈密顿量。 让 表示每层的动态变量集。 第层动态变量到第层动态变量的变换遵循以下规则:
| (1) |
其中 是给定的非线性激活函数, 是权重矩阵, 是与 中的神经元相关的偏差向量第层,通过训练来确定。 我们将输出设置为输入变量的空间导数,以迫使神经网络的动力学遵循汉密尔顿运动方程。 导数是通过反向传播算法计算的。 一旦输出已知,损失函数定义为
| (2) |
可以计算。 通过训练过程,我们优化了方程中的权重和偏差。 (1) 通过最小化损失函数。 这是通过使用标准 SGD 方法Goodfellow 等人 (2016) 来完成的。 从网络搭建、训练到进行预测的整个过程都是使用开源包Tensorflow和KerasAbadi等人(2016)完成的; Chollet等人(2015)。
表 1 总结了我们的 HNN 的结构和参数。 它有大约40,000个未知参数需要通过训练来优化确定。 即使不使用并行或 GPU 加速,计算也可以非常高效。 预期的是,在使用来自少量不同分岔参数值的时间序列数据进行训练后,HNN 可以在较宽的参数区间内预测目标哈密顿系统的动态行为,其中参数变化是通过输入参数通道实现的到 HNN。
| Description | Values |
| Number of hiden layers | |
| Neurons per layer | |
| Optimizer | Adam |
| Epochs | |
| Activation functioin | tanh |

III 用于预测混沌过渡的自适应哈密顿神经网络
为了测试我们的参数认知 HNN 在预测哈密顿系统中的状态演化和动态转换方面的适应性,我们使用范例 Hénon-Heiles 模型 Hénon 和 Heiles (1964)。 它是一个二自由度系统,用于研究不同类型的哈密顿动力学,包括可积、混合和混沌行为以及它们之间的转换。 它起源于引力三体系统Hénon and Heiles (1964),并在分子动力学Waite and Miller (1981)等领域得到应用;费特和小弗莱克 (1984); Vendrell 和 Meyer (2011)。
III.1系统说明
Hénon-Heiles 哈密顿量是
| (3) |
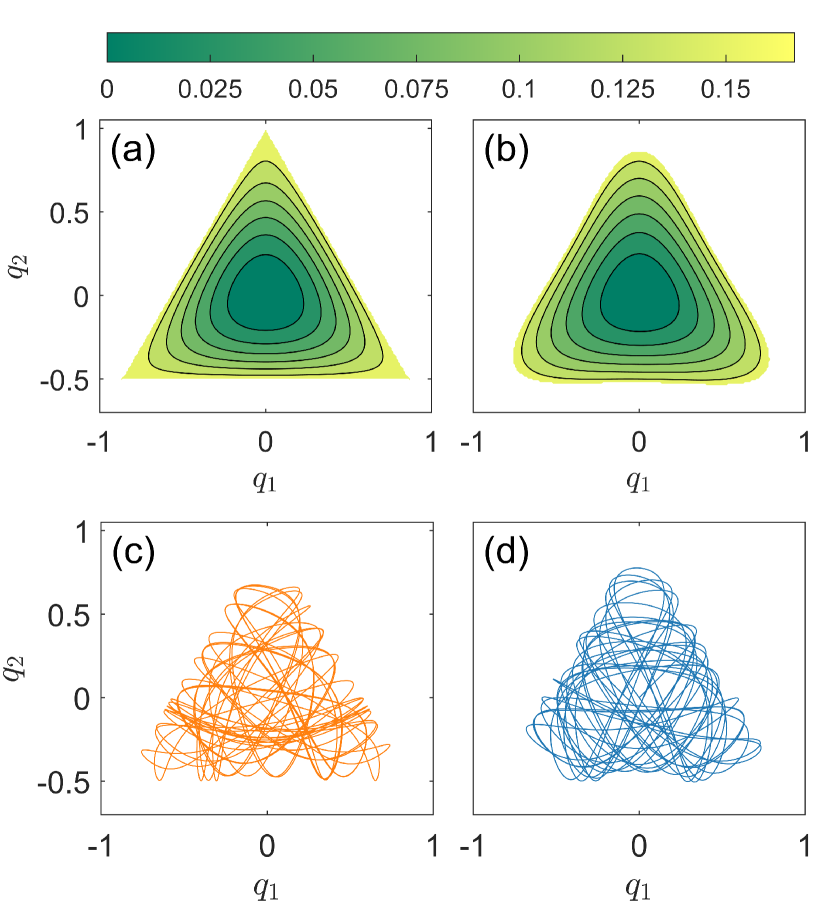
其中和表示坐标,和是相应的动量,是分叉设置非线性势函数大小的参数,描述例如分子中的解离能 Waite 和 Miller (1981);费特和小弗莱克 (1984); Vendrell 和 Meyer (2011)。 系统动力学方程。 (3)不仅取决于,还取决于系统在动态演化过程中守恒的能量。 势函数的最大值为。 对于,发散,因此所有轨迹都是有界的。 对于,如果粒子能量超过,哈密顿系统将变得开放,散射轨迹可以逃逸到无穷大。 为了训练适应性强的 HNN,需要有界轨迹,因此我们设置 和 。 (对于高于阈值的粒子能量,可能会出现混沌散射动力学和分形几何de Moura 和 Letelier (1999);Seoane 等人 (2006, 2007)。) 随着 的值从 0 增加到 1,可能会出现具有不同特征的动态行为,例如可积、混合和混沌。 特别是,对于,方程中的非线性项。 (3) 消失,系统变成谐振子——可积系统。 此时,整个相空间仅包含周期轨道和准周期轨道,如图2(a)所示。 随着 从零增加,系统变得非线性,相空间中会出现 Kol'mogorov-Arnol'd-Moser (KAM) 岛屿中的混沌海洋,从而产生混合动力学,如图所示图2(b)为和。 对于、和,相空间中的大部分轨迹是混沌的,如图1和图2所示。 2(c) 和 2(d)。
III.2适应性训练与测试
我们训练的目标是向HNN“灌输”一定的适应性能力。 为了实现这一点,我们选择分叉参数 的多个不同值。 对于每个 值,我们随机选择能量低于逃逸阈值 的初始条件,并对哈密顿运动方程进行数值积分,以生成相空间中的粒子轨迹。 由于混合动力学,训练数据包含可积轨道和混沌轨道。 具体来说,轨迹的时间间隔为,包含数百个振荡周期,我们使用采样时间步长收集训练数据。 与训练数据相关的能量在 范围内保持恒定。
一般来说,SGD 方法确定的自适应 HNN 的权重和偏差取决于训练数据集。 为了减少预测误差,可以使用 HNN 集合Kong 等人 (2021)。 具体来说,对于 的每个值,我们为训练生成 不同的数据集,从而形成 20 个 HNN 的集合。 训练的参数设置如表 1 所示。 2.
| Description | Values |
| Neural network ensembles | |
| Energy samples | |
| Orbit per energy | |
| Orbit length | |
| Time step | |
| Training parameter set |
训练结束后,方程中的所有权重和偏差都得到了。 (1) 被确定。 HNN 集合中每个网络的哈密顿量及其导数可以针对任何输入进行评估,从而得出平均导数值。 为了表征不同分岔参数值的预测精度,我们使用均方根误差 (RMSE),该误差可以根据 HNN 预测轨道与真实轨道之间的差异计算得出。 对于,运动是可积的,因此预测轨道总是接近某个真实轨道,从而导致误差极小。 在这种情况下,我们利用了 HNN 的一个特性,即它直接产生哈密顿函数,从中可以计算势函数。 因此,可以方便地使用预测势函数与真实势函数之间的相对误差来表征 HNN 性能,其定义为
| (4) |
其中平均值是在 区域中获取的。 预测的电势分布由 给出,其中 使得 的最小值为零。 请注意,方程中的平均值。 (4)是根据物理空间中的二维域中的积分计算的,需要指定域的边界。 设置边界的标准的自然选择是,但有时预测的轨道会发散。 从数字上看,有不同的方法可以克服这个困难。 例如,如果根据标准设置边界:,则几乎所有轨道都是有界的,从而可以计算误差。
我们证明 HNN 可用于重建目标系统的哈密顿量。 考虑 的相空间点并使用泰勒级数展开关于原点的哈密顿量:
| (5) |
其中为展开系数,根据求和,共包含项。 与真实的哈密顿方程相比。 (3),只有六项是非零的。
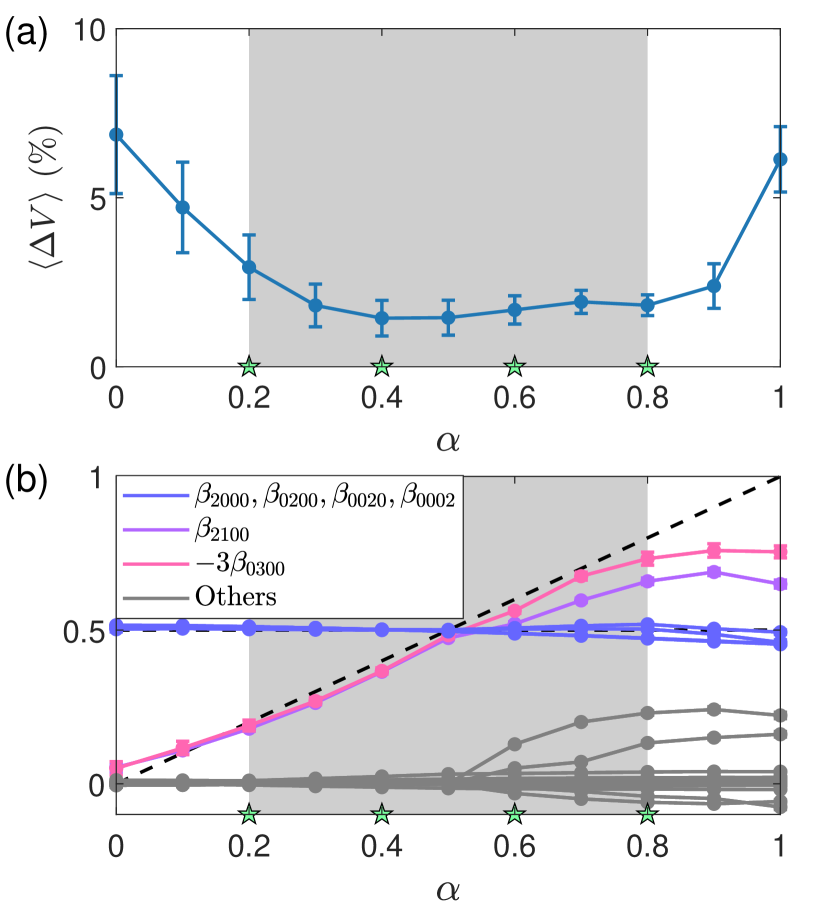
我们在分叉参数的四个值处训练 HNN:。 对于每个 值,我们选择七个随机初始条件,其能量低于阈值。 图3(a)显示了预测势函数的相对误差。 训练中的间隔可以分为两部分:阴影区域包含了中使用的四个值,以及两者上的空白区域阴影区域的一侧。 在阴影区域内,相对误差小于,但远离阴影区域误差增大。 图3(b) 显示了预测的哈密顿量的展开系数。 与真实哈密顿量中的项相比,我们的 HNN 可以准确地预测线性项。 对于非线性项,HNN 再现了分岔参数 变化的行为,其中图 3(b) 中阴影区域的误差很小,但相对而言区外较大。
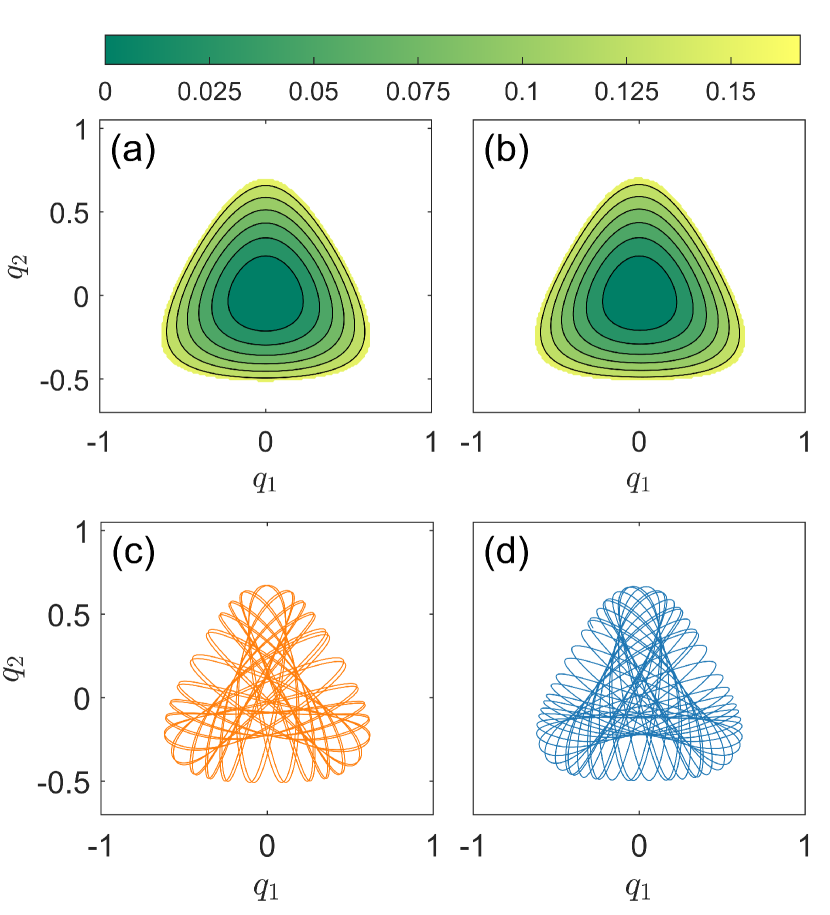
为了更详细地检查我们的参数识别 HNN 的适应性,我们以两个训练点 和 之间的 为例,对于其中绝大多数能量为的轨道都是准周期的,如图2(b)所示。 图4(a)和4(b)分别显示了的真实势函数和预测势函数,它们本质上是无法区分的。 图4(c)和4(d)显示了从相同初始条件开始的一些具有代表性的真实轨道和预测轨道,它们在定性上彼此一致,但在细节上有所不同。 特别值得强调的是,对于预测的准周期轨道,能量可以保持在恒定值。 事实上,我们已经测试了储层计算的方法Haynes等人(2015);较大等人 (2017); Pathak 等人 (2017);卢等人 (2017); Duriez 等人 (2017);卢等人 (2018); Pathak 等人 (2018a, b);卡罗尔(2018);中井和齐木 (2018);罗兰和帕利茨(2018);翁等人 (2019);格里菲斯等人 (2019);蒋和赖(2019); Vlachas 等人 (2019);范等人 (2020);张等人(2020)用于预测轨道,发现虽然它通常在短时间内(例如几个周期)产生更准确的轨道,但从长远来看,能量不守恒,并且预测误差变大。 总的来说,由于测试分叉参数值 夹在两个训练点之间,因此我们的参数认知 HNN 表现出很强的适应性。
对于,能量为时,大部分轨道都是混沌的,相空间中KAM岛的部分变得相对微不足道,如图2(d)。 此时,真实势函数的等高线图呈三角形,如图5(a)所示。 预测的电位等值线图如图5(b)所示,与真实情况吻合得相当好。 图5(c)和5(d)显示了相同初始条件下的真实混沌轨道和预测混沌轨道。 虽然细节不同,但 HNN 正确预测了轨道是混乱的。 事实上,正如第 2 节所示。 III.3,对于表征轨道统计行为的两个量,例如最大李雅普诺夫指数和对齐指数,预测轨道得到的结果与真实轨道的结果相同。 一般来说,测试参数值越接近训练点之一,预测精度越高。
III.3 哈密顿系统的适应性预测
在典型的哈密顿系统中,随着非线性参数的增加,遍历性的转变路径如下Lichtenberg and Lieberman (1992)。 在弱非线性状态下,系统是可积的,其中运动是准周期的,并且发生在由不同初始条件生成的圆环上,如图2(a)中的Hénon-Heiles系统所示。 随着非线性参数的增加,出现各种大小的混沌海,导致混合相空间,如图2(b)所示。 在强非线性区域,例如,大部分相空间构成混沌海,只有一小部分仍然被KAM岛占据,如图2( c)和(d)。 在这里,我们通过证明参数识别 HNN 的适应性提供了强有力的证据,证明它可以准确预测转换场景,并且基于仅少数非线性参数值的时间序列进行训练。
与耗散系统不同,在耗散系统中,吸引子(周期性或混沌)吸引盆中的随机初始条件导致轨迹最终都位于同一吸引子中,在哈密顿系统中,不同的初始条件通常会导致不同的动态不变集。 由于哈密顿系统的这一特征,为了研究转变场景,需要从整个相空间中的初始条件进行计算,从而对所得轨道进行统计评估和表征。 我们关注两个统计量:最大李雅普诺夫指数和最小对齐指数,前者表征无限接近轨迹的指数分离率,后者衡量两个任意向量沿轨迹的相对“接近度”(例如,它们是否成为平行、反平行或两者都不是)Skokos (2001)。 对于混沌轨迹,无穷小向量分别沿着不稳定或稳定方向呈指数拉伸或收缩。 结果,一个随机向量将沿着轨迹接近不稳定方向,并且两个随机向量将快速彼此对齐。 特别是,给定两个初始向量 和 ,在 个时间步之后,它们变为 和 分别。 最小对齐索引定义为
| (6) |
当混乱出现时, 的值将随着时间迅速趋近于零。
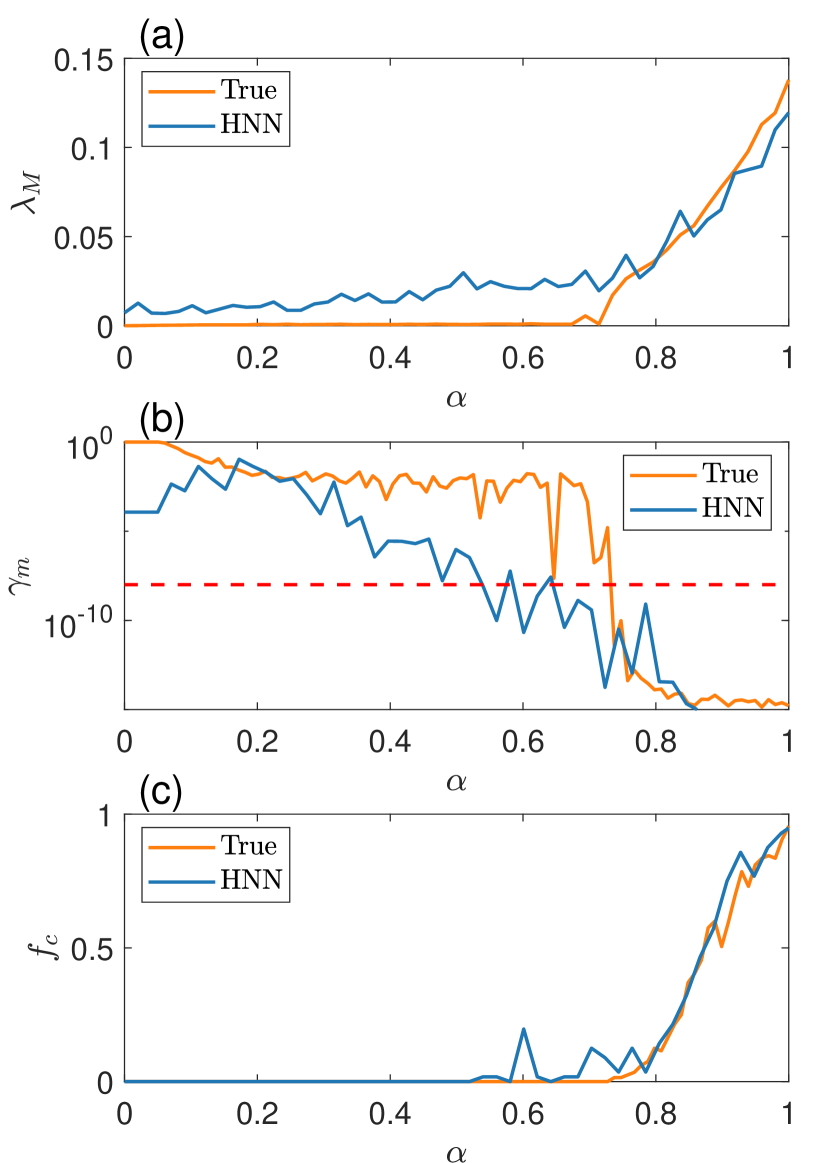
对于确定了权重和偏差的经过适当训练的 HNN,输出包含预测的哈密顿量,其相对于坐标和动量向量的偏导数可以直接基于神经网络的架构计算。 这些偏导数构成了底层动力系统的速度场,然后可以确定其雅克比矩阵,然后可以根据该矩阵计算机器预测的李亚普诺夫指数和对齐指数(参见附录A)。 Lyapunov指数和最小对齐指数的真实值可以直接从目标系统的原始哈密顿量(3)计算出来。
在我们的计算中,我们在单位间隔内取100个等距的分叉参数值。 对于每个 值,我们选择 200 个随机初始条件,并为每个初始条件计算最大 Lyapunov 指数和最小对齐索引的值。 如果最大指数为正并且最小对齐索引小于,则轨迹被视为混沌Zotos (2015)。 我们将 200 个轨迹集合中的最大李雅普诺夫指数和最小对齐索引分别表示为 和 ,它们是 的函数。 另一个有趣的量是混沌轨迹的分数,表示为 ,它也取决于 。 特征量的三元组 、 和 可以根据 HNN 和原始哈密顿量作为 然后可以进行比较来评估我们的参数识别 HNN 的预测适应性能力。
IV 与哈密顿神经网络适应性相关的问题
我们通过提出以下三个问题来解决 HNN 的适应性。 首先,HNN的适应性是否可以通过增加分叉参数的训练值数量来增强? 第二,多参数通道能否实现适应性? 第三,适应性对于不同的目标哈密顿系统是否成立?
IV.1 训练参数值数量的影响
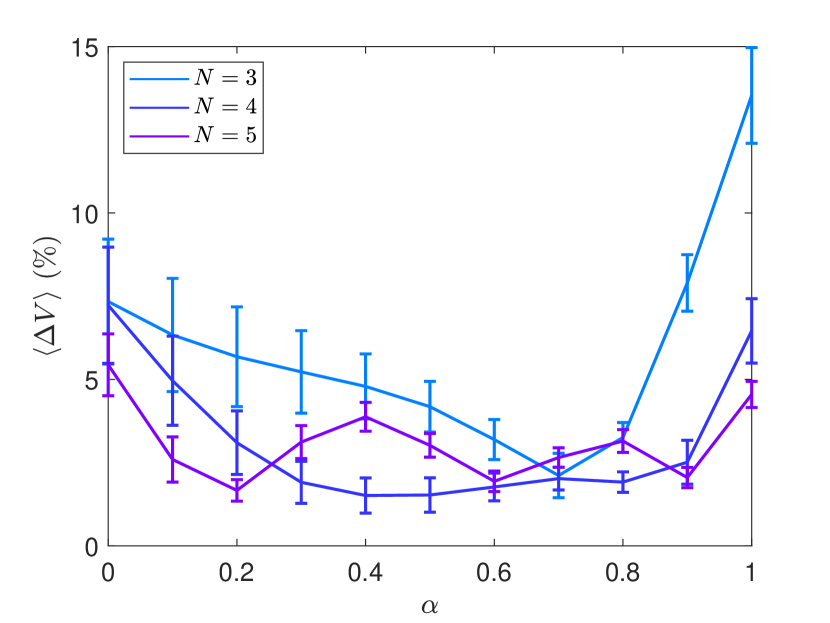
到目前为止,我们已经使用了分叉参数的四个不同值来训练我们的参数识别 HNN。 我们现在研究是否可以通过增加训练参数值的数量来增强适应性。 这里的“增强”是指在包含不在训练集中的值的参数区间中预测哈密顿量的总体误差的减少。 为了测试这一点,我们进行了以下数值实验。 我们选择 训练参数值,对于每个参数值,我们使用从低于 能量值收集的时间序列集合来训练 HNN 次。阈值(能量低于阈值的 10 个随机初始条件的 10 个时间序列)。 为了使比较有意义,我们选择 和 的值,使得 近似恒定。 特别是,对于模拟1,我们设置:、0.5和0.75以及。 对于模拟 2,我们选择 :、0.4、0.6 和 0.8 以及 。 对于模拟 3,我们有 :、0.3、0.5、0.7 和 0.9 以及 。 对于每次模拟,我们计算预测势函数时的集成误差,如方程(1)中定义的那样。 (4) 为 。 结果如图7所示。 可以看出, 的误差通常比 的误差大,但是两种情况( 和 5)的误差大约是同样,表明将增加到4以上不会导致适应性预测的误差显着减少。 也就是说,通过对分叉参数的四个值的多个时间序列进行训练,HNN 已经获得了预测其他附近参数值下的系统行为所需的适应性。
IV.2 具有两个参数通道的 HNN
我们构建了具有多个参数通道的参数识别 HNN。 为此,我们修改了 Hénon-Heiles 哈密顿方程。 (3) 到
| (7) |
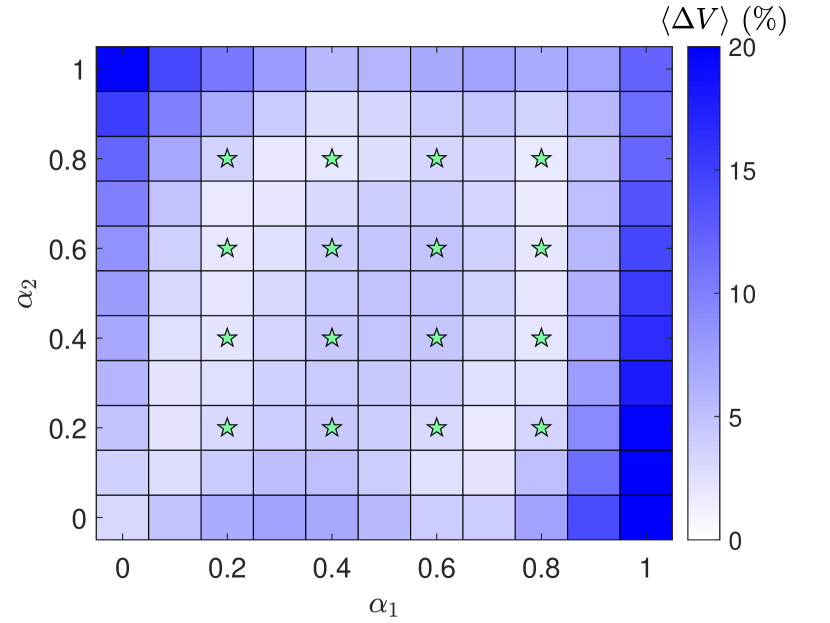
其中和是两个独立的分叉参数,需要两个独立的参数输入通道到HNN。 有界运动的能量阈值可以用数字来评估。 我们针对 和 值的多种组合进行训练:。 训练数据的生成方式如下:对于每个参数对,我们选择低于阈值的五个能量值,并且对于每个能量值,收集单个时间序列。 训练完成后,我们在参数变化的每个方向上以间隔预测的势函数。 图8显示了平面中颜色编码的整体预测误差。 对于一些数值相差较大的和的组合,阈值能量小于。 对于这种情况,方程中的积分域。 (4)根据阈值进行相应修改。 可以看出,在参数区域内,预测误差约为,而该区域外的误差则呈增大趋势。 在两个非对角线的拐角处,由于电位分布的强烈不对称性,误差最大。 图8展示了具有两个参数通道的HNN可以被训练以适应预测。
IV.3 双原子分子系统的 HNN
我们考虑一个不同的目标哈密顿系统,该系统由一维莫尔斯势定义,描述双原子分子 Morse (1929) 之间的相互作用。 该系统之前曾用于混沌散射的研究Lai (1999);赖等人(2000). 哈密顿量由下式给出
| (8) |
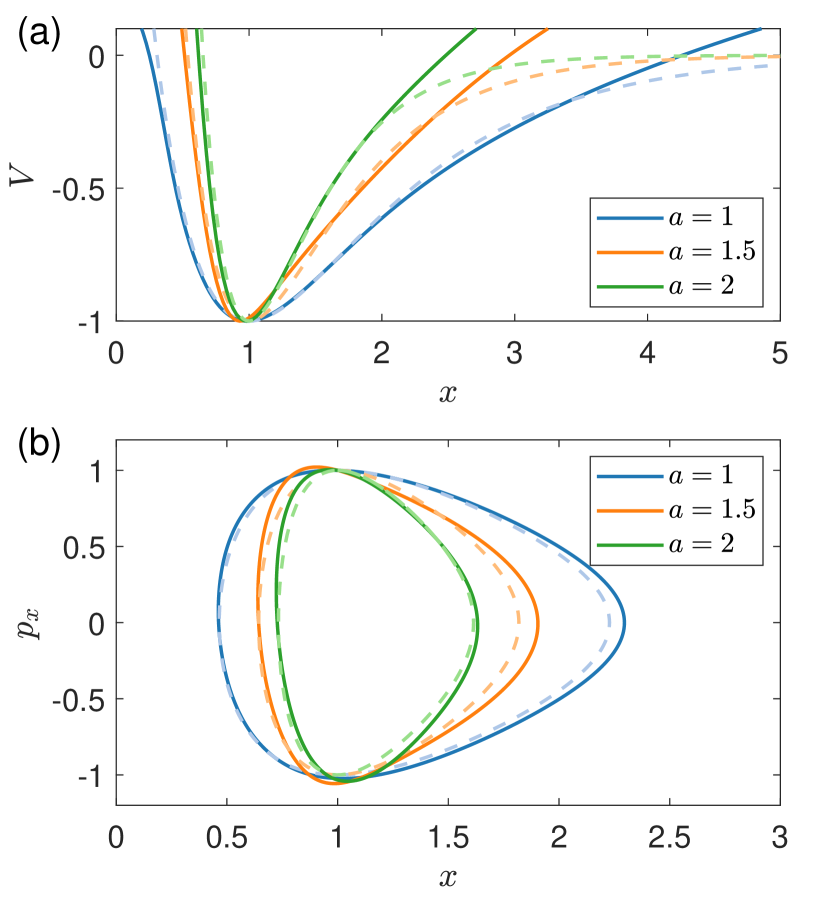
其中势函数 在 、 和 处具有最小值。 以最小势能值作为能量参考点,所有轨道都以为界。 我们设置并选择作为分叉参数。 训练数据是根据 的四个不同值生成的:、1.0、2.0 和 4.0,其中对于每个训练参数值,使用五个能量值的集合,产生 20 个独立时间序列的集合。 每个时间序列的时间跨度为,采样时间步长为。
图9显示了的预测潜力概况,以及两个训练点和的预测潜力概况。 对于最小势点附近的,结果是准确的,但当位置远离最小点时,误差较大。 一个可能的原因是,对于较大的 值,势能变化缓慢,导致动量变化较小。 因此,时间序列的相应部分表现出较小的变化,导致 HNN 的预测误差较大。 经过训练的 HNN 显然获得了一定的适应性,因为 的预测结果不是 和 预测结果的插值。
V讨论
一般来说,开发适应性强的机器学习对于当前感兴趣的关键问题具有广泛的应用。 例如,最重要的问题是根据当前可用的信息来预测当系统的一些关键参数可能发生漂移时系统将来的行为方式。 举个例子,假设一个生态系统当前处于正常状态。 由于环境恶化,其一些参数,例如承载能力和/或物种腐烂率将在未来发生漂移。 当发生一定量的参数漂移时,当系统方程未知并且唯一可用的信息是可以测量之前但包括现在的时间序列数据时,是否可以预测系统是否会崩溃t0>? 适应性机器学习提供了一种可能的解决方案。 例如,最近的研究表明,Kong 等人 (2021) 将参数识别机制纳入储层计算机中,可以针对任何给定数量的参数预测未来可能的关键转变和系统崩溃漂移。 然而,目前正在深入研究的最先进的储层计算方案Haynes 等人(2015);较大等人 (2017); Pathak 等人 (2017);卢等人 (2017); Duriez 等人 (2017);卢等人 (2018); Pathak 等人 (2018a, b);卡罗尔(2018);中井和齐木 (2018);罗兰和帕利茨(2018);翁等人 (2019);格里菲斯等人 (2019);蒋和赖(2019); Vlachas 等人 (2019);范等人 (2020);张等人(2020)没有考虑能量守恒等物理约束,因此它们适用于耗散动力系统。
将物理定律与传统机器学习相结合有可能显着提高神经网络的性能和预测能力。 最近的研究表明,在传统前馈神经网络中执行哈密顿运动方程可以提高哈密顿系统在可积和混沌体系中的预测精度Greydanus等人(2019);托特等人 (2019); Bertalan 等人 (2019); Choudhary 等人 (2020a); Garg 和 Kagi (2019)。 在这些研究中,训练和预测是针对目标哈密顿系统的同一组参数值进行的,因此底层哈密顿神经网络不具有适应性,因为它们无法预测系统在不同条件下的动态行为。参数设置。
我们开发的适应性强的HNN有什么实际意义吗? 从预测受参数漂移影响的哈密顿系统的未来状态的角度来看,答案也许是否定的。 主要原因是 HNN 需要所有坐标和动量时间序列。 例如,人们可能有兴趣预测一个复杂的多体天体物理系统是否会失去稳定性并在未来变得非常混乱,其中唯一可用的信息是系统运行之前或当前的位置和动量测量。仍处于基本可积的状态。 由于该系统的物理定律是已知的,因此训练所需的数据并不比了解哈密顿量本身更轻。 尽管如此,我们的工作还是对 HNN 的工作产生了深入的了解,如下所示。
我们的参数认知、适应性强的 HNN 具有到标准多层网络的参数输入通道,其损失函数由哈密顿运动方程规定,并且能够成功预测哈密顿系统中向混沌的转变。 特别是,通过使用来自四个不同分叉(非线性)参数值的坐标和动量时间序列进行训练,机器获得了适应性,其成功预测了包含训练参数的整个参数区间中目标系统的动态行为就证明了这一点价值观。 也就是说,训练的好处在于,HNN 不仅学习了目标哈密顿系统的动态“气候”,而且还学习了“气候”如何随分叉参数变化。 因此,机器学习可以被视为神经网络自我调整其动态演化规则以合并目标系统的动态演化规则的过程。
当系统地改变分岔参数的值输入 HNN 时,它可以预测从大部分可积状态到混沌的转变,这由系综最大 Lyapunov 指数和最小对齐指数以及混沌分数作为函数来确定分岔参数。 对于单个参数通道,只要训练参数集包含至少三个或四个不同值,就可以实现自适应预测能力。 对于具有双工参数通道的 HNN,所需训练参数集的大小应至少为 4 x 4。 对于由莫尔斯势函数定义的不同哈密顿系统也完成了适应性预测。 我们期望本文设计的参数识别 HNN 的原理和训练方法适用于一般哈密顿系统。
问题之一是能量表面对分岔参数的依赖性。 随着参数的不断变化,能量面也会随之演化。 如果我们打算预测固定能量值的分岔参数的某些特定值的系统动力学,则训练数据集应包含从较大能量值收集的时间序列,以覆盖所需能量值处的相关相空间区域。
还应该指出的是,使用 HNN 来预测 Hénon-Heiles 系统中从可积动力学到混沌的转变最早是 Choudhary 等人 (2020a) 报道的,它依赖于使用能量 作为非线性参数固定值的控制参数(例如,)。 在这里,我们研究了使用 作为固定能量值(例如 )的分叉参数的转变。 这两条路线是等价的,因为 Hénon-Heiles 系统方程。 (3) 在配置空间中具有三重对称性。 这种等价也出现在势函数包含非线性平方项的系统中,例如经典的或FPU模型Fermi等人(1955); Caiani等人(1998)。 然而,对于双参数哈密顿方程。本文研究的(7),三重对称性被破缺,破坏了改变非线性参数和能量之间的等价性。 事实上,对于诸如莫尔斯和双摆系统之类的哈密顿系统,等价性并不成立 Morse (1929);赖等人(2000); Levien 和 Tan (1993)。 我们的适应性强的 HNN 不依赖于任何此类等价性,并且可以有效地预测任何类型的哈密顿系统中向混沌的转变。
致谢
我们要感谢万尼瓦尔·布什教职人员奖学金计划的支持,该计划由负责研究和工程的助理国防部长基础研究办公室赞助,并由海军研究办公室通过拨款号 2011 资助。 N00014-16-1-2828。
附录A计算哈密顿神经网络李亚普诺夫指数和对齐指数的算法
给定一个动力系统,雅可比矩阵由给出。 对于哈密顿系统,动态变量为 和
| (9) |
对于 HNN,原则上,哈密顿量 由神经网络的一系列操作给出,其权重和偏差如式(1)所示。 (1) 由训练决定。 计算雅可比矩阵 的另一种有效方法是有限差分法。 特别是,对于给定的初始条件,我们生成一个由 点组成的轨道,时间间隔为 ,并在每个时间步计算 。 令雅可比矩阵序列表示为,并令为单位矩阵。 如果目标哈密顿系统的相空间为维(对于Hénon-Heiles系统为),则存在李亚普诺夫指数。 令为李亚普诺夫指数的向量:并将指数的初始值设置为零:。经过 步骤后,我们有
| (10) |
对矩阵 进行 QR 分解,得到的矩阵分别表示为 和 ,我们有
| (11) | |||||
| (12) |
其中是矩阵的第对角线元素。 李亚普诺夫指数由下式给出
| (13) |
最大李亚普诺夫指数为。
为了计算对齐索引,我们引入一个矩阵并将其设置为初始时刻的单位矩阵:。 令和为初始时刻的两个线性无关向量。 在 步骤之后,我们有
| (14) |
将向量 按其各自的大小归一化为单位长度,我们获得最小对齐索引为
| (15) |
参考
- LeCun et al. (2015) Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature 521, 436 (2015).
- Goodfellow et al. (2016) I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning (MIT, Cambridge, MA, 2016).
- Jaeger (2001) H. Jaeger, “The “echo state” approach to analysing and training recurrent neural networks-with an erratum note,” German National Research Center for Information Technology GMD Technical Report 148, 13 (2001).
- Mass et al. (2002) W. Mass, T. Nachtschlaeger, and H. Markram, “Real-time computing without stable states: A new framework for neural computation based on perturbations,” Neur. Comp. 14, 2531 (2002).
- Jaeger and Haas (2004) H. Jaeger and H. Haas, “Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication,” Science 304, 78 (2004).
- Manjunath and Jaeger (2013) G. Manjunath and H. Jaeger, “Echo state property linked to an input: Exploring a fundamental characteristic of recurrent neural networks,” Neur. Comp. 25, 671 (2013).
- Haynes et al. (2015) N. D. Haynes, M. C. Soriano, D. P. Rosin, I. Fischer, and D. J. Gauthier, “Reservoir computing with a single time-delay autonomous Boolean node,” Phys. Rev. E 91, 020801 (2015).
- Larger et al. (2017) L. Larger, A. Baylón-Fuentes, R. Martinenghi, V. S. Udaltsov, Y. K. Chembo, and M. Jacquot, “High-speed photonic reservoir computing using a time-delay-based architecture: Million words per second classification,” Phys. Rev. X 7, 011015 (2017).
- Pathak et al. (2017) J. Pathak, Z. Lu, B. Hunt, M. Girvan, and E. Ott, “Using machine learning to replicate chaotic attractors and calculate Lyapunov exponents from data,” Chaos 27, 121102 (2017).
- Lu et al. (2017) Z. Lu, J. Pathak, B. Hunt, M. Girvan, R. Brockett, and E. Ott, “Reservoir observers: Model-free inference of unmeasured variables in chaotic systems,” Chaos 27, 041102 (2017).
- Duriez et al. (2017) T. Duriez, S. L. Brunton, and B. R. Noack, Machine Learning Control - Taming Nonlinear Dynamics and Turbulence (Springer, 2017).
- Lu et al. (2018) Z. Lu, B. R. Hunt, and E. Ott, “Attractor reconstruction by machine learning,” Chaos 28, 061104 (2018).
- Pathak et al. (2018a) J. Pathak, A. Wilner, R. Fussell, S. Chandra, B. Hunt, M. Girvan, Z. Lu, and E. Ott, “Hybrid forecasting of chaotic processes: Using machine learning in conjunction with a knowledge-based model,” Chaos 28, 041101 (2018a).
- Pathak et al. (2018b) J. Pathak, B. Hunt, M. Girvan, Z. Lu, and E. Ott, “Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach,” Phys. Rev. Lett. 120, 024102 (2018b).
- Carroll (2018) T. L. Carroll, “Using reservoir computers to distinguish chaotic signals,” Phys. Rev. E 98, 052209 (2018).
- Nakai and Saiki (2018) K. Nakai and Y. Saiki, “Machine-learning inference of fluid variables from data using reservoir computing,” Phys. Rev. E 98, 023111 (2018).
- Roland and Parlitz (2018) Z. S. Roland and U. Parlitz, “Observing spatio-temporal dynamics of excitable media using reservoir computing,” Chaos 28, 043118 (2018).
- Weng et al. (2019) T. Weng, H. Yang, C. Gu, J. Zhang, and M. Small, “Synchronization of chaotic systems and their machine-learning models,” Phys. Rev. E 99, 042203 (2019).
- Griffith et al. (2019) A. Griffith, A. Pomerance, and D. J. Gauthier, “Forecasting chaotic systems with very low connectivity reservoir computers,” Chaos 29, 123108 (2019).
- Jiang and Lai (2019) J. Jiang and Y.-C. Lai, “Model-free prediction of spatiotemporal dynamical systems with recurrent neural networks: Role of network spectral radius,” Phys. Rev. Research 1, 033056 (2019).
- Vlachas et al. (2019) P. R. Vlachas, J. Pathak, B. R. Hunt, T. P. Sapsis, M. Girvan, E. Ott, and P. Koumoutsakos, “Forecasting of spatio-temporal chaotic dynamics with recurrent neural networks: A comparative study of reservoir computing and backpropagation algorithms,” arXiv preprint arXiv:1910.05266 (2019).
- Fan et al. (2020) H. Fan, J. Jiang, C. Zhang, X. Wang, and Y.-C. Lai, “Long-term prediction of chaotic systems with machine learning,” Phys. Rev. Research 2, 012080 (2020).
- Zhang et al. (2020) C. Zhang, J. Jiang, S.-X. Qu, and Y.-C. Lai, “Predicting phase and sensing phase coherence in chaotic systems with machine learning,” Chaos 30, 083114 (2020).
- De Wilde (1993) P. De Wilde, “Class of Hamiltonian neural networks,” Phys. Rev. E 47, 1392 (1993).
- Greydanus et al. (2019) S. Greydanus, M. Dzamba, and J. Yosinski, “Hamiltonian neural networks,” arXiv:1906.01563 (2019).
- Toth et al. (2019) P. Toth, D. J. Rezende, A. Jaegle, S. Racanière, A. Botev, and I. Higgins, “Hamiltonian generative networks,” arXiv:1909.13789 (2019).
- Bertalan et al. (2019) T. Bertalan, F. Dietrich, I. Mezić, and I. G. Kevrekidis, “On learning Hamiltonian systems from data,” Chaos 29, 121107 (2019).
- Choudhary et al. (2020a) A. Choudhary, J. F. Lindner, E. G. Holliday, S. T. Miller, S. Sinha, and W. L. Ditto, “Physics-enhanced neural networks learn order and chaos,” Phys. Rev. E 101, 062207 (2020a).
- Garg and Kagi (2019) A. Garg and S. S. Kagi, “Hamiltonian neural networks,” https://github.com/ayushgarg31/HNN-Neurips2019 (2019).
- Chen et al. (2019) Z. Chen, J. Zhang, M. Arjovsky, and L. Bottou, “Symplectic recurrent neural networks,” arXiv:1909.13334 (2019).
- Cranmer et al. (2020) M. Cranmer, S. Greydanus, S. Hoyer, P. Battaglia, D. Spergel, and S. Ho, “Lagrangian neural networks,” arXiv preprint arXiv:2003.04630 (2020).
- Sanchez-Gonzalez et al. (2019) A. Sanchez-Gonzalez, V. Bapst, K. Cranmer, and P. Battaglia, “Hamiltonian graph networks with ode integrators,” arXiv preprint arXiv:1909.12790 (2019).
- Dulberg and Cohen (2020) Z. Dulberg and J. Cohen, “Learning canonical transformations,” arXiv preprint arXiv:2011.08822 (2020).
- Choudhary et al. (2020b) A. Choudhary, J. F. Lindner, E. G. Holliday, S. T. Miller, S. Sinha, and W. L. Ditto, “Forecasting Hamiltonian dynamics without canonical coordinates,” arXiv preprint arXiv:2010.15201 (2020b).
- Lutter et al. (2019) M. Lutter, C. Ritter, and J. Peters, “Deep Lagrangian networks: Using physics as model prior for deep learning,” arXiv preprint arXiv:1907.04490 (2019).
- Havoutis and Ramamoorthy (2010) I. Havoutis and S. Ramamoorthy, “Geodesic trajectory generation on learnt skill manifolds,” in 2010 IEEE International Conference on Robotics and Automation (IEEE, 2010) pp. 2946–2952.
- Falahian et al. (2015) R. Falahian, M. M. Dastjerdi, M. Molaie, S. Jafari, and S. Gharibzadeh, “Artificial neural network-based modeling of brain response to flicker light,” Nonlinear Dyn. 81, 1951 (2015).
- Cestnik and Abel (2019) R. Cestnik and M. Abel, “Inferring the dynamics of oscillatory systems using recurrent neural networks,” Chaos 29, 063128 (2019).
- Kim et al. (2020) J. Z. Kim, Z. Lu, E. Nozari, G. J. Pappas, and D. S. Bassett, “Teaching recurrent neural networks to modify chaotic memories by example,” arXiv preprint arXiv:2005.01186 (2020).
- Klos et al. (2020) C. Klos, Y. F. K. Kossio, S. Goedeke, A. Gilra, and R.-M. Memmesheimer, “Dynamical learning of dynamics,” Phys. Rev. Lett. 125, 088103 (2020).
- Kong et al. (2021) L.-W. Kong, H.-W. Fan, C. Grebogi, and Y.-C. Lai, “Machine learning prediction of critical transition and system collapse,” Phys. Rev. Research 3, 013090 (2021).
- Guest et al. (2018) D. Guest, K. Cranmer, and D. Whiteson, “Deep learning and its application to LHC physics,” Annu. Rev. Nucl. Part. Sci. 68, 161 (2018).
- Radovic et al. (2018) A. Radovic, M. Williams, D. Rousseau, M. Kagan, D. Bonacorsi, A. Himmel, A. Aurisano, K. Terao, and T. Wongjirad, “Machine learning at the energy and intensity frontiers of particle physics,” Nature 560, 41 (2018).
- Carleo and Troyer (2017) G. Carleo and M. Troyer, “Solving the quantum many-body problem with artificial neural networks,” Science 355, 602 (2017).
- Peurifoy et al. (2018) J. Peurifoy, Y. Shen, L. Jing, Y. Yang, F. Cano-Renteria, B. G. DeLacy, J. D. Joannopoulos, M. Tegmark, and M. Soljačić, “Nanophotonic particle simulation and inverse design using artificial neural networks,” Sci. Adv. 4, eaar4206 (2018).
- Dunjko and Briegel (2018) V. Dunjko and H. J. Briegel, “Machine learning & artificial intelligence in the quantum domain: a review of recent progress,” Rep. Prog. Phys. 81, 074001 (2018).
- Carleo et al. (2019) G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová, “Machine learning and the physical sciences,” Rev. Mod. Phys. 91, 045002 (2019).
- Iten et al. (2020) R. Iten, T. Metger, H. Wilming, L. Del Rio, and R. Renner, “Discovering physical concepts with neural networks,” Phys. Rev. Lett. 124, 010508 (2020).
- Karkar et al. (2020) S. Karkar, I. Ayed, E. de Bézenac, and P. Gallinari, “A principle of least action for the training of neural networks,” arXiv preprint arXiv:2009.08372 (2020).
- Yang et al. (2020) S. Yang, X. He, and B. Zhu, “Learning physical constraints with neural projections,” Adv. Neu. Info. Process. Sys. 33 (2020).
- Abadi et al. (2016) M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, et al., “Tensorflow: A system for large-scale machine learning,” in 12th USENIX symposium on operating systems design and implementation (OSDI 16) (2016) pp. 265–283.
- Chollet et al. (2015) F. Chollet et al., “Keras,” https://keras.io (2015).
- Hénon and Heiles (1964) M. Hénon and C. Heiles, “The applicability of the third integral of motion: some numerical experiments,” Astron. J. 69, 73 (1964).
- Waite and Miller (1981) B. A. Waite and W. H. Miller, “Mode specificity in unimolecular reaction dynamics: The Henon–Heiles potential energy surface,” J. Chem. Phys. 74, 3910 (1981).
- Feit and Fleck Jr (1984) M. Feit and J. Fleck Jr, “Wave packet dynamics and chaos in the Hénon–Heiles system,” J. Chem. Phys. 80, 2578 (1984).
- Vendrell and Meyer (2011) O. Vendrell and H.-D. Meyer, “Multilayer multiconfiguration time-dependent Hartree method: Implementation and applications to a Henon–Heiles Hamiltonian and to pyrazine,” J. Chem. Phys. 134, 044135 (2011).
- de Moura and Letelier (1999) A. P. de Moura and P. S. Letelier, “Fractal basins in Hénon–Heiles and other polynomial potentials,” Phys. Lett. A 256, 362 (1999).
- Seoane et al. (2006) J. M. Seoane, J. Aguirre, M. A. Sanjuán, and Y.-C. Lai, “Basin topology in dissipative chaotic scattering,” Chaos 16, 023101 (2006).
- Seoane et al. (2007) J. M. Seoane, M. A. Sanjuán, and Y.-C. Lai, “Fractal dimension in dissipative chaotic scattering,” Phys. Rev. E 76, 016208 (2007).
- Lichtenberg and Lieberman (1992) A. Lichtenberg and M. Lieberman, Regular and Chaotic Dynamics, 2nd ed. (Springer, Berlin, New York, 1992).
- Skokos (2001) C. Skokos, “Alignment indices: a new, simple method for determining the ordered or chaotic nature of orbits,” J. Phys. A Math. Gen. 34, 10029 (2001).
- Zotos (2015) E. E. Zotos, “Classifying orbits in the classical Hénon–Heiles Hamiltonian system,” Nonlinear Dyn. 79, 1665 (2015).
- Morse (1929) P. M. Morse, “Diatomic molecules according to the wave mechanics II. Vibrational levels,” Phys. Rev. 34, 57 (1929).
- Lai (1999) Y.-C. Lai, “Abrupt bifurcation to chaotic scattering with discontinuous change in fractal dimension,” Phys. Rev. E 60, R6283 (1999).
- Lai et al. (2000) Y.-C. Lai, A. P. De Moura, and C. Grebogi, “Topology of high-dimensional chaotic scattering,” Phys. Rev. E 62, 6421 (2000).
- Fermi et al. (1955) E. Fermi, P. Pasta, S. Ulam, and M. Tsingou, Studies of the nonlinear problems, Tech. Rep. (Los Alamos National Laboratory, 1955).
- Caiani et al. (1998) L. Caiani, L. Casetti, C. Clementi, G. Pettini, M. Pettini, and R. Gatto, “Geometry of dynamics and phase transitions in classical lattice -4 theories,” Phys. Rev. E 57, 3886 (1998).
- Levien and Tan (1993) R. B. Levien and S. M. Tan, “Double pendulum: An experiment in chaos,” Am. J. Phys. 61, 1038 (1993).