异构制胜:一次性联合集群
摘要
在这项工作中,我们探讨了无监督联合学习 (FL) 的独特挑战和机遇。 我们开发并分析了一种一次性联合聚类方案,k-FED,基于广泛使用的劳埃德-均值聚类方法。 与许多监督问题相反,我们表明联邦网络中的统计异质性问题实际上可以有利于我们的分析。 我们在中心分离假设下分析k-FED,并将其与集中式对应设备的最著名要求进行比较。 我们的分析表明,在每个设备的集群数量 小于网络上的集群总数 、 的异构机制中,我们可以利用异质性来发挥我们的优势——显着削弱 k-FED 的簇分离要求。 从实用的角度来看,k-FED还具有许多理想的特性:它只需要一轮通信,可以异步运行,并且可以处理部分参与或节点/网络故障。 我们通过常见 FL 基准测试的实验来激发我们的分析,并通过个性化 FL 和设备采样中的用例强调一次性聚类的实用性。
1简介
联邦学习 (FL) 旨在在手机或可穿戴设备等大型异构设备网络上执行机器学习(McMahan 等人,2017)。 虽然此类环境中的监督学习问题受到了极大关注,但无监督联邦学习问题相对尚未得到探索(Kairouz 等人,2019)。 在这项工作中,我们证明无监督学习为 FL 提供了独特的机会,特别是对于驻留在联邦网络中的数据进行聚类的任务。
聚类是许多学习任务中至关重要的第一步。 就联邦学习而言,聚类已在客户选择(Cho等人,2020)、个性化(Gho等人,2020)和探索性数据分析中找到了应用。 虽然许多工作探索了分布式集群技术(第 2 节),但大多数工作没有考虑联邦学习的独特挑战,例如统计异质性、系统异质性和严格的通信约束(李等人, 2020a)111隐私虽然是许多联合应用程序的一个重要关注点,但并不是我们工作的主要重点。 然而,k-FED 的一次性特性的一个可能的好处是,相对于标准迭代技术(例如分布式),它需要在网络上共享的消息少得多。 -表示。. 这些挑战可能会使分析变得复杂,降低效率,并导致落后者和设备故障等实际问题。 在这项工作中,我们研究了数据在网络上分布不同(即异构)并且设备可以突然加入和离开网络的环境中的通信高效分布式集群。 对于此类设置,我们基于经典的 Lloyd 启发式 (Lloyd,1982) 开发并分析了一次性聚类方案 k-FED > 用于聚类。
我们提出的方法k-FED只需要与中央服务器进行一轮通信。 每个由 索引的设备解决本地 均值问题,然后通过大小为 的消息与其本地集群均值进行通信。 正如我们在第 3 节中所示,这允许设备故障,只需要网络中有足够的可用设备,以便数据中存在 目标集群。 此外,可以通过中央服务器上的简单重新计算来对以前不可用的设备中的点进行聚类。
除了k-FED的实际好处之外,我们的工作在严格证明联邦学习存在统计异质性可能带来的问题设置方面是独一无二的。 特别是在监督学习中,许多工作都强调了统计异质性的有害影响,观察到异质性会导致联邦优化方法收敛性差(McMahan等人,2017;Li等人,2020b),导致不公平的模型(Mohri等人,2019),或需要新颖的个性化形式(Smith等人,2017;Mansour等人,2020)。 与这些工作相反,我们表明,对于本文考虑的异质性的具体概念(定义3.2中提供并由聚类的应用激发),异质性实际上可以为我们的方法带来可衡量的好处。
更具体地说,与聚类中的许多工作类似(Kumar & Kannan (2010);Awasthi & Sheffet (2012) 以及其中的参考文献),我们分析 k-FED 在中心分离假设下;也就是说,我们假设聚类的平均值是很好分离的。 我们还考虑了异质性的具体概念:给定一个具有 集群的目标集群,我们希望从数据中恢复,我们假设每个设备仅包含来自这些目标的 的数据集群。 例如,对于由 良好分离的高斯分布的混合生成的聚类数据,我们假设每个设备都包含来自 分量高斯分布的数据。 在这种制度下,我们表明我们的分离要求与集中式对应机构的要求类似。 此外,集中式设置要求所有集群中心对都满足 中心分离要求,而联合式方法可以处理大部分集群中心对只满足较弱的 分离要求的情况。 这是我们知道的第一个结果,它分析了联邦集群背景下异构性的好处。
贡献。 我们提出并分析了一种用于联邦集群的一次性通信方案。 我们提出的方法 k-FED 解决了联邦环境中常见的实际问题,例如高通信成本、落后者和设备故障。 理论上,我们表明 k-FED 的表现与集中式集群类似,其中每个设备仅具有来自最多 个集群的数据,这些集群具有相似的 中心分离要求。 此外,与集中式设置相反,我们表明,异构网络中的大量簇对只需要 较弱的分离假设,因此与集中式设置相比,可以在此设置中解决更广泛的问题。集中式集群。 我们通过常见 FL 基准的实验展示了我们的方法,并探索了 k-FED 在个性化联合学习和设备采样问题中的适用性。 我们的工作强调,异构性可以为联邦学习中的一部分问题带来明显的好处。
2 背景及相关工作
集中式集群。 聚类是最广泛使用的无监督学习任务之一,并且在集中式和分布式设置中都得到了广泛的研究。 尽管存在多种聚类方法,但劳埃德启发式(Lloyd,1982)仍然很受欢迎,部分原因在于其简单性。 在劳埃德的方法中,我们从一组初始的 中心开始。 然后,我们将每个点分配给它最近的中心,并将这些中心重新分配为分配给它的所有点的平均值,继续这个过程直到终止。 虽然很容易证明该方法终止,但众所周知,该过程可能需要超多项式时间才能收敛(Arthur & Vassivitskii,2006)。 然而,在适当的假设和仔细选择初始中心的情况下,可以证明它可以在多项式时间内收敛(Arthur & Vassilvitskii, 2006; Ostrovsky 等人, 2013; Kumar & Kannan, 2010; Awasthi & Sheffet, 2012) 。
我们提出的方法k-FED(第3.2节)是这些经典技术的简单、通信高效的分布式变体。 k-FED 运行 Lloyd 方法的变体,用于 - 表示在每个设备上进行本地集群,然后执行一轮通信以聚合和分配集群。 我们的工作建立在对 Kumar & Kannan (2010) 开发的 Lloyd 算法变体的分析基础上,后来在 Awasthi & Sheffet (2012) 中针对数据聚类问题进行了改进来自混合分布和其他相关结果(例如,McSherry,2001;Ostrovsky 等人,2013)。 这些工作开发了一个确定性框架,不对数据进行生成假设。 我们的分析遵循这个框架,不对数据做出任何生成假设。
并行和分布式集群。 许多工作探索了集中式集群技术的并行或分布式实现(Dhillon & Modha, 2002; Tasoulis & Vrahatis, 2004; Datta 等人, 2005; Bahmani 等人, 2012; Xu 等人, 1999) 。 与本文探讨的一次性通信方案不同,这些方法通常是 Lloyd 启发式或 DBSCAN (Ester 等人,1996) 等方法的直接并行实现,并且需要多轮通信。 另一项工作考虑了仅需要一轮或两轮通信的通信高效的分布式集群变体(例如,Kargupta 等人,2001;Januzaj 等人,2004;Feldman 等人,2012;Balcan 等人,2013 ; Bateni 等人, 2014; Bachem 等人, 2018). 这些工作大多是经验性的,因为对分布式方案的近似质量没有可证明的保证; Balcan 等人的作品 (2013); Bateni 等人 (2014); Bachem 等人 (2018) 的不同之处在于为集群提供了通信高效的分布式核心集方法,以及可证明的近似保证。 然而,这些工作并没有探索联邦环境或异构性的潜在好处。
联合集群。 有几项工作探索了监督 FL 背景下的聚类,作为更好地建模非 IID 数据的方法(Smith 等人,2017;Ghosh 等人,2019、2020;Sattler 等人,2020)。 这些工作与我们自己的工作不同,具体是在设备方面进行聚类,专注于下游监督学习任务,并使用迭代(Smith等人,2017;Ghosh等人,2020;Sattler等人,2020) 或集中式(Ghosh 等人, 2019) 聚类方案。 虽然不是我们工作的主要重点,但在第 4 节中,我们通过展示 k-FED 如何展示一次性聚类的适用性用作提供个性化联邦学习的简单预处理步骤,相对于 Ghosh 等人 (2020) 中提出的最近的集群 FL 迭代方法,实现类似或更好的性能。
最近,Wang & Chang (2020) 出于无监督学习的目的,探索了一种基于分布式矩阵分解的聚类方法。 然而,虽然作者考虑了统计异质性对其收敛保证的影响,但重点并不是一次性聚类或在分析中显示异质性的明显好处。
3 k-FED:基础知识和主要结果
在本节中,我们首先讨论与 Lloyd 类型方法相关的聚类的一些基本知识和现有结果。 在 3.1 节中,我们提出了 Awasthi & Sheffet (2012) 用于集中式集群的确定性框架,我们在此基础上进行构建。 我们提出我们的方法k-FED并在3.2节中陈述我们的理论结果。 我们在附录A中提供了详细的证明。
3.1 集中式-表示
在标准(集中)-means问题中,我们给出一个矩阵,其中每行是中的一个数据点>。 我们还给出了一个固定的正整数,我们的目标是将数据点划分为个不相交的分区,,从而最小化-表示成本:
| (1) |
这里我们使用作为运算符来表示索引的点的平均值,即。 为了简化表示法,当 明确时,我们将其简化为 。
虽然此处所述的 k 均值问题没有为数据点 指定任何生成模型,但要考虑的一个流行设置是从 的混合中采样数据时 - 维度 () 中的分布。 例如,我们可以想象数据点是从 高斯分布的混合中采样的。 该生成模型还引入了目标聚类、的概念,其中集合包含由生成的所有点 - th 分量分布。 许多与分布相关的结果因聚类分布问题而闻名(参见 Kumar & Kannan (2010))。 一般来说,它们可以表述为:如果分布的均值相差 个标准差,那么我们可以在多项式时间内对数据进行聚类。 Kumar & Kannan (2010) 引入了一个包含许多已知结果的确定性(独立于分布)框架。 这项工作后来被 Awasthi & Sheffet (2012) 简化和改进。 在说明我们使用的符号之后,我们在这里说明该框架的主要结果。 我们强调,在我们的分析中,我们不对数据的生成方式做出任何假设;所有相关数量仅取决于所提供的数据。
符号。 我们现在介绍将在整篇论文中使用的几个定义和符号。 让 表示矩阵 的谱范数,定义为 ,并让 表示 向量的范数。 为了保持一致性,我们使用 和 对 的各个行进行索引。 此外,当目标聚类固定时,我们用索引聚类,例如,是由索引的点矩阵>。 为了符号方便,我们让 表示数据点 的簇索引,例如 。 对于某些点集 和另一个点 ,让 表示 到集合 ,定义为。 最后,令 为 矩阵,每行为 。 对于具有 的簇 ,我们定义
| (2) |
这里的量可以被认为是标准差的确定性类似物;它测量沿任意方向的最大平均方差。 因此,我们将使用 ,而不是根据标准差来推理两个簇 和 之间的分离。 特别是,如果对于足够大的常数,我们说两个簇和是很好地分离,它们的均值满足:
| (3) |
同样,我们可以将其解释为如果两个簇的均值相差 -标准差,则它们可以很好地分离。222 任何 都足以满足我们的论点(参见引理 5)。 使用 (3) 中的中心分离假设,Awasthi & Sheffet (2012) 表明,对于满足分离假设的目标聚类 ,变体当应用于集中式聚类问题时,算法 1 中提出的劳埃德算法可以正确地对除一小部分数据点之外的所有数据点进行聚类。 我们在引理1中正式陈述了他们的结果,但在此之前我们定义了一个邻近条件,它将用于精确地表征错误分类的点。
Definition 3.1。
对于某些,如果对于每个,在直线上的投影,则称点满足邻近条件连接和,记为满足
因此,如果 的点 在连接 和 的直线上的投影更接近 由。 我们将不满足邻近条件的点称为“坏点”。 现在,我们在以下引理中陈述 Awasthi & Sheffet (2012) 的主要结果。
Lemma 1 (Awasthi-Sheffet,2011)。
令 为目标聚类。 假设每对簇 和 都很好地分开。 然后,在算法 1 的步骤 2 之后,对于每个 ,它都保持 。 此外,如果坏点的数量为 ,则 (a) 聚类 错误分类不超过 个点,并且 (b) . 最后,如果 则所有点都被正确分配。
当我们说错误分类时,我们指的是关于 以及标签的排列。 引理 1 告诉我们聚类均值 距离目标聚类均值 不是很远。 请注意,此声明中没有与分布相关的术语;所有相关量均根据数据矩阵和定义。
3.2 k-FED:方法和主要结果
现在,我们将注意力转向联合网络中的数据集群。 在我们的设置中,我们假设网络中的所有设备都可以与中央服务器通信。 我们的聚类方法k-FED(在算法2中描述)可以被认为是分两个阶段工作的。 在第一阶段,每个设备解决局部聚类子问题并计算该子问题的聚类均值。 在第二阶段,中央服务器累积并聚合结果以计算最终的聚类。
符号。 令 为网络中所有数据点的 数据矩阵。 我们用 对各个设备进行索引,因此,我们用 表示任何特定设备的数据矩阵,其中 是设备上数据点的数量。设备。 让。 请注意, 是 行的某些子集。 令为所有数据的聚类,称为目标聚类。 对于固定的 ,让 是驻留在设备 上的目标集群的子集。 请注意,某些 可能为空。 令 为设备 上非空子集的数量,并令 。 我们的异质性概念是根据 的值正式定义的,如下所述。
Definition 3.2 (聚类的异质性)。
在集群的背景下,如果,我们就说具有足够数据的联邦网络是异构的。 和之间的比率越低,网络中存在的异质性就越大。
直观地,异质性的定义表明,与来自 总簇的数据在网络上以 IID 方式分区相比,数据以非 IID 方式分区,这样只有数据每个设备上都存在少量集群(最多 )。 在具有大量集群的异构联合网络中,这种非 IID 分区是合理的,因为每个设备上的数据分布可能不同,并且不可能在网络上主动重新分布数据。 例如,考虑根据应用程序上的交互数据来识别移动电话用户的兴趣。 这里的交互数据是由用户在其特定设备上生成的,并且将反映个人的品味。 虽然整个网络上的“品味”(集群)总数可能相当大,但典型的用户只会对其中的一小部分感兴趣。 考虑到这个定义,我们接下来描述我们的一次性聚类方法,k-FED,并在异构机制中对其进行分析。
方法说明。
与集中情况类似(第 3.1 节),令 为局部聚类均值的 矩阵,即 。 考虑某个设备上集群的非空susbset,并让。 我们假设有一个常数,这样对于所有来说。我们将使用这个数量来确保各个设备有“足够”的积分。 让,
| (4) |
在k-FED(算法-2)的第一步中,每个(可用)设备在本地运行算法-1并求解本地聚类本地数据集 和参数 存在问题。 我们假设 是已知的。 此阶段输出设备集群中心和每个设备的集群分配。 在此阶段,请注意,即使每个设备都已将自己的点分类为簇,但我们还没有跨设备的点的聚类。 中央服务器尝试通过聚合设备集群中心并将它们分成 集 来创建此集群。 这些集合引起网络上数据的聚类,如下定义:
Definition 3.3 (k-FED诱导聚类)。
为了将 k-FED 诱导的聚类 的质量与我们的目标聚类 的质量进行比较,我们需要两种不同的分离假设。 我们将它们称为active和inactive分离,并通过以下两个定义来介绍它们。
Definition 3.4 (活动/非活动簇对)。
如果存在至少一个设备同时包含来自 和 的数据点,则一对簇 被称为活动对。 如果没有设备同时具有来自集群 和 的数据点,我们将集群对 称为非活动对。
Definition 3.5。
对于一些足够大的常数,我们说两个簇和满足主动分离要求,如果。类似地,如果,我们就说它们满足非活动分离要求。
直观上,这些概念反映了对两种不同类型的簇对(活动簇对和非活动簇对)进行聚类的难度。 如果没有设备同时拥有来自 和 (即非活动对)的数据,则各个设备必须解决的聚类子问题会更容易,因为它们从不涉及来自这两个设备的数据这些集群同时进行。 因此,非活动簇对的分离要求弱于活动簇对的分离要求。 现在我们陈述我们的主要定理,它描述了k-FED的性能。 我们在附录A中提供了详细的证明。
Theorem 3.1 (主定理).
令 为联合网络上数据的固定目标聚类。 让 使得 对于所有 和所有 而言。 假设每个主动簇对和满足主动分离要求,即
此外,假设对于每个非活动簇对,
然后,在 k-FED 终止时,除了 点之外的所有点都被正确分类。 此外,如果对于每个设备,数据点满足其局部问题的邻近条件(定义3.1),则所有点都被正确分类。
和之前一样,通过分类,我们的意思是 k-FED 和 产生的聚类 与除 点,直到 标签的排列。 请注意,当时,我们的主动分离要求比集中式集群与中的要求更严格。 此外,正如人们所预料的那样,随着每个设备上每个集群的点数减少,本地集群变得更加困难。 我们对 的不利依赖凸显了这一点。
然而,与每个设备通常具有数据的随机子集的通用分布式学习框架相比,驻留在联邦网络中的设备上的数据通常是本地生成的,因此设备之间的数据分区是不相同分布的。 具体地,在实践中,驻留在设备上的目标集群的子集的数量可能远小于集群的总数。 因此,正如定义 3.2 中所述,我们研究 的情况。 观察到,在这种设置中,我们的主动分离要求减少为集中式 均值问题(带有额外的 惩罚),而我们的非主动分离要求减弱为 . 我们在推论 1.1 中正式声明了这一点。
Corollary 1.1。
假设,一个主动簇对满足主动分离要求,如果
类似地,如果满足非活动簇对 则满足非活动分离要求
因此,在的设置中,k-FED仅在一轮通信中恢复目标分区。 此外,非活动簇对只需要满足我们的 分离要求,而不是所有簇对在引理 1 的集中设置中需要满足的 分离要求> 持有。 这凸显了在联合网络上运行 k-FED 的情况下存在异构性的好处。
k-FED 的实际好处。
最后,我们强调 k-FED 方法的几个实际好处:
-
•
一次性: k-FED 每个设备只需要一轮通信:一条传出消息发送本地聚类结果,一条传入消息接收集群身份信息的消息。
-
•
无全网同步: Lloyd 启发式和变体的经典并行实现(例如,Dhillon & Modha,2002),需要网络范围的同步/初始化步骤。 与这些方法不同,k-FED中的每个设备独立工作,不需要初始化/同步步骤。
-
•
新设备/设备故障: 假设我们已经在当前网络上进行了聚类,对于任何进入网络的新设备,无论是由于先前的故障还是作为新的参与者,都可以在不涉及网络中任何其他设备的情况下计算聚类信息。 正如我们在定理 3.2(下面)中所示,只需将新设备 中的任何新本地集群中心 分配给最近的设备集群均值 足够了。 中央服务器只需维护集群意味着即可执行此更新。
Theorem 3.2.
k-FED的步骤2-8以成对距离计算结束。 此外,在计算出步骤 6 中的集合 后,可在 距离计算中正确分配来自未知设备 的新本地群集中心 。
正如我们在第 4 节中所示,k-FED 的这些属性使其成为用作廉价启发式<的理想候选者。 /t4> 用于联邦网络中的聚类,无论是用于数据探索还是作为另一种算法的预处理步骤的一部分,即使在未正式满足分离要求的设置中也是如此。
4应用与实验
我们现在提出k-FED的实验评估。 我们首先将理论专门针对特殊情况,其中数据是从第 4.1 节中的 高斯混合中提取的,以验证我们关于合成数据的理论。 在第 4.2 节中,我们在真实数据集上评估 k-FED - 提供实验证据,强调异质性的好处和 k-FED 的通信效率。 我们进一步介绍了k-FED在客户选择和个性化方面的两种应用。 每个实验的数据集详细信息可以在相应部分找到。 k-FED 的实现和实验设置详细信息可以在以下位置找到:http://github.com/metastableB/kfed/。
4.1 分离高斯混合体
我们首先将定理专门用于分离由 高斯 混合生成的数据的情况。 令 为混合物成分 的平均值,令 为混合权重。 最后,令 为最小混合权重。 令 为所有分量分布中沿任意方向的最大方差。 假设此数据驻留在我们的设备上,这样任何单个设备都不会拥有来自多个 组件的数据。 我们陈述以下定理(在附录 A 中证明),该定理指定了此设置满足我们的分离假设所需的条件:
Theorem 4.1.
设数据品脱总数。 则任何活跃簇对以高概率满足活跃分离要求:
此外,如果不活动簇对满足不活动分离要求,则概率较高
最后,通过这种分离,所有点都以很高的概率满足邻近条件。
具体来说,在此设置中 k-FED 以高概率准确地恢复目标聚类。 为了根据经验评估我们的理论,我们实例化了上述设置的简化实例,如下所示:
| Parameters | Accuracy |
|---|---|
设置。 再次考虑高斯分量,并定义整数集。 因此,这些集合可用于索引高斯分量。 对于每个,通过从的每个组件中采样样本来构造一组数据点 >。 因此集合包含样本。 选择,并为每组数据点,在个设备之间分配数据,以便每个设备准确接收个样本。 现在,我们在此设置上运行 k-FED,并测量 10 次运行的平均聚类质量(如表 1 所示)。 正如人们所期望的那样,k-FED 生成的聚类与目标聚类非常一致。 请注意,通过构造,具有来自同一组 的数据的所有设备都包含来自同一组高斯分量的数据。 此外,具有来自不同集合的数据的设备没有共同的高斯分量。 因此,同一集合内的所有簇对都是活动簇对,并且存在这样的簇对。 此外,任何对 使得 、 形成非活动簇对,并且有 这样的对。 这些仅需要满足较弱的非活性分离要求。
请注意,虽然我们规定 来保持参数,但图 1 表明即使在 小得多的设置中也可以恢复聚类。
4.2真实数据的实证评估
在本节中,我们将实证探讨k-FED以及第3节中的相关分析。 首先,我们验证了我们的理论结果,表明相对于随机 IID 分区数据的聚类,结构化(异构)分区上的聚类可以提高聚类性能。 其次,我们探讨了一次性聚类相对于通信密集型基线的影响。 最后,我们研究了一次性聚类在客户抽样和个性化联邦学习方面的实际应用。
4.2.1 k-FED的性质
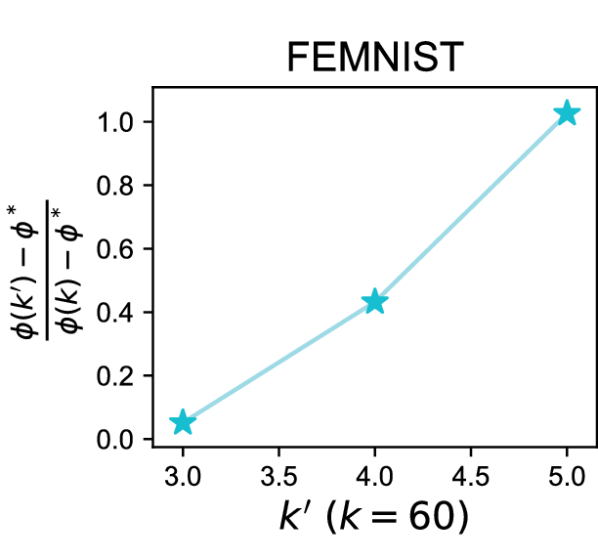
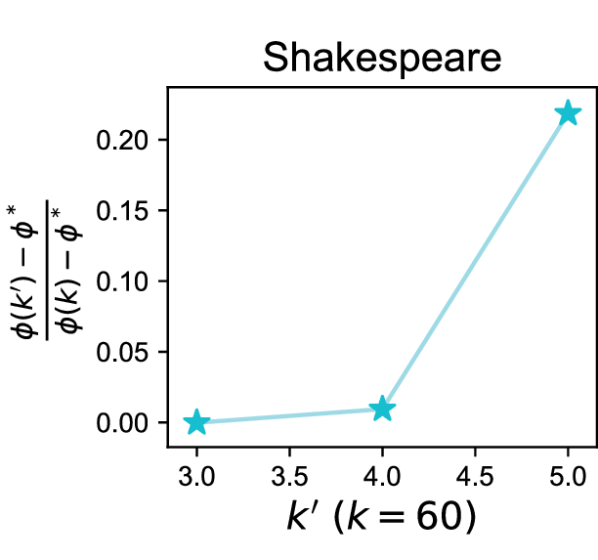
异质性的好处(Def. 3.2)。 我们比较了k-FED在设备中两个不同数据分区上的性能:(i)一个具有IID随机分区,以及(ii) )另一个具有结构化分区。 为了生成本实验的底层结构化分区,我们使用以下启发式方法。 首先,我们将所有数据聚类到 簇中,以获得 值的范围。对于每个,我们将已有的聚类作为目标聚类,并构造数据矩阵和中心矩阵.最后,对于每对聚类均值,我们计算数量,即聚类均值的实际分离与所需的主动分离的比率。 我们选择一个 值,在该值下,大量簇可以很好地分离(参见附录 B,图 5)。 我们将其称为oracle 集群。 现在,为了生成 (i) 的 IID 分区,我们在 设备之间随机分配此数据。 为了生成 (ii) 的结构化分区,我们将数据划分到 设备中,以便每个设备仅接收来自不超过 集群的随机子集的数据。 对于 的每个值,我们使用 k-FED 对设备上两种情况的数据进行聚类,并计算 - 表示成本。 让 表示 - 表示原始 oracle 集群的成本。 让 表示 - 表示将 集群分配给每个设备时的成本。 图2展示了结构化分区()和随机分区()的成本变化之间的相对成本比率。
我们在 FEMNIST 和 Shakespeare 数据集(Caldas 等人,2018)(详细信息参见附录B)上进行了此实验。 从图2中绘制的结果可以看出,与在IID随机分区上实现的成本相比,基于结构化分割的聚类实现的成本更接近于oracle分区的成本。 我们注意到,即使经过如此仔细的构造,实际数据集中实现的分离也比所需的要小得多(附录B)。 即便如此,我们的实验表明,异构性可以使基于共同基准的联合集群受益。
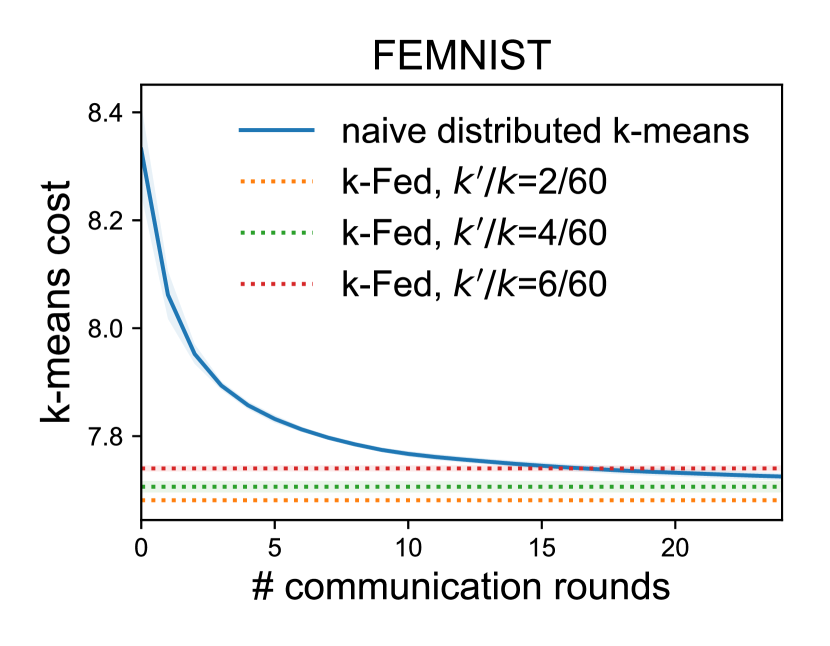
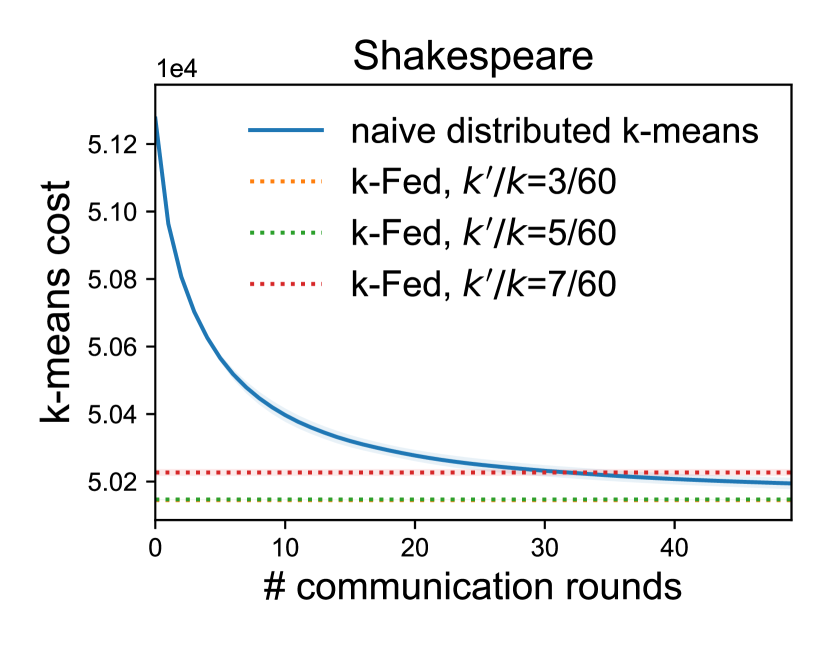
沟通效率。 该方法的一个优点是它只需要一轮通信。 鉴于此,我们很自然地想知道 k-FED 的性能与其他通信密集型集群基线相比如何。 特别是,在分布式设置中解决 -means 的常见方法是简单地并行化每个步骤的集群分配和集群均值计算。 在这里,我们表明,对于具有多个 值的数据集的不同分区,我们的一次性方法 -FED 能够产生类似的聚类输出(就 -意味着成本;越低越好)作为简单的分布式-意味着,需要多轮通信。 在这里,我们使用与之前实验相同的预言机集群来构建我们的设备数据。
4.2.2 -Fed的应用
个性化的佛罗里达州。 与将单一全局模型拟合到所有设备上的数据相比,联合学习个性化(独立但相关)模型可以提高有效样本量,同时适应联邦网络中的异质性(例如,Smith 等人,2017;Mansour 等)人,2020)。
Ghosh 等人 (2020) 最近提出了一种通过联邦网络学习模型的算法,当聚类信息不可用时,设备将被划分为集群。 考虑每个设备集群想要解决的监督学习问题,并假设集群 的数量已知。 他们的方法,即迭代联合聚类算法 (IFCA),在第一步中初始化 模型 ,每个聚类都有一个模型。 在每轮开始时,所有 模型都会发送到设备。 每个设备都会选择能够最小化其本地可用数据的损失函数的模型。 该设备现在可以配置为计算并传输该模型的损失函数的梯度,或者可以在本地执行一些模型更新并将更新的模型发送到中央服务器。 作为本轮的最后一步,对于每个模型 ,将识别选择该模型的所有设备。 所有这些设备都分配有集群 ID 。 然后,使用集群 中的设备发送的信息,通过模型平均或梯度平均来更新模型 。
| Global | IFCA | -FED | |
|---|---|---|---|
| 100 devices () | 95.0 | 98.0 | 98.0 |
| 200 devices () | 94.5 | 97.2 | 97.8 |
| 100 devices () | 95.3 | 95.6 | 97.1 |
| 200 devices () | 94.5 | 95.1 | 96.4 |
我们在学习集群个性化模型的问题上实例化了 IFCA。 如(Ghosh 等人, 2020) 所示,我们使用 MNIST 数据集进行此实验。 我们通过 和 度旋转构建 集群并将它们分布在设备之间。 请注意,在 IFCA 的设置中,每个设备仅包含来自单个集群的数据(因为我们是集群设备而不是单个数据点)。 因此,我们设置 并将 IFCA 与简单的基于 k-FED 的方法进行比较:我们首先执行一次性聚类以获得初始聚类,然后我们使用 FedAvg (McMahan 等人, 2017) 来学习每个集群的一个模型。 作为基线,我们还学习一个全局模型并将其包括在内以进行比较。 从表2()的测试精度可以看出,k-FED与IFCA具有竞争力。 此外,k-FED还有一个额外的优点,即一旦分配了簇标识,我们只需要传输一个模型而不是模型通过 IFCA 传输。
由于 k-FED 对数据进行聚类,因此 k-FED + FedAvg 方法也可以处理有数据的情况来自同一设备上的多个集群。 表2 () 显示了此类分区的测试精度。 在这里,我们观察到 IFCA 的性能与 k-FED 相比有所下降。
客户选择。 最后,我们证明-FED产生的聚类信息对于客户端选择应用(Cho等人,2020)是有用的先验。 在实践中,跨设备联合优化算法需要容忍部分设备参与(Kairouz等人,2019)。 直观地说,与随机采样设备相比,在每轮通信中合并来自“代表性”设备的信息可能会加速联合网络上学习任务的收敛。 随机抽样时,可以选择相似且可能冗余的客户。 最近的设备选择方法提出在随机选择的设备子集中额外选择训练损失较大的设备(Cho等人,2020)以帮助提高收敛速度。 我们将 -FED 与此方法结合起来,进一步过滤掉来自同一集群的设备。 请注意,-FED 不会给基线算法增加显着的额外开销,因为它只需要在训练之前运行一次性聚类。 结果如图4所示。 我们发现,利用 -FED 学习到的底层结构可以促进这些现实联合基准的收敛。
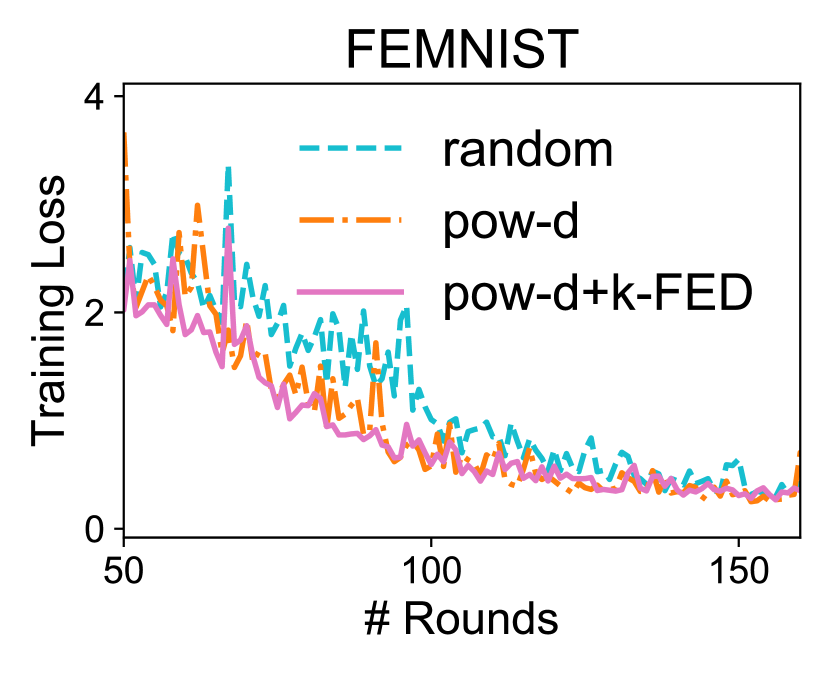
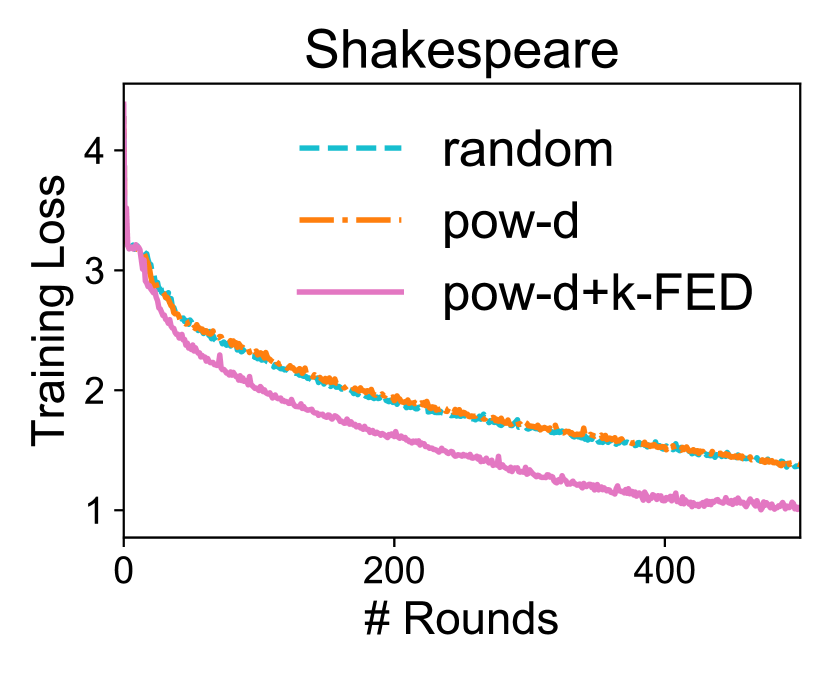
与 Cho 等人 (2020) 类似,我们还观察到,对于图 4 中的实验,使用有利于客户端选择策略来减少所有设备上的测试性能差异与随机选择相比,客户信息更丰富(可能代表性不足)。 例如,在 FEMNIST 上,当使用 k-fed 结合 pow-d 而不是随机选择时,最终测试精度的方差降低了 35%。 这在我们希望为联邦学习强加公平概念的场景中可能很有用(Mohri等人,2019;Li等人,2020c)。
5结论
在这项工作中,我们通过严格分析异构性对 Lloyd 分布式集群算法的简单一次性变体的影响,提供了一个示例,说明联邦网络中的异构性如何有益。 我们提出的方法 k-FED 解决了联邦环境中常见的实际问题,例如高通信成本、落后者和设备故障。 我们相信,异质性的其他具体概念——加上仔细的分析——可能会为联邦学习中的许多其他问题带来好处,这是未来工作的一个有趣的方向。
6致谢
这项工作得到了国家科学基金会拨款 IIS1838017、Google 学院奖、Facebook 学院奖和 CONIX 研究中心的部分支持。 本材料中表达的任何意见、发现、结论或建议均为作者的观点,并不一定反映国家科学基金会或任何其他资助机构。
参考
- Arthur & Vassilvitskii (2006) Arthur, D. and Vassilvitskii, S. How slow is the k-means method? In Proceedings of the Twenty-Second Annual Symposium on Computational Geometry, 2006.
- Awasthi & Sheffet (2012) Awasthi, P. and Sheffet, O. Improved spectral-norm bounds for clustering. In Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques. 2012.
- Bachem et al. (2018) Bachem, O., Lucic, M., and Krause, A. Scalable k-means clustering via lightweight coresets. In International Conference on Knowledge Discovery & Data Mining, 2018.
- Bahmani et al. (2012) Bahmani, B., Moseley, B., Vattani, A., Kumar, R., and Vassilvitskii, S. Scalable k-means+. Proceedings of the VLDB Endowment, 2012.
- Balcan et al. (2013) Balcan, M.-F., Ehrlich, S., and Liang, Y. Distributed -means and -median clustering on general topologies. In Advances in Neural Information Processing Systems, 2013.
- Bateni et al. (2014) Bateni, M., Bhaskara, A., Lattanzi, S., and Mirrokni, V. Distributed balanced clustering via mapping coresets. In Advances in Neural Information Processing Systems, 2014.
- Caldas et al. (2018) Caldas, S., Duddu, S. M. K., Wu, P., Li, T., Konečnỳ, J., McMahan, H. B., Smith, V., and Talwalkar, A. Leaf: A benchmark for federated settings. arXiv preprint arXiv:1812.01097, 2018.
- Cho et al. (2020) Cho, Y. J., Wang, J., and Joshi, G. Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv preprint arXiv:2010.01243, 2020.
- Dasgupta et al. (2007) Dasgupta, A., Hopcroft, J., Kannan, R., and Mitra, P. Spectral clustering with limited independence. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 2007.
- Datta et al. (2005) Datta, S., Giannella, C., Kargupta, H., et al. K-means clustering over peer-to-peer networks. In International Workshop on High Performance and Distributed Mining, 2005.
- Dhillon & Modha (2002) Dhillon, I. S. and Modha, D. S. A data-clustering algorithm on distributed memory multiprocessors. In Large-Scale Parallel Data Mining. 2002.
- Ester et al. (1996) Ester, M., Kriegel, H.-P., Sander, J., Xu, X., et al. A density-based algorithm for discovering clusters in large spatial databases with noise. In International Conference on Knowledge Discovery & Data Mining, 1996.
- Feldman et al. (2012) Feldman, D., Sugaya, A., and Rus, D. An effective coreset compression algorithm for large scale sensor networks. In International Conference on Information Processing in Sensor Networks, 2012.
- Ghosh et al. (2019) Ghosh, A., Hong, J., Yin, D., and Ramchandran, K. Robust federated learning in a heterogeneous environment. arXiv preprint arXiv:1906.06629, 2019.
- Ghosh et al. (2020) Ghosh, A., Chung, J., Yin, D., and Ramchandran, K. An efficient framework for clustered federated learning. Advances in Neural Information Processing Systems, 2020.
- Januzaj et al. (2004) Januzaj, E., Kriegel, H.-P., and Pfeifle, M. Dbdc: Density based distributed clustering. In International Conference on Extending Database Technology, 2004.
- Kairouz et al. (2019) Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., et al. Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977, 2019.
- Kargupta et al. (2001) Kargupta, H., Huang, W., Sivakumar, K., and Johnson, E. Distributed clustering using collective principal component analysis. Knowledge and Information Systems, 2001.
- Kumar & Kannan (2010) Kumar, A. and Kannan, R. Clustering with spectral norm and the k-means algorithm. In Annual Symposium on Foundations of Computer Science, 2010.
- Li et al. (2020a) Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 2020a.
- Li et al. (2020b) Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V. Federated optimization in heterogeneous networks. In Proceedings of Machine Learning and Systems, 2020b.
- Li et al. (2020c) Li, T., Sanjabi, M., Beirami, A., and Smith, V. Fair resource allocation in federated learning. In International Conference on Learning Representations, 2020c.
- Lloyd (1982) Lloyd, S. Least squares quantization in pcm. IEEE Transactions on Information Theory, 1982.
- Mansour et al. (2020) Mansour, Y., Mohri, M., Ro, J., and Suresh, A. T. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619, 2020.
- McMahan et al. (2017) McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics, 2017.
- McSherry (2001) McSherry, F. Spectral partitioning of random graphs. In Symposium on Foundations of Computer Science, 2001.
- Mohri et al. (2019) Mohri, M., Sivek, G., and Suresh, A. T. Agnostic federated learning. In International Conference on Machine Learning, 2019.
- Ostrovsky et al. (2013) Ostrovsky, R., Rabani, Y., Schulman, L. J., and Swamy, C. The effectiveness of lloyd-type methods for the k-means problem. Journal of the ACM, 2013.
- Sattler et al. (2020) Sattler, F., Müller, K.-R., and Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Transactions on Neural Networks and Learning Systems, 2020.
- Smith et al. (2017) Smith, V., Chiang, C.-K., Sanjabi, M., and Talwalkar, A. S. Federated multi-task learning. In Advances in Neural Information Processing Systems, 2017.
- Tasoulis & Vrahatis (2004) Tasoulis, D. K. and Vrahatis, M. N. Unsupervised distributed clustering. In Parallel and Distributed Computing and Networks, 2004.
- Wang & Chang (2020) Wang, S. and Chang, T.-H. Federated clustering via matrix factorization models: From model averaging to gradient sharing. arXiv preprint arXiv:2002.04930, 2020.
- Xu et al. (1999) Xu, X., Jäger, J., and Kriegel, H.-P. A fast parallel clustering algorithm for large spatial databases. In High Performance Data Mining. 1999.
附录A证明
A.1 证明定理3.1(主定理)
在我们继续证明定理3.1之前,我们首先建立一些基本知识结果。 令 为我们的目标聚类,让 为设备 上聚类 的点的子集。 对于设备 上的任何点 ,让 表示它所属集群的索引。 那是,
还记得矩阵 的定义,即均值矩阵。 这里 的第 行包含包含数据点 的簇的平均值,即 。 我们的第一个引理限制了“本地”簇的意思 可以偏离 多远。
Lemma 2 (Kumar & Kannan (2010) 中的引理 5.2)。
令 为设备 上 的子集。 让 表示 索引的点的平均值。 然后,
证明。
令 为设备 上 的子矩阵,并令 为均值矩阵的相应子矩阵。令 为 中点的指示向量。 观察到,
在这里,对于最后一个不等式,我们注意到 包含 行的子集,因此包含 。 ∎
现在考虑每个设备上的本地集群问题。 该设备有一个数据矩阵,其行是的子集。 令 为该设备上 的子集,其中不超过 为非空。 构造一个与 具有相同维度的矩阵 ,其中对于 的每一行, 的相应行包含平均值该点所属的本地簇的名称。 即, 的第 行包含 。 使用下一个引理,我们用 来限制矩阵 的算子范数。
Lemma 3.
令 为驻留在设备上的目标集群的子集,其中 不为空。 令为对应的数据矩阵。 设为相应的均值矩阵;即每一行。 然后,
证明。
我们分四个部分证明定理3.1:
- 1.
- 2.
-
3.
在下一步中,我们展示了在k-FED的步骤2-6中挑选初始中心的过程恰好挑选了一个本地聚类中心 对于每个集群 。也就是说,我们选择与每个目标簇相对应的 本地中心。 (引理 6)
-
4.
最后,我们认为通过这种初始化,产生的局部聚类中心 的聚类具有这样的属性,即对应于同一聚类(例如 )的所有局部聚类中心将是在同一组中(例如 )。 而且,任何、对应的本地聚类中心都不在中。 正如我们稍后讨论的,这足以使 产生的诱导聚类与我们的目标聚类 一致,直到局部聚类阶段发生的标签排列和错误分类。
Lemma 4.
令 为簇对,使得 令 和 为设备 上的大子集。 然后,
证明。
由于算法 1 在每个设备上本地运行,因此它不受非活动分离条件的影响,因为根据定义,每个设备上都存在仅活动集群对的子集。 这意味着算法1成功解决了局部聚类问题。 特别是在包含来自某个集群 的数据的设备 上, 距离 不太远。 显示此结果是我们的第二步,我们在下面的引理 5 中正式声明这一点。
Lemma 5.
令 为 在某些设备 上的子集,其中不超过 为非空。 此外,假设所有非空子集都很大,即。 最后,假设上的所有活动簇对都满足活动分离要求。 然后,在算法 1 终止时,对于每个非空 ,我们有
和,
证明。
这意味着对于固定的,中央服务器从设备接收到的所有都“接近”。
下一步是证明在步骤 2-6 中选择的 初始中心 k-FED 中,每个目标都有一个对应的集群。 稍后我们将证明,这足以让算法的最后一步将本地聚类中心正确分配给正确的分区。
Lemma 6.
让 成为我们的目标聚类。 假设所有活动簇对和非活动簇对满足其分离要求。 进一步设。 然后,在 k-FED 第 6 步结束时,对于每个目标簇 ,都存在一个 ,使得 对于一些。
在我们继续证明这个引理之前,我们声明并证明本地聚类中心 与 的某个聚类平均值 的接近程度的下界:
Lemma 7。
让。 对于任何 、,
证明。
证明。
(引理6)令表示k-FED的步骤2-6中的集合 t4>,在选取第一个 点之后 。 让我们将迭代中选择的点k-FED表示为。 那是,
我们将证明集合 在每次迭代 时包含与 个不同目标簇相对应的 个点。这个不变量在 处是微不足道的。 假设该语句首先在某个 处变为 false。 让点 对应于集群 的局部集群平均值。 那么必须存在一些 ,使得 也对应于 的本地集群平均值。 此外,必须存在某个簇,使得对于任何。
现在我们准备证明我们的主要定理3.1。
A.2 k-FED的运行时间和处理新设备
现在我们分析k-FED步骤2-8的运行时间。 由于步骤 1 是在各个设备上运行 Algorithm-1,因此我们在分析中不包括此步骤的运行时间。 请注意,在分离假设到位的情况下,算法 1 将在多项式时间内收敛。 然而,正如在实践中观察到的,类似 Lloyd 的方法通常只需要几次迭代即可终止。
Theorem A.1.
k-FED的步骤2-8需要成对距离计算来终止。 此外,在计算出步骤 6 中的集合 后,可在 距离计算中正确分配来自未见设备 的新本地群集中心 。
A.3 从高斯混合中分离数据
现在我们证明定理4.1。 回想一下,我们正在 的设置中工作。 我们的证明基于引理 6.3、Kumar 和 Kannan (2010) 的结果。
证明。
首先考虑一个活动簇对。 根据我们的分离要求,我们有:
我们进一步简化右手得到,
现在请注意,每个组件 的点数非常接近 ,概率非常高。 这里是分量的混合权重,是数据点的数量。 使用这个,我们很可能有
进一步地,可以证明是的概率很高(参见(Dasgupta等人, 2007))。 因此我们得出结论,很有可能
从而满足主动分离的要求。 非活动分离条件的证明是类似的。 最后,邻近条件源自高斯的浓度特性。 ∎
附录B实验细节
B.1 数据集
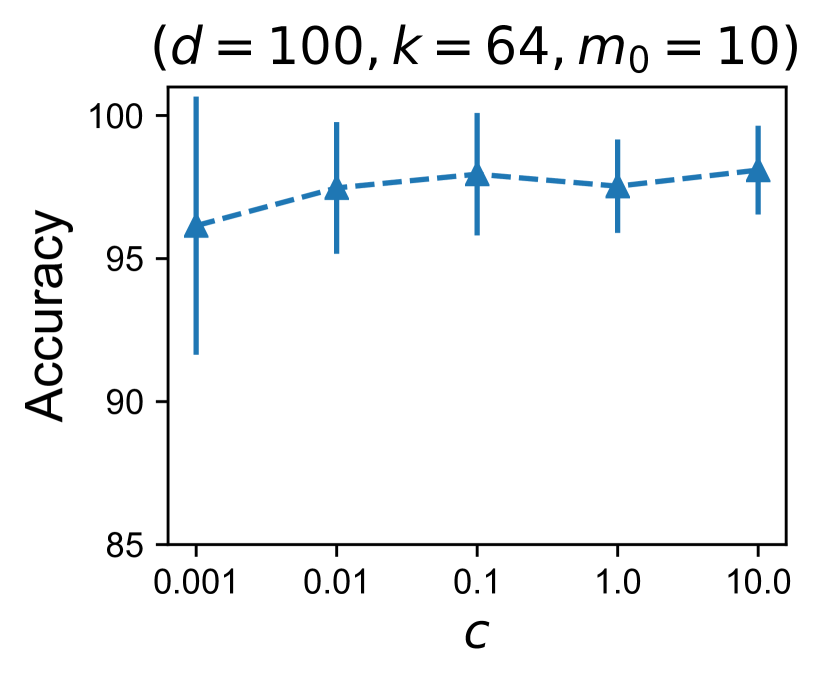
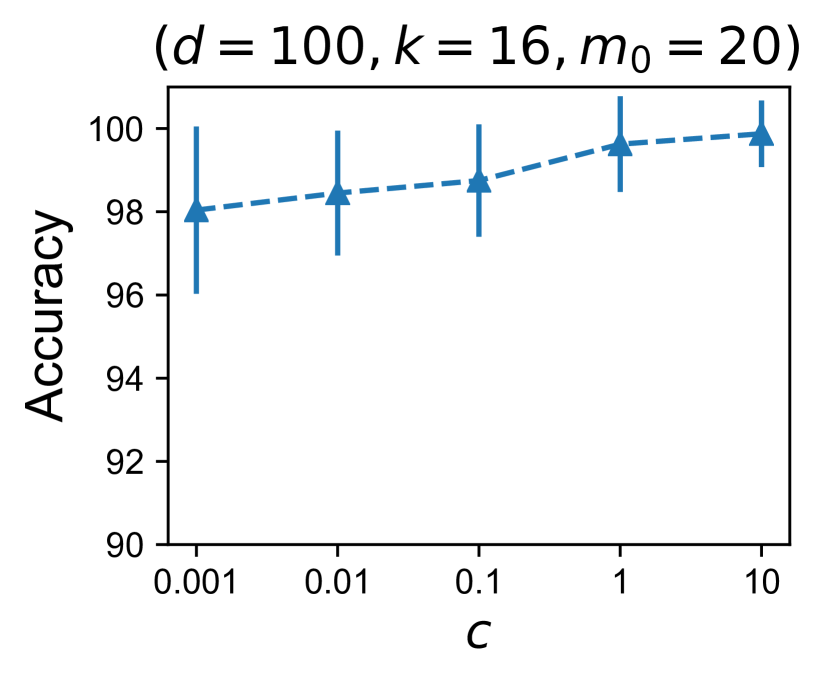
对于涉及真实数据的所有实验,我们使用 EMNIST、FEMNIST 和 Shakespeare 数据集。 这些数据集及其相应的模型可在 LEAF 基准测试中获取:https://leaf.cmu.edu/。 对于客户端选择实验,我们通过为每个设备分配 2 个类别来手动划分 FEMNIST 的子集(前 10 个类别)。 总共有 500 台设备。 所有设备上的训练样本数量以及每个设备中每个类别的训练样本数量都遵循幂律。 我们使用莎士比亚的自然划分,其中每个设备对应于威廉·莎士比亚戏剧中的一个说话角色。 我们从整个数据集中随机抽取 109 个用户。 对于个性化实验,遵循Ghosh等人(2020),我们使用基于CNN的模型,该模型具有一个隐藏层和200个隐藏单元,并以和 每台设备上的本地更新。
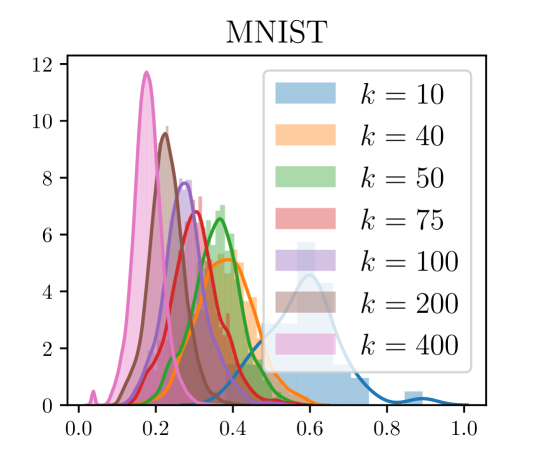
B.2 根据分离选择
如第 4.2 节所述,为了创建 oracle 聚类,我们会针对 的每个候选值,为每个聚类对 计算数量 。 我们构建了这些的分布图。 图 5 提供了 MNIST 数据集的此类绘图示例。 从这里可以看出,对于 的所有值,相对间隔都非常小。 因此,即使对于这种预言聚类,聚类平均值之间的实际间隔也很小。 要为 Oracle 集群选择 ,我们选择一个固定值 (例如 ),然后选择 的值这导致簇对的最大分数具有。