MoViNets:用于高效视频识别的移动视频网络
摘要
我们提出了移动视频网络 (MoViNets),这是一系列计算和内存高效的视频网络,可以在流视频上运行以进行在线推理。 3D 卷积神经网络(CNN)在视频识别方面非常准确,但需要大量的计算和内存预算,并且不支持在线推理,这使得它们很难在移动设备上工作。 我们提出了一种三步方法来提高计算效率,同时大幅降低 3D CNN 的峰值内存使用量。 首先,我们设计了一个视频网络搜索空间,并采用神经架构搜索来生成高效且多样化的 3D CNN 架构。 其次,我们引入了流缓冲区技术,该技术将内存与视频剪辑持续时间解耦,允许 3D CNN 嵌入任意长度的流视频序列,用于训练和推理,并且占用较小的恒定内存。 第三,我们提出了一种简单的集成技术,可以在不牺牲效率的情况下进一步提高准确性。 这三种渐进技术使 MoViNets 能够在 Kinetics、Moments in Time 和 Charades 视频动作识别数据集上实现最先进的准确性和效率。 例如,MoViNet-A5-Stream 在 Kinetics 600 上实现了与 X3D-XL 相同的精度,同时需要减少 80% 的 FLOP 和 65% 的内存。 代码将在 https://github.com/tensorflow/models/tree/master/official/vision 提供。
1简介
高效的视频识别模型为移动摄像头、物联网和自动驾驶应用开辟了新的机遇,在这些应用中,高效、准确的设备处理至关重要。 尽管深度视频建模最近取得了进展,但仍然很难找到在移动设备上运行并实现高视频识别精度的模型。 一方面,3D 卷积神经网络 (CNN) [76, 80, 25, 24, 63] 提供最先进的精度,但会消耗大量内存和计算量。 另一方面,2D CNN [48, 88] 需要少得多的适合移动设备的资源,并且可以使用逐帧预测在线运行,但精度较差。
许多使 3D 视频网络变得准确的操作(例如,时间卷积、非局部块 [80] 等)需要立即处理所有输入帧,从而限制了准确模型的机会部署在移动设备上。 最近提出的 X3D 网络[24]为提高 3D CNN 的效率做出了巨大的努力。 然而,它们在大时间窗口上需要大量内存资源,这会产生高成本,或者在小时间窗口上需要降低准确性。 其他工作旨在使用时间聚合来提高 2D CNN 的准确性[48,23,82,51,22],但是它们有限的帧间交互降低了这些模型充分建模远程时间的能力像 3D CNN 这样的依赖关系。
本文介绍了设计高效视频模型的三个渐进步骤,我们使用这些模型来生成移动视频网络 (MoViNets),这是一系列内存和计算高效的 3D CNN。
-
1.
我们首先定义一个 MoViNet 搜索空间,以允许神经架构搜索 (NAS) 有效地权衡时空特征表示。
-
2.
然后,我们引入了 MoViNet 的流缓冲区,它可以处理连续的小子剪辑中的视频,需要恒定的内存而不牺牲长时间依赖性,并且可以实现在线推理。
-
3.
最后,我们创建流式 MoViNet 的时间集合,从流缓冲区中恢复稍微丢失的精度。
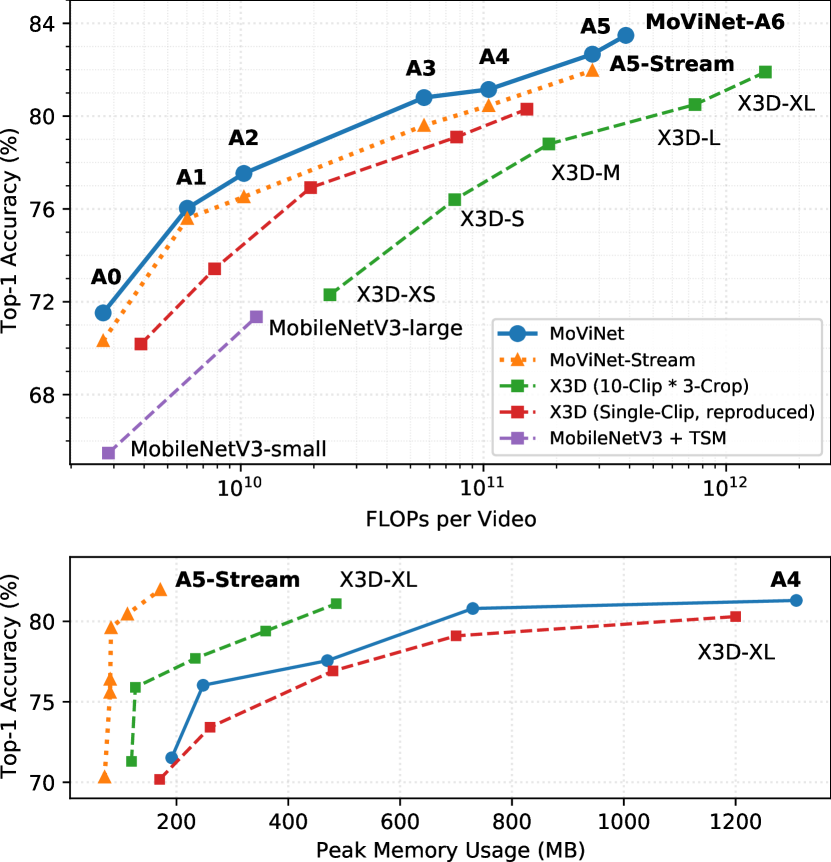
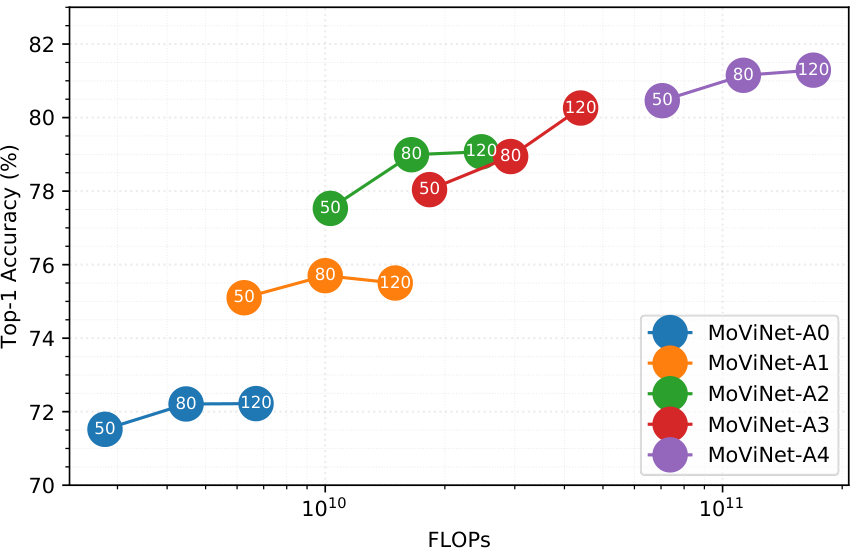
首先,我们设计 MoViNet 搜索空间来探索如何混合空间、时间和时空操作,以便 NAS 可以找到最佳的特征组合来权衡效率和准确性。 图 1 直观地展示了生成的 MoViNet 的效率。 MoViNet-A0 在 Kinetics 600 [39] 上实现了与 MobileNetV3-large+TSM [33, 48] 相似的精度,但 FLOP 减少了 75%。 MoViNet-A6 实现了最先进的 83.5% 准确率,比 X3D-XL [24] 高 1.6%,所需的 FLOP 减少了 60%。
其次,我们通过引入流缓冲区来创建流式 MoViNet,以将训练和推理的输入帧数量从线性减少到恒定的内存使用量,从而使 MoViNet 能够在内存瓶颈显着减少的情况下运行。 例如,流缓冲区将 MoViNet-A5 的内存使用量减少了 90%。 与同样减少内存的传统多剪辑评估(测试时数据增强)方法 [65, 78] 相比,流缓冲区通过缓存特征图来传递连续非重叠子剪辑之间的时间依赖性在子剪辑边界处。 与最近提出的时间移位[48]相比,流缓冲区允许更大类的操作来增强在线时间建模。 我们为流缓冲区配备了时间单向因果操作,例如因果卷积 [55]、累积池化和因果挤压和激励 [34] 以及位置编码以强制时间感受野仅查看过去的帧,使 MoViNet 能够增量地对流视频进行在线推理。 然而,因果运算的成本很小,Kinetics 600 的准确度平均降低了 1%。
第三,我们暂时集成了 MoViNet,表明它们比单个大型网络更准确,同时实现了相同的效率。 我们独立训练两个流式 MoViNet,其总 FLOP 数与单个模型相同,并平均它们的 logits。 这种简单的技术弥补了使用流缓冲区时准确性的损失。
综合起来,这三种技术创建了准确度高、内存占用低、计算高效并支持在线推理的 MoViNet。 我们使用 Kinetics 600 数据集 [9] 搜索 MoViNet,并在 Kinetics 400 [39]、Kinetics 700 [10] 上对其进行广泛测试,时间时刻 [54]、Charades [64] 和 Something-Something V2 [28]。
2相关工作
高效的视频建模。
深度神经网络在视频理解方面取得了显着进展[35,65,74,79,12,80,60,24,25]。 他们在时间维度上扩展了 2D 图像模型,最引人注目的是结合了 3D 卷积[35,73,74,84,29,59,36,63]。
提高视频模型的效率越来越受到关注[25,75,26,24,48,23,6,14,45,57]。 一些作品探索使用 2D 网络进行视频识别,方法是处理较小片段的视频,然后进行后期融合[38,20,86,79,26,69,44,47,80,87,88]。 时间平移模块[48]使用早期融合沿时间轴移动部分通道,在支持在线推理的同时提高准确性。
因果建模。
WaveNet [55] 引入了因果卷积,其中一维卷积堆栈的感受野仅扩展到当前时间步长的特征。 我们从使用因果卷积 [11, 13, 17, 15, 18] 的其他作品中汲取灵感,设计用于在线视频模型推理的流缓冲区,从而允许使用 3D 内核进行逐帧预测。
多目标 NAS。
使用 NAS [89,49,56,71,8,37] 进行多目标架构搜索也引起了人们的兴趣,在图像识别过程中产生了更高效的模型[ 71, 8, 4] 和视频识别[57, 63]。 我们使用 TuNAS [4],这是一种一次性 NAS 框架,它使用积极的权重共享,非常适合计算密集型视频模型。
高效的乐团。
深度集成广泛应用于分类挑战中,以提高 CNN [7,66,70,30]的性能。 最近的结果表明,在图像分类方面,小型模型的深度集成比单个大型模型更有效[40,52,67,42,27],并且我们将这些发现扩展到视频分类。
3 移动视频网络 (MoViNets)
本节介绍我们的 MoViNet 渐进式三步方法。 我们首先详细介绍搜索 MoViNet 的设计空间。 然后我们定义流缓冲区并解释它如何减少网络的内存占用,然后进行时间集成以提高准确性。
3.1 搜索MoViNet
继2D移动网络搜索[71, 72]的实践之后,我们从TuNAS框架[4]开始,它是一种具有权重的一次性NAS的可扩展实现在候选模型的超级网络上共享,并将其重新用于 3D CNN 进行视频识别。 我们使用 Kinetics 600 [39] 作为视频数据集来搜索我们的所有模型,其中包含 10 秒的视频序列,每个视频序列的帧率为 25fps,总共 250 帧。
| Stage | Network Operations | Output size |
|---|---|---|
| data | stride , RGB | |
| conv1 | , | |
| block2 | ||
| blockn | ||
| convn+1 | , | |
| pooln+2 | ||
| densen+3 | , | |
| densen+4 | , # classes |
MoViNet 搜索空间。
我们在 MobileNetV3 [33] 上构建基础搜索空间,它为移动 CPU 提供了强大的基线。 它由多个反向瓶颈层块组成,每层具有不同的过滤器宽度、瓶颈宽度、块深度和内核大小。 与X3D [24]类似,我们扩展MobileNetV3中的2D块来处理3D视频输入。 表1提供了搜索空间的基本概述,详细信息如下。
我们分别用 和 (5fps) 表示目标 MoViNets 输入的尺寸和帧步长。 对于网络中的每个块,我们搜索基本过滤器宽度 和要在块内重复的层数 。 我们对每个块内的特征图通道应用乘数 ,四舍五入为 8 的倍数。 我们设置块,除了第四块之外,每个块的第一层都进行跨步空间下采样(以确保最后一个块具有空间分辨率)。 这些块逐渐增加其特征图通道:。 最终卷积层的基本滤波器宽度为,分类层之前是D密集层。
使用新的时间维度,我们定义每层内的 3D 内核大小 ,选择以下值之一:{1x3x3, 1x5x5, 1x7x7, 5x1x1, 7x1x1, 3x3x3, 5x3x3}(我们排除较大的内核)。 这些选择使层能够专注于并聚合不同的维度表示,在最相关的方向上扩展网络的感受野,同时减少沿其他维度的 FLOP。 某些内核大小可能会受益于具有不同数量的输入过滤器,因此我们搜索一系列瓶颈宽度,定义为中相对于的乘数。 每层都用两个 1x1x1 卷积包围 3D 卷积,以在 和 之间扩展和投影。 我们不应用任何时间下采样来实现逐帧预测。
我们没有应用空间挤压和激励(SE)[34],而是使用 SE 块通过 3D 平均池化来聚合时空特征,并将其应用到每个瓶颈块,如 [33, 72]。 我们允许 SE 可搜索,也可以选择禁用它以节省 FLOP。
扩展搜索空间。
我们的基本搜索空间构成了 MoViNet-A2 的基础。 对于其他 MoViNet,我们应用了类似于 EfficientNet [72] 中使用的复合缩放启发式算法。 我们方法的主要区别在于我们缩放搜索空间本身而不是单个模型(即模型 A0-A5 的搜索空间)。 我们不是找到一个好的架构然后对其进行扩展,而是搜索所有架构的所有扩展,从而扩大可能模型的范围。
我们使用小型随机搜索来查找缩放系数(初始目标为每帧 300 MFLOP),这大约使搜索空间中采样模型的预期大小加倍或减半。 对于系数的选择,我们调整基本分辨率 、帧步长 、块滤波器宽度 和块深度 的大小。我们对不同的 FLOPs 目标进行搜索,以生成一系列模型,范围从 MobileNetV3 类尺寸到 ResNet3D-152 [30, 29] 的尺寸。 附录A提供了搜索空间、缩放技术以及搜索算法的描述的更多详细信息。
MoViNet 搜索空间催生了一系列多功能网络,这些网络在流行的基准数据集上优于最先进的高效视频识别 CNN。 然而,它们的内存占用量与输入帧的数量成比例增长,这使得它们难以在移动设备上处理长视频。 下一小节介绍了一个流缓冲区,以将网络的内存消耗从视频长度的线性减少到恒定。

3.2 具有因果操作的流缓冲区
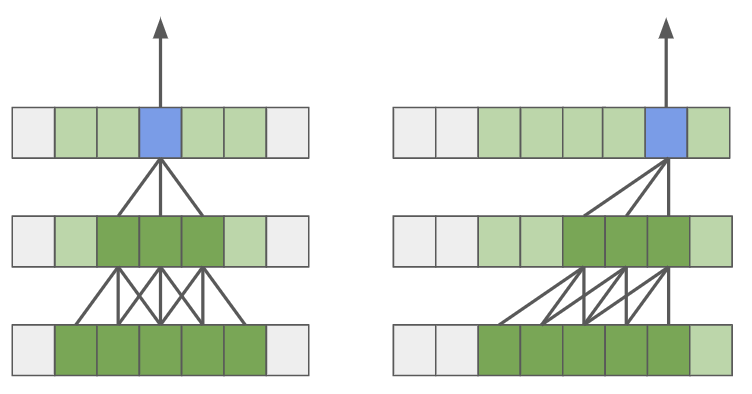
假设我们有一个带有 帧的输入视频 ,这可能会导致模型超出设定的内存预算。 减少内存的常见解决方案是多剪辑评估 [65, 78],其中模型对每个 帧的 重叠子剪辑的预测进行平均,如图2(左)所示。 它将内存消耗减少到。 然而,它有两个主要缺点:1)它限制了每个子剪辑的时间感受野并忽略了远程依赖性,可能会损害准确性。 2)它重新计算重叠的帧激活,降低了效率。
流缓冲区。
为了克服上述限制,我们提出流缓冲区作为一种在子剪辑边界上缓存特征激活的机制,使我们能够跨子剪辑扩展时间感受野并且不需要重新计算,如图2所示>(右)。
正式地,让 为步骤 中的当前子剪辑(原始输入或激活),我们将视频分割为 相邻的 不重叠的部分 个长度为 的子剪辑。 我们从一个零初始化的张量开始,表示我们的缓冲区 ,其长度为 沿时间维度,其其他维度匹配 。 我们计算沿时间维度与子剪辑连接的缓冲区 () 的特征图 如下:
| (1) |
其中 表示时空操作(例如 3D 卷积)。 当处理下一个剪辑时,我们将缓冲区的内容更新为:
| (2) |
其中我们将 表示为连接输入的最后 帧的选择。 因此,我们的内存消耗取决于 ,随着总视频帧 或子剪辑 数量的增加,该内存消耗保持不变。
与 TSM 的关系。
时间移位模块(TSM)[48]可以看作流缓冲区的特例,其中和是移位的操作在计算帧 处的空间卷积之前,将缓冲区 中的通道比例与输入 进行比较。
3.2.1 因果运算
将 3D CNN 的操作与流缓冲区相匹配的合理方法是强制因果关系,即不得从未来帧计算任何特征。 这具有许多优点,包括能够将子剪辑 减少到单个帧而不影响激活或预测,并使 3D CNN 能够处理流视频以进行在线推理。 虽然可以使用非因果操作,例如在两个时间方向上进行缓冲,但我们将失去在线建模功能,而这对于移动设备来说是一个理想的属性。
因果卷积(CausalConv)。
通过利用卷积的平移等变特性,我们用 CausalConvs [55] 替换所有时间卷积,有效地使它们沿时间维度单向。 具体来说,我们首先计算填充以平衡所有轴上的卷积,然后移动最终帧之后的任何填充,并将其与第一帧之前的任何填充合并。 有关感受野与标准卷积有何不同的说明,以及因果填充算法的说明,请参阅附录C。
当将流缓冲区与 CausalConv 结合使用时,我们可以用缓冲区本身替换因果填充,将前一个子剪辑的最后几帧向前移动,并将它们复制到下一个子剪辑的填充中。 如果我们的时间内核大小为 (并且我们不使用任何跨步采样),那么我们的填充和缓冲区宽度将变为 。 通常, 意味着 ,从而占用较小的内存。 仅在跨多个帧聚合特征的层之前才需要流缓冲区,因此空间和逐点卷积(例如 1x3x3、1x1x1)可以保持原样,进一步节省内存。
累积全球平均池 (CGAP)。
我们使用 CGAP 来近似涉及时间维度的任何全局平均池化。 对于帧 之前的任何激活,我们可以将其计算为累积和:
| (3) |
其中 表示激活张量。 为了因果地计算 CGAP,我们保留一个单帧流缓冲区来存储直到 的累积和。
具有位置编码的因果SE。
我们将 CausalSE 表示为 CGAP 在 SE 上的应用,其中我们将帧 处的空间特征图与从 计算出的 SE 相乘。 根据我们的经验结果,CausalSE 很容易不稳定,可能是因为 SE 投影层很难确定 CGAP 估计的质量,而 CGAP 估计在视频的早期具有很高的方差。 为了解决这个问题,我们应用了受 Transformers [77, 50] 启发的基于正弦的固定位置编码 (PosEnc) 方案。 在应用 SE 投影之前,我们直接使用帧索引作为位置,并将向量与 CGAP 输出求和。
3.2.2 使用流缓冲区进行训练和推理
训练。
为了减少训练期间的内存需求,我们使用循环训练策略,将给定批次的示例分割为 子剪辑,应用前向传递输出每个子剪辑的预测,使用流缓冲区来缓存激活。 但是,我们不会反向传播梯度通过缓冲区,以便可以释放先前子剪辑的内存。 相反,我们计算损失并累积子剪辑之间的计算梯度,类似于批量梯度累积。 这允许网络考虑所有 帧,在应用梯度之前执行 前向传递。 这种训练策略允许网络学习更长期的依赖关系,因此比用较短视频长度训练的模型具有更高的准确性(参见附录C)。
我们可以将 设置为任何值,而不会影响准确性。 然而,ML 加速器(例如 GPU)受益于乘以大张量,因此对于训练,我们通常设置 的值。 这可以加速训练,同时可以仔细控制内存成本。
在线推理。
使用 CausalConv 和 CausalSE 等因果运算的一大好处是允许 3D 视频 CNN 在线工作。 与训练类似,我们使用流缓冲区来缓存子剪辑之间的激活。 但是,我们可以将子剪辑长度设置为单帧 (),以最大限度地节省内存。 这还减少了帧之间的延迟,使模型能够在流视频上逐帧输出预测,像循环网络 (RNN) 一样逐步积累新信息[32]。 但与传统的卷积 RNN 不同,我们可以每步输入可变数量的帧来产生相同的输出。 对于使用 CausalConv 的流式架构,我们通过使用 CGAP 汇集逐帧输出特征来预测视频的标签。
3.3 时间系综
流缓冲区可以将 MoViNet 的内存占用量减少一个数量级,但 Kinetics 600 的精度会下降约 1%。 我们可以使用简单的集成策略来恢复这种准确性。 我们使用相同的架构独立训练两个 MoViNet,但将帧速率减半,保持时间持续时间相同(导致输入帧减半)。 我们将视频输入到两个网络中,其中一个网络的帧偏移一帧,并在应用 softmax 之前对未加权的 logits 应用算术平均值。 在将帧速率减半之前,该方法会产生与单个模型具有相同 FLOP 的双模型集成,从而提供具有丰富表示的预测。 根据我们的观察,尽管集成中的两个模型单独的精度可能低于单个模型,但集成时它们可以比单个模型具有更高的精度。
4视频分类实验
在本节中,我们评估 MoViNets 在五个代表性动作识别数据集上进行推理时的准确性、效率和内存消耗。
数据集。
我们报告所有 Kinetics 数据集的结果,包括 Kinetics 400 [12, 39]、Kinetics 600 [9] 和 Kinetics 700 [10] ,其中包含 25 fps 的 10 秒、250 帧视频序列,分别标记有 400、600 和 700 个动作类别。 我们使用撰写本文时可用的示例,分别占训练示例的 87.5%、92.8% 和 96.2%(参见附录 C)。 此外,我们还尝试了 Moments in Time [54](包含 3 秒、75 帧序列、25fps、339 个动作类)和 Charades [64](它具有具有 157 个动作类别的可变长度视频,其中视频可以包含多个类别注释。 我们在附录 C 中包含 Something-Something V2 [28] 和 Epic Kitchens 100 [19] 结果。
实施细节。
对于每个数据集,所有模型都从头开始使用 RGB 帧进行训练,即我们不应用任何预训练。 对于所有数据集,我们以不同的帧速率使用 64 帧(除非推理帧较少)进行训练,并以相同的帧速率运行推理。
我们使用 Kinetics 600 运行 TuNAS,并保留 7 个 MoViNet,每个 MoViNet 都有一个在 [24] 中使用的 FLOPs 目标。 随着我们的模型变得更大,我们的缩放系数会增加网络的输入分辨率、帧数、深度和特征宽度。 我们还尝试在图像分类中使用 AutoAugment [16] 增强,即我们为每个视频采样随机图像增强,并对每个帧应用相同的增强。 7个模型的架构以及训练超参数参见附录B。
单剪辑与多剪辑评估。
我们使用从输入视频中采样的单个剪辑来评估所有模型,该剪辑具有固定的时间步幅,覆盖整个视频持续时间。 当单剪辑和多剪辑评估总共使用相同数量的帧以使 FLOP 相等时,我们发现单剪辑评估会产生更高的准确度(参见附录C)。 这可能部分是由于 3D CNN 能够对更远距离的依赖关系进行建模,即使评估的帧数比训练时多得多。 由于现有模型通常使用多剪辑评估,因此我们报告每个视频而不是每个剪辑的总 FLOP,以进行公平比较。
然而,单剪辑评估会极大地增加网络的峰值内存使用量(如图1所示),这可能就是以前的工作中普遍使用多剪辑评估的原因。 流缓冲区消除了这个问题,使 MoViNet 能够像嵌入完整视频一样进行预测,并且比多剪辑评估占用更少的峰值内存。
我们还重现了 X3D [24](可以说是与我们最相关的工作),以测试其在单剪辑和 10 剪辑评估下的性能,以提供更多见解。 我们将 30-clip 表示为每个视频使用 10 个剪辑乘以 3 个空间裁剪的评估策略,而 10-clip 仅使用一种空间裁剪。 我们在推理过程中避免了 MoViNet 中的任何空间增强或时间采样,以提高效率。
4.1 Kinetics 600 的比较结果
没有流缓冲区的 MoViNet。
表2展示了Kinetics 600上的七个MoViNet在应用流缓冲区之前的主要结果,主要与各种X3D模型[24]进行比较,其中最近开发的用于高效视频识别。 表的各列对应Top-1分类精度;模型产生的每个视频的 GFLOP 数;输入视频帧的分辨率(我们将 缩短为 224);每个视频的输入帧,其中 表示 30 个剪辑评估,每次运行 4 帧作为输入;每秒帧数 (FPS),由 MoViNet 搜索空间中的时间步长 确定;和网络参数的数量。
| Model | Top-1 | gflops | Res | Frames | FPS | Param |
| MoViNet-A0 | 71.5 | 2.71 | 172 | 150 | 5 | 3.1M |
| MobileNetV3-S* [33] | 61.3 | 2.80 | 224 | 150 | 5 | 2.5M |
| MobileNetV3-S+TSM* [48] | 65.5 | 2.80 | 224 | 150 | 5 | 2.5M |
| X3D-XS* [24] | 70.2 | 3.88 | 182 | 120 | 2 | 3.8M |
| MoViNet-A1 | 76.0 | 6.02 | 172 | 150 | 5 | 4.6M |
| X3D-S* [24] | 73.4 | 7.80 | 182 | 140 | 4 | 3.8M |
| X3D-S* [24] | 74.3 | 9.75 | 182 | 150 | 5 | 3.8M |
| MoViNet-A2 | 77.5 | 10.3 | 224 | 150 | 5 | 4.8M |
| MobileNetV3-L* [33] | 68.1 | 11.0 | 224 | 150 | 5 | 5.4M |
| MobileNetV3-L+TSM* [48] | 71.4 | 11.0 | 224 | 150 | 5 | 5.4M |
| X3D-XS [24] | 72.3 | 23.3 | 182 | 304 | 2 | 3.8M |
| X3D-M* [24] | 76.9 | 19.4 | 256 | 150 | 5 | 3.8M |
| MoViNet-A3 | 80.8 | 56.9 | 256 | 1120 | 12 | 5.3M |
| MoViNet-A3 + AutoAugment | 81.3 | 56.9 | 256 | 1120 | 12 | 5.3M |
| X3D-S [24] | 76.4 | 76.1 | 182 | 3013 | 4 | 3.8M |
| X3D-L* [24] | 79.1 | 77.5 | 356 | 150 | 5 | 6.1M |
| MoViNet-A4 | 81.2 | 105 | 290 | 180 | 8 | 4.9M |
| MoViNet-A4 + AutoAugment | 83.0 | 105 | 290 | 180 | 8 | 4.9M |
| X3D-M [24] | 78.8 | 186 | 256 | 3016 | 5 | 3.8M |
| X3D-L* [24] | 80.7 | 187 | 356 | 1120 | 2 | 6.1M |
| X3D-XL* [24] | 80.3 | 151 | 356 | 150 | 5 | 11.0M |
| I3D [9] | 71.6 | 216 | 224 | 1250 | 25 | 12M |
| ResNet3D-50* | 78.7 | 390 | 224 | 1250 | 25 | 34.0M |
| MoViNet-A5 | 82.7 | 281 | 320 | 1120 | 12 | 15.7M |
| MoViNet-A5 + AutoAugment | 84.3 | 281 | 320 | 1120 | 12 | 15.7M |
| X3D-L [24] | 80.5 | 744 | 356 | 3016 | 5 | 6.1M |
| MoViNet-A6 | 83.5 | 386 | 320 | 1120 | 12 | 31.4M |
| MoViNet-A6 + AutoAugment | 84.8 | 386 | 320 | 1120 | 12 | 31.4M |
| ViViT-L/16x2 [2] | 83.0 | 3990 | 320 | 1232 | 12 | 88.9M |
| TimeSformer-HR [5] | 82.4 | 5110 | 224 | 38 | 1.5 | 120M |
| X3D-XL [24] | 81.9 | 1452 | 356 | 1016 | 5 | 11.0M |
| ResNet3D-152* | 81.1 | 1400 | 224 | 1250 | 25 | 80.1M |
| ResNet3D-50-G [46] | 82.0 | 3666 | 224 | 1250 | 25 | - |
| SlowFast-R50 [25] | 78.8 | 1080 | 256 | 3016 | 5 | 34.4M |
| SlowFast-R101 [25] | 81.8 | 7020 | 256 | 3016 | 5 | 59.9M |
| LGD-R101 [60] | 81.5 | - | 224 | 1516 | 25 | - |
MoViNet-A0 的 GFLOP 训练次数更少,并且比基于帧的 MobileNetV3-S [33](我们使用我们的训练设置的 MobileNetV3,跨帧平均 logits)准确率高 10%。 MoViNet-A0 在精度和 GFLOP 方面也优于 X3D-S。 MoViNet-A1 的 GFLOP 与 X3D-S 相当,但其精度比 X3D-S 高 2%。
将目标 GFLOP 增加到 X3D-S 和 30 剪辑 X3D-XS 之间的范围,我们得到 MoViNet-A2。 我们可以通过使用几乎一半的 GFLOP 来实现比 30 剪辑 X3D-XS 或 X3D-M 稍高的精度。 此外,我们还包括逐帧 MobileNetV3-L 并验证它可以从 TSM [48] 中受益约 3%。
较大的 MoViNet (A3-A6) 与 X3D 系列中的同类产品之间存在更大的差距。 这并不奇怪,因为当设计空间很大时,NAS 直观上应该比 X3D 的手工制作方法更有优势。 MoViNet-A5 和 MoViNet-A6 的性能优于多个最先进的视频网络,包括最近的 Transformer 模型,如 ViViT [2] 和 TimeSformer [5](请参阅表 2 的最后 6 行)。 具有 AutoAugment 功能的 MoViNet-A6 可达到 84.8% 的准确率(无需预训练),同时仍然比同类模型效率更高(通常高一个数量级)。 即使与 TimeSformer-HR [5] 等完全 Transformer [77] 模型相比,MoViNet-A6 的准确率也高出了 1%,并且使用了 40% 的 FLOP。
| Model | Top-1 | Res | Frames | FPS | gflops | Mem (MB) |
| MobileNetV3-L* [33] | 68.1 | 224 | 150 | 5 | 11.0 | 23 |
| MoViNet-A0 | 71.5 | 172 | 150 | 5 | 2.71 | 173 |
| MoViNet-A0-Stream | 70.3 | 172 | 150 | 5 | 2.73 | 71 |
| MoViNet-A1 | 76.0 | 172 | 150 | 5 | 6.02 | 191 |
| MoViNet-A1-Stream | 75.6 | 172 | 150 | 5 | 6.06 | 72 |
| MoViNet-A1-Stream-Ens (x2) | 75.9 | 172 | 125 | 2.5 | 6.06 | 72 |
| MoViNet-A2 | 77.5 | 224 | 150 | 5 | 10.3 | 470 |
| MoViNet-A2-Stream | 76.5 | 224 | 150 | 5 | 10.4 | 85 |
| MoViNet-A2-Stream-Ens (x2) | 77.0 | 224 | 125 | 2.5 | 10.4 | 85 |
| MoViNet-A3 | 80.8 | 256 | 1120 | 12 | 56.9 | 1310 |
| MoViNet-A3-Stream | 79.6 | 256 | 1120 | 12 | 57.1 | 82 |
| MoViNet-A3-Stream-Ens (x2) | 80.4 | 256 | 160 | 6 | 57.1 | 82 |
| MoViNet-A4 | 81.2 | 290 | 180 | 8 | 105 | 1390 |
| MoViNet-A4-Stream | 80.5 | 290 | 180 | 8 | 106 | 112 |
| MoViNet-A4-Stream-Ens (x2) | 81.4 | 290 | 140 | 4 | 106 | 112 |
| MoViNet-A5 | 82.7 | 320 | 1120 | 12 | 281 | 2040 |
| MoViNet-A5-Stream | 82.0 | 320 | 1120 | 12 | 282 | 171 |
| MoViNet-A5-Stream-Ens (x2) | 82.9 | 320 | 160 | 6 | 282 | 171 |
| ResNet3D-50 | 78.7 | 224 | 1250 | 25 | 390 | 3040 |
| ResNet3D-50-Stream | 76.9 | 224 | 1250 | 25 | 390 | 2600 |
| ResNet3D-50-Stream-Ens (x2) | 78.6 | 224 | 1125 | 12.5 | 390 | 2600 |
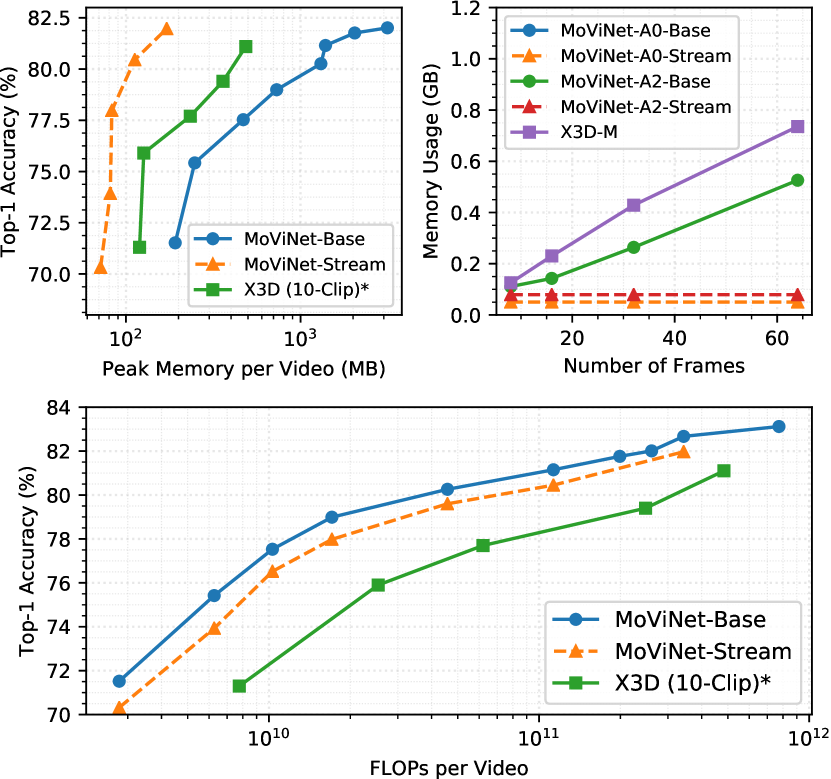
带有流缓冲区的 MoViNet。
在没有修改的情况下,我们的基本 MoViNet 架构可能会消耗大量内存,尤其是随着模型大小和输入帧的增长。 使用具有因果操作的流缓冲区,我们可以将大型网络 (MoViNets A3-A6) 的峰值内存减少一个数量级,如表3的最后一列所示。
此外,图 3 可视化了流架构对内存的影响。 从顶部左侧面板可以看出,与采用多片段评估的 X3D 相比,我们的 MoViNet 在所有模型尺寸上都更准确且内存效率更高。 当我们缩放右上方面板输入感受野中的帧总数时,我们还展示了恒定的记忆。 底部面板表明流式 MoViNet 在每个输入视频的 GFLOP 方面仍然保持高效。
我们还将流缓冲区应用于 ResNet3D-50(请参阅表 3 中的最后两行)。 然而,我们并没有看到内存减少那么多,这可能是因为与 MoViNet 中的深度卷积相比,使用全 3D 卷积时的开销更大。
具有流缓冲区和集成的 MoViNet。
从表 3 中我们可以看到,在应用流缓冲区后,所有模型的准确率仅下降了 1%。 我们可以使用时间集成来恢复准确性,而无需任何额外的推理成本。 表 3 报告了以原始模型一半的帧速率训练的两个模型的集成效果(以便 GFLOP 保持不变)。 我们可以看到所有流式架构的准确性都有所提高,这表明集成可以弥合流式和非流式架构之间的差距,特别是随着模型大小的增长。 值得注意的是,与之前的工作不同,集成以与[40]相同的精神平衡了准确性和效率(GFLOPs),而不仅仅是为了提高准确性。
4.2其他数据集的比较结果
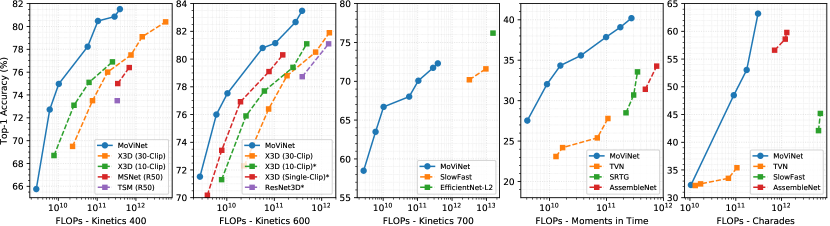
图 4 总结了 MoViNets 在所有五个数据集上的主要结果以及在各个数据集上报告结果的最先进模型。 我们将 MoViNet 与 X3D [24]、MSNet [41]、TSM [48]、ResNet3D [30] 进行比较>、SlowFast [25]、EfficientNet-L2 [83]、TVN [57]、SRTG [68] 和 AssembleNet [63, 62]。 附录C以表格形式列出了包含更多详细信息的结果。
尽管仅在 Kinetics 600 上寻找高效的架构,但 NAS 生成的模型也比之前在其他数据集上的工作有了显着改进。 在 Moments in Time 上,我们的模型在低 GFLOP 下比微型视频网络 (TVN) [57] 准确率高 5-8%,MoViNet-A5 的准确率达到 39.9%,优于 AssembleNet [ 63] (34.3%),它使用光流作为附加输入(而我们的模型没有)。 在 Charades 上,MoViNet-A5 的准确率达到 63.2%,击败了使用光流和对象分割作为附加输入的 AssembleNet++ [62] (59.8%)。 Charades 的结果证明我们的模型也能够进行复杂的时间理解,因为这些视频的持续时间剪辑比动力学和时刻中的剪辑更长。
4.3 其他分析
MoViNet 运营。
我们在表4中提供了一些关于一些关键 MoViNet 操作的消融研究。 对于没有流缓冲区的基础网络,SE对于实现高精度至关重要;如果我们删除 SE,MoViNet-A1 的准确度会下降 2.9%。 我们发现,与使用全局 SE 的 CausalConv 相比,使用不带 SE 的 CausalConv 时,准确率下降要大得多,这表明全局 SE 可以发挥标准 Conv 的某些作用,从未来的帧中提取信息。 然而,当我们切换到使用 CausalConv 和 CausalSE 的完全流式架构时,来自未来帧的信息不再可用,并且我们看到准确性大幅下降,但与没有 SE 的 CausalConv 相比仍然有显着提高。 使用 PosEnc,我们可以恢复因果模型的一些准确性。
| Model | CausalConv | SE | CausalSE | PosEnc | Top-1 | gflops |
|---|---|---|---|---|---|---|
| 73.3 | 6.04 | |||||
| ✓ | 72.1 | 6.04 | ||||
| ✓ | ✓ | 73.5 | 6.06 | |||
| MoViNet-A1 | ✓ | ✓ | ✓ | 74.0 | 6.06 | |
| ✓ | ✓ | 74.9 | 6.06 | |||
| ✓ | 75.2 | 6.06 | ||||
| 77.7 | 56.9 | |||||
| MoViNet-A3 | ✓ | ✓ | 79.0 | 57.1 | ||
| ✓ | ✓ | ✓ | 79.6 | 57.1 | ||
| ✓ | 80.3 | 57.1 |
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 16 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 640 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |
MoViNet 架构。
我们在表5中提供了MoViNet-A2的架构描述 - 附录B有其他MoViNet的详细架构。 最值得注意的是,网络更喜欢 [2.5, 3.5] 范围内的大瓶颈宽度乘数,通常在每层之后扩展或缩小它们。 相比之下,具有类似计算要求的 X3D-M 具有更宽的基本特征宽度和更小的恒定瓶颈乘数(2.25)。 搜索到的网络更喜欢平衡的 3x3x3 内核,但后面块中的第一个下采样层除外,该层具有 5x3x3 内核。 最后阶段几乎只使用大小为 1x5x5 的空间内核,这表明用于分类的高级特征主要受益于空间特征。 这与 S3D [85] 形成鲜明对比,S3D 报告在较低层使用 2D 卷积并在较高层使用 3D 卷积时效率有所提高。
4.3.1 硬件基准测试
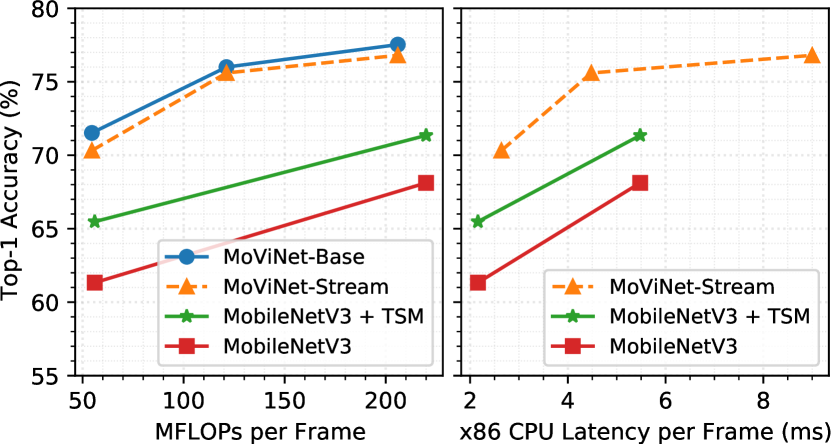
MoViNets A0、A1 和 A2 代表最快的模型,最适合在移动设备上使用。 我们将它们与图 5 中的 MobileNetV3 进行比较,比较 3.70GHz 的 x86 Intel Xeon W-2135 CPU 上的 FLOP 和实时延迟。 这些模型的每帧计算成本相当,因为我们对所有模型的 50 帧进行了评估。 从这些结果我们可以得出结论,流式 MoViNet 可以在 CPU 上运行得更快,同时更准确,即使进行了像 TSM 这样的时间修改。 虽然 FLOP 和延迟之间存在差异,但在 NAS 中显式搜索延迟目标可以减少这种影响。 然而,我们仍然认为 FLOP 是 CPU 延迟的合理代理指标,这对于移动设备来说可以很好地转化。
| Model | Streaming | Video (ms) | Frame (ms) | Top-1 |
|---|---|---|---|---|
| MoViNet-A0-Stream | ✓ | 183 | 3.7 | 70.3 |
| MoViNet-A1-Stream | ✓ | 315 | 6.3 | 75.6 |
| MoViNet-A2-Stream | ✓ | 325 | 6.5 | 76.5 |
| MoViNet-A3-Stream | ✓ | 1110 | 9.2 | 79.6 |
| MoViNet-A4-Stream | ✓ | 1130 | 14.1 | 80.5 |
| MoViNet-A5-Stream | ✓ | 2310 | 19.2 | 82.0 |
| MobileNetV3-S* | ✓ | 68 | 1.4 | 61.3 |
| MobileNetV3-L* | ✓ | 81 | 1.6 | 68.1 |
| X3D-M* (Single Clip) | ✗ | 345 | 6.9 | 76.9 |
| X3D-XL* (Single Clip) | ✗ | 943 | 18.9 | 80.3 |
我们还在表 6 中展示了在 Nvidia V100 GPU 上运行的 MoViNet 的基准测试。 与移动 CPU 类似,我们的流模型延迟与单剪辑 X3D 模型相当。 然而,我们确实注意到 MobileNetV3 可以比我们在 GPU 上的网络运行得更快,这表明 NAS 的 FLOPs 指标有其局限性。 通过针对真实硬件而不是 FLOP,MoViNet 可以变得更加高效,我们将其留待将来的工作。
5结论
MoViNets 提供了一组高效的模型,可以在不同的视频识别数据集之间很好地传输。 与流缓冲区相结合,MoViNet 显着降低了训练和推理内存成本,同时还支持流视频的在线推理。 我们希望我们的 MoViNet 设计方法能够改进未来和现有的模型,从而减少过程中的内存和计算成本。
参考
- [1] Activitynet task b: Kinetics challenge. http://activity-net.org/challenges/2020/tasks/guest_kinetics.html. 2020.
- [2] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. arXiv preprint arXiv:2103.15691, 2021.
- [3] Thomas Bachlechner, Bodhisattwa Prasad Majumder, Huanru Henry Mao, Garrison W Cottrell, and Julian McAuley. Rezero is all you need: Fast convergence at large depth. arXiv preprint arXiv:2003.04887, 2020.
- [4] Gabriel Bender, Hanxiao Liu, Bo Chen, Grace Chu, Shuyang Cheng, Pieter-Jan Kindermans, and Quoc V Le. Can weight sharing outperform random architecture search? an investigation with tunas. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14323–14332, 2020.
- [5] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? arXiv preprint arXiv:2102.05095, 2021.
- [6] Shweta Bhardwaj, Mukundhan Srinivasan, and Mitesh M Khapra. Efficient video classification using fewer frames. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 354–363, 2019.
- [7] Yunlong Bian, Chuang Gan, Xiao Liu, Fu Li, Xiang Long, Yandong Li, Heng Qi, Jie Zhou, Shilei Wen, and Yuanqing Lin. Revisiting the effectiveness of off-the-shelf temporal modeling approaches for large-scale video classification. arXiv preprint arXiv:1708.03805, 2017.
- [8] Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv preprint arXiv:1812.00332, 2018.
- [9] Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600. arXiv preprint arXiv:1808.01340, 2018.
- [10] Joao Carreira, Eric Noland, Chloe Hillier, and Andrew Zisserman. A short note on the kinetics-700 human action dataset. arXiv preprint arXiv:1907.06987, 2019.
- [11] Joao Carreira, Viorica Patraucean, Laurent Mazare, Andrew Zisserman, and Simon Osindero. Massively parallel video networks. In Proceedings of the European Conference on Computer Vision (ECCV), pages 649–666, 2018.
- [12] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- [13] Shuo-Yiin Chang, Bo Li, Gabor Simko, Tara N Sainath, Anshuman Tripathi, Aäron van den Oord, and Oriol Vinyals. Temporal modeling using dilated convolution and gating for voice-activity-detection. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5549–5553. IEEE, 2018.
- [14] Chun-Fu Chen, Quanfu Fan, Neil Mallinar, Tom Sercu, and Rogerio Feris. Big-little net: An efficient multi-scale feature representation for visual and speech recognition. arXiv preprint arXiv:1807.03848, 2018.
- [15] Changmao Cheng, Chi Zhang, Yichen Wei, and Yu-Gang Jiang. Sparse temporal causal convolution for efficient action modeling. In Proceedings of the 27th ACM International Conference on Multimedia, pages 592–600, 2019.
- [16] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018.
- [17] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
- [18] Divyanshu Daiya, Min-Sheng Wu, and Che Lin. Stock movement prediction that integrates heterogeneous data sources using dilated causal convolution networks with attention. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8359–8363. IEEE, 2020.
- [19] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Evangelos Kazakos, Jian Ma, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Rescaling egocentric vision. arXiv preprint arXiv:2006.13256, 2020.
- [20] Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2625–2634, 2015.
- [21] Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Networks, 107:3–11, 2018.
- [22] Linxi Fan, Shyamal Buch, Guanzhi Wang, Ryan Cao, Yuke Zhu, Juan Carlos Niebles, and Li Fei-Fei. Rubiksnet: Learnable 3d-shift for efficient video action recognition. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
- [23] Quanfu Fan, Chun-Fu Richard Chen, Hilde Kuehne, Marco Pistoia, and David Cox. More is less: Learning efficient video representations by big-little network and depthwise temporal aggregation. In Advances in Neural Information Processing Systems, pages 2264–2273, 2019.
- [24] Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 203–213, 2020.
- [25] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE international conference on computer vision, pages 6202–6211, 2019.
- [26] Christoph Feichtenhofer, Axel Pinz, and Richard P Wildes. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4768–4777, 2017.
- [27] Tommaso Furlanello, Zachary C Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. arXiv preprint arXiv:1805.04770, 2018.
- [28] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, pages 5842–5850, 2017.
- [29] Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6546–6555, 2018.
- [30] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [31] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 558–567, 2019.
- [32] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [33] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, pages 1314–1324, 2019.
- [34] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018.
- [35] Shuiwang Ji, Wei Xu, Ming Yang, and Kai Yu. 3d convolutional neural networks for human action recognition. IEEE transactions on pattern analysis and machine intelligence, 35(1):221–231, 2012.
- [36] Boyuan Jiang, MengMeng Wang, Weihao Gan, Wei Wu, and Junjie Yan. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, pages 2000–2009, 2019.
- [37] Kirthevasan Kandasamy, Willie Neiswanger, Jeff Schneider, Barnabas Poczos, and Eric P Xing. Neural architecture search with bayesian optimisation and optimal transport. In Advances in neural information processing systems, pages 2016–2025, 2018.
- [38] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014.
- [39] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017.
- [40] Dan Kondratyuk, Mingxing Tan, Matthew Brown, and Boqing Gong. When ensembling smaller models is more efficient than single large models. arXiv preprint arXiv:2005.00570, 2020.
- [41] Heeseung Kwon, Manjin Kim, Suha Kwak, and Minsu Cho. Motionsqueeze: Neural motion feature learning for video understanding. In European Conference on Computer Vision, pages 345–362. Springer, 2020.
- [42] Stefan Lee, Senthil Purushwalkam Shiva Prakash, Michael Cogswell, Viresh Ranjan, David Crandall, and Dhruv Batra. Stochastic multiple choice learning for training diverse deep ensembles. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29, pages 2119–2127. Curran Associates, Inc., 2016.
- [43] Youngwan Lee, Hyung-Il Kim, Kimin Yun, and Jinyoung Moon. Diverse temporal aggregation and depthwise spatiotemporal factorization for efficient video classification. arXiv preprint arXiv:2012.00317, 2020.
- [44] Dong Li, Zhaofan Qiu, Qi Dai, Ting Yao, and Tao Mei. Recurrent tubelet proposal and recognition networks for action detection. In Proceedings of the European conference on computer vision (ECCV), pages 303–318, 2018.
- [45] Xianhang Li, Yali Wang, Zhipeng Zhou, and Yu Qiao. Smallbignet: Integrating core and contextual views for video classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1092–1101, 2020.
- [46] Yinxiao Li, Zhichao Lu, Xuehan Xiong, and Jonathan Huang. Perf-net: Pose empowered rgb-flow net. arXiv preprint arXiv:2009.13087, 2020.
- [47] Zhenyang Li, Kirill Gavrilyuk, Efstratios Gavves, Mihir Jain, and Cees GM Snoek. Videolstm convolves, attends and flows for action recognition. Computer Vision and Image Understanding, 166:41–50, 2018.
- [48] Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision, pages 7083–7093, 2019.
- [49] Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, and Kevin Murphy. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), pages 19–34, 2018.
- [50] Rosanne Liu, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, and Jason Yosinski. An intriguing failing of convolutional neural networks and the coordconv solution. In Advances in Neural Information Processing Systems, pages 9605–9616, 2018.
- [51] Zhaoyang Liu, Limin Wang, Wayne Wu, Chen Qian, and Tong Lu. Tam: Temporal adaptive module for video recognition. arXiv preprint arXiv:2005.06803, 2020.
- [52] Ekaterina Lobacheva, Nadezhda Chirkova, Maxim Kodryan, and Dmitry Vetrov. On power laws in deep ensembles. arXiv e-prints, pages arXiv–2007, 2020.
- [53] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- [54] Mathew Monfort, Alex Andonian, Bolei Zhou, Kandan Ramakrishnan, Sarah Adel Bargal, Tom Yan, Lisa Brown, Quanfu Fan, Dan Gutfruend, Carl Vondrick, et al. Moments in time dataset: one million videos for event understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–8, 2019.
- [55] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
- [56] Hieu Pham, Melody Y Guan, Barret Zoph, Quoc V Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. arXiv preprint arXiv:1802.03268, 2018.
- [57] AJ Piergiovanni, Anelia Angelova, and Michael S Ryoo. Tiny video networks: Architecture search for efficient video models. 2020.
- [58] Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30(4):838–855, 1992.
- [59] Zhaofan Qiu, Ting Yao, and Tao Mei. Learning spatio-temporal representation with pseudo-3d residual networks. In proceedings of the IEEE International Conference on Computer Vision, pages 5533–5541, 2017.
- [60] Zhaofan Qiu, Ting Yao, Chong-Wah Ngo, Xinmei Tian, and Tao Mei. Learning spatio-temporal representation with local and global diffusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 12056–12065, 2019.
- [61] Prajit Ramachandran, Barret Zoph, and Quoc V Le. Searching for activation functions. arXiv preprint arXiv:1710.05941, 2017.
- [62] Michael S Ryoo, AJ Piergiovanni, Juhana Kangaspunta, and Anelia Angelova. Assemblenet++: Assembling modality representations via attention connections-supplementary material. 2020.
- [63] Michael S Ryoo, AJ Piergiovanni, Mingxing Tan, and Anelia Angelova. Assemblenet: Searching for multi-stream neural connectivity in video architectures. arXiv preprint arXiv:1905.13209, 2019.
- [64] Gunnar A Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In European Conference on Computer Vision, pages 510–526. Springer, 2016.
- [65] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems, pages 568–576, 2014.
- [66] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [67] Saurabh Singh, Derek Hoiem, and David Forsyth. Swapout: Learning an ensemble of deep architectures. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29, pages 28–36. Curran Associates, Inc., 2016.
- [68] Alexandros Stergiou and Ronald Poppe. Learn to cycle: Time-consistent feature discovery for action recognition. arXiv preprint arXiv:2006.08247, 2020.
- [69] Lin Sun, Kui Jia, Kevin Chen, Dit-Yan Yeung, Bertram E Shi, and Silvio Savarese. Lattice long short-term memory for human action recognition. In Proceedings of the IEEE International Conference on Computer Vision, pages 2147–2156, 2017.
- [70] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
- [71] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2820–2828, 2019.
- [72] Mingxing Tan and Quoc V Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019.
- [73] Graham W Taylor, Rob Fergus, Yann LeCun, and Christoph Bregler. Convolutional learning of spatio-temporal features. In European conference on computer vision, pages 140–153. Springer, 2010.
- [74] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015.
- [75] Du Tran, Heng Wang, Lorenzo Torresani, and Matt Feiszli. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 5552–5561, 2019.
- [76] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6450–6459, 2018.
- [77] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [78] Limin Wang, Yuanjun Xiong, Zhe Wang, and Yu Qiao. Towards good practices for very deep two-stream convnets. arXiv preprint arXiv:1507.02159, 2015.
- [79] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision, pages 20–36. Springer, 2016.
- [80] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018.
- [81] Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4):229–256, 1992.
- [82] Wenhao Wu, Dongliang He, Xiao Tan, Shifeng Chen, Yi Yang, and Shilei Wen. Dynamic inference: A new approach toward efficient video action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 676–677, 2020.
- [83] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10687–10698, 2020.
- [84] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning for video understanding. arXiv preprint arXiv:1712.04851, 1(2):5, 2017.
- [85] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Conference on Computer Vision (ECCV), pages 305–321, 2018.
- [86] Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, and George Toderici. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4694–4702, 2015.
- [87] Bolei Zhou, Alex Andonian, Aude Oliva, and Antonio Torralba. Temporal relational reasoning in videos. In Proceedings of the European Conference on Computer Vision (ECCV), pages 803–818, 2018.
- [88] Linchao Zhu, Du Tran, Laura Sevilla-Lara, Yi Yang, Matt Feiszli, and Heng Wang. Faster recurrent networks for efficient video classification. In AAAI, pages 13098–13105, 2020.
- [89] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016.
附录
我们通过以下材料补充正文。
AMoViNet 架构搜索
A.1 搜索空间的缩放算法
为了生成具有良好扩展性的模型,我们在宽度、深度、输入分辨率和帧速率上逐步扩展搜索空间,例如 EfficientNet [72]。 具体来说,我们使用单个缩放参数 来定义搜索空间的大小。 然后我们定义以下系数:
这样。 这将确保 增加 1 将使搜索空间中的平均模型大小乘以 4。 在这里,我们使用 4 的乘数(而不是 2)来分散我们的搜索空间,以便我们可以运行具有多个效率目标的相同搜索空间,并从中采样我们所需的目标模型大小。
因此,给定搜索空间的参数如下:
| depth: | |||
| base width: | |||
| resolution: | |||
| frame-rate: |
我们将上述每个参数四舍五入到最接近的 8 的倍数。 如果,这形成MoViNet-A2的基本搜索空间。 请注意, 是相对于 定义的,因此我们不需要它的系数。
我们通过对这些参数进行随机搜索找到了系数。 更具体地说,我们以 0.05 的增量选择 范围内的值来表示系数的可能值。 我们确保系数的选择满足,其中每帧的初始计算目标是300 MFLOP。 对于每种组合,我们按系数 缩放搜索空间,并从每个搜索空间中随机采样三种架构。 我们为选定的搜索空间训练模型 10 个时期,对该搜索空间的准确度结果进行平均。 然后我们选择使最终精度最大化的系数。 我们不是选择一组系数,而是对前 5 个候选系数进行平均以产生最终系数。 虽然模型的样本量很小并且容易产生噪声,但我们发现小平均值在实践中效果很好。
A.2搜索算法
在搜索过程中,我们使用 TuNAS [4] 训练一次性模型,将所有可能的架构重叠到超网络中。 在优化过程中的每一步,我们都会交替学习网络权重和学习策略 ,我们使用该策略对通过超网络的路径进行随机采样,以生成初始随机网络架构。 是使用REINFORCE [81]学习的,针对采样架构的质量进行了优化,定义为由采样网络的准确性和成本组成的绝对奖励。 在每个阶段,强化学习控制器必须选择一个单一的分类决策来选择架构组件。 网络架构是每个决策绑定一个值的结果。 例如,决策可能会在空间 1x3x3 卷积和时间 5x1x1 卷积之间进行选择。 我们使用 FLOP 作为架构搜索的成本指标,并使用 Kinetics 600 作为数据集来优化高效视频网络。 在搜索过程中,我们获得了 Kinetics 600 训练集的保留子集的验证集准确度,总共训练了 90 个时期。
在我们的搜索空间中添加 SE [34] 可以使 FLOP 增加如此之少 (%),以至于搜索可以为所有层启用它。 SE 与 S3D-G [84] 中的特征门控起着类似的作用,除了投影操作内部的非线性挤压。
A.3 NAS 的流缓冲区
我们将流缓冲区应用于 MoViNets,作为正文中 NAS 之后的单独步骤。 我们还可以将它们用于 NAS,以减少搜索过程中的内存使用。 内存是 NAS 面临的最大挑战之一,因为模型被迫使用有限数量的帧和小批量大小,以便能够在优化期间将模型保留在内存中。 虽然这并不妨碍我们直接进行搜索,但它需要使用内存要求非常高的加速器,需要很高的入门成本。 为了避免这种情况,我们可以使用较小剪辑大小的流缓冲区来减少内存。 因此,我们可以增加嵌入帧总数并增加批量大小,以便在运行 NAS 时提供更好的模型精度估计。 表7提供了一个实验示例,其中使用流缓冲区可以通过这种方式减少内存需求。 使用流缓冲区,我们可以将输入大小从 16 帧的单个剪辑减少到每个 8 帧的 2 个剪辑,并将批量大小加倍。 与不使用缓冲区相比,这会导致内存相对适度的增加,否则我们可能会遇到内存不足 (OOM) 问题。
我们注意到每层中的值都会影响模型的内存消耗。 这完全取决于 3D 卷积的时间内核宽度。 如果,那么我们只需要缓存最后4帧。 可以更大,但这会导致我们丢弃额外的帧,因此我们将其设置为最小值以节省内存。 因此,没有必要直接用NAS指定它,因为NAS只关心内核大小。 然而,我们可以向 NAS 添加一个目标来最小化内存使用,这将施加压力来减少时间内核宽度,从而间接影响每层中 的值。 在未来的工作中可以探索通过保持内核大小来进一步减少内存消耗。
| Config | Full Input | Batch Size | Memory | Top-1 |
|---|---|---|---|---|
| No Buffer | 161722 | 8 | 5.8 GB | 55.9 |
| Buffer (8 frames) | 161722 | 16 | 6.6 GB | 58.5 |
| No Buffer | 161722 | 16 | 10.4 GB | OOM |
B MoViNets的架构
请参见表17、18、19、20、21和22 对于 MoViNet-A6,我们使用正文中描述的策略集成架构 A4 和 A5,即,我们独立训练两个模型,并在推理过程中对 logits 应用算术平均值。 所有模型的所有层都启用了 SE 层,因此为了简洁起见,我们从所有表中删除了此搜索超参数。
B.1 架构和训练的更多细节
我们对架构和模型训练进行了额外的更改,以进一步提高性能。 为了提高搜索和训练的收敛速度,我们通过应用零初始化的可学习标量权重来使用 ReZero [3],这些权重在残差块中的最终总和之前与特征相乘。 我们还应用了 ResNet 中传统使用的跳跃连接,在每个块的第一层添加 1x1x1 卷积,这可能会改变基本通道或对输入进行下采样。 然而,我们将其修改为类似于 ResNet-D [31],其中我们在卷积之前应用 1x3x3 空间平均池化以改进特征表示。
我们在每个优化步骤之后将 Polyak 平均 [58] 应用于权重,使用衰减为 0.99 的指数移动平均线 (EMA)。 我们采用Hard Swish激活函数,它是MobileNetV3 [33]提出的SiLU/Swish [21, 61]的变体,对量化和CPU推理更加友好。 我们使用动量为 0.9 且基础学习率为 1.8 的 RMSProp 优化器。 我们训练 240 个时期,批量大小为 1024,对所有数据集进行同步批量归一化,并使用余弦学习率计划 [53] 和 5 个时期的线性预热来衰减学习率。
我们在训练期间使用标签平滑度为 0.1 的 softmax 交叉熵损失,但 Charades 除外,我们应用 sigmoid 交叉熵来处理每个视频的多类标签。 对于 Charades,我们跨帧聚合预测,类似于 AssembleNet [63],其中我们在应用时间全局平均池化之前跨帧应用 softmax,以查找可能出现在不同帧中的多个动作类。
有些作品还扩大了推理的分辨率。 例如,X3D-M 使用 分辨率进行训练,同时在使用空间裁剪时评估 。 我们以与训练相同的分辨率评估所有模型,以确保推理期间每帧的 FLOP 与训练相同。
我们对帧速率的选择可能因模型而异,根据架构提供不同的最优性。 我们在图 6 中绘制了在 Kinetics 600 上以不同帧速率训练各种 MoViNet 的准确性。 大多数模型在每个视频 50 帧 (5fps) 或 80 帧 (8fps) 时都具有良好的效率。 然而,我们可以看到 MoViNet-A4 受益于 12fps 的更高帧速率。 对于 Charades,我们使用 64 帧、6fps 进行训练和推理。
C 更多实现细节和实验
C.1 通过填充实现因果卷积
为了使时间卷积运算具有因果性,我们可以应用一个简单的填充技巧,将感受野向前移动,使得卷积核以最远的未来帧为中心。 图7说明了这种效果。 对于内核大小 和步长 的正常 3D 卷积运算,相对于维度 的填充如下:
| (4) |
其中 分别是左右填充量。 对于因果卷积,我们将 转换为:
| (5) |
使得时间位置 处体素的有效时间感受野仅跨越 。
C.2 数据集的其他详细信息
我们注意到,由于视频离线,所有动力学数据集随着时间的推移逐渐缩小,因此很难与较新的作品进行比较。 我们报告最新可用的视频。 虽然我们的工作与之前的工作相比处于劣势,但我们希望未来的工作能够更加公平地进行比较。 尽管如此,我们仍按原样报告数字,并报告表 8 中数据集中示例的减少。
我们在下表中报告了所有模型的全部结果:Kinetics 400 的表 9、Kinetics 600 的表 10(前五名准确率)、Kinetics 700 的表 11、Moments in Time 的表 12、Charades 的表 13、Something-Something V2 的表 14,以及 Epic Kitchens 100 的表 15。 有关 Kinetics 600 的结果表,请参阅表 10 以及正文。
| Dataset | Train | Valid | Released |
|---|---|---|---|
| Kinetics 400 | 215,435 (87.5%) | 17,686 (88.4%) | May 2017 |
| Kinetics 600 | 364,305 (92.8%) | 27,764 (92.5%) | Aug 2018 |
| Kinetics 700 | 524,595 (96.2%) | 33,567 (95.9%) | Jul 2019 |
| Model | Top-1 | Top-5 | gflops | Param |
| MoViNet-A0 | 65.8 | 87.4 | 2.71 | 3.1M |
| MoViNet-A1 | 72.7 | 91.2 | 6.02 | 4.6M |
| X3D-XS [24] | 69.5 | - | 23.3 | 3.8M |
| MoViNet-A2 | 75.0 | 92.3 | 10.3 | 4.8M |
| X3D-S [24] | 73.5 | - | 76.1 | 3.8M |
| MoViNet-A3 | 78.2 | 93.8 | 56.9 | 5.3M |
| X3D-M [24] | 76.0 | 92.3 | 186 | 3.8M |
| MoViNet-A4 | 80.5 | 94.5 | 105 | 5.9M |
| X3D-L [24] | 77.5 | 92.9 | 744 | 6.1M |
| MoViNet-A5 | 80.9 | 94.9 | 281 | 15.7M |
| X3D-XL [24] | 79.1 | 93.9 | 1452 | 11.0M |
| MoViNet-A6 | 81.5 | 95.3 | 386 | 31.4M |
| X3D-XXL [24] | 80.4 | 94.6 | 5800 | 20.3M |
| TimeSformer-L [5] | 80.7 | 94.7 | 7140 | 120M |
| ViViT-L/16x2 [2] | 81.3 | 94.7 | 3990 | 88.9M |
| Model | Top-1 | Top-5 | gflops | Param |
| MoViNet-A0 | 71.5 | 90.4 | 2.71 | 3.1M |
| MoViNet-A0-Stream | 70.3 | 90.1 | 2.73 | 3.1M |
| MoViNet-A1 | 76.0 | 92.6 | 6.02 | 4.6M |
| MoViNet-A1-Stream | 75.6 | 92.8 | 6.06 | 4.6M |
| MoViNet-A2 | 77.5 | 93.4 | 10.3 | 4.8M |
| MoViNet-A2-Stream | 76.5 | 93.3 | 10.4 | 4.8M |
| MoViNet-A3 | 80.8 | 94.5 | 56.9 | 5.3M |
| MoViNet-A3 + AutoAugment | 81.3 | 95.3 | 56.9 | 5.3M |
| MoViNet-A4 | 81.2 | 94.9 | 105 | 4.9M |
| MoViNet-A4 + AutoAugment | 83.0 | 96.0 | 105 | 4.9M |
| X3D-M [24] | 78.8 | 94.5 | 186 | 3.8M |
| MoViNet-A5 | 82.7 | 95.7 | 281 | 15.7M |
| MoViNet-A5 + AutoAugment | 84.3 | 96.4 | 281 | 15.7M |
| MoViNet-A6 | 83.5 | 96.2 | 386 | 15.7M |
| MoViNet-A6 + AutoAugment | 84.8 | 96.5 | 386 | 15.7M |
| X3D-XL [24] | 81.9 | 95.5 | 1452 | 11.0M |
| SlowFast-R50 [25] | 78.8 | 94.0 | 1080 | 34.4M |
| SlowFast-R101 [25] | 81.8 | 95.1 | 7020 | 59.9M |
| Model | Top-1 | gflops | Param |
|---|---|---|---|
| MoViNet-A0 | 58.5 | 2.71 | 3.1M |
| MoViNet-A1 | 63.5 | 6.02 | 4.6M |
| MoViNet-A2 | 66.7 | 10.3 | 4.8M |
| MoViNet-A3 | 68.0 | 56.9 | 5.3M |
| MoViNet-A4 | 70.7 | 105 | 4.9M |
| MoViNet-A5 | 71.7 | 281 | 15.7M |
| MoViNet-A6 | 72.3 | 386 | 31.4M |
| SlowFast-R101 [25, 1] | 70.2 | 3200 | 30M |
| SlowFast-R152 [25, 1] | 71.6 | 9500 | 80M |
| EfficientNet-L2 (pretrain) [83, 1] | 76.2 | 15400 | 480M |
| Model | Top-1 | gflops | Param |
|---|---|---|---|
| MoViNet-A0 | 27.5 | 4.07 | 3.1M |
| MoViNet-A1 | 32.0 | 9.03 | 4.6M |
| TVN-1 [57] | 23.1 | 13.0 | 11.1M |
| MoViNet-A2 | 34.3 | 15.5 | 4.8M |
| MoViNet-A2-Stream | 33.6 | 15.6 | 4.8M |
| TVN-2 [57] | 24.2 | 17.0 | 110M |
| MoViNet-A3 | 35.6 | 35.6 | 5.3M |
| TVN-3 [57] | 25.4 | 69.0 | 69.4M |
| MoViNet-A4 | 37.9 | 98.4 | 4.9M |
| TVN-4 [57] | 27.8 | 106 | 44.2M |
| MoViNet-A5 | 39.1 | 175 | 15.7M |
| SRTG-R3D-34 [68] | 28.5 | 220 | - |
| MoViNet-A6 | 40.2 | 274 | 31.4M |
| ResNet3D-50 [63] | 27.2 | - | - |
| SRTG-R3D-50 [68] | 30.7 | 300 | - |
| SRTG-R3D-101 [68] | 33.6 | 350 | - |
| AssembleNet-50 (RGB+Flow) [63] | 31.4 | 480 | 37.3M |
| AssembleNet-101 (RGB+Flow) [63] | 34.3 | 760 | 53.3M |
| ViViT-L/16x2 [2] | 38.0 | 3410 | 100M |
| Model | mAP | gflops | Param |
|---|---|---|---|
| MoViNet-A2 | 32.5 | 6.59 | 4.8M |
| TVN-1 [57] | 32.2 | 13.0 | 11.1M |
| TVN-2 [57] | 32.5 | 17.0 | 110M |
| TVN-3 [57] | 33.5 | 69.0 | 69.4M |
| MoViNet-A4 | 48.5 | 90.4 | 4.9M |
| TVN-4 [57] | 35.4 | 106 | 44.2M |
| MoViNet-A6 | 63.2 | 306 | 31.4M |
| AssembleNet-50 (RGB+Flow) [63] | 53.0 | 700 | 37.3M |
| AssembleNet-101 (RGB+Flow) [63] | 58.6 | 1200 | 53.3M |
| AssembleNet++ (RGB+Flow+Seg)[62] | 59.8 | 1300 | - |
| SlowFast 16x8 R101 [25] | 45.2 | 7020 | 59.9M |
| Model | Top-1 | Top-5 | gflops | Param |
|---|---|---|---|---|
| MoViNet-A0 | 61.3 | 88.2 | 2.71 | 3.1M |
| MoViNet-A0-Stream | 60.9 | 88.3 | 2.73 | 3.1M |
| TRN [87] | 48.8 | 77.6 | 33.0 | - |
| MoViNet-A1 | 62.7 | 89.0 | 6.02 | 4.6M |
| MoViNet-A1-Stream | 61.6 | 87.3 | 6.06 | 4.6M |
| MoViNet-A2 | 63.5 | 89.0 | 10.3 | 4.8M |
| MoViNet-A2-Stream | 63.1 | 89.0 | 10.4 | 4.8M |
| TSM [48] | 63.4 | 88.5 | 390 | 24.3M |
| VoV3D-M (16 frame) [43] | 63.2 | 88.2 | 34.2 | 3.3M |
| MoViNet-A3 | 64.1 | 88.8 | 23.7 | 5.3M |
| VoV3D-M (32 frame) [43] | 65.2 | 89.4 | 69.0 | 3.3M |
| VoV3D-L (32 frame) [43] | 67.3 | 90.5 | 125 | 5.8M |
| ViViT-L/16x2 [2] | 65.4 | 89.8 | 3410 | 100M |
| Model | Action | Verb | Noun | gflops | Param |
|---|---|---|---|---|---|
| MoViNet-A0 | 36.8 | 64.8 | 47.4 | 1.74 | 3.1M |
| MoViNet-A2 | 41.2 | 67.1 | 52.3 | 7.59 | 4.8M |
| MoViNet-A4 | 44.4 | 68.8 | 56.2 | 42.2 | 4.9M |
| MoViNet-A5 | 44.5 | 69.1 | 55.1 | 74.9 | 15.7M |
| MoViNet-A6 | 47.7 | 72.2 | 57.3 | 117 | 31.4M |
| ViViT-L/16x2 [2] | 44.0 | 66.4 | 56.8 | 3410 | 100M |
| TSM [48] | 38.3 | 67.9 | 49.0 | - | - |
| SlowFast [25] | 38.5 | 65.6 | 50.0 | - | - |
| TSN [79] | 33.2 | 60.2 | 46.0 | - | - |
C.3单剪辑与多剪辑评估
我们在单个视图上报告所有结果,而不进行多剪辑评估。 此外,我们还报告用于评估的帧总数和帧速率(请注意,当子剪辑重叠时,评估帧可能会超过参考视频中的帧总数)。
如图 1 和表 2(在正文中)所示,在 Kinetics 600 上从多剪辑切换到单剪辑 X3D 模型(我们覆盖整个 10 秒剪辑)会导致每个视频的计算效率更高。 现有的工作通常会根据每个子剪辑的 FLOP 来分解 FLOP,但它可以隐藏计算的真实成本,因为我们可以不断添加更多剪辑来提高准确性。
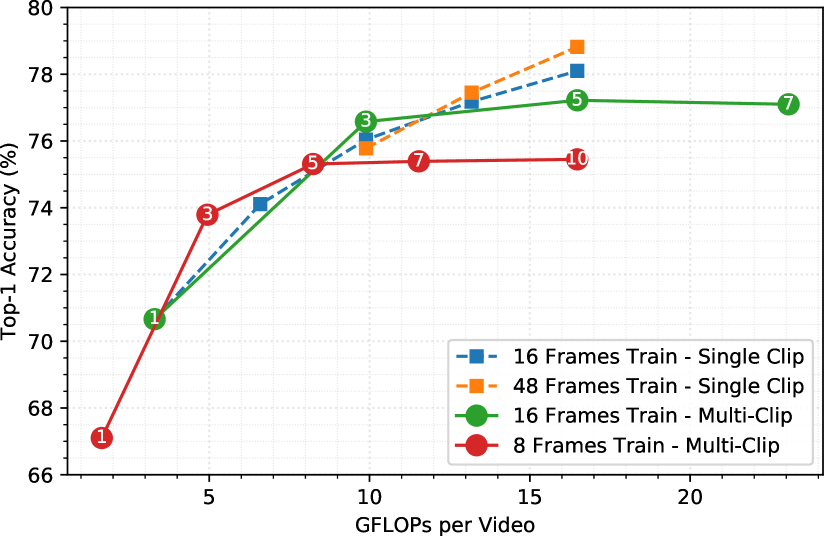
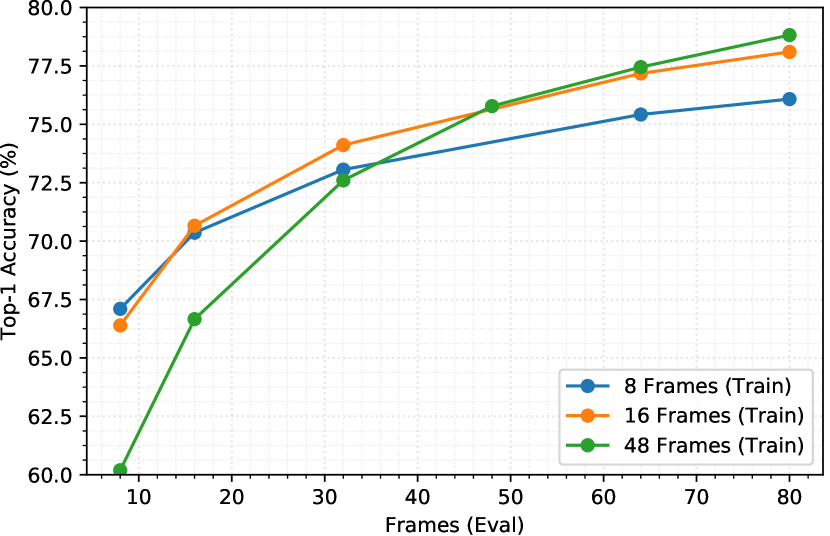
我们还评估了在较小剪辑和较长剪辑上训练相同 MoViNet-A2 模型之间的差异,以及使用多剪辑和单剪辑评估模型,如图 8 所示。 对于多剪辑评估,我们可以看到,当剪辑数量填满视频的整个持续时间时,准确性会提高(这可以在 8 个训练帧的 5 个剪辑和 16 个训练帧的 3 个剪辑中看到),而且只有非常轻微的提高随着我们添加更多剪辑,效果会有所改善。 然而,如果我们在 16 帧上训练 MoViNet-A2 并在 80 帧上进行评估(这样我们就覆盖了视频的所有 10 秒),这会比使用多剪辑评估相同帧数时获得更高的准确度。 此外,如果我们使用 48 帧来训练我们的模型,我们可以将精度提高得更高。 使用流缓冲区,我们可以减少训练的内存使用量,这样我们就可以使用 48 帧进行训练,而一次只使用嵌入 16 帧的内存。
C.4 流式与非流式评估
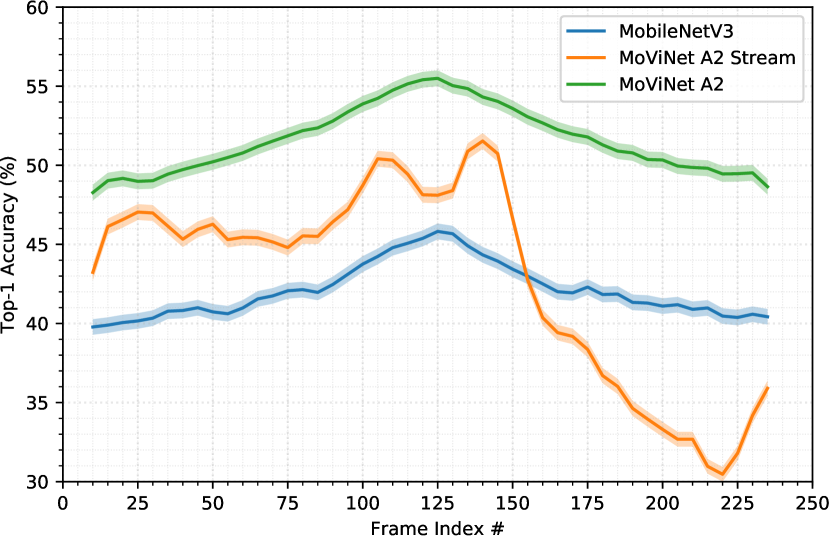
我们想知道的一个问题是,所学习的特征的分布是否与流式和非流式架构不同。 在图 9 中,我们通过嵌入整个视频、跨空间维度池化以及在每个帧上独立应用分类层,绘制了在单帧上评估的模型在 Kinetics 600 上的平均准确度。
我们首先注意到 MobileNetV3 和 MoViNet-A2 的准确度呈现拉普拉斯分布,平均峰值位于每个视频的中心帧。 由于 MobileNetV3 是在每一帧上独立评估的,因此我们可以观察到,动作中最显着的部分平均位于视频的中点。 这是一个很好的指标,表明 Kinetics 中的视频经过精心修剪,以每个动作最显着的部分为中心。 同样,具有平衡 3D 卷积的 MoViNet-A2 具有与 MobileNetV3 相同的特性,只是精度更高。
然而,具有因果卷积的流式传输 MoViNet-A2 的动力学完全不同。 与非流式架构相比,准确性的分布波动和变化更大。 通过消除网络通过因果卷积将所有帧视为一个整体的能力,特征的聚合与使用平衡卷积时不同。 尽管存在这种差异,但总体而言,所有视频的准确率差异仅为 1% 左右。 通过查看表10中的top-5准确度,我们可以注意到流式架构的性能几乎相同,尽管在转换到具有时间单向感受野的模型时存在明显的信息损失。
C.5 长视频序列
图10显示了训练剪辑持续时间如何影响在不同持续时间评估的模型的准确性。 我们可以看到,MoViNet 的泛化能力远远超出了其训练时使用的原始剪辑持续时间,并且随着帧数的增加,准确性始终得到提高。 然而,如果对持续时间比训练时间短的剪辑进行评估,该模型的表现会明显更差。 训练的剪辑持续时间越长,整体上对较长剪辑的评估就越准确。 通过流缓冲区,我们可以训练更长的序列,以进一步提高评估性能。
然而,我们还看到我们可以使用流缓冲区逐帧操作,大大节省内存,显示出比多剪辑方法更好的内存效率,并且随着输入帧数量的增加(因此时间感受野)需要恒定的内存。 尽管精度有所下降,但我们可以看到 MoViNet-Stream 模型在长视频序列上表现非常好,并且仍然比需要将视频分割成更小的子剪辑的 X3D 更高效。 我们鼓励未来的工作使用多剪辑评估来报告没有重叠子剪辑的结果,这不仅提供了更具代表性的准确性测量,而且往往也更加高效。
| Model | Top-1 | gflops | Params |
|---|---|---|---|
| MoViNet-A2b-3D | 79.0 | 17.1 | 4.8M |
| MoViNet-A2b-(2+1)D | 79.4 | 16.8 | 5.0M |
C.6 流缓冲区与其他操作
WaveNet [55] 引入了因果卷积,其中一维卷积堆栈上的感受野被迫只看到当前时间步之前的激活,而不是平衡卷积,平衡卷积在两个方向上扩展其感受野方向。 我们从因果卷积 [15, 13, 18] 中汲取灵感来设计流缓冲区。 然而,WaveNet 仅提出用于生成建模的一维卷积,利用它们的自回归特性。 我们将因果卷积的思想推广到任何本地操作,并引入流缓冲区以便能够使用因果操作进行在线推理,从而允许逐帧预测。 此外,Transformer-XL [17] 将激活缓存在时间缓冲区中,就像我们的工作一样,用于远程序列建模。 然而,该模型仅在固定序列之间具有因果关系,而我们的工作可以在各个帧之间具有因果关系,甚至可以改变每个剪辑中的帧数(只要帧是连续的,剪辑之间没有间隙或重叠)。 我们也可以将相同的原理应用于其他操作以及概括因果操作。 请注意,这种方法本质上并不与任何数据类型或模式相关。 流缓冲区还可用于对多种时间数据进行建模,例如音频、文本。
(2+1)D CNN。
此外,目前移动设备上对高效 3D 卷积的支持还比较分散,而 2D 卷积则得到了很好的支持。 我们提供了搜索 (2+1)D 架构的选项,将任何 3D 深度卷积分解为 2D 空间卷积,然后是 1D 时间卷积。 我们证明,将 3D 架构简单地更改为 (2+1)D 可以减少 FLOP,同时保持相似的精度,如表 16 所示。 这里我们将 MoViNet-A2b 定义为类似于 MoViNet-A2 的搜索模型。
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 8 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 480 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 16 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 600 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 16 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 640 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 16 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 744 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 24 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 856 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |
| Stage | Operation | Output size |
| data | stride 5, RGB | |
| conv1 | , 24 | |
| block2 | ||
| block3 | ||
| block4 | ||
| block5 | ||
| block6 | ||
| conv7 | , 992 | |
| pool8 | ||
| dense9 | , 2048 | |
| dense10 | , 600 |