ViViT:一种视频视觉Transformer
摘要
我们提出了一种基于纯Transformer的视频分类模型,该模型借鉴了此类模型在图像分类中的最新成功。 我们的模型从输入视频中提取时空符元,然后由一系列Transformer层对其进行编码。 为了处理视频中遇到的长符元序列,我们提出了几种高效的模型变体,这些变体将输入的空间和时间维度分解。 尽管众所周知,基于Transformer的模型只有在可用的大型训练数据集时才有效,但我们展示了如何在训练期间有效地规范化模型并利用预训练的图像模型,以便能够在相对较小的数据集上进行训练。 我们进行了彻底的消融研究,并在多个视频分类基准测试(包括Kinetics 400和600、Epic Kitchens、Something-Something v2和Moments in Time)上取得了最先进的结果,优于基于深度3D卷积网络的先前方法。 为了便于进一步研究,我们发布了代码,网址为 https://github.com/google-research/scenic。
1 引言
自AlexNet [38]以来,基于深度卷积神经网络的方法在许多针对视觉问题的标准数据集上取得了最先进的结果。 同时,序列到序列建模中最突出的架构选择(例如,在自然语言处理中)是Transformer [68],它不使用卷积,而是基于多头自注意力。 该操作在建模长距离依赖关系方面特别有效,并允许模型关注输入序列中的所有元素。 这与卷积形成鲜明对比,在卷积中,相应的“感受野”是有限的,并且随着网络深度的增加而线性增长。
注意力模型在NLP中的成功最近激发了计算机视觉中将Transformer集成到CNN [75, 7] 中的方法,以及一些尝试完全替换卷积 [49, 3, 53] 的方法。 然而,直到最近的视觉Transformer (ViT) [18] 出现,基于纯Transformer的架构才在图像分类方面超过了其卷积对应物。 Dosovitskiy 等. [18] 紧随[68] 的原始Transformer架构,并注意到其主要好处是在大规模上观察到的——由于Transformer缺乏卷积的一些归纳偏差(例如平移等变),它们似乎需要更多数据 [18] 或更强的正则化 [64]。
受 ViT 和基于注意力的架构是建模视频中长程上下文关系的直观选择这一事实的启发,我们开发了几个基于 Transformer 的视频分类模型。 目前,性能最好的模型是基于深度 3D 卷积架构 [8, 20, 21],它是图像分类 CNN [27, 60] 的自然扩展。 最近,这些模型通过在其后层中加入自注意力来增强,以更好地捕获长程依赖关系 [75, 23, 79, 1]。
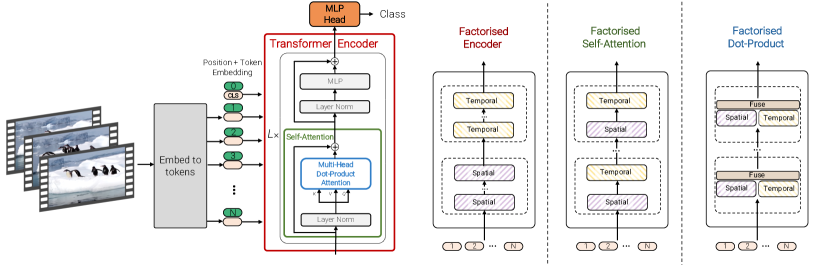
如图 1 所示,我们为视频分类提出了纯 Transformer 模型。 此架构执行的主要操作是自注意力,它是在我们从输入视频中提取的一系列时空符元上计算的。 为了有效地处理视频中可能遇到的大量时空符元,我们提出了几种沿着空间和时间维度分解模型的方法,以提高效率和可扩展性。 此外,为了有效地在较小的数据集上训练我们的模型,我们展示了如何在训练过程中规范化我们的模型并利用预训练的图像模型。
我们还注意到,卷积模型已由社区开发多年,因此与这类模型相关的许多“最佳实践”。 由于纯 Transformer 模型具有不同的特性,我们需要确定此类架构的最佳设计选择。 我们对符元化策略、模型架构和正则化方法进行了彻底的消融分析。 基于此分析,我们在多个标准视频分类基准测试中取得了最先进的结果,包括 Kinetics 400 和 600 [35]、Epic Kitchens 100 [13]、Something-Something v2 [26] 和 Moments in Time [45]。
2 相关工作
用于视频理解的体系结构已经反映了图像识别方面的进展。 早期的视频研究使用手工制作的特征来编码外观和运动信息[41, 69]。 AlexNet 在 ImageNet 上的成功[38, 16] 最初导致将 2D 图像卷积网络 (CNN) 作为“双流”网络[34, 56, 47] 用于视频。 这些模型在最终融合之前独立处理 RGB 帧和光流图像。 Kinetics 等大型视频分类数据集的可用性[35] 随后促进了时空 3D CNN 的训练[8, 22, 65],这些网络具有明显更多的参数,因此需要更大的训练数据集。 由于 3D 卷积网络比其图像对应物需要明显更多的计算,因此许多体系结构在空间和时间维度上对卷积进行因式分解和/或使用分组卷积[59, 66, 67, 81, 20]。 我们还利用视频空间和时间维度的因式分解来提高效率,但在基于 Transformer 的模型的背景下。
同时,在自然语言处理 (NLP) 中,Vaswani等人.[68] 通过用仅包含自注意力、层归一化和多层感知器 (MLP) 操作的 Transformer 网络替换卷积和循环网络,取得了最先进的结果。 NLP 中当前最先进的体系结构[17, 52] 仍然是基于 Transformer 的,并且已扩展到网络规模数据集[5]。 还提出了 Transformer 的许多变体,以减少在处理更长序列时自注意力的计算成本[10, 11, 37, 62, 63, 73] 并提高参数效率[40, 14]。 虽然自注意力已在计算机视觉中得到广泛应用,但相反,它通常作为网络末端或后期阶段的一层[75, 7, 32, 77, 83] 或在 ResNet 体系结构[27] 中增强残差块[30, 6, 9, 57]。
尽管以前的工作试图在视觉体系结构中替换卷积[49, 53, 55],但直到最近,Dosovitisky等人.[18] 证明了他们的 ViT 体系结构,即与 NLP 中使用的纯 Transformer 网络类似,也能在图像分类方面取得最先进的结果。 作者表明,这些模型仅在大规模情况下才有效,因为 Transformer 缺乏卷积网络的一些归纳偏差(例如平移等变性),因此需要比常见的 ImageNet ILSRVC 数据集[16] 更大的数据集进行训练。 ViT 启发了社区中大量后续工作,我们注意到,有一些并行的方法将其扩展到计算机视觉中的其他任务[71, 74, 84, 85] 并提高其数据效率[64, 48]。 特别是,[4, 46] 也提出了基于 Transformer 的视频模型。
在本文中,我们开发了用于视频分类的纯 Transformer 体系结构。 我们提出了我们模型的几个变体,包括通过对输入视频的时空维进行分解来提高效率的变体。 我们还展示了如何使用额外的正则化和预训练模型来克服视频数据集不像 ViT 最初训练的图像数据集那样大的事实。 此外,我们在五个流行的数据集上超越了最先进的技术。
3 视频视觉Transformer
我们首先在第 3.1 节中总结最近提出的视觉Transformer [18],然后在第 3.2 节中讨论从视频中提取符元的两种方法。 最后,我们在第 3.3 节和第 3.4 节中开发了几个用于视频分类的基于Transformer的架构。
3.1 视觉Transformer (ViT) 的概述
视觉Transformer (ViT) [18] 调整了 [68] 的Transformer架构,以对 2D 图像进行最小更改的处理。 特别地,ViT 提取 不重叠的图像块,,执行线性投影,然后将它们栅格化为 1D 符元 。 输入到以下Transformer编码器的符元序列为
| (1) |
其中,由 进行的投影等效于 2D 卷积。 如图 1 所示,一个可选的学习分类符元 被附加到此序列的前面,并且它在编码器的最后一层的表示被用作分类层 [17] 使用的最终表示。 此外,一个学习的位置嵌入,,被添加到符元中以保留位置信息,因为Transformer中的后续自注意力操作是置换不变的。 然后,符元被传递到由 Transformer 层序列组成的编码器。 每个层 包含多头自注意力 [68],层归一化 (LN) [2],以及 MLP 模块,如下所示:
| (2) | ||||
| (3) |
MLP 由两个线性投影组成,它们之间由 GELU 非线性 [28] 分隔,并且符元维数 在所有层中保持不变。 最后,使用线性分类器根据 对编码后的输入进行分类,如果它被预先附加到输入中,或者对所有符元进行全局平均池化,,否则。
由于 Transformer [68],它是 ViT [18] 的基础,是一个灵活的架构,可以对任何输入符元序列进行操作 ,因此我们接下来描述了对视频进行标记化的方法。
3.2 嵌入视频剪辑
我们考虑两种将视频 映射到符元序列 的简单方法。 然后我们添加位置嵌入并重新整形为 以获得 ,即 Transformer 的输入。
均匀帧采样
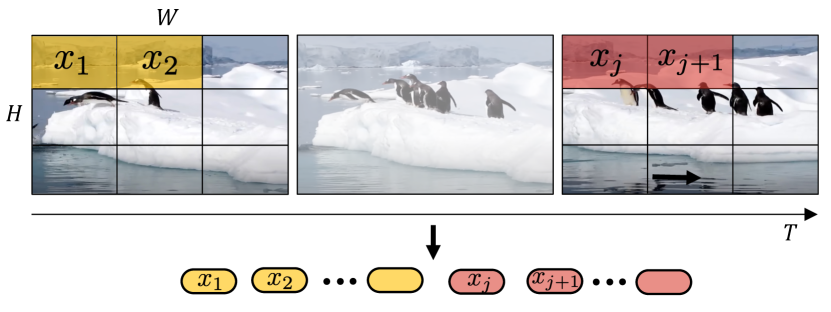
如图 2 所示,对输入视频进行标记化的一种简单方法是,从输入视频剪辑中均匀采样 帧,使用与 ViT [18] 相同的方法独立地嵌入每个 2D 帧,并将所有这些符元连接在一起。 具体来说,如果从每一帧中提取 个非重叠图像补丁,如 [18] 中所示,那么总共 个符元将被转发到 Transformer 编码器。 直观地,这个过程可以看作是简单地构建一个大的 2D 图像,然后按照 ViT 进行标记化。 我们注意到,这是由 [4] 的并发工作所采用的输入嵌入方法。
Tubelet 嵌入
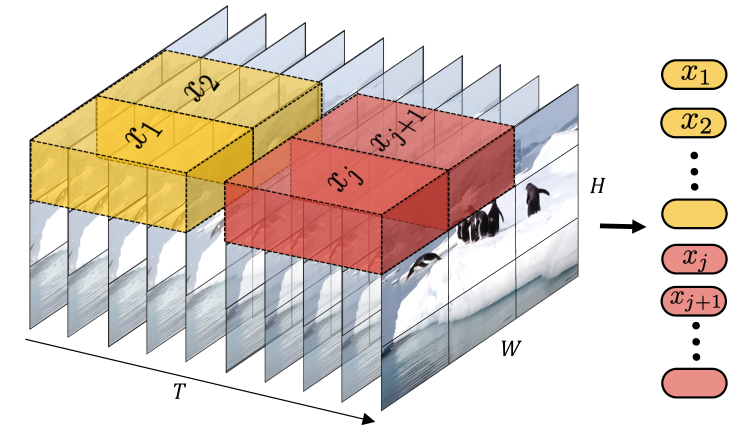
如图 3所示,另一种方法是从输入体积中提取不重叠的时空“管”,并将其线性投影到 。 此方法是 ViT 嵌入到 3D 的扩展,对应于 3D 卷积。 对于一个维度为 、、 和 的管,分别从时间、高度和宽度维度提取符元。 因此,较小的管维度会导致更多的符元,从而增加计算量。 直观地讲,此方法在符元化期间融合了时空信息,这与“均匀帧采样”形成对比,在均匀帧采样中,来自不同帧的时间信息由 Transformer 融合。
3.3 用于视频的 Transformer 模型
如图 1所示,我们提出了多种基于 Transformer 的架构。 我们从对 ViT [18] 的直接扩展开始,该扩展对所有时空符元之间的成对交互进行建模,然后开发更有效的变体,这些变体在 Transformer 架构的不同级别对输入视频的空间和时间维度进行分解。
模型 1:时空注意力
此模型简单地将从视频中提取的所有时空符元,,通过 Transformer 编码器转发。 我们注意到,这也已被 [4] 在其“联合时空”模型中同时探索。 与 CNN 架构形成对比,在 CNN 架构中,感受野随层数线性增长,每个 Transformer 层对所有时空符元之间的所有成对交互进行建模,因此它从第一层开始对整个视频中的远程交互进行建模。 然而,由于它对所有成对交互进行建模,多头自注意力(MSA)[68] 对于符元数量具有二次复杂度。 这种复杂度对于视频来说是相关的,因为符元数量随输入帧的数量线性增加,因此促使我们接下来开发更有效的架构。
模型 2:分解编码器
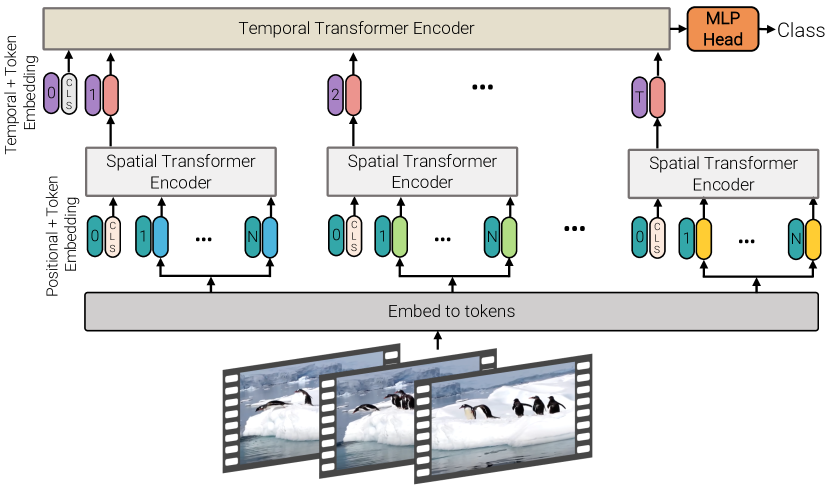
如图 4 所示,此模型由两个独立的 Transformer 编码器组成。 第一个空间编码器仅对从相同时间索引提取的符元之间的交互作用进行建模。 在 层之后,将获得每个时间索引 的表示:如果它被预先添加到输入中(公式 1),则这是编码的分类符元 ,否则是空间编码器输出的符元的全局平均池化 。 帧级表示 被连接到 中,然后通过由 个 Transformer 层组成的时态编码器转发以对来自不同时间索引的符元之间的交互作用进行建模。 然后,此编码器的输出符元最终被分类。
此架构对应于时间信息的“后期融合” [34, 56, 72, 46],初始空间编码器与用于图像分类的编码器相同。 因此,它类似于 CNN 架构,例如 [24, 34, 72, 86],它们首先提取每帧特征,然后将它们聚合到最终表示中,然后对其进行分类。 尽管此模型比模型 1 具有更多的 Transformer 层(因此具有更多参数),但它需要更少的浮点运算(FLOP),因为两个独立的 Transformer 块的复杂度为 ,而模型 1 的复杂度为 。
模型 3:因式分解自注意力
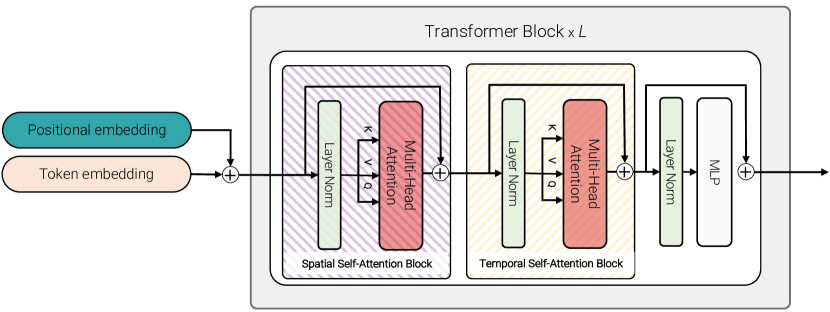
与此相反,该模型包含与模型 1 相同数量的 Transformer 层。 但是,与在所有符元对之间计算多头自注意力不同,,在层 ,我们将操作分解为首先仅在空间上计算自注意力(在从同一时间索引提取的所有符元之间),然后在时间上(在从同一空间索引提取的所有符元之间)计算自注意力,如图 5 所示。 Transformer 中的每个自注意力块因此对时空交互进行建模,但通过将操作分解为两个较小的元素集,比模型 1 更有效地做到这一点,从而实现了与模型 2 相同的计算复杂度。 我们注意到,将注意力分解到输入维度在 [29, 78] 中也得到了探索,并且在 [4] 的“分割时空”模型中,在视频环境下也得到了同步探索。
模型 4:分解点积注意力
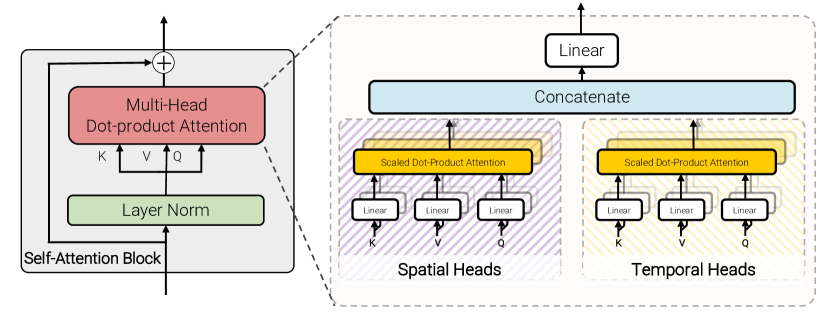
最后,我们开发了一个模型,该模型具有与模型 2 和 3 相同的计算复杂度,同时保持与未分解模型 1 相同的参数数量。 空间和时间维度的因式分解在精神上类似于模型 3,但我们对多头点积注意操作进行了因式分解(图 6)。 具体来说,我们使用不同的头分别计算每个符元在空间和时间维度上的注意权重。 首先,我们注意到每个头的注意操作定义为
| (7) |
在自注意中,查询 、键 和值 是输入 的线性投影,带有 。 请注意,在未分解的情况下(模型 1),空间和时间维度合并为 。
此处的主要想法是修改每个查询的键和值,以便仅通过构建 和 来关注来自相同空间和时间索引的符元,即对应于这些维度的键和值。 然后,对于一半的注意力头,我们通过计算 来关注来自空间维度的符元,对于其余的,我们通过计算 来关注来自时间维度的符元。 鉴于我们只改变每个查询的注意力邻域,注意力操作的维度与未分解情况下的维度相同,即 。 然后,我们通过将多个头的输出连接起来并使用线性投影 [68] 来组合它们, 。
3.4 利用预训练模型进行初始化
ViT [18] 已被证明仅在大型数据集上训练时才有效,因为 Transformer 缺乏卷积网络 [18] 的一些归纳偏差。 但是,即使是 Kinetics [35] 等最大的视频数据集,与图像对应物 [16, 39, 58] 相比,其标记示例的数量也少几个数量级。 结果,从头开始训练大型模型以达到高精度极具挑战性。 为了规避这个问题并实现更有效的训练,我们从预训练的图像模型初始化我们的视频模型。 但是,这会引发一些实际问题,特别是关于如何初始化图像模型中不存在或不兼容的参数。 我们现在讨论了几种有效策略来初始化这些大型视频分类模型。
位置嵌入
为每个输入符元添加位置嵌入 (,公式 1)。 然而,我们的视频模型的符元数量是预训练图像模型的 倍。 因此,我们通过在时间上“重复”位置嵌入从 到 来初始化它们。 因此,在初始化时,所有具有相同空间索引的符元都具有相同的嵌入,然后进行微调。
嵌入权重,
模型 3 的 Transformer 权重
4 经验评估
4.1 实验设置
网络架构和训练
我们的主干架构遵循 ViT [18] 和 BERT [17] 的架构。 我们考虑 ViT-Base (ViT-B, =, =, =), ViT-Large (ViT-L, =, =, =), 和 ViT-Huge (ViT-H, =, =, =), 其中 是 Transformer 层数,每个层包含 个头的自注意力块,隐藏维度为 。 我们也对我们的模型应用相同的命名方案(例如,ViViT-B/16x2 表示一个 ViT-Base 主干,其管状块大小为 )。 在所有实验中,管状块的高度和宽度相等。 注意,较小的管状块大小对应于输入端更多的符元,因此计算量更大。
我们使用同步 SGD 和动量、余弦学习率计划和 TPU-v3 加速器训练我们的模型。 我们从在 ImageNet-21K [16] (除非另有说明)或更大的 JFT [58] 数据集上训练的 ViT 图像模型初始化我们的模型。 我们使用 Scenic 库 [15] 实现我们的方法,并已发布我们的代码和模型。
数据集
我们在一组不同的视频分类数据集上评估我们提出的模型的性能:
Kinetics [35] 包含从 YouTube 采样的每秒 25 帧的 10 秒视频。 我们在 Kinetics 400 和 600 上进行评估,分别包含 400 个和 600 个类别。 由于这些是动态数据集(视频可能从 YouTube 中删除),我们注意到我们的数据集大小分别约为 267 000 和 446 000。
Epic Kitchens-100 包含以自我为中心视角的视频,捕捉日常厨房活动,涵盖 100 个小时和 90 000 个片段 [13]。 我们根据标准的“动作识别”协议报告结果。 这里,每个视频都被标记了“动词”和“名词”,因此我们使用具有两个“头部”的单个网络来预测这两个类别。 网络预测的得分最高的动词和动作对形成一个“动作”,而动作准确率是主要指标。
Moments in Time [45] 包含 800 000 个 3 秒的 YouTube 剪辑,这些剪辑捕捉了涉及动物、物体、人和自然现象的动态场景的要旨。
Something-Something v2 (SSv2) [26] 包含 220 000 个视频,持续时间从 2 秒到 6 秒不等。 与其他数据集相比,视频中的物体和背景在不同的动作类别之间保持一致,因此该数据集更加强调模型识别细粒度运动线索的能力。
| Top-1 accuracy | |
|---|---|
| Uniform frame sampling | 78.5 |
| Tubelet embedding | |
| Random initialisation [25] | 73.2 |
| Filter inflation [8] | 77.6 |
| Central frame | 79.2 |
推断
我们网络的输入是一个 32 帧的视频剪辑,步长为 2,除非另有说明,与 [21, 20] 相似。 遵循惯例,在推理时,我们处理较长视频的多个视图,并对每个视图的 logits 进行平均以获得最终结果。 除非另有说明,否则我们每个视频使用总共 4 个视图(因为这足以“看到”各种数据集中的整个视频剪辑),接下来我们将对这些和其他设计选择进行消融。
4.2 消融研究
输入编码
我们首先考虑使用我们的非因子模型 (Model 1) 和 ViViT-B 在 Kinetics 400 上不同输入编码方法 (Sec. 3.2) 的影响。 当我们向网络传递 32 帧输入时,采样 8 帧并提取长度为 的管状物对应于两种情况下相同数量的符元。 表 1 显示使用“中心帧”方法(公式 9)初始化的管状嵌入表现良好,其性能优于常用的“滤波器膨胀”初始化方法 [8, 22] 1.6%,以及“均匀帧采样”方法 0.7%。 因此,我们在后续的所有实验中使用此编码方法。
| K400 | EK | FLOPs () | Params () | Runtime (ms) | |
|---|---|---|---|---|---|
| Model 1: Spatio-temporal | 80.0 | 43.1 | 455.2 | 88.9 | 58.9 |
| Model 2: Fact. encoder | 78.8 | 43.7 | 284.4 | 115.1 | 17.4 |
| Model 3: Fact. self-attention | 77.4 | 39.1 | 372.3 | 117.3 | 31.7 |
| Model 4: Fact. dot product | 76.3 | 39.5 | 277.1 | 88.9 | 22.9 |
| Model 2: Ave. pool baseline | 75.8 | 38.8 | 283.9 | 86.7 | 17.3 |
| 0 | 1 | 4 | 8 | 12 | |
|---|---|---|---|---|---|
| Top-1 | 75.8 | 78.6 | 78.8 | 78.8 | 78.9 |
模型变体
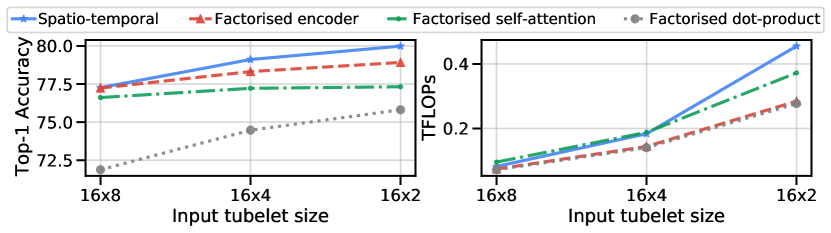
我们在表 2 中比较了我们提出的模型变体(第 3.3 节)在 Kinetics 400 和 Epic Kitchens 数据集上的表现,包括准确率和效率。 在所有情况下,我们都使用“Base”主干网络和管状大小为 。 模型 2(“Factorised 编码器”)有一个额外的超参数,即时间 Transformer 的数量 。 我们在所有实验中都设置了 ,并在表 3 中展示了模型对该选择的敏感性。
非分解模型(模型 1)在 Kinetics 400 上表现最佳。 然而,它也可能在较小的数据集(如 Epic Kitchens)上过拟合,而我们发现“Factorised 编码器”(模型 2)在这些数据集上表现最佳。 我们还考虑了一个额外的基线(最后一行),基于模型 2,其中我们不使用任何时间 Transformer,而是在分类之前简单地对空间编码器中的帧级表示进行平均池化。 此平均池化基线表现最差,并且在 Epic Kitchens 上的精度下降更大,这表明该数据集需要更详细的时间关系建模。
如第 3.3 节所述,我们模型的所有分解变体都比未分解的模型 1 使用的 FLOP 少得多,因为注意力是在空间和时间维度上分别计算的。 模型 4 没有向未分解的模型 1 添加任何额外的参数,并且使用最少的计算。 模型 2 中的时间 Transformer 编码器仅对 个标记进行操作,这就是为什么即使它显着提高了精度(在 Kinetics 上提高了 3%,在 Epic Kitchens 上提高了 4.9%),但与平均池化基线相比,计算量和运行时间几乎没有变化的原因。 最后,模型 3 比其他分解模型需要更多的计算量和参数,因为它的额外自注意力块意味着它在每个 Transformer 层中执行另一个查询、键、值和输出投影 [68]。
| Top-1 accuracy | |
|---|---|
| Random crop, flip, colour jitter | 38.4 |
| + Kinetics 400 initialisation | 39.6 |
| + Stochastic depth [31] | 40.2 |
| + Random augment [12] | 41.1 |
| + Label smoothing [61] | 43.1 |
| + Mixup [82] | 43.7 |
| (a) Accuracy | (b) Compute |
| (a) Accuracy | (b) Compute |
模型正则化
众所周知,ViT [18] 等纯 Transformer 架构需要大型训练数据集,并且我们观察到即使使用 ImageNet 预训练模型,在 Epic Kitchens 和 SSv2 等较小的数据集上也会出现过拟合。 为了在这些数据集上有效地训练我们的模型,我们采用了多种正则化策略,我们在 Tab. 4 中使用我们的“分解编码器”模型对其进行了消融。 我们注意到这些正则化器最初是为训练 CNN 提出的,并且 [64] 最近已探索将其用于训练 ViT 进行图像分类。
Tab. 4 的每一行都包含了其上方行中的所有方法,并且我们观察到随着每个正则化器的添加,性能逐步提高。 总的来说,我们在 Epic Kitchens 上获得了 5.3% 的显著整体改进。 通过使用 Tab. 4 中的所有正则化,我们在 SSv2 上也获得了类似的 5% 的改进。 请注意,我们从 Tab. 2 中初始化的 Kinetics 预训练模型,以及 Tab. 2 中的所有 Epic Kitchens 模型都是使用 Tab. 4 中的所有正则化器进行训练的。 对于 Kinetics 和 Moments in Time 这样的更大数据集,我们不使用这些额外的正则化器(我们只使用 Tab. 4 的第一行),因为我们没有它们也能获得最先进的结果。 附录包含所有正则化器的超参数值和额外细节。
改变主干
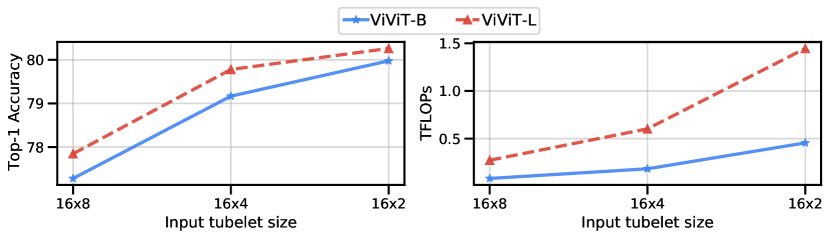
图 7 比较了用于非分解时空模型的 ViViT-B 和 ViViT-L 主干。 我们观察到随着主干容量的增加,准确性不断提高。 如预期的那样,计算量也随着主干大小而增长。
| Crop size | 224 | 288 | 320 |
|---|---|---|---|
| Accuracy | 80.3 | 80.7 | 81.0 |
| GFLOPs | 1446 | 2919 | 3992 |
| Runtime | 58.9 | 147.6 | 238.8 |
改变符元数量
我们首先在图 8 中分析了性能随时间维度上的符元数量的变化。 我们观察到,使用更小的输入 tubelet 大小(因此更多的符元)会导致我们所有模型架构的准确性一致提高。 同时,以 FLOPs 衡量的计算量也相应增加,未分解模型(模型 1)受到的影响最大。
然后,我们通过在表 5 中将空间裁剪大小从默认的 224 增加到 320 来改变输入模型的符元数量。 正如预期的那样,精度和计算量都一致增加。 我们注意到,与之前的工作相比,我们使用 224 的空间分辨率始终获得最先进的结果(第 4.3 节),但我们也强调,在更高的空间分辨率下可以获得进一步的改进。
| Method | Top 1 | Top 5 | Views | TFLOPs |
| blVNet [19] | 73.5 | 91.2 | – | – |
| STM [33] | 73.7 | 91.6 | – | – |
| TEA [42] | 76.1 | 92.5 | 2.10 | |
| TSM-ResNeXt-101 [43] | 76.3 | – | – | – |
| I3D NL [75] | 77.7 | 93.3 | 10.77 | |
| CorrNet-101 [70] | 79.2 | – | 6.72 | |
| ip-CSN-152 [66] | 79.2 | 93.8 | 3.27 | |
| LGD-3D R101 [51] | 79.4 | 94.4 | – | – |
| SlowFast R101-NL [21] | 79.8 | 93.9 | 7.02 | |
| X3D-XXL [20] | 80.4 | 94.6 | 5.82 | |
| TimeSformer-L [4] | 80.7 | 94.7 | 7.14 | |
| ViViT-L/16x2 FE | 80.6 | 92.7 | 3.98 | |
| ViViT-L/16x2 FE | 81.7 | 93.8 | 11.94 | |
| Methods with large-scale pretraining | ||||
| ip-CSN-152 [66] (IG [44]) | 82.5 | 95.3 | 3.27 | |
| ViViT-L/16x2 FE (JFT) | 83.5 | 94.3 | 11.94 | |
| ViViT-H/14x2 (JFT) | 84.9 | 95.8 | 47.77 | |
| Method | Top 1 | Top 5 |
|---|---|---|
| AttentionNAS [76] | 79.8 | 94.4 |
| LGD-3D R101 [51] | 81.5 | 95.6 |
| SlowFast R101-NL [21] | 81.8 | 95.1 |
| X3D-XL [20] | 81.9 | 95.5 |
| TimeSformer-L [4] | 82.2 | 95.6 |
| ViViT-L/16x2 FE | 82.9 | 94.6 |
| ViViT-L/16x2 FE (JFT) | 84.3 | 94.9 |
| ViViT-H/14x2 (JFT) | 85.8 | 96.5 |
| Top 1 | Top 5 | |
|---|---|---|
| TSN [72] | 25.3 | 50.1 |
| TRN [86] | 28.3 | 53.4 |
| I3D [8] | 29.5 | 56.1 |
| blVNet [19] | 31.4 | 59.3 |
| AssembleNet-101 [54] | 34.3 | 62.7 |
| ViViT-L/16x2 FE | 38.5 | 64.1 |
| Method | Action | Verb | Noun |
|---|---|---|---|
| TSN [72] | 33.2 | 60.2 | 46.0 |
| TRN [86] | 35.3 | 65.9 | 45.4 |
| TBN [36] | 36.7 | 66.0 | 47.2 |
| TSM [43] | 38.3 | 67.9 | 49.0 |
| SlowFast [21] | 38.5 | 65.6 | 50.0 |
| ViViT-L/16x2 FE | 44.0 | 66.4 | 56.8 |
| Method | Top 1 | Top 5 |
|---|---|---|
| TRN [86] | 48.8 | 77.6 |
| SlowFast [20, 80] | 61.7 | – |
| TimeSformer-HR [4] | 62.5 | – |
| TSM [43] | 63.4 | 88.5 |
| STM [33] | 64.2 | 89.8 |
| TEA [42] | 65.1 | – |
| blVNet [19] | 65.2 | 90.3 |
| ViVIT-L/16x2 FE | 65.9 | 89.9 |
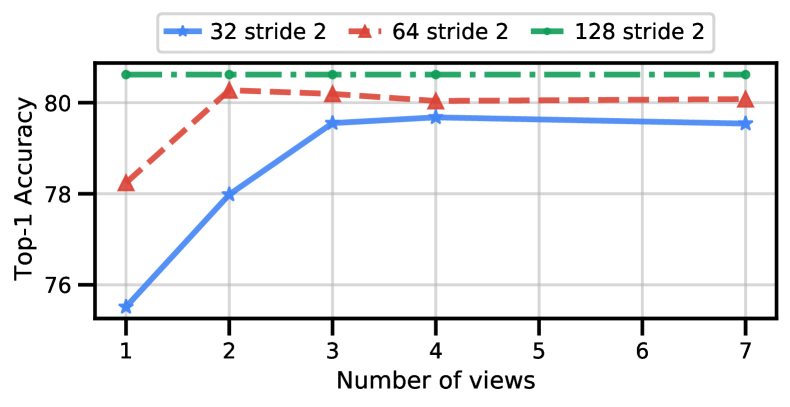
改变输入帧的数量
在我们到目前为止的实验中,我们一直将输入帧的数量固定为 32。 我们现在增加输入模型的帧数,从而按比例增加符元数量。
图 9 显示,随着我们增加输入网络的帧数,处理单个视图的准确率会提高,因为网络整合了更长的时序上下文。 但是,在 Kinetics 等数据集 [21, 75, 42] 上的常见做法是,对同一个视频片段的多个较短“视图”的结果进行平均。 图 9 还显示,一旦视图数量足以覆盖整个视频,准确率就会饱和。 由于 Kinetics 视频包含 250 帧,我们以 2 的步长采样帧,因此处理 128 帧的模型只需一个视图就能“看到”整个视频并达到其最大准确率。
请注意,我们在这里使用了 ViViT-L/16x2 分解编码器(模型 2)。 由于该模型效率更高,因此与未分解的模型 1 相比,它可以处理更多的 Token ,模型 1 在使用小管长度 和“大”骨干网的 48 帧后耗尽内存。 处理更多帧(因此更多标记)的模型始终能够实现更高的单视图和多视图精度,这与我们在之前实验中的观察结果一致(表5,图8) >)。 此外,请观察到,通过使用模型 2 处理更多帧(因此也有更多标记),我们能够获得比模型 1 更高的准确度(总 FLOP 数也更少)。
最后,我们观察到,对于模型 2,FLOP 的数量实际上随着输入帧的数量线性增加,因为整体计算由初始空间变换器主导。 结果,为了实现最大精度的所需时间视图数量,所有模型的总 FLOPs 数量都是恒定的。 换句话说,ViViT-L/16x2 FE 在 32 帧情况下,每个视图需要 995.3 GFLOPs,并且需要 4 个视图才能使多视图精度饱和。 128 帧模型需要 3980.4 GFLOPs,但只需要一个视图。 如图 9 所示,后一种模型实现了最高的精度。
4.3 与最先进技术的比较
基于我们在上一节中的消融研究,我们使用我们模型的两个变体与当前最先进技术进行比较。 我们主要使用因子分解编码器模型(模型 2),因为它可以比模型 1 处理更多的标记,以实现更高的准确性。
动力学
表 6(a) 和 6(c) 表明,我们的时空注意模型在 Kinetics 400 和 600 上分别优于最先进技术。 遵循标准做法,我们对每个时间视图进行 3 个空间裁剪(左、中、右)[21, 20, 66, 75],值得注意的是,与之前基于 CNN 的方法相比,我们需要的视图要少得多。
我们使用在 ImageNet 上预训练的 ViViT-L/16x2 因子分解编码器 (FE) 超越了之前基于 CNN 的最先进技术,并且也优于同时提出纯 Transformer 架构的 [4] 。 此外,通过从在更大 JFT 数据集 [58] 上预训练的模型初始化我们的主干,我们获得了进一步的改进。 虽然这些模型与以前的工作无法直接比较,但我们也优于 [66],该模型在大型 Instagram 数据集 [44] 上进行了预训练。 我们最好的模型使用在 JFT 上预训练的 ViViT-H 主干,并在 Kinetics 400 和 600 上显著提高了最佳报告结果,分别达到 84.9% 和 85.8%。
时间中的时刻
如 Tab. 6(c) 所示,我们以显著优势超过了最先进水平。 我们注意到,此数据集中的视频种类繁多,并且包含大量的标签噪声,这使得这项任务具有挑战性,并导致准确率低于其他数据集。
史诗厨房 100
东西-东西 v2 (SSv2)
最后,Tab. 6(e) 显示,我们使用分解编码器模型(模型 2)实现了最先进的 Top-1 准确率,尽管与以前的方法相比,优势较小。 值得注意的是,我们的分解编码器模型显著优于同时期 TimeSformer [4] 方法 2.9%,该方法也提出了一种纯 Transformer 模型,但没有考虑我们的分解编码器变体或我们额外的正则化。
5 结论和未来工作
我们介绍了四种用于视频分类的纯 Transformer 模型,这些模型具有不同的准确性和效率特征,在五个流行的数据集中取得了最先进的结果。 此外,我们展示了如何在较小的数据集上有效地正则化这种高容量模型,并彻底消除了我们主要设计选择的影响。 未来工作是消除我们对图像预训练模型的依赖。 最后,超越视频分类,走向更复杂的任务是下一步的明确方向。
参考文献
- [1] Anurag Arnab, Chen Sun, and Cordelia Schmid. Unified graph structured models for video understanding. In ICCV, 2021.
- [2] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. In arXiv preprint arXiv:1607.06450, 2016.
- [3] Irwan Bello, Barret Zoph, Ashish Vaswani, Jonathon Shlens, and Quoc V Le. Attention augmented convolutional networks. In ICCV, 2019.
- [4] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? In arXiv preprint arXiv:2102.05095, 2021.
- [5] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, et al. Language models are few-shot learners. In NeurIPS, 2020.
- [6] Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, and Han Hu. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In CVPR Workshops, 2019.
- [7] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- [8] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017.
- [9] Yunpeng Chen, Yannis Kalantidis, Jianshu Li, Shuicheng Yan, and Jiashi Feng. A2-nets: Double attention networks. In NeurIPS, 2018.
- [10] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. In arXiv preprint arXiv:1904.10509, 2019.
- [11] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. In ICLR, 2021.
- [12] Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V. Le. Randaugment: Practical automated data augmentation with a reduced search space. In NeurIPS, 2020.
- [13] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision. In arXiv preprint arXiv:2006.13256, 2020.
- [14] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. In ICLR, 2019.
- [15] Mostafa Dehghani, Alexey Gritsenko, Anurag Arnab, Matthias Minderer, and Yi Tay. Scenic: A JAX library for computer vision research and beyond. arXiv preprint arXiv:2110.11403, 2021.
- [16] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- [17] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
- [18] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [19] Quanfu Fan, Chun-Fu Chen, Hilde Kuehne, Marco Pistoia, and David Cox. More is less: Learning efficient video representations by big-little network and depthwise temporal aggregation. In NeurIPS, 2019.
- [20] Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In CVPR, 2020.
- [21] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, 2019.
- [22] Christoph Feichtenhofer, Axel Pinz, and Richard Wildes. Spatiotemporal residual networks for video action recognition. In NeurIPS, 2016.
- [23] Rohit Girdhar, Joao Carreira, Carl Doersch, and Andrew Zisserman. Video action transformer network. In CVPR, 2019.
- [24] Rohit Girdhar and Deva Ramanan. Attentional pooling for action recognition. In NeurIPS, 2017.
- [25] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
- [26] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. In ICCV, 2017.
- [27] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [28] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). In arXiv preprint arXiv:1606.08415, 2016.
- [29] Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. Axial attention in multidimensional transformers. In arXiv preprint arXiv:1912.12180, 2019.
- [30] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018.
- [31] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Weinberger. Deep networks with stochastic depth. In ECCV, 2016.
- [32] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. In ICCV, 2019.
- [33] Boyuan Jiang, Mengmeng Wang, Weihao Gan, Wei Wu, and Junjie Yan. Stm: Spatiotemporal and motion encoding for action recognition. In ICCV, 2019.
- [34] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.
- [35] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. In arXiv preprint arXiv:1705.06950, 2017.
- [36] Evangelos Kazakos, Arsha Nagrani, Andrew Zisserman, and Dima Damen. Epic-fusion: Audio-visual temporal binding for egocentric action recognition. In ICCV, 2019.
- [37] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In ICLR, 2020.
- [38] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS, volume 25, 2012.
- [39] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Tom Duerig, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. IJCV, 2020.
- [40] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. In ICLR, 2020.
- [41] Ivan Laptev. On space-time interest points. IJCV, 64(2-3), 2005.
- [42] Yan Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, and Limin Wang. Tea: Temporal excitation and aggregation for action recognition. In CVPR, 2020.
- [43] Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. In ICCV, 2019.
- [44] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens Van Der Maaten. Exploring the limits of weakly supervised pretraining. In ECCV, 2018.
- [45] Mathew Monfort, Alex Andonian, Bolei Zhou, Kandan Ramakrishnan, Sarah Adel Bargal, Tom Yan, Lisa Brown, Quanfu Fan, Dan Gutfreund, Carl Vondrick, et al. Moments in time dataset: one million videos for event understanding. PAMI, 42(2):502–508, 2019.
- [46] Daniel Neimark, Omri Bar, Maya Zohar, and Dotan Asselmann. Video transformer network. In arXiv preprint arXiv:2102.00719, 2021.
- [47] Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, and George Toderici. Beyond short snippets: Deep networks for video classification. In CVPR, 2015.
- [48] Zizheng Pan, Bohan Zhuang, Jing Liu, Haoyu He, and Jianfei Cai. Scalable visual transformers with hierarchical pooling. In arXiv preprint arXiv:2103.10619, 2021.
- [49] Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. In ICML, 2018.
- [50] Will Price and Dima Damen. An evaluation of action recognition models on epic-kitchens. In arXiv preprint arXiv:1908.00867, 2019.
- [51] Zhaofan Qiu, Ting Yao, Chong-Wah Ngo, Xinmei Tian, and Tao Mei. Learning spatio-temporal representation with local and global diffusion. In CVPR, 2019.
- [52] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2020.
- [53] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. Stand-alone self-attention in vision models. In NeurIPS, 2019.
- [54] Michael S Ryoo, AJ Piergiovanni, Mingxing Tan, and Anelia Angelova. Assemblenet: Searching for multi-stream neural connectivity in video architectures. In ICLR, 2020.
- [55] Zhuoran Shen, Irwan Bello, Raviteja Vemulapalli, Xuhui Jia, and Ching-Hui Chen. Global self-attention networks for image recognition. In arXiv preprint arXiv:2010.03019, 2021.
- [56] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In NeurIPS, 2014.
- [57] Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pieter Abbeel, and Ashish Vaswani. Bottleneck transformers for visual recognition. In CVPR, 2021.
- [58] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In ICCV, 2017.
- [59] Lin Sun, Kui Jia, Dit-Yan Yeung, and Bertram E Shi. Human action recognition using factorized spatio-temporal convolutional networks. In ICCV, 2015.
- [60] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In CVPR, 2015.
- [61] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016.
- [62] Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A benchmark for efficient transformers. In arXiv preprint arXiv:2011.04006, 2020.
- [63] Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. In arXiv preprint arXiv:2009.06732, 2020.
- [64] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In arXiv preprint arXiv:2012.12877, 2020.
- [65] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In ICCV, 2015.
- [66] Du Tran, Heng Wang, Lorenzo Torresani, and Matt Feiszli. Video classification with channel-separated convolutional networks. In ICCV, 2019.
- [67] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In CVPR, 2018.
- [68] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- [69] Heng Wang, Alexander Kläser, Cordelia Schmid, and Cheng-Lin Liu. Dense trajectories and motion boundary descriptors for action recognition. IJCV, 103(1), 2013.
- [70] Heng Wang, Du Tran, Lorenzo Torresani, and Matt Feiszli. Video modeling with correlation networks. In CVPR, 2020.
- [71] Huiyu Wang, Yukun Zhu, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Max-deeplab: End-to-end panoptic segmentation with mask transformers. In arXiv preprint arXiv:2012.00759, 2020.
- [72] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV, 2016.
- [73] Sinong Wang, Belinda Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. In arXiv preprint arXiv:2006.04768, 2020.
- [74] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In arXiv preprint arXiv:2102.12122, 2021.
- [75] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, 2018.
- [76] Xiaofang Wang, Xuehan Xiong, Maxim Neumann, AJ Piergiovanni, Michael S Ryoo, Anelia Angelova, Kris M Kitani, and Wei Hua. Attentionnas: Spatiotemporal attention cell search for video classification. In ECCV, 2020.
- [77] Yuqing Wang, Zhaoliang Xu, Xinlong Wang, Chunhua Shen, Baoshan Cheng, Hao Shen, and Huaxia Xia. End-to-end video instance segmentation with transformers. In arXiv preprint arXiv:2011.14503, 2020.
- [78] Dirk Weissenborn, Oscar Täckström, and Jakob Uszkoreit. Scaling autoregressive video models. In ICLR, 2020.
- [79] Chao-Yuan Wu, Christoph Feichtenhofer, Haoqi Fan, Kaiming He, Philipp Krahenbuhl, and Ross Girshick. Long-term feature banks for detailed video understanding. In CVPR, 2019.
- [80] Chao-Yuan Wu, Ross Girshick, Kaiming He, Christoph Feichtenhofer, and Philipp Krahenbuhl. A multigrid method for efficiently training video models. In CVPR, 2020.
- [81] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In ECCV, 2018.
- [82] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. Mixup: Beyond empirical risk minimization. In ICLR, 2018.
- [83] Li Zhang, Dan Xu, Anurag Arnab, and Philip HS Torr. Dynamic graph message passing networks. In CVPR, 2020.
- [84] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip Torr, and Vladlen Koltun. Point transformer. In arXiv preprint arXiv:2012.09164, 2020.
- [85] Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In arXiv preprint arXiv:2012.15840, 2020.
- [86] Bolei Zhou, Alex Andonian, Aude Oliva, and Antonio Torralba. Temporal relational reasoning in videos. In ECCV, 2018.
附录
附录 A 其他实验细节
| K400 | K600 | MiT | EK | SSv2 | |
| Optimisation | |||||
| Optimiser | Synchronous SGD | ||||
| Momentum | 0.9 | ||||
| Batch size | 64 | ||||
| Learning rate schedule | cosine with linear warmup | ||||
| Linear warmup epochs | 2.5 | ||||
| Base learning rate | 0.1 | 0.1 | 0.25 | 0.5 | 0.5 |
| Epochs | 30 | 30 | 10 | 50 | 35 |
| Data augmentation | |||||
| Random crop probability | 1.0 | ||||
| Random flip probability | 0.5 | ||||
| Scale jitter probability | 1.0 | ||||
| Maximum scale | 1.33 | ||||
| Minimum scale | 0.9 | ||||
| Colour jitter probability | 0.8 | 0.8 | 0.8 | – | – |
| Rand augment number of layers [12] | – | – | – | 2 | 2 |
| Rand augment magnitude [12] | – | – | – | 15 | 20 |
| Other regularisation | |||||
| Stochastic droplayer rate, [31] | – | – | – | 0.2 | 0.3 |
| Label smoothing [61] | – | – | – | 0.2 | 0.3 |
| Mixup [82] | – | – | – | 0.1 | 0.3 |
A.1 关于正则化的更多细节
随机深度
随机深度正则化最初是为训练非常深的残差网络提出的 [31]。 直观地,在训练过程中,层 的输出以概率 被“丢弃”,通过将层的输出设置为等于其输入来实现。
遵循 [31],我们根据层在网络中的深度线性地增加丢弃层的概率,
| (10) |
其中 是网络中层的索引,而 是层的总数。
随机增强
随机增强 [12] 随机地将数据增强变换依次应用于输入示例。 我们遵循公开的实现111https://github.com/tensorflow/models/blob/master/official/vision/beta/ops/augment.py,但修改了数据增强操作,使其在整个视频中时间上保持一致(换句话说,相同的变换应用于视频的每一帧)。
作者为随机增强定义了两个超参数,“层数”,即依次应用于视频的增强变换的数量,以及“幅度”,即所有增强操作共享的变换强度。 我们对这些参数的值如表 7 所示。
标签平滑
标签平滑最初由 [61] 提出,用于正则化 Inception-v3 的训练。 具体来说,训练期间使用的标签分布,,是独热地面真实标签,,和均匀分布,,的混合,以鼓励网络在训练期间产生不太自信的预测:
| (11) |
因此,存在一个标量超参数,。
混合
Mixup [82] 构建虚拟训练样本,这些样本是训练样本对及其标签的凸组合。 具体来说,给定 和 ,其中 表示输入向量, 表示独热输入标签,mixup 构建虚拟训练样本,
| (12) |
,并且是从 Beta 分布,,中采样。 我们对超参数 的选择在 Tab. 7 中详细说明。
A.2 训练超参数
表格 7 详细说明了我们所有实验的超参数。 我们对所有实验使用带有动量的同步 SGD、带有线性预热的余弦学习率计划,以及 64 的批次大小。 如前所述,我们只在更小的 Epic Kitchens 和 Something-Something v2 数据集上训练时才使用额外的正则化。