LoFTR:与 Transformers 进行无检测器局部特征匹配
摘要
我们提出了一种局部图像特征匹配的新方法。 我们建议首先在粗略水平上建立像素级密集匹配,然后在精细水平上细化良好的匹配,而不是依次执行图像特征检测、描述和匹配。 与使用成本量来搜索对应关系的密集方法相比,我们在 Transformer 中使用自注意力层和交叉注意力层来获取以两张图像为条件的特征描述符。 Transformer 提供的全局感受野使我们的方法能够在低纹理区域产生密集匹配,而特征检测器通常很难在这些区域产生可重复的兴趣点。 室内和室外数据集的实验表明,LoFTR 的性能大幅优于最先进的方法。 LoFTR 还在已发布的方法中的两个视觉本地化公共基准中排名第一。 代码可在我们的项目页面获取:https://zju3dv.github.io/loftr/。
1简介
图像之间的局部特征匹配是许多 3D 计算机视觉任务的基石,包括运动结构 (SfM)、同步定位和建图 (SLAM)、视觉定位等。 给定两个要匹配的图像,大多数现有的匹配方法由三个独立的阶段组成:特征检测、特征描述和特征匹配。 在检测阶段,首先将角点等显着点检测为每个图像中的兴趣点。 然后在这些兴趣点的邻域区域周围提取局部描述符。 特征检测和描述阶段产生两组带有描述符的兴趣点,随后通过最近邻搜索或更复杂的匹配算法找到它们的点对点对应关系。
特征检测器的使用减少了匹配的搜索空间,并且得到的稀疏对应足以满足大多数任务,例如相机姿态估计。 然而,由于各种因素(例如不良纹理、重复图案、视点变化、照明变化和运动模糊),特征检测器可能无法提取图像之间可重复的足够的兴趣点。 这个问题在室内环境中尤其突出,低纹理区域或重复图案有时占据视野中的大部分区域。 图1展示了一个例子。 如果没有可重复的兴趣点,即使有完美的描述符也无法找到正确的对应关系。

最近的几项工作[34,33,19]试图通过建立像素级密集匹配来解决这个问题。 可以从密集匹配中选择具有高置信度分数的匹配,从而避免特征检测。 然而,这些作品中卷积神经网络(CNN)提取的密集特征的感受野有限,可能无法区分不明显的区域。 相反,人类不仅基于本地邻域,而且还基于更大的全局上下文在这些不明显的区域中找到对应关系。 例如,图1中的低纹理区域可以根据它们与边缘的相对位置来区分。 这一观察结果告诉我们,特征提取网络中较大的感受野至关重要。
受上述观察的启发,我们提出了局部特征变换器(LoFTR),这是一种新颖的无检测器局部特征匹配方法。 受开创性工作 SuperGlue [37] 的启发,我们使用具有自关注层和交叉关注层的 Transformer [48] 来处理(转换)从卷积主干提取的密集局部特征。 首先以低特征分辨率(图像维度的)在两组变换后的特征之间提取密集匹配。 从这些密集匹配中选择具有高置信度的匹配,然后使用基于相关性的方法将其细化到子像素级别。 Transformer 的全局感受野和位置编码使变换后的特征表示与上下文和位置相关。 通过多次交错自注意力层和交叉注意力层,LoFTR 学习了地面实况匹配中展示的密集排列的全局同意的匹配先验。 还采用线性 Transformer 将计算复杂度降低到可管理的水平。
我们在室内和室外数据集的多个图像匹配和相机姿态估计任务上评估了所提出的方法。 实验表明,LoFTR 的性能大大优于基于检测器和无检测器的特征匹配基线。 LoFTR 还实现了最先进的性能,并在两个视觉本地化公共基准上的已发布方法中排名第一。 与基于检测器的基线方法相比,LoFTR 即使在低纹理、运动模糊或重复模式的不明显区域也可以产生高质量的匹配。
2相关工作
基于检测器的局部特征匹配。 基于检测器的方法一直是局部特征匹配的主要方法。 在深度学习时代之前,很多具有地方特色的传统手工作品都取得了不俗的表现。 SIFT [26] 和 ORB [35] 可以说是最成功的手工局部特征,并在许多 3D 计算机视觉任务中广泛采用。 基于学习的方法可以显着提高局部特征的大视点和光照变化的性能。 值得注意的是,LIFT [51] 和 MagicPoint [8] 是首批成功的基于学习的局部特征。 他们采用手工方法中基于检测器的设计并取得了良好的性能。 SuperPoint [9] 训练建立在 MagicPoint 的基础上,并提出了一种通过单应适应的自我监督方法。 许多基于学习的局部特征[32,11,25,28,47]也采用了基于检测器的设计。
上述局部特征使用最近邻搜索来查找提取的兴趣点之间的匹配。 最近,SuperGlue [37]提出了一种基于学习的局部特征匹配方法。 SuperGlue 接受两组兴趣点及其描述符作为输入,并通过图神经网络 (GNN) 学习它们的匹配,这是 Transformers [16] 的一般形式。 由于特征匹配的先验可以通过数据驱动的方法来学习,SuperGlue 实现了令人印象深刻的性能,并在局部特征匹配方面树立了新的技术水平。 然而,作为一种依赖于检测器的方法,它的根本缺点是无法检测不明显区域中的可重复兴趣点。 SuperGlue 中的注意力范围也仅限于检测到的兴趣点。 我们的工作受到 SuperGlue 的启发,在 GNN 中使用自注意力和交叉注意力在两组描述符之间传递消息,但我们提出了一种无检测器设计,以避免特征检测器的缺点。 我们还使用 Transformer 中注意力层的有效变体来降低计算成本。
无探测器局部特征匹配。 无检测器方法消除了特征检测器阶段并直接产生密集描述符或密集特征匹配。 密集特征匹配的思想可以追溯到 SIFT Flow [23]。 [6, 39] 是第一个基于学习的方法,用于学习具有对比损失的像素级特征描述符。 与基于检测器的方法类似,最近邻搜索通常用作后处理步骤来匹配密集描述符。 NCNet [34]提出了一种不同的方法,以端到端的方式直接学习密集对应关系。 它构建 4D 成本量来枚举图像之间所有可能的匹配,并使用 4D 卷积来正则化成本量并在所有匹配之间强制执行邻域共识。 稀疏 NCNet [33] 在 NCNet 的基础上进行了改进,并通过稀疏卷积使其更加高效。 与我们的工作同时,DRC-Net [19] 遵循这一工作路线,并提出了一种从粗到细的方法来产生更高精度的密集匹配。 尽管在 4D 成本量中考虑了所有可能的匹配,但 4D 卷积的感受野仍然仅限于每个匹配的邻域区域。 除了邻域共识之外,我们的工作重点是借助《变形金刚》中的全局感受野在比赛之间达成全局共识,而 NCNet 及其后续作品中并未利用这一点。 [24]提出了一种针对内窥镜视频的 SfM 的密集匹配流程。 最近的研究方向[46,45,44,15]专注于桥接局部特征匹配和光流估计的任务,也与我们的工作相关。
视觉相关任务中的变形金刚。 Transformer [48] 因其简单性和计算效率而成为自然语言处理 (NLP) 中序列建模的事实上的标准。 最近,Transformers 在计算机视觉任务中也得到了更多关注,例如图像分类[10]、对象检测[3]和语义分割[49]. 与我们的工作同时,[20]建议使用 Transformer 进行视差估计。 由于查询向量和键向量之间的乘法,普通 Transformer 的计算成本随着输入序列的长度呈二次方增长。 最近在处理长语言序列的背景下提出了许多有效的变体[42,18,17,5]。 由于这些工作中没有对输入数据进行假设,因此它们也非常适合处理图像。
3方法
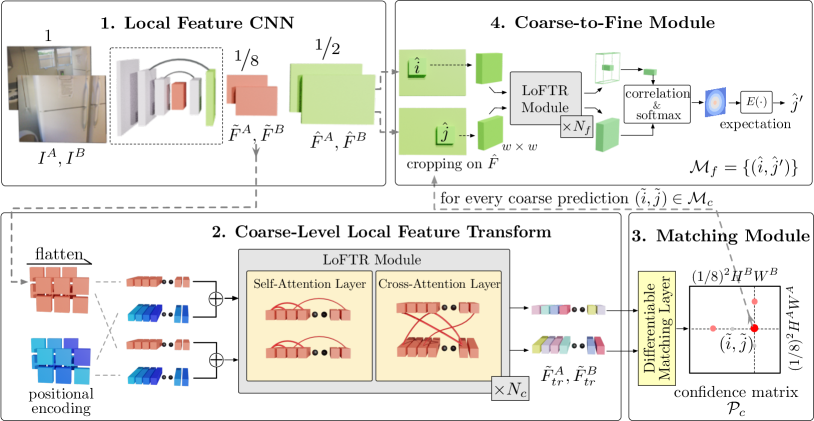
给定图像对和,现有的局部特征匹配方法使用特征检测器来提取兴趣点。 我们建议通过无检测器设计来解决特征检测器的可重复性问题。 图2展示了所提出的LoFTR方法的概述。
3.1 局部特征提取
我们使用带有 FPN [22](表示为局部特征 CNN)的标准卷积架构从两个图像中提取多级特征。 我们使用和表示原始图像维度处的粗级特征,和原始图像尺寸处的精细级别特征。
卷积神经网络(CNN)具有平移等方差和局部性的归纳偏差,非常适合局部特征提取。 CNN 引入的下采样还减少了 LoFTR 模块的输入长度,这对于确保可管理的计算成本至关重要。
3.2 局部特征转换器(LoFTR)模块
局部特征提取后,和通过LoFTR模块来提取位置和上下文相关的局部特征。 直观上,LoFTR 模块将特征转换为易于匹配的特征表示。 我们将转换后的特征表示为 和 。
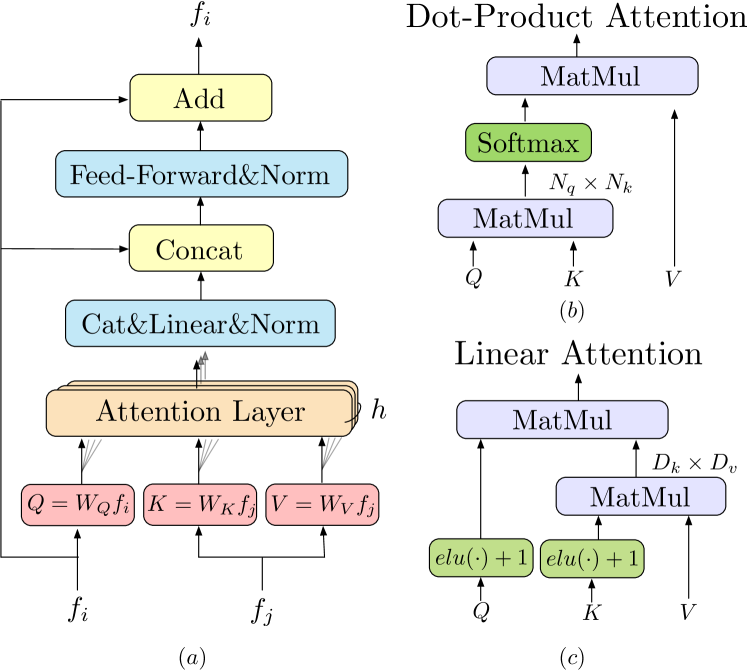
初步知识: Transformer [48]。 这里我们首先简单介绍一下Transformer作为背景。 Transformer 编码器由顺序连接的编码器层组成。 图3(a)显示了编码器层的架构。
编码器层的关键元素是注意力层。 注意力层的输入向量通常称为查询、键和值。 与信息检索类似,查询向量 根据 和键的点积计算出的注意力权重,从值向量 中检索信息对应于每个值的向量。注意力层的计算图如图3(b)所示。 形式上,注意力层表示为:
直观上,注意力操作通过测量查询元素与每个关键元素之间的相似度来选择相关信息。 输出向量是按相似度分数加权的值向量的总和。 结果,如果相似度高,则从值向量中提取相关信息。 这个过程在图神经网络中也称为“消息传递”。
线性 Transformer 。 将和的长度表示为,将其特征尺寸表示为,之间的点积Transformer 中的 > 和 引入的计算成本随着输入序列的长度呈二次方增长 ()。 即使局部特征 CNN 减少了输入长度,在局部特征匹配的情况下直接应用 Transformer 的普通版本也是不切实际的。 为了解决这个问题,我们建议在 Transformer 中使用普通注意力层的有效变体。 Linear Transformer [17]提出通过用替代核函数替换原始注意力层中使用的指数核,将Transformer的计算复杂度降低到 >。 图3(c)中的计算图说明了该操作。 利用矩阵乘积的结合性,可以先进行和之间的乘法。 从开始,计算成本减少到。
3.3 建立粗级匹配
LoFTR 中可以应用两种类型的可微匹配层,要么使用 [37] 中的最佳传输 (OT) 层,要么使用双 softmax 算子 [34, 47]. 首先通过计算变换后的特征之间的得分矩阵。 当与OT匹配时,可以用作部分分配问题的成本矩阵,如[37]。 我们还可以在的两个维度上应用softmax(以下简称dual-softmax)来获得软互近邻匹配的概率。 形式上,当使用dual-softmax时,匹配概率通过以下方式获得:
匹配选择。 基于置信度矩阵,我们选择置信度高于阈值的匹配,并进一步强制执行相互最近邻(MNN)标准,过滤可能的异常粗略匹配。 我们将粗略匹配预测表示为:
3.4粗到精模块
建立粗略匹配后,使用从粗到细的模块将这些匹配细化到原始图像分辨率。 受[50]的启发,我们使用基于相关性的方法来实现此目的。 对于每个粗略匹配,我们首先在精细级别特征图和处定位其位置,然后裁剪两个大小为 的本地窗口集。 然后,较小的 LoFTR 模块将每个窗口内的裁剪特征变换 倍,产生两个以 为中心的变换后的局部特征图 和 分别为 t3> 和 。 然后,我们将 的中心向量与 中的所有向量相关联,从而生成一个热图,表示 邻域中每个像素的匹配概率与。 通过计算概率分布的期望,我们得到了 上亚像素精度的最终位置 。 收集所有匹配 会产生最终的精细匹配 。
3.5监督
最终的损失由粗级和细级的损失组成:。
粗层次监管。 粗级损失函数是最优传输层或双 softmax 算子返回的置信矩阵 上的负对数似然损失。 我们按照 SuperGlue [37] 使用相机姿势和深度图来计算训练期间置信矩阵的地面实况标签。 我们将地面实况粗匹配定义为两组分辨率网格的相互最近邻居。 两个网格之间的距离是通过其中心位置的重投影距离来测量的。 补充材料中提供了更多详细信息。 对于最佳传输层,我们使用与[37]中相同的损失公式。 当使用 Dual-softmax 进行匹配时,我们最小化 中网格的负对数似然损失:
精细化监管。 我们使用 损失进行精细级别的细化。 继[50]之后,对于每个查询点,我们还通过计算相应热图的总方差来衡量其不确定性。 目标是优化不确定性较低的细化仓位,得到最终的加权损失函数:
其中 是通过使用地面真实相机姿态和深度将每个 从 扭曲到 来计算的。 在计算 时,如果 的翘曲位置位于 的局部窗口之外,我们将忽略 (, )。 训练期间梯度不会通过 反向传播。
3.6实现细节
我们在 ScanNet [7] 数据集上训练 LoFTR 的室内模型,在 [37] 之后在 MegaDepth [21] 上训练室外模型。 在 ScanNet 上,模型使用 Adam 进行训练,初始学习率为 ,批量大小为 64。 它在 64 个 GTX 1080Ti GPU 上训练 24 小时后收敛。 局部特征CNN使用ResNet-18 [12]的修改版本作为主干。 整个模型使用随机初始化的权重进行端到端训练。 设置为 4, 设置为 1。 选择为 0.2。 窗口大小等于5。 和 在通过实现中的精细级 LoFTR 之前进行上采样并与 和 连接。 对于 RTX 2080Ti 上的 640480 图像对,具有双 softmax 匹配的完整模型的运行时间为 116 毫秒。 在最佳传输设置下,我们使用 3 次 Sinkhorn 迭代,模型运行时间为 130 毫秒。我们建议读者参阅补充材料,了解训练和计时分析的更多详细信息。
4实验
4.1 单应性估计
在第一个实验中,我们在广泛采用的 HPatches 数据集 [1] 上评估 LoFTR 以进行单应性估计。 HPatches 包含 52 个在显着光照变化下的序列和 56 个在视点上表现出较大变化的序列。
评估协议。 在每个测试序列中,一张参考图像与其余五张图像配对。 所有图像都调整为较短尺寸等于 480。 对于每个图像对,我们使用在 MegaDepth [21] 上训练的 LoFTR 提取一组匹配。 我们使用 OpenCV 来计算单应性估计,并以 RANSAC 作为鲁棒估计器。 为了与产生不同匹配数量的方法进行公平比较,我们计算用估计的 扭曲的图像和真实值 之间的角点误差作为正确性标识符:在[9]中。 在[37]之后,我们分别报告角点误差的累积曲线(AUC)下的面积,阈值分别为3、5和10像素。 我们报告 LoFTR 的结果,最多 1K 输出匹配。
基线方法。 我们将 LoFTR 与三类方法进行比较:1)基于检测器的局部特征,包括 R2D2 [32]、D2Net [11] 和 DISK [47], 2) 基于检测器的局部特征匹配器,即 SuperPoint [9] 特征之上的 SuperGlue [37],以及 3) 无检测器匹配器包括 Sparse-NCNet [33] 和 DRC-Net [19]。 对于局部特征,我们最多提取 2K 个特征,并用这些特征提取相互最近的邻居作为最终匹配。 对于直接输出匹配的方法,我们限制最多 1K 匹配,与 LoFTR 相同。 我们对所有基线使用原始实现中的默认超参数。
结果。 标签。 1 表明 LoFTR 在所有错误阈值下均显着优于其他基线。 具体来说,LoFTR 与其他方法之间的性能差距随着更严格的正确性阈值而增加。 我们将顶级性能归因于无检测器设计提供的大量匹配候选以及 Transformer 带来的全局感受野。 此外,从粗到细模块还通过将匹配细化到子像素级别来提高估计精度。
| Category | Method | Homography est. AUC | #matches | ||
|---|---|---|---|---|---|
| @3px | @5px | @10px | |||
| Detector-based | D2Net [11]+NN | 23.2 | 35.9 | 53.6 | 0.2K |
| R2D2 [32]+NN | 50.6 | 63.9 | 76.8 | 0.5K | |
| DISK [47]+NN | 52.3 | 64.9 | 78.9 | 1.1K | |
| SP [9]+SuperGlue [37] | 53.9 | 68.3 | 81.7 | 0.6K | |
| Detector-free | Sparse-NCNet [33] | 48.9 | 54.2 | 67.1 | 1.0K |
| DRC-Net [19] | 50.6 | 56.2 | 68.3 | 1.0K | |
| LoFTR-DS | 65.9 | 75.6 | 84.6 | 1.0K | |
4.2 相对姿态估计
| Category | Method | Pose estimation AUC | ||
|---|---|---|---|---|
| @5° | @10° | @20° | ||
| Detector-based | ORB [35]+GMS [2] | 5.21 | 13.65 | 25.36 |
| D2-Net [11]+NN | 5.25 | 14.53 | 27.96 | |
| ContextDesc [27]+Ratio Test [26] | 6.64 | 15.01 | 25.75 | |
| SP [9]+NN | 9.43 | 21.53 | 36.40 | |
| SP [9]+PointCN [52] | 11.40 | 25.47 | 41.41 | |
| SP [9]+OANet [53] | 11.76 | 26.90 | 43.85 | |
| SP [9]+SuperGlue [37] | 16.16 | 33.81 | 51.84 | |
| Detector-free | DRC-Net † [19] | 7.69 | 17.93 | 30.49 |
| LoFTR-OT† | 16.88 | 33.62 | 50.62 | |
| LoFTR-OT | 21.51 | 40.39 | 57.96 | |
| LoFTR-DS | 22.06 | 40.8 | 57.62 | |
| Category | Method | Pose estimation AUC | ||
|---|---|---|---|---|
| @5° | @10° | @20° | ||
| Detector-based | SP [9]+SuperGlue [37] | 42.18 | 61.16 | 75.96 |
| Detector-free | DRC-Net [19] | 27.01 | 42.96 | 58.31 |
| LoFTR-OT | 50.31 | 67.14 | 79.93 | |
| LoFTR-DS | 52.8 | 69.19 | 81.18 | |
数据集。 我们使用 ScanNet [7] 和 MegaDepth [21] 分别证明 LoFTR 在室内和室外场景中姿态估计的有效性。
ScanNet 包含 1613 个单眼序列,具有地面真实姿势和深度图。 遵循 SuperGlue [37] 的过程,我们对 2.3 亿个图像对进行采样以进行训练,重叠分数在 0.4 到 0.8 之间。 我们在 [37] 的 1500 个测试对上评估我们的方法。 所有图像和深度图的大小都调整为 。 该数据集包含具有宽基线和广泛无纹理区域的图像对。
MegaDepth 由 196 个不同户外场景的 100 万张互联网图像组成。 作者还提供了 COLMAP [40] 的稀疏重建和多视图立体计算的深度图。 我们按照DISK [47]仅使用“Sacre Coeur”和“St. John's”的场景。 圣彼得广场”进行验证,我们从中抽取了 1500 对进行公平比较。 调整图像大小,使其较长尺寸等于训练时的 840 和验证时的 1200。 MegaDepth 的关键挑战是极端视点变化和重复模式下的匹配。
评估协议。 在[37]之后,我们报告了阈值()处姿态误差的AUC,其中姿态误差被定义为旋转和平移中的最大角度误差。 为了恢复相机姿态,我们通过 RANSAC 预测匹配来求解基本矩阵。 由于缺乏针对无检测器的明确定义的指标(例如,匹配分数或召回率 [13, 30]),我们不比较 LoFTR 和其他基于检测器的方法之间的匹配精度图像匹配方法。 我们认为 DRC-Net [19] 是无检测器方法 [34, 33] 中最先进的方法。
室内姿态估计的结果。 与所有竞争对手相比,LoFTR 在姿势精度方面实现了最佳性能(参见表 1)。 2和图5)。 将 LoFTR 与最佳传输或双 softmax 配对作为可微匹配层可实现可比的性能。 由于DRC-Net发布的模型是在MegaDepth上训练的,因此我们提供在MegaDepth上训练的LoFTR的结果以进行公平比较。 在本次评估中,LoFTR 的性能也大幅优于 DRC-Net(见图5),这证明了我们的模型在跨数据集上的通用性。
| Method | Day | Night |
|---|---|---|
| (0.25m,2°) / (0.5m,5°) / (1.0m,10°) | ||
| Local Feature Evaluation on Night-time Queries | ||
| R2D2 [32]+NN | - | 71.2 / 86.9 / 98.9 |
| LISRD [31]+SP [9]+AdaLam [4] | - | 73.3 / 86.9 / 97.9 |
| ISRF [29]+NN | - | 69.1 / 87.4 / 98.4 |
| SP [9]+SuperGlue [37] | - | 73.3 / 88.0 / 98.4 |
| LoFTR-DS | - | 72.8 / 88.5 / 99.0 |
| Full Visual Localization with HLoc | ||
| SP [9]+SuperGlue [37] | 89.8 / 96.1 / 99.4 | 77.0 / 90.6 / 100.0 |
| LoFTR-OT | 88.7 / 95.6 / 99.0 | 78.5 / 90.6 / 99.0 |
4.3 视觉本地化
视觉本地化。 除了在相对姿态估计方面实现有竞争力的性能外,LoFTR 还可以有益于视觉定位,即估计给定图像相对于相应 3D 场景模型的 6-DoF 姿态的任务。 我们在长期视觉定位基准[43](以下简称VisLoc基准)上评估LoFTR。 它专注于在不同条件下对视觉定位方法进行基准测试,例如昼夜变化、场景几何变化以及具有大量无纹理区域的室内场景。 因此,视觉定位任务依赖于高度鲁棒的图像匹配方法。
评估。 我们在 VisLoc 的两个轨道上评估 LoFTR,这两个轨道包含几个挑战。 首先,“手持设备视觉本地化”赛道需要完整的本地化管道。 它对两个数据集进行基准测试,即涉及室外场景的 Aachen-Day-Night 数据集 [38, 54] 和涉及室内场景的 InLoc [41] 数据集。 我们使用开源本地化管道 Hloc [36] 以及 LoFTR 提取的匹配项。 其次,“长期定位的局部特征”轨道提供了一个固定的定位管道来评估局部特征提取器本身以及可选的匹配器。 该赛道使用 Aachen v1.1 数据集[54]。 我们在补充材料中提供了在 VisLoc 上测试 LoFTR 的实现细节。
| Method | DUC1 | DUC2 |
|---|---|---|
| (0.25m,10°) / (0.5m,10°) / (1.0m,10°) | ||
| ISRF [29] | 39.4 / 58.1 / 70.2 | 41.2 / 61.1 / 69.5 |
| KAPTURE [14]+R2D2 [32] | 41.4 / 60.1 / 73.7 | 47.3 / 67.2 / 73.3 |
| HLoc [36]+SP [9]+SuperGlue [37] | 49.0 / 68.7 / 80.8 | 53.4 / 77.1 / 82.4 |
| HLoc [36]+LoFTR-OT | 47.5 / 72.2 / 84.8 | 54.2 / 74.8 / 85.5 |
| Method | Pose estimation AUC | |||
|---|---|---|---|---|
| @5° | @10° | @20° | ||
| 1) replace LoFTR with convolution | 14.98 | 32.04 | 49.92 | |
| 2) coarse-resolution + fine-resolution | 16.75 | 34.82 | 54.0 | |
| 3) positional encoding per layer | 18.02 | 35.64 | 52.77 | |
| 4) larger model with | 20.87 | 40.23 | 57.56 | |
| Full () | 20.06 | 40.8 | 57.62 | |
结果。 我们在表中提供了 LoFTR 的评估结果。 4 和选项卡。 5. 我们评估了 LoFTR 与最佳传输层或双 softmax 算子的配对,并报告了结果更好的配对。 LoFTR-DS 优于本地特征挑战赛道中的所有基线,显示出其在昼夜变化下的鲁棒性。 然后,对于手持设备跟踪的视觉定位,LoFTR-OT 在具有挑战性的 InLoc 数据集上优于所有已发布的方法,该数据集包含广泛的外观变化、更多无纹理区域、对称和重复元素。 我们将其突出归功于Transformer和最佳传输层的使用,利用全球信息并共同将全球共识带入最终比赛。 无检测器设计也发挥着关键作用,可以防止基于检测器的方法在低纹理区域中出现重复性问题。 LoFTR-OT 在 Aachen v1.1 数据集的夜间查询上的表现与最先进的方法 SuperPoint + SuperGlue 相当,但在白天查询上的表现稍差。
4.4了解LoFTR


消融研究。 为了充分理解 LoFTR 中的不同模块,我们评估了五种不同的变体,结果如表 1 所示。 6:1)用具有相当数量参数的卷积替换 LoFTR 模块会导致 AUC 显着下降,正如预期的那样。 2) 使用较小版本的 LoFTR,分别在粗略和精细级别具有 和 分辨率特征图,导致运行时间为 104 ms,姿态估计精度下降。 3)使用 DETR 风格的 [3] Transformer 架构,该架构在每一层都有位置编码,导致结果明显下降。 4) 通过将 LoFTR 层数加倍到 来增加模型容量,结果几乎没有改变。 我们使用与 ScanNet 上的室内姿态估计相同的训练和评估协议以及用于匹配的最佳传输层来进行这些实验。
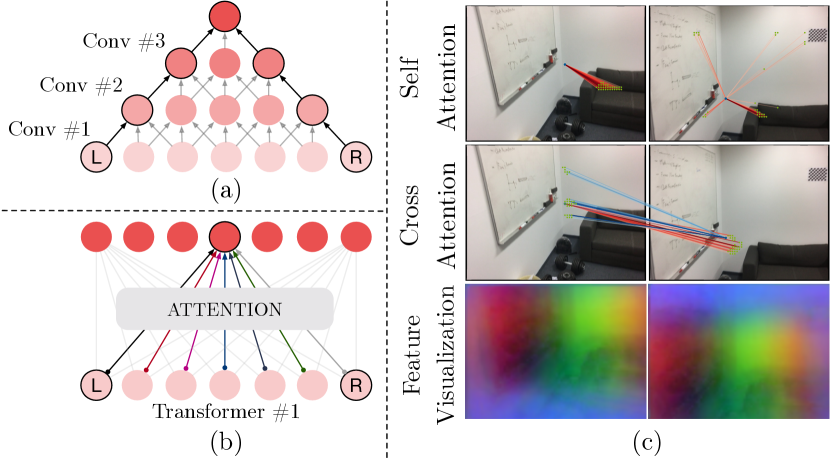
可视化注意力。 我们在图 6 中可视化注意力权重。
5结论
本文提出了一种新颖的无检测器匹配方法,名为 LoFTR,它可以以从粗到细的方式与 Transformer 建立精确的半密集匹配。 所提出的LoFTR模块使用Transformers中的自注意力层和交叉注意力层将局部特征转换为上下文和位置相关的,这对于LoFTR在具有低纹理或重复模式的不明显区域上获得高质量匹配至关重要。 我们的实验表明,LoFTR 在多个数据集上的相对姿态估计和视觉定位方面实现了最先进的性能。 我们相信LoFTR为局部图像特征匹配中的无检测器方法提供了新的方向,并且可以扩展到更具挑战性的场景,例如匹配具有严重季节变化的图像。
致谢。 作者谨此感谢国家重点研发计划(No. 2020AAA0108901),国家自然科学基金(No. 61806176),以及浙江大学-商汤3D视觉联合实验室。
参考
- [1] Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krystian Mikolajczyk. HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. In CVPR, 2017.
- [2] JiaWang Bian, Wen-Yan Lin, Yasuyuki Matsushita, Sai-Kit Yeung, Tan-Dat Nguyen, and Ming-Ming Cheng. GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. In CVPR, 2017.
- [3] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- [4] Luca Cavalli, Viktor Larsson, Martin Ralf Oswald, Torsten Sattler, and Marc Pollefeys. Handcrafted Outlier Detection Revisited. In ECCV, 2020.
- [5] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. ICLR, 2021.
- [6] Christopher B Choy, JunYoung Gwak, Silvio Savarese, and Manmohan Chandraker. Universal correspondence network. NeurIPS, 2016.
- [7] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, 2017.
- [8] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Toward geometric deep slam. arXiv:1707.07410.
- [9] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperPoint: Self-supervised interest point detection and description. In CVPRW, 2018.
- [10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- [11] Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-Net: A trainable cnn for joint detection and description of local features. CVPR, 2019.
- [12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [13] Jared Heinly, Enrique Dunn, and Jan-Michael Frahm. Comparative evaluation of binary features. In ECCV, 2012.
- [14] Martin Humenberger, Yohann Cabon, Nicolas Guerin, Julien Morat, Jérôme Revaud, Philippe Rerole, Noé Pion, Cesar de Souza, Vincent Leroy, and Gabriela Csurka. Robust Image Retrieval-based Visual Localization using Kapture. arXiv:2007.13867.
- [15] Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasacchi, and Kwang Moo Yi. COTR: Correspondence Transformer for Matching Across Images, 2021.
- [16] Chaitanya Joshi. Transformers are Graph Neural Networks. https://thegradient.pub/transformers-are-graph-neural-networks/, 2020.
- [17] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. In ICML, 2020.
- [18] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. ICLR, 2020.
- [19] Xinghui Li, Kai Han, Shuda Li, and Victor Prisacariu. Dual-resolution correspondence networks. NeurIPS, 2020.
- [20] Zhaoshuo Li, Xingtong Liu, Francis X Creighton, Russell H Taylor, and Mathias Unberath. Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers. arXiv:2011.02910.
- [21] Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. In CVPR, 2018.
- [22] Tsung-Yi Lin, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan, and Serge J. Belongie. Feature Pyramid Networks for Object Detection. CVPR, 2017.
- [23] Ce Liu, Jenny Yuen, and Antonio Torralba. SIFT Flow: Dense correspondence across scenes and its applications. T-PAMI, 2010.
- [24] X. Liu, Y. Zheng, B. Killeen, M. Ishii, G. D. Hager, R. H. Taylor, and M. Unberath. Extremely Dense Point Correspondences Using a Learned Feature Descriptor. In CVPR, 2020.
- [25] Yuan Liu, Zehong Shen, Zhixuan Lin, Sida Peng, Hujun Bao, and Xiaowei Zhou. GIFT: Learning transformation-invariant dense visual descriptors via group cnns. NeurIPS, 2019.
- [26] David G Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 2004.
- [27] Zixin Luo, Tianwei Shen, Lei Zhou, Jiahui Zhang, Yao Yao, Shiwei Li, Tian Fang, and Long Quan. ContextDesc: Local Descriptor Augmentation with Cross-Modality Context. CVPR, 2019.
- [28] Zixin Luo, Lei Zhou, Xuyang Bai, Hongkai Chen, Jiahui Zhang, Yao Yao, Shiwei Li, Tian Fang, and Long Quan. ASLFeat: Learning local features of accurate shape and localization. In CVPR, 2020.
- [29] Iaroslav Melekhov, Gabriel J Brostow, Juho Kannala, and Daniyar Turmukhambetov. Image Stylization for Robust Features. arXiv:2008.06959.
- [30] Krystian Mikolajczyk and Cordelia Schmid. A performance evaluation of local descriptors. T-PAMI, 2005.
- [31] Rémi Pautrat, Viktor Larsson, Martin R Oswald, and Marc Pollefeys. Online Invariance Selection for Local Feature Descriptors. In ECCV, 2020.
- [32] Jerome Revaud, Philippe Weinzaepfel, César De Souza, Noe Pion, Gabriela Csurka, Yohann Cabon, and Martin Humenberger. R2D2: repeatable and reliable detector and descriptor. NeurIPS, 2019.
- [33] Ignacio Rocco, Relja Arandjelović, and Josef Sivic. Efficient neighbourhood consensus networks via submanifold sparse convolutions. In ECCV, 2020.
- [34] Ignacio Rocco, Mircea Cimpoi, Relja Arandjelović, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Neighbourhood consensus networks. NeurIPS, 2018.
- [35] Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. ORB: An efficient alternative to SIFT or SURF. In ICCV, 2011.
- [36] Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From coarse to fine: Robust hierarchical localization at large scale. In CVPR, 2019.
- [37] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning feature matching with graph neural networks. In CVPR, 2020.
- [38] Torsten Sattler, Tobias Weyand, Bastian Leibe, and Leif Kobbelt. Image Retrieval for Image-Based Localization Revisited. In BMVC, 2012.
- [39] Tanner Schmidt, Richard Newcombe, and Dieter Fox. Self-supervised visual descriptor learning for dense correspondence. RAL, 2016.
- [40] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-Motion revisited. In CVPR, 2016.
- [41] Hajime Taira, Masatoshi Okutomi, Torsten Sattler, Mircea Cimpoi, Marc Pollefeys, Josef Sivic, Tomas Pajdla, and Akihiko Torii. InLoc: Indoor visual localization with dense matching and view synthesis. In CVPR, 2018.
- [42] Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. arXiv:2009.06732.
- [43] Carl Toft, Will Maddern, Akihiko Torii, Lars Hammarstrand, Erik Stenborg, Daniel Safari, Masatoshi Okutomi, Marc Pollefeys, Josef Sivic, Tomas Pajdla, et al. Long-Term Visual Localization Revisited. T-PAMI, 2020.
- [44] Prune Truong, Martin Danelljan, L. Gool, and R. Timofte. Learning Accurate Dense Correspondences and When to Trust Them. ArXiv, abs/2101.01710, 2021.
- [45] Prune Truong, Martin Danelljan, Luc Van Gool, and Radu Timofte. GOCor: Bringing Globally Optimized Correspondence Volumes into Your Neural Network. In NeurIPS, 2020.
- [46] Prune Truong, Martin Danelljan, and Radu Timofte. GLU-Net: Global-Local Universal Network for dense flow and correspondences. In CVPR, 2020.
- [47] Michał Tyszkiewicz, Pascal Fua, and Eduard Trulls. DISK: Learning local features with policy gradient. NeurIPS, 2020.
- [48] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. NeurIPS, 2017.
- [49] Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Axial-Deeplab: Stand-alone axial-attention for panoptic segmentation. In ECCV, 2020.
- [50] Qianqian Wang, Xiaowei Zhou, Bharath Hariharan, and Noah Snavely. Learning feature descriptors using camera pose supervision. In ECCV, 2020.
- [51] Kwang Moo Yi, Eduard Trulls, Vincent Lepetit, and Pascal Fua. LIFT: Learned invariant feature transform. In ECCV, 2016.
- [52] Kwang Moo Yi, Eduard Trulls, Yuki Ono, Vincent Lepetit, Mathieu Salzmann, and Pascal Fua. Learning to find good correspondences. In CVPR, 2018.
- [53] Jiahui Zhang, Dawei Sun, Zixin Luo, Anbang Yao, Lei Zhou, Tianwei Shen, Yurong Chen, Long Quan, and Hongen Liao. Learning Two-View Correspondences and Geometry Using Order-Aware Network. ICCV, 2019.
- [54] Zichao Zhang, Torsten Sattler, and Davide Scaramuzza. Reference Pose Generation for Long-term Visual Localization via Learned Features and View Synthesis. IJCV, 2020.