您的皮肤科分类器知道它不知道什么吗?
检测未见条件的长尾
摘要
事实证明,监督深度学习模型在皮肤病分类方面非常有效。 这些模型依赖于丰富的标记训练示例的可用性。 然而,在现实世界中,许多皮肤病单独出现的频率太低,无法通过监督学习进行按条件分类。 尽管个别情况并不常见,但这些病症总体上可能很常见,因此总的来说具有临床意义。 为了防止模型在此类示例上生成错误的输出,对于能够更好地检测此类罕见情况的深度学习系统仍然存在相当大的未满足需求。 这些罕见的“异常”情况在训练中很少见(或根本没有)。 在本文中,我们将此任务定义为分布外(OOD)检测问题。 我们建立了一个基准,确保模型训练、验证和测试集之间的异常条件不相交。 与传统的 OOD 检测基准不同,传统的 OOD 检测基准的任务是检测数据集分布变化,而我们的目标是检测细微语义差异这一更具挑战性的任务。 我们提出了一种新颖的分层异常值检测(HOD)损失,它分配与每个训练异常值类别相对应的多个弃权类别,并联合执行内部值与异常值的粗分类,以及对异常值的细粒度分类。个别班级。 我们证明了所提出的基于 HOD 损失的方法优于在训练期间利用异常数据的领先方法。 此外,通过使用最新的表示学习方法(BiT、SimCLR、MICLe),性能得到显着提升。 此外,我们探索了 OOD 检测的集成策略,并提出了一种多样化的集成选择过程以获得最佳结果。 我们还对不同风险水平和不同皮肤类型的条件进行亚组分析,以研究每个亚组的 OOD 性能如何变化,并展示我们的框架与基线相比的增益。 此外,我们超越了传统的性能指标,并引入了模型信任分析的成本矩阵,以估算下游临床影响。 我们使用这个成本矩阵将所提出的方法与基线进行比较,从而更有力地证明其在现实场景中的有效性。
关键词:
深度学习、皮肤病学、集成、长尾识别、分布外检测、异常值暴露、表示学习。1简介
深度学习已被用来估算临床医生在医学影像领域大量具有临床意义的分类任务中的表现(Liu 等人,2019),数百个系统已获得监管部门批准用于临床护理(Muehlematter 等人,2021)。 虽然大多数此类系统使用监督学习来执行二元分类任务(例如存在/不存在病理),但实际临床环境往往需要识别由多种可能情况组成的 "长尾 "分布中的罕见实体。 虽然分布中的一些条件可能足够常见,足以实现每个条件分类模型的监督训练,但长尾通常包含大量的“离群”条件:这些条件对于使用监督学习进行分类来说太罕见务实(周等人,2020)。
换句话说,临床安全性能要求分类器不仅应在独立且同分布的输入(即内点)上实现高精度,还要可靠地检测异常输入(这可能会混淆分类器,做出错误的预测)不属于训练期间遇到的任何类别。 开发这种强大而可靠的分类器可以通过在出现模型在训练期间未遇到的情况时进行标记来提高临床使用的安全性。 该信息可用于触发各种实际保护措施,例如让模型放弃做出决定,而是听从临床医生的决定。
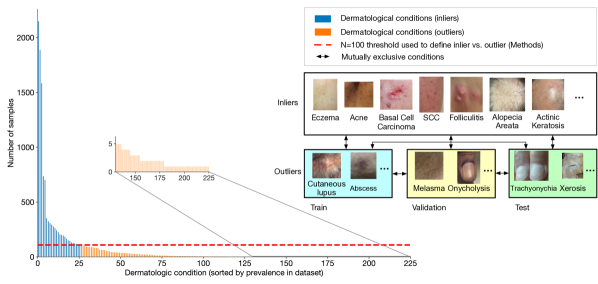
通过深度学习技术对皮肤病进行分类是一种典型的临床应用,其中以前未见过的异常值的长尾分布提出了挑战(Prabhu等人,2018)。 在之前的工作中,Liu 等人 (2020) 证明了深度学习系统可以有效地区分 最常见的皮肤状况。 这些代表了所使用的远程皮肤病学数据集中大约 例病例。 其余的病例呈长尾分布,有数百种皮肤状况,但发生频率要低得多。 这种长尾分布如图1所示,常见的情况用蓝色表示,罕见的情况用橙色表示。 由于缺乏可用的每种条件的训练示例,用于对这些罕见条件进行分类的训练模型极具挑战性。
可能的解决方案包括使用类别平衡技术或少样本学习方法(Weng等人,2020;Prabhu等人,2018)。 然而,Weng 等人 (2020) 表明,此类方法并不能显着提高这些罕见条件下的性能,这表明这些方法不能被视为现实世界部署可接受的解决方案。 此外,上述解决方案需要在训练期间见过罕见的条件,而在现实环境中可能会遇到新的未见过的条件。
另一种可能的框架是在测试期间检测此类罕见情况 - 将此挑战视为分布外 (OOD) 检测问题(Bulusu 等人,2020)。 此类方法通常利用模型置信度来实现此目的。 研究表明,深度学习模型经常会对 OOD 输入产生过于自信的预测(Goodfellow 等人,2014;Nguyen 等人,2015),这表明仍有改进的空间。
在本文中,我们的目标是解决可靠检测训练期间未发现的 OOD 罕见皮肤病的挑战。 大多数 OOD 检测仅在训练期间使用内点样本(Hendrycks 和 Gimpel,2017;Liang 等人,2018;Lakshminarayanan 等人,2017;Lee 等人,2018)。 相比之下,我们可以在训练期间访问一些“已知异常值”样本,并且我们希望利用它们来帮助在测试期间检测“未知异常值”样本。 这与 Hendrycks 等人 (2019b) 中使用的设置类似; Thulasidasan 等人 (2021),称为异常值暴露,已被证明对于 OOD 检测更有效。 此外,计算机视觉中大多数传统的 OOD 基准旨在检测数据集之间的分布变化。 我们的任务旨在检测条件之间的语义变化(两个不同类别的图像的语义信息的差异),称为近 OOD 检测问题(Winkens 等人,2020). 这更具挑战性,因为与数据集分布变化相比,语义分布变化更加微妙,因此更难以检测。
本文的主要贡献是:
-
1.
我们提出了一种新颖的分层异常值检测 (HOD) 损失,并表明该损失优于现有的基于异常值暴露的 OOD 输入检测技术。
-
2.
我们介绍了近 OOD 基准测试框架以及正确验证 OOD 检测算法所需的关键设计选择。
-
3.
我们在多种不同的最先进的表示学习方法(基于 SimCLR 和 MICLe 的自监督对比预训练)的背景下展示了新颖的 HOD 损失的附加实用性。 我们还展示了大规模标准基准(在大规模 JFT 数据集上预训练的 ImageNet 和 BiT 模型)上的 OOD 检测性能提升。
-
4.
我们建议使用具有不同表示学习和目标的多样化集成来提高 OOD 检测性能。 我们展示了它相对于普通集成的优越性,并进行了分析,研究多样性如何有助于更好的 OOD 检测性能。
-
5.
我们提出了一种用于模型信任分析的成本加权评估指标,其中纳入了下游临床影响,以帮助评估现实世界的影响。
2相关工作
在本节中,我们概述了 OOD 检测的相关最新工作,特别是在医学成像和皮肤病学中的应用。
2.1 深度学习的 OOD 检测
在深度学习文献中,max-of-softmax 概率(MSP)(Hendrycks 和 Gimpel,2017) 由于其简单性和良好的性能,是广泛使用的 OOD 检测基线方法。 顾名思义,MSP 定义为模型预测类别概率的最大值。 该方法基于这样的假设:监督训练生成的模型对 OOD 输入的信心较低。 为了对 OOD 数据实施低置信度预测,一种方法是向 softmax 层引入温度超参数,以降低分类决策的置信度。 该超参数在包含异常值的验证集上进行调整(Platt,2000;Liang等人,2018)。 尽管在大多数应用中,OOD 数据在训练或验证期间可能不可用,但某些医疗应用是例外,其中可能会出现一些罕见的情况。 为了在训练过程中利用此类额外的异常数据,可以使用异常值暴露(OE)(Hendrycks等人,2019b)等方法。 OE 的关键思想是在 OOD 训练数据的训练目标中包含一个额外项,作为常规交叉熵损失的补充。 该额外项迫使模型产生接近 OOD 样本均匀分布的输出,从而使 MSP 分数较低。 Hafner 等人 (2019) 针对回归任务提出了类似的想法,他们通过最小化 KL 散度来强制 OOD 数据的模型预测分布接近先验不确定性分布。 利用 OOD 训练数据的另一种常见方法是在 内部类 旁边添加额外的 个 OOD 弃权类(Thulasidasan 等人,2021;Zhang 和LeCun,2017;任等人,2019)。
OOD 检测在概念上与分类决策中的置信度或不确定性的估计相关。 使用深度集成可以显着提高不确定性估计(Lakshminarayanan 等人,2017;Ovadia 等人,2019)。 深度集成涉及使用随机初始化的网络权重和随机洗牌的训练输入来训练多个模型。 所有模型的平均预测类别概率的 MSP 用作置信度得分。 根据经验,当使用不同的超参数设置(例如学习率计划或权重衰减)训练模型或在集成中组合不同的模型架构时,可以实现对普通集成的改进(Wenzel 等人,2020;Kamnitsas 等人,2017) 。 尽管这种方法已知可以增强集合多样性并提高内点预测精度,但其对 OOD 检测的影响以前尚未被探索过。
最近的技术,如预训练、数据增强和自监督学习,增强了模型的鲁棒性和泛化性,也被证明可以提高 OOD 检测性能(Hendrycks 等人, 2020b, 2019a, a, c; Venkatakrishnan 等人,2020;温肯斯等人,2020)。 特别是,Winkens 等人 (2020) 表明,使用对比自监督训练技术 SimCLR (Chen 等人, 2020) 可以显着提高近 OOD 检测性能。 SimCLR 使用一组类保留变换,最大化从同一原始图像变换而来的图像之间学习嵌入的相似性,并最小化从不同图像变换而来的图像之间的相似性。 这被认为可以鼓励模型学习稳健且不变的特征,这可能会带来更好的 OOD 检测。
除了 MSP 之外,用于 OOD 检测的另一种测试统计量是基于马哈拉诺比斯距离的 OOD 评分(Lee 等人,2018;Çallı 等人,2019)。 与网络概率输出相反,它利用中间层激活。 使用训练内点数据对激活进行拟合类条件高斯分布。 测试样本与拟合分布之间的马哈拉诺比斯距离用作 OOD 分数。
另一种流行的方法是使用生成模型直接拟合内点训练数据,并使用测试输入的可能性作为 OOD 分数。 类似的方法有:似然比(Ren 等人, 2019)、DoSE (Morningstar 等人, 2021)、变分自动编码器(Thiagarajan 等人, 2020) 和混合流(Zhang 等人, 2020) 在 OOD 检测方面表现出良好的性能,但涉及对训练过程和超参数调整的重大修改。
上面讨论的现有方法存在一些局限性。 首先,大多数通用 OOD 检测方法仅使用标准基准数据集(例如 CIFAR-10、CIFAR-100、SVHN 等)进行评估。 虽然这些方法对于原型设计来说是可行的,但它们往往需要大量的内部训练数据,并且它们的 OOD 检测性能仍然需要在每个特定应用的背景下仔细评估,特别是对于医学成像等具有挑战性的设置。 其次,除了Hendrycks等人(2019b)和Thulasidasan等人(2021)之外,大多数方法在训练过程中都不使用异常值数据。 在许多实际的医疗应用中,可以访问一些“已知的异常值”样本。 我们相信将它们纳入训练过程应该有助于提高检测“未知异常值”的性能。
2.2 医学影像中的 OOD 检测
处理 OOD 输入是广泛的医学成像应用中面临的常见问题。 最近的研究调查了胸部 X 射线(Cao 等人,2020;Çallı 等人,2019;Shi 等人,2021)、脑部 CT 扫描(Venkatakrishnan 等人,2020)的挑战)、眼底图像(Cao 等人, 2020)和组织学图像(Cao 等人, 2020; Linmans 等人, 2020)。 由于包含多种条件的长尾分布具有独特的挑战性特性,皮肤科环境中的 OOD 检测引起了研究界的极大关注(Pacheco 等人,2020;Li 等人,2020;Combalia 等人, 2020;Yasin 等人,2020;Thiagarajan 等人,2020)。 然而,目前的研究有一些局限性。 首先,皮肤病学中 OOD 检测的大多数研究都是使用 ISIC 挑战数据集 等标准数据集来处理色素性皮肤病变的皮肤镜图像分类(Pacheco 等人,2020;Combalia 等人,2020;Li 等人,2020; Thiagarajan 等人, 2020)。 此类研究在更广泛的临床应用中可能受到限制,因为图像需要通过称为皮肤镜的特殊设备获取,而这种设备通常在皮肤科诊所之外无法获得。 此外,这些研究只涉及少数色素性皮肤病变状况,而在现实生活中,存在数百或数千种皮肤状况,例如皮疹、毛发脱落和指甲状况,并且可能更频繁地发生。 这些数据集中的图像在病理区域上也具有良好的照明和放大效果,没有背景变化,使得分类和 OOD 任务相对容易。 其次,大多数现有方法要么使用不同的后处理方法,要么使用复杂的密度模型。 Pacheco 等人 (2020) 和 Li 等人 (2020) 利用预训练模型中的特征图进行 OOD 检测。 Thiagarajan 等人 (2020) 使用变分自动编码器来学习解缠结的潜在表示,以提高模型的可解释性,并设计了一种校准驱动的学习方法来生成不确定性量化的预测区间。 然而,该方法需要对原始分类模型进行大量修改和非常仔细的超参数调整。 第三,这些方法大多数主要关注远距离 OOD 检测相对简单的任务:非皮肤科图像或质量较差的图像。 更具挑战性的任务是检测以前未见过的皮肤病状况,这是一个近乎 OOD 的问题,并且仍然相对未经探索。
3 基准设置和问题表述
3.1 数据集描述
在本文中,我们使用 Liu 等人 (2020) 中使用的去识别数据集的子集进行模型开发。 该数据集中的案例是从加利福尼亚州和夏威夷州的不同地点收集的。 数据集中的每个病例最多包含 个 RGB 图像,由医疗助理使用消费级数码相机拍摄。 这些图像在受影响的解剖位置、背景物体、分辨率、透视和照明方面表现出很大的变化。 为了训练,我们将每个图像的大小调整为 像素。 该数据集由 个病例组成,并通过汇总多个美国或印度委员会认证的皮肤科医生的诊断来生成基本事实。 详细的标注流程参见Liu 等人 (2020)。 请注意,为了简单起见,我们删除了具有多种条件或在基本事实中具有多个主要诊断的病例。
我们使用额外的未标记皮肤病学训练数据集,其中包含来自 病例和 患者的 图像,用于第 2 节中概述的基于对比的表示学习。 4.3 与Azizi 等人 (2021) 类似。 这些图像主要来自澳大利亚和新西兰的皮肤癌诊所,分布在不同地点和澳大利亚各州。 疾病的分布偏向于癌症疾病,但没有可用的标签。
3.2 数据拆分策略
我们数据集的长尾分布如图1所示。 与之前的工作(Liu等人,2020)一致,我们选择最常见的情况(根据每个病例的初步诊断,至少有 每个条件)并将它们视为内点(指示为蓝色)。 其余的 条件(以橙色表示)被视为异常值。 根据定义,内部值和异常值条件是相互排斥的。
为了建立 OOD 基准,我们将此数据集分为 3 组:(i) 训练、(ii) 验证和 (iii) 测试。 对于每个 内点条件,我们分别将样本大致分成 分割,用于训练验证测试。 对于异常值条件,我们还将样本分为训练、验证和测试,以便分配给每个分割的异常值条件具有互斥条件,如图 1 所示。 表 7 详细列出了内部值和异常值条件的完整列表。 分裂过程满足以下要求:
-
1.
患者在分割之间不会重叠。
-
2.
跨分割分配的离群值条件是互斥的。
-
3.
不同分割的异常样本数量相似。
-
4.
各个分割中的离群值条件数量相似,从而确保各个分割之间的离群值异质性相似。
-
5.
如果不及时治疗,每种异常情况都与临床并发症的最坏风险水平相关(低、中或高)。 我们确保了各个细分中风险类别的相似分布,以便能够对 OOD 检测方法在不同风险级别上的执行情况进行下游分析。
-
6.
不同 Fitzpatrick 皮肤类型的病例在各个分割中的分布相似,以便能够对 OOD 检测方法在不同皮肤类型上的执行情况进行下游分析。
这些要求可以概括为建立一个可靠的基准,用于评估具有长尾类分布的任何数据集的 OOD 方法。 表 1 详细列出了我们工作的分割结果的统计数据。 请注意,实际部署可能涉及之前在训练中看到的测试异常类。 因此,我们对互斥条件的更困难设置可能会低估 OOD 检测方法的实际性能。
| Train | Validation | Test | ||||
| Inlier | Outlier | Inlier | Outlier | Inlier | Outlier | |
| Num. classes | 26 | 68 | 26 | 66 | 26 | 65 |
| Num. samples | 8854 | 1111 | 1251 | 1082 | 1192 | 937 |
3.3问题表述
在本节中,我们为问题陈述提供更正式的定义,并介绍本文稍后将使用的符号。 我们用 表示数据集中所有皮肤病的标签集(例如“湿疹”、“痤疮”等;见图 1)。 类总数用表示。 让我们的带有 案例的长尾标记数据集 表示为 。 这里 的 表示 示例输入,它对应于一组 图像实例 和用表示其对应的groundtruth标签。 让 指示任何条件 被视为内点时每个条件所需的最小样本量。 我们为所有实验修复了与 Liu 等人 (2020) 类似的 。 给定 ,我们将 分成两个互斥的内部值和异常值标签集作为 ,其中我们正式定义 ,本质上是计数数据集中具有标签 的实例数。 是一个指示函数。 因此,。 这也将数据集 自然地划分为两个相互不相交的集合 ,分别作为内部数据集和异常数据集。
我们进一步将 拆分为 、 和 。 同样,我们将 拆分为 、 和 ,这样分配给每个拆分的异常值条件是互斥的,如图所示在图 1 中,并在第 2 节中详细介绍。 3.2。 我们分别用 、 和 表示这些互斥的异常值条件集。 训练数据集为,验证数据集为,测试数据集为。 我们使用 训练深度神经网络,并使用 选择超参数。 最后的任务是正确区分 和 。
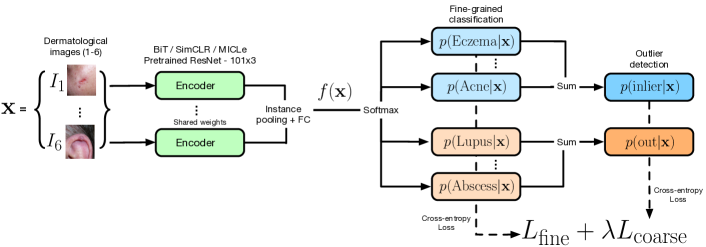
4方法
在本节中,我们将描述模型架构、提出的分层异常值检测损失,以及最后我们为提高 OOD 检测性能而研究的各种表示学习和模型集成策略。
4.1架构细节
我们在图2中说明了整体设置。 正如 Sec 中详细介绍的那样。 3.3,我们正在处理多实例皮肤科图像分类任务。 具体来说,每个案例都包含 个图像实例,并且每个案例都被分配一个主要诊断。 我们使用通用编码器来处理所有实例。 选择宽 ResNet 模型作为编码器,该模型使用不同的表示学习方法进行预训练,稍后将在第 2 节中详细介绍。 4.3。 编码器为案例中的每个图像实例提供特征表示。 然后,该输出通过实例级平均池化层,该层为给定情况的所有实例生成通用特征图。 这被传递到分类头,该分类头具有一个具有 维度的中间全连接隐藏层,然后是具有 softmax 层的最终分类,该层为每个细粒度内点和训练异常值类别提供概率。 请注意,为了简单起见,我们始终使用 ResNet- 作为编码器架构,尽管对其他架构的扩展很简单。
4.2 分层异常值检测损失
我们以 Thulasidasan 等人 (2021) 最近的工作为基础,该工作提出建立一个专用的弃权类,也称为用于检测 OOD 样本的拒绝桶,并使用离群数据进行训练。 与传统的基于熵归一化的异常值暴露方法相比,这被证明是有效的(Hendrycks等人,2019b)。 用于训练的异常样本在语义、采集源、分辨率等方面可能具有很高的可变性。 将这样的异构异常值集封装在单个弃权类别中可能具有挑战性。 这里的一种自然缓解策略是分配多个弃权训练类别作为可能的输出,代表通过细粒度设置可用的每个单独的异常值类别。 在皮肤病学环境中,使用多个离群值类别的方法也很实用,因为我们通常可以访问与训练离群值数据相关的一些标签。 我们的设置与此类似;我们知道训练数据集中的独特异常值类,即使某些异常值类的样本数量可能低至每个 个样本。 我们推测,允许多个弃权类别有两个主要优点:(i)它大大减少了拟合单个高度异构类别的负担,从而允许更加结构化的决策边界,(ii)它提供了正确建模内点和内点的高能力。异常值类,最终产生更丰富的特征表示。
显然,有了更好的训练异常值模型,我们最终希望我们的网络能够泛化以测试不属于细粒度训练异常值类的异常值样本。 这可以通过鼓励模型学习内部与异常类的高级语义分离特征来实现。 这可以通过限制内点类内的概率质量来潜在地帮助对内点样本进行建模,而不是与多个异常值弃权类共享,反之亦然。
为此,我们建议采用分层异常值检测(HOD)损失。 这是由细粒度的低级损失和粗粒度的高级损失组成。 给定输入样本 及其来自 的关联标签 ,让 表示模型倒数第二层的输出。 在我们的例子中,是维度的向量。 类 的预测概率表示为
| (1) |
其中 和 是类 和 的最后一层的权重和偏差。 请注意,网络提供维度 的输出,具有 弃权类别。
然后根据预测概率构建两级分层损失。 细粒度损失定义为真实标签类的交叉熵损失,即负对数似然,
| (2) |
对于粗粒度损失,我们首先将 为内点的概率定义为 、 类似地,成为离群值的概率是、中细粒度离群值类的概率之和。 如图2所示。 粗粒度级别是类之间的二元分类。 粗粒度损失定义为
| (3) |
在测试时, 弃权类别的各个概率没有任何重要性,因为它们都没有出现在测试集中。 使用指示 OOD 分数 的这些概率的总和。
我们认为 HOD 损失为 OOD 检测提供了两个主要好处。 首先,细粒度的损失有助于减少每个弃权类别的 OOD 数据异质性,从而允许更结构化的决策边界。 其次,粗粒度损失起到动态标签平滑的作用,提高了未见异常值检测的泛化能力。 特别是,对于 OOD 输入 (其中 ),它贡献的对数似然是,
| (7) |
其中第一项代表细粒度损失,第二项代表粗粒度损失。 为了最小化损失,相当于最大化对数似然,模型可以通过梯度下降增加 ,或者增加其余 OOD 类的 。 换句话说,细粒度损失是增加特定类的概率,而粗粒度损失是增加其余 OOD 类的概率质量。 即使该数据点适用于 OOD 类 ,与其余 OOD 类 相关的参数也会根据此损失的梯度进行更新,从而导致与标签平滑类似的效果。 当测试 OOD 类与训练 OOD 类互斥时,此属性非常有用。 当使用训练 OOD 类训练模型时,测试 OOD 数据对于任何特定训练 OOD 类 的概率不会很高,因为测试 OOD 类是看不见的。 但由于粗粒度的损失,它在 OOD 类 的聚合概率中可能具有相对较高的概率,从而导致 OOD 性能更好的泛化。
对这种综合损失的一种解释是按照数据增强的思路来思考。 让我们想象每个输入 都与一个粗粒度标签和一个细粒度标签相关联。 我们将此示例复制 次,并将其与其细粒度标签配对。 类似地,我们复制相同的样本 次,并将它们与其粗略标签配对。 样本 增强 次的组合对数似然贡献相当于我们的损失函数 ,其中 。
请注意,Yan 等人 (2015) 也将图像类之间的层次结构合并到模型中,但方式不同:为每个高级类构建独立的细粒度分类头。 此外,他们的研究是为了提高内点预测精度,而不是为了 OOD 检测。 据我们所知,我们是第一个使用这种分层损失进行 OOD 检测的人。
4.3 表示学习
表征学习已被证明对于训练数据量有限的半监督学习是有效的(Kolesnikov 等人,2019;Chen 等人,2020)。 虽然表示学习的主要目标是在下游任务中实现标签效率,但在本文中,我们将主要探讨表示学习对下游 OOD 检测任务的有效性。 我们假设可以在预训练阶段学习通用特征。 虽然这些特征在仅使用监督目标进行训练时可能会被丢弃,因为它们可能无法直接用于分类,但我们可以利用它们进行 OOD 检测。
在图像分类中,常见的表示学习方法是通过在 ImageNet 上预训练的模型。 我们使用在 ImageNet 数据集中的自然图像上预先训练的宽 ResNet- 特征提取器作为基线表示学习方法。 Liu 等人 (2020) 中也使用了基于 ImageNet 的预训练策略。
此外,我们还为我们的任务探索了另外两种表示方法:大转移(BiT)作为监督方法,对比训练作为自监督方法。 下面详细介绍这些内容。
4.3.1 使用 JFT 进行大传输 (BiT)
Big Transfer(BiT)是一种用于视觉表示学习的大规模监督预训练,由Kolesnikov等人(2019)提出。 后来扩展到不同的医疗应用,并展示了有希望的结果(Mustafa 等人,2021)。 该方法提供了一种以最少的超参数调整实现高效迁移学习的方法,其有效性在大量视觉任务中得到了证明。 主要架构变化包括:(i) 使用 Group Normalization (Wu 和 He,2018) 代替 Batch Normalization,以及 (ii) 包含权重标准化 (Qiao 等人,2019) t1>,这有助于使用可变批量大小进行有效的迁移学习。 在本文中,我们使用在大型 JFT 数据集 (Sun 等人,2017) 上预训练的宽 ResNet- BiT 模型。 这被称为 BiT-L。 此实验选择的目的是调查与 ImageNet 基线相比,添加更多自然图像是否有助于学习通用特征以改进 OOD 检测。
4.3.2 对比训练
我们在应用中使用了两种对比的自监督学习方法,这已被证明在表示学习(Chen等人,2020)方面非常有效。 与 ImageNet 和 BiT-L 预训练相反,我们利用来自目标皮肤病学领域的未标记数据来预训练我们的编码器,优化对比目标。
首先,我们使用基于 SimCLR (Chen 等人, 2020) 的对比预训练,因为它很简单。 基于 SimCLR 的预训练已被证明在基准 OOD 任务中有效(Winkens 等人,2020),这可能是由于学习了丰富的表示形式。 对于我们的应用程序,我们使用 SimCLR 来预训练广泛的 ResNet- 模型。 该模型首先在 ImageNet 上进行预训练,然后使用对比目标对一组未标记的皮肤科图像进行进一步训练。 这包括来自 和第二节中详细介绍的其他未标记皮肤病学数据集的图像。 3.1。 此对比预训练中使用的数据增强是随机颜色增强、随机裁剪( 像素)、高斯模糊和随机翻转。 我们希望使用皮肤病学图像进行预训练将有助于学习下游 OOD 检测的特定领域表示。
其次,由于我们的下游分类任务本质上是多实例的,因此我们还使用了对比训练的多实例版本,称为 MICLe (Azizi 等人, 2021)。 与 SimCLR 试图最小化同一图像的两个增强版本之间的距离相比,MICLe 旨在最小化特征空间中同一案例的两个增强图像实例之间的距离。 此修改有助于学习可以区分每个多实例情况的表示。 训练使用与 SimCLR 相同的未标记皮肤病数据集。
我们将使用 ImageNet、BiT、SimCLR 和 MICLe 表示学习的 OOD 性能与结果中的 HOD 损失和单个拒绝桶进行比较。
4.4 集成中的表征多样性
我们集成了多个模型以进一步提高 OOD 检测性能。 对于通过随机初始化和输入随机洗牌训练的一组 训练集成成员,我们使用预测的 OOD 分数 的平均值作为最终的 OOD 分数。 这里 表示 模型的 OOD 分数。 如果模型使用 HOD 损失,则 OOD 分数是 中细粒度异常值类的概率之和。 如果模型使用拒绝桶损失,则 OOD 分数就是拒绝桶的概率。 对于每个提出的模型,我们选择 ,因为超过 的收益递减(Lakshminarayanan 等人,2017)。
请注意,深度集成的性能提升取决于网络权重的随机初始化引入的模型多样性。 在我们的设置中,由于我们使用预先训练的模型,因此仅对最后一层的权重进行随机初始化。 这降低了多样性。 为了引入更多的多样性,我们还使用不同的表示学习和目标函数训练集成模型,以增加集成成员的多样性。 给定一组候选模型,我们使用 Wenzel 等人 (2020) 提出的贪婪搜索算法来选择其集合提供最佳 OOD 性能的最佳模型子集。 特别是,我们首先收集使用不同表示学习和目标训练的所有模型:有和没有 HOD 损失的 ImageNet 初始化模型、有和没有 HOD 损失的 BiT 模型、有和没有 HOD 损失的 SimCLR 模型以及有和没有 HOD 损失的 MICLe 模型。 我们贪婪地增长一个集成,直到达到固定的集成大小,通过替换选择模型,从而在验证数据集上实现 OOD 性能的最佳改进。 我们将选定的整体称为多样化整体。 我们相信,这种多样性将利用从我们研究的不同表示学习方法和目标函数中学到的互补特征来提高 OOD 性能。 我们在结果中比较了这种多样化集成与普通集成的性能。
5实验结果
在本节中,我们介绍实验设置和实验结果,其中包括我们提出的不同组件的消融以及与基线方法的比较。
| Method | OOD detection metrics | |||
|---|---|---|---|---|
| AUROC () | FPR @ 0.95 TPR () | AUPR-in () | Inlier accuracy () | |
| BiT-L + MSP⋆ | ||||
| BiT-L + Mahalanobis⋆ | ||||
| BiT-L + Outlier exposure + MSP | ||||
| BiT-L with reject bucket | ||||
| BiT-L with fine-grained outlier () | ||||
| BiT-L + HOD () | ||||
| BiT-L + HOD () | ||||
| BiT-L + HOD () | ||||
5.1实验设置和评估指标
在这里,我们详细介绍了所有模型的实验设置,并介绍了我们用于比较不同方法的评估指标。
实验设置
我们使用训练分割(如表1中详细说明)来训练所有模型。 我们使用数据增强进行训练。 This includes: random horizontal and vertical flips, random variations of brightness (max intensity = ), contrast (intensity = []), saturation (intensity = []) and hue (max intensity = ), random Gaussian blurring using standard deviation between and and random rotations between and . 我们使用随机梯度下降优化器,其动量具有指数衰减的学习率来进行训练。 每个模型都经过 步骤的训练。 确保验证集上所有模型的收敛。 我们使用 例的批量大小进行训练。 我们使用验证分割来设置超参数(例如初始学习率、衰减因子、动量)并为所有模型选择最佳检查点。 检查点选择基于接受者操作特征曲线 (AUROC) 下的 OOD 区域。 AUROC 使用 OOD 分数提供异常值预测性能的定量测量,值越高表示使用 OOD 分数区分内部值和异常值的能力越高。 我们在以下部分中报告保留测试分组 中所有样本的所有结果。 请注意,用于评估的所有指标不需要选择固定工作点。
评估指标
为了评估不同方法的 OOD 性能,我们使用 3 个常用指标:(i) AUROC(越高越好),(ii) 真阳性率 (FPR TPR,越低越好)和 (iii) 内点精确回忆曲线下的面积(AUPR-in,越高越好)。 除了 OOD 指标之外,我们还跟踪模型的内部准确性,以研究模型的准确性和 OOD 性能之间可能的权衡。 仅在测试内点集上计算内点精度,将真实值与 top-1 内点预测进行比较。
5.2HOD损失与现有方法的比较
在本节中,我们将我们提出的 HOD 损失与现有方法进行比较,并消除 HOD 损失的不同部分。 作为这种消融的架构骨干,我们选择 BiT-L 初始化的宽 ResNet 。 首先我们研究最常用的 OOD 检测方法:MSP (Hendrycks and Gimpel, 2017) 和 Mahalanobis distance (Lee 等人, 2018)。 请注意,这些基线在训练过程中不使用异常样本。 我们在表 2 的前两行中显示结果。 我们观察到 MSP 基线优于 Mahalanobis 基线 AUROC 点。 接下来,我们研究使用训练离群值:离群值暴露(OE)和 MSP (Hendrycks 等人,2019b) 并拒绝桶 (Thulasidasan 等人,2021) 的现有方法。 我们在表2中列出了结果。 我们观察到,采用 MSP 的 OE 性能优于 MSP 基线 AUROC 点。 剔除桶基线的性能进一步优于 OE AUROC 点。 从结果可以清楚地看出,在训练过程中使用异常值的方法比不使用异常值的方法要好。 在现有的所有方法中,拒绝桶方法具有最好的OOD检测性能,我们将其用于下一步实验的比较。
请注意,基于拒绝桶的基线使用单个弃权类来封装 OOD 数据(Thulasidasan 等人,2021)。 如第 2 节所示。 4.2 HOD 在此基础上引入了两项修改:(i) 将拒绝桶扩展到细粒度的训练异常值类,以及 (ii) 包含粗粒度损失项和细粒度损失。 我们还探索了 的不同选择,它决定了细粒度和粗粒度损失项的相对贡献。 我们在选项卡中显示了测试集上所有设置的结果。 2.
| Method | OOD detection metrics | |||
|---|---|---|---|---|
| AUROC () | FPR @ 0.95 TPR () | AUPR-in () | Inlier accuracy () | |
| ImageNet + reject bucket | ||||
| ImageNet + HOD | ||||
| BiT-L + reject bucket | ||||
| BiT-L + HOD | ||||
| SimCLR + reject bucket | ||||
| SimCLR + HOD | ||||
| MICLe + reject bucket | ||||
| MICLe + HOD | ||||
首先,我们观察到,与拒绝桶基线相比,将弃权类别扩展到细粒度异常类别可将 OOD 检测 AUROC 提高 点,将内部精度提高 点。 这表明,对于 OOD 检测和异常值准确性,将多个特定于类的桶分配给离群值样本比将所有高度异构的离群值样本封装在单个弃权类中更好。 与具有多个弃权类别相比,包含的粗略损失进一步提高了点AUROC的性能,但点精度略有下降。 。 包含粗略损失对将 FPR TPR 降低 点有很大影响,但在 中未观察到。
此外,我们还观察到,为粗略损失 分配较高的权重会极大地降低内点精度和 OOD 检测性能。 我们认为这是由于粗略损失提供的强大标签平滑正则化效果。 设置非常高的 类似于仅训练二元内部值/异常值分类的模型。 请注意,随着 值较高,内点准确度急剧下降。 因此,我们将的值固定为,并使用此设置进行以下实验。
请注意,Mahalanobis 方法 (Lee 等人, 2018) 也可以用作 OOD 分数。 这涉及对高维特征空间中的内点进行类条件高斯拟合,并使用测试样本到拟合分布的马哈拉诺比斯距离作为 OOD 分数。 我们使用 维度 进行实验。 我们观察到,与使用 作为 OOD 分数相比,它始终表现不佳。 对于带有拒绝桶的 BiT-L,在验证集 上,AUROC 为 ,而 Mahalanobis 方法的 AUROC 为 。 我们认为这种下降是由于特征空间中高斯函数的拟合不足造成的。 在 维空间中拟合高斯需要估计均值向量和协方差矩阵的 参数。 请注意,对于我们的应用程序,我们的内部条件之间也存在类不平衡(参见图 1)。 某些内点类的样本计数不足以在特征空间中可靠地拟合高维高斯分布。 马哈拉诺比斯方法在大多数公共基准测试中效果良好,因为它们具有平衡的内类分布。 因此,我们仅使用 作为本工作中的 OOD 分数。
5.3不同表示学习方法的效果
在本节中,我们将研究不同类型的表示学习(参见第 4 节)如何与 HOD 结合使用进行 OOD 检测:ImageNet 预训练、BiT-L 预训练、SimCLR 预训练和MICLe 预训练模型。 首先,如表 3 所示,我们观察到,对于所有四种表示学习方法,与拒绝桶相比,包含 HOD 损失可以提高 OOD 性能。 对于 ImageNet、BiT-L、SimCLR 和 MICLe pre,AUROC 增加了 点、 点、 点和 点-分别训练的模型。 与其他相比,BiT-L 的提升要高得多。 HOD 还将 BiT-L 检查点的内部精度提高了 1.2 个点。 然而,我们观察到 ImageNet、SimCLR 和 MICLe 的 HOD 的内点精度分别下降了 、 和 点。 请注意,训练后,模型检查点是根据验证分割的最佳 AUROC 性能选择的。 对于 ImageNet、SimCLR 和 MICLe,HOD 损失、内点精度和 AUROC 峰值在训练的不同阶段出现,两者之间似乎存在权衡。 这可能是内部精度下降的可能原因。
比较基于自然图像的预训练方法(ImageNet、BiT-L),我们观察到 BiT-L 具有更好的内点精度和 OOD 性能。 我们可以得出结论,使用更大规模的数据集(JFT)进行预训练不仅有助于更好的分类性能,而且有助于更好的 OOD 检测任务。 比较基于对比训练的方法(SimCLR、MICLe),我们观察到虽然 MICLe 和 SimCLR 产生相似的内点精度,但 MICLe 的 OOD 性能比 SimCLR 好得多。 基于 SimCLR 的预训练学习区分每个图像,并且不考虑我们任务的多实例方面。 通过考虑多实例方面,MICLe 可能已经学习了特定于案例的特征,这些特征对于检测案例级 OOD 样本更有用。
比较基于拒绝桶的模型,我们还观察到基于对比学习的模型与基于自然图像的表示学习模型相比具有更高的内部精度。 我们认为这是由于用于对比学习的额外未标记皮肤病图像有助于学习领域特定特征。 这仅对于带有剔除桶的型号发挥了主要作用。
| Method | OOD detection metrics | |||
|---|---|---|---|---|
| AUROC () | FPR @ 0.95 TPR () | AUPR-in () | Inlier accuracy () | |
| ImageNet + reject bucket + Ensemble | ||||
| ImageNet + HOD + Ensemble | ||||
| BiT-L + reject bucket + Ensemble | ||||
| BiT-L + HOD + Ensemble | ||||
| SimCLR + reject bucket + Ensemble. | ||||
| SimCLR + HOD + Ensemble | ||||
| MICLe + reject bucket + Ensemble | ||||
| MICLe + HOD + Ensemble | ||||
| Diverse ensemble | ||||
5.4集成策略比较
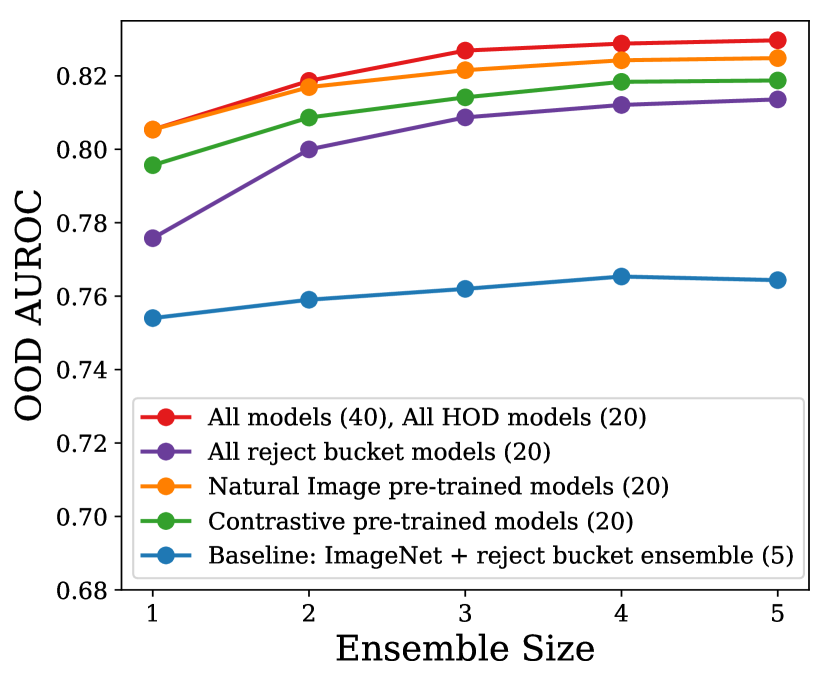
在本节中,我们研究不同的集成策略并研究它们对 OOD 检测的功效。 在本研究中,我们使用了第 2 节中详细介绍的所有不同的表示学习方法。 5.3,带有剔除桶和 HOD 损失。 首先,我们研究普通的集成策略。 对于每种方法,我们集成了五个通过随机初始化和随机数据改组独立训练的模型。 请注意,由于我们使用预训练模型进行初始化,因此仅随机初始化最终的全连接层和分类器层权重。 表4显示了集成后每种方法的性能。 与表 3 相比,很明显,对于每种方法,与单模型对应方法相比,集成都提高了内点精度和 OOD 检测性能。
其次,我们研究了具有不同表示学习方法的集成模型,如第 2 节中所述。 4.4。 为了测试多样化的集成策略,我们将 ImageNet、BiT-L、SimCLR 和 MICLe 的所有 模型与拒绝桶和 HOD 汇集在一起,并采用贪婪搜索算法 (Wenzel等人, 2020) 选择一组 模型。 贪婪搜索算法的选择标准度量是所有 3 个 OOD 度量的平均值:AUROC、 FPR TPR 和 AUPR-in。 选择使用具有最高验证集性能的集成(表4)。 所选的五个模型是三个具有 HOD 损失的 BiT-L 预训练模型和两个具有 HOD 损失的 MICLe 预训练模型。 这种多样化的集成实现了 的最高 AUROC、 的 AUROC、 的内点精度以及 的最低 FPR TPR 。 多样化的集成仅选择基于 HOD 损失的模型,表明它们是比基于拒绝桶的模型更强的候选者。 此外,请注意,贪婪搜索算法从两种不同的表示学习(BiT 和 MICLe)中选择模型。 我们相信基于自然图像的预训练 BiT-L 和基于对比学习的预训练 MICLe 模型可以学习互补的特征。 使用自然图像进行训练可能有助于学习更通用的低级特征,而对比学习可能有助于在预训练阶段学习更多皮肤科特定特征。 这促进了高级和低级特征的学习,这些特征对于内部分类可能不是很有用,但对于识别以前未见过的 OOD 示例可能很有用。 这种互补性可能增强了选择过程中的多样性。 此外,请注意,普通集成的 MICLe 模型中 HOD 损失的内部精度性能下降由多样化的集成补偿。 我们使用这种多样化的集成模型作为后续分析的最终模型。
6讨论
随着最终模型的确定,在本节中我们讨论一些可能为进一步改进提供有用指导的因素。 我们还对不同风险水平和皮肤类型亚组的模型性能进行下游分析,并进行信任分析以更好地了解模型的总体临床影响。
| AUROC | |||
|---|---|---|---|
| classes | samples | () | |
| BiT-L + MSP | |||
| BiT-L + HOD-17 | |||
| BiT-L + HOD-34 | |||
| BiT-L + HOD-51 | |||
| BiT-L + HOD-68 |
6.1 可用的训练异常数据
在本节中,我们将研究具有不同数量的训练异常数据的模型的 OOD 性能。 我们假设数量(训练异常值样本的数量)和质量(异常值训练类的数量)在部署期间有效检测异常值方面发挥着重要作用。 为了研究这个问题,我们使用不同比例的训练异常数据来训练模型,并在表 5 中显示结果。 我们在这个实验中使用带有 HOD 损失的 BiT-L。 对于每个设置,我们训练 不同的模型并报告 OOD 检测 AUROC 的平均值和标准差。 我们使用相同的验证集进行检查点选择和超参数调整,并在所有设置的相同测试集上报告结果。
作为第一个设置,我们展示了训练期间不使用任何异常值的结果。 为此,我们仅使用内点样本训练 BiT-L 预训练模型,并使用 max-of-softmax (MSP) 概率作为 OOD 分数(Hendrycks 和 Gimpel,2017)。 我们在表 5 中将其表示为 BiT-L + MSP。 接下来,我们统一增加更多的训练异常类和样本。 每个条目由 BiT-L + 训练 HOD-xx 表示,其中 xx 对应于训练离群值类别的数量 即 中使用的弃权类别的数量。 最后一行包括我们的整个训练离群值集,其中包含 离群值类别,如表 1 所示。 我们观察到,随着训练异常值异质性和数量的增加,OOD 检测性能持续提高。 鉴于缺乏稳定,引入额外的训练异常类和样本可能会进一步提高 OOD 检测性能。
6.2 集合的多样性
在秒。 5.4,我们证明了通过贪婪搜索算法选择的多样化集成优于所有普通集成模型。 在本节中,我们将研究多样性如何在实现绩效提升方面发挥作用。 在我们的 模型池中,我们在以下方面具有多样性:(i) 表征多样性(使用 ImageNet、BiT-L、SimCLR 和 MICLe 的预训练策略),(ii) 目标函数的多样性(两种不同的损失:拒绝桶损失和 HOD 损失)和(iii)由于最后一层初始化和随机输入混洗(普通集成)引起的多样性。
为了量化任意两个模型 和 之间的多样性,我们使用它们之间的平均预测差异,类似于 (Fort 等人, 2019)。 对于每个输入样本,让给出的top-1预测类为,给出的top-1预测类为. 多样性给出为
| (8) |
其中 表示期望运算符。 请注意,为了计算 top-1 预测,我们对输出类概率执行 ,其中包括所有细粒度的内部条件和由 给出的单个异常值类。
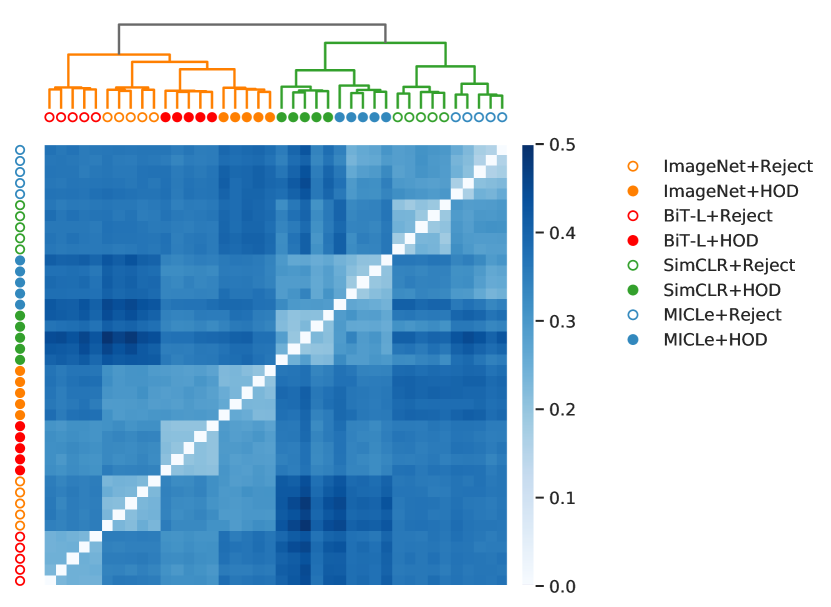
在图3(a)中,我们展示了池中所有模型的多样性热图。 较深的阴影表示较高的多样性,较浅的阴影表示较低的多样性。 使用方程中的多样性。 8 作为模型之间的成对距离,我们使用 Ward 最小方差对模型池应用分层聚类,并在图顶部显示相应的树状图。 3(a). 在树状图的最高级别,我们观察到所有对比预训练(SimCLR、MICLe)模型和自然图像预训练(ImageNet、BiT-L)模型之间的分离。 这表明不同的表示学习在我们的池中提供了最大的多样性。 在中间层,我们观察到使用拒绝桶损失和 HOD 损失训练的模型之间的分离。 这表明目标函数的差异提供了第二大多样性。 在最低级别,我们观察到所有具有相同表示学习和损失函数的 普通集成模型都聚集在一起。 它是沿着热矩阵对角线的 8 个大小为 的块矩阵,颜色较浅。 这表明其中多样性最小。
如第 2 节所述。 4.4,我们在 模型池上采用贪婪搜索算法来选择不同的集成成员。 贪婪搜索算法旨在选择一个在每一步都能提供最高性能提升的集成成员。 这种提升可以通过利用模型之间的互补性能来实现多样性。 我们认为,选择的多样化集成取决于模型池的多样性。 为了研究这一点,我们在不同的模型池上采用贪婪搜索算法,并在图 3(b) 中绘制不同集合大小下它们的 OOD AUROC。 子池是由主要多样性因素即表示学习和目标函数生成的,如图3(a)所示。 作为基线,我们展示了带有拒绝桶(蓝色,池大小:5)的 ImageNet 预训练模型的性能。 我们展示了使用拒绝桶损失训练的所有模型池的性能(紫色,池大小:20),使用 HOD 损失训练的所有模型池(红色,池大小:20),使用对比学习预训练的所有模型池的性能(绿色,池大小:20),使用自然图像预训练的所有模型池(橙色,池大小:20)和整体池(红色,池大小:40)。 在所有模型和所有具有 HOD 损失的模型中选择相同的模型,并且我们观察到这组选定的模型表现最好。 在使用自然图像预训练的模型池中选择的多样化集成优于在每个集成大小的对比预训练模型池中选择的集成。 与其他模型相比,在使用拒绝桶训练的模型上选择的多样化集成的表现较差。
除了选择的集合成员之外,观察贪婪搜索算法在每一步选择它们的顺序也很有趣。 例如,所有模型的最终多样化集成有 3 个 BiT-L + HOD 模型和 2 个 MICLe + HOD 模型。 它们被添加到不同集合中的顺序是: BiT-L-HOD MiCLe-HOD BiT-L-HOD MiCLe-HOD BiT-L-HOD。 请注意 BiT-L 和 MICLe 模型的交替添加。 这表明贪婪搜索算法通过平衡模型的表示多样性,在每一步都获得了最大的性能提升。 上述结果还表明,引入额外的表示学习策略和损失函数可以进一步丰富模型池的多样性,并可能带来更好的 OOD 性能。
6.3OOD检测性能的亚组分析
在本节中,我们将研究最终的多样化集成模型在不同皮肤状况风险类别和皮肤类型子组中的表现。 作为基线模型,我们与 ImageNet 预训练模型的普通集合进行比较,这些模型使用类似于 Liu 等人 (2020) 的拒绝桶进行训练。
| Subgroups | Num. Inlier | Num. Outlier | Baseline ensemble | Diverse ensemble |
|---|---|---|---|---|
| samples | samples | AUROC () | AUROC () | |
| High Risk | ||||
| Medium Risk | ||||
| Low Risk | ||||
| Skin-types-1&2 | ||||
| Skin-types-3 | ||||
| Skin-types-4 | ||||
| Skin-types-5&6 |
6.3.1 风险亚组分析
为此,皮肤科医生将测试集中的每个 异常值类别标记为三个风险类别之一。 低风险表示可能不会造成伤害或仅造成暂时不适的情况;中等风险表示可能导致伤害或损害的情况,需要医疗干预以防止永久性损害;高风险表示可能导致永久性损伤或危及生命的伤害或死亡的情况。 所有风险类别分配均基于如果不加以处理的最坏情况;例如,虽然像“荨麻疹”这样的疾病导致死亡的可能性很小,但它们被归为高风险类别。 我们在表 6 中展示了测试集上的亚组分析结果。 每个 AUROC 值都会比较子组 X 的内部值 与 异常值。 我们观察到,对于高风险、中风险和低风险亚组,我们的多样化集成的 AUROC 分别比基线集成高 7.6、2.5 和 8.2 点。 收益最大的是高风险和低风险亚组。
6.3.2 皮肤类型亚组分析
对于此分析,我们根据 Fitzpatrick 皮肤类型划分测试集样本。 我们分析了 4 个亚组:(i) 类型 1 和 2(浅白色和白色皮肤)、(ii) 类型 3(米色皮肤)、(iii) 类型 4(棕色皮肤)和 (iv) 类型 5 和 6(深色皮肤)棕色和黑色皮肤)。 该分析的目标与风险亚组略有不同。 在这里,我们不是根据皮肤状况的类别(用户可能不知道)进行分层,而是根据用户可能知道的信息(他们的皮肤类型)来分析子组。 为此,我们计算了 AUROC 指标,比较子组 X 的内部值与子组 X 的异常值。 我们在表6中展示了测试集的结果。 请注意,在 测试样本中,我们可以访问 样本的真实皮肤类型。 总的来说,我们观察到我们的多元化整体的所有 4 个亚组都有较高的 AUROC。 5 型和 6 型的 17 分 AUROC 差距尤其引人注目,因为这些皮肤类型在我们的数据集中很少见,尽管较小的样本量使得难以得出可靠的结论。
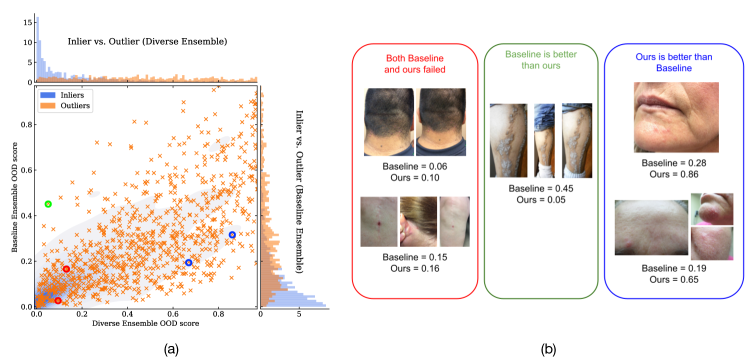
6.4定性分析及失败案例
在本节中,我们对结果进行定性分析并展示失败案例。 为此,我们将我们的多样化集成与类似于第二节的基线集成进行比较。 6.3。 首先,我们显示所有测试离群样本(橙色)和内联样本(蓝色作为图 4 中的密度图)的散点图(图 4a) >a) 比较基线集成与多样化集成分配的 OOD 分数。 左下区域中的异常值样本(内部值密度较高)对应于我们的模型和基线模型都失败的困难情况。 我们从这个类别中选择两个案例(用红色圆圈表示)并将其显示在图4b中(用红色框框出)。 图 4a 中的左上角区域代表基线优于我们模型的情况。 我们选择一个这样的案例(由绿色圆圈表示)并在图4b(由绿色框框出)中显示。 图 4 中的右下区域代表我们的模型优于基线模型的情况。 我们从该区域中随机选择两个案例(图4a中的蓝色圆圈表示)并将其显示在图4b中(蓝色框框出)。 图 4a 中的右上角区域代表基线和我们的模型都表现良好的情况。 这些大多对应于相对简单的情况。
在图4a中,我们还显示了由基线集合(右)和我们的多样化集合(上)建模的内点(以蓝色表示)和异常值(以橙色表示)的边缘分布。 我们可以观察到,与基线集成相比,由我们的多样化集成建模的内点分布更紧凑、更窄。 此外,与我们的模型相比,我们观察到基线的内值和离群值分布之间的重叠明显更多。 这提供了定性证据,表明我们的模型与基线相比能够更好地检测异常值。
6.5 内部值和异常值预测的联合评估
尽管在本文中我们主要关注于提高 OOD 检测的性能,但我们的皮肤病学模型的最终目标是对异常值和异常值都具有较高的检测精度。 因此,在本节中,我们研究模型对异常值和异常值的联合预测精度。
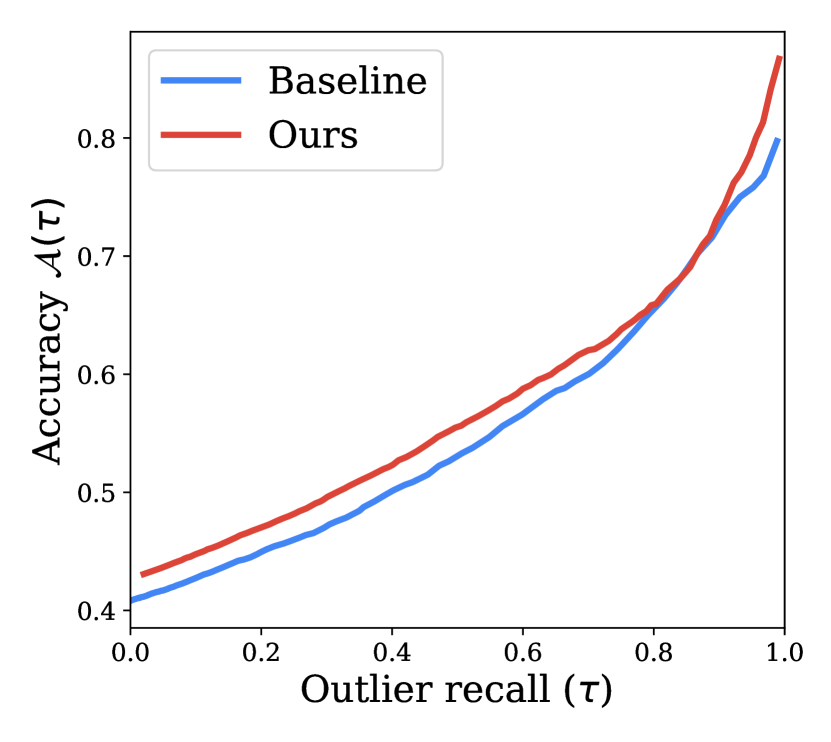
让我们考虑一个置信度分数阈值,高于该阈值我们允许模型进行预测,即测试样本是否具有置信度分数 其相关输出将被预测,如果 我们放弃预测。 对于固定的,预测样本的相应模型精度)可以计算为
| (9) |
它评估预测样本的内部精度,并认为所有异常值的预测都是错误的。
请注意,我们的多样化集成模型和基线集成模型之间存在校准差异。 因此,不同集成的 和固定 的基线集成不能直接比较。 因此,为了标准化置信度阈值 ,我们计算 值的离群值召回率,该值根据模型校准的差异进行调整。
我们评估不同阈值下的和异常值召回率,并将它们绘制在图5(a)中,类似于Lakshminarayanan等人(2017) );范阿默斯福特等人 (2020)。 我们观察到,对于所有异常值召回率,我们的多样化集成模型比基线集成模型具有更高的准确性。 这表明,与不同操作点选择的基线相比,我们的模型更擅长联合识别异常值和正确的内部值。
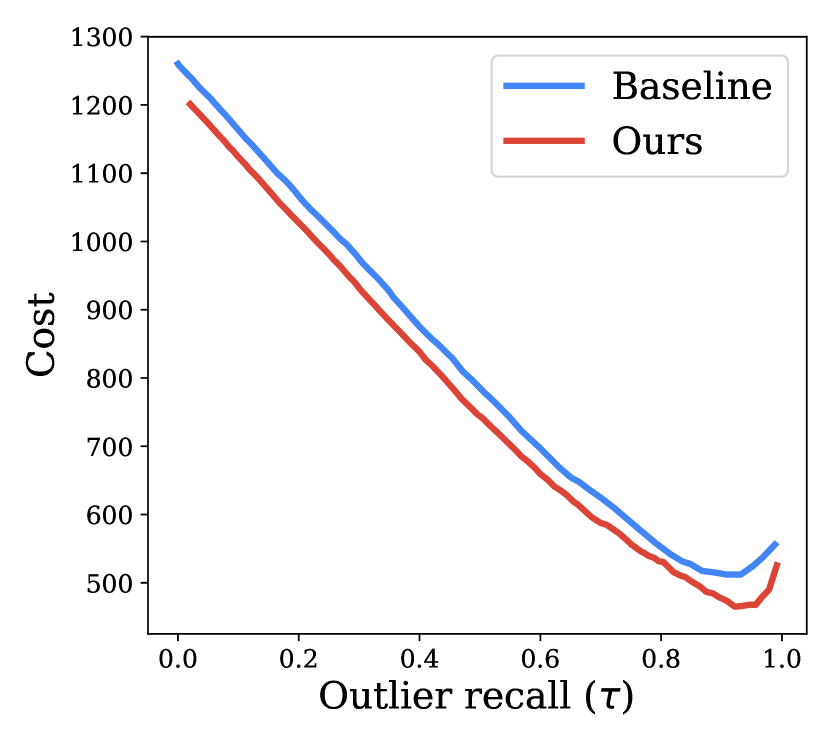
6.6模型信任分析
在本节中,我们进行模型信任分析,以更好地了解模型对内部值和异常值进行错误分类的总体下游临床影响。 对于固定置信度阈值,我们计算以下类型的错误:(i)对内点的错误预测(即将内点条件A误认为内点条件B),(ii)不正确地放弃内点(即放弃对内点进行预测),(iii) 将异常值错误地预测为内点类别之一。 为了解释这些不同类型错误的不对称临床后果,我们提出了一个成本矩阵,为图6中的不同错误分配不同的成本。 内部错误预测和异常值作为内部错误预测均受到 分数的惩罚。 此类错误可能会削弱用户对模型的信任。
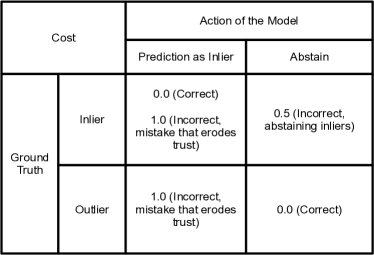
将异常值错误地弃权为异常值会受到 分数的处罚,以反映模型的潜在用户将能够在模型表达的不确定性或弃权的情况下寻求额外的指导。 请注意,这些数字是用于模拟下游影响的定性近似值。 现实场景更加复杂,包含多种未知变量;这已被简化,以便更好地理解这项工作的主要焦点:异常值检测和异常值准确性。 这些选择均经过皮肤科医生的验证。
我们估计了不同置信阈值 下多样化集成模型和基线集成模型的成本,并在图 5(b) 中显示了绘图。 与准确性类似,我们使用不同 处的异常值召回来调整两个模型中 的不同校准。 我们观察到,在所有异常值召回率上,我们的多样化集成模型的总体成本都低于基线集成模型,并且在异常值召回率 下实现了最低成本。 持续较低的成本表明我们的模型在考虑了不同的下游临床影响后表现更好。
7结论
在医疗机器学习模型的实际部署中,经常会遇到具有以前未见过的条件的测试输入。 为了安全起见,识别此类输入并避免分类可能很重要,以防止对模型输出的不当过度依赖,并使模型用户能够采取安全的后续步骤,例如咨询临床医生。
在本文中,我们解决了这一具有挑战性的任务,即检测皮肤病学分类模型中以前未见过的罕见情况的长尾。 我们将此任务定义为分布外(OOD)检测问题。 利用带有长尾条件的标记数据集,我们首先构建一个可靠评估 OOD 方法的基准。
我们进一步提出了一种用于 OOD 检测的新颖的分层异常值检测(HOD)损失函数。 与为 OOD 分配单个弃权类别的现有方法相比,我们根据训练集中可用的 OOD 类别数量分配多个弃权类别。 此外,除了细粒度分类损失之外,我们还包括粗略损失以帮助内部值和异常值的高级聚类。 我们展示了与使用基线相比,使用 HOD 损失带来的额外性能提升。
我们还探讨了 HOD 损失在多种不同的最先进表示学习方法的背景下的效用。 除了常用的 ImageNet 预训练模型之外,我们还研究了在大规模 JFT 数据集上预训练的 BiT 模型,以及基于 SimCLR 和 MICLe 方法的对比预训练。 我们证明了更好的表示学习可以提高 OOD 检测性能,并且这些也可以通过 HOD 损失来改进。
我们还探索了不同的集成策略。 对于使用或不使用 HOD 损失和不同表示学习技术训练的所有模型,普通集成提高了 OOD 性能和内部精度。 在具有不同表示学习和损失函数的模型池上使用贪婪搜索算法的多样化集成选择方法在 OOD 性能和内部精度方面进一步优于普通集成模型。
我们还研究了不同风险级别和皮肤类型亚组的 OOD 表现。 我们表明,与所有子组的基线相比,我们提出的方法表现出优越的性能。
为了量化潜在的下游临床影响,我们超越了传统的性能指标,并构建了模型信任分析的成本矩阵。 我们在这个指标中证明了我们的方法相对于基线的优越性,表明我们的模型在实际部署中的有效性。 理想情况下,我们可以在训练期间直接优化这个成本矩阵作为目标函数。 我们将此作为未来可能的工作。
总而言之,我们相信我们提出的方法可以帮助人工智能算法成功转化为现实场景。 尽管我们主要关注皮肤病学的 OOD 检测,但我们的大部分贡献都是相当通用的,并且可以很容易地推广到其他应用中的 OOD 检测。
致谢
我们要感谢来自 DeepMind 的 Olaf Ronneberger、Ali Eslami、Rudy Bunel、Simon Kohl、Krishnamurthy Dvijotham、来自 Google Health 的 Jonathan Deaton 和来自 Google Research 的 Neil Houlsby 对于初步构思的有益讨论。 我们还要感谢 Google Research 的 Joshua Dillon、Jasper Snoek、Jeremiah Liu、Google Health 的 Atilla Kiraly、Terry Spitz 和 Dale Webster,以及 Kimberly Kanada,他们为这项工作进行了富有洞察力的讨论并提供了宝贵的反馈,来自 Google Health 的 Jay Hartford 在数据相关物流方面提供帮助。
参考
- Azizi et al. (2021) Azizi, S., Mustafa, B., Ryan, F., Beaver, Z., Freyberg, J., Deaton, J., Loh, A., Karthikesalingam, A., Kornblith, S., Chen, T., et al., 2021. Big self-supervised models advance medical image classification. arXiv preprint arXiv:2101.05224 .
- Bulusu et al. (2020) Bulusu, S., Kailkhura, B., Li, B., Varshney, P.K., Song, D., 2020. Anomalous example detection in deep learning: A survey. IEEE Access 8, 132330–132347. doi:10.1109/ACCESS.2020.3010274.
- Çallı et al. (2019) Çallı, E., Murphy, K., Sogancioglu, E., Van Ginneken, B., 2019. Frodo: Free rejection of out-of-distribution samples: application to chest x-ray analysis. arXiv preprint arXiv:1907.01253 .
- Cao et al. (2020) Cao, T., Huang, C., Hui, D.Y.T., Cohen, J.P., 2020. A benchmark of medical out of distribution detection. arXiv preprint arXiv:2007.04250 .
- Chen et al. (2020) Chen, T., Kornblith, S., Norouzi, M., Hinton, G., 2020. A simple framework for contrastive learning of visual representations. International conference on machine learning , 1597–1607.
- Combalia et al. (2020) Combalia, M., Hueto, F., Puig, S., Malvehy, J., Vilaplana, V., 2020. Uncertainty estimation in deep neural networks for dermoscopic image classification. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , 744–745.
- Fort et al. (2019) Fort, S., Hu, H., Lakshminarayanan, B., 2019. Deep ensembles: A loss landscape perspective. arXiv preprint arXiv:1912.02757 .
- Goodfellow et al. (2014) Goodfellow, I.J., Shlens, J., Szegedy, C., 2014. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 .
- Hafner et al. (2019) Hafner, D., Tran, D., Lillicrap, T., Irpan, A., Davidson, J., 2019. Noise contrastive priors for functional uncertainty. Uncertainty in Artificial Intelligence , 905–914.
- Hendrycks et al. (2020a) Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., et al., 2020a. The many faces of robustness: A critical analysis of out-of-distribution generalization. arXiv preprint arXiv:2006.16241 .
- Hendrycks and Gimpel (2017) Hendrycks, D., Gimpel, K., 2017. A baseline for detecting misclassified and out-of-distribution examples in neural networks. ICLR .
- Hendrycks et al. (2019a) Hendrycks, D., Lee, K., Mazeika, M., 2019a. Using pre-training can improve model robustness and uncertainty. International Conference on Machine Learning , 2712–2721.
- Hendrycks et al. (2020b) Hendrycks, D., Liu, X., Wallace, E., Dziedzic, A., Krishnan, R., Song, D., 2020b. Pretrained transformers improve out-of-distribution robustness. arXiv preprint arXiv:2004.06100 .
- Hendrycks et al. (2019b) Hendrycks, D., Mazeika, M., Dietterich, T., 2019b. Deep anomaly detection with outlier exposure. ICLR .
- Hendrycks et al. (2020c) Hendrycks, D., Mu, N., Cubuk, E.D., Zoph, B., Gilmer, J., Lakshminarayanan, B., 2020c. Augmix: A simple data processing method to improve robustness and uncertainty. ICLR .
- Kamnitsas et al. (2017) Kamnitsas, K., Bai, W., Ferrante, E., McDonagh, S., Sinclair, M., Pawlowski, N., Rajchl, M., Lee, M., Kainz, B., Rueckert, D., et al., 2017. Ensembles of multiple models and architectures for robust brain tumour segmentation. International MICCAI brainlesion workshop , 450–462.
- Kolesnikov et al. (2019) Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., Houlsby, N., 2019. Big transfer (bit): General visual representation learning. preprint arXiv:1912.11370 .
- Lakshminarayanan et al. (2017) Lakshminarayanan, B., Pritzel, A., Blundell, C., 2017. Simple and scalable predictive uncertainty estimation using deep ensembles. NeurIPS .
- Lee et al. (2018) Lee, K., Lee, K., Lee, H., Shin, J., 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. arXiv preprint arXiv:1807.03888 .
- Li et al. (2020) Li, X., Lu, Y., Desrosiers, C., Liu, X., 2020. Out-of-distribution detection for skin lesion images with deep isolation forest. International Workshop on Machine Learning in Medical Imaging , 91–100.
- Liang et al. (2018) Liang, S., Li, Y., Srikant, R., 2018. Enhancing the reliability of out-of-distribution image detection in neural networks. ICLR .
- Linmans et al. (2020) Linmans, J., van der Laak, J., Litjens, G., 2020. Efficient out-of-distribution detection in digital pathology using multi-head convolutional neural networks. Proceedings of Machine Learning Research .
- Liu et al. (2019) Liu, X., Faes, L., Kale, A.U., Wagner, S.K., Fu, D.J., Bruynseels, A., Mahendiran, T., Moraes, G., Shamdas, M., Kern, C., et al., 2019. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: a systematic review and meta-analysis. The lancet digital health 1, e271–e297.
- Liu et al. (2020) Liu, Y., Jain, A., Eng, C., Way, D.H., Lee, K., Bui, P., Kanada, K., de Oliveira Marinho, G., Gallegos, J., Gabriele, S., et al., 2020. A deep learning system for differential diagnosis of skin diseases. Nature Medicine 26, 900–908.
- Morningstar et al. (2021) Morningstar, W., Ham, C., Gallagher, A., Lakshminarayanan, B., Alemi, A., Dillon, J., 2021. Density of states estimation for out of distribution detection. International Conference on Artificial Intelligence and Statistics , 3232–3240.
- Muehlematter et al. (2021) Muehlematter, U.J., Daniore, P., Vokinger, K.N., 2021. Approval of artificial intelligence and machine learning-based medical devices in the usa and europe (2015–20): a comparative analysis. The Lancet Digital Health .
- Mustafa et al. (2021) Mustafa, B., Loh, A., Freyberg, J., MacWilliams, P., Karthikesalingam, A., Houlsby, N., Natarajan, V., 2021. Supervised transfer learning at scale for medical imaging. arXiv preprint arXiv:2101.05913 .
- Nguyen et al. (2015) Nguyen, A., Yosinski, J., Clune, J., 2015. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. Proceedings of the IEEE conference on computer vision and pattern recognition , 427–436.
- Ovadia et al. (2019) Ovadia, Y., Fertig, E., Ren, J., Nado, Z., Sculley, D., Nowozin, S., Dillon, J.V., Lakshminarayanan, B., Snoek, J., 2019. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. NeurIPS .
- Pacheco et al. (2020) Pacheco, A.G., Sastry, C.S., Trappenberg, T., Oore, S., Krohling, R.A., 2020. On out-of-distribution detection algorithms with deep neural skin cancer classifiers. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , 732–733.
- Platt (2000) Platt, J., 2000. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 10.
- Prabhu et al. (2018) Prabhu, V., Kannan, A., Ravuri, M., Chablani, M., Sontag, D., Amatriain, X., 2018. Prototypical clustering networks for dermatological disease diagnosis. arXiv preprint arXiv:1811.03066 .
- Qiao et al. (2019) Qiao, S., Wang, H., Liu, C., Shen, W., Yuille, A., 2019. Weight standardization. arXiv preprint arXiv:1903.10520 .
- Ren et al. (2019) Ren, J., Liu, P.J., Fertig, E., Snoek, J., Poplin, R., DePristo, M.A., Dillon, J.V., Lakshminarayanan, B., 2019. Likelihood ratios for out-of-distribution detection. NeurIPS .
- Shi et al. (2021) Shi, S., Malhi, I., Tran, K., Ng, A.Y., Rajpurkar, P., 2021. Chexseen: Unseen disease detection for deep learning interpretation of chest x-rays. arXiv preprint arXiv:2103.04590 .
- Sun et al. (2017) Sun, C., Shrivastava, A., Singh, S., Gupta, A., 2017. Revisiting unreasonable effectiveness of data in deep learning era. Proceedings of the IEEE international conference on computer vision , 843–852.
- Thiagarajan et al. (2020) Thiagarajan, J.J., Sattigeri, P., Rajan, D., Venkatesh, B., 2020. Calibrating healthcare ai: Towards reliable and interpretable deep predictive models. arXiv preprint arXiv:2004.14480 .
- Thulasidasan et al. (2021) Thulasidasan, S., Thapa, S., Dhaubhadel, S., Chennupati, G., Bhattacharya, T., Bilmes, J., 2021. A simple and effective baseline for out-of-distribution detection using abstention URL: https://openreview.net/forum?id=q_Q9MMGwSQu.
- Van Amersfoort et al. (2020) Van Amersfoort, J., Smith, L., Teh, Y.W., Gal, Y., 2020. Uncertainty estimation using a single deep deterministic neural network. International Conference on Machine Learning , 9690–9700.
- Venkatakrishnan et al. (2020) Venkatakrishnan, A.R., Kim, S.T., Eisawy, R., Pfister, F., Navab, N., 2020. Self-supervised out-of-distribution detection in brain ct scans. arXiv preprint arXiv:2011.05428 .
- Weng et al. (2020) Weng, W.H., Deaton, J., Natarajan, V., Elsayed, G.F., Liu, Y., 2020. Addressing the real-world class imbalance problem in dermatology. Proceedings of the Machine Learning for Health NeurIPS Workshop 136, 415–429.
- Wenzel et al. (2020) Wenzel, F., Snoek, J., Tran, D., Jenatton, R., 2020. Hyperparameter ensembles for robustness and uncertainty quantification. NeurIPS .
- Winkens et al. (2020) Winkens, J., Bunel, R., Roy, A.G., Stanforth, R., Natarajan, V., Ledsam, J.R., MacWilliams, P., Kohli, P., Karthikesalingam, A., Kohl, S., et al., 2020. Contrastive training for improved out-of-distribution detection. arXiv preprint arXiv:2007.05566 .
- Wu and He (2018) Wu, Y., He, K., 2018. Group normalization. Proceedings of the European conference on computer vision (ECCV) , 3–19.
- Yan et al. (2015) Yan, Z., Zhang, H., Piramuthu, R., Jagadeesh, V., DeCoste, D., Di, W., Yu, Y., 2015. HD-CNN: hierarchical deep convolutional neural networks for large scale visual recognition. Proceedings of the IEEE international conference on computer vision , 2740–2748.
- Yasin et al. (2020) Yasin, Y., Rumala, D.J., Purnomo, M.H., Ratna, A.A.P., Hidayati, A.N., Nurtanio, I., Rachmadi, R.F., Purnama, I.K.E., 2020. Open set deep networks based on extreme value theory (EVT) for open set recognition in skin disease classification. 2020 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM) , 332–337.
- Zhang et al. (2020) Zhang, H., Li, A., Guo, J., Guo, Y., 2020. Hybrid models for open set recognition. European Conference on Computer Vision .
- Zhang and LeCun (2017) Zhang, X., LeCun, Y., 2017. Universum prescription: Regularization using unlabeled data. Proceedings of the AAAI Conference on Artificial Intelligence .
- Zhou et al. (2020) Zhou, S.K., Greenspan, H., Davatzikos, C., Duncan, J.S., van Ginneken, B., Madabhushi, A., Prince, J.L., Rueckert, D., Summers, R.M., 2020. A review of deep learning in medical imaging: Image traits, technology trends, case studies with progress highlights, and future promises. arXiv preprint arXiv:2008.09104 .
| Inlier conditions | Acne, Tinea, Tinea Versicolor, Actinic Keratosis, Folliculitis, Allergic Contact Dermatitis, Alopecia Areata, Urticaria, Androgenetic Alopecia, Verruca vulgaris, Vitiligo, Basal Cell Carcinoma, Hidradenitis, Post-Inflammatory hyperpigmentation, Lentigo, Psoriasis, Cyst, SCC/SCCIS, SK/ISK, Scar Condition, Seborrheic Dermatitis, Melanocytic Nevus, Melanoma, Skin Tag, Eczema, Stasis Dermatitis |
|---|---|
| Outlier conditions in Train set | Abscess, Erythema annulare centrifugum, Acanthosis nigricans, Erythema dyschromicum perstans, Erythema gyratum repens, Tattoo, Traction alopecia, Traumatic ulcer, Acute generalised exanthematous pustulosis, Nevus sebaceous, Nevus spilus, Fordyce spots, Ochronosis, Foreign body reaction of the skin, Amyloidosis of skin, Varicose veins of lower extremity, Ganglion cyst, Viral Exanthem, Xanthoma, Angiosarcoma of skin, Oral fibroma, Yellow nail syndrome, Hairy tongue, Atypical Nevus, Pearly penile papules, Pemphigus foliaceus, Pemphigus vulgaris, Blue sacral spot, Hordeolum internum, Photodermatitis, Phrynoderma, Burn of skin, Calcinosis cutis, Infected eczema, Pitted keratolysis, Insect Bite, Chilblain, Poikiloderma, Irritant Contact Dermatitis, Porphyria cutanea tarda, Keratolysis exfoliativa, Keratosis pilaris, Pretibial myxedema, Prurigo nodularis, Pruritic urticarial papules and plaques of pregnancy, Leukonychia, Cutaneous capillary malformation, Lichen Simplex Chronicus, Lichen nitidus, Lichen planopilaris, Cutaneous lupus, Lichen planus/lichenoid eruption, Cutaneous metastasis, Puncture wound - injury, Lichenoid myxedema, Purpura, Cutaneous sarcoidosis, Lipodermatosclerosis, Pyoderma Gangrenosum, Livedo reticularis, Livedoid vasculopathy, Dental fistula, Diabetic dermopathy, Diabetic ulcer, Dissecting cellulitis of scalp, Drug Rash, Skin striae |
| Outlier conditions in Validation set | Necrobiosis lipoidica, Telangiectasia disorder, Telogen effluvium, Erythema nodosum, Erythrasma, Symmetrical dyschromatosis of extremities, Nevus lipomatosus cutaneous superficialis, Traumatic bulla, Nevus of Ota, Trichotillomania, Onycholysis, Onychomadesis, Venous Stasis Ulcer, Onychomycosis, Onychoschizia, Granuloma annulare, Granulomatous cheilitis, Hailey Hailey disease, Paronychia, Hematoma of skin, Pemphigoid gestationis, Becker’s nevus, Benign neoplasm of nail apparatus, Hemosiderin pigmentation of skin, Hirsutism, Periungual fibroma, Perleche, Hypersensitivity, Bullosis diabeticorum, Idiopathic guttate hypomelanosis, Pigmented purpuric eruption, Impetigo, Pincer nail deformity, Candida, Canker sore, Cellulitis, Central centrifugal cicatricial alopecia, Pityriasis lichenoides, Pityriasis rosea, Chondrodermatitis nodularis, Porokeratosis, Clubbing of fingers, Post-Inflammatory hypopigmentation, Knuckle pads, Condyloma acuminatum, Confluent and reticulate papillomatosis, Leprosy, Leukocytoclastic Vasculitis, Cutaneous T Cell Lymphoma, Pseudopelade, Pterygium of nail, Lichen sclerosus, Lichen striatus, Cutaneous neurofibroma, Cylindroma of skin, Deep fungal infection, Dermatitis herpetiformis, Dermatofibroma, SJS/TEN, Dermatomyositis, Scabies, Morphea/Scleroderma, Melasma, Molluscum Contagiosum, Erosive pustular dermatosis, Erythema ab igne |
| Outlier conditions in Test set | Nail dystrophy due to trauma, Syphilis, Accessory nipple, Acne keloidalis, Acquired digital fibrokeratoma, Erythema migrans, Erythema multiforme, Erythromelalgia, Nevus comedonicus, Trachyonychia, Triangular alopecia, Adnexal neoplasm, Folliculitis decalvans, Notalgia paresthetica, O/E - ecchymoses present, Fox-Fordyce disease, Angiofibroma, Angiokeratoma of skin, Onychorrhexis, Xerosis, Osteoarthritis, Zoon’s balanitis, Arsenical keratosis, Grover’s disease, Hand foot and mouth disease, Hemangioma, Beau’s lines, Herpes Simplex, Herpes Zoster, Perforating dermatosis, Perioral Dermatitis, Hyperhidrosis, Brachioradial pruritus, Ichthyosis, Bullous Pemphigoid, Cafe au lait macule, Pilonidal cyst, Inflammatory linear verrucous epidermal nevus, Inflicted skin lesions, Ingrown hair, Pityriasis alba, Pityriasis amiantacea, Chicken pox exanthem, Intertrigo, Pityriasis rubra pilaris, Clavus, Kaposi’s sarcoma of skin, Keratoderma, Pressure ulcer, Comedone, Leukoplakia of skin, Pseudolymphoma, Pyogenic granuloma, Lipoma, Cutis verticis gyrata, Retention hyperkeratosis, Rheumatoid nodule, Longitudinal melanonychia, Rosacea, Dermatofibrosarcoma protuberans, Sebaceous hyperplasia, Skin and soft tissue atypical mycobacterial infection, Milia, Epidermal nevus, Mucocele |