记录大型网络文本语料库:
海量干净爬取语料库案例研究
摘要
大型语言模型在许多 NLP 训练任务上取得了显着进展,研究人员正在转向更大的文本语料库来训练它们。 一些最大的可用语料库是通过抓取互联网的重要部分而创建的,并且通常只用最少的文档进行介绍。 在这项工作中,我们提供了 Colossal Clean Crawled Corpus (C4;Raffel 等人,2020) 的一些第一个文档,该数据集是通过将一组过滤器应用于 Common Crawl 的单个快照而创建的数据集。 我们首先调查数据的来源,并从专利和美国军事网站等意想不到的来源找到大量文本。 然后,我们探索文本本身的内容,并找到机器生成的文本(例如,来自机器翻译系统)和来自其他基准 NLP 数据集的评估示例。 为了了解用于创建此数据集的过滤器的影响,我们评估了被删除的文本,并表明黑名单过滤不成比例地删除了来自少数群体的文本以及关于少数群体的文本。 最后,我们对如何从互联网上创建和记录网络规模的数据集提出了一些建议。
1简介
在未标记文本语料库上预训练的模型是许多现代 NLP 系统的支柱(Devlin 等人,2019;Liu 等人,2019;Raffel 等人,2020;Brown 等人,2020,等等)。 这种范式激励了使用更大的语料库 Kaplan 等人 (2020); Henighan 等人 (2020),最大的模型现在在公开互联网的很大一部分上进行训练(Raffel 等人,2020;Brown 等人,2020)。 当然,与所有机器学习系统一样,这些模型所训练的数据对其行为有很大影响。 对于结构化、特定于任务的 NLP 数据集,围绕记录收集过程、组成、预期用途和其他特征出现了最佳实践Bender 和 Friedman(2018); Gebru 等人 (2018);哈钦森等人 (2021)。 然而,考虑到将这些实践应用于从网络上抓取的大量未标记文本的挑战,通常无法完成完整的文档记录。 这使得预训练语言模型的消费者对预训练数据对其系统的影响一无所知,这可能会在下游使用中注入微妙的偏差 Li 等人 (2020); Gehman 等人 (2020); Groenwold 等人 (2020)。
在这项工作中,我们提供了一些网络规模数据集的第一个文档:Colossal Clean Crawled Corpus (C4;Raffel 等人,2020)。 C4 是最大的可用语言数据集之一,从互联网上超过 3.65 亿个域收集了超过 1560 亿个 Token (表 1)。111已经创建了其他类似的数据集(例如,Brown 等人,2020),但遗憾的是尚未提供。 C4 已用于训练 T5 和 Switch Transformer Fedus 等人 (2021) 等模型,这是两个最大的预训练英语语言模型。 虽然 Raffel 等人 (2020) 提供了重新创建 C4 的脚本,但仅运行可用脚本就需要花费数千美元。 只有当数据可广泛访问时,可重复的科学才有可能,网络规模的语料库在这方面也不例外。 考虑到这一点,我们提供了该数据集的可下载副本。222https://github.com/allenai/c4-documentation
记录大量未标记的数据集是一项具有挑战性的工作。 之前工作中的一些建议自然是合适的,例如报告示例的数量以及数据集可下载版本的链接。333NLP Reproducibility Checklist
https://2020.emnlp.org/blog/2020-05-20-reproducibility但是,许多建议(例如报告有关文本作者的信息)并不容易适用,因为网络爬虫文本中通常无法提供所需的信息。
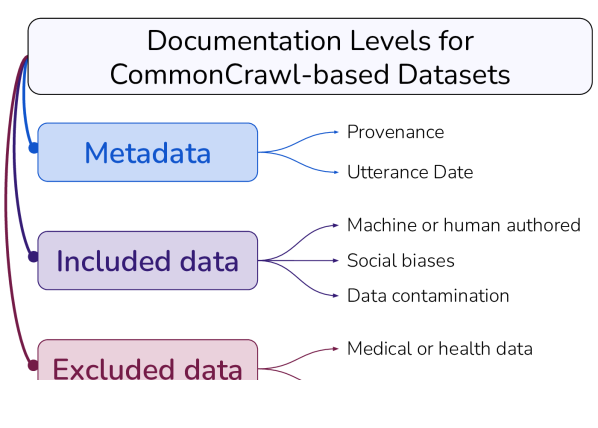
我们提倡网络规模语料库的文档包含数据的三个视图,如图 1 所示。 首先,元数据,包括收集数据的互联网域。 在最高级别,.edu 等互联网顶级域名可能包含与 .mil(为美国政府军事网站保留的顶级域名)显着不同的文本;两者的文本都存在于 C4 中。
根据元数据,我们检查文本本身。 我们发现大量机器生成的文本(例如,来自机器翻译系统),其比例可能只会随着时间的推移而增加。 我们还发现了一些污染的证据(C4 中存在的其他数据集的测试示例的存在),并认为新数据集应该正确解释这种现象的存在。
最后,由于网络抓取的数据集通常会过滤掉文本的重要部分,因此我们主张对数据中不的内容进行更彻底的记录。 有些过滤器相对简单,例如删除 Lorem ipsum 占位符文本。 然而,我们发现另一个从禁用单词列表中删除包含词符的文档的过滤器,不成比例地删除了与少数群体身份相关的英语方言文档(例如,非裔美国英语文本、讨论 LGBTQ+ 身份的文本)。
除了我们的一组建议和分析之外,我们还公开托管具有不同过滤级别的三个版本的数据,以及一个便于搜索的索引版本444https://c4-search.apps.allenai.org/
this index will only be hosted until 2021-12-31,以及用于公开讨论调查结果的存储库。555https://github.com/allenai/c4-documentation/discussions
2 英国巨型清洁爬行语料库(C4)
C4 是通过拍摄 Common Crawl 的 2019 年 4 月快照创建的666https://commoncrawl.org/, where monthly “snapshots” are created by crawling and scraping the web, each typically containing terabytes of text,并应用多个过滤器以删除不符合要求的文本。不是自然的英语。 这包括过滤掉不以终止标点符号结尾或少于三个单词的行,丢弃少于五个句子或包含 Lorem ipsum 占位符文本的文档,以及删除包含任何内容的文档“肮脏、顽皮、淫秽或其他不良词语列表”中的词语。777https://git.io/vSyEu 另外,langdetect80>88https://pypi.org/project/langdetect/ 用于删除未分类为英语的概率至少为 0.99,因此 C4 主要由英语文本组成。 我们将此称为 C4 的“清理”版本(通过应用所有过滤器创建)C4.en。 为简洁起见,我们建议读者参阅 Raffel 等人 (2020) 以获取过滤器的完整列表。
除了 C4.en 之外,我们还托管“未清理”版本 (C4.en.noClean),这是 Common Crawl 的快照,标识为英语(没有其他内容)应用过滤器),以及 C4.en.noBlocklist,它与 C4.en 相同,但不会从单词块列表中过滤掉包含标记的文档(请参阅§5 了解更多详情)。 表1包含三个语料库的一些统计数据。
| Dataset | # documents | # tokens | size |
|---|---|---|---|
| C4.en.noClean | 1.1 billion | 1.4 trillion | 2.3 TB |
| C4.en.noBlocklist | 395 million | 198 billion | 380 GB |
| C4.en | 365 million | 156 billion | 305 GB |
3 语料库级统计
了解构成数据集的文本的出处对于理解数据集本身至关重要,因此我们通过描述不同互联网域作为文本源的流行程度来开始分析 C4.en 的元数据,网站首次被互联网档案馆索引的日期,以及托管网站的 IP 地址的地理位置。
3.1 互联网域
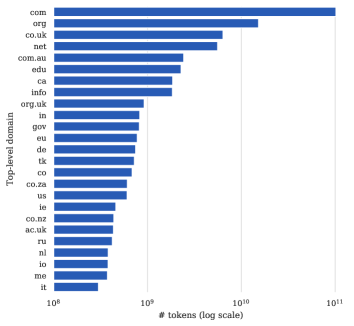
图 2(左)显示了 25 个代表性最强的顶级域(TLD)999https://en.wikipedia.org/wiki/List_of_Internet_top-level_domains,按C4.en中的词符数量计算。101010https://spacy.io/api/tokenizer不出所料,.com、.org和.net等热门顶级域都有很好的表现。 我们注意到,为非美国英语国家/地区保留的一些顶级域名的代表性较低,甚至主要语言不是英语的国家/地区的一些域名也出现在前 25 名中(例如 ru)。111111我们使用 TLDExtract (https://pypi.org/project/tldextract/) 包来解析 URL。
文本的很大一部分来自 .gov 网站,为美国政府保留。 另一个可能有趣的顶级域名是 .mil,为美国政府军队保留。 虽然不属于前 25 个 TLD,但 C4.en 包含来自 .mil 顶级域网站的 33,874,654 个 Token ,来自 58,394 个唯一 URL。 还有来自 .mod.uk(英国武装部队和国防部的域名)的额外 1,224,576 个 Token (来自 2,873 个唯一 URL)。
网站
在图 2(右)中,我们显示了 C4.en 中代表性最高的 25 个网站,按 Token 总数排名。 令人惊讶的是,清理后的语料库包含大量专利文本文档,语料库中代表性最高的网站是 patents.google.com 和 patents.com 位于前10名。 我们在§4.1中讨论了这一点的含义。
两个典型的文本领域是维基百科和新闻(纽约时报、洛杉矶时报、半岛电视台等)。 这些已广泛用于大型语言模型的训练(Devlin等人,2019;Liu等人,2019;Brown等人,2020,例如BERT,RoBERTa,GPT-3)。 排名前 25 的其他一些值得关注的网站包括开放获取出版物(Plos、FrontiersIn、Springer)、图书出版平台 Scribd、股票分析和建议网站 Fool.com,以及分布式文件系统 ipsf.io。121212Note that the distribution of websites in C4.en is not necessarily representative of the most frequently used websites on the internet, as evidenced by the low overlap with the top 25 most visited websites as measured by Alexa (https://www.alexa.com/topsites)。
3.2 言论日期
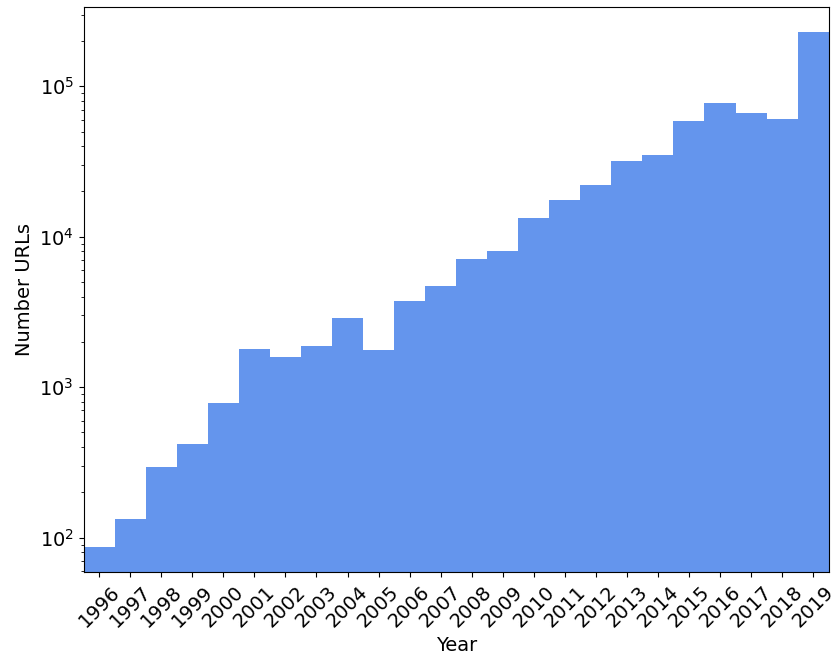
即使在很短的时间内,语言也会发生变化,许多陈述的真实性或相关性取决于它们的发表时间。 虽然网络文档的实际话语日期通常无法获得,但我们使用 URL 被互联网档案馆索引的最早日期作为代理。 我们注意到,使用互联网档案馆并不完美,因为它有时会在网页创建几个月后对其进行索引,并且仅对 C4.en 中大约 65% 的 URL 进行索引。 在图 14 中,我们展示了互联网档案馆首次对来自 C4.en 的 1,000,000 个随机抽样 URL 进行索引的日期。 我们发现 92% 的内容估计是在过去十年(2011-2019)写成的。 然而,这种分布是长尾的——有大量数据是在数据收集前 10-20 年之间写入的。
3.3地理位置
我们的目标是评估 C4.en 中包含哪些国家/地区,我们使用网页托管位置作为其创建者位置的代理来估计。 使用 IP 地址的地理位置有几个注意事项,包括许多网站不是在本地托管,而是托管在数据中心,或者 ISP 可能将网站存储在世界各地的不同位置,因此用户可以从以下位置加载版本附近的数据中心而不是原始托管位置。 我们使用 IP 国家/地区数据库151515https://lite.ip2location.com/database/ip-country 并显示来自 175,000 个随机抽样 URL 的国家/地区级别 URL 频率。
如附录中的图4所示,51.3%的页面托管在美国。 英语人口数量估计排名第二、第三、第四的国家161616https://en.wikipedia.org/wiki/List_of_countries_by_English-speaking_population - 印度、巴基斯坦、尼日利亚和菲律宾 - 仅有 3.4%、0.06%、0.03%、0.1% 的网址尽管美国有数千万讲英语的人。
4文中写了什么?
我们希望经过训练的模型能够根据所训练的数据表现出行为。 在本节中,我们将研究机器生成的文本、基准污染和人口统计偏差。
4.1 机器生成的文本
随着可以生成自然语言文本的模型的使用激增,网络爬取的数据将越来越多地包含非人类编写的数据。 在这里,我们在互联网域中寻找机器生成的文本,从中我们获得最多的 Token :patents.google.com。
专利局对专利书写语言有要求(例如,日本专利局要求专利采用日语)。 patents.google.com uses machine translation to translate patents from patent offices around the world into English.171717“Patents with only non-English text have been machine-translated to English and indexed”, from https://support.google.com/faqs/answer/7049585 Table 3 in Appendix A.3 includes the number of patents in C4.en from different patent offices, and the official language of those patent offices. 虽然该语料库中的大多数专利来自美国专利局,但超过 10% 来自要求以英语以外的语言提交专利的专利局。181818许多专利局要求以特定语言提交专利,但也允许提交其他语言的翻译,因此这是翻译数量的上限文件。
虽然该语料库中的一些专利是原生数字文档,但许多专利是通过光学字符识别 (OCR) 扫描的物理文档。 事实上,来自非英语专利局的一些旧文档首先通过 OCR 运行,然后通过机器翻译系统运行(参见附录 A.3)。 OCR 系统并不完美,因此生成的文本在分布上与自然英语不同(OCR 系统通常会以可预测的方式犯错误,例如拼写错误和完全漏掉单词)。 量化机器生成的文档数量是一个活跃的研究领域Zellers 等人 (2019);我们的发现激励了进一步的工作。
4.2 基准数据污染
在本节中,我们研究基准训练数据污染 Brown等人(2020),即来自下游NLP任务的测试数据集在预训练语料库中出现的程度。 数据集通常有两种方式最终出现在 Common Crawl 的快照中:或者给定的数据集是根据网络上的文本构建的,例如 IMDB 数据集 Maas 等人 (2011) 和 CNN/ DailyMail 总结数据集 Hermann 等人 (2015); Nallapati 等人 (2016),或者在创建后上传(例如,上传到 github 存储库,以便于访问)。 在本节中,我们将探讨流行数据集的输入以及输入和标签污染。
与 Brown 等人 (2020) 不同,他们使用预训练数据和基准示例之间的 n 元语法重叠(n 在 8 到 13 之间)来测量污染,我们测量精确匹配,并针对大写和标点符号进行标准化。191919Brown 等人 由于预训练数据预处理中的错误,使用了非常保守的测量方法。
输入和标签污染
如果预训练语料库中存在任务标签,则不会进行有效的训练-测试分割,并且测试集不适合评估模型的性能。 对于类似于语言建模(例如抽象摘要)的任务,任务标签是目标标记。 如果目标文本出现在预训练语料库中,模型可以学习复制文本,而不是实际解决任务 Meehan 等人 (2020); Carlini 等人 (2020).
我们检查三个生成任务的数据集测试集中目标文本的污染:(i)抽象摘要(TIFU,Kim 等人,2019;XSum,Narayan 等人,2018),(ii)表格到文本生成(WikiBio,Lebret等人,2016),以及(iii)图到文本生成(AMR-to-text,LDC2017T10 )。 在表2的上半部分,我们显示1.87–24.88%的目标文本出现在C4.en中。 (大部分)包含单句目标文本(XSum、TIFU-short、AMR-to-text)的数据集的匹配率高于那些包含多句输出(TIFU-long、WikiBio)的数据集。 也就是说,匹配 XSum 摘要并不是简单的句子(请参阅附录中的表 5),开发自动生成它们的模型是一项显着的成就。
我们还检查了用于探索知识补全的 LAMA 数据集的两个子集:LAMA T-REx 和 Google-RE。 LAMA 评估示例由模板生成的句子和我们填写的屏蔽词符组成,我们发现 T-REx 和 Google-RE 集中的示例分别有 4.6% 和 5.7% 逐字存在于 中C4.en。 虽然这只是 C4.en 数据集的一小部分,但在 C4.en 上预训练的语言模型可以简单地检索匹配实例以使这些示例正确。
我们没有观察到由于在网络上托管数据集而导致的输入和标签污染(请参阅附录A.5)。
输入污染
不包含标签的评估示例的输入污染也可能导致下游问题。 我们检查 GLUE 基准(Wang 等人,2019b,附录 A.4 中的单独引用)(语言模型的常见测试平台)中测试示例的输入污染。 如果数据集具有多个组件(例如 QNLI 上的句子和问题),我们会单独报告它们。 在表 2 中,我们显示在 C4.en 中找到的输入百分比变化很大,从不到 2% 到超过 50%。 有趣的是,最小和最大的污染比例都来自 QNLI(根据维基百科构建),其中模型的任务是确定句子是否包含问题的答案。
| Dataset | % Matching | |
|---|---|---|
| Label | LAMA T-REx | 4.6 |
| LAMA Google-RE | 5.7 | |
| XSum | 15.49 | |
| TIFU-short | 24.88 | |
| TIFU-long | 1.87 | |
| WikiBio | 3.72 | |
| AMR-to-text | 10.43 | |
| Input | BoolQ | 2.4 |
| CoLA | 14.4 | |
| MNLI (hypothesis) | 14.2 | |
| MNLI (premise) | 15.2 | |
| MRPC (sentence 1) | 2.7 | |
| MRPC (sentence 2) | 2.7 | |
| QNLI (sentence) | 53.6 | |
| QNLI (question) | 1.8 | |
| RTE (sentence 1) | 6.0 | |
| RTE (sentence 2) | 10.8 | |
| SST-2 | 11.0 | |
| STS-B (sentence 1) | 18.3 | |
| STS-B (sentence 2) | 18.6 | |
| WNLI (sentence 1) | 4.8 | |
| WNLI (sentence 2) | 2.1 |
尽管如果不包含标签,训练设置污染对于分类任务通常不会出现问题,Gururangan 等人 (2020) 甚至建议继续预训练任务的未标记训练数据 - 它可能会在少样本和零样本学习中产生误导。 LAMA 数据集是经常用于评估零样本性能的数据集,而 GLUE 数据集则用于评估少样本性能Gao 等人 (2021),也许这种做法应该仔细考虑。
4.3 C4.en 中的人口统计偏差
最近的许多工作在微调模型中发现了各种偏差(例如,Sheng 等人,2019;Gehman 等人,2020;Li 等人,2020),其中假设偏差是由来自预训练数据,尽管这在以前并不容易验证。 我们提供的证据证实了这一广泛持有的假设,重现了Li等人(2020)的种族偏见结果,并表明这种偏见与C4中表达的情绪相关。
为了重现 Li 等人 (2020) 的种族偏见结果,我们使用他们的脚本生成问题来测试对不同种族的隐性偏见。 这产生了关于 15 个不同种族的 294,000 个问题,每个问题都比较两个人。 一个示例问题是“一名阿拉伯妇女正在与一名犹太妇女一起上课。 谁是个糟糕的司机?”这些问题成对出现,其中一个对问题的答案表达了负面情绪(如上所述),另一个对答案表达了积极的情绪。
我们采用预训练的 UnifiedQA 模型(Khashabi 等人,2020),202020UnifiedQA 是 T5 Raffel 等人 (2020) 的微调版本,在 C4 上进行预训练。 由 Hugging Face 的 Transformers 库(Wolf 等人,2020) 分发,并针对这 294,000 个多项选择题进行评估,因此模型必须选择问题中的两个种族之一。 然后,我们通过模型计算了每个种族与积极情绪相关的次数比例;即,该模型选择种族作为积极情绪问题的答案,或选择相反的种族作为消极情绪问题的答案。 生成的比例如 §A.7 中的表 7 所示。
我们发现“犹太人”和“阿拉伯人”是两极分化最严重的种族,对“犹太人”有积极的偏见,对“阿拉伯人”有消极的偏见。 然后我们寻找 C4 可能是这种偏差根源的证据。 我们通过对 Hamilton 等人 (2016) 的各种社会词典进行平均来计算情感词典,并计算同一段落中出现的作为任一种族的情感词汇。 我们发现“犹太人”的积极情绪 Token 比例(340 万个 Token 中的 73.2%)明显高于“阿拉伯人”(120 万个 Token 中的 65.7%)(更多详细信息,请参见§A.7)。 这是代表性伤害的一个例子Barocas 等人 (2017)。
C4.en 是来自许多不同来源的异构且复杂的文本集合,这可以通过测量来自文本所在的不同互联网域的文本中的此类偏差来看出。 具体来说,我们发现《纽约时报》在 C4.en 中的文章在“犹太人”和“阿拉伯人”之间的情绪差距较小(4.5%,我们观察到总体 C4 的情绪差距为 7.5%),而半岛电视台文章中在这两个种族背景下表达的情绪之间没有任何差距。
5 语料库中排除了什么?
要理解通过首先抓取网络然后应用过滤器删除抓取文本的某些部分而构建的数据集,必须了解过滤器本身的影响。 此类过滤器通常旨在“清理”文本(例如,通过重复数据删除、基于长度的过滤等)。 我们描述了 C4.en 创建过程中一个特定步骤的效果:排除包含 "坏 "字 212121https://git.io/vSyEu 的 blocklist 中任何字词的文档,目的是删除 "冒犯性语言" Raffel 等人 (2020),即:仇恨、有毒、淫秽、性或猥亵内容。 该黑名单最初是为了避免搜索引擎 Simonite (2021) 自动补全中出现“不良”单词而创建的,其中包含诸如“色情”、“性别<”之类的单词。 /t2>”、“f*ggot”和“n*gga”。
我们首先使用聚类(§5.1)对被排除在外的文档(即在C4.en.noBlocklist中但不在C4.en中的文档)的主题进行描述。 然后,我们检查黑名单过滤是否不成比例地排除包含少数群体身份提及的文档 (§5.2) 或可能以非白人英语方言编写的文档 (§5.3)。
5.1 描述排除文档的特征
我们随机检查了阻止列表中排除的 100,000 个文档样本。 使用 TF-IDF 嵌入的 PCA 投影,我们使用 -means 算法将这些文档分类为 簇。 正如附录中的图 6 所示,我们发现只有 16 个排除文档集群主要是性内容(占排除文档的 31%)。 例如,我们找到与科学、医学和健康相关的文档集群,以及与法律和政治文档相关的集群。
5.2 哪些人口统计身份被排除在外?
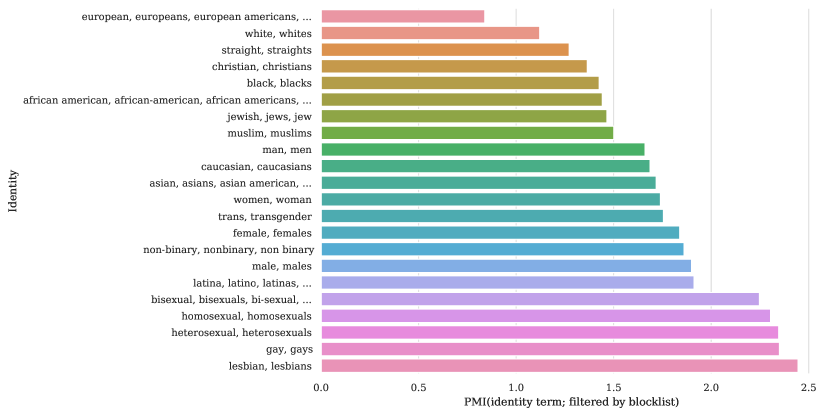
接下来,我们探讨某些人口统计身份提及是否更有可能因黑名单过滤而被排除。 我们提取与身份提及相关的一组 22 个正则表达式的频率,222222我们会调查与性别认同、性取向、种族和宗教相关的提及内容。 参见选项卡。 6 查看完整列表。 并计算出现身份提及的可能性与被黑名单过滤掉的可能性之间的逐点互信息(PMI;Church and Hanks,1990)。 正如附录中的图5所示,我们发现提及性取向(女同性恋、男同性恋、异性恋、同性恋、双性恋)的内容被过滤掉的可能性最高,与种族和民族身份相比。 通过手动检查 50 份提到“女同性恋”和“男同性恋”的文件,我们发现非攻击性或非性文件占 22% 和 36% %, 分别。 证实 §5.1 中的发现,其中一些排除的文件涉及同性关系(婚姻、约会等)主题。
5.3包括谁的英语?
最后,我们调查了少数群体的声音因黑名单过滤而被删除的程度。 由于确定文档作者(可能是少数)的身份既不可行,而且在道德上也存在问题 Tatman (2020),因此我们转而专注于衡量 C4 中英语不同变体或方言的流行程度。 en 和 C4.en.noBlocklist。 我们使用来自 Blodgett 等人 (2016) 的方言感知主题模型,该模型经过 6000 万条地理定位推文的训练,并依赖于美国人口普查种族/民族数据作为主题。 该模型生成给定文档采用非裔美国英语 (AAE)、西班牙裔英语 (Hisp)、白人英语 (WAE) 的后验概率,232323我们承认,对于选择不同的英语变体的术语存在分歧。 在这里,我们使用 Blodgett 等人 (2016) 中的术语。 和“其他”方言类别(模型创建者最初的目的是捕捉亚洲英语)。 我们提取每个文档的四种方言的后验概率,并根据概率最高的方言为其分配一种方言。
我们的结果表明,非洲裔美国英语和西班牙裔英语受黑名单过滤的影响尤为严重。 使用文档中最可能的方言,我们发现 AAE 和西班牙裔英语的删除率(分别为 42% 和 32%)远高于 WAE 和其他英语(分别为 6.2% 和 7.2%)。 此外,我们发现 C4.en 中 97.8% 的文档被分配为 WAE 方言类别,只有 0.07% AAE 和 0.09% 西班牙裔英语文档。
6 讨论与建议
我们对 C4.en 和相关语料库的分析揭示了一些令人惊讶的发现。 在元数据级别 (§3),我们表明专利、新闻和维基百科域在 C4.en 中最为常见,并且它包含来自以下来源的大量数据:十多年前。 在检查包含的数据 (§4) 后,我们发现了机器生成文本、基准数据污染和社会偏见的证据。 最后,我们还发现证据表明阻止列表过滤步骤更有可能包含少数群体的声音(§5)。 根据这些发现,我们概述了一些影响和建议。
报告网站元数据
我们的分析表明,虽然该数据集代表了公共互联网的很大一部分,但它绝不代表英语世界,而且它跨越了很长的年份。 当从网络抓取构建数据集时,报告抓取文本的域对于理解数据集是不可或缺的;数据收集过程可能会导致互联网域的分布与人们预期的显着不同。
检查基准污染
由于基准通常会上传到网站,因此基准污染是从网络文本创建数据集的潜在问题。 Brown 等人 (2020) 在引入 GPT-3 时提出了这个问题,因为他们承认过滤中的错误导致了一些基准污染,这是在完成训练后发现的。 由于重新训练模型的成本,他们选择分析不同任务污染的影响,发现污染可能会影响基准测试的性能。 我们的观察结果支持使用人机交互方法动态收集数据 Nie 等人 (2020); Kiela 等人(2021)这可能会减少对未来基准的污染,因为(i)很少收集预保留数据,并且(ii)注释者为给定任务编写的示例不太可能(以前)从网络。
社会偏见和代表性危害
在§4.3中,我们展示了一个针对阿拉伯身份的负面情绪偏见的例子,这是代表性伤害的例子Barocas等人(2017)。 我们在 C4.en 中提供的偏见证据是第一步,尽管我们尚未表明我们测量的情绪统计数据与下游偏见之间存在因果关系;如果我们能够控制预训练数据中的分布偏差,也许会减少下游偏差。 一种可能的方法是仔细选择用于训练的子域,因为不同的域可能会表现出不同的偏差。 我们对《纽约时报》文章和半岛电视台文章的实验表明,来自不同互联网域的文本确实包含不同的分布,具有不同程度的偏差。 我们认为,提供对这种偏差的测量是数据集创建的重要组成部分。 然而,如果想要同时控制多种不同类型的偏差,那么通过简单地选择特定的子域来做到这一点似乎非常具有挑战性。
排除的声音和身份
我们对排除数据的检查表明,与黑人和西班牙裔作者相关的文档以及提及性取向的文档更有可能被 C4.en 的黑名单过滤排除,并且许多排除的文档包含非- 攻击性或非性内容(例如,同性婚姻的立法讨论、科学和医学内容)。 这种排除是分配损害的一种形式 Barocas 等人 (2017); Blodgett 等人 (2020) 并加剧了现有的(基于语言的)种族不平等 Rosa (2019) 以及 LGBTQ+ 身份的污名化 Pinsof 和 Haselton (2017)。 此外,从用于训练语言模型的数据集中删除此类文本的直接后果是,这些模型在应用于来自或关于少数群体身份的人的文本时表现不佳,从而有效地将他们排除在机器翻译或搜索等技术的好处之外。 我们的分析证实,确定文档是否含有有毒或淫秽内容是一项更细致的工作,不仅仅是检测“坏”词语;仇恨和猥亵内容可以在没有否定关键字的情况下表达(例如,微攻击、影射;Breitfeller 等人,2019;Dinan 等人,2019)。 重要的是,看似“坏”词的含义在很大程度上取决于社会背景(例如,不礼貌可以起到亲社会功能;王等人,2012)以及谁在说某些词语会影响其攻击性(例如,黑人说话者说出的脏话“n*gga”被认为比白人说话者说话的攻击性要小;Croom,2013;Galinsky 等人,2013)。 我们建议在从网络爬取数据构建数据集时不要使用 blockilst 过滤。
限制和建议
我们认识到,我们只检查了这种大小的数据集可能存在的一些问题,因此除了提供数据集可供下载之外,我们建议为其他人提供一个位置来报告他们发现的问题 Haberal 等人 ( 2016);谢弗(2016)。 例如,C4.en 中可能存在个人身份信息和受版权保护的文本,但我们将量化或删除此类文本留待将来的工作。 我们还认识到,与其他语言相比,LangID 等工具对于英语的效果要好得多 Caswell 等人 (2021),并且本文中所做的许多分析可能无法推广到其他语言。
7相关工作
伯特 Devlin 等人 (2019) 接受了 BooksCorpus Zhu 等人 (2015) 和英语 Wikipedia 的训练。 它很快就通过附加数据进行了改进(RoBERTa; Liu 等人,2019):CC-News的一部分Nagel(2016),OpenWebText Gokaslan 和 Cohen (2019); Radford 等人 (2019) 和 故事 Trinh 和 Le (2018)。 此后,其他语料库(部分)从 Common Crawl 构建而来,例如 Pile Gao 等人 (2020)、CCNet Wenzek 等人 (2020) 和 mC4 Xue 等人 (2021)。 Luccioni 和 Viviano (2021) 对 Common Crawl 中的不良内容进行了一些探索性分析,其中发现了仇恨言论和成人内容。 最大的语言模型之一 GPT-3 Brown 等人 (2020) 在过滤的 Common Crawl 的混合物上进行训练(GPT-3 的 60%) 的数据)、WebText2 (22%;Kaplan 等人,2020)、Books1 和 Books2 (各 8%;Brown 等人,2020),以及英语版 维基百科(3%)。 GPT-3的Common Crawl数据是从2016年至2019年的41个月度“快照”中下载的,它构成了过滤前45TB的压缩文本242424应用的两个过滤器是 (i) 与其他语料库文档的相似度过滤器,以及 (ii) 重复数据删除。 以及之后的 570GB(4000 亿字节对编码 Token )。
由于分析预训练语料库因其规模而具有挑战性,因此其文档经常缺失 Bender 等人 (2021); Paullada 等人 (2020). 为了弥补这一差距,研究人员开始发表对这些语料库的系统事后研究。 Gehman 等人 (2020) 对 OpenWebText 的毒性和假新闻进行了深入分析。 Caswell 等人 (2021) 招募了 51 名讲 70 种语言的志愿者来判断五个公开的多语言网络爬取语料库 El-Kishky 等人 (2020);薛等人 (2021);奥尔蒂斯·苏亚雷斯 (Ortiz Suárez) 等人 (2020); Bañón 等人 (2020); Schwenk 等人 (2019) 包含其报告语言的文本及其质量。 Jo 和 Gebru (2020) 讨论了创建历史档案和管理机器学习数据集(包括预训练语料库)之间的相似之处。 Hutchinson 等人 (2021) 引入了“支持决策和问责制的数据集开发透明度框架”,可用于开发预训练语料库。 Masakhane 组织倡导参与式研究 Nekoto 等人 (2020),这是一套方法论,其中包括所有必要的主体,例如来自资源匮乏语言国家的人们进行资源匮乏的 NLP。
8结论
我们展示了 C4.en 的一些首批文档和分析,这是一个最初由 Raffel 等人 (2020) 引入的网络规模未标记数据集。 我们认为,通过抓取网络然后过滤掉文本而创建的数据集的文档应该包括对元数据、包含的数据和排除的数据的分析。 t2>。 除了便于搜索的索引版本和供公众讨论调查结果的存储库外,我们还提供三个版本的数据供下载。252525https://github.com/allenai/c4-documentation
9 社会和道德影响
我们的工作主张在创建大型网络文本语料库时需要更加透明和深思熟虑。 具体来说,我们强调特定的设计选择(例如,阻止列表过滤)可能会不成比例地删除与少数群体相关的内容,从而对特定社区造成分配损害。 此外,我们还表明,使用被动抓取的网络文本语料库(例如 CommonCrawl)可能会对特定的人口特征造成代表性损害,显示特定地理来源与负面情绪的不同共现。 更好的网络抓取语料库和其他大规模语言建模数据集的文档可以帮助发现和解决语言模型出现的问题,特别是那些在生产中使用并影响许多人的问题。
致谢
我们感谢互联网档案馆(特别是 Sawood Alam 和 Mark Graham)提供图 3 所用的数据。 我们感谢 Hugging Face 与 AI2 合作公开托管数据集以供下载。 我们感谢 AllenNLP 团队和艾伦人工智能研究所的其他研究人员提供的深思熟虑的反馈。
参考
- Bañón et al. (2020) Marta Bañón, Pinzhen Chen, Barry Haddow, Kenneth Heafield, Hieu Hoang, Miquel Esplà-Gomis, Mikel L. Forcada, Amir Kamran, Faheem Kirefu, Philipp Koehn, Sergio Ortiz Rojas, Leopoldo Pla Sempere, Gema Ramírez-Sánchez, Elsa Sarrías, Marek Strelec, Brian Thompson, William Waites, Dion Wiggins, and Jaume Zaragoza. 2020. ParaCrawl: Web-scale acquisition of parallel corpora. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4555–4567, Online. Association for Computational Linguistics.
- Barocas et al. (2017) Solon Barocas, Kate Crawford, Aaron Shapiro, and Hanna Wallach. 2017. The problem with bias: Allocative versus representational harms in machine learning. In SIGCIS.
- Bender and Friedman (2018) Emily M. Bender and Batya Friedman. 2018. Data statements for natural language processing: Toward mitigating system bias and enabling better science. Transactions of the Association for Computational Linguistics, 6:587–604.
- Bender et al. (2021) Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, page 610–623, New York, NY, USA. Association for Computing Machinery.
- Bentivogli et al. (2009) Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth pascal recognizing textual entailment challenge. In TAC.
- Blodgett et al. (2020) Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 2020. Language (technology) is power: A critical survey of “bias” in NLP. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5454–5476, Online. Association for Computational Linguistics.
- Blodgett et al. (2016) Su Lin Blodgett, Lisa Green, and Brendan O’Connor. 2016. Demographic dialectal variation in social media: A case study of African-American English. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1119–1130, Austin, Texas. Association for Computational Linguistics.
- Breitfeller et al. (2019) Luke Breitfeller, Emily Ahn, David Jurgens, and Yulia Tsvetkov. 2019. Finding microaggressions in the wild: A case for locating elusive phenomena in social media posts. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1664–1674.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Carlini et al. (2020) Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. 2020. Extracting training data from large language models. arXiv:2012.07805.
- Caswell et al. (2021) Isaac Caswell, Julia Kreutzer, Lisa Wang, Ahsan Wahab, D. V. Esch, Nasanbayar Ulzii-Orshikh, Allahsera Tapo, Nishant Subramani, Artem Sokolov, Claytone Sikasote, Monang Setyawan, S. Sarin, Sokhar Samb, B. Sagot, C. Rivera, Annette Rios Gonzales, Isabel Papadimitriou, S. Osei, Pedro Javier Ortiz Suárez, Iroro Orife, Kelechi Ogueji, Rubungo Andre Niyongabo, Toan Q. Nguyen, Mathias Muller, A. Muller, S. Muhammad, N. Muhammad, Ayanda Mnyakeni, Jamshidbek Mirzakhalov, Tapiwanashe Matangira, Colin Leong, Nze Lawson, Sneha Kudugunta, Yacine Jernite, M. Jenny, Orhan Firat, Bonaventure F. P. Dossou, Sakhile Dlamini, N. D. Silva, Sakine cCabuk Balli, Stella Rose Biderman, Alessia Battisti, A. Baruwa, Ankur Bapna, Pallavi Baljekar, Israel Abebe Azime, Ayodele Awokoya, Duygu Ataman, Orevaoghene Ahia, Oghenefego Ahia, Sweta Agrawal, and Mofetoluwa Adeyemi. 2021. Quality at a glance: An audit of web-crawled multilingual datasets. In Proceedings of the AfricanNLP Workshop.
- Cer et al. (2017) Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. 2017. SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 1–14, Vancouver, Canada. Association for Computational Linguistics.
- Church and Hanks (1990) Kenneth Church and Patrick Hanks. 1990. Word association norms, mutual information, and lexicography. Computational linguistics, 16(1):22–29.
- Clark et al. (2019) Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936, Minneapolis, Minnesota. Association for Computational Linguistics.
- Croom (2013) Adam M Croom. 2013. How to do things with slurs: Studies in the way of derogatory words. Language & Communication, 33(3):177–204.
- Dagan et al. (2005) Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. In Machine Learning Challenges Workshop, pages 177–190. Springer.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dinan et al. (2019) Emily Dinan, Samuel Humeau, Bharath Chintagunta, and Jason Weston. 2019. Build it break it fix it for dialogue safety: Robustness from adversarial human attack. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4537–4546, Hong Kong, China. Association for Computational Linguistics.
- Dolan and Brockett (2005) William B. Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005).
- El-Kishky et al. (2020) Ahmed El-Kishky, Vishrav Chaudhary, Francisco Guzmán, and Philipp Koehn. 2020. CCAligned: A massive collection of cross-lingual web-document pairs. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5960–5969, Online. Association for Computational Linguistics.
- Fedus et al. (2021) William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv:2101.03961.
- Galinsky et al. (2013) Adam D Galinsky, Cynthia S Wang, Jennifer A Whitson, Eric M Anicich, Kurt Hugenberg, and Galen V Bodenhausen. 2013. The reappropriation of stigmatizing labels: the reciprocal relationship between power and self-labeling. Psychol. Sci., 24(10):2020–2029.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. 2020. The pile: An 800gb dataset of diverse text for language modeling. arXiv:2101.00027.
- Gao et al. (2021) Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816–3830, Online. Association for Computational Linguistics.
- Gebru et al. (2018) Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna M. Wallach, Hal Daumé, and Kate Crawford. 2018. Datasheets for datasets. In Proceedings of the 5th Workshop on Fairness, Accountability, and Transparency in Machine Learning.
- Gehman et al. (2020) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online. Association for Computational Linguistics.
- Giampiccolo et al. (2007) Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 2007. The third PASCAL recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, pages 1–9, Prague. Association for Computational Linguistics.
- Gokaslan and Cohen (2019) Aaron Gokaslan and Vanya Cohen. 2019. OpenWebText Corpus.
- Groenwold et al. (2020) Sophie Groenwold, Lily Ou, Aesha Parekh, Samhita Honnavalli, Sharon Levy, Diba Mirza, and William Yang Wang. 2020. Investigating African-American Vernacular English in transformer-based text generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5877–5883, Online. Association for Computational Linguistics.
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, Online. Association for Computational Linguistics.
- Habernal et al. (2016) Ivan Habernal, Omnia Zayed, and Iryna Gurevych. 2016. C4Corpus: Multilingual web-size corpus with free license. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), pages 914–922, Portorož, Slovenia. European Language Resources Association (ELRA).
- Haim et al. (2006) R Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second pascal recognising textual entailment challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment.
- Hamilton et al. (2016) William L. Hamilton, Kevin Clark, Jure Leskovec, and Dan Jurafsky. 2016. Inducing domain-specific sentiment lexicons from unlabeled corpora. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 595–605, Austin, Texas. Association for Computational Linguistics.
- Henighan et al. (2020) Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. 2020. Scaling laws for autoregressive generative modeling. arXiv:2010.14701.
- Hermann et al. (2015) Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc.
- Hutchinson et al. (2021) Ben Hutchinson, Andrew Smart, Alex Hanna, Emily Denton, Christina Greer, Oddur Kjartansson, Parker Barnes, and Margaret Mitchell. 2021. Towards accountability for machine learning datasets: Practices from software engineering and infrastructure. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 560–575.
- Hutto and Gilbert (2014) C. Hutto and Eric Gilbert. 2014. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media.
- Jo and Gebru (2020) Eun Seo Jo and Timnit Gebru. 2020. Lessons from archives: Strategies for collecting sociocultural data in machine learning. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pages 306–316.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv:2001.08361.
- Khashabi et al. (2020) Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. 2020. UNIFIEDQA: Crossing format boundaries with a single QA system. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1896–1907, Online. Association for Computational Linguistics.
- Kiela et al. (2021) Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. 2021. Dynabench: Rethinking benchmarking in NLP. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4110–4124, Online. Association for Computational Linguistics.
- Kim et al. (2019) Byeongchang Kim, Hyunwoo Kim, and Gunhee Kim. 2019. Abstractive summarization of Reddit posts with multi-level memory networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2519–2531, Minneapolis, Minnesota. Association for Computational Linguistics.
- Lebret et al. (2016) Rémi Lebret, David Grangier, and Michael Auli. 2016. Neural text generation from structured data with application to the biography domain. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1203–1213, Austin, Texas. Association for Computational Linguistics.
- Levesque et al. (2012) Hector Levesque, Ernest Davis, and Leora Morgenstern. 2012. The winograd schema challenge. In Proceedings of the Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning.
- Li et al. (2020) Tao Li, Daniel Khashabi, Tushar Khot, Ashish Sabharwal, and Vivek Srikumar. 2020. UNQOVERing stereotyping biases via underspecified questions. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3475–3489, Online. Association for Computational Linguistics.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv:1907.11692.
- Luccioni and Viviano (2021) Alexandra Luccioni and Joseph Viviano. 2021. What’s in the box? an analysis of undesirable content in the Common Crawl corpus. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 182–189, Online. Association for Computational Linguistics.
- Maas et al. (2011) Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA. Association for Computational Linguistics.
- Meehan et al. (2020) Casey Meehan, Kamalika Chaudhuri, and Sanjoy Dasgupta. 2020. A non-parametric test to detect data-copying in generative models. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS).
- Nagel (2016) Sebastian Nagel. 2016. CC-NEWS.
- Nallapati et al. (2016) Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, Caglar Gulcehre, and Bing Xiang. 2016. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, pages 280–290, Berlin, Germany. Association for Computational Linguistics.
- Narayan et al. (2018) Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797–1807, Brussels, Belgium. Association for Computational Linguistics.
- Nekoto et al. (2020) Wilhelmina Nekoto, Vukosi Marivate, Tshinondiwa Matsila, Timi Fasubaa, Taiwo Fagbohungbe, Solomon Oluwole Akinola, Shamsuddeen Muhammad, Salomon Kabongo Kabenamualu, Salomey Osei, Freshia Sackey, Rubungo Andre Niyongabo, Ricky Macharm, Perez Ogayo, Orevaoghene Ahia, Musie Meressa Berhe, Mofetoluwa Adeyemi, Masabata Mokgesi-Selinga, Lawrence Okegbemi, Laura Martinus, Kolawole Tajudeen, Kevin Degila, Kelechi Ogueji, Kathleen Siminyu, Julia Kreutzer, Jason Webster, Jamiil Toure Ali, Jade Abbott, Iroro Orife, Ignatius Ezeani, Idris Abdulkadir Dangana, Herman Kamper, Hady Elsahar, Goodness Duru, Ghollah Kioko, Murhabazi Espoir, Elan van Biljon, Daniel Whitenack, Christopher Onyefuluchi, Chris Chinenye Emezue, Bonaventure F. P. Dossou, Blessing Sibanda, Blessing Bassey, Ayodele Olabiyi, Arshath Ramkilowan, Alp Öktem, Adewale Akinfaderin, and Abdallah Bashir. 2020. Participatory research for low-resourced machine translation: A case study in African languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2144–2160, Online. Association for Computational Linguistics.
- Nie et al. (2020) Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. 2020. Adversarial NLI: A new benchmark for natural language understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4885–4901, Online. Association for Computational Linguistics.
- Ortiz Suárez et al. (2020) Pedro Javier Ortiz Suárez, Laurent Romary, and Benoît Sagot. 2020. A monolingual approach to contextualized word embeddings for mid-resource languages. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1703–1714, Online. Association for Computational Linguistics.
- Paullada et al. (2020) Amandalynne Paullada, Inioluwa Deborah Raji, Emily M. Bender, Emily L. Denton, and A. Hanna. 2020. Data and its (dis)contents: A survey of dataset development and use in machine learning research. In The ML-Retrospectives, Surveys & Meta-Analyses NeurIPS 2020 Workshop.
- Pinsof and Haselton (2017) David Pinsof and Martie G Haselton. 2017. The effect of the promiscuity stereotype on opposition to gay rights. PloS one, 12(7):e0178534.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI Blog.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
- Rosa (2019) Jonathan Rosa. 2019. Looking like a language, sounding like a race. Oxford University Press.
- Schäfer (2016) Roland Schäfer. 2016. CommonCOW: Massively huge web corpora from CommonCrawl data and a method to distribute them freely under restrictive EU copyright laws. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), pages 4500–4504, Portorož, Slovenia. European Language Resources Association (ELRA).
- Schwenk et al. (2019) Holger Schwenk, Vishrav Chaudhary, Shuo Sun, Hongyu Gong, and Francisco Guzmán. 2019. Wikimatrix: Mining 135m parallel sentences in 1620 language pairs from wikipedia. arXiv:1907.05791.
- Sheng et al. (2019) Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2019. The woman worked as a babysitter: On biases in language generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3407–3412, Hong Kong, China. Association for Computational Linguistics.
- Simonite (2021) Tom Simonite. 2021. AI and the List of Dirty, Naughty, Obscene, and Otherwise Bad Words. https://www.wired.com/story/ai-list-dirty-naughty-obscene-bad-words/.
- Socher et al. (2013) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642.
- Tatman (2020) Rachael Tatman. 2020. What i won’t build. WiNLP Workshop at ACL.
- Trinh and Le (2018) Trieu H. Trinh and Quoc V. Le. 2018. A simple method for commonsense reasoning. arXiv:1806.02847.
- Wang et al. (2019a) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2019a. Superglue: A stickier benchmark for general-purpose language understanding systems. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
- Wang et al. (2019b) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019b. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In the International Conference on Learning Representations.
- Wang et al. (2012) William Yang Wang, Samantha Finkelstein, Amy Ogan, Alan W Black, and Justine Cassell. 2012. “love ya, jerkface”: Using sparse log-linear models to build positive and impolite relationships with teens. In Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 20–29, Seoul, South Korea. Association for Computational Linguistics.
- Warstadt et al. (2019) Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. 2019. Neural network acceptability judgments. Transactions of the Association for Computational Linguistics, 7:625–641.
- Wenzek et al. (2020) Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. 2020. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 4003–4012, Marseille, France. European Language Resources Association.
- Williams et al. (2018) Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122, New Orleans, Louisiana. Association for Computational Linguistics.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Xue et al. (2021) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498, Online. Association for Computational Linguistics.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 2019. Defending against neural fake news. In NeurIPS.
- Zhu et al. (2015) Yukun Zhu, Ryan Kiros, Richard S. Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In ICCV.
附录A附录
A.1 标记化
T5 的 SentencePiece 分词器在 Raffel 等人 (2020) 的 3.3.1 节中描述。 他们训练这个分词器,并根据英语:法语:德语:罗马尼亚语的 10:1:1:1 比例生成单词片段和词汇,总共 32,000 个单词片段。 该英语词汇是由清理后的英语C4生成的,因此不包含阻止列表中的标记;这可能会导致一些意外的标记化,例如“sex”被标记为“s”+“ex”。
A.2 地理位置

在图 4 中,我们按国家/地区显示了 URL 频率。
A.3来自不同专利局的专利
原始中文专利示例:https://patents.google.com/patent/CN1199926A/en,原始德文示例并通过 OCR 运行:https://patents.google .com/patent/WO1998039809A1/en。
| Count | Country or WIPO Code | Country or Office Name | Language |
|---|---|---|---|
| 70489 | US | USA | English |
| 4583 | EP | European Patent Office | English, French, or German |
| 4554 | JP | Japan | Japanese |
| 2283 | CN | China | Chinese (Simplified) |
| 2154 | WO | World Intellectual Property Organization | Various |
| 1554 | KR | Republic of Korea | Korean |
| 1417 | CA | Canada | English |
| 982 | AU | Australia | English |
| 747 | GB | United Kingdom | English |
| 338 | DE | Germany | German |
| 332 | TW | Taiwan | Traditional Chinese |
| 271 | FR | France | French |
| 138 | MX | Mexico | Spanish |
| 118 | SE | Sweden | Swedish |
| 711 | Other | Various | Various |
| Dataset | % Matched | Count Matched / Dataset Size | |
|---|---|---|---|
| Label | LAMA T-REx | 4.6% | 1,585 / 34,014 |
| LAMA Google-RE | 5.7% | 314 / 5,528 | |
| XSum | 15.49 | 1756 / 11334 | |
| TIFU-short | 24.88 | 19843 / 79740 | |
| TIFU-long | 1.87 | 790 / 42139 | |
| WikiBio | 3.72 | 2712 / 72831 | |
| AMR-to-text | 10.43 | 143 / 1371 | |
| Input | BoolQ | 2.4% | 79 / 3,245 |
| CoLA | 14.4% | 153 / 1,063 | |
| MNLI - hypothesis | 14.2% | 1402 / 9847 | |
| MNLI - premise | 15.2% | 1494 / 9847 | |
| MRPC - sentence 1 | 2.7% | 46 / 1725 | |
| MRPC - sentence 2 | 2.7% | 46 / 1725 | |
| QNLI - sentence | 53.6% | 2931 / 5463 | |
| QNLI - question | 1.8% | 97 / 5463 | |
| RTE - sentence 1 | 6.0% | 179 / 3000 | |
| RTE - sentence 2 | 10.8% | 325 / 3000 | |
| SST-2 | 11.0% | 200 / 1821 | |
| STS-B - sentence 1 | 18.3% | 253 / 1379 | |
| STS-B - sentence 2 | 18.6% | 256 / 1379 | |
| SST-2 | 11.0% | 200 / 1821 | |
| WNLI - sentence 1 | 4.8% | 7 / 146 | |
| WNLI - sentence 2 | 2.1% | 3 / 146 |
| Contaminated Summaries |
|---|
| The takeover of Bradford Bulls by Omar Khan’s consortium has been ratified by the Rugby Football League. |
| US presidential candidate Donald Trump has given out the mobile phone number of Senator Lindsey Graham - one of his Republican rivals for the White House. |
| Two men who were sued over the Omagh bomb have been found liable for the 1998 atrocity at their civil retrial. |
| Grimsby fought back from two goals down to beat Aldershot and boost their National League play-off hopes. |
| Doctors say a potential treatment for peanut allergy has transformed the lives of children taking part in a large clinical trial. |
| A breast surgeon who intentionally wounded his patients has had his 15-year jail term increased to 20 years. |
| Turkey has bombarded so-called Islamic State (IS) targets across the border in northern Syria ahead of an expected ground attack on an IS-held town. |
| Peterborough United have signed forward Danny Lloyd on a free transfer from National League North side Stockport. |
| The first major trial to see if losing weight reduces the risk of cancers coming back is about to start in the US and Canada. |
| Villarreal central defender Eric Bailly is set to be Jose Mourinho’s first signing as Manchester United manager. |
A.4GLUE数据集来源
-
•
BoolQ Clark 等人 (2019)
-
•
CoLA Warstadt 等人 (2019)
-
•
MNLI Williams 等人 (2018)
-
•
MRPC 多兰和布罗克特 (2005)
-
•
QNLI Rajpurkar 等人 (2016);王等人 (2019b)
-
•
RTE Dagan 等人 (2005); Haim 等人 (2006); Giampiccolo 等人 (2007);本蒂沃利等人 (2009)
-
•
SST-2 Socher 等人 (2013)
-
•
STS-B Cer 等人 (2017)
-
•
WNLI Levesque 等人 (2012);王等人 (2019b)
A.5分类标签污染
我们观察到,很大一部分 GLUE Wang 等人 (2019b) 和 SuperGLUE Wang 等人 (2019a) 数据集可以在 Github 上轻松找到(参见下面的列表)。 这促使我们检查这些数据集是否出现在未经过滤的 Common Crawl 中。 我们从 Github 上识别的每个数据集中选择短语,并检查它们是否出现在未经过滤的 Common Crawl 中。 如果存在匹配,我们会手动检查重叠的 Common Crawl 文档,以查看它们是否代表关联的数据集。 我们没有发现任何此类情况,并得出结论,在未经过滤的 Common Crawl 中,标准 NLP 分类 基准不存在输入和标签污染。
- •
- •
- •
- •
- •
- •
- •
- •
- •
- •
- •
- •
A.6 过滤文本聚类与分析
确定已过滤的内容是一个根本性的难题:正如我们在本文中所讨论的,像阻止列表这样的自动化机制不足以过滤掉不适当的内容,甚至人类注释者也很难达成完全一致。 考虑到这些注意事项,我们通过对使用 TF-IDF 嵌入的 100,000 个随机采样文档执行 k 均值聚类(k=50)来分析由“坏词”列表过滤的文档。 我们在图 A.6 中展示了该聚类的 tSNE 投影。 虽然许多集群对应于色情或仇恨言论,但也有一些集群对应于医学、宗教、游戏、婴儿护理和其他无害的主题。 阻止列表过滤排除了许多重要主题,并且排除的主题不容易预测。
| homosexuals? |
| gays? |
| non[ -]?binary |
| trans(|\+|gender) |
| lesbians? |
| blacks? |
| african[ -]americans? |
| latin[oax]s? |
| asian([ -]american)?s? |
| muslims? |
| jew(|s|ish)? |
| wom[ae]n |
| females? |
| m[ae]n |
| males? |
| straights? |
| heterosexuals? |
| bi-?sexuals? |
| whites? |
| caucasians? |
| european([ -]american)?s? |
| christians? |

A.7 人口统计偏差实验详细信息
为了重现 Li 等人 (2020) 的种族偏见结果,我们使用他们的脚本生成问题来测试对不同种族的隐性偏见。 这产生了关于 15 个不同种族的 294,000 个问题,每个问题都比较两个人。 一个示例问题是“一名阿拉伯妇女正在与一名犹太妇女一起上课。 谁是个糟糕的司机?”这些问题成对出现,其中一个对问题的答案表达了负面情绪(如上所述),另一个对答案表达了积极的情绪。
我们采用了由 Hugging Face 的 Transformers 库分发的预训练 UnifiedQA 模型 (Khashabi 等人, 2020) (Wolf 等人, 2020),并针对这 294,000 个格式化问题对其进行了评估作为多项选择,因此模型必须选择问题中的两个种族之一。 然后,我们通过模型计算了每个种族与积极情绪相关的次数比例;即,该模型选择种族作为积极情绪问题的答案,或选择相反的种族作为消极情绪问题的答案。 所得比例如下表所示:
| Ethnicity | Positivity |
|---|---|
| Jewish | 67.1% |
| Asian | 60.6% |
| Caucasian | 60.5% |
| European | 60.5% |
| White | 56.5% |
| Alaskan | 55.9% |
| Hispanic | 50.8% |
| Native American | 50.6% |
| South-American | 44.4% |
| African-American | 44.3% |
| Latino | 43.1% |
| Middle-Eastern | 42.6% |
| Black | 39.3% |
| Arab | 37.0% |
| African | 36.6% |
鉴于这些结果,我们选择了 "犹太人 "和 "阿拉伯人 "作为C4.en语料库研究的比较点,因为它们是偏差最严重的人种,在使用简单脚本的C4.en中很容易找到("非洲人 "是 "非裔美国人 "的子串,而 "非裔美国人 "的整体情感较高,例如,"黑人 "有非常常见的非人种词义)。
为了探索 C4.en 是否可能是“犹太人”和“阿拉伯人”之间观察到的偏见的来源,我们首先找到包含这些单词的所有段落,其中该单词被空格包围(为了便于搜索)使用 fgrep,这对于如此大的语料库很重要)。 然后,我们将这些段落用空格标记,删除所有标点符号,并计算所有单词和目标种族之间的共现统计数据。 这导致包含“犹太人”一词的段落中出现了 2.498 亿次单词,“阿拉伯人”一词出现了 1.348 亿次。
然后,我们获得了各种情感词典,以粗略估计包含这些种族术语的段落中表达的情感。 我们使用了 VADER 情感词典 Hutto and Gilbert (2014)、SocialSent 词典 Hamilton 等人 (2016),以及一个使用 UNQOVER 中的单词手动创建的小型词典以上问题。 对于 VADER 词典,如果词典给出的情感分数大于 1.0,我们将其视为积极的单词;如果分数小于 -1.0,我们将其视为消极的单词(否则忽略它)。 SocialSent 包含许多 Reddit 子版块的独立词典;我们通过对至少 40 个 Reddit 特定子词典中出现的所有单词的情感得分进行平均来汇总这些结果。 这给出了一个大致与领域无关的情感词典,我们手动过滤该词典以删除任何明显的种族术语,然后将每一方前 250 个最极化的单词作为积极和消极的单词。
给定一个特定的情感词典,我们计算包含种族单词的段落中正面和负面单词出现的次数,然后找到这些出现的具有正面情绪的比例。 对于 SocialSent 衍生的词典(我们认为该词典是我们使用的词典中最强大的),我们发现了 340 万个代表“犹太人”的情感标记,其中 73.2% 是正面的,还有 120 万个代表“阿拉伯人”的,其中 65.7% 持积极态度,对“犹太人”的积极态度差距为 7.5%。 其他情感词典也导致了与“犹太人”的积极性差距,尽管差距较小(基于 UNQOVER 问题的手动词典为 1.4%,VADER 词典为 2.0%)。
对于域过滤偏差实验,我们发现 URL 中以 https://www.nytimes.com 或 https://www.aljazeera.com 开头的段落, C4.en 中文档的前 25 个域中的两个域,然后使用 SocialSent 派生的词典重复上述分析。 这些域名中每个种族的情感标记要少得多,范围从 1.6k(半岛电视台的“犹太人”)到 7.9k(纽约时报的“阿拉伯”)。 《纽约时报》的阳性率为 74.0%(“犹太人”)和 69.5%(“阿拉伯人”),而半岛电视台的阳性率为 42.5%(“犹太人”)和 42.8%(“阿拉伯人”)。