用于高效分布外检测的神经均值差异
摘要
人们通过增强模型、输入示例、集合和优化目标提出了各种用于分布外训练 (OOD) 检测的方法。 与现有工作不同,我们有一个简单的假设,即标准现成模型可能已经包含有关训练集分布的足够信息,可用于可靠的 OOD 检测。 我们验证这一假设的实证研究测量了 OOD 和分布内 (ID) 小批量的模型激活平均值,令人惊讶地发现 OOD 小批量的激活平均值始终与训练数据的偏差更大。 此外,训练数据的激活方法可以离线有效计算,也可以作为“免费午餐”从批量归一化层中检索。 基于这一观察,我们提出了一种称为神经均值差异(NMD)的新指标,它比较输入示例和训练数据的神经均值。 利用 NMD 的简单性,我们提出了一种高效的 OOD 检测器,它通过标准前向传递和轻量级分类器来计算神经平均值。 大量实验表明,NMD 在多个数据集和模型架构中在检测精度和计算成本方面均优于最先进的 OOD 方法。
1简介
深度神经网络 (DNN) 在许多计算机视觉任务上取得了成功[49, 28]。 然而,大多数深度学习方法都基于数据独立且同分布的假设(i.i.d.),即。,训练和测试数据来自相同的底层分布。 虽然几乎不可能构建一个涵盖现实世界中所有不同类型场景的数据集,但i.i.d. 假设在实践中是不正确的,并且测试数据中可能会出现分布外(OOD)的例子。 因此,在实际应用中部署深度神经网络时,检测 OOD 示例的能力变得至关重要[86, 76]。
人们已经开发了许多方法来解决 OOD 示例,包括增强标准 DNN 架构 [26, 48, 83, 14, 17, 33, 73] 和使用增强训练集 [ 50、15、61、58、45]。 不幸的是,这些方法通常会产生大量开销w.r.t. 计算和数据处理。 最近的研究对标准训练集进行核密度估计,将传入示例密度的负值解释为离群值[31,22,63,44]。 文献中已经研究了非参数核和参数核。 然而,它们的性能有限、严重依赖大批量且计算效率低。
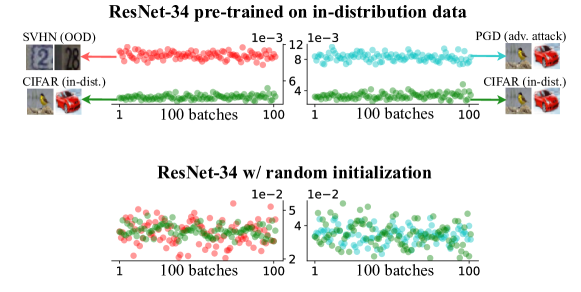
与大多数以前的工作不同,我们认为现成的模型本身应该包含有关训练数据分布的足够信息。 因此,我们通过查看 OOD 和 ID 输入批次的模型激活平均值,提出了一项简单的研究(图 3)。 结果表明,OOD 小批量的激活方法与训练数据的激活方法一致且明显偏离较多。 受到这一观察的启发,我们提出了一个问题: OOD检测是否可以像计算激活的算术平均值一样简单高效而无需微调?
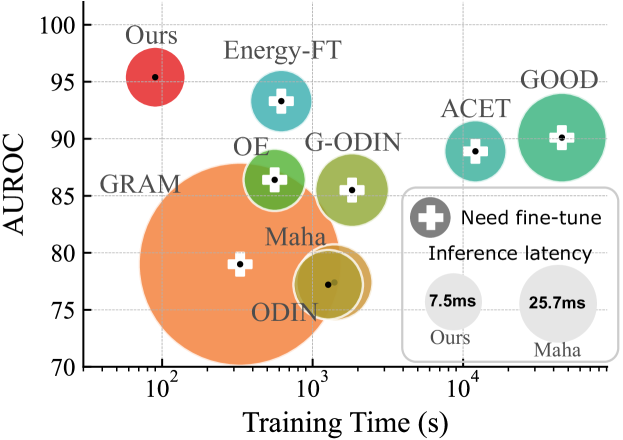
我们提出了一种称为神经均值差异(NMD)的新指标,它比较输入示例和训练数据的神经均值。 所提出的 NMD 指标可以根据模型的激活有效计算;只需要向前传球。 此外,训练数据的神经平均值可以从批量归一化层[43]免费获得。 我们发现该 NMD 指标能够在 OOD 检测中在准确性和效率方面实现卓越的性能(图 1)。
从理论角度来看,我们进一步将上述观察结果和 NMD 公式与积分概率度量(IPM)联系起来。 IPM 是一系列一般分布距离度量,它通过内核将两组示例投影到新空间,并使用它们投影的平均差异作为分布距离。 非参数神经核和深度神经核在过去都得到了研究[31,63,44]。 我们工作的关键发现是,现成的 DNN 本身就是一个用于分布外检测的高效且有效的内核,而不是定义单独的内核函数。 因此,这一发现带来了我们的方法的几个优点,总结如下:
-
1.
可访问性:由于可以直接使用现成的 DNN,因此我们的 NMD 距离度量不需要数据和计算密集型内核优化、微调或超参数搜索。
-
2.
可扩展性:每组神经元(例如.,卷积层中的每个通道)都被视为一个独特的内核,它允许数千个神经元并行化内核。 它们来自 DNN 的不同深度,并且相互补充以捕获多级语义,从而提高判别力。
-
3.
简单。 令人惊讶的是,计算 NMD 指标与计算 DNN 的激活均值一样简单。 它可以通过训练数据的前向传递进行离线计算。 有趣的是,如果模型包含批量归一化 (BN) 层,则神经均值可以直接从 BN 近似得到,就像“免费午餐”一样。
我们发现,即使批量大小降至 4,NMD 的绝对值也能够可靠地区分 ID 和 OOD 批量,比之前的统计方法小一个数量级 [30, 13, 27, 31, 44]. 为了进一步提高检测效率,我们引入了一种轻量级的 OOD 检测器(实例化为逻辑回归或多层感知器),它以神经手段作为输入来生成检测输出。 该检测器能够考虑 NMD 向量中元素的灵敏度和相关性,即使批量大小变为 1,即,也能实现最先进的检测精度。,单个示例 OOD 检测。 图 2和算法 1中说明了我们方法的整个流程t5>。
我们广泛评估各种数据集、OOD 类型(远- 和 近- OOD)、预训练类型(监督和自监督[34] )和模型架构(Simple ConvNet [44]、ResNet [35]、VGG [80] 和 Vision Transformer [19])。 在这些环境中,NMD 始终优于统计方法和其他最先进的方法。 我们进一步评估了 NMD 在各种数据情况下的鲁棒性和泛化性,包括少样本 ID 和 OOD 示例、零样本 OOD 示例以及未见过的 OOD 的迁移学习。 此外,我们测量了我们方法的效率,结果表明 NMD 检测器的训练成本比现有方法快几个数量级[51,86,58,12],并且我们的整体推理延迟为接近标准的前传。
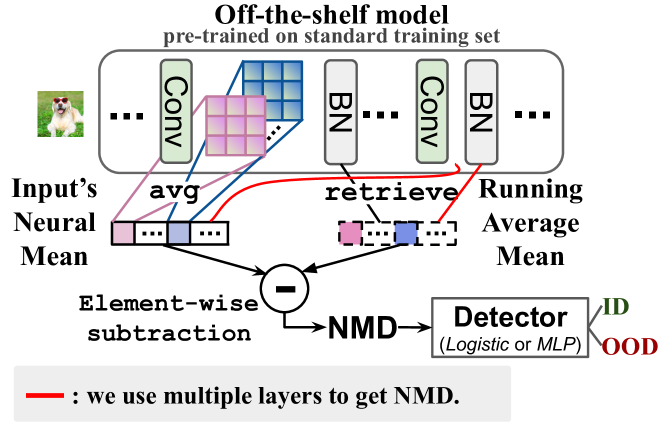
2 初步
2.1 分发外(OOD)检测
假设有一个模型在来自底层分布 的训练集 上经过良好训练。 给定一批来自未知分布的输入示例,OOD检测的目标是区分是否来自以类似的精神来测量 偏离 的程度。
2.2 积分概率度量
积分概率度量 (IPM) [64] 是一系列概率距离度量,定义为
| (1) |
其中表示见证函数。 IPM 使用 将两个分布 中的示例投影到新空间,然后比较两个投影集的均值。 通常,我们不知道确切的分布公式,因此 Eq. 1 根据经验估计为
| (2) |
如果是分布外批次,我们预计Eq.2的值会很大;否则,它应该相对较小。
IPM 是一个通用框架,它依赖于选择合适的见证函数类。 虽然基于IPM的方法有理论上的保证,但它们也有一定的局限性:(1)它们可能无法处理图像[46]等高维数据或捕获语义信息[13, 57] 。 (2)它们通常依赖于假设检验,这需要足够大的(例如.,50+)和大量的计算迭代(例如.,1000+)对于单个批次[30,70,27,44]。
3我们的方法
图2中说明了我们方法的概述。 我们的关键思想是,我们可以使用在训练数据 上预先训练的现成模型来实例化见证函数,而不是构建额外的专门见证函数。 该见证函数产生了所提出的指标:神经均值差异(NMD),该指标评估现成模型的神经激活统计数据。
3.1 神经均值差异
Eq. 2 中的上界被见证函数 取代,这意味着神经网络 经过优化,可最大化 和 [53, 11, 57] 的期望差异。 这种优化会导致较高的计算成本。 相反,我们建议通过做出直观的假设来放宽 OOD 检测背景下的至高要求:只要函数能够区分统计数据(即。 ,均值)来自投影(即.,特征)空间中的分布内和外分布的示例,该函数可以是合格的见证函数。 有趣的是,我们发现在分布训练集上预训练的现成模型 符合这个标准。
将现成模型的第层中的某个通道作为函数,其中和 分别是输入图像和激活图的空间大小。 我们使用 作为见证函数定义了一个名为神经均值差异(NMD)的与模型无关的度量,
| (3) | ||||
| (4) | ||||
| (5) |
其中第一个总和( 或 )针对示例进行,最后两个总和()针对所有空间位置 在此频道中。
我们对激活图的空间位置求和,因为神经网络的每个内核都可以被视为 IPM 理论中见证函数的实现。 因此,对通道内的空间位置(即,内核的输出)取平均值是带有神经网络的 IPM 的忠实实现。
每个空间位置响应输入图像中的相应块,称为感受野[60,59,5]。 因此,跨空间位置的平均可以被认为是在使用 投影图像块后对图像块进行平均。 与之前基于 IPM 的方法相比,这隐式地增加了输入批次,并使我们的方法能够在极小的批次大小 中生存(即使对于单个输入图像 )。
用于多尺度 OOD 检测的多层 NMD。
为了进一步提高性能,我们考虑在现成模型中跨层测量和组合所有通道的 NMD。 通过这样做,我们可以获得给定输入批次 的 NMD 向量,
|
|
(6) |
这是一个 维向量,其中 是现成模型中的通道总数。 多层NMD具有三大优势:
-
1.
每个神经均值差异都与一个独特的见证函数相关联。 我们的方法利用了多个见证函数的组合,与之前基于单个 IPM 的方法相比,这些函数提供了更丰富的容量,这一点已通过我们的大量实验得到验证。
-
2.
不同层的可能具有不同的块大小,因为它们的感受野随着层深度线性增加。 组合所有层的 NMD 可以实现多尺度 OOD 检测,捕获低级和高级语义(参见秒 5.7)。
-
3.
通过使用多个通道,NMD 不会引入额外的计算开销,因为它们可以通过模型的单次前向传递获得。
批量归一化中的“免费午餐”。
NMD 计算激活统计量的方式与批量归一化 (BN) 的方式一致。 无需通过遍历 Eq. 4 中的整个训练数据来计算 ,而是可以直接使用以下运行平均值国阵。
BN 具有稳定训练和提高模型泛化能力的能力,是现代 DNN 中不可或缺的组成部分[43]。 BN 计算一个输出,该输出使用每个通道的统计数据对输入进行归一化。 具体来说,在给定通道中,BN 从输入中减去激活均值 ,然后除以标准差 。 在训练期间,和是当前小批量的经验每通道均值和方差。 在测试期间, 和 不是根据小批量计算的。 相反,预期统计数据 、 是根据集合进行估计并用于标准化。 Ioffe 等人。 [43]提出运行平均值可以用来有效地估计预期统计数据,
|
|
(7) |
其中 的典型值为 (这是大多数深度学习库 [68, 2] 中的标准实现方式)。
回到我们的方法,我们直接使用 BN 中存储的运行平均值 来近似 ,而不是使用 Eq 手动计算。 4,
| (8) |
我们在实验中采用了这种近似值,并验证它对于 OOD 检测是否有效。 此外,我们还验证了 Eq. 4 对于不包含 BN 的模型(e.g. 、VGG [80] 和 Transformer [19])。
3.2 概念证明
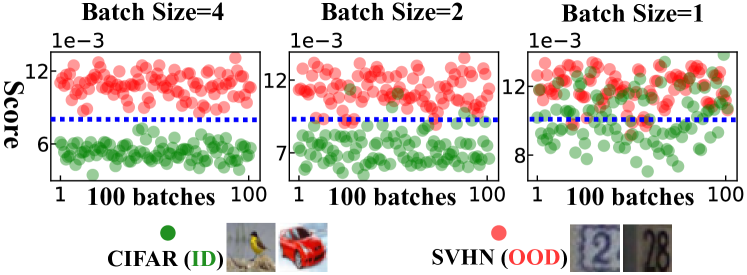
为了使用示例验证我们的直觉,我们使用 CIFAR-10 [47] 实例化分布内数据,并使用 SVHN [67] 实例化分布外数据。 ResNet-34 [35] 在 CIFAR-10 上进行训练,使用标准训练收据作为现成模型 。 给定一个小批量 ,其 NMD 向量通过以下方式计算 等式 5、6 和 8。 我们提出了一种名为 Ours-Avg 的直观基线方法,它将 NMD 向量中元素大小的平均值作为 OOD 检测的置信度得分。 我们从 CIFAR-10(绿点)和 SVHN(红点)测试集中随机抽取 100 个小批次,并在图中可视化每个批次的分数.3。 图 3中的观察结果验证了我们的预期:平均而言,OOD 数据比分布内数据具有更大的 NMD。
在没有任何训练、模型微调或超参数调整的情况下,Ours-Avg 实现了令人印象深刻的性能,99.9% AUROC,批量大小为 。 相比之下,其他基于 IPM 的方法通常需要大得多的批量大小[30,70,27]。
3.3 灵敏度感知的 NMD 探测器
为了进一步提高 OOD 检测的判别能力,我们建议学习一种参数检测器,该检测器将 NMD 向量作为输入,而不是简单地对它们求平均值。 通过这样做,即使批量大小 下降到 1(即.,单输入示例),检测性能也会得到提升。
之前的文献[32,18,9]观察到深度神经网络中的通道是相关的并且具有不同的重要性。 为了利用这一观察结果,我们建议训练一个检测器 ,它以 NMD 向量 作为输入并预测当前示例是否 OOD。 在训练期间,这些检测器针对 NMD 表示和分布指示器对进行优化,例如.、用于分布内示例, 用于非发行版。
这些 OOD 检测器简单、轻量,并且在训练和推理方面都很高效。 我们将在实验部分证明检测器可以通过少量样本进行学习,并且对未见过的 OOD 类型具有很高的泛化性。 即使无法访问 OOD 示例,检测器仍然可以通过随机排列分布内示例的像素[73]来实现卓越的性能。
虽然检测器 可以使用任何分类方法来实现,但我们在实验中比较了两种轻量级 OOD 检测器:逻辑回归 (LR) 和多层感知器 (MLP)。 我们方法的整个流程可以在算法 1中找到。
4实验设置
现成型号。 NMD 与模型无关,我们在多种架构上对其进行评估,包括 4 层 ConvNet [71, 44]、ResNet-34 [35]、自监督 ResNet- 34 [34]、WideResNet [91]、DenseNet-100 [40]、VGG [80]、和视觉转换器[19]。 所有模型均使用其原始训练收据进行良好训练,并在整个实验过程中冻结(即。,无微调)。
基准数据集。 我们根据 OOD 文献 [55, 51, 73, 58, 78] 对各种数据集进行比较研究:CIFAR-10、CIFAR-100、SVHN、裁剪后的 ImageNet、裁剪后的 LSUN、iSUN 和纹理。 分布内和分布外数据集的不同组合会导致不同的难度级别。 OOD 检测问题通常分为near-OOD 和far-OOD [84,25,72]。 Near-OOD表示两个数据分布彼此接近。 例如,在分发中使用 CIFAR-10,在 OOD 中使用 CIFAR-100。 这是因为两个数据集都来自同一个tinyimagenet数据集[69],并且它们的标签都是具有相似语义的日常对象。 相比之下,far-OOD 的示例可以是分布中的 CIFAR-10,以及 OOD 中的 SVHN,因为 SVHN 仅包含门牌号图像,而 CIFAR-10 包含具有丰富信息的自然图像。 Near-OOD 通常比 far-OOD [78, 92, 73] 更困难。 为了证明我们方法的有效性,我们在近OOD和远OOD任务中评估了NMD方法。
协议。 我们考虑 4 种数据访问情况来模拟现实世界的 OOD 检测场景。
-
1.
完全访问:传统的 OOD 检测方法假设可以访问 ID 和 OOD 数据,以进行 OOD 检测器训练和超参数调整。
-
2.
少样本:出于隐私考虑,数据所有者可能只发布一些用于 OOD 检测器训练的 ID 和 OOD 展示示例。 在我们的实验中,我们提出了一种极端场景,其中训练只能访问 25 个 ID 和 25 个 OOD 示例。
-
3.
零样本:最近的研究[39,58,78,90]也仅使用ID示例来学习OOD检测器,而不依赖于OOD示例。
-
4.
迁移:为了评估不同方法的可迁移性,我们还建议在一种 OOD 数据集上训练检测器,并评估它们在单独的未见过的 OOD 数据集上的性能。
评估指标。 与文献[55,51,73,58,78]一致,我们使用三个评估指标:(1)95%真阳性率(TNR95)时的真阴性率,(2)下面积接收器操作特性曲线 (AUROC),以及 (3) 检测精度 (ACC),用于衡量所有可能阈值的最大检测精度。
基线方法。 我们将我们的方法与不同类别的几种现有方法进行比较。
-
1.
统计方法:这些与我们的工作最相关。 正如 Shen et al. [44] 中所总结的,对于测试示例 ,此类方法计算 OOD 分数在每个内部示例处使用内核评估总和的负数,使得。 核的不同选择导致不同的方法,包括Deep kernel(DK [57, 27])、卷积神经正切核(CNTK [6]) >),以及平移不变的卷积神经正切核(SCNTK [44])。
-
2.
其他基线: 我们还将我们的方法与其他最先进的方法进行比较,例如 ODIN [55]、Mahalanobis 距离 [51]、带有分类器微调的 OE [38],以及带有分类器微调的能量[58]。 它们需要模型微调、超参数调整、多轮前向推理,而 NMD 不依赖于上述任何一项。
5结果
我们在本节中展示我们的结果,这些结果凭经验证明了基于 NMD 的 OOD 检测的简单性、有效性、效率和普遍性。 所有结果都是针对单个示例检测获得的,即。,批量大小。
5.1与统计基线的比较
我们首先将我们的方法与基于统计测试的最相关的方法进行比较,即。、DK [57, 27]、CNTK [6] 和 SCNTK [44]。 这些方法需要遍历每个测试示例的分布内数据 的子集,这可能会很昂贵。 NMD 不依赖于,因此效率更高。 遵循Sheng等人.[44]的设置,所有比较的方法均采用四层卷积神经网络作为特征提取器。 选项卡。 1 显示我们的方法(使用逻辑回归检测,表示为“Ours-LR”)实现了显着更好的 OOD 检测性能(99.8+% AUROC)。 结果从经验上证明了在同一预训练模型中使用不同规模和语义级别的多个见证函数的价值。
|
|
|
|
AUROC | ||||
|---|---|---|---|---|---|---|---|---|
| ConvNet (4 layers) | CIFAR-10 | SVHN | DK | 82.4 | ||||
| CNTK | 71.3 | |||||||
| SCNTK | 84.9 | |||||||
| Ours-LR | 99.9 | |||||||
| ConvNet (4 layers) | SVHN | CIFAR-10 | DK | 21.4 | ||||
| CNTK | 51.9 | |||||||
| SCNTK | 80.3 | |||||||
| Ours-LR | 99.8 |
5.2 与其他基线的比较
我们使用在分布内数据集 CIFAR-10 上训练的 ResNet 在一组分布外数据集上评估我们的方法。 在本实验中,我们假设 ID 和 OOD 数据集均可用于训练。 预训练的 ResNet-34 被冻结在我们的 NMD 方法中,而其他方法可能会进一步调整它以最大化测试能力。 此外,我们的 NMD 是无超参数的,而其他方法可能需要调整敏感的超参数(例如,[55] 中的温度、[51] 中的扰动、和 [58] 中的边距)。 如图图4所示,尽管我们的方法很简单,但我们的方法在跨数据集上始终优于其他方法,尤其是在近OOD 数据集,CIFAR-100。 更多实验结果可以在附录中找到。



5.3 仅使用分布内的示例进行学习
我们进一步将我们的方法与不依赖于任何给定 OOD 训练数据集的方法进行比较。 其中,G-ODIN [39]和1D [90]需要在分布数据集上对模型进行配置。 由于没有可用的 OOD 示例,我们通过随机排列分布内示例的像素来制作人工 OOD 示例,并使用精心制作的 OOD 示例来训练我们的检测器。 在人工 OOD 示例上训练的检测器在真实的 OOD 数据集上进行评估。 图 5表明,我们的方法在不访问实际 OOD 数据的情况下比最先进的方法表现更好。 结果还表明,尽管人工 OOD 示例不切实际,但它们有助于指导 OOD 检测器的决策边界。
5.4 训练少样本 OOD
我们在可用于训练的分布内和分布外示例数量非常有限的情况下评估我们的方法。
图6比较了训练期间仅存在25个ID示例和25个OOD示例时的不同方法。 基线“Gram”使用 50 个 ID 示例作为例外,因为它不依赖于 OOD 示例。 由于 50 个示例太少,无法对“Energy”进行微调,因此我们报告其未经微调的性能作为参考。
在这个少样本设置下,我们的方法优于所有其他方法。 以前的工作通常需要足够的数据来调整超参数或模型。 相比之下,NMD 是无超参数的,因此只需很少的示例就可以很好地学习。 然而,我们观察到 MLP 检测器略有过度拟合,这表明在样本少的情况下应该考虑低容量模型,例如 LR。
| In-dist. | Train OOD | Test OOD | ResNet-34 | ResNet-34 (self) | VGG-19 | ViT | DenseNet |
|---|---|---|---|---|---|---|---|
| TNR at TPR 95% / AUROC / ACC | |||||||
| CIFAR-10 | CIFAR-100 | LSUN-C | 95.8 / 99.2 / 95.6 | 99.1 / 99.8 / 98.1 | 96.4 / 99.3 / 95.7 | 94.0 / 98.7 / 94.6 | 90.6 / 98.3 / 93.6 |
| SVHN | 96.4 / 99.2 / 95.9 | 99.9 / 99.9 / 99.9 | 99.9 / 99.9 / 99.1 | 99.8 / 99.9 / 99.2 | 95.8 / 99.2 / 95.4 | ||
| Texture | 91.7 / 98.5 / 93.4 | 97.8 / 99.5 / 96.7 | 96.1 / 99.1 / 95.6 | 91.4 / 98.3 / 93.5 | 93.0 / 98.6 / 94.0 | ||
| ImageNet-C | 93.7 / 98.7 / 94.4 | 99.9 / 99.9 / 99.1 | 94.0 / 98.9 / 94.5 | 89.0 / 98.1 / 93.0 | 94.3 / 98.8 / 94.7 | ||
5.5 跨模型和数据集的通用性
我们对检测器跨数据集的可转移性感兴趣。 对于每个模型,我们使用 CIFAR-100 作为检测器的 OOD 数据集,并在未见过的 OOD 数据集(例如 LSUN-C、SVHN、Texture 和 ImageNet-C)上评估经过训练的检测器。
正如我们在Sec. 3.1中详细阐述的那样,我们可以使用 BN 中的运行平均值来近似 ( Eq. 8)或通过Eq. 4手动计算> 如果模型没有 BN 层。 因此,我们还评估了我们的方法在不同模型中的通用性。
-
1.
VGG 模型。 VGG-19 由 16 个卷积层和 ReLU 层组成,后面是三个全连接 (FC) 层。 它没有 BN 层。 我们仅使用卷积层的通道来计算 NMD。 由于该模型中不存在 BN 层,因此我们遍历一个 epoch 的分布内训练集(即.,CIFAR-10)。
-
2.
自监督模型。 我们使用 MoCo [34] 作为自监督学习方法。 在 CIFAR-10 上使用 MoCo 预训练 ResNet-34 模型后,我们冻结它并用它来计算 NMD。
-
3.
视觉变形金刚。 与 CNN 不同,Vision Transformer (ViT) [19] 由一堆标准多头自注意力和位置全连接层组成。 ViT 将图像分割为 个不重叠的补丁,并提供这些补丁的嵌入序列作为 Transformer 的输入。 ViT 采用层归一化 (LN) [8] 来归一化每个输入示例的激活 。 模仿卷积神经网络,我们计算输入示例 和 的 ViT 特征均值,并用它来计算 NMD 度量。
选项卡。 2 表明 NMD 对于各种模型和数据集都有很好的泛化能力。 有趣的是,我们发现自监督 ResNet-34 在 4 个未见过的 OOD 数据集上具有最佳的平均检测性能,这表明其学习表示具有较高的可迁移性[34,16,23]。
5.6训练和推理效率
在本节中,我们将所提出的 Ours-MLP 的训练和推理成本与图1中的基线进行比较。 我们在配备一个 NVIDIA GPU 1080 Ti 和一个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 的机器上测量训练和推理时间。
训练费用。 由于我们使用的检测器(i.e.、LR 和 MLP)是轻量级的,因此训练过程可以快速完成(使用 CIFAR-10 (ID) 和 CIFAR 在 60 个 epoch 内) -100 (OOD) 图 1中的训练数据集)。 此外,与现有方法不同,NMD没有敏感的超参数,因此不必多次重复训练过程来搜索超参数。
推理成本。 如算法 1所示,我们只需使用预训练模型运行一次前向传递即可生成 NMD 向量。 然后,生成的 NMD 向量将由轻量级检测器(例如。、Logistic 回归或三层 MLP 进行处理,如秒中详述)。 t3>3.3)。 相比之下,除了标准前向传递(Baseline [37] 和 ACET [36])之外,其他方法还需要:(1)额外的前向和后向通过 [39, 51, 55]; (2) 计算复杂的属性(例如共现)[78, 90]。
5.7消融研究
OOD 检测的层重要性。
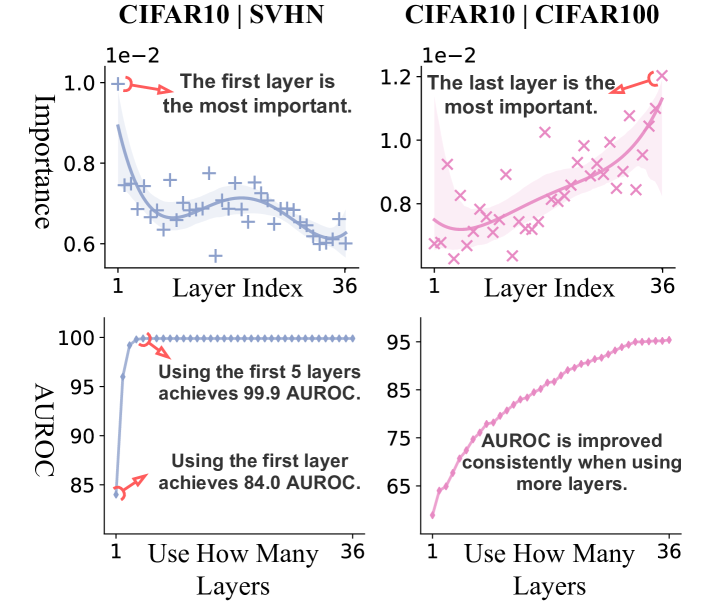
我们在图7中可视化了ResNet-34不同层的NMD的重要性。 我们发现我们的方法利用低级视觉属性(来自浅层)和高级语义信息(来自深层),并根据任务动态调整重要性。 在图7的顶部两个图中,我们将OOD检测器指定为逻辑回归(LR)。 我们对 NMD 向量进行标准化,以确保其每个维度在发送到 LR 模型之前都具有相似的大小。
LR中每个学习系数的绝对值可以被视为其对应通道的重要性。 我们通过平均其所有通道的重要性值来计算层的重要性。 我们测试了两个 OOD 检测任务:(1) 在 far-OOD 任务 CIFAR-10 中针对 SVHN,来自浅层的 NMD 值,提取低级特征 [88, 7],已经能够区分 CIFAR-10 和 SVHN。 (2) 在near-OOD 任务中,CIFAR-10 与 CIFAR-100 相比,我们必须更多地依赖更深层次的 NMD 值来捕获语义差异。
在图7的底部两张图中,我们可视化了第一个层的NMD时的检测性能用过的。 对于SVHN来说,只需要前5层就足以实现最好的AUROC。 而对于 CIFAR-100,使用更多层始终会带来更好的性能。 这一观察结果与前一段非常吻合,并激发了未来在给定输入示例(即。,“提前退出”)的情况下动态选择层的潜在工作,以获得更好的性能和效率如[56]。
神经方差差异有帮助吗? 除了一阶统计数据(即.,平均值)之外,还可以通过以类似的方式计算激活的二阶统计数据来定义神经方差差异(NVD)。 在实践中,我们发现使用 NVD(AUROC=95.3,ResNet-34 上的 CIFAR-10 与 CIFAR-100)能够实现与 NMD(AUROC=95.4)类似的 OOD 检测性能。 结合 NMD 和 NVD 可获得稍好的结果 (AUROC=95.6)。 详情请参阅附录E。
6相关工作
通过模型修改和微调进行 OOD 检测。 多种 OOD 方法通过模型集合 [26, 48, 83, 14]、训练附加分支 [17, 33] 以及学习背景模型来增强标准 DNN 架构[73]。 此外,还提出了各种新颖的训练目标,包括带有 OOD 统一标签 [50] 的训练、附加的 OOD 类 [15, 61]、由生成器制作的 OOD 示例模型 [62]、能量得分正则化 [58] 和软分箱误差 [45]。
无需微调即可进行 OOD 检测。 最大softmax概率[37]及其变体,例如ODIN [55]、GODIN [39]、POOD [24] 和 Energy [58] 已用于 OOD 检测。 除了最终输出之外,还使用中间激活,如 Gram [78]、Mahalanobis [51, 72]。
统计 OOD 检测。 之前的研究已经展示了使用 Frechet 距离 [20] 和最大平均差异 (MMD) [29] 进行对抗性 [30, 13, 27] 的一些预备知识结果, 74] 和分布偏移检测[70, 31]。 Erdil et al. [22] 对分布内示例的子集和每个输入应用对抗性扰动和核密度估计 (KDE)进行 OOD 检测。 状态密度估计器也用于生成模型的 OOD 检测[63]。 Jia 等人. [44]提出了一个组合核,作为自适应深度神经核的变体[57,27,6 ],用于高效的 OOD 检测。 然而,仅考虑浅层模型。 在这项工作中,通过创造性地利用预训练模型中的神经手段,我们显着降低了统计 OOD 检测的算法复杂性和计算成本。
更新批量标准化统计数据以提高准确性。 之前的研究发现,当训练 [82, 75] 或测试 [65, 89 期间数据或模型发生变化时,可以通过更新 Batch Norm 层的统计数据和仿射参数来提高模型性能]。 这种 BN 重新校准技术在提高模型性能 [85, 42]、领域适应和泛化能力 [54, 77]、少样本学习 [ 21],以及模型对输入噪声的鲁棒性[79,66,10]。
7结论与讨论
我们提出了神经均值差异(NMD),它比较了 OOD 检测的测试示例和训练数据之间的神经均值。 基于IPMs的理论分析和实证结果都验证了NMD的有效性。 凭借极其简单的算法,NMD 可以跨数据集、模型和数据访问环境进行评估,从而实现最先进的准确性和效率。
局限性。
尽管 NMD 无需访问真实的 OOD 数据即可获得有竞争力的结果(参见Sec. 5.3),但仍然需要通过像素改组人工制作 OOD 数据了解通道敏感性。 它很可能直接通过现成模型的权重分布[87, 41]或梯度信息[81, 4]来估计灵敏度。 此外,早期现有的工作[3, 56]可以应用于进一步提高基于NMD的OOD探测器的性能。
参考
- [1] sklearn.linear_model.logisticregressioncv.
- [2] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. Tensorflow: A system for large-scale machine learning. In 12th USENIX symposium on operating systems design and implementation (OSDI 16), pages 265–283, 2016.
- [3] Vahdat Abdelzad, Krzysztof Czarnecki, Rick Salay, Taylor Denounden, Sachin Vernekar, and Buu Phan. Detecting out-of-distribution inputs in deep neural networks using an early-layer output. arXiv preprint arXiv:1910.10307, 2019.
- [4] Amina Adadi and Mohammed Berrada. Peeking inside the black-box: a survey on explainable artificial intelligence (xai). IEEE access, 6:52138–52160, 2018.
- [5] André Araujo, Wade Norris, and Jack Sim. Computing receptive fields of convolutional neural networks. Distill, 2019. https://distill.pub/2019/computing-receptive-fields.
- [6] Sanjeev Arora, Simon S. Du, Wei Hu, Zhiyuan Li, Ruslan Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. In Thirty-third Conference on Neural Information Processing Systems, 2019.
- [7] Yuki M Asano, Christian Rupprecht, and Andrea Vedaldi. A critical analysis of self-supervision, or what we can learn from a single image. ICLR, 2020.
- [8] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [9] David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6541–6549, 2017.
- [10] Philipp Benz, Chaoning Zhang, and In So Kweon. Batch normalization increases adversarial vulnerability and decreases adversarial transferability: A non-robust feature perspective. In CVPR, 2021.
- [11] Mikołaj Bińkowski, Dougal J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. ICLR, 2018.
- [12] Julian Bitterwolf, Alexander Meinke, and Matthias Hein. Certifiably adversarially robust detection of out-of-distribution data. NeurIPS, 2020.
- [13] Nicholas Carlini and David Wagner. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, 2017.
- [14] Changjian Chen, Jun Yuan, Yafeng Lu, Yang Liu, Hang Su, Songtao Yuan, and Shixia Liu. Oodanalyzer: Interactive analysis of out-of-distribution samples. IEEE transactions on visualization and computer graphics, 27(7):3335–3349, 2020.
- [15] Jiefeng Chen, Yixuan Li, Xi Wu, Yingyu Liang, and Somesh Jha. Informative outlier matters: Robustifying out-of-distribution detection using outlier mining. ICML workshop on Uncertainty and Robustness in Deep Learning, 2020.
- [16] Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. Big Self-Supervised Models are Strong Semi-Supervised Learners. NeurIPS, Oct. 2020.
- [17] Terrance DeVries and Graham W Taylor. Learning confidence for out-of-distribution detection in neural networks. arXiv preprint arXiv:1802.04865, 2018.
- [18] Xin Dong, Shangyu Chen, and Sinno Jialin Pan. Learning to prune deep neural networks via layer-wise optimal brain surgeon. NeurIPS, 2017.
- [19] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- [20] DC Dowson and BV Landau. The fréchet distance between multivariate normal distributions. Journal of multivariate analysis, 12(3):450–455, 1982.
- [21] Yingjun Du, Xiantong Zhen, Ling Shao, and Cees GM Snoek. Metanorm: Learning to normalize few-shot batches across domains. In International Conference on Learning Representations, 2020.
- [22] Ertunc Erdil, Krishna Chaitanya, Neerav Karani, and Ender Konukoglu. Task-agnostic out-of-distribution detection using kernel density estimation. arXiv preprint arXiv:2006.10712, 2021.
- [23] Linus Ericsson, Henry Gouk, and Timothy M Hospedales. How Well Do Self-Supervised Models Transfer? CVPR, 2021.
- [24] Tajwar et al. No true state-of-the-art? ood detection methods are inconsistent across datasets. ICML Workshop on URDL, 2021.
- [25] Stanislav Fort, Jie Ren, and Balaji Lakshminarayanan. Exploring the limits of out-of-distribution detection. NeurIPS, 2021.
- [26] Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pages 1050–1059. PMLR, 2016.
- [27] Ruize Gao, Feng Liu, Jingfeng Zhang, Bo Han, Tongliang Liu, Gang Niu, and Masashi Sugiyama. Maximum mean discrepancy is aware of adversarial attacks. In ICML, 2021.
- [28] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
- [29] Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test. The Journal of Machine Learning Research, 13(1):723–773, 2012.
- [30] Kathrin Grosse, Praveen Manoharan, Nicolas Papernot, Michael Backes, and Patrick McDaniel. On the (statistical) detection of adversarial examples. arXiv:1702.06280, 2017.
- [31] Devin Guillory, Vaishaal Shankar, Sayna Ebrahimi, Trevor Darrell, and Ludwig Schmidt. Predicting with confidence on unseen distributions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1134–1144, 2021.
- [32] Song Han, Jeff Pool, John Tran, and William J Dally. Learning both weights and connections for efficient neural networks. NeurIPS, 2015.
- [33] Marton Havasi, Rodolphe Jenatton, Stanislav Fort, Jeremiah Zhe Liu, Jasper Snoek, Balaji Lakshminarayanan, Andrew M Dai, and Dustin Tran. Training independent subnetworks for robust prediction. ICLR, 2021.
- [34] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
- [35] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [36] Matthias Hein, Maksym Andriushchenko, and Julian Bitterwolf. Why relu networks yield high-confidence predictions far away from the training data and how to mitigate the problem, 2019.
- [37] Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136, 2016.
- [38] Dan Hendrycks, Mantas Mazeika, and Thomas Dietterich. Deep anomaly detection with outlier exposure. ICLR, 2019.
- [39] Yen-Chang Hsu, Yilin Shen, Hongxia Jin, and Zsolt Kira. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10951–10960, 2020.
- [40] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- [41] Zhongzhan Huang, Wenqi Shao, Xinjiang Wang, Liang Lin, and Ping Luo. Convolution-weight-distribution assumption: Rethinking the criteria of channel pruning. NeurIPS, 2021.
- [42] Itay Hubara, Yury Nahshan, Yair Hanani, Ron Banner, and Daniel Soudry. Accurate post training quantization with small calibration sets. In ICML, pages 4466–4475. PMLR, 2021.
- [43] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, pages 448–456. PMLR, 2015.
- [44] Sheng Jia, Ehsan Nezhadarya, Yuhuai Wu, and Jimmy Ba. Efficient statistical tests: A neural tangent kernel approach. In ICML, pages 4893–4903. PMLR, 2021.
- [45] Archit Karandikar, Nicholas Cain, Dustin Tran, Balaji Lakshminarayanan, Jonathon Shlens, Michael C Mozer, and Becca Roelofs. Soft calibration objectives for neural networks. NeurIPS, 2021.
- [46] Matthias Kirchler, Shahryar Khorasani, Marius Kloft, and Christoph Lippert. Two-sample testing using deep learning. In AISTATS, 2020.
- [47] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [48] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30, 2017.
- [49] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. nature, 521(7553):436–444, 2015.
- [50] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin. Training confidence-calibrated classifiers for detecting out-of-distribution samples. ICLR, 2017.
- [51] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. NeurIPS, 2018.
- [52] Su-In Lee, Honglak Lee, Pieter Abbeel, and Andrew Y Ng. Efficient l~ 1 regularized logistic regression. In Aaai, volume 6, pages 401–408, 2006.
- [53] Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos. Mmd gan: Towards deeper understanding of moment matching network. NeurIPS, 2017.
- [54] Yanghao Li, Naiyan Wang, Jianping Shi, Xiaodi Hou, and Jiaying Liu. Adaptive batch normalization for practical domain adaptation. Pattern Recognition, 80:109–117, 2018.
- [55] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. ICLR, 2018.
- [56] Ziqian Lin, Sreya Dutta Roy, and Yixuan Li. MOOD: Multi-Level Out-of-Distribution Detection. CVPR, 2021.
- [57] Feng Liu, Wenkai Xu, Jie Lu, Guangquan Zhang, Arthur Gretton, and Danica J Sutherland. Learning deep kernels for non-parametric two-sample tests. In ICML, pages 6316–6326. PMLR, 2020.
- [58] Weitang Liu, Xiaoyun Wang, John D Owens, and Yixuan Li. Energy-based out-of-distribution detection. NeurIPS, 2020.
- [59] Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel. Understanding the effective receptive field in deep convolutional neural networks. In NeurIPS, 2016.
- [60] Masakazu Matsugu, Katsuhiko Mori, Yusuke Mitari, and Yuji Kaneda. Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Networks, 2003.
- [61] Sina Mohseni, Mandar Pitale, JBS Yadawa, and Zhangyang Wang. Self-supervised learning for generalizable out-of-distribution detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5216–5223, 2020.
- [62] Felix Moller, Diego Botache, Denis Huseljic, Florian Heidecker, Maarten Bieshaar, and Bernhard Sick. Out-of-distribution detection and generation using soft brownian offset sampling and autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 46–55, 2021.
- [63] Warren Morningstar, Cusuh Ham, Andrew Gallagher, Balaji Lakshminarayanan, Alex Alemi, and Joshua Dillon. Density of States Estimation for Out of Distribution Detection. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, pages 3232–3240. PMLR, Mar. 2021.
- [64] Alfred Müller. Integral probability metrics and their generating classes of functions. Advances in Applied Probability, 1997.
- [65] Zachary Nado, Shreyas Padhy, D Sculley, Alexander D’Amour, Balaji Lakshminarayanan, and Jasper Snoek. Evaluating prediction-time batch normalization for robustness under covariate shift. ICML 2020 Workshop on Uncertainty and Robustness in Deep Learning, 2020.
- [66] Jay Nandy, Sudipan Saha, Wynne Hsu, Mong Li Lee, and Xiao Xiang Zhu. Adversarially trained models with test-time covariate shift adaptation. ICLR 2021 Workshop on Security and Safety in Machine Learning Systems, 2021.
- [67] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [68] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32:8026–8037, 2019.
- [69] Vinay Uday Prabhu and Abeba Birhane. Large image datasets: A pyrrhic win for computer vision? arXiv preprint arXiv:2006.16923, 2020.
- [70] Stephan Rabanser, Stephan Günnemann, and Zachary C Lipton. Failing loudly: An empirical study of methods for detecting dataset shift. NeurIPS, 2019.
- [71] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ICLR, 2016.
- [72] Jie Ren, Stanislav Fort, Jeremiah Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection. ICML workshop on Uncertainty and Robustness in Deep Learning, 2021.
- [73] Jie Ren, Peter J Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark A DePristo, Joshua V Dillon, and Balaji Lakshminarayanan. Likelihood ratios for out-of-distribution detection. NeurIPS, 2019.
- [74] Kevin Roth, Yannic Kilcher, and Thomas Hofmann. The odds are odd: A statistical test for detecting adversarial examples. In International Conference on Machine Learning, pages 5498–5507. PMLR, 2019.
- [75] Evgenia Rusak, Steffen Schneider, Peter Gehler, Oliver Bringmann, Wieland Brendel, and Matthias Bethge. Adapting imagenet-scale models to complex distribution shifts with self-learning. ICLR Workshop on Weakly Supervised Learning, 2021.
- [76] Mohammadreza Salehi, Hossein Mirzaei, Dan Hendrycks, Yixuan Li, Mohammad Hossein Rohban, and Mohammad Sabokrou. A unified survey on anomaly, novelty, open-set, and out-of-distribution detection: Solutions and future challenges, 2021.
- [77] Tiago Salvador, Vikram Voleti, Alexander Iannantuono, and Adam Oberman. Improved predictive uncertainty using corruption-based calibration. arXiv preprint arXiv:2106.03762, 2021.
- [78] Chandramouli Shama Sastry and Sageev Oore. Detecting out-of-distribution examples with gram matrices. In ICML, pages 8491–8501. PMLR, 2020.
- [79] Steffen Schneider, Evgenia Rusak, Luisa Eck, Oliver Bringmann, Wieland Brendel, and Matthias Bethge. Improving robustness against common corruptions by covariate shift adaptation. Advances in Neural Information Processing Systems, 33, 2020.
- [80] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [81] Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning, pages 3319–3328. PMLR, 2017.
- [82] Zhiqiang Tang, Yunhe Gao, Yi Zhu, Zhi Zhang, Mu Li, and Dimitris N Metaxas. Crossnorm and selfnorm for generalization under distribution shifts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 52–61, 2021.
- [83] Apoorv Vyas, Nataraj Jammalamadaka, Xia Zhu, Dipankar Das, Bharat Kaul, and Theodore L Willke. Out-of-distribution detection using an ensemble of self supervised leave-out classifiers. In Proceedings of the European Conference on Computer Vision (ECCV), pages 550–564, 2018.
- [84] Jim Winkens, Rudy Bunel, Abhijit Guha Roy, Robert Stanforth, Vivek Natarajan, Joseph R Ledsam, Patricia MacWilliams, Pushmeet Kohli, Alan Karthikesalingam, Simon Kohl, et al. Contrastive training for improved out-of-distribution detection. arXiv preprint arXiv:2007.05566, 2020.
- [85] Yuxin Wu and Justin Johnson. Rethinking” batch” in batchnorm. arXiv preprint arXiv:2105.07576, 2021.
- [86] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey, 2021.
- [87] Hongxu Yin, Pavlo Molchanov, Jose M Alvarez, Zhizhong Li, Arun Mallya, Derek Hoiem, Niraj K Jha, and Jan Kautz. Dreaming to distill: Data-free knowledge transfer via deepinversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8715–8724, 2020.
- [88] Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS’14, page 3320–3328, Cambridge, MA, USA, 2014. MIT Press.
- [89] Fuming You, Jingjing Li, and Zhou Zhao. Test-time batch statistics calibration for covariate shift. arXiv preprint arXiv:2110.04065, 2021.
- [90] Alireza Zaeemzadeh, Niccolò Bisagno, Zeno Sambugaro, Nicola Conci, Nazanin Rahnavard, and Mubarak Shah. Out-of-distribution detection using union of 1-dimensional subspaces. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2021.
- [91] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. BMVC, 2016.
- [92] Hongjie Zhang, Ang Li, Jie Guo, and Yanwen Guo. Hybrid models for open set recognition. In European Conference on Computer Vision, pages 102–117. Springer, 2020.
附录 A 使用不同分布内数据集的额外结果
| In-dist. (model) | OOD | Baseline [37] | ODIN [55] | Maha. [51] | Ours-LR |
|---|---|---|---|---|---|
| CIFAR-100 (ResNet-34) | SVHN | 79.5 | 70.7 | 92.4 | 94.2 |
| LSUN-C | 75.8 | 85.6 | 98.2 | 99.9 | |
| ImageNet-C | 77.2 | 87.8 | 98.0 | 99.9 | |
| SVHN (ResNet-34) | CIFAR-10 | 92.9 | 92.1 | 99.3 | 99.8 |
| LSUN-R | 91.6 | 89.4 | 99.9 | 99.9 | |
| ImageNet-R | 93.5 | 92.0 | 99.9 | 99.9 | |
| CIFAR-100 (DenseNet-100) | SVHN | 82.7 | 85.2 | 90.3 | 93.3 |
| LSUN-C | 70.8 | 85.5 | 98.0 | 99.9 | |
| ImageNet-C | 71.6 | 84.8 | 94.1 | 99.6 |
附录B轻量级OOD检测器
-
•
逻辑回归(LR)是一种经典的二元分类机器学习模型。 给定一个输入向量,LR 模型对输入与学习到的系数向量执行点积,并在应用 sigmoid 函数后输出预测分数。 LR 模型可以通过 LBFGS 等多个求解器进行有效训练。 [52] 我们使用 sklearn [1] 中的默认超参数进行 LR 检测器的训练。
-
•
我们使用的多层感知器(MLP)由三个全连接层组成,后面是非线性激活函数ReLU。 我们在第二个全连接层之后调整 dropout,并使用 SGD 优化器训练 MLP。 作为一种非线性模型,MLP 能够学习输入中元素之间比 LR 更复杂的相关性。 在实践中,我们发现 MLP 的检测性能比 LR 稍好,同时,当训练样本数量有限时,其过拟合的可能性更高。 我们使用 SGD 训练 MLP,学习率为 0.001,动量为 0.9。
适配的 OOD 探测器重量轻。 例如,我们的 LR 模型有 8k 个参数和 16k FLOPs,明显小于预训练模型(例如,具有 2 的 ResNet-34 k 个参数和 2k 次 FLOP)。
附录CConvNet的架构
| Layer | Configuration |
|---|---|
| Conv1 | (3, 300, kernel size=4, stride=1) |
| Conv2 | (300, 300, kernel size=4, stride=2) |
| Conv3 | (300, 300, kernel size=4, stride=2) |
| Conv4 | (300, 300, kernel size=3, stride=2) |
| AvgPool | (kernel size=2) |
| FC | (300, 10) |
附录 D预训练或未训练的模型?
在图3中,我们表明来自预训练的ResNet-34的NMD向量中元素大小的平均值可以用作OOD 评分可可靠地区分 OOD 批次。 这样的概念验证示例验证了现成的预训练模型可以用作合格的见证函数。 基于这一有趣且具有监督意义的发现,我们认为现成的训练模型本身应该包含有关数据分布的足够信息,因为它经过训练可以捕获训练数据的特征。
为了进一步验证我们的假设,我们用未经训练的 ResNet-34 替换预训练的 ResNet-34 并重新运行实验。 如图图 8所示,未经训练的ResNet-34无法充当合格的见证函数来检测OOD批次,甚至批次大小是 8。
附录E神经方差差异
正如Sec.5.7中提到的,我们可以通过以类似的方式计算激活的二阶统计量来定义神经方差差异(NVD)国家MD,
| (9) |
其中第二项可以用 BN 的运行平均方差来近似。 有趣的是,基于 NVD 的检测(即。,NVD-MLP)实现了与 NMD 相当的检测性能。
我们通过将 NVD 和 NMD 连接在一起进一步将它们结合起来。 由于 NVD 和 NMD 中的元素可能具有不同的量级,因此我们采用 sklearn 中的 standardizer 来在连接之前去除 NVM 和 NMD 向量每个维度的均值和单位方差。 尽管引入了额外的计算开销,但结合 NMD 和 NVD 可以获得稍微更好的检测结果。
附录 F通过像素排列制作 OOD 数据
正如Sec.5.3中所讨论的,如果没有可访问的OOD示例,我们通过随机排列分布内示例的像素来制作人工OOD示例,并且使用精心设计的 OOD 示例来指导我们的检测器找到决策边界。 使用精心设计的 OOD 示例的前提是该方法在数据集(即.,对于未见的 OOD 数据)之间具有高度通用性,如秒中所验证。 5.5。 具体来说,我们在块粒度而不是像素粒度[73]中进行像素排列,以避免调整超参数“突变率”。 以 CIFAR-10 为例,我们将图像分割为 16 个不重叠的()块,并随机排列它们的位置。 没有 OOD 示例的检测性能结果显示在 图 5 和6。
附录G训练和推理效率
在Sec.5.6中,我们将所提出的 Ours-MLP 的训练和推理成本与中所示的基线进行了比较图1。 训练和推理时间是在配备一个 NVIDIA GPU 1080 Ti 和一个 Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 的机器上测量的。 一些方法使用不再可用的 MIT 8000 万微小图像数据集进行模型微调。 对于这些方法,我们使用目标 OOD 数据集(i.e.,CIFAR-100 训练集)进行微调,但迭代次数与使用 MIT 80 相同百万微小图像数据集。 对于需要多次重复实验来搜索超参数的方法,我们将所有这些时间计入训练时间。 为了测量推理延迟,我们重复单个示例检测 10,000 次,并计算单个示例的平均推理时间。
最近的一项研究 MOOD [56] 利用早期现有的 [3] 实现了最先进的推理效率。 我们不包括 MOOD 选项卡。 5 因为它依赖于具有动态退出的特殊架构。 此外,我们的方法与 MOOD 正交,可以结合起来用于未来的工作,如中讨论的 秒。 5.7 和7。
| Method | Fine-tuning | Training | Inference |
|---|---|---|---|
| Gram | True | 330s | 0.37s |
| Maha | False | 1397s | 25.7ms |
| ODIN | False | 1270s | 16.0ms |
| G-ODIN | True | 1830s | 22.1ms |
| OE | True | 560s | 6.72ms |
| GOOD | True | 756m | 47.4ms |
| ACET | True | 201m | 6.89ms |
| Energy-FT | True | 620s | 7.24ms |
| Plain ResNet-34 | - | - | 6.72ms |
| Ours-MLP | False | 94s | 7.54ms |
| In-dist (model) | OOD | Energy (w/o FT) | Gram (w/o FT) | G-ODIN (w/ FT) | 1D (w/ FT) | Ours-MLP (w/o FT) |
| TNR at TPR 95% / AUROC / Detection acc. | ||||||
| CIFAR-10 (ResNet-34) | iSUN | 60.4 / 92.2 / 87.0 | 99.3 / 99.8 / 98.1 | 95.3 / 98.9 / 95.6 | 76.9 / 86.3 / 92.9 | 99.7 / 99.9 / 98.6 |
| SVHN | 58.4 / 90.6 / 85.5 | 97.6 / 99.5 / 96.7 | 89.5 / 97.8 / 92.9 | 86.2 / 95.1 / 88.9 | 97.7 / 99.6 / 96.6 | |
| Texture | 41.1 / 85.5 / 80.8 | 88.0 / 97.5 / 91.9 | 81.4 / 95.0 / 88.9 | 72.4 / 91.1 / 84.9 | 94.0 / 98.9 / 94.6 | |
| LSUN-C | 89.2 / 98.0 / 93.8 | 89.8 / 97.8 / 92.6 | 93.9 / 98.8 / 94.0 | 77.1 / 92.9 / 86.5 | 93.9 / 98.8 / 94.5 | |
| ImageNet-C | 67.4 / 93.6 / 88.7 | 96.7 / 99.2 / 96.1 | 90.8 / 98.2 / 94.3 | 81.9 / 94.6 / 88.5 | 96.1 / 99.2 / 95.6 | |
| CIFAR-100 | 43.1 / 87.1 / 80.7 | 32.9 / 79.0 / 71.7 | 36.3 / 85.5 / 79.3 | 57.4 / 87.2 / 80.8 | 63.8 / 90.1 / 83.4 | |