用户偏好感知的假新闻检测
摘要。
近年来,虚假信息和假新闻对个人和社会造成了不利影响,引起了对假新闻检测的广泛关注。 大多数现有的假新闻检测算法侧重于挖掘新闻内容和/或周围的外源上下文以发现欺骗性信号;而用户在决定是否传播一条假新闻时的内生偏好却被忽略了。 确认偏差理论表明,当用户确认他/她现有的信念/偏好时,他/她更有可能传播假新闻。 用户的历史、社交活动(例如帖子)提供了有关用户对新闻的偏好的丰富信息,并且具有推进假新闻检测的巨大潜力。 然而,探索用户对假新闻检测的偏好的工作有些有限。 因此,在本文中,我们研究了利用用户偏好进行假新闻检测的新问题。 我们提出了一个新的框架,它通过联合内容和图形建模同时捕获来自用户偏好的各种信号。 真实世界数据集的实验结果证明了所提出框架的有效性。 我们发布代码和数据作为基于 GNN 的假新闻检测的基准:https://github.com/safe-graph/GNN-FakeNews。
1. 介绍
近年来,社交媒体使得虚假信息和虚假新闻广泛传播——在新闻文章中伪装虚假或误导性信息来误导消费者(Zhou and Zafarani,2020;舒等人,2017)。 虚假信息造成了有害影响并引起了严重关注,需要新的方法来检测假新闻。
在各种假新闻检测技术中,事实核查是最直接的方法;然而,从领域专家那里获取证据通常需要耗费大量人力(Hassan等人,2017)。 此外,使用特征工程或深度学习的计算方法已经显示出许多有希望的结果(Wang 等人,2018;Karimi 等人,2018;Ruchansky 等人,2017;Chandra 等人,2020)。 例如,SAFE (Zhou 等人, 2020) 和 FakeBERT (Kaliyar 等人, [n.d.]) 使用 TextCNN (Zhang 和 Wallace, 2015) 和 BERT (Devlin 等人, 2018; Sun 等人, 2020b; Sun 等人, 2020a) 分别对新闻文本信息进行编码; GCNFN (Monti 等人,2019) 和 GNN-CL (Han 等人,2020) 利用了 GCN (Kipf 和 Welling,2017)对社交媒体上的新闻传播模式进行编码(例如,社交媒体帐户之间的级联新闻共享)。 然而,这些方法侧重于对新闻内容及其用户外生上下文进行建模,而忽略了用户内生偏好。
新闻社会学和心理学研究理论化了用户偏好与其在线新闻消费行为之间的相关性(舒等人,2019)。 例如,朴素现实主义(Ross和Ward,1995)表明消费者倾向于相信他们对现实的看法是唯一准确的观点,而其他不同意的人则被视为无知、非理性或有偏见;和确认偏差理论(Nickerson,1998)表明,消费者更喜欢接收证实他们现有观点的信息。 例如,用户认为选举舞弊可能会以支持的立场分享类似的新闻,而声称选举被盗的新闻会吸引具有类似信念的用户(Abilov等人,2021)。 为了建模用户内生偏好,现有作品尝试利用历史帖子作为代理,并在检测讽刺(Khattri等人,2015)、仇恨言论(Qian等人, 2018),以及社交媒体上的假新闻传播者(Rangel 等人,2020)。
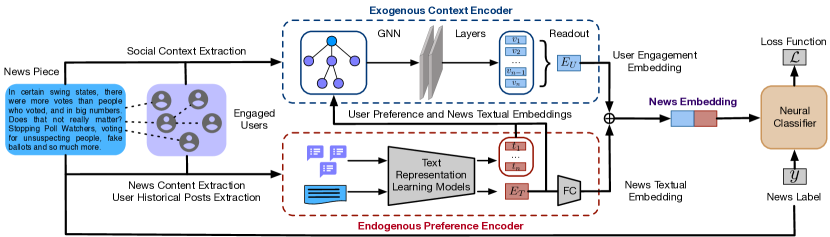
在本文中,我们将社交媒体用户的历史帖子视为他们在新闻消费中的内生偏好。 我们提出了一个名为 User Preference-aware Fake D 的端到端假新闻检测框架检测()来联合建模内生偏好和外生情境(如图1所示)。 具体来说,由以下主要组成部分组成:(1)为了建模用户内生偏好,我们使用各种文本表示学习方法对新闻内容和用户历史帖子进行编码。 (2)为了获取用户外生上下文,我们根据每个新闻在社交媒体上的共享级联构建了一个树形结构的传播图。 该新闻帖子被视为根节点,其他节点代表分享相同新闻帖子的用户。 (3)为了整合内源和外源信息,我们将新闻和用户的向量表示作为节点特征,并采用图神经网络(GNN)(Hamilton等人,2017;Monti等人,2019) 学习联合用户参与嵌入。 用户参与嵌入和新闻文本训练嵌入用于神经分类器来检测假新闻。 我们的主要贡献可概括如下:
-
•
我们研究了社交媒体上用户偏好感知假新闻检测的新问题;
-
•
我们提出了一种原则性的方法,联合利用内生偏好和外生背景来检测假新闻;和
-
•
我们对现实世界的数据集进行了广泛的实验,以证明 在检测假新闻方面的有效性。
2. 我们的方法
在本节中,我们将详细介绍名为 的假新闻检测提议框架(User P参考感知Fake 新闻D检测)。 如图1所示,我们的框架具有三个主要组件。 首先,给定一条新闻,我们爬取参与该新闻的用户的历史帖子,以了解用户内生偏好。 我们通过使用文本表示学习技术对历史帖子进行编码来隐式提取参与用户的偏好(例如,word2vec (Mikolov 等人, 2013)、BERT (Devlin 等人, 2018))。 新闻文本数据使用相同的方法进行编码。 其次,为了利用用户外源上下文,我们根据社交媒体平台上的参与信息(例如 Twitter 上的转发)构建新闻传播图。 第三,我们设计了一个分层信息融合过程来融合用户的内生偏好和外生背景。 具体来说,我们使用 GNN 作为图编码器获得用户参与嵌入,其中文本编码器编码的新闻和用户嵌入被用作新闻传播图中相应的节点特征。 最终的新闻嵌入由用户参与嵌入和新闻文本嵌入串联而成。
接下来,我们将介绍如何编码内源偏好、提取外源上下文并融合这两种信息。
2.1. 内生偏好编码
仅使用用户的社交网络信息来显式建模用户的内生偏好并不简单。 类似于(Ahmad and Siddique,2017;Khattri 等人,2015;Qian 等人,2018),使用用户的历史帖子来建模用户的个性、情绪和立场,我们利用用户隐式地编码他/她的偏好。 然而,之前的假新闻数据集都不包含此类信息。 在本文中,我们选择 FakeNewsNet 数据集 (Shu 等人, 2020b),其中包含 Twitter 上的新闻内容及其社交参与信息。 然后我们使用 Twitter Developer API (Developer, 2021) 抓取 FakeNewsNet 中转发该新闻的所有账户的历史推文。
为了获得丰富的历史信息用于用户偏好建模,我们爬取了每个账户最近的200条推文,总共爬取了近2000万条推文。 对于帐户被暂停或删除的不可访问用户,我们使用来自可访问用户的随机抽样推文,其新闻与其相应的历史帖子相同。 因为删除不可访问的用户将破坏完整的新闻传播级联,并导致外源上下文编码器的效率降低。 在应用文本表示学习方法之前,我们还删除了特殊字符,例如“@”字符和 URL。
为了对新闻文本信息和用户偏好进行编码,我们采用了两种基于语言预训练的文本表示学习方法。 在大型语料库上预训练的单词嵌入应该编码不同单词和句子之间更多的语义相似性,而不是在本地语料库上进行训练。 对于预训练的 word2vec 向量,我们选择由 spaCy (Honnibal 和 Montani,2017)预训练的 680k 300 维向量。 我们还采用预训练的 BERT 嵌入,使用 bert-as-a-service (Xiao, 2018) 将历史推文和新闻内容编码为序列 (Devlin 等人, 2018) >。
接下来,我们详细阐述应用上述文本表示学习模型的细节。 spaCy 包含 68 万个单词的预训练向量,我们对最近 200 条推文中现有单词的向量进行平均,以获得用户偏好表示。 类似地获得新闻文本嵌入。 对于 BERT 模型,我们使用 cased BERT-Large 模型对新闻和用户信息进行编码。 新闻内容使用最大输入序列长度(即 512 个 Token )的 BERT 进行编码。 由于 BERT 的输入序列长度限制,我们无法使用 BERT 将 200 条推文编码为一个序列,因此我们对每条推文分别进行编码,然后对它们进行平均以获得用户的偏好表示。 一般来说,推文文本比新闻文本短得多,我们根据经验将 BERT 的最大输入序列长度设置为 16 个 token,以加快推文编码时间。
2.2. 外源上下文提取
给定社交媒体上的新闻报道,用户外生上下文由参与该新闻的所有用户组成。 我们利用新闻片段的转发信息来构建新闻传播图。 如图1所示的新闻传播图的玩具示例,它是一个树形结构图,其中根节点代表新闻片段,其他节点代表分享根新闻的用户。 在本文中,我们将 Twitter 上的假新闻传播作为概念验证用例进行调查。 为了在 Twitter 中构建传播网络,我们遵循 (Shu 等人, 2020a; Monti 等人, 2019; Han 等人, 2020) 中使用的类似策略。 具体来说,我们将一个新片段定义为 ,将 定义为按时间排序的转发 的用户列表。 我们定义以下两条规则来确定新闻传播路径:
-
•
对于任何帐户 ,如果 比 中至少一个后续帐户转发相同新闻的时间晚,我们就会估计最新的帐户的新闻传播帐户 的时间戳。 由于最新的推文首先出现在 Twitter 应用程序的时间轴中,因此有更高的概率被转发。
-
•
如果帐户 没有关注转发序列中的任何帐户(包括源帐户),我们会保守地估计关注者数量最多的帐户的新闻传播。 因为根据 Twitter 内容分发规则,关注者越多的账户的推文被其他用户查看/转发的机会就越高。
根据上述规则,我们可以构建Twitter上的新闻传播图。 请注意,这种方法也可以应用于 Facebook 等其他社交媒体平台。
2.3. 信息融合
之前的工作(Lu和Li,2020;Monti等人,2019;Han等人,2020)已经证明,将用户特征与新闻传播图融合可以提高假新闻检测性能。 由于 GNN 可以以端到端的方式编码节点特征和图结构,因此它非常适合我们的任务。 具体来说,我们提出了一种分层信息融合方法。 我们首先使用 GNN 融合内源和外源信息。 使用 GNN,新闻文本嵌入和用户偏好嵌入可以作为节点特征。 给定新闻传播图,大多数 GNN 都会聚合其相邻节点的特征来学习节点的嵌入。 与之前基于 GNN 的图分类模型(Xu 等人, 2018; Ying 等人, 2018) 一样,我们对所有节点嵌入应用读出函数来获得新闻传播图的嵌入。 读出函数对所有节点嵌入进行均值池化操作以获得图嵌入(即用户参与度嵌入)。 其次,由于新闻内容通常包含有关新闻可信度的更明确信号(Chandra等人,2020)。 我们通过串联将新闻文本嵌入和用户参与嵌入融合为最终的新闻嵌入,以丰富新闻嵌入信息。
融合的新闻嵌入最终被输入一个两层多层感知器(MLP),其中两个输出神经元代表假新闻和真实新闻的预测概率。 该模型使用二元交叉熵损失函数进行训练,并使用 SGD 进行更新。
| Dataset |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Politifact (POL) |
|
41,054 | 40,740 | 131 | ||||||||
| Gossipcop (GOS) |
|
314,262 | 308,798 | 58 |
3. 实验
在实验中,我们想要解决以下两个问题:RQ1:与之前的作品相比,所提出的框架的性能如何? RQ2:内源/外源信息以及拟议框架的其他变体有何贡献?
3.1. 实验装置
3.1.1. 数据集。
之前的工作提出了一些假新闻数据集,其中包含来自不同网站的新闻片段及其事实核查信息(Wang,2017;Potthast等人,2018)。 为了研究假新闻的用户偏好和传播模式,我们选择 FakeNewsNet 数据集(Shu 等人,2020b)。 它包含来自两个事实核查网站的虚假和真实新闻信息以及来自 Twitter 的相关社交参与。 数据集统计数据如表1所示。
3.1.2. 基线
我们将 与利用不同信息的假新闻检测模型进行比较。 许多基线方法利用 FakeNewsNet (Shu 等人,2020b)中未包含的图像信息等额外信息。 为了确保公平比较,我们仅使用用于编码新闻内容、用户评论和新闻传播图的部分来实现基线。 CSI (Ruchansky 等人, 2017) 采用 LSTM 对新闻内容信息进行编码来检测假新闻。 SAFE (Zhou 等人, 2020) 使用 TextCNN (Zhang and Wallace, 2015) 对新闻文本信息进行编码。 GCNFN (Monti 等人, 2019) 是第一个使用 GCN (Kipf 和 Welling, 2017) 对新闻传播图进行编码的假新闻检测框架。 它将个人资料信息和评论文本嵌入作为用户特征。 GNN-CL (Han 等人, 2020) 使用 DiffPool (Ying 等人, 2018)(一种专为图分类而设计的 GNN)对新闻传播图进行编码。 节点特征是从 Twitter 上的用户个人资料属性中提取的。 十个配置文件特征名称的列表可以在(Han等人,2020;Lu和Li,2020)中找到。我们还添加了两个基线,直接将MLP应用于由word2vec和BERT编码的新闻文本嵌入。
3.1.3. 实验设置
我们使用 PyTorch 实现所有模型,所有 GNN 模型均使用 PyTorch-Geometric 包(Fey 和 Lenssen,2019) 实现。 我们对所有模型使用统一的图嵌入大小 (128)、批量大小 (128)、优化器 (Adam) 和 L2 正则化权重 (0.001)、训练-验证-测试分割 (20%-10%-70%)。 实验结果是五次不同运行的平均值。 每个模型的其他超参数都随代码一起报告。
3.2. RQ1:绩效评估
| Model | POL | GOS | |||
|---|---|---|---|---|---|
| ACC | F1 | ACC | F1 | ||
| News Only | SAFE (Zhou et al., 2020) | 73.30 | 72.87 | 77.37 | 77.19 |
| CSI (Ruchansky et al., 2017) | 76.02 | 75.99 | 75.20 | 75.01 | |
| BERT+MLP | 71.04 | 71.03 | 85.76 | 85.75 | |
| word2vec+MLP | 76.47 | 76.36 | 84.61 | 84.59 | |
| News + User | GNN-CL (Han et al., 2020) | 62.90 | 62.25 | 95.11 | 95.09 |
| GCNFN (Monti et al., 2019) | 83.16 | 83.56 | 96.38 | 96.36 | |
| (ours) | |||||
表2显示了和六个基线的假新闻检测性能。 首先,我们可以观察到,与所有基线相比, 具有最佳性能。 在两个数据集上均优于最佳基线 GCNFN 约 1%,具有统计显着性。 和GCNFN的实验结果表明,用户评论(GCNFN使用的)也有利于假新闻检测;当用户评论信息有限时,用户内生偏好可以强加额外的信息。 其次,由于所有基线都对新闻内容或用户评论进行编码,而不考虑历史帖子,因此我们可以看出,利用历史帖子作为用户内生偏好可以提高假新闻检测性能。 请注意,在两个数据集上性能最佳的 使用 BERT 作为文本编码器,使用 GraphSAGE 作为图形编码器。
| Feature | POL | GOS | ||||||
|---|---|---|---|---|---|---|---|---|
| GraphSAGE | GCNFN | GraphSAGE | GCNFN | |||||
| ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | |
| Profile | 77.38 | 77.12 | 76.94 | 76.72 | 92.19 | 92.16 | 89.00 | 88.96 |
| word2vec | 80.54 | 80.41 | 80.54 | 80.41 | 96.81 | 96.80 | 94.97 | 94.95 |
| BERT | 84.62 | 84.53 | 83.26 | 83.14 | 97.23 | 97.22 | 96.18 | 96.17 |
3.3. RQ2:消融研究
3.3.1. 编码器变体
正如我们在 2.3 节中提到的,我们采用不同的文本编码器和 GNN 来编码内源和外源信息。 在表3中,我们展示了使用三种不同节点特征的两种 GNN 变体的假新闻检测性能。 请注意,“word2vec”和“BERT”表示编码用户内生偏好的特征,而“Profile”特征被视为基线。 GraphSAGE (Hamilton 等人, 2017) 是一个通过聚合邻居节点信息来学习节点嵌入的 GNN,GCNFN (Monti 等人, 2019) 是一个基于 GNN 的假新闻检测模型利用两个 GCN 层对新闻传播图进行编码。
表3显示内生特征(word2vec和BERT)始终优于仅对用户个人资料信息进行编码的个人资料特征。 我们还观察到 GraphSAGE 和 BERT 在其他模型和特征变体中具有平均最佳性能。 这表明 BERT 在编码文本特征方面优于 word2vec,这已在其他 NLP 任务上得到验证(Devlin 等人,2018)。 请注意,BERT 性能可以通过微调进一步提高,我们将其留作未来的工作。
3.3.2. 框架变体
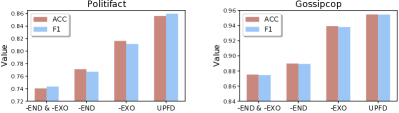
为了验证内源偏好和外源上下文的有效性,我们修复了文本和图形编码器,并设计了三个 变体来删除内源信息、外源信息或两者。
具体来说,我们使用 GCNFN (word2vec) 作为两个数据集的图形(文本)编码器,并删除新闻串联以确保公平比较。 没有外源信息的 变体(-EXO)是通过删除新闻传播图中的所有边来实现的。 因此,-EXO仅根据节点特征对新闻嵌入进行编码,而不在节点之间交换信息。 无内生信息的变体(-END)将用户配置文件作为节点特征,不包含用户内生偏好信息。 没有内源和外源信息的 变体(-END 和 -EXO)用用户配置文件特征替换 -EXO 的节点特征。
图2显示了不同变体在两个数据集上的假新闻检测性能。 我们可以发现,从 中删除任何一个组件都会降低其性能。 此外,联合编码内源和外源信息可以获得最佳性能。 /-EXO 的准确率为 85.61%/81.63%,/-EXO 在 Politifact 上的 F1 得分为 85.97%/81.15%。 /-EXO 的准确率为 95.47%/93.92%,/-EXO 在 Politifact 上的 F1 得分为 95.46%/93.81%。 所有实验结果经t检验()均具有统计学意义。 这表明外生信息(即新闻传播图)在 Politifact 上信息量更大,因为删除它会导致更大的性能下降。 很明显,内源信息比外源信息对性能增益的贡献更大。 这一观察结果进一步验证了对用户内生偏好进行建模的必要性。
4. 结论
在本文中,我们认为用户内生的新闻消费偏好在假新闻检测问题中起着至关重要的作用。 为了验证这一论点,我们收集用户历史帖子来隐式建模用户内生偏好,并利用社交媒体上的新闻传播图作为用户的外生社交背景。 提出了一种名为的端到端假新闻检测框架来融合内源和外源信息并预测社交媒体上新闻的可信度。 实验结果证明了对用户内生偏好进行建模的优势。
致谢。
这项工作得到了 NSF 拨款 III-1763325、III-1909323 和 SaTC-1930941 的部分支持。 Kai Shu 得到了 John S. 和 James L. Knight 基金会的资助,向乔治华盛顿大学数据、民主与政治研究所提供资助。参考
- (1)
- Abilov et al. (2021) Anton Abilov, Yiqing Hua, Hana Matatov, Ofra Amir, and Mor Naaman. 2021. VoterFraud2020: a Multi-modal Dataset of Election Fraud Claims on Twitter. arXiv preprint arXiv:2101.08210 (2021).
- Ahmad and Siddique (2017) Nadeem Ahmad and Jawaid Siddique. 2017. Personality assessment using Twitter tweets. Procedia computer science 112 (2017), 1964–1973.
- Chandra et al. (2020) Shantanu Chandra, Pushkar Mishra, Helen Yannakoudakis, and Ekaterina Shutova. 2020. Graph-based Modeling of Online Communities for Fake News Detection. arXiv preprint arXiv:2008.06274 (2020).
- Developer (2021) Twitter Developer. 2021. Twitter API. https://developer.twitter.com/.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Fey and Lenssen (2019) Matthias Fey and Jan E. Lenssen. 2019. Fast Graph Representation Learning with PyTorch Geometric. In ICLR Workshop on Representation Learning on Graphs and Manifolds.
- Hamilton et al. (2017) William L Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In NeurIPS.
- Han et al. (2020) Yi Han, Shanika Karunasekera, and Christopher Leckie. 2020. Graph Neural Networks with Continual Learning for Fake News Detection from Social Media. arXiv preprint arXiv:2007.03316 (2020).
- Hassan et al. (2017) Naeemul Hassan, Gensheng Zhang, Fatma Arslan, Josue Caraballo, Damian Jimenez, Siddhant Gawsane, Shohedul Hasan, Minumol Joseph, Aaditya Kulkarni, Anil Kumar Nayak, et al. 2017. ClaimBuster: the first-ever end-to-end fact-checking system. VLDB (2017).
- Honnibal and Montani (2017) Matthew Honnibal and Ines Montani. 2017. spacy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing. To appear 7, 1 (2017).
- Kaliyar et al. ([n.d.]) Rohit Kumar Kaliyar, Anurag Goswami, and Pratik Narang. [n.d.]. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimedia Tools and Applications ([n. d.]), 1–24.
- Karimi et al. (2018) Hamid Karimi, Proteek Roy, Sari Saba-Sadiya, and Jiliang Tang. 2018. Multi-Source Multi-Class Fake News Detection. In COLING.
- Khattri et al. (2015) Anupam Khattri, Aditya Joshi, Pushpak Bhattacharyya, and Mark Carman. 2015. Your sentiment precedes you: Using an author’s historical tweets to predict sarcasm. In Proceedings of the 6th workshop on computational approaches to subjectivity, sentiment and social media analysis. 25–30.
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In ICLR.
- Lu and Li (2020) Yi-Ju Lu and Cheng-Te Li. 2020. GCAN: Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
- Mikolov et al. (2013) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013).
- Monti et al. (2019) Federico Monti, Fabrizio Frasca, Davide Eynard, Damon Mannion, and Michael M Bronstein. 2019. Fake news detection on social media using geometric deep learning. ICLR Workshop (2019).
- Nickerson (1998) Raymond S Nickerson. 1998. Confirmation bias: A ubiquitous phenomenon in many guises. Review of general psychology 2, 2 (1998), 175.
- Potthast et al. (2018) Martin Potthast, Johannes Kiesel, Kevin Reinartz, Janek Bevendorff, and Benno Stein. 2018. BuzzFeed-Webis Fake News Corpus 2016. https://doi.org/10.5281/zenodo.1239675
- Qian et al. (2018) Jing Qian, Mai ElSherief, Elizabeth M Belding, and William Yang Wang. 2018. Leveraging intra-user and inter-user representation learning for automated hate speech detection. arXiv preprint arXiv:1804.03124 (2018).
- Rangel et al. (2020) Francisco Rangel, Anastasia Giachanou, Bilal Ghanem, and Paolo Rosso. 2020. Overview of the 8th Author Profiling Task at PAN 2020: Profiling Fake News Spreaders on Twitter. In CLEF.
- Ross and Ward (1995) Lee Ross and Andrew Ward. 1995. Naive realism in everyday life: Implications for social conflict and misunderstanding. (1995).
- Ruchansky et al. (2017) Natali Ruchansky, Sungyong Seo, and Yan Liu. 2017. Csi: A hybrid deep model for fake news detection. In CIKM.
- Shu et al. (2019) Kai Shu, H Russell Bernard, and Huan Liu. 2019. Studying fake news via network analysis: detection and mitigation. In Emerging Research Challenges and Opportunities in Computational Social Network Analysis and Mining. Springer, 43–65.
- Shu et al. (2020b) Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2020b. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big Data 8, 3 (2020), 171–188.
- Shu et al. (2020a) Kai Shu, Deepak Mahudeswaran, Suhang Wang, and Huan Liu. 2020a. Hierarchical propagation networks for fake news detection: Investigation and exploitation. In Proceedings of the International AAAI Conference on Web and Social Media.
- Shu et al. (2017) Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu. 2017. Fake News Detection on Social Media: A Data Mining Perspective. KDD exploration newsletter (2017).
- Sun et al. (2020a) Lichao Sun, Kazuma Hashimoto, Wenpeng Yin, Akari Asai, Jia Li, Philip Yu, and Caiming Xiong. 2020a. Adv-BERT: BERT is not robust on misspellings! Generating nature adversarial samples on BERT. arXiv preprint arXiv:2003.04985 (2020).
- Sun et al. (2020b) Lichao Sun, Congying Xia, Wenpeng Yin, Tingting Liang, Philip S Yu, and Lifang He. 2020b. Mixup-Transfomer: Dynamic Data Augmentation for NLP Tasks. arXiv preprint arXiv:2010.02394 (2020).
- Wang (2017) William Yang Wang. 2017. ” Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. arXiv preprint arXiv:1705.00648 (2017).
- Wang et al. (2018) Yaqing Wang, Fenglong Ma, Zhiwei Jin, Ye Yuan, Guangxu Xun, Kishlay Jha, Lu Su, and Jing Gao. 2018. EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. In KDD.
- Xiao (2018) Han Xiao. 2018. bert-as-service. https://github.com/hanxiao/bert-as-service.
- Xu et al. (2018) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826 (2018).
- Ying et al. (2018) Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. 2018. Hierarchical graph representation learning with differentiable pooling. In Advances in neural information processing systems.
- Zhang and Wallace (2015) Ye Zhang and Byron Wallace. 2015. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv preprint arXiv:1510.03820 (2015).
- Zhou et al. (2020) Xinyi Zhou, Jindi Wu, and Reza Zafarani. 2020. SAFE: Similarity-Aware Multi-modal Fake News Detection. In Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 354–367.
- Zhou and Zafarani (2020) Xinyi Zhou and Reza Zafarani. 2020. A survey of fake news: Fundamental theories, detection methods, and opportunities. ACM Computing Surveys (CSUR) 53, 5 (2020), 1–40.