[table]capposition=底部 capbtabboxtable[][]
平安创投ICDAR 2021科学文献解析竞赛B题解决方案:表格识别转HTML
摘要
本文介绍了我们在 ICDAR 2021 科学文献解析任务 B 竞赛中的解决方案:表格识别到 HTML。 在我们的方法中,我们将表格内容识别任务分为四个子任务:表格结构识别、文本行检测、文本行识别和框分配。 我们的表格结构识别算法是基于MASTER [1](一种鲁棒的图像文本识别算法)定制的。 PSENet [2] 用于检测表格图像中的每个文本行。 对于文本行识别,我们的模型也是建立在 MASTER 之上的。 最后,在框分配阶段,我们将PSENet检测到的文本框与表结构预测重建的结构项相关联,并将文本行的识别内容填充到相应的项中。 我们提出的方法在开发阶段对 9,115 个验证样本实现了 96.84% 的 TEDS 得分,在最终评估阶段对 9,064 个样本实现了 96.32% 的 TEDS 得分。
1简介
ICDAR 2021科学文献解析竞赛任务B是将表格图像重建为HTML代码。 本次比赛提供PubTabNet数据集(v2.0.0)[3]作为官方评估数据,并使用基于Tree-Edit-Distance的相似度(TEDS)度量进行评估。 PubTabNet数据集由500,777个训练样本、9,115个验证样本、9,138个开发阶段样本和9,064个最终评估阶段样本组成。 对于训练和验证数据,向参与者提供真实 HTML 代码和非空表格单元格的位置。 本次比赛的参赛者需要开发一个模型,可以将表格数据的图像转换为相应的 HTML 代码,该代码应正确表示表格的结构和每个单元格的内容。 开发和最终评估阶段样品的标签由组织者保存。
我们将此任务分为四个子任务:表格结构识别、文本行检测、文本行识别和框分配。 并尝试了一些技巧来改进模型。 每个子任务的详细信息将在下一节中讨论。
2方法
在本节中,我们将按顺序介绍这四个子任务。
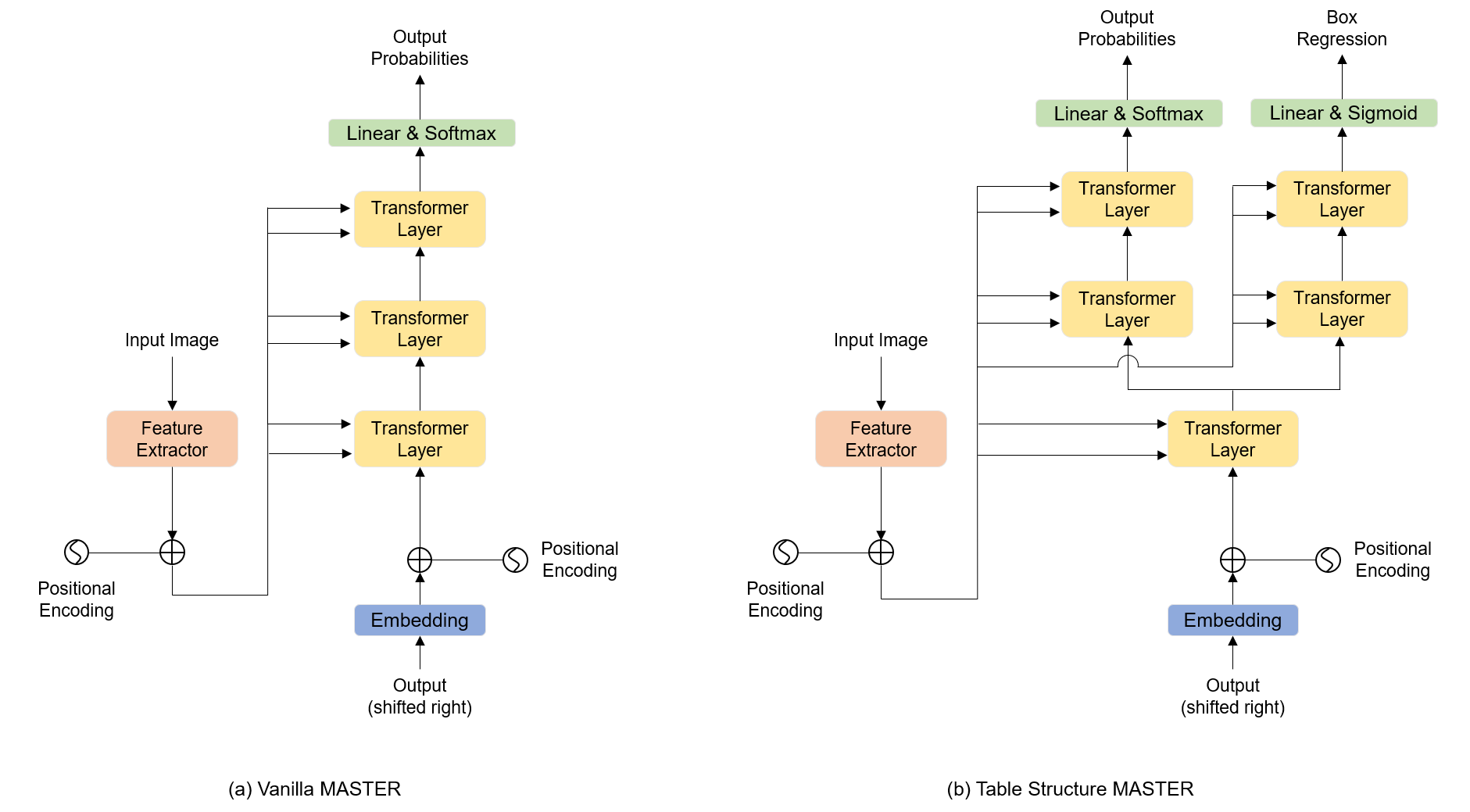
2.1表结构识别
表结构识别的任务是重建HTML序列项及其在表格上的对应位置,但忽略每个项中的文本内容。 我们的模型结构如图1(b)所示。 它是基于 MASTER [1]定制的,这是一个功能强大的图像到序列模型,最初设计用于场景文本识别。 与图 1(a) 所示的普通 MASTER 不同,我们的模型有两个分支。 一个分支是预测 HTML 项目序列,另一个分支是进行框回归。 我们没有在最后一层将模型分成两个分支,而是在第一个 Transformer 解码层之后将序列预测和框回归解耦。

为了构建 HTML 序列,我们需要为该序列定义一个字母表。 如图2左侧所示,我们为序列预测定义了39个类标签。 对于成对的 <thead> 和 </thead>, <tbody> 和 </tbody>, 以及 <tr> 和 </tr>, 这些字符对之间可能会出现一些其他控制字符。 因此,我们需要为它们中的每一个定义一个单独的类。 我们将最大“colspan”和“rowspan”定义为 10,因此我们分别为它们使用 9 个标签。 <td></td> 有两种形式,即 <td> 和 </td> 之间的空内容或非空内容。 我们使用一个类来表示整个 <td>[内容]</td>。 值得注意的是,使用一个标签而不是为 <td> 和 </td> 定义两个单独的标签,可以大大减少序列的长度。 对于内容为空的 <td></td> 形式,我们可以找到 11 种特殊形式。 如图2右侧所示,每个表单都由一个特殊的类标签表示。 根据上面的描述,PubTabNet数据集中99.6%的HTML的序列长度都小于500。
对于序列预测,我们使用标准交叉熵损失。 对于框回归,我们使用 L1 损失来回归 [x,y,w,h] 的坐标。 坐标标准化为 [0,1]。 对于盒回归头,我们在损失计算之前使用 Sigmoid 激活函数。

在图3中,我们展示了序列预测和框回归的结果示例。 我们可以看到结构 MASTER 可以正确预测框坐标。
2.2 文本行检测
PSENet 是一种高效的文本检测算法,可以被视为实例分割网络。 它有两个优点。 首先,PSENet 作为一种基于分割的方法,能够定位任意形状的文本。 其次,该模型提出了一种渐进规模扩展网络,可以成功识别相邻文本实例。 PSENet不仅适应任意角度的文本检测,而且对于相邻文本分割也有更好的效果。

与自然场景中的文本检测相比,打印文档中的文本检测是一项简单的任务。 在训练PSENet中,需要注意三个关键点,输入图像大小、最小面积和最小内核大小。 为了避免真阴性,特别是一些小区域(如虚线),输入图像的分辨率应较大,最小区域尺寸应设置较小。 在图4中,我们可视化了 PSENet 的检测结果。
2.3文本行识别
我们还使用 MASTER 作为我们的文本行识别算法。 MASTER功能强大,可以根据不同的数据形式自由适配不同的任务,例如:曲线文本预测、多行文本预测、垂直文本预测、多语言文本预测。

PubTabNet数据集(v2.0.0)中的位置标注是单元格级别的,根据数据集中的位置裁剪文本图像,包含单行和多行文本图像。 我们根据标注文件中提供的位置信息构建文本行识别数据库。 该文本行识别数据库包含从 50 万张训练图像中裁剪出来的约 3200 万个样本。 我们分割出 20k 文本行图像作为检查点选择的验证集。 部分训练示例如图5所示。 我们可以看到有些文字是模糊的,有些是黑色的,有些是灰色的。 在我们的 MASTER OCR 中,最大序列长度设置为 100。 超过 100 个字符的文本行将被丢弃。 部分训练示例如图5所示。
需要注意的是,在训练阶段,我们的算法是在单行文本图像和多行文本图像混合的数据库上训练的,但在测试阶段,仅输入单行文本图像。 通过文本行识别,我们可以得到文本行图像对应的文本内容。 这些文本内容将被合并到 HTML 序列中的非空 <td></td> 项中。 文本内容合并的细节也将在下一小节中讨论。
2.4 框分配
根据以上三小节,我们得到了表格结构以及每个单元格的框,以及每个文本行的框及其对应的文本内容。 为了生成完整的 HTML 序列,我们需要将文本行的每个框分配到其相应的表结构单元格中。 在本小节中,我们将详细介绍我们使用的匹配规则。 我们的方法中使用了三种匹配规则,我们称之为中心点规则、IOU规则和距离规则。 详细内容将在下面讨论。
2.4.1 中心点规则
在这个匹配规则中,我们首先计算PSENet获得的每个框的中心坐标。 如果坐标在结构预测得到的回归框的矩形区域内,我们称它们为匹配对。 文本行的内容将填充到 <td></td> 中。 需要注意的是,一个表结构单元可以与多个 PSENet 框关联,因为一个表结构单元可能具有多个文本行。
2.4.2 IOU规则
如果不满足上述规则,我们将计算所选文本行的框与所有结构单元框之间的 IOU。 IOU 值最大的方框单元将被选择。 文本内容将填充到所选的结构单元中。
2.4.3 距离规则
最后,如果上述两条规则都不成功。 我们将计算所选文本行的框与所有结构单元框之间的欧几里德距离。 与IOU规则类似,将选择欧氏距离最小的结构单元。
2.4.4匹配管道
所有上述三个规则将按顺序应用。 首先,PSENet 检测到的大多数框将通过中心点规则分配给其相应的结构单元。 由于结构预测的预测偏差,PSENet框的一些中心点超出了结构预测得到的结构单元框的矩形区域。 其次,中心点规则下一些未匹配的PSENet框将在IOU规则下进行匹配。 在上述两步中,我们使用PSENet框来匹配其相应的结构项。 如果有一些结构项不匹配。 这样,我们使用结构项来查找左侧 PSENet 框。 为此,需要应用距离规则。

3实验
在本节中,我们将详细描述表格识别系统的实现。
数据集。 我们使用的数据是PubTabNet数据集(v2.0.0),其中包含开发阶段的500,777个训练数据和9,115个验证数据,用于开发阶段的9,138个样本以及用于最终评估阶段的9,064个样本。 除了提供训练数据外,训练中不使用额外的数据。 为了获得所有文本框训练的文本行级别标注,为 PSENet 训练重新标记了 2k 数据图像。 其实我们只需要将多行标注的标注调整为单行方框标注即可。
实施细节。 在 PSENet 训练中,使用 8 个 Tesla V100 GPU,每个 GPU 的批量大小为 10。 输入图像同等大小调整,保持长边分辨率为 1280。 RandomFilp 和 RandomCrop 用于数据增强。 从每个图像中裁剪 区域。 采用 Adam 优化器,初始学习率为 0.001,学习率逐步衰减。
在表结构训练中,使用 8 个 Tesla V100 GPU,每个 GPU 的批量大小为 6。 输入图像大小为,最大序列长度为500。 本实验采用同步BN[4]和Ranger优化器[5],优化器的初始学习率为0.001,学习率逐步衰减。
在文本行识别的训练中,使用了 8 个 Tesla V100 GPU,每个 GPU 的批量大小为 64。 输入大小为,最大长度为100。 也应用了同步BN和Ranger优化器训练,超参数设置与表结构相同。
所有模型都是基于我们自己的 FastOCR 工具箱进行训练的。
3.1消融研究
我们的桌子识别系统如上所述。 这次比赛我们进行了很多尝试。 在本小节中,我们将讨论一些有用的技巧,但忽略一些不成功的尝试。
Ranger 是一个协同优化器,结合了 RAdam(修正 Adam)[6]、LookAhead [7] 和 GC(梯度集中) [8]。 我们观察到Ranger优化器在本次比赛中表现出了比Adam更好的性能,并且它被应用于表结构预测和文本行识别。 我们使用默认的 Ranger。 Adam和Ranger的结果对比如表1(a)所示。
同步批量标准化(SyncBN)是一种有效的批量标准化方法,适用于多GPU或分布式训练。 在标准批量归一化中,数据仅在每个 GPU 设备上的数据内进行归一化。 但 SyncBN 对整个小批量内的输入进行标准化。 SyncBN 非常适合每个 GPU 显卡上的批量大小相对较小的情况。 我们的实验中应用了SyncBN。
Transformer 解码器中层的特征串联。 在结构MASTER和文本识别MASTER中,三个连续的Transformer层[1]被用作解码器。 与原始 MASTER 不同,我们连接每个 Transformer 层 [9] 的输出,然后对连接的特征应用线性投影。
结构预测中的标签编码 在检查 PubtabNet 数据集(v2.0.0)的训练数据后,我们发现一些关于空表格单元格的模糊注释。 表格中的一些空单元格标记为 <td></td>,而其他单元格标记为 <td></td>,其中插入了一个空格字符。 然而,这两个不同的表格单元格在视觉上看起来是相同的。 据统计,<td></td>和<td></td>之间的比例约为 4:1。 在我们的实验中,我们将这两个不同的单元编码为不同的 Token 。 我们的动机是让模型通过训练发现内在的视觉特征。
| Optimizer | Structure prediction Acc. |
| Adam | 0.7784 |
| Ranger | 0.7826 |
| Feature Concatenation | Text line recognition Acc. |
| No | 0.9313 |
| Yes | 0.9347 |
| SyncBN | FC | Structure prediction Acc. |
| 0.7734 | ||
| ✓ | 0.7750 | |
| ✓ | ✓ | 0.7785 |
在本次比赛中,我们进行了一些评估并记录了结果。 结果如表1所示。
根据表1,我们有以下观察结果:
-
•
Ranger 优化器的性能始终优于 Adam 优化器。 我们在另一份关于 ICDAR 2021 LaTeX 科学表格图像识别竞赛的报告 [10] 中也发现了类似的观察结果 [11]。 在我们对标准基准的评估中,我们还发现 Ranger 可以将平均准确率提高约 1%。
-
•
SyncBN可以稍微提高性能。 我们还观察到,在 ICDAR 2021 数学公式检测竞赛中,SyncBN 也表现出了比标准 BN 更好的性能。
-
•
特征串联可以提高该任务结构预测的准确性。 应该注意的是,在[10]中,我们没有观察到性能改进。
| TLD | TSR | TLR | BA | ME | ForC | TEDS | ||
| PSE | ESB | SyncBN | FeaC | FeaC | Extra Insert | |||
| ✓ | 0.9385 | |||||||
| ✓ | ✓ | ✓ | ✓ | ✓ | 0.9621 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 0.9626 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 0.9635 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 0.9684 |
3.2 验证集的端到端评估
我们通过合并结构预测、文本行检测、文本行识别和框分配来生成最终的 HTML 代码。 我们在这些阶段评估一些技巧。 结果如表2所示。 TEDS 用作我们的指标。
我们从这次比赛中得到了一些总体结论,
-
•
ESB(空白框编码)对于最终的 TEDS 指标非常重要。
-
•
FeaC(特征串联)对于表结构识别和文本行识别都有效。
-
•
ME(模型集成)稍微提高了性能。 TSR 中的三个模型集成可以将端到端 TEDS 分数提高约 0.2%。 文本行识别中的三个模型集成只能将 TEDS 分数提高约 0.03%。 我们只使用一种 PSENet 模型。
-
•
SyncBN 对 TSR 和 TLR 均有效。
-
•
ForC(格式校正)有助于最终指标。 我们对格式的修正是承诺<thead>和</thead>之间的所有内容均为黑色字体。
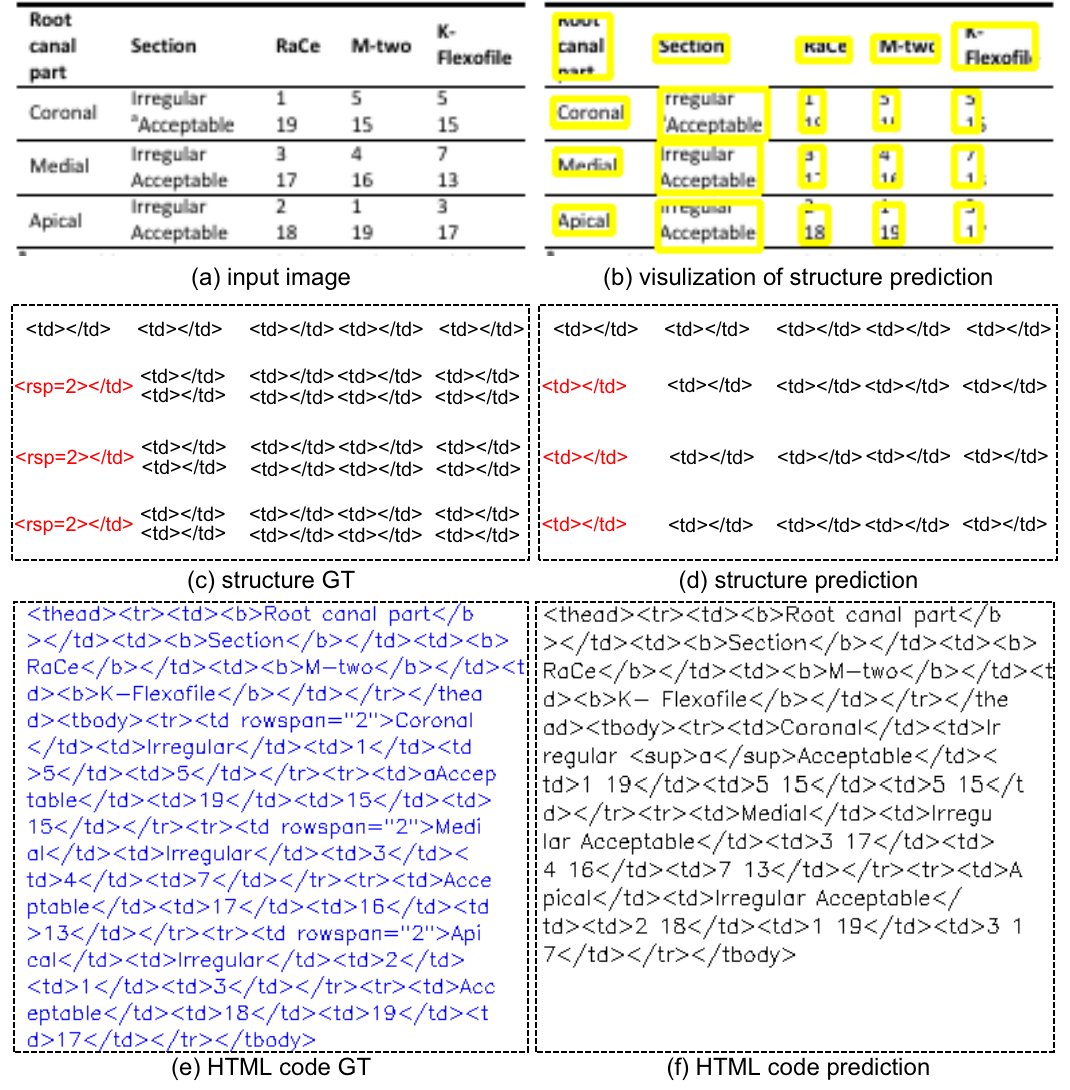
讨论。 从这次比赛中,我们有一些反思。 对于HTML代码的端到端表格识别,结构预测是极其重要的阶段,特别是对于TEDS指标。 如图7所示,虽然所有文本行信息都被正确识别。 由于错误的结构预测,我们的方法获得了非常低的 TEDS (0.423)。 尽管提供的数据集很大,但我们仍然相信覆盖更多模板的更大规模的数据可能会进一步改善结构预测。 其次,考虑到所有表格图像都是打印的,文本行检测和文本行识别是很容易的任务。 第三,存在一些标签不一致的问题,如 <td></td> 和 <td></td>。 最后,框分配子任务可以通过图神经网络(GNN)[12]来执行,而不是手工制定的规则。
4结论
在本文中,我们提出了 ICDAR 2021 科学文献解析任务 B 竞赛的解决方案:表格识别到 HTML。 我们将表格识别系统分为四个子任务,表格结构预测、文本行检测、文本行识别和框分配。 我们的系统在开发阶段在验证数据集上获得了 96.84 TEDS 分数,在最终评估阶段获得了 96.324 TEDS 分数。
参考
- [1] Ning Lu, Wenwen Yu, Xianbiao Qi, Yihao Chen, Ping Gong, Rong Xiao, and Xiang Bai. Master: Multi-aspect non-local network for scene text recognition. Pattern Recognition, 2021.
- [2] Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu, Gang Yu, and Shuai Shao. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9336–9345, 2019.
- [3] Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. Image-based table recognition: data, model, and evaluation. arXiv preprint arXiv:1911.10683, 2019.
- [4] Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang, Xiaogang Wang, Ambrish Tyagi, and Amit Agrawal. Context encoding for semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7151–7160, 2018.
- [5] Less Wright. Ranger-Deep-Learning-Optimizer, 2019.
- [6] Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han. On the variance of the adaptive learning rate and beyond. In Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020), April 2020.
- [7] Michael R Zhang, James Lucas, Geoffrey Hinton, and Jimmy Ba. Lookahead optimizer: k steps forward, 1 step back. arXiv preprint arXiv:1907.08610, 2019.
- [8] Hongwei Yong, Jianqiang Huang, Xiansheng Hua, and Lei Zhang. Gradient centralization: A new optimization technique for deep neural networks. In European Conference on Computer Vision, pages 635–652. Springer, 2020.
- [9] Zi-Yi Dou, Zhaopeng Tu, Xing Wang, Shuming Shi, and Tong Zhang. Exploiting deep representations for neural machine translation. arXiv preprint arXiv:1810.10181, 2018.
- [10] Yelin He, Xianbiao Qi, Jiaquan Ye, Peng Gao, Yihao Chen, Bingcong Li, Xin Tang, and Rong Xiao. Pingan-vcgroup’s solution for icdar 2021 competition on scientific table image recognition to latex. arXiv, 2021.
- [11] Pratik Kayal, Mrinal Anand, Harsh Desai, and Mayank Singh. Icdar 2021 competition on scientific table image recognition to latex. In 2021 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2021.
- [12] Yihao Chen, Xin Tang, Xianbiao Qi, Chun-Guang Li, and Rong Xiao. Learning graph normalization for graph neural networks. arXiv preprint arXiv:2009.11746, 2020.