深度学习哈密顿蒙特卡罗
摘要
我们用一堆神经网络层来推广哈密顿蒙特卡罗算法,并评估其从二维晶格规范理论中的不同拓扑进行采样的能力。 我们证明我们的模型能够成功地混合不同拓扑的模式,从而显着降低生成独立规范场配置所需的计算成本。 我们的实现可在 https://github.com/saforem2/l2hmc-qcd 获取。
1简介
在Lévy等人(2017)中,作者提出了学习哈密顿蒙特卡罗(L2HMC)算法,并证明了其在各种目标分布上优于传统哈密顿蒙特卡罗(HMC)的能力。 他们表明,经过训练的 L2HMC 采样器能够通过探索传统 HMC 无法访问的相空间区域来在模式之间进行混合。 在本文中,我们提出了一种通用采样器,使用深度神经网络进行自训练,以提出新的马尔可夫链状态,该状态在 Metropolis-Hastings (Hastings,1970) 算法的帮助下变得精确。 我们的深度学习哈密顿蒙特卡罗 (DLHMC) 算法的目标是模拟晶格规范理论,其中最先进的模拟具有数十亿个自由度,并在具有数千个节点的超级计算机上运行,但在接近连续体时会出现指数级减速物理学(Schaefer等人,2009;Cossu等人,2017)。
2 主要贡献
3相关工作
最近,人们对应用生成机器学习技术来构建更智能、更高效的科学模拟越来越感兴趣。 随着 RealNVP (Dinh 等人, 2017) 架构的发展,已经提出了许多旨在利用其可逆结构的技术。 特别是,格子规理论和格子 QCD 的模拟将从这种新方法中获益匪浅,这一点可以从网络架构 (Dinh 等人,2017 年;Favoni 等人,2020 年;Toth 等人,2020 年)、生成模型 (Albergo 等人,2019 年;2021 年;Medvidovic 等人,2020 年;Boyda 等人,2020 年;Kanwar 等人,2020 年;Wehenkel & Louppe, 2020 年;Tompe, 2020 年) 等在这方面迅速增长的研究成果中得到证明、2019;2021;Medvidovic 等人,2020;Boyda 等人,2020;Kanwar 等人,2020;Wehenkel & Louppe,2020;Tomiya & Nagai,2021),以及新型 MCMC 方法 (Pasarica & Gelman,2010;Tanaka & Tomiya,2017;Hoffman et al、2019; Neklyudov & Welling, 2020; Neklyudov et al.
4DLHMC算法
我们回顾了通用哈密顿蒙特卡罗 (HMC) 算法,并在 A.1 节中设置了一些相关符号。 在模拟系统 时,我们使用理论上给定的概率密度 和可能难以实现的归一化,用目标分布 将马尔科夫链状态增强为 。 HMC 算法中通常使用的共轭动量 具有已知且易于采样的分布。 二进制方向变量,如 L2HMC (Lévy 等人, 2017)、 中介绍的,表示我们更新的“方向”(向前/向后)。
DLHMC 使用单独的神经网络进一步概括了 L2HMC 中的蛙跳步骤,这些神经网络由权重 共同参数化。 DLHMC 中的每个蛙跳步骤都是深度神经网络的一层,它将第 层的输入 转换为输出 ,其中 保持不变,选择向前或向后的蛙跳层。 随后,第 层使用 作为其输入。 为了简单起见,我们考虑向前的方向,并引入符号:
| (1) | ||||
| (2) |
其中:(1.) 和,表示(分别为,)网络的输入111网络与正在更新的变量无关,网络将与掩码。 ,其中 表示逐元素乘法; (2.) 我们通过上的上标来指示更新的方向; (3.) 表示当前沿着轨迹的蛙跳步。 我们在图 1 中展示了用于公式 1 和公式 2 更新的 第三跃迁层的网络结构。
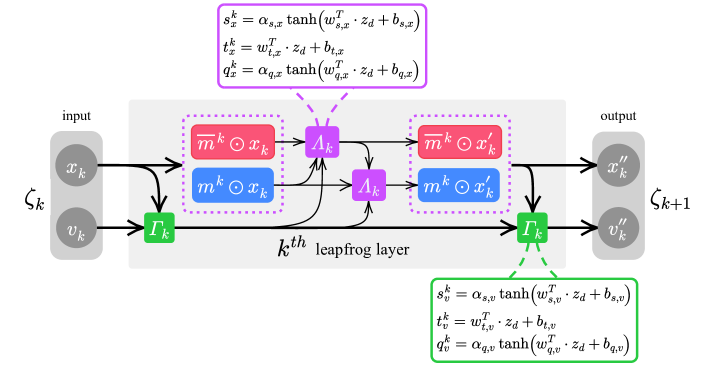
使用这种表示法,我们可以编写一个完整的蛙跳更新(向前 方向)222为了获得相反方向的表达式,我们可以反转每个函数,并以相反的顺序执行更新。 作为:
-
1.
半步动量更新:
-
2.
全步半位置更新:333这意味着我们正在对 的一半索引执行完整更新(由 确定) >),然后是补充索引 的类似更新。
-
3.
全步半位置更新:
-
4.
半步动量更新:
总的来说,我们将这一系列更新称为单个leapfrog层,它执行单个更新。 请注意,为了保持更新的可逆性,我们引入了一个二进制掩码 ,将 更新拆分为两个子更新,该掩码会按顺序更新 的一半组件。
与在 HMC 中一样,我们通过按顺序执行 蛙跳步骤,然后执行 Metropolis-Hastings 接受/拒绝步骤(如方程 7 中所述)来形成完整的轨迹。 然而,与 HMC 的表达式不同,我们必须考虑更新 中的整体雅可比因子,可以轻松计算为 、 。 我们保持个体自由度的雅可比因子易于处理。
5 格子规范理论
6结果
我们将 DLHMC 算法与 C 节中的训练过程和 B 节中的退火计划应用到二维 规范理论,参数逐渐接近连续极限。 然后,我们使用经过训练的模型进行推理来生成马尔可夫链,并将其效率与 HMC 进行比较。 我们使用 Horovod (Sergeev & Balso,2018) 和 TensorFlow (Abadi 等人,2016) 在阿贡领导计算设施的 ThetaGPU 超级计算机上训练我们的模型。 在 1 个节点( NVIDIA A100 GPU)上运行一个典型的训练,使用批量大小 、每个 跃迁层的隐藏层形状 ,在 网格上运行 训练步骤,大约需要 小时才能完成。

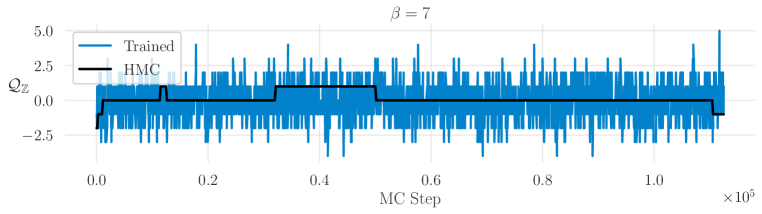
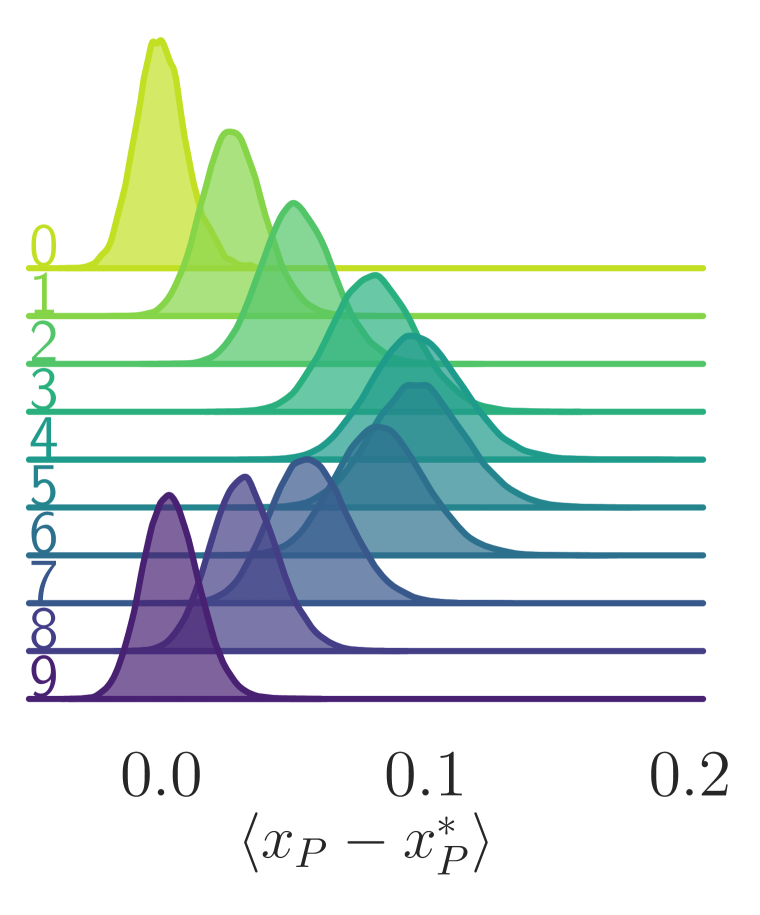
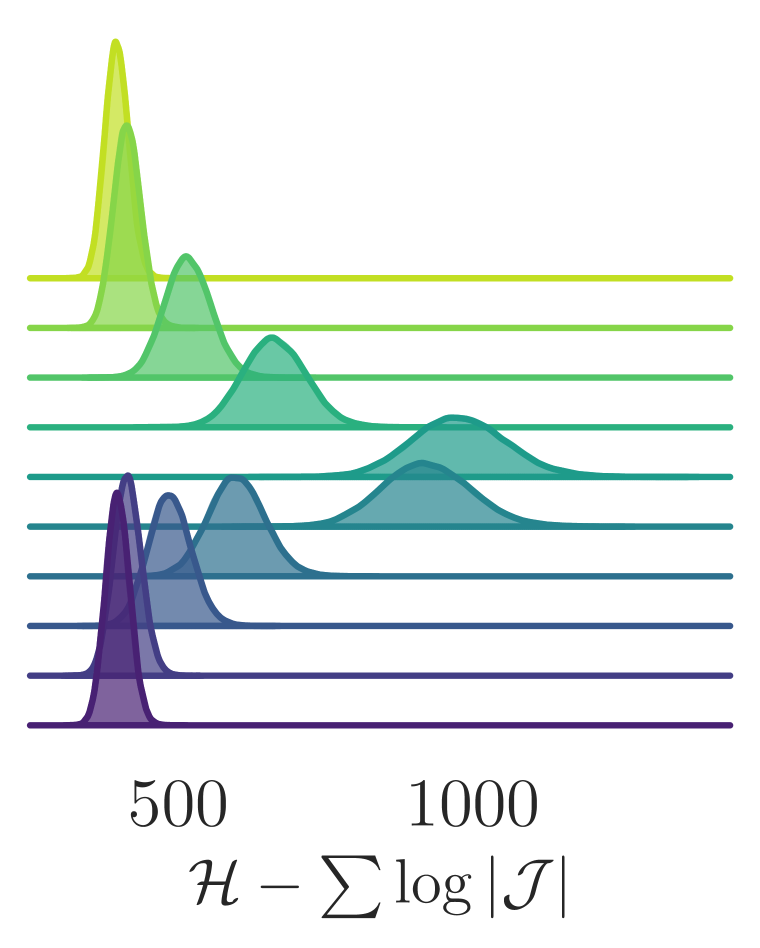
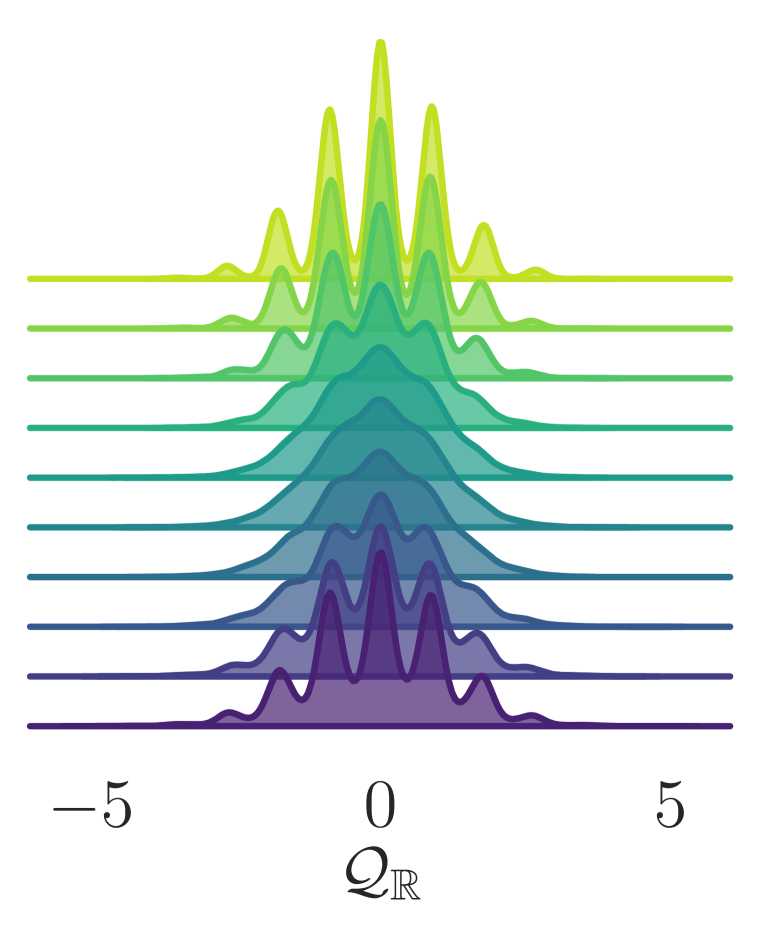
为了衡量我们模型的改进,我们评估了拓扑电荷的积分自相关时间 ,它可以粗略地解释为绘制独立样本之前所需的轨迹数量(平均)。 为了更准确地捕获两种方法之间的计算量,我们通过跳跃步数 来缩放对积分自相关时间的估计。 我们可以在图3中看到,经过训练的模型在范围内始终优于通用HMC,并且对于研究的最大晶格耦合,标准HMC将采用大约一百倍的更新才能生成与 DLHMC 一样的独立配置。 为了确保我们结果的有效性,每次训练运行都会与 和 值范围内的多次 HMC 运行进行比较。 我们在图 4 中看到,对于大部分模拟,HMC 仍停留在特定的 值,而经过训练的采样器在值之间快速跳转。 为了更好地理解驱动这种改进行为的机制,我们在系统通过 蛙跳层期间评估了系统的不同量。 图5(a)和图5(b)显示了通过 越级层数。 我们的采样器在轨迹的前半段人为地增加了物理系统的能量密度,然后返回到其原始物理值。 这不是规定的行为,而是在训练中自学的。 我们相信,这种在轨迹期间改变能量的能力有助于采样器克服拓扑扇区之间的能量壁垒,而 HMC 仍然停滞不前。 从图5(c)可以看出,连续拓扑电荷在深度神经网络的中间表现出混合行为。
7讨论和进一步研究
我们提出 DLHMC 作为 MCMC 的有效算法,并观察到模拟 2D 规范理论的显着改进。 能够有效地隧道拓扑扇区是朝着有效模拟描述我们宇宙的晶格规范理论迈出的重要的第一步。 我们计划继续开发这种方法,目标是最终扩展到 QCD 的 4D 规范理论。
致谢
这项研究得到了百亿亿级计算项目 (17-SC-20-SC) 的支持,该项目是美国能源部科学办公室和国家核安全管理局的合作项目。 这项研究是使用阿贡领导计算设施 (ALCF) 的资源进行的,该设施是能源部科学用户设施办公室,根据合同 DE_AC02-06CH11357 提供支持。 这项工作描述了客观的技术结果和分析。 作品中可能表达的任何主观观点或意见并不一定代表美国能源部或美国政府的观点。 本研究中提出的结果是使用 Python (Van Rossum & Drake,2012)、编程语言及其许多数据科学库(Hunter,2007;Harris 等人,2020;Abadi 等)获得的人,2016;Pérez & Granger,2007;
参考
- Abadi et al. (2016) Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viegas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems, 2016. URL http://arxiv.org/abs/1603.04467.
- Albergo et al. (2021) Michael S. Albergo, Denis Boyda, Daniel C. Hackett, Gurtej Kanwar, Kyle Cranmer, Sébastien Racanière, Danilo Jimenez Rezende, and Phiala E. Shanahan. Introduction to Normalizing Flows for Lattice Field Theory. arXiv preprint arXiv:2101.08176, 2021. URL http://arxiv.org/abs/2101.08176.
- Albergo et al. (2019) M. S. Albergo, G. Kanwar, and P. E. Shanahan. Flow-based generative models for markov chain monte carlo in lattice field theory. Physical Review D, 100(3), Aug 2019. ISSN 2470-0029. doi: 10.1103/physrevd.100.034515. URL http://dx.doi.org/10.1103/PhysRevD.100.034515.
- Boyda et al. (2020) Denis Boyda, Gurtej Kanwar, Sébastien Racanière, Danilo Jimenez Rezende, Michael S. Albergo, Kyle Cranmer, Daniel C. Hackett, and Phiala E. Shanahan. Sampling using gauge equivariant flows. arXiv, 2020. URL https://arxiv.org/abs/2008.05456.
- Cossu et al. (2017) Guido Cossu, Peter Boyle, Norman Christ, Chulwoo Jung, Andreas Jüttner, and Francesco Sanfilippo. Testing algorithms for critical slowing down. In arXiv, volume 175, pp. 2008. EDP Sciences, 2017. URL https://arxiv.org/abs/1710.07036.
- Dinh et al. (2017) Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real NVP. 5th International Conference on Learning Representations, ICLR 2017 - Conference Track Proceedings, may 2017. URL http://arxiv.org/abs/1605.08803.
- Favoni et al. (2020) Matteo Favoni, Andreas Ipp, David I. Müller, and Daniel Schuh. Lattice gauge equivariant convolutional neural networks. arXiv preprint arXiv:2012.12901, 2020. URL http://arxiv.org/abs/2012.12901.
- Harris et al. (2020) Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin Sheppard, Tyler Reddy, Warren Weckesser, Hameer Abbasi, Christoph Gohlke, and Travis E. Oliphant. Array programming with NumPy. Nature, 585(7825):357–362, sep 2020. ISSN 14764687. doi: 10.1038/s41586-020-2649-2. URL https://doi.org/10.1038/s41586-020-2649-2.
- Hastings (1970) W. K. Hastings. Monte carlo sampling methods using Markov chains and their applications. Biometrika, 57(1):97–109, 1970. ISSN 00063444. doi: 10.1093/biomet/57.1.97.
- Hoffman et al. (2019) Matthew Hoffman, Pavel Sountsov, Joshua V. Dillon, Ian Langmore, Dustin Tran, and Srinivas Vasudevan. NeuTra-lizing bad geometry in Hamiltonian Monte Carlo using neural transport. arXiv, 2019. URL https://arxiv.org/abs/1903.03704.
- Hunter (2007) John D. Hunter. Matplotlib: A 2D graphics environment. Computing in Science and Engineering, 9(3):90–95, 2007. ISSN 15219615. doi: 10.1109/MCSE.2007.55.
- Kanwar et al. (2020) Gurtej Kanwar, Michael S. Albergo, Denis Boyda, Kyle Cranmer, Daniel C. Hackett, Sébastien Racanière, Danilo Jimenez Rezende, and Phiala E. Shanahan. Equivariant flow-based sampling for lattice gauge theory. Physical Review Letters, 125(12), Sep 2020. ISSN 1079-7114. doi: 10.1103/physrevlett.125.121601. URL http://dx.doi.org/10.1103/PhysRevLett.125.121601.
- Kumar et al. (2019) Ravin Kumar, Colin Carroll, Ari Hartikainen, and Osvaldo Martin. Arviz a unified library for exploratory analysis of bayesian models in python. Journal of Open Source Software, 4(33):1143, 2019. doi: 10.21105/joss.01143. URL https://doi.org/10.21105/joss.01143.
- Lévy et al. (2017) Daniel Lévy, Matthew D. Hoffman, Jascha Sohl-Dickstein, Daniel Levy, Matthew D. Hoffman, and Jascha Sohl-Dickstein. Generalizing Hamiltonian Monte Carlo with neural networks. arXiv, abs/1711.0, nov 2017. URL http://arxiv.org/abs/1711.09268.
- Li et al. (2021) Zengyi Li, Yubei Chen, and Friedrich T. Sommer. A neural network mcmc sampler that maximizes proposal entropy. Entropy, 23(3):1–18, 2021. doi: 10.3390/e23030269. URL https://arxiv.org/abs/2010.03587.
- Medvidovic et al. (2020) Matija Medvidovic, Juan Carrasquilla, Lauren E. Hayward, and Bohdan Kulchytskyy. Generative models for sampling of lattice field theories. arXiv preprint arXiv:2012.01442, 2020. URL http://arxiv.org/abs/2012.01442.
- Neklyudov & Welling (2020) Kirill Neklyudov and Max Welling. Orbital MCMC. arXiv preprint arXiv:2010.08047, 2020. URL http://arxiv.org/abs/2010.08047.
- Neklyudov et al. (2020) Kirill Neklyudov, Max Welling, Evgenii Egorov, and Dmitry Vetrov. Involutive mcmc: A unifying framework. In arXiv, pp. 7273–7282. PMLR, 2020. URL https://arxiv.org/abs/2006.16653.
- Pasarica & Gelman (2010) Cristian Pasarica and Andrew Gelman. Adaptively scaling the metropolis algorithm using expected squared jumped distance. Statistica Sinica, 20(1):343–364, 2010. ISSN 10170405. doi: 10.2139/ssrn.1010403. URL http://www.jstor.org/stable/24308995.
- Pérez & Granger (2007) Fernando Pérez and Brian E. Granger. IPython: A system for interactive scientific computing. Computing in Science and Engineering, 9(3):21–29, 2007. ISSN 15219615. doi: 10.1109/MCSE.2007.53.
- Rezende et al. (2020) Danilo Jimenez Rezende, George Papamakarios, Sébastien Racanière, Michael S. Albergo, Gurtej Kanwar, Phiala E. Shanahan, and Kyle Cranmer. Normalizing flows on tori and spheres. In arXiv, pp. 8083–8092. PMLR, 2020. URL https://arxiv.org/abs/2002.02428.
- Schaefer et al. (2009) Stefan Schaefer, Rainer Sommer, and Francesco Virotta. Investigating the critical slowing down of QCD simulations. Proceedings of Science, 91, 2009. ISSN 18248039. doi: 10.22323/1.091.0032.
- Sergeev & Balso (2018) Alexander Sergeev and Mike Del Balso. Horovod: Fast and easy distributed deep learning in tensorflow. arXiv, 2018. URL https://arxiv.org/abs/1802.05799.
- Tanaka & Tomiya (2017) Akinori Tanaka and Akio Tomiya. Towards reduction of autocorrelation in HMC by machine learning. arXiv, 2017. URL https://arxiv.org/abs/1712.03893.
- Tomiya & Nagai (2021) Akio Tomiya and Yuki Nagai. Gauge covariant neural network for 4 dimensional non-abelian gauge theory, 2021. URL https://arxiv.org/abs/2103.11965.
- Toth et al. (2020) Peter Toth, Danilo Jimenez Rezende, Andrew Jaegle, Sébastien Racanière, Aleksandar Botev, and Irina Higgins. Hamiltonian generative networks, 2020.
- Van Rossum & Drake (2012) Guido Van Rossum and Fred L Drake. Python Tutorial. Centrum voor Wiskunde en Informatica Amsterdam, The Netherlands, 2012.
- Waskom et al. (2017) Michael Waskom, Olga Botvinnik, Drew O’Kane, Paul Hobson, Saulius Lukauskas, David C Gemperline, Tom Augspurger, Yaroslav Halchenko, John B Cole, Jordi Warmenhoven, Julian de Ruiter, Cameron Pye, Stephan Hoyer, Jake Vanderplas, Santi Villalba, Gero Kunter, Eric Quintero, Pete Bachant, Marcel Martin, Kyle Meyer, Alistair Miles, Yoav Ram, Tal Yarkoni, Mike Lee Williams, Constantine Evans, Clark Fitzgerald, Brian, Chris Fonnesbeck, Antony Lee, and Adel Qalieh. mwaskom/seaborn: v0.8.1 (September 2017), sep 2017. URL https://doi.org/10.5281/zenodo.883859.
- Wehenkel & Louppe (2020) Antoine Wehenkel and Gilles Louppe. You say Normalizing Flows I see Bayesian Networks. arXiv, 2020. URL https://arxiv.org/abs/2006.00866.
附录A附录
A.1 哈密尔顿蒙特卡罗 (HMC)
哈密顿蒙特卡罗算法是一种广泛使用的技术,它允许我们通过构建状态链 从分析已知的目标分布 中进行采样,使得 在限制 内。 出于我们的目的,我们假设我们的目标分布可以表示为玻尔兹曼分布 ,其中 是我们理论的作用,并且 是归一化因子(配分函数)。 在这种情况下,HMC 首先使用虚拟动量变量 来扩充状态空间,该变量呈独立于 的正态分布,即 。 我们的联合分布可以写为 ,其中 是联合 (x, v) 系统的哈密顿量。 该系统遵循哈密顿方程:、,可以沿着的等概率轮廓进行数值积分。 明确地,对于步长和初始状态,蛙跳积分器通过执行以下一系列更新来生成提案配置:
-
1.
半步动量更新:
-
2.
全步位置更新:
-
3.
半步动量更新:
然后,我们可以通过按顺序执行个蛙步来构建长度为的完整轨迹。 在我们的轨迹结束时,我们根据 Metropolis-Hastings 接受标准接受或拒绝提案配置,
| (7) |
蛙跳积分器是辛的,因此雅可比因子减小为。
附录 B退火时间表
为了帮助我们的采样器克服隔离模式之间的巨大能量障碍,我们在训练阶段(训练步骤)引入了退火计划,其中,。 只要我们在训练结束时使用 恢复真实分布并在没有此因素的情况下评估我们训练的模型,我们就可以在初始训练阶段自由改变 。 明确地说,对于 ,此缩放因子有助于降低能垒的高度,使我们的采样器更容易探索以前无法访问的相空间区域。 就这个额外的退火计划而言,我们的目标分布选择一个额外的索引 来表示我们在训练阶段的进度,可以明确地写为
| (8) |