扩散模型在图像合成方面胜过 GANs
摘要
我们证明了扩散模型能够实现优于当前最先进生成模型的图像样本质量。 我们通过一系列消融实验,在无条件图像合成方面找到了更好的架构,从而实现了这一目标。 对于有条件的图像合成,我们通过分类器引导进一步提高样本质量:这是一种简单且计算效率高的方法,可以通过使用来自分类器的梯度来平衡多样性和保真度。 在 ImageNet 128128 上,我们实现了 2.97 的 FID,在 ImageNet 256256 上实现了 4.59 的 FID,在 ImageNet 512512 上实现了 7.72 的 FID,并且即使每个样本只有 25 次正向传播,我们也与 BigGAN-deep 相匹配,同时保持了对分布的更好覆盖。 最后,我们发现分类器引导与上采样扩散模型很好地结合在一起,进一步将 FID 提高到 ImageNet 256256 上的 3.94 和 ImageNet 512512 上的 3.85。 我们在 https://github.com/openai/guided-diffusion 发布了我们的代码。
1 介绍

在过去的几年里,生成模型已经获得了生成人类自然语言 Brown et al. (2020)、无限高质量的合成图像 Brock et al. (2018); Karras et al. (2019b); Razavi et al. (2019) 以及高度多样化的人类语音和音乐 van den Oord et al. (2016); Dhariwal et al. (2020) 的能力。 这些模型可以在各种方式中使用,例如根据文本提示生成图像 Zhang et al. (2016); Ramesh et al. (2021) 或学习有用的特征表示 Donahue and Simonyan (2019); Chen et al. (2020a)。 虽然这些模型已经能够生成逼真的图像和声音,但与当前最先进水平相比,仍有很大的改进空间,更好的生成模型可能会对图形设计、游戏、音乐制作以及无数其他领域产生广泛的影响。
GANs Goodfellow et al. (2014) 目前在大多数图像生成任务 Brock et al. (2018); Wu et al. (2019); Karras et al. (2019b) 上处于最先进水平,这是根据 FID Heusel et al. (2017)、Inception Score Salimans et al. (2016) 和 Precision Kynkäänniemi et al. (2019) 等样本质量指标衡量的。 然而,其中一些指标并没有完全捕捉到多样性,并且已经证明,与最先进的基于似然的模型相比,GANs 捕捉到的多样性更少 Razavi et al. (2019); Nichol and Dhariwal (2021); Nash et al. (2021)。 此外,GANs 通常难以训练,如果没有精心选择的超参数和正则化器,就会崩溃 Brock 等人 (2018);Miyato 等人 (2018);Brock 等人 (2016)。
虽然 GANs 处于最先进水平,但它们的缺点使它们难以扩展并应用于新领域。 因此,人们做了很多工作来实现具有基于似然的模型的 GAN 式样本质量 Razavi 等人 (2019);Ho 等人 (2020);Nash 等人 (2021);Child (2021)。 虽然这些模型捕获了更多多样性,并且通常比 GANs 更容易扩展和训练,但它们在视觉样本质量方面仍然不足。 此外,除了 VAE 之外,从这些模型中采样比 GANs 在挂钟时间方面更慢。
扩散模型是一类基于似然的模型,最近已被证明可以生成高质量的图像 Sohl-Dickstein 等人 (2015);Song 和 Ermon (2020b);Ho 等人 (2020),同时提供了诸如分布覆盖、固定训练目标和易于扩展性等理想特性。 这些模型通过逐渐从信号中去除噪声来生成样本,它们的训练目标可以表示为重新加权的变分下界 Ho 等人 (2020)。 这一类模型已经在 CIFAR-10 Krizhevsky 等人 (2009) 上处于最先进水平 Song 等人 (2020b),但在 LSUN 和 ImageNet 等困难的生成数据集上仍然落后于 GANs。 Nichol 和 Dhariwal [43] 发现这些模型随着计算量的增加而可靠地改进,即使在困难的 ImageNet 256256 数据集上使用上采样堆栈,也可以生成高质量的样本。 但是,此模型的 FID 仍然无法与 BigGAN-deep Brock 等人 (2018) 相比,后者是该数据集上当前最先进的技术。
我们假设扩散模型与 GANs 之间的差距至少源于两个因素:首先,最近 GAN 文献中使用的模型架构已被深入探索和改进;其次,GANs 能够在多样性和保真度之间进行权衡,生成高质量的样本,但不涵盖整个分布。 我们旨在将这些优势带入扩散模型,首先通过改进模型架构,然后通过设计一种在多样性和保真度之间进行权衡的方案。 通过这些改进,我们实现了新的最先进技术,在几个不同的指标和数据集上超过了 GANs。
本文的其余部分组织如下。 在第2节中,我们简要介绍了基于 Ho 等人 [25] 以及 Nichol 和 Dhariwal [43] 的改进以及 Song 等人 [57],我们描述了我们的评估设置。 在第 3 节中,我们介绍了简单的架构改进,可以显着提升 FID。 在第 4 节中,我们描述了一种在采样期间使用分类器梯度来指导扩散模型的方法。 我们发现可以调整单个超参数(分类器梯度的比例)以牺牲多样性来换取保真度,并且我们可以将这个梯度比例因子增加一个数量级,而无需获得对抗性示例 Szegedy 等人 (2013) 。 最后,在第 5 节中,我们展示了具有改进架构的模型在无条件图像合成任务上实现了最先进的技术,并且在分类器指导下在条件图像合成上实现了最先进的技术。 使用分类器指导时,我们发现只需 25 次前向传递即可进行采样,同时保持与 BigGAN 相当的 FID。 我们还将改进的模型与上采样堆栈进行比较,发现这两种方法提供了互补的改进,并且将它们结合起来可以在 ImageNet 256256 和 512512 上提供最佳结果。
2 背景
在本节中,我们简要概述扩散模型。 对于更详细的数学描述,我们建议读者参阅附录B。
在较高的层面上,扩散模型通过逆转逐渐的噪声过程来从分布中进行采样。 特别是,采样从噪声开始,并逐渐产生噪声较小的样本,直到达到最终样本。 每个时间步对应于一定的噪声水平,可以被认为是信号与一些噪声的混合> 其中信噪比由时间步确定。对于本文的其余部分,我们假设噪声 来自对角高斯分布,这对于自然图像非常有效,并简化了各种推导。
扩散模型学习从 生成稍微“降噪”的 。 何等人 [25] 将此模型参数化为函数 ,该函数可预测噪声样本 的噪声分量。 为了训练这些模型,小批量中的每个样本都是通过随机抽取数据样本 、时间步长 和噪声 来生成的,它们一起产生到噪声样本(方程17)。 训练目标是,即真实噪声和预测噪声之间的简单均方误差损失(方程26)。
如何从噪声预测器 中进行采样并不是立即显而易见的。 回想一下,扩散采样是通过从 开始,从 重复预测 来进行的。 Ho 等人。 [25]表明,在合理的假设下,我们可以将给定的的分布建模为对角高斯,其中平均值 可以作为 的函数计算(公式 27)。 此高斯分布的方差 可以固定为已知常数 Ho 等人 (2020) 或使用单独的神经网络头学习 Nichol 和 Dhariwal (2021) ,当扩散步骤总数足够大时,两种方法都会产生高质量的样本。
Ho 等人。 [25] 观察到简单的均方误差目标 在实践中比实际变分下界 效果更好,后者可以从将去噪扩散模型解释为 VAE。 他们还注意到,使用该目标进行训练并使用相应的采样程序等同于来自 Song and Ermon [58] 的去噪分数匹配模型,他们使用 Langevin 动力学从使用多个噪声级别训练的去噪模型中采样,以产生高质量的图像样本。 我们通常使用“扩散模型”作为简写来指代这两类模型。
2.1 改进
继 Song and Ermon [58] 和 Ho 等人。 [25], 近期已有几篇论文提出了对扩散模型的改进。 本文描述了其中几种改进,这些改进被应用于我们的模型。
Nichol 和 Dhariwal [43] 发现,将方差 固定为常数,如在 Ho 等人 [25] 中所做的那样,对于使用较少扩散步骤的采样来说,效果不佳,并提出将 参数化为一个神经网络,其输出 通过插值得到:
| (1) |
其中, 和 (公式 19) 是在 Ho 等人 [25] 中对应于反向过程方差的上限和下限的方差。 此外,Nichol 和 Dhariwal [43] 提出了一种混合目标,用于使用加权和 训练 和 。 使用其混合目标来学习反向过程方差,可以进行较少步骤的采样,而不会显著降低样本质量。 我们采用了这种目标和参数化,并在所有实验中使用它。
Song 等人 [57] 提出了 DDIM,它制定了一种替代的非马尔可夫噪声过程,该过程具有与 DDPM 相同的正向边缘分布,但允许通过改变反向噪声的方差来生成不同的反向采样器。 通过将该噪声设置为 0,他们提供了一种方法,可以将任何模型 转换为从潜在变量到图像的确定性映射,并发现这提供了一种使用较少步骤进行采样的替代方法。 当使用少于 50 个采样步骤时,我们采用了这种采样方法,因为 Nichol 和 Dhariwal [43] 发现它在该范围内是有益的。
2.2 样本质量指标
为了比较不同模型的样本质量,我们使用以下指标进行定量评估。 虽然这些指标在实践中经常使用,并且与人类判断高度吻合,但它们并非完美的替代指标,寻找更好的样本质量评估指标仍然是一个开放问题。
Inception Score (IS) 由 Salimans 等人 [54] 提出,它衡量一个模型在生成单个样本作为单个类的令人信服的示例的同时,能够多大程度地捕捉完整的 ImageNet 类别分布。 该指标的一个缺点是它不奖励覆盖整个分布或捕捉类别内部的多样性,并且记忆完整数据集的子集的模型仍然会具有较高的 IS Barratt 和 Sharma (2018)。 为了更好地捕捉多样性而不是 IS,Fréchet Inception Distance (FID) 由 Heusel 等人 [23] 提出,他们认为 FID 比 Inception Score 更一致地符合人类判断。 FID 提供了两个图像分布在 Inception-V3 Szegedy 等人 (2015) 潜在空间中的距离的对称度量。 最近,sFID 由 Nash 等人 [42] 提出,它是 FID 的一个版本,它使用空间特征而不是标准的池化特征。 他们发现该指标更好地捕捉了空间关系,奖励具有连贯的高级结构的图像分布。 最后, Kynkäänniemi 等人 [32] 提出了改进的精确度和召回率指标,分别测量样本保真度,即模型样本中落入数据流形的比例(精确度),以及数据样本中落入样本流形的比例(召回率)。
我们使用 FID 作为我们对整体样本质量比较的默认指标,因为它同时捕获了多样性和保真度,并且一直是最先进的生成模型工作的事实标准指标 Karras 等人 (2019a, b); Brock 等人 (2018); Ho 等人 (2020)。 我们使用精确度或 IS 来衡量保真度,使用召回率来衡量多样性或分布覆盖率。 在与其他方法进行比较时,我们尽可能使用公开的样本或模型重新计算这些指标。 这是出于两个原因:首先,一些论文 Karras 等人 (2019a, b); Ho 等人 (2020) 与训练集的任意子集进行比较,这些子集不容易获得;其次,细微的实现差异会影响生成的 FID 值 Parmar 等人 (2021)。 为了确保一致的比较,我们使用整个训练集作为参考批次 Heusel 等人 (2017); Brock 等人 (2018),并使用相同的代码库评估所有模型的指标。
3 架构改进
在本节中,我们进行了几次架构消融实验,以找到为扩散模型提供最佳样本质量的模型架构。
Ho 等人 [25] 引入了用于扩散模型的 UNet 架构,该架构 Jolicoeur-Martineau 等人 [26] 发现与之前用于降噪评分匹配的架构相比,该架构显着提高了样本质量 Song 和 Ermon (2020a); Lin 等人 (2016)。 UNet 模型使用一组残差层和下采样卷积,然后是一组具有上采样卷积的残差层,跳跃连接将具有相同空间大小的层连接起来。 此外,他们还在 1616 分辨率处使用一个全局注意力层,该层只有一个头,并将时间步嵌入的投影添加到每个残差块中。 Song 等人 [60] 发现对 UNet 架构的进一步更改提高了在 CIFAR-10 Krizhevsky 等人 (2009) 和 CelebA-64 Liu 等人 (2015) 数据集上的性能。 我们在 ImageNet 128128 上展示了相同的结果,发现架构确实可以显著提高更大、更多样化数据集上更高分辨率的样本质量。
我们探索了以下架构变更:
-
•
在保持模型大小相对恒定的情况下,增加深度而不是宽度。
-
•
增加注意力头的数量。
-
•
在 3232、1616 和 88 分辨率上使用注意力,而不是只在 1616 上使用。
-
•
使用 BigGAN Brock et al. (2018) 残差块来对激活进行上采样和下采样,遵循 Song et al. (2020b)。
-
•
使用 对残差连接进行重新缩放,遵循 Song et al. (2020b); Karras et al. (2019a, b)。
| Channels | Depth | Heads | Attention | BigGAN | Rescale | FID | FID |
|---|---|---|---|---|---|---|---|
| resolutions | up/downsample | resblock | 700K | 1200K | |||
| 160 | 2 | 1 | 16 | ✗ | ✗ | 15.33 | 13.21 |
| 128 | 4 | -0.21 | -0.48 | ||||
| 4 | -0.54 | -0.82 | |||||
| 32,16,8 | -0.72 | -0.66 | |||||
| ✓ | -1.20 | -1.21 | |||||
| ✓ | 0.16 | 0.25 | |||||
| 160 | 2 | 4 | 32,16,8 | ✓ | ✗ | -3.14 | -3.00 |
| Number of heads | Channels per head | FID |
| 1 | 14.08 | |
| 2 | -0.50 | |
| 4 | -0.97 | |
| 8 | -1.17 | |
| 32 | -1.36 | |
| 64 | -1.03 | |
| 128 | -1.08 |
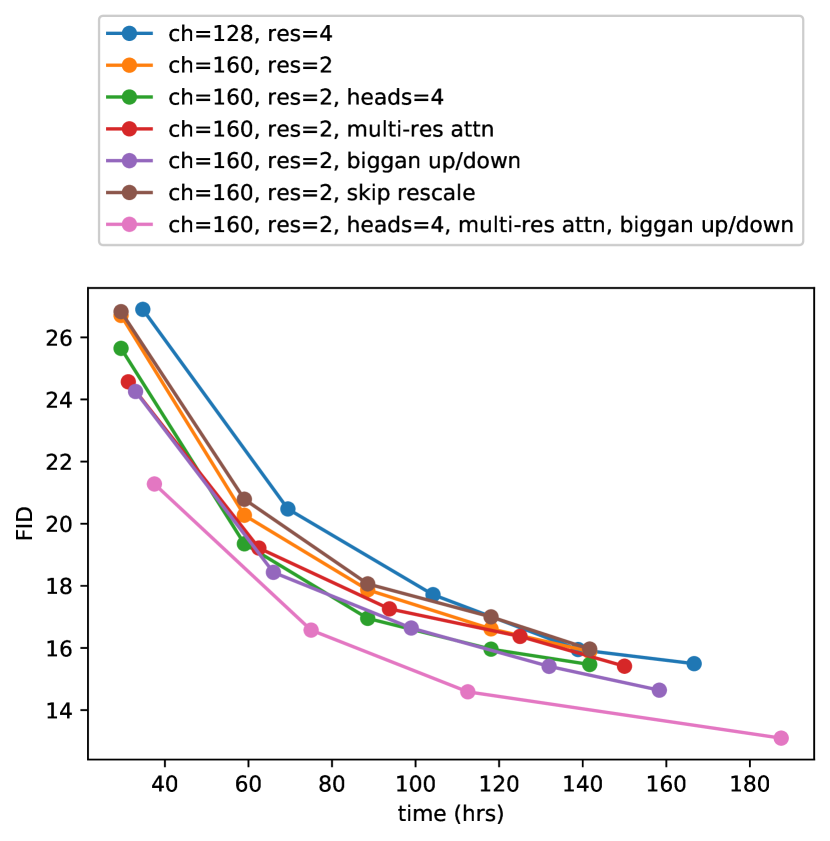
在本节的所有比较中,我们使用批量大小 256 在 ImageNet 128128 上训练模型,并使用 250 个采样步骤进行采样。 我们使用上述架构变更训练模型,并在表 1 中比较它们在 FID 上的性能,并在训练的两个不同点进行评估。 除了重新缩放残差连接之外,所有其他修改都提高了性能,并具有积极的累加效应。 我们在图 2 中观察到,虽然增加深度有助于提高性能,但它会增加训练时间,并且需要更长的时间才能达到与更宽模型相同的性能,因此我们选择在后续实验中不使用这种变更。
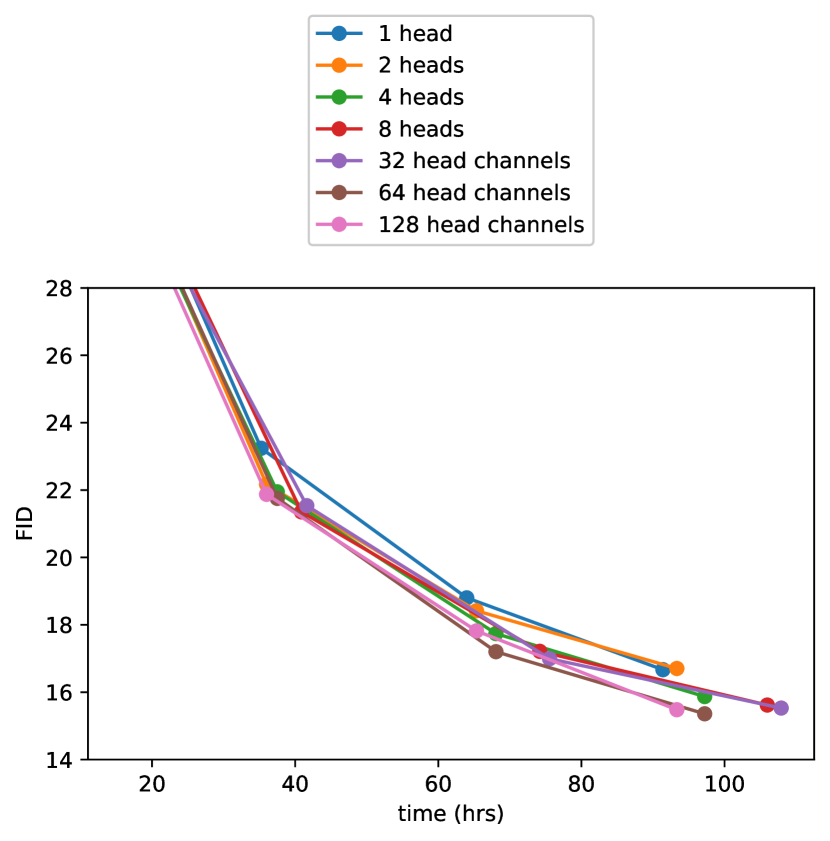
我们还研究了其他更匹配 Transformer 架构 Vaswani 等人 (2017) 的注意力配置。 为此,我们尝试将注意力头固定为常数,或者固定每个头的通道数。 对于架构的其余部分,我们使用 128 个基本通道、每个分辨率 2 个残差块、多分辨率注意力和 BigGAN 上/下采样,并将模型训练 700K 次迭代。 表格 2 显示了我们的结果,表明更多的头或更少的每个头的通道会提高 FID。 在图 2 中,我们看到 64 个通道对于挂钟时间是最好的,因此我们选择使用每个头 64 个通道作为默认设置。 我们注意到,这种选择也更符合现代 Transformer 架构,并且在最终 FID 方面与我们的其他配置相当。
3.1 自适应组归一化
| Operation | FID |
|---|---|
| AdaGN | 13.06 |
| Addition + GroupNorm | 15.08 |
我们还尝试了一个层 Nichol 和 Dhariwal (2021),我们将其称为自适应组归一化 (AdaGN),它将时间步长和类嵌入合并到每个残差块中,在组归一化操作 Wu 和 He (2018) 之后,类似于自适应实例规范化 Karras 等人 (2019a) 和 FiLM Perez 等人 (2017)。 我们将此层定义为 ,其中 是第一个卷积之后的残差块的中间激活,而 是从时间步长和类别嵌入的线性投影获得的。
我们已经看到 AdaGN 改善了我们最早的扩散模型,因此我们在所有运行中默认包含了它。 在表 3 中,我们明确地消除了这种选择,发现自适应组归一化层确实改善了 FID。 这两个模型都使用 128 个基础通道和每个分辨率 2 个残差块,多分辨率注意力,每个头 64 个通道,以及 BigGAN 上/下采样,并且训练了 700K 次迭代。
在本文的其余部分,我们将使用这种最终改进的模型架构作为我们的默认值:可变宽度,每个分辨率 2 个残差块,多个头,每个头 64 个通道,在 32、16 和 8 个分辨率上的注意力,用于上采样和下采样的 BigGAN 残差块,以及自适应组归一化,用于将时间步长和类别嵌入注入残差块。
4 分类器引导
除了采用精心设计的架构外,用于条件图像合成的 GAN Mirza 和 Osindero (2014); Brock 等人 (2018) 广泛利用类别标签。 这通常采用类别条件归一化统计 Dumoulin 等人 (2017); de Vries 等人 (2017) 以及具有专门设计为像分类器一样工作的头的鉴别器 Miyato 和 Koyama (2018)。 作为进一步的证据,表明类别信息对于这些模型的成功至关重要, Lucic 等人。 [36] 发现,在标签有限的制度下,生成合成标签是有帮助的。
鉴于 GAN 的这种观察结果,探索将扩散模型以不同方式条件化到类别标签上是有意义的。 我们已经将类别信息纳入归一化层(第 3.1 节)。 在这里,我们探索了一种不同的方法:利用一个分类器 来改进扩散生成器。 Sohl-Dickstein 等人。 [56] 和 Song 等人。 [60] 展示了一种实现方法,其中预训练的扩散模型可以使用分类器的梯度进行条件化。 特别地,我们可以在带噪声的图像 上训练一个分类器 ,然后使用梯度 来引导扩散采样过程朝着任意类别标签 方向进行。
在本节中,我们首先回顾两种使用分类器推导条件采样过程的方法。 然后,我们描述了在实践中如何使用这些分类器来提高样本质量。 为了简洁起见,我们选择符号 和 ,注意它们指的是每个时间步 的独立函数,在训练时,模型必须根据输入 进行条件化。
4.1 条件反向噪声过程
我们从具有无条件反向噪声过程 的扩散模型开始。 要对此进行标签 条件化,只需对每个转换进行采样 1 11我们还必须对 进行条件采样 ,但足够噪声的扩散过程会导致 即使在条件情况下也近似为高斯分布。 按照
| (2) |
其中 是一个归一化常数(证明见附录 H)。 从这个分布中精确采样通常是难以处理的,但是 Sohl-Dickstein 等人 [56] 表明它可以近似为一个扰动高斯分布。 在这里,我们回顾一下这个推导过程。
回想一下,我们的扩散模型使用高斯分布从时间步 预测之前的时间步 :
| (3) | ||||
| (4) |
我们可以假设 与 相比具有较低的曲率。 在无限扩散步骤的极限情况下,此假设是合理的,其中 。 在这种情况下,我们可以使用围绕 的泰勒展开式来近似 ,如下所示:
| (5) | ||||
| (6) |
这里, 和 是一个常数。 这给出了
| (7) | ||||
| (8) | ||||
| (9) | ||||
| (10) |
我们可以安全地忽略常数项 ,因为它对应于方程 2 中的归一化系数 。 因此,我们发现条件转移算子可以用与无条件转移算子类似的高斯函数来近似,但其均值由 偏移。 算法 1 总结了相应的采样算法。 我们包含一个可选的梯度比例因子 ,我们在第 4.3 节中对其进行了更详细的描述。
4.2 DDIM 的条件采样
上述关于条件采样的推导仅对随机扩散采样过程有效,无法应用于确定性采样方法,如 DDIM Song 等人 (2020a)。 为此,我们使用一种从 Song 等人。 [60],它利用扩散模型和分数匹配 Song 和 Ermon (2020b) 之间的联系。 特别是,如果我们有一个模型 可以预测添加到样本中的噪声,那么可以使用它来导出得分函数:
| (11) |
我们现在可以将其代入 的得分函数中:
| (12) | ||||
| (13) |
最后,我们可以定义一个新的 epsilon 预测 ,它对应于联合分布的分数:
| (14) |
然后,我们可以使用与常规 DDIM 完全相同的采样过程,但使用修改后的噪声预测 而不是 。 算法2总结了相应的采样算法。
4.3 缩放分类器梯度


为了将分类器指导应用于大规模生成任务,我们在 ImageNet 上训练分类模型。 我们的分类器架构只是 UNet 模型的下采样主干,在 8x8 层有一个注意力池 Radford 等人 (2021) 以产生最终输出。 我们在与相应的扩散模型相同的噪声分布上训练这些分类器,并添加随机裁剪以减少过度拟合。 训练后,我们使用方程 10 将分类器合并到扩散模型的采样过程中,如算法 1 所示。
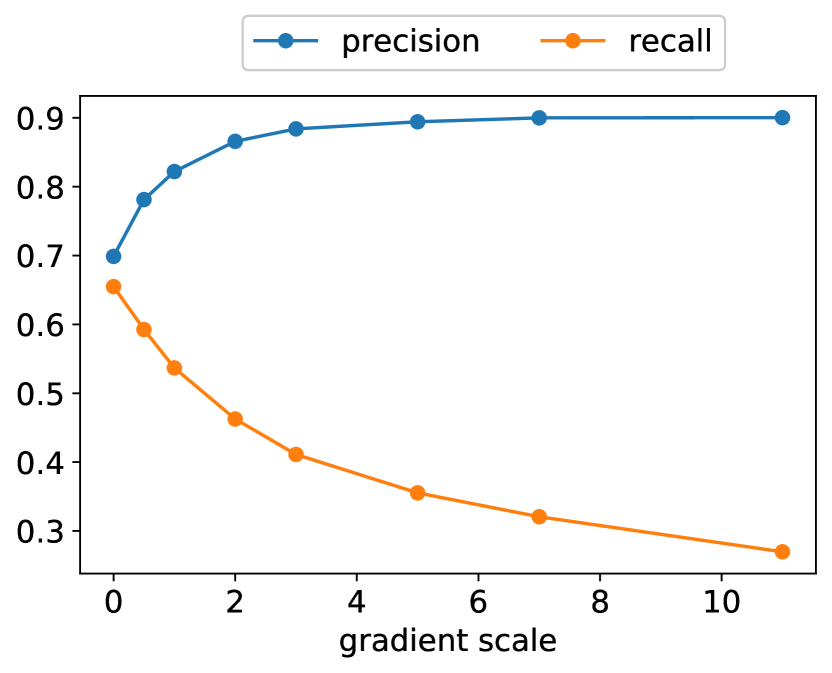
在使用无条件 ImageNet 模型的初始实验中,我们发现有必要按大于 1 的常数因子缩放分类器梯度。 当使用 1 的尺度时,我们观察到分类器为最终样本的所需类别分配了合理的概率(大约 50%),但这些样本在目视检查时与预期类别不匹配。 放大分类器梯度解决了这个问题,分类器的类概率增加到接近 100%。 图 3 显示了这种效果的示例。
为了理解缩放分类器梯度的影响,请注意 ,其中 是任意常数。 结果,条件化过程在理论上仍然基于与 成比例的重新归一化分类器分布。 当 时,该分布比 更尖锐,因为较大的值被指数放大。 换句话说,使用更大的梯度尺度更关注分类器的模式,这对于生成更高保真度(但多样性较低)的样本可能是有利的。
| Conditional | Guidance | Scale | FID | sFID | IS | Precision | Recall |
|---|---|---|---|---|---|---|---|
| ✗ | ✗ | 26.21 | 6.35 | 39.70 | 0.61 | 0.63 | |
| ✗ | ✓ | 1.0 | 33.03 | 6.99 | 32.92 | 0.56 | 0.65 |
| ✗ | ✓ | 10.0 | 12.00 | 10.40 | 95.41 | 0.76 | 0.44 |
| ✓ | ✗ | 10.94 | 6.02 | 100.98 | 0.69 | 0.63 | |
| ✓ | ✓ | 1.0 | 4.59 | 5.25 | 186.70 | 0.82 | 0.52 |
| ✓ | ✓ | 10.0 | 9.11 | 10.93 | 283.92 | 0.88 | 0.32 |
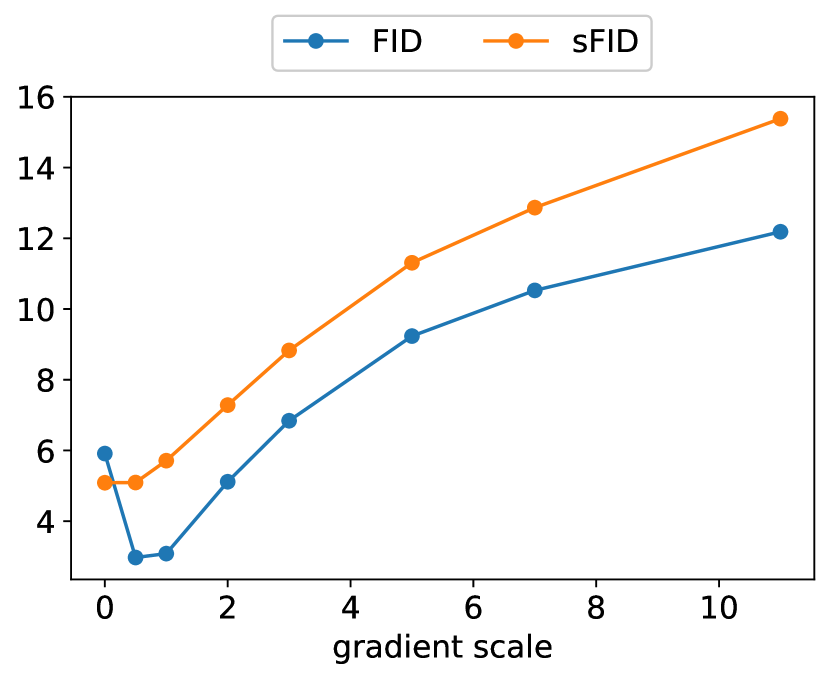
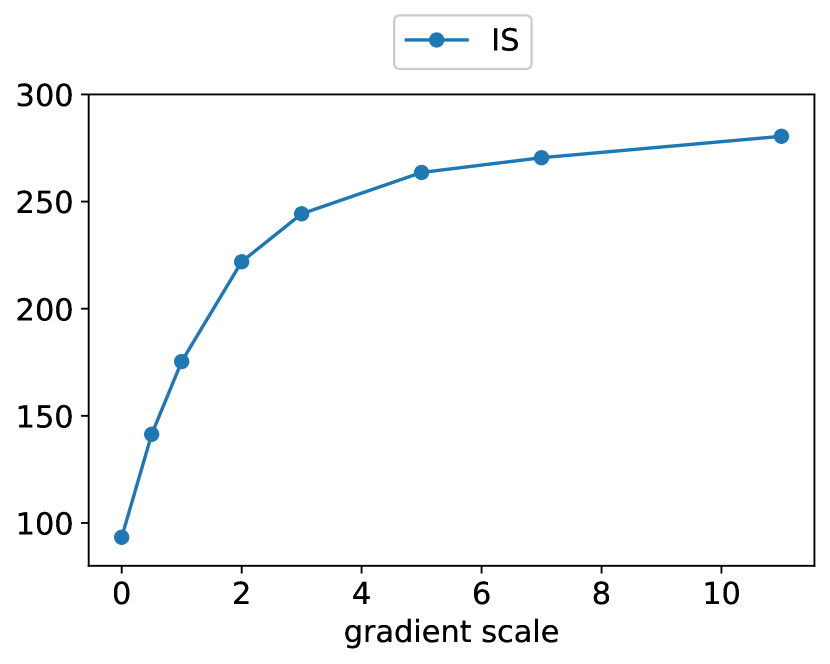
在上述推导中,我们假设底层扩散模型是无条件的,对 进行建模。 也可能训练条件扩散模型,,并以完全相同的方式使用分类器引导。 表 4 显示,通过分类器引导,无条件模型和条件模型的样本质量都可以得到大幅提升。 我们看到,在足够大的规模下,引导的无条件模型可以非常接近于未引导的条件模型的 FID,尽管直接使用类别标签进行训练仍然有帮助。 引导条件模型进一步改善了 FID。
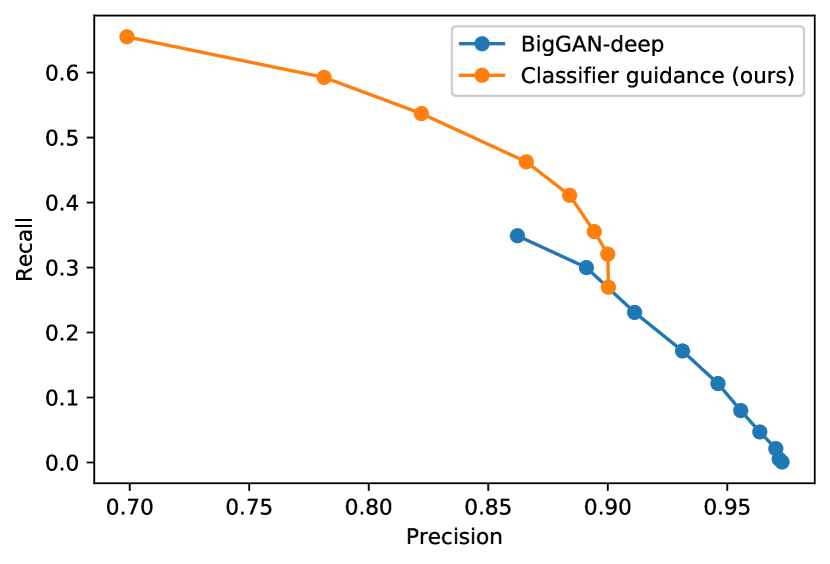
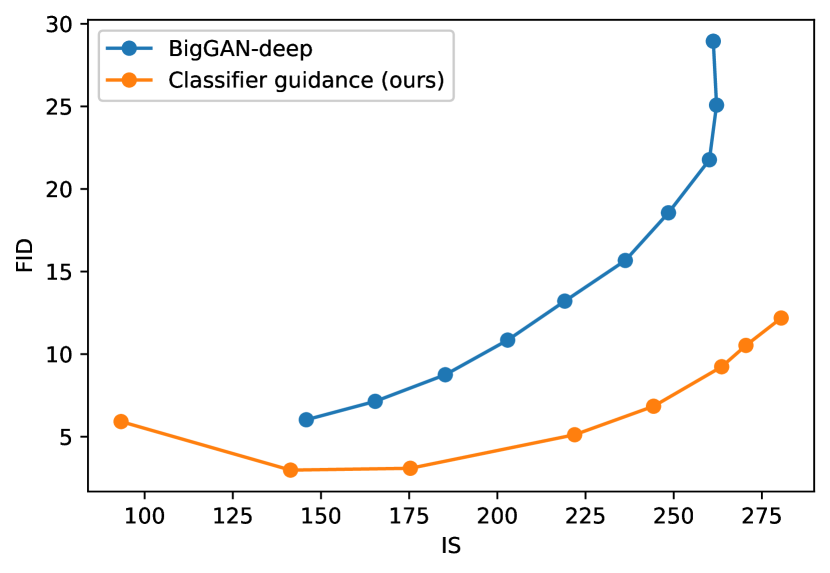
表 4 还显示,分类器引导提高了精确度,但降低了召回率,因此在样本保真度和多样性之间引入了权衡。 我们在图 4 中明确评估了这种权衡如何随梯度尺度的变化而变化。 我们看到,将梯度缩放超过 1.0 会平滑地权衡召回率(多样性的衡量指标)以获得更高的精确度和 IS(保真度的衡量指标)。 由于 FID 和 sFID 依赖于多样性和保真度,因此它们的最佳值是在中间点获得的。 我们还在图 5 中将我们的引导与 BigGAN 的截断技巧进行了比较。 我们发现,在权衡 FID 与 Inception Score 时,分类器引导严格优于 BigGAN-deep。 精确度/召回率权衡并不那么清晰,这表明分类器引导只是一种更好的选择,直到达到一定的精确度阈值,之后它就无法实现更好的精确度。
5 结果
为了评估我们改进的模型架构在无条件图像生成方面的表现,我们在三个 LSUN Yu et al. (2015) 类别上训练了独立的扩散模型:卧室、马和猫。 为了评估分类器引导,我们在 ImageNet Russakovsky et al. (2014) 数据集上训练了条件扩散模型,分辨率为 128128、256256 和 512512。
5.1 最先进的图像合成
| Model | FID | sFID | Prec | Rec |
|---|---|---|---|---|
| LSUN Bedrooms 256256 | ||||
| DCTransformer† Nash et al. (2021) | 6.40 | 6.66 | 0.44 | 0.56 |
| DDPM Ho et al. (2020) | 4.89 | 9.07 | 0.60 | 0.45 |
| IDDPM Nichol and Dhariwal (2021) | 4.24 | 8.21 | 0.62 | 0.46 |
| StyleGAN Karras et al. (2019a) | 2.35 | 6.62 | 0.59 | 0.48 |
| ADM (dropout) | 1.90 | 5.59 | 0.66 | 0.51 |
| LSUN Horses 256256 | ||||
| StyleGAN2 Karras et al. (2019b) | 3.84 | 6.46 | 0.63 | 0.48 |
| ADM | 2.95 | 5.94 | 0.69 | 0.55 |
| ADM (dropout) | 2.57 | 6.81 | 0.71 | 0.55 |
| LSUN Cats 256256 | ||||
| DDPM Ho et al. (2020) | 17.1 | 12.4 | 0.53 | 0.48 |
| StyleGAN2 Karras et al. (2019b) | 7.25 | 6.33 | 0.58 | 0.43 |
| ADM (dropout) | 5.57 | 6.69 | 0.63 | 0.52 |
| ImageNet 6464 | ||||
| BigGAN-deep* Brock et al. (2018) | 4.06 | 3.96 | 0.79 | 0.48 |
| IDDPM Nichol and Dhariwal (2021) | 2.92 | 3.79 | 0.74 | 0.62 |
| ADM | 2.61 | 3.77 | 0.73 | 0.63 |
| ADM (dropout) | 2.07 | 4.29 | 0.74 | 0.63 |
| Model | FID | sFID | Prec | Rec |
|---|---|---|---|---|
| ImageNet 128128 | ||||
| BigGAN-deep Brock et al. (2018) | 6.02 | 7.18 | 0.86 | 0.35 |
| LOGAN† Wu et al. (2019) | 3.36 | |||
| ADM | 5.91 | 5.09 | 0.70 | 0.65 |
| ADM-G (25 steps) | 5.98 | 7.04 | 0.78 | 0.51 |
| ADM-G | 2.97 | 5.09 | 0.78 | 0.59 |
| ImageNet 256256 | ||||
| DCTransformer† Nash et al. (2021) | 36.51 | 8.24 | 0.36 | 0.67 |
| VQ-VAE-2 Razavi et al. (2019) | 31.11 | 17.38 | 0.36 | 0.57 |
| IDDPM‡ Nichol and Dhariwal (2021) | 12.26 | 5.42 | 0.70 | 0.62 |
| SR3 Saharia et al. (2021) | 11.30 | |||
| BigGAN-deep Brock et al. (2018) | 6.95 | 7.36 | 0.87 | 0.28 |
| ADM | 10.94 | 6.02 | 0.69 | 0.63 |
| ADM-G (25 steps) | 5.44 | 5.32 | 0.81 | 0.49 |
| ADM-G | 4.59 | 5.25 | 0.82 | 0.52 |
| ImageNet 512512 | ||||
| BigGAN-deep Brock et al. (2018) | 8.43 | 8.13 | 0.88 | 0.29 |
| ADM | 23.24 | 10.19 | 0.73 | 0.60 |
| ADM-G (25 steps) | 8.41 | 9.67 | 0.83 | 0.47 |
| ADM-G | 7.72 | 6.57 | 0.87 | 0.42 |
表 5 总结了我们的结果。 我们的扩散模型可以在每个任务上获得最佳 FID,并在除一项任务外的所有任务上获得最佳 sFID。 凭借改进的架构,我们已经在 LSUN 和 ImageNet 6464 上获得了最先进的图像生成。 对于更高分辨率的 ImageNet,我们观察到分类器指导使我们的模型能够显著优于最佳 GAN。 这些模型获得了与 GAN 相似的感知质量,同时保持了更高的分布覆盖范围(通过召回率衡量),并且甚至可以使用只有 25 步的扩散步骤实现这一点。
图 6 将来自最佳 BigGAN-deep 模型的随机样本与我们最好的扩散模型进行了比较。 虽然样本具有相似的感知质量,但扩散模型比 GAN 包含更多模式,例如放大的鸵鸟头、单只火烈鸟、汉堡的不同方向以及没有人的金鱼。 我们还在 Inception-V3 特征空间中检查了我们生成的样本的最近邻,并显示了附录 C 中的附加样本,以及附录 K-M 中的其他样本。



5.2 与上采样比较
我们还将指导与使用两阶段上采样堆栈进行了比较。 Nichol 和 Dhariwal [43] 和 Saharia 等人。 [53] 通过将低分辨率扩散模型与相应的上采样扩散模型相结合来训练两阶段扩散模型。 在这种方法中,上采样模型经过训练,可以对训练集中的图像进行上采样,并对低分辨率图像进行条件化,这些图像使用简单的插值(例如双线性)按通道方式连接到模型输入。 在采样过程中,低分辨率模型生成样本,然后上采样模型以该样本为条件。 这极大地提高了 ImageNet 256256 上的 FID,但没有达到 BigGAN-deep 等最先进模型的相同性能 Nichol 和 Dhariwal (2021); Saharia 等人 (2021),如表 5 所示。
在表 6 中,我们展示了指导和上采样沿着不同的轴线提高了样本质量。 虽然上采样提高了精度,同时保持了高召回率,但指导提供了一个旋钮,可以权衡多样性以获得更高的精度。 我们通过在更高分辨率上采样之前在较低分辨率下使用指导,获得了最佳的 FID,表明这些方法互为补充。
| Model | FID | sFID | IS | Precision | Recall | ||
| ImageNet 256256 | |||||||
| ADM | 250 | 10.94 | 6.02 | 100.98 | 0.69 | 0.63 | |
| ADM-U | 250 | 250 | 7.49 | 5.13 | 127.49 | 0.72 | 0.63 |
| ADM-G | 250 | 4.59 | 5.25 | 186.70 | 0.82 | 0.52 | |
| ADM-G, ADM-U | 250 | 250 | 3.94 | 6.14 | 215.84 | 0.83 | 0.53 |
| ImageNet 512512 | |||||||
| ADM | 250 | 23.24 | 10.19 | 58.06 | 0.73 | 0.60 | |
| ADM-U | 250 | 250 | 9.96 | 5.62 | 121.78 | 0.75 | 0.64 |
| ADM-G | 250 | 7.72 | 6.57 | 172.71 | 0.87 | 0.42 | |
| ADM-G, ADM-U | 25 | 25 | 5.96 | 12.10 | 187.87 | 0.81 | 0.54 |
| ADM-G, ADM-U | 250 | 25 | 4.11 | 9.57 | 219.29 | 0.83 | 0.55 |
| ADM-G, ADM-U | 250 | 250 | 3.85 | 5.86 | 221.72 | 0.84 | 0.53 |
6 相关工作
基于分数的生成模型由 Song 和 Ermon [59] 引入,作为使用其梯度对数据分布进行建模,然后使用 Langevin 动力学进行采样的一种方法 Welling 和 Teh (2011)。 Ho 等人。 [25] 发现了这种方法和扩散模型之间的联系 Sohl-Dickstein 等人 (2015),并通过利用这种联系获得了极佳的样本质量。 在这项突破性工作之后,许多作品紧随其后,取得了更令人鼓舞的结果: Kong 等人。 [30] 和 Chen 等人。 [8] 证明了扩散模型在音频方面效果很好; Jolicoeur-Martineau 等人。 [26] 发现类似 GAN 的设置可以提高这些模型的样本质量; Song 等人。 [60] 探索了利用随机微分方程技术来提高基于评分模型的样本质量的方法; Song 等人。 [57] 和 Nichol 和 Dhariwal [43] 提出了提高采样速度的方法;Nichol 和 Dhariwal [43] 和 Saharia 等人。 [53] 在使用上采样扩散模型的困难的 ImageNet 生成任务中展示了有希望的结果。 同时也与扩散模型相关,并且遵循了 Sohl-Dickstein 等人。 [56] 的工作, Goyal 等人。 [21] 描述了一种学习模型的技术,该模型具有学习的迭代生成步骤,并且发现当使用似然目标进行训练时,它可以实现良好的图像样本。
先前有关扩散模型的工作中缺少的一个要素是一种以多样性换取保真度的方法。 其他生成技术为这种权衡提供了天然的杠杆。 布洛克等人 [5] 引入了 GAN 的截断技巧,其中潜在向量是从截断的正态分布中采样的。 他们发现,增加截断自然会导致多样性下降,但保真度增加。 最近, 拉扎维等人 [51]提出使用分类器拒绝采样从基于自回归似然的模型中过滤掉不良样本,并发现该技术改进了FID。 大多数基于似然的模型还允许低温采样Ackley 等人 (1985),这提供了一种自然的方式来强调数据分布模式(参见附录G) 。
其他基于似然的模型已被证明可以生成高保真图像样本。 VQ-VAE van den Oord 等人 (2017) 和 VQ-VAE-2 Razavi 等人 (2019) 是在量化潜在代码之上训练的自回归模型,大大减少了在大型图像上训练这些模型所需的计算资源。 这些模型生成多样化且高质量的图像,但仍无法与 GAN 相媲美,因为它们没有昂贵的拒绝采样和特殊的指标来弥补模糊。 DCTransformer Nash 等人 (2021) 是一种相关方法,它依赖于更智能的压缩方案。 VAE 是另一类很有前途的基于似然的模型,最近的方法,如 NVAE Vahdat 和 Kautz (2020) 和 VDVAE Child (2021) 已成功应用于困难的图像生成领域。 基于能量的模型是另一类具有悠久历史的基于似然的模型 Ackley 等人 (1985); Dayan 等人 (1995); Hinton (2002)。 从 EBM 分布中采样具有挑战性,并且 谢 等人 [70] 证明了朗之万动力学可以用来从这些模型中采样连贯的图像。 Du 和 Mordatch [15] 进一步改进了这种方法,获得了高质量的图像。 最近, Gao 等人。 [18] 将扩散步骤合并到基于能量的模型中,并发现这样做可以改善这些模型的图像样本。
其他工作已经使用预先训练的分类器来控制生成模型。 例如,一项新兴研究Galatolo 等人 (2021);Patashnik 等人 (2021);Adverb (2021)旨在使用预训练 CLIPRadford 等人 (2021)模型优化文本提示的 GAN 潜在空间。 更类似于我们的工作, Song 等人。 [60] 使用分类器生成具有扩散模型的类条件 CIFAR-10 图像。 在某些情况下,分类器可以充当独立的生成模型。 例如, Santurkar 等人。 [55] 证明了一个强大的图像分类器可以用作独立的生成模型,并且 Grathwohl 等人。 [22] 训练了一个模型,该模型既是分类器又是基于能量的模型。
7 局限性和未来工作
虽然我们相信扩散模型是生成建模的一个非常有前景的方向,但由于使用了多个去噪步骤(因此需要正向传递),它们在采样时间上仍然比 GAN 慢。 这个方向上一个有希望的工作来自Luhman 和 Luhman [37],他们探索了一种将 DDIM 采样过程提炼成单步模型的方法。 单步模型的样本还没有达到 GAN 的水平,但比之前的单步基于似然的模型好得多。 未来在这个方向上的工作可能会完全弥合扩散模型和 GAN 之间的采样速度差距,而不会牺牲图像质量。
我们提出的分类器引导技术目前仅限于标记数据集,并且我们没有提供在未标记数据集上权衡多样性和保真度的有效策略。 在未来,我们的方法可以通过对样本进行聚类以生成合成标签Lucic 等人 (2019)或通过训练判别模型来预测样本是在真实数据分布中还是在采样分布中来扩展到未标记数据。
分类器引导的有效性表明,我们可以从分类函数的梯度中获得强大的生成模型。 这可以用来以多种方式对预训练模型进行调节,例如通过使用 CLIPRadford 等人 (2021)的噪声版本用文本标题调节图像生成器,类似于最近使用文本提示引导 GAN 的方法Galatolo 等人 (2021);Patashnik 等人 (2021);Adverb (2021)。 它还表明,将来可以利用大型未标记数据集对强大的扩散模型进行预训练,这些模型随后可以通过使用具有理想属性的分类器来改进。
8 结论
我们已经证明,扩散模型,一种具有固定训练目标的基于似然的模型,可以获得比最先进的 GAN 更好的样本质量。 我们改进的架构足以在无条件图像生成任务上实现这一点,而我们的分类器引导技术使我们在类条件任务上也能实现这一点。 在后一种情况下,我们发现分类器梯度的规模可以调整以在多样性和保真度之间进行权衡。 这些引导的扩散模型可以缩短 GAN 和扩散模型之间的采样时间差距,尽管扩散模型在采样期间仍然需要多次前向传递。 最后,通过将引导与上采样结合起来,我们可以进一步提高高分辨率条件图像合成中的样本质量。
9 致谢
感谢 Alec Radford、Mark Chen、Pranav Shyam 和 Raul Puri 对这项工作的反馈。
参考文献
- Ackley et al. [1985] David Ackley, Geoffrey Hinton, and Terrence Sejnowski. A learning algorithm for boltzmann machines. Cognitive science, 9(1):147-169, 1985.
- Adverb [2021] Adverb. The big sleep. https://twitter.com/advadnoun/status/1351038053033406468, 2021.
- Barratt and Sharma [2018] Shane Barratt and Rishi Sharma. A note on the inception score. arXiv:1801.01973, 2018.
- Brock et al. [2016] Andrew Brock, Theodore Lim, J. M. Ritchie, and Nick Weston. Neural photo editing with introspective adversarial networks. arXiv:1609.07093, 2016.
- Brock et al. [2018] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv:1809.11096, 2018.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. arXiv:2005.14165, 2020.
- Chen et al. [2020a] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In International Conference on Machine Learning, pages 1691–1703. PMLR, 2020a.
- Chen et al. [2020b] Nanxin Chen, Yu Zhang, Heiga Zen, Ron J. Weiss, Mohammad Norouzi, and William Chan. Wavegrad: Estimating gradients for waveform generation. arXiv:2009.00713, 2020b.
- Child [2021] Rewon Child. Very deep vaes generalize autoregressive models and can outperform them on images. arXiv:2011.10650, 2021.
- Dayan et al. [1995] Peter Dayan, Geoffrey E Hinton, Radford M Neal, and Richard S Zemel. The helmholtz machine. Neural computation, 7(5):889–904, 1995.
- de Vries et al. [2017] Harm de Vries, Florian Strub, Jérémie Mary, Hugo Larochelle, Olivier Pietquin, and Aaron Courville. Modulating early visual processing by language. arXiv:1707.00683, 2017.
- DeepMind [2018] DeepMind. Biggan-deep 128x128 on tensorflow hub. https://tfhub.dev/deepmind/biggan-deep-128/1, 2018.
- Dhariwal et al. [2020] Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. Jukebox: A generative model for music. arXiv:2005.00341, 2020.
- Donahue and Simonyan [2019] Jeff Donahue and Karen Simonyan. Large scale adversarial representation learning. arXiv:1907.02544, 2019.
- Du and Mordatch [2019] Yilun Du and Igor Mordatch. Implicit generation and generalization in energy-based models. arXiv:1903.08689, 2019.
- Dumoulin et al. [2017] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur. A learned representation for artistic style. arXiv:1610.07629, 2017.
- Galatolo et al. [2021] Federico A. Galatolo, Mario G. C. A. Cimino, and Gigliola Vaglini. Generating images from caption and vice versa via clip-guided generative latent space search. arXiv:2102.01645, 2021.
- Gao et al. [2020] Ruiqi Gao, Yang Song, Ben Poole, Ying Nian Wu, and Diederik P. Kingma. Learning energy-based models by diffusion recovery likelihood. arXiv:2012.08125, 2020.
- Goodfellow et al. [2014] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. arXiv:1406.2661, 2014.
- Google [2018] Google. Cloud tpus. https://cloud.google.com/tpu/, 2018.
- Goyal et al. [2017] Anirudh Goyal, Nan Rosemary Ke, Surya Ganguli, and Yoshua Bengio. Variational walkback: Learning a transition operator as a stochastic recurrent net. arXiv:1711.02282, 2017.
- Grathwohl et al. [2019] Will Grathwohl, Kuan-Chieh Wang, Jörn-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, and Kevin Swersky. Your classifier is secretly an energy based model and you should treat it like one. arXiv:1912.03263, 2019.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in Neural Information Processing Systems 30 (NIPS 2017), 2017.
- Hinton [2002] Geoffrey E Hinton. Training products of experts by minimizing contrastive divergence. Neural computation, 14(8):1771–1800, 2002.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv:2006.11239, 2020.
- Jolicoeur-Martineau et al. [2020] Alexia Jolicoeur-Martineau, Rémi Piché-Taillefer, Rémi Tachet des Combes, and Ioannis Mitliagkas. Adversarial score matching and improved sampling for image generation. arXiv:2009.05475, 2020.
- Karras et al. [2019a] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. arXiv:arXiv:1812.04948, 2019a.
- Karras et al. [2019b] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. arXiv:1912.04958, 2019b.
- Kingma and Ba [2014] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv:1412.6980, 2014.
- Kong et al. [2020] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. arXiv:2009.09761, 2020.
- Krizhevsky et al. [2009] Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. CIFAR-10 (Canadian Institute for Advanced Research), 2009. URL http://www.cs.toronto.edu/~kriz/cifar.html.
- Kynkäänniemi et al. [2019] Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. arXiv:1904.06991, 2019.
- Lin et al. [2016] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian Reid. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. arXiv:1611.06612, 2016.
- Liu et al. [2015] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv:1711.05101, 2017.
- Lucic et al. [2019] Mario Lucic, Michael Tschannen, Marvin Ritter, Xiaohua Zhai, Olivier Bachem, and Sylvain Gelly. High-fidelity image generation with fewer labels. arXiv:1903.02271, 2019.
- Luhman and Luhman [2021] Eric Luhman and Troy Luhman. Knowledge distillation in iterative generative models for improved sampling speed. arXiv:2101.02388, 2021.
- Micikevicius et al. [2017] Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. arXiv:1710.03740, 2017.
- Mirza and Osindero [2014] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv:1411.1784, 2014.
- Miyato and Koyama [2018] Takeru Miyato and Masanori Koyama. cgans with projection discriminator. arXiv:1802.05637, 2018.
- Miyato et al. [2018] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. arXiv:1802.05957, 2018.
- Nash et al. [2021] Charlie Nash, Jacob Menick, Sander Dieleman, and Peter W. Battaglia. Generating images with sparse representations. arXiv:2103.03841, 2021.
- Nichol and Dhariwal [2021] Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. arXiv:2102.09672, 2021.
- NVIDIA [2019] NVIDIA. Stylegan2. https://github.com/NVlabs/stylegan2, 2019.
- Parmar et al. [2021] Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On buggy resizing libraries and surprising subtleties in fid calculation. arXiv:2104.11222, 2021.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. arXiv:1912.01703, 2019.
- Patashnik et al. [2021] Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. arXiv:2103.17249, 2021.
- Perez et al. [2017] Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. arXiv:1709.07871, 2017.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. arXiv:2103.00020, 2021.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. arXiv:2102.12092, 2021.
- Razavi et al. [2019] Ali Razavi, Aaron van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with VQ-VAE-2. arXiv:1906.00446, 2019.
- Russakovsky et al. [2014] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. arXiv:1409.0575, 2014.
- Saharia et al. [2021] Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement. arXiv:arXiv:2104.07636, 2021.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. arXiv:1606.03498, 2016.
- Santurkar et al. [2019] Shibani Santurkar, Dimitris Tsipras, Brandon Tran, Andrew Ilyas, Logan Engstrom, and Aleksander Madry. Image synthesis with a single (robust) classifier. arXiv:1906.09453, 2019.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. arXiv:1503.03585, 2015.
- Song et al. [2020a] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv:2010.02502, 2020a.
- Song and Ermon [2020a] Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. arXiv:2006.09011, 2020a.
- Song and Ermon [2020b] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. arXiv:arXiv:1907.05600, 2020b.
- Song et al. [2020b] Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv:2011.13456, 2020b.
- Szegedy et al. [2013] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv:1312.6199, 2013.
- Szegedy et al. [2015] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. arXiv:1512.00567, 2015.
- Vahdat and Kautz [2020] Arash Vahdat and Jan Kautz. Nvae: A deep hierarchical variational autoencoder. arXiv:2007.03898, 2020.
- van den Oord et al. [2016] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv:1609.03499, 2016.
- van den Oord et al. [2017] Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. arXiv:1711.00937, 2017.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv:1706.03762, 2017.
- Welling and Teh [2011] Max Welling and Yee W Teh. Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th international conference on machine learning (ICML-11), pages 681–688. Citeseer, 2011.
- Wu et al. [2019] Yan Wu, Jeff Donahue, David Balduzzi, Karen Simonyan, and Timothy Lillicrap. Logan: Latent optimisation for generative adversarial networks. arXiv:1912.00953, 2019.
- Wu and He [2018] Yuxin Wu and Kaiming He. Group normalization. arXiv:1803.08494, 2018.
- Xie et al. [2016] Jianwen Xie, Yang Lu, Song-Chun Zhu, and Ying Nian Wu. A theory of generative convnet. arXiv:1602.03264, 2016.
- Yu et al. [2015] Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv:1506.03365, 2015.
- Zhang et al. [2016] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. arXiv:1612.03242, 2016.
- Zhu [2018] Ligeng Zhu. Thop. https://github.com/Lyken17/pytorch-OpCounter, 2018.
附录 A 计算需求
计算对于现代机器学习应用至关重要,更多的计算通常会产生更好的结果。 因此,将我们方法的计算需求与竞争方法进行比较非常重要。 在本节中,我们将证明,我们可以以相同或更低的计算预算实现优于 StyleGAN2 和 BigGAN-deep 的结果。
A.1 吞吐量
我们首先在表 7 中对我们模型的吞吐量进行基准测试。 为了进行理论吞吐量计算,我们使用 THOP Zhu [2018] 测量了模型的理论 FLOPs,并假设 NVIDIA Tesla V100 (120 TFLOPs) 的利用率为 100%,而实际吞吐量则使用测量的实际运行时间。 每当训练批次大小无法容纳在一台机器上时,我们都会将两台机器之间的通信时间纳入计算,其中每台机器都有 8 个 V100。
我们发现,在 PyTorch 1.7 中对模型进行简单实现效率非常低,仅利用了 20-30% 的硬件资源。 我们还对经过优化的版本进行了基准测试,该版本使用更大的每个 GPU 批次大小、融合的 GroupNorm-Swish 和融合的 Adam CUDA 操作。 特别是对于我们的 ImageNet 128128 模型,我们发现,即使将每个 GPU 批次大小从 4 增加到 32,仍然可以容纳在 GPU 内存中,并且这会带来很大的利用率差异。 我们的实现距离最优还很远,进一步优化应该可以让我们实现更高的利用率。
| Model | Implementation | Batch Size | Throughput | Utilization |
|---|---|---|---|---|
| per GPU | Imgs per V100-sec | |||
| 6464 | Theoretical | - | 182.3 | 100% |
| Naive | 32 | 37.0 | 20% | |
| Optimized | 96 | 74.1 | 41% | |
| 128128 | Theoretical | - | 65.2 | 100% |
| Naive | 4 | 11.5 | 18% | |
| Optimized | 32 | 24.8 | 38% | |
| 256256 | Theoretical | - | 17.9 | 100% |
| Naive | 4 | 4.4 | 25% | |
| Optimized | 8 | 6.4 | 36% | |
| 64 256 | Theoretical | - | 31.7 | 100% |
| Naive | 4 | 6.3 | 20% | |
| Optimized | 12 | 9.5 | 30% | |
| 128 512 | Theoretical | - | 8.0 | 100% |
| Naive | 2 | 1.9 | 24% | |
| Optimized | 2 | 2.3 | 29% |
A.2 提前停止
此外,我们可以在训练过程中进行更少的迭代,同时保持比 BigGAN-deep 更好的样本质量。 表 8 和 9 评估了我们 ImageNet 128128 和 256256 模型在整个训练过程中的表现。 我们发现,ImageNet 128128 模型在 500K 次训练迭代后就超过了 BigGAN-deep 的 FID (6.02),只完成了训练过程的八分之一。 同样,ImageNet 256256 模型在 750K 次迭代后就超过了 BigGAN-deep,大约完成了训练过程的三分之一。
| Iterations | FID | sFID | Precision | Recall |
|---|---|---|---|---|
| 250K | 7.97 | 6.48 | 0.80 | 0.50 |
| 500K | 5.31 | 5.97 | 0.83 | 0.49 |
| 1000K | 4.10 | 5.80 | 0.81 | 0.51 |
| 2000K | 3.42 | 5.69 | 0.83 | 0.53 |
| 4360K | 3.09 | 5.59 | 0.82 | 0.54 |
| Iterations | FID | sFID | Precision | Recall |
|---|---|---|---|---|
| 250K | 12.21 | 6.15 | 0.78 | 0.50 |
| 500K | 7.95 | 5.51 | 0.81 | 0.50 |
| 750K | 6.49 | 5.39 | 0.81 | 0.50 |
| 1000K | 5.74 | 5.29 | 0.81 | 0.52 |
| 1500K | 5.01 | 5.20 | 0.82 | 0.52 |
| 1980K | 4.59 | 5.25 | 0.82 | 0.52 |
A.3 计算比较
最后,在表 10 中,我们将我们模型的计算量与 StyleGAN2 和 BigGAN-deep 进行了比较,并表明我们可以在类似的计算预算下获得更好的 FIDs。 对于 BigGAN-deep, Brock 等人。 [5] 没有明确描述训练其模型的计算要求,而是提供了 Google TPUv3 集群上的天数的大致估计值 Google [2018]。 我们根据 2 TPU-v3 天 = 1 V100 天将他们的 TPU-v3 估计值转换为 V100 天。 对于 StyleGAN2,我们使用报告的吞吐量,即在一个 V100 上 config-f 32 天 13 小时超过 2500 万张图像 NVIDIA [2019]。 我们注意到,与训练生成模型相比,我们的分类器训练相对轻量级。
| Model | Generator | Classifier | Total | FID | sFID | Precision | Recall |
| Compute | Compute | Compute | |||||
| LSUN Horse 256256 | |||||||
| StyleGAN2 Karras et al. [2019b] | 130 | 3.84 | 6.46 | 0.63 | 0.48 | ||
| ADM (250K) | 116 | - | 116 | 2.95 | 5.94 | 0.69 | 0.55 |
| ADM (dropout, 250K) | 116 | - | 116 | 2.57 | 6.81 | 0.71 | 0.55 |
| LSUN Cat 256256 | |||||||
| StyleGAN2 Karras et al. [2019b] | 115 | 7.25 | 6.33 | 0.58 | 0.43 | ||
| ADM (dropout, 200K) | 92 | - | 92 | 5.57 | 6.69 | 0.63 | 0.52 |
| ImageNet 128128 | |||||||
| BigGAN-deep Brock et al. [2018] | 64-128 | 6.02 | 7.18 | 0.86 | 0.35 | ||
| ADM-G (4360K) | 521 | 9 | 530 | 3.09 | 5.59 | 0.82 | 0.54 |
| ADM-G (450K) | 54 | 9 | 63 | 5.67 | 6.19 | 0.82 | 0.49 |
| ImageNet 256256 | |||||||
| BigGAN-deep Brock et al. [2018] | 128-256 | 6.95 | 7.36 | 0.87 | 0.28 | ||
| ADM-G (1980K) | 916 | 46 | 962 | 4.59 | 5.25 | 0.82 | 0.52 |
| ADM-G (750K) | 347 | 46 | 393 | 6.49 | 5.39 | 0.81 | 0.50 |
| ADM-G (750K) | 347 | 14† | 361 | 6.68 | 5.34 | 0.81 | 0.51 |
| ADM-G (540K), ADM-U (500K) | 329 | 30 | 359 | 3.85 | 5.86 | 0.84 | 0.53 |
| ADM-G (540K), ADM-U (150K) | 219 | 30 | 249 | 4.15 | 6.14 | 0.82 | 0.54 |
| ADM-G (200K), ADM-U (150K) | 110 | 10‡ | 126 | 4.93 | 5.82 | 0.82 | 0.52 |
| ImageNet 512512 | |||||||
| BigGAN-deep Brock et al. [2018] | 256-512 | 8.43 | 8.13 | 0.88 | 0.29 | ||
| ADM-G (4360K), ADM-U (1050K) | 1878 | 36 | 1914 | 3.85 | 5.86 | 0.84 | 0.53 |
| ADM-G (500K), ADM-U (100K) | 189 | 9* | 198 | 7.59 | 6.84 | 0.84 | 0.53 |
附录 B DDPM 的详细公式
在这里,我们提供了从 Ho 等人。 [25]。 我们首先定义我们的数据分布 和马尔可夫噪声过程 ,它逐渐将噪声添加到数据中,以通过 生成带噪声的样本 。 具体来说,噪声过程的每个步骤根据由 给出的某些方差时间表添加高斯噪声:
| (15) |
Ho 等人。 [25] 指出我们不需要重复应用 来从 中采样。 相反, 可以表示为高斯分布。 用 和
| (16) | ||||
| (17) |
这里, 告诉我们任意时间步长的噪声方差,我们可以等效地使用它来定义噪声时间表,而不是 。
使用贝叶斯定理,可以发现后验 也是一个高斯分布,其均值为 ,方差为 ,定义如下:
| (18) | ||||
| (19) | ||||
| (20) |
如果我们希望从数据分布 中采样,我们可以首先从 中采样,然后采样反向步骤 ,直到我们到达 。 在 和 的合理设置下,分布 几乎是各向同性的高斯分布,因此采样 是微不足道的。 剩下的只是使用神经网络来近似 ,因为它在数据分布未知时无法精确计算。 为此, Sohl-Dickstein 等人。 [56] 注意到 随着 以及相应的 接近对角高斯分布,因此只需训练一个神经网络来预测平均值 和对角协方差矩阵 就足够了:
| (21) |
为了训练该模型,使 学习真实数据分布 ,我们可以针对 对以下变分下界 进行优化:
| (22) | ||||
| (23) | ||||
| (24) | ||||
| (25) |
虽然上述目标是合理的, Ho 等人。 [25] 发现,在实践中,不同的目标会产生更好的样本。 特别地,他们没有直接将 参数化为神经网络,而是训练一个模型 来预测公式 17 中的 。 此简化目标定义如下:
| (26) |
在采样过程中,我们可以使用替换法从 中推导出 :
| (27) |
注意到 不会为 提供任何学习信号。 Ho 等人。 [25] 发现他们可以选择 或 将其固定为常量,而不是学习 。 这些值对应于真实逆步方差的上界和下界。
附录 C 样本的最近邻


当使用分类器来减少生成的样本多样性时,我们的模型可以达到最佳的 FID。 人们可能会担心,这样的过程会导致模型回忆训练数据集中的现有图像,尤其是在分类器尺度增加时。 为了测试这一点,我们查看了少量样本的最近邻居(在 InceptionV3 Szegedy et al. [2015] 特征空间中)。 图 7 显示了我们的结果,结果表明这些样本确实是唯一的,而不是存储在训练集中。
附录 D 改变分类器尺度的影响

附录 E LSUN 多样性比较


附录 F 使用 DDIM 在数据集图像之间插值
给定初始噪声 ,DDIM Song et al. [2020a] 采样过程是确定的,因此产生了隐式潜在空间。 它对应于在正向方向上积分一个 ODE,并且我们可以反向运行该过程以获得生成给定真实图像的潜在变量。 在这里,我们尝试将真实图像编码到这个潜在空间中,然后在它们之间进行插值。
DDIM 中生成过程的方程 13 看起来像
因此,在小步长的极限情况下,我们可以预期这个 ODE 在正向方向上的反转看起来像
我们发现,即使只有 250 个反向步骤,这个反向 ODE 近似值也能给出具有合理重建的潜在变量。 然而,我们注意到在反转所有 250 个步骤时出现了一些噪声伪影,并且发现反转前 249 个步骤可以得到更好的重建。 为了对潜在变量、类别嵌入和分类器对数概率进行插值,我们使用 ,其中 从 0 线性地扫到 。
图 10(a) 到 11(b) 显示了在类条件 256256 模型上进行的 DDIM 潜在空间插值,同时改变分类器尺度。 左侧和最右侧的图像分别是地面实况数据集示例,它们之间的图像是在 DDIM 潜在空间中重建的插值(包括两个端点)。 我们看到,由于其高召回率,没有指导的模型几乎具有完美的重建,而将指导尺度提高到 2.5 只能找到近似相似的重建。


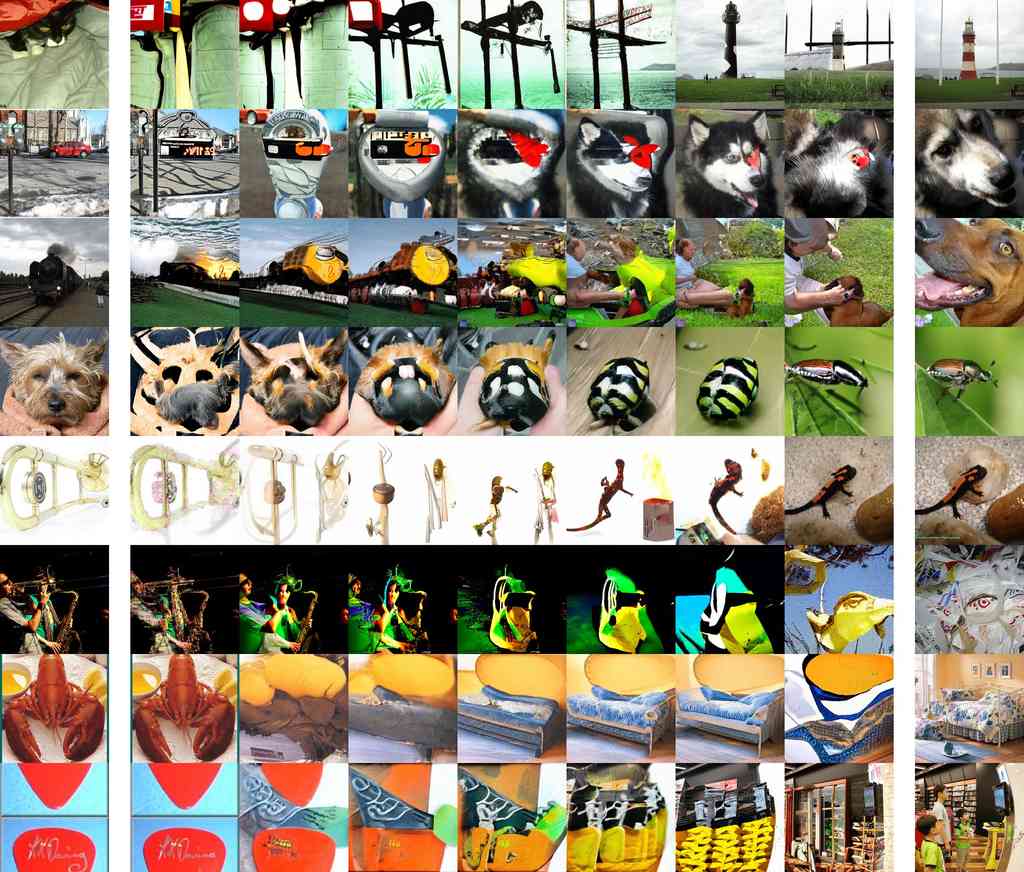
附录 G 降低温度采样
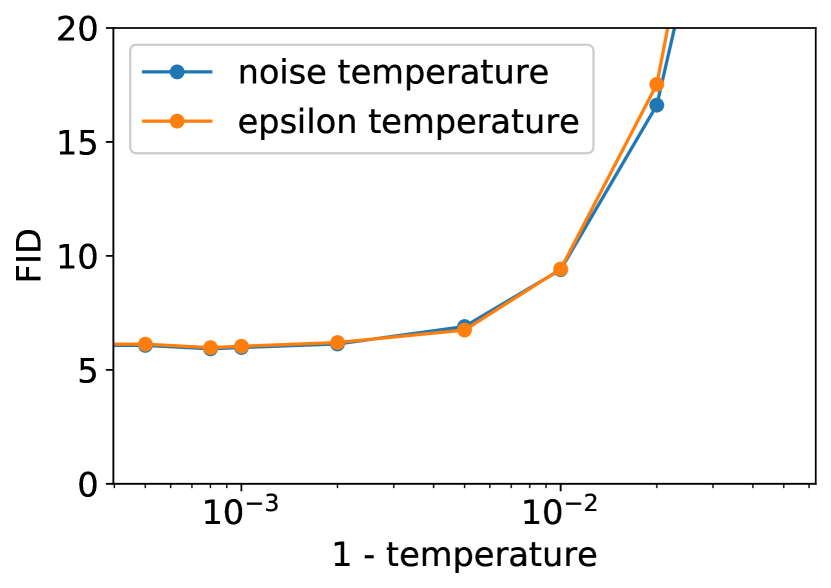
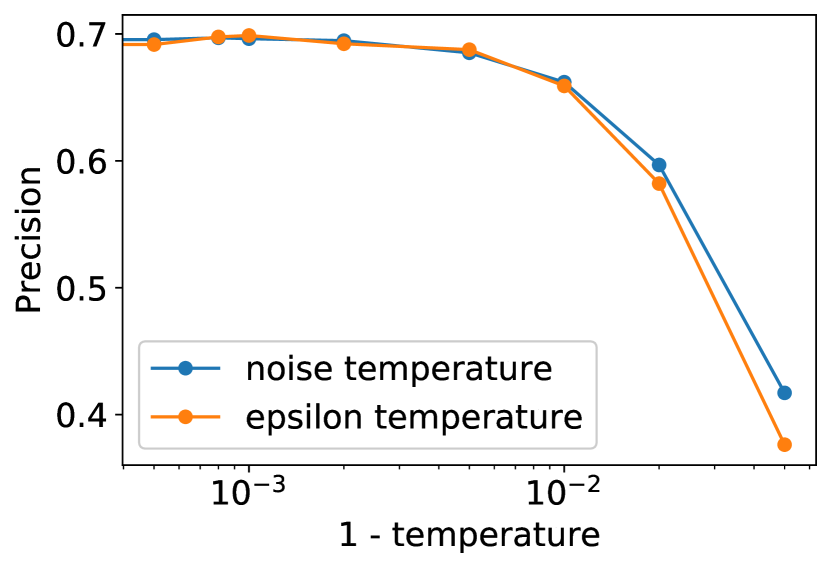
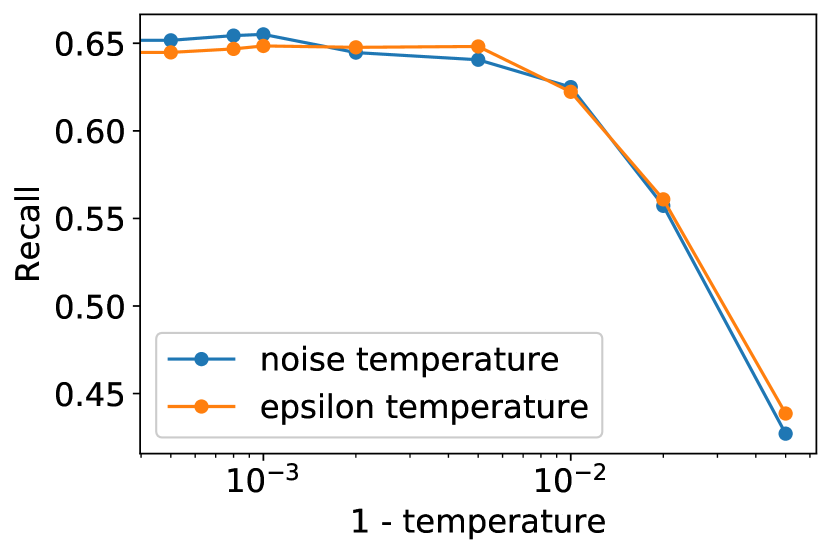
我们通过使用分类器指导来降低模型的多样性,从而获得了最佳的 ImageNet 样本。 对于许多类型的生成模型来说,存在一种更简单的方法来降低多样性:降低温度 Ackley 等人 [1985]。 温度参数 通常设置得当,使得 对应于标准采样,而 更关注高密度样本。 我们尝试了两种在扩散模型中实现这一点的方法:首先,通过 来缩放每次转换中使用的 Gaussian 噪声,其次是将 除以 。 当将 视为重新缩放的得分函数时,后一种实现方法是有道理的(参见第 4.2 节),并且放大得分函数类似于放大分类器梯度。
为了衡量温度缩放对样本的影响,我们使用 ImageNet 128128 模型进行实验,评估了不同温度下的 FID、精度和召回率(图 12)。 我们发现这两种技术的行为相似,并且这两种技术都没有在我们的评估指标中提供任何实质性的改进。 我们还发现,低温既有低精度又有低召回率,这表明模型没有关注真实数据分布的模式。 图 13 突出了这种效应,表明降低温度会产生模糊、平滑的图像。


附录 H 条件扩散过程
在本节中,我们展示了条件采样可以通过与 成比例的转换算子来实现,其中 近似于 ,而 近似于噪声样本 的标签分布。
我们首先定义一个类似于 的条件马尔可夫噪声过程 ,并假设 是每个样本的已知且可用的标签分布。
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) |
虽然我们定义了条件于 的噪声过程 ,但我们可以证明,当不条件于 时, 的行为与 完全相同。 沿着这些思路,我们首先推导出无条件噪声算子 :
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) |
遵循类似的逻辑,我们找到了联合分布 :
| (38) | ||||
| (39) | ||||
| (40) | ||||
| (41) | ||||
| (42) | ||||
| (43) | ||||
| (44) |
使用公式 44,我们现在可以推导出 :
| (45) | ||||
| (46) | ||||
| (47) | ||||
| (48) | ||||
| (49) |
使用等式 和 ,通过贝叶斯规则很容易证明无条件逆过程 。
关于 的一个观察结果是,它产生了一个噪声分类函数,。 我们可以证明,这种分类分布不依赖于 ( 的一个更噪声的版本),这是一个我们稍后会用到的事实:
| (51) | ||||
| (52) | ||||
| (53) |
现在我们可以推导出条件逆过程:
| (55) | ||||
| (56) | ||||
| (57) | ||||
| (58) | ||||
| (59) | ||||
| (60) |
由于 项不依赖于 ,因此它可以被视为常数。 因此,我们想要从分布 中采样,其中 是一个归一化常数。 我们已经有了 的神经网络近似,称为 ,因此剩下的只是 的近似。 这可以通过在从 中采样得到的噪声图像 上训练一个分类器 来获得。
附录 I 超参数
在为我们的采样器选择最佳分类器尺度时,我们对 ImageNet 128128 和 ImageNet 256256 的 以及 ImageNet 512512 的 进行了扫描。 对于 DDIM,我们在 ImageNet 128128 上对 进行扫描,在 ImageNet 256256 上对 进行扫描,在 ImageNet 512512 上对 进行扫描。
扩散模型和分类模型的超参数分别在表 11 和表 12 中。 指导采样的超参数在表 14 中。 用于训练上采样模型的超参数在表 13 中。 我们使用 Adam Kingma 和 Ba [2014] 或 AdamW Loshchilov 和 Hutter [2017] 训练所有模型,并使用 和 。 我们使用 16 位精度进行训练,使用损失缩放 Micikevicius 等人 [2017],但保留 32 位权重、EMA 和优化器状态。 我们在所有实验中使用 0.9999 的 EMA 率。 我们使用 PyTorch Paszke 等人 [2019],并在 NVIDIA Tesla V100 上进行训练。
对于所有架构消融,我们使用 256 的批次大小进行训练,并使用 250 个采样步骤进行采样。 对于我们的注意力头消融,我们使用 128 个基本通道,每个分辨率 2 个残差块,多分辨率注意力和 BigGAN 上/下采样,并且我们训练模型 700K 次迭代。 默认情况下,我们所有实验都使用自适应组归一化,除非明确地对它进行消融。
当使用 1000 个时间步长进行采样时,我们使用与训练相同的噪声时间表。 在 ImageNet 上,我们使用 Nichol 和 Dhariwal [43] 中的均匀步长进行 250 步采样,以及来自 Song 等人 [57] 的略微不同的均匀步长进行 25 步 DDIM。
| LSUN | ImageNet 64 | ImageNet 128 | ImageNet 256 | ImageNet 512 | |
| Diffusion steps | 1000 | 1000 | 1000 | 1000 | 1000 |
| Noise Schedule | linear | cosine | linear | linear | linear |
| Model size | 552M | 296M | 422M | 554M | 559M |
| Channels | 256 | 192 | 256 | 256 | 256 |
| Depth | 2 | 3 | 2 | 2 | 2 |
| Channels multiple | 1,1,2,2,4,4 | 1,2,3,4 | 1,1,2,3,4 | 1,1,2,2,4,4 | 0.5,1,1,2,2,4,4 |
| Heads | 4 | ||||
| Heads Channels | 64 | 64 | 64 | 64 | |
| Attention resolution | 32,16,8 | 32,16,8 | 32,16,8 | 32,16,8 | 32,16,8 |
| BigGAN up/downsample | ✓ | ✓ | ✓ | ✓ | ✓ |
| Dropout | 0.1 | 0.1 | 0.0 | 0.0 | 0.0 |
| Batch size | 256 | 2048 | 256 | 256 | 256 |
| Iterations | varies* | 540K | 4360K | 1980K | 1940K |
| Learning Rate | 1e-4 | 3e-4 | 1e-4 | 1e-4 | 1e-4 |
| ImageNet 64 | ImageNet 128 | ImageNet 256 | ImageNet 512 | |
| Diffusion steps | 1000 | 1000 | 1000 | 1000 |
| Noise Schedule | cosine | linear | linear | linear |
| Model size | 65M | 43M | 54M | 54M |
| Channels | 128 | 128 | 128 | 128 |
| Depth | 4 | 2 | 2 | 2 |
| Channels multiple | 1,2,3,4 | 1,1,2,3,4 | 1,1,2,2,4,4 | 0.5,1,1,2,2,4,4 |
| Heads Channels | 64 | 64 | 64 | 64 |
| Attention resolution | 32,16,8 | 32,16,8 | 32,16,8 | 32,16,8 |
| BigGAN up/downsample | ✓ | ✓ | ✓ | ✓ |
| Attention pooling | ✓ | ✓ | ✓ | ✓ |
| Weight decay | 0.2 | 0.05 | 0.05 | 0.05 |
| Batch size | 1024 | 256* | 256 | 256 |
| Iterations | 300K | 300K | 500K | 500K |
| Learning rate | 6e-4 | 3e-4* | 3e-4 | 3e-4 |
| ImageNet | ImageNet | ||
| Diffusion steps | 1000 | 1000 | |
| Noise Schedule | linear | linear | |
| Model size | 312M | 309M | |
| Channels | 192 | 192 | |
| Depth | 2 | 2 | |
| Channels multiple | 1,1,2,2,4,4 | 1,1,2,2,4,4* | |
| Heads | 4 | ||
| Heads Channels | 64 | ||
| Attention resolution | 32,16,8 | 32,16,8 | |
| BigGAN up/downsample | ✓ | ✓ | |
| Dropout | 0.0 | 0.0 | |
| Batch size | 256 | 256 | |
| Iterations | 500K | 1050K | |
| Learning Rate | 1e-4 | 1e-4 |
| ImageNet 64 | ImageNet 128 | ImageNet 256 | ImageNet 512 | |
|---|---|---|---|---|
| Gradient Scale (250 steps) | 1.0 | 0.5 | 1.0 | 4.0 |
| Gradient Scale (DDIM, 25 steps) | - | 1.25 | 2.5 | 9.0 |
附录 J 在 LSUN 上使用更少的采样步骤
我们最初发现,当以 1000 步而不是 250 步进行采样时,我们的 LSUN 模型取得了更好的结果,这与 Nichol 和 Dhariwal [43] 的先前结果相反。 为了解决这个问题,我们对采样时间噪声计划进行了扫描,发现改进的计划可以在很大程度上弥合差距。 我们在 LSUN 卧室上扫描了计划,并选择了 FID 最佳的计划用于其他两个数据集。 表 15 详细说明了此次扫描的结果,表 16 将此计划应用于三个 LSUN 数据集。
虽然扫描采样计划不如从头开始重新训练模型那么昂贵,但它确实需要大量的采样计算。 因此,我们没有进行详尽的搜索,并且可能存在更优的计划。
| Schedule | FID |
|---|---|
| 2.31 | |
| 2.17 | |
| 2.10 | |
| 2.09 | |
| 2.09 | |
| 2.07 | |
| 2.03 | |
| 2.02 |
| Schedule | FID | sFID | Prec | Rec |
|---|---|---|---|---|
| LSUN Bedrooms 256256 | ||||
| 1000 steps | 1.90 | 5.59 | 0.66 | 0.51 |
| 250 steps (uniform) | 2.31 | 6.12 | 0.65 | 0.50 |
| 250 steps (sweep) | 2.02 | 6.12 | 0.67 | 0.50 |
| LSUN Horses 256256 | ||||
| 1000 steps | 2.57 | 6.81 | 0.71 | 0.55 |
| 250 steps (uniform) | 3.45 | 7.55 | 0.68 | 0.56 |
| 250 steps (sweep) | 2.83 | 7.08 | 0.69 | 0.56 |
| LSUN Cat 256256 | ||||
| 1000 steps | 5.57 | 6.69 | 0.63 | 0.52 |
| 250 steps (uniform) | 7.03 | 8.24 | 0.60 | 0.53 |
| 250 steps (sweep) | 5.94 | 7.43 | 0.62 | 0.52 |
附录 K 来自 ImageNet 512512 的样本







附录 L 来自 ImageNet 256256 的样本





附录 M 来自 LSUN 的样本


