使用 APPS 衡量编码挑战能力
摘要
虽然编程是现代社会最广泛应用的技能之一,但目前尚不清楚最先进的机器学习模型编写代码的能力如何。 尽管它很重要,但令人惊讶的是,评估代码生成的工作却很少,而且很难以准确而严格的方式评估代码生成性能。 为了应对这一挑战,我们引入了 APPS,这是代码生成的基准。 与之前在更受限的环境中进行的工作不同,我们的基准测试衡量模型采用任意自然语言规范并生成令人满意的 Python 代码的能力。 与公司评估候选软件开发人员的方式类似,我们通过检查测试用例生成的代码来评估模型。 我们的基准测试包括 问题,范围从简单的单行解决方案到重大的算法挑战。 我们在 GitHub 和训练集上测试大型语言模型,发现随着模型的改进,语法错误的发生率呈指数级下降。 最近的模型(例如 GPT-Neo)可以通过大约 个介绍性问题的测试用例,因此我们发现机器学习模型现在开始学习如何编码。 随着自动代码生成的社会意义在未来几年不断增加,我们的基准测试可以为跟踪进展提供客观的衡量标准。
“每个人都应该学习计算机编程,因为它教会你如何思考。” – 史蒂夫·乔布斯
1简介
计算机编程几乎存在于社会的各个领域。 编程是一种非常通用的工具,涵盖娱乐、医疗保健、教育等领域,其应用范围非常广泛。 随着计算机在现代生活中变得越来越普遍,对高质量代码的需求不断增长,吸引了越来越多有抱负的程序员加入这一行业。 经过多年的学习成为熟练的编码员,人类专家能够将各种认知任务的抽象规范转换为具体的程序。
在过去的几年中,大规模语言模型在泛化各种认知任务方面表现出了良好的前景,包括语言推理(Wang等人,2019a)、常识推理(Zellers等人,2019) ; Huang 等人, 2019; Bisk 等人, 2019)、逻辑演绎(Liu 等人, 2020b)、数学(Polu 等人, 2020; Hendrycks 等人, 2021c),以及对人类知识多个领域的一般理解(Hendrycks 等人, 2021b)。 然而,大规模语言模型是否能够可靠地编写代码仍然是一个悬而未决的问题。
受语言模型潜力和彻底代码生成评估需求的推动,我们引入了 APPS,这是根据自然语言规范生成代码的基准。 与之前使用 Transformer 语言模型进行代码生成的工作不同(Vaswani 等人,2017),主要关注代码翻译(Lachaux 等人,2020) 和伪代码到- code (Kulal 等人, 2019),我们评估模型接受自然语言给出的规范并编写满足这些规范的代码的能力。 此设置反映了如何评估人类编码员,并且是对模型进行基准测试的更现实且信息丰富的设置。

APPS 提供了精确且全面的代码生成视图。 APPS 不仅评估模型编写语法正确的程序的能力,还评估其理解任务描述和设计算法来解决这些任务的能力。 它包含不同难度级别的编程问题,涵盖简单的入门问题、面试级别问题和编码竞赛挑战。 如果一个模型在APPS上表现良好,这将表明它能够灵活地使用数据结构和编程技术,以及正确解释不同任务规范、遵循指令和理解人类意图的能力(Hendrycks等人,2021a)。
对于大多数文本生成任务,高质量的评估需要人工反馈,这可能非常耗时或需要金钱成本。 因此,诸如BLEU(Papineni等人,2002)之类的自动度量经常被用来比较方法,但这些度量不一定跟踪程序的正确性。 由于代码生成的目标是生成正确的程序,因此我们不使用 BLEU 来评估程序,而是使用测试用例和错误捕获来评估程序。 大量超过 的测试用例有助于评估 APPS 上的代码生成。 测试用例经过专门选择,以探测输入空间中的正确功能。 通过使用测试用例,我们为代码生成质量提供了黄金标准指标。
在我们的实验中,我们发现模型现在开始表现出非零精度并解决一些编码问题。 此外,随着模型的改进,我们观察到语法错误呈指数级减少。 我们还发现了进一步的证据,表明 BLEU 是代码生成的一个有问题的指标,有时与黄金标准准确性反相关。 我们发现准确性随着难度级别的增加而降低,并通过微调和模型大小的增加而提高。 我们在介绍性问题上评估的最强模型在五次尝试后几乎通过了 个测试用例。 这些结果将代码生成定位为大规模语言模型的具有挑战性但现在易于处理的测试平台。
用自然语言编写符合规范的代码是一项具有经济价值的任务,如果它得到解决,将会产生广泛的社会影响,因为它最终可能促进恶意代码的生成,并有一天导致工作自动化。 由于大规模语言模型有可能在代码生成方面取得重大进展,因此我们有必要开始跟踪这项任务的进展。 我们的新基准有助于以准确而严格的方式衡量绩效。 使用APPS,我们发现对于现代语言模型来说,编程非常困难,尽管性能正在提高。 因此,APPS 基准测试可以为未来大规模语言模型在自然语言程序合成这一关键任务中的性能提供预见性。 该数据集可从 https://github.com/hendrycks/apps 获取。
| PY150 | CONCODE | SPoC | APPS | |
| Programming Language | Python | Java | C++ | Python |
| Test Cases | ✕ | ✕ | ||
| Number of Programs | N/A | 104,000 | 18,356 | 232,421 |
| Lines per Program (Avg.) | 1 | 26.3 | 14.7 | 18.0 |
| Number of Exercises | 3,000 | 104,000 | 677 | 10,000 |
| Text Input | Python | Docstrings | Pseudocode | Problem Descriptions |
2相关工作
程序综合。 程序综合是生成满足给定规格的计算机程序的任务。 演绎程序综合使用形式逻辑规范来定义搜索问题。 使用复杂的优化技术来生成满足这些规范的程序(Alur等人,2018)。 由于规范必须转换为正式语言,因此这些方法可能很僵化。 从示例输入输出行为进行归纳综合可以提供正式规范的替代方案(Cai等人,2017;Gulwani等人,2017),但通常很难用示例来完全指定行为,因为任何机器学习从业者很清楚。
形式或归纳规范的替代方法是用自然语言指定程序行为,先前的工作已经在受限设置中考虑了这一点。 Raza 等人 (2015) 和 Desai 等人 (2016) 使用临时编程语言生成短程序来解决诸如“任意 2 个字母后跟任意组合”之类的规范6 个整数。” Yu 等人 (2018) 介绍了用于将自然语言查询转换为短 SQL 数据库命令的 Spider 数据集。 相比之下,我们考虑较长的自然语言规范和通用编程语言。
代码理解数据集。 语言建模是一种引人注目的代码生成工具,并且一些工作已经在有限的设置下成功地使用语言模型生成代码。 Lachaux 等人 (2020) 使用无监督机器翻译技术跨编程语言翻译函数,在许多情况下翻译后获得相同的行为。 Kulal 等人 (2019) 介绍了 SPoC,这是一种利用 seq2seq 机器翻译和附加搜索步骤将伪代码转换为代码的方法。 为了训练 SPoC,他们使用 Amazon Mechanical Turk 收集 C++ 程序的逐行描述。 最近,Lu 等人 (2021) 推出了 CodeXGLUE 基准测试,该基准测试聚合了之前的各种基准测试,并使用 CodeBLEU (Ren 等人, 2020) 和 CONCODE。 Iyer 等人 (2018) 研究从文档字符串生成 Java 代码并使用 BLEU 评估性能。 文档字符串通常是应编码内容的不完整规范,平均只有 个单词长,例如“将大小写混合转换为下划线。”相比之下,我们新的 APPS 基准测试中的问题规范是独立的,并且 单词的平均长度要大得多。 与 Iyer 等人 (2018) 不同,APPS 包含每个练习的测试用例,从而能够对代码正确性进行高质量评估。 进一步的比较在附录中。
评估大规模语言模型。 现代大规模语言模型在各种基于文本的任务中表现出了令人印象深刻的能力。 在 SuperGLUE 基准(Wang 等人,2019b) 上,一些模型现在超过了人类的表现。 在许多常识推理基准上,性能正在快速提升(Zellers 等人,2019;Huang 等人,2019;Bisk 等人,2019)。 即使在法律和医学等不同技术领域对语言模型进行评估,性能也出人意料地高,并且随着模型的进一步扩大,性能还将不断提高(Hendrycks 等人,2021b)。 随着大量数据集的快速改进,找到模型表现明显低于人类的弹性基准具有挑战性。 APPS 试图填补这一空白,并将模型性能与人类专家的性能完全分开。
3 APPS 数据集
APPS 数据集由从不同开放访问编码网站(例如 Codeforces、Kattis 等)收集的问题组成。 APPS 基准测试试图反映如何通过以不受限制的自然语言提出编码问题并使用测试用例来评估解决方案的正确性来评估人类程序员。 问题的难度从入门级到大学竞赛级别不等,并衡量编码和解决问题的能力。
自动编程进度标准,缩写为 APPS,总共由 个编码问题组成,其中 个用于检查解决方案的测试用例和 个由作者编写的真实解决方案人类。 问题可能很复杂,因为问题的平均长度为 个字。 数据被均匀地分成训练集和测试集,每个集都有 问题。 测试集中,每个问题都有多个测试用例,平均测试用例数为。 每个测试用例都是针对相应问题专门设计的,使我们能够严格评估程序功能。
数据集构建。 为了创建 APPS 数据集,我们手动从开放访问站点(包括 Codewars、AtCoder、Kattis 和 Codeforces)中程序员相互分享问题的问题中整理问题。 问题以应编码内容的自然语言规范提出,并且有多种格式。 为了提高质量和一致性,我们为每个问题源编写了自定义 HTML 解析器,这使我们能够正确格式化问题文本中的 LaTeX 表达式、列表和部分。 如有必要,我们使用 MathPix API 将方程图像转换为 LaTeX,并消除依赖图像数字的问题。 我们还使用 tf-idf 特征以及 SVD 降维和余弦相似度来执行重复数据删除。 几位研究生和本科生作者在六个月的时间里完善和完善了这个数据集,确保了一组高质量的问题。
执行和评估任意 Python 代码具有挑战性。 在我们获取数据的网站上,人类解决方案可以运行任意代码,包括常见模块和库的导入语句。 为了解决这个问题,每个网站都实施了一个定制的解决方案判断系统。 我们考虑到这一点设计了一个测试框架,它合并了多个网站的评审功能。 我们还标准化了测试用例的格式。 最终结果是允许解决方案执行任意 Python 代码,并将结果与给定问题的测试用例进行比较。
数据集难度。 我们的每个问题源都使用单独的量表来衡量难度。 我们将这些不同来源的问题分为三类。 例如,Kattis 中难度低于 的问题被归类为“入门”,难度在 和 之间的问题被归类为“面试”,而难度在 和 之间的问题被归类为“面试”。难度大于的为“竞争”。
-
1.
入门级。 这些是大多数具有 1-2 年经验的程序员可以回答的问题,而不需要复杂的算法。 此类问题的示例包括计算字符串中元音的数量,或返回整数列表的运行总和。 测试集中有 个问题被分类为入门级问题和 问题。
-
2.
面试级别。 这些问题本质上更具算法性和难度,并且处于编程技术面试中提出的问题级别。 此类问题的示例可能包括涉及树或图等数据结构的问题,或需要重要算法的问题。 测试集中有 个问题被分类为面试级别,并且有 个问题。
-
3.
竞争级别。 这些问题最具挑战性,并且达到最先进的高中和大学编程竞赛的水平,包括 USACO、IOI 和 ACM。 测试集中存在个竞赛级别问题和。
问题格式。 为了适应广泛的问题源,APPS 中的问题有两种格式。
-
•
基于调用的格式问题通常提供初始起始代码(通常以函数头的形式),并要求提供解决方案作为函数的返回值。
-
•
标准输入格式问题通常缺乏起始代码。 相反,模型仅提供问题,并且必须将其答案输出到 STDOUT 流,例如通过使用 print 语句。
对于基于调用的格式问题,我们使用以下输入提示模型:
":" + q_str + "" + starter_code_str + "" + "基于调用的格式:"
对于上面的提示,变量q_str表示问题陈述的原始文本。 变量 starter_code_str 表示问题定义中给出的起始代码,如果未提供起始代码,则为空字符串。 对于标准输入格式问题,我们像以前一样用输入字符串提示模型,但我们将“基于调用的格式”替换为“标准输入格式”。请注意,如果给出了起始代码,它只是输入的一部分。 这意味着要使用起始代码,模型必须学会在其输出答案的开头复制起始代码,以获得正确的问题。 我们发现经过微调的模型能够毫无困难地做到这一点。
Problem
You are given a string of length , which only contains digits , ,…, . A substring of is a string . A substring of is called even if the number represented by it is even. Find the number of even substrings of . Note, that even if some substrings are equal as strings, but have different and , they are counted as different substrings. The first line contains an integer () — the length of the string . The second line contains a string of length . The string consists only of digits , ,…, . Print the number of even substrings of .
Model Output
Problem
You are given two integers and . Calculate the number of pairs of arrays such that: the length of both arrays is equal to ; each element of each array is an integer between and (inclusive); for any index from to ; array is sorted in non-descending order; array is sorted in non-ascending order. As the result can be very large, you should print it modulo . Input: The only line contains two integers and (, ). Output: Print one integer – the number of arrays and satisfying the conditions described above modulo .
Model Output
测试用例质量。
在APPS测试拆分中,平均测试用例数为,但有些问题只有两个测试用例。 这些问题主要来自 Kattis,由于竞赛问题数量有限而被选择用于测试分组。 一个潜在的担忧是,如果模型碰巧正确猜测了两个测试用例,这些问题可能会导致误报。 这在输出空间较大的问题中不太可能出现,但有些问题的输出空间较小,例如。 尽管模型必须从所有可能的字符串的空间中缩小这两个选项的范围,但我们发现这对于当前的模型来说并不难实现,并且这可能会导致我们的评估出现误报。
为了量化这些问题的影响,我们采用了 GPT-Neo 2.7B 通过的所有 2 和 3 测试用例问题,并手动检查是否有误报。 模型通过 2 个测试用例正确解决了 12 个问题,其中 8 个问题是误报。 在 3 个测试用例的 6 个问题中,只有 1 个是误报。 由于测试用例来自具有许多用户的编码挑战网站,我们可以假设不存在误报。 因此,2 个测试用例的假阳性率为 ,3 个测试用例的假阳性率为 。 结果是,潜在的噪声明显低于大多数自然注释的数据集。
4实验
4.1 实验设置
楷模。
我们使用 GPT-2 (Radford 等人, 2019)、GPT-3 (Brown 等人, 2020) 和 GPT-Neo (Black 等人, 2021) 型号。 GPT 架构特别适合文本生成,因为它是自回归的。 然而,GPT-2 并未在代码上进行预训练,因此我们在 GitHub 上预训练了它,如下一段所述。 传闻证据表明 GPT-3 可以生成代码。 为了确定其代码生成能力的程度,我们使用“davinci”(Instruct 系列)模型,这是最大的公开模型,据推测拥有 1750 亿个参数。 最后,GPT-Neo 具有与 GPT-3 类似的架构,并且在包括 GitHub 的 Pile (Gao 等人, 2020) 上进行预训练。 与 GPT-3 不同,GPT-Neo 的权重是公开的,因此我们可以使用 APPS 对其进行调整。
GPT-2 预训练。
由于 GPT-2 是在自然语言而不是代码上进行训练的,因此我们收集了 GitHub 代码来进一步预训练 GPT-2。 少于一颗星的 GitHub 存储库被过滤掉。 虽然 Neo 的 GitHub 预训练数据没有经过 APPS 数据净化过程,但我们的 GPT-2 模型是在净化数据上进行训练的。 具体来说,所有与某些关键字匹配的存储库都被删除,这些关键字表明与常见的编程练习重叠。 我们在补充材料中提供了关键字列表。 我们还会丢弃任何包含与许多 APPS 问题中的起始代码中的函数具有相同签名的函数的 GitHub 代码。 这给我们留下了 30 GB 的 Python 代码。 为了提高预训练的效率,我们通过从空格转换为制表符来处理预训练数据集中的所有Python代码,这节省了运行模型分词器时的字符转换。
微调。
在使用 APPS 进行微调期间,目标是在给定英文文本问题陈述和问题格式(基于调用的格式或标准输入格式)的情况下预测整个代码解决方案。 对于起始代码的问题,我们将起始代码从训练损失中排除。
在预训练和微调过程中,我们使用 AdamW 优化器 (Loshchilov 和 Hutter,2019),批量大小为 ,权重衰减为 。 我们对 纪元造成了压力。 我们使用 DeepSpeed 及其 ZeRO 训练优化器的实现来减少大型模型的内存消耗(Rasley 等人,2020;Rajbhandari 等人,2020)。 除非另有说明,我们使用默认的 HuggingFace 生成参数,只不过我们使用波束大小为 的波束搜索。 模型在 8 个 A100 GPU 上进行了微调。
4.2指标
为了获得代码生成能力的综合评估,我们使用了 APPS 提供的大量测试用例和真实解决方案。 测试用例允许自动评估,即使可能的程序空间可能非常庞大。 因此,与许多其他文本生成任务不同,不需要手动分析。 我们使用两个指标来汇总生成的代码在测试用例上的性能:“测试用例平均值”和“严格准确性”。
测试用例平均值。 我们计算通过的测试用例的平均比例。 具体来说,令测试集中的问题数量为。对于给定的问题,让生成的解决问题的代码表示为,并为问题设置测试用例是。 那么测试用例的平均值是
通常,解决方案可以成功通过测试用例的子集,但不能涵盖所有极端情况。 这允许不太严格的模型评估,因为严格的准确性目前可能会掩盖模型的改进。
| Test Case Average | Strict Accuracy | |||||||
| Model | Introductory | Interview | Competitive | Average | Introductory | Interview | Competition | Average |
| GPT-2 0.1B | 5.64 | 6.93 | 4.37 | 6.16 | 1.00 | 0.33 | 0.00 | 0.40 |
| GPT-2 1.5B | 7.40 | 9.11 | 5.05 | 7.96 | 1.30 | 0.70 | 0.00 | 0.68 |
| GPT-Neo 2.7B | 14.68 | 9.85 | 6.54 | 10.15 | 3.90 | 0.57 | 0.00 | 1.12 |
| GPT-3 175B | 0.57 | 0.65 | 0.21 | 0.55 | 0.20 | 0.03 | 0.00 | 0.06 |
严格的准确性。 最终,生成的解决方案应该通过所有测试用例,包括极端情况。 为了计算要求程序通过每个测试用例的严格准确性,我们在每个问题的每个测试用例上运行模型生成的代码。 然后通过将通过每个测试用例的解决方案数量除以练习总数来计算严格准确性。 使用之前的符号,我们可以将严格精度写为 当模型变得足够强大时,未来的研究可能只会使用严格的准确性。
4.3模型性能分析
定性输出分析。
测试用例评估。
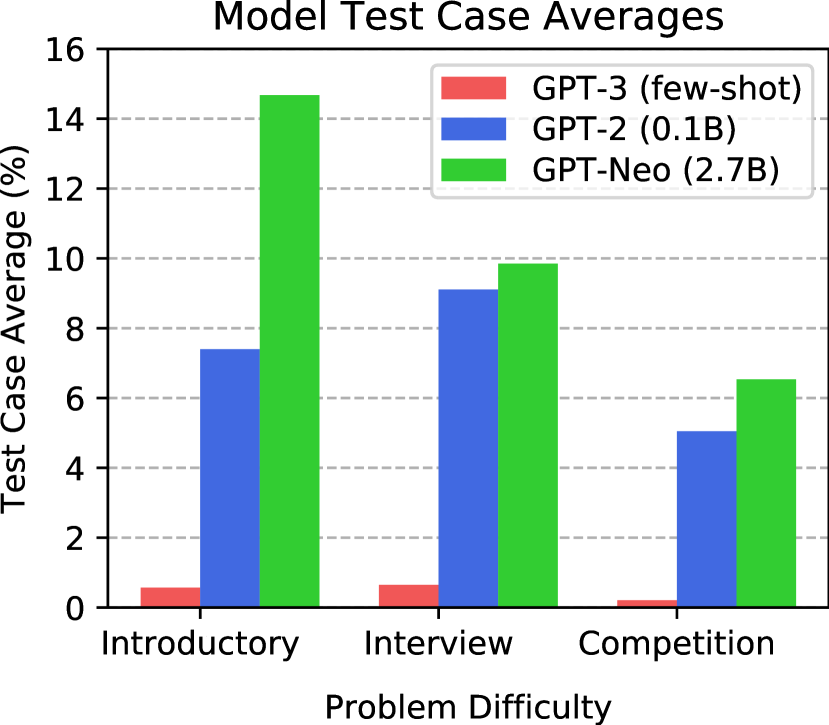
我们在表2中显示了主要结果。 我们观察到模型能够生成通过一些测试用例的代码,这意味着许多生成的程序没有语法错误,并且可以成功处理输入测试用例以产生正确的答案。 请注意,对于介绍性问题,GPT-Neo 通过了大约 的测试用例。 我们在图5中可视化测试用例平均结果。 这表明模型在代码生成方面显示出显着的改进,并且现在开始对代码生成产生吸引力。
| Top-1 | Top-5 | |
| Test Case Average | ||
| Strict Accuracy |
通过对多个解决方案进行采样并选择最佳的,可以进一步提高性能。 在这里,我们使用波束宽度 执行波束搜索并评估其 波束,以便每个模型有五次尝试来解决问题而不是一次。 通过这种设置,GPT-Neo 在介绍性问题上的严格精度就超过了 ,如 Table 3 所示。 我们在补充材料中的结果显示,GPT-2 0.1B 的前 5 个测试用例平均值为 10.75,而 GPT-2 1.5B 的前 1 个测试用例平均值为 7.96。 这凸显了简单地对多个候选解决方案进行采样是显着提高性能的有效方法。
我们的结果还为我们提供了有关模型选择重要性的信息。 显然,现有的少样本 GPT-3 模型在代码生成方面并不一定比小两个数量级的微调模型更好。 此外,从GPT-2 1.5B到GPT-Neo 2.7B的性能提升比从GPT-2 0.1B到GPT-2 1.5B的性能提升还要大。 GPT-Neo 性能更好的潜在原因是 GPT-Neo 在 GitHub 上接受了更多代码的训练,它有更多的参数,或者它的架构超参数选择得更好。 用记忆来解释所有的表现是一个令人难以置信的解释,因为表现跟踪问题的难度;如果模型只是记忆,我们会期望在困难中表现一致。 由于模型仍有很大的改进空间,在没有不合理数量的计算资源的情况下解决 APPS 基准测试可能需要架构或算法的改进。
语法错误。
我们现在评估语法错误的频率,这些错误会阻止程序被解释,包括不一致的间距、不平衡的括号、缺少冒号等。 我们的测试框架中根据 pyext 是否能够将生成的代码作为 Python 模块加载的启发式来识别语法错误。 就我们的目的而言,这几乎完全是由于语法错误而发生的。 我们在图5中可视化语法错误的普遍程度。 虽然 GPT-3 为介绍性问题生成的解决方案中大约有 存在语法错误,但 GPT-Neo 语法错误频率大约为 。 请注意,最近的工作,例如Yasunaga和Liang(2020)创建了一个单独的模型来修复源代码以解决编译问题,但我们的结果表明,这种努力在未来可能是不必要的,因为语法错误频率是自动急剧减少。
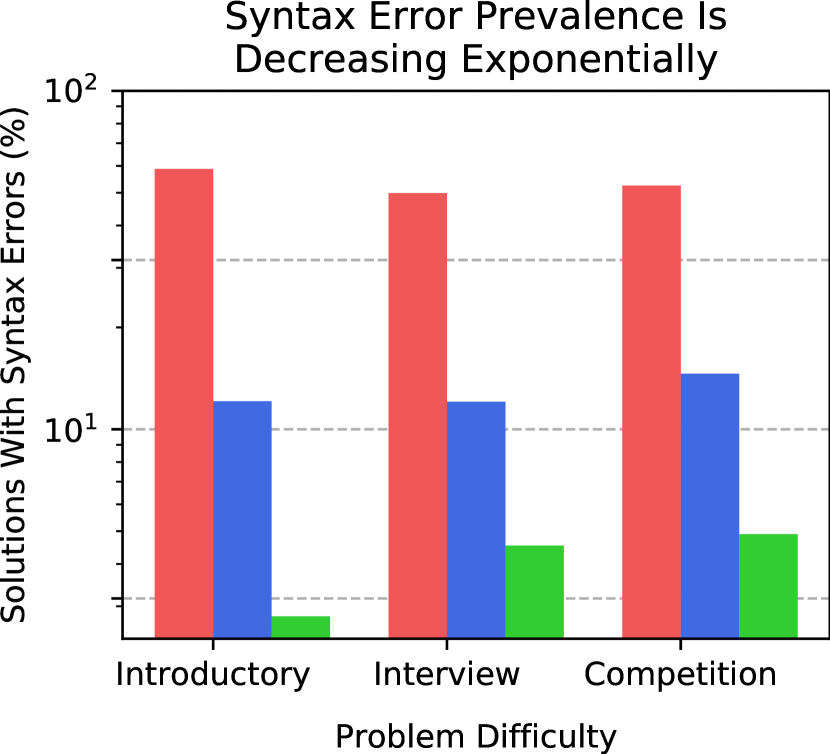
蓝色。
我们发现使用 BLEU 评估模型性能并不能很好地替代使用测试用例进行评估。 为了评估 BLEU,我们采用生成的解决方案,并使用给定问题的每个人工编写的解决方案计算其 BLEU;然后我们记录最高的 BLEU 分数。 从图 6中观察,BLEU 随着问题源变得更加困难而增加,尽管模型实际上在更困难的问题上表现较差。 此外,较差的模型可能具有相似或更高的 BLEU 分数。 例如,GPT-2 0.1B 将 、 和 分别作为入门问题、面试问题和竞赛问题的 BLEU 分数。 同时,GPT-Neo 2.7B 的 BLEU 分数分别为 、 和 。 因此 BLEU 错误地认为 GPT-Neo 是一个更糟糕的模型。
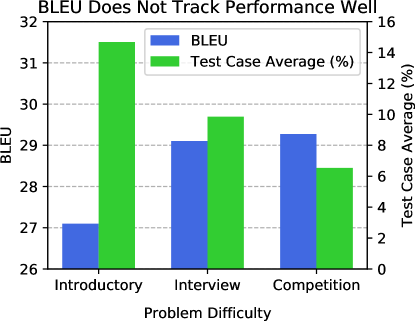
评估 GPT-3。
我们在少样本设置中评估了 APPS 上的 GPT-3 175B。 标准输入和基于调用的问题使用单独的提示,每个提示都包含说明文本以及两个示例问题和相应问题类型的解决方案。 我们发现 GPT-3 只能解决 中的 个问题:两个介绍性问题和一个面试问题。 两个介绍性问题是简单的解释任务,例如实现指定的代数表达式。 面试问题需要更高层次的思考,需要进行非平凡的推理。 然而,GPT-3 有可能在预训练期间记住了解决方案,或者根据问题中的启发法进行了幸运的猜测。 GPT-3 性能不佳的一个潜在因素是它对语法的处理很差。 也就是说,我们观察到其他功能代码的格式不正确会导致语法错误的情况。 有关具体示例和更多详细信息,请参阅补充材料。
对较大模型的评估。
自从 APPS 公开发布以来,其他几个人已经在 APPS 上训练了比我们在这里评估的更大的模型。 OpenAI Codex 是一个基于大量公共代码和注释进行预训练的 12B 参数 Transformer 语言模型。 Chen 等人 (2021) 在各种配置下对 APPS 上的 Codex 进行评估,在入门问题上实现了 top-1 和 top-5 准确率分别为 4.14% 和 9.65%,接近 top-5 准确率的两倍GPT-Neo 2.7B。 此外,通过扩大到前 1000 名评估,他们获得了 25% 的准确率。 这表明专门为代码生成而训练的较大模型可以进一步提高 APPS 性能,但距离解决任务还很远。
5结论
我们引入了 APPS,这是 Python 编程问题的基准。 与之前专注于伪代码到代码生成或编程语言之间的翻译的工作不同,我们的基准测试衡量的是语言模型在给定自然语言规范的情况下生成 python 代码的能力。 通过执行广泛的质量保证并包含数十万个不同难度级别的测试用例和地面实况解决方案,我们创建了一个全面且严格的测试平台来评估模型。 我们根据基准评估了最先进的生成模型,发现整体性能较低。 然而,随着模型的改进,语法错误的发生率呈指数下降,并且最近的模型(例如 GPT-Neo)解决了超过 的介绍性问题。 随着模型在代码生成方面变得越来越有能力,拥有一个代理来跟踪这一功能非常重要,这有一天可能会导致自动化或恶意代码生成。 APPS 基准测试可以为跟踪上游程序综合进展提供重要的衡量标准。
参考
- Allamanis and Sutton (2013) Miltiadis Allamanis and Charles Sutton. Mining source code repositories at massive scale using language modeling. In 2013 10th Working Conference on Mining Software Repositories (MSR), pages 207–216. IEEE, 2013.
- Alur et al. (2018) Rajeev Alur, Dana Fisman, Saswat Padhi, Rishabh Singh, and Abhishek Udupa. Sygus-comp 2018: Results and analysis. SYNT, 2018.
- Bisk et al. (2019) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language, 2019.
- Black et al. (2021) Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow, March 2021. URL https://doi.org/10.5281/zenodo.5297715. If you use this software, please cite it using these metadata.
- Brown et al. (2020) T. Brown, B. Mann, Nick Ryder, Melanie Subbiah, J. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, G. Krüger, T. Henighan, R. Child, Aditya Ramesh, D. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, E. Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, J. Clark, Christopher Berner, Sam McCandlish, A. Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. ArXiv, abs/2005.14165, 2020.
- Cai et al. (2017) Jonathon Cai, Richard Shin, and D. Song. Making neural programming architectures generalize via recursion. 2017.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde, Jared Kaplan, Harri Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Desai et al. (2016) Aditya Desai, Sumit Gulwani, Vineet Hingorani, Nidhi Jain, Amey Karkare, Mark Marron, and Subhajit Roy. Program synthesis using natural language. In Proceedings of the 38th International Conference on Software Engineering, pages 345–356, 2016.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
- Gebru et al. (2018) Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumeé III, and Kate Crawford. Datasheets for datasets. arXiv preprint arXiv:1803.09010, 2018.
- Gulwani et al. (2017) Sumit Gulwani, Oleksandr Polozov, and R. Singh. Program synthesis. Found. Trends Program. Lang., 4:1–119, 2017.
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning AI with shared human values. Proceedings of the International Conference on Learning Representations (ICLR), 2021a.
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021b.
- Hendrycks et al. (2021c) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021c.
- Huang et al. (2019) Lifu Huang, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Cosmos qa: Machine reading comprehension with contextual commonsense reasoning, 2019.
- Iyer et al. (2018) Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. Mapping language to code in programmatic context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October-November 2018. Association for Computational Linguistics.
- Kulal et al. (2019) Sumith Kulal, Panupong Pasupat, Kartik Chandra, Mina Lee, Oded Padon, Alex Aiken, and Percy S Liang. Spoc: Search-based pseudocode to code. In Advances in Neural Information Processing Systems, volume 32, 2019.
- Lachaux et al. (2020) Marie-Anne Lachaux, Baptiste Roziere, Lowik Chanussot, and Guillaume Lample. Unsupervised translation of programming languages. arXiv preprint arXiv:2006.03511, 2020.
- Ling et al. (2016) W. Ling, P. Blunsom, Edward Grefenstette, K. Hermann, Tomás Kociský, Fumin Wang, and A. Senior. Latent predictor networks for code generation. ArXiv, abs/1603.06744, 2016.
- Liu et al. (2020a) Hui Liu, Mingzhu Shen, Jiaqi Zhu, Nan Niu, Ge Li, and Lu Zhang. Deep learning based program generation from requirements text: Are we there yet? IEEE Transactions on Software Engineering, 2020a.
- Liu et al. (2020b) J. Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. LogiQA: A challenge dataset for machine reading comprehension with logical reasoning. In IJCAI, 2020b.
- Loshchilov and Hutter (2019) I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- Lu et al. (2021) Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, A. Blanco, C. Clément, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, L. Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, N. Duan, N. Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. Codexglue: A machine learning benchmark dataset for code understanding and generation. 2021.
- Oda et al. (2015) Yusuke Oda, Hiroyuki Fudaba, Graham Neubig, Hideaki Hata, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. Learning to generate pseudo-code from source code using statistical machine translation. In International Conference on Automated Software Engineering (ASE), 2015.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- Polu and Sutskever (2020) Stanislas Polu and Ilya Sutskever. Generative language modeling for automated theorem proving. ArXiv, abs/2009.03393, 2020.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models, 2020.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2020.
- Raychev et al. (2016) Veselin Raychev, Pavol Bielik, and Martin T. Vechev. Probabilistic model for code with decision trees. Proceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, 2016.
- Raza et al. (2015) Mohammad Raza, Sumit Gulwani, and Natasa Milic-Frayling. Compositional program synthesis from natural language and examples. In IJCAI, 2015.
- Ren et al. (2020) Shuo Ren, Daya Guo, Shuai Lu, L. Zhou, Shujie Liu, Duyu Tang, M. Zhou, A. Blanco, and S. Ma. Codebleu: a method for automatic evaluation of code synthesis. ArXiv, abs/2009.10297, 2020.
- Tang and Mooney (2001) L. Tang and R. Mooney. Using multiple clause constructors in inductive logic programming for semantic parsing. In ECML, 2001.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, L. Kaiser, and Illia Polosukhin. Attention is all you need. ArXiv, abs/1706.03762, 2017.
- Wang et al. (2019a) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. In NeurIPS, 2019a.
- Wang et al. (2019b) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. In NeurIPS, 2019b.
- Wang et al. (2019c) Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. Rat-sql: Relation-aware schema encoding and linking for text-to-sql parsers. arXiv preprint arXiv:1911.04942, 2019c.
- Yasunaga and Liang (2020) Michihiro Yasunaga and Percy Liang. Graph-based, self-supervised program repair from diagnostic feedback. ArXiv, abs/2005.10636, 2020.
- Yu et al. (2018) Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. arXiv preprint arXiv:1809.08887, 2018.
- Zavershynskyi et al. (2018) Maksym Zavershynskyi, A. Skidanov, and Illia Polosukhin. Naps: Natural program synthesis dataset. 2nd Workshop on Neural Abstract Machines and Program Induction, 2018.
- Zelle and Mooney (1996) J. Zelle and R. Mooney. Learning to parse database queries using inductive logic programming. In AAAI/IAAI, Vol. 2, 1996.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?, 2019.
| Hearthstone | Django | NAPS | APPS | |
| Programming Language | Python | Python | UAST | Python |
| Test Cases | ✕ | ✕ | ||
| Number of Programs | 665 | 18,805 | 17,477 | 232,421 |
| Lines per Program (Avg.) | 7.7 | 1 | 21.7 | 18.0 |
| Number of Exercises | 665 | 18,805 | 2,231 | 10,000 |
| Text Input | Card Text | Comment | Pseudocode | Problem Descriptions |
| Top-5 Test Case Average | Top-5 Strict Accuracy | |||||||
| Model | Introductory | Interview | Competitive | Average | Introductory | Interview | Competition | Average |
| GPT-2 0.1B | 13.81 | 10.97 | 7.03 | 10.75 | 2.70 | 0.73 | 0.00 | 1.02 |
| GPT-2 1.5B | 16.86 | 13.84 | 9.01 | 13.48 | 3.60 | 1.03 | 0.00 | 1.34 |
| GPT-Neo 2.7B | 19.89 | 13.19 | 9.90 | 13.87 | 5.50 | 0.80 | 0.00 | 1.58 |
附录A辅助数据集信息
合法合规。
在 APPS 中,我们从各种编码挑战网站上抓取问题文本、真实解决方案和测试用例。 这些网站包括 AtCoder、CodeChef、Codeforces、Codewars、HackerRank、Kattis 和 LeetCode。 在所有情况下,我们只抓取面向公众的数据。 例如,我们避免从网站的付费部分抓取数据。 就 Kattis 而言,我们抓取的所有问题均采用 CC BY-SA 3.0 许可证 (https://creativecommons.org/licenses/by-sa/3.0/)。 对于其他网站,某些内容可能受版权保护。 在这些情况下,我们遵守合理使用§107:“对受版权保护的作品的合理使用,包括……学术或研究的使用,不构成对版权的侵犯”,其中合理使用由“目的和特征”决定使用的情况,包括这种使用是商业性质还是非营利教育目的”、“与整个受版权保护的作品相关的使用部分的数量和实质性”以及“使用对版权作品的影响”受版权保护的作品的潜在市场或价值。” APPS 数据集是非商业性的,可能对原始问题的价值没有影响。 此外,对于所有问题源,我们只抓取了可用问题和地面实况解决方案的一小部分。
关于国际版权法,我们抓取的网站位于美国、日本、印度和俄罗斯,这些国家都是《产权组织版权条约》的缔约方。 在美国,《WIPO 版权条约》是通过《数字千年版权法》(DMCA) 实施的。 由于APPS是在美国制定的,DMCA是我们必须遵守的相关立法。 值得注意的是,DMCA §1201 规定,“任何人不得规避有效控制对受本标题保护的作品的访问的技术措施。”我们在创建应用程序时不会规避访问控制,因此遵守§1201。 合理使用延伸至受 DMCA 保护的内容,对此我们建议读者参阅上一段。
尽管 GDPR 仅适用于欧盟,但 APPS 中的一些真实解决方案可能是由欧盟公民编写的。 GDPR 主要关注保护从事经济活动的实体收集的个人数据。 APPS 中唯一的个人链接信息是由个人编写并以别名发布到公共网站的问题解决方案。 在某些情况下,这些解决方案在评论中包含识别信息,我们会删除这些信息以保护隐私。 我们遵守 GDPR,因为我们经过处理的解决方案删除了标识符,我们遵守 GDPR,因为我们收集数据用于学术研究目的。
作者声明和许可。
如果侵犯权利,我们承担所有责任。 APPS 数据根据 Kattis 问题许可证和相同方式共享条款,在 CC BY-SA 3.0 下获得许可。 我们的代码是根据 MIT 许可证开源的。
附录 B数据表
我们遵循 Gebru 等人 (2018) 的建议,并在本节中提供 ETHICS 数据集的数据表。
B.1 动机
创建数据集的目的是什么? 是否有特定的任务? 是否有需要填补的具体空白? 请提供说明。
创建 APPS 数据集是为了跟踪代码生成模型在从复杂的自然语言规范生成任意 Python 代码的任务中的进度,这是一个具有挑战性的设置,在我们工作之前没有严格的基准。
谁创建了数据集(例如哪个团队、研究小组)并代表哪个实体(例如公司、机构、组织)?
请参阅主要文档。
谁资助了数据集的创建? 如果有相关赠款,请提供赠款人姓名以及赠款名称和编号。
没有相关补助金。
还有其他评论吗?
不。
B.2组成
组成数据集的实例代表什么(例如文档、照片、人物、国家)? Are there multiple types of instances (e.g., movies, users, and ratings; people and interactions between them; nodes and edges)? 请提供说明。
这些实例是以自然语言提出的编码挑战问题,每个实例都由问题文本、真实答案和测试用例组成。 请参阅主要文档了解更多详细信息。
总共有多少个实例(每种类型,如果适用)?
APPS 包含 10,000 个问题、232,421 个真实解决方案和 131,777 个测试用例。
数据集是否包含所有可能的实例,或者它是来自更大集合的实例的样本(不一定是随机的)? 如果数据集是一个样本,那么更大的集合是多少? 样本是否代表更大的集合(例如地理覆盖范围)? 如果是,请描述如何验证/核实这种代表性。 如果它不能代表更大的集合,请描述为什么不代表(例如,为了覆盖更多样化的实例,因为实例被保留或不可用)。
APPS 包含其问题的所有可能测试用例的子集。 这些测试用例由问题设计者编写,以涵盖重要的功能。
每个实例包含哪些数据? “原始”数据(例如,未经处理的文本或图像)或特征? 无论哪种情况,请提供说明。
每个实例都由文本和数字数据组成。
是否有与每个实例关联的标签或目标? 如果是,请提供描述。
每个实例都与测试用例相关联,测试用例为功能正确性提供了真实信号。
个别实例是否缺少任何信息? 如果是这样,请提供描述,解释为什么缺少此信息(例如,因为它不可用)。 这不包括故意删除的信息,但可能包括例如经过编辑的文本。
不。
各个实例之间的关系是否明确(例如,用户的电影评分、社交网络链接)? 如果是这样,请描述如何使这些关系变得明确。
我们从 APPS 中删除重复或接近重复的问题。
是否有推荐的数据分割(例如训练、开发/验证、测试)? 如果是这样,请提供这些拆分的描述,并解释其背后的理由。
我们提供训练和测试分开。 对拆分进行了优化,以增加测试拆分中的测试用例数量,同时保持每个难度的问题数量固定。
数据集中是否存在任何错误、噪声源或冗余? 如果是,请提供描述。
有关测试用例质量的讨论,请参阅主论文中的第 3 节。
数据集是独立的,还是链接到或以其他方式依赖外部资源(例如网站、推文、其他数据集)?
该数据集是独立的。
数据集是否包含可能被视为机密的数据(例如,受法律特权或医患机密保护的数据、包含个人非公开通信内容的数据)? 如果是,请提供描述。
不。
数据集是否包含如果直接查看可能具有冒犯性、侮辱性、威胁性或可能引起焦虑的数据? 如果是这样,请描述原因。
未知。
数据集与人相关吗? 如果没有,您可以跳过本节中的其余问题。
是的。
数据集是否识别任何亚群(例如,按年龄、性别)? 如果是这样,请描述如何识别这些亚群,并提供它们在数据集中各自的分布的描述。
不。
是否可以直接或间接(即与其他数据结合)从数据集中识别个人(即一个或多个自然人)? 如果是这样,请描述如何
不。
数据集是否包含可能以任何方式被视为敏感的数据(例如,揭示种族或民族出身、性取向、宗教信仰、政治观点或工会成员身份或位置的数据;财务或健康数据;生物识别或遗传数据;表格)政府身份证明,例如社会安全号码;犯罪记录)? 如果是,请提供描述。
不。
还有其他评论吗?
不。
B.3收集流程
与每个实例相关的数据是如何获取的? 数据是直接可观察的(例如,原始文本、电影评级)、由受试者报告(例如,调查答复),还是从其他数据(例如,词性标签、基于模型的年龄或年龄猜测)间接推断/得出?语言)? 如果数据由受试者报告或从其他数据间接推断/得出,数据是否经过验证/验证? 如果是这样,请描述如何。
所有数据都是通过从编码挑战网站(例如 Codewars、AtCoder 和 Kattis)中抓取问题来收集的。
使用什么机制或程序来收集数据(例如,硬件设备或传感器、人工管理、软件程序、软件 API)? 这些机制或程序是如何验证的?
我们使用现成的和定制的刮刀。 我们手动检查抓取的数据是否与网站上的文本匹配。
如果数据集是来自较大集合的样本,那么采样策略是什么(例如,确定性、具有特定采样概率的概率性)?
由于各种原因,我们抓取的一些问题被排除在 APPS 之外,例如它们需要图像来解决,它们缺乏真实的解决方案和测试用例,或者它们是重复的问题。
谁参与了数据收集过程(例如学生、众包工作者、承包商)以及他们如何获得报酬(例如众包工作者支付了多少钱)?
所有数据均由本科生和研究生作者在论文中收集。
数据是在多长时间内收集的? 此时间范围是否与实例关联的数据的创建时间范围相匹配(例如,最近对旧新闻文章的爬网)? 如果没有,请描述创建与实例关联的数据的时间范围。
数据收集于 2020 年底至 2021 年初,并经过六个月的完善。
是否进行了任何道德审查流程(例如,由机构审查委员会进行)? 如果是,请提供这些审核流程的描述,包括结果,以及任何支持文档的链接或其他访问点
不。
数据集与人相关吗? 如果没有,您可以跳过本节中的其余问题。
是的。
您是直接从相关个人那里收集数据,还是通过第三方或其他来源(例如网站)获取数据?
我们通过个人公开发布问题解决方案的网站抓取数据。
相关个人是否收到有关数据收集的通知? 如果是这样,请描述(或用屏幕截图或其他信息显示)如何提供通知,并提供链接或其他访问点,或以其他方式复制通知本身的确切语言。
在互联网上发帖的用户不会收到我们收集的通知,因为他们的示例是公开发布的。
有关个人是否同意收集和使用他们的数据? 如果是这样,请描述(或用屏幕截图或其他信息显示)如何请求和提供同意,并提供链接或其他访问点,或以其他方式复制个人同意的确切语言。
不适用
如果获得同意,是否为同意的个人提供了在未来或出于某些用途撤销其同意的机制? 如果是,请提供描述以及该机制的链接或其他访问点(如果适用)。
不适用
是否对数据集的潜在影响及其对数据主体的使用进行了分析(例如数据保护影响分析)? 如果是,请提供此分析的描述,包括结果,以及任何支持文档的链接或其他访问点。
不。
还有其他评论吗?
不。
B.4预处理/清洁/标签
是否对数据进行了任何预处理/清理/标记(例如,离散化或分桶、标记化、词性标记、SIFT 特征提取、实例删除、缺失值处理)? 如果是,请提供描述。 如果没有,您可以跳过本节中的其余问题。
是的,如主论文第 3 节所述。
除了预处理/清理/标记的数据之外,是否还保存了“原始”数据(例如,以支持意外的未来用途)? 如果是这样,请提供“原始”数据的链接或其他访问点。
不。
用于预处理/清理/标记实例的软件是否可用? 如果是,请提供链接或其他访问点。
目前还不行。
还有其他评论吗?
不。
B.5用途
该数据集是否已用于任何任务? 如果是,请提供描述。
是的,请参阅主要论文。
是否有一个存储库链接到使用该数据集的任何或所有论文或系统? 如果是,请提供链接或其他访问点。
不。
该数据集可以用于哪些(其他)任务?
不适用
数据集的组成或其收集和预处理/清理/标记的方式是否有任何可能影响未来使用的因素? 例如,未来的用户是否需要了解一些信息,以避免使用可能导致个人或团体受到不公平待遇(例如,刻板印象、服务质量问题)或其他不良伤害(例如,经济损失、法律风险)如果是,请提供描述。 未来的用户可以采取什么措施来减轻这些不良伤害?
我们在附录 A 中描述了我们的数据收集如何合法合规。
是否存在不应使用该数据集的任务? 如果是,请提供描述。
不适用
还有其他评论吗?
不。
B.6分布
数据集是否会分发给代表其创建的实体(例如公司、机构、组织)之外的第三方? 如果是,请提供描述。
是的,数据集将公开分发。
数据集将如何分发(例如网站上的 tarball、API、GitHub)? 数据集是否有数字对象标识符 (DOI)?
该数据集可从 https://github.com/hendrycks/apps 获取。
数据集什么时候分发?
该数据集目前可用。
数据集是否会根据版权或其他知识产权 (IP) 许可和/或适用的使用条款 (ToU) 进行分发? 如果是,请描述本许可和/或 ToU,并提供任何相关许可条款或 ToU 以及与这些限制相关的任何费用的链接或其他访问点,或以其他方式复制。
我们的实验框架的代码是根据 MIT 许可证分发的。 在适用的情况下,
是否有第三方对与实例相关的数据施加基于 IP 或其他的限制? 如果是,请描述这些限制,并提供任何相关许可条款以及与这些限制相关的任何费用的链接或其他访问点,或以其他方式复制。
如果我们从中抓取数据的网站有版权政策,我们会遵守第 107 条规定的合理使用,并遵守 GDPR,即使我们的真实解决方案的所有问题来源都位于美国。 详细信息请参见附录 A。
任何出口管制或其他监管限制是否适用于数据集或单个实例? 如果是这样,请描述这些限制,并提供任何支持文档的链接或其他访问点,或以其他方式复制。
不。
还有其他评论吗?
不。
B.7维护
谁支持/托管/维护数据集?
请参阅主要文档。
如何联系数据集的所有者/管理者/管理者(例如电子邮件地址)?
请参阅主要文档。
有勘误吗? 如果是,请提供链接或其他访问点。
目前还不行。
数据集是否会更新(例如,纠正标签错误、添加新实例、删除实例)? 如果是,请描述向用户传达更新的频率、由谁以及如何传达(例如,邮件列表、GitHub)?
我们计划使用每个问题的问题文本中存在的测试用例的附加 JSON 来更新数据集。 这可以通过 GitHub 获得。
如果数据集与人相关,与实例相关的数据的保留是否有适用的限制(例如,相关个人是否被告知他们的数据将保留一段固定的时间,然后被删除)? 如果是这样,请描述这些限制并解释它们将如何执行
不。
旧版本的数据集是否会继续得到支持/托管/维护? 如果是这样,请描述如何。 如果没有,请描述如何将其过时信息传达给用户。
不适用
如果其他人想要扩展/增强/构建数据集/为数据集做出贡献,是否有一种机制可以让他们这样做? 如果是,请提供描述。 这些贡献会被验证/验证吗? 如果是这样,请描述如何。 如果没有,为什么不呢? 是否有一个流程可以将这些贡献传达/分发给其他用户? 如果是,请提供描述。
我们的数据集可以根据现有问题的格式来扩展其他问题。
还有其他评论吗?
不。
附录 C其他数据集信息
扩展数据集比较。
我们与(Kulal 等人, 2019; Yu 等人, 2018; Raychev 等人, 2016; Iyer 等人, 2018; Lu 等人, 2021)主论文中的几个数据集进行了比较。 下面我们继续进行比较。 Ling等人(2016)介绍基于《炉石传说》和《万智牌》卡牌游戏的数据集进行代码生成。 Oda 等人 (2015) 使用简单的代码注释提供了语言到代码的数据集。 Zavershynskyi 等人 (2018) 介绍了用于将伪代码转换为代码的 NAPS 数据集,该数据集是通过众包编程练习的低级描述获得的,并将机器翻译技术应用于该问题。 最近社交媒体上的轶事帖子表明,现代 Transformer 在某些情况下可以根据用户请求生成 JSX 代码,但我们的工作通过定量评估为讨论提供了精确性。 Allamanis 和 Sutton (2013) 介绍了用于对 Java 代码执行语言建模的 GitHub Java 语料库。 Liu 等人 (2020a) 对代码生成进行了小规模分析,但由于语言特定的训练数据模型有限,在 300 个测试问题上“甚至无法通过单个预定义的测试用例”,而借助我们庞大的训练集和测试集,经过训练的模型可以通过数万个测试用例。 Zelle and Mooney (1996) 和 Tang and Mooney (2001) 领先于 Yu 等人 (2018),也促进了数据库查询的综合,尽管最近的程序综合作品,例如 Wang 等人 (2019c) 使用 Yu 等人 (2018) 中的 Spider。
表 4将APPS与炉石传说(Ling等人,2016),Django (Oda等人)进行比较,2015),和Zavershynskyi 等人(2018)。 “程序数量”是指数据集中人类编写的程序或函数的数量,“练习数量”是指网络必须解决的任务数量。 这些数字在数据集中可能有所不同,例如每次练习都有多个人工编写的解决方案的 APPS。
排除的关键字。
在创建 GitHub 预训练数据集时,我们排除了以下关键字,以防止与应用程序中类似的编码挑战问题重叠:'atcoder'、'coderbyte'、'leetcode'、'codeforces'、'codewars'、'hackerrank'、 'topcoder'、'codechef'、'checkio'、'HackerEarth'、'Programmr'、'Exercism'、'Codier'、'PyBites'、'Tynker'、'CodinGame'、'CodeCombat'、'usaco'、'IOI ', 'UVA', 'ICFP', 'EPIJudge', 'SPOJ', 'UVaOJ', '法官', '面试', '解决方案', '编码', '代码', '问题', '练习', “挑战”、“算法”、“练习”、“竞争”、“程序”。
附录 D其他结果
前 5 名表现。
我们不是让模型只生成一种潜在的解决方案,而是让模型生成五个,然后选择性能最佳的解决方案。 完整的前 5 名性能结果位于表5中。
GPT-3。
我们在少样本设置中评估了 APPS 上的 GPT-3 175B。 标准输入和基于调用的问题使用单独的提示,每个提示都包含说明文本以及两个示例问题和相应问题类型的解决方案。 我们为每个提示选择的解决方案是通过相应问题的所有测试用例的最短解决方案。 在预备知识实验中,我们发现原来的GPT-3 175B表现不佳,而instruct系列是合理代数所必需的。 对 APPS 测试集中的 问题进行推断只需大约 500 美元。
我们发现 GPT-3 只能解决 中的 个问题:两个介绍性问题和一个面试问题。 两个介绍性问题是简单的解释任务,例如实现指定的代数表达式。 面试问题需要更高层次的思考,如图7所示。 合法地解决这个问题需要进行非平凡的推理。 然而,GPT-3 有可能在预训练期间记住了解决方案,或者根据问题中的启发法进行了幸运的猜测。
我们还发现 GPT-3 往往无法很好地处理语法。 在图 8 中,我们看到 if-else 块格式不正确的生成,这会导致语法错误。 相比之下,GPT-2 0.1B 的语法错误更少,参数少了三个数量级,而 GPT-Neo 2.7B 几乎没有语法错误。 这两个模型在 GitHub 和 APPS 训练集上进行了微调。
Problem
Mahmoud and Ehab play a game called the even-odd game. Ehab chooses his favorite integer and then they take turns, starting from Mahmoud. In each player’s turn, he has to choose an integer and subtract it from such that: . If it’s Mahmoud’s turn, has to be even, but if it’s Ehab’s turn, has to be odd.
If the current player can’t choose any number satisfying the conditions, he loses. Can you determine the winner if they both play optimally?
—–Input—–
The only line contains an integer , the number at the beginning of the game.
—–Output—–
Output “Mahmoud” (without quotes) if Mahmoud wins and “Ehab” (without quotes) otherwise.
Model Output
更多生成的代码示例。
生成代码的其他示例可以在图 9、图 10中找到t5>和图11。
Problem
Given is a directed graph G with N vertices and M edges. The vertices are numbered 1 to N, and the i-th edge is directed from Vertex A_i to Vertex B_i. It is guaranteed that the graph contains no self-loops or multiple edges. Determine whether there exists an induced subgraph (see Notes) of G such that the in-degree and out-degree of every vertex are both 1. If the answer is yes, show one such subgraph. Here the null graph is not considered as a subgraph.
Model Output
Problem
Given is a tree G with N vertices. The vertices are numbered 1 through N, and the i-th edge connects Vertex a_i and Vertex b_i. Consider painting the edges in G with some number of colors. We want to paint them so that, for each vertex, the colors of the edges incident to that vertex are all different. Among the colorings satisfying the condition above, construct one that uses the minimum number of colors.
Model Output
Problem
There is a special square room with mirrors on each of the four walls. Except for the southwest corner, there are receptors on each of the remaining corners, numbered 0, 1, and 2. The square room has walls of length p, and a laser ray from the southwest corner first meets the east wall at a distance q from the 0th receptor. Return the number of the receptor that the ray meets first. (It is guaranteed that the ray will meet a receptor eventually.)
Example 1:
Input: p = 2, q = 1
Output: 2
Explanation: The ray meets receptor 2 the first time it gets reflected back to the left wall.
Starter Code
Model Output