使用基于分数的模型生成数据时必须快速
抽象的
基于分数(去噪扩散)的生成模型最近在生成逼真且多样化的数据方面取得了很大成功。 这些方法定义了一个将数据转换为噪声的正向扩散过程,并通过逆转它(从而从噪声到数据)来生成数据。 不幸的是,由于数值 SDE 求解器所需的评分网络评估次数众多,目前的基于分数的模型生成数据的速度非常慢。
在这项工作中,我们旨在通过设计一种更有效的 SDE 求解器来加速这一过程。 现有方法依赖于欧拉-丸山 (EM) 求解器,它使用固定步长。 我们发现,用其他 SDE 求解器简单地替换它效果不佳 - 它们要么导致低质量样本,要么变得比 EM 更慢。 为了解决这个问题,我们仔细地设计了一种具有自适应步长的 SDE 求解器,该求解器专门针对基于分数的生成模型逐段设计。 我们的求解器只需要两次分数函数评估,很少拒绝样本,并能产生高质量的样本。 我们的方法比 EM 生成数据的速度快 2 到 10 倍,同时还能达到更好或相同的样本质量。 对于高分辨率图像,我们的方法比测试的所有其他方法都产生了显著更高质量的样本。 我们的 SDE 求解器具有无需步长调整的优点。
代码可在 https://github.com/AlexiaJM/score_sde_fast_sampling 获取。
1简介
基于分数的生成模型 (Song and Ermon, 2019, 2020; Ho et al., 2020; Jolicoeur-Martineau et al., 2020; Song et al., 2020a; Piché-Taillefer, 2021) 在从各种模态(如图像 (Ho et al., 2020; Song et al., 2020a)、音频 (Chen et al., 2020; Kong et al., 2020; Mittal et al., 2021; Kameoka et al., 2020) 和图形 (Niu et al., 2020))生成数据方面取得了很大成功。 它们已被有效地用于超分辨率 (Saharia 等人,2021;Kadkhodaie 和 Simoncelli,2020)、图像修复 (Kadkhodaie 和 Simoncelli,2020;Song 和 Ermon,2020)、源分离 (Jayaram 和 Thickstun,2020) 和图像到图像的转换 (Sasaki 等人,2021)。 在大多数这些应用中,得分模型在质量和多样性方面都比历史上占主导地位的生成对抗网络 (GAN) (Goodfellow 等人,2014) 取得了更好的性能。
在基于得分的方案中,扩散过程将真实数据逐步转换为高斯噪声。 然后,该过程被反转以从高斯噪声生成真实数据。 反转该过程需要得分函数,该函数由神经网络(称为得分网络)估计。 虽然非常强大,但基于得分的模型通过一个不可取的漫长迭代过程生成数据;同时,其他最先进的方法,如 GAN,从神经网络的单个前向传递生成数据。 因此,提高生成过程的速度是一个活跃的研究领域。
Chen 等人 (2020) 和 San-Roman 等人 (2021) 提出了针对 VP 扩散的更快的步长计划,这些计划仍然可以产生相对较好的质量/多样性指标。 虽然速度很快,但这些计划是任意的,需要仔细调整,而且最佳计划会因模型而异。
Block 等人 (2020) 提议从低分辨率图像逐步生成数据到高分辨率图像,并表明该方案提高了速度。 同样,Nichol 和 Dhariwal (2021) 提议生成低分辨率图像,然后对其进行放大,因为生成低分辨率图像更快。 他们还建议通过学习特定维度的噪声而不是假设处处噪声相等来加速基于 VP 的模型。 请注意,这些方法不会影响数据生成算法,因此将补充我们的方法。
Song 等人 (2020a) 和 Song 等人 (2020b) 提出从数据生成算法中去除噪声,并求解常微分方程 (ODE) 而不是随机微分方程 (SDE);他们在没有噪声的情况下报告了能够更快地收敛。 尽管它提高了生成速度,但 Song 等人 (2020a) 报告称,在使用 ODE 公式进行 VE 过程时,获得的图像质量较低 (Song 等人,2020a)。 我们将在后面证明,我们的 SDE 求解器通常比 ODE 求解器在类似速度下产生更好的结果。
因此,现有的加速方法通常需要相当大的步长/调度调整(这对于基线方法也是如此),并且并不总是适用于 VE 和 VP 过程。 为了提高速度并消除对步长/调度调整的需要,我们建议使用具有自适应步长的 SDE 求解器来解决逆扩散过程。
事实证明,现成的 SDE 求解器不适合生成式建模,并表现出 (1) 发散,(2) 比基线慢的数据生成,或 (3) 比基线质量明显更差(参见附录 A)。 这可以归因于基于分数的生成模型中出现的 SDE 的独特特征,这些特征将它们与数值 SDE 求解器文献中传统考虑的 SDE 区分开来,即:(1) 未知函数的陪域是极高维的,尤其是在图像生成的情况下;(2) 评估分数函数在计算上很昂贵,需要通过大型神经网络对大型小批量进行前向传递;(3) 所需的解精度比平时更小,因为只要误差不可感知,我们就满意(例如,图像上的一个 RGB 增量)。
我们考虑到这些特征,设计了自己的 SDE 求解器,从而产生了一种算法,可以解决现成求解器遇到的问题。 为了解决高维问题,我们使用 范数而不是 范数来测量不同维度上的误差,以防止单个像素减慢求解器的速度。 为了在仍然获得高精度的情况下解决分数函数评估的成本问题,我们 (1) 采取了自适应步长所需的最小分数函数评估次数(两次评估),以及 (2) 使用外推法以无额外成本获得高精度。 为了利用对精度的降低要求,我们将误差的绝对容差设置为根据 RGB 值的范围。
我们的主要贡献是针对基于分数的生成模型量身定制的新的 SDE 求解器,具有以下优点:
-
•
我们的求解器比基线方法快得多,即使用朗之万动力学和欧拉-丸山 (EM) 的逆扩散方法;
-
•
在使用相同计算预算时,它比 EM 产生更高质量/多样性的样本;
-
•
它不需要任何步长或调度调整;
-
•
它可用于快速解决任何类型的扩散过程(例如,VE、VP)
2 背景
2.1 基于分数的 SDE 建模
令 为来自数据分布 的样本。 该样本随着时间的推移逐渐被破坏,这通过一个正向扩散过程 (FDP) 完成,这是一种常见的随机微分方程 (SDE):
| (1) |
其中 是漂移项, 是扩散项, 是由 索引的维纳过程。 数据点及其概率分布分别沿着轨迹 和 演化,其中 。 函数 和 的选择使得 近似于高斯分布,并且与 独立。 推断是通过反转这种扩散过程实现的,从其高斯分布中抽取 并求解反向扩散过程 (RDP),其等于:
| (2) |
其中 称为时间 处分布的分数 (Hyvärinen, 2005), 是时间向后流动的维纳过程 (Anderson, 1982)。
可以从方程 2 中观察到,RDP 需要知道分数(或 ),而我们无法访问它。 幸运的是,它可以通过优化以下目标的神经网络(称为分数网络)来估计:
| (3) |
其中 是权重函数,通常选择为与以下值成反比:
可以证明,该目标 的最小化器将使得 (Vincent, 2011),这使我们能够近似反向扩散过程。 如图所示,评估目标需要能够在任意时间 从 FDP 生成样本。 幸运的是,只要漂移项是仿射的(即,),转移核 将始终是正态分布的 (Särkkä and Solin, 2019),这意味着我们可以一步完成正向扩散。 此外,高斯转移核的分数很容易计算,这使得损失成为一个廉价的训练目标。
在文献中,FDP 主要有两种选择,我们将在下面进行讨论。
2.2 方差爆炸 (VE) 过程
方差爆炸 (VE) 过程包含以下 FDP:
它的关联转换核为:
在实践中,我们令 ,其中 且 是数据集 (Song 和 Ermon, 2020) 中两个样本之间的最大欧氏距离。 使用最大欧氏距离确保 不依赖于 ;因此, 大致服从 分布。
2.3 方差保持 (VP) 过程
方差保持 (VP) 过程包含以下 FDP:
它的关联转换核为:
在实践中,我们令 ,其中 且 。 因此, 大致服从 分布,并且不依赖于 。
2.4 解决反向扩散过程 (RDP)
解决 RDP 的方法有很多,最基本的方法是 Euler-Maruyama (Kloeden 和 Platen, 1992),它是求解 ODE 的欧拉方法的 SDE 模拟。 Song 等人 (2020a) 还提出了 反向扩散,它包含使用与 FDP 中相同的离散化进行的祖先采样 (Ho 等人,2020)。 对于反向扩散,(Song 等人,2020a) 获得的结果很差,除非在每个反向扩散步骤之后应用额外的朗之万动力学步骤。 他们将这种方法称为预测器-校正器 (PC) 采样,预测器对应于反向扩散,校正器对应于朗之万动力学。 尽管使用校正步骤可以产生更好的样本,但 PC 采样只是一种启发式的动机,其理论基础尚未得到理解。 然而,(Song 等人,2020a) 报告了他们使用反向扩散与朗之万动力学进行 VE 模型的最佳结果(以最低的弗雷歇初始距离 (Heusel 等人,2017) 为衡量标准)。 对于 VP 模型,他们使用欧拉-丸山方法获得了最佳结果。
3 用于解决反向扩散过程的有效方法
3.1 算法设置
我们从一个用于求解 SDE 的通用算法开始(类似于大多数 ODE/SDE 求解器)。 我们根据理论和实验的混合选择各种选项/超参数;在附录 B 中也可以找到对不同超参数的消融研究。
3.1.1 积分方法
求解 RDP 以生成数据可能需要很长的时间。 人们会认为,使用高阶方法求解 SDE 比欧拉-丸山方法更快,就像高阶 ODE 求解器在求解 ODE 时比欧拉方法更快一样。 然而,情况并不总是如此:虽然高阶求解器可能实现更低的离散化误差,但它们需要更多的函数评估,而且改进的精度可能不值得增加的计算成本 (Lehn 等人,2002; Lamba,2003)。
我们初步尝试使用 DifferentialEquations.jl Julia 包 (Rackauckas 和 Nie,2017a) 中的 SDE 求解器证实,高阶方法明显更慢(慢 6 到 8 倍;参见附录 A)。 Lamba 算法 (Lamba,2003) 是一种低阶自适应方法,它产生了最快的结果,因此促使我们将搜索范围限制在低阶方法空间。 尽管如此,生成的图像质量仍然较低。
为了能够随时间动态调整步长,从而比固定步长算法更快,采用了两种积分方法。 传统上,对于 ODE,低阶 () 方法与高阶 () 方法结合使用。 局部误差 可用于确定低阶方法在当前步长下的稳定性;越接近零,步长越合适。 从这些信息中,我们可以动态调整步长,并决定是否接受低阶方法提出的样本。 或者,可以选择 作为提议,我们将称之为 外推法.
我们没有像 Lamba (2003) 中那样使用改进的欧拉方法 (Süli 和 Mayers, 2003),也没有像 Rackauckas 和 Nie (2017b) 中那样使用高阶随机龙格-库塔方法 (Rößler, 2010)(这在我们的 Julia 包的初步尝试中效果不佳),而是依靠随机改进的欧拉方法 (Roberts, 2012) 作为我们的高阶方法。 此方法只需要两次得分函数评估,并重复使用 EM 用的同一个得分函数评估,这意味着它的成本仅是 EM 的两倍。 与 Lamba 的算法类似,这种方法虽然快速,但会导致图像质量低下。 然而,通过使用外推法(采用 而不是 作为我们的提议),我们能够与基线方法 (EM) 相匹配并超越它。 因此,使用随机改进的欧拉方法是能够在不牺牲精度的情况下迈出更大步的关键。 请注意,Lamba 的算法不能使用外推法,因为它使用的是非随机常微分方程求解器(改进的欧拉方法)。
3.1.2 容差
在常微分方程/随机微分方程求解器中,局部误差除以 容差 项。 传统上,混合容差 计算为绝对容差和相对容差之间的最大值:
| (4) |
其中绝对值 应用于逐元素。
在 DifferentialEquations.jl Julia 包则通过当前样本和先前样本的最大值来计算混合容差:
| (5) |
由于我们的重点是图像生成,我们可以先验地设置 。 在训练期间和数据生成结束时,图像表示为具有范围 的浮点张量。 在评估时,它们必须转换为 8 位彩色图像;这意味着图像要缩放到范围 并转换为最近的整数(以表示每个颜色通道的 256 个值之一)。 考虑到 8 位彩色编码,绝对容差 对应于容忍最多一个颜色的局部误差(例如, 中的红色 = 5 和 中的红色 = 6 被接受,但 中的红色 = 5 和 中的红色 = 7 则不被接受),逐通道。 一色差不可感知,不应影响用于评估生成图像的指标。 对于范围为 的 VP 模型,这对应于 ,而对于范围为 的 VE 模型,这对应于 。
为了控制速度/质量,我们改变 ,其中较大的值会导致更快的速度但精度较低,而较小的值会导致相反的结果。
3.1.3 缩放误差的范数
缩放误差(用混合容差缩放的误差)计算为
许多算法使用 (Lamba, 2003; Rackauckas and Nie, 2017b),其中 在所有 元素 上。 虽然这对于低维 SDE 可以奏效,但对于高维 SDE(例如图像空间中的 SDE)来说,这非常成问题。 原因是,单个像素的单个通道(对于 色彩图像,总共 个像素)具有较大的局部误差,会导致所有像素的步长减小,并可能导致步长拒绝。 事实上,我们的实验证实,使用 会大大减慢生成速度(参见附录 B)。 为此,我们使用缩放的 范数:
3.1.4 动态步长算法的超参数
计算缩放误差后,如果,我们接受提案,并将时间增加。无论是否接受,我们都会更新下一步的大小 按照通常的方式:
其中 是最大步长, 是安全参数,它决定我们调整步长的强度(0 非常安全;1 很快,但拒绝率很高), 是指数缩放项。
其中 是最大步长, 是安全参数,它决定我们调整步长的力度(0 表示非常安全;1 表示快速,但拒绝率高),而 是一个指数缩放项。 因此,正如 Rackauckas 和 Nie (2017b) 所建议的那样,我们通过经验测试值发现任何 在 VE 和 VP 流程上都能很好地工作,但 稍快一些(参见附录B)。 我们随意选择 作为默认设置。
最后,我们按照文献中常见的方式默认设置安全参数,并选择等于可能的最大步长,即剩余时间。
3.1.5 处理小批量
对小批量中的每个样本使用相同的步长意味着每个图像都会因其他图像而减慢。 由于每个图像的 RDP 相互独立,我们对每个数据样本应用不同的步长;有些图像可能比其他图像收敛更快,但我们等待所有图像收敛。
3.2 算法
我们现在已经定义了数值求解图像方程 (2) 所需算法的各个方面。 算法 1 描述了由此产生的算法。 该算法很容易在批次维度上并行化。 注意,该算法仅用于解决 RDP;解决任意前向时间扩散过程的更通用版本可以在附录 C 中找到。此外,我们在附录 F 中展示了外推步骤如何保留 EM 步骤的稳定性和收敛性。
4 实验
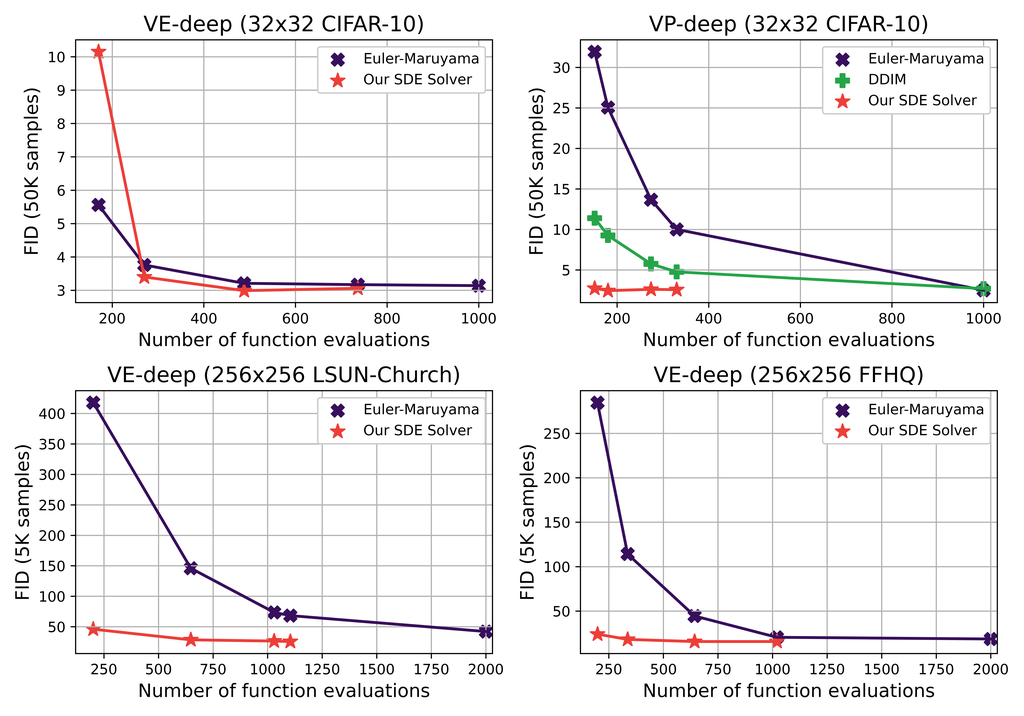
为了测试算法 1 在RDPs上的表现,我们将其应用于Song et al. (2020a) 中的各种预训练模型。 首先,我们通过在CIFAR-10 (Krizhevsky et al., 2009) 上测试VP、VE、VP-deep和VE-deep模型来生成低分辨率图像 (32x32)。 然后,我们通过在LSUN-Church (Yu et al., 2015) 和 Flickr-Faces-HQ (FFHQ) (Karras et al., 2019) 上测试VE模型来生成更高分辨率的图像 (256x256)。 请参阅附录 D 中的实现细节。我们使用四块或更少的 V100 GPU 来运行实验。
为了衡量图像生成性能,我们计算了 Fréchet Inception 距离 (FID) (Heusel 等人,2017) 和 Inception 分数 (IS) (Salimans 等人,2016),其中较低的 FID 和较高的 IS 对应于更高的质量/多样性。 我们将我们的方法与 Song 等人 (2020a) 中使用的三种基本求解器进行比较:具有 Langevin 动力学的反向扩散、Euler-Maruyama (EM) 和概率流,其中后者使用 Runge-Kutta 45 (Dormand 和 Prince,1980) 求解 ODE 而不是 SDE。 我们还比较了 (Song 等人,2020b) 提出的快速求解器,称为去噪扩散隐式模型 (DDIM),该模型仅针对 VP 模型定义。 我们定义了 基线 方法为 Song 等人 (2020a) 中使用的求解器,该求解器导致最低的 FID(VP 模型的 EM 和 VE 模型的反向扩散与 Langevin)。 对于我们的算法,唯一可调的超参数是相对容差,我们将其设置为 。
FID 和分数函数评估次数 (NFE) 分别在表 1 中(针对低分辨率图像)和表 2 中(针对高分辨率图像)进行描述。 Inception 分数 (IS) 在附录 E 中针对 CIFAR-10 进行描述。
| Method | VP | VP-deep | VE | VE-deep |
| Reverse-Diffusion & Langevin | 1999 / 4.27 | 1999 / 4.69 | 1999 / 2.40 | 1999 / 2.21 |
| Euler-Maruyama | 1000 / 2.55 | 1000 / 2.49 | 1000 / 2.98 | 1000 / 3.14 |
| DDIM | 1000 / 2.86 | 1000 / 2.69 | – | – |
| Ours () | 329 / 2.70 | 330 / 2.56 | 738 / 2.91 | 736 / 3.06 |
| Euler-Maruyama (same NFE) | 329 / 10.28 | 330 / 10.00 | 738 / 2.99 | 736 / 3.17 |
| DDIM (same NFE) | 329 / 4.81 | 330 / 4.76 | – | – |
| Ours () | 274 / 2.74 | 274 / 2.60 | 490 / 2.87 | 488 / 2.99 |
| Euler-Maruyama (same NFE) | 274 / 14.18 | 274 / 13.67 | 490 / 3.05 | 488 / 3.21 |
| DDIM (same NFE) | 274 / 5.75 | 274 / 5.74 | – | – |
| Ours () | 179 / 2.59 | 180 / 2.44 | 271 / 3.23 | 270 / 3.40 |
| Euler-Maruyama (same NFE) | 179 / 25.49 | 180 / 25.05 | 271 / 3.48 | 270 / 3.76 |
| DDIM (same NFE) | 179 / 9.20 | 180 / 9.25 | – | – |
| Ours () | 147 / 2.95 | 151 / 2.73 | 170 / 8.85 | 170 / 10.15 |
| Euler-Maruyama (same NFE) | 147 / 31.38 | 151 / 31.93 | 170 / 5.12 | 170 / 5.56 |
| DDIM (same NFE) | 147 / 11.53 | 151 / 11.38 | – | – |
| Ours () | 49 / 72.29 | 48 / 82.42 | 52 / 266.75 | 50 / 307.32 |
| Euler-Maruyama (same NFE) | 49 / 92.99 | 48 / 95.77 | 52 / 169.32 | 50 / 271.27 |
| DDIM (same NFE) | 49 / 37.24 | 48 / 38.71 | – | – |
| Probability Flow (ODE) | 142 / 3.11 | 145 / 2.86 | 183 / 7.64 | 181 / 5.53 |
| Method | VE (Church) | VE (FFHQ) |
| Reverse-Diffusion & Langevin | 3999 / 29.14 | 3999 / 16.42 |
| Euler-Maruyama | 2000 / 42.11 | 2000 / 18.57 |
| Ours () | 1104 / 25.67 | 1020 /15.68 |
| Euler-Maruyama (same NFE) | 1104 / 68.24 | 1020 / 20.45 |
| Ours () | 1030 / 26.46 | 643 / 15.67 |
| Euler-Maruyama (same NFE) | 1030 / 73.47 | 643 / 44.42 |
| Ours () | 648 / 28.47 | 336 / 18.07 |
| Euler-Maruyama (same NFE) | 648 / 145.96 | 336 / 114.23 |
| Ours () | 201 / 45.92 | 198 / 24.02 |
| Euler-Maruyama (same NFE) | 201 / 417.77 | 198 / 284.61 |
| Probability Flow (ODE) | 434 / 214.47 | 369 / 135.50 |
4.1 性能
与 EM 相比,我们观察到我们的方法在高分辨率图像的质量/多样性方面立即具有优势,同时具有 到 倍的加速 ()。 虽然这种优势在 CIFAR-10 上的 FID 方面变得不那么明显,但我们的方法仍然提供 计算加速,而没有明显的缺点 ()。
朗之万逆扩散在 CIFAR-10 上的 VE 模型中实现了最低的 FID,但代价是 比我们的方法计算开销更大。 此外,它们的优势在 VP 模型中以及生成高分辨率图像时消失了。
我们进一步将我们的 SDE 求解器与 EM 在相同的计算预算下进行比较,并观察到我们的方法在高分辨率和 VP 模型中始终非常优越。 对于 CIFAR-10 上的 VE 模型,我们观察到我们的算法只要 NFE 足够大 (270) 就会导致更好的 FID。 请注意,由于我们的算法每步需要两个分数函数评估,因此在相同 NFE 的情况下,EM 具有执行两倍步数的优势,这似乎是一个比低预算低分辨率 VE 中方法顺序更重要的因素。 尽管如此,比较相同迭代步数,结果仍然表明我们的方法始终更优越。 对于高分辨率图像,我们看到 EM 由于高维性,无法在中等到小的 NFE 上收敛,使得我们的 SDE 求解器成为首选。
通常,我们观察到 VE 过程不能像 VP 过程那样快地解决;这是因为 VE 过程中的巨大高斯噪声会导致更大的局部误差。 这反映了第 3.1.1 节中提到的关于高阶 SDE 求解器在速度方面并不总是对具有严重高斯噪声的 SDE 有益的问题。 在实践中,对于 VE,该算法在开始时使用较小的步长以确保高精度,并随着噪声变得不那么明显而最终增加步长。
4.2 解微分方程而不是 SDE
我们看到,我们的 SDE 求解器通常比概率流更好,尤其是在高分辨率下,我们以类似的预算获得了更低的 FID。 我们的算法在 情况下对于低分辨率图像以及 情况下对于高分辨率图像,实现了与概率流相同的 NFE。 对于相同的预算,概率流在除低分辨率 VE 模型以外的所有模型上的 FID 都高于我们的方法。 但是,在这种情况下,我们的算法在 时实现了更低的 FID,尽管速度较慢。 在高分辨率下,概率流会导致非常差的 FIDs,表明没有收敛。
4.3 DDIM
与 Song 等人 (2020b) 相反,当 NFE 减少时,DDIM 的 FID 会显着恶化。 这可能是由于 Song 等人 (2020a) 连续时间评分匹配与 DDIM 训练过程和架构之间的差异造成的。 然而,减少预算带来的 FID 增加比 EM 要小得多。 需要注意的是,DDIM 在极小的 NFE () 下成功地保持了比我们的求解器更低的 FID,尽管性能很差。
5 限制
尽管我们在广泛的设置上测试了我们的方法,但我们只测试了连续时间图像生成模型。 我们这样做是因为解决 SDE 需要连续时间,并且在发布时唯一这样的预训练模型是 Song 等人 (2020a) 的模型。 未来工作应该训练来自不同数据类型、模型架构的连续时间版本的模型,以及 Nichol 和 Dhariwal (2021) 的学习方差方法,该方法天生可以更快地生成数据;然后可以将我们的 SDE 求解器用于这些模型。
虽然我们的方法消除了步长和调度调优,但我们仍然需要选择一个相对容差的值,这间接地影响了所采取的步数;理论上可以调优这个超参数以优化某个指标,这与消除调优的初衷背道而驰。 尽管如此,让 为了获得精确的结果,而 为了获得快速的结果是合理的选择,因为所有证据都表明 FID 相对于 是稳定的。
6 结论
我们构建了一个 SDE 求解器,它允许以快得多的速度生成与欧拉-丸山相当(或更好)质量的图像。 我们的方法通过将所需的计算预算缩减 2 到 5 倍 ,并提供了一种合理的方法来权衡质量以换取更高的速度,使基于评分的模型的图像生成更易于使用。 然而,与其他可以在神经网络的单个正向传递中生成数据的生成模型相比,数据生成仍然很慢(几分钟)。 因此,需要开展进一步的研究以寻求方法,使这些模型运行速度更快,从而更具吸引力和实用性,以便在实时应用中发挥作用。
7 更广泛的影响
我们的工作使得能够更快地从基于分数的生成模型中生成数据,将该技术更接近于实时应用。 虽然生成模型在许多社会效益应用中具有优势,但它们也可能被用于恶意欺骗人类(例如深度伪造)。 生成模型还存在着复制现有数据集中的偏差的风险。
参考文献
- Song and Ermon [2019] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems, pages 11918–11930, 2019.
- Song and Ermon [2020] Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. arXiv preprint arXiv:2006.09011, 2020.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv preprint arxiv:2006.11239, 2020.
- Jolicoeur-Martineau et al. [2020] Alexia Jolicoeur-Martineau, Rémi Piché-Taillefer, Rémi Tachet des Combes, and Ioannis Mitliagkas. Adversarial score matching and improved sampling for image generation. arXiv preprint arXiv:2009.05475, 2020.
- Song et al. [2020a] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020a.
- Piché-Taillefer [2021] Rémi Piché-Taillefer. Hamiltonian monte carlo and consistent sampling for score-based generative modeling. Master’s thesis, Université de Montréal, Québec, 2021.
- Chen et al. [2020] Nanxin Chen, Yu Zhang, Heiga Zen, Ron J Weiss, Mohammad Norouzi, and William Chan. Wavegrad: Estimating gradients for waveform generation. arXiv preprint arXiv:2009.00713, 2020.
- Kong et al. [2020] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761, 2020.
- Mittal et al. [2021] Gautam Mittal, Jesse Engel, Curtis Hawthorne, and Ian Simon. Symbolic music generation with diffusion models. arXiv preprint arXiv:2103.16091, 2021.
- Kameoka et al. [2020] Hirokazu Kameoka, Takuhiro Kaneko, Kou Tanaka, and Nobukatsu Hojo. Voicegrad: Non-parallel any-to-many voice conversion with annealed langevin dynamics. arXiv preprint arXiv:2010.02977, 2020.
- Niu et al. [2020] Chenhao Niu, Yang Song, Jiaming Song, Shengjia Zhao, Aditya Grover, and Stefano Ermon. Permutation invariant graph generation via score-based generative modeling. In International Conference on Artificial Intelligence and Statistics, pages 4474–4484. PMLR, 2020.
- Saharia et al. [2021] Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement. arXiv preprint arXiv:2104.07636, 2021.
- Kadkhodaie and Simoncelli [2020] Zahra Kadkhodaie and Eero P Simoncelli. Solving linear inverse problems using the prior implicit in a denoiser. arXiv preprint arXiv:2007.13640, 2020.
- Jayaram and Thickstun [2020] Vivek Jayaram and John Thickstun. Source separation with deep generative priors. In International Conference on Machine Learning, pages 4724–4735. PMLR, 2020.
- Sasaki et al. [2021] Hiroshi Sasaki, Chris G Willcocks, and Toby P Breckon. Unit-ddpm: Unpaired image translation with denoising diffusion probabilistic models. arXiv preprint arXiv:2104.05358, 2021.
- Goodfellow et al. [2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc., 2014. URL http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
- San-Roman et al. [2021] Robin San-Roman, Eliya Nachmani, and Lior Wolf. Noise estimation for generative diffusion models. arXiv preprint arXiv:2104.02600, 2021.
- Block et al. [2020] Adam Block, Youssef Mroueh, Alexander Rakhlin, and Jerret Ross. Fast mixing of multi-scale langevin dynamics underthe manifold hypothesis. arXiv preprint arXiv:2006.11166, 2020.
- Nichol and Dhariwal [2021] Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. arXiv preprint arXiv:2102.09672, 2021.
- Song et al. [2020b] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020b.
- Hyvärinen [2005] Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(Apr):695–709, 2005.
- Anderson [1982] Brian DO Anderson. Reverse-time diffusion equation models. Stochastic Processes and their Applications, 12(3):313–326, 1982.
- Vincent [2011] Pascal Vincent. A connection between score matching and denoising autoencoders. Neural computation, 23(7):1661–1674, 2011.
- Särkkä and Solin [2019] Simo Särkkä and Arno Solin. Applied stochastic differential equations, volume 10. Cambridge University Press, 2019.
- Kloeden and Platen [1992] Peter E Kloeden and Eckhard Platen. Stochastic differential equations. In Numerical Solution of Stochastic Differential Equations, pages 103–160. Springer, 1992.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, pages 6626–6637, 2017.
- Lehn et al. [2002] Jürgen Lehn, Andreas Rößler, and Oliver Schein. Adaptive schemes for the numerical solution of sdes—a comparison. Journal of computational and applied mathematics, 138(2):297–308, 2002.
- Lamba [2003] H Lamba. An adaptive timestepping algorithm for stochastic differential equations. Journal of computational and applied mathematics, 161(2):417–430, 2003.
- Rackauckas and Nie [2017a] Christopher Rackauckas and Qing Nie. Differentialequations.jl – a performant and feature-rich ecosystem for solving differential equations in julia. The Journal of Open Research Software, 5(1), 2017a. doi: 10.5334/jors.151. URL https://app.dimensions.ai/details/publication/pub.1085583166. Exported from https://app.dimensions.ai on 2019/05/05.
- Süli and Mayers [2003] Endre Süli and David F Mayers. An introduction to numerical analysis. Cambridge university press, 2003.
- Rößler [2010] Andreas Rößler. Runge–kutta methods for the strong approximation of solutions of stochastic differential equations. SIAM Journal on Numerical Analysis, 48(3):922–952, 2010.
- Rackauckas and Nie [2017b] Christopher Rackauckas and Qing Nie. Adaptive methods for stochastic differential equations via natural embeddings and rejection sampling with memory. Discrete and continuous dynamical systems. Series B, 22(7):2731, 2017b.
- Roberts [2012] AJ Roberts. Modify the improved euler scheme to integrate stochastic differential equations. arXiv preprint arXiv:1210.0933, 2012.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009.
- Yu et al. [2015] Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in neural information processing systems, pages 2234–2242, 2016.
- Dormand and Prince [1980] John R Dormand and Peter J Prince. A family of embedded runge-kutta formulae. Journal of computational and applied mathematics, 6(1):19–26, 1980.
- Efron [2011] Bradley Efron. Tweedie’s formula and selection bias. Journal of the American Statistical Association, 106(496):1602–1614, 2011.
- Gardiner [2009] Crispin Gardiner. Stochastic methods, volume 4. Springer Berlin, 2009.
- Arnold [1974] Ludwig Arnold. Stochastic differential equations. New York, 1974.
- Artemiev and Averina [2011] Sergej S Artemiev and Tatjana A Averina. Numerical analysis of systems of ordinary and stochastic differential equations. Walter de Gruyter, 2011.
- Saito and Mitsui [1996] Yoshihiro Saito and Taketomo Mitsui. Stability analysis of numerical schemes for stochastic differential equations. SIAM Journal on Numerical Analysis, 33(6):2254–2267, 1996.
附录
附录 A 微分方程.jl
| Method | Strong-Order | Adaptive | Speed |
|---|---|---|---|
| Euler-Maruyama (EM) | 0.5 | No | Baseline speed |
| SOSRA [Rößler, 2010] | 1.5 | Yes | 5.92 times slower |
| SRA3 [Rößler, 2010] | 1.5 | Yes | 6.93 times slower |
| Lamba EM (default) [Lamba, 2003] | 0.5 | Yes | Did not converge |
| Lamba EM (atol=1e-3) [Lamba, 2003] | 0.5 | Yes | 2 times faster |
| Lamba EM (atol=1e-3, rtol=1e-3) [Lamba, 2003] | 0.5 | Yes | 1.27 times faster |
| Euler-Heun | 0.5 | No | 1.86 times slower |
| Lamba Euler-Heun [Lamba, 2003] | 0.5 | Yes | 1.75 times faster |
| SOSRI [Rößler, 2010] | 1.5 | Yes | 8.57 times slower |
| RKMil (at various tolerances) [Kloeden and Platen, 1992] | 1.0 | Yes | Did not converge |
| ImplicitRKMil [Kloeden and Platen, 1992] | 1.0 | Yes | Did not converge |
| ISSEM | 0.5 | Yes | Did not converge |
在这里,我们报告了使用 DifferentialEquations.jl 进行的预备实验。 Julia 包 [Rackauckas 和 Nie, 2017a],然后才设计我们自己的 SDE 求解器。 可以看出,大多数方法要么没有收敛(并发出“检测到不稳定性”的警告),要么收敛,但速度远比欧拉-丸山法慢。 唯一有希望的方法是拉姆巴方法 [Lamba, 2003]。 请注意,当从 到 的局部误差为 )时,算法具有强阶 。
附录 B 修改算法 1 的影响
| Change(s) in Algorithm 1 | IS | FID | NFE |
| No change | 9.38 | 4.70 | 3972 |
| Small modifications | |||
| 9.26 | 4.69 | 4166 | |
| No Extrapolation (thus, using Euler–Maruyama) | 9.58 | 11.73 | 3978 |
| 9.48 | 4.90 | 14462 | |
| 9.41 | 4.69 | 4104 | |
| 9.36 | 4.68 | 3938 | |
| 9.41 | 4.69 | 4048 | |
| Variations of Lamba [2003] Algorithm | |||
| , Lamba integration | 7.80 | 52.98 | 1468 |
| , Lamba integration, Extrapolation | 7.32 | 64.65 | 1438 |
| , Lamba integration, | 9.28 | 21.09 | 2360 |
| , Lamba integration, , | 9.21 | 18.82 | 2346 |
| Change(s) in Algorithm 1 | IS | FID | NFE |
| No change | 9.39 | 4.89 | 8856 |
| Small modifications | |||
| 9.39 | 4.99 | 17514 | |
| No Extrapolation (thus, using Euler–Maruyama) | 9.58 | 6.57 | 8802 |
| 9.41 | 5.03 | 39500 | |
| 9.47 | 4.87 | 9594 | |
| 9.45 | 4.84 | 8952 | |
| 9.43 | 4.93 | 8784 | |
| Variations of Lamba [2003] Algorithm | |||
| , Lamba integration | 9.08 | 18.28 | 2492 |
| , Lamba integration, Extrapolation | 3.70 | 169.78 | 2252 |
| , Lamba integration, | 9.42 | 6.80 | 5886 |
| , Lamba integration, , | 9.35 | 6.20 | 2970 |
如图所示,大多数选定的设置都导致了更好的结果。 然而, 似乎对 FID 影响很小。 尽管如此,使用 导致分数函数评估次数略少,有时也会导致 FID 降低。
附录 C 用于解决任何类型 SDE(而不仅仅是反向扩散过程)的动态步长算法
假设我们有一个如下形式的扩散过程:
| (6) |
解决它的算法在算法 2 中表示。 不同之处在于:
-
•
它是正向时间
-
•
必须给出时间范围
-
•
扩散可能取决于 ,这会导致一个稍微复杂的公式,该公式取决于某个随机数 [Roberts, 2012]。
-
•
我们保留了完整的轨迹,而不是仅仅保留结束点。
-
•
我们保留了拒绝后的噪声,以确保拒绝中没有偏差。
附录 D 实现细节
我们从 Song 等人 [2020a] 的原始代码开始,但更改了一些关于 SDE 求解的设置。 这导致了他们的报告结果和我们的结果之间的一些微小差异。 对于 VP 和 VP-deep 模型,我们获得了 2.55 和 2.49,而不是基线方法(EM)的原始 2.55 和 2.41。 对于 VE 和 VE-deep 模型,我们获得了 2.40 和 2.21,而不是基线方法(带朗之万的反向扩散)的原始 2.38 和 2.20。
在求解 SDE 时,时间遵循序列 、,其中 用于 CIFAR-10, 用于 LSUN, 用于 VP 模型,以及 用于 VE 模型。
同时,用于欧拉-丸山 (EM) 代码中的实际步长 等于 。 因此,算法中使用的步长 () 与 所隐含的实际步长 () 之间几乎没有差异。 请注意,这几乎没有影响。
较大的问题是在最后一步预测中从 到 。 因此, 变为负数。 此外,在假设 的情况下,样本在 处被降噪。 有两种方法可以解决这个问题:1) 只从 到 进行一步,不进行降噪(因为你无法用不正确的 或 进行降噪),或者 2) 在 处停止,然后进行降噪。 由于降噪非常有用,我们采用了方法 2;但是,两种方法都是合理的。
最后,降噪之前没有正确实现。 降噪实现为一步预测器(反向扩散或 EM),不添加噪声。 这对应于:
在最后一次迭代中,这种不正确的降噪将是:
对于 VE 以及
对于 VP。
同时,基于 Tweedie 公式 [Efron, 2011] 的正确降噪方法是:
其中 是转换核的方差:对于 VE 为 ,对于 VP 为 。 这意味着正确的 Tweedie 公式对应于
用于 VE 和
用于 VP.
可以看出,去噪对 VE 的影响非常小,因此正确和错误去噪之间的差异很小。 同时,对于 VP,错误去噪会导致微小的变化,而正确去噪会导致较大的变化。 在实践中,我们观察到,将去噪方法更改为正确的方法不会显着影响 VE 的 FID,但会显着降低 VP 的 FID。
附录 E CIFAR-10 上的 Inception 得分
| Method | VP | VP-deep | VE | VE-deep |
|---|---|---|---|---|
| Reverse-Diffusion & Langevin | 9.94 | 9.85 | 9.86 | 9.83 |
| Euler-Maruyama | 9.71 | 9.73 | 9.49 | 9.31 |
| Ours () | 9.46 | 9.54 | 9.50 | 9.48 |
| Ours () | 9.51 | 9.48 | 9.57 | 9.50 |
| Ours () | 9.50 | 9.61 | 9.64 | 9.63 |
| Ours () | 9.69 | 9.64 | 9.87 | 9.75 |
| Probability Flow (ODE) | 9.37 | 9.33 | 9.17 | 9.32 |
附录 F 数值方案的稳定性和偏差
以下构造依赖于随机动力学由维纳过程驱动的基本假设。 更重要的是,我们还假设布朗运动是时间对称的。 这两个假设在文献中是一致的,并被广泛使用;例如,参见 [Gardiner, 2009] [Arnold, 1974]。
算法 1 中描述的方法在计算时间和操作方面为我们提供了显著的加速。 尽管速度提升来自算法中的分段步骤,该步骤将传统的欧拉马鲁山 (EM) 与一种自适应步长预测校正器形式相结合。 我们在此表明,通过引入我们新方案的额外自适应步长,EM 方案的稳定性和收敛性都得以保留。 作为第一步,我们定义了随机微分方程 (SDE) 数值解中的稳定性和偏差。
我们将 表示为复值 的真实值。
线性测试 SDE 的定义如下:
| (7) |
以及其数值对应项
其中 是不依赖于 或 的随机变量,EM 方案为
如果对于给定由双边维纳过程驱动的线性 SDE (7),数值解 的分布随着 收敛到均值为零、方差为 的正态分布,则数值方案在步长为 时是渐进无偏的 [Artemiev and Averina, 2011]。 这是由于线性 SDE (7) 的解在初始条件为高斯(或确定性)时是一个高斯过程;因此,算法中的偏差只有两个时刻控制:
如果应用于线性 SDE 的数值解 满足以下条件,则步长为 的数值方案在平均值上是数值稳定的
并且在均方[Saito and Mitsui, 1996]中稳定,如果我们有
在接下来的内容中,我们将通过我们的算法跟踪偏差的标准,并证明它仍然是无偏的。 由于构造原因,第一个 EM 步骤保持无偏,而对于 RDP,我们将时间反向维纳过程写成
在反向时间步骤 中,即 、,… 。
因此,如果
那么
在算法 1 中,我们正在进行连续的前后时间步骤,因此 使得
因此,该方案在数值上稳定且相对于均值无偏。
接下来,我们关注均方误差中的数值解:
在相同连续步长的假设下,我们有
假设 的虚部为零,我们有
因此,该数值方案在均方误差中是稳定的且无偏的。
按照计算 和 的两个步骤,步长减小且不会改变大小;因此,上述所有陈述都成立,并且整个算法相对于均值和均方误差都是稳定的且无偏的。
附录 G 样本
