决策 Transformer :强化
通过序列建模学习
摘要
我们引入了一个将强化学习(RL)抽象为序列建模问题的框架。 这使我们能够利用 Transformer 架构的简单性和可扩展性,以及 GPT-x 和 BERT 等语言建模的相关进步。 特别是,我们提出了 Decision Transformer,这是一种将 RL 问题转化为条件序列建模的架构。 与之前拟合价值函数或计算策略梯度的强化学习方法不同,Decision Transformer 只是通过利用因果屏蔽 Transformer 来输出最佳操作。 通过根据期望的回报(奖励)、过去的状态和行动来调节自回归模型,我们的决策转换器模型可以生成实现期望回报的未来行动。 尽管很简单,Decision Transformer 在 Atari、OpenAI Gym 和 Key-to-Door 任务上的性能可与最先进的无模型离线 RL 基线相媲美或超过。
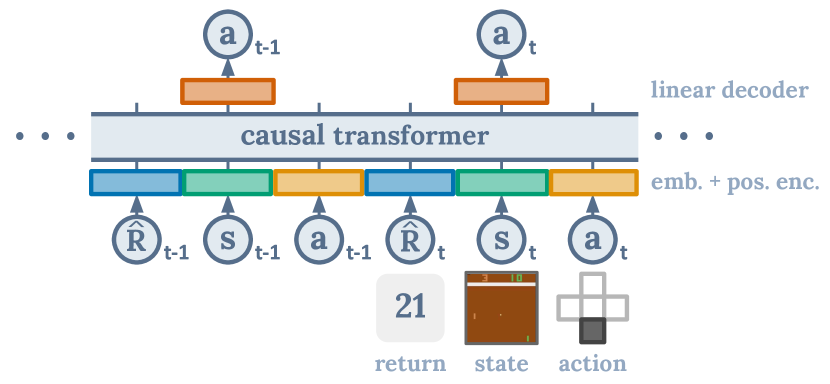
1简介
最近的工作表明, Transformer [1]可以大规模地模拟语义概念的高维分布,包括语言[2]中有效的零样本泛化和分布外图像生成[3]。 鉴于此类模型成功应用的多样性,我们试图研究它们在形式化为强化学习(RL)的顺序决策问题中的应用。 与之前使用 Transformer 作为传统 RL 算法[4, 5]中组件架构选择的工作不同,我们试图研究生成轨迹建模(即对状态、行动和奖励序列的联合分布建模)能否作为传统 RL 算法的替代。
我们考虑以下范式转变:我们将使用序列建模目标根据收集的经验来训练 Transformer 模型,而不是通过传统的 RL 算法(例如时间差 (TD) 学习 [6])来训练策略。 这将使我们能够绕过长期信用分配引导的需要,从而避免已知破坏强化学习稳定的“致命三合一”[6]之一。 它还避免了对未来奖励进行折扣的需要,正如 TD 学习中通常所做的那样,这可能会导致不良的短视行为。 此外,我们可以利用广泛用于语言和视觉的现有 Transformer 框架,这些框架易于扩展,并利用大量研究 Transformer 模型稳定训练的工作。
除了所展示的长序列建模能力之外,Transformer 还具有其他优势。 Transformer 可以通过自注意力直接执行信用分配,与贝尔曼备份相反,贝尔曼备份缓慢地传播奖励并且容易出现“干扰”信号[7]。 这可以使 Transformer 在奖励稀疏或分散注意力的情况下仍然有效地工作。 最后,经验证据表明 Transformer 建模方法可以对广泛的行为分布进行建模,从而实现更好的泛化和迁移[3]。
我们通过考虑离线强化学习来探索我们的假设,其中我们将任务智能体从次优数据中学习策略——从固定的、有限的经验中产生最有效的行为。 由于错误传播和价值高估[8],该任务传统上具有挑战性。 然而,当以序列建模为目标进行训练时,这是一个自然的任务。 通过在状态、动作和返回序列上训练自回归模型,我们将策略采样简化为自回归生成模型。 我们可以通过选择所需的返回 Token 来指定策略的专业知识 - 查询哪个“技能”,作为生成的提示。
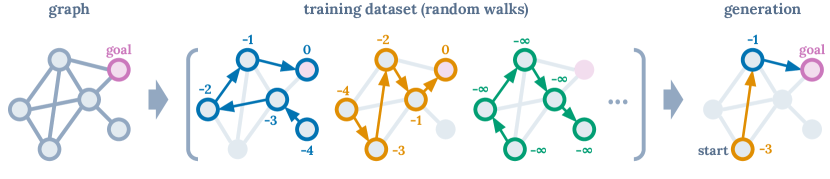
说明性示例。 为了直观地理解我们的建议,请考虑在有向图上寻找最短路径的任务,这可以被视为 RL 问题。 当智能体位于目标节点时,奖励为 ,否则奖励为 。 我们训练一个 GPT [9] 模型来预测 return-to-go(未来奖励的总和)、状态和动作序列中的下一个词符。 仅在随机游走数据上进行训练 - 没有专家演示 - 我们可以在测试时通过添加先验来生成最佳轨迹,以生成最高可能的回报(请参阅附录中的更多详细信息和经验结果),然后生成通过条件反射产生相应的动作序列。 因此,通过将序列建模工具与事后返回信息相结合,我们无需动态规划即可实现策略改进。
受这一观察的启发,我们提出了 Decision Transformer,其中我们使用 GPT 架构对轨迹进行自回归建模(如图 1 所示)。 我们通过在 Atari [10]、OpenAI Gym [11] 和 Key-to-Door [12] 环境中的离线 RL 基准上评估 Decision Transformer,来研究序列建模是否能够执行策略优化。 我们的研究表明,在不使用动态编程的情况下,Decision Transformer 的性能达到或超过了最先进的无模型离线 RL 算法[13, 14] 。 此外,在需要长期信用分配的任务中,Decision Transformer 能够优于 RL 基线。 通过这项工作,我们的目标是在序列建模和 Transformer 与强化学习之间架起桥梁,并希望序列建模能够成为强化学习的强大算法范例。
2 预赛
2.1离线强化学习
我们考虑在元组(、、、)描述的马尔可夫决策过程(MDP)中进行学习。 MDP 元组由状态 、动作 、转换动态 和奖励函数 组成。 我们使用 、 和 分别表示时间步 处的状态、操作和奖励。 轨迹由一系列状态、动作和奖励组成:。 时间步 、 处轨迹的回报是该时间步的未来奖励之和。 强化学习的目标是学习一种最大化 MDP 中预期回报 的策略。 在离线强化学习中,我们不能通过环境交互获取数据,而是只能访问一些由任意策略的轨迹推出组成的固定有限数据集。 此设置比较困难,因为它消除了代理探索环境和收集额外反馈的能力。
2.2变形金刚
Transformer 是由 Vaswani 等人 [1] 提出的,作为一种有效建模顺序数据的架构。 这些模型由具有残差连接的堆叠自注意力层组成。 每个自注意力层接收与唯一输入标记相对应的 嵌入 ,并输出 嵌入 ,保留输入维度。 第 个词符通过线性变换映射到键 、查询 和值 。 自我关注层的 输出是通过查询 与其他关键字 之间的归一化点积对 值进行加权而得到的:
| (1) |
正如我们稍后将看到的,这允许该层通过查询和键向量的相似性(最大化点积)隐式形成状态返回关联来分配“信用”。 在这项工作中,我们使用 GPT 架构 [9],它使用因果自注意力掩码修改 Transformer 架构以实现自回归生成,替换 上的求和/softmax > 仅包含序列中前一个标记的标记 ()。 我们将其他架构细节推迟到原始论文中。
3方法
轨迹表示。 我们选择轨迹表示的关键需求是它应该使 Transformer 能够学习有意义的模式,并且我们应该能够在测试时有条件地生成动作。 对奖励进行建模并非易事,因为我们希望模型根据未来期望的回报而不是过去的奖励来生成操作。 因此,我们不是直接提供奖励,而是向模型提供回报 。 这导致以下轨迹表示,适合自回归训练和生成:
| (2) |
在测试时,我们可以指定所需的性能(例如,1 表示成功,0 表示失败)以及环境起始状态,作为启动生成的条件信息。 在执行当前状态生成的操作后,我们将目标回报减去所获得的奖励并重复直到情节终止。
架构。 我们将最后的 时间步输入 Decision Transformer,以获得总共 个标记(每种模式一个:返回、状态或操作)。 为了获得词符嵌入,我们为每种模态学习一个线性层,它将原始输入投影到嵌入维度,然后进行层归一化[15]。 对于具有视觉输入的环境,状态被输入卷积编码器而不是线性层。 此外,每个时间步长的嵌入都会被学习并添加到每个词符中 - 请注意,这与 Transformer 使用的标准位置嵌入不同,因为一个时间步长对应于三个标记。 然后,这些标记由 GPT [9] 模型进行处理,该模型通过自回归建模来预测未来的操作标记。
训练。 我们得到了离线轨迹的数据集。 我们从数据集中采样序列长度 的小批量。 与输入词符相对应的预测头被训练来预测——离散动作的交叉熵损失或连续动作的均方误差——以及每个时间步均取平均值。 我们没有发现预测状态或返回来提高性能,尽管它在我们的框架内很容易被允许(如 5.4 节所示),并且对于未来的工作来说将是一项有趣的研究。
4 离线强化学习基准评估
在本节中,我们将研究 Decision Transformer 相对于专用离线 RL 和模仿学习算法的性能。 特别是,我们的主要比较点是基于 TD 学习的无模型离线 RL 算法,因为我们的 Decision Transformer 架构本质上也是无模型的。 此外,TD 学习是 RL 中提高样本效率的主要范式,并且在许多基于模型的 RL 算法中作为子例程也具有显着的特征[16, 17]。 我们还与行为克隆和变体进行比较,因为它也涉及与我们类似的基于可能性的策略学习公式。 确切的算法取决于环境,但我们的动机如下:
-
•
TD 学习:这些方法中的大多数都使用动作空间约束或价值悲观主义,并且将是与代表标准 RL 方法的 Decision Transformer 最忠实的比较。 最先进的无模型方法是保守 Q 学习 (CQL) [14],它是我们的主要比较。 此外,我们还与其他先前的无模型 RL 算法(如 BEAR [18] 和 BRAC [19])进行比较。
-
•
模仿学习:这种制度同样使用监督损失进行训练,而不是贝尔曼备份。 我们在这里使用行为克隆,并在 5.1 节中进行更详细的讨论。
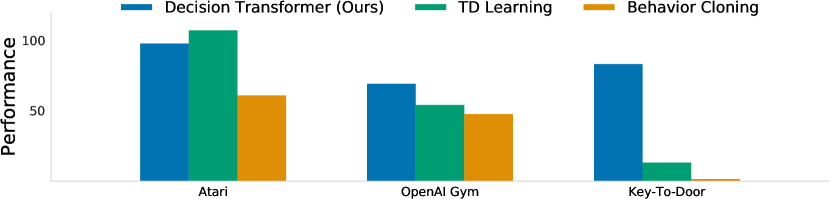
我们评估离散(Atari [10])和连续(OpenAI Gym [11])控制任务。 前者涉及高维观察空间,需要长期的信用分配,而后者需要细粒度的连续控制,代表多样化的任务集。 我们的主要结果总结在图 3 中,其中我们显示了每个域的平均标准化性能。
4.1雅达利
Atari 基准 [10] 具有挑战性,因为它具有高维视觉输入,并且由于操作和奖励之间的延迟而导致信用分配困难。 我们根据 Agarwal 等人 [13] 在 DQN-replay 数据集中所有样本的 1% 上评估我们的方法,代表在线 DQN 代理观察到的 5000 万个转换中的 50 万个转换[ 20]训练期间;我们报告 3 个种子的平均值和标准差。 我们根据Hafner等人[21]的协议对职业玩家的分数进行归一化,其中100代表职业玩家分数,0代表随机策略。
| Game | DT (Ours) | CQL | QR-DQN | REM | BC |
|---|---|---|---|---|---|
| Breakout | |||||
| Qbert | |||||
| Pong | |||||
| Seaquest |
我们与 CQL [14]、REM [13]和 QR-DQN [22]在四个 Atari 任务(Breakout、Qbert、Pong 和 Seaquest)上进行了比较,这些任务在 Agarwal 等人 [13] 中进行了评估。 我们对决策转换器使用 的上下文长度(Pong 的 除外)。 我们还报告了行为克隆(BC)的性能,它使用与决策转换器相同的网络架构和超参数,但没有返回条件222我们还尝试像之前的工作一样使用带有 的 MLP,但发现这比 Transformer 更糟糕。. 对于 CQL、REM 和 QR-DQN 基线,我们直接报告 CQL 和 REM 论文中的数字。 我们在表 1 中显示结果。 我们的方法在 4 场比赛中的 3 场中与 CQL 具有竞争力,并且在所有 4 场比赛中都优于或匹配 REM、QR-DQN 和 BC。
4.2OpenAI健身房
在本节中,我们考虑 D4RL 基准[23]中的连续控制任务。 我们还考虑了不属于基准测试一部分的 2D 接触器环境,并使用与 D4RL 基准测试类似的方法生成数据集。 Reacher 是一项以目标为条件的任务,奖励稀疏,因此它代表了与标准运动环境(HalfCheetah、Hopper 和 Walker)不同的设置。 下面描述了不同的数据集设置。
-
1.
中:由“中”策略生成的 100 万个时间步,其得分约为专家策略的三分之一。
-
2.
Medium-Replay:针对中等策略性能进行训练的代理的重播缓冲区(在我们的环境中大约为 25k-400k 时间步长)。
-
3.
中级专家:由中级策略生成的 100 万个时间步与由专家策略生成的 100 万个时间步相连接。
我们与 CQL [14]、BEAR [18]、BRAC [19] 和 AWR [24] 进行比较>。 CQL 代表了无模型离线 RL 的最先进水平,是具有价值悲观主义的 TD 学习的实例。 根据 Fu 等人 [23],分数被标准化,100 代表专家策略。 CQL 数字来自原始论文; BC 号码由我们运营;其他方法来自 D4RL 论文的报道。 我们的结果如表3所示。 Decision Transformer 在大多数任务中取得了最高分,并且在其余任务中与最先进的技术具有竞争力。
| Dataset | Environment | DT (Ours) | CQL | BEAR | BRAC-v | AWR | BC |
|---|---|---|---|---|---|---|---|
| Medium-Expert | HalfCheetah | ||||||
| Medium-Expert | Hopper | ||||||
| Medium-Expert | Walker | ||||||
| Medium-Expert | Reacher | - | - | - | |||
| Medium | HalfCheetah | ||||||
| Medium | Hopper | ||||||
| Medium | Walker | ||||||
| Medium | Reacher | - | - | - | |||
| Medium-Replay | HalfCheetah | ||||||
| Medium-Replay | Hopper | ||||||
| Medium-Replay | Walker | ||||||
| Medium-Replay | Reacher | - | - | - | |||
| Average (Without Reacher) | |||||||
| Average (All Settings) | - | - | - | ||||
5讨论
5.1 Decision Transformer 是否对数据子集执行行为克隆?
在本节中,我们试图深入了解 Decision Transformer 是否可以被视为对具有一定回报的数据子集执行模仿学习。 为了研究这个问题,我们提出了一种新方法,百分位数行为克隆 (%BC),我们仅在数据集中的顶部 时间步上运行行为克隆,并按情节返回排序。 百分位数 在对整个数据集进行训练的标准 BC () 和仅克隆最佳观察轨迹 () 之间进行插值,在更好的泛化之间进行权衡通过训练一个专门的模型来训练更多的数据,该模型专注于所需的数据子集。
我们在表 3 中显示了将 %BC 与决策转换器和 CQL 进行比较的完整结果,涵盖了 。 请注意,选择克隆的最佳子集的唯一方法是使用环境中的部署进行评估,因此 %BC 不是一个现实的方法;相反,它有助于深入了解 Decision Transformer 的行为。 当数据充足时(如在 D4RL 体系中),我们发现 %BC 可以匹配或击败其他离线 RL 方法。 在大多数环境中,Decision Transformer 与最佳 %BC 的性能具有竞争力,这表明它可以在对整个数据集分布进行训练后在特定子集上进行磨练。
| Dataset | Environment | DT (Ours) | 10%BC | 25%BC | 40%BC | 100%BC | CQL |
|---|---|---|---|---|---|---|---|
| Medium | HalfCheetah | ||||||
| Medium | Hopper | ||||||
| Medium | Walker | ||||||
| Medium | Reacher | ||||||
| Medium-Replay | HalfCheetah | ||||||
| Medium-Replay | Hopper | ||||||
| Medium-Replay | Walker | ||||||
| Medium-Replay | Reacher | ||||||
| Average | |||||||
相比之下,当我们研究低数据状况时(例如 Atari,我们使用 1% 的重播缓冲区作为数据集),%BC 很弱(如表 4 所示)。 这表明,在数据量相对较少的场景中,决策转换器可以通过使用数据集中的所有轨迹来提高泛化能力,从而优于 %BC,即使这些轨迹与返回调节目标不同。 我们的结果表明,Decision Transformer 比简单地对数据集的子集执行模仿学习更有效。 在我们考虑的任务中,Decision Transformer 要么优于 %BC,要么与 %BC 具有竞争力,而不必担心必须选择最佳子集。
| Game | DT (Ours) | 10%BC | 25%BC | 40%BC | 100%BC |
|---|---|---|---|---|---|
| Breakout | |||||
| Qbert | |||||
| Pong | |||||
| Seaquest |
5.2 Decision Transformer 对收益分布的建模效果如何?
我们通过在大范围内改变期望的目标回报来评估 Decision Transformer 理解 return-to-go Token 的能力 - 评估 Transformer 的多任务分布建模能力。 图 4 显示了代理在评估过程中针对不同目标回报值累积的平均采样回报。 在每项任务中,期望的目标回报和真实观察到的回报都高度相关。 在 Pong、HalfCheetah 和 Walker 等某些任务上,Decision Transformer 生成的轨迹几乎完全匹配所需的回报(如与预言线的重叠所示)。 此外,在 Seaquest 等一些 Atari 任务中,我们可以提示 Decision Transformer 获得比数据集中可用的最大剧集回报更高的回报,这表明 Decision Transformer 有时能够进行推断。


5.3 使用较长的上下文长度有什么好处?
为了评估访问先前状态、操作和返回的重要性,我们消除了上下文长度 。这很有趣,因为通常认为,当像我们一样使用帧堆叠时,先前的状态(即 )对于强化学习算法来说已经足够了。 表5显示决策转换器的性能在时显着变差,表明过去的信息对于Atari游戏是有用的。 一个假设是,当我们表示策略的分布时(例如序列建模),上下文允许 Transformer 识别哪个策略生成了操作,从而实现更好的学习和/或改进训练动态。
| Game | DT (Ours) | DT with no context () | |
|---|---|---|---|
| Breakout | |||
| Qbert | |||
| Pong | |||
| Seaquest |
5.4Decision Transformer 是否执行有效的长期信用分配?
为了评估我们模型的长期信用分配能力,我们考虑了 Mesnard 等人 [12] 中提出的 Key-to-Door 环境的变体。 这是一个基于网格的环境,分为三个阶段:(1)在第一阶段,代理被放置在一个有钥匙的房间里; (2)然后,将代理放置在一个空房间中; (3)最后,代理被放置在一个有门的房间里。 代理在第三阶段到达门口时会收到二进制奖励,但只有在第一阶段拿起钥匙时才会收到。 这个问题对于信用分配来说很困难,因为信用必须从情节的开始到结束传播,跳过中间采取的行动。
我们对通过应用随机动作生成的轨迹数据集进行训练,并在表 6 中报告成功率。 此外,对于“钥匙到门”环境,我们使用整个剧集长度作为上下文,而不是像其他环境中那样具有固定的内容窗口。 使用 highsight 返回信息的方法:我们的 Decision Transformer 模型和 %BC(仅在成功的事件上进行训练)能够学习有效的策略 - 生成接近最优的路径,尽管仅在随机游走上进行训练。 TD 学习 (CQL) 无法在涉及的长范围内有效地传播 Q 值,并且性能较差。
| Dataset | DT (Ours) | CQL | BC | %BC | Random |
|---|---|---|---|---|---|
| 1K Random Trajectories | |||||
| 10K Random Trajectories |
5.5 变形金刚可以在稀疏奖励设置中成为准确的批评者吗?
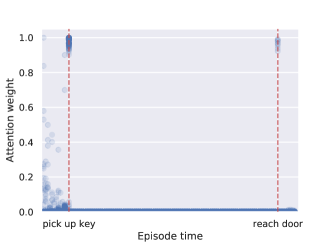
在前面的章节中,我们确定决策 Transformer 可以产生有效的策略(参与者)。 我们现在评估 Transformer 模型是否也可以成为有效的批评者。 我们修改 Decision Transformer 以在 Key-toor 环境中除了输出操作 Token 之外还输出返回 Token 。 此外,没有给出第一个返回词符,而是预测它(即模型学习初始分布),类似于标准自回归生成模型。 我们发现 Transformer 根据剧集期间的事件不断更新奖励概率,如图 5(左)所示。 此外,我们还发现 Transformer 会关注情节中的关键事件(拿起钥匙或走到门口),如图 5(右图)所示,这表明形成了状态-奖励关联,正如 Raposo 等人 [25] 所讨论的那样,并能进行准确的价值预测。

5.6 Decision Transformer 在稀疏奖励设置中表现良好吗?
TD 学习算法的一个已知弱点是它们需要密集的奖励才能表现良好,这可能不现实和/或昂贵。 相比之下,Decision Transformer 可以提高这些设置中的鲁棒性,因为它对奖励密度做出最少的假设。 为了评估这一点,我们考虑 D4RL 基准的延迟返回版本,其中代理不会沿着轨迹获得任何奖励,而是在最终时间步中接收轨迹的累积奖励。 我们的延迟退货结果如表 7 所示。 延迟返回对 Decision Transformer 的影响最小;由于训练过程的性质,模仿学习方法与奖励无关。 虽然 TD 学习崩溃,但 Decision Transformer 和 %BC 仍然表现良好,这表明 Decision Transformer 对于延迟奖励可以更加鲁棒。
| Delayed (Sparse) | Agnostic | Original (Dense) | |||||
|---|---|---|---|---|---|---|---|
| Dataset | Environment | DT (Ours) | CQL | BC | %BC | DT (Ours) | CQL |
| Medium-Expert | Hopper | ||||||
| Medium | Hopper | ||||||
| Medium-Replay | Hopper | ||||||
5.7 为什么 Decision Transformer 避免了价值悲观主义或行为正则化的需要?
Decision Transformer 和之前的离线 RL 算法之间的一个关键区别是,我们不需要策略正则化或保守性来实现良好的性能。 我们的猜想是,基于 TD 学习的算法学习近似值函数,并通过优化该值函数来改进策略。 这种优化学习函数的行为可能会加剧并利用价值函数近似中的任何不准确性,从而导致策略改进失败。 由于 Decision Transformer 不需要使用学习函数作为目标进行显式优化,因此它避免了正则化或保守主义的需要。
5.8 Decision Transformer 如何使在线强化学习机制受益?
离线强化学习和行为建模能力有可能为下游任务实现样本高效的在线强化学习。 研究从离线到在线过渡的工作通常发现基于可能性的方法(例如我们的序列建模目标)更成功[26, 27]。 因此,尽管我们在这项工作中研究了离线 RL,但我们相信 Decision Transformer 可以通过充当行为生成的强大模型来有意义地改进在线 RL 方法。 例如,Decision Transformer 可以充当强大的“记忆引擎”,并与 Go-Explore [28] 等强大的探索算法结合使用,有可能同时建模和生成一组不同的行为。
6相关工作
6.1离线强化学习
为了减轻离线强化学习中分布变化的影响,先前的算法要么 (a) 限制策略行动空间 [29, 30, 31] 要么 (b) 纳入价值悲观主义 [29, 14 ],或 (c) 将悲观主义纳入学习动态模型[32, 33]。 由于我们不使用决策转换器来显式学习动态模型,因此我们主要在工作中与无模型算法进行比较;特别是,添加动力学模型往往会提高无模型算法的性能。 另一项工作探索通过学习一组与任务无关的技能来从离线数据集中学习广泛的行为分布,无论是使用基于可能性的方法[34,35,36,37]还是通过最大化互信息[38,39,40]。 我们的工作类似于基于可能性的方法,它不使用迭代贝尔曼更新——尽管我们使用更简单的序列建模目标而不是变分方法,并使用奖励来条件生成行为。
6.2 强化学习设置中的监督学习
一些先前的强化学习方法与静态监督学习更加相似,例如 Q-learning [41, 42],它仍然使用迭代备份,或者基于可能性的方法,例如行为克隆,它不使用迭代备份。不是(在上一节中讨论过)。 最近的工作[43,44,45]研究了“颠倒”强化学习(UDRL),这与我们寻求以目标回报为条件的监督损失来建模行为的方法类似。 我们工作的一个关键区别是动机转向序列建模而不是监督学习:虽然实际方法主要在上下文长度和架构上有所不同,但序列建模即使在没有获得奖励的情况下也能以与语言类似的风格进行行为建模[9] 或图像 [46],并且已知可以很好地缩放 [2]。 Kumar 等人 [44] 提出的方法与我们的 方法最相似,我们发现序列建模/长上下文优于该方法(参见第 5.3)。 Ghosh 等人 [47] 扩展了先前的 UDRL 方法以使用状态目标调节,而不是奖励,并且 Paster 等人 [48] 进一步使用具有状态目标调节的 LSTM目标条件在线强化学习设置。
与我们的工作同时,Janner 等人[49]提出了 Trajectory Transformer,它与 Decision Transformer 类似,但还使用状态和返回预测以及离散化,其中包含基于模型的组件。 我们相信,除了我们的结果之外,他们的实验强调了序列建模成为强化学习普遍适用的想法的潜力。
6.3 学分分配
许多作品研究了通过状态关联更好的信用分配,学习一种分解奖励函数的架构,使得某些“重要”状态包含大部分信用[50,51,12]。 他们使用学习到的奖励函数来改变演员批评算法的奖励,以帮助在长期范围内传播信号。 特别是,与我们的长期设置类似,一些工作特别表明这种状态关联架构可以在延迟奖励设置中表现更好[52,7,53,25]。 相比之下,我们允许这些属性自然地出现在 Transformer 架构中,而无需显式学习奖励函数或批评者。
6.4 条件语言生成
各种工作研究了图像 [54] 和语言 [55, 56] 的引导生成。 多部作品[57,58,59,60,61,62]探索了模型的训练或微调以实现可控文本生成。 类条件语言模型还可以用于学习鉴别器来指导生成[63,55,64,65]。 然而,这些方法大多假设“类别”恒定,而在强化学习中,奖励信号是随时间变化的。 此外,更自然的做法是提示模型期望的目标回报,并随着时间的推移通过观察到的奖励不断减少它,因为 Transformer 模型和环境共同生成轨迹。
6.5 注意力和 Transformer 模型
Transformer [1] 已成功应用于自然语言处理 [66, 9] 和计算机视觉 [67, 68] 中的许多任务。 然而, Transformer 在强化学习中相对较少被研究,主要是由于问题的性质不同,例如训练中的方差较高。 Zambaldi 等人 [5] 表明,通过关系推理增强 Transformer 可以提高组合环境中的性能,而 Ritter 等人 [69] 表明,迭代自注意力可以让 RL 智能体更好地利用情景记忆。 Parisotto 等人 [4] 讨论了在高方差 RL 设置中更稳定地训练 Transformer 的设计决策。 与我们的工作不同,这些仍然使用 actor-critic 算法进行优化,专注于架构的新颖性。 此外,在模仿学习中,一些作品研究了 Transformer 作为 LSTM 的替代品:Dasari 和 Gupta [70] 研究了一次性模仿学习,Abramson 等人 [71] 结合语言和图像模式来生成文本条件行为。
7结论
我们提出了 Decision Transformer,寻求统一语言/序列建模和强化学习的思想。 在标准离线 RL 基准测试中,我们证明 Decision Transformer 可以匹配或超越专门为离线 RL 设计的强大算法,只需对标准语言建模架构进行最少的修改。
我们希望这项工作能够激发更多关于使用大型 Transformer 模型进行强化学习的研究。 我们在实验中使用了有效的简单监督损失,但大规模数据集的应用可以从自我监督的预训练任务中受益。 此外,我们可以考虑对回报、状态和动作进行更复杂的嵌入——例如,以回报分布为条件来建模随机设置而不是确定性回报。 Transformer 模型还可用于对轨迹的状态演化进行建模,有可能作为基于模型的 RL 的替代方案,我们希望在未来的工作中对此进行探索。
对于现实世界的应用,了解 Transformer 在 MDP 设置中产生的错误类型以及可能的负面后果非常重要,而这些后果尚未得到充分研究。 考虑我们训练模型的数据集也很重要,这可能会增加破坏性偏差,特别是当我们考虑使用更多可能来自可疑来源的数据来研究增强强化学习代理时。 例如,邪恶行为者的奖励设计可能会产生意想不到的行为,因为我们的模型通过以期望回报为条件来产生行为。
致谢
这项研究得到了 Berkeley Deep Drive、开放慈善事业和国家科学基金会 NSF:NRI #2024675 的支持。 这项工作的一部分是在 Aravind Rajeswaran 在华盛顿大学攻读博士生时完成的,他在那里得到了摩根大通人工智能博士奖学金(2020-21)的支持。 我们还感谢 Luke Metz 和 Daniel Freeman 提供的宝贵反馈和讨论,感谢 Justin Fu 在设置 D4RL 基准方面提供的帮助,以及 Aviral Kumar 在 CQL 基线和超参数方面提供的帮助。
参考
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017.
- Brown et al. [2020] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. arXiv preprint arXiv:2102.12092, 2021.
- Parisotto et al. [2020] Emilio Parisotto, Francis Song, Jack Rae, Razvan Pascanu, Caglar Gulcehre, Siddhant Jayakumar, Max Jaderberg, Raphael Lopez Kaufman, Aidan Clark, Seb Noury, et al. Stabilizing transformers for reinforcement learning. In International Conference on Machine Learning, 2020.
- Zambaldi et al. [2018] Vinicius Zambaldi, David Raposo, Adam Santoro, Victor Bapst, Yujia Li, Igor Babuschkin, Karl Tuyls, David Reichert, Timothy Lillicrap, Edward Lockhart, et al. Deep reinforcement learning with relational inductive biases. In International Conference on Learning Representations, 2018.
- Sutton and Barto [2018] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT Press, 2018.
- Hung et al. [2019] Chia-Chun Hung, Timothy Lillicrap, Josh Abramson, Yan Wu, Mehdi Mirza, Federico Carnevale, Arun Ahuja, and Greg Wayne. Optimizing agent behavior over long time scales by transporting value. Nature communications, 10(1):1–12, 2019.
- Levine et al. [2020] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Bellemare et al. [2013] Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
- Brockman et al. [2016] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Mesnard et al. [2020] Thomas Mesnard, Théophane Weber, Fabio Viola, Shantanu Thakoor, Alaa Saade, Anna Harutyunyan, Will Dabney, Tom Stepleton, Nicolas Heess, Arthur Guez, et al. Counterfactual credit assignment in model-free reinforcement learning. arXiv preprint arXiv:2011.09464, 2020.
- Agarwal et al. [2020] Rishabh Agarwal, Dale Schuurmans, and Mohammad Norouzi. An optimistic perspective on offline reinforcement learning. In International Conference on Machine Learning, 2020.
- Kumar et al. [2020] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Sutton [1990] Richard S. Sutton. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In ICML, 1990.
- Janner et al. [2019] Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization. In Advances in Neural Information Processing Systems, pages 12498–12509, 2019.
- Kumar et al. [2019a] Aviral Kumar, Justin Fu, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. arXiv preprint arXiv:1906.00949, 2019a.
- Wu et al. [2019] Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361, 2019.
- Mnih et al. [2015] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 518(7540):529–533, 2015.
- Hafner et al. [2020] Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. arXiv preprint arXiv:2010.02193, 2020.
- Dabney et al. [2018] Will Dabney, Mark Rowland, Marc Bellemare, and Rémi Munos. Distributional reinforcement learning with quantile regression. In Conference on Artificial Intelligence, 2018.
- Fu et al. [2020] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020.
- Peng et al. [2019] Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019.
- Raposo et al. [2021] David Raposo, Sam Ritter, Adam Santoro, Greg Wayne, Theophane Weber, Matt Botvinick, Hado van Hasselt, and Francis Song. Synthetic returns for long-term credit assignment. arXiv preprint arXiv:2102.12425, 2021.
- Gao et al. [2018] Yang Gao, Huazhe Xu, Ji Lin, Fisher Yu, Sergey Levine, and Trevor Darrell. Reinforcement learning from imperfect demonstrations. arXiv preprint arXiv:1802.05313, 2018.
- Nair et al. [2020] Ashvin Nair, Murtaza Dalal, Abhishek Gupta, and Sergey Levine. Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020.
- Ecoffet et al. [2019] Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley, and Jeff Clune. Go-explore: a new approach for hard-exploration problems. arXiv preprint arXiv:1901.10995, 2019.
- Fujimoto et al. [2019] Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning, 2019.
- Kumar et al. [2019b] Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. In Advances in Neural Information Processing Systems, 2019b.
- Siegel et al. [2020] Noah Y Siegel, Jost Tobias Springenberg, Felix Berkenkamp, Abbas Abdolmaleki, Michael Neunert, Thomas Lampe, Roland Hafner, and Martin Riedmiller. Keep doing what worked: Behavioral modelling priors for offline reinforcement learning. In International Conference on Learning Representations, 2020.
- Kidambi et al. [2020] Rahul Kidambi, Aravind Rajeswaran, Praneeth Netrapalli, and Thorsten Joachims. Morel: Model-based offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020.
- Yu et al. [2020] Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization. In Advances in Neural Information Processing Systems, 2020.
- Ajay et al. [2020] Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, and Ofir Nachum. Opal: Offline primitive discovery for accelerating offline reinforcement learning. arXiv preprint arXiv:2010.13611, 2020.
- Campos et al. [2020] Víctor Campos, Alexander Trott, Caiming Xiong, Richard Socher, Xavier Giro-i Nieto, and Jordi Torres. Explore, discover and learn: Unsupervised discovery of state-covering skills. In International Conference on Machine Learning, 2020.
- Pertsch et al. [2020] Karl Pertsch, Youngwoon Lee, and Joseph J Lim. Accelerating reinforcement learning with learned skill priors. arXiv preprint arXiv:2010.11944, 2020.
- Singh et al. [2021] Avi Singh, Huihan Liu, Gaoyue Zhou, Albert Yu, Nicholas Rhinehart, and Sergey Levine. Parrot: Data-driven behavioral priors for reinforcement learning. In International Conference on Learning Representations, 2021.
- Eysenbach et al. [2019] Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. In International Conference on Learning Representations, 2019.
- Lu et al. [2020] Kevin Lu, Aditya Grover, Pieter Abbeel, and Igor Mordatch. Reset-free lifelong learning with skill-space planning. arXiv preprint arXiv:2012.03548, 2020.
- Sharma et al. [2020] Archit Sharma, Shixiang Gu, Sergey Levine, Vikash Kumar, and Karol Hausman. Dynamics-aware unsupervised discovery of skills. In International Conference on Learning Representations, 2020.
- Watkins [1989] Christopher Watkins. Learning from delayed rewards. 01 1989.
- Mnih et al. [2013] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Srivastava et al. [2019] Rupesh Kumar Srivastava, Pranav Shyam, Filipe Mutz, Wojciech Jaśkowski, and Jürgen Schmidhuber. Training agents using upside-down reinforcement learning. arXiv preprint arXiv:1912.02877, 2019.
- Kumar et al. [2019c] Aviral Kumar, Xue Bin Peng, and Sergey Levine. Reward-conditioned policies. arXiv preprint arXiv:1912.13465, 2019c.
- ogm [2019] Acting without rewards. 2019. URL https://ogma.ai/2019/08/acting-without-rewards/.
- Chen et al. [2020] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In International Conference on Machine Learning, pages 1691–1703. PMLR, 2020.
- Ghosh et al. [2019] Dibya Ghosh, Abhishek Gupta, Justin Fu, Ashwin Reddy, Coline Devin, Benjamin Eysenbach, and Sergey Levine. Learning to reach goals without reinforcement learning. arXiv preprint arXiv:1912.06088, 2019.
- Paster et al. [2020] Keiran Paster, Sheila A McIlraith, and Jimmy Ba. Planning from pixels using inverse dynamics models. arXiv preprint arXiv:2012.02419, 2020.
- Janner et al. [2021] Michael Janner, Qiyang Li, and Sergey Levine. Reinforcement learning as one big sequence modeling problem. arXiv preprint arXiv:2106.02039, 2021.
- Ferret et al. [2019] Johan Ferret, Raphaël Marinier, Matthieu Geist, and Olivier Pietquin. Self-attentional credit assignment for transfer in reinforcement learning. arXiv preprint arXiv:1907.08027, 2019.
- Harutyunyan et al. [2019] Anna Harutyunyan, Will Dabney, Thomas Mesnard, Mohammad Azar, Bilal Piot, Nicolas Heess, Hado van Hasselt, Greg Wayne, Satinder Singh, Doina Precup, et al. Hindsight credit assignment. arXiv preprint arXiv:1912.02503, 2019.
- Arjona-Medina et al. [2018] Jose A Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter. Rudder: Return decomposition for delayed rewards. arXiv preprint arXiv:1806.07857, 2018.
- Liu et al. [2019] Yang Liu, Yunan Luo, Yuanyi Zhong, Xi Chen, Qiang Liu, and Jian Peng. Sequence modeling of temporal credit assignment for episodic reinforcement learning. arXiv preprint arXiv:1905.13420, 2019.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Conference on Computer Vision and Pattern Recognition, 2019.
- Ghazvininejad et al. [2017] Marjan Ghazvininejad, Xing Shi, Jay Priyadarshi, and Kevin Knight. Hafez: an interactive poetry generation system. In Proceedings of ACL, System Demonstrations, 2017.
- Weng [2021] Lilian Weng. Controllable neural text generation. lilianweng.github.io/lil-log, 2021. URL https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html.
- Ficler and Goldberg [2017] Jessica Ficler and Yoav Goldberg. Controlling linguistic style aspects in neural language generation. arXiv preprint arXiv:1707.02633, 2017.
- Hu et al. [2017] Zhiting Hu, Zichao Yang, Xiaodan Liang, Ruslan Salakhutdinov, and Eric P Xing. Toward controlled generation of text. In International Conference on Machine Learning, 2017.
- Rajani et al. [2019] Nazneen Fatema Rajani, Bryan McCann, Caiming Xiong, and Richard Socher. Explain yourself! leveraging language models for commonsense reasoning. arXiv preprint arXiv:1906.02361, 2019.
- Yu et al. [2017] Lantao Yu, Weinan Zhang, Jun Wang, and Yong Yu. Seqgan: Sequence generative adversarial nets with policy gradient. In AAAI conference on artificial intelligence, 2017.
- Ziegler et al. [2019] Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
- Keskar et al. [2019] Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858, 2019.
- Dathathri et al. [2019] Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. arXiv preprint arXiv:1912.02164, 2019.
- Holtzman et al. [2018] Ari Holtzman, Jan Buys, Maxwell Forbes, Antoine Bosselut, David Golub, and Yejin Choi. Learning to write with cooperative discriminators. arXiv preprint arXiv:1805.06087, 2018.
- Krause et al. [2020] Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. Gedi: Generative discriminator guided sequence generation. arXiv preprint arXiv:2009.06367, 2020.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision, 2020.
- Dosovitskiy et al. [2020] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Ritter et al. [2020] Sam Ritter, Ryan Faulkner, Laurent Sartran, Adam Santoro, Matt Botvinick, and David Raposo. Rapid task-solving in novel environments. arXiv preprint arXiv:2006.03662, 2020.
- Dasari and Gupta [2020] Sudeep Dasari and Abhinav Gupta. Transformers for one-shot visual imitation. arXiv preprint arXiv:2011.05970, 2020.
- Abramson et al. [2020] Josh Abramson, Arun Ahuja, Iain Barr, Arthur Brussee, Federico Carnevale, Mary Cassin, Rachita Chhaparia, Stephen Clark, Bogdan Damoc, Andrew Dudzik, et al. Imitating interactive intelligence. arXiv preprint arXiv:2012.05672, 2020.
- Wolf et al. [2020] Thomas Wolf, Julien Chaumond, Lysandre Debut, Victor Sanh, Clement Delangue, Anthony Moi, Pierric Cistac, Morgan Funtowicz, Joe Davison, Sam Shleifer, et al. Transformers: State-of-the-art natural language processing. In Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
附录A实验细节
实验代码可以在补充材料中找到。
A.1雅达利
我们基于 minGPT (https://github.com/karpathy/minGPT) 构建 Atari 游戏的 Decision Transformer 实现,minGPT 是一个公开可用的 GPT 重新实现。 我们使用字符级 GPT 示例中的大部分默认超参数 (https://github.com/karpathy/minGPT/blob/master/play_char.ipynb)。 我们减少了批量大小(Pong 除外)、块大小、层数、注意力头和嵌入维度,以加快训练速度。 为了处理观察结果,我们使用 Mnih 等人 [20] 中的 DQN 编码器以及附加的线性层来投影到嵌入维度。
对于返回去调节,我们使用或数据集中的最大返回,但原则性返回去调节存在更多可能性。 在 Atari 实验中,我们在嵌入每种模态后使用 Tanh 代替 LayerNorm(如第 3 节中所述),但这并不会在性能上产生显着差异。 超参数的完整列表可以在表8中找到。
| Hyperparameter | Value |
|---|---|
| Number of layers | |
| Number of attention heads | |
| Embedding dimension | |
| Batch size | Pong |
| Breakout, Qbert, Seaquest | |
| Context length | Pong |
| Breakout, Qbert, Seaquest | |
| Return-to-go conditioning | Breakout ( max in dataset) |
| Qbert ( max in dataset) | |
| Pong ( max in dataset) | |
| Seaquest ( max in dataset) | |
| Nonlinearity | ReLU, encoder |
| GeLU, otherwise | |
| Encoder channels | |
| Encoder filter sizes | |
| Encoder strides | |
| Max epochs | |
| Dropout | |
| Learning rate | |
| Adam betas | |
| Grad norm clip | |
| Weight decay | |
| Learning rate decay | Linear warmup and cosine decay (see code for details) |
| Warmup tokens | |
| Final tokens |
A.2OpenAI 健身房
A.2.1 决策 Transformer
我们的代码基于 Huggingface Transformers 库 [72]。 我们在所有 OpenAI Gym 任务上的超参数如下表 9 所示。 启发式地,我们发现与标准 RL 模型大小(学习一种策略)相比,使用更大的模型有助于对回报分布进行建模。 对于到达者,我们使用比其他环境更小的上下文长度,我们发现这很有帮助,因为环境是目标条件的并且情节更短。 我们根据每个环境的专家表现来选择回报目标,但 HalfCheetah 除外,我们发现 50% 的表现更好,因为数据集包含相对于其他环境的较低回报。 使用 AdamW 优化器 [73] 遵循 PyTorch 默认值对模型进行 梯度步骤训练。
| Hyperparameter | Value |
|---|---|
| Number of layers | |
| Number of attention heads | |
| Embedding dimension | |
| Nonlinearity function | ReLU |
| Batch size | |
| Context length | HalfCheetah, Hopper, Walker |
| Reacher | |
| Return-to-go conditioning | HalfCheetah |
| Hopper | |
| Walker | |
| Reacher | |
| Dropout | |
| Learning rate | |
| Grad norm clip | |
| Weight decay | |
| Learning rate decay | Linear warmup for first training steps |
A.2.2 行为克隆
正如 4.2 节中简要提到的,我们发现之前报告的行为克隆基线很弱,因此我们使用与 Decision Transformer 类似的设置来运行它们。 我们尝试使用 Transformer 架构,但发现使用 MLP(如之前的工作)更强大。 我们训练 梯度步骤;训练更多并不能提高表现。 其他超参数如表10所示。 百分位行为克隆实验使用相同的超参数。
| Hyperparameter | Value |
|---|---|
| Number of layers | |
| Embedding dimension | |
| Nonlinearity function | ReLU |
| Batch size | |
| Dropout | |
| Learning rate | |
| Weight decay | |
| Learning rate decay | Linear warmup for first training steps |
A.3 图最短路径
我们提供了引言中讨论的说明性示例的详细信息。 任务是在固定有向图上找到最短路径,可以将其表示为 MDP,其中当代理位于目标节点时奖励为 ,否则为 。 观察结果是代理所在图节点的整数索引。 该操作是要移动到下一个的图节点的整数索引。 如果图中存在边,则动态转移将智能体传输到操作的节点索引,否则智能体将保留在过去的节点。 该问题中的回程对应于负路径长度,最大化它们对应于生成最短路径。
在此环境中,我们使用第 3 节中所述的 GPT 模型来生成操作和返回 Token 。 这使得模型可以生成自己的(可实现的)返回。 由于我们需要返回提示来生成操作,并且我们确实假设预先知道最佳路径长度,因此我们使用一个简单的先验优先于返回,有利于较短的路径:,其中是最大轨迹长度。 然后,与 GPT 模型生成的返回概率相结合:。 请注意,先前和返回预测完全可以由模型计算,因此避免了对任何外部或预言信息(例如最佳路径长度)的需要。 在先前的工作[65]中,通过先验生成的调整也被用于可控文本生成中的类似目的。
我们在一个 步数为 的图形随机行走轨迹数据集上进行了训练,每个数据集的随机图形节点数为 ,边缘稀疏系数为 。 我们在图6中报告了结果,我们发现 Transformer 模型能够显着改进达到目标所需的步骤数,与最佳路径的性能紧密匹配。

这项任务的良好表现有两个原因。 在一种情况下,随机行走轨迹的训练数据集可能包含直接对应于所需最短路径的段,在这种情况下,它将由模型生成。 在第二种情况下,生成的路径完全是原始的,并且不是训练数据集中轨迹的子集 - 它们是通过缝合次优片段生成的。 我们发现这种情况占实验中生成路径的。
虽然这是一个简单的示例,并且使用了为简单起见而在其他实验中不使用的生成先验,但它说明了如何将事后返回信息与生成先验一起使用,以避免显式动态编程的需要。
附录 B Atari 任务分数
表11显示了Hafner等人[21]中使用的标准化分数。 表12和13分别显示了与表1和4相对应的原始分数。 对于 %BC 分数,我们使用与 Decision Transformer 相同的超参数进行公平比较。 对于 REM 和 QR-DQN,Agarwal 等人 [13] 和 Kumar 等人 [14] 之间存在轻微差异;我们报告 REM 作者提供给我们的原始数据。
| Game | Random | Gamer |
|---|---|---|
| Breakout | ||
| Qbert | ||
| Pong | ||
| Seaquest |
| Game | DT (Ours) | CQL | QR-DQN | REM | BC |
|---|---|---|---|---|---|
| Breakout | |||||
| Qbert | |||||
| Pong | |||||
| Seaquest |
| Game | DT (Ours) | 10%BC | 25%BC | 40%BC | 100%BC |
|---|---|---|---|---|---|
| Breakout | |||||
| Qbert | |||||
| Pong | |||||
| Seaquest |