从话语到叙事:用于事件关系提取的知识投影
摘要
当前以事件为中心的知识图高度依赖显式连接词来挖掘事件之间的关系。 不幸的是,由于连接词的稀疏性,这些方法严重破坏了 EventKG 的覆盖范围。 缺乏高质量的标记语料库进一步加剧了这个问题。 在本文中,我们提出了一种用于事件关系提取的知识投影范式:通过利用叙述之间的共性将话语知识投影到叙述中。 具体来说,我们提出M多层K知识P投影网络工作(MKPNet),可以有效地利用多层话语知识进行事件关系提取。 这样,大大减少了标记数据的需求,并且可以有效地提取隐含的事件关系。 内在实验结果表明MKPNet实现了新的state-of-the-art性能,外在实验结果验证了提取的事件关系的价值。 ††脚注文本:∗通讯作者。
1简介
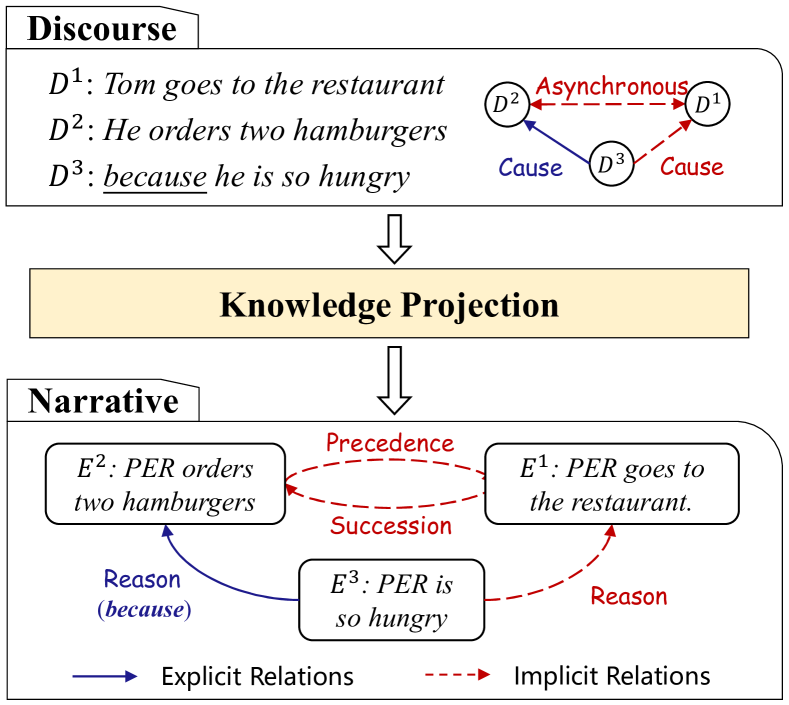
以事件为中心的知识图谱(EventKG)通过表示事件并识别事件之间的关系来对世界的叙述进行建模,这对于机器理解至关重要,并且可以使许多下游任务受益,例如问答(Costa等人,2020) 、新闻阅读(Vossen,2018)、常识知识获取(张等人,2020a)等等。
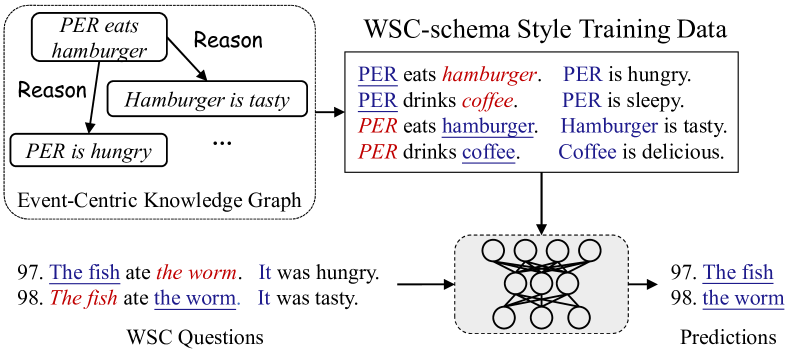
近年来,半自动构建EventKG引起了广泛关注(Tandon等人,2015;Rospocher等人,2016;Gottschalk和Demidova,2018;Zhang等人,2020b)。 这些方法在很少人工干预的情况下从大量原始语料库中提取事件知识,这使得它们成为构建大规模 EventKG 的可扩展解决方案。 通常,EventKGs中的每个节点代表一个事件,每条边代表事件对之间的预定义关系111 计算和认知研究将节点定义为偶发事件,包括活动、状态和事件。 在本文中,由于其受欢迎程度,我们将每个节点的定义简化为“事件”。 . 目前,事件关系主要是根据事件之间的显式连接词来提取的。 例如,在图1中,在之间提取了原因关系:“PER订购了两个汉堡”和:“PER 太饿了” 在它们之间使用显式连接词 “because”。
不幸的是,由于连接词的稀疏性,基于连接词的方法面临着关键的覆盖问题。 也就是说,很大一部分事件对并不与显式连接词相关,而是与潜在的事件关系相关。 我们将它们表示为隐式事件关系。 此外,相关事件在文档中甚至可以彼此不接近。 对于图 1 中的示例, 之间的隐含关系 Reason:“PER 去餐厅” 和 :由于缺乏显式连接词以及这两个子句之间的不连续性,无法提取“PER is so eager”。 以前基于连接的方法中的常见做法是忽略所有这些隐式实例(Zhang等人,2020b)。 因此,EventKG 的覆盖范围被严重削弱。 此外,由于现有事件关系语料库(洪等人,2016)的规模有限,通过监督学习构建有效的事件关系分类器也是不切实际的。
在本文中,我们提出了一种新的事件关系提取范式——知识投影。 我们不是依赖稀疏的连接词或从头开始构建分类器,而是通过利用事件叙述之间的人类学语言联系将话语知识投射到事件叙述中。 Enlightened by Livholts and Tamboukou (2015); Altshuler (2016); Reyes and Wortham (2017), discourses and narratives have significant associations, and their knowledge are shared at different levels: 1) token-level knowledge: discourses and narratives share similar lexical and syntactic structures, 2) semantic-level knowledge: the semantics entailed in discourse pairs and event pairs are analogical, e.g., -Reason and -Cause in Figure 1., and 3) label-level knowledge: heterogeneous event and discourse relations have the same coarse categories, e.g., both the event relation Reason and the discourse relation Cause are included in the coarse-grained relation Contingency. 通过利用手动标记语料库中的丰富知识并将其投影到事件关系提取模型中,可以显着提高事件关系提取的性能,并且可以显着减少数据需求。
具体来说,我们设计了M多层K知识P投影网络工作(MKPNet),可以有效地利用多层话语知识进行事件关系提取。 MKPNet 引入了三种适配器将知识从话语投射到叙述中:(a)用于 token 级知识投射的词符适配器; (b) 用于语义级知识投影的语义适配器; (c) 用于标签级知识投影的粗类别适配器。 通过共享这三个适配器的参数,可以有效地探索不同层面的话语和叙事之间的共性。 因此,我们可以获得更通用的词符表示、更准确的语义表示和更可信的粗类别表示,以更好地预测事件关系。
我们在具有代表性的EventKG之一ASER(Zhang等人,2020b)上进行了内在实验,并在Winograd计划挑战赛(WSC)(Levesque等人,2012)上进行了外在实验>,具有代表性的自然语言理解基准之一。 内在实验结果表明,所提出的 MKPNet 显着优于最先进的(SoA)基线,外在实验结果验证了提取的事件关系的价值222 我们的源代码以及相应的实验数据集和增强的EventKG可在https://github.com/TangJiaLong/Knowledge-Projection-for-公开获取ERE。 .
本文的主要贡献是:
-
•
我们提出了一种新的知识投影范式,它可以有效地利用话语和叙述之间的共性来提取事件关系。
-
•
我们设计了MKPNet,它可以通过词符适配器、语义适配器和粗类别适配器有效地利用多层话语知识进行事件关系提取。
-
•
我们的方法实现了新的 SotAevent 关系提取性能,并通过提取显式和隐式事件关系来发布丰富的 EventKG。 我们相信它可以使许多下游 NLP 任务受益。
2 背景
事件关系提取(ERE)。 给定一个现有的 EventKG ,其中节点 是事件,边 是它们的关系。 是通过基于连接词的方法提取的显式事件关系,是没有连接词的隐式事件关系。 通常,隐式事件关系提取(IERE)将两个事件、、作为输入,然后使用神经网络对它们的潜在关系进行分类。
话语关系识别(DRR)。 DRR 旨在识别两个话语论证之间的关系。 话语关系可以是显性的,也可以是隐性的,显性关系由连接词揭示,而隐性关系缺乏这些表面线索。 为了解决隐式话语关系识别(IDRR)任务,研究人员构建了高质量的标记数据集(Prasad等人,2008)并设计了精细的模型(Zhang等人,2016b;Bai和Zhao ,2018;岸本等人,2020)。
话语与叙事之间的关联。 最近的自然语言处理研究证明,话语和叙事相互密切互动,利用话语知识对叙事分析有显着的帮助,例如子事件检测(Aldawsari and Finlayson,2019)和主要事件相关识别 (Choubey 等人,2020)。 受上述观察的启发,本文通过知识投影范式利用话语知识。 得益于符号、语义和粗类别级别的关联,话语语料库和知识可以有效地用于事件关系提取。
3用于事件关系提取的多层知识投影网络
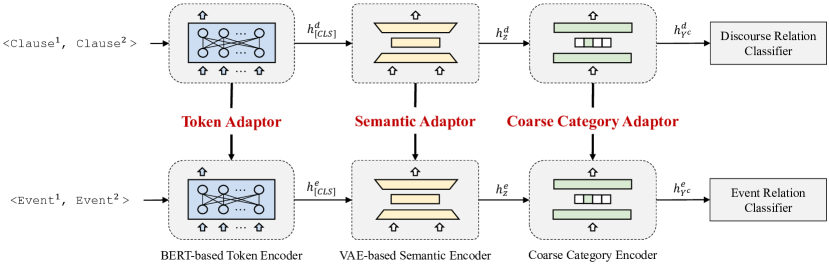
在本节中,我们描述如何通过将资源丰富的话语知识投射到资源贫乏的叙事任务来学习有效的事件关系提取器。 具体来说,我们提出M多层K知识P投影网络工作(MKPNet)可以有效地利用多层话语知识进行隐式事件关系提取。 图2显示了MKPNet的概述,它使用词符适配器、语义适配器和粗类别适配器来充分利用不同层次的话语知识。 下面,我们首先描述 MKPNet 的神经架构,然后描述三个适配器的细节。
3.1 MKPNet的神经架构
对于知识投影,我们将事件关系提取(ERE)和话语关系识别(DRR)建模为实例对分类任务(Devlin等人,2019;Kishimoto等人,2020)。 对于 ERE,输入是事件对,例如 <:“PER 去餐厅”、:“PER 是这样饥饿”>,输出是事件关系,例如 Reason。 对于 DRR,输入是一个子句对,例如 <:“Tom 去餐厅”、:“he is so饥饿”>,输出是诸如Cause之类的话语关系。
具体来说,MKPNet 通过基于 VAE 的语义编码器和粗类别编码器扩展了 SotADRR 模型 — BERT-CLS (Kishimoto 等人,2020),以逐层对知识进行建模(Pan等人,2016;郭等人,2019;康等人,2020b)。 1)首先利用基于BERT的词符编码器将实例对编码为词符表示; 2)然后通过基于VAE的语义编码器获得语义表示; 3)预测粗粒度标签并将其嵌入为粗粒度类别表示; 4)最终在聚合实例对表示的指导下对其关系进行分类:
| (1) |
其中表示串联操作。 这样,MKPNet的参数就可以按照进行分组,其中为基于BERT的词符编码器,为基于VAE的语义编码器, 用于粗类别编码器, 分别用于最终关系分类器层。
3.2 Token 适配器
最近的研究表明,相似的任务通常具有相似的词汇和句法结构,因此会导致相似的词符表示 Pennington 等人 (2014); Peters 等人 (2018). 词符适配器尝试通过与 DRR 共享基于 BERT 的编码器的参数 来改进 ERE 的词符编码。 这样,编码器由于更多的监督信号而更加有效,并且由于多任务设置而更加通用。
具体来说,给定一个事件对 <, >,我们将其表示为一个序列:
其中[CLS]和[SEP]是特殊标记。 对于输入中的每个词符,其表示是通过连接相应的词符、段和位置嵌入来构造的。 然后,事件对表示将被输入到 BERT 架构(Devlin 等人,2019)并由多层 Transformer 块(Vaswani 等人,2017)更新。 最后,我们获得最后一层特殊的[CLS]词符对应的隐藏状态作为 Token 级事件对表示:
| (2) |
对于DRR,可以通过相同的方式获得 Token 级话语对表示。
为了投影 token 级知识,我们使用相同的 BERT 进行事件对和话语对编码。 在优化过程中,它使用来自 ERE 和 DRR 的监督信号进行微调。
3.3 语义适配器
由于叙事和话语分析需要准确地表示实例对的深层语义,因此基于 BERT 的词符编码器捕获的浅层标记级知识是不够的。 然而,BERT 总是会产生非平滑的各向异性语义空间,这不利于大粒度语言单元的语义建模(Li等人,2020a)。
为了解决这个问题,我们引入了一种基于变分自动编码器(基于 VAE)的语义编码器,通过将各向异性语义分布转换为平滑且各向同性的高斯分布 来表示事件和子句的语义(Kingma 和 Welling,2014) ;Rezende等人,2014;Sohn等人,2015)。 为了更好地学习语义编码器,语义适配器在 ERE 和 DRR 之间共享其参数 ,并使用分类监督信号和 KL 散度对其进行训练。
具体来说,VAE是一个有向图模型,具有生成模型和变分模型,它通过自动编码器框架学习输入的语义表示 。 图3说明了语义编码器的图形表示。 具体来说,我们假设存在连续潜变量,其中和分别是高斯分布的均值和方差。 在此假设下,事件/话语关系的原始条件概率可以用以下公式表示:
| (3) | ||||
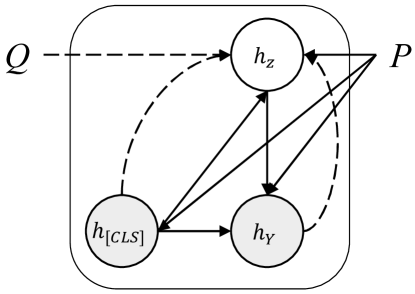
后验近似为 ,其中 可以是 或 , 可以是 或根据不同的任务。 我们1)首先通过共享的基于BERT的词符编码器和单独的关系嵌入网络获得输入和输出侧表示,即和; 2)然后执行非线性变换,将它们投影到语义空间上:
| (4) |
3)通过线性回归得到上述高斯参数和:
| (5) |
其中和分别是参数矩阵和偏差项; 4)使用重新参数化技巧(Kingma and Welling,2014;Sohn等人,2015)来获得最终的语义表示:
| (6) |
其中 和 可以是 或 。
除了缺少 之外,先验 的神经模型与后验 的神经模型相同。 此外,这两个模型具有彼此独立的参数。
在测试过程中,由于缺少输出端表示 ,我们将 设置为 (Zhang 等人, 2016a),即。 在训练过程中,我们最小化生成模型和推理模型之间的Kullback-Leibler散度。 直观上,KL 散度将这两个模型联系起来:
| (7) |
为了投影语义级知识,我们对事件对和话语对使用相同的 VAE。 因此,可以更准确地捕捉事件语义和话语语义的共性。
3.4 粗类别适配器
值得称赞的是,词符适配器和语义适配器涵盖了输入端所需的知识。 此外,我们发现 ERE 和 DRR 具有相同的粗粒度类别:Temporal、Contingency、Comparison 和 Expansion (Prasad 等人,2008;Zhang 等人,2020b),尽管它们有不同的细粒度类别。
为此,我们在从粗到细的框架(Petrov,2009)中设计了粗类别适配器,以弥合异构细粒度目标之间的差距。 具体来说,我们共享粗粒度分类器和粗标签嵌入网络的参数,以获得更可信的粗类别表示。
具体来说,我们首先使用词符表示 和语义表示 来预测粗粒度标签:
| (8) |
在哪里 {时间、意外事件、比较、扩展}。 之后,我们使用粗粒度标签嵌入网络来获得相应的粗粒度标签嵌入,这被称为粗类别表示。
为了投射标签级知识,我们使用相同的粗粒度分类器和相同的粗标签嵌入网络。 在优化过程中,事件实例和话语实例都可以用来训练这个粗类别编码器。 监管信号越多,监管就越有效。
3.5 完整模型训练
在本文中,我们利用多任务学习(Caruana,1997)来实现从话语到叙事的知识投影。 它期望相关任务(ERE 和 DRR)可以通过共享三个适配器的参数来帮助彼此更好地学习。 给定 ERE 和 DRR 训练数据集,使用替代优化方法(Dong等人,2015)来优化 MKPNet:
| (9) | ||||
其中根据任务的不同可以是或,、是两个超参数, 是语义编码器中的KL散度,和分别是细粒度和粗粒度目标:
| (10) | |||
| (11) |
需要注意的是,在MKPNet中,{}是ERE和DRR之间基于BERT的词符编码器、基于VAE的语义编码器以及粗类别编码器的共享参数。 {}是细粒度ERE和DRR分类器的独立参数。
4实验
我们在 ASER (Zhang 等人, 2020b) 上进行内在实验来评估所提出的 MKPNet 的有效性,并在 WSC (Levesque 等人, 2012) 上进行外在实验来验证提取的事件关系的值。
4.1 内在实验
数据集。 对于话语关系识别(DRR),我们使用 PDTB 2.0 (Prasad 等人, 2008) 以及 Ji 和 Eisenstein (2015) 的相同分割:第 2-20 节/训练/开发/测试分别为 0-1/21-22。 对于事件关系提取(ERE),由于没有标记的训练语料库,我们通过删除 ASER 核心版本中显式事件关系实例的连接词来构建新的数据集333 https://hkust-knowcomp.github.io/ASER 并保留最多 2200 个实例每个类别的最高置信度分数444 置信度分数越高意味着实例越可信。. 通过这种方式,我们获得了 23,181/1400/1400 个训练/开发/测试实例——我们将其表示为隐式事件关系提取(IERE)数据集。
实施。 我们基于 pytorch-transformers (Wolf 等人, 2020) 实现我们的模型。 我们使用 BERT-base 并使用 SotADRR 模型的默认设置(Kishimoto 等人,2020)设置所有超参数。
基线。 对于 ERE,我们将提出的 MKPNet 与以下基线进行比较:
-
•
没有话语知识的基线仅在 IERE 训练集上进行训练。 由于其 SotA 性能,我们选择 BERT-CLS 作为其中的代表。
-
•
包含话语知识的基线通过从话语模型进行迁移学习(Pan and Yang,2009;Pan 等人,2010)来改进 ERE 的学习,即首先在 PDTB 2.0 上预训练一个参数,然后在 IERE 上,我们将其表示为 BERT-Transfer。
对于 DRR,我们将提出的 MKPNet 与以下基线进行比较:
-
•
Bai 和Zhao (2018) 是一种深度神经网络模型,通过字符、句子和句子对级别等可变粒度文本表示进行增强。
-
•
Kishimoto 等人 (2020) 是 SotADRR 模型 BERT-CLS,它将 BERT 与一个额外的输出层结合在一起。
4.1.1 总体结果
表1-3显示了基线和MKPNet的总体ERE/DRR结果。 对于我们的方法,我们使用完整的 MKPNet 及其四个消融设置:MKPNet w/o SA、MKPNet w/o CA、MKPNet w/o SA & CA 和 MKPNet w/o KP,其中 SA、CA 和 KP 表示语义适配器、粗类别适配器和相应的知识投影。 我们可以看到:
| Number of Relations | |
| FrameNet (Baker et al., 1998) | 1,709 |
| ConceptNet (Speer et al., 2017) | 116,097 |
| Event2Mind (Smith et al., 2018) | 57,097 |
| ATOMIC (Sap et al., 2019) | 877,108 |
| Knowlywood (Tandon et al., 2015) | 2,644,415 |
| ASER (Zhang et al., 2020b) | 1,287,059 |
| ASER++ (core) | 2,034,963 |
| ASER++ (high) | 3,530,771 |
| ASER++ (full) | 8,766,098 |
| Acc | F1 | |
| Baselines w/o Discourse Knowledge | ||
| BERT-CLS | 53.00 | 52.24 |
| MKPNet w/o KP | 53.94 | 53.52 |
| Baselines with Discourse Knowledge | ||
| BERT-Transfer | 54.29 | 53.44 |
| Multi-tier Knowledge Projection | ||
| MKPNet w/o SA & CA | 54.79△0.85 | 53.90△0.38 |
| MKPNet w/o CA | 55.14△1.20 | 54.42△0.90 |
| MKPNet w/o SA | 55.29△1.35 | 54.92△1.40 |
| MKPNet | 55.86△1.92 | 55.36△1.84 |
| Model | Acc |
| Bai and Zhao (2018) | 48.22 |
| BERT-CLS (Kishimoto et al., 2020) | 51.40 |
| BERT-CLS (Ours) | 50.91 |
| MKPNet w/o KP | 52.86 |
| MKPNet | 54.09 |
1. 基于MKPNet,我们通过丰富的隐式事件关系丰富了原始ASER。 考虑到计算复杂性,我们对同一文档中同时出现的事件对进行分类,并通过置信度分数对其进行过滤。 具体来说,我们通过将分类概率与事件对的频率相乘来计算置信度分数。 与原始显式事件关系相结合,我们可以获得具有不同阈值置信度(3/2/1)的丰富EventKG ASER++(核心/高/完整)。 表1显示,与现有的事件相关资源相比,ASER++在事件关系数量上具有压倒性的优势。
2. 所提出的 MKPNet 实现了 ERE 的 SotAperformance。 MKPNet 可以显着优于 BERT-Transfer,达到 55.86 的准确率和 55.36 F1。 与 BERT-CLS 相比,没有 KP 的 MKPNet 获得了相当大的性能提升。 我们认为这是因为MKPNet充分探索了不同层次的知识,并且逐层建模知识是有效的。
3. 通过在标记级别、语义级别和标签级别投射知识,这三个适配器都很有用并且相互补充。 与完整模型 MKPNet 相比,其四个变体表现出不同程度的性能下降。 MKPNet 的性能优于没有 CA 的 MKPNet,精度为 0.72,F1 为 0.94,这表明我们的粗类别适配器成功地弥补了异构细粒度目标的差距。 MKPNet 优于 MKPNet w/o SA 0.57 准确度和 0.44 F1,因此我们相信我们的潜在语义适配器有助于捕获语义级共性。 最后,没有 KP 的 MKPNet 和没有 SA & CA 的 MKPNet 之间有明显的下降,这意味着词符适配器是必不可少的。 这些观察的见解是,在层次结构下话语和叙述之间存在共性,因此将它们投射到不同的层次是有效的,并且三个适配器可以相互补充。
4. 话语和叙述之间的共性对 ERE 和 DRR 都有好处。 与没有话语知识的基线 - BERT-CLS 和没有 KP 的 MKPNet 相比,朴素转移方法 - BERT-Transfer 和我们的 MKPNet 都实现了显着的性能改进:与 BERT 相比,BERT-Transfer 的准确率提高了 1.29,F1 提高了 1.20 -CLS 和 MKPNet 与没有 KP 的 MKPNet 相比,精度提高了 1.92,F1 提高了 1.84。 此外,对于 DRR,我们的方法 MKPNet 也大大优于其他基线及其变体 MKPNet w/o KP。 这些结果验证了话语知识和叙事知识之间的共性。
4.1.2详细分析
语义级知识和标签级知识的影响。 在这些实验中,我们比较了模型的性能,MKPNet、无 CA 的 MKPNet 和无 SA 的 MKPNet 有或没有知识投影,以找出语义级知识和标签级知识的影响。 从表4可以看出:(1)与同类模型相比,带有知识投影的MKPNet、无CA的MKPNet和无SA的MKPNet带来了显着的改进。 因此,令人信服的是,性能改进主要来自于话语知识而不是神经架构; (2)当前的知识投影可以通过利用更准确的话语知识来进一步改进:使用黄金粗类别的 MKPNet w/o SA* 取得了惊人的性能(Acc 70.50;F1 70.32)。
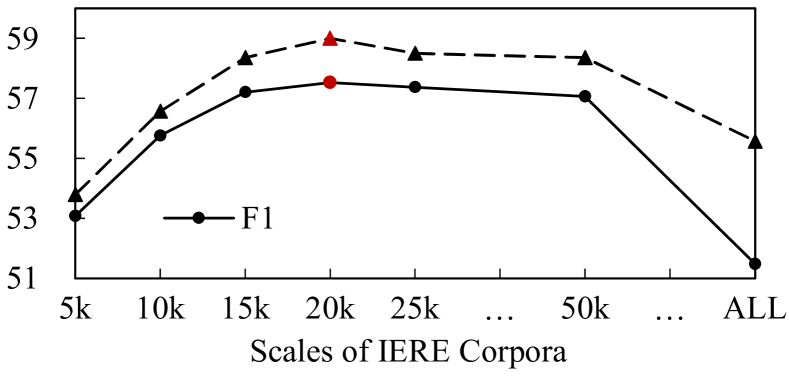
数据集质量和大小之间的权衡。 如上所述,IERE 训练数据集是使用 ASER 核心版本中最置信的实例构建的。 我们可以通过合并更多置信度较低的实例来构建更大但质量较低的数据集,即质量大小权衡问题。 为了分析质量和大小之间的权衡,我们构建了一组具有不同大小/质量的数据集,图4显示了MKPNet在开发集上的相应结果。 我们可以看到,规模是一开始性能提升的主要因素:每增加 5000 个实例就可以带来显着的提升(大约 2 到 3 个 F1 增益)。 当规模较大时(在我们的实验中超过 20,000 个实例),更多的实例不会带来性能提升,而低质量的实例会损害性能。
| KP | Fine-grained | Coarse-grained | |||
| Acc | F1 | Acc | F1 | ||
| BERT-CLS | 53.00 | 52.24 | — | — | |
| MKPNet | 53.94 | 53.52 | — | — | |
| ✓ | 55.86 | 55.36 | — | — | |
| MKPNet w/o CA | 53.79 | 53.39 | — | — | |
| ✓ | 55.14 | 54.42 | — | — | |
| MKPNet w/o SA | 53.21 | 52.48 | 66.57 | 63.04 | |
| ✓ | 55.29 | 54.92 | 67.93 | 64.76 | |
| MKPNet w/o SA* | 70.50 | 70.32 | 100.0 | 100.0 | |
4.2外部实验
上述内在实验验证了所提出的 MKPNet 对于 ERE 的有效性。 在本节中,我们使用我们丰富的EventKGs的核心版本——ASER++,然后在Winograd Schema Challenge(WSC)(Levesque等人,2012)上进行外在实验来验证ASET++的效果。
WSC 实施。 WSC 具有挑战性,因为它的模式是一对仅在一个或两个单词上不同的句子,并且包含在两个句子中以相反方向解决的指称歧义。 根据 Certu 等人 (2019) 的说法,在 WSC 模式样式训练集上微调预训练语言模型是解决 WSC 问题的稳健方法。 因此,如图 5 所示,我们将 ASER++ 转换为 WSC-schema 风格的数据,方法与 Zhang 等人 (2020b) 以及其上的伯特 BERT 相同,我们将其转换为 WSC-schema 风格的数据。称为 BERT (ASER++)。 我们将 BERT (ASER++) 与这些基线进行比较:
-
•
纯基于知识的方法是基于规则的启发式方法,例如知识搜索(Emami等人,2018)和字符串匹配(Zhang等人,2020b) 。
-
•
基于语言模型的方法使用在大规模语料库上训练并专门针对 WSC 任务进行调整的语言模型,例如 LM (Trinh 和 Le,2018)。
-
•
外部知识增强方法是基于BERT并使用不同外部知识资源进行训练的模型,例如WscR (Ng, 2012; Certu等人, 2019)
我们基于 pytorch-transformers (Wolf 等人, 2020) 实现我们的模型。 使用 BERT-large。 所有超参数均默认设置为Certu等人(2019)。
| Model | WSC |
| Pure Knowledge-based Methods | |
| Knowledge Hunting (Emami et al., 2018) | 57.3 |
| String Match (Zhang et al., 2020b) | 56.6 |
| Language Model-based Methods | |
| LM (Single) (Trinh and Le, 2018) | 54.5 |
| LM (Ensemble) (Trinh and Le, 2018) | 61.5 |
| BERT (w/o finetuning) (Devlin et al., 2019) | 61.9 |
| External Knowledge Enhanced Methods | |
| BERT (WscR) Certu et al. (2019) | 71.4 |
| BERT (ASER) Zhang et al. (2020b) | 64.5 |
| BERT (ASER & WscR) Zhang et al. (2020b) | 72.5 |
| BERT (ASER++) | 66.2 |
| BERT (ASER++ & WscR) | 74.1 |
外在结果。 表5显示了外部实验的总体结果。 我们可以看到:通过在我们丰富的EventKG ASER++上微调BERT,可以显着提高WSC性能。 BERT (ASER++) 和 BERT (ASER++ & WscR) 分别优于 BERT (ASER) 和 BERT (ASER & WscR),这验证了 ASER++ 的有效性,并且隐式事件关系有利于下游 NLU 任务。
5相关工作
以事件为中心的知识图。 知识图谱已经从以实体为中心的(Banko等人,2007;Suchanek等人,2007;Bollacker等人,2008;Wu等人,2012)转变为以事件为中心的知识图。 然而,传统知识图谱的构建需要领域专家投入大量精力和时间,而且往往规模有限,无法有效解决现实世界的应用,例如FrameNet(Baker等人,1998)。 近年来,许多现代化、大型的KG以半自动方式建成,主要关注事件(Tandon等人,2015;Rospocher等人,2016;Gottschalk和Demidova,2018;Zhang等人,2020b)和常识(Speer等人,2017;Smith等人,2018;Huang等人,2018;Sap等人,2019)。 具体来说,Yu 等人 (2020) 提出了一种提取事件之间蕴涵关系的方法,例如,“我吃苹果”蕴含“我吃水果”,并发布事件蕴涵图(EEG)。 与脑电图不同,本文关注的是隐含的事件关系,这些关系由于缺乏连接词和不连续性而未被提取。
知识传输。 由于数据稀缺问题,许多知识迁移研究被提出,包括多任务学习(Caruana,1997)、迁移学习(Pan and Yang,2009;Pan等人,2010) ),以及知识蒸馏Hinton 等人(2014)。 最近,研究人员对逐层训练/共享/转移/蒸馏模型感兴趣,以充分挖掘知识 Pan 等人 (2016);郭等人 (2019);康等人 (2020);李等人(2020b)。 在本文中,我们提出了一种知识投影方法,可以将话语知识投影到不同层次的叙述中。
6 结论
在本文中,我们提出了一种用于事件关系提取和M多层K知识P投影N的知识投影范式t3>etwork (MKPNet) 旨在利用多层话语知识。 通过有效地将知识从话语投射到叙事,MKPNet 实现了新的最先进的事件关系提取性能,并且外部实验结果验证了提取的事件关系的价值。 对于未来的工作,我们希望设计新的数据高效算法,以使用低质量和异构知识学习有效的模型。
致谢
该工作得到中国科学院战略性先导科技专项资助,批准号: XDA27020200,国家自然科学基金项目,批准号: U1936207,部分由中国科学院青年创新促进会提供(2018141)。
参考
- Aldawsari and Finlayson (2019) Mohammed Aldawsari and Mark Finlayson. 2019. Detecting subevents using discourse and narrative features. In Proceedings of ACL 2019.
- Altshuler (2016) Daniel Altshuler. 2016. Events, States and Times: An Essay on Narrative Discourse in English. Walter de Gruyter GmbH & Co KG.
- Bai and Zhao (2018) Hongxiao Bai and Hai Zhao. 2018. Deep enhanced representation for implicit discourse relation cecognition. In Proceedings of ICCL 2018.
- Baker et al. (1998) Collin F. Baker, Charles J. Fillmore, and John B. Lowe. 1998. The berkeley framenet project. In Proceedings of COLING-ACL 1998.
- Banko et al. (2007) Michele Banko, Michael J. Cafarella, Stephen Soderland, Matthew Broadhead, and Oren Etzioni. 2007. Open information extraction from the web. In Proceedings of IJCAI 2007.
- Bollacker et al. (2008) Kurt D. Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of SIGMOD 2008.
- Caruana (1997) Rich Caruana. 1997. Multitask learning. Machine learning, 28(1).
- Certu et al. (2019) Vid Kocijanand Ana-Maria Certu, Oana-Maria Camburu, Yordan Yordanov, and Thomas Lukasiewicz. 2019. A surprisingly robust trick for the winograd schema challenge. In Proceedings of ACL 2019, pages 4837–4842.
- Choubey et al. (2020) Prafulla Kumar Choubey, Aaron Lee, Ruihong Huang, and Lu Wang. 2020. Discourse as a function of event: Profiling discourse structure in news articles around the main event. In Proceedings of ACL 2020.
- Costa et al. (2020) Tarcísio Souza Costa, Simon Gottschalk, and Elena Demidova. 2020. Event-qa: A dataset for event-centric question answering over knowledge graphs. arXiv preprint arXiv:2004.11861.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL 2019.
- Dong et al. (2015) Daxiang Dong, Hua Wu, Wei He, Dianhai Yu, and Haifeng Wang. 2015. Multi-task learning for multiple language translation. In Proceedings of ACL-IJCNLP 2015.
- Emami et al. (2018) Ali Emami, Noelia De La Cruz, Adam Trischler, Kaheer Suleman, and Jackie Chi Kit Cheung. 2018. A knowledge hunting framework for common sense reasoning. In Proceedings of EMNLP 2018, pages 1949–1958.
- Gottschalk and Demidova (2018) Simon Gottschalk and Elena Demidova. 2018. Eventkg: A multilingual event-centric temporal knowledge graph. In Proceedings of ESWC 2018.
- Guo et al. (2019) Yunhui Guo, Honghui Shi, Abhishek Kumar, Kristen Grauman, Tajana Rosing, and Rogerio Feris. 2019. Spottune: Transfer learning through adaptive fine-tuning. In Proceedings of CVPR 2019.
- Hinton et al. (2014) Geoffrey Hinton, Oriol Vinyals, and Jeff Dea. 2014. Distilling the knowledge in a neural network. In Proceedings of The Workshop on NIPs 2014.
- Hong et al. (2016) Yu Hong, Tongtao Zhang, Tim O’Gorman, Sharone Horowit-Hendler, Heng Ji, and Martha Palmer. 2016. Building a cross-document event-event relation corpus. In Proceedings of ACL 2016.
- Huang et al. (2018) Bhavana Dalviand Lifu Huang, Niket Tandon, Wen tau Yih, and Peter Clark. 2018. Tracking state changes in procedural text: A challenge dataset and models for process paragraph comprehension. In Proceedings of NAACL-HLT 2018.
- Ji and Eisenstein (2015) Yangfeng Ji and Jacob Eisenstein. 2015. One vector is not enough: Entity-augmented distributed semantics for discourse relations. In Proceedings of TACL 2015.
- Kang et al. (2020) Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. 2020. Decoupling representation and classifier for long-tailed recognition. In Proceedings of ICLR 2020.
- Kingma and Welling (2014) Kingma and Welling. 2014. Auto-encoding variational bayes. In Proceedings of ICLR 2014.
- Kishimoto et al. (2020) Yudai Kishimoto, Yugo Murawaki, and Sadao Kurohashi. 2020. Adapting bert to implicit discourse relation classification with a focus on discourse connectives. In Proceedings of LREC 2020.
- Levesque et al. (2012) Hector Levesque, Ernest Davis, and Leora Morgenstern. 2012. The winograd schema challenge. In Proceedings of KR 2012.
- Li et al. (2020a) Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. 2020a. On the sentence embeddings from pre-trained language models. In Proceedings of EMNLP 2020.
- Li et al. (2020b) Jianquan Li, Xiaokang Liu, Honghong Zhao, Ruifeng Xu, Min Yang, and Yaohong Jin. 2020b. Bert-emd: Many-to-many layer mapping for bert compression with earth mover’s distance. In Proceedings of EMNLP 2020.
- Livholts and Tamboukou (2015) Mona Livholts and Maria Tamboukou. 2015. Discourse and Narrative Methods: Theoretical Departures, Analytical Strategies and Situated Writings. Sage.
- Ng (2012) Altaf Rahmanand Vincent Ng. 2012. Resolving complex cases of definite pronouns: the winograd schema challenge. In Proceedings of EMNLP–CoNLL 2012, pages 777–789.
- Pan et al. (2016) Jianhan Pan, Xuegang Hu, Peipei Li, Huizong Li, Wei He, Yuhong Zhang, and Yaojin Lin. 2016. Domain adaptation via multi-layer transfer learning. Neurocomputing.
- Pan et al. (2010) Sinno Jialin Pan, Ivor W Tsang, James T Kwok, and Qiang Yang. 2010. Domain adaptation via transfer component analysis. IEEE Transactions on Neural Networks, 22(2).
- Pan and Yang (2009) Sinno Jialin Pan and Qiang Yang. 2009. A survey on transfer learning. TKDE, 22(10).
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of EMNLP 2014.
- Peters et al. (2018) Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of NAACL 2018.
- Petrov (2009) Slav Orlinov Petrov. 2009. Coarse-to-Fine Natural Language Processing. Ph.D. thesis, EECS Department, University of California, Berkeley.
- Prasad et al. (2008) Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Miltsakaki, Livio Robaldo, Aravind K Joshi, and Bonnie L Webber. 2008. The penn discourse treebank 2.0. In Proceedings of LREC 2008.
- Reyes and Wortham (2017) Angela Reyes and Stanton Wortham. 2017. Discourse and Education, chapter Discourse Analysis Across Events. Springer International Publishing.
- Rezende et al. (2014) Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. 2014. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of ICML 2014.
- Rospocher et al. (2016) Marco Rospocher, Marieke van Erp, Piek Vossen, Antske Fokkens, Itziar Aldabe, German Rigau, Aitor Soroa, Thomas Ploeger, and Tessel Bogaard. 2016. Building event-centric knowledge graphs from news. Journal of Web Semantics.
- Sap et al. (2019) Maarten Sap, Ronan LeBras, Emily Allaway, Chandra Bhagavatula, Nicholas Lourie, Hannah Rashkin, Brendan Roof, Noah A. Smith, and Yejin Choi. 2019. Atomic: An atlas of machine commonsense for if-then reasoning. In Proceedings of AAAI 2019.
- Smith et al. (2018) Noah A. Smith, Yejin Choi, Maarten Sap, Hannah Rashkin, and Emily Allaway. 2018. Event2mind: Commonsense inference on events, intents, and reactions. In Proceedings of ACL 2018.
- Sohn et al. (2015) Kihyuk Sohn, Honglak Lee, and Xinchen Yan. 2015. Learning structured output representation using deep conditional generative models. In Proceedings of NIPS 2015.
- Speer et al. (2017) Robert Speer, Joshua Chin, and Catherine Havasi. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of AAAI 2017.
- Suchanek et al. (2007) Fabian M. Suchanek, Gjergji Kasneci, and Gerhard Weikum. 2007. Yago: A core of semantic knowledge. In Proceedings of WWW 2007.
- Tandon et al. (2015) Niket Tandon, Gerard De Melo, Abir De, and Gerhard Weikum. 2015. Knowlywood: Mining activity knowledge from hollywood narratives. In Proceedings of CIKM 2015.
- Trinh and Le (2018) Trieu H. Trinh and Quoc V. Le. 2018. A simple method for commonsense reasoning. arXiv preprint arXiv:1806.02847.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomezand Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of NIPS 2017.
- Vossen (2018) Piek Vossen. 2018. Newsreader at semeval-2018 task 5: Counting events by reasoning over event-centric-knowledge-graphs. In Proceedings of The 12th International Workshop on Semantic Evaluation.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of EMNLP 2020: System Demonstrations.
- Wu et al. (2012) Wentao Wu, Hongsong Li, Haixun Wang, and Kenny Q. Zhu. 2012. Probase: A probabilistic taxonomy for text understanding. In Proceedings of SIGMOD 2012.
- Yu et al. (2020) Changlong Yu, Hongming Zhang, Yangqiu Song, Wilfred Ng, and Lifeng Shang. 2020. Enriching large-scale eventuality knowledge graph with entailment relations. In Proceedings of AKBC 2020.
- Zhang et al. (2016a) Biao Zhang, Deyi Xiong, Jinsong Su, Hong Duan, and Min Zhang. 2016a. Variational neural machine translation. In Proceedings of EMNLP 2016.
- Zhang et al. (2016b) Biao Zhang, Deyi Xiong, Jinsong Su, Qun Liu, Rongrong Ji, Hong Duan, and Min Zhang. 2016b. Variational neural discourse relation recognizer. In Proceedings of EMNLP 2016.
- Zhang et al. (2020a) Hongming Zhang, Daniel Khashabi, Yangqiu Song, and Dan Roth. 2020a. Transomcs: From linguistic graphs to commonsense knowledge. In Proceedings of IJCAI 2020.
- Zhang et al. (2020b) Hongming Zhang, Xin Liu, Haojie Pan, Yangqiu Song, and Cane Wing-Ki Leung. 2020b. Aser: A large-scale eventuality knowledge graph. In Proceedings of WWW 2020.