BernNet:通过伯恩斯坦近似学习任意图谱滤波器
摘要
许多代表性的图神经网络,、GPR-GNN 和 ChebNet,都使用图谱滤波器来近似图卷积。 然而,现有的工作要么应用预定义的过滤器权重,要么在没有必要限制的情况下学习它们,这可能会导致过滤器过于简化或不适定。 为了克服这些问题,我们提出了BernNet,这是一种具有理论支持的新型图神经网络,为设计和学习任意图谱滤波器提供了一种简单但有效的方案。 特别是,对于图的归一化拉普拉斯谱上的任何滤波器,我们的 BernNet 通过 阶 Bernstein 多项式近似来估计它,并通过设置 Bernstein 基的系数来设计其谱属性。 此外,我们可以根据观察到的图及其相关信号来学习系数(以及相应的滤波器权重),从而实现专门针对数据的BernNet。 我们的实验表明,BernNet 可以学习任意光谱滤波器,包括复杂的带阻滤波器和梳状滤波器,并且在现实世界的图建模任务中实现了卓越的性能。 代码可在 https://github.com/ivam-he/BernNet 获取。
1简介
图神经网络(GNN)因其在社会分析等各种图学习任务上的出色表现而受到了研究人员的广泛关注 qiu2018deepinf ; li2019编码; tong2019杠杆,药物发现jian2021can; rathi2019practical 、流量预测li2017diffusion ; bogaerts2020图; cui2019traffic 、推荐系统ying2018graph ; wu2019session 和计算机视觉 zhao2019semantic ; chen2019multi . 最近的研究表明,许多流行的 GNN 都以多项式图谱滤波器的方式运行Chebnet; kipf2016半; chien2021GPR-GNN ; Levie2018凯莱网;比安奇2021ARMA; xu2018graphWavelet 。 具体来说,我们将节点集和边集的无向图表示为,其邻接矩阵为。 给定图上的信号,其中是节点数,我们可以将其图频谱过滤操作表示为,是滤波器权重,是的对称归一化拉普拉斯矩阵,是的对角度矩阵t7>. 另一个等效的多项式滤波操作是,其中是归一化邻接矩阵,是滤波器权重。
我们可以将应用上述过滤操作的 GNN 大致分为两类,具体取决于它们是设计过滤器权重还是基于观察到的图来学习它们。 这两类中的一些代表性模型如下所示。
-
•
由设计过滤器驱动的 GNN: GCN kipf2016semi 使用简化的一阶切比雪夫多项式,它被证明是一个低通滤波器 balcilar2021analyzing ; wu2019sgc ; xu2020graphheat ; zhu2021口译 . APPNP appnp 利用个性化 PageRank (PPR) 来设置过滤器权重并实现低通过滤器 klicpera2019diffusion ; zhu2021口译 . GNN-LF/HFzhu2021terpreting从图优化函数的角度设计滤波器权重,可以模拟高通和低通滤波器。
-
•
由学习过滤器驱动的 GNN: ChebNet Chebnet 使用切比雪夫多项式近似过滤操作,并通过切比雪夫基的可训练权重学习过滤器。 GPR-GNN chien2021GPR-GNN 通过直接对滤波器权重执行梯度下降来学习多项式滤波器,从而可以导出高通或低通滤波器。 ARMA bianchi2021ARMA 通过自回归移动平均滤波器系列 narang2013signal 学习有理滤波器。
尽管上述 GNN 在各种图建模任务中取得了一些令人鼓舞的结果,但它们仍然存在两个主要缺点。 首先,大多数现有方法侧重于设计或学习简单的滤波器(、低通和/或高通滤波器),而实际应用通常需要更复杂的滤波器,例如带阻和梳状滤波器过滤器。 据我们所知,现有的工作都不支持设计任意可解释的光谱滤波器。 由学习过滤器驱动的 GNN 理论上可以学习任意过滤器,但它们无法直观地显示它们学习了哪些过滤器。 换句话说,它们的可解释性很差。 例如,GPR-GNN chien2021GPR-GNN 学习滤波器权重 ,但仅证明学习权重序列的一小部分对应于低通或高通滤波器。 其次,GNN 通常根据经验设计滤波器或在没有任何必要约束的情况下学习滤波器权重。 因此,它们的过滤权重往往可控性较差。 例如,GNN-LF/HF zhu2021interpreting 使用复杂且非直观的多项式和难以调整的超参数来设计其滤波器。 多层GCN/SGCkipf2016semi; wu2019sgc 导致“不适定”滤波器(,那些产生负光谱响应的滤波器)。 此外,GPR-GNN chien2021GPR-GNN 或 ChebNet Chebnet 学习到的过滤器也有可能是不适定的。
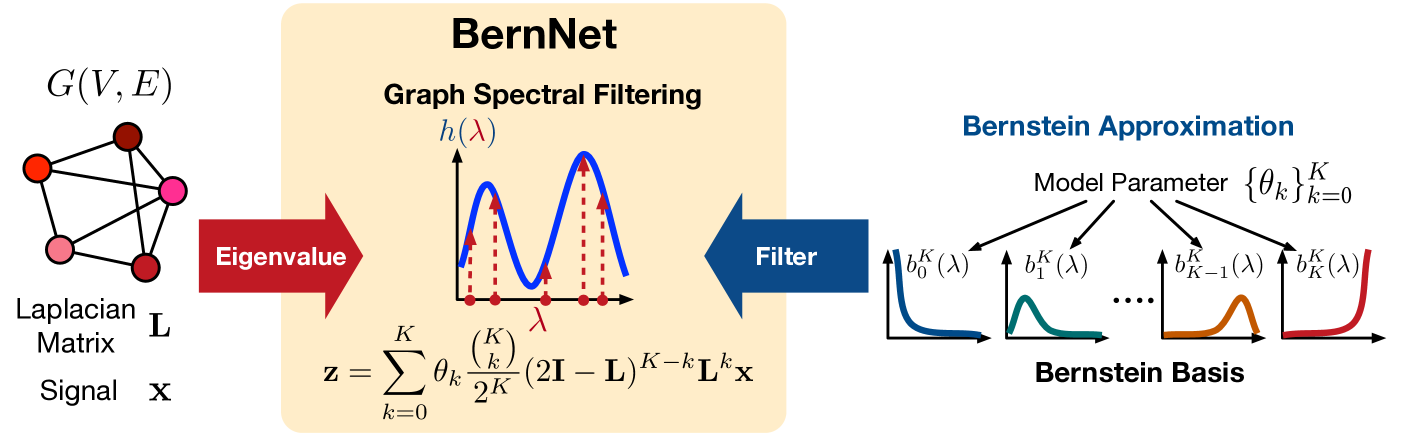
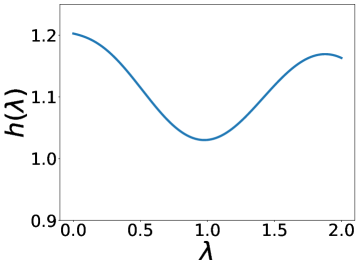
为了克服上述问题,我们提出了一种名为 BernNet 的新型图神经网络,它为设计和学习任意图谱滤波器提供了有效的算法框架。 如图1所示,对于对称归一化拉普拉斯频谱上的任意频谱滤波器,我们的BernNet近似于 通过 阶 Bernstein 多项式近似,、。 伯恩斯坦基的非负系数作为模型参数,可以解释为,( ,从统一采样的过滤器值)。 通过设计或学习,我们可以获得各种频谱滤波器,其滤波操作可以表示为,其中是图形信号。 我们从图优化的角度进一步证明了 BernNet 的合理性——任何有效的多项式过滤器 ,那些映射 到 的多项式函数,总是可以由我们的 BernNet 表达,因此,我们的 BernNet 学习到的过滤器总是有效的。 最后,我们进行实验来证明:1)BernNet 可以学习任意图谱滤波器(例如带阻、梳状、低带通等),2)BernNet 在现实数据集上实现了卓越的性能。
2 伯尔尼网
2.1 光谱滤波器的伯恩斯坦近似
给定任意滤波器函数,让表示对称归一化拉普拉斯矩阵的特征分解,其中是矩阵特征向量, 是特征值的对角矩阵。 我们用
| (1) |
表示图形信号 上的频谱滤波器。 我们工作的关键大约是(或者等效的)。 为此,我们利用下面定义的伯恩斯坦基和伯恩斯坦多项式近似。
Definition 2.1 (farouki2012bernstein)。
(伯恩斯坦多项式近似) 给定 上的任意连续函数 , 的 Bernstein 多项式近似(阶 )定义为
| (2) |
这里,对于 , 是第 个伯恩斯坦基, 是 处的函数值,用作 的系数。
Lemma 2.1 (farouki2012bernstein)。
给定 上的任意连续函数 ,让 表示 的 Bernstein 近似,如方程 (2)。 我们将 作为 。
对于过滤函数,我们让和,以便伯恩斯坦多项式近似变得适用,其中和 为 。 因此,我们可以通过来近似,并且引理2.1确保为。
将替换为,我们将方程(1)中的光谱滤波器近似为并且推导所提出的 BernNet。 特别是,给定一个图信号 ,我们的 BernNet 的卷积算子定义如下:
| (3) |
其中每个系数可以设置为以近似预定的滤波器,或者从端到端的图结构和信号中学习时尚。 作为引理 2.1 的自然扩展,我们的 BernNet 拥有以下命题。
Proposition 2.1.
对于任意连续滤波函数,通过设置,式(3)中的满足 为 。
2.2用BernNet实现现有的过滤器。
如命题2.1所示,我们的 BernNet 可以以足够的精度逼近任意连续光谱滤波器。 下面我们给出一些有代表性的例子来说明我们的 BernNet 如何准确地实现 GNN 中常用的现有过滤器。
-
•
全通滤波器。 我们为设置,近似值与完全相同。 相应地,我们的BernNet就变成了单位矩阵,完美地实现了全通滤波器。
-
•
线性低通滤波器。 我们为设置并获得。 BernNet变为,准确地实现了线性低通滤波器。 请注意, 也与重整化之前的图卷积网络(GCN)相同 kipf2016semi 。
-
•
线性高通滤波器。 类似地,我们可以为设置以获得完美的近似,BernNet就变成了。
请注意,即使对于那些非连续频谱滤波器 、脉冲低/高/带通滤波器,我们的 BernNet 也可以提供良好的近似值(具有足够大的 )。
-
•
脉冲低通滤波器 。222The impulse function if , otherwise 我们将和设置为和。因此,BernNet 变为 ,得出 层线性低通滤波器。
-
•
脉冲高通滤波器。 我们为和设置和。 BernNet 变成、、层线性高通滤波器。
-
•
脉冲带通滤波器。 同样,我们为和设置和。 BernNet变为,可以解释为堆叠了层线性低通滤波器和层线性高通滤波器。 显然,在这种情况下 应该是偶数。
表 1 总结了上述滤波器的 BernNet 设计。 我们可以发现 BernNet 的一个吸引人的优点是它的系数与目标滤波器的光谱特性高度相关。 特别是,我们可以通过使用大或小的来确定通过或拒绝带有的光谱信号,因为每个Bernstein碱基对应于一个“凹凸” ”位于。 此属性在设计过滤器时提供了有用的指导,从而增强了 BernNet 的可解释性。
| Filter types | Filter | for | Bernstein approximation | BernNet |
| All-pass | 1 | 1 | ||
| Linear low-pass | ||||
| Linear high-pass | ||||
| Impulse low-pass | and other | |||
| Impulse high-pass | and other | |||
| Impulse band-pass | and other |
2.3 使用 BernNet 学习复杂的过滤器
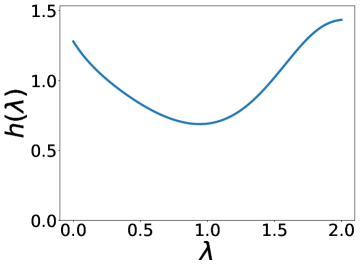
除了设计上述典型滤波器之外,我们的 BernNet 还可以表达更复杂的滤波器,例如带通、带阻、梳状、低带通滤波器、。 此外,给定应用此类过滤器之前和之后的图形信号(、 和相应的 ),我们的 BernNet 可以学习它们的以端到端的方式进行近似。 具体来说,给定对,我们通过梯度下降学习BernNet的系数。 更多实现细节可以在下面的实验部分找到。 图2说明了四个复数滤波器和我们学到的近似值(低带通滤波器为,其中当,否则)。 一般来说,我们的 BernNet 可以学习这些复杂滤波器的平滑近似,并且近似精度随着阶数 的增加而提高。请注意,尽管由于 的限制,BernNet 无法精确定位梳状滤波器的峰值,或者对于梳状滤波器或低带通滤波器的谷值降至 0,但它在以下方面仍然明显优于其他 GNN:学习如此复杂的过滤器。
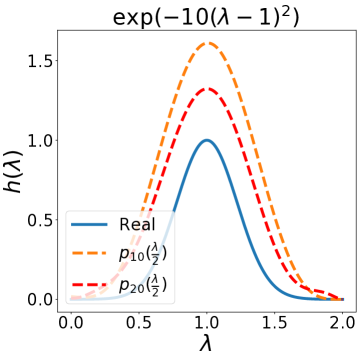
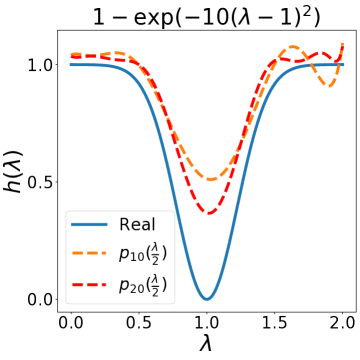
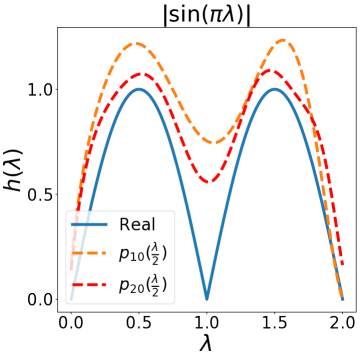
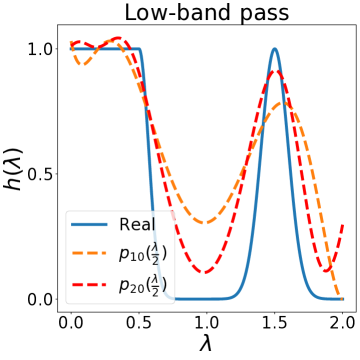
3 图优化视角下的 BernNet
在本节中,我们从图优化的角度来激励 BernNet。 特别是,我们表明任何试图逼近有效滤波器的多项式滤波器都必须采用 BernNet 的形式。
3.1 广义图优化问题
给定一个维图信号,我们考虑广义图优化问题
| (4) |
其中是权衡参数,表示输入图信号的传播表示,表示能量 的函数,确定传播速率 spielman2019spectral 。 一般来说,在的频谱上运行,我们有。
我们可以使用方程(4)的最优解来对现有 GNN 的多项式滤波操作进行建模。 例如,如果我们设置,那么优化函数(4)就变成,这是Zhou等人提出的著名凸图优化函数周学林 . 在导数 时取最小值,求解为
通过取后缀和 ,我们获得 APPNP appnp 的多项式滤波运算。 Zhu 等人 zhu2021interpreting 进一步证明 GCN kipf2016semi 、 DAGNN liu2020DAGNN 和 JKNet xu2018jknet 可以通过优化进行解释函数 (4) 与 。
方程 (4) 的广义形式允许我们模拟更复杂的多项式滤波操作。 例如,让和,一个以为温度参数的热核。 然后在导数时取最小值,求解为
通过取后缀和,我们获得了基于热核的GNN的多项式滤波操作,例如GDC klicpera2019diffusion和GraphHeat xu2020graphheat。
3.2 多项式滤波器的非负约束
一个自然的问题是,任意能量函数 是否对应于有效或不适定的光谱滤波器? 相反,任何多项式滤波操作是否对应于某个能量函数的优化函数(4)的最优解?
事实证明,能量函数有一个“最低要求”; 必须是正半定。 特别地,如果不是正半定的,则优化函数不是凸的,并且的解可能对应于鞍点。 此外,如果没有 的正半定约束, 可能会转到 ,因为我们将 设置为特征向量的倍数对应于负特征值。
非负多项式滤波器。 给定正半定能量函数,我们现在考虑相应的多项式滤波运算应该是什么样子。 回想一下,我们假设 。 通过正半定约束,我们有 的 。 由于目标函数是凸的,因此在时取最小值。 因此,最优可以导出为
| (5) |
让表示精确的光谱滤波器,表示的多项式近似(例如的泰勒的后缀和扩张)。 从到,我们有作为。 因此,很自然地假设多项式滤波器也满足。
Constraint 3.1。
假设能量函数是半正定的,逼近方程(4)最优解的多项式滤波器必须满足
| (6) |
3.3非负多项式和伯恩斯坦基
约束3.1促使我们设计多项式滤波器,使得当时 部分很简单,因为我们总是可以将每个 重新缩放 倍。 然而, 部分需要更多的阐述。 请注意,我们不能简单地为每个 设置 ,因为在 chien2021GPR-GNN 中显示,此类多项式仅对应于低通滤波器。
事实证明,伯恩斯坦基具有以下良好的性质:在一定区间上非负的多项式总是可以表示为伯恩斯坦基的非负线性组合。 具体来说,我们有以下引理。
Lemma 3.1 (幂2000多项式)。
假设多项式对于满足。 那么存在一个非负系数序列,,使得
4相关工作
图神经网络(GNN)大致可以分为基于频谱的 GNN 和基于空间的 GNN wu2020compressive 。
基于谱的 GNN 在谱域中设计谱图滤波器。 ChebNet Chebnet 使用切比雪夫多项式来近似滤波器。 GCN kipf2016semi 使用一阶近似简化了切比雪夫滤波器。 GraphHeat xu2020graphheat 使用 heat 内核来设计图形过滤器。 APPNP appnp 利用个性化 PageRank (PPR) 来设置过滤器权重。 GPR-GNN chien2021GPR-GNN 通过多项式系数的梯度下降来学习多项式滤波器。 ARMA bianchi2021ARMA 通过自回归移动平均滤波器系列 narang2013signal 学习有理滤波器。 AdaGNN adagnn 通过针对每层每个特征通道的单个参数来学习跨多个层的简单滤波器。 如上所述,这些方法主要集中于设计低通或高通滤波器或没有任何约束的学习滤波器,这可能导致错误指定甚至不适定滤波器。
另一方面,基于空间的 GNN 直接在空间域中传播和聚合图信息。 从这个角度来看,GCN kipf2016semi可以解释为图上一跳邻居信息的聚合。 GAT gat 使用注意力机制来学习聚合权重。 最近,Balcilar 等人 balcilar2021analyzing 弥合了基于频谱的 GNN 和基于空间的 GNN 之间的差距,并将 GNN 统一在同一框架中。 他们的工作表明,GNN 可以解释为复杂的数据驱动过滤器。 这激发了 BernNet 的设计,它可以从现实世界的图形信号中学习任意非负谱滤波器。
5实验
在本节中,我们进行实验来评估 BernNet 学习任意滤波器的能力以及 BernNet 在真实数据集上的性能。 所有实验均在配备 NVIDIA TITAN V GPU(12GB 内存)、Intel Xeon CPU(2.20 GHz)和 512GB RAM 的机器上进行。




| Low-pass | High-pass | Band-pass | Band-rejection | Comb | |
| GCN | 3.4799(.9872) | 67.6635(.2364) | 25.8755(.1148) | 21.0747(.9438) | 50.5120(.2977) |
| GAT | 2.3574(.9905) | 21.9618(.7529) | 14.4326(.4823) | 12.6384(.9652) | 23.1813(.6957) |
| GPR-GNN | 0.4169(.9984) | 0.0943(.9986) | 3.5121(.8551) | 3.7917(.9905) | 4.6549(.9311) |
| ARMA | 1.8478(.9932) | 1.8632(.9793) | 7.6922(.7098) | 8.2732(.9782) | 15.1214(.7975) |
| ChebNet | 0.8220(.9973) | 0.7867(.9903) | 2.2722(.9104) | 2.5296(.9934) | 4.0735(.9447) |
| BernNet | 0.0314(.9999) | 0.0113(.9999) | 0.0411(.9984) | 0.9313(.9973) | 0.9982(.9868) |
5.1 从信号中学习过滤器
我们对Matlab图像处理工具箱中的50幅分辨率为100×100的真实图像进行了实证分析。 我们对这 50 张图像进行独立实验并报告评估指数的平均值。 按照 balcilar2021analyzing 中的实验设置,我们将每个图像视为 2D 规则 4 邻域网格图。 图结构转换为 邻接矩阵,而像素强度转换为 维信号向量。
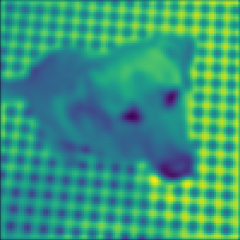
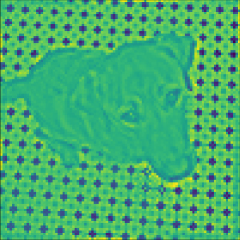
对于 50 个图像中的每一个,我们对其信号的谱域应用 5 个不同的滤波器(低通、高通、带通、带阻和梳状滤波器)。 各滤波器的公式如表2所示。 回想一下,将低通滤波器 应用于谱域 意味着将 应用于图形信号。 图3显示了输入图像和相应的过滤结果。
在这个任务中,我们使用原始图信号作为输入和过滤信号来监督训练过程。 目标是通过学习正确的滤波器来最小化输出与滤波信号之间的平方误差。 我们针对五种流行的 GNN 模型评估 BernNet:GCN kipf2016semi 、GAT gat 、GPR-GNN chien2021GPR-GNN 、ARMA bianchi2021ARMA 和 ChebNet Chebnet 。 为了确保公平性,我们对所有模型使用两个卷积单元和一个线性输出层。 我们使用大约 2k 个可训练参数来训练所有模型,并调整隐藏单元以确保它们具有相似的参数。 在 balcilar2021analyzing 之后,我们丢弃任何正则化或 dropout,并简单地强制 GNN 学习输入输出关系。 对于所有模型,我们将最大 epoch 数设置为 2000,如果连续 100 次损失没有下降,则停止训练,并使用 Adam 优化,学习率为 0.01,无衰减。 模型不使用图片像素的位置信息。 我们使用掩模来覆盖图片的边缘节点,因此该问题可以视为一个简单的回归问题。 对于 BernNet,我们使用两层模型,每层共享相同的 集 和 集。 对于GPR-GNN,我们使用官方发布的代码(URL和提交编号请参阅补充材料)并设置多项式滤波器的阶数。 其他基线模型基于 Pytorch Geometric 实现 fey2019fast 。 更详细的实验设置可以在附录中找到。
表2显示了平方误差之和(越低越好)和分数(越高越好)的平均值。 我们首先观察到 GCN 和 GAT 只能处理低通滤波器,这与 balcilar2021analyzing 中的理论分析一致。 GPR-GNN、ARMA 和 ChebNet 可以从信号中学习不同的滤波器。 然而,在所有任务中,BernNet 在这两个指标上始终大幅优于这些模型。 我们将这种质量归因于 BernNet 调整系数 的能力,该系数直接对应于均匀采样的滤波器值。
5.2 真实数据集上的节点分类
现在,我们在现实数据集上评估 BernNet 与竞争对手的性能。 继chien2021GPR-GNN之后,我们包括三个引用图Cora、CiteSeer和PubMedsen2008collective; yang2016revisiting ,与亚马逊共同采购图形计算机和照片mcauley2015image 。 如chien2021GPR-GNN所示,这5个数据集是同亲图,其连接的节点往往共享相同的标签。 我们还包括维基百科图 Chameleon 和 Squirrel musae、Actor 共现图以及来自 WebKB333http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-11/www/wwkb/ pei2020geom 。 这 5 个数据集是异质数据集,连接的节点往往具有不同的标签。 我们在表3中总结了这些数据集的统计数据。
| Cora | CiteSeer | PubMed | Computers | Photo | Chameleon | Squirrel | Actor | Texas | Cornell | |
| Nodes | 2708 | 3327 | 19717 | 13752 | 7650 | 2277 | 5201 | 7600 | 183 | 183 |
| Edges | 5278 | 4552 | 44324 | 245861 | 119081 | 31371 | 198353 | 26659 | 279 | 277 |
| Features | 1433 | 3703 | 500 | 767 | 745 | 2325 | 2089 | 932 | 1703 | 1703 |
| Classes | 7 | 6 | 5 | 10 | 8 | 5 | 5 | 5 | 5 | 5 |
按照 chien2021GPR-GNN ,我们对每个模型执行全监督节点分类任务,其中我们将节点集随机分为训练/验证/测试集,比例为 60%/20%/20%。 为了公平起见,我们通过随机种子生成 10 个随机分割,并在同一分割上评估所有模型,并报告每个模型的平均指标。
我们将 BernNet 与 6 个基线模型进行比较:MLP、GCN kipf2016semi 、GAT gat 、APPNP appnp 、ChebNet Chebnet 、和 GPR-GNN chien2021GPR-GNN 。 对于GPR-GNN,我们使用官方发布的代码(URL和提交编号请参阅补充材料)并设置多项式滤波器的阶数。 对于其他模型,我们使用相应的 Pytorch Geometric 库实现 fey2019fast 。 对于 BernNet,我们使用以下传播过程:
| (7) |
其中是特征矩阵上具有64个隐藏单元的2层MLP。 请注意,此传播过程与 APPNP 或 GPR-GNN 的传播过程几乎相同。 唯一的区别是我们用 Bernstein 多项式代替了 Generalized PageRank 多项式。 我们设置并对线性层和传播层使用不同的学习率和dropout。 对于所有模型,我们的最佳倾斜率超过 和权重衰减 。 更详细的实验设置在附录中讨论。
我们使用置信区间为 95% 的 micro-F1 分数作为评估指标。 相关结果总结于表4中。 粗体字母表示给定置信区间的最佳结果。 我们观察到 BernNet 在十个数据集中的七个上提供了最佳结果。 在其他三个数据集上,BernNet 也取得了与 SOTA 方法竞争的结果。
| GCN | GAT | APPNP | MLP | ChebNet | GPR-GNN | BernNet | |
| Cora | 87.14 | 88.03 | 88.14 | 76.96 | 86.67 | 88.57 | 88.52 |
| CiteSeer | 79.86 | 80.52 | 80.47 | 76.58 | 79.11 | 80.12 | 80.09 |
| PubMed | 86.74 | 87.04 | 88.12 | 85.94 | 87.95 | 88.46 | 88.48 |
| Computers | 83.32 | 83.32 | 85.32 | 82.85 | 87.54 | 86.85 | 87.64 |
| Photo | 88.26 | 90.94 | 88.51 | 84.72 | 93.77 | 93.85 | 93.63 |
| Chameleon | 59.61 | 63.13 | 51.84 | 46.85 | 59.28 | 67.28 | 68.29 |
| Actor | 33.23 | 33.93 | 39.66 | 40.19 | 37.61 | 39.92 | 41.79 |
| Squirrel | 46.78 | 44.49 | 34.71 | 31.03 | 40.55 | 50.15 | 51.35 |
| Texas | 77.38 | 80.82 | 90.98 | 91.45 | 86.22 | 92.95 | 93.12 |
| Cornell | 65.90 | 78.21 | 91.81 | 90.82 | 83.93 | 91.37 | 92.13 |
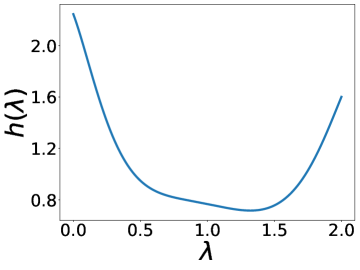
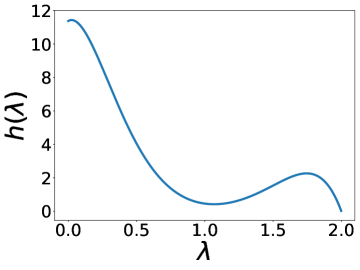
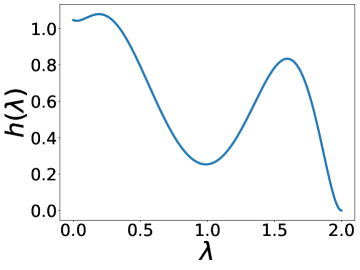
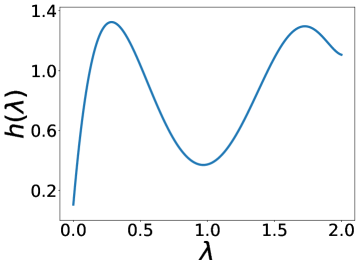
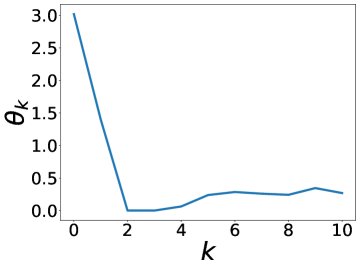
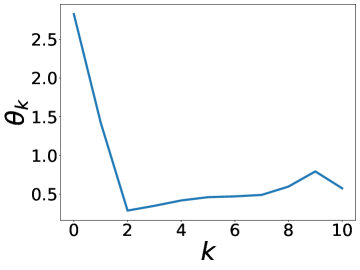
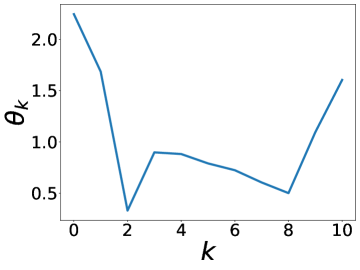
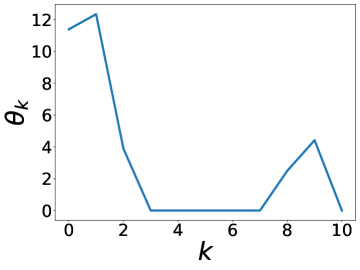
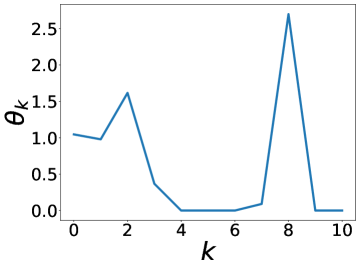
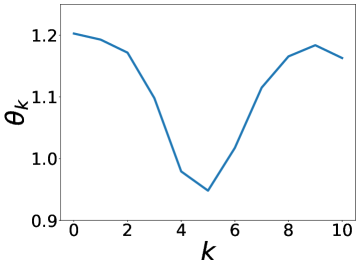
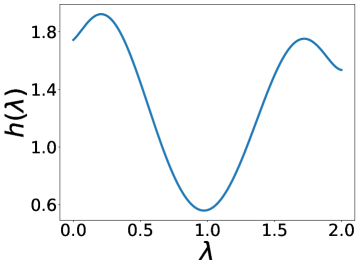
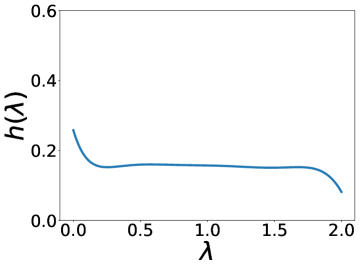
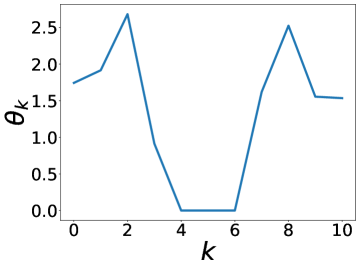
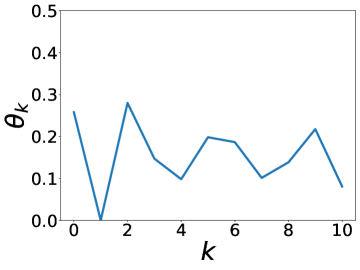
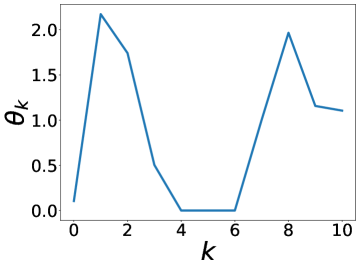
更有趣的是,这个实验还表明 BernNet 可以仅在节点标签的监督下从现实数据集中学习复杂的过滤器。 图4绘制了BernNet在训练过程中学到的一些过滤器。 在 Actor 上,BernNet 学习了一个全通类似的过滤器,这与 MLP 优于该数据集上的所有其他基线的事实相一致。 在 Chameleon 和 Squirrel 上,BernNet 学习了两个梳状滤波器。 鉴于 BernNet 在这两个数据集上的表现优于所有竞争对手至少 1%,这可能表明梳状滤波器对于 Chameleon 和 Squirrel 是必要的。 图5显示了BernNet从真实数据集中学习到的系数。 比较图4和5,我们观察到滤波器的曲线和系数的曲线几乎相同。 这是因为 BernNet 的系数与目标滤波器的光谱特性高度相关,这表明 BernNet Bernnet 具有很强的可解释性。
最后,我们在表 5 中列出了每种方法的训练时间。 由于 BernNet 对度 的二次依赖,因此比其他方法慢。然而,与SOTA方法GPR-GNN相比,余量一般小于,这在实践中往往是可以接受的。 理论上,ChebNet Chebnet 和 GPR-GNN chien2021GPR-GNN 都是与传播步数相关的线性时间复杂度,但 BernNet 是与传播步长相关的二次时间复杂度到。 Delgado 等人 delgado2003linear 表明,使用切角算法可以在与 相关的线性时间内评估 Bernstein 近似。 然而,BernNet不能直接使用这个算法,因为我们需要乘以信号。 如何将BernNet转化为线性复杂度将是未来值得研究的问题。
| GCN | GAT | APPNP | MLP | ChebNet | GPR-GNN | BernNet | |
| Cora | 4.59/1.62 | 9.56/2.03 | 7.16/2.32 | 3.06/0.93 | 6.25/1.76 | 9.94/2.21 | 19.71/5.47 |
| CiteSeer | 4.63/1.95 | 9.93/2.21 | 7.79/2.77 | 2.95/1.09 | 8.28/2.56 | 11.16/2.37 | 22.36/6.32 |
| PubMed | 5.12/1.87 | 16.16/3.41 | 8.21/2.63 | 2.91/1.61 | 18.04/3.03 | 10.45/2.81 | 22.02/8.19 |
| Computers | 5.72/2.52 | 30.91/7.85 | 9.19/3.48 | 3.47/1.31 | 20.64/9.64 | 16.05/4.38 | 28.83/8.69 |
| Photo | 5.08/2.63 | 19.97/5.41 | 8.69/4.18 | 3.67/1.66 | 13.25/7.02 | 13.96/3.94 | 24.69/7.37 |
| Chameleon | 4.93/0.99 | 13.11/2.66 | 7.93/1.62 | 3.14/0.63 | 10.92/2.25 | 10.93/2.41 | 22.54/4.75 |
| Actor | 5.43/1.09 | 11.94/2.45 | 8.46/1.71 | 3.82/0.77 | 7.99/1.62 | 11.57/2.35 | 23.34/5.81 |
| Squirrel | 5.61/1.13 | 22.76/4.91 | 8.01/1.61 | 3.41/0.69 | 38.12/7.78 | 9.87/5.56 | 25.58/9.23 |
| Texas | 4.58/0.92 | 9.65/1.96 | 7.83/1.63 | 3.19/0.65 | 6.51/1.34 | 10.45/2.16 | 23.35/4.81 |
| Cornell | 4.83/0.97 | 9.79/1.99 | 8.23/1.68 | 3.25/0.66 | 5.85/1.22 | 9.86/2.05 | 22.23/5.26 |
6结论
本文提出了 BernNet,这是一种图神经网络,它提供了一种简单直观的机制,用于通过 Bernstein 多项式逼近设计和学习任意光谱滤波器。 与以前的方法相比,BernNet可以近似复杂的滤波器,例如带阻滤波器和梳状滤波器,并且可以提供更好的可解释性。 此外,BernNet 设计和学习的多项式滤波器始终有效。 实验表明,BernNet 在合成数据集和真实数据集上的有效性均优于 SOTA 方法。 对于未来的工作,一个有趣的方向是提高 BernNet 的效率。
更广泛的影响
所提出的 BernNet 算法解决了在图上设计和学习任意光谱滤波器的挑战。 我们认为该算法是一般性的技术和理论贡献,没有任何可预见的具体影响。 对于生物信息学、计算机视觉和自然语言处理方面的应用,应用 BernNet 算法可能会提高现有 GNN 模型的性能。 我们将对其他潜在影响的探索留给未来的工作。
致谢和资金披露
魏哲伟得到国家自然科学基金项目(No. 61972401,编号 61932001 和第 61932001 号 61832017), 北京市杰出青年科学家计划 BJJWZYJH012019100020098,由阿里巴巴集团通过阿里巴巴创新研究计划、CCF-百度开放基金资助(NO.2021PP15002000)。 黄增峰获得国家自然科学基金资助,批准号: 61802069,上海市科学技术委员会批准号:61802069 17JC1420200。 徐宏腾得到了腾讯AI Lab犀牛鸟联合研究项目的支持。 本研究得到中国联通创新生态合作计划、智能社会治理平台、中国人民大学 "双一流 "建设重大创新规划交叉学科平台的支持。 我们还要感谢中国人民大学公共政策与决策研究室的支持和贡献。
参考
- [1] Muhammet Balcilar, Pierre Héroux, Benoit Gaüzère, Sébastien Adam, and Paul Honeine. Analyzing the expressive power of graph neural networks in a spectral perspective. In ICLR, 2021.
- [2] Filippo Maria Bianchi, Daniele Grattarola, Lorenzo Livi, and Cesare Alippi. Graph neural networks with convolutional arma filters. TPAMI, 2021.
- [3] Toon Bogaerts, Antonio D Masegosa, Juan S Angarita-Zapata, Enrique Onieva, and Peter Hellinckx. A graph cnn-lstm neural network for short and long-term traffic forecasting based on trajectory data. Transportation Research Part C: Emerging Technologies, 2020.
- [4] Zhao-Min Chen, Xiu-Shen Wei, Peng Wang, and Yanwen Guo. Multi-label image recognition with graph convolutional networks. In CVPR, 2019.
- [5] Eli Chien, Jianhao Peng, Pan Li, and Olgica Milenkovic. Adaptive universal generalized pagerank graph neural network. In ICLR, 2021.
- [6] Zhiyong Cui, Kristian Henrickson, Ruimin Ke, and Yinhai Wang. Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting. T-ITS, 21(11):4883–4894, 2019.
- [7] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In NeurIPS, pages 3844–3852, 2016.
- [8] Jorge Delgado and Juan Manuel Pena. A linear complexity algorithm for the bernstein basis. In GMP, pages 162–167, 2003.
- [9] Yushun Dong, Kaize Ding, Brian Jalaian, Shuiwang Ji, and Jundong Li. Graph neural networks with adaptive frequency response filter. In CIKM, 2021.
- [10] Rida T Farouki. The bernstein polynomial basis: A centennial retrospective. Computer Aided Geometric Design, 29(6):379–419, 2012.
- [11] Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geometric. In ICLR, 2019.
- [12] Dejun Jiang, Zhenxing Wu, Chang-Yu Hsieh, Guangyong Chen, Ben Liao, Zhe Wang, Chao Shen, Dongsheng Cao, Jian Wu, and Tingjun Hou. Could graph neural networks learn better molecular representation for drug discovery? a comparison study of descriptor-based and graph-based models. Journal of cheminformatics, 13(1):1–23, 2021.
- [13] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR, 2017.
- [14] Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. In ICLR, 2019.
- [15] Johannes Klicpera, Stefan Weißenberger, and Stephan Günnemann. Diffusion improves graph learning. In NeurIPS, 2019.
- [16] Ron Levie, Federico Monti, Xavier Bresson, and Michael M Bronstein. Cayleynets: Graph convolutional neural networks with complex rational spectral filters. Transactions on Signal Processing, 67(1):97–109, 2018.
- [17] Chang Li and Dan Goldwasser. Encoding social information with graph convolutional networks forpolitical perspective detection in news media. In ACL, 2019.
- [18] Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. In ICLR, 2018.
- [19] Meng Liu, Hongyang Gao, and Shuiwang Ji. Towards deeper graph neural networks. In KDD, 2020.
- [20] Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. Image-based recommendations on styles and substitutes. In SIGIR, 2015.
- [21] Sunil K Narang, Akshay Gadde, and Antonio Ortega. Signal processing techniques for interpolation in graph structured data. In ICASSP. IEEE, 2013.
- [22] Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. In ICLR, 2020.
- [23] Victoria Powers and Bruce Reznick. Polynomials that are positive on an interval. Transactions of the American Mathematical Society, 352(10):4677–4692, 2000.
- [24] Jiezhong Qiu, Jian Tang, Hao Ma, Yuxiao Dong, Kuansan Wang, and Jie Tang. Deepinf: Social influence prediction with deep learning. In KDD, 2018.
- [25] Prakash Chandra Rathi, R Frederick Ludlow, and Marcel L Verdonk. Practical high-quality electrostatic potential surfaces for drug discovery using a graph-convolutional deep neural network. Journal of medicinal chemistry, 63(16):8778–8790, 2019.
- [26] Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-scale attributed node embedding. Journal of Complex Networks, 9(2):cnab014, 2021.
- [27] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- [28] Daniel Spielman. Spectral and algebraic graph theory. Yale lecture notes, draft of December, 4, 2019.
- [29] Peihao Tong, Qifan Zhang, and Junjie Yao. Leveraging domain context for question answering over knowledge graph. Data Science and Engineering, 4(4):323–335, 2019.
- [30] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. In ICLR, 2018.
- [31] Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In ICML, 2019.
- [32] Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. Session-based recommendation with graph neural networks. In AAAI, 2019.
- [33] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems, 2020.
- [34] Bingbing Xu, Huawei Shen, Qi Cao, Keting Cen, and Xueqi Cheng. Graph convolutional networks using heat kernel for semi-supervised learning. In IJCAI, 2019.
- [35] Bingbing Xu, Huawei Shen, Qi Cao, Yunqi Qiu, and Xueqi Cheng. Graph wavelet neural network. In ICLR, 2018.
- [36] Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In ICML, 2018.
- [37] Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. In ICML, pages 40–48. PMLR, 2016.
- [38] Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In KDD, 2018.
- [39] Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, and Dimitris N Metaxas. Semantic graph convolutional networks for 3d human pose regression. In CVPR, 2019.
- [40] Dengyong Zhou, Olivier Bousquet, Thomas Lal, Jason Weston, and Bernhard Schölkopf. Learning with local and global consistency. In NeurIPS, 2004.
- [41] Meiqi Zhu, Xiao Wang, Chuan Shi, Houye Ji, and Peng Cui. Interpreting and unifying graph neural networks with an optimization framework. In WWW, 2021.
附录 A 其他实验细节
A.1 从信号中学习滤波器(第 5.1 节)
对于所有模型,我们使用两个卷积层和一个线性输出层,将最终节点表示投影到每个节点的单个输出上。 我们使用大约 2k 个可训练参数来训练所有模型,并调整隐藏单元以确保它们具有相似的参数。 我们放弃任何正则化或 dropout,只是强制 GNN 学习输入输出关系。 如果损失在 100 个连续的 epoch 内没有下降(最大限制为 2000 个 epoch),我们就停止训练,并使用 Adam 优化,学习率为 0.01,没有衰减。 对于GPR-GNN,我们使用官方发布的代码(表6中的URL和提交号),其他基线模型基于Pytorch Geometric实现[11]。
对于 GCN,我们将隐藏单元设置为 32,将线性单元设置为 64。 对于GAT,第一层有4个注意力头,每个头有8个隐藏层;第二层有8个注意力头,每个头有8个隐藏层。 我们将线性单位设置为 64。 对于 ARMA,我们将 ARMA 层和 ARMA 堆栈设置为 1,将隐藏单元设置为 32,将线性单元设置为 64。 对于 ChebNet,我们对每层使用 3 步传播,具有 32 个隐藏单元,并将线性单元设置为 64。 对于 GPR-GNN,我们将隐藏单元设置为 32,传播 10 步,将线性单元设置为 64,并对 GPR 部分使用随机初始化。 对于 BernNet,我们在每一层中为 使用相同的 集,并设置 。
| URL | Commit | |
| GRP-GNN | https://github.com/jianhao2016/GPRGNN | 2507f10 |
A.2 真实数据集上的节点分类(第 5.2 节)
在本实验中,我们还使用 GPR-GNN 的官方发布代码(表 6 中的 URL 和提交编号)以及其他模型的 Pytorch 几何实现 [11]。 对于所有模型,我们使用两个卷积层,并为所有数据集使用提前停止 200 个时期,最多 1000 个时期。 我们使用 Adam 优化器来训练模型以及 和权重衰减 上的最佳学习率。
| Datasets | 线性层 学习率 | 传播层 学习率 | 隐藏 维度 | 传播层 退出 | 线性层 退出 | 重量 衰变 | |
| Cora | 0.01 | 0.01 | 64 | 0.0 | 0.5 | 10 | 0.0005 |
| CiteSeer | 0.01 | 0.01 | 64 | 0.5 | 0.5 | 10 | 0.0005 |
| PubMed | 0.01 | 0.01 | 64 | 0.0 | 0.5 | 10 | 0.0 |
| Computers | 0.01 | 0.05 | 64 | 0.6 | 0.5 | 10 | 0.0005 |
| Photo | 0.01 | 0.01 | 64 | 0.5 | 0.5 | 10 | 0.0005 |
| Chameleon | 0.05 | 0.01 | 64 | 0.7 | 0.5 | 10 | 0.0 |
| Actor | 0.05 | 0.01 | 64 | 0.9 | 0.5 | 10 | 0.0 |
| Squirrel | 0.05 | 0.01 | 64 | 0.6 | 0.5 | 10 | 0.0 |
| Texas | 0.05 | 0.002 | 64 | 0.5 | 0.5 | 10 | 0.0005 |
| Cornell | 0.05 | 0.001 | 64 | 0.5 | 0.5 | 10 | 0.0005 |
对于 GCN,我们为每个 GCN 卷积层使用 64 个隐藏单元。 对于 MLP,我们使用具有 64 个隐藏单元的 2 层全连接网络。 对于GAT,我们使第一层有8个注意力头,每个头有8个隐藏单元,第二层有1个注意力头和64个隐藏单元。 对于 APPNP,我们使用具有 64 个隐藏单元的 2 层 MLP,并将传播步数 设置为 10。 我们在内搜索最优的。 对于ChebNet,我们将传播步数设置为2,每层使用32个隐藏单元,本例中等效隐藏单元的数量为64个。 对于 GPR-GNN,我们使用具有 64 个隐藏单元的 2 层 MLP,并将传播步骤 设置为 10,并使用带有 的 PPR 初始化作为 GPR 权重。 对于 BernNet,我们使用具有 64 个隐藏单元的 2 层 MLP 并设置顺序 ,并优化线性层和传播层的学习率。 我们将所有模型的卷积层或线性层的dropout率固定为0.5,并优化GPR-GNN和BernNet的传播层的dropout率。 表7显示了BernNet在真实数据集上的超参数。
图6绘制了 BernNet 从现实数据集中学习到的过滤器。 除了5.2节中讨论的一些特殊滤波器之外,我们发现BernNet在Cora和CiteSeer上学习了一个低通滤波器,这与[1]中的分析一致。 图7显示了BernNet从真实数据集中学习到的系数。 我们观察到滤波器的曲线和系数的曲线几乎相同,这是因为 BernNet 的系数与目标滤波器的谱特性高度相关,这表明 BernNet Bernnet 具有很强的可解释性。