使用 CorGIE 可视化图神经网络:将 Graph 对应于 Its E 嵌入
摘要
图神经网络 (GNN) 是一类功能强大的机器学习工具,可对节点关系进行建模以预测节点或链接。 GNN 开发人员依靠预测的定量指标来评估 GNN,但与许多其他神经网络类似,他们很难理解 GNN 是否真正按照预期学习了图的特征。 我们提出了一种将输入图与其节点嵌入(也称为潜在空间)相对应的方法,这是 GNN 的常见组件,稍后用于预测。 我们对数据和任务进行抽象,并开发了一个名为 CorGIE 的交互式多视图界面来实例化抽象。 作为 CorGIE 中的关键功能,我们提出了 K 跳图布局来显示跳数中的拓扑邻居及其聚类结构。 为了评估 CorGIE 的功能和可用性,我们介绍了如何在两种使用场景中使用 CorGIE,并与五位 GNN 专家进行了案例研究。
可用性:开源代码位于https://github.com/zipengliu/CorGIE/,补充材料和视频位于https://osf.io/ tr3sb/。
索引术语:
机器学习、图形神经网络、图形布局的可视化。1 简介
图神经网络 (GNN) 是机器学习 (ML) 模型,由于其处理关系和交互等抽象概念的能力,最近受到了广泛关注。 除了自然语言处理和计算机视觉等经典的 ML 应用领域之外,GNN 模型还广泛应用于欺诈检测、流量建模和产品推荐等下游 ML 应用。
在训练期间,GNN 模型接收节点链接图并生成节点嵌入作为输出;也就是说,图中所有离散节点表示为连续潜在空间中的固定维度向量。 潜在空间中嵌入节点之间的邻近度表示训练期间学习的输入图中节点之间有意义的相似性。 节点嵌入利用了输入图的拓扑(相邻节点之间的连接性)和节点特征(与每个节点关联的信息)。 (与节点相关的信息,在机器学习文献中通常称为节点特征,有时在可视化文献中称为节点属性。) 然后,节点嵌入可用于输入下游 ML 应用程序,例如对节点和链接进行预测。 图1a总结了标准GNN管道。
为了实现最佳性能,模型开发人员必须评估训练是否成功生成了实际上从输入图中学习了重要特征的 GNN 模型。 模型开发人员通常需要确定训练 GNN 模型的停止标准;换句话说,要回答“我们到了吗?”的问题。当训练模型或调整超参数时。 除了何时停止训练和调整等全局问题外,模型开发人员还需要调试和跟踪训练模型中的错误和次优状态。 例如,他们可能想要识别和理解最容易遭受错误分类的节点组。 在某些情况下,他们还需要比较不同模型架构或超参数的结果,以选择最适合生产使用的模型架构或超参数。
当前最流行的模型评估方法是基于下游机器学习应用[1]计算定量指标,例如用于节点分类的精度和 F1 以及用于链接预测的 Hit@k,它们用于训练期间的交叉验证。 一些研究人员提出了算法来计算对有影响力的节点的预测结果的解释,或者哪些特征在确定特定节点[2]方面很重要。 另一种常见的方法是进行定性健全性检查,例如手动检查节点或链接实例,例如通过使用降维节点嵌入 [3] 的多类散点图进行可视化。 图1b总结了这些先前的评估方法。
然而,这些现有的评估方法存在不足,因为它们不足以支持开发人员直接理解输入图与其节点嵌入之间的对应关系。 开发人员必须将 GNN 模型视为黑匣子,因为很难检查所有重要信息是否都已编码在嵌入中。 即使他们在下游预测节点标签中发现错误,也很难将这些错误追溯到上游 GNN,或者改进 GNN 来避免它们。
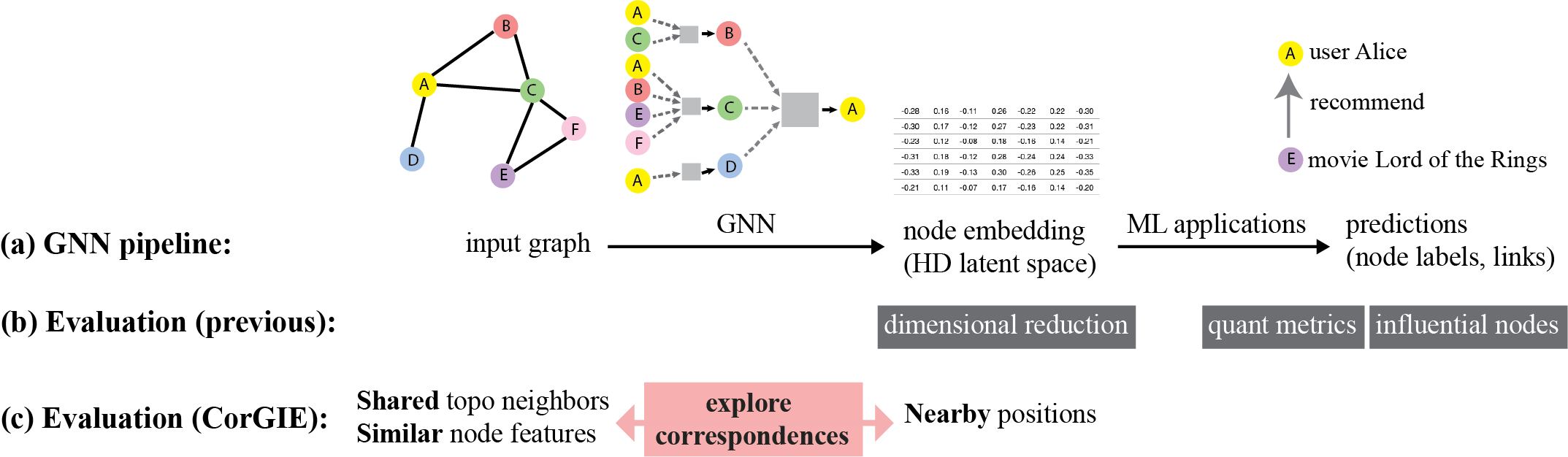
我们的关键思想是通过显示输入图与其 GNN 生成的节点嵌入之间的对应关系或缺乏对应关系来帮助 GNN 评估。 图1c说明了这种方法。 从几何角度来说,GNN 应该学习将具有相似邻居和特征值的图节点放置在高维潜在空间中的附近位置。 因此,我们可以通过验证 GNN 在节点嵌入中保留输入图特征的程度来评估 GNN。 例如,我们可以探索节点嵌入中的簇如何对应于输入图中拓扑和/或节点特征的相似性。 如果节点在拓扑和/或特征方面相似,我们就能够验证 GNN 是否已成功将它们聚集在潜在空间中。 相反,我们可以探索共享许多拓扑邻居的两个节点在节点嵌入中表示的接近程度。 为了实现这些目标,我们提出了三项贡献。
我们的第一个贡献,在第二节中提出。 3.3,是一种数据和任务抽象,用于直观地探索输入图和派生节点嵌入之间的对应关系,以了解 GNN 模型是否已经学习了输入图的重要特征来构建嵌入。 抽象是广泛迭代细化的结果。
为了实例化抽象,我们的第二个贡献是交互式多视图界面 CorGIE 的设计和实现(Cor响应 Graph 到 Its E嵌入)。 CorGIE 与特定的 GNN 模型无关,采用“灰盒”方法,忽略神经元和权重等内部模型细节,仅假设 GNN 聚合来自相邻节点的信息。 我们在第 2 节中描述了 CorGIE 的设计。 4。
为了完成显示感兴趣节点的拓扑邻居的重要任务,我们的第三个贡献是一种新的可视化技术,即 K-hop 图布局。 K 跳布局逐跳揭示节点邻居,类似于 GNN 聚合信息的方式,并揭示节点邻居内的聚类结构。 以前的图形表示和布局算法不足以满足这种情况。 我们在第 2 节中介绍了该技术的细节。 5。
我们通过两种方式验证我们的主张。 我们提供了两个使用场景,详细介绍了 CorGIE 设计如何支持任务和数据抽象。 我们还与五位 GNN 专家讨论了一项研究结果,这些专家提供了 CorGIE 实用性和可用性的基本知识证据。
2 背景
我们首先提供 GNN 的最低限度必要的技术背景,以使这项工作独立。 然后我们描述了激发 CorGIE 的两个具体使用场景。 我们将对相关工作的讨论推迟到第二节。 7。
2.1 图神经网络
广泛的编码器-解码器视角是理解通用图神经网络[4]的有用起点。 编码器结合拓扑和可选的节点特征来产生节点嵌入。 解码器利用节点嵌入在下游 ML 应用程序中进行推理。 在 GNN 文献中,节点嵌入是管道内的中间表示,其外部不一定具有直接兴趣。 我们的观点不同:我们强调对学习嵌入的检查是理解的关键。 此外,下游 ML 应用程序通常被视为 GNN 管道的内在组件。 相比之下,我们将下游 ML 应用程序与前面的管道分开,以便 CorGIE 可以支持多个下游应用程序。 CorGIE 的不可知论方法支持预测单个节点属性的节点分类(用于电影标记或文档主题标记)和预测节点对属性的链接预测(用于电影推荐)。
GNN 通常使用节点标签或节点连接进行训练,具体取决于应用程序。 对于节点标签,如果所有节点标签都可用,则可以通过将节点分为训练集、验证集和测试集来监督训练;如果只有少量标签可用,则可以半监督训练。 对于节点连接,训练可以是有监督的,也可以是无监督的。 由边连接的两个节点被视为正节点对,而负节点对之间没有边;在训练期间对正负对进行采样。
GNN 通过邻域聚合(又称消息传递)从输入图中学习,其中节点的嵌入是通过遍历其拓扑邻域来收集和聚合其中的节点特征来计算的。 GNN 具有多个层,允许逐跳进行聚合:每个节点将其邻居的输出从一层聚合到下一层。 输入层采用节点特征,最后一层输出高维节点嵌入,第 层从第 跳邻居聚合。 上图1a 的示例显示了节点 A 如何聚合来自其两跳邻居的信息。 层数通常较小,有,表明是浅层网络。 GNN 的不同之处在于聚合函数,从简单的均值到复杂的非线性函数[5]。 我们的方法确实将 作为参数,但完全不知道聚合函数的细节。
2.2 激励场景
在本文中,我们将 CorGIE 的目标用户称为GNN 开发人员,范围从使用预训练 GNN 的用户到可以提出新模型架构的经验丰富的研究人员。
在深入研究我们的方法和工具的细节之前,我们先介绍假设的 GNN 开发人员 Alice 的两个代表性场景。 对于每个数据集,我们引入一个数据集,其中包含输入图和由经过训练的 GNN 模型构建的嵌入,以及一组适用于它的可视化任务。 我们在补充章节中提供了大量具体任务的附加示例。 S1。
2.2.1电影:推荐
Alice 有一个二分电影用户图111Extracted from a Kaggle dataset: https://www.kaggle.com/rounakbanik/the-movies-dataset,其中边表示用户已观看或评价电影。 该图中的节点特征取决于节点类型:电影节点特征是预算、受欢迎程度、平均投票数、#cast、#crew;用户节点特征是平均投票数和#votes。 目标是向用户推荐电影;也就是说,下游的ML应用是链路预测。 Alice利用二分图中的节点连接和节点特征训练GCN(图卷积网络,一种著名的GNN模型[6]),产生16维的节点嵌入。 她根据之前的经验选择了超参数设置16。
为了评估训练结果,Alice 想要了解 GNN 学到了什么。 除了准确性等典型的定量指标之外,她还想检查:
-
1.
节点嵌入的整体聚类结构,回答如下问题 电影和用户是分开的吗? 是否存在用户集群?
-
2.
在用户集群中,她对节点分组在一起的原因感兴趣: 他们看类似的电影吗?也就是说,电影是否共享第一跳邻居? 他们对评分相似的电影进行评分吗? 他们看过的电影有相似的预算吗? 拓扑和/或特征值的相似性表明 GNN 在对这些用户进行分组方面做得很好。
-
3.
在两个用户集群之间,她想看看他们的差异: 他们看不同系列的电影吗? 他们对电影的评价不同吗? 显着差异表明 GNN 在区分两个用户组方面做得很好。
-
4.
电影推荐的实例级检查是 Alice 的下一步工作。 她希望抽查某个用户的推荐电影列表,例如,为看过 The Matrix 和 Guardians of the Galaxy 的观众推荐 Interstellar 。 她想了解 GNN 生成它们的原因: 推荐是否由共享观看模式决定,如协作过滤[7]? 他们是否受到类似节点特征的激励? 他们是否捕捉到主题相似性,就像科幻小说一样?
2.2.2 Cora:论文主题标签
Cora 数据集通常用作 GNN 文献[8]中的基准。 这是一张学术论文引用图,其中节点特征是一个由 1433 个单热向量组成的字典,显示论文中是否存在特定单词。 下游 ML 应用程序是根据一组给定主题(类别)对论文进行分类。 Alice 使用 Cora 图中的节点标签训练 GAT(图注意力网络,另一个著名的 GNN 模型[9]),并生成代表 7 维概率分布的 7 维节点嵌入。论文主题类别。 因此,她将每个维度的值转换为属于该类别的概率,这是 GNN 文献中的常见做法。
遵循对电影场景的类似分析过程,Alice 首先通过从概述级别可视化共享拓扑邻居和节点特征的相似性来探索聚类结构。 然后,她尝试了解错误分类节点的模式。 她选择这些节点的组,这些节点要么位于潜在空间的同一区域,要么具有相同的预测标签;也就是说,同样的错误。 她检查共享的邻居和组内的单词,以确定是否存在共同点导致错误分类。
3 数据和任务抽象
在考虑了 GNN 开发人员面临的许多具体任务示例之后,我们将它们进行了概括,以便在更高层次上理解问题。 我们在几个月内通过四个并行的重点迭代地形成了数据和任务抽象:回顾 GNN 和视觉分析文献、对三个不同组织内的四位 GNN 开发人员的非正式采访、CorGIE 接口原型的开发和使用以及反思论文作者之间。
3.1 概述
我们将 GNN 开发人员在将模型训练为三个驱动问题时面临的许多担忧进行了概括。 为了便于记忆,我们将它们设计为公路旅行中可能会问到的问题:
-
•
问题一: 我们到了吗: 我们应该训练还是调整更多?
-
•
问题2: 我们迷路了吗: 它的行为符合我们的预期吗?
-
•
Q3: 那是什么: 这个范例有什么作用?
第一个大问题涉及是否需要将模型训练更多的时期,调整超参数,或重新考虑它们如何构建图表。 通过了解结果是否令人满意来回答。 第二个问题也是一个大问题,涉及开发人员对 GNN 是否从输入图中学习固有特征的理解和信任;也就是说,它的行为是否符合他们的预期。 这两个大问题用以前的评估方法特别难以回答,这些方法严重依赖下游机器学习应用程序的定量指标;我们的目标是提供视觉和定性证据和见解,以更详细和彻底的方式回答这两个问题。 第三个问题更加具体,涉及调查节点或链接的示例实例。 之前的一些方法(例如 GNNExplainer [2])确实支持此类单实例检查,但我们力求使它们变得更容易、更快。
我们假设找到 1)潜在空间中的节点位置和聚类结构,2)输入图中的拓扑邻居,以及 3)输入图中的节点特征分布之间的对应关系,可以阐明这些问题。 因此,我们讨论三个摘要数据空间,如图2所示:潜在空间、拓扑空间和特征空间。

3.2 数据空间抽象
我们的数据抽象具有三个子空间:潜在空间、拓扑空间和特征空间。 我们计算每个空间中的距离度量。 如果有预测结果,我们也会纳入其中。 我们按照CorGIE界面中的视图顺序来介绍这三个空间。
3.2.1 潜在空间
潜在空间是 GNN 学习的节点嵌入所在的位置。 输入图中的每个节点都有自己的高维向量表示。 维数通常小于一千,尽管这个数字不会影响任务的复杂性,因此不是 CorGIE 设计的约束。
在潜在空间中,绝对向量值通常无法直接解释。 我们感兴趣的是向量的相似性,特别是节点向量之间是否存在聚类结构。 例如,在 Cora 场景中,一个相关问题是潜在空间中是否恰好有七个论文簇,这与地面实况中的七个主题相匹配。
本文研究的范围是节点嵌入;边缘嵌入和图嵌入等不太受欢迎的案例留给未来的工作。
3.2.2 拓扑空间
拓扑空间由单个输入图的拓扑连通性组成。 输入图可以是同质的(具有单一类型的节点),也可以是异构的(具有多种节点类型)。 CorGIE 的设计目标是处理最多 6 种节点类型,涵盖了异构图的许多有用案例[10]。 对于图大小,CorGIE 将容纳多达 20K 个节点,以处理 GNN 文献[1]中的许多流行基准数据集。
在拓扑空间中,我们感兴趣的是拓扑邻域和节点对之间的连接(边)。 GNN 沿着边缘聚合信息来计算节点嵌入。 因此,我们得出节点的邻居集,其中包含其k跳邻居;也就是说,在k个拓扑跳数内从节点v可到达的所有节点的集合。
我们将范围限制为一个输入图,将多图情况留给未来的工作。 我们还为未来保留了多种边缘类型的支持。
3.2.3 特征空间
特征空间由图节点的所有特征(在可视化文献中通常称为属性)组成。 我们区分密集特征和稀疏特征。 密集特征是可以独立收集和理解的数字或布尔特征,每个特征都具有可解释的语义含义,例如来自电影<的预算或平均投票 /t2> 场景。
稀疏特征通常被收集在一起并共享组合语义,其中解释通常发生在整个集合被视为一个整体。 通常,它们存储为单热编码的分类特征,例如城市名称或 Cora 场景中的单词词典,其中集合由数百或数千个位向量表示。
在特征空间中,我们对特征值的分布感兴趣,这涉及导出聚合。 我们在第 2 节中深入研究了特征聚合的细节。 4.2.4。
CorGIE的设计目标是处理多达十几个密集特征和多达2K个稀疏特征。 请注意,我们认为边缘或图形特征超出了本文的范围。
3.2.4 距离指标
为了量化空间之间的对应关系,我们在每个空间内的任意一对节点之间引入距离度量,以便可以比较不同空间之间的标量距离值。 在潜在空间中,我们导出嵌入向量的余弦距离,这在下游机器学习应用中常用。 在拓扑空间中,我们推导了一个面向拓扑的距离度量,即输入图中每对节点的完整 k 跳邻居集的逆 Jaccard 指数。 该度量基于杰卡德指数:邻居集的并集的交集。 它直观且易于计算,但扁平化的邻居集有时过于简单化,因为不同跳中的邻居无法相互区分。 在特征空间中,我们推导出特征向量的欧几里德距离(线性缩放至 ),这也是 GNN 开发人员所熟悉的。
3.2.5 预测结果(可选)
训练完成后,GNN 可用于下游 ML 应用中的预测(图 1)。 我们通过将预测结果与可用的真实情况进行比较来利用预测数据,以获得真/假阴性和阳性。 对于节点分类应用,我们比较真实节点标签和预测节点标签,以得出每个节点的标签正确性值(正确与错误)。 对于链路预测应用,我们获得预测的正负节点对,并将它们与输入图的边进行比较。 我们为两个有趣类别的节点对导出标签:误报,其中未连接的节点对被预测为已连接(推荐对);和假阴性,它们是与边缘连接但预测为断开连接的节点对。 如果需要,我们还提供选项来得出真正的积极因素和消极因素。 尽管基础数据和任务抽象不依赖于这些预测结果,但它们可以用于过滤。
3.3 任务抽象
我们确定了围绕两个阶段的迭代周期构建的统一任务抽象,如图2所示:指定三个数据空间中任意一个中的项,以及对应潜在空间和拓扑空间或者潜在空间和特征空间之间的项。 值得注意的是,我们的任务抽象并不需要寻找拓扑和特征空间之间的对应关系,因为这种探索只会关注输入图中的特征,并且不会提供对 GNN 行为的直接洞察。
指定步骤允许用户根据每个空间中可见的目标来指示任何空间中感兴趣的节点。 在潜在空间中,他们可以根据相对于任何可见簇结构或潜在距离分布的相对位置来指定节点。 在拓扑空间中,他们可以根据邻居、派系或拓扑距离分布来指定节点。 在特征空间中,他们可以指定特定特征值的节点。 如果可用,他们还可以根据预测结果(例如标签正确性或节点之间新预测的链接)指定节点的集合。 下面,我们将一组指定的节点称为焦点组,它具有双重含义:它是用户在数据分析过程的当前步骤中思想中的心理焦点,并且是内部操作和计算的焦点。 CorGIE 接口。
然后,对应步骤允许用户探索一个空间中指定节点的特征与其他空间中的特征的对应程度。 例如,对于潜在空间中的紧密簇,用户可以验证簇中的节点是否在拓扑空间中共享许多邻居以及在特征空间中是否具有相似的特征。 如果是这样,则 GNN 已成功学习如何将这些节点分组在一起。 这些空间相互排列的程度是一个定性判断,而不是一个精确计算的指标。 这种抽象的目的是支持 GNN 开发人员获得比纯粹的定量汇总指标(例如准确性)更高的信心和信任。
该抽象支持将指定和对应作为迭代循环的过程,其中探索对应关系可以触发用户指定其他节点集的兴趣。 例如,用户可能首先在潜在空间中指定一个簇,在检查其与拓扑空间的对应关系后会变得好奇,然后在其中指定一个子簇以探索进一步的连接。 基于视觉对应关系的多次细化和更改指定节点集的循环允许用户将这些点连接起来并找到所有三个驱动问题的答案。
这个任务抽象包含了我们所有三个驱动问题。 它是通过考虑我们分析的所有具体任务之间的共性而开发的,不仅是激励场景(第 2.2 节)中提出的任务,而且还包括补充第 2.2 节中总结的许多其他具体示例。 S1。 在抽象过程中,我们最初考虑了一组更复杂的目标和操作,例如分析集群的异常值,或分析一个节点与所有其他节点,或者验证差异是否应与验证相似性区别对待。 最后,我们意识到几乎所有这些问题都可以更简单地构建,即指定极少数群体作为目标,然后检查对应关系。 很少需要三组:一到两组就足以解决几乎所有的分析问题。 我们的最终设计最多针对两组进行优化,尽管可以指定更多组来处理边缘情况。
4 CorGIE设计
基于数据空间和任务抽象,我们设计了CorGIE,一个多视图工具,可以揭示输入图与其嵌入之间的对应关系。 我们描述了每个视图的设计,然后是它们之间的视图协调,最后是实现。
4.1 概述
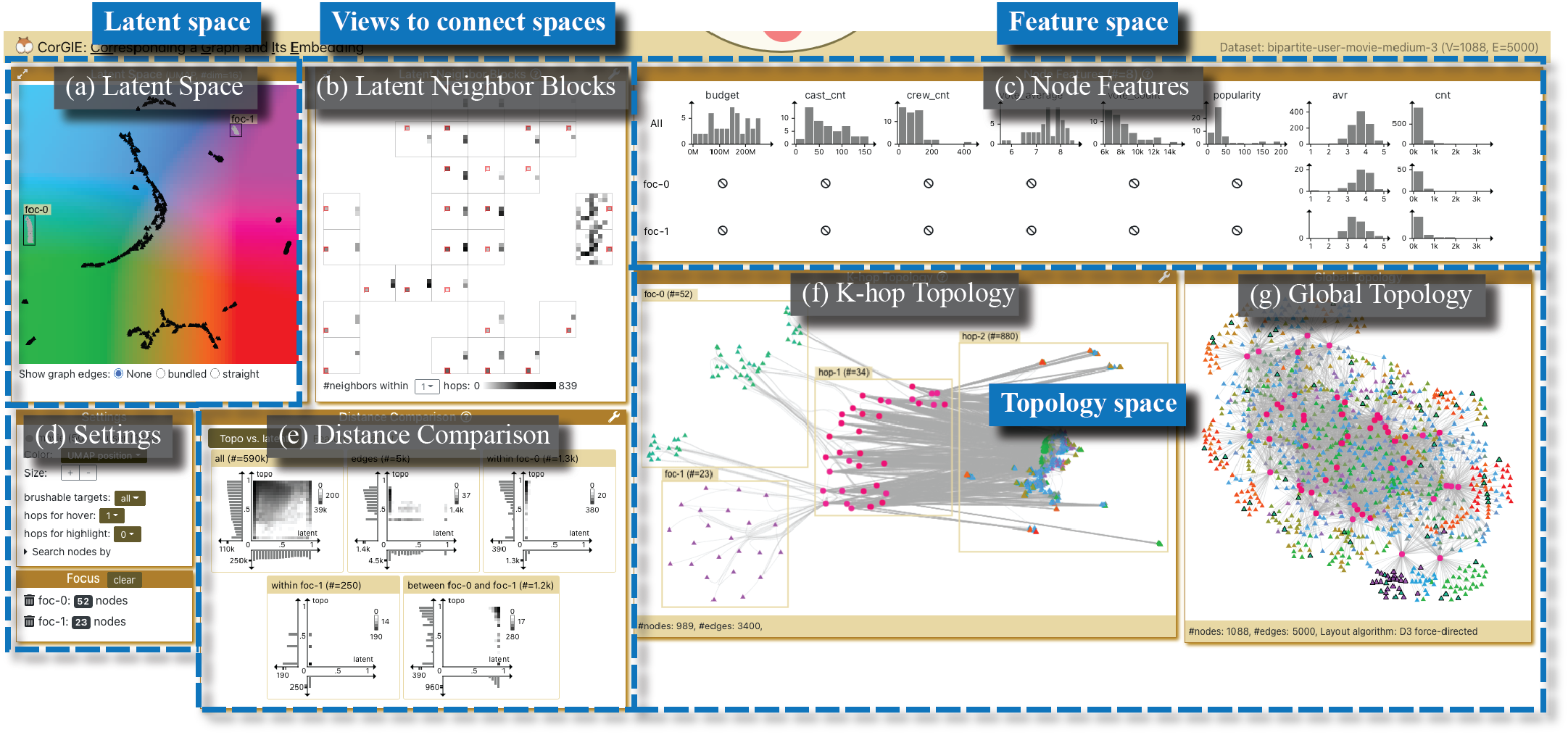
图3显示了电影场景中CorGIE界面的概述,它有七个主要视图。 使用第二节中的语言。 3.2和图2,视图要么显示特定空间中的目标,要么连接多个空间。 潜在空间视图位于左上角。 右下角的两个视图显示拓扑空间、全局拓扑视图以及K-hop 拓扑视图中用户选择的节点子集的新颖图形布局。 特征空间显示在节点特征视图的右上角。 为了实现直接、快速的对应探索,我们在中间有两个视图,可以同时合并两个或三个空间。 我们引入潜在邻居块视图来连接潜在空间和拓扑空间,并引入距离比较视图来连接所有三个空间。 最后,左下角有一个设置视图。
为了支持任务抽象中的指定和对应两个步骤,CorGIE的交互设计涉及三个动作:悬停、选择和焦点。
节点规范通过 focus 操作进行,对应探索通过 hover 和 select 操作触发。 focus 操作创建一个或几个感兴趣的特殊节点组,用 foc-0、foc-1 等表示。 当悬停或选择时,节点会在视图中突出显示。 当节点聚焦时,将会有一个新颖的图形布局显示它们的 k 跳拓扑邻居。 整个界面解决了第 2 节中的三个问题。 3.1 使用所有视图和交互。
4.2 查看设计
我们介绍每个视图的视觉编码和设计原理。
4.2.1 潜在空间
界面左上方潜在空间视图(图3a、图6a、图8a) 显示了聚类结构和潜在空间中节点的相对位置(图2中的目标)。 我们使用 UMAP [11] 将潜在空间投影到二维,并将降维后的节点绘制为散点图。 GNN 开发人员通常熟悉降维,因此意识到在此过程中信息丢失是不可避免的。
CorGIE 通过所有视图中的 UMAP 位置支持颜色编码节点,在该模式下,整个 2D 潜在空间视图的彩虹背景为潜在空间内的位置提供了显着参考,如图 3 所示>。 我们选择了高度饱和的 CIELAB 颜色图(x 轴代表变量 ,y 轴代表 ),它具有大量的颜色开发和强大的性能,可用于检测组的天气定位任务。节点[12]。 降维和此颜色图的组合显示了潜在空间距离,因此相似的节点接收相似的颜色,而不同的节点接收不同的颜色。
节点针对具有多种节点类型的异构图进行形状编码,在潜在空间视图和拓扑空间视图中保留相同的形状。 默认情况下,边缘处于关闭状态以避免混乱,但可以根据需要在此视图中显示为直边缘或捆绑边缘。
4.2.2 全局拓扑
我们在 CorGIE 中展示了带有节点链接图的图拓扑。 我们对全局拓扑视图采用D3力导向布局[13](图3g,图8b)。 它可视化整个输入图的拓扑,并在预处理步骤中计算一次。 与潜在空间视图一样,我们将同质图的图节点编码为圆形,将异构图的不同节点类型编码为不同形状的字形。 当启用边缘捆绑时,我们使用直线作为图形边缘,使用曲线。
尽管这种简单的逆止布局可以在较小的图形中提供有用的见解,但对于较大的图形来说,这种全局视图可能会非常混乱。 在这种情况下,在 k 跳拓扑视图中,用于探索用户指定的图子集的局部邻域的自定义布局至关重要。
4.2.3 K跳拓扑
4.2.4节点特性
右上角的节点特征视图(图3c)显示最多三组的特征分布(图2中的目标)节点数:所有节点,以及两组可能的焦点节点中的每组(foc-0 和 foc-1)。 由于尺度差异,密集和稀疏特征的可视化方式有所不同。
对于密集特征,我们选择直方图,因为它们直观且众所周知,可用于可视化和比较标量值的分布。 它们还可以很好地适应可用的显示空间,以处理多达十几个密集属性的设计目标。 我们将这些特征直方图组织为矩阵。 每一列代表一个特征,而行显示不同的节点集合。 第一行显示所有节点的完整分布;下一行显示焦点节点集foc-0的分布,其下方是集foc-1。 例如,在图3c中,两个焦点组用户节点的平均投票数(倒数第二个avr列)分布不同,但数量差异不大票数(最后一栏)。 请注意,对于异构图,不同类型的节点可以具有不同的特征,因此焦点节点集可能最终会出现一些空的直方图。 图3中的两个焦点组仅包含用户节点,因此没有六个电影属性的数据。
与密集特征相比,稀疏特征可能有数千个,并且它们的顺序没有明确的意义。 因此,稀疏特征的视觉编码与密集特征的直方图不同,我们在补充图 S14 中包含了显示稀疏特征的完整屏幕截图,供读者比较显示密集特征的图 3。 我们设计了一个两级自定义视图,以在紧凑的区域中有效利用屏幕空间,如图8f所示。顶部是一个功能条概述,它聚合了下面更详细的功能矩阵部分中的信息。 下部的特征矩阵是一个热图,每个特征包含一个方形单元(例如,单词训练),其亮度编码具有该特征的节点的数量(例如, Cora 数据集中包含 训练 一词的论文数量)。 从概念上讲,热图包含一条很长的线,只需将其包裹以适合矩形纵横比。 它不是真正的二维矩阵,因此单元格在行/列方面的绝对位置没有意义。 上面的特征条将热图中的信息聚合成高度压缩的基于像素的描述,其中许多连续的特征被组合成同一条垂直线,亮度代表整个范围内的最大值。 要聚合的特征数量由视图的可用水平像素预算决定,以便条带适合其中。
与密集特征一样,顶部的所有节点都有一行,下面的两个焦点组各有一行,以显示部分特征分布。 此外,还有一个较低的 diff 行,是通过减去两个焦点节点组的特征值而得出的。 图 8f 显示了一个示例(底行),该示例直观地显示了 foc-0 和 foc-1 的单词分布差异,其中深色条表明这些字数存在较大差异。
在每一行中,可以隐藏特征矩阵以节省空间,或展开以检查细节。 由于值范围可能完全不同,因此每行中的亮度值都单独标准化,因此它们每个都需要单独的图例。
4.2.5 潜在邻居块
潜在邻居块视图(图3b,图8c)在2D潜在空间上覆盖拓扑邻居分布。 挑战是为每个节点显示每个节点的邻居在潜在空间中的位置。 我们通过聚合和嵌套来做到这一点。 我们通过将空间划分为 88 网格来进行聚合,以创建具有 64 个块的空间的粗略表示,并将每个节点映射为属于包含它的块。 在每个块中,我们嵌套了潜在空间本身的完整副本,同样以粗分辨率作为 88 个单元格的网格。 图中省略了不包含任何节点的块。
此视图的灵感来自于地理空间网络的起点-目的地 (OD) 地图[14],但我们显示的是邻居集分布而不是地理移动。 在每个高级块中,我们用红色勾勒出与其块索引相对应的单个低级单元格,就像 OD 图中的原点一样。 对于块中的每个其他单元格,我们使用亮度对落在红色轮廓的原始单元格内的节点的邻居数量进行编码,例如 OD 图中的目的地。 如果红色轮廓的块及其周围的单元比所有块中的其他单元更暗,则该模式表明拓扑空间中的邻居仍然是潜在空间中的邻居,并且 GNN 已成功保留邻居结构。 Cora 场景的图 8c 说明了这种情况。
然而,这种视觉编码有一个限制:对于二分图来说,它的信息量较少,例如 Movie 场景,其中电影节点只允许将用户节点作为其第一跳邻居。 在这种情况下,图 3b 没有提供太多见解。
4.2.6 距离比较
距离比较视图(图3e、图7e和7f)显示了距离分布在每个空间中并支持空间之间的比较。 在数据抽象(第 3.2.4 节)中,我们在每个空间中导出一个距离度量。 此视图显示一个选项卡中拓扑与潜在空间之间以及第二个选项卡中要素与潜在空间之间距离的匹配和不匹配。 匹配构成两个空间中距离的正相关。 此视图显示节点对,这些节点可能代表一条边,也可能在输入图中断开连接。
为了同时呈现和比较两个标量分布,我们将两个直方图和一个网格散点图组合成一张图表,其中 x 轴表示潜在空间中的距离分布,y 轴表示拓扑或特征空间中的距离分布。 散点图中要绘制的项目数量可能很大,因此我们使用网格分箱方法来避免过度绘制,并且为了加快计算速度,如果节点对超过一百万,我们还会对节点对进行下采样。
每个选项卡可容纳多个图表,以并排显示不同的节点对集,例如焦点组内的所有节点对、两个焦点组之间的节点对,或基于连接性和链路预测值(如果可用)的用户自定义过滤集。 补充图 S18 显示了自定义选项,包括在线性和对数刻度之间进行选择以处理数据差异。
4.3 视图协调
为了在视觉上强调视图之间的联系,我们仔细维护跨视图节点的视觉编码的一致性,包括形状、颜色和大小。 用户可以在设置视图(图3d)中配置节点颜色,以设置潜在空间位置(相似性彩虹)、特定节点特征(顺序Ramp)、节点类型(可区分的分类颜色)或节点分类标签(如果可用)(也是分类的)。 形状取决于异构图的节点类型,或者在同构情况下是圆形。 大小也可以在设置中进行全局配置。
我们还在所有视图中开发具有一致语义的用户交互。 在CorGIE中,从轻量级到重量级主要有3种交互:hover、select和focus。 通常,它们按顺序使用:hover用于快速临时探索,然后select为通过悬停识别的感兴趣的节点提供更持久的视觉提示,最后focus 将当前选定的节点存储到持久组中。 补充视频中显示了交互的外观和感觉。
当用户将鼠标悬停在对象上时,例如拓扑视图中的节点或边以及潜在邻居块视图中的块上,就会触发悬停操作t2>。 悬停时,CorGIE 会做出强烈的视觉提示反应(图 7c 和 e):在激活的节点和边缘上进行描边,同时使用半透明蒙版(黑色)降低背景的饱和度节点顶部的部分分布具有直方图、工具提示和节点标签。
select 动作是通过点击节点/边或刷多个节点来触发的。 视觉提示与 hover 高度相似(图 6c 和 d),但即使用户将光标移开,该提示仍然存在。 用户可以通过设置视图中的下拉菜单控制在悬停和选择操作期间是否突出显示目标节点的邻居。
重量级的focus操作使用户能够找到一组或两组指定节点的对应关系。 创建或修改焦点组时,许多视图都会更新,特征和距离视图发生变化,并且创建新K-hop的计算密集型操作拓扑布局。 CorGIE 支持多种焦点操作:创建新的焦点组、添加到/单出/从现有组中删除以及清除组。 这些操作使用户能够根据任务迭代性质的要求细化和更改指定的节点(第 3.3 节)。 由于只有选定的节点才能成为焦点操作的目标,因此仅在选择节点后才会出现用于选择这些操作之一的焦点菜单。 它从窗口顶部落下,看起来像柯基犬的爪子,与系统名称一致,如视频和补充图 S6 所示。 焦点节点由框界定,并在焦点布局和潜在空间<中用foc-0或foc-1标记。 /t3> 意见。
4.4 实施
CorGIE是使用ReactJS实现的 222https://reactjs.org/ 和 Redux 333https://redux.js.org/ 作为前端脚手架。 为了浏览器性能,我们在大多数视图中选择 Canvas 而不是 SVG。 对于具有一千多个节点的图,将会有数千个 DOM 元素,因此在用户交互上重新渲染 SVG 将非常昂贵。 我们使用 Konva 库开发分层系统 444https://konvajs.org/ 在静态画布上添加视觉元素,以避免尽可能昂贵的重新渲染。 由于 focus 操作涉及大量计算,需要几秒甚至几分钟的时间,因此我们将其卸载到多个 Web Worker 以保持应用程序响应,并使用 Comlink 库5 55https://github.com/GoogleChromeLabs/comlink 在线程之间进行通信。
4.5 设计替代方案
在 CorGIE 界面的迭代细化过程中,我们广泛尝试了不同的替代方案来探索单个焦点组的邻居集,包括基于 Upset 的邻居集 [15] 视图和部分邻接具有汇总直方图的矩阵。 我们在补充章节中详细讨论了这些设计方案。 S3。 然而,所需的像素空间对于实际大小的图形(例如具有数百个节点的图形)来说是不可行的,并且没有明显的扩展来比较两个焦点组之间的邻居集。 我们的最终设计更广泛地依赖于交互式探索,一次探索一组或两组的邻居集,而不是尝试同时对所有可能性进行视觉编码。 在案例研究会议中,一位领域专家建议我们可以对 Movie 场景使用传统的二分布局,但我们认为力导向布局是适用于所有类型图的更通用的解决方案。
5 韩流布局
我们提出了一种新的视觉编码技术,即 K-hop 图形布局,该技术用于 CorGIE 的 K-hop 拓扑视图(图 3f、图 7b & e、图8d、图9b、图10d & e)显示邻居感兴趣的节点的跳数。 这种编码与 GNN 中邻域聚合的概念一致,反映了用户对模型的看法。 我们在本节中介绍 K 跳布局的计算可扩展性,并评估其对第 2 节中任务的适用性。 6。 我们还讨论了我们考虑的三种设计方案及其局限性。

5.1 算法
我们首先概述布局算法,然后介绍每个步骤的技术细节和基本原理,最后讨论其可扩展性。
K-hop 布局旨在通过跳数及其聚类结构来组织用户指定节点的拓扑邻居。 如图4所示,它的计算主要分为四个步骤:1)将相关节点分组,2)将节点绑定在盒子内并布局盒子,3)在每个盒子内布局节点独立地,4) 执行转换以优化全局可读性。 可选的最后一步是 5) 边缘捆绑。 我们遵循这种自上而下的布局策略,以确保最重要的信息以有效的视觉通道显示:空间分隔。
划分邻居。 我们将节点分组:用户指定的焦点组、焦点节点的所有第一跳邻居、焦点节点的所有第二跳邻居,依此类推,直到第 K 跳(其中 K3) 。 其余节点被视为不相关并因此被丢弃,因此该视图仅显示全局布局中节点的子集。 这种划分在设计上自然地与 GNN 中的邻域聚合相匹配(第 2.1 节)。 请注意,节点只能出现在一组中,以避免混淆重复,并优先考虑其出现的最左侧视图。
放置盒子。 我们将组的节点绑定在框中,并将框从左到右放置。 对于左侧的焦点组,从上到下放置多个焦点节点。 正如我们在采访中所证实的那样,这种布局模仿了 GNN 开发人员通常如何看待信息流。
布置在组内。 我们独立地布置每个组内的节点。 为了揭示节点的聚类结构,我们使用降维技术 UMAP [11] 将节点的高维拓扑距离矩阵降低到二维。 用户可以选择本地距离(仅到前一跳的连接)或全局距离(所有 K 跳连接)。 如果没有足够的节点来运行 UMAP,布局将回退到 D3 强制导向布局。 由于组之间的独立性,我们可以并行化 UMAP 流程以提高性能。 在此步骤中可以使用替代布局算法,例如 t-SNE [16];我们选择 UMAP 是因为它在揭示全局结构方面的速度和强度[17]。
调整组。 我们需要对上一步的布局进行调整,因为纯粹的本地布局决策可能会危及全局可读性。 例如,图4的步骤3中可能存在许多边缘交叉,即使每个盒子内的局部布局已经被优化。 我们使用类似于 Procrustes 分析[18] 的方法来潜在地重新定位每个组。 具体来说,我们可以对每个组应用六种可能的变换:旋转(0、90、180、270 度)和翻转(水平和垂直)。 这些严格的变换不会改变群体内的相对位置。 我们用简单的枚举算法找到每个组的最佳变换,即枚举所有组的所有 6 种可能的变换,总共 种组合,其中 是数量组。 节点排斥 Linlog 函数 [19] 用作找到最佳值的可读性度量。 请注意,测量中仅考虑框之间的节点对,并且我们对它们进行随机采样以计算性能加速函数的近似值。
束边。 最后,为了进一步揭示连接模式,我们将边缘捆绑应用于图形布局以减少视觉混乱。 在几种边缘捆绑算法[20]中,我们选择多级聚合算法[21],因为它的速度和有竞争力的视觉性能。 我们注意到,它可能会引入扭曲的边缘,这比未更改的边缘更难追踪,因此我们允许用户在直边和捆绑边缘之间切换。
5.2 可扩展性
| Times (sec) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset |
|
|
|
|
B |
|
total | ||||||||||
| Movie | 1K/5K | 1088 | 5000 | 633 | 4 | 4.1 | 5.5 | ||||||||||
| Movie | 1K/5K | 1088 | 5000 | 370 | 5 | 2.5 | 4.7 | ||||||||||
| Cora | 3K/5K | 989 | 2010 | 576 | 3 | 3.3 | 3.9 | ||||||||||
| Cora | 3K/5K | 2116 | 4222 | 1028 | 4 | 8.5 | 9.6 | ||||||||||
| Coauthor | 10K/54K | 9528 | 43317 | 4254 | 3 | 47.1 | 57.6 | ||||||||||
| Coauthor | 10K/54K | 9951 | 44261 | 6544 | 4 | 110.1 | 123.9 | ||||||||||
为了帮助我们的方法的感知可扩展性,我们的重点是减少边缘交叉,这会妨碍用户对拓扑和连接性的判断。 我们选择通过 K 跳布局来揭示聚类结构是一种权衡,其中 K 跳布局中可能存在大量的节点到节点重叠。
为了计算可扩展性,我们对代码进行检测以获得经过的(挂钟)计时,并测量三个数据集的不同交互选择的焦点组的运行时间:电影(N = 1K,E = 3K)和Cora(N=3K,E=5K),如第 2 节中介绍的那样。 2.2 和 Coauthor(N=10K,E=54K)从 69K 个节点的较大图中提取[22]。 该实验在配备 2.3GHz 8 核 i9 CPU 的 2020 款 MacBook Pro 上的 Chrome 中进行。 我们在选项卡中呈现结果。 I。 除了总图大小之外,我们还提供 k 跳图布局中使用的节点和边的数量(k 跳内焦点节点及其邻居的组合)。 我们看到,有时 k 跳焦点布局包含所有节点和边,但有时仅显示其中的子集,具体取决于焦点组的选择。
具有 1K 节点的图(例如 Movie 数据集中的图)需要几秒钟的时间来计算,而具有 10K 节点的图则需要更长的时间。 UMAP 计算(步骤 3)是我们算法中的计算瓶颈,如最右边两列上的计时数字所示。 我们注意到,时间并不取决于节点总数,而是取决于单个边界框内的最大数量,因为我们在每个框的多个工作线程之间并行运行 UMAP 进程。 因此,我们将节点数包含在表中最大框中。 例如,在同一 Coauthor 数据集上,上次运行(最多 6544 个节点)的时间为 110 秒,是上次运行(最多 4254 个节点)50 秒的时间的两倍。 与 UMAP 计算相比,步骤 1(划分邻居)、2(放置框)和 4(调整组)所需的时间可以忽略不计;可选的第五步(边缘捆绑)大约需要总时间的。
5.3 设计替代方案
我们尝试了 K-hop 拓扑 的三种设计替代方案,它们在显示邻居跃点和集群结构方面不如我们的最终选择有效:D3 力导向、WebCola 和空间填充螺旋。
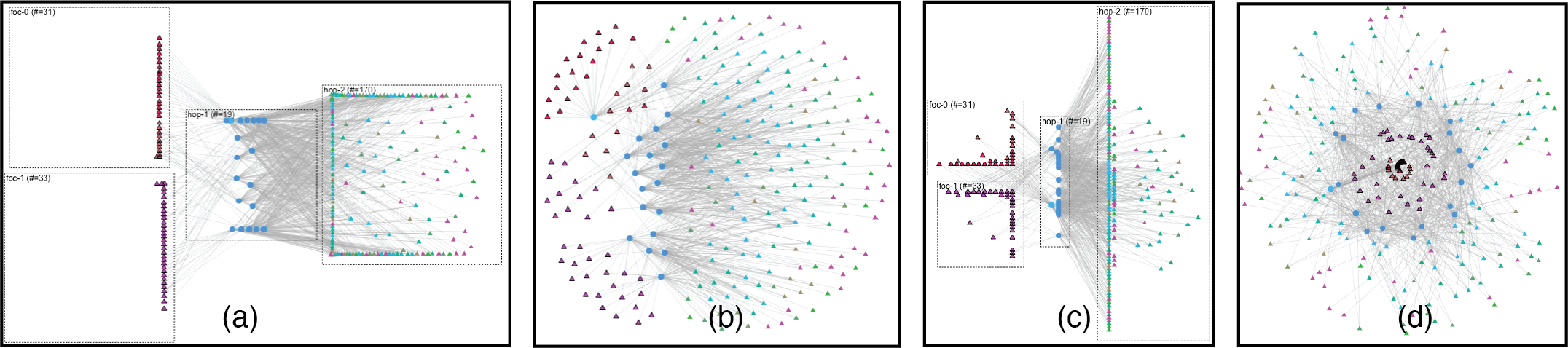
D3 力导向布局具有多种用途,因为我们可以配置力的强度类型。 与K-hop布局类似,我们使用拓扑距离作为节点之间的拉力,而不是通常使用边来控制力的方法。 图5(a)和(b)显示了该布局的两个版本。 第一个镜头以 K-hop 布局等框为边界,但节点被拉向其他组并位于组边界旁边,作为不需要的工件。 它不显示组内的聚类结构。 第二条路线没有严格限制,但对不同邻居组的节点有很强的排斥力。 跳跃的分离不够明显,特别是对于节点没有形状编码的同构图。
空间填充曲线布局[24]是最快的布局算法之一。 我们选择螺旋曲线,因为它可以将不同组的节点从中心到外围分开。 在极坐标系上,我们使用拓扑距离作为曲线上两个连续节点之间的距离。 从图5d可以看出,不同组之间有一定的空间划分,但比D3版本更差。 它还带有一个伪像,有时极坐标系中的邻近度与拓扑中的邻近度不匹配:节点以不同的半径但相似的角度放置。 此外,这种螺旋式的空间填充设计并没有有效地利用空间,在不太重要的邻居所在的外围区域有大量未使用的空间。
6 结果
我们通过两种方式评估 CorGIE:我们用它来解决两个激励场景中的问题,我们招募了五位 GNN 专家参与用户研究来评估它的实用性和可用性。
我们首先介绍我们的两种使用场景。 然后,我们描述我们的研究设计,并讨论在流行的 Cora 数据集上使用 CorGIE 的专家用户会话之一的亮点。 然后我们总结研究参与者的反馈。 我们在补充章节中描述了另一个专家用户会话。 S4.4。
下面,我们系统地描述CorGIE使用的四个方面:正在执行的可视化任务、CorGIE界面中使用的可视化操作、直接观察这可以通过 CorGIE 显示以及作者或参与者的任何结果推论来实现。 这里我们只用颜色标记可视化任务;在补充第 4 节中,我们提供了所有四个方面都用颜色编码的文本版本。
6.1 使用场景一:电影推荐
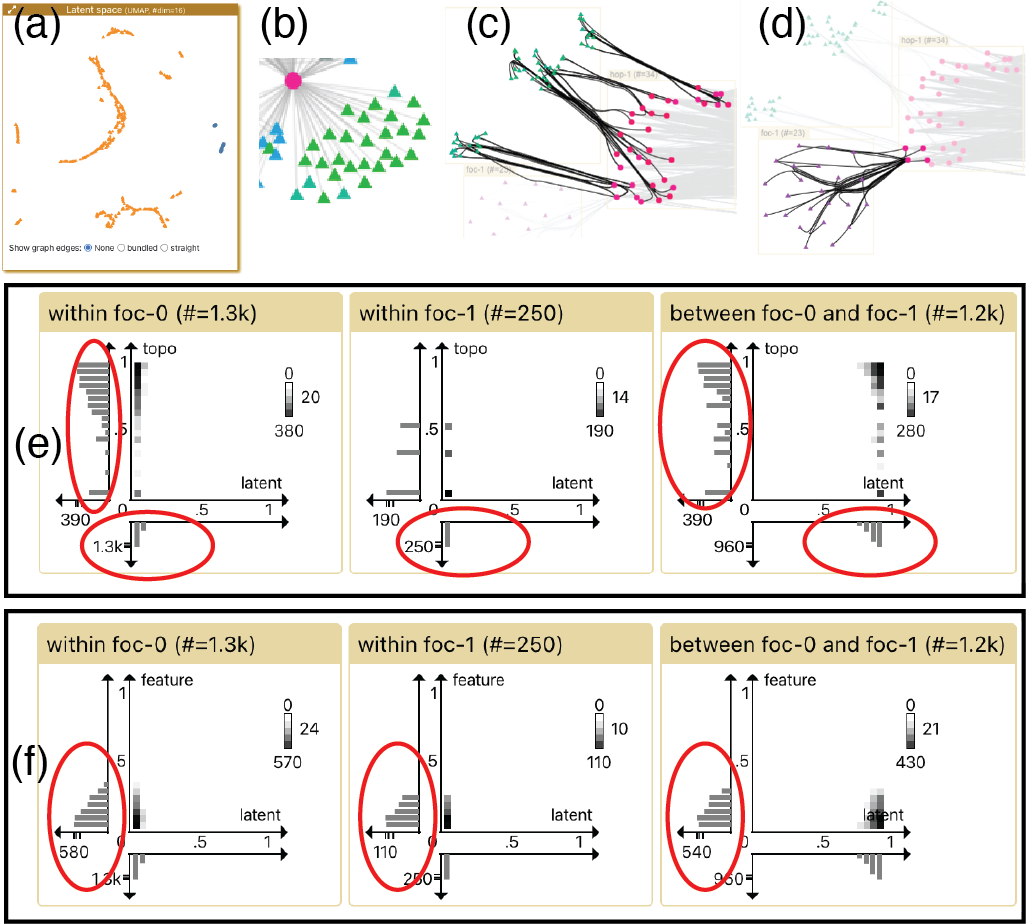
为了获得数据集的概述,我们首先根据节点类型(用户和电影)对节点进行着色。 图6a显示,我们可以在右侧看到两个蓝色的电影集群,在其余的潜在空间中看到许多橙色的用户集群。 在通过潜在空间中的底层位置颜色图对节点进行着色后,我们在全局拓扑视图(图3g)中观察到大多数用户节点(三角形)被放置围绕电影节点(圆圈)。 许多仅由一条边连接的节点被放置在布局的外围,这表明有很多用户只观看了一部电影。 在图6b中,我们注意到连接到同一部电影的外围用户具有相似的颜色:例如,右下角的三角形都是绿色的。 因此,我们可以推断 GNN 在将这些一次性用户评论同一部电影方面做得很好。
为了比较用户集群,我们从潜在空间中选择并关注两个集群,其中一个位于网络上的绿色区域 (foc-0)左,另一个位于右上方紫色区域(foc-1),如图3所示。 在K-hop拓扑中(图3b),foc-0中似乎存在三个绿色子簇,并且绿色节点连接到 hop-1 框中的许多节点,而 foc-1 没有显示任何显着的内部结构。 为了了解两个焦点组之间的拓扑差异,我们通过悬停和选择操作探索它们在K-hop拓扑中的联系。 图6c和6d显示了选择绿色foc-0时K-hop拓扑中的视觉亮点分别是 t5> 节点和紫色 foc-1 节点。 我们可以看到顶部 foc-0 框中的绿色节点连接到所有 hop-1 邻居,但下部 foc-1 框中的紫色节点仅连接到其中四个邻居。 我们推断 GNN 已经学习了拓扑差异,从而在潜在空间中将它们分开。
除了图拓扑之外,我们还想检查空间之间的距离是否匹配。 在距离比较视图(图6e)中,我们可以看到潜在空间中的组内距离很小,而组间距离很大,这证实了我们从潜在空间中挑选了两个遥远的簇。 我们注意到绿色簇(foc-0)内的拓扑距离相对较大,因为它们属于同一簇(图6e中最左边的垂直直方图),这实际上与 K-hop 拓扑中存在三个子集群 相匹配。 图6f的三个图表中的特征距离都很小并且相似,表明节点特征(#votes和用户的平均投票)无法区分foc-0 和foc-1。 我们通过选择一些其他节点组(图中未显示)读取特征距离来进一步确认特征的无效性,这表明它们不是有用的特征,并且可能会从数据集中删除。

在探索聚类结构之后,我们检查推荐实例。 在图7a中,我们选择用户节点5355,并列出其前5名推荐的电影。 第一个是指环王:王者归来(LotR)。 我们想了解为什么 GNN 决定推荐 LotR,因此我们通过点击来关注此推荐。 CorGIE 自动创建两个焦点组,用户 5355 位于 foc-0 中,电影 LotR 位于 foc-1 中(图7b)。 K-hop 拓扑 显示用户 5355 之前观看了两部电影(粉红色)。 当我们将鼠标悬停在 hop-1 框中的两个粉红色节点上时(图 7c),我们发现每个节点仅与推荐电影 LotR 共享一些用户;例如,自杀小队只有 5 个 hop-1 共享邻居。 我们认为,这一建议很糟糕,可能表明我们在 GNN 训练方面还没有达到目标。 我们通过读取用户5355和电影LotR之间的拓扑和潜在距离进一步证实了这个问题(图7e),这似乎是负相关的。
我们后来找到了一个有意义的推荐:用户587和电影LotR。 如图7e所示,587观看的两部电影盗梦空间和暗夜共享许多用户推荐电影LotR(当鼠标悬停在Inception上时,许多 hop-1 邻居会突出显示)。 而且,本例中的拓扑距离为,与整体距离分布相比(图中未示出)相对较小。 因此,CorGIE 有证据表明该建议得到了很好的支持。
我们重复此过程来检查其他建议建议,我们发现许多建议没有意义。 我们的结论是,本次训练结果并不令人满意。 这可能是由于在如此小的数据集中存在“冷启动”问题,大多数用户只观看 1 或 2 部电影。 此外,节点特征并不是很有用:例如,我们知道#votes无法有效地区分用户。 为了改进推荐,我们可能会尝试不同的模型或修复数据集问题。
6.2 使用场景2:Cora

与电影场景一样,我们首先检查纸张节点的聚类 结构。 我们根据预测的标签对节点进行着色,以查看标签分布是否有意义。 在潜在空间(图8a)中,我们可以看到不同类别的论文大致分为不同的区域。 在全局拓扑中(图8b),虽然力导向布局缺乏太多结构,但我们仍然可以看到附近的节点具有相似的颜色。 在潜在邻居块(图8c)中,我们可以看到所有块的红色轮廓原点及其周围的单元格都较暗。 所有三个观察结果都表明 GNN 在使用图拓扑对论文进行分类方面做得很好。
接下来,我们检查并比较几个集群。 例如,当我们比较(选择并聚焦)整个红色集群和蓝色集群的左侧部分(图8d)时,K-hop 拓扑(图8e)显示大多数相同颜色的节点相互连接,以及节点特征视图中的差异图(图8f) 表示两个纸簇之间存在大量不同的单词(差异行上有许多可见的深色条带)。 这些观察加深了我们对训练结果的良好印象。
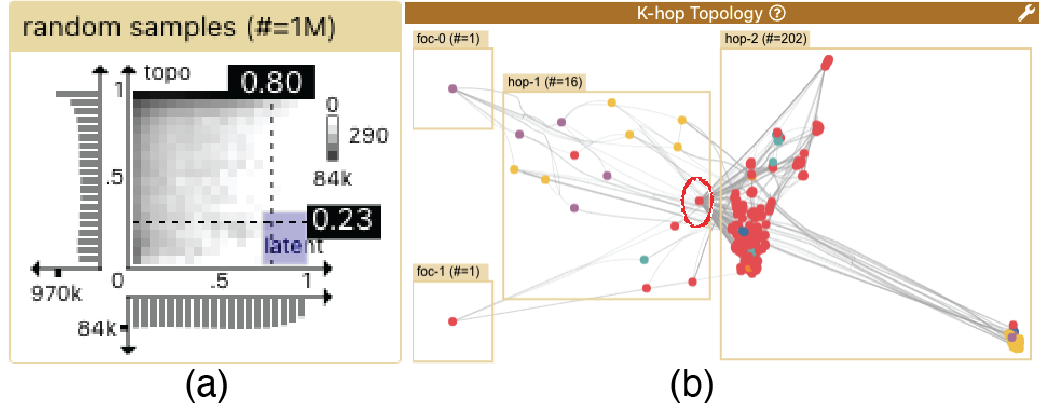
由于 GNN 似乎成功地对大多数节点进行了分类,因此我们寻找有问题的节点和边。 我们刷距离散点图来突出显示潜在距离大但拓扑距离小的节点对(即右下区域),如图9a所示,我们重点关注这些有问题的节点对之一。 在K-hop拓扑中(图9b),通过几轮交互式悬停,我们发现两个焦点节点仅共享一个第一跳邻居(圆圈中)红色),其中有许多节点在第二跳中连接。 由于杰卡德距离考虑了邻居的多跳,因此大量共享跳 2 邻居可以解释较低的拓扑距离 ()。 我们推测,由于第一跳差异较大,GNN 决定将它们放置在远离彼此的位置。 进一步的调查表明,foc-0中的节点被错误分类,这暗示了该 GNN 模型在处理此类情况时的局限性。
6.3 专家研究概述
所有参与者都在积极致力于 GNN 研究。 他们是一名工业实验室研究员(P2)、一名本科生(P4)和三名高年级博士生(P1、P3和P5)。 研究前几个月,我们与 P1 和 P2 进行了一次会议,当时我们正在迭代 CorGIE 的任务和设计。 在这次会议中,我们讨论了他们模型训练工作流程中的痛点,并确认我们的对应方法符合他们的心智模型,但当时没有向参与者展示任何版本的 CorGIE 界面。 在远程学习环节,第一作者对CorGIE进行了约40分钟的介绍和演示。 然后参与者在自己的数据集或演示数据集上使用 CorGIE 大约 30 分钟,然后进行半结构化访谈以收集他们的反馈。 P1 和 P2 使用 CorGIE 的接近最终版本,而其他人则使用最终版本。
结果提供了 CorGIE 在完成我们在第 2 节中提出的任务方面的效用的基本知识证据。 3.3,专家们对CorGIE的有效性高度肯定。
6.4 专家会议:Cora 决策边界
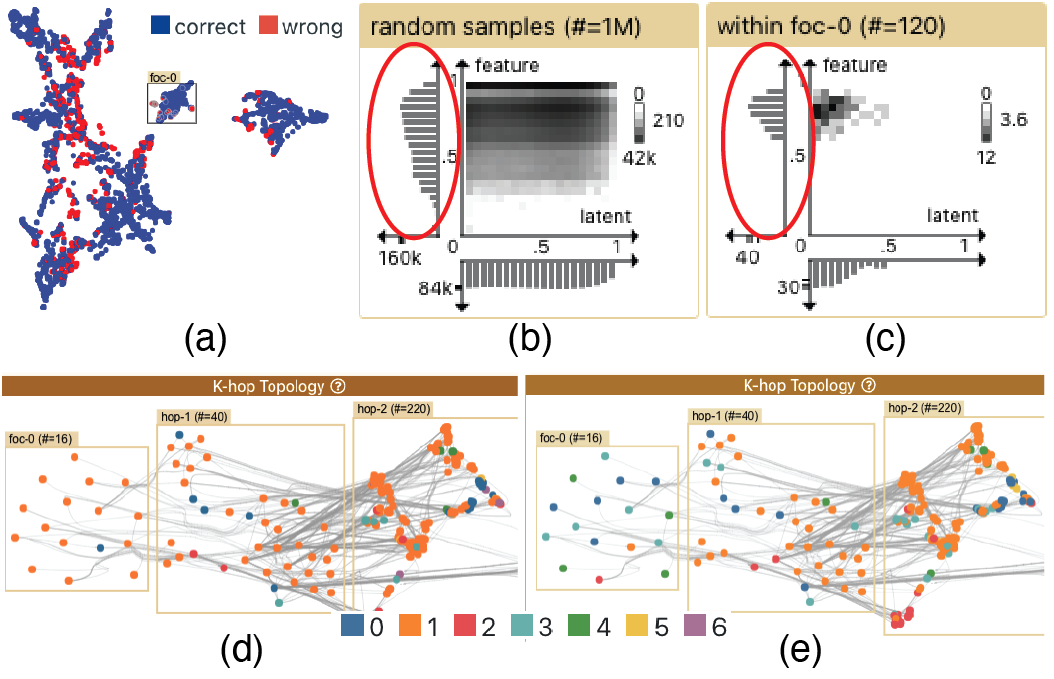
在本案例研究中,专家 P1 首先选择执行与我们的使用场景中非常相似的任务。 然后他想检查概述以研究错误分类。 他根据标签正确性对节点进行着色(图 10a),他看到红色(错误分类)节点分布在不同的集群中。 他使用经过过滤的画笔选择来突出显示并集中潜在空间中中间簇内错误预测的节点。 他分别用预测标签(图 10d)和真实标签(图 10e)为节点着色,这样他就可以了解哪些类是错误的。 看来 GNN 将这些节点预测为类似于其 hop-1 邻居的橙色类,但地面实况标签表明它们属于多个不同的类(蓝色、绿色、红色等),尽管 hop-1 邻居仍然是橙子。 通过悬停和画笔选择进行进一步检查表明,焦点节点与其 hop-1 邻居松散连接,但 hop-1 邻居与 hop-2 邻居紧密连接。 根据真实标签的方差和拓扑的稀疏性,P1 推断这些节点位于图拓扑中两个或多个类之间的决策边界。 尽管他已经使用这个数据集多年,但这是他第一次目视检查边界节点。 他强调了如果需要改进 GNN 模型,理解决策边界的重要性。
在探索了拓扑之后,P1转向距离比较来获取有关节点特征的更多信息,他发现焦点节点内的特征距离与整体分布相比相对较大(图10c&b)。 他推测当前模型的表现符合他的预期,即使他保持训练更多的 epoch,也不太可能正确分类边界节点。 他还推测GNN应该以更好的方式利用节点特征来纠正这些节点。 当他确认GNN除了一些边界节点之外对大多数节点都做得很好时,他的结论是没有必要保持更多的训练epoch,并且应该停止训练以避免过度拟合。
6.5 专家会议反馈
总的来说,参与者在观看我们的演示后印象深刻,并且能够第一次自己使用该工具。 在这里,我们总结了他们在整个研究过程中的反馈。 请参阅补充章节。 S5 详细的面试问题和回答。
任务。 参与者确认,两步(指定和对应)任务框架有助于帮助评估 GNN,特别是在焦点节点的迭代细化和调试节点时嵌入。 P1指出,CorGIE可以帮助找到决策边界节点,这是一个人们通常忽视的问题,也是他以前无法解决的问题。 他认为 CorGIE 可以帮助他理解数据、模型以及数据和模型之间的差距。 他认为他也许能够利用 CorGIE 的见解来改进他的模型。 P2 发现他可以在机器学习研究领域激烈的排行榜竞争中快速调试模型。
视觉编码。 参与者表示,在介绍性解释中,CorGIE 中的大多数观点都很简单易懂。 尽管所有参与者都理解节点特征视图背后的直觉,但有些人认为他们不太可能使用它,因为他们不需要探索单个节点特征的分布。 P3 指出,GNN 研究人员对 Cora 数据集中的实际单词不感兴趣,因为它更多的是自然语言处理问题。 两位专家(P1 和 P2)发现热图和热条在没有解释的情况下不太直观。
K-hop 布局。 所有参与者都认为 K-hop 拓扑 很直观,可视化有助于他们推理 GNN 如何运作。 我们认为这种积极的回应是对我们新颖的 K-hop 布局算法成功的验证。
互动。 所有参与者都能快速掌握主要互动内容。 他们在采访中都口头确认,三级交互易于遵循,并且很好地促进了任务的完成。
可用性。 尽管 CorGIE 是一个研究原型,但参与者在远程研究期间的大部分时间里都成功地自行使用了它。 尽管如此,某些可用性问题引起了我们的注意;例如,鼠标必须停留在画布区域内才能在潜在空间视图中执行矩形画笔选择。 能够指示选择操作是否应该仅影响目标节点本身,或者还影响其 k 跳邻居以获得所需的 k 值,需要对五个参与者中的四个进行解释;该控件是使用设置视图中的下拉菜单实现的,很容易被忽略。
使用 CorGIE 接近最终版本的参与者 P1 和 P2 批评该界面在视觉上过于繁忙,使得乍一看很难找到特定对象。 因此,我们改进了界面布局以纳入他们的反馈,例如将重要的焦点操作控件更改为视觉上非常显着的下拉菜单,看起来像柯基犬的爪子。 使用最终版本的 P3、P4 和 P5 对流程和视觉复杂性感到满意(P5:“这比编写 Python 脚本来分析我的训练结果容易得多”)。
总体而言,专家的反馈是积极的,CorGIE 是一个可用且可学习的系统。 所有参与者都表达了将 CorGIE 纳入他们的研究工作流程的兴奋。
7 相关工作
CorGIE 与之前关于可解释人工智能的研究相关,它使用可视化来解释机器学习模型。 在本节中,我们将 CorGIE 与非图模型、潜在空间和图神经网络的可解释可视化相关联并进行比较。 我们还讨论了新的 K-hop 布局的相关工作。
7.1 机器学习模型的可视化
人们开发了许多可视化工具来解释和评估机器学习模型,特别是在最近五年。 读者可以参考许多调查论文来全面了解该主题[25, 26]。 大多数此类工具的目标是图像/视频和文本序列模型,其中大多数并未建模为图形。 尽管开创性的 GNN 工作 GCN [6] 源于图像的卷积神经网络 (CNN)(因为它们都使用卷积运算),但简单地将 CNN 工具重新定位到 GNN 是不切实际的。 主要区别在于图像中的像素邻居本质上不同于图中的拓扑邻居。 自然语言中的文本等序列数据则更加不同。 与许多试图打开神经网络“黑匣子”以及保持“黑匣子”完全不透明的可视化不同,我们提出了一种“灰匣子”方法,它仅利用 GNN 中的一个关键概念——邻域聚合(第 2 节)。 2.1) - 平衡 GNN 模型的通用性和特异性。
7.2 潜在空间解释器
潜在空间(也称为嵌入空间)的研究引起了广泛关注,特别是在基于文本的机器学习实践中。 嵌入消除了容易出错的特征选择过程,并且可以针对许多不同的下游应用程序进行预训练[27]。 由于 CorGIE 支持探索潜在空间和图形之间的对应关系,因此它与先前有关潜在空间可视化的许多工作直接相关。
主题之一是揭示一个或多个潜在空间的局部和全局结构。 Ghosh 等人 [28] 开发了 VisExPres,这是一个用于用户驱动的嵌入评估的交互式工具包。 Heimerl 等人 [29] 根据不同的定量指标比较嵌入,而 Cutura 等人则使用降维技术和矩阵可视化 [30] 来比较嵌入。 刘等人[31]将潜在空间内语义维度的映射和比较过程类比为潜在空间制图。 这个主题主要侧重于深入挖掘潜在空间,这与我们尝试将潜在空间连接到输入的方法不同。
另一个主题,降维 (DR),也松散相关,因为许多非线性 DR 技术会产生潜在空间[32]。 DR 结果有许多可视化工具:一些用于呈现数据点 [33],一些将 DR 结果连接回其语义上有意义的高维空间 [34, 35]. 它们的原始输入通常是表格数据,其中一个数据项具有多个特征(也称为属性),但它们都没有像 CorGIE 那样考虑图拓扑。
7.3 GNN解释器
GNN 社区在 GNN 解释方面做出了一些努力。 之前的大部分工作都集中在生成算法或模型来进行特征和邻居分析[36]。 Huang等人[37]提出GraphLIME在节点的邻域中产生一些最具代表性的特征。 其中最著名的工作之一是 Ying 等人的 GNNExplainer [2],他提出了一种基于信息论计算一个或一组用户指定节点中最重要节点的方法。 Rao 等人[38]跟进GNNExplainer,提出xFraud专门针对欺诈检测。 Pope 等人[39]将 CNN 的可解释性算法(如显着图、类激活映射和反向传播)扩展到 Graph-CNN。 该工作线程不足以支持人机交互的视觉探索,因此无法概述 GNN 从输入图中学习的情况以及迭代连接示例检查的情况。
最近的两篇论文将图模型可视化。 Li等人[40]提出EmbeddingVis来比较不同模型生成的多个图嵌入。 它关注如何在嵌入中保留节点度量(例如度、中心性),但不直接支持拓扑邻域探索或节点特征。 由于该研究项目是在使用邻域聚合的图神经网络最近流行之前进行的,因此它们的嵌入不是由 GNN 生成的,而是由其他图模型生成的。 Jin等人[41]的一篇论文,开发了GNNVis来诊断GNN中的错误,是与CorGIE最相似的相关工作。 它仅针对一种下游机器学习应用程序,即节点分类,这限制了其使用范围。 与 CorGIE 不同,GNNVis 忽略潜在空间并采取另一条路线:它支持在分类预测中查找错误,并与两个代理模型进行比较以近似 GNN 中的错误分量。
7.4 图表布局
我们讨论了我们的技术贡献的相关工作,即 K-hop 布局。 Gibs等人[42]的图布局调查将图布局分为三种方法:力导向布局、降维布局(例如MDS、t-SNE、UMAP)和多级图布局(参见 McGee 等人 [43] 的调查)。 我们的 K-hop 布局结合了 DR 和多级方法。 在数十种布局算法中,我们的算法与专注于集群的算法最为相关。 Dwyer 等人的 IPSep-CoLa [23] 是一种专门针对分离约束的力导向布局。 我们对该设置的实用性的调查表明,它会产生不需要的伪影(图5c)。 我们的 K-hop 布局类似于 Rodrigues 等人[44]提出的针对社交网络基于类别的分区的 Group-In-a-Box 布局。 它使用空间填充树形图技术来分离集群,而我们的组划分是根据用户选择动态进行的,并结合了 DR 技术。 Noack提出的LinLog布局[19]是一种基于能量的簇分离模型,它启发了我们在调整步骤中的可读性度量。
8 讨论和未来工作
经过反思,在描述问题、设计界面和评估问题的整个过程之后,我们认为探索输入、输出和内部数据结构之间对应关系的高级思想对于 GNN 解释是有用的,并且可以推广到其他深度神经网络。 由于神经网络本身通常由于多种原因(例如非线性、分层)而无法解释,因此“打开黑匣子”的方法完全需要相当复杂的解释,并且需要用户具有很高的专业知识。 我们更喜欢“灰盒”方法,将内部结构的暴露平衡到非零但最低的水平。 尽管节点嵌入通常不会暴露给最终用户进行解释,但它对所有 GNN 都是通用的。 通过找到它与输入数据(图)之间的对应关系,我们可以推断 GNN 是否取得了令人满意的结果,而无需摆弄神经网络的内部结构。 我们认为这种方法可以推广到其他类型的神经网络和机器学习应用。
我们还想推广我们的数据空间概念。 我们的数据抽象由三个数据空间(潜在数据空间、拓扑空间和特征空间)以及连接它们的任务抽象组成。 这种连接数据空间的心理模型有助于我们设计视图:有些视图专用于单个空间,而有些则连接多个空间。 它还有助于提高 CorGIE 的可用性和可学习性,通过五位 GNN 专家的反馈,我们已经掌握了足够的知识证据。 引入更多数据空间(例如处理专门处理地理空间数据的 GNN 的地理空间空间)将是有趣的未来工作[45]。
为了在现实环境中评估 CorGIE,我们在训练数据集时遵循 GNN 研究社区的常见做法。 我们确保超参数设置正确并训练足够的时期,直到模型使用损失值和分类准确性等定量指标收敛。 我们的结果显示了 CorGIE 的价值,即使这些实践似乎已经成功:在准确度超过 的电影场景中,我们仍然可以使用 CorGIE 定位有问题的节点或建议。
CorGIE 提供了一种可视化的方式来探索数据集中的局部区域,这对于其他方法来说是一个耗时甚至不可能的过程。 从我们与 ML 专家的讨论中,我们知道,由于缺乏工具,大多数 GNN 开发人员目前并没有如此详细地分析他们的结果。 如第 2 节所示。 6,CorGIE 特别擅长帮助用户生成有关训练结果质量的假设。 当然,验证这些假设可能需要在此可视化工具范围之外进行额外的工作。
处理更大的图对未来的工作很有用。 由于K-hop布局计算的原因,当前版本的CorGIE无法保证超过20K节点的图的流畅交互用户体验。 尽管许多流行的基准数据集都在这个规模内,但 ML 社区正在向更大的数据集前进,例如 OGB 平台上的数据集[46]。 可以使用利用 GPU 的更快的 UMAP 算法来加速布局计算,如果 Javascript 实现可用,则可以直接添加该算法。 K 跳布局的另一个限制是,既是焦点节点的第一跳又是第二跳的邻居节点只能在第一跳框中显示一次;参与者P5指出这种情况有可能误导用户。 Constellation 系统建议将一个节点复制为一个主节点和多个代理[47]来解决类似的问题,但该解决方案需要大量的交互支持以确保节点复制是可以理解的。 我们选择不这样做,因为 CorGIE 界面已经具有相当大的视觉复杂性。
为了进一步扩展 CorGIE,我们可以将 GNNExplainer [2] 等算法隐式地合并到 K-hop 拓扑视图 中,或者显式地合并到专用视图中。 这个想法也是由一位GNN专家独立提出的。 我们还可以支持更多的方式来指定节点,例如拓扑统计。 最后,我们可以比较同一输入图的多个节点嵌入,以帮助评估模型重新架构和超参数调整。 未来的论文可能会研究如何让 GNN 开发人员探索多个输入图及其节点/图嵌入之间的对应关系。
9 结论
在这项工作中,我们提出了一个任务抽象,用于探索输入图和 GNN 创建的潜在空间之间的对应关系,以了解 GNN 是否从图中学习了重要特征并找到潜在空间中的错误。 基于这个抽象,我们开发了一个交互式多视图工具 CorGIE,它通过使用场景和与 GNN 专家的案例研究进行了验证。 作为 CorGIE 中最重要的组件,我们提出了 K-hop 图布局来揭示 GNN 如何聚合感兴趣节点的信息。 案例研究和专家研究都验证了将 CorGIE 引入 GNN 模型开发生命周期的有效性。 我们设想,我们的新颖数据和任务抽象,结合我们的设计原理和实施考虑,可以作为未来研究的垫脚石。
致谢
作者要感谢 Madison Elliott、Steve Kasica、Michael Oppermann、Ben Shneiderman 和 Mara Solen 对论文草稿的有益评论,以及用户研究中的匿名参与者。 我们也感谢张璐瑶设计了CorGIE的标志。 这项工作部分由 Uber Technologies 和 NSERC RGPIN-2014-06309 资助。
参考
- [1] V. P. Dwivedi, C. K. Joshi, T. Laurent, Y. Bengio, and X. Bresson, “Benchmarking graph neural networks,” arXiv preprint arXiv:2003.00982, 2020.
- [2] R. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec, “GNNExplainer: Generating explanations for graph neural networks,” Advances in neural information processing systems (NeurIPS), vol. 32, pp. 9240–9251, 2019.
- [3] J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei, “LINE: Large-scale information network embedding.” in Proc. Intl. Conf. World Wide Web (WWW). ACM, 2015, p. 1067–1077.
- [4] I. Chami, S. Abu-El-Haija, B. Perozzi, C. Ré, and K. Murphy, “Machine learning on graphs: A model and comprehensive taxonomy,” ArXiv, vol. abs/2005.03675, 2020.
- [5] N. Peng, H. Poon, C. Quirk, K. Toutanova, and W.-t. Yih, “Cross-sentence n-ary relation extraction with graph LSTMs,” Trans. Association for Computational Linguistics (ACL), vol. 5, pp. 101–115, 2017.
- [6] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [7] F. Ricci, L. Rokach, and B. Shapira, “Introduction to recommender systems handbook,” in Recommender systems handbook. Springer, 2011, pp. 1–35.
- [8] A. K. McCallum, K. Nigam, J. Rennie, and K. Seymore, “Automating the construction of internet portals with machine learning,” Information Retrieval, vol. 3, no. 2, pp. 127–163, 2000.
- [9] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” arXiv preprint arXiv:1710.10903, 2017.
- [10] C. Yang, Y. Xiao, Y. Zhang, Y. Sun, and J. Han, “Heterogeneous network representation learning: A unified framework with survey and benchmark,” IEEE Trans. Knowledge and Data Engineering (TKDE), 2020.
- [11] L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform manifold approximation and projection for dimension reduction,” arXiv preprint arXiv:1802.03426, 2018.
- [12] J. Bernard, M. Steiger, S. Mittelstädt, S. Thum, D. Keim, and J. Kohlhammer, “A survey and task-based quality assessment of static 2D colormaps,” in Visualization and Data Analysis 2015, vol. 9397. International Society for Optics and Photonics, 2015, p. 93970M.
- [13] M. Bostock, V. Ogievetsky, and J. Heer, “D3 data-driven documents,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 17, no. 12, pp. 2301–2309, 2011.
- [14] J. Wood, J. Dykes, and A. Slingsby, “Visualisation of origins, destinations and flows with OD maps,” The Cartographic Journal, vol. 47, no. 2, pp. 117–129, 2010.
- [15] A. Lex, N. Gehlenborg, H. Strobelt, R. Vuillemot, and H. Pfister, “UpSet: Visualization of intersecting sets,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 20, no. 12, pp. 1983–1992, 2014.
- [16] L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of machine learning research, vol. 9, no. 11, 2008.
- [17] A. Coenen and A. Pearce, “Understanding UMAP,” https://pair-code.github.io/understanding-umap/, 2019.
- [18] I. Borg and P. J. Groenen, Modern multidimensional scaling: Theory and applications. Springer Science & Business Media, 2005.
- [19] A. Noack, “Energy models for graph clustering.” Journal of Graph Algorithms and Applications, vol. 11, no. 2, pp. 453–480, 2007.
- [20] H. Zhou, P. Xu, X. Yuan, and H. Qu, “Edge bundling in information visualization,” Tsinghua Science and Technology, vol. 18, no. 2, pp. 145–156, 2013.
- [21] E. R. Gansner, Y. Hu, S. North, and C. Scheidegger, “Multilevel agglomerative edge bundling for visualizing large graphs,” in 2011 IEEE Pacific Visualization Symposium, pp. 187–194.
- [22] J. Tang, J. Zhang, L. Yao, J. Li, L. Zhang, and Z. Su, “Arnetminer: Extraction and mining of academic social networks,” in Proc. 14th ACM SIGKDD Intl. Conf. Knowledge Discovery and Data Mining (KDD), New York, NY, USA, 2008, p. 990–998.
- [23] T. Dwyer, Y. Koren, and K. Marriott, “IPSep-CoLa: An incremental procedure for separation constraint layout of graphs,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 12, no. 5, pp. 821–828, 2006.
- [24] C. Muelder and K.-L. Ma, “Rapid graph layout using space filling curves,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 14, no. 6, pp. 1301–1308, 2008.
- [25] A. Chatzimparmpas, R. M. Martins, I. Jusufi, K. Kucher, F. Rossi, and A. Kerren, “The state of the art in enhancing trust in machine learning models with the use of visualizations,” Computer Graphics Forum, vol. 39, no. 3, pp. 713–756, 2020.
- [26] F. Hohman, M. Kahng, R. Pienta, and D. H. Chau, “Visual analytics in deep learning: An interrogative survey for the next frontiers,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 25, no. 8, pp. 2674–2693, 2019.
- [27] T. Young, D. Hazarika, S. Poria, and E. Cambria, “Recent trends in deep learning based natural language processing,” IEEE Computational intelligence magazine, vol. 13, no. 3, pp. 55–75, 2018.
- [28] A. Ghosh, M. Nashaat, J. Miller, and S. Quader, “VisExPreS: A visual interactive toolkit for user-driven evaluations of embeddings,” IEEE Trans. Visualization and Computer Graphics (TVCG), pp. 1–1, 2020.
- [29] F. Heimerl, C. Kralj, T. Moller, and M. Gleicher, “embcomp: Visual interactive comparison of vector embeddings,” IEEE Trans. Visualization and Computer Graphics (TVCG), 2020.
- [30] R. Cutura, M. Aupetit, J.-D. Fekete, and M. Sedlmair, “Comparing and exploring high-dimensional data with dimensionality reduction algorithms and matrix visualizations,” in Proc. Intl. Conf. Advanced Visual Interfaces (AVI). ACM, 2020.
- [31] Y. Liu, E. Jun, Q. Li, and J. Heer, “Latent space cartography: Visual analysis of vector space embeddings,” Computer Graphics Forum, vol. 38, pp. 67–78, 06 2019.
- [32] L. G. Nonato and M. Aupetit, “Multidimensional projection for visual analytics: Linking techniques with distortions, tasks, and layout enrichment,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 25, no. 8, pp. 2650–2673, 2018.
- [33] D. Smilkov, N. Thorat, C. Nicholson, E. Reif, F. B. Viégas, and M. Wattenberg, “Embedding projector: Interactive visualization and interpretation of embeddings,” arXiv preprint arXiv:1611.05469, 2016.
- [34] J. Stahnke, M. Dörk, B. Müller, and A. Thom, “Probing projections: Interaction techniques for interpreting arrangements and errors of dimensionality reductions,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 22, no. 1, pp. 629–638, 2016.
- [35] R. Faust, D. Glickenstein, and C. Scheidegger, “DimReader: Axis lines that explain non-linear projections,” IEEE Trans. Visualization and Computer Graphics (TVCG), vol. 25, no. 1, pp. 481–490, 2019.
- [36] H. Yuan, H. Yu, S. Gui, and S. Ji, “Explainability in graph neural networks: A taxonomic survey,” arXiv preprint arXiv:2012.15445, 2020.
- [37] Q. Huang, M. Yamada, Y. Tian, D. Singh, D. Yin, and Y. Chang, “GraphLIME: Local interpretable model explanations for graph neural networks,” arXiv preprint arXiv:2001.06216, 2020.
- [38] S. X. Rao, S. Zhang, Z. Han, Z. Zhang, W. Min, Z. Chen, Y. Shan, Y. Zhao, and C. Zhang, “xFraud: Explainable fraud transaction detection on heterogeneous graphs,” arXiv preprint arXiv:2011.12193, 2020.
- [39] P. E. Pope, S. Kolouri, M. Rostami, C. E. Martin, and H. Hoffmann, “Explainability methods for graph convolutional neural networks,” in IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10 764–10 773.
- [40] Q. Li, K. S. Njotoprawiro, H. Haleem, Q. Chen, C. Yi, and X. Ma, “EmbeddingVis: A visual analytics approach to comparative network embedding inspection,” in IEEE Conf. Visual Analytics Science and Technology (VAST), 2018, pp. 48–59.
- [41] Z. Jin, Y. Wang, Q. Wang, Y. Ming, T. Ma, and H. Qu, “GNNVis: A visual analytics approach for prediction error diagnosis of graph neural networks,” arXiv preprint arXiv:2011.11048, 2020.
- [42] H. Gibson, J. Faith, and P. Vickers, “A survey of two-dimensional graph layout techniques for information visualisation,” Information Visualization, vol. 12, no. 3-4, pp. 324–357, 2013.
- [43] F. McGee, M. Ghoniem, G. Melançon, B. Otjacques, and B. Pinaud, “The state of the art in multilayer network visualization,” in Computer Graphics Forum, vol. 38, no. 6. Wiley Online Library, 2019, pp. 125–149.
- [44] E. M. Rodrigues, N. Milic-Frayling, M. Smith, B. Shneiderman, and D. Hansen, “Group-in-a-box layout for multi-faceted analysis of communities,” in IEEE Intl. Conf. Privacy, Security, Risk and Trust (PASSAT) and IEEE Intl. Conf. Social Computing (SocialCom), 2011, pp. 354–361.
- [45] S. Guo, Y. Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial-temporal graph convolutional networks for traffic flow forecasting,” in Proc. AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 922–929.
- [46] W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,” arXiv preprint arXiv:2005.00687, 2020.
- [47] T. M. Munzner, Interactive visualization of large graphs and networks. Stanford University, 2000.
![[Uncaptioned image]](zl.png) |
Zipeng Liu received the PhD degree from University of British Columbia in 2021, and the BS degree from Peking University in 2015. His research involves visualization of multi-level structures in trees, graphs, logs and machine learning models. |
![[Uncaptioned image]](yw.jpg) |
Yang Wang is a Research Scientist Manager at Facebook supporting the AI-aided Creative Optimization domain. His research focuses on Visual Analytics, Human-Computer Interaction, and Machine Learning. Specifically, methodologies and systems to help users better understand and leverage machine learning in their analytical and creative processes. |
![[Uncaptioned image]](jb.png) |
Jürgen Bernard is an Assistant Professor at the University of Zurich and head of the Interactive Visual Data Analysis group. He has received the Ph.D degree in computer science from the University of Darmstadt, and was a postdoctoral research fellow at the University of British Columbia, Canada. His research focus is on visual analytics and human-centered machine learning. |
![[Uncaptioned image]](tm.jpeg) |
Tamara Munzner (Senior Member, IEEE) received the PhD degree from Stanford. She is currently a professor with the University of British Columbia. She worked on visualization projects in a broad range of application domains from genomics to journalism. Her book Visualization Analysis and Design appeared in 2014. She was the recipient of the IEEE VGTC Visualization Technical Achievement Award. |