专家合作:在 ImageNet 上以 100M FLOP 实现 80%
Top-1 准确率
摘要
在本文中,我们提出了一个专家协作(CoE)框架,以汇集多个网络的专业知识以实现共同目标。 每个专家都是一个单独的网络,拥有数据集独特部分的专业知识,为集体能力做出贡献。 给定一个样本,委托人选择一位专家,同时输出一个粗略的预测,以触发潜在的提前终止。 对于 CoE 中的每个模型,我们提出了一种新颖的训练算法,该算法具有两个主要组件:权重生成模块(WGM)和标签生成模块(LGM)。 实现了专家与委托人的协同适应。 WGM 通过解决平衡传输问题,根据委托人将训练数据划分为多个部分,然后通过重新加权损失来促使每个专家专注于一个部分。 LGM生成标签构成委托人的损失供专家选择。 CoE 在 ImageNet 上实现了最先进的性能,在 194M FLOP 下达到 80.7% 的 top-1 准确率。 结合 PWLU 和 CondConv,CoE 首次在仅 100M FLOP 的情况下将准确率进一步提升至 80.0%。 此外,翻译任务的实验结果也证明了 CoE 的强大泛化性。 CoE 是硬件友好型的,与现有的条件计算方法相比,可实现 36 倍的加速。
1简介
从简单的系统到复杂的系统,各种任务的完成都依赖于多个个体的协作。 同样,与仅部署一个单独的模型相比,具有不同属性的模型的明智组合可以提高特定任务的性能。 模型协作的方法有很多种,其中集成学习(Hansen & Salamon, 1990; Wen 等人, 2020; Wenzel 等人, 2020)是一种流行的方法。 集成学习采用共识方案,通过投票决定集体结果。 然而,它需要多次前向传递,从而导致显着的运行时间成本。 MIMO (Havasi 等人,2021) 从模型稀疏性 (Frankle & Carbin,2019) 中汲取灵感,并尝试将多个子网络集成到一个常规网络中。 它只需要常规网络的一次前向传递,但与紧凑模型不兼容。 条件计算方法(Cheng等人,2020;Yan等人,2015)采用模型协作的委托方案,有条件地分配一个或多个模型,而不是所有模型来进行预测。 最近提出的一些条件计算方法(Yang等人,2019;Zhang等人,2021)基于动态卷积取得了显着的性能。 然而,它们通常具有较高的内存访问成本(MAC)和较低的并行度,从而增加了实际延迟(Ma等人,2018)。
受此启发,我们提出了专家协作(CoE)框架,以消除多次前向传递的需要并保持硬件友好。 CoE 由一名委托人和多名专家组成。 首先,委托人进行粗略预测并做出专家选择。 如果粗略预测不可靠,则由选定的专家进行精细预测。 否则,该过程将提前终止以节省 FLOP。 此外,我们只需将选定的智能交易加载到内存中,从而使 MAC 与 FLOP 的比率保持恒定。 相比之下,动态卷积方法(Zhang 等人, 2020, 2021)需要加载大量参数,即基础模型或专家,以合成依赖于输入的参数。 它扩大了MAC并降低了并行度,导致显着的减速。
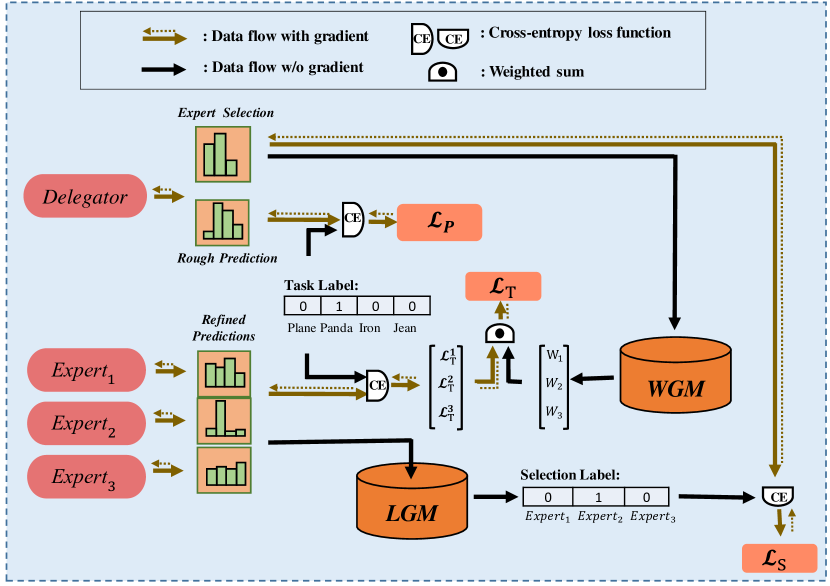
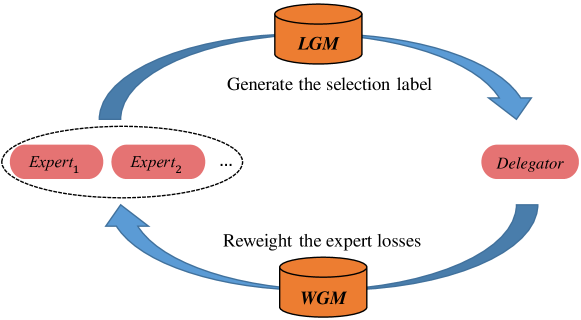
为了使CoE中的每个模型发挥作用,我们提出了一种新颖的训练算法(如图1所示),该算法由两个主要部分组成:权重生成模块(WGM)和标签生成模块(LGM) )。 LGM生成标签(选择标签)来构成委托人对专家选择的损失。 选择标签是一个单热向量,指示每个给定输入的合适专家。 它是通过解决平衡运输问题获得的(BTP,Shore 1970)。 基于委托人,WGM 通过求解 BTP 来最大化总选择概率,从而将训练数据划分为多个部分。 然后对专家损失进行重新加权,以便每个专家都可以专注于一部分。 如图2所示,这就实现了专家与委托者的协同适配。 协同适应方式使得 CoE 能够很好地泛化到验证集。 由于专家的随机初始化,训练初期的选择标签是不规则的。 尽管如此,委托人倾向于首先学习可概括的模式,因为网络在训练过程中逐渐学习更复杂的假设(Arpit等人,2017)。 因此,WGM 可以以委托人为桥梁,根据可概括的模式将训练数据划分为多个部分。 作为回报,它使选择标签更加规则,从而委托者避免了对不规则标签的过度拟合。
我们在ImageNet分类任务上进行了主要实验。 CoE 仅在 100/194M FLOP 下就实现了 78.2/80.7% 的 top-1 准确率,而集成模型(Hansen & Salamon,1990)在 920M FLOP 下的准确率仅为 79.6%。 与广泛使用的基于门值的优化方法(Shazeer等人,2017;Fedus等人,2021)相比,我们提出的训练算法将CoE的准确率提高了1.2%,表明了训练的有效性。 与动态网络方法相比,CoE 对硬件更加友好。 它不仅优于 SOTA 动态方法 BasisNet,在 198M FLOPs 下实现了 80.0% 的准确率(Zhang 等人,2021),而且在硬件上实现了 3.1 倍的加速。 此外,CoE可以配备CondConv,并在102/214M FLOPs下进一步将精度提高到79.2/81.5%。 此外,我们通过使用 PWLU 激活函数(Zhou 等人,2021),首次在仅 100M FLOP 的情况下将准确率进一步提高到 80.0%。 翻译任务的实验结果也证明了 CoE 的强大泛化性。
本文的贡献可概括如下:
-
•
我们提出了一个名为“专家协作”(CoE)的协作框架。 其核心优势在于推理效率。 与其他条件计算方法相比,CoE 具有较低的内存访问成本和较高的并行性,这是影响真实延迟的两个重要因素。
-
•
我们提出了一种新颖的 CoE 优化策略,实现了专家和委托者的共同适应。 实验结果表明其优于广泛使用的基于门值的优化方法。
-
•
CoE 更新了 ImageNet 上移动设置的最新技术,据我们所知,首次在 ImageNet 上以低于 2 亿次 FLOP 的速度实现了 80.7% 的 top-1 准确率。
-
•
由于专家选择是在模型级别完成的,CoE 可以利用条件卷积和 PWLU 激活函数等现有技术将性能提升到一个新的水平,即在仅 100M FLOPs 的 ImageNet 上达到 80.0% 的准确率。
2相关工作
2.1 集成学习和模型选择
集成学习(Hansen & Salamon,1990)旨在结合多个模型的预测以获得更稳健的模型。 最近提出的一些文献(Wen等人,2020;Wenzel等人,2020)表明,与原始模型相比,只需微不足道的额外参数即可实现显着的增益。 然而,这些方法仍然需要多次(通常是 4-10 次)前向传递来进行预测,从而导致显着的运行时间成本。 不同的是,CoE 利用委托人只选择一名专家进行精细化预测,因此最多需要两次前向传递。 MIMO (Havasi 等人, 2021) 从模型稀疏性 (Frankle & Carbin, 2019) 中汲取灵感,认为多个独立子网络可以在一个常规网络中同时训练由于参数冗余较多。 因此,这些子网络可以与常规模型的单个前向传递集成。 然而,MIMO不能应用于已经剪枝的紧凑模型或通过AutoML方法构建的模型(Cai等人,2020;Zhong等人,2018)。 这是因为这些模型的冗余参数很少。 相比之下,CoE 不受专家紧凑性的影响,因为专家选择是在模型级别完成的。 最近,提出了一些关于模型选择的工作(Li等人,2021b;You等人,2021)。 这些方法涉及对许多预先训练的模型进行排序,并找到最能转移到感兴趣的下游任务的模型。 因此,他们会根据任务明智地选择模型。 相比之下,CoE 旨在通过明智地为每个样本实例选择最合适的专家来提高任务性能。
2.2 动态网络
动态网络通过有条件地改变网络参数(Zhang等人,2020;Yang等人,2019)或网络架构(Yuan等人,2020)(Yuan等人,2020)来实现高性能和低计算成本。 t1>. HD-CNN (Yan 等人, 2015) 和 HydraNet (Mullapudi 等人, 2018) 根据类别选择分支,它们将所有类别聚类为 n 组,其中 n是分支的数量。 虽然 CoE 自动学习模型选择模式,但它可以基于任何属性,而不限于类别。 MoE (Shazeer 等人, 2017) 和 Switch Transformer (Fedus 等人, 2021) 通过路由器在层级选择专家。 每个专家的输出特征将根据路由器预测的门值进行缩放,从而路由器变得可训练。 这种基于门值的优化方式是启发式的,而 CoE 可以更合理地训练委托人。 由于 CoE 的专家选择是跨模型完成的,因此我们可以使用 True Class Probability(TCP,Corbière 等人 2019)等协议来无偏见地衡量每个专家的适合性。 根据专家适合度,可以获得监督委托人选择专家的标签。 此外,CoE 更多地利用了条件计算,因为选择了整个网络,而不是仅选择了某些特定层。 最近提出的动态卷积方法(Zhang 等人,2020;Yang 等人,2019;Chen 等人,2020)具有类似的想法,并在低 FLOPs 但高延迟的情况下实现了出色的性能。 这是因为这些方法需要加载许多基础模型或专家来综合动态参数,导致 MAC 高且并行度低(马等人,2018)。 相比之下,CoE 只需要将选定的专家加载到内存中,就避免了这些问题。 最后但重要的是,批处理是增强并行度的重要方法。 由于依赖于输入的参数(Shazeer等人,2017;Zhang等人,2021)或架构(Yuan等人,2020),这些方法无法处理以下样本批。 不同的是,CoE 支持批处理,因为专家数量有限,并且每个专家对应许多测试样本。
3方法
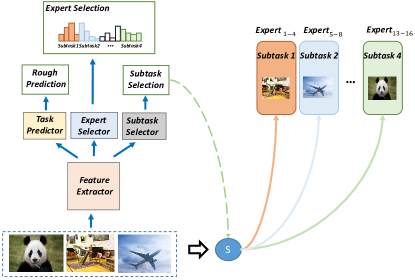
CoE 由委托人和 个专家组成,总共 个单独的神经网络。 给定一个样本,委托人将选择一位专家,同时输出一个粗略的预测,以触发潜在的提前终止。 由于委托人的推理一直在进行,因此我们更倾向于让委托人比专家更轻量。 委托器由三个模块组成:特征提取器、任务预测器和专家选择器,如图3所示。 基于特征提取器导出的特征,任务预测器和专家选择器分别输出分类概率和专家选择概率。 在接下来的小节中,我们将全面描述 CoE 的推理过程和训练策略。 样本和专家的数量表示为和。
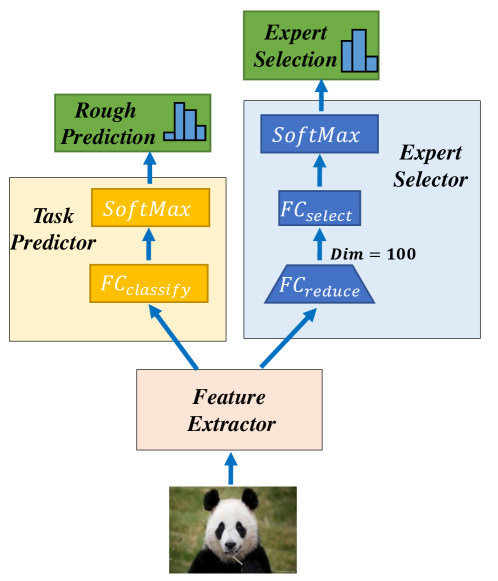
3.1 推理过程
CoE首先使用委托人获得粗略预测并确定每个样本的选定专家。 然后,计算粗略预测的最大类别概率(MCP,Corbière 等人 2019)。 它是预测类别的概率。 然后,根据粗略预测得出MCP大于给定阈值的样本的最终识别结果。 其他样本根据选择的专家分为 组。 随后,可以在每个组内进行批处理以获得精细的预测。 该流程如图4所示。 CoE 的平均 FLOPs/实例范围从 到 ,通过将 从 0 变化到 1、 和 是委托人和专家的失败。 因此,的值直接由目标FLOPs决定。
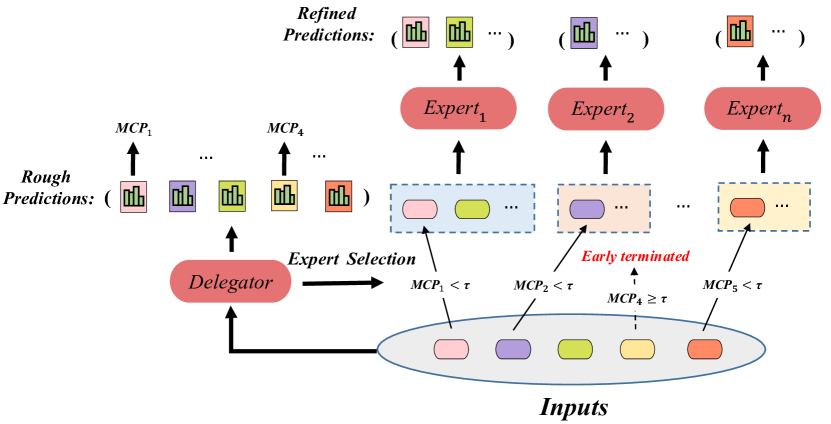
3.2标签生成模块(LGM)
由于 CoE 的专家选择是跨模型完成的,因此我们可以无偏见地衡量每个专家的适合性。 以此为基础,可以得到监督委托人选择专家的标签。 这种基于标签的委托人训练方法比广泛使用的基于门值的方法更合理(Shazeer等人, 2017; Fedus等人, 2021),它可以通过以下方式训练路由功能使用其预测的门值来缩放每个专家的输出。 接下来,我们首先介绍如何衡量每个专家的适合度,然后说明如何获得选择标签。
模型准确率可以通过True Class Probability来衡量(TCP,Corbière 等人 2019):
| (1) |
其中, 是第 j 个样本, 和 是预测类别和真实类别。 但准确性并不是适用性的唯一因素。 例如,当模型大小不同时,较大的模型通常具有较高的 TCP。 但由于推理成本较大,它可能不太合适。 鉴于我们关心的不是网络架构的优化,我们可以假设没有专家优于其他专家(无优越性假设,NSA)。 在 NSA 的推动下,我们利用标准化 TCP 作为适用性指标:
| (2) |
其中, 和 是 样本上 TCP 的平均值和标准差。
选择标签可以用二进制矩阵 表示,其中每一行都是一个选择标签。 根据NSA,每个专家应该分配相同数量的样本,因此的每个列向量之和应该相同,即为。 因此,可以通过最大化来获得:
| (3) |
这个问题可以建模为平衡运输问题(BTP,Shore 1970),其中每个样本都是一个供应源,其供应量为 1,每个专家都是一个需求源,需求量为 。 是从第j个供应源到第k个需求源的单位运输成本。 我们通过附录A.1中介绍的沃格尔近似法(VAM,Shore 1970)来解决这个问题,这是一种总能获得良好解决方案的捷径。
3.3权重生成模块(WGM)
为了最大限度地提高 CoE 的集体能力,需要将数据集划分为多个部分,然后每个专家只关注一部分。 这是通过 WGM 实现的,它重新衡量了专家的损失。 分区可以由具有 one-hot 行向量的分配矩阵 来指示。 表示第j个样本被分配给第k个专家,因此的损失权重比。
朴素分区可以基于专家适用性,即使用选择标签对训练数据进行分区。 然而,如图5(a)所示,它导致对委托者的泛化性较差。 假设适用于样本,因此。 由于,的损失权重比上的其他专家更大,使得更适合作为回报。 因此,选择标签无法更新,并且由随机初始化引起的不规则性将被保留。 因此,委托人逐渐过度适应不规则标签,产生较差的泛化能力。 这也在 4.4 节中得到了验证,其中基于专家适用性的划分导致 CoE 的性能很糟糕。


由于网络在训练(Arpit等人, 2017)过程中逐渐学习更复杂的假设,委托人倾向于首先学习可概括的模式。 因此,划分可以基于以委托人为桥梁的泛化模式,即根据委托人的输出进行划分。 通过这种方式,由于专家损失的重新加权,选择标签变得更加规则。 如图5(b)所示,委托者避免了对不规则标签的过度拟合。
委托人输出一个概率矩阵,其元素表示在第j个样本上选择第k个专家的概率。 如上所述,最好根据对训练数据进行划分,从而将最大化得到。 此外,根据NSA,分配给每个专家的样本数量应该相同,即。 因此, 通过以下方式进行优化:
| (4) |
该问题也可以建模为 BTP,并通过 VAM 解决,如 3.2 节中所述。 在训练初期,CoE 中的模型欠拟合。 因此我们不能信任,需要缩小不同专家的损失权重之间的差距来进行热身。 我们通过使用等式5将平滑到来实现这一点,其中随着训练的进行从0.2线性增长到0.8在,
| (5) |
最后,用系数对进行归一化,得到WGM的输出(即):
| (6) |
3.4培训详情
CoE的训练框架如图1所示,主要由、和三个损失组成。
是委托人粗略预测的交叉熵损失。 为了避免委托者的重复训练,我们首先使用来训练特征提取器和任务预测器(图3)。 然后固定这两个模块,仅将专家选择器和专家与联合优化,本文将设置为0.8。
用于优化专家选择器。 根据选择标签,我们可以得到第j个样本的交叉熵损失。 由于CoE的最终识别结果并不总是对专家选择敏感,因此应给予不同的重视。 例如,当专家对第j个样本具有相似的适合性(Eq.2)时,专家的选择对CoE的最终性能影响很小,因此的权重变小。 考虑到适宜性的相似性可以通过标准差来衡量,我们将的损失权重设置为。 最后,
| (7) |
用于优化专家。 根据 m 个样本的类标签,我们可以得到 交叉熵损失 ,其中 是 -th 专家对 -th 样本的交叉熵损失。 然后将WGM输出的与权重加权求和得到:
| (8) |
在本文中,我们使用了四位或十六位专家。 当使用十六名专家时,我们将任务分解为四个子任务,每个子任务涉及四名专家,如附录A.2中所述。 这减少了训练的内存成本。
4实验
我们在ImageNet分类任务上进行了主要实验。 在与一些流行的高效模型进行比较后,我们验证了 CoE 相对于现有模型协作方法(模型集成和基于类别的模型选择)的优越性。 然后,通过与广泛使用的基于门值的训练方法和详细的消融进行比较,分析了训练策略的有效性。 此外,我们尝试将 CoE 推广到翻译任务,并使用重新评估标签 (ReaL) (Beyer 等人, 2020) 重新评估 CoE。 最后,我们尝试分析学习到的专家选择模式的合理性。 4.2.1和4.2.2部分引用基线的统计数据直接引用自原始论文,其他除非另有说明,均按以下设置实现。
4.1实现细节
我们使用两种设置进行实验:CoE-Small 和CoE-Large。 对于 CoE-Small,我们通过删除最后一个全连接层,采用 24M FLOPs 的 TinyNet-E (Han 等人, 2020b) 作为委托人的特征提取器。 我们使用具有 110M FLOPs 的 OFA-110 (Cai 等人, 2020) 作为专家。 对于 CoE-Large,采用 56M FLOPs 的 MobileNetV3-Small (Howard 等人, 2019) 类推构造委托人。 我们使用具有 230M FLOPs 的 OFA-230 作为专家。 我们还尝试引入 CondConv (Zhang 等人, 2020) 和 PWLU 激活函数 (Zhou 等人, 2021) 来实现极限性能。 更多详细信息请参见附录B.1。
4.2结果与分析
4.2.1 准确性和计算成本
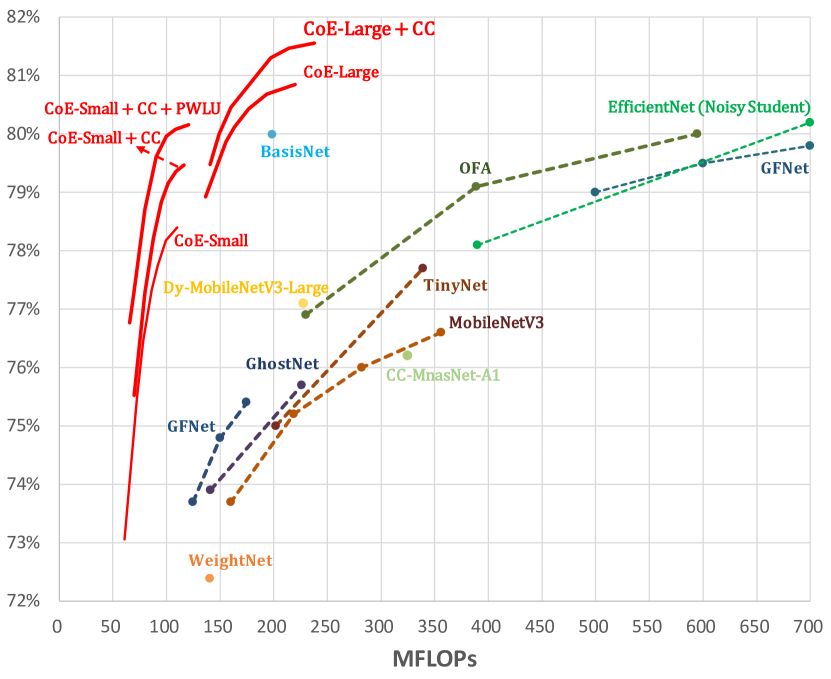
通过改变提前终止的阈值,可以获得CoE的准确度曲线。 我们将它们显示在图6中,然后从每条曲线中挑选一个点与表1中的一些有效模型进行比较。 CoE 在 16 位专家的情况下达到了 78.2% 和 80.7% 的准确率,平均 FLOPs/Instance 分别为 100M 和 194M。 与OFA相比,CoE将FLOPs从230M降低到100M,从595M降低到194M,并且具有更好的top-1精度。 尽管 GFNet、CondConv 和 BasisNet 等动态网络比传统网络更高效,但 CoE 仍然具有更高的精度和更小的 FLOP。 与这些方法相比,CoE 的准确率分别提高了 2.2/2.4/0.7%。 当与 CondConv 结合使用时,CoE 仅用 102M 和 214M FLOP 就实现了 79.2% 和 81.5% 的准确率,这表明 CoE 是对 CondConv 等动态网络的补充。 相反,由于CondConv和BasisNet有着相似的本质,即使用一组基来动态合成依赖于输入的卷积核,因此它们的组合仅产生很少的协同效益,准确率仅为80.5%。 此外,CoE进一步使用PWLU,首次在100M FLOPs下实现了80.0%的准确率。
| Method | FLOPs | TOP-1 Acc |
| WeightNet (2020) | 141M | 72.4% |
| DS-MBNet-M†‡(2021a) | 319M | 72.8% |
| GhostNet 1.0x (2020a) | 141M | 73.9% |
| MobileNetV3-Large (2019) | 219M | 75.2% |
| OFA-230 (2019) | 230M | 76.9% |
| TinyNet-A (2020b) | 339M | 77.7% |
| CondConv-EfficientNet-B0 (2019) | 413M | 78.3% |
| GFNet (2020) | 400M | 78.5% |
| CoE-Small | 100M | 78.2% |
| CoE-Small + CondConv | 102M | 79.2% |
| CoE-Small + CondConv + PWLU | 100M | 80.0% |
| BasisNet (2021) | 198M | 80.0% |
| OFA-595 (2019) | 595M | 80.0% |
| EfficientNet-B2 (2019) | 1.0B | 80.1% |
| EfficientNet-B1(Noisy Student) (2020) | 700M | 80.2% |
| BasisNet (2021) | 290M | 80.3% |
| FBNetV3-C (2020) | 557M | 80.5% |
| BasisNet + CondConv (2019) | 308M | 80.5% |
| CoE-Large | 194M | 80.7% |
| CoE-Large + CondConv | 214M | 81.5% |
4.2.2 推理速度和内存成本
CoE的核心优势是推理效率。 为了验证这一优势,我们分析了硬件上的推理延迟。 实验在CPU平台(Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz)上进行,PyTorch版本为1.8.0。 我们在表 2 中报告了 ImageNet 验证集的平均延迟。 我们注意到失败次数和实际速度之间的差异。 例如,OFA-230 与 GhostNet 1.0 倍相比,FLOPs 提高了 1.6 倍,但速度却快了 1.2 倍。 而且,这种差异可以通过CondConv放大。 CondConv-EfficientNet-B0 与原始 EfficientNet-B0 具有相似的 FLOP,但速度慢了 1.7 倍。 BasisNet一次性合成动态参数,而不是像CondConv那样“逐层”方式,因此效率更高。 然而,这种合成仍然需要加载大量的参数,这带来了很大的MAC。 这就是为什么 CoE(16 位专家)即使在小批量大小为 1 的情况下也可以比 BasisNet 减少 14.09% 的延迟。 最后但重要的是,BasisNet 和 CondConv 不支持批处理,而 CoE(16 位专家)可以利用它,与它们相比进一步实现 3.1/6.1 倍的加速。 我们从参数数量和MAC两个角度来分析内存成本。 从表2可以看出,在使用相似参数时,CoE-Large(4位专家)的准确率并不比BasisNet和CondConv-EfficientNet-B0差。 而且CoE的平均MAC/Instance比他们小很多。
| Models | CPU Latency/Instance (ms) | FLOPs | MAC | Params | Accuracy | |
| Batchsize=1 | Batchsize=64 | |||||
| MobileNetV3-Small | 14.77 | 4.18 | 56M | 2.5M | 2.5M | 67.4% |
| GhostNet 1.0x | 39.91 | 16.50 | 141M | 5.2M | 5.2M | 73.9% |
| TinyNet-B | 34.58 | 19.44 | 202M | 3.7M | 3.7M | 75.0% |
| MobileNetV3-Large | 31.55 | 18.43 | 219M | 5.4M | 5.4M | 75.2% |
| GhostNet 1.3x | 43.94 | 29.70 | 226M | 7.3M | 7.3M | 75.7% |
| OFA-230 | 33.52 | 15.21 | 230M | 5.8M | 5.8M | 76.9% |
| EfficientNet-B0 | 49.12 | 35.21 | 391M | 5.3M | 5.3M | 77.2% |
| TinyNet-A | 45.76 | 23.71 | 339M | 5.1M | 5.1M | 77.7% |
| CondConv-EfficientNet-B0 | 81.81 | - | 413M | 24.0M | 24.0M | 78.3% |
| BasisNet | 40.61 | - | 198M | 24.9M | 24.9M | 80.0% |
| CoE-Large (4 experts) | 38.67 | 15.02 | 220M | 6.6M | 25.7M | 79.9% |
| CoE-Large (16 experts) | 34.89 | 13.30 | 194M | 6.0M | 95.3M | 80.7% |
4.2.3 训练成本分析
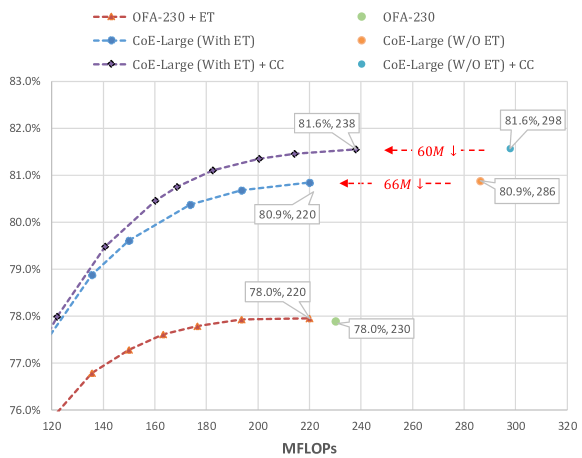
为了以更少的推理 FLOP 和延迟实现卓越的性能,CoE 可能会消耗更多的训练时间。 例如,在 OFA-230 上应用 CoE(4 名专家)将准确率从 78.0% 提高到 79.9%,但代价是 2.2 倍的训练成本。 为了验证在类似的训练成本下是否仍然存在改进,我们通过改变 epoch 的数量来获得一系列准确率,如图7所示,其中 32 个 GPU(Tesla-V100-PCIe-16GB) )被使用。 可以看出,即使成本相似,CoE 也将训练性能从 78.3% 提高到 79.9%。

4.3与现有方法的比较
4.3.1 与模型集成的比较
我们训练了四个具有不同初始化种子的 OFA-230 模型,如表 3 所示。 随机初始化通常会导致 ImageNet 分类的准确性发生微小变化,但会导致模型陷入不同的局部最小值,从而产生输出的多样性。 这种多样性使集成模型的准确率提高了 1.6%。 我们在这里采用朴素的集成,即对每个模型的输出进行平均。 如Wen等人(2020)所示; Chen 等人 (2019),虽然简单、朴素的集成在准确性方面具有竞争力的表现。 然而,CoE 的准确率仍比它高 1.1%。 最近提出的集成方法(Havasi等人,2021)主要着眼于降低计算成本,其精度比朴素集成略有下降,但计算成本始终大于基础模型的计算成本。 相比之下,CoE 将 FLOP 降低至基础模型的 0.84,这表明 CoE 在 FLOP 方面也具有优势。
| Method | FLOPs | Acc. | |
| OFA-230 | Seed1 | 230M | 78.1% |
| Seed2 | 230M | 78.0% | |
| Seed3 | 230M | 78.1% | |
| Seed4 | 230M | 78.0% | |
| Ensemble | 920M | 79.6% | |
| CoE-Large | 4 Experts | 194M | 79.8% |
| 16 Experts | 194M | 80.7% | |
4.3.2 与基于类别的方法比较
HD-CNN 和 HydraNets 根据类别选择分支。 尽管他们的方法最初设计用于选择特定块,但我们将它们应用到模型级别。 要根据类别选择专家,应将类别分为 n 组,其中 n 是专家的数量。 我们尝试两种方案:随机分区和基于聚类的分区。 然后,根据委托人的粗略预测来选择专家。 在训练过程中,我们还根据分配矩阵 和方程 5&6 重新加权每个专家的损失。 这里,是根据粗略预测直接得到的。 4 位专家 的结果如表 4 所示,表明 CoE 学习到了更好的协作模式。
| Method | FLOPs | Top-1 Acc. | |
| Category-Based | RP | 220M | 78.3% |
| CBP | 220M | 77.5% | |
| CoE-Large | - | 220M | 79.9% |
4.3.3 与基于门值的训练方法比较
MoE和Switch Transformer采用基于门值的路由功能训练方法。 它们通过使用其预测的门值来缩放每个专家的输出来启用路由器的训练。 这种优化方式是启发式的,同时 CoE 更合理地训练委托人。 由于 CoE 的专家选择是跨模型完成的,因此我们可以无偏见地衡量每个专家的适合性。 此后,可以获得选择标签来监督委托人。 尽管基于门值的方法最初是为了选择特定层而设计的,但我们将其应用于模型级别。 我们比较软门值和硬门值。 对于硬门值,它是通过用gumbel softmax替换专家选择器中的softmax(图3)而生成的one-hot向量(Jang等人,2017) 。 4位专家的结果如表5所示,其中CoE取得了更好的性能,表明我们的训练方法的有效性。
| Method | FLOPs | Top-1 Acc. | |
| Gate-Value-Based | Soft Gate-Value | 220M | 78.7% |
| Hard Gate-Value | 220M | 78.9% | |
| CoE-Large | - | 220M | 79.9% |
4.4 CoE 消融研究
我们进行了精心设计的消融,包括对我们提出的训练方法的每个元素的消融、训练技巧的消融、专家数量的消融和提前终止。 我们在这里主要介绍我们提出的训练方法的消融,其他内容在附录B.2中讨论。
CoE 由 2 个主要部分组成:LGM 和 WGM。 除了直接删除一个组件之外,我们还尝试改变其中的一些元素。 我们提出了几个用于消融的 CoE 修改版本,如下所示:
表 6 显示了具有 CoE-Large 设置和 4 位专家的 CoE 版本的结果,它演示了训练方法每个元素的重要性。
| Method | Experts | FLOPs | Acc. |
| CoE-Large | 4 | 220M | 79.9% |
| CoE-LargeLGM | 4 | 220M | 78.0% |
| CoE-Large | 4 | 220M | 79.4% |
| CoE-LargeWGM | 4 | 220M | 78.1% |
| CoE-Large | 4 | 220M | 77.0% |
| CoE-Large | 4 | 220M | 79.2% |
| CoE-Large | 4 | 220M | 79.4% |
| CoE-LargeSR | 4 | 220M | 79.5% |
4.5泛化分析
为了验证泛化性,我们进行了两个额外的实验:将 CoE 泛化到翻译任务并使用重新评估标签 (ReaL)(Beyer 等人, 2020) 来重新评估评估 CoE。 这里我们主要介绍第一个,另一个在附录B.3中讨论。
为了将 CoE 推广到翻译任务,我们基于 Transformer(基础模型)(Vaswani 等人,2017)构建了 CoE-Transformer 模型。 CoE-Transformer有四个解码器,给定一个句子,将选择一个解码器来解码编码器提取的特征。 为了选择解码器,在每个句子的开头添加一个额外的常量词符,编码器提取的特征被输入到专家选择器(图3)专家评选。 训练时,句子的TCP是通过对每个词符的TCP进行平均得到的。 CoE-Transformer的架构如图8所示。

继(Vaswani 等人,2017;Ott 等人,2019)之后,CoE-Transformer 在标准 WMT 2014 英语-德语数据集上进行训练。 如前所述,该词汇表中将添加一个额外的词符。 我们采用与(Ott等人,2019)相同的训练和评估设置,更多详细信息参见附录B.4。 从表7我们可以看到,CoE-Transformer 的性能大大优于 Transformer(基本模型),并且在 MAC 和参数少得多的情况下实现了与 Transformer(大)类似的性能。
| Model | MAC | Parameters | BLEU |
| Transformer (base) | 62.4M | 62.4M | 28.1 (2019) |
| Transformer (big) | 213.0M | 213.0M | 29.3 (2019) |
| CoE-Transformer | 62.5M | 138.2M | 29.4 |
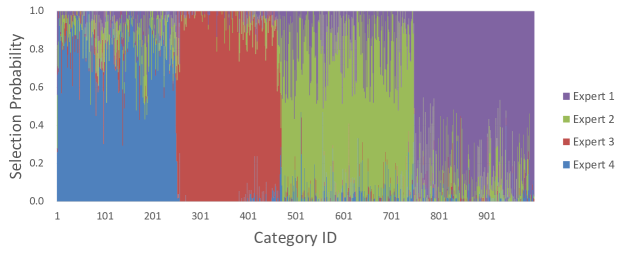
4.6 学习到的专家选择模式分析
我们还通过实验分析了CoE的专家选拔模式,发现其相当合理。 当专家具有不同的架构时,委托人倾向于将简单的样本分配给较小的专家,将复杂的样本分配给较重的专家。 当专家共享相同的架构时,委托人会自动学习专家选择模式,它可以基于任何属性(例如是否包含人类),而不是局限于类别。 我们在这里介绍专家有各种架构时的实验,更多细节在附录B.5中说明。
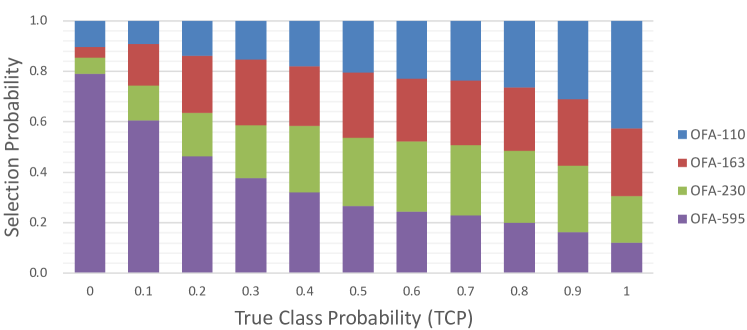
考虑到 TCP (Corbière 等人, 2019) 在推理模型固定的情况下衡量给定样本的复杂性,即样本越复杂,TCP 越小。 我们可以分析样本复杂度和专家选择之间的关系。 我们将通过 OFA (Cai 等人, 2020) 搜索到的四种架构作为专家,即 OFA-110、OFA-163、OFA-230 和 OFA-595。 OFA-xx 表示 FLOP 数为 xx。 委托者也是 MobileNetV3-small,如 4.1 节中所述。 我们根据委托人获取每个样本的 TCP 值。 我们计算验证集上不同 TCP 值下每个专家的选择概率。 如图9所示,随着输入样本变得更加复杂(随着TCP的减少),较重模型的选择概率增加。 它表明 CoE 可以自动学习合理的专家选择模式。
5结论
我们提出了一个 CoE 框架,将多个网络的专业知识汇集在一起,以实现共同的目标。 本文的实验证明了 CoE 在准确性和实际速度上的优越性。 我们还分析了协作模式并发现它们具有可解释性。 未来CoE将扩展到万亿参数级别。 同时,我们将尝试将CoE应用到更多任务中,并验证其与量化等技术的兼容性。 此外,CoE有潜力通过更新专家来解决终身学习的问题。
参考
- Arpit et al. (2017) Arpit, D., Jastrzębski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M. S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y., and Lacoste-Julien, S. A closer look at memorization in deep networks. In Precup, D. and Teh, Y. W. (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp. 233–242. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/arpit17a.html.
- Beyer et al. (2020) Beyer, L., Hénaff, O. J., Kolesnikov, A., Zhai, X., and van den Oord, A. Are we done with imagenet? CoRR, abs/2006.07159, 2020.
- Cai et al. (2020) Cai, H., Gan, C., Wang, T., Zhang, Z., and Han, S. Once-for-all: Train one network and specialize it for efficient deployment. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=HylxE1HKwS.
- Chen et al. (2019) Chen, Q., Zhang, W., Yu, J., and Fan, J. Embedding complementary deep networks for image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Chen et al. (2020) Chen, Y., Dai, X., Liu, M., Chen, D., Yuan, L., and Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11030–11039, 2020.
- Cheng et al. (2020) Cheng, A.-C., Lin, C. H., Juan, D.-C., Wei, W., and Sun, M. Instanas: Instance-aware neural architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp. 3577–3584, 2020.
- Corbière et al. (2019) Corbière, C., THOME, N., Bar-Hen, A., Cord, M., and Pérez, P. Addressing failure prediction by learning model confidence. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/757f843a169cc678064d9530d12a1881-Paper.pdf.
- Cubuk et al. (2019) Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 113–123, 2019.
- Dai et al. (2020) Dai, X., Wan, A., Zhang, P., Wu, B., He, Z., Wei, Z., Chen, K., Tian, Y., Yu, M., Vajda, P., et al. Fbnetv3: Joint architecture-recipe search using neural acquisition function. arXiv preprint arXiv:2006.02049, 2020.
- Fedus et al. (2021) Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961, 2021.
- Frankle & Carbin (2019) Frankle, J. and Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=rJl-b3RcF7.
- Gontijo-Lopes et al. (2021) Gontijo-Lopes, R., Smullin, S., Cubuk, E. D., and Dyer, E. Tradeoffs in data augmentation: An empirical study. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=ZcKPWuhG6wy.
- Han et al. (2020a) Han, K., Wang, Y., Tian, Q., Guo, J., Xu, C., and Xu, C. Ghostnet: More features from cheap operations. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1577–1586, 2020a. doi: 10.1109/CVPR42600.2020.00165.
- Han et al. (2020b) Han, K., Wang, Y., Zhang, Q., Zhang, W., Xu, C., and Zhang, T. Model rubik’s cube: Twisting resolution, depth and width for tinynets. In NeurIPS, 2020b.
- Hansen & Salamon (1990) Hansen, L. K. and Salamon, P. Neural network ensembles. IEEE transactions on pattern analysis and machine intelligence, 12(10):993–1001, 1990.
- Havasi et al. (2021) Havasi, M., Jenatton, R., Fort, S., Liu, J. Z., Snoek, J., Lakshminarayanan, B., Dai, A. M., and Tran, D. Training independent subnetworks for robust prediction. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=OGg9XnKxFAH.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- Howard et al. (2019) Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1314–1324, 2019.
- Huang et al. (2016) Huang, G., Sun, Y., Liu, Z., Sedra, D., and Weinberger, K. Q. Deep networks with stochastic depth. In European conference on computer vision, pp. 646–661. Springer, 2016.
- Jang et al. (2017) Jang, E., Gu, S., and Poole, B. Categorical reparameterization with gumbel-softmax. In ICLR, 2017.
- Li et al. (2021a) Li, C., Wang, G., Wang, B., Liang, X., Li, Z., and Chang, X. Dynamic slimmable network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8607–8617, June 2021a.
- Li et al. (2021b) Li, Y., Jia, X., Sang, R., Zhu, Y., Green, B., Wang, L., and Gong, B. Ranking neural checkpoints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2663–2673, June 2021b.
- Ma et al. (2018) Ma, N., Zhang, X., Zheng, H.-T., and Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), pp. 116–131, 2018.
- Ma et al. (2020) Ma, N., Zhang, X., Huang, J., and Sun, J. Weightnet: Revisiting the design space of weight networks. CoRR, abs/2007.11823, 2020.
- Mullapudi et al. (2018) Mullapudi, R. T., Mark, W. R., Shazeer, N., and Fatahalian, K. Hydranets: Specialized dynamic architectures for efficient inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8080–8089, 2018.
- Ott et al. (2019) Ott, M., Edunov, S., Baevski, A., Fan, A., Gross, S., Ng, N., Grangier, D., and Auli, M. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of NAACL-HLT 2019: Demonstrations, 2019.
- Shazeer et al. (2017) Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- Shore (1970) Shore, H. H. The transportation problem and the vogel approximation method. Decision Sciences, 1(3-4):441–457, 1970.
- Tan & Le (2019) Tan, M. and Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, pp. 6105–6114. PMLR, 2019.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In NIPS, pp. 6000–6010, 2017. URL http://papers.nips.cc/paper/7181-attention-is-all-you-need.
- Wang et al. (2020) Wang, Y., Lv, K., Huang, R., Song, S., Yang, L., and Huang, G. Glance and focus: a dynamic approach to reducing spatial redundancy in image classification. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 2432–2444. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/1963bd5135521d623f6c29e6b1174975-Paper.pdf.
- Wen et al. (2020) Wen, Y., Tran, D., and Ba, J. Batchensemble: an alternative approach to efficient ensemble and lifelong learning. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=Sklf1yrYDr.
- Wenzel et al. (2020) Wenzel, F., Snoek, J., Tran, D., and Jenatton, R. Hyperparameter ensembles for robustness and uncertainty quantification. arXiv preprint arXiv:2006.13570, 2020.
- Xie et al. (2020) Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698, 2020.
- Xie et al. (2017) Xie, S., Girshick, R., Dollar, P., Tu, Z., and He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Yan et al. (2015) Yan, Z., Zhang, H., Piramuthu, R., Jagadeesh, V., DeCoste, D., Di, W., and Yu, Y. Hd-cnn: hierarchical deep convolutional neural networks for large scale visual recognition. In Proceedings of the IEEE international conference on computer vision, pp. 2740–2748, 2015.
- Yang et al. (2019) Yang, B., Bender, G., Le, Q. V., and Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- You et al. (2021) You, K., Liu, Y., Wang, J., and Long, M. Logme: Practical assessment of pre-trained models for transfer learning. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 12133–12143. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/you21b.html.
- Yuan et al. (2020) Yuan, K., Li, Q., Chen, D., Zhou, A., and Yan, J. Dynamic graph: Learning instance-aware connectivity for neural networks. arXiv preprint arXiv:2010.01097, 2020.
- Zhai et al. (2019) Zhai, X., Oliver, A., Kolesnikov, A., and Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- Zhang et al. (2021) Zhang, M., Chu, C.-T., Zhmoginov, A., Howard, A., Jou, B., Zhu, Y., Zhang, L., Hwa, R., and Kovashka, A. Basisnet: Two-stage model synthesis for efficient inference. arXiv preprint arXiv:2105.03014, 2021.
- Zhang et al. (2020) Zhang, Y., Zhang, J., Wang, Q., and Zhong, Z. Dynet: Dynamic convolution for accelerating convolutional neural networks. arXiv preprint arXiv:2004.10694, 2020.
- Zhong et al. (2018) Zhong, Z., Yan, J., Wu, W., Shao, J., and Liu, C.-L. Practical block-wise neural network architecture generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- Zhou et al. (2021) Zhou, Y., Zhu, Z., and Zhong, Z. Learning specialized activation functions with the piecewise linear unit. CoRR, abs/2104.03693, 2021.
附录 A方法的额外详细信息
A.1沃格尔近似法(VAM)介绍
在权重生成模块(WGM)和标签生成模块(LGM)中,我们需要通过 Vogel 近似方法(VAM,(Shore,1970))来解决平衡运输问题(BTP,(Shore,1970))。 本节我们将对其进行介绍,样本数和专家数分别为和。
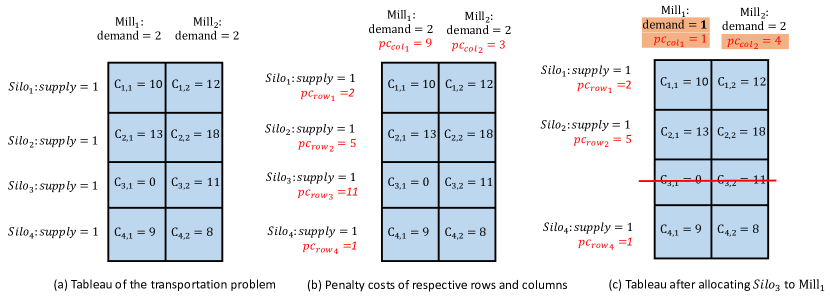
WGM和LGM涉及的BTP有个供应源,每个供应源记为,供应量为1,还有个需求源,每个都表示为,需求为。 是从到的单位运输成本。 具体来说,WGM 中为 ,LGM 中为 。 为了清楚起见,我们用一个玩具示例来说明该算法,其中问题被简化为图10(a)与,。 第一步,我们计算图10(a)中表格每行的惩罚成本和每列的惩罚成本。 惩罚成本是通过从下一个最低单位成本中减去行(列)中最低单位成本来确定的。 为了清楚起见,图10(b)中各行和列的惩罚成本已用红色标记。 由于第三行具有最大的惩罚成本 ( =11),并且 是该行的最低单位成本,因此 分配给 ,即 WGM 中的 或 LGM 中的 。 那么相应的行应该被划掉,的需求应该减一,如果这导致零需求,第一列也将被划掉。 调整每行每列的惩罚成本后,如图10(c)所示,其中更改的值用橙色标记。 所描述的过程将循环,直到没有剩余行为止。
考虑到在 WGM 和 LGM 中,由于 的原因, 的计算比 要耗时得多,我们对 VAM 进行了修改,只寻求 中最低的惩罚成本。 我们发现这种修改使得VAM更加高效,同时保持了解决方案的优越性。 这是因为VAM的机制使得只有当的需求为1时才考虑才有意义,而这种情况很少发生。 因此,我们在本文中采用这种修改来提高效率。
A.2 任务分解策略
为了实现任务分解,我们向委托者引入了一个新的模块,称为子任务选择器,如图11所示。 子任务选择器用于将输入样本分配到不同的子任务中。 专家选择器输出 16 个概率,它们也分为四组。 对于每个子任务,只有一组概率可见。 每个子任务内的专家和专家选择器的相应权重被联合优化。 至于特征提取器、任务预测器和子任务选择器,它们的权重直接来自在四位专家的设置下训练的委托器,然后固定。 在此过程中,子任务选择器的权重来自专家选择器。
附录 B实验的额外详细信息
B.1 ImageNet分类任务的实验细节
为了与 CondConv 结合,我们用 CondConv () 替换专家的每个反向残差块内的卷积。 为了利用 PWLU,我们替换了除那些具有微小输入特征图的激活层之外的所有激活层,如 Zhou 等人 (2021) 中所示。 模型使用动量为 0.9 的 SGD 优化器进行训练。 我们使用 4096 的小批量大小和 0.00002 的权重衰减。 采用余弦学习率衰减,训练迭代次数为313000次。 我们也使用 Cubuk 等人 (2019) 搜索到的增强策略(固定自动增强)。 与 BasisNet 类似,我们使用以 EfficientNet-B2 (Tan & Le, 2019; Xie 等人, 2020) 作为教师的知识蒸馏。 CoE-Small/Large 的学习率为 0.8/1.6,dropout 率为 0.2。 除了TinyNet-E 的生存概率为0.8 外,均使用随机深度(Huang 等人,2016)。 我们认为只有解决了过拟合问题,任务准确率才能准确反映模型能力。 由于本文关注的是在有限的计算成本下提高模型容量,因此我们使用知识蒸馏、固定自动增强和随机深度来克服过拟合问题。 尽管如此,我们也对它们进行了消融,如附录B.2.1所示
B.2 CoE 消融研究
B.2.1 训练技巧的消融研究
知识蒸馏(KD)、自动增强(AA)和随机深度(SD)是广泛使用的克服过度拟合问题的策略。 我们认为只有解决了过拟合问题,任务准确率才能准确反映模型能力。 因为本文关注的是在有限的计算成本下提高模型容量,所以我们使用这些策略。 尽管如此,我们在本节中对它们进行了消融。 我们采用 CoE-Large 设置,有 4 名专家。 结果如表8所示。 我们发现KD对于CoE非常重要,这可能表明CoE很容易过拟合。 此外,SD 会降低 CoE 的准确性。 通过消除 SD,CoE-Large(4 名专家)将准确性从 79.9% 提高到 80.2%。 或许,是因为SD使得委托人和每个专家的能力太小了(Gontijo-Lopes等人,2021)。
| KD | AA | SD | Experts | FLOPs | TOP-1 Acc |
| 4 | 220M | 79.9% | |||
| 4 | 220M | 80.2% | |||
| 4 | 220M | 79.4% | |||
| 4 | 220M | 76.2% | |||
| 4 | 220M | 79.7% | |||
| 4 | 220M | 76.3% | |||
| 4 | 220M | 75.2% | |||
| 4 | 220M | 75.1% |
B.2.2 专家号的影响
我们分析本节的专家数量,包括1名、4名、16名专家。 结果如表9所示。 与原始模型相比,使用一名专家几乎没有带来什么改进。 当增加专家数量时,四位专家的准确率提高了 1.9%,十六位专家的准确率提高了 2.9%。 它表明 CoE 可以充分利用多名专家,带来巨大的协作效益。 更重要的是,通过CondConv与OFA-230的结合,准确率也达到了79.9%。 这样,CoE 在 4/16 名专家的情况下,可以将准确率进一步提高到 80.8/81.5%。
| Method | Experts | FLOPs | Acc. |
| OFA-230 | - | 230M | 78.0% |
| CoE-Large | 1 | 220M | 78.0% |
| 4 | 220M | 79.9% | |
| 16 | 220M | 80.9% | |
| CC-OFA-230 | - | 242M | 79.9% |
| CoE-Large + CC | 1 | 214M | 79.9% |
| 4 | 214M | 80.8% | |
| 16 | 214M | 81.5% |
B.2.3 提前终止的影响
原始 OFA-230 在 2.3 亿次 FLOP 中具有 78.0% 的 top-1 准确率。 我们可以引入MobileNetV3-Small来进行提前终止。 通过改变阈值,我们得到了一系列精度和 FLOP,如图12所示。 可以看到,220M FLOP 时,准确率变为 78.0%。 这表明MobileNetV3-Small带来的计算成本通过提前终止策略被消除。 受此启发,我们希望通过提前终止的方式来消除委托人带来的计算成本。 它确实减少了 60/66M FLOP 的计算成本,证明了提前终止的有效性。
B.3 使用重新评估的标签进行重新评估
正如论文(Beyer等人,2020)中所述,验证集标签存在一系列缺陷,导致 ImageNet 分类基准的最新进展遭受对工件的过度拟合。 为了验证泛化性,我们使用重新评估标签(ReaL)(Beyer等人,2020)来重新评估我们的方法。 结果如表10所示。 可以看出,我们的方法仍然具有出色的性能,比对比方法具有更高的精度,并且 FLOP 明显更小。
| Method | FLOPs | ReaL Acc. | Ori. Acc. |
| OFA-595 (Cai et al., 2020) | 595M | 86.0% | 80.0% |
| S4L MOAM (Zhai et al., 2019) | 4B | 86.6% | 80.3% |
| ResNeXt-101 (Xie et al., 2017) | 16B | 85.2% | 79.2% |
| ResNet-152 (He et al., 2016) | 11B | 84.8% | 78.2% |
| CoE-Large | 194M | 86.5% | 80.7% |
| CoE-Large + CC | 214M | 86.9% | 81.5% |
B.4 翻译任务的实验详细信息
继(Vaswani等人,2017;Ott等人,2019)之后,CoE-Transformer在标准WMT 2014英语-德语数据集上进行训练,该数据集具有约37000个标记的共享源-目标词汇。 如前所述,该词汇表中将添加一个额外的词符。 默认的训练设置与(Vaswani 等人, 2017)中描述的相同,除了批量大小和学习率在(Ott 等人, 2019)之后变大>。 而且,式5中的参数随着训练的进行从0.1线性增长到0.4。 我们在 news2014 上报告了 BLEU,波束宽度为 4,长度惩罚为 0.6,基于对之后的最后 5 个检查点进行平均而获得的单个模型(Vaswani 等人,2017;Ott 等人,2019)。
B.5 学习到的专家选择模式分析
B.5.1 专家共享相同架构时的专家选择模式
我们已经分析了专家具有不同架构时的选择模式,这里我们重点关注所有专家共享相同架构的情况。 我们采用由四位专家组成的 CoE-Large 设置。
考虑到许多作品(Yan 等人, 2015; Mullapudi 等人, 2018) 基于类别选择分支,我们首先在 ImageNet 验证集上实验观察选择模式与委托者粗略预测之间的关系。 根据粗略预测的预测类别,验证集可以分为 1000 个子集。 然后我们计算选择每个子集中每个专家的概率并得到 1000 个概率向量。 聚类后,我们将概率向量绘制在图13上,其中每一列代表一个概率向量。 可以看出,具有相同粗预测类别的样本被分配给不同的专家。 因此,我们可以得出结论,专家并不总是根据类别来选择的。
此外,我们进一步对 ImageNet 验证集进行定性分析,发现了一些有趣的模式。 例如,我们发现,如果包含人类,则预测为“肉类市场”的图像最有可能被分配给第四位专家。 我们在图14中展示了这些图像。 可以看到,第四位专家分配了27张图像,其中22张图像包含人类,比例为81.5%。 相比之下,在分配给其他专家的 32 张图像中,只有 7 张图像包含人类,比例为 21.9%。 这表明 CoE 自动学习专家选择模式,它可以基于类别以外的属性。