HDMapNet:在线高精地图构建和评估框架
摘要
构建高清语义地图是自动驾驶的核心组成部分。 然而,传统的管道需要大量的人力和资源来注释和维护地图中的语义,这限制了其可扩展性。 在本文中,我们介绍了高清语义地图学习的问题,它根据机载传感器观测动态构建局部语义。 同时,我们引入了一种语义地图学习方法,称为 HDMapNet。 HDMapNet 对来自周围摄像机和/或来自 LiDAR 的点云的图像特征进行编码,并预测鸟瞰图中的矢量化地图元素。 我们在 nuScenes 数据集上对 HDMapNet 进行基准测试,并表明在所有设置中,它的性能都优于基线方法。 值得注意的是,我们基于相机-LiDAR 融合的 HDMapNet 在所有指标上都优于现有方法 50% 以上。 此外,我们还开发了语义级和实例级指标来评估地图学习性能。 最后,我们展示我们的方法能够预测局部一致的地图。 通过介绍方法和指标,我们邀请社区研究这个新颖的地图学习问题。
I简介
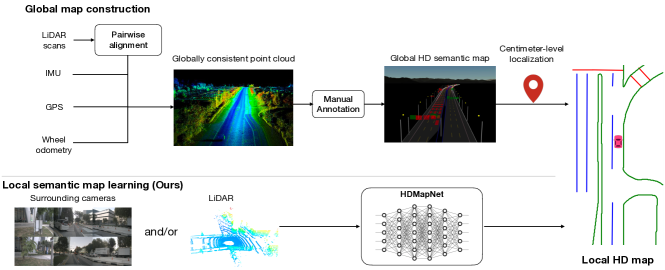
高清(HD)语义地图是自动驾驶的重要模块。 构建此类高清语义地图的传统流程包括预先捕获点云、使用 SLAM 构建全局一致的地图以及在地图中注释语义。 这种模式虽然可以生成精确的高清地图并被许多自动驾驶公司采用,但仍需要大量的人力。
作为替代方案,我们研究了可扩展且经济实惠的自动驾驶解决方案e.g。最大限度地减少人类在注释和维护高精地图方面的工作量。 为此,我们引入了一种新颖的语义地图学习框架,该框架利用机载传感器和计算来估计矢量化局部语义地图。 值得注意的是,我们的框架并不旨在取代全局高清地图重建,而是为实时运动预测和规划提供一种预测局部语义地图的简单方法。
我们提出了一种名为 HDMapNet 的语义地图学习方法,该方法从周围摄像机的图像和/或激光雷达等点云生成矢量化地图元素。 我们研究当深度缺失时如何有效地将透视图像特征转换为鸟瞰图特征。 我们提出了一种新颖的视图 Transformer,它由神经特征变换和几何投影组成。 此外,我们还研究了点云和相机图像在此任务中是否互补。 我们发现不同的地图元素在单一模式中的识别度并不相同。 为了两全其美,我们的最佳模型将点云表示与图像表示相结合。 该模型在所有类别中都明显优于单模态模型。 为了证明我们方法的实用价值,我们使用图6中的模型生成局部一致的地图;该地图可立即应用于实时运动规划。
最后,我们提出了评估地图学习性能的综合方法。 这些指标包括语义级别和实例级别评估,因为地图元素通常表示为高清地图中的对象实例。 在公共 NuScenes 数据集上,HDMapNet 在语义分割方面比现有方法改进了 12.1 IoU,在实例检测方面改进了 13.1 mAP。
总而言之,我们的贡献包括以下内容:
-
•
我们提出了一种新颖的在线框架,用于根据感官观察构建高清语义地图,并结合一种名为 HDMapNet 的方法。
-
•
我们提出了一种新颖的功能投影模块,从透视图到鸟瞰图。 该模块隐式地对 3D 环境进行建模,并显式地考虑相机的外部因素。
-
•
我们开发全面的评估协议和指标以促进未来的研究。
II 相关工作
语义地图构建。 大多数现有的高清语义地图都是在环境的 LiDAR 点云上手动或半自动注释的,这些点云是从具有高端 GPS 和 IMU 的测量车辆收集的 LiDAR 扫描合并而来的。 SLAM 算法是将 LiDAR 扫描融合成高度准确且一致的点云的最常用算法。 首先,采用 ICP [1]、NDT [2] 及其变体 [3] 等成对对齐算法来匹配两个位置的 LiDAR 数据。使用语义 [4] 或几何信息 [5] 的附近时间戳。 其次,估计自我车辆的准确姿态被表述为非线性最小二乘问题[6]或因子图[7],这对于构建全局一致的地图。 杨等。 [8]提出了一种基于成对对齐因子约束下的位姿图优化的城市尺度地图重建方法。 为了降低手动标注语义地图的成本,[9, 10]提出了几种机器学习技术,从融合的激光雷达点云和相机中提取静态元素。 然而,由于高清语义地图需要高精度和及时更新,维护起来仍然费力且成本高。 在本文中,我们认为我们提出的本地语义地图学习任务是一种潜在的更具可扩展性的自动驾驶解决方案。
透视车道检测。 传统的基于透视的车道检测流程涉及局部图像特征提取(e.g。颜色、方向滤波器[11,12,13]) 、直线拟合 (e.g. 霍夫变换 [14])、图像到世界投影、等。随着基于深度学习的图像分割和检测技术的进步[15,16,17,18],研究人员探索了更多数据驱动的方法。 开发了用于道路分割[19, 20]、车道检测[21, 22]、可行驶区域分析[23]、等等。最近,模型被构建为提供 3D 输出而不是 2D。 白等人。 [24]合并了LiDAR信号,以便图像像素可以投影到地面上。 加内特等人。 [25]和郭等人。 [26] 使用合成车道数据集对摄像机高度和俯仰的预测执行监督训练,以便输出车道位于 3D 地平面中。 除了检测车道之外,我们的工作还通过环绕摄像头或激光雷达输出车辆周围一致的局部语义地图。
跨视图学习。 最近,人们在研究交叉视图学习以提高机器人的周围感知能力方面做出了一些努力。 Pan [27]使用MLP来学习透视特征图和鸟瞰图特征图之间的关系。 Roddick 和 Cipolla [28] 在图像特征上沿水平轴应用一维卷积来预测鸟瞰图。 Philion 和 Fidler [29] 预测了单目相机的深度,并使用软注意力将图像特征投影到鸟瞰图中。 我们的工作重点是局部语义地图构建的关键任务,即我们使用跨视图传感方法来生成矢量化形式的地图元素。 此外,我们的模型可以轻松地与 LiDAR 输入融合,以进一步提高其准确性。
III 语义图学习
我们提出了语义地图学习,这是一种生成本地高清语义地图的新颖框架。 它接受相机图像和激光雷达点云等传感器输入,并输出矢量化地图元素,例如车道分隔线、车道边界和人行横道。 我们使用 和 分别表示图像和点云。 或者,该框架可以扩展以包括其他传感器信号,例如雷达。 我们将 定义为要预测的地图元素。
III-A 高精地图网
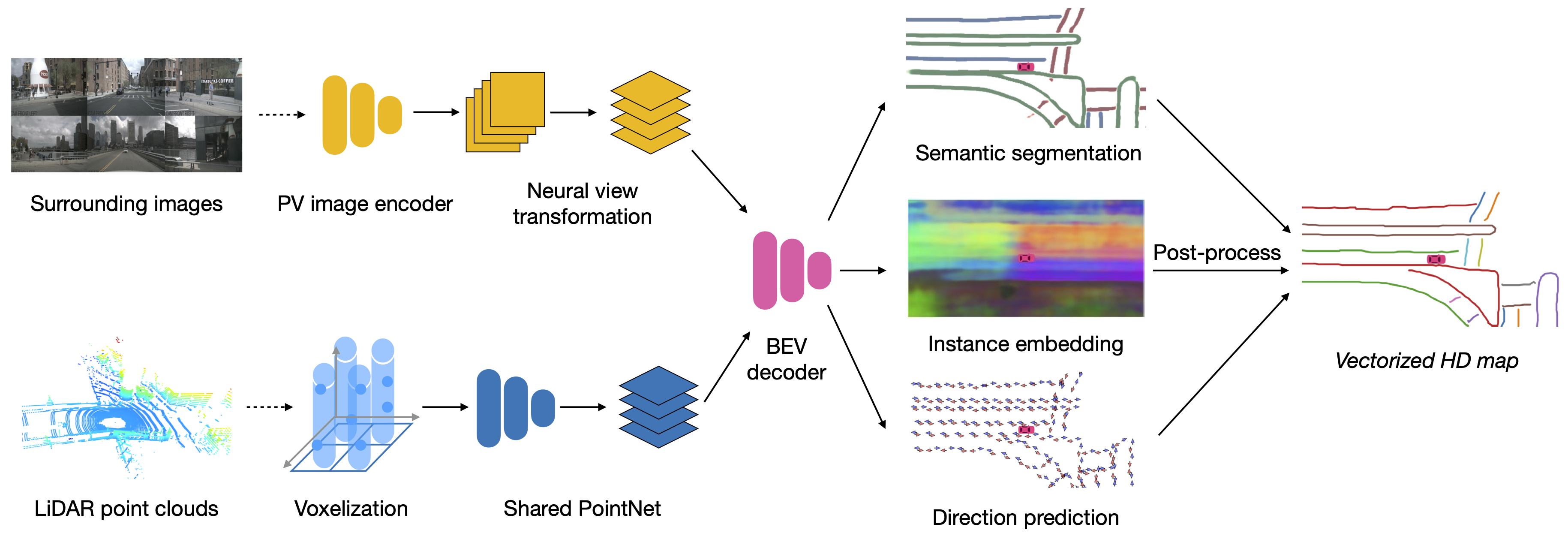
我们的语义地图学习模型名为 HDMapNet,直接使用神经网络从单帧 和 预测地图元素 。 概述如图2所示,四个神经网络参数化我们的模型:图像分支中的透视图像编码器和神经视图变换器 、基于支柱的点云编码器和地图元素解码器。 如果模型仅采用周围图像、仅 LiDAR 或两者作为输入,我们将 HDMapNet 系列表示为 HDMapNet(Surr)、HDMapNet(LiDAR)、HDMapNet(Fusion)。
III-A1 图像编码器
我们的图像编码器有两个组件,即透视图像编码器和神经视图变换器。
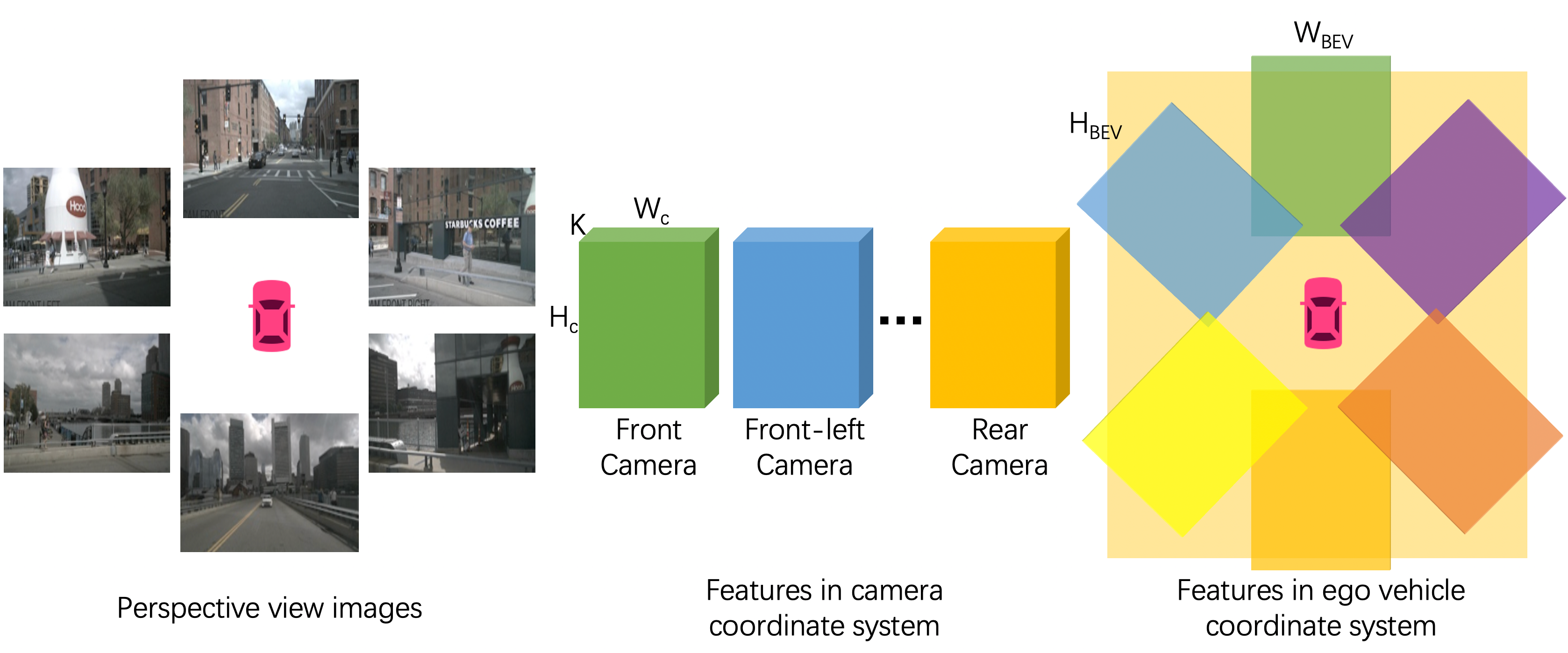
透视图像编码器。 我们的图像分支从 周围摄像机获取透视图输入,覆盖场景的全景。 每个图像由共享神经网络嵌入以获得透视图特征图,其中,和分别是高度、宽度和特征尺寸。
神经视图 Transformer 。 如图3所示,我们首先将图像特征从透视图转换到相机坐标系,然后再转换到鸟瞰图。 透视图和相机坐标系之间任意两个像素的关系由多层感知器建模:
| (1) |
其中 模拟相机坐标系统中位置 处的特征向量与透视图特征图上每个像素之间的关系。 我们将 和 表示为 自上而下的空间维度。 鸟瞰图(自我坐标系)特征 是通过使用相机外部几何投影对特征 进行变换而获得的,其中 和 是鸟瞰视图中的高度和宽度。 最终的图像特征是相机特征的平均值。
III-A2 点云编码器
我们的点云编码器 是 PointPillar [30] 的变体,具有动态体素化 [31],它将 3d 空间划分为多个支柱并学习来自逐柱点云的逐柱特征的特征图。 输入是点云中的激光雷达点。 对于每个点,它都有三维坐标和附加的维特征,表示为。
当将要素从点投影到鸟瞰图时,多个点可能会落入同一个柱子中。 我们将 定义为与支柱 对应的点集。 为了聚合支柱中点的特征,需要使用 PointNet [32] (表示为 ),其中
| (2) |
然后,通过卷积神经网络进一步编码pillar-wise特征。 我们将鸟瞰图中的特征图表示为。
III-A3 鸟瞰图解码器
该地图是一个复杂的图形网络,包括车道分隔线和车道边界的实例级和方向信息。 车道线需要矢量化,而不是像素级表示,以便自动驾驶车辆可以遵循它们。 因此,我们的 BEV 解码器 不仅输出语义分割,还预测实例嵌入和车道方向。 应用后处理过程来对嵌入的实例进行聚类并对它们进行矢量化。
整体架构。 BEV解码器是一个全卷积网络(FCN)[33],有3个分支,即语义分割分支、实例嵌入分支和方向预测分支。 BEV解码器的输入是图像特征图和/或点云特征图,如果两者都存在,我们将它们连接起来。
语义预测。 语义预测模块是一个全卷积网络(FCN)[33]我们使用交叉熵损失进行语义预测。
实例嵌入。 我们的实例嵌入模块旨在对每个鸟瞰图嵌入进行聚类。 为了便于表示,我们遵循[34]中的确切定义:是groundtruth中的簇数,是簇中的元素,是簇c的平均嵌入,是L2范数, = max(0 , x) 表示元素最大值。 和 分别是方差和距离损失的裕度。 聚类损失的计算方式为:
| (3) | |||
| (4) | |||
| (5) |
方向预测。 我们的方向模块旨在从每个像素 预测车道方向。方向被离散化为均匀分布在单位圆上的 类。 通过对当前像素的方向进行分类,可以得到车道的下一个像素为,其中 是预定义的步长。 由于我们不知道车道的方向,因此无法识别每个节点的前进和后向。 相反,我们将它们都视为积极的标签。 具体来说,每个车道节点的方向标签是一个 向量,其中 2 个索引标记为 1,其他索引标记为 0。 请注意,自上而下地图上的大多数像素并不位于车道上,这意味着它们没有方向。 这些像素的方向向量是零向量,我们在训练期间从不对这些像素进行反向传播。 我们使用softmax作为分类的激活函数。


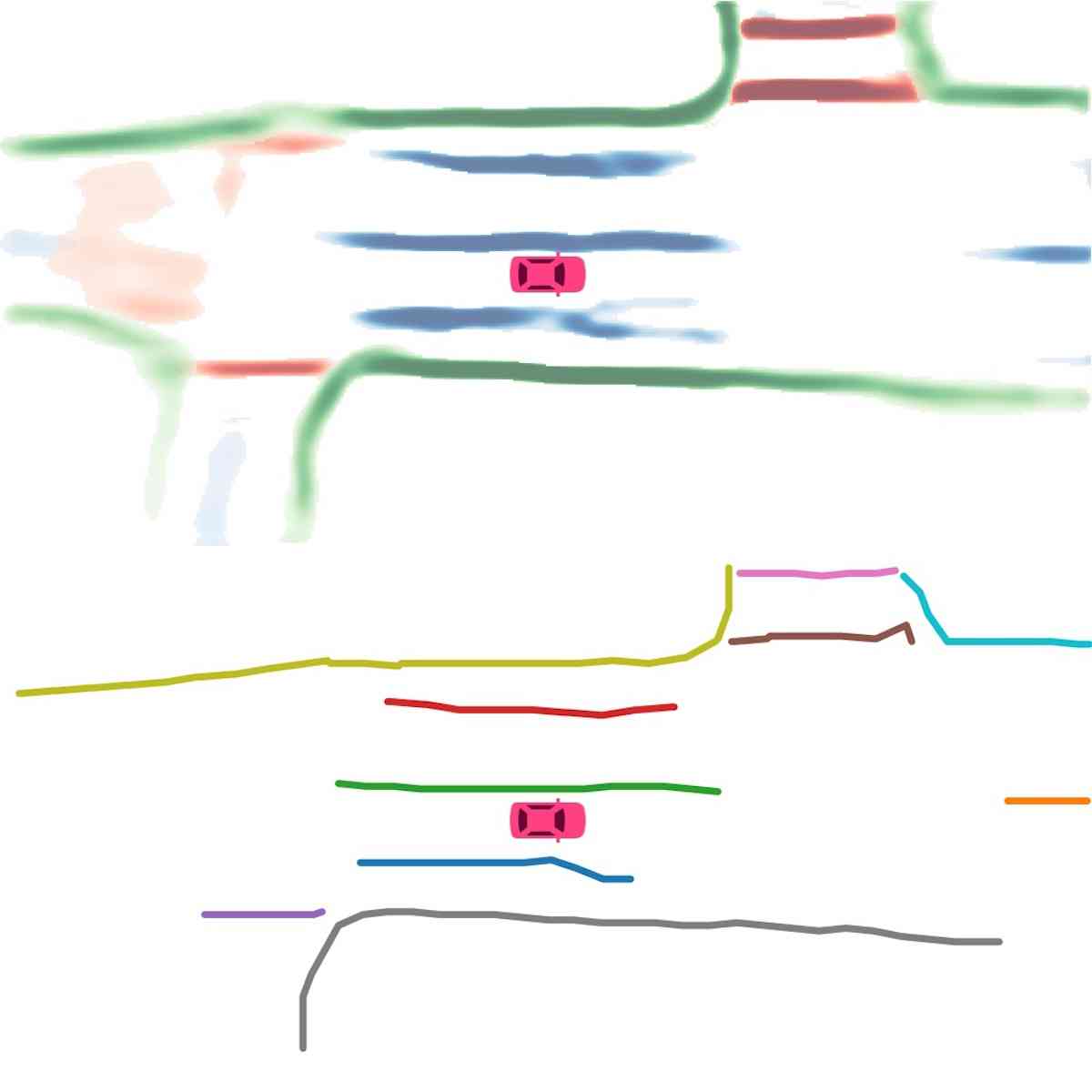
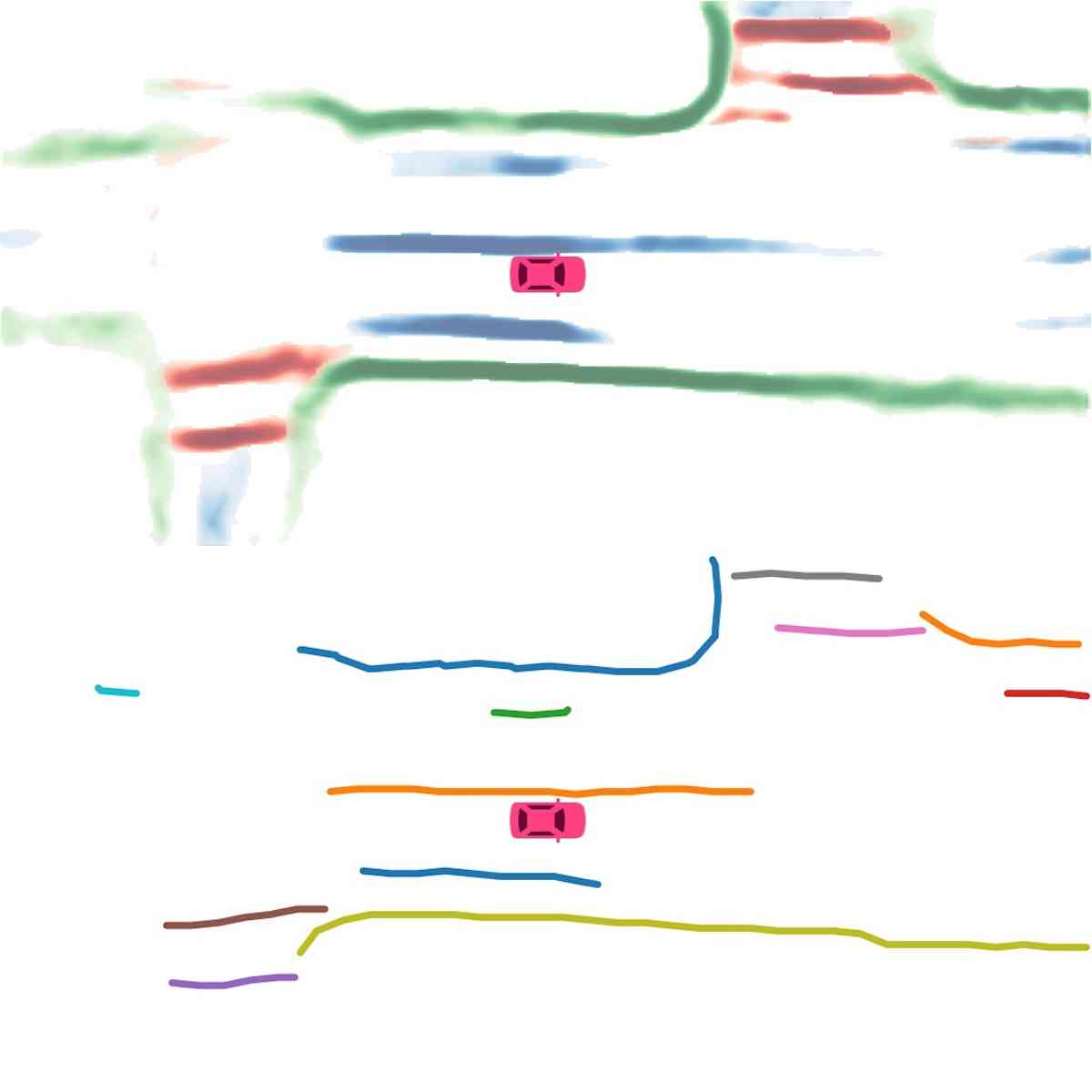
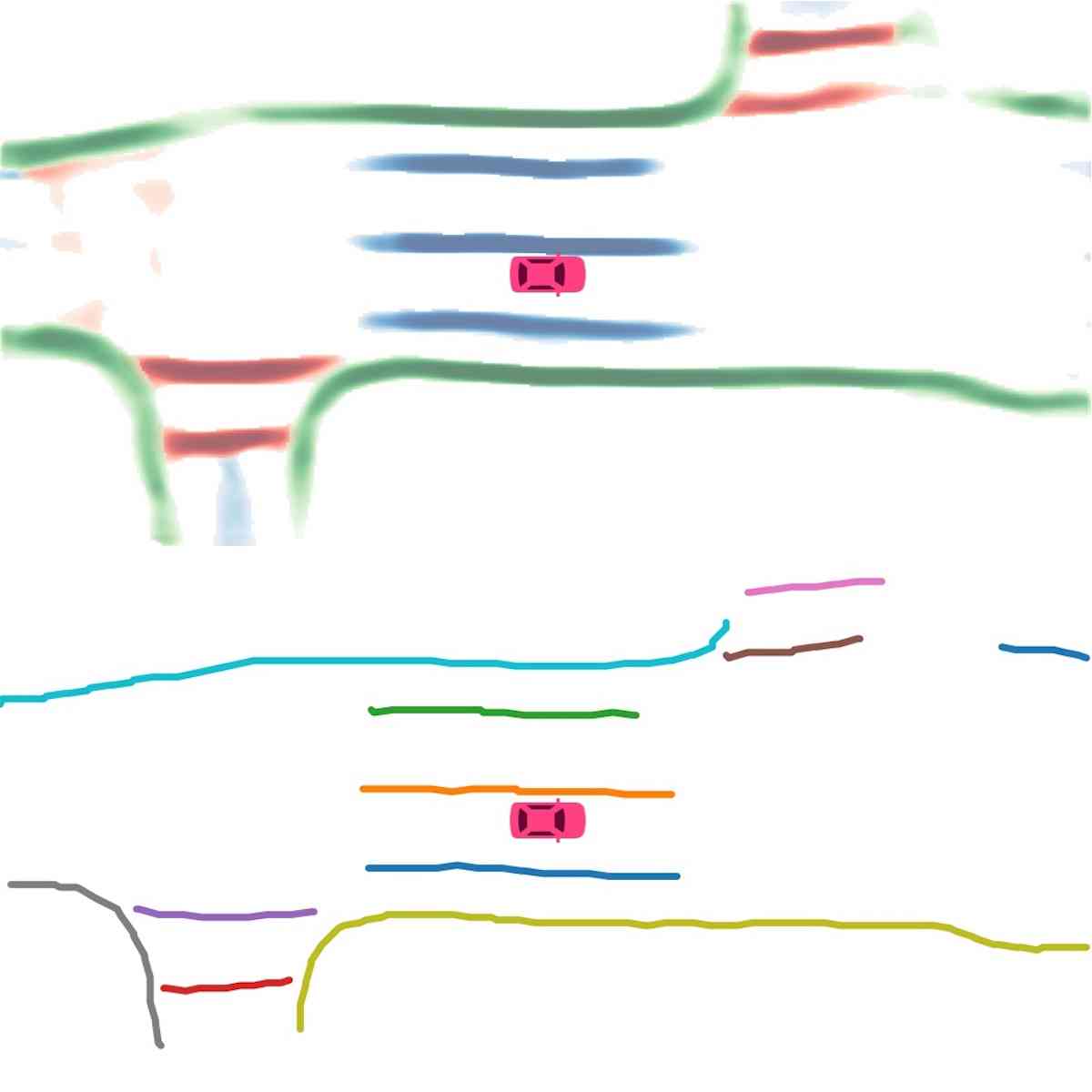
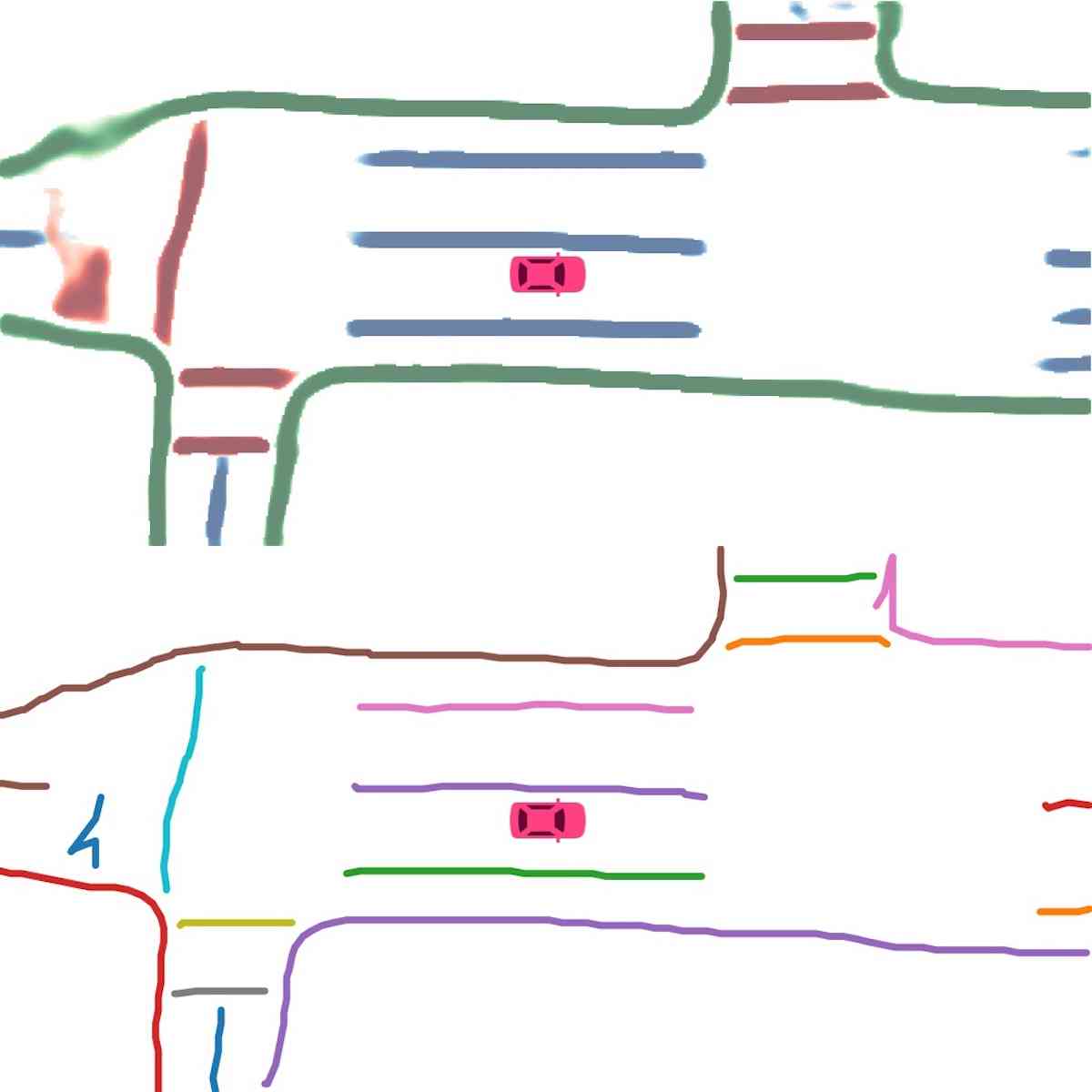

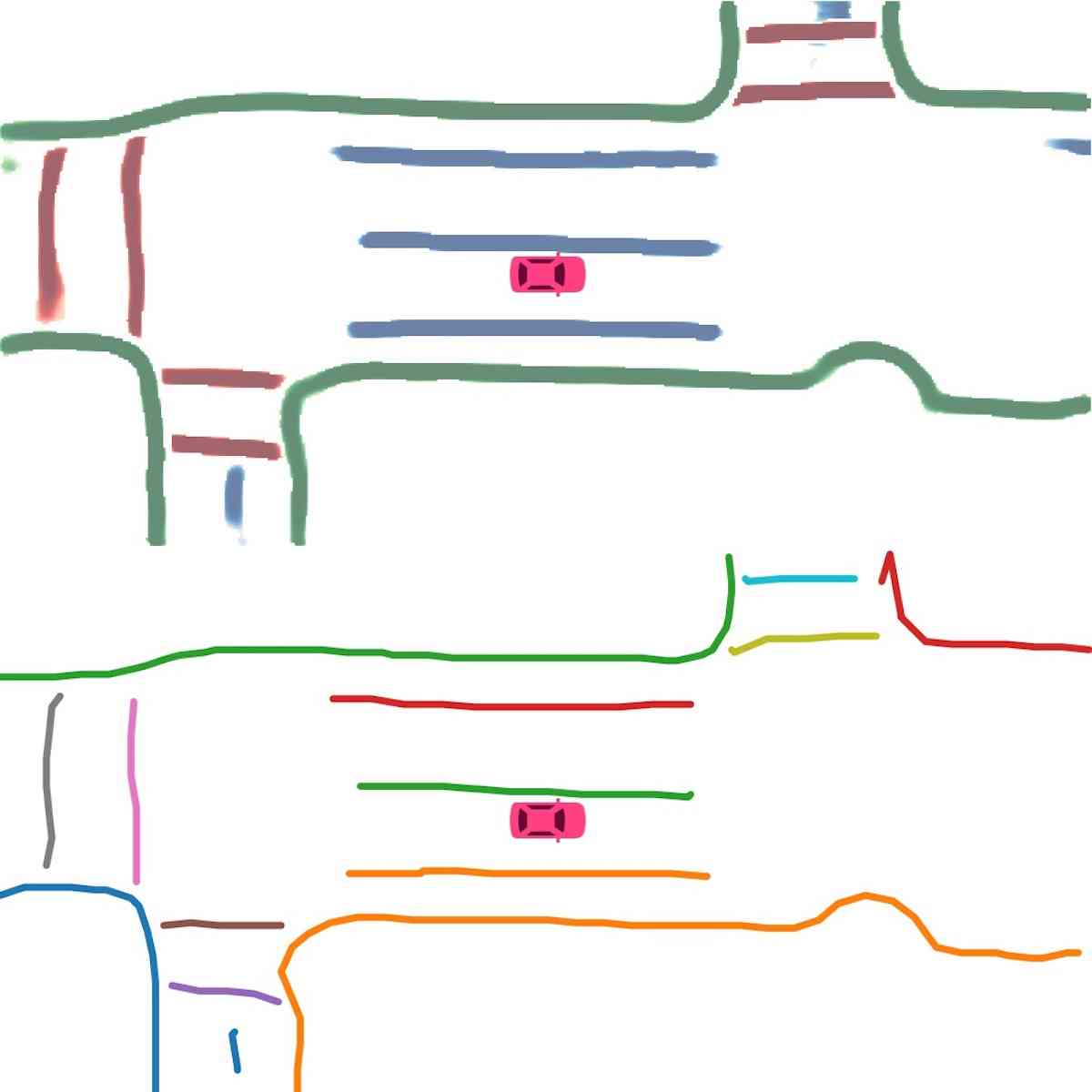
矢量化。 在推理过程中,我们首先使用基于密度的噪声应用空间聚类(DBSCAN)对实例嵌入进行聚类。 然后使用非极大值抑制(NMS)来减少冗余。 最后,在预测方向的帮助下,通过贪婪地连接像素来获得矢量表示。
III-B 评估
在本节中,我们提出了语义图学习的评估协议,包括语义度量和实例度量。
III-B1 语义度量
模型预测的语义可以通过欧拉方式和拉格朗日方式进行评估。 欧拉度量在密集网格上计算并测量像素值差异。 相比之下,拉格朗日度量随形状移动并测量形状的空间距离。
欧拉指标。 我们使用交并并(IoU)作为欧拉度量,其由下式给出:
| (6) |
其中 是形状的密集表示(网格上光栅化的曲线); 和是网格的高度和宽度,是类别数; 表示集合的大小。
拉格朗日指标。 我们对结构化输出感兴趣,即由连接点组成的曲线。 为了评估预测曲线和真实曲线之间的空间距离,我们使用曲线上采样的点集之间的倒角距离(CD):
| (7) | ||||
| (8) |
其中是方向倒角距离,是双向倒角距离; 和 是曲线上的两组点。
III-B2 实例指标
我们进一步评估我们模型的实例检测能力。 我们使用类似于目标检测中的平均精度(AP)[35],由下式给出
| (9) |
其中是recall=时的精度。 我们收集所有预测并根据语义置信度按降序排列它们。 然后,我们根据 CD 阈值对每个预测进行分类。 例如,如果 CD 低于预定义阈值,则视为真阳性,否则视为假阳性。 最后,我们获得所有精确召回对并相应地计算 AP。
IV 实验
IV-A 实施细节
任务和指标。 我们在 NuScenes 数据集 [36] 上评估我们的方法。 我们专注于两个子任务:语义图分割和实例检测。 由于 nuScenes 数据集中地图元素的类型有限,我们考虑三个静态地图元素:车道边界、车道分隔线和人行横道。
架构。 对于透视图像编码器,我们采用在 ImageNet [38] 上预训练的 EfficientNet-B0 [37],如 [29] 。 然后,我们使用多层感知器(MLP)将透视图特征转换为相机坐标系中的鸟瞰图特征。 MLP 按通道共享,并且不会改变特征维度。 对于点云,我们使用 PointPillars [39] 的变体和动态体素化 [31]。 我们使用具有 64 维层的 PointNet [32] 来聚合支柱中的点。 具有三个块的 ResNet [40] 用作 BEV 解码器。
训练细节。 我们使用交叉熵损失进行语义分割,并使用判别性损失(方程5)进行实例嵌入,其中我们设置,和。 我们使用 Adam [41] 进行模型训练,学习率为 。
IV-B 基线方法
| Method | Divider | Ped Crossing | Boundary | All Classes | ||||||||||||
| IoU | CDP | CDL | CD | IoU | CDP | CDL | CD | IoU | CDP | CDL | CD | IoU | CDP | CDL | CD | |
| IPM∗ | 14.4 | 1.149 | 2.232 | 2.193 | 9.5 | 1.232 | 3.432 | 2.482 | 18.4 | 1.502 | 2.569 | 1.849 | 14.1 | 1.294 | 2.744 | 2.175 |
| IPM(B) | 25.5 | 1.091 | 1.730 | 1.226 | 12.1 | 0.918 | 2.947 | 1.628 | 27.1 | 0.710 | 1.670 | 0.918 | 21.6 | 0.906 | 2.116 | 1.257 |
| IPM(CB) | 38.6 | 0.743 | 1.106 | 0.802 | 19.3 | 0.741 | 2.154 | 1.081 | 39.3 | 0.563 | 1.000 | 0.633 | 32.4 | 0.682 | 1.42 | 0.839 |
| Lift-Splat-Shoot [29] | 38.3 | 0.872 | 1.144 | 0.916 | 14.9 | 0.680 | 2.691 | 1.313 | 39.3 | 0.580 | 1.137 | 0.676 | 30.8 | 0.711 | 1.657 | 0.968 |
| VPN [27] | 36.5 | 0.534 | 1.197 | 0.919 | 15.8 | 0.491 | 2.824 | 2.245 | 35.6 | 0.283 | 1.234 | 0.848 | 29.3 | 0.436 | 1.752 | 1.337 |
| HDMapNet(Surr) | 40.6 | 0.761 | 0.979 | 0.779 | 18.7 | 0.855 | 1.997 | 1.101 | 39.5 | 0.608 | 0.825 | 0.624 | 32.9 | 0.741 | 1.267 | 0.834 |
| HDMapNet(LiDAR) | 26.7 | 1.134 | 1.508 | 1.219 | 17.3 | 1.038 | 2.573 | 1.524 | 44.6 | 0.501 | 0.843 | 0.561 | 29.5 | 0.891 | 1.641 | 1.101 |
| HDMapNet(Fusion) | 46.1 | 0.625 | 0.893 | 0.667 | 31.4 | 0.535 | 1.715 | 0.790 | 56.0 | 0.461 | 0.443 | 0.459 | 44.5 | 0.540 | 1.017 | 0.639 |
对于所有基线方法,我们使用与 HDMapNet 相同的图像编码器和解码器,仅更改视图转换模块。
逆透视映射(IPM)。 最直接的基线是通过 IPM [42, 43] 将分割预测映射到鸟瞰图。
带鸟瞰图解码器的 IPM (IPM(B))。 我们的第二个基线是 IPM 的扩展。 我们不是在透视图中进行预测,而是直接在鸟瞰图中进行语义分割。
具有透视特征编码器和鸟瞰图解码器的 IPM (IPM(CB))。 下一个扩展是在透视图中进行特征学习,同时在鸟瞰图中进行预测。
举起-啪-射击。 Lift-Splat-Shoot [29] 估计透视图图像中深度的分布。 然后,它将 2D 图像转换为具有特征的 3D 点云,并将其投影到自我车辆框架中。
查看解析网络(VPN)。 VPN [27]提出了一个简单的视图转换模块:一个对任意两个像素之间的关系进行建模的视图关系模块和一个融合像素特征的视图融合模块。
| Method | Divider | Ped Crossing | Boundary | All Classes | ||||||||||||
| AP@.2 | AP@.5 | AP@1. | mAP | AP@.2 | AP@.5 | AP@1. | mAP | AP@.2 | AP@.5 | AP@1. | mAP | AP@.2 | AP@.5 | AP@1. | mAP | |
| IPM(B) | 2.6 | 9.8 | 19.6 | 10.7 | 1.6 | 4.8 | 7.8 | 4.7 | 2.2 | 9.2 | 23.7 | 11.7 | 2.1 | 7.9 | 17.0 | 9.0 |
| IPM(CB) | 10.2 | 25.0 | 36.8 | 24.0 | 2.0 | 7.8 | 12.2 | 7.3 | 10.1 | 27.9 | 45.5 | 27.8 | 7.4 | 20.2 | 31.5 | 19.7 |
| Lift-Splat-Shoot [29] | 9.1 | 23.8 | 35.9 | 22.9 | 0.9 | 5.4 | 8.9 | 5.1 | 8.5 | 22.9 | 41.2 | 24.2 | 6.2 | 17.4 | 28.7 | 17.4 |
| VPN [27] | 8.8 | 22.7 | 34.9 | 22.1 | 1.2 | 5.3 | 9.0 | 5.2 | 9.2 | 24.1 | 42.7 | 25.3 | 6.4 | 17.4 | 28.9 | 17.5 |
| HDMapNet(Surr) | 13.7 | 30.7 | 40.6 | 28.3 | 1.9 | 7.4 | 12.1 | 7.1 | 13.7 | 33.9 | 50.1 | 32.6 | 9.8 | 24.0 | 34.3 | 22.7 |
| HDMapNet(LiDAR) | 1.0 | 5.7 | 15.1 | 7.3 | 1.9 | 5.8 | 9.0 | 5.6 | 5.8 | 20.2 | 39.6 | 21.9 | 2.9 | 10.6 | 21.2 | 11.6 |
| HDMapNet(Fusion) | 15.0 | 32.6 | 46.0 | 31.2 | 6.4 | 13.6 | 17.8 | 12.6 | 26.7 | 51.5 | 65.6 | 47.9 | 16.0 | 32.6 | 43.1 | 30.6 |

IV-C 结果
我们将 HDMapNet 与第 IV-B 节中的基线进行比较。 表 I 显示了比较结果。 首先,我们的 HDMapNet(Surr)(仅使用周围相机的方法)优于所有基线。 这表明我们新颖的基于学习的视图转换确实有效,无需对复杂地平面(IPM)或估计深度(Lift-Splat-Shoot)做出不切实际的假设。 其次,我们的 HDMapNet(LiDAR) 在边界方面优于 HDMapNet(Surr),但在分隔线和人行横道方面较差。 这表明不同的类别在一种模式中并不能得到同等的认可。 第三,我们的相机图像和激光雷达点云的融合模型实现了最佳性能。 它比基线和我们仅使用相机的方法相对提高了 50%。
另一个有趣的现象是,不同模型在 CD 方面的表现不同。 例如,VPN 在所有类别中具有最低的 CDP,而它在 CDL 方面的表现则低于同类产品,并且总体 CD 也最差。 相反,我们的 HDMapNet(Surr) 平衡了 CDP 和 CDL,在所有仅基于相机的方法中实现了最佳 CD。 这一发现表明 CD 与 IoU 是互补的,这显示了模型的精度和召回率方面。 这有助于我们从另一个角度理解不同模型的行为。
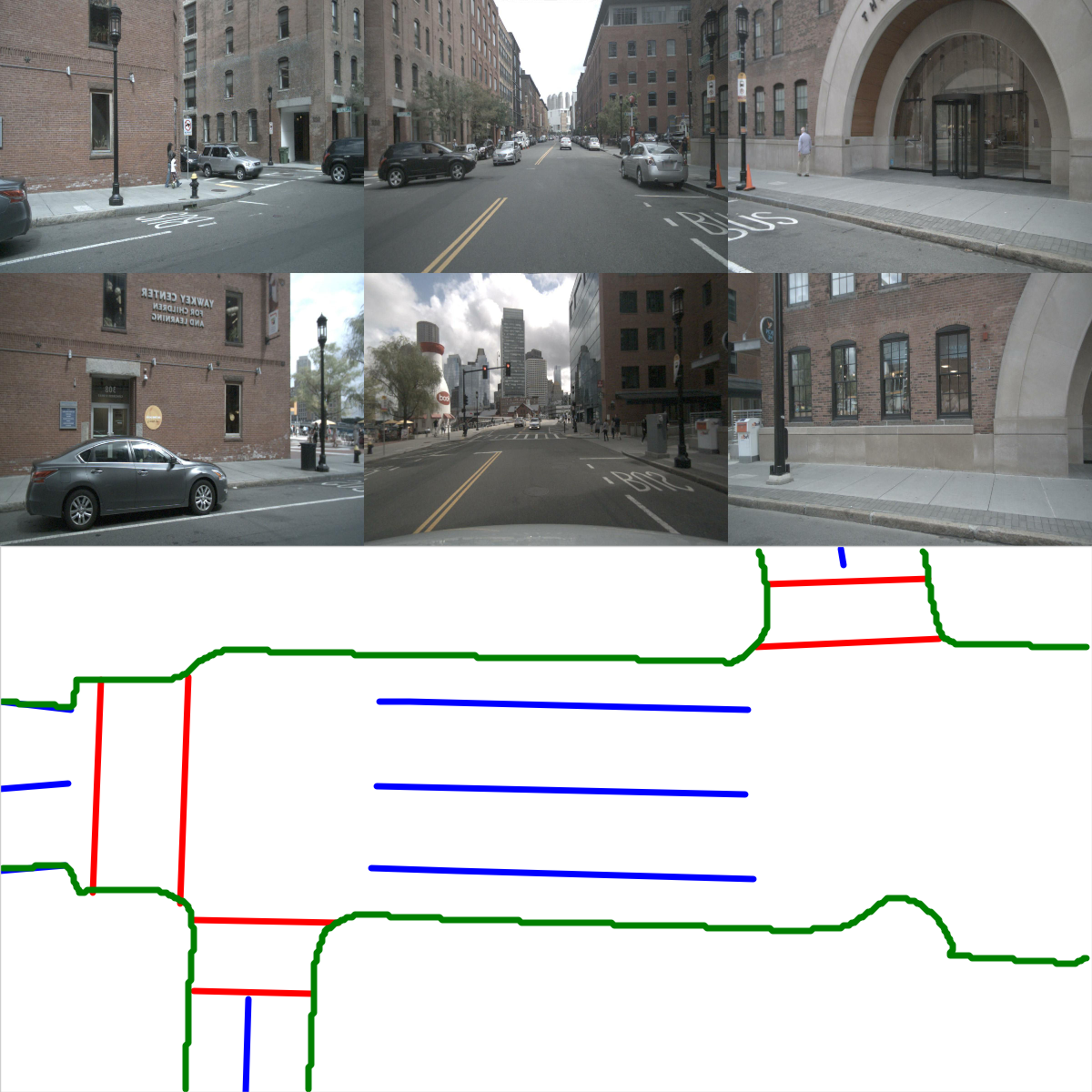
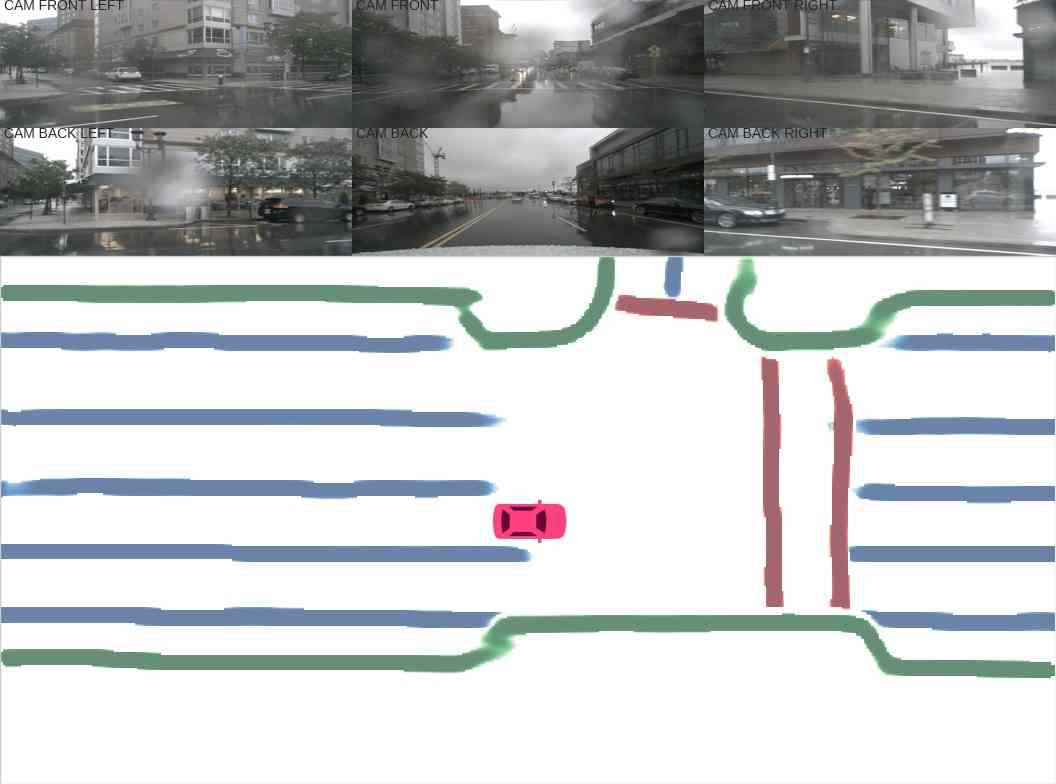
实例图检测。 在图2(实例检测分支)中,我们展示了使用主成分分析(PCA)的嵌入可视化。 即使不同的车道彼此靠近或有交叉路口,也会分配不同的颜色。 这证实了我们的模型学习实例级信息并且可以准确预测实例标签。 在图2(方向分类分支)中,我们显示了方向分支预测的方向掩模。 方向一致、流畅。 我们在图4中展示了后处理后产生的矢量化曲线。 在表II中,我们展示了实例图检测的定量结果。 HDMapNet(Surr) 已经优于基线,而 HDMapNet(Fusion) 明显优于所有同行,例如,它比 IPM 提高了 55.4%。
传感器融合。 在本节中,我们进一步分析传感器融合对于构建高清语义地图的效果。 如表I所示,对于分隔线和人行横道,HDMapNet(Surr)优于HDMapNet(LiDAR),而对于车道边界,HDMapNet(LiDAR)效果更好。 我们假设这是因为车道边界附近存在高程变化,因此很容易在激光雷达点云中检测到。 另一方面,道路分隔线和人行横道的颜色对比是有用的信息,使这两个类别在图像中更容易识别;图 4 中的可视化也证实了这一点。 激光雷达与摄像头结合时性能最强;组合模型的性能大大优于带有单个传感器的两个模型。 这表明这两个传感器包含彼此互补的信息。
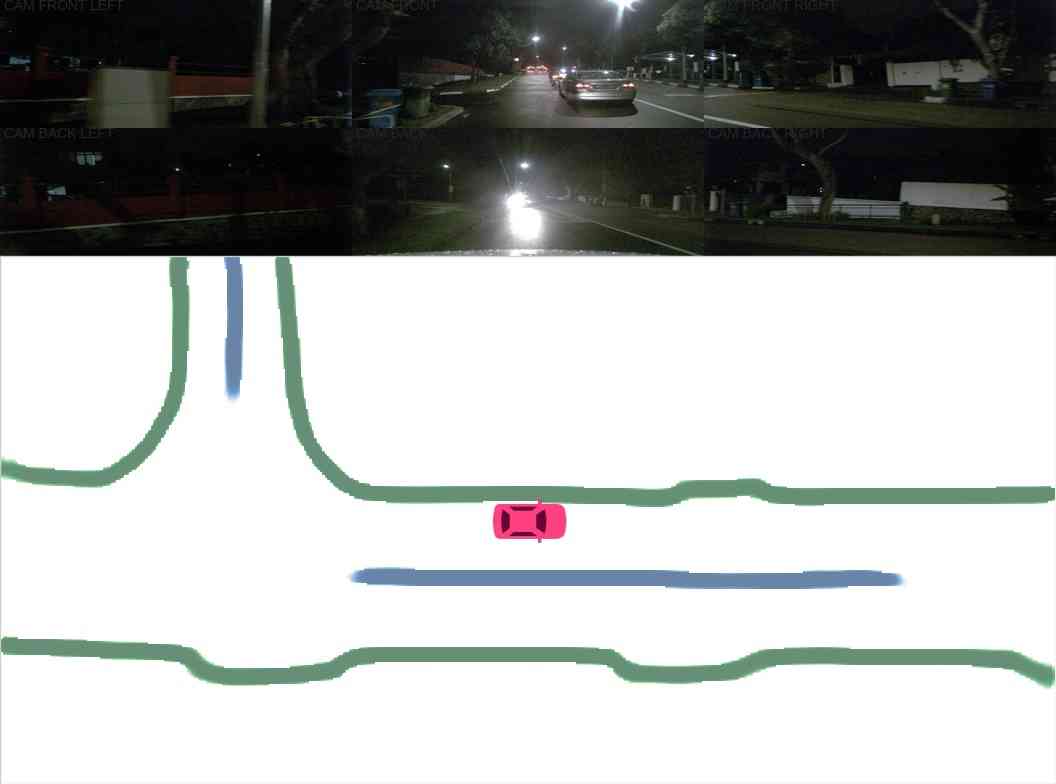
天气条件恶劣。 在这里,我们评估了我们的模型在极端天气条件下的稳健性。 如图5所示,即使在光照条件较差或下雨遮挡视线的情况下,我们的模型也可以生成完整的车道。 我们推测,当道路不完全可见时,模型可以根据部分观察来预测车道的形状。 虽然在极端天气条件下性能有所下降,但整体性能仍然合理。 (表III)
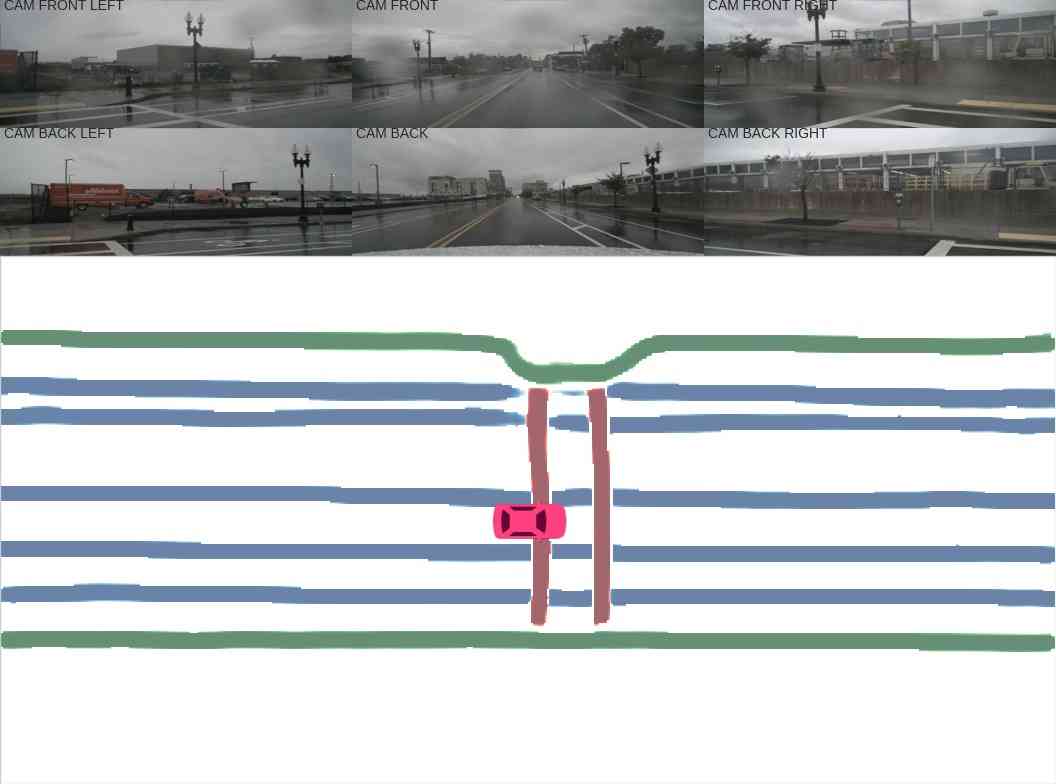
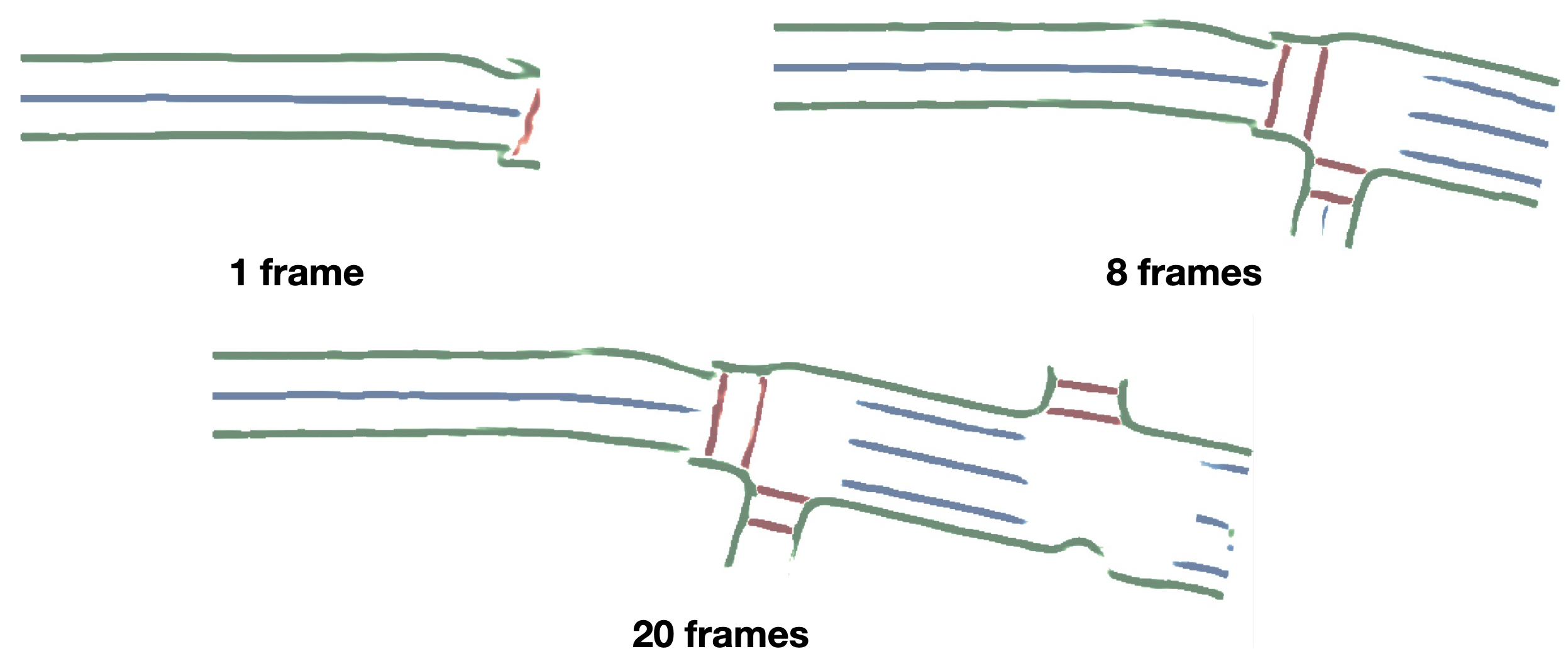
时间融合。 在这里,我们尝试时间融合策略。 我们首先根据自我姿势将前一帧的特征图粘贴到当前帧中,进行短期时间融合。 特征图通过最大池化融合,然后输入解码器。 如表IV所示,融合多帧可以提高语义的IoU。 我们通过融合分割概率进一步对长期时间积累进行实验。 如图6所示,我们的方法在融合多个帧的同时生成具有更大视野的一致语义图。
| Weather | Night | Rainy | Normal |
| IoU | 39.3 | 38.7 | 44.9 |
| # of frames | 1 | 2 | 4 |
| IoU | 32.9 | 35.8 | 36.4 |
V 结论
HDMapNet 直接从相机图像和/或 LiDAR 点云预测高清语义地图。 与需要大量人力的全球地图构建和标注管道相比,本地语义地图学习框架可能是一种更具可扩展性的方法。 尽管我们的语义地图学习基线方法不能产生准确的地图元素,但它为系统开发人员提供了在可扩展性和准确性之间进行权衡的另一种可能选择。
参考
- [1] P. J. Besl and N. D. McKay, “Method for registration of 3-d shapes,” in Sensor fusion IV: control paradigms and data structures, vol. 1611. International Society for Optics and Photonics, 1992, pp. 586–606.
- [2] P. Biber and W. Straßer, “The normal distributions transform: A new approach to laser scan matching,” in Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003)(Cat. No. 03CH37453), vol. 3. IEEE, 2003, pp. 2743–2748.
- [3] A. Segal, D. Haehnel, and S. Thrun, “Generalized-icp.” in Robotics: science and systems, vol. 2, no. 4. Seattle, WA, 2009, p. 435.
- [4] F. Yu, J. Xiao, and T. Funkhouser, “Semantic alignment of lidar data at city scale,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1722–1731.
- [5] F. Pomerleau, F. Colas, and R. Siegwart, “A review of point cloud registration algorithms for mobile robotics,” Foundations and Trends in Robotics, vol. 4, no. 1, pp. 1–104, 2015.
- [6] C. L. Lawson and R. J. Hanson, Solving least squares problems. SIAM, 1995.
- [7] F. Dellaert, “Factor graphs and gtsam: A hands-on introduction,” Georgia Institute of Technology, Tech. Rep., 2012.
- [8] S. Yang, X. Zhu, X. Nian, L. Feng, X. Qu, and T. Ma, “A robust pose graph approach for city scale lidar mapping,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1175–1182.
- [9] J. Jiao, “Machine learning assisted high-definition map creation,” in 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), vol. 1. IEEE, 2018, pp. 367–373.
- [10] L. Mi, H. Zhao, C. Nash, X. Jin, J. Gao, C. Sun, C. Schmid, N. Shavit, Y. Chai, and D. Anguelov, “Hdmapgen: A hierarchical graph generative model of high definition maps,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 4227–4236.
- [11] K.-Y. Chiu and S.-F. Lin, “Lane detection using color-based segmentation,” in IEEE Proceedings. Intelligent Vehicles Symposium, 2005. IEEE, 2005, pp. 706–711.
- [12] H. Loose, U. Franke, and C. Stiller, “Kalman particle filter for lane recognition on rural roads,” in 2009 IEEE Intelligent Vehicles Symposium. IEEE, 2009, pp. 60–65.
- [13] S. Zhou, Y. Jiang, J. Xi, J. Gong, G. Xiong, and H. Chen, “A novel lane detection based on geometrical model and gabor filter,” in 2010 IEEE Intelligent Vehicles Symposium. IEEE, 2010, pp. 59–64.
- [14] J. Illingworth and J. Kittler, “A survey of the hough transform,” Computer vision, graphics, and image processing, vol. 44, no. 1, pp. 87–116, 1988.
- [15] J. M. Alvarez, T. Gevers, Y. LeCun, and A. M. Lopez, “Road scene segmentation from a single image,” in ECCV, 2012.
- [16] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ade20k dataset,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 633–641.
- [17] A. Ess, T. Mueller, H. Grabner, and L. Van Gool, “Segmentation-based urban traffic scene understanding.” in BMVC, vol. 1. Citeseer, 2009, p. 2.
- [18] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in CVPR, 2016.
- [19] F. Yu, W. Xian, Y. Chen, F. Liu, M. Liao, V. Madhavan, and T. Darrell, “Bdd100k: A diverse driving video database with scalable annotation tooling,” arXiv preprint arXiv:1805.04687, vol. 2, no. 5, p. 6, 2018.
- [20] G. Neuhold, T. Ollmann, S. Rota Bulo, and P. Kontschieder, “The mapillary vistas dataset for semantic understanding of street scenes,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4990–4999.
- [21] Z. Wang, W. Ren, and Q. Qiu, “Lanenet: Real-time lane detection networks for autonomous driving,” arXiv preprint arXiv:1807.01726, 2018.
- [22] D. Neven, B. De Brabandere, S. Georgoulis, M. Proesmans, and L. Van Gool, “Towards end-to-end lane detection: an instance segmentation approach,” in 2018 IEEE intelligent vehicles symposium (IV). IEEE, 2018, pp. 286–291.
- [23] X. Liu and Z. Deng, “Segmentation of drivable road using deep fully convolutional residual network with pyramid pooling,” Cognitive Computation, vol. 10, no. 2, pp. 272–281, 2018.
- [24] M. Bai, G. Mattyus, N. Homayounfar, S. Wang, K. Lakshmikanth, Shrinidhi, and R. Urtasun, “Deep multi-sensor lane detection,” in IROS, 2018.
- [25] N. Garnett, R. Cohen, T. Pe’er, R. Lahav, and D. Levi, “3d-lanenet: end-to-end 3d multiple lane detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 2921–2930.
- [26] Y. Guo, G. Chen, P. Zhao, W. Zhang, J. Miao, J. Wang, and T. E. Choe, “Genlanenet: A generalized and scalable approach for 3d lane detection,” 2020.
- [27] B. Pan, J. Sun, H. Y. T. Leung, A. Andonian, and B. Zhou, “Cross-view semantic segmentation for sensing surroundings,” IEEE Robotics and Automation Letters, vol. 5, no. 3, p. 4867–4873, Jul 2020. [Online]. Available: http://dx.doi.org/10.1109/LRA.2020.3004325
- [28] T. Roddick and R. Cipolla, “Predicting semantic map representations from images using pyramid occupancy networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 138–11 147.
- [29] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” 2020.
- [30] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [31] Y. Zhou, P. Sun, Y. Zhang, D. Anguelov, J. Gao, T. Ouyang, J. Guo, J. Ngiam, and V. Vasudevan, “End-to-end multi-view fusion for 3d object detection in LiDAR point clouds,” in The Conference on Robot Learning (CoRL), 2019.
- [32] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [33] E. Shelhamer, J. Long, and T. Darrell, “Fully convolutional networks for semantic segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 4, pp. 640–651, 2017.
- [34] B. De Brabandere, D. Neven, and L. Van Gool, “Semantic instance segmentation for autonomous driving,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, July 2017.
- [35] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, “Microsoft coco: Common objects in context,” 2015.
- [36] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” 2020.
- [37] M. Tan and Q. V. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” 2020.
- [38] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “Imagenet large scale visual recognition challenge,” 2015.
- [39] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” 2019.
- [40] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
- [41] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2017.
- [42] L. Deng, M. Yang, H. Li, T. Li, B. Hu, and C. Wang, “Restricted deformable convolution-based road scene semantic segmentation using surround view cameras,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 10, p. 4350–4362, Oct 2020. [Online]. Available: http://dx.doi.org/10.1109/TITS.2019.2939832
- [43] T. Sämann, K. Amende, S. Milz, C. Witt, M. Simon, and J. Petzold, “Efficient semantic segmentation for visual bird’s-eye view interpretation,” 2018.