对齐再融合:基于动量蒸馏的视觉和语言表示学习
摘要
大规模视觉和语言表示学习在各种视觉语言任务上显示出令人鼓舞的改进。 现有的方法大多采用基于Transformer的多模态编码器来联合建模视觉符元(基于区域的图像特征)和单词符元。 由于视觉符元和单词符元未对齐, 多模态编码器难以学习图像文本之间的交互。 在本文中, 我们引入了一种对比损失来对齐图像和文本表示, 在融合(ALBEF)它们之前通过跨模态注意力进行对齐, 这使得更接地气的视觉和语言表示学习成为可能。 与大多数现有方法不同,我们的方法不需要边界框标注,也不需要高分辨率图像。 为了提高从嘈杂网络数据中学习的能力, 我们提出了动量蒸馏, 这是一种自训练方法,它从动量模型产生的伪目标中学习。 我们从互信息最大化的角度对ALBEF进行了理论分析, 表明不同的训练任务可以被解释为为图像文本对生成不同视图的不同方式。 ALBEF 在多个下游视觉语言任务上取得了最先进的性能。 在图像文本检索方面,ALBEF 的性能优于在数量级更大的数据集上预训练的方法。 在 VQA 和 NLVR2 上,ALBEF 相比最先进方法分别取得了 和 的绝对改进,同时还享受着更快的推理速度。 代码和模型可在 https://github.com/salesforce/ALBEF 获取。
1 引言
视觉和语言预训练 (VLP) 旨在从大规模图像文本对中学习多模态表示,从而改进下游视觉和语言 (V+L) 任务。 现有的 VLP 方法大多 (e.g. LXMERT [1], UNITER [2], OSCAR [3]) 依赖于预训练的物体检测器来提取基于区域的图像特征, 并采用多模态编码器来融合图像特征和单词符元。 多模态编码器被训练来解决需要图像和文本联合理解的任务,例如掩码语言建模(MLM)和图像文本匹配(ITM)。
尽管有效,但这种 VLP 框架存在几个关键限制:(1)图像特征和词符嵌入驻留在各自的空间中,这使得多模态编码器难以学习建模它们之间的交互;(2)目标检测器既需要标注又需要计算量,因为它需要在预训练期间进行边界框标注,并且在推理期间需要高分辨率(e.g. 6001000)图像;(3)广泛使用的图像文本数据集 [4, 5] 是从网络上收集的,本质上是嘈杂的,现有的预训练目标(如 MLM)可能会过度拟合嘈杂文本,并降低模型的泛化性能。
我们提出 ALign BEfore Fuse (ALBEF),一个新的 VLP 框架来解决这些限制。 我们首先使用无检测器图像编码器和文本编码器独立地对图像和文本进行编码。 然后,我们使用多模态编码器通过跨模态注意力将图像特征与文本特征融合。 我们在单模态编码器的表示上引入了一个中间图像文本对比(ITC)损失,它具有三个目的:(1)它对齐图像特征和文本特征,使多模态编码器更容易进行跨模态学习;(2)它改进单模态编码器,使其更好地理解图像和文本的语义含义;(3)它学习一个共同的低维空间来嵌入图像和文本,这使得图像文本匹配目标能够通过我们的对比硬负挖掘找到更多信息丰富的样本。
为了改进在嘈杂监督下的学习,我们提出了动量蒸馏 (MoD),这是一种简单的方法,它使模型能够利用更大的未整理网络数据集。 在训练期间,我们通过对模型参数进行移动平均来保留模型的动量版本,并使用动量模型生成伪目标作为额外的监督。 使用 MoD,模型不会因生成与网络标注不同的其他合理输出而受到惩罚。 我们表明 MoD 不仅改进了预训练,而且改进了具有干净标注的下游任务。
我们从互信息最大化的角度对 ALBEF 提供了理论上的论证。 具体而言,我们表明 ITC 和 MLM 最大化了图像文本对不同视图之间互信息的较低界限,其中视图是通过从每个对中获取部分信息生成的。 从这个角度来看,我们的动量蒸馏可以解释为用语义上相似的样本生成新视图。 因此,ALBEF 学习了对语义保持转换不变的视觉语言表示。
我们展示了 ALBEF 在各种下游 V+L 任务上的有效性,包括图像文本检索、视觉问答、视觉推理、视觉蕴涵和弱监督视觉定位。 ALBEF 在现有的最先进方法上取得了实质性的改进。 在图像文本检索方面,它优于在数量级更大的数据集上预训练的方法(CLIP [6] 和 ALIGN [7])。 在 VQA 和 NLVR2 上,与最先进的方法 VILLA [8] 相比,它实现了 和 的绝对改进,同时享受更快的推理速度。 我们还使用 Grad-CAM [9] 对 ALBEF 进行定量和定性分析,这揭示了它隐式地执行准确的对象、属性和关系接地的能力。
2 相关工作
2.1 视觉语言表示学习
大多数现有的视觉语言表示学习工作都属于两类。 第一类侧重于使用基于 Transformer 的多模态编码器 [10, 11, 12, 13, 1, 14, 15, 2, 3, 16, 8, 17, 18] 对图像和文本特征之间的交互进行建模。 此类方法在需要对图像和文本进行复杂推理的下游 V+L 任务(e.g. NLVR2 [19],VQA [20])上取得了优异的性能, 但它们大多数都需要高分辨率的输入图像和预训练的对象检测器。 最近的一种方法 [21] 通过去除对象检测器来提高推理速度,但会导致性能下降。 第二类侧重于学习图像和文本的独立单模态编码器 [22, 23, 6, 7]。 最近的 CLIP [6] 和 ALIGN [7] 使用对比损失在海量噪声网络数据上进行预训练, 对比损失是表示学习中最有效的损失之一 [24, 25, 26, 27]。 他们在图像文本检索任务上取得了显着的性能,但缺乏对其他 V+L 任务的图像和文本之间更复杂交互进行建模的能力 [21]。
ALBEF 统一了这两个类别,从而产生强大的单模态和多模态表示,在检索和推理任务上都具有优异的性能。 此外,ALBEF 不需要对象检测器,而对象检测器是许多现有方法 [1, 2, 3, 8, 17] 的主要计算瓶颈。
2.2 知识蒸馏
知识蒸馏 [28] 旨在通过从教师模型中蒸馏知识来提高学生模型的性能, 通常通过匹配学生模型的预测与教师模型的预测来实现。 虽然大多数方法侧重于从预训练的教师模型中提取知识 [28, 29, 30, 31, 32], 在线蒸馏 [33, 34] 同时训练多个模型并使用它们的集成作为教师。 我们的动量蒸馏可以解释为一种在线自蒸馏的形式,其中学生模型的时间集成被用作教师。 在半监督学习 [35]、标签噪声学习 [36] 中已经探索了类似的想法, 以及最近的对比学习 [37]。 与现有研究不同,我们从理论和实验上证明,动量蒸馏是一种通用的学习算法,可以提高模型在许多 V+L 任务上的性能。
3 ALBEF 预训练

在本节中, 我们首先介绍模型架构(第 3.1 节)。 然后我们详细说明预训练目标(第 3.2 节), 接着是提出的动量蒸馏(第 3.3 节)。 最后我们描述预训练数据集(第 3.4 节)和实现细节(第 3.5 节)。
3.1 模型架构
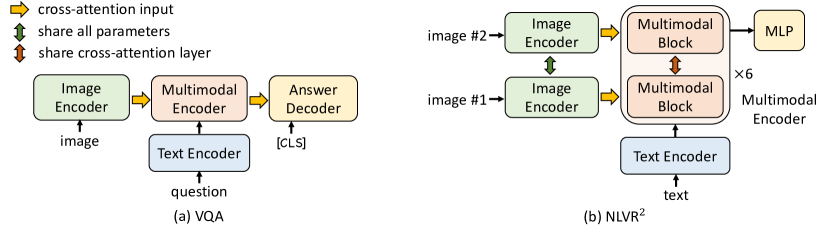
如图 1 所示, ALBEF 包含一个图像编码器、 一个文本编码器和一个多模态编码器。 我们使用一个 12 层的视觉 Transformer ViT-B/16 [38] 作为图像编码器, 并使用在 ImageNet-1k 上预训练的权重进行初始化,权重来自 [31]。 输入图像 被编码为一系列嵌入: , 其中 是 [CLS] 符元的嵌入。 我们使用一个 6 层的 Transformer [39] 作为文本编码器和多模态编码器。 文本编码器使用 BERTbase [40] 模型的前 6 层进行初始化, 而多模态编码器则使用 BERTbase 的后 6 层进行初始化。 文本编码器将输入文本 转换为一系列嵌入 , 并将其馈送到多模态编码器。 图像特征通过多模态编码器每一层的交叉注意力与文本特征融合。
3.2 预训练目标
我们使用三个目标对 ALBEF 进行预训练:图像-文本对比学习 (ITC) 用于单模态编码器, 掩码语言建模 (MLM) 和图像-文本匹配 (ITM) 用于多模态编码器。 我们通过在线对比式硬负样本挖掘来改进 ITM。
图像-文本对比学习 的目的是在融合之前学习更好的单模态表示。 它学习一个相似度函数 ,使得并行的图像-文本对具有更高的相似度分数。 和 是线性变换,将 [CLS] 嵌入映射到归一化的低维 (256 维) 表示。 受 MoCo [24] 的启发,我们维护两个队列来存储来自动量单模态编码器的最新的 图像-文本表示。 来自动量编码器的归一化特征表示为 和 。 我们定义 和 。
对于每个图像和文本, 我们计算 softmax 归一化的图像到文本和文本到图像相似度,如下:
| (1) |
其中 是一个可学习的温度参数。 令 和 表示 ground-truth 的 one-hot 相似性, 其中负样本对的概率为 0,正样本对的概率为 1。 图文对比损失被定义为 和 之间的交叉熵 :
| (2) |
掩码语言模型 利用图像和上下文文本来预测被掩码的词。 我们以 15% 的概率随机掩盖输入符元,并用特殊符元 [MASK]111following BERT, the replacements are 10% random tokens, 10% unchanged, and 80% [MASK]。 令 表示被掩码的文本, 而 表示模型对被掩码符元的预测概率。 MLM 最小化交叉熵损失:
| (3) |
其中 是一个 one-hot 词汇分布,其中 ground-truth 符元的概率为 1。
图文匹配 预测图像和文本对是否为正样本对(匹配)或负样本对(不匹配)。 我们使用多模态编码器对 [CLS] 符元的输出嵌入作为图像文本对的联合表示,并追加一个全连接(FC)层,然后进行 softmax 操作来预测一个两类概率 。 ITM 损失为:
| (4) |
其中 是一个 2 维的 one-hot 向量,表示 ground-truth 标签。
我们提出了一种策略,以零计算开销为 ITM 任务采样困难负样本。 如果一个图像文本对共享相似的语义,但在细粒度细节上有所不同,那么它就是一个困难的负样本对。 我们使用公式 1 中的对比相似度来寻找批次内的困难负样本。 对于一个 minibatch 中的每个图像, 我们根据对比相似度分布从同一个批次中采样一个负文本, 其中,与图像更相似的文本被采样的概率更高。 同样,我们也为每个文本样本一个难样本图像。
ALBEF 的完整预训练目标是:
| (5) |
3.3 动量蒸馏

用于预训练的图像-文本对主要从网络收集,并且它们往往很嘈杂。 正样本对通常是弱相关的:文本可能包含与图像无关的词语,或者图像可能包含文本中未描述的实体。 对于 ITC 学习,图像的负样本文本也可能与图像的内容匹配。 对于 MLM,可能存在其他不同于标注的词语,同样好地(甚至更好)描述图像。 然而,ITC 和 MLM 的 one-hot 标签会惩罚所有负样本预测,无论其是否正确。
为了解决这个问题,我们建议从动量模型生成的伪目标中学习。 动量模型是一个不断发展的教师,它包含单模态和多模态编码器的指数移动平均版本。 在训练期间,我们训练基础模型,使其预测与动量模型的预测相匹配。 具体来说,对于 ITC,我们首先使用动量单模态编码器的特征计算图像-文本相似度,作为 和 。 然后,我们通过将公式 1 中的 替换为 来计算软伪目标 和 。 ITCMoD 损失定义为:
| (6) |
同样,对于 MLM,令 表示动量模型对掩码符元的预测概率, MLMMoD 损失为:
| (7) |
在图 2 中, 我们展示了来自伪目标的前 5 个候选者的示例, 它们有效地捕获了图像的相关词语/文本。 更多示例可以在附录中找到。
我们还将 MoD 应用于下游任务。 每个任务的最终损失是原始任务损失与模型预测与伪目标之间的 KL 散度的加权组合。 为简单起见,我们将所有预训练和下游任务的权重 设置为 222our experiments show that yield similar performance, with slightly better。
3.4 预训练数据集
遵循 UNITER [2], 我们使用两个网络数据集(概念字幕 [4],SBU 字幕 [5])和两个领域内数据集(COCO [41] 和视觉基因组 [42])构建我们的预训练数据。 独特的图像总数为 400 万, 图像文本对的数量为 510 万。 为了表明我们的方法在更大规模的网络数据中是可扩展的, 我们还包括了噪声更大的概念 12M 数据集 [43], 将图像总数增加到 1410 万 333some urls provided by the web datasets have become invalid。 详细信息请见附录。
3.5 实施细节
我们的模型由具有 1.237 亿参数的 BERTbase 和具有 8580 万参数的 ViT-B/16 组成。 我们使用 8 个 NVIDIA A100 GPU,以 512 的批次大小对模型进行了 30 个 epochs 的预训练。 我们使用 AdamW [44] 优化器,权重衰减为 0.02。 在前 1000 次迭代中,学习率被预热到 , 然后根据余弦调度衰减到 。 在预训练期间, 我们将分辨率为 的随机图像裁剪作为输入, 并应用 RandAugment444we remove color changes from RandAugment because the text often contains color information [45]。 在微调期间, 我们将图像分辨率提高到 ,并根据 [38] 对图像块的位置编码进行插值。 更新动量模型的动量参数设置为 0.995, 用于图像文本对比学习的队列大小设置为 65,536。 我们在第一个时期内将蒸馏权重 从 0 线性增加到 0.4。
4 互信息最大化视角
在本节中, 我们提供了 ALBEF 的另一种视角,并表明它最大化了图像文本对不同“视图”之间互信息 (MI) 的下界。 ITC、MLM 和 MoD 可以解释为生成视图的不同方式。
正式地,我们将两个随机变量 和 定义为数据点的两个不同视图。 在自监督学习中 [24, 25, 46], 和 是同一图像的两个增强。 在视觉语言表示学习中, 我们将 和 视为图像文本对的不同变体,它们捕获了图像文本对的语义含义。 我们的目标是学习对视图变化不变的表示。 这可以通过最大化 和 之间的 MI 来实现。 在实践中,我们通过最小化 InfoNCE 损失 [47] 来最大化 MI 的下界,该损失定义为:
| (8) |
其中 是一个评分函数 (e.g。,两个表示之间的点积),并且 包含正样本 和从提议分布中抽取的 个负样本。
我们的带有一个热标签的 ITC 损失(公式 2)可以改写为:
| (9) |
最小化 可以被视为最大化 InfoNCE 的对称版本。 因此,ITC 将两个单独的模态(i.e., 和 )视为图像文本对的两个视角, 并训练单模态编码器以最大化图像和文本视角之间正对的 MI。
如 [48] 所示,我们还可以将 MLM 解释为最大化掩码词符元与其掩码上下文(i.e. 图像 + 掩码文本)之间的 MI。 具体来说,我们可以用 one-hot 标签(方程 3)重新编写 MLM 损失,如下所示
| (10) |
其中 是多模态编码器输出层中的一个查找函数,它将一个词符元 映射到一个向量,而 是完整的词汇集, 而 是一个返回与掩码上下文相对应的多模态编码器的最终隐藏状态的函数。 因此,MLM 将图像文本对的两个视角视为:(1)随机选择的词符元, 以及(2)图像 + 包含该词被掩码的上下文文本。
ITC 和 MLM 都通过模态分离或词掩码从图像文本对中获取部分信息来生成视角。 我们的动量蒸馏可以被认为是从整个提议分布中生成替代视角。 以方程 6 中的 ITCMoD 为例, 最小化 等效于最小化以下目标:
| (11) |
它最大化了与图像 具有相似语义含义的文本的 MI,因为这些文本将具有更大的 。 同样地, ITCMoD 也最大化了与 相似的图像的 MI。 我们可以用相同的方法来证明 MLMMoD 为掩码词 生成替代视角 , 并最大化 和 之间的 MI。 因此,我们的动量蒸馏可以被认为是对原始视角进行数据增强。 动量模型生成了一组在原始图像文本对中不存在的多样化视角, 并鼓励基础模型学习捕获视角不变语义信息的表示。
5 下游 V+L 任务
我们将预训练模型适应五个下游 V+L 任务。 我们将在下面介绍每个任务以及我们的微调策略。 数据集和微调超参数的详细信息在附录中。
图像-文本检索 包含两个子任务: 图像到文本检索 (TR) 和文本到图像检索 (IR)。 我们在 Flickr30K [49] 和 COCO 基准数据集上评估了 ALBEF, 并使用每个数据集的训练样本对预训练模型进行微调。 对于在 Flickr30K 上的零样本检索,我们使用在 COCO 上微调的模型进行评估。 在微调过程中,我们联合优化 ITC 损失 (公式 2) 和 ITM 损失 (公式 4)。 ITC 基于单峰特征的相似性学习图像-文本评分函数, 而 ITM 对图像和文本之间的细粒度交互进行建模以预测匹配分数。 由于下游数据集为每个图像包含多个文本, 我们更改了 ITC 的真实标签以考虑队列中的多个正例,其中每个正例的真实概率为 。 在推理过程中, 我们首先计算所有图像-文本对的特征相似性分数 。 然后我们获取前- 个候选并计算它们的 ITM 分数 进行排序。 由于 可以设置为非常小的值, 我们的推理速度比需要为所有图像-文本对计算 ITM 分数的方法快得多 [2, 3, 8]。
视觉蕴涵 (SNLI-VE555results on SNLI-VE should be interpreted with caution because its test data has been reported to be noisy [50] [51]) 是一项细粒度的视觉推理 任务,用于预测图像和文本之间的关系是蕴涵、中性还是矛盾。 我们遵循 UNITER [2] 并将 VE 视为一个三分类问题, 并使用多层感知器 (MLP) 对多模态编码器对 [CLS] 符元的表示进行预测类概率。
视觉问答 (VQA [52]) 需要模型根据图像和问题预测答案。 与将 VQA 视为多答案分类问题的现有方法不同 [53, 2], 我们将 VQA 视为答案生成问题,类似于 [54]。 具体来说,我们使用 6 层 Transformer 解码器来生成答案。 如图 3a 所示, 自回归答案解码器通过交叉注意力接收多模态嵌入, 并使用序列起始符 ([CLS]) 作为解码器的初始输入符。 同样,一个序列结束符 ([SEP]) 被追加到解码器输出的末尾,表示生成完成。 答案解码器使用来自多模态编码器的预训练权重进行初始化,并使用条件语言建模损失进行微调。 为了与现有方法进行公平比较,我们在推理过程中限制解码器仅从 3,192 个候选答案 [55] 中生成。
自然语言用于视觉推理 (NLVR2 [19]) 要求模型预测文本是否描述了一对图像。 我们扩展了我们的多模态编码器以支持对两幅图像进行推理。 如图 3b 所示,多模态编码器的每一层都被复制为两个连续的 Transformer 块,其中每个块包含一个自注意力层、一个交叉注意力层和一个前馈层(参见图 1)。 每层内的两个块使用相同的预训练权重进行初始化,并且两个交叉注意力层共享相同的线性投影权重用于键和值。 在训练期间,这两个块接收图像对的两个图像嵌入集。 我们在多模态编码器的 [CLS] 表示上附加一个 MLP 分类器进行预测。
对于 NLVR2,我们执行了一个额外的预训练步骤,以准备新的多模态编码器来对图像对进行编码。 我们设计了一个文本分配 (TA) 任务,如下所示:给定一对图像和一段文本,模型需要将文本分配到第一幅图像、第二幅图像或两者都不属于。 我们将其视为一个三分类问题,并在 [CLS] 表示上使用一个全连接层来预测分配。 我们使用 400 万张图像(第 3.4 节)仅对 TA 进行 1 个 epoch 的预训练。
视觉接地 旨在定位图像中与特定文本描述相对应的区域。 我们研究了弱监督设置, 其中没有边界框标注可用。 我们在 RefCOCO+ [56] 数据集上进行了实验, 并使用仅图像-文本监督对模型进行微调,遵循与图像-文本检索相同的策略。 在推理过程中, 我们扩展了 Grad-CAM [9] 来获取热图,并使用它们来对 [53] 提供的检测到的建议进行排序。
6 实验
| #Pre-train | Training tasks | TR | IR | SNLI-VE | NLVR2 | VQA |
| Images | (flickr test) | (test) | (test-P) | (test-dev) | ||
| 4M | MLM + ITM | 93.96 | 88.55 | 77.06 | 77.51 | 71.40 |
| ITC + MLM + ITM | 96.55 | 91.69 | 79.15 | 79.88 | 73.29 | |
| ITC + MLM + ITM | 97.01 | 92.16 | 79.77 | 80.35 | 73.81 | |
| ITC + MLM + ITM | 97.33 | 92.43 | 79.99 | 80.34 | 74.06 | |
| Full (ITC + MLM + ITM) | 97.47 | 92.58 | 80.12 | 80.44 | 74.42 | |
| ALBEF (Full + MoD) | 97.83 | 92.65 | 80.30 | 80.50 | 74.54 | |
| 14M | ALBEF | 98.70 | 94.07 | 80.91 | 83.14 | 75.84 |
6.1 对所提出的方法进行评估
首先, 我们评估了所提出的方法的有效性(i.e。图像-文本对比学习、对比式难负样本挖掘和动量蒸馏)。 表 1 展示了我们方法的不同变体在不同下游任务上的表现。 与基准预训练任务(MLM+ITM)相比, 添加 ITC 大大提高了预训练模型在所有任务上的表现。 提出的硬负样本挖掘通过寻找更有信息的训练样本来改进 ITM。 此外, 添加动量蒸馏改进了 ITC(第 4 行)、MLM(第 5 行)和所有下游任务(第 6 行)的学习。 在最后一行,我们展示了 ALBEF 可以有效地利用更多噪声的网络数据来提高预训练性能。
| Method | # Pre-train | Flickr30K (1K test set) | MSCOCO (5K test set) | ||||||||||
| Images | TR | IR | TR | IR | |||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| UNITER | 4M | 87.3 | 98.0 | 99.2 | 75.6 | 94.1 | 96.8 | 65.7 | 88.6 | 93.8 | 52.9 | 79.9 | 88.0 |
| VILLA | 4M | 87.9 | 97.5 | 98.8 | 76.3 | 94.2 | 96.8 | - | - | - | - | - | - |
| OSCAR | 4M | - | - | - | - | - | - | 70.0 | 91.1 | 95.5 | 54.0 | 80.8 | 88.5 |
| ALIGN | 1.2B | 95.3 | 99.8 | 100.0 | 84.9 | 97.4 | 98.6 | 77.0 | 93.5 | 96.9 | 59.9 | 83.3 | 89.8 |
| ALBEF | 4M | 94.3 | 99.4 | 99.8 | 82.8 | 96.7 | 98.4 | 73.1 | 91.4 | 96.0 | 56.8 | 81.5 | 89.2 |
| ALBEF | 14M | 95.9 | 99.8 | 100.0 | 85.6 | 97.5 | 98.9 | 77.6 | 94.3 | 97.2 | 60.7 | 84.3 | 90.5 |
6.2 图像-文本检索的评估
| Method | # Pre-train | Flickr30K (1K test set) | |||||
| Images | TR | IR | |||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| UNITER [2] | 4M | 83.6 | 95.7 | 97.7 | 68.7 | 89.2 | 93.9 |
| CLIP [6] | 400M | 88.0 | 98.7 | 99.4 | 68.7 | 90.6 | 95.2 |
| ALIGN [7] | 1.2B | 88.6 | 98.7 | 99.7 | 75.7 | 93.8 | 96.8 |
| ALBEF | 4M | 90.5 | 98.8 | 99.7 | 76.8 | 93.7 | 96.7 |
| ALBEF | 14M | 94.1 | 99.5 | 99.7 | 82.8 | 96.3 | 98.1 |
表 2 和表 3 分别报告了微调和零样本图像-文本检索的结果。 我们的 ALBEF 实现了最先进的性能, 超越了在数量级更大的数据集上训练的 CLIP [6] 和 ALIGN [7]。 鉴于当训练图像数量从 400 万增加到 1400 万时 ALBEF 的性能有了相当大的提升, 我们假设它有潜力通过在更大规模的网络图像-文本对上训练来进一步提升。
| Method | VQA | NLVR2 | SNLI-VE | |||
| test-dev | test-std | dev | test-P | val | test | |
| VisualBERT [13] | 70.80 | 71.00 | 67.40 | 67.00 | - | - |
| VL-BERT [10] | 71.16 | - | - | - | - | - |
| LXMERT [1] | 72.42 | 72.54 | 74.90 | 74.50 | - | - |
| 12-in-1 [12] | 73.15 | - | - | 78.87 | - | 76.95 |
| UNITER [2] | 72.70 | 72.91 | 77.18 | 77.85 | 78.59 | 78.28 |
| VL-BART/T5 [54] | - | 71.3 | - | 73.6 | - | - |
| ViLT [21] | 70.94 | - | 75.24 | 76.21 | - | - |
| OSCAR [3] | 73.16 | 73.44 | 78.07 | 78.36 | - | - |
| VILLA [8] | 73.59 | 73.67 | 78.39 | 79.30 | 79.47 | 79.03 |
| ALBEF (4M) | 74.54 | 74.70 | 80.24 | 80.50 | 80.14 | 80.30 |
| ALBEF (14M) | 75.84 | 76.04 | 82.55 | 83.14 | 80.80 | 80.91 |
6.3 VQA、NLVR 和 VE 的评估
表 4 报告了在其他 V+L 理解任务中与现有方法的比较。 使用 400 万张预训练图像, ALBEF 已经实现了最先进的性能。 使用 1400 万张预训练图像, ALBEF 大幅超越了现有方法, 包括额外使用对象标签 [3] 或对抗性数据增强 [8] 的方法。 与 VILLA [8] 相比, ALBEF 在 VQA test-std 上获得了 的绝对提升, 在 NLVR2 test-P 上获得了 的绝对提升, 在 SNLI-VE test 上获得了 的绝对提升。 由于 ALBEF 是无检测器且需要较低分辨率的图像, 因此与大多数现有方法相比,它的推理速度也快得多(在 NLVR2 上比 VILLA 快 10 倍以上)。
6.4 弱监督视觉接地
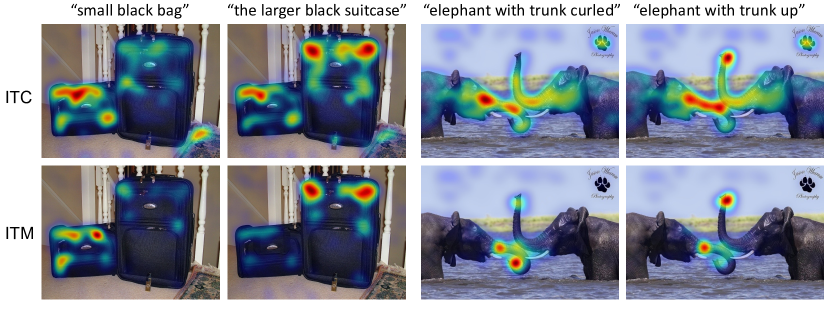
表 5 显示了 RefCOCO+ 的结果, 其中 ALBEF 大幅超越了现有方法 [57, 58](使用较弱的文本嵌入)。 ALBEFitc 变体在图像编码器最后一层的自注意力图上计算 Grad-CAM 可视化, 其中梯度是通过最大化图像文本相似度 获得的。 ALBEFitm 变体在多模态编码器第 3 层的交叉注意力图上计算 Grad-CAM(这是一层专门用于接地的层), 其中梯度是通过最大化图像文本匹配得分 获得的。 图 4 提供了一些可视化示例。 更多分析见附录。
我们在图 5 中提供了 VQA 的 Grad-CAM 可视化。 如附录所示,ALBEF 的 Grad-CAM 可视化与人类在做出决策时会看的位置高度相关。 在图 6 中,我们展示了 COCO 的每个词可视化。 请注意,我们的模型不仅对对象进行接地,还对其属性和关系进行接地。
| Method | Val | TestA | TestB |
| ARN [57] | 32.78 | 34.35 | 32.13 |
| CCL [58] | 34.29 | 36.91 | 33.56 |
| ALBEFitc | 51.58 | 60.09 | 40.19 |
| ALBEFitm | 58.46 | 65.89 | 46.25 |
接地。



6.5 消融研究
| Flickr30K | w/ hard negs | w/o hard negs | |||
| TR | 97.30 | 98.60 | 98.57 | 98.57 | 98.22 (0.35) |
| IR | 90.95 | 93.64 | 93.99 | 93.95 | 93.68 (0.31) |
表 6 研究了各种设计选择对图像-文本检索的影响。 由于我们在推理过程中使用 来过滤前 个候选者, 因此我们改变了 并报告了其影响。 通常, 获得的排名结果对 的变化不敏感。 我们还验证了最后一列中硬负样本挖掘的影响。
| NLVR2 | w/ TA | w/o TA | ||||
| share all | share CA | no share | share all | share CA | no share | |
| dev | 82.13 | 82.55 | 81.93 | 80.52 | 80.28 | 77.84 |
| test-P | 82.36 | 83.14 | 82.85 | 81.29 | 80.45 | 77.58 |
表格 7 研究了文本分配 (TA) 预训练和参数共享对 NLVR2 的影响。 我们考察了三种策略: (1) 两个多模态块共享所有参数, (2) 仅共享交叉注意力 (CA) 层, (3) 不共享。 在没有 TA 的情况下,共享整个块具有更好的性能。 使用 TA 对模型进行图像对预训练,共享 CA 导致最佳性能。
7 结论和社会影响
本文提出 ALBEF,一种用于视觉语言表示学习的新框架。 ALBEF 首先对单模态图像表示和文本表示进行对齐,然后使用多模态编码器将它们融合。 我们从理论和实验上验证了所提出的图像-文本对比学习和动量蒸馏的有效性。 与现有方法相比,ALBEF 在多个下游 V+L 任务上提供了更好的性能和更快的推理速度。
虽然我们的论文在视觉语言表示学习方面显示出有希望的结果,但在实践中部署之前,还需要对数据和模型进行额外的分析,因为网络数据可能包含意外的私人信息、不合适的图像或有害文本,并且仅优化准确性可能会产生不希望的社会影响。
参考文献
- [1] Tan, H., M. Bansal. LXMERT: learning cross-modality encoder representations from transformers. In K. Inui, J. Jiang, V. Ng, X. Wan, eds., EMNLP, pages 5099–5110. 2019.
- [2] Chen, Y., L. Li, L. Yu, et al. UNITER: universal image-text representation learning. In ECCV, vol. 12375, pages 104–120. 2020.
- [3] Li, X., X. Yin, C. Li, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, pages 121–137. 2020.
- [4] Sharma, P., N. Ding, S. Goodman, et al. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In I. Gurevych, Y. Miyao, eds., ACL, pages 2556–2565. 2018.
- [5] Ordonez, V., G. Kulkarni, T. L. Berg. Im2text: Describing images using 1 million captioned photographs. In J. Shawe-Taylor, R. S. Zemel, P. L. Bartlett, F. C. N. Pereira, K. Q. Weinberger, eds., NIPS, pages 1143–1151. 2011.
- [6] Radford, A., J. W. Kim, C. Hallacy, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- [7] Jia, C., Y. Yang, Y. Xia, et al. Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918, 2021.
- [8] Gan, Z., Y. Chen, L. Li, et al. Large-scale adversarial training for vision-and-language representation learning. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, H. Lin, eds., NeurIPS. 2020.
- [9] Selvaraju, R. R., M. Cogswell, A. Das, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In ICCV, pages 618–626. 2017.
- [10] Su, W., X. Zhu, Y. Cao, et al. Vl-bert: Pre-training of generic visual-linguistic representations. In ICLR. 2020.
- [11] Lu, J., D. Batra, D. Parikh, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, R. Garnett, eds., NeurIPS, pages 13–23. 2019.
- [12] Lu, J., V. Goswami, M. Rohrbach, et al. 12-in-1: Multi-task vision and language representation learning. In CVPR, pages 10434–10443. 2020.
- [13] Li, L. H., M. Yatskar, D. Yin, et al. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557, abs/1908.03557, 2019.
- [14] Qi, D., L. Su, J. Song, et al. Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data. arXiv preprint arXiv:2001.07966, 2020.
- [15] Li, G., N. Duan, Y. Fang, et al. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In AAAI, pages 11336–11344. 2020.
- [16] Yu, F., J. Tang, W. Yin, et al. Ernie-vil: Knowledge enhanced vision-language representations through scene graph. arXiv preprint arXiv:2006.16934, 2020.
- [17] Zhang, P., X. Li, X. Hu, et al. Vinvl: Making visual representations matter in vision-language models. arXiv preprint arXiv:2101.00529, 2021.
- [18] Huang, Z., Z. Zeng, Y. Huang, et al. Seeing out of the box: End-to-end pre-training for vision-language representation learning. arXiv preprint arXiv:2104.03135, 2021.
- [19] Suhr, A., S. Zhou, A. Zhang, et al. A corpus for reasoning about natural language grounded in photographs. In A. Korhonen, D. R. Traum, L. Màrquez, eds., ACL, pages 6418–6428. 2019.
- [20] Antol, S., A. Agrawal, J. Lu, et al. VQA: visual question answering. In ICCV, pages 2425–2433. 2015.
- [21] Kim, W., B. Son, I. Kim. Vilt: Vision-and-language transformer without convolution or region supervision. arXiv preprint arXiv:2102.03334, 2021.
- [22] Faghri, F., D. J. Fleet, J. R. Kiros, et al. VSE++: improving visual-semantic embeddings with hard negatives. In BMVC, page 12. 2018.
- [23] Li, K., Y. Zhang, K. Li, et al. Visual semantic reasoning for image-text matching. In ICCV, pages 4653–4661. 2019.
- [24] He, K., H. Fan, Y. Wu, et al. Momentum contrast for unsupervised visual representation learning. In CVPR. 2020.
- [25] Chen, T., S. Kornblith, M. Norouzi, et al. A simple framework for contrastive learning of visual representations. In ICML. 2020.
- [26] Li, J., P. Zhou, C. Xiong, et al. Prototypical contrastive learning of unsupervised representations. In ICLR. 2021.
- [27] Li, J., C. Xiong, S. C. Hoi. Mopro: Webly supervised learning with momentum prototypes. In ICLR. 2021.
- [28] Hinton, G., O. Vinyals, J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [29] Zagoruyko, S., N. Komodakis. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In ICLR. 2017.
- [30] Furlanello, T., Z. C. Lipton, M. Tschannen, et al. Born-again neural networks. In J. G. Dy, A. Krause, eds., ICML, pages 1602–1611. 2018.
- [31] Touvron, H., M. Cord, M. Douze, et al. Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.
- [32] Sanh, V., L. Debut, J. Chaumond, et al. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
- [33] Zhang, Y., T. Xiang, T. M. Hospedales, et al. Deep mutual learning. In CVPR, pages 4320–4328. 2018.
- [34] Anil, R., G. Pereyra, A. Passos, et al. Large scale distributed neural network training through online distillation. In ICLR. 2018.
- [35] Tarvainen, A., H. Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In NIPS, pages 1195–1204. 2017.
- [36] Li, J., R. Socher, S. C. Hoi. Dividemix: Learning with noisy labels as semi-supervised learning. In ICLR. 2020.
- [37] Cheng, R., B. Wu, P. Zhang, et al. Data-efficient language-supervised zero-shot learning with self-distillation. arXiv preprint arXiv:2104.08945, 2021.
- [38] Dosovitskiy, A., L. Beyer, A. Kolesnikov, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR. 2021.
- [39] Vaswani, A., N. Shazeer, N. Parmar, et al. Attention is all you need. In I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, R. Garnett, eds., NIPS, pages 5998–6008. 2017.
- [40] Devlin, J., M. Chang, K. Lee, et al. BERT: pre-training of deep bidirectional transformers for language understanding. In J. Burstein, C. Doran, T. Solorio, eds., NAACL, pages 4171–4186. 2019.
- [41] Lin, T., M. Maire, S. J. Belongie, et al. Microsoft COCO: common objects in context. In D. J. Fleet, T. Pajdla, B. Schiele, T. Tuytelaars, eds., ECCV, vol. 8693, pages 740–755. 2014.
- [42] Krishna, R., Y. Zhu, O. Groth, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 123(1):32–73, 2017.
- [43] Changpinyo, S., P. Sharma, N. Ding, et al. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR. 2021.
- [44] Loshchilov, I., F. Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [45] Cubuk, E. D., B. Zoph, J. Shlens, et al. Randaugment: Practical automated data augmentation with a reduced search space. In CVPR Workshops, pages 702–703. 2020.
- [46] Tian, Y., C. Sun, B. Poole, et al. What makes for good views for contrastive learning? In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, H. Lin, eds., NeurIPS. 2020.
- [47] Oord, A. v. d., Y. Li, O. Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- [48] Kong, L., C. de Masson d’Autume, L. Yu, et al. A mutual information maximization perspective of language representation learning. In ICLR. OpenReview.net, 2020.
- [49] Plummer, B. A., L. Wang, C. M. Cervantes, et al. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In ICCV, pages 2641–2649. 2015.
- [50] Do, V., O.-M. Camburu, Z. Akata, et al. e-snli-ve: Corrected visual-textual entailment with natural language explanations. arXiv preprint arXiv:2004.03744, 2020.
- [51] Xie, N., F. Lai, D. Doran, et al. Visual entailment: A novel task for fine-grained image understanding. arXiv preprint arXiv:1901.06706, 2019.
- [52] Goyal, Y., T. Khot, D. Summers-Stay, et al. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In CVPR, pages 6325–6334. 2017.
- [53] Yu, L., Z. Lin, X. Shen, et al. Mattnet: Modular attention network for referring expression comprehension. In CVPR, pages 1307–1315. 2018.
- [54] Cho, J., J. Lei, H. Tan, et al. Unifying vision-and-language tasks via text generation. arXiv preprint arXiv:2102.02779, 2021.
- [55] Kim, J., J. Jun, B. Zhang. Bilinear attention networks. In S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, R. Garnett, eds., NIPS, pages 1571–1581. 2018.
- [56] Yu, L., P. Poirson, S. Yang, et al. Modeling context in referring expressions. In B. Leibe, J. Matas, N. Sebe, M. Welling, eds., ECCV, pages 69–85. 2016.
- [57] Liu, X., L. Li, S. Wang, et al. Adaptive reconstruction network for weakly supervised referring expression grounding. In ICCV, pages 2611–2620. 2019.
- [58] Zhang, Z., Z. Zhao, Z. Lin, et al. Counterfactual contrastive learning fo weakly-supervised vision-language grounding. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, H. Lin, eds., NeurIPS. 2020.
- [59] Karpathy, A., F. Li. Deep visual-semantic alignments for generating image descriptions. In CVPR, pages 3128–3137. 2015.
- [60] Bowman, S. R., G. Angeli, C. Potts, et al. A large annotated corpus for learning natural language inference. In L. Màrquez, C. Callison-Burch, J. Su, D. Pighin, Y. Marton, eds., EMNLP, pages 632–642. 2015.
- [61] Yu, Z., J. Yu, Y. Cui, et al. Deep modular co-attention networks for visual question answering. In CVPR, pages 6281–6290. 2019.
- [62] Kazemzadeh, S., V. Ordonez, M. Matten, et al. Referitgame: Referring to objects in photographs of natural scenes. In A. Moschitti, B. Pang, W. Daelemans, eds., EMNLP. 2014.
- [63] Das, A., H. Agrawal, C. L. Zitnick, et al. Human Attention in Visual Question Answering: Do Humans and Deep Networks Look at the Same Regions? 2016.
附录 A 下游任务细节
在这里,我们描述了微调预训练模型的实现细节。 对于所有下游任务,我们使用与预训练期间相同的 RandAugment、AdamW 优化器、余弦学习率衰减、权重衰减和蒸馏权重。 所有下游任务接收分辨率为 的输入图像。 在推断过程中,我们调整图像大小,不进行裁剪。
图像-文本检索。 我们考虑了两个数据集来执行这项任务:COCO 和 Flickr30K。 我们采用这两个数据集广泛使用的 Karpathy 分割 [59]。 COCO 包含 113/5k/5k 用于训练/验证/测试。 Flickr30K 包含 29k/1k/1k 图像用于训练/验证/测试。 我们进行了 10 个 epoch 的微调。 批次大小为 256,初始学习率为 。
视觉蕴涵。 我们在 SNLI-VE 数据集 [51] 上进行评估,该数据集是使用斯坦福自然语言推理 (SNLI) [60] 和 Flickr30K 数据集构建的。 我们遵循原始数据集分割,其中 29.8k 图像用于训练,1k 用于评估,1k 用于测试。 我们对预训练模型进行了 5 个 epoch 的微调,批次大小为 256,初始学习率为 。
VQA。 我们在 VQA2.0 数据集 [52] 上进行了实验,该数据集是使用 COCO 中的图像构建的。 它包含 83k 图像用于训练,41k 用于验证,81k 用于测试。 我们报告了 test-dev 和 test-std 分割的性能。 遵循大多数现有工作 [1, 2, 61], 我们使用训练集和验证集进行训练, 并从视觉基因组中包含额外的问答对。 由于 VQA 数据集中许多问题包含多个答案, 我们根据每个答案在所有答案中出现的百分比来加权每个答案的损失。 我们对模型进行了 8 个 epochs 的微调, 使用 256 的批量大小和 的初始学习率。
NLVR2。 我们按照 [19] 中的原始训练/验证/测试分割进行实验。 我们对模型进行了 10 个 epochs 的微调, 使用 128 的批量大小和 的初始学习率。 由于 NLVR 接收两个输入图像, 我们执行了一个额外的文本分配 (TA) 预训练步骤,以准备模型对两个图像进行推理。 TA 预训练使用大小为 的图像。 我们在 4M 数据集上进行了 1 个 epochs 的预训练,使用 256 的批量大小和 的学习率。
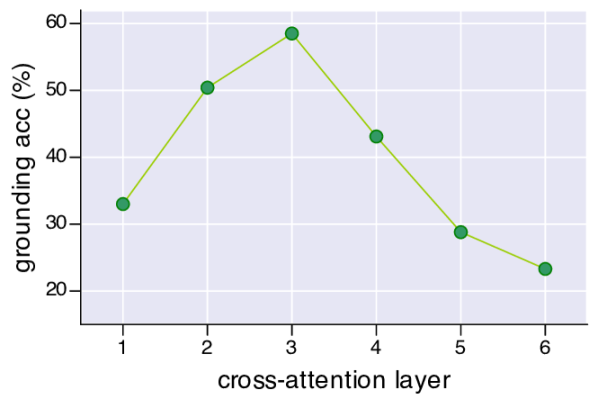
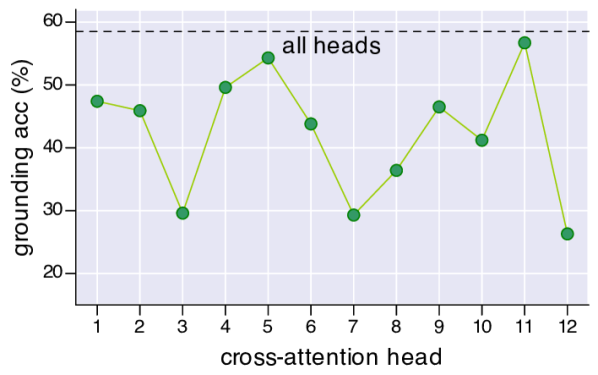
视觉接地。 我们在 RefCOCO+ 数据集 [56] 上进行了实验, 该数据集是使用双人 ReferitGame [62] 收集的。 它包含来自 COCO 训练集的 19,992 张图像的 141,564 个表达式。 严格来说, 我们的模型不允许查看 RefCOCO+ 的验证/测试图像, 但它在预训练期间已经接触过这些图像。 我们假设这影响很小,因为这些图像只占整个 14M 预训练图像中的一小部分, 并将对数据进行去污染留作以后的工作。 在弱监督微调期间,我们遵循与图像-文本检索相同的策略,只是我们不执行随机裁剪,并对模型进行了 5 个 epochs 的训练。 在推断期间,我们使用 或 来计算每个 图像块的重要性分数。 对于 ITC, 我们在视觉编码器最后一层的自注意力图上计算 Grad-CAM 可视化 w.r.t [CLS] 符元, 并将所有注意力头的热图进行平均。 对于 ITM,我们在多模态编码器第 3 层的交叉注意力图上计算 Grad-CAM,并将所有注意力头的得分以及所有输入文本符元进行平均。 表格 5 显示了 ITC 和 ITM 之间的定量比较。 图 7 显示了定性比较。 由于多模态编码器可以更好地模拟图像-文本交互, 因此它可以生成更好的热图,捕捉更细粒度的细节。 在图 8 中, 我们报告了每个交叉注意力层的接地精度 以及性能最佳层中的每个单独注意力头。
(一个)
(二)

附录 B 每个词的附加可视化
在图 9 中, 我们展示了更多每个词 Grad-CAM 的可视化,以展示我们的模型在执行物体、动作、属性和关系的视觉接地方面的能力。
附录 C 与人类注意力的比较
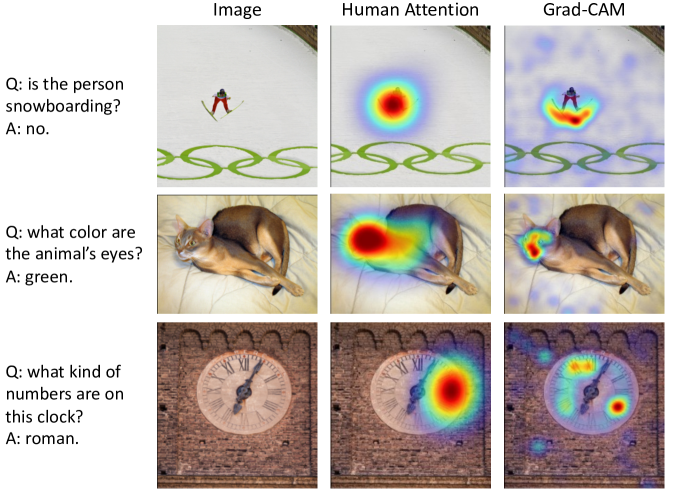
Das 等人 [63] 为 VQA 数据集 [20] 的子集收集了人类注意力图。 给定一个问题和图像的模糊版本,要求 Amazon Mechanical Turk 上的人员交互式地去除图像区域的模糊,直到他们能够自信地回答问题。 在这项工作中,我们将人类注意力图与 Grad-CAM 可视化进行了比较,这些可视化是针对 ALBEF VQA 模型计算的,该模型在第三个多模态交叉注意力层上计算了 1374 个验证问题-图像对,使用与 [63] 中相同的秩相关评估协议。 我们发现,为真实答案计算的 Grad-CAM 和人类注意力图具有 0.205 的高相关性。 这表明,尽管 ALBEF 没有在接地的图像-文本对上进行训练,但在做出决策时,它会查看适当的区域。 在图 10 中可以找到与人类注意力图进行比较的定性示例。
附录 D 伪目标的附加示例


附录 E 预训练数据集详细信息
表 8 显示了预训练数据集的图像和文本的统计信息。
| COCO (Karpathy-train) | VG | CC | SBU | CC12M | |
| # image | 113K | 100K | 2.95M | 860K | 10.06M |
| # text | 567K | 769K | 2.95M | 860K | 10.06M |