Rajat Konerkoner@dbs.ifi.lmu.com1 Poulami Sinhamahapatrapoulami.sinhamahapatra@iks.fraunhofer.de2 Karsten Roscherkarsten.roscher@iks.fraunhofer.de2 Stephan Günnemannguennemann@in.tum.de3 Volker Trespvolker.tresp@siemens.com14 路德维希马克西米利安大学,慕尼黑,
德国 Fraunhofer IKS,弗劳恩霍夫认知系统研究所 IKS,慕尼黑,
德国慕尼黑工业大学,
德国西门子公司,慕尼黑,
德国 OODformer:Out-Of-配电检测 Transformer
OODformer:分布外检测 Transformer
摘要
图像分类中的一个严重问题是,经过训练的模型对于来自与模型训练可用数据相同分布的输入数据可能表现良好,但对于分布外 (OOD) 样本的表现则较差。 特别是在现实世界的安全关键应用中,了解新数据点是否 OOD 非常重要。 迄今为止,OOD 检测通常使用置信度分数、基于自动编码器的重建或对比学习来解决。 然而,尚未探索全局图像上下文来区分分布内样本和 OOD 样本之间的非局部对象性。 本文提出了一种名为 OODformer 的首创 OOD 检测架构,它利用了 Transformer 的上下文化功能。 将 Transformer 合并为主要特征提取器使我们能够通过视觉注意来利用对象概念及其辨别属性以及它们的共现。 基于上下文嵌入,我们使用类条件潜在空间相似性和网络置信度得分来演示 OOD 检测。 我们的方法显示了跨各种数据集的改进的通用性。 我们在 CIFAR-10/-100 和 ImageNet30 上取得了新的最先进结果。 代码位于:https://github.com/rajatkoner08/oodformer。
1简介
事实证明,当应用程序中的数据来自与可用于模型训练的数据(也称为分布内 (ID) 数据)相同的分布时,深度学习可以提供出色的结果。 不幸的是,对于分布外 (OOD) 数据,性能可能会急剧恶化。 应用程序数据可能出现 OOD 的原因可能是多方面的,通常归因于复杂的分布变化、全新概念的出现或来自故障传感器的随机噪声。 随着深度学习成为自动驾驶、监控系统和医疗应用等许多安全关键应用的核心,区分 ID 和 OOD 数据变得至关重要。
生成建模和对比学习的最新进展导致各种 OOD 检测方法取得了显着进步。 [Liang 等人(2017)Liang, Li, and Srikant, Hsu 等人(2020)Hsu, Shen, Jin, and Kira]改进了用于异常值检测的softmax分布。 [Tack 等人(2020)Tack, Mo, Jeong, and Shin, Winkens 等人(2020)Winkens, Bunel, Roy, Stanforth, Natarajan, Ledsam, MacWilliams, Kohli, Karthikesalingam, Kohl, Cemgil, Eslami, and Ronneberger、Sehwag 等人(2021)Sehwag、Chiang 和 Mittal] 使用对比学习进行 OOD 检测。 这些作品的共同想法是,在对比训练的网络中,相似的对象将具有相似的嵌入,而不同的对象将被对比损失所排斥。 然而,这些方法通常需要使用 OOD 数据进行微调,或者依赖于多个负样本,并且经常受到基于卷积的架构中普遍存在的归纳偏差的影响。 因此,很难对它们进行开箱即用的训练和部署。 这促使我们在设计 OOD 检测器时超越使用负样本或感应偏差的传统做法。 沿着这个思路,我们认为全局图像上下文的系统利用提供了获得语义紧凑表示的潜在替代方案。 为了系统地利用全局图像上下文,我们利用视觉变换器(ViT)的多跳上下文积累[Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人]。
Transformer 的视觉注意力在各种图像分类上显着优于卷积架构[Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人, Touvron 等人(2020 )Touvron, Cord, Douze, Massa, Sablayrolles, and Jégou],物体检测[Carion 等人(2020)Carion, Massa, Synnaeve, Usunier, Kirillov, and Zagoruyko],关系检测[Koner 等人(2020)Koner, Sinhamahapatra, and Tresp, Koner 等人(2021b)Koner, Sinhamahapatra, and Tresp]以及其他视觉导向任务[Liu 等人(2021)Liu, Lin, Cao, Hu, Wei, Zhang, Lin, and Mao, Hildebrandt 等人(2020)Hildebrandt, Li, Koner, Tresp, and Günnemann, Caron 等人(2021)Caron, Touvron, Misra, Jégou ,Mairal,Bojanowski 和 Joulin,Koner 等人 (2021a)Koner,Li,Hildebrandt,Das,Tresp 和 Günnemann]。 然而,迄今为止,Transformer 作为通用 OOD 检测器的能力仍未得到探索。 作为合适的 Transformer 候选者,我们研究了图像分类任务中新兴的 Transformer 架构,即 Vision Transformer (ViT) [Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer , Heigold, Gelly, 等人],及其数据高效变体 DeiT [Touvron 等人(2020)Touvron, Cord, Douze, Massa, Sablayrolles, and Jégou].ViT 探索使用视觉注意力从小图像块中提取图像的全局上下文及其特征相关性。 直观上,ID 和 OOD 之间的区别是由小到大的扰动,其形式为错误排序或损坏(包括错误)。 插入或删除)。 因此,我们认为捕获类/对象属性交互对于 OOD 检测很重要,我们通过 Transformer 实现了 OOD 检测。
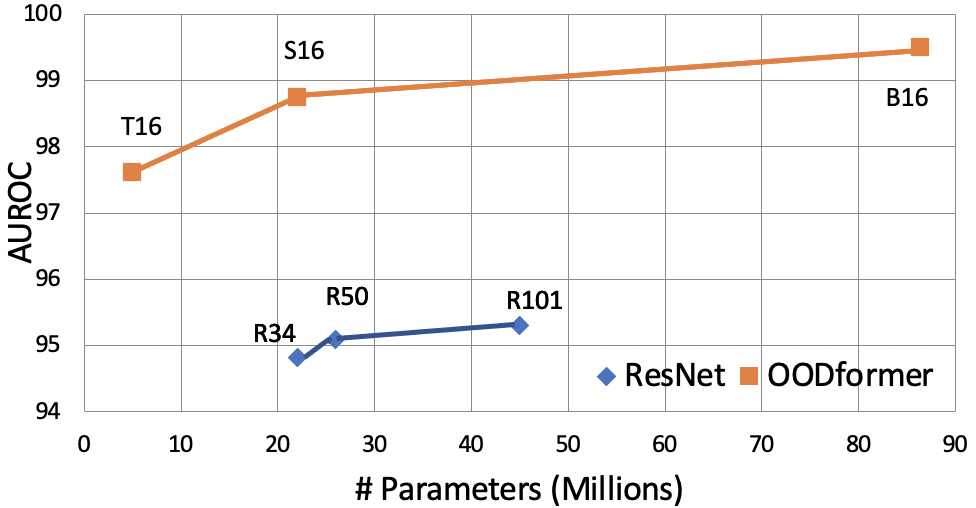
据我们所知,我们是第一个提出并研究全局上下文和特征相关性的作用的人,使用视觉 Transformer 来概括 OOD 检测方面的数据。 我们的关键思想是使用 ID 数据集训练 ViT,并利用其最终代表性嵌入的相似性进行异常值检测。 通过对属性的补丁式关注,我们的目标是实现能够区分 ID 和 OOD 的歧视性嵌入。 首先,我们使用交叉熵损失对分布内数据集进行正式的 ViT 监督训练。 第二步,我们从分类头(词符)中提取学习到的特征,并计算用于 OOD 检测的类条件距离度量。 我们的实验表明,ViT 的 softmax 置信度预测在 OOD 检测方面比对应的卷积预测更具通用性。 我们还观察到前者克服了后者的多个缺点,例如较差的边际概率[Elsayed 等人(2018)Elsayed, Krishnan, Mobahi, Regan, and Bengio, Liu 等人(2016)Liu, Wen, Yu 、杨]。 图 1 说明了我们的主张:即使参数少得多,基于 Transformer 的架构与传统的基于卷积的架构相比,性能也明显更好。 这显示了 Transformer 在异常值检测任务中的优越性。
我们在多个数据集上评估模型的有效性,例如 CIFAR-10、CIFAR-100 [Krizhevsky 等人(2009)Krizhevsky, Hinton, 等人]、ImageNet30 [Hendrycks 等人(2019b)Hendrycks、Mazeika、Kadavath 和 Song] 具有多种设置(例如,类条件相似性、softmax 分数)。 我们的模型在所有设置中都远远优于卷积基线和其他最先进的模型。 最后,我们进行了广泛的消融研究,以加强对 ViT 的普遍性和数据变化影响的理解。 总之,本文的主要贡献是:
-
•
我们将 OOD 任务建模为基于对象属性的紧凑语义表示学习。 在此背景下,我们第一个提出了一种基于视觉转换器的 OOD 检测框架,名为 OODformer,并深入研究了其效率。
-
•
我们使用基于类条件嵌入和基于 softmax 置信度得分的 OOD 检测对学习的表示进行了广泛的研究,以验证所提出方法的有效性。
-
•
我们对学习到的注意力图、softmax 置信度和嵌入属性进行深入分析,以直观地解释 OOD 检测机制。
-
•
我们在 CIFAR-10、CIFAR-100 和 ImageNet30 等众多具有挑战性的数据集上取得了最先进的结果,并获得了显着的巨大增益。
2相关工作
OOD 检测方法可以分为许多类别。 第一个也是最直观的方法是使用从网络得出的置信度得分对 OOD 样本进行分类。 [Hendrycks and Gimpel(2018)]提出最大softmax概率,通过ODIN使用温度缩放连续改进[Liang等人(2017)Liang, Li, and Srikant ]。 [Lee 等人(2018)Lee, Lee, Lee, and Shin]利用马哈拉诺比斯距离和[Hsu 等人(2020)Hsu, Shen, Jin, and Kira]改进了 ODIN,而无需进一步使用 OOD 数据。 其他基于密度近似的生成模型[Ren 等人(2019)Ren, Liu, Fertig, Snoek, Poplin, Depristo, Dillon, and Lakshminarayanan, Serrà 等人(2019)Serrà, Álvarez, Gómez, Slizovskaia, Núñez, Luque, Slizovskaia, José, Nú, ñ, ez, and Luque, Nalisnick 等人(2019)Nalisnick, Matsukawa, Teh, Gorur, and Lakshminarayanan]也在这种方法中做出了贡献。 [Charpentier 和 Günnemann(2020)] 还表明,基于密度的不确定性估计也可用于 OOD 检测。 OOD 检测的第二个方向是训练用于似然估计的生成模型。 [Zong 等人(2018)Zong, Song, Min, Cheng, Lumezanu, Cho, and Chen, Pidhorskyi 等人(2018)Pidhorskyi, Almohsen, and Doretto]专注于学习训练样本的表示,使用瓶颈层进行样本的有效重建和泛化。 OOD 检测的另一个进步是基于自监督[Chen 等人(2020a)Chen, Kornblith, Norouzi, and Hinton, Chen 等人(2020b)Chen, Kornblith, Swersky, Norouzi, and Hinton, Li 等人(2020)Li, Zhou, Xiong, Socher, and Hoi, Chen 等人(2020c)Chen, Fan, Girshick, and He] 或监督[Khosla 等人(2020)Khosla, Teterwak, Wang , Sarna, Tian, Isola, Maschinot, Liu, and Krishnan, Chuang 等人(2020)Chuang, Robinson, Yen-Chen, Torralba, and Jegelka]对比学习。 它的目的是通过迫使网络学习相似语义类别的相似表示,同时排斥其他类别,来学习有效的歧视性表示。 该属性已被许多近期作品所利用[Tack 等人(2020)Tack, Mo, Jeong, and Shin, Winkens 等人(2020)Winkens, Bunel, Roy, Stanforth, Natarajan, Ledsam, MacWilliams, Kohli, Karthikesalingam, Kohl, Cemgil, Eslami, and Ronneberger, Sehwag 等人(2021)Sehwag, Jiang, and Mittal] 用于 OOD 检测。 这些工作的共同想法是,在对比训练的网络中,ID 样本中语义上较接近的对象将具有相似的表示,而 OOD 样本在嵌入空间中会相距很远。
3 基于注意力的OOD检测
在本节中,将介绍 OOD 检测问题,然后简要介绍视觉 Transformer 的背景以及基于特征相似性的异常值检测。 由于 OOD 标签可能不适用于大多数场景,因此我们的方法主要依赖于基于相似度得分的检测。
3.1 问题分解:OOD检测
令 为一个具有 尺寸的训练样本,并令 为其类标签,其中 为类数。 对于给定的神经特征提取器(),学习的特征向量被获取为。 最后我们得到后验类概率为 ,其中 和 。 和 是两个学习函数,将图像从数据空间映射到特征空间,然后导出后验概率分布。 在现实环境中,从应用程序中的 提取的数据可能不遵循与训练样本 () 相同的分布。 我们将这些数据称为 OOD ()。 现在的问题是 OOD 数据在其表示中与 ID 的差异有多大? 第二个问题是 OOD 数据后验概率分布预测的可靠性。 为了量化 ID 样本数据的变化,我们计算样本( 或 )之间嵌入与最接近的 ID 类均值的相似度。 在理想情况下,OOD () 的表示相似性应远小于 ID ()。 此外,它的 softmax 置信度应该显着低于 ID 样本的置信度,从而允许使用简单的阈值来区分 ID 和 OOD 样本。
3.2特征提取:Vision Transformer
在我们的工作中,我们使用了 Vision Transformer (ViT) [Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人] 及其数据高效变体 DeiT [Touvron 等人(2020)Touvron, Cord, Douze, Massa, Sablayrolles, and Jégou];他们使用相同配置的相同 Transformer 编码器[Vaswani 等人(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin] 架构。 然而,ViT 使用 ImageNet-21K 进行预训练,而 DeiT 使用更稳健的数据增强,并且仅使用 ImageNet 进行训练。 ViT 的编码器仅采用一维标记序列作为输入。 但是,为了处理高度 和宽度 的 2D 图像,它将图像划分为 个小 2D 块,并展平为 1D 序列 ,其中是通道数,是每个补丁的分辨率,是获得的序列数。 前面添加了类似于 BERT [Devlin 等人(2018)Devlin, Chang, Lee, and Toutanova] 的 词符 ()(第一个位置)序列)到补丁嵌入的序列,如方程1所示,
| (1) |
其中 是 维度的可学习嵌入。 是用于补丁嵌入的 维度的线性投影层(例如,)。 编码器最后一层的 词符嵌入 () 用于分类。 这个分类词符是使用全局注意力积累的所有补丁的代表性特征。
每个编码器层的核心(详细信息,请参阅补充)是多头自注意力(MSA)和多层感知(MLP)块。 MSA 层为每个图像块提供全局关注;因此,与 CNN 相比,它对局部特征或邻域模式的归纳偏差较小。 一个图像块或其组合表示对象的语义或空间属性。 因此,我们假设对这些补丁的累积全局注意力将有助于编码有区别的对象特征。 编码器的位置嵌入 () 也有利于学习特征或块的相对位置。 随后,局部 MLP 块使这些图像特征平移不变。 编码器中 MSA 和 MLP 层的组合对属性的重要性、相关性和共现性进行联合编码。 最后,词符作为图像的代表,通过全局上下文整合了多个属性及其相关特征,这有助于对特定对象进行定义和分类类别。
最后一层的[]词符用于OOD检测有两种方式:首先,它被传递到 以获得 softmax 置信度分数,其次它用于潜在空间距离计算,如下一节所述。
3.3 OOD检测
对于 OOD 样本,假设对象的一个或多个属性是不同的(例如损坏的或新的属性)。 因此,OOD 样本应该位于与样本有显着分布偏移的训练分布中。 我们假设这些数据变化将被从 ViT 中提取的表征特征所捕获。 与 ID 样本相比,我们使用 1) 潜在空间嵌入的距离度量和 2) softmax 置信度得分来量化特征或属性的这种变化。
潜在空间距离: 可以在图像的不同空间位置找到对象的多个属性。 在视觉 Transformer 中,图像块是表示每个单独属性的理想候选者。 来自这些属性的全局信息上下文在对象分类中起着至关重要的作用(参见第 4.2 节)。 监督学习(例如交叉熵)应该受益于通过 词符积累特定于对象的语义线索来获取此类全局属性及其上下文。 这激励了具有相似属性和特征的对象类的隐式聚类,这有利于泛化。 为了利用属性相似性,我们计算 词符激活上的类距离。 首先,我们计算训练样本中所有类类别的平均值 ()。 其次,对于测试样本,我们计算其嵌入与每个类的平均嵌入之间的距离。 最后,如果测试样本与其最近类别的距离大于阈值 (),则该测试样本被分类为 OOD。 我们在实验中使用了马哈拉诺比斯距离度量。 对于每个词符,代表性 词符的输出均使用 Transformer 默认层归一化 [Ba 等人(2016)Ba, Kiros, and Hinton] 进行归一化。 它使嵌入分布呈正态,因此马氏距离可以利用正态分布的均值和协方差,而不像欧几里得距离仅使用均值。 样本到均值和协方差分布的马氏距离可以定义为
| (2) |
Softmax 置信度得分: 我们从 到 softmax 获得最终的类别概率。 早期研究表明,基于 Softmax 的后验概率在遇到异常值时会给出错误的高置信度分数[Lee 等人(2018)Lee, Lee, Lee, and Shin]。 先前的工作使用这种后验概率进行 OOD 检测任务,使用二元分类器 [Hendrycks 和 Gimpel(2018)] 或温度缩放 [Liang 等人(2017)Liang, Li, and Srikant ]。 我们认为,对于良好的属性簇表示(如 Transformer 的情况),不需要用于 OOD 检测的额外模块(参见表 1)。 3)。 因此,在这项工作中,我们仅使用 ID 样本中的简单数字阈值 () 来检测异常值,而不使用额外的 OOD 数据进行微调。
4实验
| ID | CIAFR-10 | CIFAR-100 | IM-30 | |||
|---|---|---|---|---|---|---|
| (Out-of-Distribution) | SVHN | CIFAR-100 | SVHN | CIFAR-10 | CUB | Dogs |
| Baseline OOD[Hendrycks and Gimpel(2018)] | 95.9 | 89.8 | 78.9 | 78.0 | - | - |
| ODIN[Liang et al.(2017)Liang, Li, and Srikant] | 96.4 | 89.6 | 60.9 | 77.9 | - | - |
| Mahalanobis[Lee et al.(2018)Lee, Lee, Lee, and Shin] | 99.4 | 90.5 | 94.5 | 55.3 | - | - |
| Residual Flows[Zisselman and Tamar(2020)] | 99.1 | 89.4 | 97.5 | 77.1 | - | - |
| Outlier exposure[Hendrycks et al.(2019a)Hendrycks, Mazeika, and Dietterich] | 98.4 | 93.3 | 86.9 | 75.7 | - | - |
| Rotation pred[Hendrycks et al.(2019c)Hendrycks, Mazeika, Kadavath, and Song] | 98.9 | 90.9 | - | - | - | - |
| Contrastive + Supervised[Winkens et al.(2020)Winkens, Bunel, Roy, Stanforth, Natarajan, Ledsam, MacWilliams, Kohli, Karthikesalingam, Kohl, Cemgil, Eslami, and Ronneberger] | 99.5 | 92.9 | 95.6 | 78.3 | 86.3 | 95.6 |
| CSI[Tack et al.(2020)Tack, Mo, Jeong, and Shin] | 97.9 | 92.2 | - | - | 94.6 | 98.3 |
| SSD+[Sehwag et al.(2021)Sehwag, Chiang, and Mittal] | 99.9 | 93.4 | 98.2 | 78.3 | - | - |
| OODformer(Ours) | 99.5 | 98.6 | 98.3 | 96.1 | 99.7 | 99.9 |
在本节中,我们评估我们方法的性能,并将其与最先进的 OOD 检测方法进行比较。 在秒。 4.1,我们报告了标记的多类 OOD 检测和一类异常检测的结果。 它还包含与最先进方法和 ResNet [He 等人(2016)He、Zhang、Ren 和 Sun] 基线的比较。 在4.2节中,我们在 OOD 检测的背景下研究了架构方差和距离度量对 OODformer 的影响。
PR 和 ROC 下的区域: 单个阈值分数可能无法扩展到所有数据集。 为了使多个数据集的性能均质,应考虑一系列阈值。 因此,我们报告了潜在空间嵌入的精确召回率(PR)和 ROC 曲线(AUROC)下的面积以及 softmax 分数。
设置:我们使用 ViT-B-16 [Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人] 作为我们所有实验和消融研究的基础模型。 ViT 的变体(Base-16、Large-16,嵌入大小为 768 和 1024,补丁大小为 16)和 DeiT(Tiny-16、Small-16,相应嵌入大小为 192 和 384)使用类似的架构,但嵌入不同以及注意力头的数量(附录中提供了完整的详细信息)。 由于与 CNN 相比,Transformer 本质上具有较小的归纳偏差,因此当使用大型数据集进行预训练时,它们可以更有效地利用相似性,如 BERT [Devlin 等人(2018)Devlin, Chang, Lee, and Toutanova] 或 GPT2 [Radford 等人(2019)Radford, Wu, Child, Luan, Amodei, and Sutskever]。 因此,使用大型数据集进行预训练是大多数基于 Transformer 的架构及其用例的必要先决条件。
因此,我们使用的所有模型都按照 [Dosovitskiy 中的建议在 ImageNet [Deng 等人(2009)Deng, Dong, Socher, Li, Li, and Fei-Fei] 上进行预训练等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人]。 监督交叉熵损失用于沿着 SGD 作为优化器进行训练,我们遵循相同的数据增强策略,例如 [Khosla 等人(2020)Khosla, Teterwak, Wang, Sarna, Tian, Isola, Maschinot, Liu, and克里希南]。 ResNet-50 [He 等人(2016)He、Zhang、Ren 和 Sun] 是我们在所有结果和消融研究中使用的默认基于卷积的基线架构。 表征嵌入的基于马哈拉诺比斯距离的分数用作 AUROC 计算的默认分数。
数据集:我们在以下分布数据集上训练了我们的网络:CIFAR-10/-100 [Krizhevsky 等人(2009)Krizhevsky, Hinton, 等人] 和 ImageNet-30 (IM-30) [Hendrycks 等人(2019b)Hendrycks、Mazeika、Kadavath 和 Song]。 作为 CIFAR-10/-100 的 OOD 数据,我们选择了调整大小的 Imagenet (ImageNet_r) [Liang 等人(2017)Liang, Li, and Srikant] 和 LSUN [Hendrycks 等人(2019b) )Hendrycks、Mazeika、Kadavath 和 Song] 和 SVHN [Netzer 等人(2011)Netzer、Wang、Coates、Bissacco、Wu 和 Ng],如 [ 中指定Tack 等人(2020)Tack, Mo, Jeong, and Shin]。 对于 IM-30,我们采用相同的设置 [Tack 等人(2020)Tack、Mo、Jeong 和 Shin],并使用 Places-365 [Zhou 等人(2017) )Zhou, Lapedriza, Khosla, Oliva, and Torralba], DTD [Cimpoi 等人(2014)Cimpoi, Maji, Kokkinos, Mohamed, and Vedaldi], Dogs [Khosla等人(2011)Khosla, Jayadevaprakash, Yao, and Li], Food-101 [Bossard 等人(2014)Bossard, Guillaumin, and Van Gool], Caltech-256 [Griffin 等人(2007)Griffin、Holub 和 Perona],以及 CUB-200 [Wah 等人(2011)Wah、Branson、Welinder、Perona 和 Belongie]。 有关这些数据集的详细信息在附录中给出。
4.1结果
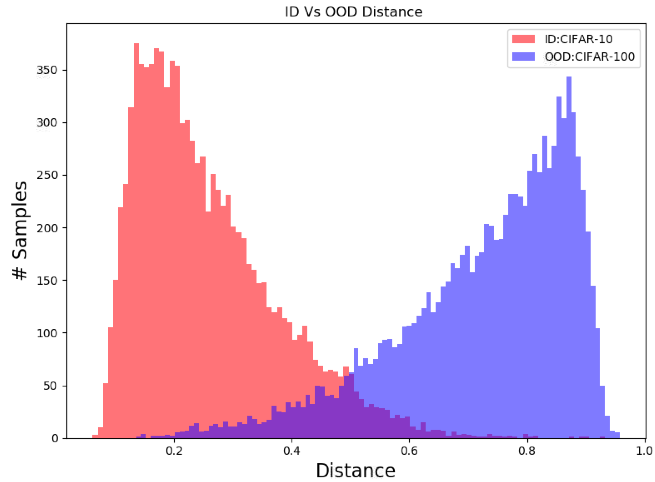
与最先进的比较: 表1表明,即使有简单的交叉熵损失,OODformers 在所有数据集上都取得了新的最先进的结果。 最重要的是,OODformer 在复杂的近 OOD 数据集上取代了其前身,这有力地证明了泛化能力的重大改进。 特别是,使用 CIFAR-10 (ID) 训练的网络将 CIFAR-100 检测为 OOD 样本,反之亦然,这是最具挑战性的任务,因为它们在相似的类别中共享大量共同属性。 例如,“卡车”是 CIFAR-10 中的 ID 样本,而 CIFAR-100 中的“皮卡车”是 OOD 样本,尽管在语义上更接近并且具有许多相似的属性。 这些属性与类的权衡导致以前方法的 AUROC 值显着下降,特别是当 CIFAR-100 是 ID 而 CIFAR-10 是 OOD 时。 当我们分别在 CIFAR-10 和 CIFAR-100 上进行训练时,我们在 AUROC 上获得了显着的 和 增益。 这也可以在图3b 中直观地看出。 这些结果表明,由于来自单个或多个补丁的对象属性的全局上下文化,即使是复杂的近 OOD 分类,OODformer 也具有卓越的表征嵌入的泛化性。
一类异常检测: 与 OOD 检测类似,异常检测涉及某些数据类型或特定的一类。 除此之外,任何类别的特定类别存在都将被视为异常。 在此设置中,我们将 CIFAR-10 中的一类视为分布内的类,其余类视为异常值或离群值。 我们用一个类别(ID)训练我们的网络,其余九个类别成为 OOD,我们对每个类别重复这些实验,类似于 [Tack 等人(2020)Tack, Mo, Jeong, and Shin]。 表 2 显示我们的 OODformer 优于所有现有方法并实现了新的最先进结果。
| Methods | Airplane | Automobile | Bird | Cat | Dear | Dog | Frog | Horse | Ship | Truck | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GT[Golan and El-Yaniv(2018)] | 74.7 | 95.7 | 78.1 | 72.4 | 87.8 | 87.8 | 83.4 | 95.5 | 93.3 | 91.3 | 86.0 |
| Inv-AE[Huang et al.(2019)Huang, Cao, Ye, Li, Zhang, and Lu] | 78.5 | 89.8 | 86.1 | 77.4 | 90.5 | 84.5 | 89.2 | 92.9 | 92 | 85.5 | 86.6 |
| Goad[Bergman and Hoshen(2020)] | 77.2 | 96.7 | 83.3 | 77.7 | 87.8 | 87.8 | 90 | 96.1 | 93.8 | 92 | 88.2 |
| CSI[Tack et al.(2020)Tack, Mo, Jeong, and Shin] | 89.9 | 99.9 | 93.1 | 86.4 | 93.9 | 93.2 | 95.1 | 98.7 | 97.9 | 95.5 | 94.3 |
| SSD[Sehwag et al.(2021)Sehwag, Chiang, and Mittal] | 82.7 | 98.5 | 84.2 | 84.5 | 84.8 | 90.9 | 91.7 | 95.2 | 92.9 | 94.4 | 90.0 |
| OODformer | 92.3 | 99.4 | 95.6 | 93.1 | 94.1 | 92.9 | 96.2 | 99.1 | 98.6 | 95.8 | 95.7 |
| ID | OOD | Emb-Distance | Softmax | ||
| ResNet | OODformer | ResNet | OODformer | ||
| CIFAR-10 | CIFAR-100 | 87.8 | 98.6 | 87.4 | 97.7 |
| Imagenet_r | 91.4 | 98.8 | 90.9 | 96.0 | |
| LSUN | 93.4 | 99.2 | 92.4 | 97.6 | |
| CIFAR-100 | CIFAR-10 | 73.7 | 96.1 | 69.3 | 88.9 |
| Imagenet_r | 79.9 | 92.5 | 72.4 | 86.1 | |
| LSUN | 79.0 | 94.6 | 72.9 | 86.2 | |
| IM-30 | Places-365 | 82.9 | 99.2 | 91.8 | 98.2 |
| DTD | 97.8 | 99.3 | 90.9 | 98.2 | |
| Dogs | 75.29 | 99.9 | 92.3 | 99.0 | |
| Food-101 | 73.44 | 99.2 | 83.2 | 97.2 | |
| Caltech256 | 86.37 | 98.0 | 91.4 | 96.8 | |
| CUB-200 | 87.22 | 99.7 | 91.9 | 99.4 | |
与ResNet的比较: 表3显示了 OODformer 与 ResNet 基线相比的性能。 为了展示通用性和可扩展性,我们使用三个分布数据集来训练我们的网络,并在九个不同的 OOD 数据集上进行测试。 在这里,除了用于 OOD 检测的默认嵌入基于距离的分数之外,我们还使用 softmax 置信度分数。 正如第 1 节中所讨论的,softmax 在用于 CNN 的 ODD 检测时存在决策裕度较差且缺乏泛化能力的问题。 这可以使用我们建议的 OODformer 来解决。 表 3 显示我们基于 softmax 的 OOD 检测显着且一致地优于 ResNet,并实现了高达 的改进。 我们使用嵌入相似性的默认 AUROC 分数也大大优于我们的基线。 这一结果证明了客观性属性以及通过全局注意力对其相关属性的利用在异常值检测中发挥着最关键的作用。 它支持了我们的假设,即对于异常值检测,Transformer 可以充当事实上的特征提取器,而无需任何附加功能。


4.2 OODformer剖析
在本节中,我们通过消融研究广泛分析不同环境的注意力和影响。 我们使用 CIFAR-10 作为 ID,使用 ViT-B-16 作为实验的默认模型架构。
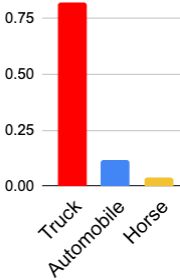
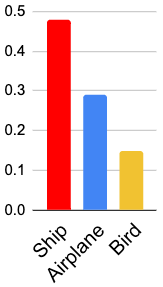
全局背景和自注意力: 为了理解视觉转换器如何区分 ID 和 OOD,我们分析了它的自注意力和嵌入空间。 图2描述了ID和OOD样本的示例以及从最后一层收集的注意力图。 自注意力从定义对象的所有相关补丁中积累信息。 对于ID样本(“卡车”),词符注意力主要集中在感兴趣的对象上,而其他选定的补丁则根据与它们相似的属性(例如颜色或纹理)来关注。 然而,在 OOD 样本的情况下,对象“山”对于网络来说是未知的,词符注意力主要集中在天空和水上,而我们对其他补丁进行了与之前类似的观察。 这种注意力错位和已知对象属性的缺乏导致相似性得分较低,并且仅仅因为背景相似性而预测错误的类别。
| Model | Acc. | CIFAR100 | Imagenet_r | LSUN |
| Resnet-34 | 95.6 | 87.2 | 89.7 | 91.4 |
| Resnet-50 | 95.4 | 87.5 | 90.0 | 91.7 |
| Resnet-101 | 95.7 | 87.8 | 91.4 | 93.4 |
| Resnet-34(PT) | 97.0 | 89.5 | 93.8 | 96.0 |
| Resnet-50(PT) | 97.1 | 89.9 | 94.1 | 96.1 |
| Resnet-101(PT) | 98.0 | 90.1 | 94.6 | 96.0 |
| DeiT-T-16 | 95.4 | 94.4 | 95.2 | 97.3 |
| DeiT-S-16 | 97.6 | 96.6 | 96.3 | 98.4 |
| ViT-B-16 | 98.6 | 98.6 | 98.8 | 99.2 |
| ViT-L-16 | 98.8 | 99.1 | 99.2 | 99.4 |
图2也显示了对象性及其相关属性的分层方式探索对于OOD距离得分至关重要。 这也可以从图 3b 中推断出来,我们注意到 Transformer 不仅减少了 ID 样本的类内距离,还增加了 OOD 样本与 ID 类平均值的距离。
ResNet 与 ViT: 本节检查模型复杂性或模型表达力对 OOD 或异常值检测的影响。 我们对 ViT 的多个变体与 ResNet 基线的变体(顶行)进行了比较,如表 4 所示。 由于 ViT 和 DeiT 的所有变体都是在 ImageNet 上预训练的,为了进行比较,我们还评估了在 ImageNet 上预训练的 ResNet 变体。 由于所有预训练的 ResNet 模型都是使用较大的图像尺寸(ImageNet 为 224x224 像素)进行训练的,因此为了有效利用预训练,需要进行放大。 我们使用 7 倍的放大倍数(从 32 到 224)在训练分布数据集上对 ResNet 进行预训练。
-
•
ResNet 基线: 表 4 显示 Deit-T-16 是所有 ViT 变体中最轻的,其尺寸比所有 ResNet 基线变体小得多,在 OOD 检测上表现明显更好(94.4 相比 ViT 的 87.8) CIFAR-100 的 R-101)。 此外,尽管精度相似,但与所有其他 ViT 变体一样,DeiT-T-16 在 OOD 检测方面明显优于其他 ViT 变体。
-
•
在 ImageNet 上预训练的 ResNet Baseline : 基于 Transformer 的架构依赖于大规模数据的训练来实现卓越的性能。 ViT 还需要在 ImageNet 上进行大规模预训练,以获得类似于一些著名的基于 Transformer 的架构(如 BERT[Devlin 等人(2018)Devlin, Chang, Lee, and Toutanova])的高效性能,GPT2[Radford 等人(2019)Radford, Wu, Child, Luan, Amodei, and Sutskever]。 此外,最近的一些工作[Reiss 等人(2021)Reiss, Cohen, Bergman, and Hoshen]表明,卷积的预训练可以为异常值检测提供更好的性能。 因此,为了展示 OODformer 的真实性能,我们将其与 ResNets(中间行)等预训练的卷积模型进行比较。 表4表明,使用高档图像进行微调可以提供良好的准确性,但相对于 OOD 检测的增益有限。 预训练的 ResNet 遵循类似的趋势,因为与 ViT 变体相比,增加模型容量等基线模型对 OOD 检测具有边际影响。 我们发现的关键观察之一,除了预训练之外,图像的放大有助于在准确性和 OOD 检测得分方面获得更高的性能。
根据上述基于表4的讨论,我们可以清楚地观察到,无论其准确性、图像大小如何,从 ResNet 中提取的预训练特征与 ViT 的所有变体相比都提供了次优的性能。 此外,随着模型复杂性的增加,ResNet 的性能达到稳定水平,而 ViT 的性能随着表达能力的增加而不断提高。 这清楚地证明了对象性上下文的重要性、对象属性的作用以及它们在第 1 节中假设的相互关联(例如,空间)。 这些观察结果让我们相信,Transformer 架构比经典 CNN 更适合 OOD 检测任务,主要是因为归纳偏差较小,使用注意力进行对象属性积累。
(a) (b)
5结论
在本文中,我们进行了利用视觉 Transformer(即 OODformer)进行 OOD 检测的早期尝试。 与依赖于自定义损失或负样本挖掘的先前方法不同,我们可以使用 Transformer 的多跳上下文聚合将 OOD 检测制定为特定于对象的属性累积问题。 这种简单的方法不仅具有可扩展性和鲁棒性,而且大大优于所有现有方法。 与其他方法相比,OODformer 也更适合在安全关键型应用中部署,因为它简单且可解释性更高。 基于我们的工作,自我监督、预训练和对比学习方面的新兴方法将在未来与 OODformer 结合进行研究。
致谢
我们衷心感谢 Suprosnna Shit 对手稿的建议和修改。
参考
- [Ba et al.(2016)Ba, Kiros, and Hinton] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [Bergman and Hoshen(2020)] Liron Bergman and Yedid Hoshen. Classification-based anomaly detection for general data. arXiv preprint arXiv:2005.02359, 2020.
- [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. In European conference on computer vision, pages 446–461. Springer, 2014.
- [Carion et al.(2020)Carion, Massa, Synnaeve, Usunier, Kirillov, and Zagoruyko] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer, 2020.
- [Caron et al.(2021)Caron, Touvron, Misra, Jégou, Mairal, Bojanowski, and Joulin] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294, 2021.
- [Charpentier and Günnemann(2020)] Daniel Zügner Charpentier, Bertrand and Stephan Günnemann. Posterior network: Uncertainty estimation without ood samples via density-based pseudo-counts. In Advances in Neural Information Processing Systems 33. Curran Associates, Inc., 2020.
- [Chen et al.(2020a)Chen, Kornblith, Norouzi, and Hinton] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A Simple Framework for Contrastive Learning of Visual Representations. In International Conference on Machine Learning, pages 1597–1607. PMLR, November 2020a.
- [Chen et al.(2020b)Chen, Kornblith, Swersky, Norouzi, and Hinton] Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. Big Self-Supervised Models are Strong Semi-Supervised Learners. arXiv:2006.10029 [cs, stat], June 2020b.
- [Chen et al.(2020c)Chen, Fan, Girshick, and He] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved Baselines with Momentum Contrastive Learning. arXiv:2003.04297 [cs], March 2020c. Comment: Tech report, 2 pages + references.
- [Chuang et al.(2020)Chuang, Robinson, Yen-Chen, Torralba, and Jegelka] Ching-Yao Chuang, Joshua Robinson, Lin Yen-Chen, Antonio Torralba, and Stefanie Jegelka. Debiased Contrastive Learning. arXiv:2007.00224 [cs, stat], July 2020.
- [Cimpoi et al.(2014)Cimpoi, Maji, Kokkinos, Mohamed, and Vedaldi] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3606–3613, 2014.
- [Deng et al.(2009)Deng, Dong, Socher, Li, Li, and Fei-Fei] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 10.1109/CVPR.2009.5206848.
- [Devlin et al.(2018)Devlin, Chang, Lee, and Toutanova] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [Dosovitskiy et al.(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, et al.] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [Elsayed et al.(2018)Elsayed, Krishnan, Mobahi, Regan, and Bengio] Gamaleldin F Elsayed, Dilip Krishnan, Hossein Mobahi, Kevin Regan, and Samy Bengio. Large margin deep networks for classification. arXiv preprint arXiv:1803.05598, 2018.
- [Golan and El-Yaniv(2018)] Izhak Golan and Ran El-Yaniv. Deep Anomaly Detection Using Geometric Transformations. arXiv:1805.10917 [cs, stat], November 2018.
- [Goyal et al.(2017)Goyal, Dollár, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia, and He] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- [Griffin et al.(2007)Griffin, Holub, and Perona] Gregory Griffin, Alex Holub, and Pietro Perona. Caltech-256 object category dataset. 2007.
- [He et al.(2016)He, Zhang, Ren, and Sun] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [Hendrycks and Gimpel(2018)] Dan Hendrycks and Kevin Gimpel. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. arXiv:1610.02136 [cs], October 2018.
- [Hendrycks et al.(2019a)Hendrycks, Mazeika, and Dietterich] Dan Hendrycks, Mantas Mazeika, and Thomas Dietterich. Deep Anomaly Detection with Outlier Exposure. arXiv:1812.04606 [cs, stat], January 2019a. Comment: ICLR 2019; PyTorch code available at https://github.com/hendrycks/outlier-exposure.
- [Hendrycks et al.(2019b)Hendrycks, Mazeika, Kadavath, and Song] Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, and Dawn Song. Using self-supervised learning can improve model robustness and uncertainty. arXiv preprint arXiv:1906.12340, 2019b.
- [Hendrycks et al.(2019c)Hendrycks, Mazeika, Kadavath, and Song] Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, and Dawn Song. Using Self-Supervised Learning Can Improve Model Robustness and Uncertainty. In H. Wallach, H. Larochelle, A. Beygelzimer, F. dAlché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 15663–15674. Curran Associates, Inc., October 2019c. Comment: NeurIPS 2019; code and data available at https://github.com/hendrycks/ss-ood.
- [Hildebrandt et al.(2020)Hildebrandt, Li, Koner, Tresp, and Günnemann] Marcel Hildebrandt, Hang Li, Rajat Koner, Volker Tresp, and Stephan Günnemann. Scene graph reasoning for visual question answering. arXiv preprint arXiv:2007.01072, 2020.
- [Hoffer et al.(2017)Hoffer, Hubara, and Soudry] Elad Hoffer, Itay Hubara, and Daniel Soudry. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. arXiv preprint arXiv:1705.08741, 2017.
- [Hsu et al.(2020)Hsu, Shen, Jin, and Kira] Yen-Chang Hsu, Yilin Shen, Hongxia Jin, and Zsolt Kira. Generalized ODIN: Detecting Out-of-Distribution Image Without Learning From Out-of-Distribution Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10951–10960, 2020.
- [Huang et al.(2019)Huang, Cao, Ye, Li, Zhang, and Lu] Chaoqing Huang, Jinkun Cao, Fei Ye, Maosen Li, Ya Zhang, and Cewu Lu. Inverse-transform autoencoder for anomaly detection. 2019.
- [Khosla et al.(2011)Khosla, Jayadevaprakash, Yao, and Li] Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao, and Fei-Fei Li. Novel dataset for fine-grained image categorization: Stanford dogs. In Proc. CVPR Workshop on Fine-Grained Visual Categorization (FGVC), volume 2. Citeseer, 2011.
- [Khosla et al.(2020)Khosla, Teterwak, Wang, Sarna, Tian, Isola, Maschinot, Liu, and Krishnan] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised Contrastive Learning. arXiv:2004.11362 [cs, stat], April 2020.
- [Koner et al.(2020)Koner, Sinhamahapatra, and Tresp] Rajat Koner, Poulami Sinhamahapatra, and Volker Tresp. Relation transformer network. arXiv preprint arXiv:2004.06193, 2020.
- [Koner et al.(2021a)Koner, Li, Hildebrandt, Das, Tresp, and Günnemann] Rajat Koner, Hang Li, Marcel Hildebrandt, Deepan Das, Volker Tresp, and Stephan Günnemann. Graphhopper: Multi-hop scene graph reasoning for visual question answering. In International Semantic Web Conference, pages 111–127. Springer, 2021a.
- [Koner et al.(2021b)Koner, Sinhamahapatra, and Tresp] Rajat Koner, Poulami Sinhamahapatra, and Volker Tresp. Scenes and surroundings: Scene graph generation using relation transformer. arXiv preprint arXiv:2107.05448, 2021b.
- [Krizhevsky et al.(2009)Krizhevsky, Hinton, et al.] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [Lee et al.(2018)Lee, Lee, Lee, and Shin] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks. arXiv:1807.03888 [cs, stat], October 2018. Comment: Accepted in NIPS 2018.
- [Li et al.(2020)Li, Zhou, Xiong, Socher, and Hoi] Junnan Li, Pan Zhou, Caiming Xiong, Richard Socher, and Steven C. H. Hoi. Prototypical Contrastive Learning of Unsupervised Representations. arXiv:2005.04966 [cs], July 2020.
- [Liang et al.(2017)Liang, Li, and Srikant] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv preprint arXiv:1706.02690, 2017.
- [Liu et al.(2016)Liu, Wen, Yu, and Yang] Weiyang Liu, Yandong Wen, Zhiding Yu, and Meng Yang. Large-margin softmax loss for convolutional neural networks. In ICML, volume 2, page 7, 2016.
- [Liu et al.(2021)Liu, Lin, Cao, Hu, Wei, Zhang, Lin, and Guo] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030, 2021.
- [Nalisnick et al.(2019)Nalisnick, Matsukawa, Teh, Gorur, and Lakshminarayanan] Eric Nalisnick, Akihiro Matsukawa, Yee Whye Teh, Dilan Gorur, and Balaji Lakshminarayanan. Do Deep Generative Models Know What They Don’t Know? arXiv:1810.09136 [cs, stat], February 2019. Comment: ICLR 2019.
- [Netzer et al.(2011)Netzer, Wang, Coates, Bissacco, Wu, and Ng] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [Pidhorskyi et al.(2018)Pidhorskyi, Almohsen, and Doretto] Stanislav Pidhorskyi, Ranya Almohsen, and Gianfranco Doretto. Generative Probabilistic Novelty Detection with Adversarial Autoencoders. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31, pages 6822–6833. Curran Associates, Inc., 2018.
- [Radford et al.(2019)Radford, Wu, Child, Luan, Amodei, and Sutskever] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- [Reiss et al.(2021)Reiss, Cohen, Bergman, and Hoshen] Tal Reiss, Niv Cohen, Liron Bergman, and Yedid Hoshen. Panda: Adapting pretrained features for anomaly detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2806–2814, 2021.
- [Ren et al.(2019)Ren, Liu, Fertig, Snoek, Poplin, Depristo, Dillon, and Lakshminarayanan] Jie Ren, Peter J. Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark Depristo, Joshua Dillon, and Balaji Lakshminarayanan. Likelihood ratios for out-of-distribution detection. In H. Wallach, H. Larochelle, A. Beygelzimer, F. dAlché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 14707–14718. Curran Associates, Inc., 2019. Comment: Accepted to NeurIPS 2019.
- [Sehwag et al.(2021)Sehwag, Chiang, and Mittal] Vikash Sehwag, Mung Chiang, and Prateek Mittal. Ssd: A unified framework for self-supervised outlier detection. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=v5gjXpmR8J.
- [Serrà et al.(2019)Serrà, Álvarez, Gómez, Slizovskaia, Núñez, Luque, Slizovskaia, José, Nú, ñ, ez, and Luque] Joan Serrà, David Álvarez, Vicenç Gómez, Olga Slizovskaia, José F. Núñez, Jordi Luque, Olga Slizovskaia, José, F. Nú, ñ, ez, and Jordi Luque. Input Complexity and Out-of-distribution Detection with Likelihood-based Generative Models. In Proc. ICLR 2020, September 2019.
- [Smith(2017)] Leslie N Smith. Cyclical learning rates for training neural networks. In 2017 IEEE winter conference on applications of computer vision (WACV), pages 464–472. IEEE, 2017.
- [Tack et al.(2020)Tack, Mo, Jeong, and Shin] Jihoon Tack, Sangwoo Mo, Jongheon Jeong, and Jinwoo Shin. CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances. arXiv:2007.08176 [cs, stat], July 2020. Comment: 23 pages; Code is available at https://github.com/alinlab/CSI.
- [Touvron et al.(2020)Touvron, Cord, Douze, Massa, Sablayrolles, and Jégou] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers and distillation through attention. arXiv preprint arXiv:2012.12877, 2020.
- [Vaswani et al.(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
- [Wah et al.(2011)Wah, Branson, Welinder, Perona, and Belongie] Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011.
- [Winkens et al.(2020)Winkens, Bunel, Roy, Stanforth, Natarajan, Ledsam, MacWilliams, Kohli, Karthikesalingam, Kohl, Cemgil, Eslami, and Ronneberger] Jim Winkens, Rudy Bunel, Abhijit Guha Roy, Robert Stanforth, Vivek Natarajan, Joseph R. Ledsam, Patricia MacWilliams, Pushmeet Kohli, Alan Karthikesalingam, Simon Kohl, Taylan Cemgil, S. M. Ali Eslami, and Olaf Ronneberger. Contrastive Training for Improved Out-of-Distribution Detection. arXiv:2007.05566 [cs, stat], July 2020.
- [Zhou et al.(2017)Zhou, Lapedriza, Khosla, Oliva, and Torralba] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017.
- [Zisselman and Tamar(2020)] Ev Zisselman and Aviv Tamar. Deep residual flow for out of distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13994–14003, 2020.
- [Zong et al.(2018)Zong, Song, Min, Cheng, Lumezanu, Cho, and Chen] Bo Zong, Qi Song, Martin Renqiang Min, Wei Cheng, Cristian Lumezanu, Daeki Cho, and Haifeng Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In International Conference on Learning Representations, 2018.
附录 A ViT 架构
Vision Transformer [Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人] 使用 Transformer 编码器 [Vaswani 等人( 2017)Vaswani、Shazeer、Parmar、Uszkoreit、Jones、Gomez、Kaiser 和 Polosukhin] 用于基于补丁的图像分类。 ViT 的核心依赖于多头自注意力(MSA)和多层感知(MLP)来处理图像块序列。
多头自注意力:
注意力机制被表述为一种可训练的基于加权和的方法。 人们可以将自注意力定义为
| (3) |
其中 是一组可学习的查询、键和值, 是嵌入维度。 使用从等式 1 中指定的标记序列获得的内积,将查询向量 与键 相乘。 1。 查询词符的重要特征是通过对查询向量和键向量的乘积进行 softmax 动态学习的。 然后将其与值向量 相乘,该值向量根据学习到的重要性合并了其他 Token 的特征。
多层感知:
Transformer 编码器在每个 MSA 层之上使用前馈网络 (FFN)。 FFN 层由两个由 GleU 激活分隔的线性层组成。 FFN 使用残差连接处理来自 MSA 块的特征,并通过层归一化[Ba 等人(2016)Ba、Kiros 和 Hinton] 进行归一化。 与 MSA(MSA 充当全局层)不同,每个 FFN 层对于每个 patch 都是局部的,因此 FFN 使编码器图像平移不变。
附录B实施细节
我们的骨干 ViT [Dosovitskiy 等人(2020)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, 等人] 和 DeiT [Touvron 等人( 2020)Touvron、Cord、Douze、Massa、Sablayrolles 和 Jégou] 在 ImageNet 上进行预训练,并使用 SGD 优化器在分布内数据集中进行微调,批量大小为 256,图像大小为 。 我们使用学习率 和循环学习率调度器 [Smith(2017)],权重衰减= 并训练 50 个时期。 我们遵循与[Khosla 等人(2020)Khosla, Teterwak, Wang, Sarna, Tian, Isola, Maschinot, Liu, and Krishnan]相同的数据增强方案。
B.1模型详细信息
我们使用 ViT 和 DeiT 的多个变体,主要是因为 DeiT 提供更轻的模型,而 ViT 主要关注哈维尔模型。 用更轻的变体增强离群值检测性能的想法将支持我们的假设,即使用全局注意力探索对象的属性及其相关性在 OOD 检测中起着至关重要的作用。 相比之下,较重的变体将提供更大的模型容量,以提高 OODformer 的性能。 桌子。 4 展示了 OODformer 具有多个骨干变体的性能,支持我们的假设。 特别是 DeiT (T-16) 最小变体的显着性能提升支持了我们的主张。 表5显示了它们的参数、层数、隐藏或嵌入大小、MLP大小、注意力头数量的变化。
| Model | Prams | #Layers | Hidden Size | MLP Size | #Heads |
|---|---|---|---|---|---|
| DeiT-T-16 | 5 | 12 | 192 | 768 | 3 |
| DeiT-S-16 | 22 | 12 | 384 | 1536 | 6 |
| ViT-B-16 | 86.5 | 12 | 768 | 3072 | 12 |
| ViT-L-16 | 307 | 24 | 1024 | 4096 | 16 |
B.2 数据集详细信息
在分布内数据集中,CIFAR-10/-100 [Krizhevsky 等人(2009)Krizhevsky, Hinton, 等人] 由 50K 训练图像和 10K 测试图像组成,对应 10 和 100 个类别。 CIFAR-100 数据集还包含其中所有一百个类的二十个超类。 尽管 CIFAR-10 和 CIFAR-100 对于任何类别都没有重叠,但某些类别共享相似的属性或概念(例如“卡车”和“皮卡车”),如第 4.2 节中所述。 由于这种密切的语义相似性,这两个数据集提出了最具挑战性的近 OOD 问题,并且 OODformer 在这种情况下的性能如表 1 所示。 另一个分布内数据集 ImageNet-30 [Hendrycks 等人(2019b)Hendrycks, Mazeika, Kadavath, and Song] 是 ImageNet[Deng 等人(2009)Deng, Dong、Socher、Li、Li 和 Fei-Fei],有 30 个类,包含 39K 训练图像和 3K 测试图像。
用于 CIFAR-10/-100 的 Out-Of-Distribution 数据集如下:街景房屋号码或 SHVN [Netzer 等人(2011)Netzer, Wang, Coates, Bissacco, Wu, and Ng ] 包含大约 26K 十位数字的测试图像,LSUN [Hendrycks 等人(2019b)Hendrycks, Mazeika, Kadavath, and Song] 包含十个不同场景的 10K 测试图像,ImageNet- resize [Hendrycks 等人(2019b)Hendrycks, Mazeika, Kadavath, and Song] 也是 ImageNet 的一个子集,包含 10K 图像和 200 个类。 对于多类 ImageNet-30,我们遵循 [Tack 等人(2020)Tack, Mo, Jeong, and Shin] 中指定的相同 OOD 数据集,它们是: Places-365 [Zhou 等人(2017)Zhou, Lapedriza, Khosla, Oliva, and Torralba],可描述纹理数据集[Cimpoi 等人(2014)Cimpoi, Maji, Kokkinos, Mohamed, and Vedaldi]、Food-101 [Bossard 等人(2014)Bossard、Guillaumin 和 Van Gool]、Caltech-256 [Griffin 等人(2007)Griffin、Holub 和 Perona] t4> 和 CUB-200 [Wah 等人(2011)Wah, Branson, Welinder, Perona, and Belongie]。
附录C消融和解释
除了第 2 节中提供的分析之外。 4.2,我们在各种批量大小、时期上消融 OODformer 并分析嵌入空间中的集群。
(a) (b)
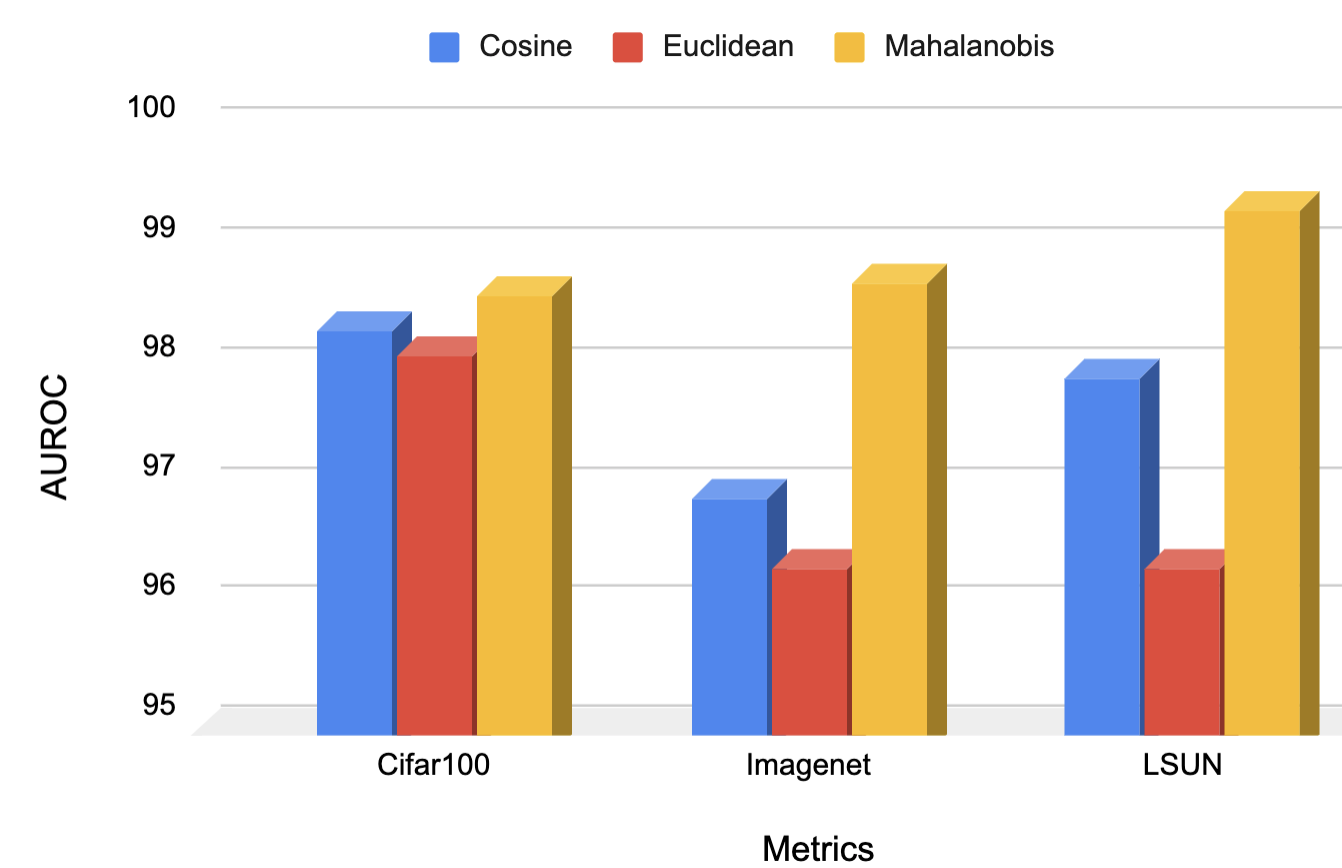
数字。 4a,证明大批量有助于 OOD 检测,尽管我们观察到它不会显着影响分布内测试集的准确性。 一个直观的原因可能是大批量可以提高泛化能力[Hoffer 等人(2017)Hoffer, Hubara, and Soudry],这使得网络能够泛化有助于异常值识别的特定于对象的属性。 尽管有这样的增益,我们观察到 OODformer 在所有批量大小上保持相对稳定,OOD 检测精度 。 然而,随着批量大小的增加,AUROC 的增益逐渐变得停滞,这表明需要使用线性缩放进一步调整学习率[Goyal 等人(2017)Goyal, Dollár, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch、Jia 和 He]。
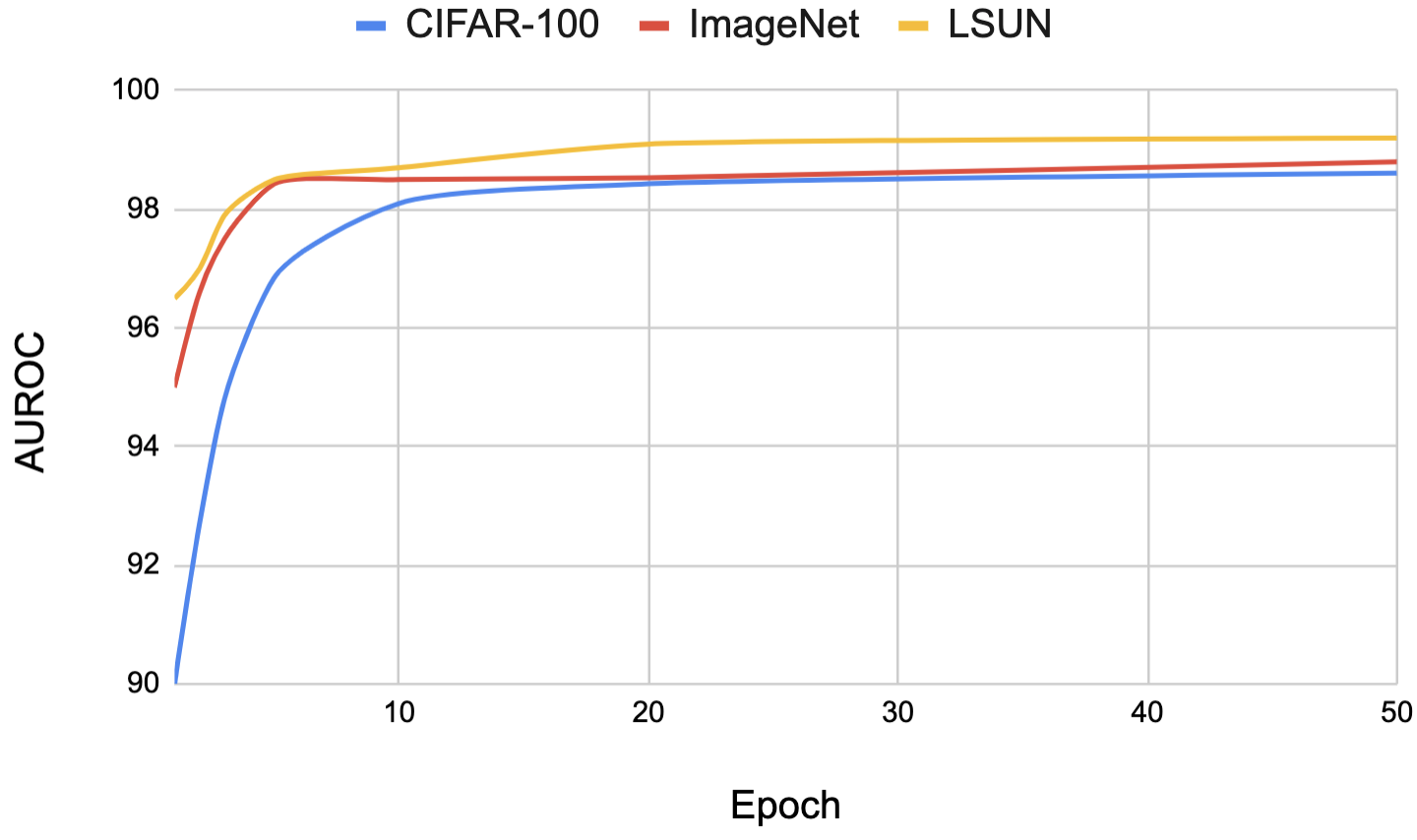
图。 4b,显示异常值检测精度随着纪元数量的增加而增加。 重要的观察之一是更容易的 OOD 数据集(例如 LSUN、ImageNet)可以用更少的 epoch 来区分,而像 CIFAR-100 这样困难的 OOD 数据集需要更多时间。 与最先进的卷积 [Hendrycks 等人(2019c)Hendrycks, Mazeika, Kadavath, and Song] 或对比 [Sehwag 等人(2021)Sehwag, Jiang 和 Mittal],我们提出的 OODformer 收敛速度明显更快,即使批量大小要小得多。 这一令人鼓舞的结果展示了 OODfromer 在现实场景中的功效,并指导 Transformer 在异常值检测方面的进一步研究范围。
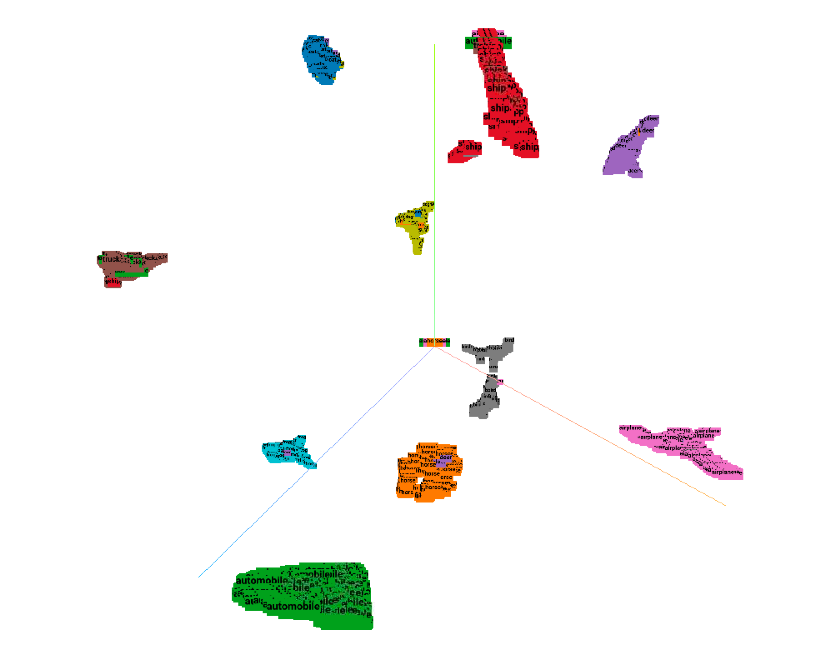
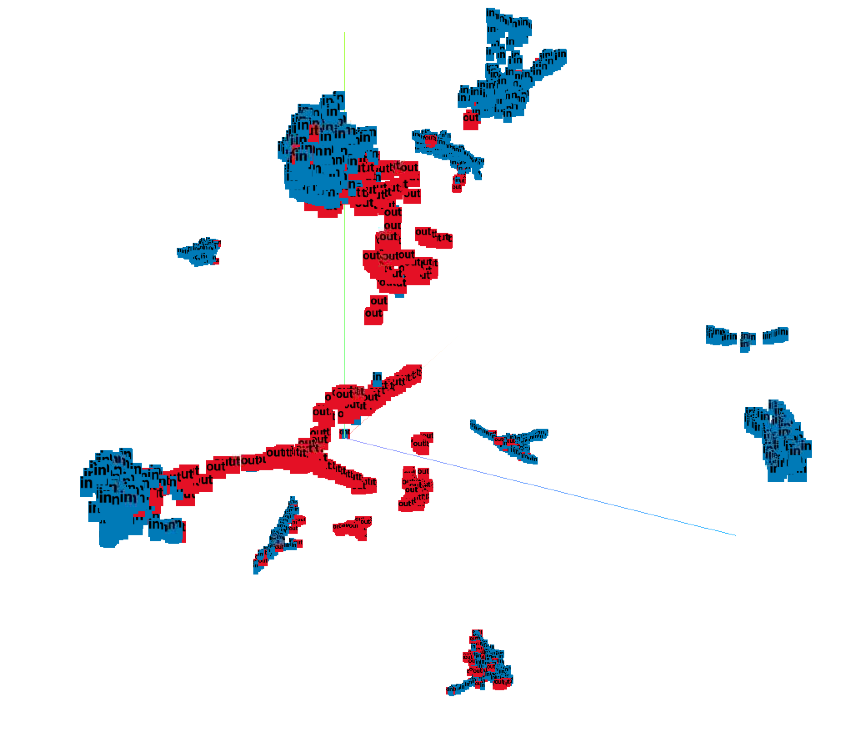
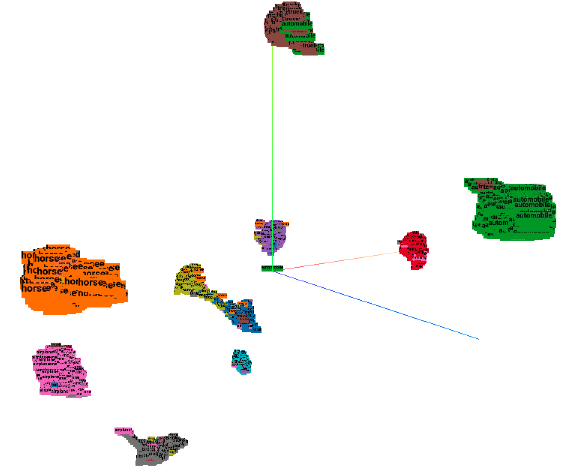
流形分析: 图5a和6a显示了OODformer和ResNet-50基线,CIFAR-10中的所有类都形成了一个紧凑的簇,如其相应的UMAP所示。 正如第 2 节中所讨论的。 3,我们可以观察到监督损失有助于形成紧凑的聚类,只要 ID 和 OOD 数据之间存在可分离性,就可以将其用于类条件 OOD 检测。 数字。 5b,表明对于 OODformer,嵌入空间中的 OOD 样本由于其较大的分布偏移或缺乏特定于对象的属性而远离分布内样本的任何聚类中心。 我们的距离度量有效地利用了 ID 和 OOD 样本之间距离的这种变化。 然而,图 6 表明,尽管能够为 ID 样本形成独特的聚类,但我们的 ResNet 基线未能保持 ID 和 OOD 样本之间的清晰分离。
此 UMAP 分析支持我们之前对表 4 结果的假设,尽管 ID 样本的分类精度较低或相似,但从 Transformer 提取的特征对于 OOD 检测具有更独特的可分离特征。
(a) (b)

(a) (b)