基于场景的随机运动预测
摘要
在计算机视觉领域,一个长期目标是捕获、建模和逼真地合成人类行为。 具体来说,我们的目标是通过从数据中学习,使虚拟人能够在杂乱的室内场景中导航,并自然地与物体交互。 这种具身行为在虚拟现实、电脑游戏和机器人领域都有应用,而合成行为可以被用作训练数据。 这个问题具有挑战性,因为真实的人类运动是多种多样的,并且会适应场景。 例如,一个人可以坐在沙发上或躺在沙发上,有很多地方和不同的风格。 我们必须对这种多样性进行建模,以合成逼真地执行人与场景交互的虚拟人。 我们提出了一种新颖的数据驱动、随机运动合成方法,该方法对以目标物体执行给定动作的不同风格进行建模。 我们的基于场景的运动预测方法 (SAMP) 能够推广到各种几何形状的目标物体,同时使角色能够在杂乱的场景中导航。 为了训练 SAMP,我们收集了涵盖各种坐姿、躺姿、走姿和跑姿的 MoCap 数据。 我们在复杂的室内场景中展示了 SAMP,并取得了优于现有解决方案的性能。 代码和数据可在 https://samp.is.tue.mpg.de 上获取,供研究使用。
![[Uncaptioned image]](x1.png)
1 简介
计算机视觉领域在 3D 场景理解和捕捉 3D 人体运动方面取得了重大进展,但合成 3D 场景中的人员的工作较少。 然而,这两个子领域的进步为虚拟世界中的具身智能体(例如 [35, 55, 42, 56])和将人放置到场景中(例如 [6, 21])提供了工具,并引起了人们的兴趣。 然而,创建像真人一样移动和行动的虚拟人具有挑战性,需要解决许多较小但困难的问题,例如对看不见的环境的感知、合理的运动建模以及与复杂场景的具身互动。 尽管由于大型数据集的可用性 [33, 50, 7, 45, 38] 在人体运动建模方面 [23, 32] 取得了进展,但现实地合成在 3D 场景中移动和交互的虚拟人,仍然是一个很大程度上未解决的问题。
想象一下,在一个杂乱的场景中,指示一个虚拟人“坐在沙发上”,如 图 1 所示。 为了实现这个目标,角色需要执行一系列复杂的操作。 首先,它应该在场景中导航,到达目标物体,同时避开场景中其他物体的碰撞。 接下来,角色需要在沙发上选择一个 接触点,这将导致面向正确方向的合理坐姿。 最后,如果角色多次执行此操作,运动应该有自然的变化,模仿现实世界的人与场景的交互;例如,坐在沙发的不同部分,以不同的风格,例如交叉腿,手臂姿势不同,等等。 实现这些目标需要一个系统来共同推理场景几何形状,在循环(例如,步行)和非循环(例如,坐着)运动之间平滑过渡,以及对人与场景交互的多样性进行建模。
为此,我们提出了 SAMP 用于 场景感知运动预测。 SAMP 是一个随机模型,它以 3D 场景作为输入,采样有效的交互目标,并生成目标条件的和场景感知的运动序列,描述角色与场景之间逼真的动态交互。 SAMP 的核心是一个新颖的自回归条件变分自动编码器 (cVAE),称为 MotionNet。 给定一个目标物体和一个动作,MotionNet 在每个帧中采样一个随机的潜在向量,以使下一个姿势同时依赖于角色的先前姿势和随机向量。 这使得 MotionNet 能够在执行目标动作时模拟各种风格。 给定目标物体的几何形状,SAMP 进一步使用另一个新颖的神经网络,称为 GoalNet,以在目标物体上生成多个合理的接触点和方向(例如,沙发坐垫上的不同位置和坐姿)。 此组件使 SAMP 能够跨越具有不同几何形状的对象进行泛化。 最后,为了确保角色在杂乱的场景中到达目标时避开障碍物,我们使用显式路径规划算法(A* 搜索)来预先计算角色的起始位置和目标之间的无障碍路径。 这条分段线性路径包含多个路点,SAMP 将其视为中间目标,以驱动角色在场景中移动。 SAMP 以 fps 的实时速度运行。 据我们所知,这些单独的组件使 SAMP 成为第一个解决在杂乱环境中生成描绘逼真的人机交互的各种动态运动序列问题的系统。
训练 SAMP 需要一个包含丰富多样的人物场景交互的数据集。 现有的大型 MoCap 数据集主要以运动为主,而少数交互示例缺乏多样性。 此外,传统的 MoCap 侧重于身体,很少捕捉场景。 因此,我们捕获了一个新的数据集,涵盖了与多个对象进行的各种人机交互。 在每个运动序列中,我们使用高分辨率光学标记 MoCap 系统跟踪身体运动和物体。 该数据集可用于研究目的。
我们的贡献是:(1)一种新颖的随机模型,用于实时合成各种以目标为导向的人物场景交互。 (2)一种新方法,用于根据目标物体几何形状对合理的动作相关目标位置和身体方向进行建模。 (3)将显式路径规划融入变分运动合成网络,使导航在杂乱场景中成为可能。 (4)一个新的 MoCap 数据集,其中包含各种人机交互。
2 相关工作
交互合成: 分析和合成合理的人机交互场景一直受到计算机视觉和图形学界的广泛关注。 针对预测物体功能 [16, 66]、可供性分析 [18, 53] 和合成静态人机交互 [16, 18, 21, 27, 41, 62, 64],已经提出了各种算法。
然而,一个鲜为人知的领域涉及生成动态的人机交互。 早期的工作 [28] 专注于在捕获运动的相同环境中合成角色的运动,后续工作 [29, 43, 2, 26] 从大型数据库中汇集运动序列,以合成与新环境或角色的交互。 然而,这些方法需要大型数据库和昂贵的最近邻匹配。
人机交互的一个重要子类别涉及运动,其中角色必须根据地形的变化做出相应的脚部放置。 相位功能神经网络 [23] 通过使用表示运动循环状态的引导信号(即相位)取得了令人印象深刻的结果。 张等人 [61] 将这一想法扩展到使用专家混合 [25, 13, 60] 作为运动预测网络。 另一个门控网络用于在运行时预测专家混合权重。 与我们的工作更密切相关的是神经状态机 (NSM) [47],它扩展了相位标签和专家网络的概念,以模拟人机交互,例如坐、提、开。 虽然 NSM 是一种强大的方法,但它不会生成这种交互的变体,这也是我们关键贡献之一。 我们的实验也表明,NSM 经常无法避免 3D 角色和物体在杂乱场景中的交叉(第 5.2 节)。 此外,训练 NSM 需要耗时的手动操作,而且往往需要对非周期性动作的相位进行模糊的标记。 Starke 等人 [48] 提出了一种方法,用于在双人篮球比赛的背景下自动提取每个身体部位的局部相位变量。 然而,将局部相位扩展到非周期性动作并非易事。 我们发现使用计划采样 [5] 提供了一种在没有阶段标签的情况下生成平滑过渡的替代方法。 最近,Wang 等人 [52] 引入了一个分层框架来合成人与场景的交互。 他们生成场景中的子目标位置,预测每个子目标的位置,并合成这些位置之间的运动。 该方法需要一个后优化框架来确保平滑性和稳健的足部接触,并阻止与场景发生穿透。 Corona 等人 [11] 使用语义图来模拟人与物体的关系,然后使用 RNN 来预测人与物的运动。
一种替代方法是使用强化学习 (RL) 来构建一个控制策略来模拟交互。 Merel 等人 [37] 和 Eom 等人 [14] 专注于从自我视角的视觉中捕捉球。 Chao 等人 [10] 训练子任务控制器和元控制器来执行子任务以完成坐姿任务。 然而,与 SAMP 相反,他们的方法无法实现目标位置和方向的变化。 此外,与许多基于 RL 的方法一样,将学习到的策略推广到新环境或动作通常具有挑战性。
运动合成: 神经网络(前馈网络、LSTM 或 RNN)已广泛应用于运动合成问题 [15, 19, 24, 36, 49, 51, 1]。 一种典型的方法是根据前一帧(或几帧)预测角色的未来运动。 虽然在生成短序列时显示出令人印象深刻的结果,但这些方法中的许多方法在测试长序列时要么收敛到平均姿势,要么发散。 一个常见的解决方案是采用计划采样 [5] 以确保在测试时生成稳定的预测,从而生成长的运动和舞蹈序列 [65, 32]。
许多工作重点研究了人类运动的随机性质建模,特别强调轨迹预测。 在给定角色的过去轨迹的情况下,他们对多个可能的未来轨迹进行建模 [6, 8, 17, 34, 40, 44, 4]。 最近,Cao 等人 [6] 对多个未来的目标进行采样,然后使用这些目标来生成不同的未来骨骼运动。 这与我们使用 GoalNet 的精神类似。 区别在于我们的目标是预测各种始终通向相同目标对象的轨迹(而不是预测任何可能的未来轨迹)。
对完整人体运动的随机性进行建模是一个鲜为人知的领域 [58, 59, 54]。 Motion VAE [32] 使用条件变分自动编码器的潜在空间来预测下一个姿势的分布,而不是单个姿势。 MoGlow 是一种基于归一化流的可控概率生成模型 [22]。 最近也探索了从音乐中生成不同的舞蹈动作 [30, 31]。 Xu 等人 [57] 通过混合来自数据库的短序列来生成不同的运动。 据我们所知,之前没有工作解决生成不同的“人-场景”交互的问题。

3 方法
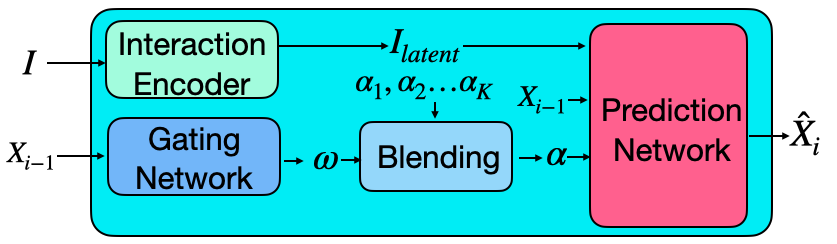
在杂乱的环境中生成动态的人类场景交互需要解决几个子问题。 首先也是最重要的是,角色的合成运动应该逼真,并捕捉自然的变异。 给定一个目标物体,重要的是为执行特定动作(例如,坐在椅子上的位置和面向的方向)采样合理的接触点和方向。 最后,需要合成运动,使其能够导航到目标位置,同时避免穿透场景中的物体。 我们的系统包含三个主要组件,分别解决这些子问题:MotionNet、GoalNet 和 路径规划模块。 我们方法的核心是 MotionNet,它根据之前的姿势以及其他因素(如交互物体几何形状、目标目标位置和方向)预测角色的姿势。 GoalNet 预测目标物体上交互的目标位置和方向。 路径规划模块计算角色起始位置和目标位置之间的无障碍路径。 完整流程如图 2 所示。
3.1MotionNet
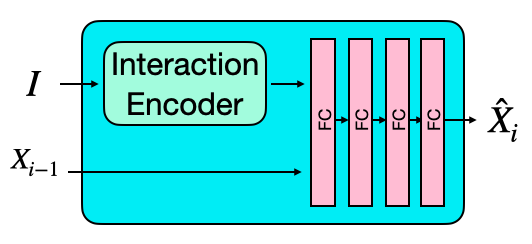
MotionNet 是一个自回归条件变分自动编码器 (cVAE) [12, 46],它生成角色的姿势,以其之前状态(例如,姿势、轨迹、目标)以及交互物体的几何形状为条件。 MotionNet 包含两个组件:编码器和解码器。 编码器将角色和交互物体的先前和当前状态编码为一个潜在向量 。 解码器接收这个潜在向量、角色的先前状态和交互物体,以预测角色的下一个状态。 流程如图 3 所示。 请注意,在测试时,我们只使用 MotionNet 的解码器,并从标准正态分布中采样 。

编码器: 编码器由两个子编码器组成:状态编码器 和 交互编码器。 状态编码器将字符的先前状态和当前状态编码成一个低维向量。 同样,交互编码器将物体几何形状编码成一个不同的低维向量。 接下来,将这两个向量连接起来并通过两个相同的全连接层,以预测表示潜在嵌入空间的正态分布的均值 和标准差 。 然后我们采样一个随机潜在代码 ,在预测字符的下一个状态时将其提供给解码器。
状态表示: 我们使用与 Starke 等人 [47] 类似的表示来编码字符的状态。 具体来说,帧 处的状态定义为
| (1) |
其中 是每个关节相对于根节点的位置、旋转和速度。 是骨骼中的关节数量,在我们的数据中为 。 是相对于未来根节点提前 1 秒的关节位置。 和 是相对于帧 根部的根位置和前进方向。 和 是相对于帧 目标的根位置和前进方向。 我们为 个时间步定义这些输入,这些时间步在 秒窗口内以 秒均匀采样。 是每个 样本上的连续动作标签的向量。 在我们的实验中, 是 ,它是我们建模的动作总数(即闲置、行走、奔跑、坐下、躺下)。 是目标位置和方向, 是一个独热动作标签,描述了在每个 样本上要执行的动作。 是骨盆、脚和手的接触标签。
状态编码器: 状态编码器采用当前 和先前状态 ,并将它们编码成一个低维向量,使用三个完全连接的层。
交互编码器: 交互编码器采用交互对象的体素表示 ,并将其编码成一个低维向量。 我们使用大小为 的体素网格。 每个体素存储一个 维向量。 前三个分量指的是体素中心相对于角色根部的相对位置。 第四个元素存储体素的实值占用率(在 0 到 1 之间)。 该架构包含三个完全连接的层。
解码器: 解码器接收随机潜在代码 ,交互对象表示 和先前状态 ,并预测下一个状态 。 与最近的工作[32, 47]类似,我们的解码器被构建为一个具有两个组件的专家混合:预测网络和门控网络。
预测网络负责预测下一个状态。 预测网络的权重通过混合专家权重来计算:
| (2) |
其中混合权重由门控网络预测。 每个专家都是一个三层全连接网络。 门控网络也是一个三层全连接网络,它将和作为输入。
MotionNet 经过端到端训练,以最小化损失
| (3) |
其中第一项最小化了角色的真实状态和预测状态之间的差异,表示 Kullback-Leibler 散度。
3.2GoalNet
给定一个目标交互对象(可以在测试时由用户交互定义,或从场景中的对象中随机采样),角色由目标位置和方向驱动,这些位置和方向是在对象的表面上采样的。 为了执行真实的交互,角色需要能够从对象几何形状预测这些目标位置和方向。 例如,虽然普通椅子允许在坐姿方向方面有所变化,但坐在扶手椅上的方向受到限制(见图7)。 我们使用 GoalNet 来模拟特定于对象的目標位置和方向。 GoalNet 是一个条件变分自动编码器 (cVAE),它根据目标交互对象的体素表示预测合理的目標位置和方向,如图4所示。 编码器将交互对象、目标位置和方向编码成潜在代码。 解码器从和重建目标位置和方向。 我们使用类似于 MotionNet (第 3.1 节) 中使用的体素表示来表示物体。 唯一的区别是,我们计算相对于物体中心而不是角色根部的体素位置。 在编码器中,我们使用类似于 MotionNet 中使用的交互编码器 (参见第 3.1 节) 来将物体表示 编码为低维向量。 然后将此向量与 和 连接起来,并进一步编码为潜在向量 。 解码器与编码器具有相同的架构,如图 4 所示。 网络被训练以最小化损失:
| (4) |
在测试时,给定目标物体 ,我们随机采样 ,并使用解码器生成各种目标位置 和方向 。

3.3 路径规划
为了确保角色可以在避开障碍物的同时在杂乱的环境中导航,我们采用显式 A* 路径规划算法 [20]。 给定所需的目标位置,我们使用 A* 从角色的起始位置到目标计算一条无障碍路径。 该路径定义为一系列航点 ,它们定义了路径改变方向的位置。 我们将执行最终所需动作的任务分解为子任务,每个子任务都需要角色走到下一个航点。 最终子任务要求角色在最终航点执行所需的动作。
3.4 训练策略
使用标准监督训练训练 MotionNet 会在运行时产生质量较差的预测(参见 补充材料)。 这是因为当网络的输出在下一步被反馈作为输入时,在运行时会累积错误。 为了解决这个问题,我们使用 计划采样 [5] 训练网络,这已被证明可以产生长期稳定的运动预测 [32]。 在训练过程中,当前网络的预测以 的概率被用作下一步训练的输入。 为(参见补充材料 ):
| (5) |
4 数据准备
4.1 运动数据
为了模拟人与场景交互的变化,我们使用具有 Vicon 摄像头的光学 MoCap 系统捕获了一个新的数据集。 我们将七个不同的物体放置在 MoCap 区域的中心,分别是两张沙发、一张扶手椅、一张椅子、一张高吧椅、一张矮凳和一张桌子。 我们记录了每种交互方式的不同风格的多个片段。 在每个序列中,受试者从 MoCap 空间中随机位置的 A 姿势开始,走向物体,并进行 秒的动作。 最后,受试者从物体上站起来走开。 我们的目标是捕捉执行相同动作的不同风格,因此我们要求受试者在每个序列中改变风格。 除了受试者之外,我们还使用附着的标记捕捉物体的姿态。 我们还拥有每个物体的 CAD 模型。 最后,我们捕获了跑步、行走和静止序列,其中主体以不同的速度和方向行走和跑步,并处于静止状态。 我们的数据集包含 分钟的运动数据,以 fps 的速度从单个主体记录,产生 K 帧。 我们使用 MoSh++ [33] 将 SMPL-X [39] 体模型拟合到光学标记。 有关数据的更多详细信息,请参阅 Sup. Mat. 。
4.2 运动数据增强
由于只有七个捕获的对象,MotionNet 将无法适应新的未见对象。 使用各种各样的对象捕获 MoCap 需要大量的努力和时间。 我们通过使用类似于 [3, 47] 的高效增强管道来解决这个问题。 由于我们既捕获了身体运动,也捕获了物体姿态,因此我们计算了身体和物体之间的接触。 我们检测了角色骨骼的五个关键关节的接触。 即骨盆、手和脚。 然后,我们在每一帧随机切换或缩放物体来增强我们的数据。 当切换时,我们用从 ShapeNet [9] 中选择的类似大小的随机物体替换原始物体。 对于每个新物体(缩放或切换),我们将从地面实况数据中检测到的接触投影到新物体上。 最后,我们使用 IK 求解器重新计算完整的姿势,以保持接触。 请参阅 Sup. Mat. 。 了解更多详情。
4.3 目标数据
为了训练 GoalNet,我们为来自 ShapeNet [9] 的不同对象标记各种目标位置 和方向 。 这些目标代表角色在对象表面上可以坐下的位置以及角色坐下时的前进方向。 我们从 ShapeNet 中选择 类别,即沙发、L 形沙发、椅子、扶手椅和桌子。 从每个类别中,我们选择 实例,并为每个实例手动标记 目标。 每个实例标记的目标数量取决于对象可以承受的不同目标的数量。 例如,L 形沙发比椅子提供更多的座位。 总的来说,我们使用 对象作为训练数据。 我们通过在 轴上随机缩放对象来增强数据,从而得到 K 个训练样本。
5实验与评估
5.1定性评估
在本节中,我们提供定性结果并讨论要点。 我们参考Sup。垫子。 以及随附的视频以获取更多结果。
产生多样化的运动: 与之前的确定性方法 [47] 相比,SAMP 生成了各种各样的动作风格,同时保证了真实感。 图 5 显示了 SAMP 生成的几种不同的坐姿和躺姿。 使用交互编码器 3.1 和数据增强(第 4.2 节)进一步确保 SAMP 能够适应不同几何形状的对象。 注意角色如何自然地将头靠在沙发上。 动作的风格也取决于交互对象。 当角色坐在高椅/桌上时,会抬起双腿,但当坐在非常矮的桌子上时,会伸直双腿。 我们观察到躺下是一个更难的任务,几个基线方法无法执行此任务(参见第 5.2 节)。 虽然 SAMP 合成了合理的序列,但我们的结果并不总是完美的。 生成的运动可能涉及一些与物体的穿透。

目标生成: 当遇到一个新的对象时,角色需要预测动作应该在哪里以及向哪个方向执行。 在 [47] 中,目标被计算为对象中心。 然而,这种启发式方法对于几何形状复杂的对象不起作用。 图 6 显示了使用对象中心会导致无效动作,而 GoalNet 允许我们的方法推理动作应该在哪里执行。 如图 7 所示,通过采样不同的潜在代码 ,GoalNet 为不同的物体生成多个目标位置和方向。 注意到 GoalNet 如何捕捉到,虽然一个人可以侧坐在普通椅子上,但这对扶手椅来说是无效的。


图 8 显示了 GoalNet 生成的不同目标如何引导角色的运动。 从相同的起始位置、方向和初始姿势开始,虚拟人执行“坐在沙发上”的动作时,会沿着两条不同的路径到达不同的目标位置。 由于 MotionNet 的随机性,角色的最终姿势在两种情况下也不同。

路径规划: 当在杂乱的场景中导航到特定的目标位置时,避免障碍物至关重要。 我们的路径规划模块通过使用基于 3D 场景计算的导航网格来预测起始角色位置和目标之间的最短无障碍路径,从而实现了这一目标。 导航网格定义了场景中可行走区域,并在离线状态下进行一次计算。 在图 9 中,我们展示了路径规划模块计算出的示例路径。 没有这个模块,角色经常会在场景中的物体上行走。 我们在 NSM [47] 的先前工作中观察到类似的行为,即使 NSM 使用环境的体积表示来帮助角色导航。

5.2 定量评估
确定性与随机性: 为了量化生成运动的多样性,我们将角色放在一个固定的起始位置和方向,并用相同目标运行我们的方法十次。 例如,我们指示角色从同一个初始状态/位置/方向开始,多次坐在/躺在同一个物体上。 对于行走和跑步,我们指示角色以四个方向中的每一个方向运行 秒。 我们记录每次运行的角色运动,然后计算平均成对距离 (APD) [58, 63],如表 1 所示。 APD 定义为:
| (6) |
代表角色在帧 处的局部姿态特征。 。 是所有序列的总帧数。 为了比较,我们还在表中报告了真实数据 (GT) 的 APD。 1.
| Walk | Run | Sit | Liedown | |
|---|---|---|---|---|
| GT | ||||
| SAMP |
GoalNet: 给定 ,我们测量 GoalNet 的平均位置和方向重建误差为 和 (我们注意到这些对象具有现实世界的测量值)。 为了衡量生成目标的多样性,我们计算了生成目标位置 和方向 :
| APD-Pos | (7) | |||
| APD-Rot | (8) |
是对象的数目,而 是为每个对象生成的目標数目。 我们发现,我们生成的目標的 APD-Pos 和 APD-Rot 分别为 和 ,而真实数据 (GT) 的 APD-Pos 和 APD-Rot 分别为 和 。
路径规划模块: 为了定量评估我们路径规划模块的有效性,我们在一个杂乱的场景中测试了我们的方法。 我们将角色置于一个随机的初始位置和方向,并选择一个随机目标。 我们重复这个过程 次。 我们发现,在 SAMP 中,具有路径规划模块、不具有路径规划模块和 NSM [47] 的帧中,穿透发生的百分比分别为 、 和 。 虽然 NSM 使用体积传感器来检测与环境的碰撞,但它不如显式路径规划有效。
与先前模型的比较: 我们通过测量三个指标来比较我们的模型和基线:平均执行时间、平均精度和生成运动分布与真实数据之间的 Frèchet 距离 (FD)。 执行时间是从空闲状态过渡到目标动作标签所需的时间。 精度是目标处的方位(PE)和旋转(RE)误差。 我们在状态特征的一个子集上测量 FD,我们称之为 :
| (9) |
作为我们的基线,我们选择一个前馈网络 (MLP) 作为运动预测网络,专家混合 (MoE) [61] 和 NSM [47](参见 补充材料 了解详情)。
桑普 与 MLP 和 MoE 相比: 我们使用与 SAMP 相同的训练策略和数据重新训练了 MLP 和 MoE。 MLP 和 MoE 都需要更长的时间来执行任务,并且经常无法执行“躺下”动作(用 表示),如表中所示。 2 和表 3 中的精度。 这些架构有时会生成不可信的姿态,如 补充材料 所示,这反映在表中较低的 FD 中。 4
| MLP | MoE | SAMP | GT | |
|---|---|---|---|---|
| Sit | ||||
| Liedown |
| Method | Sit | Liedown | ||
|---|---|---|---|---|
| PE(cm) | RE(deg) | PE(cm) | RE(deg) | |
| MLP | ||||
| MoE | ||||
| SAMP | ||||
| Idle | Walk | Run | Sit | Liedown | |
|---|---|---|---|---|---|
| MLP | |||||
| MoE | |||||
| SAMP |
桑普 与 NSM 相比: 对于 NSM,我们使用公开的预训练模型,因为由于缺少阶段标签,在我们的数据上重新训练 NSM 是不可行的。 我们在 NSM 训练的相同数据上训练了 SAMP。 在表 5 中,我们观察到我们的模型在实现目标方面与 NSM 相当,而无需阶段标签,这些标签繁琐且通常难以标注。 此外,我们的主要重点是通过随机模型来模拟各种运动,而 NSM 是确定性的。 我们的路径规划模块有助于 SAMP 安全地导航复杂的场景,而 NSM 在这些场景中会失败,如穿透量所示。
在所有评估中,所有测试对象都是从 ShapeNet 中随机选择的,并且没有一个是我们的训练集的一部分。
| Metric | Sit | Carry | ||
|---|---|---|---|---|
| SAMP | NSM | SAMP | NSM | |
| Precision PE (cm) | ||||
| Precision RE (deg) | ||||
| Execution Time (sec) | ||||
| FD | ||||
| Diversity | ||||
| Penetration () | ||||
限制和未来工作: 我们观察到,有时角色与交互对象之间可能会发生轻微的穿透。 一种潜在的解决方案是加入一个后处理步骤,以优化角色的姿势,避免此类交叉。 为了将 SAMP 泛化到与训练中看到的物体几何形状明显不同的交互物体,在未来的工作中,我们希望探索编码局部物体几何形状的方法。
6 结论
在这里,我们介绍了 SAMP,它在创建栩栩如生的化身方面迈出了几项重要步骤,这些化身在以前从未见过的复杂环境中像真人一样移动和行动。 关键的是,我们引入了必须作为解决方案一部分的三个元素。 首先,角色必须能够在世界中导航并避开障碍物。 为此,我们使用现有的路径规划方法。 其次,角色可以以不同的方式与物体交互。 为了解决这个问题,我们训练 GoalNet 来获取一个物体并随机产生交互位置和方向。 第三,角色应该产生实现目标的运动,这些运动自然地变化。 为此,我们训练了一个新的 MotionNet,它根据过去的运动和目标增量生成身体姿势。 我们使用涉及人机交互的运动捕捉数据的新数据集训练 SAMP。
致谢 这项工作是在 MH 在 Adobe 实习期间发起的。 我们感谢 Sebastian Starke 的鼓舞人心的工作、有益的讨论以及公开他的代码。 我们感谢 Joachim Tesch 对 Unity 和渲染的反馈、Nima Ghorbani 对 MoSH++ 的反馈以及 Meshcapade 对角色纹理的反馈。 对于在数据收集方面提供帮助,我们感谢 Tsvetelina Alexiadis、Galina Henz、Markus Höschle 和 Tobias Bauch。
披露: MJB 已从 Adobe、英特尔、英伟达、Facebook 和亚马逊获得研究资金。 虽然 MJB 是亚马逊的兼职员工,但他的研究仅在马克斯·普朗克研究所进行,也仅由马克斯·普朗克研究所资助。 MJB 在亚马逊、Datagen Technologies 和 Meshcapade GmbH 拥有财务利益。
参考文献
- [1] Vida Adeli, Mahsa Ehsanpour, Ian Reid, Juan Carlos Niebles, Silvio Savarese, Ehsan Adeli, and Hamid Rezatofighi. Tripod: Human trajectory and pose dynamics forecasting in the wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2021.
- [2] Shailen Agrawal and Michiel van de Panne. Task-based locomotion. ACM Trans. Graph., 35(4), 2016.
- [3] Rami Ali Al-Asqhar, Taku Komura, and Myung Geol Choi. Relationship descriptors for interactive motion adaptation. In Proceedings of the 12th ACM SIGGRAPH/Eurographics Symposium on Computer Animation, SCA ’13, page 45–53, New York, NY, USA, 2013. Association for Computing Machinery.
- [4] Alexandre Alahi, Kratarth Goel, Vignesh Ramanathan, Alexandre Robicquet, Li Fei-Fei, and Silvio Savarese. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 961–971, 2016.
- [5] Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, page 1171–1179, Cambridge, MA, USA, 2015. MIT Press.
- [6] Zhe Cao, Hang Gao, Karttikeya Mangalam, Qi-Zhi Cai, Minh Vo, and Jitendra Malik. Long-term human motion prediction with scene context. In European Conference on Computer Vision (ECCV), pages 387–404. Springer, 2020.
- [7] Carnegie Mellon University. CMU MoCap Dataset.
- [8] Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. In Proceedings of the Conference on Robot Learning, volume 100 of Proceedings of Machine Learning Research, pages 86–99. PMLR, 30 Oct–01 Nov 2020.
- [9] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago, 2015.
- [10] Yu-Wei Chao, Jimei Yang, Weifeng Chen, and Jia Deng. Learning to sit: Synthesizing human-chair interactions via hierarchical control. Proceedings of the AAAI Conference on Artificial Intelligence, 2019.
- [11] Enric Corona, Albert Pumarola, Guillem Alenya, and Francesc Moreno-Noguer. Context-aware human motion prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6992–7001, 2020.
- [12] P Kingma Diederik and Max Welling. Auto-encoding variational bayes. In International Conference on Learning Representations ICLR, 2014.
- [13] David Eigen, Marc’Aurelio Ranzato, and Ilya Sutskever. Learning factored representations in a deep mixture of experts. In International Conference on Learning Representations ICLR, 2014.
- [14] Haegwang Eom, Daseong Han, Joseph S. Shin, and Junyong Noh. Model predictive control with a visuomotor system for physics-based character animation. ACM Trans. Graph., 39(1), Oct. 2019.
- [15] Katerina Fragkiadaki, Sergey Levine, Panna Felsen, and Jitendra Malik. Recurrent network models for human dynamics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), ICCV ’15, page 4346–4354, USA, 2015. IEEE Computer Society.
- [16] Helmut Grabner, Juergen Gall, and Luc Van Gool. What makes a chair a chair? In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 1529–1536, 2011.
- [17] Agrim Gupta, Justin Johnson, Li Fei-Fei, Silvio Savarese, and Alexandre Alahi. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 2255–2264, 2018.
- [18] A. Gupta, S. Satkin, A. A. Efros, and M. Hebert. From 3D scene geometry to human workspace. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 1961–1968, 2011.
- [19] I. Habibie, Daniel Holden, Jonathan Schwarz, Joe Yearsley, and T. Komura. A recurrent variational autoencoder for human motion synthesis. In BMVC, 2017.
- [20] P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 4(2):100–107, 1968.
- [21] Mohamed Hassan, Partha Ghosh, Joachim Tesch, Dimitrios Tzionas, and Michael J. Black. Populating 3D scenes by learning human-scene interaction. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2021.
- [22] Gustav Eje Henter, Simon Alexanderson, and Jonas Beskow. MoGlow: Probabilistic and controllable motion synthesis using normalising flows. ACM Trans. Graph., 39(6), Nov. 2020.
- [23] Daniel Holden, Taku Komura, and Jun Saito. Phase-functioned neural networks for character control. ACM Trans. Graph., 36(4), July 2017.
- [24] Daniel Holden, Jun Saito, and Taku Komura. A deep learning framework for character motion synthesis and editing. ACM Trans. Graph., 35(4):1–11, 2016.
- [25] R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural Computation, 3(1):79–87, 1991.
- [26] Mubbasir Kapadia, Xu Xianghao, Maurizio Nitti, Marcelo Kallmann, Stelian Coros, Robert W. Sumner, and Markus Gross. Precision: Precomputing environment semantics for contact-rich character animation. In Proceedings of the 20th ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, I3D ’16, page 29–37, New York, NY, USA, 2016. Association for Computing Machinery.
- [27] Vladimir G. Kim, Siddhartha Chaudhuri, Leonidas Guibas, and Thomas Funkhouser. Shape2Pose: Human-centric shape analysis. ACM Trans. Graph., Aug. 2014.
- [28] Jehee Lee, Jinxiang Chai, Paul S. A. Reitsma, Jessica K. Hodgins, and Nancy S. Pollard. Interactive control of avatars animated with human motion data. ACM Trans. Graph., 21(3):491–500, July 2002.
- [29] Kang Hoon Lee, Myung Geol Choi, and Jehee Lee. Motion patches: Building blocks for virtual environments annotated with motion data. In ACM SIGGRAPH 2006 Papers, SIGGRAPH ’06, page 898–906, New York, NY, USA, 2006. Association for Computing Machinery.
- [30] Jiaman Li, Yihang Yin, Hang Chu, Yi Zhou, Tingwu Wang, Sanja Fidler, and Hao Li. Learning to generate diverse dance motions with transformer. arXiv preprint arXiv:2008.08171, 2020.
- [31] Ruilong Li, Shan Yang, David A Ross, and Angjoo Kanazawa. Learn to dance with AIST++: Music conditioned 3D dance generation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2021.
- [32] Hung Yu Ling, Fabio Zinno, George Cheng, and Michiel Van De Panne. Character controllers using motion vaes. ACM Trans. Graph., 39(4), July 2020.
- [33] Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 5442–5451, Oct. 2019.
- [34] O. Makansi, E. Ilg, Ö. Çiçek, and T. Brox. Overcoming limitations of mixture density networks: A sampling and fitting framework for multimodal future prediction. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
- [35] Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019.
- [36] Julieta Martinez, Michael J Black, and Javier Romero. On human motion prediction using recurrent neural networks. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 2891–2900, 2017.
- [37] Josh Merel, Saran Tunyasuvunakool, Arun Ahuja, Yuval Tassa, Leonard Hasenclever, Vu Pham, Tom Erez, Greg Wayne, and Nicolas Heess. Catch & carry: Reusable neural controllers for vision-guided whole-body tasks. ACM Trans. Graph., 39(4), July 2020.
- [38] M. Müller, T. Röder, M. Clausen, B. Eberhardt, B. Krüger, and A. Weber. Documentation mocap database HDM05. Technical Report CG-2007-2, Universität Bonn, June 2007.
- [39] Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
- [40] Amir Sadeghian, Vineet Kosaraju, Ali Sadeghian, Noriaki Hirose, Hamid Rezatofighi, and Silvio Savarese. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1349–1358, 2019.
- [41] Manolis Savva, Angel X Chang, Pat Hanrahan, Matthew Fisher, and Matthias Nießner. PiGraphs: Learning interaction snapshots from observations. ACM Trans. Graph., 35(4):1–12, 2016.
- [42] Bokui Shen, Fei Xia, Chengshu Li, Roberto Martín-Martín, Linxi Fan, Guanzhi Wang, Claudia Pérez-D’Arpino, Shyamal Buch, Sanjana Srivastava, Lyne P. Tchapmi, Micael E. Tchapmi, Kent Vainio, Josiah Wong, Li Fei-Fei, and Silvio Savarese. iGibson 1.0: a simulation environment for interactive tasks in large realistic scenes. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems, page accepted. IEEE, 2021.
- [43] Hubert P. H. Shum, Taku Komura, Masashi Shiraishi, and Shuntaro Yamazaki. Interaction patches for multi-character animation. ACM Trans. Graph., 27(5), Dec. 2008.
- [44] H. Sidenbladh, M. J. Black, and L. Sigal. Implicit probabilistic models of human motion for synthesis and tracking. In European Conf. on Computer Vision (ECCV), volume 1, pages 784–800, 2002.
- [45] L. Sigal, A. Balan, and M. J. Black. HumanEva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. International Journal of Computer Vision, 87(4):4–27, Mar. 2010.
- [46] Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. In Advances in Neural Information Processing Systems 28, pages 3483–3491. Curran Associates, Inc., 2015.
- [47] Sebastian Starke, He Zhang, Taku Komura, and Jun Saito. Neural state machine for character-scene interactions. ACM Trans. Graph., 38(6), Nov. 2019.
- [48] Sebastian Starke, Yiwei Zhao, Taku Komura, and Kazi Zaman. Local motion phases for learning multi-contact character movements. ACM Trans. Graph., 39(4), July 2020.
- [49] Graham W. Taylor and Geoffrey E. Hinton. Factored conditional restricted boltzmann machines for modeling motion style. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, page 1025–1032, New York, NY, USA, 2009. Association for Computing Machinery.
- [50] Matthew Trumble, Andrew Gilbert, Charles Malleson, Adrian Hilton, and John Collomosse. Total capture: 3D human pose estimation fusing video and inertial sensors. In Proceedings of the British Machine Vision Conference (BMVC), pages 14.1–14.13, Sept. 2017.
- [51] Ruben Villegas, Jimei Yang, Yuliang Zou, Sungryull Sohn, Xunyu Lin, and Honglak Lee. Learning to generate long-term future via hierarchical prediction. In international conference on machine learning, pages 3560–3569. PMLR, 2017.
- [52] Jiashun Wang, Huazhe Xu, Jingwei Xu, Sifei Liu, and Xiaolong Wang. Synthesizing long-term 3D human motion and interaction in 3D scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9401–9411, 2021.
- [53] Xiaolong Wang, Rohit Girdhar, and Abhinav Gupta. Binge watching: Scaling affordance learning from sitcoms. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2017.
- [54] Z. Wang, J. Chai, and S. Xia. Combining recurrent neural networks and adversarial training for human motion synthesis and control. IEEE Transactions on Visualization and Computer Graphics, 27(1):14–28, 2021.
- [55] Fei Xia, Amir R. Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson env: real-world perception for embodied agents. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
- [56] Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A simulated part-based interactive environment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitio), June 2020.
- [57] Jingwei Xu, Huazhe Xu, Bingbing Ni, Xiaokang Yang, Xiaolong Wang, and Trevor Darrell. Hierarchical style-based networks for motion synthesis. In European Conference on Computer Vision (ECCV), pages 178–194, Cham, 2020. Springer International Publishing.
- [58] Ye Yuan and Kris Kitani. Dlow: Diversifying latent flows for diverse human motion prediction. In European Conference on Computer Vision (ECCV), 2020.
- [59] Ye Yuan and Kris M. Kitani. Diverse trajectory forecasting with determinantal point processes. In International Conference on Learning Representations, 2020.
- [60] S. E. Yuksel, J. N. Wilson, and P. D. Gader. Twenty years of mixture of experts. IEEE Transactions on Neural Networks and Learning Systems, 23(8):1177–1193, 2012.
- [61] He Zhang, Sebastian Starke, Taku Komura, and Jun Saito. Mode-adaptive neural networks for quadruped motion control. ACM Trans. Graph., 37(4), July 2018.
- [62] Siwei Zhang, Yan Zhang, Qianli Ma, Michael J Black, and Siyu Tang. Place: Proximity learning of articulation and contact in 3D environments. In International Conference on 3D Vision (3DV), 2020.
- [63] Yan Zhang, Michael J. Black, and Siyu Tang. We are more than our joints: Predicting how 3D bodies move. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), page 3372–3382, June 2021.
- [64] Yan Zhang, Mohamed Hassan, Heiko Neumann, Michael J Black, and Siyu Tang. Generating 3D people in scenes without people. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6194–6204, 2020.
- [65] Yi Zhou, Zimo Li, Shuangjiu Xiao, Chong He, Zeng Huang, and Hao Li. Auto-conditioned recurrent networks for extended complex human motion synthesis. In International Conference on Learning Representations ICLR, 2018.
- [66] Yixin Zhu, Yibiao Zhao, and Song-Chun Zhu. Understanding tools: Task-oriented object modeling, learning and recognition. In Proceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.
附录 A 数据准备
A.1 运动数据


| Labels | Minutes | Percentage % |
|---|---|---|
| Idle | ||
| Walk | ||
| Run | ||
| Sit | ||
| Lie down | ||
| Total |
A.2 目标数据
我们从 ShapeNet 中选择 个类别,分别是沙发、L 形沙发、椅子、扶手椅和桌子。 从每个类别中,我们选择 个实例,并手动为每个实例标记 个目标。 表格。 S.2 显示了每个类别的实例数量。 我们手动为每个实例标记 个目标。 每个实例标记的目标数量取决于对象可以承担多少不同的目标。 例如,我们为 L 形沙发标记 个不同的目标,而为椅子标记 个目标,如图 S.3 所示。

| Category | Number of Objects |
|---|---|
| Armchairs | |
| Chairs | |
| Sofa | |
| L-Sofa | |
| Tables | |
| Total |
附录 B 训练细节
B.1 运动网络
字符状态 的大小为 。 状态编码器、交互编码器、门控网络和预测网络都是三层全连接网络,具有修正线性函数 ELU。 每个网络的维度如表 S.3 所示。 编码器潜在代码 的大小为 ,我们将专家数量 设置为 。 我们使用 的学习率,并训练我们的网络 个 epoch。 我们使用带有线性权重衰减的 Adam 优化器。 Kullback-Leibler 散度的权重 为 。
| Network | Architecture |
|---|---|
| State Encoder | |
| Interaction Encoder | |
| Gating Network | |
| Prediction Network |
B.2GoalNet
GoalNet 的交互编码器是一个形状为 的三层全连接网络。 潜在向量 的大小为 。 Kullback-Leibler 散度的权重 为 。 我们使用学习率为 的 Adam 优化器,并训练 GoalNet 个 epoch。
B.3 调度采样
对于调度采样训练策略,我们设置 和 。 我们定义了一个大小为 的滚动窗口,在我们的实验中我们设置 。 对于每次展开,我们将地面实况的第一帧作为网络的输入,然后使用计划采样策略依次预测后续帧。 我们将训练数据划分为大小为 的等长片段。
附录 C 基线
作为基线,我们选择了一个前馈网络 (MLP) 和一个专家混合 (MoE)。 MLP 的架构如图 S.4 所示。 我们使用与 MotionNet 相同的交互编码器,后跟四个大小为 的全连接层。 MoE 的架构如图 S.5 所示。 交互编码器、门控网络和预测网络都与 MotionNet 中使用的一样。
附录 D 计划采样
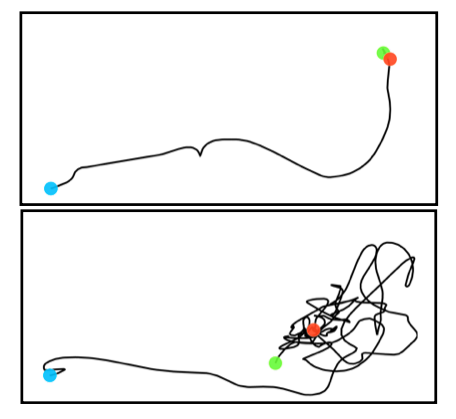
我们发现使用计划采样对于使角色成功地到达目标并执行动作至关重要。 据我们观察,如果没有计划采样,模型通常会发散,陷入困境,或者需要很长时间才能到达目标,如图 S.6 所示。
附录 E 路径规划公式
为了使用路径规划模块,我们首先计算角色可以站立或移动的表面积。 我们称之为 导航网格。 这是从角色圆柱碰撞体和场景几何体计算得出的。 导航网格 存储为凸多边形。 为了找到给定起点和终点之间的路径,我们首先将这些点映射到最近的多边形,然后使用 A* 算法找到多边形之间的最短路径 111https://docs.unity3d.com/Manual/nav-InnerWorkings.html。
附录 F 数据增强细节
当物体被变换时,接触点也随之变换。 当物体被替换为一个新的物体时,我们通过找到新物体表面上的最近点来投影原始接触点。 新的运动曲线通过插值计算,整个全身姿态使用 CCD IK 求解器计算。 这不能保证平滑性,但我们发现它在实践中是稳定的。 更多细节请参见 [47]。
附录 G 交互编码器消融研究:
为了量化交互编码器的重要性,我们在没有交互编码器的情况下训练了 SAMP。 我们发现,当使用交互编码器时,达到目标的精度下降到 厘米和 度,而没有使用交互编码器时,精度为 厘米和 度。
附录 H 与曹等人比较:
虽然相关,但曹等人 [6] 的公式与我们的方法存在显著差异,因此难以进行直接比较。 给定目标交互对象和动作(例如,“坐在沙发上”),SAMP 在对象上采样目标位置和方向,计算通往对象的无障碍路径,并合成各种长度的运动序列,直到目标执行。 我们假设角色从静止位置开始动作,没有任何关于过去的知识。 相反,曹等人给定一秒钟的运动 历史,在图像空间中采样一个目标 位置。 基于此轨迹,合成一个固定长度(两秒)的确定性运动序列。 此轨迹中执行的动作是不可控的。
附录 I 失败案例
我们观察到,SAMP 可能无法很好地适应与训练中看到的对象几何形状有显著差异的对象,如图 S.7 所示。 未来工作可以探索不同的对象几何编码方法。
