LOT:评估中文长文本理解和生成的以故事为中心的基准
摘要
标准的多任务基准对于开发可推广到各种下游任务的预训练模型至关重要。 现有的自然语言处理(NLP)基准通常只关注理解或生成短文本。 然而,长文本建模需要许多与短文本不同的能力,例如长距离话语和常识关系的建模,以及生成的连贯性和可控性。 由于缺乏标准化基准,很难评估模型的这些能力并公平地比较不同模型,尤其是中国模型。 因此,我们提出了一个以故事为中心的基准,名为 LOT,用于评估中文长文本建模,它聚合了两个理解任务和两个生成任务。 我们根据人类编写的数百字的中国故事为这些任务构建了新的数据集。 此外,我们还发布了基于编码器-解码器的中文长文本预训练模型,名为 LongLM,参数多达 10 亿个。 我们在 120G 中文小说上预训练 LongLM,包括文本填充和条件延续两个生成任务。 大量实验表明,LongLM 在 LOT 中的理解和生成任务上均明显优于类似大小的预训练模型。
1简介
| Effendi’s son is eccentric, always behaving opposed to what Effendi has ordered him to do. Familiar to his son’s temper, Effendi usually communicates using irony. One day, the father and son were blocked by a river after purchasing flour from a mill. And while they were crossing the river, one bag on the donkey’s back lost its weight and leaned. Effendi told his son with irony:“My boy! drop the sack into the river!” The son heard the words and thought:“I have been opposed to my father for so many years. For this only time, I have to obey him.” Therefore, he followed Effendi’s words and indeed pushed the sack into the river. “My boy! What are you doing?”Effendi shouted in anger.” … |
预训练语言模型在各种自然语言理解(NLU)和生成(NLG)任务中取得了显着进展Devlin 等人 (2019); Radford 等人 (2019). GLUE Wang 等人 (2019) 等标准基准进一步推动了预训练模型的改进和快速迭代。 流行的基准测试通常会聚合多个任务来刺激可推广模型的进展。 但这些基准主要侧重于理解或生成短文本。 例如,GLUE 任务最多接受两个句子作为输入。 NLG 基准中的大多数任务,例如 GLGE Liu 等人 (2020) 和 GEM Gehrmann 等人 (2021) 只需要生成几个单词(例如,对话生成)。 尽管已经有很多针对长文本进行预训练的模型,例如 GPT3 Brown 等人 (2020) 和 CPM Zhang 等人 (2020)),但缺乏基准数据集使得很难充分评估和比较他们的长文本建模能力。
在本文中,我们提出了 LOT,一个评估中文LOng文本文本理解和生成的基准。 如表1所示,与短文本相比,长文本建模需要许多独特的能力,包括(1)有关人物反应和意图的常识推理,以及有关物理对象(例如“河流”)的知识摘要概念(例如“讽刺”); (2)对话语层面的特征进行建模,例如句子间关系(例如因果关系)和全局话语结构(例如事件的顺序); (3)生成的连贯性和可控性,这需要保持连贯的情节并遵守可控属性(例如主题)。 因此,LOT包含关于上述能力的两个理解任务和两个生成任务。 考虑到故事通常包含丰富的常识和话语关系,我们根据从公共网络资源收集的各种故事(例如寓言和童话故事)为这些任务构建新的数据集。 所有这些任务都需要处理数百个单词的故事。 请注意,LOT不涉及数千字的超长文本,因为这些文本中复杂的语言现象使得难以测试个体能力并指导生成模型的改进。
此外,我们还发布了LongLM,一个中文Long文本预训练L语言Model。 LongLM 是一个基于 Transformer 的模型,具有编码器-解码器架构。 LongLM 具有三个不同的版本,参数范围从 6000 万到 10 亿不等。 我们在 120G 中文小说上预训练 LongLM,包含两个生成任务,包括文本填充 Lewis 等人 (2020) 和条件延续 Radford 等人 (2018)。 预训练数据不包括其他类型的文本(例如新闻、维基文本),因为我们主要关注一般长文本中的常识和话语关系,而不是事实和技术知识。 据我们所知,LongLM 是第一个相同规模的预训练模型,专注于对长篇故事进行建模。 LOT 上的大量实验表明,LongLM 在理解和生成任务上都大大优于强大的基线。 然而,我们也观察到 LongLM 仍然远远落后于人类的表现,这需要更好的事件语义表示以及对事件之间的常识和话语关系进行更深入的建模。 我们总结本文的主要贡献如下:
我。 我们提出了一个新的以故事为中心的基准 LOT 来评估中文长文本的理解和生成。 LOT 包含四个任务,用于测试长文本建模的基本能力。 我们还为这些任务提供了新的数据集。
二。 我们发布了一个新的中文预训练模型,名为 LongLM。 实验结果证明了LongLM在LOT上的强大性能,但仍然存在巨大的改进空间 111LOT 基准、预训练资源和附录可在 https://github.com/thu-coai/LOT-LongLM。
2相关工作
自然语言处理基准
最近,已经提出了许多多任务基准来推动可泛化模型的进步。 基准通常将多个与模型无关的任务聚合在一个统一的框架下,使研究人员能够公平地比较不同的模型。 SentEval Conneau 和 Kiela (2018) 收集了多个分类任务,涉及一个或两个句子作为输入来评估句子表示。 DiscoEval Chen 等人 (2019) 将这些任务扩展到有关句子间关系的话语层面。 GLUE Wang 等人 (2019) 包括更多样化的任务,例如自然语言推理 Rocktäschel 等人 (2016)。 Sarlin 等人 (2020) 通过引入多句任务,提出 SuperGLUE 作为 GLUE 更具挑战性的对应物。 但额外的任务仅限于共指消解和问答的形式。 除了这些英语基准之外,还提出了许多基准来评估其他语言的 NLU,例如中文的 CLUE Xu 等人 (2020a)。 此外,GLGE Liu 等人 (2020) 和 GEM Gehrmann 等人 (2021) 被提出用于评估跨多种生成任务(例如文本摘要和个性化对话)的 NLG 模型。 然而,目前还没有专门针对长文本建模(尤其是中文)设计的基准。 此外,上述基准测试最初旨在涵盖尽可能多样化的任务格式。 相比之下,我们在Ribeiro等人(2020)建议的长文本建模必要能力的指导下设计了LOT任务,从而更容易找出模型失败的地方以及如何改进他们。
| Tasks | Abilities | Inputs | Outputs | Metrics |
|---|---|---|---|---|
| ClozeT | Commonsense Reasoning | A text with a sentence removed (the position specified); Two candidate sentences. | Choosing the correct sentence from two candidates. | Accuracy |
| SenPos | Inter-sentence Relationship | A text with a sentence removed (the position unspecified); The removed sentence. | Choosing the correct position for the removed sentence. | Accuracy |
| PlotCom | Commonsense Reasoning; Inter-sentence Relationship | A text with a sentence removed (the position specified). | Generating a sentence to complete the text. | BLEU; Dist |
| OutGen |
Discourse Structure;
Coherence; Controllability |
A title, an outline as an out-of-order set of phrases about characters and events. | Generating a coherent text adhering to the title and outline. |
BLEU; Dist;
Cover; Order |
长文本数据集
以往长文本建模领域的研究经常集中在 ROCStories Mostafazadeh 等人 (2016) 和writingPrompts Fan 等人 (2018) 数据集上。 ROCStories包含10万个人工五句故事,而WritingPrompts则包含30万对提示和数百个单词的故事。 最近的作品收集了数千个单词的故事来建模长期依赖关系,例如 WikiText-103 Merity 等人 (2016)、roleplayerguild Louis and Sutton (2018)、PG -19 Rae 等人 (2020)、STORIUM Akoury 等人 (2020) 和 Long-Range Arena Tay 等人 (2020)。 然而,这些数据集是用英语编写的。 LOT将推动中文语言模型的发展。
此外,LOT 不包含像 PG-19 这样的超长文本数据集,原因有二:(1)超长文本远远超出了当前机器学习模型的范围,因为语篇层面的语言现象错综复杂。在这些文本中。 因此,超长文本通常用于计算语言模型的复杂度Dai等人(2019),但很难为改进模型设计提供细粒度的指导。 (2) LOT 的目的不是推动在超长序列中跨 token 建立更完整连接的研究,而是推动机器在上述长文本建模基本能力方面的进步。
故事理解与生成
LOT以长文本建模的基本能力为中心,因此包括四个涉及常识和话语关系的故事理解和生成任务。 最近的研究提出了各种评估故事理解和生成的任务。 首先是故事结局选择Mostafazadeh 等人(2016)、故事结局生成Guan 等人(2019)以及故事完成王和万(2019) 侧重于事件间因果关系和时间关系的常识推理能力。 其次,Chen 等人(2019)评估了通过预测文本中句子或段落的位置来建模话语关系的能力。 第三,一些作品注重故事生成的连贯性,以短提示范等人(2018)、标题姚等人(2019)和开头关等为条件。人(2020)。 第四,一些研究以可控性为中心,即在故事生成中施加可控属性,如关键词徐等人(2020b)、情感轨迹Brahman and Chaturvedi (2020) ,概述 Rashkin 等人 (2020) 和样式 Kong 等人 (2021)。 LOT是测试中文长文本建模能力的综合基准。
另一方面,LOT 并不涉及那些需要学习故事更多特定特征的任务,例如事件链Chambers and Jurafsky (2008)、人物类型Bamman 等人(2013)、人物间关系Chaturvedi 等人 (2016, 2017)、社交网络 Agarwal 等人 (2013) 和抽象结构Finlayson (2012). 非神经故事生成模型通常根据手工规则李等人(2013)从具有预先指定语义关系的知识库中检索事件,这种方法成本高昂且缺乏泛化性。 在本文中,我们主要关注评估故事理解和生成的神经模型。
3 很多基准
| Datasets | Train | Val | Test |
|---|---|---|---|
| Task: ClozeT | |||
| # Examples | 644 | 294 | 294 |
| Vocabulary Size | 9k | 7k | 7k |
| Avg. # Char in Input Text | 139.07 | 138.95 | 141.15 |
| Avg. # Word in Input Text | 89.28 | 89.03 | 90.20 |
| Avg. # Sent in Input Text | 5.95 | 5.94 | 5.95 |
| Avg. # Word in Candidate | 15.60 | 16.38 | 15.75 |
| Task: SenPos | |||
| # Examples | 20,000 | 800 | 863 |
| Vocabulary Size | 147k | 10k | 22k |
| Avg. # Char in Input Text | 289.59 | 258.48 | 258.52 |
| Avg. # Word in Input Text | 254.11 | 224.20 | 223.25 |
| Avg. # Sent in Input Text | 9.61 | 8.43 | 8.44 |
| Avg. # Word in Removed Sent | 30.48 | 29.28 | 30.26 |
| Avg. # Candidate Positions | 8.05 | 6.91 | 6.91 |
| Task: PlotCom | |||
| # Examples | 13,099 | 465 | 464 |
| Vocabulary Size | 22k | 8k | 8k |
| Avg. # Char in Input Text | 164.35 | 137.67 | 133.26 |
| Avg. # Word in Input Text | 105.48 | 87.56 | 84.98 |
| Avg. # Sent in Input Text | 7.17 | 5.59 | 5.48 |
| Avg. # Word in Output Sent | 15.08 | 15.96 | 16.15 |
| Task: OutGen | |||
| # Examples | 1,456 | 242 | 729 |
| Vocabulary Size | 19k | 6k | 12k |
| Avg. # Word in Input Title | 4.64 | 4.89 | 4.64 |
| Avg. # Word in Input Outline | 19.20 | 19.05 | 19.47 |
| Avg. # Phrase in Input Outline | 8.00 | 8.00 | 8.00 |
| Avg. # Char in Output Text | 169.94 | 169.80 | 170.49 |
| Avg. # Word in Output Text | 108.91 | 108.68 | 109.04 |
| Avg. # Sent in Output Text | 7.20 | 7.11 | 7.15 |
我们将LOT设计为两个理解任务的聚合,包括完形填空测试(ClozeT)和句子位置预测(SenPos),以及两个生成任务,包括绘图完成 (PlotCom) 和轮廓条件生成 (OutGen)。 我们分别在表2和3中显示任务描述和数据统计。 我们使用 jieba 分词器222https://github.com/fxsjy/jieba 用于单词标记化。
我们根据以下原则设计LOT: (1)任务多样性: 这些任务在任务格式、输入和输出的类型和长度、重点能力方面各不相同,使 LOT 成为评估模型泛化能力的综合框架。 (2)任务难度: 这些任务需要数百个单词作为输入或输出,并且不涉及科学、电影等特定领域的知识。 因此,它们超出了当前最先进模型的范围,但大多数中文母语者都可以解决。 (3)任务制定: 这些任务在之前的研究中已经得到很好的阐述,并且一致认为具有挑战性但有意义。 我们为这些任务引入了新的中国数据集,这些数据集的构建是为了比原始数据集更具体地专注于测试某种能力。 (4)自动评价: 这些任务具有可靠的自动指标来评估重点能力。 我们从标题中排除了诸如故事生成之类的开放式生成任务,这些任务很难自动评估 Guan 等人 (2021),因为这些任务存在臭名昭著的一对多问题:有很多对于相同的输入 Zhao 等人 (2017) 的合理输出。
我们通过自动和手动标注为 LOT 构建了数据集。 首先,我们从公共网页中抓取人类编写的故事作为数据源。 这些故事已获得许可,允许出于研究目的使用和重新分发。 然后,我们聘请了一个商业团队来创建 LOT 示例。 团队由专业编剧带领,承接了数百个NLP标注项目。 所有注释者都是中文母语,并且接受过良好的标注任务培训。 我们在附录中显示了源网页的完整列表和标注详细信息。
3.1 完形填空测试
Mostafazadeh 等人 (2016) 引入了用于评估故事理解能力的故事完形填空测试 (SCT) 任务,该任务需要从两个候选者中为四句主导语境选择正确的结局。 然而,SCT 存在以下问题:(1)它的数据集是人为的,并且在某些特征中包含正确和错误结尾之间的固有偏差,例如长度 Schwartz 等人(2017); Sharma 等人 (2018). 这种偏差可能会泄露有关目标标签的信息。 (2)SCT只注重推理结尾,而忽略其他类型的推理,例如溯因推理Bhagavatula等人(2019),它需要推理观察到的开头和结尾之间发生的事情。 (3) SCT将常识推理的范围限制在现实事件上。 这种限制可能既不是必要的,也不是充分的。 例如,“丘比特会飞”虽然不现实,但可以根据常识进行推理,而有些故事设置可能很现实,但仅根据上下文和常识无法推理,如表4。 因此,在构建我们的 ClozeT 数据集时,我们采用以下方法来缓解上述问题:(1)所有示例均来自现有的人类编写的故事。 (2) 我们允许注释者创建示例,其中删除的句子最初位于故事的中间。 (3)我们将常识推理的范围改为所有体现人物反应和意图的事件,或者物理对象和概念的本质。 表 6 显示了两个 ClozeT 示例。 此外,我们还在5.5节中进行了实验来调查数据集的潜在偏差。
| A goblin had buried a treasure under the ground. After that, he received a long flight mission from the Devil King. The goblin began to worry about how to guard the treasure during his mission. The goblin thought for a long time and decided to give the treasure to a miser. The miser clung to his vault even when he was asleep, so the goblin trusted him very much |
故事过滤
为了确保 LOT 示例的质量,我们要求注释者判断每个爬取的故事是否符合以下定义:“以连贯事件序列的形式讲述的任何内容,涉及多个特定且相关的角色” Mostafazadeh 等人 (2016 )。 我们为注释者提供了详细的案例来指导他们了解这个定义。 然后,注释者需要通过重写情节来完善那些不符合定义的故事。 他们还应该通过以下启发式清理故事:(1)拒绝可能违反道德原则(例如歧视)的例子; (2) 删除噪音词(例如链接); (三)将俚语、非正式用语改为标准现代汉语; (4)将所有对话重写为客观事件。 最后,我们收集了 2,427 个高质量的中文故事,这些故事将用于构建 ClozeT、PlotCom 和 OutGen 任务的数据集。
数据集构建
我们将这些故事呈现给另一组注释者来构建 ClozeT 数据集。 对于每个故事,他们应该选择一个可以根据上下文和常识进行推理的句子作为正确的候选者。 表4展示了一个提供给标注者的例子,来说明如何判断一个句子是否满足这个要求。 然后,注释者将句子重写为另一个错误的候选句子,该句子与上下文保持了良好的主题相关性,但违反了常识。 错误的候选人要么体现出不合理的反应或意图,要么违反物理对象或概念的本质。 我们要求注释者不要选择第一句话,这通常旨在介绍故事背景而不是叙述事件。 我们浏览标注结果,并在批准注释者提交的内容之前向他们提供详细的反馈。 最后,我们总共收集了 1,232 个示例,并将它们拆分用于训练、验证和测试。
3.2 句子位置预测
我们使用句子位置预测任务 Chen 等人 (2019) 来评估捕获句子间关系(例如因果关系)的能力。 我们将任务制定如下:给定一个删除了句子的文本,模型应该从多个候选者中选择该句子在文本中的正确位置。 Chen 等人 (2019) 通过从现有文本中随机删除句子来构建此任务的英语数据集。 然而,这样的例子可能是无效的,因为一个句子在文本中可能有多个看似合理的位置,如表5所示。 因此,我们基于以下流程构建任务数据集:(1)从爬取的故事中提取少于 500 个单词的段落; (2)为每个段落随机选择一个句子进行删除,并将两个相邻句子之间的所有位置作为候选333我们将删除的句子的最小长度设置为 10 个汉字,如果故事中的句子少于 10 个字符,我们会将其与其邻居合并。,(3)要求注释者将自动构建的示例的一部分细化为验证集和测试集,其余的作为训练集。 表 7 显示了两个 SenPos 示例。
| Text: I couldn’t control my anger very well.[1]My parents would yell at me, and i ran to my room.[2]I buried my head in a pillow and screamed.[3]I threw my pillow and hit it hard. |
| Removed Sentence: I tried to express my anger. |
| Context | Wrong Candidates | Right Candidates |
|---|---|---|
| 傻狼和狐狸偷来一罐蜂蜜藏在树洞里,它俩规定谁也不许偷吃。可狐狸第二天就把蜂蜜偷吃光了。傻狼几次找狐狸去吃蜂蜜,狐狸总是不去。傻狼实在忍不住,结果跑过去一看,蜂蜜竟然见了底。傻狼心里懊恼,它想着,都怪狐狸不来吃,蜂蜜全都干掉了,丝毫没有怀疑狐狸。[MASK] | 狐狸听说后非常生气,他再也不跟傻狼一起找吃的了。 | 狐狸听说后,更加积极地跟傻狼一起去找吃的了。 |
| A silly wolf and a fox stole a jar of honey and then hid it in a tree hole. They agreed that neither of them were allowed to eat the honey alone. However, the fox sneaked back to eat up all the honey the next day. Afterwards, whenever the wolf asked the fox to eat the honey together, the fox always refused its request. Finally the wolf could not help coming back to the tree hole and found that the jar had been empty. The wolf felt very regretful that the honey became dry because it had been too long. It had no doubts about the fox at all. [MASK] | When hearing this, the fox became very angry and decided no longer to look for food together with the wolf. | After hearing this, the fox became more active to look for food together with the wolf. |
| 从前,山脚下住着母子二人。儿子长大后出门学艺,一直没有回来。妈妈就到城里找。哪知道儿子当了官竟不认她了。老妈妈坐在路边伤心地哭了,一个青年路过,知道了原由,将她接回家里。[MASK]他下令将那个不孝顺的儿子贬为了平民。而他的妈妈则在王宫里过上了幸福的生活。 | 谁知,这个青年也是一个官。 | 谁知,这个青年竟是王子。 |
| Once upon a time, there lived a mother and her son at the foot of a mountain. After her son grew up, he went out to learn skills and never came back. Therefore, the mother went to the nearby city to look for him. However, her son became an official and disowned his mother. The mother sat by the roadside and cried sadly. A young man passed by and knew the cause. Then the man took her home. [MASK] He decreed to remove the position of the disobedient son. And the mother lived happily in the palace. | Actually the man was also an official. | Actually the man was the prince of the city. |
| Texts | Removed Sentences | Labels |
|---|---|---|
| 有一个姓蒋的人,祖父和父亲在捕蛇的时候被蛇咬死了,但是他却继续捕蛇。[1] 当柳宗元劝他不要在捕蛇的时候,这个人竟大哭起来,宁愿被蛇咬死,也不愿意放弃捕蛇。[2] 有的乡亲早已倾家荡产,食不裹腹了。[3] 差役们到进村子里收税赋的时候,横冲直撞,粗声叫骂,大打出手,乡亲们胆战心惊,苦苦哀求。[4] 这种场面连鸡狗都得不到安宁,何况人呢! | 因为他必须靠捕蛇才能上缴官府的赋税。 | [2] |
| There was a man named Jiang, whose grandfather and father were killed by snakes when catching them. But he still made his living by catching snakes. [1] When Liu advised him no longer to catch snakes, the man cried and said that he would rather be killed by snakes than give up catching snakes. [2] Actually some villagers had already lost everything and have nothing to eat. [3] They could do nothing but tremble with fear when the officers went into their houses to collect taxes and struck out violently. [4] Even dogs and chickens couldn’t get any peace in such scenario, let alone humans! | This was because he was able to pay taxes to the government only by catching snakes. | [2] |
| 一只狼出去找食物,偶然经过一户人家,听到小孩哭声,接着又听见老太婆的声音:“别哭了,再哭就把你扔出去喂狼。 [1]”狼一听心中大喜,便蹲在墙角等着,谁知等到天黑也不见把小孩扔出来。 [2]却又听到老太婆说:“快睡吧,别怕,狼来了,咱们就把它杀死煮了吃。 [3]”狼吓得一溜烟跑回了窝。 [4]同伴问它收获怎样,它沮丧地说:“别提了” | 太阳落山了,狼已经等得不耐烦了.转到房前想伺机而入。 | [2] |
| A wolf went out to look for food. It happened to pass by a house. It heard a child crying and then an old woman scared the child to say: “Do not cry! If you cry again, I will fling out you to feed wolves right away. [1]” Hearing this, the wolf was overjoyed and then squatted down and waited. However, the child was not flung out even when it was dark. [2] Suddenly, the woman said: “Don’t be afraid. If the wolf comes, let’s kill and eat it.”[3] The wolf was so frightened that he ran back to its lair. [4] When its friends asked it what happened, it said in dismay: “Don’t mention it.” | After sunset, the wolf was getting impatient and planned to break into the house. | [2] |
数据集构建
我们要求注释者细化每个示例,以便删除的句子在文本中只有一个合理的位置。 我们不允许注释者选择原始文本的第一个或最后一个句子作为删除的句子,因为它们通常包含明显的措辞特征(例如,“曾经”、“他们幸福地生活在一起”),这可能会使这项任务变得困难。琐碎的。 与 ClozeT 不同,我们允许 SenPos 的文本不完整或包含也体现丰富的句子间关系的对话。 最后,我们收集了 1,663 个示例,通过人类标签进行验证和测试。 我们为训练自动构建了 20,000 个示例。
3.3绘图完成
我们使用绘图完成任务Wang and Wan (2019)来测试基于常识进行推理的能力。 我们将这个任务表述如下:给定一个删除了句子的故事,模型应该生成一个句子来完成故事并使其合理且连贯。
数据集构建
之前的研究Wang 和 Wan (2019); Paul 和 Frank (2021) 通过从故事中随机删除一个句子,根据现有数据集自动构建此任务的数据集。 然而,如表4所示,并非故事中的所有句子都可以仅根据上下文和常识来推理。 因此,我们仅使用上述自动方法来构建训练数据。 我们将 ClozeT 数据应用于此任务进行验证和测试,因为注释者已经标记出了合格的句子。 具体来说,我们随机抽取了一些 ClozeT 示例,并将每个示例的不完整故事作为输入,并将正确的候选作为要生成的目标句子。
3.4 轮廓条件生成
之前的工作倾向于通过输入有限信息(例如标题 Yao 等人(2019))的故事生成来测试长文本生成的能力。 然而,这些任务极其开放,因此很难使用自动指标Guan and Huang (2020)可靠地衡量发电质量。 为了缓解这个问题,我们引入了大纲条件生成任务 Rashkin 等人 (2020),该任务需要根据人物和事件的大纲生成一个连贯的长篇故事。 我们将大纲制定为一组无序短语,这不仅缩小了合理故事的范围,而且还可以测试模型在话语层面合理安排给定事件的可控性和规划能力。
数据集构建
我们根据过滤后的故事自动构建此任务的数据集。 我们按照 Rashkin 等人 (2020) 使用 RAKE 算法 Rose 等人 (2010) 提取故事大纲。 我们为每个故事最多提取八个短语,每个短语包含不超过八个单词。 例如,表1中的故事大纲是{“讽刺地告诉他的儿子”,“去磨坊买面粉”,“过河”,“把麻袋扔进河里, ” “确实推了麻袋”,“熟悉儿子的脾气”,“大喊”,“一袋”}。 大纲可以作为生成模型的话语层面的指导,合理地重新安排事件并生成具有良好全局话语结构的故事,而不是只关注于局部连贯性的建模。
3.5总分
现有的基准通常通过对所有指标分数进行平均来将模型的性能总结为单个分数,而不考虑任务难度。 为了鼓励模型在机器和人类之间存在较大差距的任务上取得进展,我们建议使用不同的权重来平均指标分数。 假设所有任务总共有 个指标,我们得出总体得分如下:
| (1) | ||||
| (2) |
其中 、 和 是人类的分数、预选基线和第 的评估模型分别为 metric, 是该指标的权重。 直观上,基线模型与人类差距较大的指标分数在计算总体分数时将具有较大的权重。 我们分别使用 BERT 和 GPT2 作为 LOT 中理解和生成任务的基线模型。
4 长文本预训练模型
为了在理解和生成任务上提供更大的灵活性,我们按照 Transformer Vaswani 等人 (2017) 的原始编码器-解码器设计构建了具有三种不同尺寸的 LongLM,如表 8. 我们按照 Cui 等人 (2020) 使用 32,000 个单词的句子词汇 Kudo and Richardson (2018)。 我们将编码器和解码器的最大序列长度设置为 512。
| Versions | / | # P | ||||
|---|---|---|---|---|---|---|
| Small | 512 | 2,048 | 64 | 8 | 6/6 | 60M |
| Base | 768 | 3,072 | 64 | 12 | 12/12 | 223M |
| Large | 1,536 | 3,072 | 64 | 12 | 24/32 | 1B |
预训练数据
我们收集了120G的小说作为LongLM的预训练数据,涵盖了言情、军事等各种题材。 由于小说通常比 LongLM 的最大输入和输出长度长得多,因此我们将小说分成多个片段进行预。
预训练任务
编码器-解码器模型通常通过最大化给定输入的目标输出的可能性来训练。 为了提高编码器和解码器的能力,我们建议使用两个预训练任务来训练 LongLM,包括文本填充 Raffel 等人 (2020) 和条件延续 Radford 等人 (2019). 对于第一个任务,输入是一个文本,其中对多个范围进行采样并替换为具有唯一 ID 的特殊标记,而输出是由输入中使用的特殊标记分隔的范围。 屏蔽跨度的长度是根据 =3 的泊松分布得出的,并且所有屏蔽标记压缩原始文本的 15%。 对于第二个任务,输入和输出分别是文本的前半部分和后半部分,文本被随机分成两部分。 我们在图 1 中展示了预训练任务的示例。
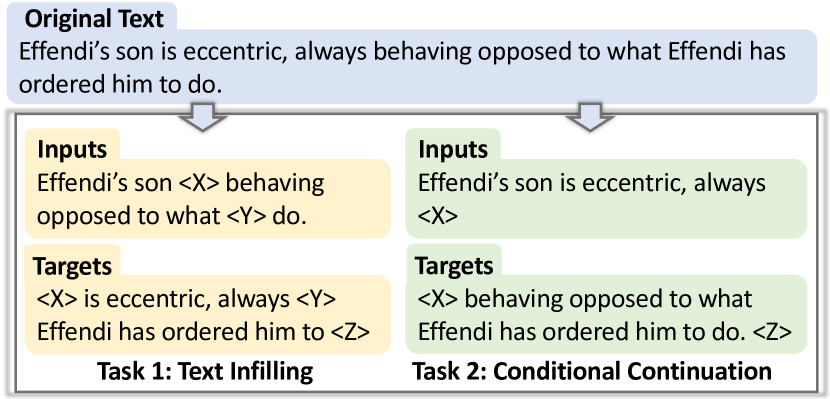
预训练细节
我们使用 Adam 优化器将学习率设置为 1e-4,并将批量大小设置为 1,000。 我们对 LongLM 进行了 250 万步的预训练。 使用八个 NVIDIA V100 GPU 训练最大的模型大约需要两个月的时间。
模型性能
为了评估 LongLM 在预训练任务上的表现,我们从初始预训练数据中随机分离出 1000 条文本进行测试,这些文本在预训练阶段从未见过。 我们使用 perplexity 和 BLEU- (=3,4) 来评估这两个预训练任务。 我们使用文本填充任务的贪婪解码算法生成输出,并使用 和 softmax 进行 top- 采样 Fan 等人 (2018)条件延续任务的温度为 0.7 Goodfellow 等人 (2014)。 如表9所示,随着参数数量的增加,性能大幅提高。
| Models | TextInfill | CondCont | ||
|---|---|---|---|---|
| PPL | BLEU-3/4 | PPL | BLEU-3/4 | |
| LongLMsmall | 11.61 | 73.80/68.96 | 22.91 | 5.30/2.43 |
| LongLMbase | 8.24 | 75.65/71.05 | 17.03 | 5.73/2.64 |
| LongLMlarge | 6.50 | 77.08/72.65 | 14.08 | 8.91/5.97 |
5实验
在本节中,我们通过自动和手动评估在 LOT 上测试了 LongLM 和现有模型。 此外,我们进行了广泛的实验来研究 ClozeT 和 SenPos 数据集的潜在偏差(第 5.5 节),并测量训练数据和测试数据之间的重叠(第 5.6 节)。
5.1 评估模型
我们评估了以下模型,这些模型是基于 HuggingFace Transformers 的寄存器模型实现的444https://huggingface.co/models: (1) 普通 Transformer : 它与 BERTbase 具有相同的架构,只是层数设置为 3 Vaswani 等人 (2017)。 (2)伯特: 它是基于 bert-base-Chinese 寄存器模型 Devlin 等人 (2019) 实现的。 (3)罗伯塔: 它是基于hfl/chinese-roberta-wwm-ext寄存器模型Cui等人(2020)实现的。 (4)GPT2: 它是基于uer/gpt2-chinese-cluecorpussmall寄存器模型Zhao等人(2019)实现的。 (5)mT5: 它是基于 google/mt5-base 寄存器模型 Xue 等人 (2021) 实现的。 由于计算资源有限,我们将所有基线模型设置为基础版本。
为了展示 LongLM 预训练数据对于长文本建模的一般优势,我们使用标准语言建模目标从头开始对数据进行了从左到右的语言模型预训练。 该模型与 GPT2base 具有相同的架构,记为 GPT2。 此外,我们评估了两个特定于任务的预训练模型,包括 PlotMachines (PM) Rashkin 等人 (2020) 和 Plan&Write (PW) Yao 等人 (2019),以及两个典型的非预训练模型,包括 ConvS2S Gehring 等人 (2017) 和 Fusion Fan 等人 (2018) 关于 LOT 中的生成任务。 我们使用GPT2base作为PM和PW的骨干模型。 对于 PM,我们将输入句子(对于 PlotCom)或输入短语(对于 OutGen)视为记忆网络中使用的绘图元素,并在解码的每个步骤中更新记忆表示。 对于PW,我们采用RAKE算法(对于PlotCom)从目标句子中提取的关键字或按顺序排序的输入短语(对于OutGen)作为规划的中间表示。 我们根据原始论文提供的代码实现了这些模型。
5.2实验设置
了解任务
对于这两个任务,我们对每个示例的输入进行编码,然后通过标准化每个候选表示和上下文之间的点积值来预测所有候选的分布。 我们使用概率最大的候选作为预测结果。 对于 ClozeT,我们使用其末尾的隐藏状态来表示候选者,并将原始文本中出现的删除句子位置处的隐藏状态视为上下文表示。 对于SenPos,我们将每个候选位置的隐藏状态作为候选表示,将删除的句子末尾的隐藏状态作为上下文表示。 在评估 mT5 和 LongLM 时,我们将相同的输入输入到编码器和解码器 Lewis 等人 (2020) 中,并以上述方式使用解码器的隐藏状态进行预测。
生成任务
对于 PlotCom,我们将示例的不完整故事作为输入来生成缺失的句子。 对于 OutGen,我们将大纲中的所有短语与特殊标记连接起来作为输入来生成故事。
超参数
对于所有模型,我们将批量大小设置为 12,最大序列长度设置为 512,学习率设置为 3e-5。 我们使用 的 top- 采样和 0.7 的 softmax 温度来解码输出以进行生成任务。
| Models | # P | ClozeT | SenPos | Overall |
|---|---|---|---|---|
| Validation Set | ||||
| Transformer | 38M | 55.78 | 17.38 | 31.46 |
| BERTbase | 102M | 70.75 | 40.13 | 51.36 |
| RoBERTabase | 102M | 72.11 | 51.63 | 59.14 |
| GPT2base | 102M | 70.07 | 37.78 | 49.62 |
| GPT2 | 102M | 74.49 | 39.25 | 52.17 |
| mT5base | 582M | 72.45 | 63.25 | 66.62 |
| LongLMsmall | 60M | 73.81 | 48.75 | 57.94 |
| LongLMbase | 223M | 75.17 | 64.38 | 68.34 |
| LongLMlarge | 1B | 79.93 | 70.00 | 73.64 |
| Humans | N/A | 99.00 | 97.00 | 97.73 |
| N/A | 0.37 | 0.63 | 1.00 | |
| Test Set | ||||
| Transformer | 38M | 54.42 | 16.34 | 31.23 |
| BERTbase | 102M | 69.39 | 43.68 | 53.74 |
| RoBERTabase | 102M | 67.69 | 51.35 | 57.74 |
| GPT2base | 102M | 73.13 | 37.25 | 51.28 |
| GPT2 | 102M | 76.87 | 39.28 | 53.98 |
| mT5base | 582M | 75.17 | 61.41 | 66.79 |
| LongLMsmall | 60M | 77.21 | 53.07 | 62.51 |
| LongLMbase | 223M | 77.55 | 62.34 | 68.29 |
| LongLMlarge | 1B | 80.61 | 69.41 | 73.39 |
| Humans | N/A | 100.00 | 98.00 | 98.78 |
| N/A | 0.39 | 0.61 | 1.00 | |
| Models | # P | PlotCom | OutGen | Overall | ||||||||
| B-1 | B-2 | D-1 | D-2 | B-1 | B-2 | D-1 | D-2 | Cover | Order | |||
| Validation Set | ||||||||||||
| ConvS2S | 58M | 18.92 | 4.18 | 6.31 | 32.18 | 29.23 | 10.38 | 3.45 | 21.79 | 14.81 | 25.34 | 11.85 |
| Fusion | 109M | 20.56 | 4.69 | 8.63 | 35.73 | 29.22 | 10.34 | 3.39 | 22.67 | 17.41 | 26.55 | 12.61 |
| GPT2base | 102M | 22.67 | 6.22 | 24.75 | 70.57 | 30.43 | 14.87 | 10.95 | 44.38 | 60.90 | 55.52 | 20.24 |
| GPT2 | 102M | 22.49 | 5.43 | 26.88 | 74.87 | 35.29 | 18.31 | 13.89 | 51.36 | 64.01 | 57.64 | 21.73 |
| PM | 102M | 22.11 | 5.49 | 23.89 | 69.74 | 31.81 | 14.94 | 12.99 | 50.56 | 62.98 | 56.75 | 20.45 |
| PW | 102M | 22.45 | 5.57 | 25.64 | 71.54 | 35.84 | 18.47 | 11.86 | 47.62 | 64.93 | 57.30 | 21.48 |
| mT5base | 582M | 22.56 | 6.46 | 24.44 | 71.31 | 36.71 | 22.25 | 14.52 | 50.01 | 77.98 | 63.15 | 23.53 |
| LongLMsmall | 60M | 21.78 | 7.11 | 20.17 | 59.63 | 35.03 | 19.17 | 10.80 | 39.70 | 62.53 | 56.53 | 21.02 |
| LongLMbase | 223M | 22.91 | 8.28 | 22.16 | 63.54 | 40.33 | 24.29 | 14.66 | 51.82 | 79.60 | 62.78 | 24.75 |
| LongLMlarge | 1B | 23.76 | 8.70 | 25.93 | 72.18 | 42.79 | 24.91 | 16.13 | 57.71 | 80.46 | 64.36 | 26.12 |
| Truth | N/A | 100.00 | 100.00 | 35.32 | 84.33 | 100.00 | 100.00 | 21.66 | 71.43 | 100.00 | 100.00 | 92.23 |
| N/A | 0.11 | 0.40 | 0.04 | 0.03 | 0.08 | 0.17 | 0.05 | 0.04 | 0.04 | 0.04 | 1.00 | |
| Test Set | ||||||||||||
| ConvS2S | 58M | 19.60 | 4.20 | 6.00 | 32.42 | 29.00 | 10.14 | 1.60 | 13.95 | 15.45 | 25.77 | 11.27 |
| Fusion | 109M | 20.52 | 4.90 | 8.43 | 35.09 | 28.77 | 10.22 | 1.47 | 14.12 | 17.10 | 26.36 | 11.91 |
| GPT2base | 102M | 22.94 | 5.76 | 24.69 | 70.30 | 30.17 | 14.91 | 7.62 | 36.87 | 60.87 | 55.90 | 19.21 |
| GPT2 | 102M | 22.45 | 5.38 | 26.08 | 73.26 | 35.79 | 18.68 | 9.89 | 43.52 | 64.43 | 56.96 | 20.76 |
| PM | 102M | 22.87 | 5.75 | 24.08 | 71.19 | 31.85 | 15.24 | 8.62 | 41.32 | 63.15 | 57.21 | 19.77 |
| PW | 102M | 22.76 | 6.07 | 25.55 | 70.72 | 35.12 | 17.96 | 8.68 | 40.17 | 63.70 | 55.17 | 20.52 |
| mT5base | 582M | 22.52 | 6.48 | 24.33 | 70.53 | 36.33 | 22.07 | 10.90 | 43.65 | 78.66 | 63.79 | 22.59 |
| LongLMsmall | 60M | 22.05 | 7.45 | 19.93 | 59.79 | 34.48 | 19.17 | 7.93 | 34.25 | 63.75 | 57.64 | 20.48 |
| LongLMbase | 223M | 23.28 | 8.58 | 21.37 | 62.43 | 40.25 | 24.15 | 10.75 | 44.40 | 79.88 | 63.67 | 23.93 |
| LongLMlarge | 1B | 24.20 | 9.06 | 25.75 | 71.08 | 42.10 | 24.77 | 12.04 | 50.29 | 81.48 | 64.82 | 25.29 |
| Truth | N/A | 100.00 | 100.00 | 35.01 | 84.56 | 100.00 | 100.00 | 15.71 | 63.46 | 100.00 | 100.00 | 91.64 |
| N/A | 0.10 | 0.42 | 0.03 | 0.03 | 0.08 | 0.16 | 0.05 | 0.04 | 0.04 | 0.04 | 1.00 | |
5.3自动评估
指标
我们使用准确性来评估理解任务。 对于生成任务,我们使用BLEU-(B-)和Distinct-(D-)来评估-gram 与真实文本重叠 Papineni 等人 (2002) 和 -gram 生成多样性 Li 等人 (2016)分别。 我们为两个生成任务设置。 此外,我们还使用以下两个指标来评估 OutGen: (1) 覆盖范围(Cover): 它用于评估生成可控性,计算为生成文本和每个输入短语之间的平均 Rouge-L 召回分数 Lin (2004)。 覆盖率分数越高,表示生成的文本覆盖了更多的输入短语。 (2)订单: 它用于测量生成文本和真实文本中出现的输入短语的位置顺序之间的差距。 具体来说,我们将顺序得分计算为生成的故事中的倒装数量与任意两个短语的所有位置对数量的平均比率。 反转是指不符合真实顺序的位置对。 我们使用故事和短语之间的最长公共子序列的位置作为短语在故事中的位置。 由于输入短语并不总是出现在生成的故事中,因此我们将此类短语和其他短语的所有位置对视为倒装。
结果
表10和11分别显示了理解和生成任务的结果。 为了获得人类在理解任务上的表现,我们从验证集或测试集中随机抽取了 100 个示例,并聘请了三名众包注释者(母语为中文的人)来完成这些任务。 我们通过多数投票在他们中间做出了最终决定。 所有结果都显示与 Fleiss 的 Fleiss 和 Joseph (1971) 几乎完美的注释者间一致性。 对于生成任务,我们将真实文本的分数视为人类的表现。
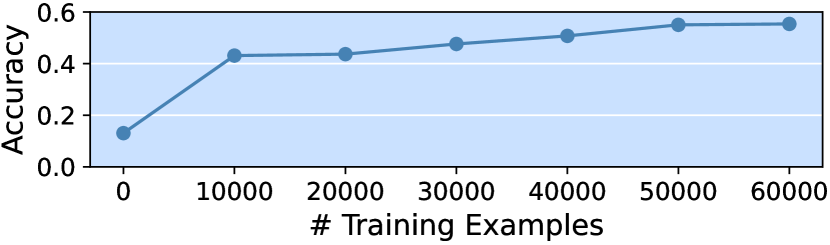
我们将评估结果总结如下:(1)预训练模型的性能明显优于非预训练模型。 (2) LongLMlarge 在理解和生成任务上都大大优于其他基线。 LongLMbase/LongLMsmall 使用比 mT5/GPT2 少一半的参数实现了更好的总体得分。 (3)通过比较GPT2†和GPT2,我们可以得出我们的预训练数据可以有效提高长文本建模的能力。 (4) LongLMsmall 在理解任务上比 GPT2† 表现更好,与 GPT2† 相当> 在生成任务上,提出了编码器-解码器框架和文本填充任务的好处。 (5) 对于所有模型来说,捕获长文本中事件之间的常识和句子间的话语关系以解决 ClozeT 和 SenPos 任务仍然极具挑战性。 此外,我们还研究了训练数据的大小如何影响 SenPos 的 BERT 准确性。 图2中的结果表明有必要开发更好的话语关系表示,而不是仅仅依赖于增加数据大小。 (6) 生成任务的结果表明,与两个任务的类似大小的基线相比,LongLM 在生成更多与参考文献重叠的单词方面表现出色,并且覆盖了更多的输入短语并将其按正确的顺序排列以供 OutGen 。 但 LongLM 在 PlotCom 上的多样性方面不如基于 GPT2 的模型。 (7) 与 GPT2 相比,动态跟踪情节状态(即 PM)并没有给生成任务带来显着的改进,这表明它可能需要显式地建模话语结构来处理生成任务。 PW 在 OutGen 上相对于 GPT2 的优越性进一步表明了建模话语级特征的好处。 综上所述,我们相信LOT将作为一种有效的评估方法,捕捉长文本超越表面事件的常识和话语关系,并生成连贯且可控的长文本。
5.4手动评估
由于自动指标对于评估 NLG Guan 和 Huang (2020) 可能不可靠,因此我们进行了逐点手动评估,以衡量机器和人类在 LOT 中的生成任务上的差异。 对于每个任务,我们从测试集中随机抽取 100 个示例,并从 GPT2base、mT5base 和 LongLM 等三种典型模型中获得 100 个真实文本和 300 个生成文本大。 对于每个文本以及输入,我们聘请了三名众包工作人员,从三个方面进行二进制评分(1 表示好,0 表示好)来判断其质量:(1) 语法 (生成文本的句内语法质量),(2)连贯性(生成文本内的因果和时间依赖性),以及(3)与输入的相关性(与输入的合理逻辑连接) PlotCom 的输入上下文;以及 OutGen 输入短语的合理利用)。 这些方面是独立评估的。 我们通过多数投票在三位注释者中做出了最终决定。 我们在附录中显示了标注说明。
| Models | Gram () | Cohe () | Relat () |
|---|---|---|---|
| Task: PlotCom | |||
| GPT2base | 0.84 (0.49) | 0.41 (0.71) | 0.01 (0.50) |
| mT5base | 0.85 (0.24) | 0.53 (0.65) | 0.01 (0.50) |
| LongLMlarge | 0.95 (0.48) | 0.82 (0.64) | 0.09 (0.69) |
| Truth | 1.00 (1.00) | 1.00 (1.00) | 0.99 (0.49) |
| Task: OutGen | |||
| GPT2base | 0.54 (0.52) | 0.18 (0.52) | 0.39 (0.43) |
| mT5base | 0.53 (0.26) | 0.08 (0.46) | 0.49 (0.38) |
| LongLMlarge | 0.81 (0.23) | 0.37 (0.43) | 0.62 (0.45) |
| Truth | 1.00 (1.00) | 1.00 (1.00) | 1.00 (1.00) |
5.5偏差调查
调查数据集的潜在偏差至关重要,这可能会泄露有关目标标签的信息,并使模型能够轻松地使用快捷方式来处理复杂的输入,而无需真正掌握重点能力Ribeiro 等人(2020)。 因此,我们尝试使用以下基线来检查 ClozeT 和 SenPos 数据集: (1)随机: 它随机选择一名候选人。 (2) 多数: 它选择具有训练集中最常选择的索引的候选者。 (3) 长度: 对于 ClozeT,它选择包含更多单词的候选者;而对于SenPos,它选择相邻句子与被删除句子的单词数最接近的位置。 (4)BLEU-: 对于 ClozeT,它会根据上下文选择 BLEU- 分数 Papineni 等人 (2002) 较高的候选者;对于SenPos,它选择相邻句子与删除的句子具有最大平均BLEU-得分的位置(=1,2)。 (5) 情绪: 对于 ClozeT,它选择由现成的中文情感分析器计算出的情感得分较高的候选者555https://github.com/isnowfy/snownlp;对于SenPos,它选择其相邻两个句子的平均情感得分与被删除句子的得分最接近的位置。 (6) 话语标记: 对于 ClozeT,它选择其相邻句子包含与其匹配的话语标记的候选者。 例如,如果“because”出现在候选位置之前的最后一个句子中,则该基线将选择包含“so”的候选666与英语不同的是,汉语中“because”-“so”等成对的话语标记应该一起使用。. 如果示例中不存在此类配对标记或存在多个符合条件的候选者,则该基线将随机选择一个。 SenPos 的基线设置与 ClozeT 类似。 我们为此基线手动定义 24 个标记对。 (7) 无上下文的 BERT: 我们对 BERT 进行了微调,使其直接选择,而不将上下文作为输入 Schwartz 等人 (2017)。 (8) 不带长整型的 BERT: 它用于研究解决这些任务是否需要对远程依赖关系进行建模。 对于 ClozeT,我们对 BERT 进行了微调,仅选择已删除句子的相邻句子作为输入。 对于SenPos,我们使用BERT分别对每个位置及其相邻句子进行编码,然后采用这些位置的隐藏状态进行预测。 这些基线涵盖了不同级别的特征,从词符级别(例如长度)、句子级别(例如情感)到话语级别(例如话语标记,无上下文的 BERT)。 我们相信这些基线将为我们的数据集的潜在偏差提供全面的检查。
| Baselines | ClozeT | SenPos |
|---|---|---|
| Random | 50.00 | 16.03 |
| Majority | 52.72 | 16.24 |
| Length | 52.72 | 16.45 |
| BLEU-1/2 | 46.94/48.98 | 14.14/14.95 |
| Sentiment | 50.34 | 16.49 |
| Discouse Markers | 45.92 | 9.15 |
| BERT w/o Context | 57.82 | 18.08 |
| BERT w/o Long | 62.24 | 19.00 |
| BERT | 69.39 | 43.68 |
如表13所示,这两个任务都不能通过这些基线轻松解决,这表明数据集在上述特征方面可能没有偏差。 因此,我们认为任务可以侧重于测试模型捕获远程常识和话语关系的能力。
| Tasks | ClozeT | SenPos | PlotCom | OutGen |
|---|---|---|---|---|
| Overlap with the Training Sets | ||||
| Percent | 0.00% | 0.62% | 0.02% | 0.00% |
| # 8-grams | 0 | 1,040 | 6 | 2 |
| # Exam | 0 | 45 | 3 | 2 |
| # Exam>10% | 0 | 17 | 0 | 0 |
| Max Percent | 0.00% | 60.98% | 2.53% | 1.00% |
| Overlap with the Pretraining Data | ||||
| Percent | 0.67% | 4.68% | 0.38% | 1.22% |
| # 8-grams | 172 | 7,844 | 151 | 1,212 |
| # Exam | 83 | 486 | 88 | 161 |
| # Exam>10% | 4 | 71 | 1 | 26 |
| Max Percent | 47.22% | 60.96% | 30.77% | 41.18% |
5.6记忆调查
训练和测试数据之间的重叠可能会导致机器泛化性能的过度报告。 因此,有必要调查有多少测试数据也出现在训练数据中。 为此,我们按照 Radford 等人 (2019) 的方法,通过计算一个数据集中也存在另一个数据集的 8-gram 的百分比来测量两个数据集之间的重叠度。 我们使用 jieba 分词器进行分词。
表14显示了LOT中四个任务的测试集的重叠分析。 我们可以看到,所有测试集与自己的训练集的重叠度都小于 1%。 值得注意的是,有 17 个 SenPos 测试示例包含超过 10% 与训练集重叠的 8-gram。 这是因为训练示例和测试示例可能来自同一个故事,因此它们共享相似的信息(例如角色、位置)。 测试示例最多包含 60.98% 的重叠 8-gram,这表明训练集和测试集不包含完全相同的示例。 至于LongLM的预训练数据,ClozeT和PlotCom的测试集仍然有不到1%的重叠。 然而,SenPos 和 OutGen 中有数十个测试示例包含超过 10% 的重叠 8-gram。 通过人工检查重叠部分,我们发现它们主要来自于成语、谚语和经典童话故事,这可能是预训练数据中某些小说的一部分。
| SenPos | Total | w/o Overlap | |
|---|---|---|---|
| (Training Set) | |||
| # Exam | 863 | 846 | N/A |
| mT5base | 61.41% | 61.82% | +0.41% |
| LongLMlarge | 69.41% | 69.50% | +0.09% |
| SenPos | Total | w/o Overlap | |
| (Pretraining Data) | |||
| # Exam | 863 | 792 | N/A |
| mT5base | 61.41% | 61.24% | -0.17% |
| LongLMlarge | 69.41% | 69.32% | -0.09% |
| OutGen | Total | w/o Overlap | |
|---|---|---|---|
| (Pretraining Data) | |||
| # Exam | 729 | 703 | N/A |
| mT5base | 36.33 | 36.45 | +0.12 |
| LongLMlarge | 42.10 | 42.22 | +0.12 |
6 结论
我们推出了 LOT,一个以故事为中心的中文长文本理解和生成基准。 LOT包括两个故事理解任务和两个故事生成任务,综合考察常识推理、可控生成、句间关系和全局话语结构建模的能力。 我们为这四个任务提供了标准数据集,这些数据集是根据自动和手动标注处理的人类编写的故事构建的。 此外,我们发布了一个新的中文长文本预训练模型 LongLM,它在 LOT 中的理解和生成任务上都远远优于强大的基线模型。 LOT基准、预训练模型和评估平台将鼓励中文长文本建模的进一步研究。
7致谢
该工作得到国家杰出青年科学基金资助(No. 62125604)和国家自然科学基金项目(重点项目,No.62125604) 61936010 和常规项目 61876096)。 该工作还得到了清华大学国强研究院的支持,批准号为: 2019GQG1 和 2020GQG0005。 我们还要感谢我们的动作编辑 Dipanjan Das 和匿名审稿人的宝贵建议和反馈。
参考
- Agarwal et al. (2013) Apoorv Agarwal, Anup Kotalwar, and Owen Rambow. 2013. Automatic extraction of social networks from literary text: A case study on alice in wonderland. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, pages 1202–1208.
- Akoury et al. (2020) Nader Akoury, Shufan Wang, Josh Whiting, Stephen Hood, Nanyun Peng, and Mohit Iyyer. 2020. STORIUM: A Dataset and Evaluation Platform for Machine-in-the-Loop Story Generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6470–6484, Online. Association for Computational Linguistics.
- Bamman et al. (2013) David Bamman, Brendan O’Connor, and Noah A Smith. 2013. Learning latent personas of film characters. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 352–361.
- Bhagavatula et al. (2019) Chandra Bhagavatula, Ronan Le Bras, Chaitanya Malaviya, Keisuke Sakaguchi, Ari Holtzman, Hannah Rashkin, Doug Downey, Wen-tau Yih, and Yejin Choi. 2019. Abductive commonsense reasoning. In International Conference on Learning Representations.
- Brahman and Chaturvedi (2020) Faeze Brahman and Snigdha Chaturvedi. 2020. Modeling protagonist emotions for emotion-aware storytelling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5277–5294, Online. Association for Computational Linguistics.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.
- Chambers and Jurafsky (2008) Nathanael Chambers and Dan Jurafsky. 2008. Unsupervised learning of narrative event chains. In Proceedings of ACL-08: HLT, pages 789–797.
- Chaturvedi et al. (2017) Snigdha Chaturvedi, Mohit Iyyer, and Hal Daume III. 2017. Unsupervised learning of evolving relationships between literary characters. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 31.
- Chaturvedi et al. (2016) Snigdha Chaturvedi, Shashank Srivastava, Hal Daume III, and Chris Dyer. 2016. Modeling evolving relationships between characters in literary novels. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30.
- Chen et al. (2019) Mingda Chen, Zewei Chu, and Kevin Gimpel. 2019. Evaluation benchmarks and learning criteria for discourse-aware sentence representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 649–662.
- Conneau and Kiela (2018) Alexis Conneau and Douwe Kiela. 2018. Senteval: An evaluation toolkit for universal sentence representations. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
- Cui et al. (2020) Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. 2020. Revisiting pre-trained models for Chinese natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 657–668, Online. Association for Computational Linguistics.
- Dai et al. (2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdinov. 2019. Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2978–2988.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- Fan et al. (2018) Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898.
- Finlayson (2012) Mark Mark Alan Finlayson. 2012. Learning narrative structure from annotated folktales. Ph.D. thesis, Massachusetts Institute of Technology.
- Fleiss and Joseph (1971) Fleiss and L. Joseph. 1971. Measuring nominal scale agreement among many raters. Psychological Bulletin, 76(5):378–382.
- Gehring et al. (2017) Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. 2017. Convolutional sequence to sequence learning. In International Conference on Machine Learning, pages 1243–1252. PMLR.
- Gehrmann et al. (2021) Sebastian Gehrmann, Tosin Adewumi, Karmanya Aggarwal, Pawan Sasanka Ammanamanchi, Aremu Anuoluwapo, Antoine Bosselut, Khyathi Raghavi Chandu, Miruna Clinciu, Dipanjan Das, Kaustubh D Dhole, et al. 2021. The gem benchmark: Natural language generation, its evaluation and metrics. arXiv preprint arXiv:2102.01672.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680.
- Guan et al. (2020) Jian Guan, Fei Huang, Zhihao Zhao, Xiaoyan Zhu, and Minlie Huang. 2020. A knowledge-enhanced pretraining model for commonsense story generation. Transactions of the Association for Computational Linguistics, 8:93–108.
- Guan and Huang (2020) Jian Guan and Minlie Huang. 2020. UNION: an unreferenced metric for evaluating open-ended story generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 9157–9166. Association for Computational Linguistics.
- Guan et al. (2019) Jian Guan, Yansen Wang, and Minlie Huang. 2019. Story ending generation with incremental encoding and commonsense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6473–6480.
- Guan et al. (2021) Jian Guan, Zhexin Zhang, Zhuoer Feng, Zitao Liu, Wenbiao Ding, Xiaoxi Mao, Changjie Fan, and Minlie Huang. 2021. OpenMEVA: A benchmark for evaluating open-ended story generation metrics. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6394–6407, Online. Association for Computational Linguistics.
- Kong et al. (2021) Xiangzhe Kong, Jialiang Huang, Ziquan Tung, Jian Guan, and Minlie Huang. 2021. Stylized story generation with style-guided planning. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2430–2436, Online. Association for Computational Linguistics.
- Kudo and Richardson (2018) Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 7871–7880. Association for Computational Linguistics.
- Li et al. (2013) Boyang Li, Stephen Lee-Urban, George Johnston, and Mark Riedl. 2013. Story generation with crowdsourced plot graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 27.
- Li et al. (2016) Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and William B Dolan. 2016. A diversity-promoting objective function for neural conversation models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 110–119.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Liu et al. (2020) Dayiheng Liu, Yu Yan, Yeyun Gong, Weizhen Qi, Hang Zhang, Jian Jiao, Weizhu Chen, Jie Fu, Linjun Shou, Ming Gong, et al. 2020. Glge: A new general language generation evaluation benchmark. arXiv preprint arXiv:2011.11928.
- Louis and Sutton (2018) Annie Louis and Charles Sutton. 2018. Deep dungeons and dragons: Learning character-action interactions from role-playing game transcripts. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 708–713.
- Merity et al. (2016) Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843.
- Mostafazadeh et al. (2016) Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 2016. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of NAACL-HLT, pages 839–849.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Paul and Frank (2021) Debjit Paul and Anette Frank. 2021. COINS: Dynamically generating COntextualized inference rules for narrative story completion. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5086–5099, Online. Association for Computational Linguistics.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rae et al. (2020) Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. 2020. Compressive transformers for long-range sequence modelling. In International Conference on Learning Representations.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21:1–67.
- Rashkin et al. (2020) Hannah Rashkin, Asli Celikyilmaz, Yejin Choi, and Jianfeng Gao. 2020. Plotmachines: Outline-conditioned generation with dynamic plot state tracking. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4274–4295.
- Ribeiro et al. (2020) Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond accuracy: Behavioral testing of NLP models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902–4912, Online. Association for Computational Linguistics.
- Rocktäschel et al. (2016) Tim Rocktäschel, Edward Grefenstette, Karl Moritz Hermann, Tomás Kociský, and Phil Blunsom. 2016. Reasoning about entailment with neural attention. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings.
- Rose et al. (2010) Stuart Rose, Dave Engel, Nick Cramer, and Wendy Cowley. 2010. Automatic keyword extraction from individual documents. Text mining: applications and theory, 1:1–20.
- Sarlin et al. (2020) Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. 2020. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947.
- Schwartz et al. (2017) Roy Schwartz, Maarten Sap, Ioannis Konstas, Leila Zilles, Yejin Choi, and Noah A Smith. 2017. The effect of different writing tasks on linguistic style: A case study of the roc story cloze task. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 15–25.
- Sharma et al. (2018) Rishi Sharma, James Allen, Omid Bakhshandeh, and Nasrin Mostafazadeh. 2018. Tackling the story ending biases in the story cloze test. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 752–757.
- Tay et al. (2020) Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. 2020. Long range arena: A benchmark for efficient transformers. In International Conference on Learning Representations.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Wang et al. (2019) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In International Conference on Learning Representations.
- Wang and Wan (2019) Tianming Wang and Xiaojun Wan. 2019. T-CVAE: transformer-based conditioned variational autoencoder for story completion. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, pages 5233–5239. ijcai.org.
- Xu et al. (2020a) Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. 2020a. Clue: A chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, pages 4762–4772.
- Xu et al. (2020b) Peng Xu, Mostofa Patwary, Mohammad Shoeybi, Raul Puri, Pascale Fung, Anima Anandkumar, and Bryan Catanzaro. 2020b. MEGATRON-CNTRL: controllable story generation with external knowledge using large-scale language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 2831–2845. Association for Computational Linguistics.
- Xue et al. (2021) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mt5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498.
- Yao et al. (2019) Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. 2019. Plan-and-write: Towards better automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7378–7385.
- Zhang et al. (2020) Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, et al. 2020. Cpm: A large-scale generative chinese pre-trained language model. arXiv preprint arXiv:2012.00413.
- Zhao et al. (2017) Tiancheng Zhao, Ran Zhao, and Maxine Eskenazi. 2017. Learning discourse-level diversity for neural dialog models using conditional variational autoencoders. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 654–664.
- Zhao et al. (2019) Zhe Zhao, Hui Chen, Jinbin Zhang, Xin Zhao, Tao Liu, Wei Lu, Xi Chen, Haotang Deng, Qi Ju, and Xiaoyong Du. 2019. Uer: An open-source toolkit for pre-training models. EMNLP-IJCNLP 2019, page 241.