用于图像分类的量子经典混合机器学习
(ICCAD特别会议论文)
摘要
图像分类是传统深度学习(DL)的主要应用领域。 量子机器学习 (QML) 有潜力彻底改变图像分类。 在任何典型的基于深度学习的图像分类中,我们使用卷积神经网络 (CNN) 从图像中提取特征,并使用多层感知器网络 (MLP) 来创建实际的决策边界。 QML 模型在这两项任务中都很有用。 一方面,与参数化量子电路(Quanvolution)的卷积可以从图像中提取丰富的特征。 另一方面,量子神经网络(QNN)模型可以创建复杂的决策边界。 因此,Quanvolution 和 QNN 可用于创建用于图像分类的端到端 QML 模型。 或者,我们可以使用经典的降维技术(例如主成分分析(PCA)或卷积自动编码器(CAE))单独提取图像特征,并使用提取的特征来训练 QNN。 我们回顾了关于用于图像分类的量子经典混合机器学习模型的两个提案,即量子卷积神经网络和使用经典算法进行降维,然后使用 QNN。 特别是,我们在 Quanvolution 和基于 CAE 的图像数据集特征提取中使用可训练滤波器(而不是使用 PCA 等线性变换来降维)。 我们讨论这些模型的各种设计选择、潜在机会和缺点。 我们还发布了一个基于 Python 的框架来创建和探索这些具有多种设计选择的混合模型。
我简介
量子计算是一种新的计算范式,具有巨大的未来潜力。 尽管该技术仍处于起步阶段,但社区正在寻求量子计算机的计算优势(即量子霸权)以实现实际应用。 最近,谷歌声称即使使用 53 量子比特的量子处理器,也可以通过在 200 秒内完成可能需要 1 万年的特定计算来实现量子霸权[1](后来修正为 2.5 天[ 2])在最先进的超级计算机上。
近期的量子设备的量子位数量有限。 此外,它们还受到各种类型的噪声(退相干、门误差、测量误差、串扰等)的影响。 由于这些限制,这些机器尚不完全适合执行依赖于高阶纠错的量子算法(例如,Shor 分解、Grover 搜索)。 量子机器学习 (QML) 有望通过近期机器实现量子优势,因为它基于变分原理(类似于其他近期算法,例如量子近似优化算法或 QAOA [3]、变分量子本征解算器或 VQE [4] 等),不需要纠错[5]。
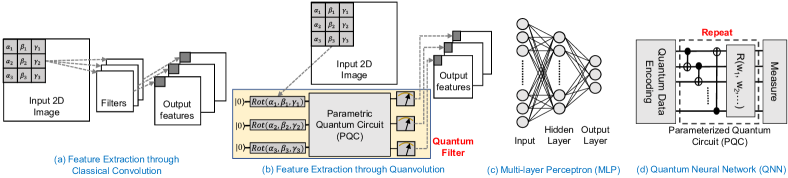
图像分类是最有用的机器学习任务之一,在自动驾驶[7, 8]、医疗诊断[9, 10]、生物识别安全[ 11, 12],仅举几例。 图像分类 ML 管道通常包含两个阶段:(i) 特征提取,以及 (ii) 基于提取的特征进行分类。 在卷积神经网络 (CNN) 兴起之前,各种统计技术主导了图像特征提取(例如 SIFT、SURF、FAST 等),通常称为特征工程[13]。 随后,这些提取的特征被用作分类器(例如 KNN、SVM、决策树、朴素贝叶斯、MLP 等)的输入[14]。 CNN可以同时提取特征并学习分类决策边界,从而消除了特征工程的繁琐步骤。 因此,CNN 近年来已成为图像分类的首选 ML 算法。 它还在许多图像识别任务中达到了人类水平的准确率[9,10,15]。
已经提出了几种用于图像分类的 QML 模型,以在实际用例中利用量子计算机[16,6,17,18,19,20,21,22]。 在[6]中,作者提出了量子卷积神经网络,其中参数量子电路用作滤波器/内核来从图像中提取特征。 这些量子滤波器将图像片段作为输入,并通过在量子空间中转换数据来生成输出特征图。 输出特征用作 MLP 网络的输入。 在[17]中,作者将经典的迁移学习方法扩展到了量子领域。 在这里,经典深度神经网络中经过训练的卷积层用于提取图像特征。 随后,单独训练量子神经网络(QNN)以从这些特征中学习分类决策边界。 一些作品使用了经典的降维技术(例如主成分分析或 PCA)来提取图像特征,然后将它们用作 QNN [23, 24] 的输入。 在[16]中,作者提出了受CNN启发的量子卷积神经网络(QCNN)。 这里,卷积是在相邻的量子位对上执行的多量子位运算。 这些卷积后面是池化层,池化层是通过测量量子位的子集并使用结果来控制后续操作来实现的。 在测量之前,网络以对剩余量子位的成对操作结束。
在本文中,我们回顾了两种有前景的图像分类混合架构:(i) 量化神经网络(Quanvolution + MLP)和 (ii) 经典降维 + QNN。 我们讨论它们的设计选择、特征、增强功能和潜在缺点。 特别是,我们提倡在 Quanvolution 中使用可训练的量子滤波器,以及在量子经典混合图像分类模型中用于图像特征提取的经典卷积自动编码器 (CAE)。 QNN/量子滤波器在编码方法、参数电路和测量操作方面有多种设计选择。 然而,在这项工作中,我们仅使用两种配置进行演示。 随附的基于 Python 的框架支持各种 QNN/量子滤波器设计选择(6 个编码电路、19 个参数电路和 6 个测量电路)。 有兴趣的读者可以利用/扩展这个框架来探索设计空间。
II 预赛
量子位、量子门、状态向量和测量: 量子比特类似于经典比特。 然而,与经典位不同,量子位可以处于叠加状态,即同时 和 的组合。 存在多种量子位技术,例如超导量子位、俘获离子、中性原子、硅自旋量子位等等[25]。 量子门,例如单量子位(例如,Pauli-X () 门)或多量子位(例如,2 量子位 CNOT 门)门可调制量子位的状态以执行计算。 这些门可以执行固定或可调计算,例如,X 门翻转量子位状态,而 RY() 门将量子位沿 Y 轴旋转 。 双量子位门根据另一个量子位(控制量子位)的当前状态更改一个量子位(目标量子位)的状态。 量子电路可以包含许多门操作。 量子位以所需的基础进行测量,以检索量子程序的最终状态。 在物理量子计算机中,测量通常仅限于计算基础,例如 IBM 量子计算机中的 Z 基础。
算子的期望值: 期望值是特征值的平均值,由测量到的状态处于相应特征状态的概率加权。 从数学上讲,运算符的期望值 () 定义为 ,其中 是量子位状态向量。 它在算子的最小和最大特征值之间变化。 例如,Pauli-Z () 运算符有两个特征值:+1 和 -1。 因此,量子位的 Pauli-Z 期望值将根据量子位状态在 [-1, 1] 范围内变化。
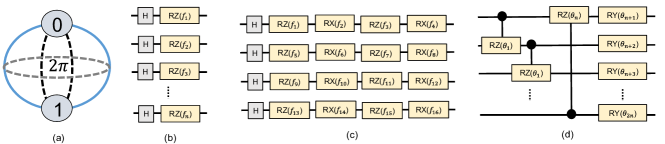
量子神经网络: QNN 涉及 PQC 的参数优化以获得所需的输入输出关系。 QNN 通常由三部分组成:(i) 经典的量子数据编码(或嵌入)电路,(ii) 参数化电路,以及 (iii) 测量操作。 文献[26]中提供了多种编码方法。 对于连续变量,最广泛使用的编码方案是角度编码,其中连续变量输入经典特征被编码为量子位沿所需轴 (X/Y/Z) 的旋转 [27, 28, 26, 29 ]。 对于“n”个经典特征,我们需要“n”个量子位。 例如,叠加量子位上的 RZ(f1)(Hadamard - H 门用于将量子位叠加)用于编码图 2(b) 中的经典特征“f1” 。 我们还可以使用顺序旋转在单个量子位中编码多个连续变量。 例如,“f1”、“f2”、“f3”和“f4”在图 1 中的单个量子位上使用连续的 RZ(f1)、RX(f2)、RZ(f2) 和 RX(f4) 旋转进行编码。 2(c)。 由于量子位沿任意轴旋转产生的状态将以 2 间隔重复(图 2(a)),因此特征通常在 0 到 2(或 - 至 )。
参数电路有两个组成部分:纠缠操作和参数化单量子位旋转。 纠缠操作是所有量子位之间的一组多量子位操作,用于生成相关状态[29]。 以下参数化单量子位运算用于搜索解空间。 这种纠缠和单量子位旋转操作的组合在 QNN 中被称为参数层。 一种广泛使用的参数层架构如图2(d)[30, 27]所示。 此处,相邻量子位之间的 CRZ() 门创建了纠缠,然后使用 RY() 沿 Y 轴旋转。 通常,这些层会重复多次以扩展搜索空间[28, 27]。
QNN 成本函数: QNN 电路中的量子位在计算基础上进行测量以检索输出状态。 成本函数是从训练网络 [27, 31, 28] 的测量中得出的。 例如,在二元分类问题中,作者在 Pauli-Z 基础上测量了 QNN 模型中的所有量子位,并将类 0 与获得偶校验的概率相关联,类 1 与奇校验[27]. 然后,使用二元交叉熵损失训练模型。 在[32]中,作者使用单个量子位的 Pauli-Z 期望值(-1 与类 1 相关,+1 与类 0 相关)作为二元分类器,并使用均方对其进行训练误差(MSE)损失。在[23]中,作者将 QNN 的输出输入经典神经网络,并使用二元交叉熵损失函数对其进行训练。
训练 QNN: QNN 可以使用任何基于梯度的优化算法进行训练,例如 Adam [33] 或 Adagrad [34]。 为了应用这些方法,我们需要计算 QNN 输出相对于电路参数的梯度 [35, 36]。 参数移位规则是计算梯度[35, 36]的已知方法。 从概念上讲,参数转移规则与古老的有限差分方法非常相似,后者使用目标函数的两次评估来计算相对于参数的梯度。 与有限差分不同,参数转移规则中两个数据点可以彼此远离。 因此,与有限差分[36]相比,它对散粒噪声和测量误差表现出更大的弹性。 或者,也可以使用无梯度优化器(例如 Nelder-Mead)来训练 QNN [37]。 然而,当网络有大量参数时,无梯度优化器可能表现不佳。
III 图像分类混合架构
III-A 量子卷积 + MLP
Quanvolution 只是经典卷积的扩展,其中使用相同的内核/滤波器顺序处理图像的小局部区域。 内核是一个小的二维矩阵。 内核和图像片段之间的点积用于生成输出特征。 对于 3D RGB 图像,跨通道(2D 平面)应用单独的内核,它们统称为滤波器。 对于 2D 图像,滤波器和内核是同义词。 为每个区域获得的结果通常与单个输出像素的不同通道相关联。 所有输出像素的联合产生一个新的类似图像的对象,可以通过附加层进一步处理。 一个玩具卷积层操作如图1(a)所示。 在 Quanvolution 中,量子电路模仿经典 CNN 滤波器的行为。
量子滤波器: 量子滤波器将图像片段编码为量子电路的输入状态。 使用参数化量子电路来转换状态,随后的测量操作会产生与该段相对应的输出特征。 图1(b) 显示了一个玩具 Quanvolution 层。 这里,使用 3 量子位量子电路作为滤波器。 它使用 3 Rot() 旋转将 3x3 图像片段编码为 3 量子位量子态(Rot 是采用三个旋转参数的任意量子门)。 与 CNN 类似,这些量子滤波器以有限步长(步幅)在 2D 平面上移动,以生成图像的完整输出特征图。
滤波器的量子位大小取决于所选的编码方法和内核大小。 例如,如果我们使用 1 变量/量子位编码方法(图2(b)),生成的量子滤波器将是内核大小为 4x4 的 16 量子位电路。 如果我们选择4个变量/量子位编码方法,它将减少到4个量子位电路(图2(c))。 诸如数据重新上传[38]之类的概念可用于在任意数量的量子位中编码任意数量的变量。 编码方法的选择很可能取决于量子资源的可用性[21]。 在这项工作中,我们对 4x4 内核使用 4 个变量/量子位编码方法。 我们使用图2(d)([30]的电路13)所示的电路架构作为量子滤波器中的首选PQC。 我们还使用量子位的 Pauli-Z 期望值作为输出特征(n 量子位滤波器生成 n 特征/图像片段)。 增加过滤器的数量会增加下游分类器提取的特征的数量。 与具有大量级的 CNN 类似,大量量子滤波器可以提高性能(更低的成本/更高的精度/更快的训练)[6]。
过滤器可训练性: 在[6]的原始工作中,量子滤波器没有任何可训练的参数。 然而,在 CNN 中,过滤器具有可训练的权重,并且它们是在训练过程中学习的。 同样,量子滤波器也可以具有可训练的参数。 例如,我们可以随机初始化PQC参数(图2(d)中的)并在整个训练过程中保持不变,或者我们可以在训练过程中更新它们以及网络中的其他参数。
可训练的过滤器将导致训练期间量子电路执行能力成倍增加。 例如,如果量子滤波器具有 p 个可训练参数,它将为每个图像片段添加 2xp 的量子电路执行次数,以使用参数移位规则 [36] 计算所需的梯度。 请注意,使用不可训练的量子滤波器生成特征相当于图像片段的随机变换。 经典的随机函数可以取代此类滤波器。 事实上,[6] 中的工作表明,图像片段的经典随机变换的性能与不可训练量子滤波器的随机变换的性能相匹配。 然而,可训练的量子电路很难进行经典模拟[39]。 如果它们比不可训练的同类表现出显着的性能优势,那么研究界就值得探索它们以获得可能的量子优势[40]。
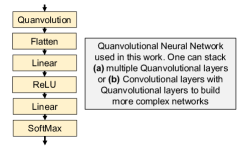
网络设计: 与 CNN 类似,一个 Quanvolutional 层可以有许多滤波器,并且多个 Quanvolutional 层可以相互堆叠以开发深度 Quanvolutional 神经网络[6, 21]。 最终 Quanvolutional 层的输出可以馈送到 MLP(或 QNN)。 人们还可以在 Quanvolutional 层的输出处应用经典的非线性激活函数(用于额外的非线性)和 maxpooling(下采样)。 人们可以通过使用不同的随机种子初始化相同的 PQC 来创建单独的过滤器。 或者,我们可以使用不同的 PQC 架构、编码方法和测量操作来创建不同的滤波器。 我们还可以将经典卷积层与量子卷积层堆叠在一起。 图3显示了本工作中使用的网络图,其中包含单个量子卷积层,后面跟着两个完全连接的经典层。
电路执行次数: 训练/推理期间每个样本的量子电路执行数量取决于内核大小、图像大小和步幅(以像素为单位的内核移动量)。 对于 28x28 图像和 4x4 内核大小,当步长 = 4 时,我们需要执行总共 7x7 量子电路(单个不可训练的量子滤波器)。 如果该滤波器有 10 个可训练参数,则电路执行总数变为 7x7 + 2x10x7x7,其中需要使用参数移位规则计算梯度(每个参数 [36]< 需执行 2x10x7x7 次电路)(每个参数需要执行 2 次额外电路) /t0>)。 如果我们每批次采集 50 个样本,则训练期间每批次需要执行 50x(7x7 + 2x10x7x7) 次过滤器。 事实上,对于单个批次和过滤器来说,这是一个非常大的数字。 然而,所有这些电路都是彼此独立的。 因此,人们可以说,如果能够访问多个量子计算资源,所有这些计算都可以同时完成。
III-B 经典降维+QNN
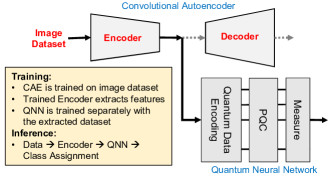
另一种针对较小量子器件的流行混合 QML 模型使用经典算法(例如主成分分析或 PCA、线性判别分析或 LDA 等)将数据维度减少到小型 QNN 模型可处理的水平[ 24、41、23]。 尽管 PCA/LDA 可以很好地从小表格数据中提取最显着的特征,但它们不适合从大图像中提取特征。 自动编码器 (AE),特别是卷积自动编码器 (CAE) 是用于图像特征提取/降维的更强大的工具[42, 43]。 PCA 是数据的线性变换,而 AE/CAE 可以使用非线性激活函数和正则化对数据中更复杂的非线性关系进行建模[43]。
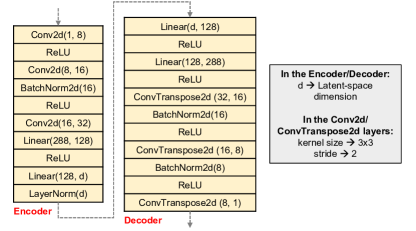
AE/CAE:AE 是一种特定类型的前馈神经网络。 他们使用编码器网络将输入压缩为较低维的代码,然后通过解码器网络重建该表示的输出。 该代码是输入的紧凑表示,也称为潜在空间表示。 输入和重建输出之间的距离(例如,MSE 损失)用作网络的反馈信号。 简单 AE 中的编码器和解码器都由几个完全连接的层组成。 CAE 提供了比 AE 更好的架构来提取图像的纹理特征。 在 CAE 中,编码器块从一个或多个连续的卷积层开始。 解码器块以卷积转置/反卷积层结束。 中间有一个全连接的AE,其最内层由少量神经元组成。 经过训练后,编码器块可以用作独立实体来提取输入数据的较低维表示。
图 4 显示了本工作中使用的 CAE 网络架构(针对 MNIST 和 Fashion-MNIST 数据集)。 最终的 ConvTranspose2d 层使用 Sigmoid 激活,其中“d”是潜在空间的维度。
网络设计: 混合网络(图5)由两个独立的网络组成 - CAE 和 QNN。 CAE 使用原始图像数据集进行训练,以学习数据的较低维度表示。 经过训练的编码器网络用于提取图像特征。 使用这些提取的特征和图像标签来训练传统的 QNN 以执行最终分类。 当这两个网络都经过训练时,编码器块和 QNN 块一起使用来对数据样本进行分类。 我们将此架构称为 CAE+QNN。
QNN 设计空间: 如前所述,构建 QNN 模型的编码电路、PQC 和测量电路有多种选择。 这项工作附带的 Python 框架支持各种各样的选择,这将影响 QNN [30] 的可学习性。 然而,在这项工作中,我们仅使用单一特征/量子位编码方法(图2(b))、图2(d)的PQC层,以及QNN 中量子位的 Z 基测量。 我们还将参数层的数量限制为 3。 在[23]之后,我们将 QNN 输出馈送到全连接层。 输出神经元的数量等于数据集中的类的数量。
CAE+QNN 对比 迁移学习: 尽管 CAE+QNN 网络与迁移学习[17]有一些相似之处,但也存在一些值得注意的差异。 这两种方法都使用经典网络提取图像特征。 在迁移学习中,经典 CNN 网络的卷积层使用不同的数据集进行训练(例如,经过训练以对 ImageNet 数据集进行分类的 AlexNet),用于提取目标数据集的特征。 相比之下,CAE+QNN网络中的CAE是单独训练的,以从目标数据集中提取特征。 因此,与迁移学习相比,CAE 提取的特征可以捕获目标数据集中更多的方差,因此可以提供更好的性能(更低的训练成本/更高的准确性)。 通过迁移学习提取的特征可以更加通用[17],并且无需单独训练经典网络(因为它已经经过训练)。
![[Uncaptioned image]](x6.png)
![[Uncaptioned image]](x7.png)
IV 评估
在本节中,我们比较 (a) 具有可训练滤波器和不可训练滤波器的量子卷积神经网络,以及 (b) 针对各种数据集的 CAE + QNN 和基于 PCA 的方法之间的性能差异。
数据集:我们为这项工作选择了 MNIST 和 Fashion-MNIST 数据集,这些数据集在 QML 研究的当代作品中广泛使用(每个像素值在 0-1 范围内缩放)[44, 45]. 这两个数据集都有 60,000 个训练样本和 10,000 个属于 10 个不同类别的 2D 图像(28x28 像素)测试样本。 为了对 Quanvolution 方法进行实证评估,我们从三个不同类别中挑选了 1,200 个样本来创建 6 个较小的分类数据集 - MNIST_179、MNIST_246、MNIST_358、Fashion_012、Fashion_345 和 Fashion_678。 MNIST_179 有 400 个数字 1、7 和 9 的样本。 同样,Fashion_012 有 400 个类别 0(T 恤/上衣)、1(裤子/裤子)和 2(套头衫)的样本。 我们使用 maxpooling 将样本尺寸从 28x28 减少到 14x14,以缩短模拟时间。 为了比较 CAE 和 PCA,我们使用整个 MNIST 和 Fashion-MNIST 数据集训练了相应的 CAE(潜在维度为 5 和 10)和 PCA 模型。 后来,我们像以前一样使用具有各种潜在维度 (5/10) 和主成分 (10) 的训练模型创建了 6 个较小的分类数据集。
指标:我们将数据集分为两个相等的组用于训练和验证(600 个样本/组)。 我们使用整个训练和验证数据集的平均损失和准确率来衡量 QML 模型[46]的性能。
训练设置: 我们使用基于梯度的 Adagrad、SGD 和 Adam 优化器来处理这些模型[47, 48]。 我们在所有运行中使用同一组超参数(所有量子/混合模型的学习率 = 0.5)。
可训练与可训练Quanvolution 中的不可训练过滤器: 我们使用单个量子卷积层(图 3)训练了量子卷积神经网络,以解决具有可训练和不可训练量子滤波器(步长= 4)的六个三类分类问题。 我们使用 4 量子位电路作为量子卷积滤波器。 我们使用图2(c)所示的4变量/量子位编码方法将4x4像素编码为4量子位状态。 输入像素缩放为 0-(最初为 0-1)。 图2(d) 中的 PQC 架构采用 3 个参数层(3x2x4 参数)。 在具有可训练滤波器的 Quanvolution 中,这些 PQC 参数与其他网络参数一起使用梯度下降进行训练。 在不可训练的过滤器中,我们在开始时随机设置训练 PQC 参数(- 到 ),并在整个过程中保持它们不变。 量子位的 Pauli-Z 期望值被用作输出特征。 结果列于表I(10 个训练周期后的性能)。 在具有 16 GB RAM 的单核 Core i7-10750H 机器上,使用可训练过滤器的每个训练周期花费 195 秒,而使用不可训练过滤器则花费 57 秒。
平均而言,在 10 个训练周期后,带有可训练过滤器的 Quanvolution 训练损失降低了 15.98%,验证损失降低了 7.49%,训练准确率提高了 3.46%,验证准确率提高了 3.32%。 在某些情况下,具有不可训练滤波器的 Quanvolution 的性能与其可训练滤波器的性能相似。 例如,MNIST_179 和 MNIST_358 在这两种方法中提供了相似的性能。 然而,在所有其他情况下,这两种方法之间存在明显的性能差距。 我们使用不同随机初始化的 MNIST_179 和 MNIST_358 数据集重复实验 5 次。 然而,这两种方法的性能仍保持在相似的水平。 事实上,与其他模型相比,这两个模型在这两个数据集上的表现都很差(使用可训练过滤器时,平均训练损失为 0.535,而总体训练损失为 0.266)。 总体结果表明可训练过滤器的潜在好处值得未来探索。
CAE+QNN: 我们使用潜在维度为 5 和 10 的 MNIST 和 Fashion-MNIST 数据集的 60000 个训练样本来训练图 4 中的 CAE(优化器:Adam,学习率:0.001,权重衰减:,纪元:30,批量大小:50)。 提取的数据集(5/10 特征)用于训练 QNN。 在QNN中,我们使用了1个变量/量子位编码方法,如图2(b)所示。 我们分别对 5 个特征和 10 个特征数据集使用 5 个和 10 个量子位。 QNN 与量子滤波器共享相同的 PQC 架构和输出测量(图2(d))。 我们将 10 量子位模型中的参数层限制为 3 个(3x2x10 参数)。 为了匹配可训练电路参数的数量,我们将 5 量子位模型中的参数层限制为 6 个(6x2x5 参数)。
结果列于表II(20 个 epoch 后的性能)。 从它们的损失和准确性值可以明显看出,所有这些模型都是可训练的。 在 CAE+QNN 模型中,所选的潜在维度 (d) 数量决定了 QNN 架构。 它还会影响整体网络性能。 d 值越高意味着 QNN 模型的输入特征越多,这通常意味着 QNN 的训练性能更好。 平均而言,与 d = 5 相比,d = 10 的 CAE + QNN 模型在 20 个训练周期后训练损失降低了 29.85%,验证损失降低了 23.23%,训练精度提高了 2.08%,验证精度提高了 4.68%。 因此,较高的 d(以较大的 QNN 为代价)可能会在实际应用中提供更好的性能。
CAE + QNN 对比主成分分析+QNN: 由于 PCA 使用线性变换,提取的图像特征预计较差,这可能会导致 QNN 的训练性能较差。 为了进行这种比较,我们使用 60000 个 MNIST 训练样本训练了一个 PCA 模型,并像以前一样提取了 4000 个样本(400/类),并以 10 个主成分作为特征变量。 我们还从训练有素的 CAE 中提取了另外 4000 个样本,其中 d = 10。 后来,我们使用相同的一组训练超参数(优化器:Adagrad,学习率:0.5)使用这些数据集训练了 10 量子位 QNN 模型(参数层设置为 3)20 个 epoch。 结果如表III所示。 正如预期的那样,CAE+QNN 方法的性能显着优于 PCA+QNN 方法。 CAE + QNN 模型的训练损失降低了 48.47%,验证损失降低了 49.2%,训练准确率提高了 14.1%,验证准确率提高了 25.3%。
![[Uncaptioned image]](x8.png)
Python 框架支持: 使用各种编码方法、参数电路架构和测量的 QNN/量子滤波器设计存在多种选择。 在这项工作中,我们只探索了有限的集合(图2)。 不过,我们还发布了一个基于 Python 的框架(使用 PennyLane、TensorFlow 和 PyTorch 包 [49,48,47] 创建),支持 [30] 中的 19 种参数电路架构t1>、6 种编码技术和 6 种测量电路[50]。 我们还通过存储库提供数据集。 感兴趣的读者可以利用此存储库在任何选定的数据集上进一步探索这些模型。
V 结论
在本文中,使用经验证据,我们认为 Quanvolution 中的可训练量子滤波器可能比不可训练滤波器提供性能优势,因此,值得探索图像分类任务中潜在的量子优势。 我们还表明,在后来的架构中,与基于线性变换的方法(例如图像数据集的 PCA)相比,使用卷积自动编码器 (CAE) 进行降维可能更有用。
致谢:这项工作得到了 NSF 的部分支持(CNS-1722557、CCF-1718474、OIA-2040667、DGE-1723687 和 DGE-1821766)以及宾夕法尼亚州立大学 ICDS 和哈克研究所的种子资助生命科学。
参考
- [1] F. Arute, K. Arya, R. Babbush, D. Bacon, J. C. Bardin, R. Barends, R. Biswas, S. Boixo, F. G. Brandao, D. A. Buell et al., “Quantum supremacy using a programmable superconducting processor,” Nature, vol. 574, no. 7779, pp. 505–510, 2019.
- [2] E. Pednault, J. Gunnels, D. Maslov, and J. Gambetta, “On “quantum supremacy”,” IBM Research Blog, vol. 21, 2019.
- [3] E. Farhi and H. Neven, “Classification with quantum neural networks on near term processors,” arXiv preprint arXiv:1802.06002, 2018.
- [4] A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, “Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets,” Nature, vol. 549, no. 7671, pp. 242–246, 2017.
- [5] J. R. McClean, J. Romero, R. Babbush, and A. Aspuru-Guzik, “The theory of variational hybrid quantum-classical algorithms,” New Journal of Physics, vol. 18, no. 2, p. 023023, 2016.
- [6] M. Henderson, S. Shakya, S. Pradhan, and T. Cook, “Quanvolutional neural networks: powering image recognition with quantum circuits,” Quantum Machine Intelligence, vol. 2, no. 1, pp. 1–9, 2020.
- [7] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Proceedings of the IEEE CVPR, 2017, pp. 1907–1915.
- [8] D. Maturana and S. Scherer, “Voxnet: A 3d convolutional neural network for real-time object recognition,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2015, pp. 922–928.
- [9] S. M. McKinney, M. Sieniek, V. Godbole, J. Godwin, N. Antropova, H. Ashrafian, T. Back, M. Chesus, G. S. Corrado, A. Darzi et al., “International evaluation of an ai system for breast cancer screening,” Nature, vol. 577, no. 7788, pp. 89–94, 2020.
- [10] A. Esteva, B. Kuprel, R. A. Novoa, J. Ko, S. M. Swetter, H. M. Blau, and S. Thrun, “Dermatologist-level classification of skin cancer with deep neural networks,” nature, vol. 542, no. 7639, pp. 115–118, 2017.
- [11] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf, “Deepface: Closing the gap to human-level performance in face verification,” in Proceedings of the IEEE CVPR, 2014, pp. 1701–1708.
- [12] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE CVPR, 2015, pp. 815–823.
- [13] M. Nixon and A. Aguado, Feature extraction and image processing for computer vision. Academic press, 2019.
- [14] J. Friedman, T. Hastie, R. Tibshirani et al., The elements of statistical learning. Springer series in statistics New York, 2001, vol. 1, no. 10.
- [15] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
- [16] I. Cong, S. Choi, and M. D. Lukin, “Quantum convolutional neural networks,” Nature Physics, vol. 15, no. 12, pp. 1273–1278, 2019.
- [17] A. Mari, T. R. Bromley, J. Izaac, M. Schuld, and N. Killoran, “Transfer learning in hybrid classical-quantum neural networks,” Quantum, vol. 4, p. 340, 2020.
- [18] Y. Li, R.-G. Zhou, R. Xu, J. Luo, and W. Hu, “A quantum deep convolutional neural network for image recognition,” Quantum Science and Technology, vol. 5, no. 4, p. 044003, 2020.
- [19] I. Kerenidis, J. Landman, and A. Prakash, “Quantum algorithms for deep convolutional neural networks,” arXiv preprint arXiv:1911.01117, 2019.
- [20] Y. Dang, N. Jiang, H. Hu, Z. Ji, and W. Zhang, “Image classification based on quantum k-nearest-neighbor algorithm,” Quantum Information Processing, vol. 17, no. 9, pp. 1–18, 2018.
- [21] M. Henderson, J. Gallina, and M. Brett, “Methods for accelerating geospatial data processing using quantum computers,” Quantum Machine Intelligence, vol. 3, no. 1, pp. 1–9, 2021.
- [22] J. Li, M. Alam, C. M. Sha, J. Wang, N. V. Dokholyan, and S. Ghosh, “Drug discovery approaches using quantum machine learning,” arXiv preprint arXiv:2104.00746, 2021.
- [23] H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, “Power of data in quantum machine learning,” Nature communications, vol. 12, no. 1, pp. 1–9, 2021.
- [24] E. Grant, M. Benedetti, S. Cao, A. Hallam, J. Lockhart, V. Stojevic, A. G. Green, and S. Severini, “Hierarchical quantum classifiers,” npj Quantum Information, vol. 4, no. 1, pp. 1–8, 2018.
- [25] M. A. Nielsen and I. Chuang, Quantum computation and quantum information. American Association of Physics Teachers, 2002.
- [26] M. Schuld, R. Sweke, and J. J. Meyer, “Effect of data encoding on the expressive power of variational quantum-machine-learning models,” Physical Review A, vol. 103, no. 3, p. 032430, 2021.
- [27] A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, “The power of quantum neural networks,” Nature Computational Science, vol. 1, no. 6, pp. 403–409, 2021.
- [28] M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, “Circuit-centric quantum classifiers,” Physical Review A, 2020.
- [29] S. Lloyd, M. Schuld, A. Ijaz, J. Izaac, and N. Killoran, “Quantum embeddings for machine learning,” arXiv preprint arXiv:2001.03622, 2020.
- [30] S. Sim, P. D. Johnson, and A. Aspuru-Guzik, “Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms,” Advanced Quantum Technologies, 2019.
- [31] M. Schuld and N. Killoran, “Quantum machine learning in feature hilbert spaces,” Physical review letters, vol. 122, no. 4, p. 040504, 2019.
- [32] M. Alam, A. Ash-Saki, and S. Ghosh, “Addressing temporal variations in qubit quality metrics for parameterized quantum circuits,” in 2019 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED). IEEE, 2019, pp. 1–6.
- [33] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [34] J. Duchi, E. Hazan, and Y. Singer, “Adaptive subgradient methods for online learning and stochastic optimization.” Journal of machine learning research, vol. 12, no. 7, 2011.
- [35] L. Banchi and G. E. Crooks, “Measuring analytic gradients of general quantum evolution with the stochastic parameter shift rule,” Quantum, vol. 5, p. 386, 2021.
- [36] M. Schuld, V. Bergholm, C. Gogolin, J. Izaac, and N. Killoran, “Evaluating analytic gradients on quantum hardware,” Physical Review A, vol. 99, no. 3, p. 032331, 2019.
- [37] W. Lavrijsen, A. Tudor, J. Müller, C. Iancu, and W. de Jong, “Classical optimizers for noisy intermediate-scale quantum devices,” in 2020 IEEE International Conference on Quantum Computing and Engineering (QCE). IEEE, 2020, pp. 267–277.
- [38] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,” Quantum, vol. 4, p. 226, 2020.
- [39] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum-enhanced feature spaces,” Nature, vol. 567, no. 7747, pp. 209–212, 2019.
- [40] P. Atchade-Adelomou and G. Alonso-Linaje, “Quantum enhanced filter: Qfilter,” arXiv preprint arXiv:2104.03418, 2021.
- [41] K. Batra, K. M. Zorn, D. H. Foil, E. Minerali, V. O. Gawriljuk, T. R. Lane, and S. Ekins, “Quantum machine learning algorithms for drug discovery applications,” Journal of Chemical Information and Modeling, 2021.
- [42] J. Masci, U. Meier, D. Cireşan, and J. Schmidhuber, “Stacked convolutional auto-encoders for hierarchical feature extraction,” in International conference on artificial neural networks. Springer, 2011, pp. 52–59.
- [43] M. Chen, X. Shi, Y. Zhang, D. Wu, and M. Guizani, “Deep features learning for medical image analysis with convolutional autoencoder neural network,” IEEE Transactions on Big Data, 2017.
- [44] L. Deng, “The mnist database of handwritten digit images for machine learning research [best of the web],” IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 141–142, 2012.
- [45] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017.
- [46] M. Anthony and P. L. Bartlett, Neural network learning: Theoretical foundations. cambridge university press, 2009.
- [47] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” arXiv preprint arXiv:1912.01703, 2019.
- [48] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard et al., “Tensorflow: A system for large-scale machine learning,” in 12th USENIX symposium on operating systems design and implementation (OSDI 16), 2016, pp. 265–283.
- [49] V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, M. S. Alam, S. Ahmed, J. M. Arrazola, C. Blank, A. Delgado, S. Jahangiri et al., “Pennylane: Automatic differentiation of hybrid quantum-classical computations,” arXiv preprint arXiv:1811.04968, 2018.
- [50] https://github.com/mahabubul-alam/iccad_2021_invited_QML.