估计和利用表面法线估计中的任意不确定性
摘要
从单个图像估计表面法线是 3D 场景理解中的一项重要任务。 在本文中,我们解决了现有方法共有的两个局限性:无法估计任意不确定性和预测缺乏细节。 所提出的网络估计每像素表面正态概率分布。 我们为分布引入了一种新的参数化,使其负对数似然是学习衰减的角度损失。 然后使用角度误差的预期值作为任意不确定性的度量。 我们还提出了一种新颖的解码器框架,其中像素级多层感知器在基于估计的不确定性采样的像素子集上进行训练。 所提出的不确定性引导采样可以防止训练中对大平面的偏差,并提高预测质量,特别是在物体边界附近和小型结构上。 实验结果表明,所提出的方法优于 ScanNet [4] 和 NYUv2 [33] 中最先进的方法,并且估计的不确定性与预测错误。 代码可在 https://github.com/baegwangbin/surface_normal_uncertainty 获取。
1简介

从单个 RGB 图像估计表面法线的能力对于理解 3D 场景几何形状起着至关重要的作用。 估计的法线可用于构建增强现实 (AR) 应用[18]或控制自主机器人[41]。 在这项工作中,我们解决了最先进方法所共有的两个局限性。
(1) 无法估计任意不确定性。 最先进的基于学习的方法[39, 7, 1, 31, 14, 18, 42, 24, 32, 6, 38]通过最小化一些距离度量来训练深度网络(例如,)在预测法线和地面实况之间。 然而,根据测量的深度图计算的地面实况法线可能对深度噪声和用于计算法线的算法敏感(有关不准确的地面实况的示例,请参见图2)。 网络应该能够捕获这种随意的不确定性,以便部署在现实世界的应用程序中。
(2) 预测缺乏细节。 室内场景通常由大型平面(例如墙壁和地板)和具有复杂几何形状的小物体组成。 因此,如果将训练损失应用于所有像素,则学习会偏向于大表面,从而导致输出过度平滑。 这种偏差可以通过将损失应用于精心选择的像素子集来解决。 例如,在[40]中,将成对排序损失应用于实例边界附近的像素,以提高单目深度估计的质量。 然而,还没有为表面法线估计做出这样的努力。

在这项工作中,我们通过预测每像素表面法线的概率分布来估计任意不确定性。 虽然 von Mises-Fisher 分布 [8] 可用于此目的,但最小化其负对数似然 (NLL) 相当于最小化预测正态分布之间的 距离以及具有习得损失衰减的基本事实。 由于我们感兴趣的误差度量是两个向量之间的角度,因此我们为分布引入了一种新的参数化,使其 NLL 是具有学习衰减的角度损失。 在测试时,根据估计分布计算预期角度误差,并将其用作任意不确定性的度量。
我们还提出了一种新颖的解码器框架来提高预测的细节水平。 网络最初进行粗略预测,将训练损失应用于所有像素。 然后,粗略预测和特征图被双线性上采样 2 倍,并通过逐像素多层感知器 (MLP) 以产生精细输出。 重复此过程直到达到所需的分辨率。 MLP 在基于不确定性选择的像素子集上进行训练:选择具有最高不确定性的像素并用均匀采样的像素进行补充。 这种不确定性引导采样可以防止训练中对大平面的偏差(网络估计其不确定性较低),从而提高对象边界附近和小型结构的预测质量。
我们的贡献可概括如下:
-
•
表面法线的任意不确定性的估计。 据我们所知,我们是第一个在基于 CNN 的表面法线估计中估计任意不确定性的人。 我们为表面正态概率分布引入了一种新的参数化,并表明估计的不确定性与预测误差密切相关。
-
•
用于逐像素细化的不确定性引导采样。 我们引入了一种新颖的解码器模块,其中损失应用于基于不确定性选择的像素子集。 我们表明该模块显着提高了定量和定性性能。
-
•
最先进的性能。 实验结果表明,该方法在 ScanNet [4] 和 NYUv2 [33] 上实现了最先进的性能。 定性地讲,我们的方法做出的预测包含更高级别的细节(见图1)。
2相关工作
表面法线估计。 文献 [9, 10, 22, 39, 7, 1, 37, 31, 18, 42, 24, 32, 6, 38] 对单个 RGB 图像的表面法线估计进行了广泛的研究。 现有的方法通常由特征提取器和预测头组成。 例如,Ladicky 等人 [22] 提取手工制作的特征(例如 SIFT [26])并应用多类 Ada-boost [36] 将输出回归为一组离散法线的线性组合。 随着深度学习的成功,最近的方法用卷积神经网络(CNN)取代了这两个组件。
Wang等人[39]引入了双流CNN来学习全局和局部线索,并将它们与另一个CNN融合。 Eigen 和 Fergus [7] 提出了一种多尺度架构来联合预测深度、表面法线和语义标签。 在这些早期尝试之后,通过强制深度法线一致性[31, 32]、将任务制定为球形回归[24]以及引入空间整流器做出了贡献处理倾斜图像[6]。 在这项工作中,我们解决了表面法线的任意不确定性,这在以前的文献中尚未研究过。
深度学习的不确定性。 不确定性的两种主要类型是认知性和任意性[5]。 认知不确定性(即模型中的不确定性)可以通过近似模型权重的后验来建模。 例如,通过在测试时应用 dropout [35],可以从近似后验中对 网络进行采样,并且输出的方差可以用作不确定性的度量[11]。 后验也可以通过训练网络对数据[23]的随机子集进行近似,或者通过在单个训练期间拍摄快照来近似[17]。 上述方法与任务无关,可以轻松应用于表面法线估计。
本文的重点是任意不确定性,它捕获了数据中固有的噪声。 我们假设不确定性是异方差的[20](即某些像素比其他像素具有更高的不确定性)。 对于这种场景,常用的方法是估计输出上的每像素概率分布,并通过最大化地面实况 [20, 12] 的可能性来训练网络。 这需要特定于任务的公式,并且尚未针对基于 CNN 的表面法线估计进行研究。
单位球面上的分布。 表面正态概率分布应在单位球体上定义。 此类分布的一个示例是 von Mises-Fisher 分布 [8],它是在 球体上定义的旋转对称单峰分布。 在本文中,我们引入了 von Mises-Fisher 分布的一种变体,使得最小化其负对数似然相当于最小化预测法线与地面实况之间的角度,这是我们感兴趣的误差度量。
不确定性引导抽样。 PointRend [21] 是一个专为实例/语义分割而设计的神经网络模块。 由于在规则网格上进行推断会导致对象边界附近的像素采样不足,因此 PointRend 使用逐点 MLP 对具有高度不确定性的像素子集进行推断。 我们的解码器模块是这种框架对表面法线估计的新颖扩展。
3方法
本节提供我们方法的详细信息。 首先,我们引入了一种新的表面正态概率分布参数化,可用于不确定性估计。 其次,我们解释了网络架构和用于训练像素级细化网络的不确定性引导采样。
3.1 表面法线的任意不确定性
我们的目标是学习每像素表面正态概率分布,其中是像素索引,是输入图像。 在实践中,我们使用一组参数对分布进行参数化,这些参数由权重网络估计。 通过最小化真实值 的负对数似然 (NLL) 来训练网络。 因此训练损失可以写为
| (1) |
其中 是具有真实值的像素数。 为分布找到合适的参数化非常重要,因为它决定了训练期间最小化(或最大化)的数量。
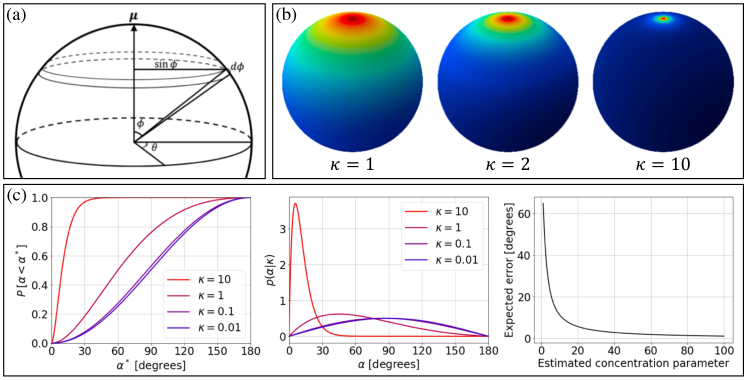
冯·米塞斯·费舍尔分布。 我们使用 von Mises-Fisher 分布 [8](以下简称 vonMF)作为基线。 它是正态分布的球形模拟,在 [15] 中的单位 球体上定义。 对于 ,概率密度函数 (PDF) 给出为
| (2) |
其中 是平均方向, 是浓度参数。 和都是单位向量,都是单位向量。 值较高意味着分布更加集中在 周围,并且该像素的不确定性较低( 时分布均匀)。 逐像素 NLL 损失可以写为
| (3) |
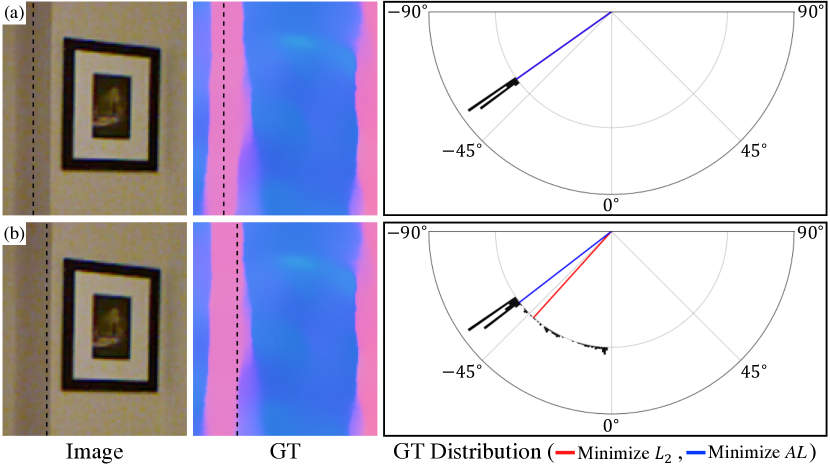
角 vonMF 分布。 而方程。 3 最小化 ,我们认为损失应该最小化预测法线与地面实况 之间的 角度。 首先,这使得损失与误差度量一致。 其次,这使得网络对于地面真实表面法线中的非对称噪声更加鲁棒。
像素的地面真实表面法线是通过将平面拟合到由像素及其局部邻域定义的点云来获得的。 如果一些相邻像素属于不同的平面(例如,因为中心像素靠近平面边界),则地面实况将受到相应影响,并且地面实况中的噪声将围绕真实法线不对称。 最小化 损失的平均方向对这种不对称噪声很敏感。 另一方面,角度损失在中线方向最小化,这对于此类噪声更稳健(见图3)。 为此,我们引入了一种分布,其 NLL 是具有学习衰减的角度损失。 PDF 和 NLL 损失如下:
| (4) |
| (5) |
我们将其称为Angular vonMF 分布(以下缩写为 AngMF)。 等式。 4 是通过将 NLL 设置为 并通过标准化(补充材料中的推导)找到 的表达式来获得的。 最小化方程5相当于最小化角度误差,同时衰减具有高不确定性(即低)的像素的损失。 我们在实验中表明,使用所提出的 AngMF 比使用 vonMF 具有更高的准确性。
不确定性的测量。 在建议的分布(方程4)中,对预测平均值中的网络置信度进行编码。 为了将其转化为直观的量,我们计算角度误差的期望值
| (6) |
并将其用作像素级任意不确定性的度量(补充材料中的推导)。
3.2 用于逐像素细化的不确定性引导采样
NLL 损失(方程 3 和方程 5)比对应的损失( 和角度损失)对于噪声数据更稳健。对于高不确定性像素会被衰减。 然而,这也使得训练更偏向于表面法线不确定性较低的大平面。 这种偏差导致预测缺乏细节,因为不鼓励网络对具有挑战性的像素做出准确的预测,其中大多数像素靠近对象边界和小型结构。 为此,我们提出了一种新颖的解码器框架,其中像素级多层感知器(MLP)在根据估计的不确定性选择的像素子集上进行训练。
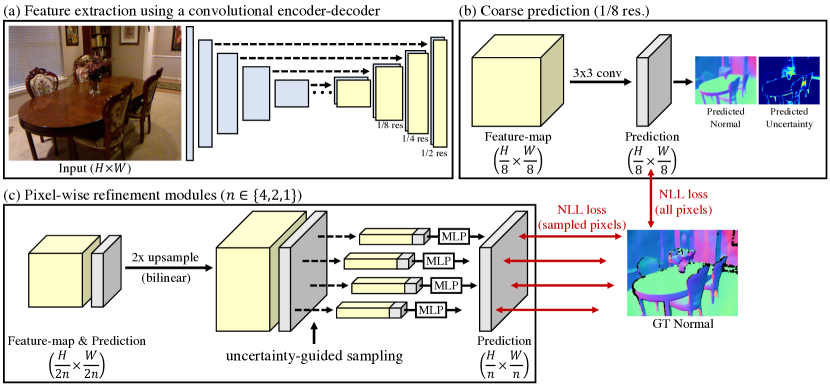
特征提取。 所提出的管道如图4所示。 网络的输入是大小为 的 RGB 图像。 我们首先使用具有跳跃连接的卷积编码器-解码器生成不同分辨率的特征图。 我们使用与[2]相同的架构。
粗略预测。 网络最初使用 卷积层根据 1/8 分辨率特征图进行粗略预测。 输出通道数为 4( 为 3, 为 1)。 前三个通道被标准化以确保。 我们对最后一个通道应用修改后的 ELU 函数 [3]、,以确保 为正。 对于粗略预测,训练损失(5)应用于所有像素。
逐像素细化模块。 然后,粗略预测通过相同架构的三个像素级细化模块。 每个模块的输入是低分辨率特征图和大小 的预测,输出是大小 的精细预测。 每个模块中的前向传播由三个步骤组成。 (1) 上采样: 特征图和预测均以 2 倍双线性上采样。 (2) 不确定性引导抽样: 在训练过程中,根据不确定性选择像素子集。 下面更详细地解释采样策略。 (3)逐像素细化: 具有三个隐藏层(每个隐藏层有 128 个节点和一个 ReLU [27] 激活)的 MLP 估计采样像素的精细输出。 MLP 的输入是像素级特征和预测的串联向量。 与粗预测层相同,归一化和修改后的ELU激活应用于和。 在训练期间,仅计算采样像素的损失。 在测试时,经过训练的 MLP 会应用于所有像素。

不确定性引导抽样。 假设双线性上采样预测中有 个像素。 总的来说,我们采样了 个像素,其中 在所有实验中都设置为 。 首先,我们对不确定性最高的 像素进行采样(即重要性采样)。 然后,从剩余像素中均匀采样像素(即覆盖范围)。 的值可以为 0 到 1,它确定采样对高不确定性像素的偏差程度。 图5说明了采样过程。
4实验设置
数据集。 我们在两个数据集上评估我们的方法:ScanNet [4] 和 NYUv2 [33]。 ScanNet 包含来自 807 个不同场景中采集的 1613 次扫描的 RGB-D 帧。 我们使用 FrameNet [18] 提供的地面真实表面法线和数据分割。 NYUv2 由捕获 464 个室内场景的 RGB-D 视频序列组成。 我们使用 Ladicky 等人 [22] 生成的真实数据对官方测试集进行评估。 由于官方训练集仅包含 795 个图像,最先进的方法从序列 [39, 1, 31, 32] 中采样额外图像或补充其他数据集 [ 24, 14]。 为了确保公平比较,我们使用与 GeoNet++ [32] 相同的训练集。
表面法线精度指标。 针对具有有效地面实况的像素测量角度误差。 在[9]之后,我们报告平均值、中值和均方根误差(越低越好),以及误差低于阈值的像素百分比(阈值越高)更好的)。
不确定性指标。 估计不确定性的显着性可以使用稀疏曲线[30]来评估。 根据不确定性对像素进行排序,并在不确定性较低的前 % 像素上评估误差度量 。 在[30]之后,我们通过从100%中减去准确度度量(误差小于的像素的百分比)将其转换为误差度量。 我们将 从 1 变化到 100,增量为 1,并报告稀疏曲线下的面积 (AUSC),如 [16] 中所示。 AUSC 受两个因素影响:预测的准确性以及基于不确定性的排序与实际基于误差的排序的相似程度。 为了仅评估后者,我们还通过从估计的稀疏化中减去预言稀疏化(通过基于错误的排序获得)来报告稀疏化误差 (AUSE) [19] 下的面积。
实施细节。 所提出的网络是用 PyTorch [28] 实现的。 对于训练,我们使用 AdamW 优化器 [25] 并使用 1cycle 策略 [34] 和 来安排学习率(其他超参数是设置为默认值)。 除非另有说明,批量大小为 4,纪元数为 5。
5实验
首先,我们进行了一系列消融研究来证明所提出方法的有效性。 然后,将准确性与最先进的方法进行比较。 最后,我们评估估计不确定性的质量,并将其与不确定性估计的其他方法进行比较。
| Architecture | Loss fn. | mean | median | rmse | |||||
| baseline | 13.53 | 7.22 | 21.16 | 35.10 | 51.44 | 65.08 | 82.38 | 87.83 | |
| (convolutional encoder-decoder with skip connections [2]) | NLL-vonMF | 14.10 | 7.19 | 22.14 | 36.20 | 51.46 | 64.09 | 80.80 | 86.34 |
| AL | 13.45 | 6.70 | 21.78 | 38.65 | 54.04 | 66.73 | 82.46 | 87.53 | |
| NLL-AngMF | 13.82 | 6.60 | 22.47 | 39.69 | 54.30 | 65.97 | 81.64 | 86.71 | |
| baseline + pixel-wise MLPs | NLL-AngMF | 13.59 | 6.53 | 22.23 | 39.92 | 54.79 | 67.03 | 82.18 | 87.06 |
| baseline + pixel-wise MLPs + uncertainty-guided sampling | 13.17 | 6.48 | 21.57 | 40.09 | 55.19 | 67.62 | 83.10 | 87.97 |
5.1消融研究
消融研究实验是在 ScanNet [4] 的子集上进行的,该子集是通过对训练集中的 20% 图像(包含 190K 图像)进行采样而获得的。
训练损失。 NLL-vonMF(等式3)是具有学习衰减的损失,并且提出的NLL-AngMF(方程5)是具有学习衰减的角度损失(AL)。 我们比较了表中的四个损失函数。 1(顶部)。 由于和AL不能用于不确定性估计,因此删除了解码器模块,并通过添加 卷积层到最终的特征图。 以下是我们可以从这个实验中获得的主要见解。
-
•
NLL-AngMF 与 NLL-vonMF。 虽然NLL-vonMF最大限度地减少了,但所提出的NLL-AngMF最大限度地减少了角度误差,这与误差指标更加一致。 因此,除了 RMSE 之外,NLL-AngMF 的准确率明显高于 NLL-vonMF。
-
•
NLL-AngMF 与 AL。 我们的 NLL-AngMF 是具有习得衰减的 AL。 由于训练偏向于低不确定性像素(主要是在大表面上),中值误差会减小,低阈值( 和 )的准确度会增加。 相反,平均误差和 RMSE 会增加,并且较高阈值的准确度会降低。 这是因为网络不会因为对具有挑战性的像素做出不准确的预测而受到强烈惩罚。
解码器架构。 标签。 1(底部)展示了所提出的解码器模块的有效性。 首先,我们添加逐像素 MLP 并在所有像素上训练它们。 然后,我们在训练期间应用不确定性引导采样(使用 )。 这两个组成部分都会导致所有指标的改进。 由于不确定性引导采样可以防止训练中对大平面的偏差,因此预测质量得到了提高,特别是在物体边界附近和小型结构上,如图6所示。
抽样策略。 标签。 2 显示不同 值的准确度变化情况。 决定重要性采样的比例。 如果,则仅对不确定性最高的像素进行采样。 如果,则像素被均匀采样。 在两者之间找到适当的平衡对于最大限度地减少训练中的偏差非常重要。 时可获得最佳性能。

| mean | median | rmse | ||||
| 0.0 | 13.58 | 6.52 | 22.18 | 66.68 | 82.09 | 87.09 |
| 0.6 | 13.34 | 6.56 | 21.76 | 66.99 | 82.78 | 87.74 |
| 0.7 | 13.17 | 6.48 | 21.57 | 67.62 | 83.10 | 87.97 |
| 0.8 | 13.28 | 6.56 | 21.69 | 67.45 | 83.00 | 87.90 |
| 1.0 | 13.26 | 6.59 | 21.57 | 67.16 | 82.98 | 87.92 |
5.2与最先进技术的比较

| Method | Train | mean | median | rmse | |||
| Ladicky et al. [22] | N | 33.5 | 23.1 | - | 27.5 | 49.0 | 58.7 |
| Fouhey et al. [10] | 35.2 | 17.9 | - | 40.5 | 54.1 | 58.9 | |
| Deep3D [39] | 26.9 | 14.8 | - | 42.0 | 61.2 | 68.2 | |
| Eigen et al. [7] | 20.9 | 13.2 | - | 44.4 | 67.2 | 75.9 | |
| SkipNet [1] | 19.8 | 12.0 | 28.2 | 47.9 | 70.0 | 77.8 | |
| SURGE [37] | 20.6 | 12.2 | - | 47.3 | 68.9 | 76.6 | |
| GeoNet [31] | 19.0 | 11.8 | 26.9 | 48.4 | 71.5 | 79.5 | |
| PAP [42] | 18.6 | 11.7 | 25.5 | 48.8 | 72.2 | 79.8 | |
| GeoNet++ [32] | 18.5 | 11.2 | 26.7 | 50.2 | 73.2 | 80.7 | |
| Ours | N | 14.9 | 7.5 | 23.5 | 62.2 | 79.3 | 85.2 |
| FrameNet[18] | 18.6 | 11.0 | 26.8 | 50.7 | 72.0 | 79.5 | |
| VPLNet[38] | S | 18.0 | 9.8 | - | 54.3 | 73.8 | 80.7 |
| TiltedSN[6] | 16.1 | 8.1 | 25.1 | 59.8 | 77.4 | 83.4 | |
| Ours | S | 16.0 | 8.4 | 24.7 | 59.0 | 77.5 | 83.7 |
| Method | mean | median | rmse | |||
| FrameNet[18] | 14.7 | 7.7 | 22.8 | 62.5 | 80.1 | 85.8 |
| VPLNet[38] | 13.8 | 6.7 | - | 66.3 | 81.8 | 87.0 |
| TiltedSN[6] | 12.6 | 6.0 | 21.1 | 69.3 | 83.9 | 88.6 |
| Ours | 11.8 | 5.7 | 20.0 | 71.1 | 85.4 | 89.8 |
纽约大学v2。 标签。 3 比较了 NYUv2 [33] 上不同方法的准确性。 请注意,与 ScanNet [4] 相比,NYUv2 的地面实况质量明显较差。 ScanNet 的基本事实是根据融合数千个 RGB-D 帧获得的 3D 网格计算得出的,而 NYUv2 的基本事实是根据单个噪声深度图计算得出的。 尽管如此,所提出的训练损失(具有学习衰减的角度损失)和解码器框架(通过不确定性引导采样进行训练)有助于网络从噪声数据中学习。 因此,我们的网络比 GeoNet++ [32] 有了决定性的改进。 图7中的定性比较表明,我们的方法做出的预测包含更高级别的细节。 我们还在 ScanNet 上训练网络并在 NYUv2 上进行测试,无需微调。 在这个跨数据集评估中,我们战胜了除中值误差和 之外的其他方法,这表明网络可以很好地泛化到未见过的数据集。
5.3 不确定性的质量
| Method | AUSC | AUSE | ||||
| mean | rmse | mean | rmse | |||
| Drop | 9.01 | 15.84 | 19.32 | 4.02 | 9.61 | 10.23 |
| Aug | 8.64 | 15.08 | 18.75 | 3.93 | 9.14 | 10.25 |
| Drop + Aug | 8.16 | 14.32 | 16.73 | 3.22 | 8.15 | 7.75 |
| Ours (NLL-vonMF) | 7.03 | 10.96 | 14.24 | 2.11 | 4.80 | 5.10 |
| Ours (NLL-AngMF) | 6.83 | 10.92 | 13.47 | 2.13 | 4.98 | 5.01 |
| Method | AUSC | AUSE | ||||
| mean | rmse | mean | rmse | |||
| Drop | 7.25 | 12.51 | 13.95 | 3.24 | 7.55 | 8.58 |
| Aug | 7.06 | 12.58 | 13.72 | 3.32 | 7.92 | 8.81 |
| Drop + Aug | 6.87 | 12.07 | 12.73 | 2.93 | 7.20 | 7.49 |
| Ours (NLL-vonMF) | 5.84 | 9.30 | 10.31 | 1.85 | 4.38 | 4.69 |
| Ours (NLL-AngMF) | 5.64 | 9.07 | 9.48 | 1.88 | 4.38 | 4.47 |

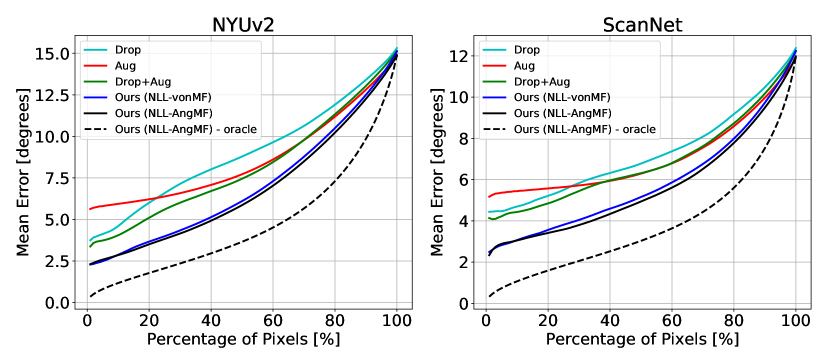
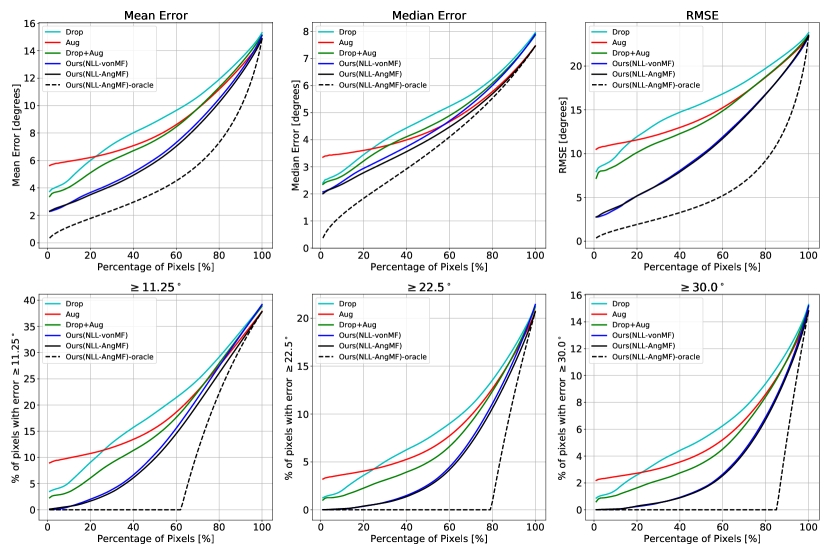
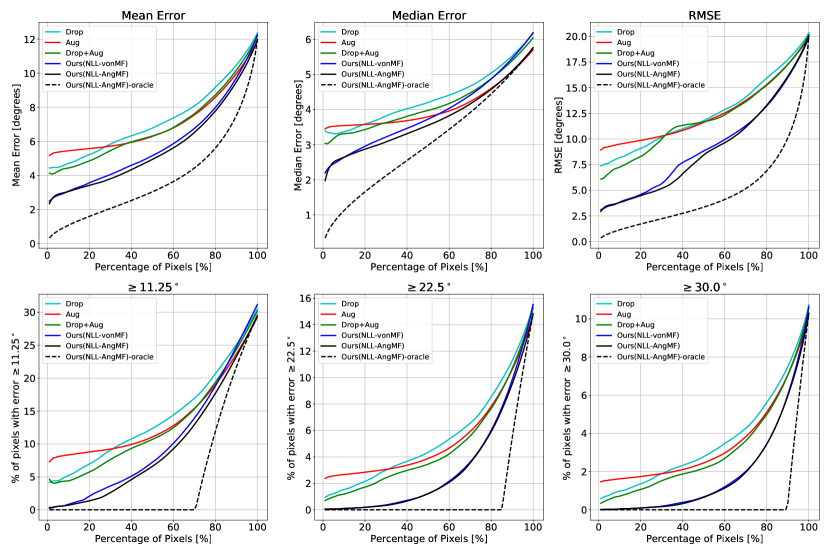
最后,我们通过绘制稀疏曲线来评估估计不确定性的质量。 由于之前的工作没有估计表面法线的不确定性,因此我们将我们的方法与任务无关的方法进行比较。 (1) 测试时丢包(Drop): 2D dropout () 添加在解码器中每个 2D 卷积块之后。 训练后,执行 8 次前向传递,并启用 dropout。 (2) 测试时间增加(8 月): 在[30]之后,我们通过翻转输入图像执行2次前向传递。 (3) 组合方法(Drop + Aug): 我们将图像翻转应用到带有 dropout 的网络中,以进行 前向传递。 对于所有三种方法,不确定性均以相对于平均方向的平均角度误差来测量。 由于无法在单次前向传递中估计不确定性,因此禁用不确定性引导采样,并使用角度损失来训练网络。 表中的定量结果。 5 和选项卡。 6表明所提出的方法在所有指标上都优于其他方法。 图8比较了稀疏化曲线。 当对所有像素进行评估时,所有方法的表现都相似。 然而,随着具有高不确定性的像素被移除,我们的方法比其他方法变得更加准确。 这表明我们的不确定性与预测误差有更好的相关性(定性比较见图9)。
5.4补充材料
在补充材料中,我们提供了 AngMF 分布的推导、附加指标的定量评估、KITTI [13] 和 DAVIS [29] 的跨数据集评估以及讨论关于故障模式。
6结论
在这项工作中,我们首次在文献中估计和评估了基于 CNN 的表面法线估计中的任意不确定性。 所提出的方法估计每像素表面正态概率分布,从中可以推断出预期的角度误差以量化任意不确定性。 我们为表面正态概率分布引入了一种新的参数化,使其负对数似然是具有学习衰减的角度损失。 我们还提出了一种新颖的解码器框架,其中逐像素 MLP 在基于不确定性选择的像素子集上进行训练。 这种不确定性引导的采样可以防止训练中对大平面的偏差,从而提高预测的细节水平。 实验结果表明,该方法在 ScanNet [4] 和 NYUv2 [33] 上实现了最先进的性能,并且估计的不确定性与预测错误。
参考
- [1] Aayush Bansal, Bryan Russell, and Abhinav Gupta. Marr revisited: 2d-3d alignment via surface normal prediction. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [2] Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [3] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). In International Conference on Learning Representations (ICLR), 2016.
- [4] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [5] Armen Der Kiureghian and Ove Ditlevsen. Aleatory or epistemic? does it matter? Structural Safety, 31(2):105–112, 2009.
- [6] Tien Do, Khiem Vuong, Stergios I Roumeliotis, and Hyun Soo Park. Surface normal estimation of tilted images via spatial rectifier. In Proc. of European Conference on Computer Vision (ECCV), 2020.
- [7] David Eigen and Rob Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proc. of IEEE/CVF International Conference on Computer Vision (ICCV), 2015.
- [8] Nicholas I Fisher, Toby Lewis, and Brian JJ Embleton. Statistical analysis of spherical data. Cambridge university press, 1993.
- [9] David F Fouhey, Abhinav Gupta, and Martial Hebert. Data-driven 3d primitives for single image understanding. In Proc. of IEEE/CVF International Conference on Computer Vision (ICCV), 2013.
- [10] David Ford Fouhey, Abhinav Gupta, and Martial Hebert. Unfolding an indoor origami world. In Proc. of European Conference on Computer Vision (ECCV), 2014.
- [11] Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In International Conference on Machine Learning (ICML), 2016.
- [12] Jochen Gast and Stefan Roth. Lightweight probabilistic deep networks. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [13] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR), 32(11):1231–1237, 2013.
- [14] Steven Hickson, Karthik Raveendran, Alireza Fathi, Kevin Murphy, and Irfan Essa. Floors are flat: Leveraging semantics for real-time surface normal prediction. In Proc. of IEEE/CVF International Conference on Computer Vision Workshops, 2019.
- [15] Thomas Hillen, Kevin J Painter, Amanda C Swan, and Albert D Murtha. Moments of von mises and fisher distributions and applications. Mathematical Biosciences & Engineering, 14(3):673, 2017.
- [16] Xiaoyan Hu and Philippos Mordohai. A quantitative evaluation of confidence measures for stereo vision. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 34(11):2121–2133, 2012.
- [17] Gao Huang, Yixuan Li, Geoff Pleiss, Zhuang Liu, John E Hopcroft, and Kilian Q Weinberger. Snapshot ensembles: Train 1, get m for free. In International Conference on Learning Representations (ICLR), 2017.
- [18] Jingwei Huang, Yichao Zhou, Thomas Funkhouser, and Leonidas J Guibas. Framenet: Learning local canonical frames of 3d surfaces from a single rgb image. In Proc. of IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [19] Eddy Ilg, Ozgun Cicek, Silvio Galesso, Aaron Klein, Osama Makansi, Frank Hutter, and Thomas Brox. Uncertainty estimates and multi-hypotheses networks for optical flow. In Proc. of European Conference on Computer Vision (ECCV), 2018.
- [20] Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [21] Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Girshick. Pointrend: Image segmentation as rendering. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [22] Lubor Ladicky, Bernhard Zeisl, and Marc Pollefeys. Discriminatively trained dense surface normal estimation. In Proc. of European Conference on Computer Vision (ECCV), 2014.
- [23] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [24] Shuai Liao, Efstratios Gavves, and Cees GM Snoek. Spherical regression: Learning viewpoints, surface normals and 3d rotations on n-spheres. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [25] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [26] David G Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision (IJCV), 60(2):91–110, 2004.
- [27] Vinod Nair and Geoffrey E Hinton. Rectified linear units improve restricted boltzmann machines. In International Conference on Machine Learning (ICML), 2010.
- [28] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [29] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [30] Matteo Poggi, Filippo Aleotti, Fabio Tosi, and Stefano Mattoccia. On the uncertainty of self-supervised monocular depth estimation. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [31] Xiaojuan Qi, Renjie Liao, Zhengzhe Liu, Raquel Urtasun, and Jiaya Jia. Geonet: Geometric neural network for joint depth and surface normal estimation. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [32] Xiaojuan Qi, Zhengzhe Liu, Renjie Liao, Philip HS Torr, Raquel Urtasun, and Jiaya Jia. Geonet++: Iterative geometric neural network with edge-aware refinement for joint depth and surface normal estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
- [33] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. In Proc. of European Conference on Computer Vision (ECCV), 2012.
- [34] Leslie N Smith and Nicholay Topin. Super-convergence: Very fast training of residual networks using large learning rates. arXiv preprint arXiv:1708.07120, 2018.
- [35] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research (JMLR), 15(1):1929–1958, 2014.
- [36] Antonio Torralba, Kevin P Murphy, and William T Freeman. Sharing features: efficient boosting procedures for multiclass object detection. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2004.
- [37] Peng Wang, Xiaohui Shen, Bryan Russell, Scott Cohen, Brian Price, and Alan L Yuille. Surge: Surface regularized geometry estimation from a single image. In Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2016.
- [38] Rui Wang, David Geraghty, Kevin Matzen, Richard Szeliski, and Jan-Michael Frahm. Vplnet: Deep single view normal estimation with vanishing points and lines. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [39] Xiaolong Wang, David Fouhey, and Abhinav Gupta. Designing deep networks for surface normal estimation. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- [40] Ke Xian, Jianming Zhang, Oliver Wang, Long Mai, Zhe Lin, and Zhiguo Cao. Structure-guided ranking loss for single image depth prediction. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [41] Peijiang Yuan, Qishen Wang, Tianmiao Wang, Chengkun Wang, and Bo Song. Surface normal measurement in the end effector of a drilling robot for aviation. In IEEE International Conference on Robotics and Automation (ICRA), 2014.
- [42] Zhenyu Zhang, Zhen Cui, Chunyan Xu, Yan Yan, Nicu Sebe, and Jian Yang. Pattern-affinitive propagation across depth, surface normal and semantic segmentation. In Proc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
补充材料
在本补充材料中,我们提供了 (A) 所提出的 AngMF 分布的推导,(B) 具有附加指标的定量评估,(C ) 对 KITTI [13] 和 DAVIS [29] 进行跨数据集评估,(D) 对失效模式的讨论和 (E
附录 A提议的 AngMF 分布的推导
在论文中,我们引入了 von Mises-Fisher 分布 [8] 的变体,其负对数似然 (NLL) 是学习衰减的角度损失。 我们称之为 Angular vonMF (AngMF) 分布。 在本节中,我们提供方程的推导。 4,等式。 5 和等式。 6。
A.1 概率密度函数(方程4)
分布的 NLL 应具有以下形式
| (7) |
其中 是像素索引, 是预测平均方向 与地面真实表面法线 之间的角度。 角度误差由浓度参数加权,该参数编码网络在预测平均方向上的置信度。 第一项应该是的单调递减函数,以防止出现的平凡解。 那么,概率密度函数(PDF)应该是这样的
| (8) |
其中。 然后我们可以计算角度误差小于某个阈值的累积概率。 有关用于积分的轴方向,请参见图 10-(a)。
| (9) | ||||
求解 给出
| (10) |
| (11) |
A.2 负对数似然(等式5)
通过最小化地面实况法线的 NLL 来训练网络。 因此训练损失可以写为
| (12) |
我们删除常数项 。 这是等式。论文中的5。
A.3 不确定性测量(方程6)
| (13) |
由此,我们可以通过微分计算出角度误差的概率密度函数。
| (14) | ||||
那么,的期望值可得为
| (15) | ||||
附录 B 使用附加指标进行定量评估
B.1 与 TiltedSN 的比较
标签。 7 提供与 ScanNet [4] 上的 TiltedSN [6] 的比较以及其他指标。 请注意,阈值较低时,准确度差异(误差小于 的像素百分比)会增加。
| Method | mean | median | rmse | |||||
| TiltedSN[6] | 12.6 | 6.0 | 21.1 | 42.8 | 57.5 | 69.3 | 83.9 | 88.6 |
| Ours | 11.8 | 5.7 | 20.0 | 45.1 | 59.6 | 71.1 | 85.4 | 89.8 |
| Difference | -0.8 | -0.3 | -1.1 | +2.3 | +2.1 | +1.8 | +1.5 | +1.2 |
B.2 估计不确定性的质量
标签。 8 和选项卡。 9比较不同的估计表面法线不确定性的方法。 “Drop”(启用 dropout 进行 8 次推理)、“Aug”(通过翻转图像进行 2 次推理)和“Drop+Aug” ”(通过应用两者进行 82 推论)是与任务无关的方法,不需要输出是分布式的。 所提出的管道经过 NLL 损失训练,在所有指标上都显着优于其他方法,这表明估计的不确定性与预测误差更好地相关。
| Method | AUSC | AUSE | ||||||||||
| mean | median | rmse | mean | median | rmse | |||||||
| Drop | 9.01 | 4.91 | 15.84 | 19.32 | 8.66 | 6.07 | 4.02 | 0.91 | 9.61 | 10.23 | 6.10 | 4.76 |
| Aug | 8.64 | 4.68 | 15.08 | 18.75 | 8.26 | 5.64 | 3.93 | 0.97 | 9.14 | 10.25 | 5.84 | 4.42 |
| Drop + Aug | 8.16 | 4.68 | 14.32 | 16.73 | 7.18 | 4.97 | 3.22 | 0.73 | 8.15 | 7.75 | 4.65 | 3.68 |
| Ours (NLL-vonMF) | 7.03 | 4.47 | 10.96 | 14.24 | 5.51 | 3.53 | 2.11 | 0.56 | 4.80 | 5.10 | 2.92 | 2.24 |
| Ours (NLL-AngMF) | 6.83 | 4.25 | 10.92 | 13.47 | 5.27 | 3.45 | 2.13 | 0.56 | 4.98 | 5.01 | 2.86 | 2.22 |
| Method | AUSC | AUSE | ||||||||||
| mean | median | rmse | mean | median | rmse | |||||||
| Drop | 7.25 | 4.35 | 12.51 | 13.95 | 5.49 | 3.60 | 3.24 | 1.02 | 7.55 | 8.58 | 4.14 | 2.94 |
| Aug | 7.06 | 4.08 | 12.58 | 13.72 | 5.36 | 3.48 | 3.32 | 1.03 | 7.92 | 8.81 | 4.13 | 2.87 |
| Drop + Aug | 6.87 | 4.17 | 12.07 | 12.73 | 4.82 | 3.13 | 2.93 | 0.92 | 7.20 | 7.49 | 3.51 | 2.49 |
| Ours (NLL-vonMF) | 5.84 | 3.92 | 9.30 | 10.31 | 3.21 | 1.94 | 1.85 | 0.64 | 4.38 | 4.69 | 1.86 | 1.30 |
| Ours (NLL-AngMF) | 5.64 | 3.73 | 9.07 | 9.48 | 3.11 | 1.90 | 1.88 | 0.66 | 4.38 | 4.47 | 1.88 | 1.29 |
B.3 稀疏化曲线
图11和图12提供了NYUv2[33]和ScanNet[4]的稀疏化曲线,分别。 当对所有像素进行评估时,所有方法的表现都相似。 然而,随着具有高不确定性的像素被移除,我们的方法比其他方法变得更加准确,这表明我们的不确定性与预测误差更好地相关。 对于“我们的(NLL-AngMF)”,我们还通过按误差对像素进行排序来显示理想的稀疏化(oracle)。
附录CKITTI和DAVIS的跨数据集评估
在本文中,我们通过在 ScanNet [4] 上训练网络并在 NYUv2 [33] 上测试网络来进行跨数据集评估,无需微调。 然而,这并不是一项具有挑战性的任务,因为两个数据集都包含具有相似视觉特征的室内场景图像。 在本节中,我们通过在两个具有挑战性的数据集 - KITTI [13] 和 DAVIS [29] 上测试网络(仅在 ScanNet 上训练)来进一步展示我们方法的泛化能力>。 结果如图LABEL:fig:supp_generalize_kitti和图LABEL:fig:supp_generalize_davis所示。 为了进行比较,我们还提供了 TiltedSN [6] 所做的预测。
附录D故障模式
在本节中,我们讨论所提出方法的故障模式。
D.1 倾斜图像
图13显示了对倾斜图像的预测。 该网络对于轻微旋转 () 具有鲁棒性,但当图像严重倾斜时就会受到影响 ()。 然而,此类图像的预期误差(在所有图像中限制在 和 之间)也会增加,这证明了估计不确定性的有用性。 可以通过使用空间整流器扭曲图像来处理倾斜图像,使其表面正态分布与训练图像的表面正态分布相匹配,如[6]中所做的那样。 这将在我们今后的工作中进行研究。

D.2 问题固有的模糊性
为了理解网络使用的视觉线索,我们创建了仅由边缘和阴影组成的人造图像。 图14显示了网络做出的预测。 前三张图像显示“Y”形结构,另外三张是它们的垂直翻转版本。 请注意,每个像素的深度可以具有任意值,这意味着表面可以具有任何形式。 它可以是凹(或凸)角,甚至可以是平坦墙壁上的图画。
对于最后三幅图像,网络认为它是一个凹角。 这是因为这种结构多见于长方体房间的下角。 然而,对于“Y”形结构的预测并不明确。 我们认为这是因为这种结构在凹角(房间的上角)和凸角(家具的外角)中都可以看到。 为了处理这种模糊性,网络应该估计一个多模态表面正态分布,它由具有混合系数的多个单模态分布组成。 这将在我们今后的工作中进行研究。

附录 E与最先进技术的额外比较
最后,我们提供了与 GeoNet++ [32](图 LABEL:fig:supp_bm_nyu)和 TiltedSN [6](图图标签:图:supp_bm_scannet)。