具有自适应速率控制的无线图像传输深度联合源通道编码
摘要
我们提出了一种用于无线图像传输的新型自适应深度联合源通道编码(JSCC)方案。 所提出的方案使用单个深度神经网络(DNN)模型支持多种速率,并学习根据通道条件和图像内容动态控制速率。 具体来说,引入策略网络来利用速率和信号质量之间的权衡空间。 为了训练策略网络,采用了 Gumbel-Softmax 技巧来使策略网络可微,因此整个 JSCC 方案可以进行端到端的训练。 据我们所知,这是第一个可以使用单一网络模型自动调整速率的深层 JSCC 方案。 实验表明,我们的方案成功地学习了一种合理的策略,可以降低高信噪比场景或简单图像内容的信道带宽利用率。 对于任意目标速率,与专门针对该固定目标速率训练的优化模型相比,我们使用单个模型的速率自适应方案实现了类似的性能。 为了重现我们的结果,我们在 https://github.com/mingyuyng/Dynamic_JSCC 上公开提供源代码。
索引词—深度联合源通道编码、无线图像传输、自适应学习、gumbel-softmax
1简介
基于香农分离定理[1],大多数现代系统采用单独的源编码(例如JPEG、BPG)和信道编码(例如LDPC、Polar等)进行无线图像传输。 然而,为了实现最优性,码字的长度需要(无限)长。 此外,非遍历源或通道分布也会导致最优性失效。 因此,使用联合源信道编码 (JSCC) 可以实现显着的增益,如矢量量化和索引分配 [2, 3, 4] 等各种方案中所证明的那样。
近年来,由于深度学习相对于传统分析方法的显着性能提升,已被应用于计算机视觉[5]和无线通信[6,7,8]等各种应用。 。 由于其提取复杂特征的能力,深度学习也已扩展到用于无线图像传输的 JSCC 系统[9,10,11,12,13,14],以实现比分离源和分离的图像传输更好的性能。信道编码。 在本文中,我们重点关注典型物联网应用中通信资源有限或昂贵的场景。 对于此类应用,期望JSCC方案动态调整速率以节省信道带宽,同时传送足够量的源信息内容。 然而,大多数现有的深度 JSCC 方法仅以固定速率进行训练,因此需要多个经过训练的模型来实现多速率 JSCC 方案。 最近,多速率深度 JSCC 的概念在 [10, 15] 中得到了研究,其中单个模型使用多个速率进行训练。 然而,[10, 15] 中的模型不能适应信道条件,因为它们仅使用单个 SNR 进行训练。 此外,他们没有考虑在给定多速率模型的情况下实现自动速率控制的内置机制或策略。
在本文中,我们提出了一种新颖的 JSCC 方案,该方案通过单一网络模型根据通道 SNR 和图像内容调整其速率。 为了训练具有各种SNR的JSCC模型,我们采用[14]中引入的SNR自适应模块来根据SNR调制中间特征。 此外,受[16,17,18,19]中自适应计算思想的启发,我们引入了一个策略网络,它可以学习动态决定要传输的活动特征的数量。 我们采用 Gumbel-Softmax 技巧[20]来使决策过程可微。 我们的实验结果表明,我们的深度学习模型可以被训练来学习为不同的 SNR 和图像内容分配不同速率的策略。 具体来说,当 SNR 高和/或源图像包含较少信息时,它会学习减少通道带宽利用率。 同时,与针对该特定速率训练的专用模型相比,所提出的方案保持了相同的图像质量。
2 自适应 JSCC 方法
2.1概述
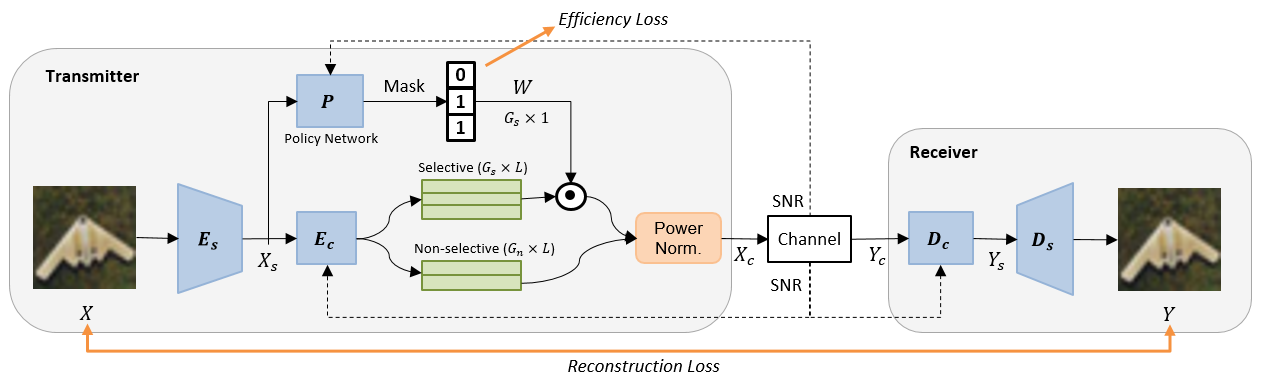
所提出的深度JSCC方案的总体结构如图1所示。 首先,源编码器从源图像中提取图像特征。 然后, 被馈送到通道编码器 ,该编码器生成 组长度为 的特征。 前组包含选择性功能,这些功能可以由策略网络控制为活动或非活动,而最后组仅包含始终处于活动状态的非选择性功能。 我们引入了一个策略网络 ,它输出二进制掩码 来为每个输入 选择活动特征,而不是手动选择。 活动组的总数表示为。 选择后,所有有效特征都经过功率归一化模块,以特征的前半部分为实部,另一半为虚部,生成具有单位平均功率的复值传输符号。 是在 通过嘈杂的无线信道传输时接收的。 然后在接收器处,被依次馈送到通道解码器和源解码器以重建源图像。
我们根据每像素无线通道使用率 (CPP) 来量化传输速率。 假设输入图像的 RGB(3 通道)像素具有 尺寸。 然后CPP被定义为,它在的范围内,具体取决于活动特征组的数量。 CPP 中的 1/2 因子是由于无线信道上的复值(正交)传输造成的。 我们仅考虑 AWGN 无线信道,使得 成立,其中 是复高斯噪声向量。 信道条件/质量完全由信噪比 (SNR) 捕获,假设发送器和接收器均已知信噪比。 SNR 值被馈送到、 和,以便模型适应无线信道条件。
2.2SNR自适应通道编码器和解码器
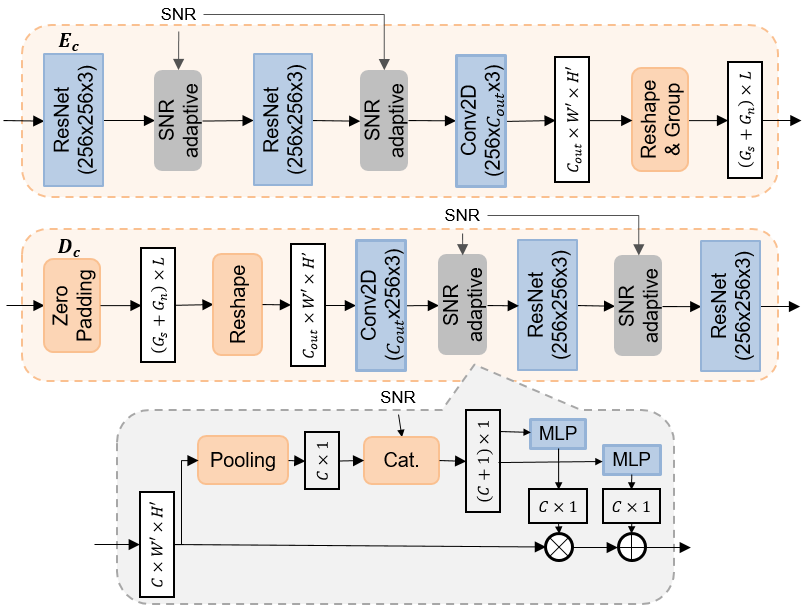
通道编码器和通道解码器网络的结构如图2所示,其中在各层之间插入了额外的SNR自适应模块调制中间特征。 信噪比自适应模块的结构受到[14]的启发,如图2底部所示。 输入特征首先在每个通道上进行平均池化111我们用“通道”来表示神经网络的特征通道,用“无线通道”来表示无线传输通道。 然后与 SNR 值连接。 之后,它们通过两个多层感知器(MLP)来生成用于通道缩放和加法的因子。 在通道编码器 中,输入特征首先被馈送到一系列 ResNet 和 SNR 自适应模块。 之后,通过 2D 卷积和重塑将它们投影到特定的输出尺寸。 在通道解码器 中,由于我们仅接收发送器选择的 活动组中的符号,因此我们只需对停用的符号进行零填充,以保持输入大小相同,而不管菲律宾人民党。
2.3学习速率控制的自适应策略
2.3.1政策网络
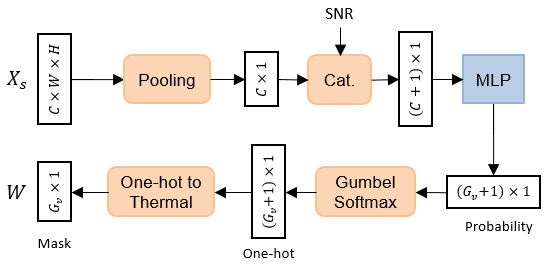
所提出的策略网络学习根据 SNR 和图像内容来选择活动特征组的数量。 整个过程可以建模为对样本空间为的分类分布进行采样。 策略网络的结构如图3所示,其中图像特征首先被平均池化并与SNR连接。 然后,它通过最后带有 softmax 函数的两层 MLP,生成每个选项的概率。 之后,我们通过 Gumbel-Softmax(稍后讨论)将决策采样为 one-hot 向量,并进一步将其转换为温度计编码向量作为最终的自适应传输掩码。 的温度计编码确保我们始终从一开始就激活连续的功能组。 因此,不需要额外的控制消息(除了传输信令结束之外)来通知接收器哪些特征组被激活或被停用。
2.3.2Gumbel Softmax
训练策略网络并不简单,因为采样过程本质上是离散的,这使得网络不可微分并且难以通过反向传播进行优化。 一种常见的选择是使用评分函数估计来避免样本反向传播(例如 REINFORCE[21])。 然而,该方法对于许多应用程序来说通常存在收敛缓慢的问题,并且还存在高方差问题[22]。 作为替代方案,我们采用 Gumbel-Softmax 方案 [20] 通过从相应的 Gumbel-Softmax 分布中采样来解决不可微性问题。
假设 的每个类别的概率为 。 然后,使用 Gumbel-Max 技巧 [20],分布中的离散样本可以绘制为:
| (1) |
其中 是标准 Gumbel 分布, 是从均匀分布 中采样的。 由于 argmax 运算不可微,因此使用 Gumbel-Softmax 分布作为 argmax 的连续松弛。 为了将 表示为 one-hot 向量 ,我们使用了 softmax 函数的宽松形式 :
| (2) |
其中是控制离散性的温度参数。 当趋于无穷大时,分布收敛到均匀分布,而使接近one-hot向量并且与离散分布无法区分。 对于网络训练期间的前向传递,我们从离散分布 (1) 中对策略进行采样,而连续松弛 (2) 用于向后传递以逼近梯度。 When the trained model is used for the adaptive-rate JSCC, we transform the one-hot vector output to a thermometer encoded mask vector satisfying .
2.4损失函数
在训练过程中,我们最大限度地减少以下损失以鼓励提高图像重建精度,并最大限度地减少活动特征组的数量以减少带宽使用(即降低 CPP)。
| (3) |
(3)中的第一项是重建损失,第二项是带有权重参数的通道使用率。
3实验
3.1 培训和实施细节
我们使用 CIFAR-10 数据集评估所提出的方法,该数据集由 50000 个训练图像和 10000 个具有 像素的测试图像组成。 模型采用Adam优化器[23]训练。 我们首先以学习率为 训练网络 150 个时期,并以学习率为 训练另外 150 个时期。 然后,我们修复编码器 和策略网络 ,并对其他模块进行另外 100 个周期的调节。 批量大小为 128。 初始温度为5,并以的指数衰减逐渐降低。 在训练过程中,我们在0dB到20dB之间均匀采样SNR。 对于所有实验,我们设置 、 和 。 因此,所提出的方法总共提供了 5 种可能的速率(CPP):。 为了作为基线,我们还训练了多个固定速率模型,这些模型使用预先确定的子组级特征屏蔽来获得恒定的目标 CPP。
3.2 CIFAR-10 的结果
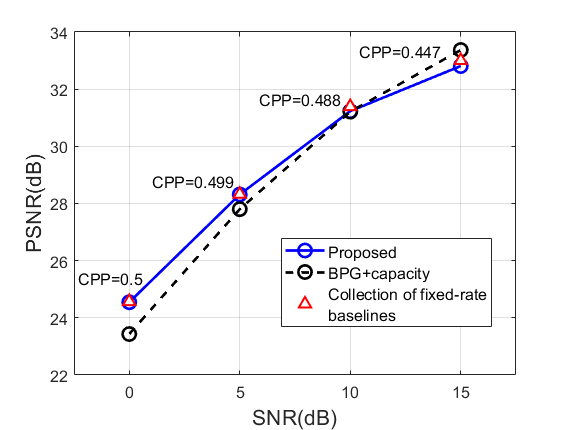
(a)
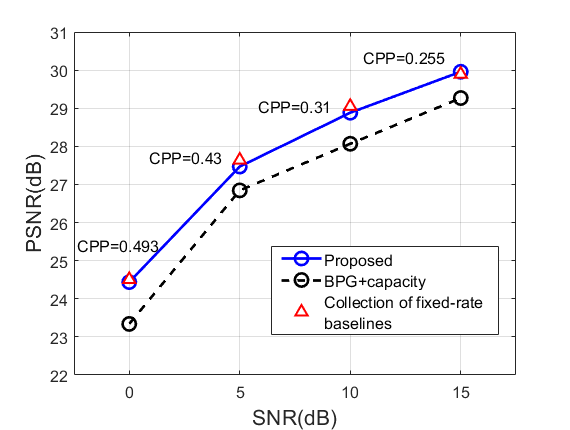
(b)
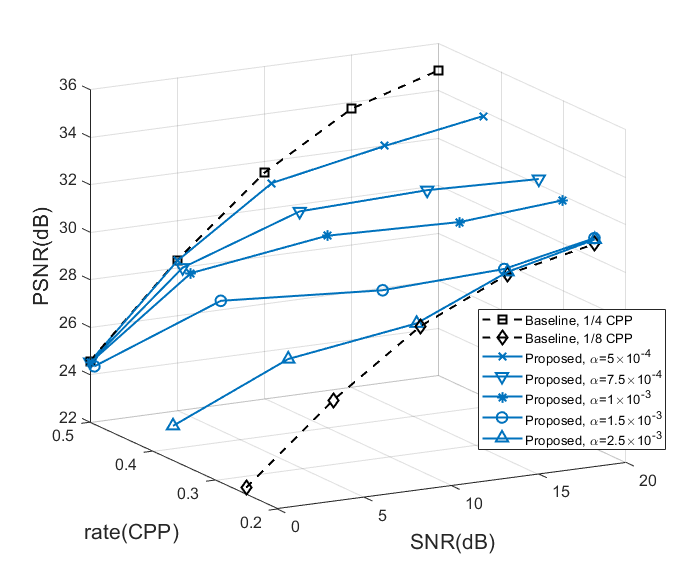
我们首先在图4中展示了所提出方法的平均速率和图像质量之间的权衡。 图像质量通过峰值信噪比 (PSNR) 进行评估。 具有最大 () 和最小 () 固定速率的基线的 PSNR 以黑色绘制作为参考。 当 SNR 较低(0dB)时,我们的方法倾向于选择最大可能的速率。 随着我们逐渐提高信噪比,平均速率会下降。 这一趋势表明,当信道条件(SNR)良好时,我们的方法可以成功学习利用较少信道资源(较低 CPP 速率)的策略,反之亦然。 当我们增加损失函数中的 时,策略网络更关注速率而不是图像质量,因此当 SNR 增加时,速率下降得更快。
接下来,我们将所提出方法的性能与 1)最先进的图像编解码器 BPG 与基于香农容量的理想无差错传输相结合,以及 2)固定速率基线模型的集合(每个模型训练一个)进行比较。特别的比率。 结果如图5所示。 在 相对较小的情况下,我们的方法在给定 SNR 的情况下选择相对较高的 CPP(与较高的 对应物相比),并且在低 SNR 区域中它的性能优于 BPG+Capacity。 然而,当使用 进行训练时,生成的 CPP 相对较小,并且我们的方法在所有 SNR 上都优于 BPG+Capacity 基线。 与专门针对具有预先确定的激活掩蔽的固定速率进行训练的基线模型相比,尽管我们的方法仅使用适应不同信噪比的单个训练模型,但我们的方法始终为每个比较点实现相似的性能。
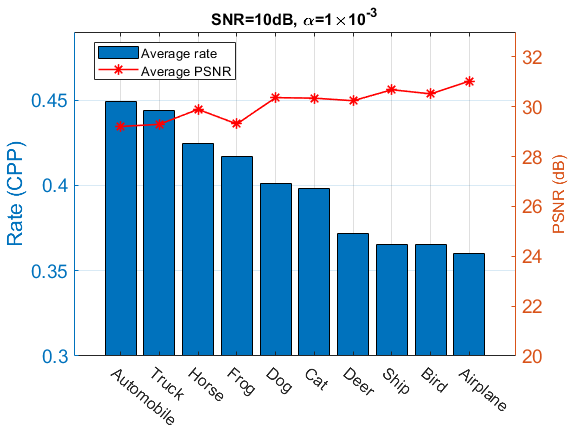
最后,我们固定 SNR 以及 以观察不同图像类别的速率变化。 在图 6 中,我们绘制了 CIFAR-10 中所有 10 个类别的平均速率和 PSNR。 可以看出,不同类别采用的费率不均匀,因为政策网络倾向于将较高的 CPP 分配给信息较丰富的类别(例如,汽车、卡车),而将较低的 CPP 分配给内容相对简单的类别(例如,船舶、飞机) )。 通过这样的策略,与为所有类别分配相同 CPP 的固定速率基线相比,我们的方案倾向于减少所有类别的重建图像质量 (PSNR) 的变化。 对于这个特定的 SNR 和 ,对于 CPP = 0.25、0.313、0.375、0.438 的五个固定速率基线模型,不同类别的 PSNR 标准差分别为 1.017、0.991、0.985、0.947 和 0.923。和0.5,分别。 相比之下,我们的自适应速率控制方法的标准偏差明显较低,为 0.613。 这表明,当平均 CPP 相同时,我们的方法会在不同类别之间产生更均衡的图像质量(每个类别具有自适应速率),而固定速率方案会生成不平衡的质量图像,以强制所有类别的 CPP 相同。
4结论
在本文中,我们提出了一种新颖的深度 JSCC 方案,该方案通过单个模型支持多种速率。 策略网络通过动态生成二进制掩模来激活或停用图像特征,自动分配以通道 SNR 和图像内容为条件的速率。 为了使策略网络可微,采用了 Gumbel-Softmax 技巧。 实验表明,当信噪比较高且图像包含的信息较少时,我们的方法可以学习到分配较少带宽的合理策略。 凭借自适应速率控制的优势,与多个单速率模型相比,我们的方法在每种操作条件下仅经历可忽略不计的性能下降。
参考
- [1] Claude E Shannon, “A mathematical theory of communication,” The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948.
- [2] Arash Vosoughi, Pamela C Cosman, and Laurence B Milstein, “Joint source-channel coding and unequal error protection for video plus depth,” IEEE Signal Processing Letters, vol. 22, no. 1, pp. 31–34, 2014.
- [3] Stefan Heinen and Peter Vary, “Transactions papers source-optimized channel coding for digital transmission channels,” IEEE transactions on communications, vol. 53, no. 4, pp. 592–600, 2005.
- [4] V Bozantizis and FH Ali, “Combined vector quantisation and index assignment with embedded redundancy for noisy channels,” Electronics Letters, vol. 36, no. 20, pp. 1711–1713, 2000.
- [5] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
- [6] Hao Ye, Geoffrey Ye Li, and Biing-Hwang Juang, “Power of deep learning for channel estimation and signal detection in ofdm systems,” IEEE Wireless Communications Letters, vol. 7, no. 1, pp. 114–117, 2017.
- [7] Mingyu Yang, Li-Xuan Chuo, Karan Suri, Lu Liu, Hao Zheng, and Hun-Seok Kim, “ilps: Local positioning system with simultaneous localization and wireless communication,” in IEEE INFOCOM 2019-IEEE Conference on Computer Communications. IEEE, 2019, pp. 379–387.
- [8] Yao-Shan Hsiao, Mingyu Yang, and Hun-Seok Kim, “Super-resolution time-of-arrival estimation using neural networks,” in 2020 28th European Signal Processing Conference (EUSIPCO). IEEE, 2021, pp. 1692–1696.
- [9] Eirina Bourtsoulatze, David Burth Kurka, and Deniz Gündüz, “Deep joint source-channel coding for wireless image transmission,” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 3, pp. 567–579, 2019.
- [10] David Burth Kurka and Deniz Gündüz, “Successive refinement of images with deep joint source-channel coding,” in 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). IEEE, 2019, pp. 1–5.
- [11] David Burth Kurka and Deniz Gündüz, “Deepjscc-f: Deep joint source-channel coding of images with feedback,” IEEE Journal on Selected Areas in Information Theory, 2020.
- [12] Mingyu Yang, Chenghong Bian, and Hun-Seok Kim, “Deep joint source channel coding for wirelessimage transmission with ofdm,” arXiv preprint arXiv:2101.03909, 2021.
- [13] Kristy Choi, Kedar Tatwawadi, Aditya Grover, Tsachy Weissman, and Stefano Ermon, “Neural joint source-channel coding,” in International Conference on Machine Learning. PMLR, 2019, pp. 1182–1192.
- [14] Jialong Xu, Bo Ai, Wei Chen, Ang Yang, Peng Sun, and Miguel Rodrigues, “Wireless image transmission using deep source channel coding with attention modules,” IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [15] David Burth Kurka and Deniz Gündüz, “Bandwidth-agile image transmission with deep joint source-channel coding,” IEEE Transactions on Wireless Communications, 2021.
- [16] Michael Figurnov, Maxwell D Collins, and et.al, “Spatially adaptive computation time for residual networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 1039–1048.
- [17] Xin Wang, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E Gonzalez, “Skipnet: Learning dynamic routing in convolutional networks,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 409–424.
- [18] Xitong Gao, Yiren Zhao, Lukasz Dudziak, Robert Mullins, and Cheng-zhong Xu, “Dynamic channel pruning: Feature boosting and suppression,” arXiv preprint arXiv:1810.05331, 2018.
- [19] Andreas Veit and Serge Belongie, “Convolutional networks with adaptive inference graphs,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3–18.
- [20] Eric Jang, Shixiang Gu, and Ben Poole, “Categorical reparameterization with gumbel-softmax,” arXiv preprint arXiv:1611.01144, 2016.
- [21] Ronald J Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine learning, vol. 8, no. 3, pp. 229–256, 1992.
- [22] Zuxuan Wu, Tushar Nagarajan, and et. al, “Blockdrop: Dynamic inference paths in residual networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8817–8826.
- [23] Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.