Omnidata:用于通过 3D 扫描制作
多任务中级视觉数据集的可扩展管道
摘要
本文介绍了一种从现实世界的全面 3D 扫描中参数化采样和渲染多任务视觉数据集的管道。 更改采样参数可以“引导”生成的数据集以强调特定信息。 除了支持有趣的研究之外,我们还展示了工具和生成的数据足以训练强大的视觉模型。 尽管没有看到基准或非管道数据,但在生成的入门数据集上训练的通用架构在多个常见视觉任务和基准上达到了最先进的性能。 深度估计网络的性能优于 MiDaS,并且表面法线估计网络是第一个在野外表面法线估计方面实现人类水平性能的网络(至少根据 OASIS 基准的一项指标)。
带有 CLI 的 Dockerized 管道、(主要是 Python)代码、用于生成数据的 PyTorch 数据加载器、生成的入门数据集、下载脚本和其他实用程序都可以通过我们的项目网站获得。
![[Uncaptioned image]](x1.png)
1简介
本文介绍了一种弥合综合 3D 扫描和静态视觉数据集之间差距的管道。 具体来说,我们实现并提供一个平台,该平台将以下内容之一作为输入:
-
•
有纹理的网格,
-
•
来自实际相机/传感器的图像的网格,
-
•
3D 点云和对齐的 RGB 图像,
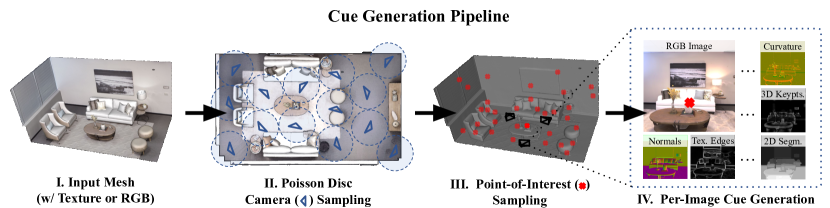
并生成一个多任务数据集,其中包含所需数量的摄像机和图像,以密集覆盖空间。 对于每个图像,有 21 个不同的默认中级提示,如图 1 所示。 该软件利用 Blender [17](一个强大的基于物理的 3D 渲染引擎)来创建标签,并公开对采样和生成过程的完全控制。 随着价格合理的 3D 传感器(例如 Kinect、Matterport 和最新的 iPhone)的普及,我们预计此类 3D 注释数据将会增加。
为了建立训练计算机视觉模型的可靠性,我们使用我们的管道注释几个现有的 3D 扫描,并生成中级线索的中等大小的入门数据集。 数据样本和不同线索如图5所示。 在此入门数据集上训练的标准模型在多个标准计算机视觉任务中实现了最先进的性能。 对于表面法线估计,在此入门数据集上训练的标准 UNet [50] 模型可在野外数据集 OASIS [13] 上产生人类水平的表面法线估计性能>,即使模型在训练期间从未见过 OASIS 数据。 对于深度估计,我们的 DPT-Hybrid [46] 相当于或优于 MiDaS DPT-Hybrid [47, 46] 等最先进的模型。 这些网络的定性性能(如图 1 和 2 所示)。 6、7)通常比数字显示的要好,尤其是对于细粒度的细节。
我们进一步提供围绕该平台的工具和文档生态系统。 我们的项目网站包含指向 Docker 的链接,其中包含注释器和所有必要的库、用于高效加载生成数据的 PyTorch [44] 数据加载器、预训练模型、用于生成图像和视频的脚本以及其他实用程序。
我们认为不应狭隘地解释这些结果。 该平台的核心思想是“环境[光场]阵列的扇区不应与阵列的临时样本混淆”(J. J. Gibson [22])。 也就是说,静态图像仅代表代理周围的整个 360 度全景光场环境的单个样本。 代理或模型如何采样和表示该环境将影响其在下游任务上的性能。 本文提出的平台旨在减少研究数据采样实践的效果以及数据分布、数据表示、模型和训练算法之间相互关系的技术障碍。 我们在这里讨论方向,并在本文的最后部分分析一些说明性示例。
首先,本文提出的流程提供了理解此类采样效应的可能途径。 也就是说,渲染管道提供了对(迄今为止)固定设计选择的完全控制,例如相机内在特性、场景照明、对象中心[45]、“摄影师偏见”水平[6 ]、数据域等等。 这使得运行干预研究(例如 A/B 测试)成为可能,而无需收集和验证新数据集或依赖事后分析。 因此,这为计算机视觉“数据集设计指南”提供了一条途径。
其次,视觉不仅仅是语义识别,但我们的数据集偏向于将其作为核心问题。 研究最好、最多样化和最大的数据集(10M 图像)通常包含某种形式的文本/类标签[19, 57]并且仅包含 RGB 图像。 另一方面,按照现代标准,大多数非分类任务的数据集仍然很小。 例如,室内场景数据集 NYU [53] 仍用于一些最先进的深度估计模型 [70],仅包含 795 个训练图像——全部用一台相机拍摄。 该管道提供了一种为非识别任务生成质量相当的数据集的方法。
第三,生成的数据允许“配对实验设计”,简化对不同任务的相互关系的研究,因为管道为每个样本生成标签。 特别是,它有助于避免以下问题:假设在 ImageNet 上训练对象分类的模型传输到 COCO [36] 比在 NYU [53] 上训练深度估计的模型更好——这是由于数据域、训练任务、相机内在的多样性还是其他原因?
现有的匹配对数据集通常集中于单个域(室内场景 [72, 53, 3, 56]、驾驶 [21, 18]、块世界 [28] 等)并包含少量提示 [18, 53, 3, 56]。 所提供的起始数据集可能比这些现有数据集更适合这项研究,因为它包含来自不同领域的超过 1450 万张图像(超过完整的 ImageNet 数据库),包含许多不同的线索(例如深度、表面法线、曲率、全景分割等),并且在此数据集上训练的模型在多个任务和现有基准测试中达到了出色的性能。 我们在第 2 节中演示了此类配对数据的价值。 5.3,
尽管我们的流程旨在帮助理解数据集设计的原理、无法识别的愿景、数据、任务和模型之间的相互关系,但本文本身并没有广泛探讨这些问题。 它提供了一些分析,但这些仅用作说明性示例。 相反,本文介绍了旨在促进此类研究的工具,因为 3D 数据变得更加广泛可用并且捕获技术得到改进。 在我们的网站上,我们提供了一个记录的、开源的和 Docker 化的注释器管道,其中包含方便的 CLI、可运行的示例、现场演示、入门数据集、预训练模型、PyTorch 数据加载器和代码论文(包括注释者和模型)。
2相关工作
在本节中,我们将研究相关数据集和其他方法。 彻底的审查会占用比我们更多的空间,因此我们将注意力限制在最相关的分组上。
静态 3D 数据集。 过去几年,基于网格的数据集数量有所增加,这主要归功于价格合理的 3D 扫描仪的出现。 然而,当前作物中的每个数据集通常由受限域中的场景组成。 室内建筑数据集的著名示例包括斯坦福建筑数据集 (S3DIS) [5]、Matterport3D [10]、Taskonomy [72]、Replica [56]、2D-3D-Semantic [4]、Habitat-Matterport [40] 和 Hypersim [49]. 其他数据集主要包含室外场景,通常是驾驶场景,例如 CARLA [21]、GTA5 [48] - 或其他狭窄领域,例如名称恰当的 Tanks 和 Temples [32] 数据集。 在此类场景级视图上训练的模型通常不会推广到以对象为中心的视图(参见图 7),但具有高分辨率对象网格的现有数据集不包含 2D 图像样本[ 1, 9]。
其他最近的数据集旨在链接不同的单目 2D 图像和相应的 3D 网格,但采用与本文相反的方法,即使用手动注释从单视图野外 RGB 样本创建网格[13, 14] 。 这种标记过程既昂贵又耗时,而且最重要的是不允许重新生成图像数据集。 在秒。 4.3,我们考虑我们的管道与其他管道 OASIS 是最大、最多样化的基准测试之一,它证明了在我们的入门数据集上训练的模型已经在 OASIS 上达到了人类水平的表现,优于在 OASIS 本身上训练的相同架构模型。
以视觉为中心的模拟器。 与我们的平台一样,模拟器通常采用纹理网格作为场景的表示,并旨在产生逼真的感官输入[40, 66]。 虽然在精神上与本文提出的管道相似,但当前一代的模拟器首先是为了训练具体代理而设计的。 他们优先考虑渲染速度和实时机制,但牺牲了真实感和提示多样性[29, 43]。 扩展此类模拟器以处理额外的提示或以参数方式渲染视觉数据集通常需要编写模拟器代码库的新组件(通常使用 C++、CUDA 或 OpenGL),这是一个可以克服但令人不快的进入障碍。 相比之下,我们的平台扩展了 Blender,它“支持整个 3D 管道”[16],并提供对大多数视觉研究人员来说直观的 Python 绑定,并且我们实现了其中许多提示和采样方法盒子外面。 简而言之,我们提供了模拟器和静态视觉数据集之间的桥梁。
多任务数据集。 基于视觉的多任务学习(MTL),就像一般的计算机视觉一样,表现出对识别的普遍偏见。 MTL 数据集通常将不同程度的分类作为感兴趣的核心问题[34,64,39]。 特别是,MTL 文献通常关注专业领域的二元属性分类,例如 Caltech-UCSD Birds [65] 或 CelebA [38]。 包含非识别任务的视觉 MTL 数据集通常仅包含单个域或几个任务(NYU [53]、CityScapes [18] 或 Taskonomy [72 ])。 有时,MTL 论文将混合数据集用于“单一”任务,并将每个数据集视为不同的任务[37,47,35,46]。
一般来说,多任务学习文献尚未集中于设置或数据集的标准化定义。 最近的工作表明,在现有数据集上开发的 MTL 方法似乎专门针对其各自的开发集,并且在大型实际数据集或其他任务上表现不佳[62,63,73]。 这强调了开发可推广到现实场景的现实训练设置和数据集的重要性。
数据增强+域随机化。 数据增强是一种修改数据或训练方案的方法,以便训练后的模型表现出理想的不变性(或等方差)。 在训练过程中,传感器输入的 任何能确定标签上唯一(可能是身份)变换的变换都可用作 "增强 "数据。 例如,简单的 2D 增强(例如 2D 仿射变换、裁剪和保持标签不变的颜色变化)在计算机视觉中很常见 [11, 23],因为即使数据集缺乏,它们也可以使用3D 几何信息。 在 3D 模拟器更为标准的机器人技术和强化学习中,数据增强被引入为“域随机化”[59],常见的增强包括场景网格上的纹理和背景随机化。 最近,[20] 引入了一种基于 Blender 的方法,用于执行域随机化并从 SunCG [58] 创建 RGB、深度和表面法线的静态数据集。
我们的管道使所有这些增强功能可用于静态计算机视觉数据集:不仅是翻转/裁剪/纹理随机化,还包括密集视点、多视图一致性、欧几里德变换、镜头眩光等。 我们在第二节中实现并检查了景深增强。 5.1。
自动标签是一组数据标签过程的总称,这些过程利用数据中的结构作为约束,以修剪或传播标签并节省标注劳动力。 这主要是通过 I) 预训练模型作为噪声注释器(例如 [2, 25, 52])和/或 II)基于已知约束(例如反投影误差、束调整、时间平滑度或[26,27,3])。 我们的管道与自动标记有联系,因为我们利用 3D 扫描数据中存在的强大结构来计算和跨图像传播标签,并减少(自动或手动)标记每个图像的负载。
3管道概述
我们将我们的管道称为Omnidata,因为它渴望将全面的场景信息(“omni”)封装在生成的“数据”中。 在这里尝试一个实例来熟悉管道。 该示例使用 CLI 和类似 YAML 的配置文件从副本 [56] 中的纹理网格生成图像。
输入: 注释器根据以下输入进行操作:
-
•
无纹理网格(.obj 或 .ply)
-
•
任一:网格纹理或对齐的 RGB 图像
-
•
可选:预生成的相机姿势文件
也可以使用 3D 点云:只需使用标准网格划分器(如 COLMAP [51])对点云进行网格划分。 补充中提供了网格划分和使用 3D 点云与注释器的示例,以及更完整的输入描述。
输出:管道在初始版本中生成 21 个中级提示。 所有标签均可用于所有生成的图像(或视频)。 图 1 提供了不同类型输出的直观摘要。 Omnidata 注释器提供的默认中级提示和附加输出的详细说明包含在补充中。
3.1采样和生成

相机和点采样: 可以提供相机位置(如果网格带有对齐的 RGB),或者如图 2 II 所示,注释器在每个空间中生成相机,以便相机不在网格内部或与网格重叠(默认:通过泊松盘采样生成的摄像机来覆盖空间)。 然后使用用户指定的采样策略从网格中采样兴趣点(默认:每个网格面均匀采样,然后在该面上均匀采样)。 然后对摄像机和点进行过滤,以便每个摄像机至少看到一个点,并且每个点至少由一些用户指定的最小数量的摄像机(默认值:3)看到。
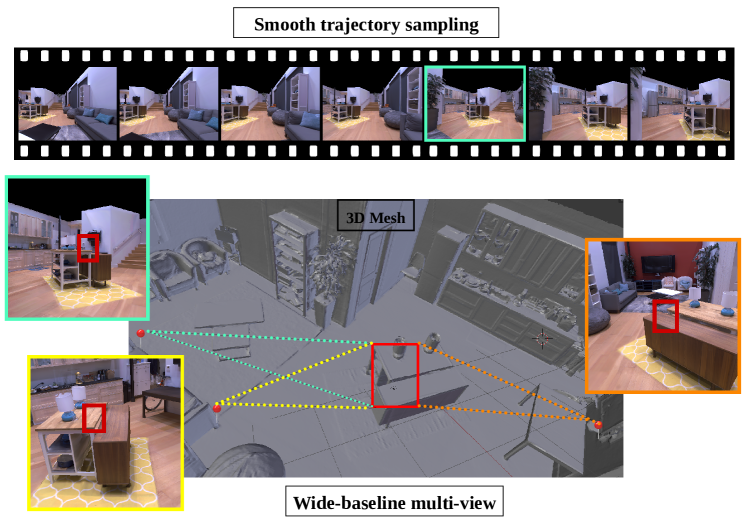
查看采样: 注释器提供了两种默认方法来生成每个点的视图。 第一种方法(宽基线)生成图像,而第二种方法(平滑轨迹模式)生成视频。
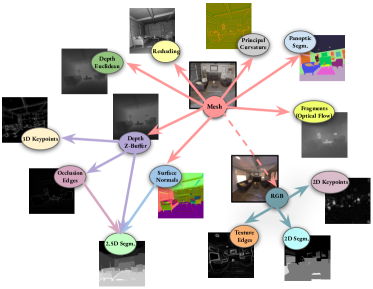
渲染中层提示: 由于没有任何一个软件能够提供所有中级提示,因此我们创建了一个互连的管道,连接多个不同的软件,这些软件都是免费提供和开源的。 我们尝试主要使用 Blender(一个 3D 创建套件),因为它拥有活跃的用户和维护社区、优秀的文档以及几乎所有内容的 python 绑定。 由专业动画师和艺术家使用,它通常经过良好优化。 整个流程相当复杂,因此我们将完整的描述推迟到补充部分。 提示生成的顺序如图4所示。 完整的代码可以在我们的网站上找到。
性能:注释器生成任何分辨率的标签。 起始数据集中的每个空间+点+视图+提示标签 () 在服务器或桌面 CPU 上通常需要 1-4 秒,并且可以在许多计算机上并行。
3.2生态系统工具
为了简化采用,我们的网站和相关的 GitHub 存储库提供了以下工具:
-
管道代码和文档。
-
Docker 包含注释器和正确链接的软件(Blender [16]、兼容的 Python 版本、MeshLab [15] 等)。
-
PyTorch 中的 Dataloader 用于正确有效地加载结果数据集
-
入门数据集,包含 1450 万张图像以及每个任务的相关标签
-
方便的实用程序,用于下载和操作数据以及自动过滤未对齐的网格(补充中的描述和敏感性分析)。
-
预训练模型和代码,包括 MiDaS [47] 训练代码的第一个公开实现。
4 入门数据集概述
我们提供了一个相对较大的起始数据集,其中包含使用 Omnidata 注释器注释的数据。 该数据集包含大约 1450 万 幅图像,这些图像来自以场景和对象为中心的场景。 图 5 显示了来自入门数据集的示例图像以及提供的 21 个中级提示中的 12 个。 原始数据集中不存在的线索用红色边框表示。 我们在第二节中根据现有基准评估了这个入门数据集。 4.3。 请注意,该数据集可以直接扩展到其他现有的户外和驾驶数据集,例如 GTA5 [48]、CARLA [21] 或 Tanks and Temples [33 ]。
4.1 包含的数据集
起始数据是根据 7 个基于网格的数据集创建的:
室内场景数据集: 副本 [56]、HyperSim [49]、Taskonomy [72]、Habitat-Matterport (HM3D)
航空/室外数据集: 混合MVG [69]
诊断/结构化数据集: 克莱夫 [28]
以对象为中心的数据集: 除了以场景为中心的视图之外,为了提供以对象为中心的视图,我们还创建了一个来自副本 [56] 数据集的分散在建筑物周围的 Google 扫描对象 [1] 的数据集(类似于 ObjectNet [8] 如何多样化图像进行图像分类)。 我们使用 Habitat [40] 环境来生成物理上合理的场景,并生成不同密度的对象。 图像示例如图5所示,生成过程的完整描述可在补充中找到。
4.2数据集统计
起始数据集包含来自 2,414 空间的 14,601,449 图像。 视图既以场景为中心又以对象为中心,并用图 1 中列出的每种模式进行标记。 相机视野是从 和 之间的截断正态分布采样的,平均值为 ,并且相机胶卷在 标签。 1 包含分解为子数据集的数据。
| Images | Spaces | Points | |||||
|---|---|---|---|---|---|---|---|
| Dataset | Train | Val | Test | Train | Val | Test | |
| CLEVR | 60,000 | 6,000 | 6,000 | 1 | 0 | 0 | 72,000 |
| Replica | 56,783 | 23,725 | 23,889 | 10 | 4 | 4 | 4,150 |
| Replica + GSO | 107,404 | 43,450 | 42,665 | 10 | 4 | 4 | 31,167 |
| Hypersim | 59,543 | 7,386 | 7,690 | 365 | 46 | 46 | 74,619 |
| Taskonomy | 3,416,314 | 538,567 | 629,581 | 379 | 75 | 79 | 684,052 |
| BlendedMVG | 79,023 | 16,787 | 16,766 | 341 | 74 | 73 | 112,576 |
| Habitat-Matterport | 8,470,855 | 1,061,021 | - | 800 | 100 | - | 564,328 |
| Total (no CLEVR) | 12,189,922 | 1,690,936 | 720,591 | 1,905 | 303 | 206 | 1,434,892 |
4.3 现有计算机视觉的可靠性
我们证明生成的数据集能够训练标准的现代视觉系统,使其在现有基准上达到最先进的性能。 一旦我们确定模型是可信的,我们就会进一步提供一些传输实验来量化不同组件数据集的相关程度。
我们表明,在入门数据集的 5 个数据集部分(4M 图像)上训练的用于深度和表面法线估计的模型在野外 OASIS 基准测试中具有最先进的性能。 为了证明语义任务管道的有效性,我们证明了在较小的 3 数据集部分(1M 图像)上进行全景分割训练的网络的预测与在 COCO [36]< 上训练的模型具有相似的质量。 /t0>. 补充中提供了完整的实验细节和更多结果。
| Method | Test Data | L1 Error () | () | () | () |
|---|---|---|---|---|---|
| XTC [71] | 1.180 | 85.28 | 71.86 | 60.22 | |
| MiDaSv3 [46] | OASIS [13] | 0.8057 | 82.03 | 67.25 | 55.35 |
| Omnidata | 0.7901 | 81.00 | 65.22 | 52.93 | |
| XTC [71] | 0.5279 | 70.41 | 49.90 | 36.28 | |
| MiDaSv3 [46] | NYU [53] | 0.3838 | 63.84 | 41.65 | 28.97 |
| Omnidata | 0.2878 | 51.73 | 30.98 | 20.86 |
| Anglular Error∘ | Within | Relative Normal | ||||||
| Method | Training Data | Mean | Median | |||||
| Hourglass [12] | OASIS [13] | 23.91 | 18.16 | 31.23 | 59.45 | 71.77 | 0.5913 | 0.5786 |
| Hourglass [12] | SNOW [14] | 31.35 | 26.97 | 13.98 | 40.20 | 56.03 | 0.5329 | 0.5016 |
| Hourglass [12] | NYU [54] | 35.32 | 29.21 | 14.23 | 37.72 | 51.31 | 0.5467 | 0.5132 |
| PBRS [74] | NYU [54] | 38.29 | 33.16 | 11.59 | 32.14 | 45.00 | 0.5669 | 0.5253 |
| UNet [50] | SunCG [55] | 35.42 | 28.70 | 12.31 | 38.51 | 52.15 | 0.5871 | 0.5318 |
| UNet [50] | Omnidata | 24.87 | 18.04 | 31.02 | 59.53 | 71.37 | 0.6692 | 0.6758 |
| Human (Approx.) | - | 17.27 | 12.92 | 44.36 | 76.16 | 85.24 | 0.8826 | 0.6514 |

单目深度估计: 当前深度估计的最佳方法是聚合多个较小的数据集,并使用尺度和平移不变损失进行训练 [47, 46] 以处理不同的未知深度范围和尺度。 截至撰写本文时,“MiDaS v3.0”[46] 中基于 DPT 的 [46] 模型定义了最先进的模型,尤其是在纽约大学[53]。 我们采用与 MiDaS v3.0 类似的设置,但在入门数据集的 5 数据集部分而不是 10 数据集混合上进行训练111 MiDaS v3.0 还使用 MTAN [37] 进行数据集平衡,尽管在秒中。 5.3 我们检查 MTAN(它确实对我们的数据集有帮助),我们在这里使用了朴素的采样策略,以便与本文中的大多数其他模型保持一致。 .
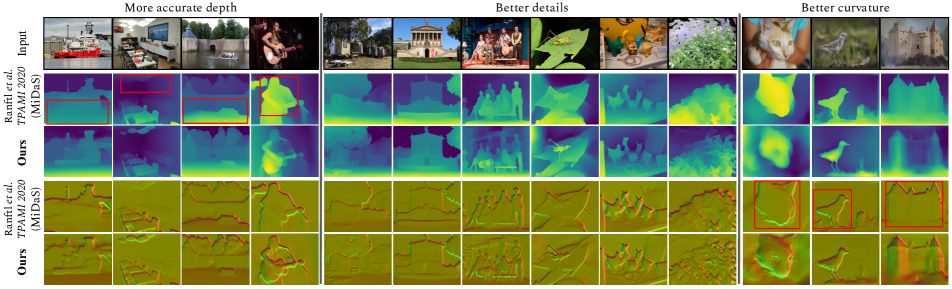
如[46]中一样,我们使用测试预测和GT在逆深度空间中的比例和移位上对齐来评估零样本跨数据集传输。 标签。 2 显示,在我们的入门数据集上训练的 DPT-Hybrid 在 NYU [53] 的测试集和 OASIS 的验证集(测试集)上均优于 MiDaS DPT-Hybrid GT 不可用)。 错误指标使用 ,其中 和 与深度和地面实况对齐。 我们的模型更好地恢复了对象的细粒度细节和真实形状 - 这在从预测中提取的表面法线中尤其明显(图 6 的最后 2 行)。 我们的网站提供完整的详细信息、代码和更多定性结果。
表面法线估计: 与 OASIS 表面法线轨道上的现有模型类似,我们训练了一个普通的 UNet [50] 架构(6 down/6 up,类似于 [71])角度和 L1 损失、光 2D 数据增强以及 256 到 512 之间的输入分辨率。 我们将 Adam [30] 与 LR 和权重衰减 结合使用。 结果如表所示。 3 表明我们的模型在 OASIS 上的表现与人类水平相匹配。 在大多数剩余指标上,它的性能优于在其他数据集(包括 OASIS 本身)上训练的相关模型以及具有专门为法线估计 (PBRS) 设计的架构的模型。 图7显示,我们的模型在所选图像上的定性表现远优于数字所示,这可能是因为标准指标与感知质量不一致,如“ “无趣”的区域(墙壁、地板)在得分中占主导地位[13]。 更多详细信息和结果请参见补充。
全景分割: 为了演示管道为非几何任务训练模型的能力,我们在起始数据集的 3 数据集子集上使用了 PanopticFPN [31]。 图 8 显示,在室内建筑物的野外图像上,生成的模型与在 COCO [36](一种广泛的手动标记的数据集)。 定量结果、完整的实验细节和代码可在我们的网站上获得。

4.3.1 数据集相关性
为了估计起始数据集的组件如何相关,我们使用零样本跨数据集传输性能来训练在不同组件上训练的表面法线和全景分割模型。 标签。 4 显示每个单一模型在其相应的测试集上表现良好,但通常泛化能力较差。 在较大分割上训练的模型总体表现更好(请参阅补充)。 在最大集上训练的模型实现了最佳平均性能(调和平均值比表面法线估计和全景分割的最佳单数据集模型好 25.8% 和 30.3%)。 传输的排名取决于任务,这可能是由于 Taskonomy 上的全景标签稀疏(来自后续论文 [2]),但我们相信这种依赖性总体上是正确的。
| Surface normal estimation: L1 Error () | Panoptic Quality (PQ) () | |||||||||
| Train/Test | Taskonomy | Replica | Hypersim | Replica+GSO | BlendedMVG | h. mean | Taskonomy* | Replica | Hypersim | h. mean |
| Taskonomy* | 4.85 | 7.76 | 8.69 | 13.89 | 15.55 | 8.53 | 8.39 | 3.95 | 11.67 | 6.55 |
| Replica | 9.36 | 3.98 | 11.78 | 10.28 | 15.02 | 8.24 | 1.01 | 41.97 | 4.50 | 2.43 |
| Hypersim | 7.28 | 7.57 | 6.72 | 11.34 | 12.94 | 8.56 | 9.35 | 14.08 | 25.39 | 13.80 |
| Replica+GSO | 13.88 | 4.94 | 15.05 | 5.17 | 14.03 | 8.26 | - | - | - | - |
| BlendedMVG | 17.1 | 14.23 | 16.93 | 14.87 | 8.85 | 13.58 | - | - | - | - |
| Omnidata | 5.32 | 4.24 | 6.53 | 6.45 | 11.53 | 6.11 | 9.14 | 41.24 | 30.16 | 17.98 |
5以数据为中心的说明性分析
现在我们已经确定注释器生成能够训练可靠模型的数据集,我们可以对这些数据集进行哪些分析? 我们在此调查了一些示例,但它们并不全面(第 1 节)。
5.1 新的 3D 数据增强
数据增强用于解决模型性能和鲁棒性方面的缺点。 例如,仅在使用窄光圈拍摄的图像(例如 NYU 或 Taskonomy)上训练的模型往往在使用大光圈(即强景深)拍摄的图像上表现不佳,并且使用 2D 高斯模糊进行增强来改进模型图像未聚焦部分的性能。 该方法非常常见,以至于 2D 模糊已包含在 Common Corruptions 基准 [24] 中。 由于完整的场景几何形状可用于我们的起始数据集,因此可以在 3D 中(图像重新聚焦)而不是 2D(平面模糊)中进行数据增强。 图 9 显示了数据集上 3D“图像重新聚焦”增强的示例。 在补充中,我们表明,仅使用 3D 增强进行表面法线估计训练的模型对于 2D 模糊和 3D 重新聚焦比使用 2D 增强训练的模型更加稳健。

5.2 作为输入的中级提示:它们有用吗?
使用多个传感器或环境的非 RGB 表示是否有优势? 多个线索也可以用作输入(如果相关传感器可用)或指定为中间表示(标签仅在训练期间用作监督),而不是预测中级线索作为下游任务(即多任务学习) ,即 PADNet [68])。
标签。 5 表明,在后两种方式中使用这些附加线索可以提高原始测试集以及未见过的数据的性能。 在本实验中,我们使用单个组件数据集(来自 Replica 的 10 个空格)训练用于语义分割的 HRNet-18 [58] 主干网,并在 Replica、Hypersim 和 Taskonomy(微小分割)上对其进行评估。 相对于仅使用 RGB 输入和语义分割标签,当将线索视为传感器(23%、34% 和 30%)或将它们用作中间表示(13%、17% 和19%)。 添加更多提示似乎有帮助。 补充中的完整实验设置。
未来的工作可以进一步分析这些不同方法的有效性如何随数据集大小而变化,使用哪些提示,中级提示值得多少额外图像,以及从同一场景获取更多数据与添加数据的相对重要性来自新场景的数据。
| GT Mid-Level | Predicted Mid-Level | |||||
| Input/Supervised Domains | Cross-Entropy () | Cross-Entropy () | ||||
| Repl. | H.Sim | Task. | Repl. | H.Sim | Task. | |
| RGB | 0.61 | 5.87 | 7.55 | 0.61 | 5.87 | 7.55 |
| (All Above) + Normals | 0.47 | 4.47 | 6.12 | 0.61 | 5.44 | 7.12 |
| (All Above) + 3D Edges | 0.46 | 4.47 | 6.75 | 0.54 | 5.06 | 6.49 |
| (All Above) + (2D Edges, Z-Depth, 3D Keypts) | 0.46 | 3.86 | 6.04 | 0.53 | 4.9 | 6.13 |
5.3多任务学习的系统评估
最近的工作[62]表明,现有的计算机视觉 MTL 技术似乎专门针对其开发环境,并且一般来说,它们在新数据集或任务上的性能并不优于单任务或共享编码器方法。 我们将这些结果扩展到其他任务(3D 关键点),并在数据集上添加数字作为比较点。 具体来说,我们遵循 [62] 并使用不同的 MTL 方法(表 1)针对一组固定任务(语义分割、3D 关键点、深度 z 缓冲区和遮挡边缘)训练模型。 6)。 在初始数据集的 3 个数据集分割中,一些方法自然表现得更好,而另一些方法则表现更差。 人们可能希望这些方法的顺序在不同任务(语义分割与 3D 关键点)上是相同的,或者至少在不同数据集上训练相同任务时(NYU [53], CityScapes [18] 或 Taskonomy [72])。 然而,标签。 6 表明 MTL 方法在这两种情况下都没有显示出明确的排名(即 Spearman 的 始终与 0 无法区分)。 忽略显着性的缺乏,跨数据集相关性仍然很弱 (),并且方法性能实际上在任务之间反相关 (= -0.4),表明这些模型确实专门针对特定任务。 即使在控制数据集时,这种反相关性也是成立的。
鉴于当前的 MTL 方法并不优于单任务基线,预测不同的中级线索对 MTL 构成了一个具有挑战性的环境。 Omnidata 管道提供了创建大型且多样化的多任务中级基准的途径,可以更系统、更可靠地评估多任务学习的进展。
| Semantic Segmentation | 3D Keypoints | |||||||||||
| Method | Ours | NYU [53] | CityScapes. [61] | Taskonomy [61] | Ours | Taskonomy [61] | ||||||
| IoU () | Rank | IoU () | Rank | IoU () | Rank | IoU () | Rank | L1 () | Rank | L1 () | Rank | |
| Single task | 85.12 | 1 | 90.69 | 2 | 65.2 | 1 | 43.5 | 4 | 0.0439 | 4 | 0.23 | 1 |
| MTL baseline | 81.82 | 3 | 90.63 | 3 | 61.5 | 4 | 47.8 | 1 | 0.0429 | 3 | 0.34 | 2 |
| MTAN [37] | 83.00 | 2 | 91.11 | 1 | 62.8 | 3 | 43.8 | 3 | 0.0426 | 1 | 0.4 | 3 |
| Cross-stitch [42] | 80.69 | 4 | 90.33 | 4 | 65.1 | 2 | 44.0 | 2 | 0.0427 | 2 | 0.50 | 4 |
| Spearman’s | Within task.: 0.43. Between segm.-3D keypts.: -0.4 | Within task: 0.2. | ||||||||||
6 结论和局限性
本文介绍了一种通过对环境的全面扫描创建可操纵数据集的管道。 生成的多任务数据集可能很大且多样化,并且足够真实,使得基于数据训练的模型在现实世界中表现良好。 为了证明这一点,我们注释了一个示例数据集,并用它来训练一些标准视觉方法,以在多个计算机视觉任务上获得最先进的性能。 我们相信此功能本身很有用,特别是因为它充当现实世界 3D 扫描、模拟器和静态视觉数据集之间的桥梁。
我们使用该工具的主要目的是更好地研究视觉数据集的属性及其与模型和任务的交互。 至关重要的是,该管道可用于在现实环境中训练强大的模型,这一事实让我们希望该管道的发现可能更普遍。 特别是,我们相信这种“可操纵数据集”方法可以在基本研究领域取得成果,例如数据采样策略和提示/传感器的选择如何影响表示和模型可靠性。
最后,我们讨论了该流程的一些重要限制以及未来工作的可能性。
-
1.
研究操纵性。 Omnidata 管道提供了一种创建可操纵数据集的方法,但我们没有对调整不同转向“旋钮”的效果进行任何分析。 IE。我们的起始数据集使用了固定的生成设置选择,并且我们没有对该初始选择进行调整。 显然,此类选择确实对数据集(例如,请参阅我们的在线演示)和生成的模型[61,60,7,67])产生重要影响。 我们相信这个方向蕴藏着丰富的见解,这就是我们创建这个管道的原因。 本文仅提供一些零星的实验来说明总体思路,并不代表系统的研究。
-
2.
捕获信息有限。 本文使用的 3D 扫描来自标准运动结构方法的输出,该方法将来自 RGB 和深度传感器的许多重叠图像拼接在一起。 这些扫描被表示为网格(带有纹理或对齐的 RGB 图像),但这种表示遗漏了有关场景的重要信息。 例如,材质缺乏反射率模型(例如 BRDF),并且没有有关场景照明的信息。 此外,扫描的重建精度通常有限(例如,Taskonomy 中的误差通常高达 2 厘米),这会影响纹理质量和生成标签的质量。 更好的传感技术(例如光场相机、更高分辨率的深度传感器)以及算法改进(例如下面的 NeRF)可以增加更多的控制维度并减少重新采样和真实线索/图像之间的差距。
-
3.
如何表示“完全捕获”。 Omnidata 管道使用 3D 网格来表示场景,并使用该表示对图像进行采样。 其他表示,例如使用光场相机和 NeRF [41] 可以用作场景的隐式表示,并且类似地用于对场景进行重采样。 NeRF 令人惊讶的有效性使得这个方向非常引人注目。
-
4.
中级线索数量有限。 Omnidata 注释器的初始版本提供了 21 个中级提示。 与计算机视觉中的大多数任务一样,当前的中级线索更多地基于人类直觉,而不是基于明显的预测性视觉理论。 随着计算机视觉和视觉科学取得新的进步,只要捕获信息中存在所需的信息(例如新的线索和增强),就可以将它们集成到采样管道中。
参考
- [1] Ignition app.
- [2] Iro Armeni, Zhi-Yang He, JunYoung Gwak, Amir R. Zamir, Martin Fischer, Jitendra Malik, and Silvio Savarese. 3d scene graph: A structure for unified semantics, 3d space, and camera. In Proceedings of the IEEE International Conference on Computer Vision, 2019.
- [3] Iro Armeni, Sasha Sax, Amir Roshan Zamir, and Silvio Savarese. Joint 2d-3d-semantic data for indoor scene understanding. CoRR, abs/1702.01105, 2017.
- [4] Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. Joint 2d-3d-semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105, 2017.
- [5] Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioannis Brilakis, Martin Fischer, and Silvio Savarese. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1534–1543, 2016.
- [6] Aharon Azulay and Yair Weiss. Why do deep convolutional networks generalize so poorly to small image transformations? arXiv preprint arXiv:1805.12177, 2018.
- [7] Aharon Azulay and Yair Weiss. Why do deep convolutional networks generalize so poorly to small image transformations? CoRR, abs/1805.12177, 2018.
- [8] Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Danny Gutfreund, Joshua Tenenbaum, and Boris Katz. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. 2019.
- [9] Berk Calli, Aaron Walsman, Arjun Singh, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M Dollar. Benchmarking in manipulation research: The ycb object and model set and benchmarking protocols. arXiv preprint arXiv:1502.03143, 2015.
- [10] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. International Conference on 3D Vision (3DV), 2017.
- [11] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations, 2020.
- [12] Weifeng Chen, Zhao Fu, Dawei Yang, and Jia Deng. Single-image depth perception in the wild. CoRR, abs/1604.03901, 2016.
- [13] Weifeng Chen, Shengyi Qian, David Fan, Noriyuki Kojima, Max Hamilton, and Jia Deng. Oasis: A large-scale dataset for single image 3d in the wild, 2020.
- [14] Weifeng Chen, Donglai Xiang, and Jia Deng. Surface normals in the wild. CoRR, abs/1704.02956, 2017.
- [15] Paolo Cignoni, Marco Callieri, Massimiliano Corsini, Matteo Dellepiane, Fabio Ganovelli, and Guido Ranzuglia. Meshlab: an open-source mesh processing tool. In Eurographics Italian chapter conference, volume 2008, pages 129–136. Salerno, Italy, 2008.
- [16] BO Community. Blender–a 3d modelling and rendering package. 2018.
- [17] Blender Online Community. Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018.
- [18] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016.
- [19] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
- [20] Maximilian Denninger, Martin Sundermeyer, Dominik Winkelbauer, Youssef Zidan, Dmitry Olefir, Mohamad Elbadrawy, Ahsan Lodhi, and Harinandan Katam. Blenderproc. arXiv preprint arXiv:1911.01911, 2019.
- [21] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. In Proceedings of the 1st Annual Conference on Robot Learning, pages 1–16, 2017.
- [22] J. Gibson. The senses considered as perceptual systems. 1966.
- [23] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning, 2020.
- [24] Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261, 2019.
- [25] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [26] Junhwa Hur and Stefan Roth. Mirrorflow: Exploiting symmetries in joint optical flow and occlusion estimation. CoRR, abs/1708.05355, 2017.
- [27] Zequn Jie, Pengfei Wang, Yonggen Ling, Bo Zhao, Yunchao Wei, Jiashi Feng, and Wei Liu. Left-right comparative recurrent model for stereo matching. CoRR, abs/1804.00796, 2018.
- [28] Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017.
- [29] Michal Kempka, Marek Wydmuch, Grzegorz Runc, Jakub Toczek, and Wojciech Jaskowski. Vizdoom: A doom-based AI research platform for visual reinforcement learning. arXiv preprint arXiv:1605.02097, 2016.
- [30] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014.
- [31] Alexander Kirillov, Ross B. Girshick, Kaiming He, and Piotr Dollár. Panoptic feature pyramid networks. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6392–6401, 2019.
- [32] Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics, 36(4), 2017.
- [33] Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics (ToG), 36(4):1–13, 2017.
- [34] Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. The omniglot challenge: a 3-year progress report. Current Opinion in Behavioral Sciences, 29:97–104, 2019.
- [35] John Lambert, Zhuang Liu, Ozan Sener, James Hays, and Vladlen Koltun. Mseg: a composite dataset for multi-domain semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2879–2888, 2020.
- [36] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, Lubomir D. Bourdev, Ross B. Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. CoRR, abs/1405.0312, 2014.
- [37] Shikun Liu, Edward Johns, and Andrew J Davison. End-to-end multi-task learning with attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1871–1880, 2019.
- [38] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015.
- [39] Davide Maltoni and Vincenzo Lomonaco. Continuous learning in single-incremental-task scenarios. CoRR, abs/1806.08568, 2018.
- [40] Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [41] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision, pages 405–421. Springer, 2020.
- [42] Ishan Misra, Abhinav Shrivastava, Abhinav Gupta, and Martial Hebert. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3994–4003, 2016.
- [43] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 02 2015.
- [44] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
- [45] Senthil Purushwalkam Shiva Prakash and Abhinav Gupta. Demystifying contrastive self-supervised learning: Invariances, augmentations and dataset biases. Advances in Neural Information Processing Systems, 33, 2020.
- [46] René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. ArXiv preprint, 2021.
- [47] René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. arXiv preprint arXiv:1907.01341, 2019.
- [48] Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors, European Conference on Computer Vision (ECCV), volume 9906 of LNCS, pages 102–118. Springer International Publishing, 2016.
- [49] Mike Roberts and Nathan Paczan. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. arXiv 2020.
- [50] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. CoRR, abs/1505.04597, 2015.
- [51] Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [52] H. Scudder. Probability of error of some adaptive pattern-recognition machines. IEEE Transactions on Information Theory, 11(3):363–371, 1965.
- [53] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. In European conference on computer vision, pages 746–760. Springer, 2012.
- [54] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor Segmentation and Support Inference from RGBD Images, pages 746–760. Springer Berlin Heidelberg, Berlin, Heidelberg, 2012.
- [55] Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image. Proceedings of 30th IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- [56] Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. Strasdat, Renzo De Nardi, Michael Goesele, Steven Lovegrove, and Richard Newcombe. The Replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797, 2019.
- [57] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and A. Gupta. Revisiting unreasonable effectiveness of data in deep learning era. 2017 IEEE International Conference on Computer Vision (ICCV), pages 843–852, 2017.
- [58] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5693–5703, 2019.
- [59] Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30. IEEE, 2017.
- [60] Antonio Torralba and Alexei A. Efros. Unbiased look at dataset bias. In CVPR 2011, pages 1521–1528, 2011.
- [61] Simon Vandenhende, Bert De Brabandere, and Luc Van Gool. Branched multi-task networks: Deciding what layers to share. CoRR, abs/1904.02920, 2019.
- [62] Simon Vandenhende, Stamatios Georgoulis, Bert De Brabandere, and Luc Van Gool. Branched multi-task networks: deciding what layers to share. arXiv preprint arXiv:1904.02920, 2019.
- [63] Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proesmans, Dengxin Dai, and Luc Van Gool. Multi-task learning for dense prediction tasks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [64] Oriol Vinyals, Charles Blundell, Timothy P. Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Matching networks for one shot learning. CoRR, abs/1606.04080, 2016.
- [65] P. Welinder, S. Branson, T. Mita, C. Wah, F. Schroff, S. Belongie, and P. Perona. Caltech-UCSD Birds 200. Technical Report CNS-TR-2010-001, California Institute of Technology, 2010.
- [66] Fei Xia, Amir Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson Env: Real-world perception for embodied agents. In 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [67] Yu Xiang, Roozbeh Mottaghi, and Silvio Savarese. Beyond pascal: A benchmark for 3d object detection in the wild. In IEEE Winter Conference on Applications of Computer Vision, pages 75–82, 2014.
- [68] Dan Xu, Wanli Ouyang, Xiaogang Wang, and Nicu Sebe. Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 675–684, 2018.
- [69] Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. Computer Vision and Pattern Recognition (CVPR), 2020.
- [70] Zhichao Yin and Jianping Shi. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1983–1992, 2018.
- [71] Amir Zamir, Alexander Sax, Teresa Yeo, Oğuzhan Kar, Nikhil Cheerla, Rohan Suri, Zhangjie Cao, Jitendra Malik, and Leonidas Guibas. Robust learning through cross-task consistency. arXiv, 2020.
- [72] Amir R. Zamir, Alexander Sax, William B. Shen, Leonidas J. Guibas, Jitendra Malik, and Silvio Savarese. Taskonomy: Disentangling task transfer learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
- [73] Jeffrey O Zhang, Alexander Sax, Amir Zamir, Leonidas Guibas, and Jitendra Malik. Side-tuning: A baseline for network adaptation via additive side networks, 2019.
- [74] Yinda Zhang, Shuran Song, Ersin Yumer, Manolis Savva, Joon-Young Lee, Hailin Jin, and Thomas A. Funkhouser. Physically-based rendering for indoor scene understanding using convolutional neural networks. CoRR, abs/1612.07429, 2016.