皮肤和疟疾图像的分布外检测
摘要
深度神经网络在使用医学图像数据进行疾病检测和分类方面显示出了有希望的结果。 然而,它们仍然面临着处理现实场景的挑战,尤其是可靠地检测分布外(OoD)样本。 我们提出了一种对皮肤和疟疾图像中的 OoD 样本进行稳健分类的方法,而无需在训练期间访问标记的 OoD 样本。 具体来说,我们使用度量学习和逻辑回归来迫使深度网络学习更丰富的类代表特征。 为了指导 OoD 示例的学习过程,我们通过删除图像中特定于类的显着区域或排列图像部分并使它们远离分布内样本来生成 ID 相似的示例。 在推理期间,采用 K 倒数最近邻来检测分布外样本。 对于皮肤癌 OoD 检测,我们采用两个标准基准皮肤癌 ISIC 数据集作为 ID,并将具有不同难度级别的 6 个不同数据集视为不分布。 对于疟疾 OoD 检测,我们使用 BBBC041 疟疾数据集作为 ID,并使用五个不同的具有挑战性的数据集作为分布外数据。 我们取得了最先进的结果,与之前最先进的皮肤癌和疟疾 OoD 检测相比,TNR TPR95% 分别提高了 5% 和 4%。
关键词:
皮肤癌、疟疾、分布不均、无监督方法、Tuplet 损失、K 互惠邻居1简介
近年来,应用深度神经网络在诊断和分析多种疾病方面取得了巨大成功,包括皮肤癌[2,15,39]和疟疾[5,6,7] 。 皮肤癌是最常见的癌症类型之一。 仅 2020 年就有约 119 万新发皮肤癌病例[33]。 早期诊断,包括癌症的检测及其正确分类,与高总体生存率相关。 同样,根据世界卫生组织的数据,仅 2019 年,全球就发生了 2.29 亿例疟疾病例,全球有 409,000 人死于疟疾[26]。 因此,开发计算机辅助诊断系统非常重要,可以使用计算方法来协助医生早期发现包括皮肤癌和疟疾在内的不同疾病。
深度学习模型的主要优势之一是它们的泛化能力,即能够在具有多种变化的测试数据上表现良好的能力。 这些变化是由于不同的图像捕获传感器、照明条件和分辨率而发生的。 尽管深度神经网络具有出色的性能,但它对训练分布之外的图像表现出过于自信的错误预测。 实验表明,向图像添加小噪声会导致网络以高概率[17]错误预测。 类似地,如[27]所示,使用最新的CNN架构(例如DenseNet、MobileNet、ResNet和VGGNet等)可以将包含狗的图像错误地分类为皮肤癌图像。 这可能会导致现实应用程序中的灾难性故障,尤其是在医疗保健系统中。 例如,经过训练以检测预定义数量的类别的网络被迫将一种新型疾病分类到预定义的类别之一。 因此,为了通过图像可靠地诊断和治疗疾病,深度神经网络必须能够避免对此类样本做出错误的过度自信的预测。 医疗保健系统的安全可靠部署要求模型准确且能够适应分布变化。 这就需要能够有效检测分布外 (OoD) 样本的方法。
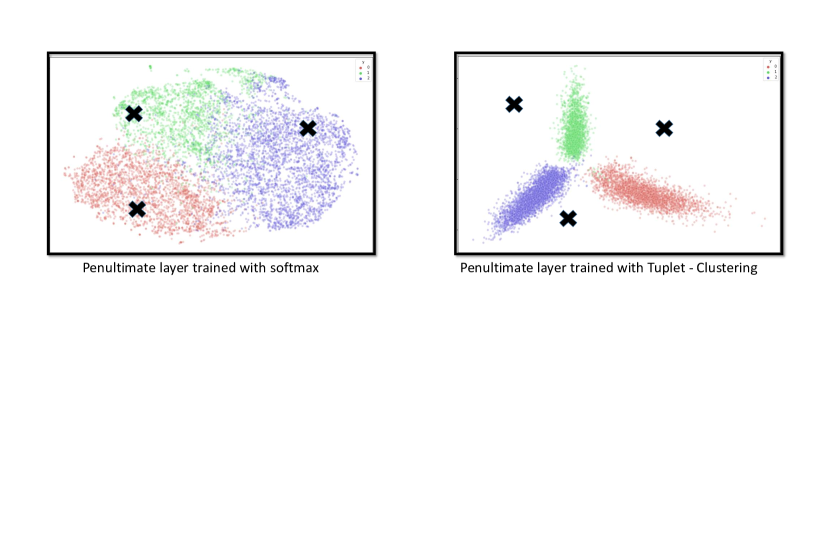
生成训练数据的分布称为分布内(ID),而不属于训练分布的分布称为分布外(OoD)样本。 如果测试期间的样本来自训练分布以外的不同分布,则使深度网络能够可靠地发出标记对于检测新型疾病非常重要。 人们已经尝试使用深度学习来检测 OoD 样本[17,24,19,31],但是尽管非常有用,但在医学领域却几乎没有取得任何进展[1]. 在模型部署过程中,OoD 样本的出现是由于不相关任务的图像、错误获取的图像以及新一类疾病的出现[9]。 许多最近的方法[24, 22]开发了有监督的OoD方法,其中它们假设在训练期间手动注释的OoD样本的可用性。 然而,手动标注的 OoD 样本很难收集,也很难标注,尤其是在处理不同的医学疾病图像时。 最重要的是,由于任何不属于 ID 的示例都可以被视为 OoD,因此任何有限采样数据都不会是 OoD 的完整表示。
在本文中,我们提出了一种对皮肤和疟疾图像中的 OoD 样本进行稳健分类的方法,而无需在训练期间访问标记的 OoD 样本。 所提出的方法对现有的分类网络进行微调以学习表示,从而最大限度地减少类内变化。 为了有区别地训练网络并解决训练期间 OoD 数据不可用的限制,我们引入了采用分布示例的 OoD 代理示例。 Chen 等人,[10] 广泛探索了不同的增强技术,并报告一些增强技术可以帮助学习更好的表示,而另一些技术也会降低性能。 此外,[34] 中的作者建议,这种性能下降的增强(例如旋转)可以通过将其视为负面来用于 OoD 检测。 受 [34] 的启发,并注意到皮肤和疟疾图像包含不同的视觉信息这一事实,我们提出了两种生成 OoD 替代项的方法。 对于皮肤 OoD 检测,设计了一种新颖的基于类别显着性的 OoD 代理生成方法 HideCam,用于从 ID 样本创建 OoD 数据集。 我们的策略产生 OoD 图像,其非显着区域与 ID 图像的非显着区域相似,并且可以假设其位于特征空间中皮肤类别的边界上。 类似地,对于疟疾 OoD 检测,OoD 代理是通过排列图像的不同部分来生成的。 之后,采用基于元组损失的度量学习来实现两个目标。 首先使 ID 样本在特征空间中接近每个样本。 其次,将此类 OoD 图像映射到远离 ID 图像的类边界的位置。 ID 样本到潜在空间的这种紧密映射使我们能够采用检索策略来识别 OoD 样本。 此外,为了保持分类器的判别能力,采用了分类损失。 最后,受 K 倒数最近邻 [40] 的启发,我们引入了一种新的鲁棒 OoD 样本排序策略,而不是对到朴素最近邻的距离进行阈值化。 我们在六个皮肤癌 OoD 数据集[27]和五个疟疾检测 OoD 数据集上将所提出的方法与五种最先进的方法进行了比较,并在所有评估指标上获得了有希望的结果。 总之,所提出的方法有以下贡献:
-
•
所提出的方法既不需要从头开始训练网络,也不需要任何特定的超参数来调整标记的 OoD 集。
-
•
我们采用了新颖的方法从 ID 样本生成 OoD 代理。
-
•
该方法不需要在训练期间访问任何真实的 OoD 数据。
-
•
我们使用了一种独特的方法,利用 K 互邻邻域来提高 OoD 分数。
-
•
我们的全面分析表明,与几个竞争基准相比,所提出的方法具有令人鼓舞的结果。
本文的结构如下:第 2 部分描述相关工作,第 3 部分包含我们提出的方法,第 4 部分提供有关数据集和实验的详细信息,第 5 部分总结本文。
2相关工作
最近开发了几种使用深度学习和计算机视觉自动检测皮肤和疟疾的方法。 Yu 等人,[39] 和 Codella 等人,[13] 表明,将深度特征与本地手工制作的描述符相结合可以产生更好的皮肤分类结果。 同样,Codella 等人,[13] 和 Gessert 等人,[16] 演示了使用许多网络的集合进行病变分类。 最近公开发布的国际皮肤影像合作组织 (ISIC) 档案[11,35,12]进一步促进了皮肤癌分类的研究。 同样,世界范围内致命疟疾疾病的检测也亟待改进。 尽管研究人员使用不同的技术做出了努力[3,23,14],但由于蚊子生态和疾病传播周期的原因,疟疾检测仍然是一项具有挑战性的任务[41] 。
检测OoD样本的直接方法之一是利用OoD和ID样本的预测概率的差异[17]。 该方法被视为所有其他方法的基线方法。 核心思想是假设ID样本将比OoD样本具有更高的最大softmax概率。 梁等人,[24]引入了一种有监督的OoD检测方法(ODIN),该方法通过微调OoD数据集上的超参数来扩大ID和OoD样本的最大softmax分数之间的差距。 Hsu等人,[19]进一步改进了ODIN,使其独立于OoD样本,同时使用预测类概率置信度分解的概率视角。 类似地,Lee 等人,[22]提出了另一种监督方法,将每一层上的预训练特征建模为类条件高斯。 然后根据其马哈拉诺比斯距离以及类条件均值和方差来评估测试时间上的样本。 与[24]类似,该方法使用输入预处理并需要OoD样本来调整超参数。 在最近的几部作品中,这种方法被命名为“Mahalanobis”。 类似地,Uwimana 等人,[36] 在疟疾细胞分类中使用基于 Mahalanobis 距离的置信度进行 OoD 样本检测。
Hendrycks 等人,[18] 演示了辅助 OoD 数据集可用于区分 ID 和 OoD 样本。 类似地,Tacket 等人,[34] 有趣地提出,同一图像的某些增强可以被视为 OoD 样本的边界情况,并且以与原始图像不同的方式对待它们应该会为图像带来更鲁棒的特征。 OoD 检测。 最近,Sastry 等人,[31] 提出了一个有趣的观察,即在输出层分配的激活和类标签的联合模式应该引导我们识别类级别模式。 除已定义的类模式外,任何遵循的样本都应被视为 OoD 样本。 他们使用不同阶的克矩阵发现了这种模式。 Pachecho 等人,[27] 基于 Gram OoD [31] 构建,并检测了皮肤癌的 OoD 样本。 在他们的工作中,样本特征与其分布的分层偏差被认为是 OoD 的指标,并且他们在皮肤癌相关的 OoD 数据集上显示了合理的结果。
由于最近在一些应用中使用了自监督学习以及对比损失,因此人们尝试使用对比学习来检测 OoD 样本。 Winkens 等人,[37] 使用著名的 SIMCLR [10] 方法进行对比训练。 它将不同的增强视为积极的,将所有其他图像视为消极的,以学习语义丰富的特征。 网络训练完成后,他们将高斯分布与训练数据上的激活值拟合到每一层的特征,并在测试时使用马哈拉诺比斯距离来查看样本是否为 OoD。 Tack 等人,[34] 有趣地提出,同一图像的某些增强可以被视为 OoD 样本。 这些增强应该是 OoD 样本的边界情况,并且使其与原始图像不同应该会为 OoD 示例的检测带来更稳健的特征。 他们还使用 SIMCLR 进行对比学习。 与上述方法相比,所提出的方法具有通用性,可以应用于不同的疾病(例如疟疾和皮肤癌),训练时不需要OoD样本,引入了新的OoD排序方式,并且具有良好的OoD与几个竞争基线相比的分类结果。

3方法论
我们提出的解决 OoD 检测挑战性问题的方法基于三个观察结果:(1)所提出的方法应该使 ID 样本的紧凑簇同时保持每个类别的可区分性,(2)由于在训练期间 OoD 样本不可用,我们需要设计一些机制来生成训练判别性 OoD 检测器的 OoD 代理,(3) 最后,由于大型数据集的 K 最近邻的限制,我们应该采用更好的距离度量来对 OoD 样本进行排名。 下面,我们提供了我们方法的每个步骤的详细信息。
我们建议采用类感知度量学习,使得属于同一类的样本比来自其他类的样本映射得更接近。 这种类内方差的最小化和类间方差的最大化也是许多聚类算法所期望的属性。 对于皮肤癌或疟疾数据集的预训练网络,我们使用连元组边缘损失[38]对其进行微调。 元组损失可以看作是三元组损失的扩展,其中元组包含多个具有锚点和正值的负样本。 然后根据比例因子对负片进行加权。 在我们的上下文中,ID 样本的损失定义为:
| (1) |
其中是权重的比例因子,是类的数量,,表示来自锚点和正样本同一类,而 是其他类的样本。 最后,和是样本和以及样本和 分别。
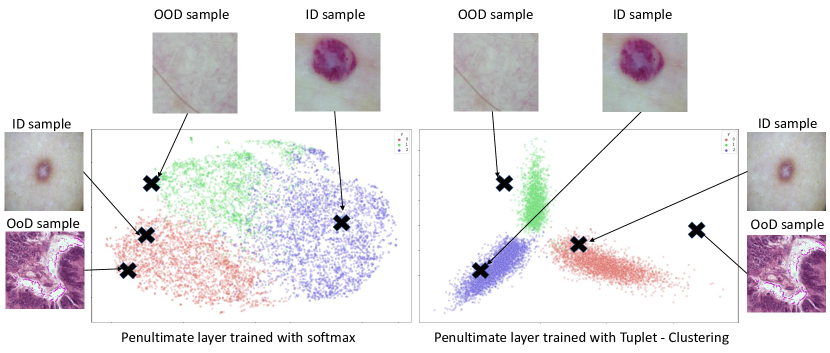
最小化损失(等式1)会导致映射属于一类的样本的空间紧凑,同时增加类间可分离性。 从图2中可以看出,与仅使用交叉熵损失训练的特征相比,通过使用tuplet损失的网络获得的特征对于OoD检测更有用。 由于损失函数仅查看 ID 样本,因此映射仍然会导致 ID 和 OoD 样本在潜在空间中彼此接近。
3.1 生成 OoD 代理
(等式1)对分布内(ID)样本进行聚类,但它不包含有关分布外(OoD)样本的任何知识。 因此,为了减轻(方程1)的缺点,我们建议借助现有的ID样本来生成OoD样本。 这些代理将使我们能够了解 ID 和 OoD 数据之间的界限。
OoD 样本空间非常大,包含不属于 ID 的所有可能分布。 因此,我们不是创建一个可以捕获所有这些可能变化的数据集,而是专注于通过操作 ID 样本来捕获 ID 流形的边界来生成 OoD 示例。
我们通过两种方式生成 OoD 代理,即针对皮肤癌的 HideCam 和针对疟疾的 Image-parts-Permutation [34]。 皮肤癌图像包含代表癌症类别的密集受限区域,因此,我们提出的方法 HideCam 删除了类别显着区域以进行 OoD。 另一方面,疟疾图像不包含任何如此密集的图案,但是整体结构信息很重要。 因此,我们采用基于图像部分的排列来生成疟疾图像的 OoD。 下面,我们提供了两种代理生成技术的详细信息。
-
(A)
HideCam: 我们生成依赖于类的代理图像。 受 [18] 和 [29] 观察的启发,我们创建了代理 OoD 样本,以便保留非显着信息并删除类代表信息。
我们使用预训练网络中基于梯度的类激活图 (CAM) [32] 来识别类显着区域。 基于梯度的 CAM 突出显示了与特定类别相关的重要区域。 一旦我们获得了有关癌症(或任何其他类别)的空间位置的信息,我们就会从同一图像中裁剪出健康区域,并用这些健康裁剪覆盖癌变区域。 生成的图像用作皮肤癌的 OoD 替代品。
-
(二)
图像部分排列:由于图像的某些变换/增强可以很好地代表 OoD 数据[34],因此我们通过基于图像部分的排列生成新图像。 具体来说,为了生成疟疾的 OoD 图像,只需将图像简单地分为 n 个相等的区域,然后对这些区域进行随机洗牌。 直观上,这改变了输入分布。
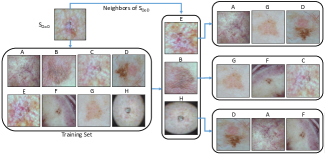
HideCam 和 Image-Parts-Permutation 的示例如图 3 所示。 与等式 1 类似,使用 ID 样本和 OoD 代理应用元组损失,使 ID 样本在特征空间中彼此靠近,而 OoD 样本彼此远离。
3.2目标函数
给定一个针对分类任务训练的网络,我们使用以下损失函数对最后几层进行处理:
| (2) | ||||
类似于等式。 1 分别代表连音的anchor、正值和负值。 表示根据 3.1 节中描述的方法创建的 OoD 代理。 是交叉熵损失。 和 分别表示仅具有 ID 和具有 ID + OoD 代理的连元组损失。 在此等式中,第一项是元组损失,其中正数和负数来自相对于锚点的相同和不同类别。 在第二项中,生成的替代 OoD 样本构成连音中的负数。 该术语负责将 OoD 代理与 ID 样本分离。 第二项是最重要的一项,因为将分类样本与远离的 OoD 代理一起聚类可以使 OoD 的识别变得更容易。 第三项确保除了 OoD 检测之外,分类器还学会区分不同的类别。

3.3推理 - OoD 分数
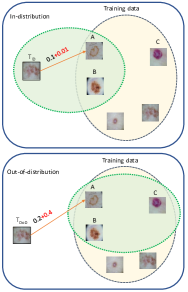
我们不依赖softmax层的输出来对OoD进行分类,而是使用检索结果的一致性作为识别OoD的参数。 输入样本的简单 OoD 分数可以通过在训练集中查找其最近邻居并确定样本与最近邻居的距离是否小于某个特定阈值来获得。 由于朴素最近邻评分对离群值的敏感性以及处理高维大数据集[4, 8]时的准确性较低,我们建议使用基于K-倒数邻居的距离[28 ],采用杰卡德距离和欧几里德距离[40]的组合。
为了使我们的论文独立,下面我们详细描述 K 互邻。 假设我们用来表示样本的K个近邻,那么的K个近邻可以写为:
| (3) |
其中 是训练集中的图像,它是查询图像 的邻居,查询图像也出现在 的邻居列表中。 很容易看出,K 互易邻居比朴素最近邻居更严格,因为成为 K 互易邻居需要互邻。 此外,两个样本 和 之间的杰卡德距离现在可以定义为:
| (4) |
其中 代表杰卡德距离, 代表从 [40] 创建的局部扩展邻域。 局部查询扩展是将样本的邻域扩展到朴素最近邻之外的过程。 它通过获取查询样本的最近邻居并获取查询的原始邻居和邻居的邻居的并集来实现这一点。 可以看出,对于具有互为K互邻的样本,会更小。 因此,要使两个样本具有较小的距离,必须是它们的邻域是相互的,如果样本距离训练样本较远,则很难实现这一点。
最后,我们使用以下公式计算测试样本 与训练样本 的距离:
| (5) |
其中是(杰卡德距离)和(欧氏距离)的加权和。 当 不在 附近时, 较高。 直观上来说,它会拉大距离训练样本较远的样本的距离。 图 4 和图 5 展示了这一想法。
为了鲁棒性,样本 的 OoD 分数 (x) 是通过采用最近邻居的中值距离来计算的,即
| (6) |
其中显示基于的的最近邻居,并且在实验中设置为15 。
4实验
我们实验的目标是通过不同的评估指标彻底评估皮肤和疟疾 OoD 数据集上提出的方法,并分析我们方法的不同组成部分。
4.1数据集
4.1.1ISIC 2019 数据集
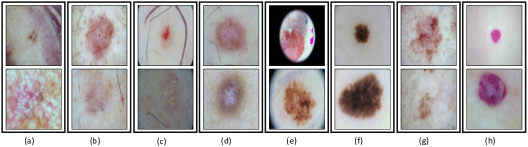
我们使用 [27] 提出的设置评估我们的方法,其中使用两个标准皮肤癌数据集 ISIC 2018 和 ISIC 2019 [11, 35, 12] 作为 ID数据。 ISIC 2019 数据集包含八种皮肤癌类别的 25,331 张图像,即黑色素瘤 (MEL)、黑色素细胞痣 (NV)、基底细胞癌 (BCC)、光化性角化病 (AK)、良性角化病 (BKL)、皮肤纤维瘤 (DF)、鳞状细胞癌癌(SCC)和血管病变鳞状细胞癌(VASC)。 它们各自的示例如图6所示。
我们使用六个不同的 OoD 数据集[27]作为在 ISIC 皮肤图像上训练的模型。 它们各自的详细信息如下:
-
•
Imagenet 包含从原始 ImageNet 数据集中随机选择的 3000 张图像。
-
•
NCT包含从NCT-CRC-HE-7K[21]中随机选择的1350张结直肠癌图像。
-
•
BBOX 包含 2025 个 ISIC 2019 图像,其中病变被黑色边框覆盖。
-
•
BBOX 70与 BBOX 相同,只是该数据集至少 70% 的病变被黑色边界框覆盖。
-
•
Derm-skin 代表取自 ISIC 2019 的 1,565 张皮肤镜健康皮肤图像。
-
•
Clinical 包含 723 个临床健康皮肤图像。
4.1.2 BBBC041 疟疾数据集
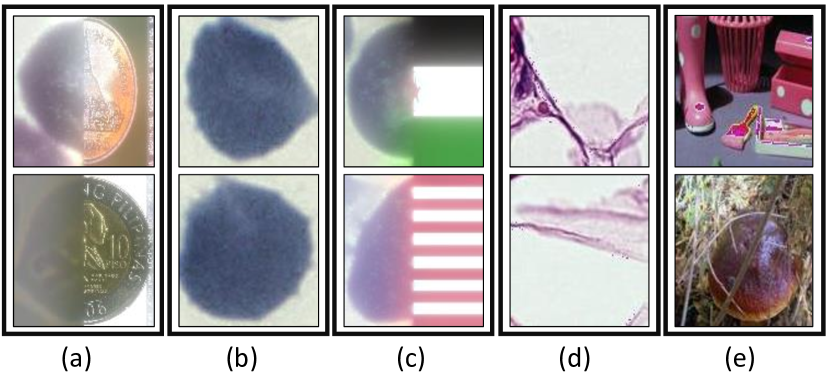
该数据集取自 Broad Bioimage Benchmark Collection [25],包含 1328 个图像,近 80,000 个细胞。 血涂片用吉姆萨试剂染色,并使用显微相机拍摄图像。 最后,专家团队对受感染的细胞进行了注释。 数据由两类健康细胞(即红细胞和白细胞)和四类疟疾感染细胞组成,即配子体(125 个图像)、环(418 个图像)、滋养体(1270 个图像)和裂殖体(1270 个图像) 。 与健康白细胞和疟疾感染细胞相比,健康红细胞的数据存在严重不平衡,其中健康细胞占所有细胞的 95% 以上。 图 7 的第二行显示了其中的一些示例。 与[27]类似,我们引入了以下疟疾OoD数据集。 它们各自的详细信息如下:
-
•
Imagenet 包含从原始 ImageNet 数据集中随机选择的 3000 张图像。
-
•
NCT包含从NCT-CRC-HE-7K[21]中随机选择的1350张结直肠癌图像。
-
•
Coin fusion 包含 500 个硬币和健康红细胞的混合图像。 使用高斯金字塔的拉普拉斯算子将硬币和电池融合在一起。
-
•
旗帜融合包含 192 个(不同国家的)旗帜与健康红细胞的混合图像。 创建这些的过程类似于硬币融合。
-
•
健康红细胞包含来自 BBBC041 数据集的 3868 个健康红细胞样本。 这是所有案例中最困难的一个。

皮肤和疟疾的这些不同OoD样本的样本分别如图8和图9所示。 除了在上述 OoD 数据集上评估模型之外,我们还通过一次将一个类保留为 OoD 类来探索该方法的功效。 这意味着我们在七个(例如皮肤数据集中)类上训练网络,并将第八个类视为 OoD 类。
| Dataset | Metric | Baseline[US] | ODIN[S] | Mahalanobis[S] | Gram-OoD[US] | Gram-OoD*[US] | Ours [US] |
| Derm-skin | TNR @ TPR 95% | 22.8 | 46.2 | 81.47 | 78.0 | 76.1 | 95.59 |
| AUROC | 74.4 | 86.8 | 96.2 | 96.5 | 95.8 | 98.66 | |
| Detection acc | 67.3 | 78.3 | 89.7 | 90.9 | 89.3 | 96.50 | |
| Clinical | TNR @ TPR 95% | 18.5 | 25.2 | 81.7 | 82.8 | 83.1 | 85.33 |
| AUROC | 72.5 | 69.5 | 96.1 | 96.6 | 96.6 | 95.59 | |
| Detection acc | 67.3 | 65.8 | 90.8 | 91.1 | 90.9 | 90.27 | |
| Imagenet | TNR @ TPR 95% | 9.30 | 50.0 | 99.9 | 80.7 | 88.4 | 90.86 |
| AUROC | 59.1 | 83.8 | 99.9 | 97.0 | 97.7 | 97.17 | |
| Detection acc | 56.6 | 78.1 | 99.1 | 92.0 | 97.9 | 94.15 | |
| BBOX | TNR @ TPR 95% | 27.9 | 68.8 | 94.8 | 88.0 | 88.1 | 97.60 |
| AUROC | 77.3 | 90.6 | 98.3 | 98.1 | 97.5 | 98.89 | |
| Detection acc | 69.8 | 83.7 | 95.3 | 94.5 | 94.0 | 98.33 | |
| BBOX-70 | TNR @ TPR 95% | 36.6 | 99.3 | 100 | 99.9 | 100 | 100 |
| AUROC | 89.4 | 99.8 | 100 | 99.7 | 99.9 | 100 | |
| Detection acc | 84.9 | 98.1 | 99.9 | 99.0 | 100 | 100 | |
| NCT | TNR @ TPR 95% | 1.44 | 32.5 | 98.7 | 98.9 | 99.9 | 99.30 |
| AUROC | 36.7 | 82.0 | 98.9 | 99.4 | 99.7 | 99.85 | |
| Detection acc | 50.1 | 75.0 | 98.7 | 97.1 | 98.5 | 92.10 | |
| Average (S) | TNR @ TPR 95% | - | 53.67 | 92.75 | - | - | 94.79 |
| AUROC | - | 85.42 | 98.23 | - | - | 98.36 | |
| Detection acc | - | 79.83 | 95.47 | - | - | 96.41 | |
| Average (US) | TNR @ TPR 95% | 19.42 | - | - | 88 | 89.27 | 94.79 |
| AUROC | 68.23 | - | - | 97.9 | 97.87 | 98.36 | |
| Detection acc | 66.0 | - | - | 94.1 | 94.97 | 96.41 |
| OoD Class | TNR @ TPR 95% | AUROC | Detection accuracy |
| BKL | 20.60 | 67.29 | 63.90 |
| AK | 14.30 | 62.40 | 62.35 |
| BCC | 36.14 | 74.24 | 69.90 |
| DF | 12.61 | 65.59 | 63.25 |
| MEL | 12.40 | 66.25 | 62.67 |
| NV | 7.36 | 70.14 | 67.21 |
| SCC | 17.43 | 61.80 | 61.84 |
| VASC | 9.74 | 61.97 | 59.53 |
| OoD dataset | TNR @ TPR 95% | AUROC | Detection accuracy |
| Derm-skin | 100 | 100 | 100 |
| Clinical | 100 | 99.90 | 99.90 |
| Imagenet | 99.30 | 99.70 | 99.30 |
| BBOX | 99.80 | 99.80 | 99.70 |
| BBOX-70 | 100 | 100 | 100 |
| NCT | 99.60 | 99.90 | 99.60 |
| Average | 99.78 | 99.88 | 99.75 |
| Standard dev | 0.0029 | 0.0012 | 0.0027 |
4.1.3评估指标
为了衡量我们区分 ID 和 OoD 示例的方法的效率,我们使用三个评估指标,为了完整性,下面将对此进行描述。
-
•
TNR@95TPR 是 OoD 样本被准确识别的可能性,真阳性率 (TPR) 高达 95%。 真阳性率的计算公式为:TPR = TP/(TP + FN),其中 TP 和 FN 分别代表真阳性和假阴性[30]。
-
•
检测精度衡量区分 ID 和 OoD 样本时在所有可能阈值内可实现的最大分类精度[30]。
-
•
AUROC 是真阳性率与假阳性率 [30] 曲线下面积的度量。
4.2实现细节
在本节中,我们提供我们方法的实现细节。 所提出的方法分为两个阶段。 在第一阶段,我们在 ID 数据(ISIC 和疟疾)上训练 DenseNet-121 [20] 以进行分类。 对于这两个数据集,我们使用加权交叉熵损失函数来解释类别不平衡,即少数类别根据频率被赋予更高的权重。 该模型经过大约 100 个 epoch 的训练,并提前停止。 作为优化器,采用随机梯度下降,学习率为 0.001,权重衰减为 0.001。 上述设置对于皮肤和疟疾数据集都是相同的。 由于疟疾数据集中存在较大的类别不平衡,我们通过不同角度的旋转来增加少数类别(配子体)样本。 在第二阶段,我们采用第一阶段训练的网络,并使用方程2给出的损失函数对其进行进一步训练。 我们使用 HideCam 生成皮肤癌的 OoD 替代项,并使用 Image-Parts-Permutation 生成疟疾相关实验。 我们在此阶段对网络进行了约 200 个时期的微调。 我们对 tuplet 损失使用默认边距 5.73,并使用学习率 。
为了进行推理,我们使用公式 5 计算测试样本与每个训练样本的距离。 正如[40]中所建议的,对于K-倒数,我们使用15个最近邻居来考虑进行查询,并使用6个最近邻居来进行本地查询扩展过程。 最后,我们使用 = 0.3。 对于皮肤和疟疾相关的实验,这些值保持相同,这表明该算法并不严重依赖于微调这些超参数。
除了在 4.1 节介绍的 OoD 数据集上进行测试外,我们还从原始 ISIC 和 BBBC401 数据集中抽取了 25% 的样本作为测试 ID 样本。 以下[27]、TNR@TPR 95%、AUROC、检测精度作为评价指标。
| Dataset | Metric | Baseline[US] | ODIN[S] | Mahalanobis[S] | Gram-OOD[US] | Gram-OOD*[US] | Ours[US] |
| RBC Healthy | TNR @ TPR 95% | 2.68 | 23.97 | 49.35 | 58.59 | 41.9 | 78.30 |
| AUROC | 48.95 | 78.71 | 90.05 | 82.64 | 91.8 | 94.05 | |
| Detection acc | 53.18 | 73.45 | 83.17 | 78.18 | 86.61 | 90.19 | |
| Coin fusion | TNR @ TPR 95% | 29.06 | 83.33 | 100 | 95.49 | 98.81 | 95.20 |
| AUROC | 87.8 | 96.09 | 100 | 98.72 | 98.67 | 96.86 | |
| Detection acc | 81.8 | 90.36 | 100 | 95.64 | 98.05 | 95.58 | |
| Flag fusion | TNR @ TPR 95% | 18.75 | 83.33 | 100 | 97.72 | 99.58 | 84.60 |
| AUROC | 85.95 | 97.25 | 100 | 99.36 | 99.12 | 95.28 | |
| Detection acc | 80.51 | 91.51 | 100 | 97.02 | 98.49 | 91.56 | |
| Imagenet | TNR @ TPR 95% | 18.44 | 73.82 | 100 | 88.82 | 98.21 | 97.60 |
| AUROC | 84.21 | 92.65 | 99.97 | 97.74 | 98.8 | 99.07 | |
| Detection acc | 79.3 | 86.88 | 99.7 | 92.22 | 97.28 | 96.79 | |
| NCT | TNR @ TPR 95% | 18.08 | 71.09 | 100 | 95.94 | 98.51 | 99.48 |
| AUROC | 77.78 | 92.98 | 99.97 | 99.16 | 98.94 | 99.10 | |
| Detection acc | 73.08 | 85.65 | 99.7 | 95.56 | 97.44 | 98.020 | |
| Average (S) | TNR @ TPR 95% | - | 67.11 | 89.87 | - | - | 91.04 |
| AUROC | - | 91.53 | 97.9 | - | - | 96.31 | |
| Detection acc | - | 85.57 | 96.5 | - | - | 94.42 | |
| Average (US) | TNR @ TPR 95% | 17.4 | - | - | 73.03 | 87.40 | 91.04 |
| AUROC | 76.93 | - | - | 92.08 | 97.47 | 96.31 | |
| Detection acc | 73.57 | - | - | 88.38 | 95.57 | 94.42 |
| OoD Class | TNR @ TPR 95% | AUROC | Detection accuracy |
| Ring | 5.98 | 81.44 | 78.37 |
| Schizont | 34.76 | 84.06 | 78.55 |
| Gametocyte | 36.57 | 82.37 | 75.47 |
| Trophozoite | 76.25 | 91.94 | 86.27 |
4.3与最先进技术的比较
我们将所提出的无监督 OoD 检测方法与有监督 OoD 检测方法(ODIN [24] 和 Mahalanobis [22])和无监督 OoD 检测方法(最大 softmax 概率 [17]、Gram OoD [31] 和 Gram OoD* [27])。 请注意,监督方法假设在训练期间可以访问标记的 OoD 样本,而无监督方法(包括我们的)假设标记的 OoD 训练数据不可用。
4.3.1 皮肤癌OoD检测
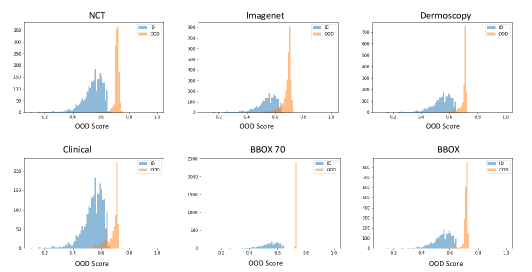
表1中的定量结果表明,在所有评估指标上,我们的无监督 OoD 检测方法显着优于最近发布的无监督和监督 OoD 方法。 上一专栏中的明显改进证明了我们的方法的有用性,并强制集群表示(使用连元组损失)和 OoD 代理对于稳健的 OoD 检测至关重要。 表2显示了当一个类保留为OoD并且整个模型在其余七个类上进行训练时的结果。 由于这种情况非常困难,由于 OoD(不包含在训练中的类)和 ID 样本看起来非常相似,因此数字不如其他 OoD 样本的情况,如表 1。 ISIC-2018数据集上的实验结果如表3所示。 在图10中,我们展示了ID测试集(ISIC-2019)和六个不同OoD数据集的OoD分数(方程)的直方图。 该直方图展示了 OoD 和 ID 样本之间 OoD 分数的区分性质。
4.3.2 OoD检测用于疟疾检测
与皮肤 OoD 数据集上的实验类似,我们在五个不同的疟疾 OoD 数据集上评估了 OoD 检测方法。 其定量结果如表4所示。 可以看出,在最困难的情况下,即健康的红细胞,我们的方法显着优于基线。 平均而言,对于 TNR @ TPR 95%,所提出的方法与基线相比具有约 4% 的更好结果,并且具有 AUROC 和检测精度的比较结果。 AUROC 和检测精度比较性能的一个可能原因可能是这些指标考虑了每个可能的阈值,并且可能存在一些基线模型运行良好的阈值。 TNR 指标基本上适用于一个严格且特定的阈值,该阈值更为重要,并且我们的模型可能会工作得更好,因为我们的目标是在需要良好性能来检测分布内和 OOD 样本的情况下工作良好。
4.4消融研究
我们分析所提出方法的不同组成部分以验证其有效性。 表 6 中皮肤 ISIC 2019 数据集的实验结果表明,我们方法的每个组成部分都很重要,并且有助于最终的准确性。
| Loss | TNR @ TPR 95% | AUROC | Detection accuracy |
| w/o ID tuplet | 81.34 | 93.14 | 88.87 |
| w/o OoD tuplet | 69.14 | 88.38 | 85.82 |
| w/o CE | 79.62 | 92.95 | 89.69 |
| w/o K-reciprocal | 90.07 | 96.80 | 92.60 |
| Complete Approach | 94.79 | 98.36 | 96.41 |
5讨论和总结
在检测样本是否来自训练分布时,深度神经网络通常被证明是错误的。 这会导致部署中的可靠性问题,特别是对于医疗应用而言。 我们建议通过学习一种不仅具有类间区分性而且具有大量类内相似性的表示来解决这个问题。 减少从 ID 数据集生成的 OoD 代理的元组损失有助于将分布外样本映射到远离类边界的位置。 为了进行稳健的 OoD 分数估计,我们使用 K 倒数邻居距离的中值。 我们通过在不同的 ID 和 OoD 数据集对上获得最先进的结果,证明了该方法的有效性。 我们将皮肤癌和疟疾含有的细胞图像作为 ID,并在不同的 OoD 数据集上评估该方法。 我们取得了最先进的结果,在皮肤癌和疟疾检测方面,TNR TPR95% 分别比之前最先进的技术提高了 5% 和 4%。 未来,我们的目标是推广这种方法,使其适用于各种临床数据集。
致谢:该项目的部分支持来自美国 Facebook 的无限制捐赠。 本出版物中表达的观点、调查结果、结论或建议均为作者的观点、调查结果、结论或建议,并不一定反映 Facebook 的观点。
参考
- Gao et al. [2020] Gao, L., Wu, S., 2020. Response score of deep learning for out-of-distribution sample detection of medical images. Journal of Biomedical Informatics 107, 103442.
- Harangi et al. [2020] Harangi, B., 2018. Skin lesion classification with ensembles of deep convolutional neural networks. Journal of Biomedical Informatics 86, 25-32.
- Baroni et al. [2020] Baroni, L., Salles, R.,Salles, S.,Guedes, G., Porto, F.,Bezerra, E., Barcellos, C.,Pedroso, M.,Ogasawara, E., 2020. An analysis of malaria in the Brazilian Legal Amazon using divergent association rules. Journal of Biomedical Informatics 108, 103512.
- Díaz et al. [2020] Xu, Z., Shen, D.,Nei, T.,Kou, Y., 2020. A hybrid sampling algorithm combining M-SMOTE and ENN based on Random forest for medical imbalanced data. Journal of Biomedical Informatics 107, 103465.
- Díaz et al. [2020] Díaz, G., González, S.,F.,Romero, E., 2009. A semi-automatic method for quantification and classification of erythrocytes infected with malaria parasites in microscopic images. Journal of Biomedical Informatics 42, 296-307.
- Lee et al. [2021] Lee, Y.W., Choi, J.W., Shin, E.H., 2021. Machine learning model for predicting malaria using clinical information. Computers in Biology and Medicine 129, 104151.
- Santosh et al. [2020] Santosh, T., Ramesh, D., Reddy, D., 2020. Lstm based prediction of malaria abundances using big data. Computers in Biology and Medicine 124, 103859.
- Balsubramani et al. [2019] Balsubramani, A., Dasgupta, S., Freund, Y., Moran, S., 2019. An adaptive nearest neighbor rule for classification., in: NeurIPS.
- Cao et al. [2020] Cao, T., Huang, C., Hui, D.Y.T., Cohen, J.P., 2020. A benchmark of medical out of distribution detection. arXiv preprint arXiv:2007.04250 .
- Chen et al. [2020] Chen, T., Kornblith, S., Norouzi, M., Hinton, G., 2020. A simple framework for contrastive learning of visual representations, in: International conference on machine learning, PMLR. pp. 1597–1607.
- Codella et al. [2019] Codella, N., Rotemberg, V., Tschandl, P., Celebi, M.E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., et al., 2019. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). ICLR .
- [12] Codella, N.C., Gutman, D., Celebi, M.E., Helba, B., Marchetti, M.A., Dusza, S.W., Kalloo, A., Liopyris, K., Mishra, N., Kittler, H., et al., . Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic), in: 2018 IEEE 15th International Symposium on Biomedical Imaging.
- Codella et al. [2017] Codella, N.C., Nguyen, Q.B., Pankanti, S., Gutman, D.A., Helba, B., Halpern, A.C., Smith, J.R., 2017. Deep learning ensembles for melanoma recognition in dermoscopy images. IBM Journal of Research and Development .
- Davis et al. [2019] Davis, J.K., Gebrehiwot, T., Worku, M., Awoke, W., Mihretie, A., Nekorchuk, D., Wimberly, M.C., 2019. A genetic algorithm for identifying spatially-varying environmental drivers in a malaria time series model .
- Esteva et al. [2017] Esteva, A., Kuprel, B., Novoa, R.A., Ko, J., Swetter, S.M., Blau, H.M., Thrun, S., 2017. Dermatologist-level classification of skin cancer with deep neural networks. nature .
- Gessert et al. [2020] Gessert, N., Nielsen, M., Shaikh, M., Werner, R., Schlaefer, A., 2020. Skin lesion classification using ensembles of multi-resolution efficientnets with meta data. MethodsX .
- Hendrycks and Gimpel [2017] Hendrycks, D., Gimpel, K., 2017. A baseline for detecting misclassified and out-of-distribution examples in neural networks. ICLR .
- Hendrycks et al. [2018] Hendrycks, D., Mazeika, M., Dietterich, T., 2018. Deep anomaly detection with outlier exposure, in: ICLR.
- Hsu et al. [2020] Hsu, Y.C., Shen, Y., Jin, H., Kira, Z., 2020. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data, in: CVPR.
- Huang et al. [2018] Huang, G., Liu, Z., van der Maaten, L., Weinberger, K.Q., 2018. Densely connected convolutional networks. arXiv:1608.06993.
- Kather et al. [2019] Kather, J.N., Krisam, J., Charoentong, P., Luedde, T., Herpel, E., Weis, C.A., Gaiser, T., Marx, A., Valous, N.A., Ferber, D., et al., 2019. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS medicine .
- Lee et al. [2018] Lee, K., Lee, K., Lee, H., Shin, J., 2018. A simple unified framework for detecting out-of-distribution samples and adversarial attacks, in: NeurIPS.
- Lee et al. [2016] Lee, K.Y., Chung, N., Hwang, S., 2016. Application of an artificial neural network (ann) model for predicting mosquito abundances in urban areas. Ecological Informatics 36, 172--180.
- Liang et al. [2018] Liang, S., Li, Y., Srikant, R., 2018. Enhancing the reliability of out-of-distribution image detection in neural networks. ICLR .
- Ljosa et al. [2012] Ljosa, V., Sokolnicki, K.L., Carpenter, A.E., 2012. Annotated high-throughput microscopy image sets for validation. Nature methods 9, 637--637.
- Organization et al. [2019] Organization, W.H., et al., 2019. World malaria report 2019 .
- Pacheco et al. [2020] Pacheco, A.G., Sastry, C.S., Trappenberg, T., Oore, S., Krohling, R.A., 2020. On out-of-distribution detection algorithms with deep neural skin cancer classifiers, in: CVPR Workshop.
- Qin et al. [2011] Qin, D., Gammeter, S., Bossard, L., Quack, T., Van Gool, L., 2011. Hello neighbor: Accurate object retrieval with k-reciprocal nearest neighbors, in: CVPR.
- Ren et al. [2019] Ren, J., Liu, P.J., Fertig, E., Snoek, J., Poplin, R., DePristo, M.A., Dillon, J.V., Lakshminarayanan, B., 2019. Likelihood ratios for out-of-distribution detection, in: NeurIPS.
- Sastry and Oore [2019] Sastry, C.S., Oore, S., 2019. Detecting out-of-distribution examples with in-distribution examples and gram matrices. arXiv preprint arXiv:1912.12510 .
- Sastry and Oore [2020] Sastry, C.S., Oore, S., 2020. Detecting out-of-distribution examples with gram matrices, in: International Conference on Machine Learning, PMLR.
- Selvaraju et al. [2017] Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D., 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization, in: CVPR.
- Sung et al. [2021] Sung, H., Ferlay, J., Siegel, R.L., Laversanne, M., Soerjomataram, I., Jemal, A., Bray, F., 2021. Global cancer statistics 2020: Globocan estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: a cancer journal for clinicians .
- Tack et al. [2020] Tack, J., Mo, S., Jeong, J., Shin, J., 2020. Csi: Novelty detection via contrastive learning on distributionally shifted instances, in: NeurIPS.
- Tschandl et al. [2018] Tschandl, P., Rosendahl, C., Kittler, H., 2018. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data .
- Uwimana and Senanayake [2021] Uwimana, A., Senanayake, R., 2021. Out of distribution detection and adversarial attacks on deep neural networks for robust medical image analysis, in: ICML 2021 Workshop on Adversarial Machine Learning. URL: https://openreview.net/forum?id=1iy7rdPCt_.
- Winkens et al. [2020] Winkens, J., Bunel, R., Roy, A.G., Stanforth, R., Natarajan, V., Ledsam, J.R., MacWilliams, P., Kohli, P., Karthikesalingam, A., Kohl, S., et al., 2020. Contrastive training for improved out-of-distribution detection. arXiv preprint arXiv:2007.05566 .
- Yu and Tao [2019] Yu, B., Tao, D., 2019. Deep metric learning with tuplet margin loss, in: CVPR.
- Yu et al. [2018] Yu, Z., Jiang, X., Zhou, F., Qin, J., Ni, D., Chen, S., Lei, B., Wang, T., 2018. Melanoma recognition in dermoscopy images via aggregated deep convolutional features. IEEE Transactions on Biomedical Engineering .
- Zhong et al. [2017] Zhong, Z., Zheng, L., Cao, D., Li, S., 2017. Re-ranking person re-identification with k-reciprocal encoding, in: CVPR.
- Zinszer et al. [2015] Zinszer, K., Kigozi, R., Charland, K., Dorsey, G., Brewer, T.F., Brownstein, J.S., Kamya, M.R., Buckeridge, D.L., 2015. Forecasting malaria in a highly endemic country using environmental and clinical predictors. Malaria journal 14, 1--9.