GFlowNet 基础
摘要
生成流网络 (GFlowNets) 已被引入作为一种在主动学习环境中对不同候选对象进行采样的方法,其训练目标使它们大致按给定奖励函数的比例进行采样。 在本文中,我们展示了 GFlowNet 的许多附加理论特性,包括一个新的本地高效训练目标,称为详细平衡,用于与 MCMC 进行类比。 GFlowNet 可用于估计联合概率分布和相应的边际分布,其中某些变量未指定,并且特别有趣的是,可以表示复合对象(如集合和图)上的分布。 GFlowNets 将通常由计算成本高昂的 MCMC 方法完成的工作分摊到一次经过训练的生成过程中。 它们还可以用于估计配分函数和自由能、给定子集(子图)的超集(超图)的条件概率,以及给定集合(图)的所有超集(超图)的边际分布。 我们引入了能够估计熵和互信息、从帕累托前沿采样、与奖励最大化策略的连接以及对随机环境、连续行动和模块化能量函数的扩展的变体。
1简介
在 Bengio 等人 (2021) 介绍生成流网络 (GFlowNets) 的基础上,我们在这里提供了深入的正式基础,并以可能感兴趣的方式扩展了一组理论结果适用于 Bengio 等人 (2021) 的主动学习场景,而且范围更广。
1.1 什么是 GFlowNet?
GFlowNet 的特性使其非常适合执行一般的摊销概率推理,无论是采样还是边缘化。 采样在训练时进行,而运行时采样或边际量的计算可以通过一系列建设性随机步骤一次性完成。 这使得 GFlowNets 成为蒙特卡罗马尔可夫链 (MCMC) 的有趣替代品,并且与摊销变分推理相关(Malkin 等人,2023)。
由于组合对象 的采样可以通过一系列随机步骤来实现,因此可以表示此类对象上非常丰富的多模态分布 ,并且离线训练目标使得探索和发现利益分配的模式。 GFlowNets 的关键属性是,它们的采样策略经过训练,使得对对象 进行采样的概率 与给定奖励的值 大致成正比应用于该对象的函数。 我们还讨论能量函数,即奖励函数是非负的并且对应于非标准化概率。 人们通常从正例数据集中训练生成模型,而 GFlowNet 则经过训练以匹配给定的能量或奖励函数并将其转换为采样器。 我们将该采样器视为生成策略,因为复合对象 是通过一系列较小的随机步骤构建的(参见图 1 ),通常对应于构造性地组合 的不同元素,例如图的边。
这种能量函数或非归一化概率函数到采样器的转换与 MCMC 方法实现的类似,但一旦经过训练,GFlowNet 将一次性生成一个样本,而不是生成一长串样本,其分布将逐渐接近所需的样本。 因此,GFlowNets 避免了此类对象空间中的冗长随机搜索以及 MCMC 方法相关的模式混合棘手挑战(Jasra 等人,2005;Bengio 等人,2013;Pompe 等人,2020) 。 通过多次调用采样器,可以从 GFlowNet 中获取多个 iid 样本。 GFlowNets 用 MCMC 来代替采样的棘手性,以应对生成策略摊销训练的挑战。 如果奖励函数的模式没有学习者可以概括的固有(但不一定已知)结构,即学习者几乎没有机会正确猜测在哪里可以找到基于在(即训练)那些它已经访问过的地方。

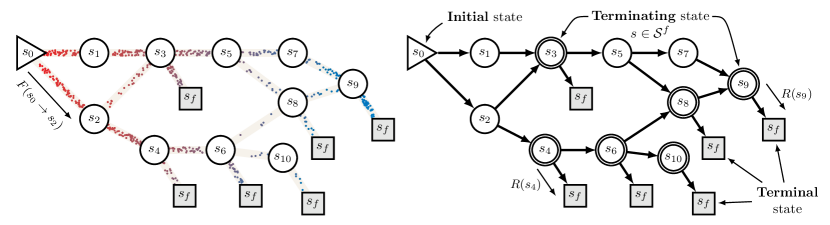
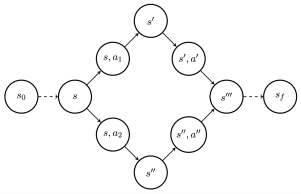
能量函数或奖励函数(负能量的指数)仅在对象 的顺序构造过程结束时进行评估,即我们所说的终止状态。 每个这样的构造序列都从单个初始状态 开始,并以最终状态结束。 如图2所示,我们可以可视化从开始并以最终状态结束的所有轨迹的集合。 “生成流网络”中的术语“流”是指可以通过 GFlowNet 学习过程学习的非标准化概率。 中间状态中的流是从可到达的终止状态的非负奖励的加权和。这些权重是为了避免重复计算:如果我们要在 中注入固定的液体流量,并将该液体按比例分配到任何状态 的每个子级中的 GFlowNet选择 的子级的策略,我们将获得每个状态的流量,并且终止状态的流量将与这些状态的奖励函数匹配。 正如这里以及第一篇 GFlowNet 论文 (Bengio 等人, 2021) 中首次显示的,这可以通过每个状态的流约束来实现:传入流的总和必须匹配流出流量的总和。
1.2本文的贡献
在本文中,一个重要的贡献是条件 GFlowNet 的概念,它能够估计与对象构造的许多步骤中的边缘化相对应的棘手总和,因此可以用于计算自由能111在机器学习中,自由能是非标准化边际概率的对数,通常是难以处理的指数负能之和。 在不同类型的联合分布上,也许最有趣的是在集合和图上。 这种边缘化还可以估计熵、条件熵和互信息。 因此,GFlowNet 可以被推广到估计与建模丰富结果(而不是标量奖励函数)相对应的多个流。
我们建议读者参考 Bengio 等人 (2021) 和 Sec. 7 来讨论相关方法和与常见生成模型和强化学习(RL)方法的差异。 在 RL 上下文中,该论文中已经提到的 GFlowNet 的两个有趣属性是:它们 (1) 可以使用从与 GFlowNet 所表示的分布不同的分布中采样的轨迹以离线方式进行训练,以及 (2) 它们与奖励相匹配概率函数,而不是试图找到最大化奖励或回报的配置。 后一个属性在探索的背景下特别有趣,以确保从生成策略中采样的配置既有趣又多样化。 将 GFlowNet 转换为摊销概率推理机也很有趣:如果我们选择奖励函数是先验(针对某个随机变量)乘以似然(给定随机变量值的选择,某些数据的拟合程度),那么GFlowNet 策略学习从相应的贝叶斯后验(与先验时间似然成正比)进行采样。 GFlowNet 生成不同样本集的能力对应于从目标分布的模式中进行采样的能力。
GFlowNets 的一个重要灵感来源是时间差分 RL 方法中信息传播的方式(Sutton 和 Barto,2018)。 两者都依赖于学分分配的一致性原则,只有当训练收敛时才能渐近实现。 虽然精确的梯度计算可能很棘手,因为要考虑的状态空间中的路径数量呈指数级增长,但这两种方法都依赖于不同组件之间的局部一致性以及训练目标,该目标表明如果所有学习的组件在本地彼此一致,然后我们获得了一个估计全球感兴趣数量的系统。 示例包括使用时间差异方法估计预期贴现收益以及使用 GFlowNet 进行概率测量。
本文在多个方向上扩展了原始 GFlowNet 构造(Bengio 等人,2021) 的理论,包括一个称为详细平衡的新局部训练目标(与蒙特卡罗的详细平衡条件进行类比)马尔可夫链)避免了形成先前提出的流匹配损失所需的显式总和,以及能够计算变量子集的边际概率(或自由能)的公式,更一般地对于较大集合的子集或子图,它们的应用例如,估计熵和互信息,以及引入无监督形式的 GFlowNet(训练时不需要奖励函数,只需要观察结果),从而可以从帕累托前沿进行采样。 尽管基本的 GFlowNet 与 bandits 更相似(因为仅在一系列操作结束时提供奖励),但它们可以扩展以考虑中间奖励,从而考虑回报的概念,并根据这些回报进行采样。 GFlowNets 的原始表述也仅限于离散和确定性环境,而本文提出了如何解除这两个限制。 最后,虽然 GFlowNets 的基本公式假设给定的奖励或能量函数,但本文考虑了如何与 GFlowNet 联合学习能量函数,为新型基于能量的建模方法和能量函数的模块化结构打开了大门和 GFlowNet。
1.3 其他作品中的GFlowNets
除了本文提出的理论之外,Malkin 等人 (2023) 和 Zimmermann 等人 (2022) 证明了 GFlowNet 和分层变分方法之间的一些部分等价性,提供了更多理论证据证明 GFlowNet 在学习按给定奖励函数按比例进行采样方面的有效性。 这些工作还为 GFlowNets 在离策略环境中的优越性提供了证据。
由于生成样本的相关多样性,GFlowNets 已经找到了广泛的应用。 在存在真实奖励函数的廉价代理的情况下,GFlowNet 已被用于显示样本,在真实奖励函数下进行更昂贵的评估之前,在这些样本下查询代理。 在这些设置中,GFlowNet 生成的样本多样性可用于增强代理错误指定的鲁棒性并纳入认知不确定性。 例如,Zhang 等人 (2023) 使用 GFlowNets 为计算图中的操作生成示例调度,其中通过代理评估示例调度的运行时间很快,但在目标硬件上评估相同的调度却很慢。昂贵的。 在主动学习问题中,Jain 等人 (2022, 2023) 使用 GFlowNet 采样作为主动学习循环内的子例程,以替代贝叶斯优化或基于 RL 的方法。 Jain 等人 (2022) 应用GFlowNets寻找新型抗菌肽,发现与人类转录因子具有高结合活性的DNA序列,并寻找具有高荧光的蛋白质。 此外,Jain 等人 (2023) 开发了偏好条件 GFlowNet,其中偏好权重向量用于将多个目标函数缩放为单个奖励。 作者将他们的技术应用于各种分子和 DNA 序列生成任务,并发现他们的方法能够沿着帕累托前沿找到不同的帕累托最优样本。
GFlowNets 已在其他几个机器学习问题中得到应用。 例如,Zhang 等人 (2022) 同时训练基于能量的模型和 GFlowNet;能量函数使用来自 GFlowNet 的样本进行训练,而 GFlowNet 又使用能量函数来形成其奖励。 他们的方法产生了高维二进制向量的生成模型,例如二值化数字。 Deleu 等人 (2022) 使用 GFlowNet 进行结构学习; GFlowNet 生成的样本近似于给定数据集的因果图上的真实后验。 他们的方法适用于观察数据和干预数据,并且与基于 MCMC 和变分推理的方法相比具有优势。 Hu 等人 (2023) 通过联合训练 GFlowNet 来从期望最大化的 E 步中通常难以处理的后验中进行近似采样,找到具有离散组合潜在变量的潜在变量模型的最大似然估计( EM)算法。
2 流网络和马尔可夫流
2.1 图论的一些要素
在本节中,我们回顾一下图的一些基本定义和属性,它们是流网络和 GFlowNet 的基础。
Definition 1。
有向图是一个元组 ,其中 是状态的有限集, 是表示有向边的 的子集。 的元素表示为 并称为 边缘或过渡.
此类图中的
轨迹是元素的序列,使得每个转换和。 我们将 表示为 位于轨迹 中,即 ,类似地 表示。 为了方便起见,我们还使用符号。 轨迹的长度是其中的边数(因此的长度是)。
有向无环图(DAG)是一种有向图,其中不存在满足的轨迹。
给定一个 DAG 和两个状态 ,如果 中存在从 开始到 ,然后我们写。 二元关系“”定义了严格偏序(即它是非自反、不对称和传递的)。 如果或,我们就写。 二元关系“”是一个(非严格)偏序(即它是自反的、反对称的和传递的)。
如果和之间没有顺序关系,我们就写。
Definition 2。
给定一个 DAG , 家长组 状态 的状态(我们表示为 )包含 中 的所有直接父级,即 ;同样, 儿童套装 包含 中 的所有直接子级,即 。
Definition 3。
给定一个 DAG 。 如果存在两个满足以下条件的状态,则称为指向DAG:
称为源状态或初始状态。 称为sink状态或最终状态。 因为“”是严格的偏序,所以这两种状态是唯一的。
此类 DAG 中的完整轨迹是从开始并以结束的任何轨迹。 我们将这样的轨迹表示为。
我们用 表示 中所有完整轨迹的集合,用 表示 中(可能不完整)轨迹的集合。 。
如果状态 是接收器状态的父状态,即 ,则称为 终止状态。 过渡称为终止边缘。 我们用以下方式表示:
-
•
,,中非终止边的集合
-
•
,,中的终止边集
-
•
,中的终止状态集。
在图 3中,我们可视化了前面定义中引入的概念。

请注意,单个源状态和单个接收器状态的约束只是数学上的便利,因为一般 DAG 和具有此约束的 DAG 之间存在双射(通过添加连接到所有其他源/接收器状态的唯一源/接收器状态) )。
Definition 4。
令 为具有源状态 和接收器状态 的尖 DAG。 A 转发(分别为 向后)与一致的概率函数是任何非负函数(resp。 )定义在 上,满足 (相应地,)。 )。
使用指向的 DAG,一致的前向和后向概率函数(即状态概率)可用于定义轨迹概率,即 的某些子集上的概率度量。 以下引理显示了如何构造此类因式分解的概率度量:
Lemma 5.
假设 是一个尖 DAG,并考虑与 一致的前向概率函数 和后向概率函数 。对于任意状态 ,我们用 表示 中从 开始到 结束的轨迹集;对于任意状态 ,我们用 表示 中从 开始到 结束的轨迹集。
考虑 和 在 上的扩展,定义如下:
| (1) | |||
| (2) |
我们有以下内容:
| (3) | |||
| (4) |
证明 为了方便起见,我们将使用来表示以开始并以结束的轨迹集合,以及 表示从 开始并以 结束的轨迹集。 这允许写:
此外,对于任何,我们用表示中的最大轨迹长度;对于任何,我们用表示中的最大轨迹长度。
基本案例: 如果和,则和。 Hence, given that is the only child of (otherwise cannot be ), and given that is the only parent of (otherwise cannot be ).
归纳步骤: 考虑 使得 和 使得 。 由于上面写的不相交联合,我们有:
我们在每行的第三个等式中使用了归纳假设。
2.2 轨迹和流程
我们使用称为流的函数来增强指向的DAG。 有助于描绘流动的类比是流经网络的粒子流,其中每个粒子从 开始,并流经某个以 终止的轨迹。 与每个完整轨迹关联的流包含共享相同路径的粒子数量。
Definition 6。
给定一个指向的 DAG,轨迹流 (或“flow”)是在完整轨迹集合上定义的任何非负函数。 在 代数 上引入 测量,即完整轨迹集 特别是,对于每个子集 ,我们有
| (5) |
对称为流网络。
此定义确保 是一个测度空间。 我们在这里滥用了符号,使用 来表示完整轨迹的函数及其对 的相应度量。 一种特殊情况是当事件是单例轨迹时,我们只需将其度量写为。 我们还滥用该符号来定义通过特定状态 或通过特定边缘 的流,如下所示。
Definition 7。
状态流 (或状态流) 对应于通过特定状态的完整轨迹集的度量:
| (6) |
类似地,流经边缘 (或边缘流) 对应于通过特定边缘的完整轨迹集的度量:
| (7) |
请注意,根据此定义,如果 不是指向的 DAG 中的边(自 起),我们就有 。 我们将终止转换的流程称为终止流程。 以下命题将状态流和边缘流联系起来:
Proposition 8。
给定一个流网络。 状态流和边缘流满足:
| (8) | |||
| (9) |
2.3 流引起的概率测量
Definition 9。
给定一个流网络, 总流量 是整个集合的度量,对应于所有完整轨迹的流量之和:
| (10) |
Proposition 10。
通过初始状态的流量等于通过最终状态的流量等于总流量。
我们使用字母 默认。 9,在概率模型和统计力学中常用来表示配分函数,因为它是一个归一化常数,可以将上面定义的测度空间转化为概率空间:
Definition 11。
给定流量网络 , 流量概率是与 相关联的可测空间 上的概率度量 :
| (13) |
对于两个事件,条件概率因此满足:
| (14) |
与流程 类似,我们滥用符号 来定义经历某种状态的概率:
| (15) |
对于穿过边缘的概率也类似。 请注意, 不对应于状态分布,即;特别是,很容易看出(换句话说,轨迹通过初始状态的概率为)。 此外,对于轨迹,我们还滥用符号而不是来表示经过特定轨迹
Definition 12。
由于流定义了状态和边上的概率,因此它们可用于定义图的终止状态(用 表示)上的概率分布,如下所示:
Definition 13。
给定流量网络 ,终止状态概率 是流量概率 下终止状态 的概率:
| (18) |
与经历状态 的概率 相反,终止状态概率 是终止状态
Proposition 14。
终止状态概率 是终止状态 上明确定义的分布,其中 对于所有 而言,并且
2.4马尔可夫流
定义流需要指定 非负值(每个轨迹 一个),该值通常与图边的数量成指数关系。 然而,马尔可夫流具有显着的特性,即可以用更少的“数字”来定义它们,因为轨迹流根据 进行因式分解。
Definition 15。
令为流网络,具有流概率度量。 被称为 马尔可夫流 (或等效于 马尔可夫流网络如果对于任何状态 、出边 ,以及任何从 开始到 结束的轨迹 :
| (19) |
请注意,马尔可夫属性并不适用于前面部分中定义的所有流(例如图 4)。 直观上,如果“流”中的粒子能够记住其过去的历史,则可以将流视为非马尔可夫;如果不是,它的未来行为只能取决于它当前的状态,并且流必须是马尔可夫的。 在这项工作中,我们将主要关注马尔可夫流,尽管稍后我们将通过状态条件流重新引入一种记忆形式,允许每个流“粒子”记住其历史的部分内容。 下面的命题表明,马尔可夫流具有完整轨迹处的流(或概率)根据图进行因式分解的性质,并且它是定义马尔可夫流的充分条件。
Proposition 16。
令为流网络,为相应的流概率。 以下三个语句是等效的:
-
1.
是马尔可夫流
-
2.
存在一个与一致的唯一概率函数,使得对于所有完整轨迹:
(20) 此外,概率函数正是与流概率相关的前向转移概率:。
-
3.
存在一个与一致的唯一概率函数,使得对于所有完整轨迹:
(21) 此外,概率函数正是与流概率相关的向后转移概率:。
证明 回想一下引理 5中的符号来表示部分轨迹的集合到,表示从到的部分轨迹集。 我们将证明 和 的等价性。
-
•
为了显示的唯一性,假设Eq. 20对于所有都满足完整的轨迹。 根据前向转移概率的定义:
任何经过状态 的完整轨迹 ,都可以(唯一地)分解为从 到 的部分轨迹 ,以及从 到 的部分轨迹 。 使用 的定义,我们有:
类似地,任何经过的完整轨迹都可以(唯一地)分解为从到的部分轨迹,并且从到的部分轨迹。 再次使用 的定义:
结合上面两个结果,我们得到:
-
•
:假设存在一个与一致的概率函数,使得对于某个完整的轨迹
出于与 证明中唯一性的相同原因, 必然等于与 相关的前向过渡概率 。
现在,我们想要通过显示 Eq. 19< 中的马尔可夫属性来表明与 关联的流 是马尔可夫的。 /t4>。 令为从到的任意部分轨迹;使用条件概率的定义:
遵循与上面相同的想法,我们现在将重写 ,作为共享相同前缀轨迹 的完整轨迹的总和。 任何这样的完整轨迹 都可以(唯一地)分解为这个共同前缀 和从 到 的部分轨迹 。
同样,任何共享相同前缀轨迹 的完整轨迹 ,都可以(唯一地)分解为这一共同前缀,以及从 到 的部分轨迹 ,从而得到:
结合上面两个结果,我们可以得出满足马尔可夫性质,因此流是马尔可夫的:
-
•
:假设是马尔可夫流。 我们在上面已经证明,这相当于将 分解为前向转移概率 的乘积。 对于一些完整的轨迹:
其中第三个等式使用 的事实,并使用向后转移概率 的定义。 的唯一性证明与中的的唯一性证明类似,并使用:
-
•
:与 的证明类似, 必然等于与 相关的后向过渡概率 。此外, 与前向过渡概率 相关:
因此,我们可以用 而不是 来编写 的分解。 对于一些完整的轨迹:
我们使用了 这个事实。 使用“”,我们可以得出是马尔可夫流的结论。
Corollary 17。
令为马尔可夫流网络,为相应的前向转移概率。 考虑从 开始的过程,并迭代地从 绘制一个样本,直到到达 。 那么过程终止于状态的概率为。
证明 首先,请注意,假设 是非循环的,则过程以概率 1 终止。
Proposition 18。
给定一个指向 DAG , 上的马尔可夫流是完全且唯一,由以下之一指定:
-
1.
所有边的总流量和前向转移概率的组合,
-
2.
所有边的总流量和向后转移概率的组合。
-
3.
所有终止边的终止流的组合和向后转移概率 对于所有非终止边缘 ,
证明 在前两个设置中,我们定义一个流函数,在轨迹处为:
-
1.
,
-
2.
我们需要证明它是唯一可以为这两种设置定义的马尔可夫流。 第三设置的证明将遵循第二设置的证明。
第一个设置:
然后,我们需要证明与 相关的前向转移概率函数 (Eq. 16) 匹配 ,并且流 是马尔可夫的。 为此,请注意,相应的流量概率满足Eq.20。 因此,由于 提案。 16,是马尔可夫流,其前向转移概率函数为。
作为最后一个要求,我们需要证明如果马尔可夫流具有划分函数和前向转移概率函数,那么它必然是等于。这是一个直接后果 提案。 16,对于任何 :
第二个设置:
首先,我们证明,由于 Lemma 5,与 相关的总流量 与 匹配:
最后,如果马尔可夫流具有划分函数和后向转移概率函数,则以下 提案。 16,。
第三个设置:
根据终止流和非终止边的向后转移概率,我们可以唯一地定义总流,并扩展 到所有边,如下所示:
这让我们回到第二个设置,我们已经证明,通过为所有边定义 和 ,马尔可夫流是唯一定义的。
2.5流匹配条件
在 提案。 18,我们看到了如何使用前向和后向概率函数来唯一定义马尔可夫流。 我们将在下一个命题中展示如何使用状态和边的非负函数来定义马尔可夫流。 此类函数不能不受约束(如 和 中 提案。 18 例如),正如我们所见 提案。 8.
Proposition 19。
令 为有尖 DAG。 考虑一个非负函数 ,将状态 或转换 作为输入。 那么对应于一个流当且仅当流匹配条件:
| (22) |
很满意。 更具体地说, 唯一定义了在状态和转换上与 匹配的马尔可夫流 :
| (23) |
证明 必要性是以下的直接结果 提案。 8. 让我们展示一下充分性。 令 为前向概率函数,定义如下:
与一致,因为满足流匹配条件(Eq. 22)。 让。 根据 提案。 18,存在一个唯一的马尔可夫流,具有前向转移概率函数和分区函数,并且对于轨迹 :
| (24) |
另外,类似于证明 提案。 16,我们可以为任何状态 编写:
其中定义了与一致的后向概率函数。因为 ,所以 也随之而来。
为了显示唯一性,让我们考虑一个在状态和边上匹配 的马尔可夫流 。 下列的 提案。 16,对于任何轨迹
请注意,如果给定 ,并且 给定,则如何使用 Eq. 22 递归地定义所有状态下的流给出了前向或后向转移概率。 无论哪种方式,我们都会从极端状态 或 之一的流开始,然后通过流网络的有向无环图递归地分配它,无论是前进还是前进落后。 一个特别令人感兴趣的设置是 Sec. 3 的中心,即我们获得所有终端流 ,我们想为流网络的其余部分推导出状态流函数和前向转移概率函数。
接下来,我们将了解如何使用与 DAG 一致的前向和后向概率函数来参数化马尔可夫流。 与中的条件不同 提案。 19,新条件不涉及转换之和,如果每个状态可以有大量后继者或者状态空间是连续的,这可能会出现问题。 有趣的是,结果条件类似于蒙特卡洛马尔可夫链的详细平衡条件。
Definition 20。
给定一个指向的 DAG ,一个前向转移概率函数 和一个与 一致的后向转移概率函数 , 和 是 兼容的 如果存在边流函数 使得
| (25) |
Proposition 21。
令 为有尖 DAG。 考虑状态上的非负函数 、前向转移概率函数 和与 一致的后向转移概率函数 。那么,当且仅当详细余额条件成立时,和共同对应一个流:
| (26) |
更具体地说,和唯一地定义了与状态上的匹配的马尔可夫流,并且转移概率与 和 。 此外,当满足该条件时,前向和后向转移概率函数和是兼容的。
证明 根据需要,考虑一个流,状态流函数表示为,以及向前和向后转换和。 从和的定义可以清楚看出(默认。 12),方程 26成立。 我们首先定义边流来证明条件的充分性
| (27) |
然后,我们将 Eq. 26 两边与 相加,得到
| (28) |
我们使用 是归一化概率分布这一事实。 将此与 Eq. 27 结合起来,我们得到
| (29) |
这是流匹配条件 (Eq. 22) 的第一个相等 提案。 19. 我们可以通过首先使用 的归一化,然后使用我们对边缘流的定义来获得第二个等式(Eq. 27 ):
| (30) |
下列的 提案。 19,存在一个唯一的马尔可夫流,其状态和边缘流由给出。 使用方程27和方程26 ,因此 具有所需的转移概率 和 。 唯一性也是 Eq. 27 的结果。 这就证明了充分性。
2.6 向后过渡可以自由选择
考虑给定要匹配的终止流的设置,即目标是找到具有正确终止流的流函数。 这是Bengio 等人 (2021) 中介绍的设置,将在Sec. 3中进行研究。 在这种情况下, 提案。 18 告诉我们,为了完全确定前向转移概率和状态或状态动作流,通常仅指定终止流是不够的;还需要指定除终端边缘之外的边缘上的后向转移概率(后者由终止流给出)。
这意味着终止流并不完全指定流,例如,因为许多不同的路径可以落在相同的终止状态。 对实现相同最终结果的不同方式的偏好由向后转移概率 指定( 除外,它是终止流和 的函数) t2>)。 例如,我们可能希望为节点 的所有父节点赋予相同的权重,或者我们可能更喜欢较短的路径,如果我们跟踪节点 的状态,则可以实现这一点到节点的最短路径的长度,或者我们可以让学习者发现一个,使学习或更轻松。
2.7 流之间的等价
在前面的章节中,我们已经看到马尔可夫流具有轨迹流或概率根据 DAG 进行分解的属性,并且我们已经看到了表征马尔可夫流的不同方法。 在Sec. 3中,我们展示了如何近似马尔可夫流以定义终止状态的概率度量。 在本节中,通过轨迹流之间的等价关系,我们证明对马尔可夫流的关注是合理的。 给定一个尖头 DAG ,我们表示为:
-
•
:上的流集,即来自的函数集,中的完整轨迹集,到,
-
•
: 中马尔可夫流的集合。
Definition 22。
令为一个指向的DAG,为两个轨迹流函数。 如果 和 在边流上重合,我们就说它们是等价的,即:
图 4显示了简单的指向 DAG 中两两等效的四个流函数。

| 2 | ||||
这定义了等价关系(即自反、对称和传递的关系)。 因此,每个流都属于一个等价类,并且流的集合可以被划分为等价类。 请注意,如果两个流相等,则相应的状态流函数也重合(作为 提案。 8)。
Proposition 23。
给定一个尖头 DAG 。如果两个流函数是等价的,那么它们是相等的。 此外,对于任何流函数,都存在唯一的马尔可夫流函数,使得和是等价的。
给定一个流函数,因为它的状态和边流函数满足流匹配条件(由于 提案。 8),然后根据 提案。 19,流 定义为:
是马尔可夫的,并且与状态流和边缘流上的 一致。 结合上面的陈述,我们得出结论:是与等价的唯一马尔可夫流。
前面的命题表明,在每个等价类中都有一个特定的流函数,它具有同一等价类中的其他流所没有的属性:它是马尔可夫的。
这样做的结果是,如果我们本质上关心状态和边缘流,而不是处理完整的流集 ,则足以将任何流学习问题限制为马尔可夫流集 。 此限制的优点是定义流需要为所有轨迹 指定 ,而定义马尔可夫流则需要为所有轨迹指定 边,一般比指数小(注意边流仍然需要满足流匹配条件 提案。 19)。 因此,为了逼近或学习在其边缘或状态值上满足某些条件的流函数,通过学习边缘流函数来逼近或学习马尔可夫流就足够了,边缘流函数是比实际流函数小得多的对象。
3 GFlowNets:学习流程
凭借Sec.1和Sec.2建立的理论物品知识t5>,我们现在考虑由 Bengio 等人 (2021) 提出的一般类问题,其中给出了对流量的一些约束或偏好。 我们的目标是利用相应的估计值 和 ,找到最符合这些要求的函数,如状态流函数 或过渡概率函数 ,这些函数可能与适当的流不一致。 这种学习机器被称为生成流网络(或简称 GFlowNet)。 我们重点关注给定目标奖励函数 的场景,并旨在估计满足以下条件的流量:
| (32) |
由于流集中存在等价性,因此在不失一般性的情况下,我们选择 GFlowNet 来仅近似马尔可夫流。 因此,我们对以下一组流程感兴趣:
| (33) |
目前,我们非正式地将GFlowNet定义为马尔可夫流函数的估计器。 我们稍后提供更正式的定义。
通过马尔可夫流的估计器,我们可以定义一个近似的前向转移概率函数,如下所示 提案。 16,为了绘制轨迹 ( 中的完整轨迹集),通过迭代采样给定前一个状态的每个状态,从 开始,然后用 直到我们达到某些 的接收器状态。
接下来,我们将阐明如何获得这样的估计量。
3.1 GFlowNets 作为 MCMC 采样的替代方案
从与能量函数 相关的分布中进行近似采样的主要已建立方法是蒙特卡罗马尔可夫链 (MCMC) 方法,该方法需要大量计算(运行可能非常长的马尔可夫链)来获取样本。 相反,GFlowNet 方法分摊前期计算来训练一个生成器,该生成器为每个新样本生成非常有效的计算(构建单个配置,不需要链)。 例如,Bengio 等人 (2021) 构建了一个 GFlowNet,它通过一小段动作序列构造一个分子,每个动作将一个原子或分子子结构添加到由图表示的现有分子中,从从一个空图表。 与 MCMC 方法相比,只需要考虑一种这样的配置,MCMC 方法可能需要很长的此类配置链,并且面临模式混合的挑战(Jasra 等人,2005;Bengio 等人,2013; Pompe 等人,2020),这可能会在模式之间的距离上花费指数级的时间。 在 GFlowNets 中,避免了这种计算挑战,但计算需求被转换为训练 GFlowNet 的计算需求。 要了解这如何非常有益,请考虑已经构建了一些配置并获得了它们的非标准化概率或奖励。 通过这些对 ,机器学习系统可能会在其他地方概括 的值,如果它是生成模型,则对新的 进行采样在大的地方。 因此,如果 的模式如何相互关联存在潜在的统计结构,则泛化的生成学习器可以利用其模式来猜测其尚未访问过的模式的存在。已经从它所看到的 对中发现了。 另一方面,如果没有结构(模式是随机放置的),那么我们不应该期望 GFlowNets 比 MCMC 做得好得多,因为训练在高维空间中变得棘手(因为它需要访问配置空间的每个区域)以确定其奖励)。
3.2 GFlowNet 和流匹配损失
我们已经在 Sec. 2.4 和 Sec. 2.5 参数化流程的不同方式。 例如,使用分区函数和前向转移概率,或者使用满足流匹配条件的边缘流。 因为参数化 GFlowNet 的方法有很多,所以我们从它们的摘要公式开始,其中 表示参数配置(例如,由 GFlowNet 训练或在 GFlowNet 训练时产生),给出轨迹 上相应的概率测度, 将马尔可夫流 映射到其参数化 。 在下面的定义中,我们展示了应该满足哪些条件才能使这种参数化有效。
Definition 24。
给定一个指向 DAG ,分别具有初始状态和接收状态 和 ,以及目标奖励函数 ,我们说则三元组是的流参数化,如果:
-
1.
是一个非空集合,
-
2.
是将每个对象映射到元素的函数,集合、 上的概率分布
-
3.
是从 到 、 的单射泛函
-
4.
对于任何,是与流相关的概率度量(默认。 11)。
对于每个对象,分布隐式定义了终止状态概率度量:
| (34) |
为了清楚起见,省略了 中对 的依赖。
引入 背后的直觉是,我们可以为每个对象 定义 上的概率度量,但其中只有一些对象对应于马尔可夫具有正确终止流的流。 对于此类对象(即对于某些流可以写为的对象),概率度量对应于利益分配,根据 默认。 13, IE。:
因此,GFlowNet 为从目标奖励函数 或其相关的能量函数 采样这一通常棘手的问题提供了解决方案:
| (35) |
直接逼近流 是一个难题,而对于某些集合 ,搜索对象 是一个更简单的问题,可以使用函数逼近技术来解决。
请注意,集合 不能是任意的,因为需要有一种方法来定义从 到 的单射函数。 下面,对于给定的 DAG ,我们展示了三个示例来阐明参数化的 Abstract 概念:
Example 1。
边流参数化: 考虑 ,从 到 的函数集,以及定义的泛函 和 :
在哪里
| (36) |
因此是 的有效流参数化。
Example 2。
前向转移概率参数化: 考虑集合 ,其中 是从 到 的函数集合, 是前向概率函数集 与 一致,并且泛函 和 定义如下:
其中 是与 相关的前向转移概率函数(Eq. 16)。 要验证 是单射的,请考虑 使得 。 这意味着、和、。 随之而来的是、。 其中,根据 提案。 23,表示。 对于任何马尔可夫流 , 等于与 相关的概率度量,如下所示 提案。 16.
因此是 的有效流参数化。
Example 3。
转移概率参数化: 如同 例如。 2,我们可以使用状态流函数及其前向和后向转移概率来参数化马尔可夫流,即 、 和 定义为:
其中是由Eq.17定义的函数。 是与一致的后向概率函数的集合。 的单射性是 的单射性的直接结果。 对于任何马尔可夫流,等于与相关的概率测度,如命题3所示。
因此是 的有效流参数化。
我们现在拥有正式定义 GFlowNet 的所有要素:
Definition 25。
GFlowNet 是一个元组 ,其中:
-
•
是一个指向的DAG,初始状态为,接收器状态为,
-
•
目标奖励函数,
-
•
的流参数化。
每个对象 称为 GFlowNet 配置。 当上下文清楚时,我们将使用术语 GFlowNet 来指代 和特定配置 ;类似于术语“神经网络”既指可以用特定架构表示的函数类别,也指该类别/权重配置的特定元素。
如果,则相应的终止状态概率度量(Eq. 34)与目标奖励。
一旦我们有了 GFlowNet ,我们仍然需要一种方法来查找对象 。 为此,只需在 上设计一个损失函数 ,该损失函数在对象 上等于 0,并且仅在这些对象上等于 0 。 如果我们的损失函数选择为非负数,则通过逼近函数的最小值来获得目标分布(在上)的近似值t2>。 这提供了将感兴趣的搜索问题转化为最小化问题的方法,就像我们在机器学习中通常所做的那样。 这种损失函数可以很容易地设计为我们考虑的自然参数化 例如。 1, 例如。 2, 和 例如。 3,正如我们将在下面说明的那样。
Definition 26。
令 为 GFlowNet。 流匹配损失是任何满足以下条件的函数:
| (37) |
我们说 是边缘可分解,如果存在一个函数 使得:
我们说是状态可分解,如果存在一个函数,使得:
如果存在这样的函数 ,我们就说 是轨迹可分解:
如上所述,有了这样的损失函数,我们的搜索问题可以写成以下形式的最小化问题
| (38) |
如果函数 可微分,则可以通过基于梯度的学习来解决这个问题。 请注意,对于边缘可分解的流匹配损失,Eq. 38 中的最小化问题等效于:
| (39) |
其中 是 上的任意全支持概率分布,即令 的概率分布。 对于状态可分解或轨迹可分解的流匹配损失可以做出类似的陈述。
Example 4。
考虑边缘流参数化,以及为每个和定义的函数:
其中 是超参数。 函数 将每个 映射到
| (40) |
是一个流匹配损失,即(根据定义)状态可分解。
这就是Bengio等人(2021)中提出的损失函数。 允许降低对小流量(小于 的流量)的重要性,并且使用对数比的平方作为确保状态的一种方式是合理的大流量对 梯度的贡献并不比小流量状态多得多。
Example 5。
Example 6。
通过随机梯度下降进行训练:
在上一节的示例中,给定一个 GFlowNet 和一个流匹配损失 ,对象 本身就是函数或函数组合,我们因此可以使用神经网络等函数逼近器对 进行参数化。 然而,大多数时候, 的评估(更不用说最小化)是很棘手的,因为即使有完整的支持分布,也只能访问边缘(或状态或轨迹)的子集。有限的时间。 在实践中,例如,对于边缘可分解损失,我们采用随机梯度,例如
| (42) |
对于边缘可分解损失,或
| (43) |
对于轨迹可分解损失,其中 称为 训练分布,是可以与 关联的边缘或轨迹上的分布,对应于强化学习中的在线设置,或者以其他方式定义,对应离线强化学习中的行为策略,参见下文Sec. 3.3.3。
3.3扩展
在本节中,我们讨论迄今为止介绍的 GFlowNet 训练范例的可能放宽。
3.3.1 引入时间戳以允许循环
请注意,GFlowNet 的状态空间可以轻松修改以适应其转换不形成 DAG 的底层状态空间,例如允许循环。 让 成为这样一个底层状态空间。 定义增广状态空间,其中是自然数集合,是增广状态,其中是状态 在轨迹中的位置。 通过这种增强的状态空间,我们可以自动避免循环。 此外,我们可以设计或训练向后转移概率,以创建朝向的较短路径的偏好,如Sec.中所讨论的2.6。 请注意,我们可以通过将 替换为任何全序索引集来进一步推广此设置;增强状态空间仍将具有关联的 DAG。 原始状态空间中的排序“”被提升到增强状态空间:当且仅当和.
3.3.2 随机奖励
我们还考虑给定奖励是随机的而不是状态的确定性函数的设置,产生基于随机梯度下降的训练程序。 例如,对于 Eq. 41 的轨迹平衡损失,如果 是随机的(即使给定 ),我们可以认为真正优化的是用替换其期望(给定)的平方损失。 这是最小化平方误差损失的期望值的直接结果(例如,在用平方误差损失和随机目标输出训练的神经网络中,神经网络有效地尝试估计该目标的期望值)。
3.3.3 GFlowNets可以离线训练
正如Sec.3.2中所讨论的,我们不需要使用来自其自身轨迹分布的样本来训练GFlowNet 。 这些训练轨迹可以在完全支持的情况下从任何训练分布 中得出,如 Bengio 等人 (2021) 所示。 这意味着 GFlowNet 可以离线训练,就像离线强化学习一样(Ernst 等人,2005;Riedmiller,2005;Lange 等人,2012)。
还应该注意的是,通过适当的自适应选择,并假设计算比在轨迹上运行GFlowNet更便宜或成本相当,它应该更高效不断地从 中抽取新的训练样本,而不是多次排练相同的轨迹。 一个例外是排练导致高回报的轨迹(如果这些轨迹很少见)。
应该如何选择训练分布? 它需要覆盖的支持,但如果统一的话会非常浪费,如果等于当前的GFlowNet策略可能没有足够的有效支持,因此错过的模式,即远大于0但的区域。 因此,训练分布应该从探索性策略中抽样,该策略访问尚未访问过的地方,并且可能会获得高回报。 当前政策的高度认知不确定性是有道理的,关于贝叶斯优化获取函数的文献(Srinivas等人,2010)可能是一个很好的指导。 更一般地说,这意味着训练分布应该是自适应的。 例如, 可能是第二个 GFlowNet 的策略,主要经过训练来匹配不同的奖励函数,当主 GFlowNet 观察到的损失很大时,该奖励函数会很高。 定期访问与已知大 相对应的轨迹(即根据 中的样本)也很好,以确保它们不会被遗忘,即使是暂时的。
3.4 利用数据作为已知终止状态
在某些应用程序中,我们可能可以访问对的数据集,并且我们希望以纯粹离线的方式使用它们来训练GFlowNet,或者我们可能希望将这些数据与奖励函数的查询结合起来 训练 GFlowNet。 例如,数据集可能包含一些高回报终止状态 的示例,这些示例很难通过从随机初始化的 GFlowNet 中采样来获得。 我们如何使用这样的 对来计算 GFlowNet 参数的梯度更新?
如果我们选择参数化向后转移概率(这对于实现详细的平衡损失是必要的),那么我们可以只采样导致的轨迹 > 使用 并使用这些轨迹来更新沿着遍历的转换的流和前向转换概率。 然而,仅此并不能保证产生正确的 GFlowNet 采样分布,因为上面定义的训练轨迹 的经验分布没有得到完全支持。 例如,假设数据集仅包含具有 的高奖励终止状态。 然后,GFlowNet 可以均匀地采样轨迹(这是错误的,我们希望不在训练集中的大多数状态的概率非常小)。 另一方面,如果我们将数据集中导致终端转换的轨迹分布与支持覆盖所有可能轨迹的训练分布相结合,那么 GFlowNet 的离线属性保证我们可以恢复流匹配模型。
4 条件流和自由能
流网络的一个显着特性是我们可以从初始状态流恢复归一化常数(提案。 10)。 还为我们提供了与指定终止流的给定终端奖励函数 关联的分配函数。
内部状态 和 怎么样? 如果我们有一个类似于从可实现的终止流的归一化常数,我们将能够获得给定状态的边缘化形式,即终止的条件概率状态 ,给定 。自然地,人们可能会问:通过状态 的流 是否只给我们带来了对下游终止流的边缘化? 不幸的是,一般来说,这个问题的答案是否,如图 5所示:在此示例中,而从可达到的终止流总和为(从可达到的终止状态为)。 造成这种差异的原因是,流经 的水流对终止水流 有贡献,但对 没有贡献,因为 和 之间不存在阶次关系。
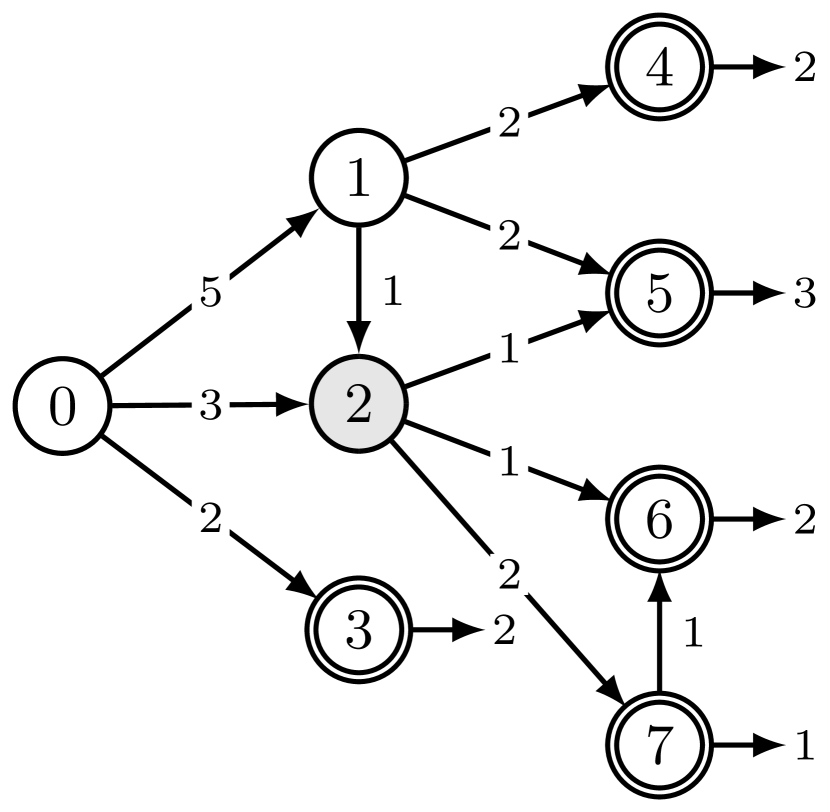
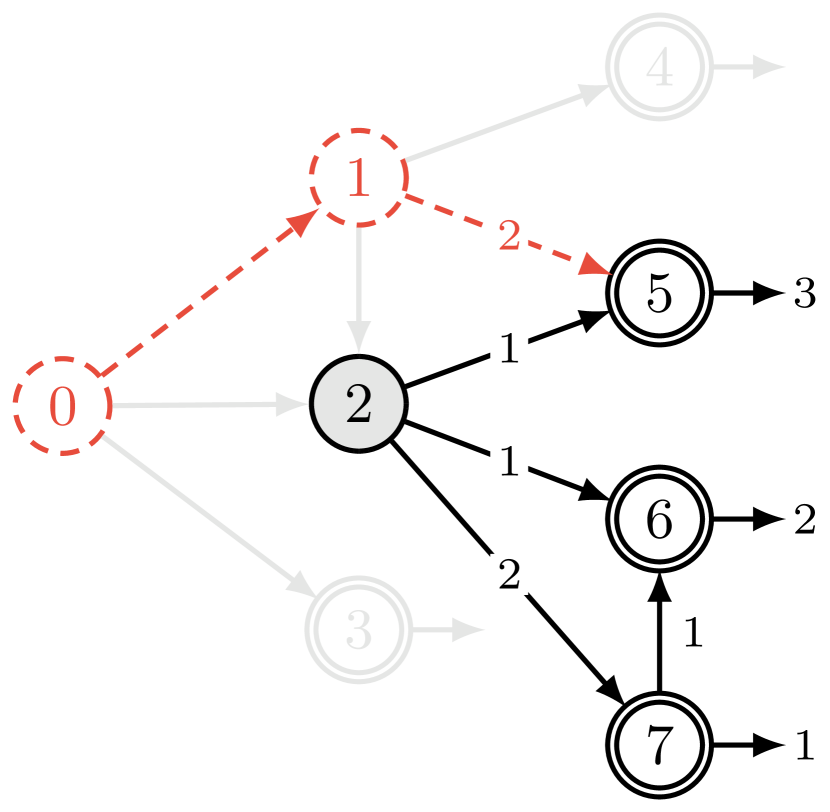
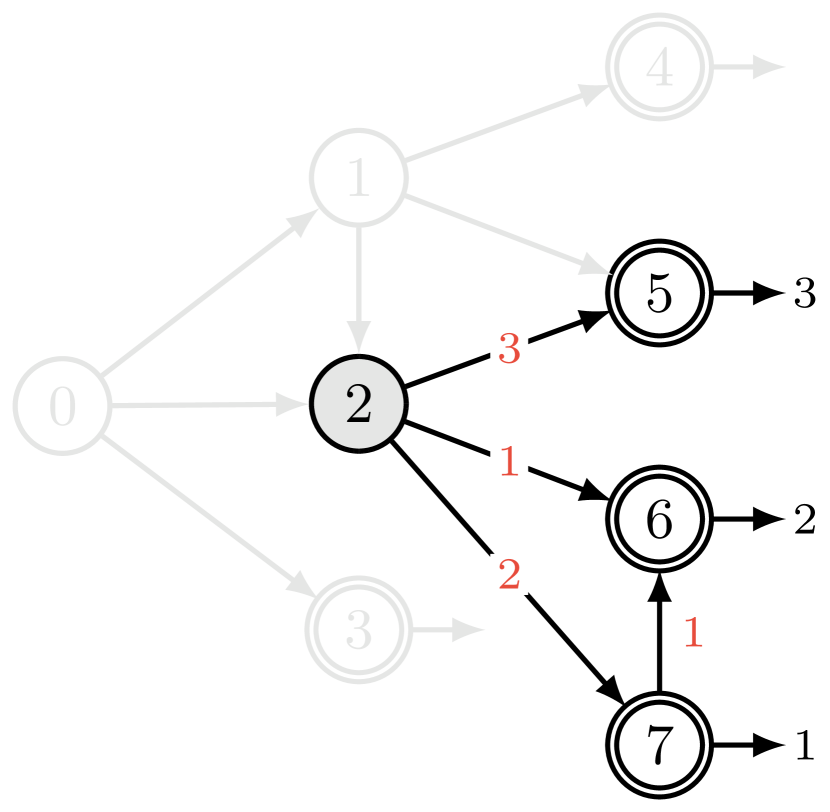
在 Sec. 5.3 中,我们展示了如何使用 GFlowNets 应用于随机变量的采样集来估计给定值的边际概率变量的子集。 它需要计算上面讨论的那种棘手的总和(针对与状态 的所有后代相关的奖励,其中 对应于这样的变量子集和状态的后代)所有变量的完整规范)。 这引发了以下定义:
Definition 27。
给定一个指向的 DAG ,相应的偏序由 表示,以及一个函数 ,称为 能量函数,我们定义自由能 状态 的 为:
| (44) |
自由能是与能量函数相关的边缘化运算(即对大量项求和)的通用公式,我们发现它们的估计为有趣的应用打开了大门,否则昂贵的 MCMC 方法通常是主要方法。
4.1 条件流网络
在Sec.2.2中,我们将流网络定义为DAG,并在一组函数上增强了一些函数完整的轨迹。 我们可以通过根据某些信息调节每个组件来扩展流网络的概念。 一般来说,这个条件变量可以表示任何条件信息,可以是流网络外部的(但影响终止流),也可以是内部的(例如,可以是另一个流网络上完整轨迹的属性,就像经过一个特定的状态)。
Definition 28。
令 为一组条件变量。 我们考虑由 索引的 DAG 系列,以及分别由 和 表示的初始状态和最终状态系列。 对于每个 DAG ,我们用 表示 中的完整轨迹集,并用 表示它们的并集:
条件流网络是(家族)的规范,以及条件流函数,即函数 使得 如果 。 为了清楚起见,对于每个 ,我们将用 表示将每个 映射到 的函数。 与 Sec. 2.2 类似, 引入 代数 对于每个 。
4.2 奖励条件流网络
Definition 29。
令 为一组条件变量。 考虑由指向 DAG 和流函数 给出的流网络。考虑 的非负函数族 :。 与族兼容的奖励条件流网络是一个条件流网络(默认。 28),对于每个 都有 ,这样由条件流函数 导出的边流函数满足:
我们将互换使用符号 和 。
请注意,上述定义意味着奖励条件流网络的所有 DAG 都是相同的,只有家庭成员之间的终止流不同。
4.3 状态条件流网络
Definition 30。
考虑由 DAG 和流函数 给出的流网络。对于每个状态 ,令 为包含所有状态 的 的子图,使得 。 状态条件流网络由族给出,以及条件流函数,其中,并且 中的完整轨迹集,满足:
| (45) |
请注意,在上面的定义中,我们滥用了符号 来指代流函数和边流函数,但也使用 来指代条件流函数(或相应的边缘流函数)。 与Sec. 4.2中定义的奖励条件流网络不同,状态条件流网络中的DAG结构取决于锚点状态。特别是,这意味着对于任何状态 ,初始状态 会发生变化,但最终状态 保持不变。
由于状态条件流网络的定义取决于原始流网络,因此我们必须确保这个定义确实正确,即满足Eq.<中条件的状态条件流网络/t1> 45 存在。
Proposition 31。
对于由 DAG 和流 F 给出的任何流网络,我们可以定义一个状态条件流网络 默认。 30.
证明 令为状态。 由于DAG的结构已经明确定义,我们只需证明存在满足方程的流函数即可。 > 45。 如果每个 都存在这样的函数,那么将条件流函数 定义为:
令为中终止于的完整轨迹集合; Eq. 45 中的条件如下:
| (46) |
请注意,在 Eq. 46 中, 是给定数量,因为流量 为已知。 由于轨迹集形成了所有完整轨迹的划分,Eq. 46 是一个线性方程组,所有 的未知数均为 ,其中每个方程都涉及单独的未知数集。 因此该系统至少存在一个解。
我们可以通过以下方式构建这样的解决方案。 对于某些,我们可以首先选择包含的完整轨迹:
DAG 和子图 之间的主要区别在于 可能包含终止于某些 的轨迹,但不包含这些轨迹。通过,因此这些不被的轨迹覆盖。 令 为 的完整轨迹集,定义为
当我们看到 提案。 10 由于初始流 等于配分函数,初始状态条件流也受益于边缘化特性,并且现在与 处的自由能相关。
Proposition 32。
请注意,状态条件流网络的定义与我们在 2.1 节中对(无条件)流网络的原始定义一致,即原始流网络是锚定在初始状态的有效状态条件流网络。
状态条件流网络允许我们评估的另一个有趣的量是,如果所有终止边缘流都转向较早的状态 ,则在状态 中终止轨迹的概率:
Corollary 33。
考虑由 DAG 和流 给出的流网络,从中我们定义任何状态条件流网络,如下所示 默认。 30. 给定状态 ,流函数 会产生 上的概率分布,我们用 表示。
在此测量下,在状态 下终止轨迹于 的概率(即轨迹的最后一条边为 )为:
| (47) |
其中 是将 的父级每个状态 映射到 的能量函数,以及 是相应的自由能函数。
4.4 条件 GFlowNet
与我们使用 GFlowNet 来估计流网络的流量的方式类似,我们也可以使用(条件)GFlowNet 来估计条件流网络,并给定目标奖励函数。 条件 GFlowNet 遵循第 3 节中提出的结构,但现在要学习的所有量都取决于条件变量 (例如, 是神经网络的附加输入)网络)。
Sec. 3.2 中提出的所有参数化和损失原则上都可以用于条件 GFlowNet,无论条件设置如何。 下面我们讨论另一个损失,该损失首次在 Deleu 等人 (2022) 中提出,可用于训练 GFlowNet 和条件 GFlowNet。
4.5 使用 GFlowNet 训练基于能量的模型
可以训练 GFlowNet 将能量函数转换为近似对应的采样器。 因此,它可以用作 MCMC 采样的替代方案(秒 3.1)。 考虑与给定参数化能量函数 关联的模型 ,参数为 :。 从 进行的采样可以通过从使用目标终端奖励 训练的 GFlowNet 的终止概率分布 中进行采样来近似(参见 Eq . 34)。 实际上, 将是真实 的估计器,因为 GFlowNet 训练目标未归零(容量不足或训练时间有限)。 然后,根据 绘制的 GFlowNet 样本可用于获得观察数据 相对于参数 的负对数似然的随机梯度估计器能量函数:
| (48) |
因此,第二项的近似随机估计量可以通过对一个或多个终止状态(即从经过训练的 GFlowNet 的采样器)进行采样来获得。 此外,如果 GFlowNet 的损失为 ,即 ,则梯度估计器将是无偏的。
因此,人们可以通过使用上述方程交替更新 来联合训练能量函数 和相应的 GFlowNet(用来自 的采样替换为来自 的采样) )并使用更新后的能量函数更新 GFlowNet 以获得目标终端奖励。
如果我们通过构造来修复 (如果奖励函数是确定性的,我们就可以这样做),那么我们可以使用计算流量的相同神经网络来参数化能量函数,因为 。 因此能量函数和 GFlowNet 使用相同的参数,这是很有吸引力的。
上述联合学习能量函数以及如何从中采样的策略可以推广到通过使用条件 GFlowNet 来学习条件分布。 假设 是观测随机变量, 是隐藏变量,GFlowNet 会在两个子轨迹中生成一对 :或者先生成 ,然后在给定 的情况下生成 ;或者先生成 ,然后在给定 的情况下生成 。这可以通过在状态中引入一个 6 值分量 来实现,以确保在退出到 之前生成 和 ,其值和约束条件如下:
| (49) | ||||
| (50) | ||||
| (51) |
其中, 表示正在生成 (先于 ), 表示正在生成 (先于 ), 表示正在生成 (以 为条件), 表示正在生成 (给定 )。 在生成 和 之前,GFlowNet 无法达到最终状态 。 因此,条件 GFlowNet 可以近似采样 、、、 以及 。 如果我们只想采样 (或仅 ),我们允许在生成后立即退出(resp. 已生成)。 有关如何表示、估计和采样边际分布的更一般性讨论,请参阅Sec. 5.3。
让我们用 表示与能量函数相关的 上的联合分布,即 。 当观察到 但未观察到 时,可以通过近似边际对数似然梯度来更新
| (52) |
使用训练有素的 GFlowNet 的估计终端采样概率 中的样本以随机梯度方式近似上述总和(使用一个或一批样本)。
请注意,我们现在如何根据实际数据进行外循环更新(能量函数,即奖励函数),以及使用能量函数作为 GFlowNet 驱动目标的内循环更新(GFlowNet)。 这种方案需要多少内循环更新才能工作是一个有趣的开放问题,但很可能取决于底层数据生成分布的形式。 如果 GAN 的工作(Goodfellow 等人,2014) 是一个很好的类比,那么一个好的策略可能是基于以下条件交错更新能量函数(减去 GFlowNet 的对数终端流)一批数据,以及基于这些样本(可以使用 从终止状态 向后采样轨迹)和来自调和的前向样本的 GFlowNet 作为采样器的更新训练策略由GFlowNet的前向转移概率定义。
4.6 使用 GFlowNet 进行主动学习
上述方案的一个有趣的变体是 GFlowNet 采样器不仅用于生成能量函数的反例,还用于主动探索环境。 Jain 等人 (2022) 使用主动学习方案,其中 GFlowNet 用于对候选 进行采样,我们预计奖励 通常会很大(因为 GFlowNet 的采样大约与 成比例)。 挑战在于,评估任何 的真实奖励 的计算成本很高,并且可能存在噪音(例如,测量药物与给定物质的结合能的生物测定)目标蛋白)。 因此,作者没有直接使用真实奖励,而是引入了一个代理(近似真实奖励函数),用于GFlowNet。 这将导致类似于 Sec. 4.5 的设置,其中有一个内部循环,其中 GFlowNet 经过训练以匹配代理 ,以及一个外循环,其中使用 对以监督方式学习代理 ,其中 是由 GFlowNet 提出的,并且 是来自环境的相应true 奖励(例如,生物或化学测定的结果)。 这里值得注意的是,GFlowNet 和代理是错综复杂的链接的,因为代理 在 域上的覆盖范围依赖于来自 GFlowNet 的不同候选者。 同样,由于 GFlowNet 匹配由代理奖励函数 定义的奖励分布,因此它也取决于真实奖励函数 的质量。
通过合并有关给定候选者的新颖性的信息,或者的预测中有多少认知不确定性的信息,可以进一步扩展此设置>。 我们可以使用贝叶斯优化 (Močkus,1975 年;Srinivas 等人,2010 年) 中的获取函数启发式(如置信度上限 (UCB) 或预期改进 (EI)),将配置 的预测有用性 与该预测的认识不确定性估计值结合起来。 使用此作为奖励可以让 GFlowNet 探索预测有用性高( 大)的区域,同时探索需要收集更多有关 。 通过适当的获取函数, 预测的不确定性可以为 GFlowNet 的探索行为提供更多控制。
正如 Bengio 等人 (2021) 在将 GFlowNet 与回报最大化强化学习方法进行比较时所讨论的那样,经过充分训练的 GFlowNet 的一个有趣特性是,它们将从奖励函数的所有模式中进行采样,即在需要探索的环境中尤其理想,例如主动学习。 论文中的实验还通过实验证明了 GFlowNet 与 PPO 相比所采样的解决方案的多样性方面的优势,PPO 是一种先前用于生成分子图且倾向于关注单一奖励模式的 RL 方法功能。
4.7 估计熵、条件熵和互信息
Definition 34。
给定奖励函数 和 ,我们定义 熵奖励函数 与 关联为:
| (53) |
简而言之,在本节中,我们展示了可以通过训练两个 GFlowNet 来估计熵:一个像往常一样估计目标终端奖励函数 的流量,另一个估计相应熵奖励函数的流量。 我们在下面展示了通过查找初始状态下的流来获得熵的估计量,如果我们使用条件流进行此练习,我们会得到条件熵。 一旦我们有了条件熵,我们就可以估计互信息。
Proposition 35。
Proposition 36。
Given a set of conditioning variables, consider a conditional flow network defined by a conditional flow function , for which the terminating flows match a target reward family (conditioned on ) that satisfies for all , and a second conditional flow network defined by a conditional flow function , for which the terminating flows match the entropic reward functions (Eq. 53), then the conditional entropy of random terminating states consistent with condition is given by
| (55) |
特别是,对于状态条件 GFlowNet( 是 DAG 的状态空间),我们得到
| (56) |
更一般地,根据的终止状态的随机抽取与条件随机变量之间的互信息MI是
| (57) |
其中 和 表示无条件流(在没有给定条件 的情况下进行训练),而 和 是他们的条件对应物。
如果我们有 的抽样机制,那么我们就可以通过从 中抽取的蒙特卡洛平均值来近似 Eq. 57 中的期望值。
5 集合、图上的 GFlowNet 以及边缘化联合分布
5.1 设置 GFlowNet
我们首先定义一个用于构造集合的动作空间,并将 GFlowNet 视为生成随机集合 并估计实现该随机变量的概率、条件概率或边际概率等数量的方法。 这些集合的元素取自更大的“宇宙”集合。
Definition 37。
给定一个“宇宙”集合 ,考虑指向的 DAG ,其中 是 的所有子集的集合,其中附加状态,是空集,对于的任意两个子集, ;这意味着 DAG 中的每次转换都对应于将 的一个元素添加到当前子集中。 此外,所有子集都连接到 ,即 。 集合流网络是该图上的流网络,集合GFlowNet是这种流网络的估计器,如秒 3。 目标终端奖励函数满足:
| (58) |
集合流网络定义了状态的终止概率分布(参见 默认。 13 和 Eq. 44),其中
| (59) |
其中代表能量。 相似地, Cor. 33 为我们提供了 下给定集合 的给定超集 的条件概率公式,
| (60) |
其中 表示自由能(参见 默认。 27)。
请记住,对于具有状态和边缘流估计器的GFlowNet,不能保证所有状态的,因此我们可以估计概率
| (61) |
或者替代地
| (62) |
类似地,我们可以使用 Eq. 60 或使用
| (63) |
其中没有一个能够保证总和恰好为 1。
我们还可以计算给定集合 的所有超集的边际概率,如下所示。
Proposition 38。
总而言之,经过训练以匹配集合上给定能量函数(即派生奖励)的 GFlowNet 可用于表示该分布,从中采样,估计其下集合的概率,估计分配函数,搜索最低能量集,对给定集的超集上的条件分布进行采样,估计给定的一组和超集的条件分布,计算子集的边际概率(即对超集的概率求和),并计算集合分布或集合超集条件分布的熵。 例如,使用 GFlowNet 对集合上的分布进行建模已在 Malik 等人 (2023) 中成功使用,其目标是迭代选择一批信息丰富的点以实现高效的主动学习。 作者还表明,由基于相互信息的奖励定义的集合上的分布(Sec. 4.7)可以使用以下方法近似于满足水平:作为 GFlowNet 策略的函数逼近器的神经网络。
5.2 图上的 GFlowNet
图是一种特殊的集合,其中有两种元素:节点和边,边是节点索引对。 图还可以具有附加到节点和/或边的内容。 因此,上一节中描述的设置操作可以相应地专门化。 某些操作(即 GFlowNet DAG 中的边)可以插入节点,而其他操作可以插入边。 允许的操作集可以受到限制,例如确保图形具有单个连接的组件,或者确保非循环性。 就像一般的集合一样,不能有一个动作来添加集合中已有的节点或边。 Deleu 等人 (2022) 使用 DAG 上的 GFlowNet 来学习贝叶斯网络图形结构上后验分布的近似值。 虽然 GFlowNet 是通过最小化源自流匹配条件的一些损失来学习的,如Sec.3.2,但他们表明,所得的分布是目标后验的精确近似。 由于图是集合,因此集合上的所有 GFlowNet 操作都可以应用于图。
5.3 边缘化缺失变量
GFlowNet 捕获集合上的概率分布的能力可应用于对随机变量的联合分布进行建模、计算给定变量值子集的边际概率,以及对任何条件(例如,对于变量子集)进行采样或计算概率给定变量的另一个子集)。
令 为复合随机变量,具有 元素随机变量 、,每个随机变量都有可能的值 (不一定是数字)。 如果我们给定一个能量函数或终端奖励函数来对任何实例进行评分,我们可以训练一种特定类型的集合GFlowNet,其中集合元素是对,对于所有,集合中最多有一个索引为的元素。 唯一允许的终止转换是当集合具有精确大小 且每个大小 集合 在下一个转换时终止时。
请注意,如果 允许该顺序,GFlowNet 如何以任何可能的顺序对 进行采样。 给定一组现有的 对(由状态 表示),我们可以估计该变量子集的边际概率(隐式地对所有缺失的变量求和,请参阅 方程 64)。 我们可以通过将状态设置为 并继续从 GFlowNet 的策略(学习到的前向转移概率函数)中采样来对其他变量进行采样。 我们可以通过限制该策略仅添加 中的元素来从其他变量的选定子集 中进行采样。 此外,我们还可以在集合 GFlowNet 上做所有其他可行的事情,例如估计配分函数、按照具有最大边际概率的早期子序列的顺序进行采样、搜索最可能的变量配置或估计分布的熵。
5.4模能量函数分解
让我们看看如何将图 GFlowNet 框架应用于一种特殊的图:具有可重用因子的因子图 (Kschischang 等人, 2001)。 这将在图 上产生分布 ,每个图都与能量函数值 相关联(以及相关奖励 )。 基于能量的模型很方便,因为它们可以将联合概率分解为独立的部分(可能对应于独立机制,Schölkopf 等人,2012;Goyal 等人,2019;Goyal 和 Bengio,2020),每个部分对应于因子图的因子。 在我们的例子中,我们希望一组共享的因子可以在许多因子图之间重用。因子图将提供一组随机变量的能量和概率。 将图 写为一组 ,其中 是具有能量函数项 的因子的索引,从可能因素池中选择,其中是随机变量的实现列表,其中是因子图的一个节点。 该列表定义了连接变量 与 的第 参数的因子图的边。 让我们表示 应用于这些值 的能量函数项 的值,即
| (65) |
这样一个图的总能量函数可以分解如下
| (66) |
这种构造的有趣之处在于,图 GFlowNet 现在可以对图 进行采样,可能给出一些条件观察 :请参阅秒 4.5 关于如何与能量函数联合训练 GFlowNet,包括仅观察到一些随机变量的情况。 因此,给定一些观测变量(不一定总是相同),图 GFlowNet 可以采样一个包含并连接(用能量函数项)观测变量和潜在随机变量的潜在因子图,其结构定义了联合观察变量和潜在变量。
我们不仅可以利用 GFlowNet 生成的对象的组合性质将总能量分解为与理想独立机制相对应的可重用能量项,而且我们还可以将 GFlowNet 本身分解为与每个机制相关的模块。 该图GFlowNet的动作空间相当复杂,每个动作对应于添加一个潜在变量或添加一个图块。 这样的操作是在 GFlowNet 状态的上下文中执行的,GFlowNet 是部分构建的图(由之前的操作产生)。 GFlowNet 及其相关的能量函数参数因此被分解为模块。 每个模块都知道如何计算能量函数 以及如何对新图块进行竞争性评分和采样(与其他模块相比)(以在图中插入相应的因子)。
考虑一些观察到的变量( 的子集及其值 ),统称为 。 考虑与 兼容的图 (即,一些节点对应于观察变量的 )并表示 尚未提供 部分的规范。 我们可以将潜在变量 视为对观察到的 的解释。 请注意如何边缘化所有可能的 ,我们可以计算 的自由能。 Sec. 4.5的原理可以应用于训练这样一个基于能量的GFlowNet。 在能量函数中表示先验图结构也是有意义的。 例如,我们可能更喜欢稀疏因子(很少有参数),并且我们可能会引入与计算机编程和自然语言中常用的类型概念有关的软或硬约束。 图中的每个随机变量都可以将类型作为其属性之一,并且每个因子能量函数参数都可以期望一个类型。 可以添加能量函数项来通过支持图块 来构造此先验,其中变量 的类型(其中 是其实现)与 的第 参数的预期类型。 这与注意力机制(Bahdanau 等人, 2014; Vaswani 等人, 2017) 非常相似,可以看出它将查询(预期类型)与键(与元素)。 例如,Pan 等人 (2023) 提出了利用能量函数模块化的前瞻性 GFlowNet 框架,如 Eq. 66 并获得比常规损失更好的目标分布近似值。
6 连续或混合操作和状态
上述所有数学发展都使用了状态或动作的总和,其思想是这些将是离散空间的元素。 然而,在大多数情况下,如果状态或动作是连续的或混合的(具有一些离散分量和一些连续分量),则可以用积分来代替这些总和。 除此之外,我们在下面讨论连续值动作和状态的存在对 GFlowNet 框架的变化。
虽然 Eq. 40 中分别对后继者和前驱者分别进行了明确的总和,但这些总和也隐藏在详细的平衡约束中等式 26。 事实上,这些总和作为 和 中下一个状态或前一个状态的条件密度中的归一化常数的一部分是隐式的。 我们考虑以下想法来应对这一挑战。
6.1 可积归一化常数
我们首先注意到,如果我们可以处理连续状态,我们也可以处理混合状态,如下所示。 让状态分解为
| (67) |
其中 是离散的, 是连续的。 然后我们可以将任何转移条件分解如下:
| (68) |
我们注意到,这在形式上相当于将转换分解为两个转换,首先执行到下一个状态的离散选择,第二个执行到下一个状态的连续选择(给定离散选择)。 向神经网络输入连续值是没有问题的。 挑战在于在输出上表示连续密度,需要能够计算特定值(例如 )的密度并能够从中进行采样。 计算分类概率并从条件分类中采样是标准费用,因此我们只讨论连续条件。 一种可能性是用密度参数化,其归一化常数是已知的易处理积分,例如高斯。 然而,这可能会过多地限制容量,并且可能会妨碍详细平衡或流量匹配损失的良好最小化。 一种解决方法是使用与“簇 ID”相对应的额外维度来增强状态 的离散部分,即将连续密度划分为混合物。 我们知道,只要有足够的混合物成分,我们就可以任意地近似一个非常大的族的密度。 其他方法包括使用自回归或归一化流模型(Rezende 和 Mohamed,2015,具有不同含义的“流”)对条件密度进行建模,或者像去噪扩散模型(Sohl -Dickstein等人, 2015),将的采样分解为多个重采样步骤,将其分布从简单的分布转变为复杂的分布。
为了保证详细的平衡约束能够完全满足,我们可以进一步考虑对边缘流进行参数化,并注意,如果我们使用基于节点的流匹配损失,这是自然的参数化。 例如,与高斯示例一致,对于由 索引的每个可行离散分量,我们现在在向量 中具有联合高斯能量。 请注意,在 GFlowNet 的实际应用中,GFlowNet 底层 DAG 中通常并不允许所有满足顺序关系的转换。 例如,对于集合 GFlowNets,唯一允许的操作是向集合中添加一个元素(而不是任意数量的元素)。 这些对动作空间的约束意味着合法 对的数量是可管理的并且对应于离散动作的数量。 因此,整体动作被视为具有离散部分(给定 选择 )和连续部分(给定 选择 ) 、 和 )。 通过这种联合流公式,可以准确计算前向和后向条件密度并且彼此兼容。
6.2 GFlowNets 中的 GFlowNets
实现涉及连续变量的边缘流的另一种方法是使用较低级别的GFlowNet、能量函数对来表示其流、条件概率和它们的样本。 请记住,可以按照Sec.4.5中讨论的方法来训练这样的对。 给定 时,我们可以使用较小规模的 GFlowNet 和能量函数(表示外部 GFlowNet 中的边缘流)来处理整个系列的转换,而不是使用 的联合高斯函数。更大规模的外部 GFlowNet 中的特定类型。 想象一下,对于这样的转变,我们有一个相当任意的能量函数,以及我们将要学习的参数。 然后我们还可以训练 GFlowNet 在任一方向(从 到 或从 到 )进行采样,并评估相应的归一化常数(以及相应的条件概率)。 状态及其转换的离散方面可能对应于一系列转换(例如,在图 GFlowNet 中插入特定类型的节点),以及单独的 GFlowNet、能量函数 模块可以经过专门化和训练来处理此类转换。
在本文审稿期间,Lahlou 等人 (2023) 将 GFlowNets 的理论扩展到更一般的状态空间,包括连续状态空间,并通过实验验证了通常的损失可以用于有效地进行推理连续域。
7相关工作
有几类相关文献涉及在给定一些能量或奖励信号的情况下生成多样性样本的问题,特别是:
-
•
生成模型(特别是深度学习模型),
-
•
强化学习方法通过某种形式的探索行为或平滑先验来最大化奖励,
-
•
原则上解决从采样问题的MCMC方法,
-
•
进化方法,可以通过对一组解决方案进行迭代来利用群体多样性。
接下来,我们将讨论这些内容,并深入探讨 GFlowNet 与这些方法之间的异同。 请注意,与此问题相关的文献比我们在这里可以引用的文献要多得多,并且扩展到 ML 的许多其他子领域,例如 GAN (Kumar 等人, 2019)、VAE (Kingma和 Welling,2013;Kusner 等人,2017),以及标准化流量(Dinh 等人,2014,2016;Rezende 和 Mohamed,2015)。 另一种相关的方法是贝叶斯优化方法(Močkus,1975;Srinivas 等人,2010),该方法也已用于分子空间搜索(Griffiths 和 Hernández-洛巴托,2017)。 与贝叶斯优化方法的主要关系在于,GFlowNet 是生成性的,因此可以补充扫描易于处理的候选列表的贝叶斯优化方法。 当搜索空间太大而无法单独计算每个候选者的贝叶斯优化获取函数分数时,使用生成模型很有吸引力。 此外,GFlowNet 用于探索分布模式,而不是搜索单一最主要的模式。 这种差异与经典强化学习方法的差异类似,下面将进一步讨论。
7.1 与生成模型对比
GFlowNet 与已建立的深度生成模型(如 VAE 或 GAN)之间的主要区别在于,后者是通过提供从感兴趣的分布中采样的有限示例集来进行训练的,而 GFlowNet 通常是通过提供能量函数或奖励来进行训练的功能。
这个奖励函数不仅告诉我们在兴趣分布下可能出现的样本(我们可以将其视为正例),而且还告诉我们不太可能的样本(我们可以将其视为负例)以及在兴趣分布下的样本。 - Between(其奖励不大但也不为零)。 如果我们用这些术语来考虑最大似然训练目标,它就像一个奖励函数,为每个示例提供高奖励(视为正例,其中概率应该很高),而在其他地方提供零奖励。 然而,其他奖励函数也是可能的,如 GFlowNets 在发现新分子中的应用(Bengio 等人,2021) 所示,其中奖励不是二元的,而是作为候选分子的所需性质的值。
但请注意,当我们将能量函数的学习与 GFlowNet 采样器的学习结合起来时,与其他生成建模方法的区别就变得模糊了,如 Sec. 4.5 中所述。 t2>。 在这种情况下,由可训练的 GFlowNet 采样器和可训练的能量函数组成的对实现了与可训练的生成模型类似的目标。 请注意,GFlowNet 旨在为潜在变量和观测变量生成离散可变大小的组合结构(如集合或图),而 GAN、VAE 或归一化流则从对实值固定大小向量建模的角度出发使用实值固定大小的潜在变量。
GFlowNet 和大多数生成模型训练框架(通常是最大似然的一些变化)之间的一个有趣的区别在于 GFlowNet 的训练目标的本质,它是在主动学习场景的背景下产生的。 而 GFlowNet 训练对 可以来自 上的任何分布(任何完全支持训练策略 ),它不必是固定的(并且实际上通常不会,在主动学习环境中),最大似然框架对其所看到的数据分布的变化非常敏感。 这与流匹配目标的“离线学习”属性相关(Sec.3.3.3等)。
7.2 与正则化强化学习对比
GFlowNets 训练(Bengio 等人,2021) 的流量匹配损失源自与 Bellman 相关的时间差异(Sutton 和 Barto,2018) 目标的启发方程。 流匹配方程类似于贝尔曼方程,因为训练目标是局部的(在时间和状态上),信用分配通过引导过程传播并尝试修复参数化,以便满足这些方程,知道如果它们(无处不在),我们将获得所需的属性。 然而,这些所需的属性是不同的,如下一段所述。 GFlowNet 的开发环境也不同于在某些环境中思考代理学习的典型方式:我们可以将 GFlowNet 的确定性环境视为涉及需要执行某种推理的认知代理通常所需的内部操作通过一系列步骤(在给定其他事物的情况下预测或采样某些事物),即通过代理内部的操作并控制其计算。 这与强化学习的起源形成鲜明对比,强化学习专注于智能体在外部和未知随机环境中的行为。 GFlowNets 被引入作为学习内部策略的工具,类似于现代深度学习中注意力的使用,我们知道动作的效果,并且这些动作的组合定义了该代理的推理机制。
经典强化学习(Sutton 和 Barto,2018) 控制方法通过最大化马尔可夫决策过程 (MDP) 中的回报来发挥作用;他们的重点是找到最大化预期回报的政策,这恰好可以通过确定性政策来实现(Sutton和Barto ,2018),即使在随机 MDP 中也是如此。 在确定性 MDP 中,我们感兴趣的是,这意味着训练 RL 代理是寻找最有回报的轨迹,或者在仅终端奖励 MDP 的情况下(这里再次令人感兴趣),是最有回报的终止状态。
另一种观点是从概率推理文献(Toussaint and Storkey,2006)和强盗文献(Auer等人,2002)中出现的,它涉及寻找策略形式为。 事实证明,在控制设置中最大化策略的回报和熵熵(Ziebart等人,2008)会产生这样的策略:
| (69) |
其中和可以看作是温度参数。 这个结果也可以在控制即推理框架(Haarnoja等人,2017;Levine,2018)下找到。 在具有最终奖励且没有未来奖励折扣的确定性 MDP 中,这简化为 ,其中 是回报。
在最近的文献中,这种熵最大化(MaxEnt)通常被解释为正则化方案(Nachum等人,2017),熵被用作内在奖励信号或作为要最大化的显式正则化目标。 理解这个方案的另一种方法是想象我们自己处于一个对抗性强盗环境中(Auer等人,2002),其中每个手臂对应一个独特的轨迹,以概率绘制。
MaxEnt RL 和 GFlowNet 之间的一个重要区别是,在一般情况下它们不会找到相同的结果。 GFlowNet 学习的策略为 ,而 MaxEnt RL(具有适当选择的温度和 )学习的策略为 ,其中 是通向 的所有轨迹的 DAG 中的路径数(Bengio 等人,2021 中提供了证明)。 仅当 DAG 减去 是一棵以 为根的树时,才存在等价性,这已被发现是有用的 (Buesing 等人,2019)。 这种按因子 过度加权的实际含义是,与较长序列(通常具有指数级更多路径)对应的状态将比对应的状态更频繁地采样(通常指数级更频繁)。到较短的序列。 显然,这打破了按照奖励比例对终止状态进行采样的目标,并为考虑 GFlowNets 提供了强有力的动机。
关于最大化强化学习中的熵的另一种观点是,我们还可以最大化状态的平稳分布(Ziebart等人,2008)的熵,而不是比政策。 事实上,我们可以证明训练 策略的目标相当于最大化 的策略。 不幸的是,计算平稳分布虽然可能(Nachum 等人,2019;Wen 等人,2020),但对于奖励正则化而言并不总是易于处理或足够精确。
7.3 与蒙特卡罗马尔可夫链方法对比
MCMC 有着悠久而丰富的历史(Metropolis 等人,1953;Hastings,1970;Andrieu 等人,2003),并且与当前的工作特别相关,因为它也是一类原则方法从 采样。 基于 MCMC 的方法已经在用于驱动采样的学习型深度神经网络上取得了一定的成功(Grathwohl 等人,2021 年;Dai 等人,2020 年;Xie 等人,2021 年;Nash 和 Durkan,2019 年;Seff 等人,2019 年)。
MCMC 的一个重要缺点是它依赖于迭代采样(形成马尔可夫链,一次一个配置,每个配置就像 GFlowNet 的终止状态):通过以下方式在链的每一步获得一个新的状态配置:对上一步中的配置进行小的随机更改。 尽管这些方法保证我们渐近地(在链的长度上)获得从正确分布中抽取的样本,但有一组重要的分布,有限链不太可能为其提供足够的分布模式多样性。
这被称为模式混合问题(Jasra 等人,2005;Bengio 等人,2013;Pompe 等人,2020):从一种模式转到相邻模式的机会可能呈指数级增长如果模式被低概率配置的长序列分隔开,则该值很小(因此需要指数长的链)。 这可以通过消耗更多的计算(采样更长的链)来缓解,但随着模式分离的增加,这种情况会呈指数级地不可持续。 通过引入随机采样(例如,绘制多个链)和模拟退火(Andrieu等人,2003)以促进模式之间的跳跃,也可以减少这个问题。 然而,在高维度以及模式占据很小的体积(随着维度的增加,其可能成为总空间的指数级小部分)时,这种方法变得不太有效,因为随机采样不太可能落在模式的附近。
相比之下,GFlowNet 属于摊销采样方法(包括 VAE、Kingma 和 Welling,2013 年),我们训练机器学习系统来生成样本:通过长链采样的复杂性换成了训练采样器的复杂性。 这种摊销采样器的潜在优势是当感兴趣的分布具有可概括的结构时:当可以根据一组已知高概率样本的知识合理地猜测在哪里可以找到高概率样本时(训练放)。 这就是深度生成模型首先发挥作用的原因,因此表明在模式占据微小体积的高维环境中(根据流形假设,Cayton,2005;Narayanan 和 Mitter,2010;Rifai 等人,2011),我们可以利用已经观察到的 对(其中 是一个已经访问过的配置, 是它的奖励)来“从已知模式跳转到尚未访问过的模式,即使这些模式与已经访问过的模式相距甚远。
这种方法的效果如何取决于学习者的泛化能力,即取决于其归纳偏差的强度和适当性,就像机器学习中常见的那样。 在根本没有结构的情况下(因此在学习分布时不可能进行概括),没有理由期望摊销 ML 方法会比 MCMC 表现得更好。 但如果有结构,那么模式之间混合的指数成本可能会消失。 有大量证据表明 ML 方法可以在如此高维的空间(如自然图像的空间)中表现出色,这表明 GFlowNet 和其他摊销采样方法值得考虑,在 ML 通常效果良好的情况下。 比较 GFlowNets 和 MCMC 方法的分子图生成实验(Bengio 等人,2021)似乎证实了这一点。
另一个需要考虑的因素(独立于模式混合问题)是计算成本的摊销:GFlowNets 预先支付较大的价格来训练网络,然后支付较小的价格(从 采样一次)来生成每个新样本。 相反,MCMC 没有前期成本,但为每个独立样本支付大量费用。 因此,如果我们只想采样一次,MCMC 可能更有效,而如果我们想生成大量样本,摊销方法可能更有利。 人们可以想象可以将 GFlowNets 和 MCMC 结合起来以实现两种方法的一些优点的设置。
进化方法
进化方法的工作原理与 MCMC 方法类似,通过随机局部搜索的迭代过程,找到最大化一个或多个目标 的候选群体(Brown 等人,2004;Salimans 等人,2017;Jensen,2019;Swersky)等人,2020)。 从这个角度来看,它们有相似的优点和缺点。 这些方法的一个实际优点是可以通过群体指标和子群体选择轻松获得自然多样性(Mouret 和 Doncieux,2012)。 这不是 GFlowNet 明确解决的问题,而是依赖于独立同分布 (i.i.d)。 采样并对次优样本给予非零概率作为多样性机制。
顺序蒙特卡罗
顺序蒙特卡罗(SMC, Naesseth 等人, 2019; Arulampalam 等人, 2002)方法是一类旨在解决推理问题的方法。 与 GFlowNet 类似,SMC 采样器经过训练,从由其非标准化概率密度给出的分布中进行采样,并且需要前向和后向内核,如 GFlowNet 中一样。 但与 GFlowNet 不同的是,它们需要指定中间目标 。 此外,对于 GFlowNets,奖励通常只出现在序列的末尾,这与 SMC 中用于重新加权粒子的每个时间步的可能性不同。 GFlowNet 可以应用于不适合典型粒子滤波器设置的设置,例如中间状态与样本空间的有效元素不对应的设置。 轨迹不一定代表与相应观察相关的潜在变量序列,如过滤任务中那样。 GFlowNet 轨迹分布仅由终端状态奖励函数定义。
8 结论和悬而未决的问题
本文扩展并深化了 GFlowNets 的数学框架和数学特性(Bengio 等人,2021)。 它将 GFlowNets 中的流概念与轨迹测量概念联系起来,并引入了一个新颖的训练目标(详细的平衡损失),这使得选择一个参数化来分离后向策略 来控制对根据目标奖励函数施加的约束来完成事情的顺序。
本文的一个重要贡献是使用 GFlowNets 进行边缘化或自由能估计的数学框架。 它依赖于调节 GFlowNet 的简单想法,以便将 Bengio 等人 (2021) 已经引入的分配函数估计能力推向更通用的设置。 这使得原则上可以估计任意状态可达到的终止状态上难以处理的奖励总和,从而为图的超图、集合的超集和(变量,值)对的超集的边缘化打开了大门。 反过来,这提供了估计熵、条件熵和互信息的公式。
附录 A引入了流量匹配目标的替代方案,该目标可以绕过从操作序列末尾开始缓慢的信用信息“引导”传播一开始就是所谓的直接信用分配(与政策梯度有一些相似之处)。 这个问题也激发了 Malkin 等人 (2022) 提出的轨迹平衡目标,并且有必要在这个方向上进一步开展工作。
为了更好地辨别 GFlowNet 和更常见的 RL 形式之间的联系,附录C考虑了不仅仅提供奖励的情况在最后但可能在每个动作之后,并且环境可能是随机的。 它还展示了如何从经过训练的 GFlowNet 中获得最大化回报的贪婪策略。 附录D中引入了与 RL 的另一个链接,通过考虑类似于 GFlowNets 中的价值函数的东西,即给定的预期下游奖励状态。本着类似的精神,附录E将GFlowNets概括为可以沿着轨迹获得奖励的情况,从而引入了回报的概念,但是保持抽样目标与回报成比例。
附录 F从另一个方向概括了GFlowNets,考虑到在同一个图上同时学习一系列流的可能性。 这为 GFlowNet 的分布式泛化(类似于分布式强化学习)以及无监督 GFlowNet 的概念(其中奖励函数可以在 GFlowNet 以无监督方式训练后定义)和学习从 Pareto 采样打开了大门Front 由一组奖励函数定义。
显然,许多悬而未决的问题仍然存在,从连续动作和状态的扩展,到具有抽象动作的 GFlowNet 的分层版本,以及将能量函数集成到 GFlowNet 参数化本身中,从而实现了一种有趣的模块化和知识分解形式。 重要的是,本文中提出的许多数学公式需要实证验证来确定它们的有用性,改进这些想法,将它们转化为有影响力的算法,并探索潜在的非常广泛的有趣应用,从取代 MCMC 或在某些方面与 MCMC 结合。设置,概率推理,进一步应用于科学发现的主动学习。
致谢
作者要感谢 Alexandra Volokhova、Marc Bellemare、Valentin Thomas、Modjtaba Shokrian Zini、Mohammad Pedramfar 和 Axel Nguyen Kerbel 对本文及其想法提供的有用建议和反馈。 他们还感谢 CIFAR、三星、IBM、谷歌、微软、摩根大通和 Thomas C. Nelson 斯坦福跨学科研究生奖学金的财务支持。
本研究由摩根大通公司部分资助。本文表达的任何观点或意见仅代表所列作者的观点和意见,可能与摩根大通公司或其附属公司表达的观点和意见不同。 本材料并非摩根大通证券有限责任公司研究部的产品。 本材料不应被视为对任何特定客户的个人推荐,也不旨在作为对特定客户的特定证券、金融工具或策略的推荐。 本材料不构成任何司法管辖区的招揽或要约。
参考
- Andrieu et al. (2003) C. Andrieu, N. De Freitas, A. Doucet, and M. I. Jordan. An introduction to mcmc for machine learning. Machine learning, 50(1):5–43, 2003.
- Arulampalam et al. (2002) M. Arulampalam, S. Maskell, N. Gordon, and T. Clapp. A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking. IEEE Transactions on Signal Processing, 50(2):174–188, 2002. doi: 10.1109/78.978374.
- Auer et al. (2002) P. Auer, N. Cesa-Bianchi, Y. Freund, and R. E. Schapire. The nonstochastic multiarmed bandit problem. SIAM journal on computing, 32(1):48–77, 2002.
- Bahdanau et al. (2014) D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. ICLR’2015, arXiv:1409.0473, 2014.
- Bai et al. (2019) S. Bai, J. Z. Kolter, and V. Koltun. Deep equilibrium models. CoRR, abs/1909.01377, 2019. URL http://arxiv.org/abs/1909.01377.
- Bellemare et al. (2017) M. G. Bellemare, W. Dabney, and R. Munos. A distributional perspective on reinforcement learning. In International Conference on Machine Learning, 2017.
- Bengio et al. (2021) E. Bengio, M. Jain, M. Korablyov, D. Precup, and Y. Bengio. Flow network based generative models for non-iterative diverse candidate generation. NeurIPS’2021, arXiv:2106.04399, 2021.
- Bengio et al. (2013) Y. Bengio, G. Mesnil, Y. Dauphin, and S. Rifai. Better mixing via deep representations. In International conference on machine learning, pages 552–560. PMLR, 2013.
- Brown et al. (2004) N. Brown, B. McKay, F. Gilardoni, and J. Gasteiger. A graph-based genetic algorithm and its application to the multiobjective evolution of median molecules. Journal of chemical information and computer sciences, 44(3):1079–1087, 2004.
- Buesing et al. (2019) L. Buesing, N. Heess, and T. Weber. Approximate inference in discrete distributions with monte carlo tree search and value functions, 2019.
- Cayton (2005) L. Cayton. Algorithms for manifold learning. Univ. of California at San Diego Tech. Rep, 12(1-17):1, 2005.
- Dai et al. (2020) H. Dai, R. Singh, B. Dai, C. Sutton, and D. Schuurmans. Learning discrete energy-based models via auxiliary-variable local exploration. In Neural Information Processing Systems (NeurIPS), 2020.
- Deleu et al. (2022) T. Deleu, A. Góis, C. Emezue, M. Rankawat, S. Lacoste-Julien, S. Bauer, and Y. Bengio. Bayesian structure learning with generative flow networks. In Uncertainty in Artificial Intelligence, pages 518–528. PMLR, 2022.
- Dinh et al. (2014) L. Dinh, D. Krueger, and Y. Bengio. Nice: Non-linear independent components estimation. ICLR’2015 Workshop, arXiv:1410.8516, 2014.
- Dinh et al. (2016) L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using real NVP. ICLR’2017, arXiv:1605.08803, 2016.
- Dosovitskiy and Djolonga (2019) A. Dosovitskiy and J. Djolonga. You only train once: Loss-conditional training of deep networks. In International Conference on Learning Representations, 2019.
- Ernst et al. (2005) D. Ernst, P. Geurts, and L. Wehenkel. Tree-based batch mode reinforcement learning. Journal of Machine Learning Research, 6:503–556, 2005.
- Ghosh et al. (2018) D. Ghosh, A. Gupta, and S. Levine. Learning actionable representations with goal-conditioned policies. arXiv preprint arXiv:1811.07819, 2018.
- Goodfellow et al. (2014) I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- Goyal and Bengio (2020) A. Goyal and Y. Bengio. Inductive biases for deep learning of higher-level cognition. arXiv, abs/2011.15091, 2020. https://arxiv.org/abs/2011.15091.
- Goyal et al. (2019) A. Goyal, A. Lamb, J. Hoffmann, S. Sodhani, S. Levine, Y. Bengio, and B. Schölkopf. Recurrent independent mechanisms. ICLR’2021, arXiv:1909.10893, 2019.
- Grathwohl et al. (2021) W. Grathwohl, K. Swersky, M. Hashemi, D. Duvenaud, and C. J. Maddison. Oops i took a gradient: Scalable sampling for discrete distributions, 2021.
- Griffiths and Hernández-Lobato (2017) R.-R. Griffiths and J. M. Hernández-Lobato. Constrained bayesian optimization for automatic chemical design. arXiv preprint arXiv:1709.05501, 2017.
- Haarnoja et al. (2017) T. Haarnoja, H. Tang, P. Abbeel, and S. Levine. Reinforcement learning with deep energy-based policies. In International Conference on Machine Learning, pages 1352–1361. PMLR, 2017.
- Hastings (1970) W. K. Hastings. Monte carlo sampling methods using markov chains and their applications. Biometrika, 1970.
- Hu et al. (2023) E. Hu, N. Malkin, M. Jain, K. Everett, A. Graikos, and Y. Bengio. Gflownet-em for learning compositional latent variable models. arvix, 2023.
- Jain et al. (2022) M. Jain, E. Bengio, A. Hernandez-Garcia, J. Rector-Brooks, B. F. P. Dossou, C. Ekbote, J. Fu, T. Zhang, M. Kilgour, D. Zhang, L. Simine, P. Das, and Y. Bengio. Biological sequence design with gflownets. International Conference on Machine Learning (ICML), 2022.
- Jain et al. (2023) M. Jain, S. C. Raparthy, A. Hernandez-Garcia, J. Rector-Brooks, Y. Bengio, S. Miret, and E. Bengio. Multi-objective gflownets. arXiv preprint arXiv:2210.12765, 2023.
- Jasra et al. (2005) A. Jasra, C. C. Holmes, and D. A. Stephens. Markov chain monte carlo methods and the label switching problem in bayesian mixture modeling. Statistical Science, pages 50–67, 2005.
- Jensen (2019) J. H. Jensen. A graph-based genetic algorithm and generative model/monte carlo tree search for the exploration of chemical space. Chemical science, 10(12):3567–3572, 2019.
- Kingma and Welling (2013) D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Kschischang et al. (2001) F. R. Kschischang, B. J. Frey, and H.-A. Loeliger. Factor graphs and the sum-product algorithm. IEEE Transactions on information theory, 47(2):498–519, 2001.
- Kumar et al. (2019) R. Kumar, S. Ozair, A. Goyal, A. Courville, and Y. Bengio. Maximum entropy generators for energy-based models, 2019.
- Kusner et al. (2017) M. J. Kusner, B. Paige, and J. M. Hernández-Lobato. Grammar variational autoencoder. In International Conference on Machine Learning, pages 1945–1954. PMLR, 2017.
- Lahlou et al. (2023) S. Lahlou, T. Deleu, P. Lemos, D. Zhang, A. Volokhova, A. Hernández-García, L. N. Ezzine, Y. Bengio, and N. Malkin. A theory of continuous generative flow networks. International Conference on Machine Learning (ICML), 2023.
- Lange et al. (2012) S. Lange, T. Gabel, and M. Riedmiller. Batch reinforcement learning. In Reinforcement learning, pages 45–73. Springer, 2012.
- Levine (2018) S. Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018.
- Malik et al. (2023) S. A. Malik, S. Lahlou, A. Jesson, M. Jain, N. Malkin, T. Deleu, Y. Bengio, and Y. Gal. Batchgfn: Generative flow networks for batch active learning. arXiv preprint arXiv: 2306.15058, 2023.
- Malkin et al. (2022) N. Malkin, M. Jain, E. Bengio, C. Sun, and Y. Bengio. Trajectory balance: Improved credit assignment in gflownets. arXiv preprint arXiv:2201.13259, 2022.
- Malkin et al. (2023) N. Malkin, S. Lahlou, T. Deleu, X. Ji, E. Hu, K. Everett, D. Zhang, and Y. Bengio. GFlowNets and variational inference. International Conference on Learning Representations (ICLR), 2023.
- Metropolis et al. (1953) N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller. Equation of state calculations by fast computing machines. The journal of chemical physics, 21(6):1087–1092, 1953.
- Močkus (1975) J. Močkus. On bayesian methods for seeking the extremum. In Optimization techniques IFIP technical conference, pages 400–404. Springer, 1975.
- Mouret and Doncieux (2012) J.-B. Mouret and S. Doncieux. Encouraging Behavioral Diversity in Evolutionary Robotics: An Empirical Study. Evolutionary Computation, 20(1):91–133, 03 2012. ISSN 1063-6560. doi: 10.1162/EVCO“˙a“˙00048. URL https://doi.org/10.1162/EVCO_a_00048.
- Nachum et al. (2017) O. Nachum, M. Norouzi, K. Xu, and D. Schuurmans. Bridging the gap between value and policy based reinforcement learning. arXiv preprint arXiv:1702.08892, 2017.
- Nachum et al. (2019) O. Nachum, Y. Chow, B. Dai, and L. Li. Dualdice: Behavior-agnostic estimation of discounted stationary distribution corrections. arXiv preprint arXiv:1906.04733, 2019.
- Naesseth et al. (2019) C. A. Naesseth, F. Lindsten, T. B. Schön, et al. Elements of sequential monte carlo. Foundations and Trends® in Machine Learning, 12(3):307–392, 2019.
- Narayanan and Mitter (2010) H. Narayanan and S. Mitter. Sample complexity of testing the manifold hypothesis. In NIPS’2010, pages 1786–1794, 2010.
- Nash and Durkan (2019) C. Nash and C. Durkan. Autoregressive energy machines. In International Conference on Machine Learning, pages 1735–1744. PMLR, 2019.
- Pan et al. (2023) L. Pan, N. Malkin, D. Zhang, and Y. Bengio. Better training of gflownets with local credit and incomplete trajectories. arXiv preprint arXiv: 2302.01687, 2023.
- Pompe et al. (2020) E. Pompe, C. Holmes, and K. Łatuszyński. A framework for adaptive mcmc targeting multimodal distributions. The Annals of Statistics, 48(5):2930–2952, 2020.
- Rezende and Mohamed (2015) D. Rezende and S. Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530–1538. PMLR, 2015.
- Riedmiller (2005) M. Riedmiller. Neural fitted q iteration–first experiences with a data efficient neural reinforcement learning method. In European conference on machine learning, pages 317–328. Springer, 2005.
- Rifai et al. (2011) S. Rifai, Y. N. Dauphin, P. Vincent, Y. Bengio, and X. Muller. The manifold tangent classifier. Advances in neural information processing systems, 24:2294–2302, 2011.
- Salimans et al. (2017) T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever. Evolution strategies as a scalable alternative to reinforcement learning, 2017.
- Schmidhuber (2019) J. Schmidhuber. Reinforcement learning upside down: Don’t predict rewards–just map them to actions. arXiv preprint arXiv:1912.02875, 2019.
- Schölkopf et al. (2012) B. Schölkopf, D. Janzing, J. Peters, E. Sgouritsa, K. Zhang, and J. Mooij. On causal and anticausal learning. In ICML’2012, pages 1255–1262, 2012.
- Seff et al. (2019) A. Seff, W. Zhou, F. Damani, A. Doyle, and R. P. Adams. Discrete object generation with reversible inductive construction. arXiv preprint arXiv:1907.08268, 2019.
- Sohl-Dickstein et al. (2015) J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- Srinivas et al. (2010) N. Srinivas, A. Krause, S. M. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. In International Conference on Machine Learning (ICML), 2010.
- Sutton and Barto (2018) R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Swersky et al. (2020) K. Swersky, Y. Rubanova, D. Dohan, and K. Murphy. Amortized bayesian optimization over discrete spaces. In Conference on Uncertainty in Artificial Intelligence, pages 769–778. PMLR, 2020.
- Toussaint and Storkey (2006) M. Toussaint and A. Storkey. Probabilistic inference for solving discrete and continuous state markov decision processes. In Proceedings of the 23rd international conference on Machine learning, pages 945–952, 2006.
- Vaswani et al. (2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- Wen et al. (2020) J. Wen, B. Dai, L. Li, and D. Schuurmans. Batch stationary distribution estimation. arXiv preprint arXiv:2003.00722, 2020.
- Xie et al. (2021) Y. Xie, C. Shi, H. Zhou, Y. Yang, W. Zhang, Y. Yu, and L. Li. {MARS}: Markov molecular sampling for multi-objective drug discovery. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=kHSu4ebxFXY.
- Zhang et al. (2022) D. Zhang, N. Malkin, Z. Liu, A. Volokhova, A. Courville, and Y. Bengio. Generative flow networks for discrete probabilistic modeling. International Conference on Machine Learning (ICML), 2022.
- Zhang et al. (2023) D. W. Zhang, C. Rainone, M. Peschl, and R. Bondesan. Robust scheduling with gflownets. International Conference on Learning Representations (ICLR), 2023.
- Ziebart et al. (2008) B. D. Ziebart, A. L. Maas, J. A. Bagnell, A. K. Dey, et al. Maximum entropy inverse reinforcement learning. In Aaai, volume 8, pages 1433–1438. Chicago, IL, USA, 2008.
- Zimmermann et al. (2022) H. Zimmermann, F. Lindsten, J.-W. van de Meent, and C. A. Naesseth. A variational perspective on generative flow networks. arXiv preprint 2210.07992, 2022.
附录 A GFlowNets 中的直接信用分配
与基于最小化贝尔曼方程失配的时间差分方法类似,流匹配和详细平衡损失将需要多次更新(并对许多轨迹进行采样)才能将终止状态上的奖励失配传播到流网络内的转移概率。 这对于较长的轨迹来说尤其严重,并引发了替代更直接的训练目标的问题。 本节试图回答以下问题:“给定训练轨迹,是否有更直接的方法将功劳分配给轨迹中的早期转换?”。 Malkin 等人 (2022) 通过引入轨迹平衡损失提供了替代答案 (例如。 6)。
我们可以将使用 GFlowNet 对轨迹进行采样的过程视为类似于对随机循环神经网络中的状态序列进行采样。 让事情变得复杂的是,这样的神经网络(i)不直接输出与某个目标匹配的预测,并且(ii)状态可能是离散的(或离散和连续分量的组合)。
关于 (i),我们记得过渡训练 中的流程(涉及目标)是通向 的所有可能轨迹的棘手总和。然而,我们也许能够获得一个随机梯度,通过平均这些轨迹来估计所需的数量。 为此,我们利用流的属性来获得随机梯度估计器,该估计器通过接下来的三个命题导出。
通过流匹配约束的导数表示法:下面我们有时需要区分全导数(记为),它考虑了由于流匹配约束与其他因素造成的间接影响导数(记为 )并仅捕获直接梯度。 当约束不改变结果时,可以使用任一表示法。 通过隐式依赖关系计算间接梯度是一个活跃的研究领域,通常利用隐式函数定理,例如定点迭代层和深度均衡模型中的隐式层(Bai等人,2019)。
Proposition 39。
考虑在流匹配约束下 处的流日志发生轻微变化的影响:遵循条件,它会导致 处的流日志发生变化概率:
| (70) |
其中 是事件在轨迹上的分布。
证明我们将考虑将经过的完整轨迹划分为也经过的轨迹(设置 )和那些没有的(设置)。 根据定义我们可以写:
因为,我们可以写。 因此:
另外,由于中的流动不影响中的轨迹,则;这导致:
Proposition 40。
考虑边 上流量对数的轻微变化所产生的影响:我们会得到 处流量对数在条件概率 之后的变化:
| (71) |
其中 是事件在轨迹上的分布。
证明我们首先使用链式法则和对数导数的性质,然后我们使用来自流匹配约束的:
直观上,方程70和方程71 告诉我们一个地方的流量扰动如何导致其他地方的变化,以便在各处保持流量匹配,使用流量匹配条件来向后和向前传播流量的无限小变化。 因此,只有当我们接近匹配流的极限时,它们才会成为正确的,并且在实践中(使用不完全训练的 GFlowNet),相应的表达式将会有偏差。 然而,我们可以利用它们来估计长期均衡梯度,并获得跨长轨迹的信用分配估计量 提案。 41 以下。
在 GFlowNet 设置中,假设我们通过参数 参数化边缘流估计器 。 为了了解 变化对损失函数 的影响,我们必须计算 total 导数 对直接和间接梯度求和。 在我们的上下文中,直接梯度 是由于更改 造成的损失的显式变化(不考虑流匹配约束),间接梯度包括引起的变化由于约束而在流动中。 有了这个,我们就可以将全导数 的无偏估计量形式化 提案。 41:
Proposition 41。
令为沿着根据GFlowNet轨迹分布采样的轨迹计算的流匹配损失。 让 将总损失分解为沿轨迹的每个状态损失 。 让参数化边缘流估计器。 然后,在流量匹配的限制下,
| (72) |
是全导数 的无偏估计量,如下
| (73) |
凸组合也是如此
| (74) |
对于任何。 直观上,表示直接通过中出现的梯度,表示存在向前或向后的流量总和在中获取经过的流量。
证明 在不考虑匹配流约束带来的间接影响时,我们将使用偏导数表示法,在考虑它时,我们将使用全导数表示法,来应用 提案。 39. 考虑Eq.72中在GFlowNet轨迹分布下的期望值,使用前面的命题(方程 70)和链式法则:
上述论证表明,当 时, 公式 74 中的 是渐近无偏的(当流量变得匹配时),因为我们恢复了 公式 72 中的 。 然后可以对 使用相同的证明技术,它使用从 采样的转换 而不是轨迹转换 ,我们得到当 时,Eq. 74 中的估计器 渐近无偏:
其中最后一个恒等式位于 证明中的第四行之后。 最后,两个无偏估计量的凸组合是无偏的,因此我们得到 Eq. 74 中的 是渐近无偏的对于任何。
这个令人惊讶的结果表明,非常接近策略梯度的东西实际上在边缘流的参数上提供了渐近(即,当流匹配时)无偏梯度,正如预期的那样222当你想象减去损失作为奖励本身时,联系变得更加清晰,我们看到我们立即得到一个训练信号序列中较早的时间为 ,与策略梯度类似。 也存在差异,因为上述命题依赖于保持靠近流匹配的学习固定点。. 请注意,它仅在在线环境中准确工作,即根据学习者当前策略对轨迹进行采样时。 否则,梯度估计器可能会有偏差(在实践中无论如何它都会有偏差,因为流量永远不会完美匹配)。 但是,如果我们不是从 GFlowNet 转换概率 中采样轨迹 ,而是从具有转换概率 的训练分布 中采样它们我们可以计算重要性权重(通过比率)并相应地修正估计器。 由于训练分布 应该更广泛并且具有完全支持,因此重要性比不会爆炸,但这种重要性加权估计量的方差仍然可能存在常见的数值问题。
我们现在考虑采样策略与 仅略有不同的设置,这种情况通常是因为我们希望采样策略更广泛且更具探索性,并且因为我们可能使用延迟数据,例如,使用重播缓冲区。 这种微小的差异可能会引起偏差,但使用上述梯度估计器仍然可能是有利的。 请注意它如何不与流匹配损失的梯度(这是 中的第一项)发生冲突。 使用 的预期优点是,它可以通过直接为完整轨迹的早期过渡提供更新来最初加速训练。 然而,类似于时间差异方法和策略梯度方法之间的权衡,这可能会以更高的方差为代价。
当流量匹配以及根据 GFlowNet 的分布对轨迹进行采样时,该估计器是无偏的,但它也具有很多直观意义:如果 处的估计流量太小(在眼睛中) ),通过增加通向 的路径上的转换概率,可以明显地推动流量上升。 即使我们考虑稍微不同的轨迹采样分布,只要它导致 ,我们就会期望增加其概率会增加最终出现 的概率(参见 提案。 39)。
如果状态具有连续分量,我们还可以通过更频繁地选择通向 的更有可能的路径来增加以 结束的概率。 这可以通过状态转换的反向传播(通过时间的某种形式的反向传播)来计算。 然而,如果转变不完全已知或不可微分,则这种方法可能更具挑战性,并且与连续状态的强化学习中的学分分配提出的类似问题相关。
最后,请记住, 中更直接的信用分配条款必须与本地条款 结合起来,以确保流量变得更好匹配,因为流量匹配是 公正的必要条件。
附录 B 条件 GFlowNet
Definition 42。
考虑一组调节信息、一系列 DAG 、一系列目标奖励函数 和一个流参数化 对于每个 的 。 三个函数、和参数化了DAG家族和目标奖励函数,我们说形成了一个的条件流参数化。 元组称为条件GFlowNet。
为了清楚起见,对于对象 ,我们将互换使用 和 。
与无条件情况一样,条件 GFlowNet 提供了一种从不同目标奖励函数同时采样的方法。 给定条件 GFlowNet 的配置 和条件 , 是 上的分布,即完整轨迹集,它在中隐式定义了终止状态概率度量:
| (75) |
为了清楚起见,省略了 中对 的依赖。
条件 GFlowNet 将目标奖励函数的采样问题转化为搜索问题:搜索对象 使得 。 对于此类对象 ,终止状态概率度量对应于兴趣分布,即:
与无条件情况类似,我们需要在 上设计一个条件损失函数 ,该函数在此类对象 上等于 0,并且只在那些物体上。
Definition 43。
令 为条件 GFlowNet。 条件流匹配损失是任何满足以下条件的函数:
| (76) |
我们说 是条件可分解,如果存在这样的函数 :
我们可以从 的任何流匹配损失族 开始获得可条件分解的条件流匹配损失(默认。 26)。 特别是,我们可以选择这些损失是状态可分解的、边缘可分解的或轨迹可分解的。
例如,如果每个 都是状态可分解的,则同时采样问题将转化为以下最小化问题:
| (77) |
其中是上的任何条件完全支持分布,即满足以下条件的概率分布:
可以从任何对 提供完全支持的发行版 和对 提供完全支持的发行版 开始获得此类有条件完全支持发行版> 对于任何 ,如:
Example 9。
这种参数化无需单独学习每个函数 ,而是可以学习条件 和非终止边 的函数 ,从而不仅在边缘上而且在条件上利用机器学习算法的泛化能力。
考虑为每个 定义的函数 如下:
其中 是超参数。 函数 将每个 映射到
是条件流匹配损失,即条件可分解和状态可分解。
附录 C确定性和随机环境中的策略
到目前为止,我们一直关注确定性环境,在该环境中可以根据给定的操作完美地计算状态变化。 当动作是代理内部的认知动作时,这是有意义的,例如,顺序构建问题的候选解决方案(解释、计划、推断的猜测等)。 如果行为是外部的并影响现实世界呢? 结果很可能无法完全预测。 为了解决这种情况,我们现在将扩展 GFlowNet 框架,以在确定性或随机环境中学习代理的策略 。
Definition 44。
一个政策 是每个状态 的操作 的概率分布 。为了表示动作空间可能基于受到限制,我们将状态下的有效动作写为。
为了表示 GFlowNet 框架中动作的引入,我们将分两步分解转换:首先根据状态 的策略 对动作 进行采样>,然后环境将其(以可能随机的方式)转换为新状态。
Definition 45。
我们将状态的概念概括如下: 甚至州 其形式为 而 奇怪的状态 其形式为。 策略 控制从偶数状态到与 兼容的下一个奇数状态的转换,而 环境 控制从奇数状态到下一个偶数状态的转换。
根据上述定义,偶数到偶数的转换总结为
| (78) |
请注意,涉及向后转换的详细平衡条件也将分解为两部分:(1)用于反转偶数到奇数的转换,
| (79) |
根据定义,(2)为了反转奇数到偶数的转换,我们必须实际表示(并学习)
| (80) |
这种条件分布包含了我们对通向相同状态的不同路径的偏好,同时与环境保持一致。 上的归一化约束可以通过详细的平衡来保证流量匹配,如围绕 Eq. 31 讨论的那样。
C.1 已知的确定性环境
确定性环境是完全可控的:我们可以在前一个状态的有效操作中选择导致最期望的下一个状态的操作。 在环境确定的情况下,我们可以直接应用Sec. 3的结果,如下。 在每个时间步骤 并从状态 开始,代理根据策略 选择允许的操作 。 允许的操作集应与 所针对的操作一致。 由于环境是确定性的且已知的,因此有一个确定性函数 为我们提供了下一个状态 。 在这种情况下,我们可以忽略偶/奇状态的区别,并用 GFlowNets 的可学习转移概率函数 来识别可学习策略 ,如下所示。
Proposition 46。
在确定性环境和具有策略 和由 给出的状态转换的 GFlowNet 代理中,转换概率 由下式给出
| (81) |
因此,如果只有一个操作 可以从 转换到 ,那么
| (82) |
证明通过对进行边缘化得到结果:
与。
由于总和仅包含一项,因此获得了具有单个可能动作来获得转移的情况。
Proposition 47。
在具有的确定性环境中,可以从后向策略导出后向转移概率函数,
| (83) |
并且在单个操作 解释每个转换 的情况下,
| (84) |
证明 证明的思路与 提案。 46.
C.2 未知的确定性环境
如果环境是确定性的但未知,我们必须学习转换函数,我们还应该学习它的逆函数,它在给定下一个状态和动作的情况下恢复先前的状态:
| (85) |
不幸的是,如果状态和动作空间是离散的并且是高维的,则学习 和 的方式会推广到看不见的转换333所看到的转换只能记录在表中,但在组合状态空间中,它们将形成未来遇到的转换的极小部分。 可能很困难,但通过持续放松可能更容易实现。 随机环境的方法可用于此目的。
C.3 随机环境
随机环境的设置不太简单,但更通用。 我们将按照 Eq. 78 分解过渡,但不假设 是狄拉克。 首先要注意的是,我们仍然可以获得马尔可夫流,但不能保证找到与所需终端奖励函数相匹配的策略。
Proposition 48。
在具有环境转换的随机环境中,任何策略都可以产生马尔可夫流,并且可能无法完美地实现期望的流。
证明 我们通过满足偶数步和奇数步的流量匹配或详细平衡方程来获得流量,这总是可以因为以下原因而完成。 从偶数状态,我们可以定义边缘流
向后过渡是。 这导致中间状态流
因为 中只有一条边,即从 开始并执行操作 的边。 从奇数状态,我们有边缘流
用代表环境,我们用通常的公式(Eq. 22)得到偶态流
如果未知,则可以通过观察三元组 并估计近似最大化这些观察的经验对数似然的转换概率,以通常的监督方式估计环境转换 。 然而,在固定环境中,转换 不依赖于策略,而后向转换 取决于前向环境转换和状态流,即策略。 如果有足够的训练时间和容量,前向和后向转换可以兼容,但与 GFlowNet 一样,在现实设置中,流匹配方程将无法完美实现。
如果有足够的容量和训练时间(训练到完成),我们就得到了一个流程。 然后,通过对上述偶数和奇数步骤的转换进行顺序采样来定义转换概率,我们获得马尔可夫流(提案。 16)。
为了表明所需的最终流量不一定可以实现,只需识别一个反例就足够了。 考虑最终奖励 ,而环境转变为 的概率为零。 在这种情况下,无论我们如何选择策略,我们都无法将所需的流放入状态。
还要记住,在实践中,即使在完全可控的环境中,由于 GFlowNet 的容量和训练时间有限,我们也不能保证找到与目标终端奖励函数匹配的流。
尽管在 GFlowNet 的确定性环境中,人们可以自由地为非终端边缘选择 ,但对于随机环境却并非如此,如下所述。 在偶数到奇数的转换中,通过构造。 在奇数到偶数转换 上,问题在于前向转换不是自由参数(它对应于环境的 )。
Counterexample 49.
对于具有固定随机环境的 GFlowNet,可能无法在匹配流量和终端奖励的同时自由选择 。
作为反例,请考虑图6中的设置。 假设和环境提供的转换。 那么,为了匹配最终奖励,我们必须要求,这意味着不能自由选择。
附录D预期下游奖励和奖励最大化政策
我们已经介绍了终止状态(退出到 之前访问的状态)的概率分布 和条件概率 。 更一般地,我们可以考虑由 GFlowNet 策略 的某种任意选择引起的终止状态上的任何分布 并计算该分布下的预期奖励:
Definition 50。
预期奖励 在访问具有终端奖励函数 的流的状态 后,在终止状态 上的某种分布下,是
| (86) |
Proposition 51。
虽然我们在 下有一个简单的预期奖励表达式,但对于任何策略 产生的分布 ,预期奖励的定义更广泛。 特别是对于任何策略,我们还可以定义在由引起的终止状态的分布下的预期奖励。 期望奖励的作用类似于强化学习中的状态和状态-动作价值函数,因此当中间奖励为且折扣因子为:
Proposition 52。
令 为策略 产生的终止状态的分布, 为预期奖励 下的贪婪策略,即,
| (88) |
然后对于所有
| (89) |
也就是说,引起的概率下的预期奖励不比引起的概率差。
证明让我们用表示贪婪策略从和中确定性选择的动作随机采样的终止状态。 然后:
我们使用了这样一个事实:对于所有 ,自 以来的 都是贪婪策略。
直接后果如下:
Corollary 53。
存在一个策略最大化所有状态的预期奖励,即贪婪策略 提案。 52 与 GFlowNet 的策略 相关联,产生终端分布 。
我们如何估计下的预期奖励? 我们只需要训练另一个流(或 GFlowNet 的头集,请参阅附录 F),其中 为奖励函数。
Proposition 54。
考虑两个流和,一个匹配终端奖励函数,另一个匹配终端奖励函数。 那么下的预期奖励(由流定义的终止状态的分布)是
| (90) |
D.1 偏好高回报的早期轨迹
附录E中间奖励和轨迹返回
到目前为止,在 GFlowNet 论文 (Bengio 等人,2021) 中,我们将终端奖励视为每个轨迹在其末尾仅发生一次的事件。 相反,考虑一个经历完整轨迹的代理,并将其返回声明为与从每个访问状态到接收器节点的所有转换相关的一些中间环境奖励的总和。
Definition 55。
轨迹返回 与部分轨迹关联的定义为
| (91) | ||||
| (92) |
和预期未来回报 与状态 关联的定义为
| (93) |
其中期望是根据流在轨迹上的概率度量来定义的(以经过 的轨迹为条件)。
Proposition 56。
从开始的轨迹可实现的预期未来回报满足以下递归:
| (94) |
证明 由return (默认。 55),我们得到以下结果:
上述递归有趣的原因之一是,它对应于无贴现情况下价值函数(即预期下游回报)的贝尔曼方程(Sutton and Barto,2018)(其中情节设置)。 将其与我们获得的状态流方程之一(Eq. 22)进行比较是很有趣的:
这两种递归是不同的:一种使用前向转换向后传播值,而另一种使用向后转换来传播流。
Definition 57。
让我们表示 可能是随机的 环境奖励,当代理访问状态 时提供(通常与 处的 GFlowNet 终端奖励不同),并考虑在部分轨迹 中累积的环境奖励导致状态。 我们称之为 GFlowNet 状态 回报增强 如果状态 包括 累积奖励 ,即存在一个函数。 让我们将具有返回增强状态的 GFlowNet 称为 返回增强的 GFlowNet.
我们希望跟踪训练 GFlowNet 状态中累积的中间奖励,以计算该状态的最终奖励,从而使 GFlowNet 按累积奖励的比例进行采样:
Proposition 58。
假设是一个回报增强的GFlowNet,其目标终端奖励函数等于累积环境奖励。 此外,假设 已训练完成。 然后从 采样产生累积奖励 ,其概率与 成正比。
证明由于是一个经过终端奖励函数训练完成的GFlowNet,我们知道从采样终端累积奖励 的概率与 成比例。
请注意,这样的 GFlowNet 只能离线训练,即使用已终止且我们已观察到返回的轨迹。
另请注意,如果我们不使用累积奖励来增强状态,那么 GFlowNet 终端奖励将不是状态的函数。 拥有回报增强状态还可以在 GFlowNet 框架中处理随机环境奖励。
附录 F多流、分布式 GFlowNet、无监督 GFlowNet 和 Pareto GFlowNet
考虑一个具有随机奖励的环境。 与 默认。 57,我们可以增强状态以包含随机累积奖励,因此(通过 提案。 58)使 GFlowNet 样本轨迹的返回 发生的概率与 成比例。 然而,与分布式 RL (Bellemare 等人,2017) 类似,推广 GFlowNets 不仅可以捕获可实现的终端奖励的预期值,还可以捕获其分布的其他统计数据,这可能会很有趣。 更一般地说,我们可以将其视为 GFlowNet 家族,每个 GFlowNet 都在其流程中对感兴趣的特定未来环境结果进行建模。 通过 GFlowNet 的粒子类比,粒子就好像具有颜色或标签(就像在光束中一起传播的一组光子中每个光子的频率一样),并且我们分别考虑与所有可能的标签类型。
如果结果的数量(可能的标签的数量)很小,则可以使用 GFlowNet 的不同输出头来实现(例如,与每个标签关联的流的一个输出)。 当观察到与特定标签结果相关的轨迹时,相应的头会获得梯度。 更强大和更通用的实现将结果事件作为 GFlowNet 的输入,从而相当于训练条件 GFlowNet(参见Sec.)。 t3> 4.4),并在下面进行了形式化。
Definition 59。
让我们定义结果 作为状态的已知函数。结果可以是环境奖励是否采用特定值,也可以是 的重要特征的向量,这些特征足以确定许多可能的环境奖励函数(特别是 可以是恒等函数)。 我们将条件 GFlowNet 称为条件 GFlowNet,以 作为条件输入,事件 的条件流 与奖励函数一致的轨迹
| (95) |
以结果为条件的 GFlowNet 具有结果函数。
为了简单起见,我们将在这里限制为一组离散的结果,但期望这种方法可以推广到一组连续的结果。 请注意,如果以结果为条件的 GFlowNet 训练完成,则可以仅对终止状态 进行采样,从而产生所选结果 。 原则上,这允许对保证具有高奖励的对象进行采样(在给定的奖励函数下)。 在实践中,GFlowNet 永远不会被完美地训练完成,我们应该将这种以结果为条件的 GFlowNet 视为类似于 RL 中以目标为条件的策略(Ghosh 等人,2018) 或奖励-条件颠倒强化学习(Schmidhuber,2019)。 未来工作的一个有趣问题是将这些外部条件 GFlowNet 扩展到随机奖励或随机环境的情况。
Definition 60。
A 分布式GFlowNet 是一个以结果为条件的 GFlowNet,将与完整轨迹相关的环境返回值作为条件输入。 这可以通过使 GFlowNet 返回增强来实现,以便可以从轨迹的终止状态读取返回。
训练一个以结果为条件的 GFlowNet 只能离线完成,因为条件输入(例如,最终返回)只能在轨迹采样后才知道。 因此,合理的对比训练程序可以如下进行:
-
1.
根据无条件训练策略对轨迹进行采样。
-
2.
从终止状态(发生在中的接收器状态之前)获取结果。
-
3.
使用 和目标终止奖励 更新条件 GFlowNet。
-
4.
根据条件 GFlowNet 策略和条件 对轨迹 进行采样。
-
5.
获取中终止状态(发生在接收器状态之前)的实际结果。 如果 GFlowNet 经过完美训练,我们应该有 ,但否则,特别是如果可能的结果数量很大,这种情况就不太可能发生。
-
6.
使用具有轨迹 的流匹配损失和目标终止奖励 更新条件 GFlowNet(如果 有许多可能值,则可能为 0) 。
未来工作中一个有趣的问题是考虑更平滑的奖励函数,而不是尖锐但稀疏的奖励 作为条件奖励,以使训练更容易。
F.1 定义后验奖励函数
奖励函数可能不是先验已知的,或者可能只知道一些未知常数(例如,定义帕累托前沿),或者我们可能希望概括 GFlowNet,以便可以以更无监督的方式对它们进行训练或预训练,特定的生成任务仅在事后指定。 下面的重要命题使我们能够做到这一点,并将以结果为条件的 GFlowNet 转换为根据给定奖励函数进行采样的 GFlowNet,而无需重新训练网络。
Proposition 61。
考虑一个针对终止状态 上的可能结果 训练完成的结果条件 GFlowNet,以及作为结果 的函数 后给定(可能在训练 GFlowNet 之后给定)的终止奖励函数 。 然后可以从结果的流中获得与目标终端奖励函数匹配的事件上的流的GFlowNet -调节GFlowNet通过
| (96) |
例如,终端奖励的GFlowNet策略可以从
| (97) |
或者
| (98) |
其中、和分别是结果条件状态流、状态动作流和动作策略。
证明我们首先明确的含义:
| (99) |
其中是在终端转换结束的轨迹中事件(例如,特定状态或转换)的概率,并且可以确定完全由(考虑从开始并返回到特定状态或转换的所有后向路径)。 这意味着 不依赖于奖励函数的选择,因此方程 99对于任何都有效。
Clearly, we see that Eq. 96 works in the extreme case where is an indicator function at some specific value since the sum in Eq. 96 reduces to which corresponds to reward function as per Eq. 95. 这产生
| (100) |
其中 表示给定 后返回 的函数。
为了完成证明,让我们从 Eq. 96 的右侧开始,并插入上面的 定义> (Eq. 100),然后交换总和并使用指示函数取消 上的总和,最后应用Eq.0>991>中的定义:
| (101) |
根据需要恢复 Eq. 96 的左侧。
这使得预测概率并对不同状态下出现的所有可能结果 执行采样操作成为可能(在极端情况下,我们对可能的奖励函数一无所知,结果是 ),然后将该 GFlowNet 即时转换为专用于给定终端奖励函数 的 GFlowNet。 然而,我们注意到,在运行时每个动作都需要更多的计算:我们必须在结果空间上执行这些求和(可能通过蒙特卡罗积分),并且在计算时间与准确性之间可能存在权衡由此产生的决策(基于使用多少蒙特卡罗样本来近似上述总和)。
F.2 帕累托 GFlowNet
这些想法的一个相关应用涉及帕累托优化,其中我们不确定正确的奖励函数,直到形成潜在目标的凸组合的几个系数。
Definition 62。
帕累托加性终端奖励函数可以写为
| (102) |
其中是凸权重,感兴趣的结果是目标,是一组离散的凸权重。
Definition 63。
帕累托乘法终端奖励函数可以写为
| (103) |
其中是凸权重,感兴趣的结果是目标,是一组离散的凸权重。
在这些情况下,我们可以训练一个条件 GFlowNet,其中 作为条件输入, 作为条件终端奖励函数。 在运行时,我们可以扫描 的集合,以获得不同的策略或预测概率或自由能。 只要组合目标由 参数化,上面的内容就可以很容易地推广到目标的非凸和非线性组合。 请注意这个想法(以及更普遍的以结果为条件的 GFlowNets)与 Dosovitskiy 和 Djolonga (2019) 的早期工作之间的相似性。 通过损失规范的形式进行调节的相同想法可以应用于 GFlowNet,以获得一系列 GFlowNet,每个损失函数对应一个 GFlowNet。
具有此类奖励函数的 Pareto GFlowNet 的一个有用应用是从 Pareto 前沿抽取样本。 Pareto GFlowNet 训练完成后,我们可以通过首先对凸权重 进行采样,然后对轨迹进行采样,从 Pareto 前沿中抽取样本。 这在多目标优化或采样中非常有用,我们希望根据不同目标的不同权衡点得出多种解决方案。
我们还可以通过提供目标值向量 作为输入来训练结果驱动的 GFlowNet,并利用有关目标的先验知识。 例如,我们可能认为不同的目标可以彼此独立地建模,并且 (或类似的 )可以写为基础扩展 以 为基础 用于表示目标 。 如果学习不同的目标应该相互分离(例如,一个是静止的,另一个不是),那么从泛化的角度来看,这可能是有利的。