FedNI:使用
N网络进行Fed联合图学习Inpainting基于人群的
疾病预测
摘要
图卷积神经网络(GCN)广泛用于图分析。 具体来说,在医学应用中,GCN 可用于人口图上的疾病预测,其中图节点代表个体,边代表个体相似性。 然而,GCN 依赖于大量数据,这对于单个医疗机构来说收集起来具有挑战性。 此外,大多数医疗机构仍然面临的一个关键挑战是在数据信息不完整的情况下孤立地解决疾病预测问题。 为了解决这些问题,联邦学习(FL)允许孤立的本地机构在不共享数据的情况下协作训练全球模型。 在这项工作中,我们提出了一个框架 FedNI,通过 FL 利用网络修复和机构间数据。 具体来说,我们首先使用图生成对抗网络(GAN)联合训练缺失节点和边缘预测器,以完成本地网络的缺失信息。 然后,我们使用联合图学习平台训练跨机构的全局 GCN 节点分类器。 这种新颖的设计使我们能够利用联邦学习和图学习方法来构建更准确的机器学习模型。 我们证明了我们的联合模型在两个公共神经影像数据集上的性能优于本地和基线 FL 方法,并且具有显着的优势。
索引术语:
联邦学习、图卷积网络、人口网络、疾病预测我简介
神经系统障碍和疾病,例如自闭症谱系障碍 (ASD) 和阿尔茨海默病 (AD) [1],可能会导致严重的社交、沟通、认知和行为挑战 [2, 3] 。 迫切需要检测神经系统疾病,促进临床上对该疾病的早期干预和有效治疗。 最近的研究已将深度学习技术应用于早期疾病诊断[4, 5],例如卷积神经网络(CNN)[6, 7]、循环神经网络(RNN) ) [8, 9] 和图卷积神经网络 (GCN) [3, 10]。 尽管 CNN 和 RNN 在 ASD 和 AD 的早期诊断中取得了合理且有希望的结果,但它们独立提取个体成像信息,并且在探索未标记个体的信息和数据固有的复杂结构方面存在局限性,例如忽视了人群中主体之间的相互作用和关联,无法保证学习到有效的模型。
可以使用图形或网络自然地对人群的疾病预测进行建模111图和网络在我们的手稿中可以互换。. 具体来说,节点表示为图像特征并根据其健康状况(患者或健康对照)进行标记,而连接两个节点的边缘捕获个体之间的相似性。 GCN 可以协同个体受试者的各种信息的表示能力,根据部分标记的个体受试者以及整个群体之间的相互作用来预测个体标签。 因此,GCN 被广泛用于疾病预测中的图分析。 例如,Parisot等人应用GCN对神经影像数据进行半监督疾病预测,其中节点被定义为受试者,边代表两个受试者之间的相互作用和关联[10].
大多数医疗机构继续面临的一个关键挑战是在没有其他机构任何见解的情况下孤立地解决疾病预测问题。 具体而言,集中共享患者数据的多机构协作面临隐私和所有权挑战,例如一般数据保护法规 (GDPR) [11] 和健康保险可移植性和责任法案 (HIPAA) [ 12]。 为了解决这个问题,联邦学习(FL)允许孤立的机构协作“利用”其私人数据,无需数据共享,但可以相互传输知识。 例如,李 等人。 [13] 提出实现一种去中心化迭代优化算法,并通过疾病诊断的差分隐私来保护共享局部模型权重的隐私。 Yang等人[14]提出在服务器和机构之间仅共享部分模型来自动进行COVID-19的诊断。
然而,大多数现有的 FL 策略都是针对 CNN 和多层感知器 (MLP) [15, 16] 设计的,而很少有方法学会将 GCN 与 FL 结合起来进行疾病预测[17]. 与只有特征矩阵作为输入的 CNN 和 MLP 不同,GCN 还有另一个输入,即 ,包含两个研究对象之间交互和关联信息的图。 如果在 FL 中实现 GCN,全局图将被分成几个局部图,其中局部图之间的边丢失。 当关注缺少邻居(自我)的节点时,损坏的信息破坏了其原始的自我网络结构222自我网络是距焦点节点(“自我”)小于一定距离的所有节点(例如直接邻居)的图 [18]。. 自网络信息已被证明在基于 GCN 的节点分类中非常重要[19, 20]。 然而,当前的 GCN 模型绝大多数假设节点和边信息是完整的。 因此,简单地将 GCN 与分布式局部图上的标准跨筒仓 FL 策略相结合可能会破坏 GCN 的有效性。 一种解决方案是连接本地图,但它需要跨客户端共享节点信息,并且可能违反隐私法规。 因此,为了解决这个问题,网络修复(预测缺失的邻居及其相关边)是一种很有前途的策略,可以提高 GCN 学习图的完整性[21]。
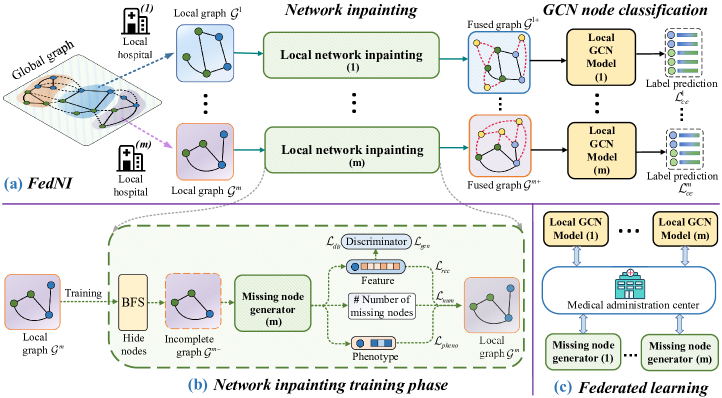
在这项工作中,我们提出了一种新的疾病预测 FL 框架,FedNI,它在群体图上进行 GCN 节点分类并解决上述问题。 为此,我们提出了一种两阶段FL管道(如图1所示)。 在第一阶段,我们从训练用于网络修复的缺失节点生成器开始。 具体来说,我们使用广度优先搜索(BFS)从本地图中随机删除节点,从而产生一组损坏的图和隐藏节点。 我们训练生成器使用谱归一化生成对抗网络 (SN-GAN)[23] 从损坏的图中预测隐藏节点和边。 然后,我们将原始局部图提供给经过训练的缺失节点生成器,以修复缺失的邻居并生成具有增强节点和边的新融合图。 在第二阶段,我们联合训练 GCN 以在本地融合图上进行节点分类,其中每个机构迭代训练本地 GCN 模型权重,与全球可信管理中心共享它们,然后接收平均模型权重。
我们的主要贡献总结如下:
-
1.
我们是第一个使用从全球人口图划分的不相交的小型局部图来制定用于疾病分类的跨孤岛联合图学习。 我们通过新颖的网络修复模块提高了 GCN 在自我网络上的有效性,并通过在 FL 框架中训练节点生成器和节点分类器来提高性能。
-
2.
所提出的 FL 网络修复模块包括三个组件以确保其有效性: BFS 节点删除以避免生成孤立的损坏的局部图; SN-GAN 合成具有真实数据分布的节点;边缘构建利用图像和非图像信息来更好地整合图形上的信息。
-
3.
我们在比较、消融研究和超参数讨论方面进行了广泛的实验。 我们的方法在广泛使用的 ABIDE 和 ADNI 数据集上分别实现了 和 分类精度,明显优于替代 FL 方法。
二相关工作
II-A 用于疾病预测的 GCN
最近,医学领域非结构化数据的图学习越来越受到关注。 例如,Parisot 等人 [10] 利用 GCN 并将群体表示为稀疏图,其中节点与成像特征相关联,表型信息被描述为边缘重量。 Hi-GCN [24]使用分层GCN来学习图特征嵌入,以进行ASD和AD的分类。
然而,当前的 GCN 模型仍然存在两个问题。 首先,GCN 的有效性高度依赖于图的质量。 当输入低质量图时,即缺少分量[21, 19]的图,分类性能会受到影响。 为了解决图包含缺失特征的问题,最流行的策略是在[25, 26]或与[19]应用之前估计并填充未知值GCN。 与现有方法不同,我们结合边缘增强策略来生成融合图。 其次,许多 GCN 仅依赖于单一模态,即成像数据[27]来探索两个节点之间的相似性。 因此,他们无法全面捕捉受试者或其个人扫描之间的相互作用和相似性[28]。 为了解决这个问题,我们探索成像和非成像数据来表示人口图。
II-B 疾病预测的联邦学习
联邦学习(FL)[22]是一种协作式、去中心化的隐私保护技术,旨在解决数据孤岛问题,同时保护数据隐私[29]。 在FL在数据隐私保护方面取得的成就的推动下,FL在疾病预测等数据敏感领域具有广泛的普及和应用前景。 Li 等人 [30] 是最早实现用于脑肿瘤分割的实用 FL 系统的作品之一。 李 等人。 [13] 将 FL 和域适应技术应用于异构多机构神经影像数据分析。 Dayan 等人 [14] 通过与佛罗里达州 20 家医院合作,促进 COVID 患者风险预测。
与之前的 FL 研究相比,我们研究了一种尚未充分探索但现实的设置,将多中心医疗数据表示为分布式群体图,并解决了 FL 在缺少邻居的局部图上的独特挑战。 最接近的相关工作是Zhang等人[19]。 然而,这项工作针对的是一般图节点分类问题,并没有考虑我们所考虑的疾病群体网络的独特性(即,小的局部子图),利用辅助信息(例如,) >表型),或者考虑医疗保健应用中的极端隐私要求。 我们提出的FedNI通过解决上述限制,对Zhang等人[19]进行了改进。
III 建议的方法
我们工作的目标是使多个机构能够协作学习强大的 GCN 模型,用于基于人群的疾病预测,而无需共享数据。 为此,我们首先定义总体图公式(在III-A节中)。 然后,我们提出了如图1所示的两阶段FL框架,其中包含一个带有缺失节点生成器的网络修复模块和一个用于节点分类的GCN学习模块。 本地网络修复模块(第 III-B 节)旨在预测缺失节点并增强边缘连接,从而产生更大的融合本地图,作为 GCN 节点分类器的输入。 为了利用分布式数据,两个建议的模块以某种 FL 方式进行训练(在第 III-C 节中)。
III-A 人口图制定
图数据由一组节点和一组边组成。 每个节点由包含该节点属性的节点特征表示,而每条边暗示两个节点之间的相似性。 构造图边的标准方法是基于节点特征执行聚类。 然而,这种方法有两个局限性。 首先,如果节点特征是高维向量,由于维数灾难,很难揭示真实的局部结构。 其次,使用单一模态生成边不足以挖掘图数据固有的复杂关系。 为了应对上述挑战,受到 Parisot 的启发 等人。 [10],在本文中,我们通过对图像特征进行降维并考虑主体的表型信息来生成边缘。
首先,我们从原始医学图像中提取低维且具有区分度的特征,然后利用这些特征构建一个相似性图,其中表示群体图中的节点数,旨在减少高维特征、例如杂讯和冗余特征以及维度诅咒的不利影响。 具体来说,给定原始特征矩阵,我们采用高斯核将边的权重定义为:
| (1) |
其中是通过降维算法(例如主成分分析和递归特征消除)提取的低维特征,是特征的宽度高斯核。
其次,我们利用表型数据(例如性别、年龄和基因)从另一个角度计算节点相似度,旨在为输出高质量的图提供更多信息。 具体来说,给定表型数据矩阵 ,其中 () 表示不同类型的表型数据,我们定义表型图 作为
| (2) |
其中代表不同表型的数量,是第表型数据的相似性度量函数。 由于表型表示的分布和底层生成过程与节点特征不同,我们可以从等式(1)中的节点特征中选择不同的相似性度量。 1。 特别是在这项工作中,我们将性别和基因表型数据的 定义为 ,将年龄表型数据定义为 ,其中 。
III-B 网络修复
在FL中,每个局部图都是全局图的子集,不同机构的局部图之间不存在重叠节点。 因此,如果本地图节点的邻居位于另一个机构,则本地图是不完整的。 着眼于缺少邻居的某个节点,其全局图的原始自我网络结构是不完整的。 因此,局部图的节点信息是不完整的。 直接在缺少特征的损坏图上应用 GCN 可能会导致性能下降和不稳定。 为了解决这个问题,我们首先设计一个缺失节点生成器来为每个局部图生成缺失的节点和边。 然后,我们对本地缺失节点生成器进行 FL,以生成新的节点和边,以完成损坏的本地图的自我网络并增强消息传递。
III-B1 用于生成丢失节点的节点屏蔽
预测图修复缺失节点的一种实用方法是训练自监督回归模型来预测隐藏节点,然后使用该模型来预测局部图中的缺失节点。 为此,我们需要隐藏每个局部图的节点和边来构建回归模型。 文献中广泛采用随机方法随机去除节点[19],但不利于图中的特征传播。 此外,随机方法可能会生成孤立和断开的组件,这可能会损害自我网络结构的完整性,导致生成网络的次优化。 为了克服上述问题,我们建议使用 BFS 算法将图表示为给定根节点的子树结构。 直觉是,删除子树结构中的叶节点对于将我们选择的 Weisfeiler-Lehman 算法 GCN 策略 [31] 应用到局部图结构几乎没有影响。
具体来说,给定一个具有根节点的连通图,我们首先通过遍历图中的节点并将信息广播到邻居节点来构建BFS树。 基于这个性质,我们可以通过删除不同深度的叶子节点来生成子图。 更具体地说,选择一个根节点()并在局部图上使用BFS算法,我们屏蔽属于第深度的一些节点获取不完整的局部图为
| (3) |
通过随机访问局部图 的节点作为根节点并删除其叶节点,我们可以生成许多对(不完整图 ,隐藏节点)用作(输入,标签)用于缺失节点生成器训练(在我们的实验中,隐藏节点的数量通常占节点总数的10%-15%)。 我们进一步将 表示为节点 () 的屏蔽邻居之一, 表示。 由于每个屏蔽节点在图 中都有其对应的父节点,因此缺失生成器的目标是根据不完整的本地图 通过其父节点 重建屏蔽邻居 的信息。
III-B2 本地网络修复
在每个局部图中通过BFS算法屏蔽了一些节点后,我们需要正确预测每个节点缺失邻居的数量以及每个缺失邻居对应的特征和表型信息(即missing)节点)。
由于 GCN [31] 及其变体(例如,GraphSAGE [32])已被广泛用于捕获语义信息和结构信息图数据,在本研究中,我们采用 GCN 编码器 来获取本地图 中每个节点的嵌入。 请注意,GCN 对于小型图数据更加稳健,而 GraphSAGE 对于大规模图数据更加灵活[33]。 因此,考虑到局部系统的局部种群图通常是一个小图,我们在本研究中应用 GCN。 尽管不同的 GNN 结构可能会产生不同的性能,但本文的主要重点不是不同的 GNN 结构,而是群体图上的联邦学习。 因此我们选择最常用的GNN结构(即GCN)。 具体来说,使用,其中和表示节点的特征矩阵和不完全图的图矩阵,嵌入通过以下方式获得
| (4) |
其中GCN编码器有多个隐藏层,每个隐藏层包括两个操作,即特征学习和邻域聚合。 更具体地说,第 隐藏 GCN 层上的 GCN 操作定义为:
| (5) |
其中是的对角矩阵,是需要在第层训练的权重矩阵,代表激活操作的函数。
此外,我们提出的缺失节点生成器在嵌入 和真实值之间构建回归模型,以预测缺失节点/邻居的数量、这些节点的特征和表型信息。
预测丢失节点的数量。 每个父节点的缺失节点数由下式预测
| (6) |
其中 表示标准化为 的第 个节点的缺失邻居数量, 是 MLP 预测器映射将 嵌入到整数, 是 sigmoid 函数, 是由等式获得的 的嵌入。 (4)。 由于嵌入 通过 GCN 编码器聚合来自其剩余邻居的信息,因此预测器 可用于基于 为。
节点特征预测。 结合预测缺失节点的数量,我们预测每个缺失节点的特征和表型信息。 具体来说,我们设计了另一个回归模型(即一个 MLP),它吸收了 GCN 编码器 形成的嵌入特征 ,通过以下方式从其父节点 重构每个屏蔽邻居(例如,)的特征
| (7) |
其中 是高斯噪声生成器,用于生成不同的缺失邻居。 此外,我们引入重建损失来优化参数和:
| (8) |
缺失节点生成器可以被视为编码器-解码器。 也就是说,是考虑不完整图信息的GCN编码器(即),而是MLP用于重建被屏蔽邻居的特征的解码器。 然而,让生成器生成的特征与缺失邻居的数据分布真实匹配是具有挑战性的。 为此,我们采用 SN-GAN [23] 来提高生成器的效率。 具体来说,令为原始数据分布,为生成数据分布,我们通过以下方式获得生成器损失
| (9) |
其中 表示鉴别器,用于评估生成的特征与隐藏邻居的特征之间的差距。 将重建损失(方程8)与生成器损失(方程9)相结合,特征重建的最终损失表示为:
| (10) |
其中和分别是和的权重。 判别器 经过训练,可以识别该特征是来自生成器还是真正缺失的邻居。
| (11) |
总之,缺失节点的特征由公式(7)中的节点特征预测器 重建,并通过重建损失(公式(8))和 GAN 损失(公式(9)和公式(11)进行优化。)
由于缺失节点的特征可能不足以探索疾病群体网络中跨受试者的复杂结构,因此我们进一步预测表型,以获得缺失节点的连接(即边)。
表型预测和边缘构建。 给定缺失节点的数量及其特征,我们使用这些节点的表型信息及其节点属性来查找每个缺失节点与已知节点之间的连接。 在这方面,我们首先采用模型来预测被屏蔽节点的表型信息,然后找到两个节点之间的连接。
对于父节点 的第 个屏蔽邻居,第 类型的表型预测 由 ,其中 和 的定义如式 1 所示。 (7)。 对于带有类别标签的表型数据(例如性别和基因),我们采用交叉熵损失函数来更新模型参数
| (12) |
其中 是表型标签。 同样,年龄预测可以通过回归损失来优化。
值得注意的是,我们的FedNI的本地图修复策略与Zhang等人[19]使用的策略显着不同。 差异如下: 1)我们将随机节点屏蔽改进为基于 BFS 的节点屏蔽,以避免在局部图中生成孤立组件; 2)我们结合基于SN-GAN的训练方案和新颖的损失函数来提高生成节点特征的质量,而不是需要来自其他本地图的辅助信息,这会暴露更多的隐私风险; 3)除了预测缺失节点特征外,我们还预测其相关表型以构造加权边; 4) 表型进一步用于重建新的边缘以增强消息传递。 我们的策略的优点在第 2 节中得到了验证。 IV-C。
获得每个缺失节点的表型信息后,我们可以通过与第 2 节中描述的相同方式为这些缺失节点生成边。 III-A。
III-C 联邦学习
尽管缺失节点生成器能够为每个局部图生成缺失节点,但众所周知,GAN 在小数据上可能表现不佳[34]。 同样,训练一个有效的节点分类GCN模型也需要大量的样本。 由于分析多机构医疗数据的隐私限制,所提出的 FedNI 包括两个 FL 阶段:i)提出联邦网络修复来填充局部图的不完整特征,ii)提出联邦 GCN获得全局节点分类器。 我们的 FL 策略遵循广泛使用的 FedAvg [22] 聚合策略。
III-C1 联合网络修复
在秒。 III-B1,我们为每个本地系统描述了一个本地缺失节点生成器。 为了增强节点生成器的能力,我们的目标是联合学习一个全局节点生成器,该生成器利用来自不同机构的本地图,而不集中数据。 然而,我们将判别器保留在本地,因为我们注意到对判别器进行平均会损害模型性能(如第 IV-C 节所示)。 直觉是生成器应该遵循全局人口网络的数据分布来预测丢失的节点,而局部判别器可以更好地适应局部图的异质性。 为了实现这个目标,FL过程是重复以下步骤直到收敛:i)每个局部缺失节点生成器(包括在方程(6)上训练的节点预测器的数量>),在方程(10)上训练的节点特征生成器,在方程(12)上训练的表型回归 >)) 并行训练和更新; ii) 医政侧的全局缺失节点生成器对局部模型参数进行聚合和平均,然后将更新后的模型权重广播给所有局部缺失节点生成器。
III-C2 联邦GCN节点分类
由于我们方法 FedNI 的最终目标是获得全局 GCN 节点分类器,因此我们执行联邦 GCN 学习方法,在多个本地图上协作训练,同时保持数据隐私。 获得所有本地机构的融合本地图 后,我们在 GCN 上迭代应用 FedAVG [22] ,如下所示: i) 将每个本地 GCN 节点分类器训练一定数量步骤,然后将 GCN 权重共享给医疗管理中心,ii)通过平均本地 GCN 参数来更新全局 GCN 节点分类器,并将更新后的全局 GCN 广播给本地机构。
具体来说,对于本地GCN节点分类器训练,第机构使用融合图训练本地GCN节点分类器,其输出为,其中表示为等式: (5),学习参数为。 此外,将交叉熵损失视为局部GCN模型的损失:
| (13) |
其中 是第 本地系统上的标记节点集。 在第 次迭代中,第 次局部模型的参数 被更新(即 )并随后发送到服务器。
III-C3 隐私保护技术
最近的工作表明,输入数据可以根据共享模型参数[35]重建。 为了增强 FedNI 的安全性,我们采用差分隐私 (DP) [36],这是隐私保护 FL 的一种流行方法。 对于从地方机构共享到医疗管理中心的本地模型参数,即缺失节点生成器和 GCN 节点分类器,我们在本地模型权重中加入均值为、标准偏差为的高斯噪声,以满足本工作中的差分隐私。 最重要的是,我们在算法1中介绍了我们提出的框架的详细过程。
IV 实验
我们评估了 FL 方法对两个真实脑部疾病数据集的神经疾病分类的有效性:自闭症脑成像数据交换 (ABIDE) [37] 和阿尔茨海默病神经影像倡议 (ADNI) [ 38]。
IV-A 实验装置
| Data | ABIDE | ADNI | ||||||||||||
| Information | ASD | HC | MCI | AD | ||||||||||
| Subject # | 485 | 544 | 492 | 375 | ||||||||||
|
71/414 | 145/399 | 223/269 | 166/209 | ||||||||||
|
|
|
|
|
||||||||||
IV-A1 数据集
所用数据集中受试者的人口统计信息列于表I中。
ABIDE包括来自ABIDE-I和ABIDE-II的受试者,即 ASD患者和 具有功能磁共振成像(fMRI)数据的健康对照(HC)。 使用静息态 fMRI 数据处理助手对 fMRI 数据进行预处理 (DPARSF [39])333从http://rfmri.org/dpabi下载。. 使用稳定簇引导分析 (BASC-122) 模板将注册的 fMRI 体积划分为 122 个感兴趣区域 (ROI)。 我们为每个主题构建一个 FC网络,其中每个节点是一个ROI,边权重是成对ROI的BOLD信号时间序列之间的皮尔逊相关性。 我们使用全连接矩阵的上三角形来表示主题,产生维特征向量。
ADNI 包括 具有 ADNI-1、ADNI-GO 和 ADNI 2 T1 MRI 的受试者(即 AD 患者和轻度认知障碍(MCI)受试者。) 结构MRI数据通过以下操作进行预处理:(1)前连合-后连合(AC-PC)校正,重采样图像采用标准256×256×256模式,N3算法[40 ]应用于校正不均匀的组织强度; (2)颅骨切除和小脑切除; (3)空间归一化至分辨率为3×3×3的MNI模板; (4)使用尺寸为6mm的半高全宽高斯平滑核进行空间平滑。 我们使用 FreeSurfer [41] 对 T1 MRI [42] 的脑组织(白质、灰质和脑脊液)进行预处理并提取解剖统计数据,得到 345 维特征向量。 考虑到不同测量的异质性,我们还分别对每个特征向量应用 z 分数归一化。
| Layer | Details |
| 1 | G-conv(, 256) + ELU |
| 2 | G-conv(256, 64) + ELU |
| 3 | FC(64, 1) +Sigmoid |
| 4 | Random-vector(4) |
| 5 | Linear(68, 128) + ReLU+BN(128) |
| 6 | Linear(128, 256) + ReLU+BN(256) |
| 7 | FC(256, ) + tanh |
| 8 | Linear(, 32) ReLU |
| 9 | FC(32, 2) |
| Layer | Details |
| 1 | SN-Linear(, 128) + ReLU |
| 2 | SN-Linear(128, 32) + ReLU |
| 3 | SN-Linear(32, 1) |
| Layer | Details |
| 1 | G-conv(, 64) + ELU |
| 2 | G-conv(64, 32) |
| 3 | FC(32, 2) |
| ABIDE | ADNI | |||||||||
| Method | Accuracy | AUC | Precision | Recall | F1-score | Accuracy | AUC | Precision | Recall | F1-score |
| LocalGCN | 0.600 | 0.598 | 0.580 | 0.559 | 0.560 | 0.703 | 0.695 | 0.666 | 0.637 | 0.643 |
| (0.012) | (0.011) | (0.012) | (0.017) | (0.012) | (0.016) | (0.018) | (0.022) | (0.037) | (0.028) | |
| CentralGCN | 0.655 | 0.654 | 0.635 | 0.633 | 0.633 | 0.757 | 0.750 | 0.734 | 0.691 | 0.710 |
| (0.008) | (0.008) | (0.010) | (0.015) | (0.011) | (0.007) | (0.006) | (0.013) | (0.014) | (0.008) | |
| FedMLP | 0.630 | 0.627 | 0.618 | 0.573 | 0.591 | 0.731 | 0.721 | 0.625 | 0.631 | 0.625 |
| (0.011) | (0.011) | (0.017) | (0.029) | (0.015) | (0.026) | (0.030) | (0.081) | (0.077) | (0.079) | |
| FedGCN | 0.644 | 0.643 | 0.625 | 0.616 | 0.613 | 0.742 | 0.735 | 0.704 | 0.693 | 0.692 |
| (0.009) | (0.009) | (0.011) | (0.022) | (0.012) | (0.007) | (0.009) | (0.010) | (0.014) | (0.009) | |
| FedSage+ | 0.658 | 0.655 | 0.641 | 0.627 | 0.626 | 0.751 | 0.744 | 0.722 | 0.699 | 0.700 |
| (0.006) | (0.008) | (0.013) | (0.017) | (0.009) | (0.008) | (0.010) | (0.009) | (0.015) | (0.010) | |
| FedNI(ours) | 0.667 | 0.663 | 0.647 | 0.640 | 0.637 | 0.758 | 0.754 | 0.725 | 0.721 | 0.717 |
| (0.006) | (0.007) | (0.009) | (0.014) | (0.007) | (0.007) | (0.007) | (0.008) | (0.017) | (0.011) | |
IV-A2 模型训练设置
我们列出了 FL 和实现平台的详细设置如下。
联邦学习设置。 考虑到 ABIDE 和 ADNI 的人口规模,我们将这两个数据集的机构数量设置为 5(即 ),除了在整个数据集上训练的 CentralGCN 之外的所有方法。 对于这两个数据集,我们将受试者平均随机分为 5 个子集,并将每个子集分配给一个机构444我们工作的主要目标不是处理不同机构收集的数据的显着分布异质性。 为了控制这个因素,我们随机划分样本,而不是按机构对样本进行聚类。. 具体来说,每个机构的 ABIDE 数据集有 206 个科目,ADNI 数据集有 182 个科目。 关注基普夫 等人。 [31],我们在小型本地图上使用 full-batch 训练。 我们使用 Adam 作为优化器,并将所有实验的学习率设置为 0.001。 我们在第 2 节中详细介绍了不同方法的训练迭代。 IV-B。
实施平台和实验因素控制。 所有实验均在 PyTorch 中实现,并在具有 8 个 NVIDIA GeForce 3090 GPU(每个 GPU 24 GB 内存)的服务器上进行。 标记率设置为 80%,训练/测试数据根据 5 倍交叉验证进行分割。 我们获得了所有比较方法的作者验证代码,并遵循相应文献中参数设置的建议,以便所有比较方法在每个数据集上都能达到最佳性能。 此外,所有方法(包括我们的方法)对原始图结构、训练/测试分区、网络维度和训练过程都使用相同的设置。 此外,表II-IV展示了缺失节点生成器、鉴别器和GCN节点预测模块所使用的网络架构,这些网络架构是用PyTorch框架实现的。 图卷积层用“G-conv”表示,批归一化层用“BN”表示。 我们使用“Linear”表示线性变换层,使用“FC”表示用于分类的全连接层。 “ReLU”用作非线性函数,“ELU”表示指数线性单元。 sigmoid 函数用“sigmoid”表示,双曲正切函数用“tanh”表示。 此外,我们在括号中显示通道维度,其中 表示输入维度。
IV-A3 绩效评估
所有方法的诊断结果均通过准确率、ROC曲线下面积(AUC)、精度、召回率和F1-score五个评价指标进行评估。 对于所有这些指标,更高的值意味着更好的性能。 在所有实验中,我们进行了 5 倍交叉验证,并使用随机种子对每种方法重复实验 5 次,以报告其平均性能和相应的标准偏差。 我们使用两个样本 t 检验进行显着性检验。
IV-B 与替代方法的比较
IV-B1 替代方法
我们比较了两种集中方法和三种 FL 方法。 详细的比较方法如下:
CentralGCN[10] 假设数据是中心化的,并在原始全局图上训练 GCN 模型。 图构建策略和我们的一样。
LocalGCN 遵循 CentralGCN 中的模型架构,但在非 FL 设置下仅在每个局部图上训练 GCN 模型。
FedMLP[13] 应用 FedAvg 策略 [22] 来训练具有个体扁平大脑连接矩阵的基本 MLP 模型,而不考虑总体图信息。
FedGCN 是在 LocalGCN 上构建的,只需在本地 GCN 上使用 FedAvg [22] 即可。
FedSage+[19] 为每个局部图训练缺失节点生成器和 GraphSage 分类器来进行 FL。 特别是,缺失节点生成器只是一个回归模型,它被设计为生成缺失节点的特征,而不考虑生成表型信息和增强边缘。
集中训练方法(CentralGCN 和 LocalGCN)的学习纪元设置为 100。 对于 FL 方法,我们需要设置每个全局聚合 之间的本地更新纪元和本地-全局模型通信轮 之间的本地更新纪元。对于 FedMLP、FedGCN 和 FedSage+,我们设置 和 。 由于我们的方法 FedNI 使用两阶段训练策略,因此我们设置 和 进行联合网络修复,然后设置 和 用于联合 GCN 节点分类。 我们选择两阶段策略,因为它可以通过降低优化的复杂性来稳定 GAN 训练。 此外,与端到端训练策略相比,我们观察到更好且稳定的性能。
IV-B2 结果与分析
表V总结了所有方法在两个神经系统疾病数据集上的分类性能。 首先,我们的方法在两个数据集上的准确性、AUC、精度、召回率和 F1 分数方面优于所有方法。 同时,我们发现与比较方法相比,改进是显着的(通过 t 检验使用 )。 特别是,首先,与孤立机构中基于人群的普通疾病分类相比,我们的方法 FedNI 平均提高了 ()( 即LocalGCN)。 这表明部署 FL 来鼓励具有隐私约束的多机构协作学习的必要性。 由于独特的FL优化方案减轻了噪声数据对模型更新方向的影响,FedNI的性能甚至可能略好于CentralGCN。 值得注意的是,神经影像数据的样本是有限的,因此FedNI生成的邻居不仅可以弥补本地客户端之间的分布差异,而且还可以在全局范围内涉及更多的训练节点以获得更好的表示。 其次,FedNI 在 ABIDE 数据集上比 FedGCN 好 3.61% (),在 ADNI 数据集上比 FedGCN 高 3.07% ()。 为此,FedNI 还取得了比 FL 最佳竞争对手 FedSage+ 更好的性能。 具体来说,与 FedSage+ 相比,我们的方法平均提高了 1.2% ()、1.4% ()、0.6% ()、2.6准确率、AUC、精确率、召回率和 F1 分数分别为 % () 和 2.1% ()。 这些结果表明,我们提出的 FedNI 联邦网络修复设计的有效性可以在小型孤立人口图上实现比最先进的技术更好的联邦图学习性能(即FedSage+)。
IV-C 消融研究
在本节中,我们进行了广泛的消融研究,以证明网络修复模块中三种基本技术的必要性(参见第 IV-C1 节);仅验证联邦训练生成器的合理性(参见第 IV-C2 节);并通过所提出的学习机制展示完整、更可靠的局部图的力量(参见第 IV-C3 节)。
IV-C1 BFS、边缘预测和鉴别器的消融
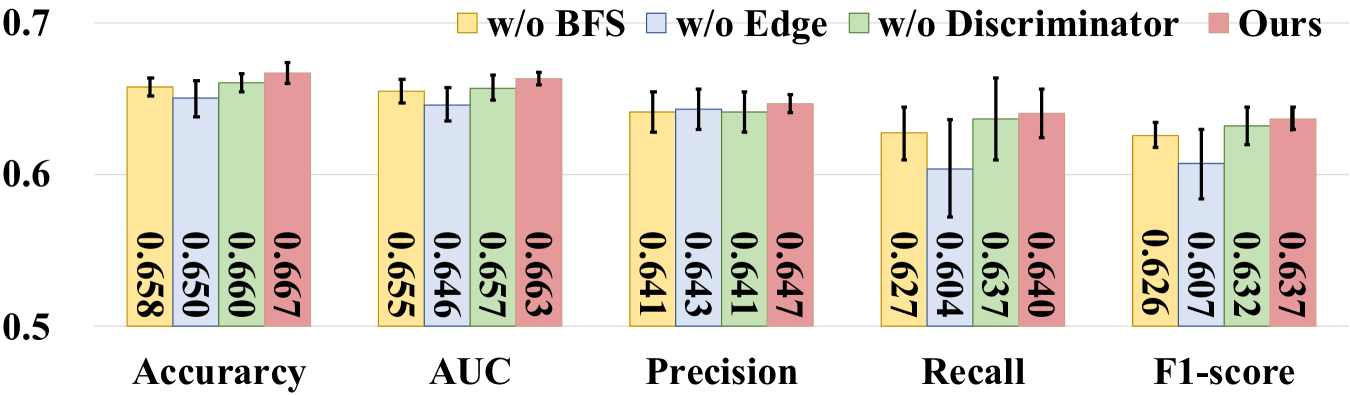
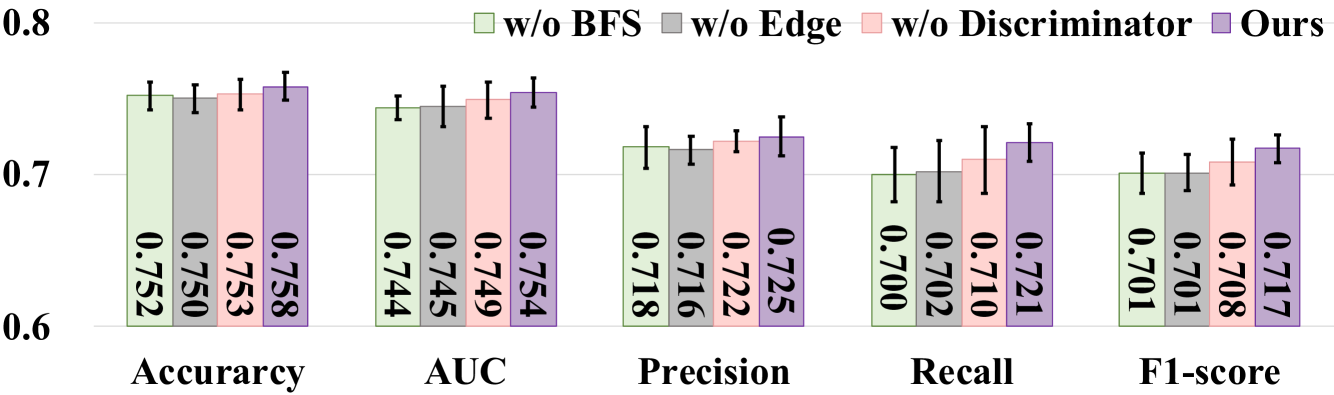
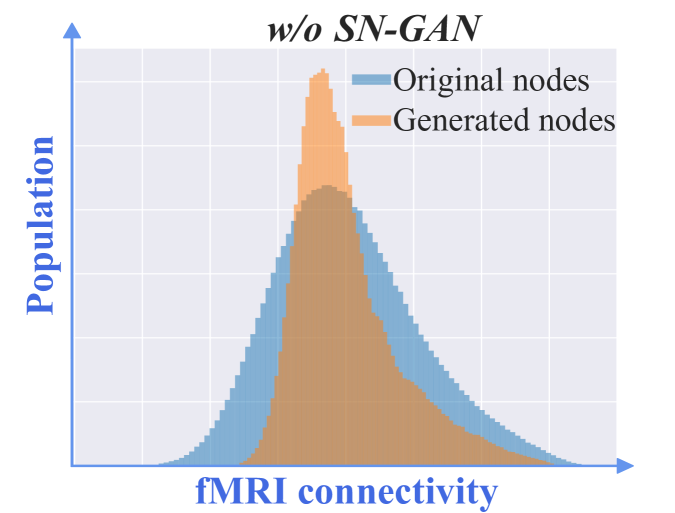
所提出的 FL 本地网络修复模块由三个基本组件组成,包括应用 BFS 生成不完整图、结合表型数据进行边缘预测以及使用 SN-GAN 判别器来提高特征保真度。 为了证实这些组件的优越性,通过从我们的方法中删除每个组件来进行全面的消融研究,图2显示了每个组件如何对最终性能做出贡献。
BFS 的有效性。 为了评估BFS算法的有效性(即方程(3)),我们分别报告了BFS算法和随机方法隐藏节点的性能,图2。 可以看出,使用BFS算法隐藏节点时,在ABIDE数据集和ADNI数据集上,与随机掩码相比,AUC的平均性能分别提高了1.0%和1.1%。
边缘预测的有效性。 边缘信息是GCN模型的基本元素。 缺失的边及其特征可能会导致图上的自我网络不完整,从而损害疾病预测的性能。 在这一部分中,我们研究利用表型数据预测边缘的有效性。 为了实现这一点,我们在缺失节点生成器方法中替换了边缘重建操作(即Sec.III-B2),添加了二值化自我节点与其缺失的邻居[19]之间的链接。 从图2可以看出,我们的方法在所有评估指标上都能取得更好的性能。 例如,我们获得的 AUC 结果为 0.663,这高于在不生成新边缘的情况下消融的结果(即 0.646)。 可以得出结论,基于表型预测生成边对于生成高质量图至关重要。
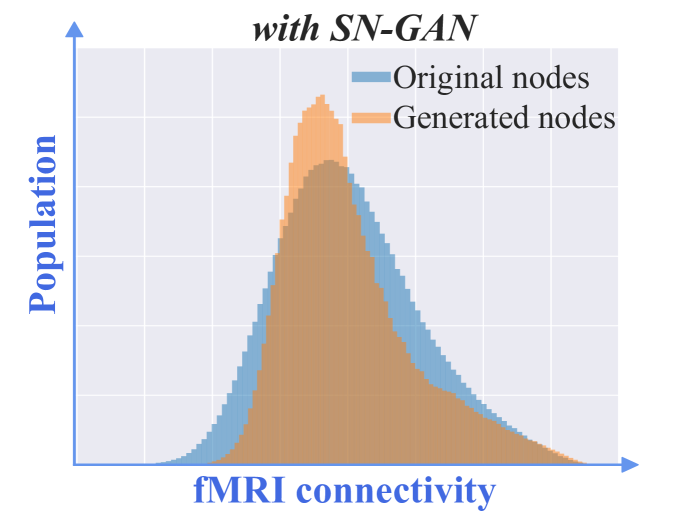
IV-C2 不同的网络修复模块训练策略
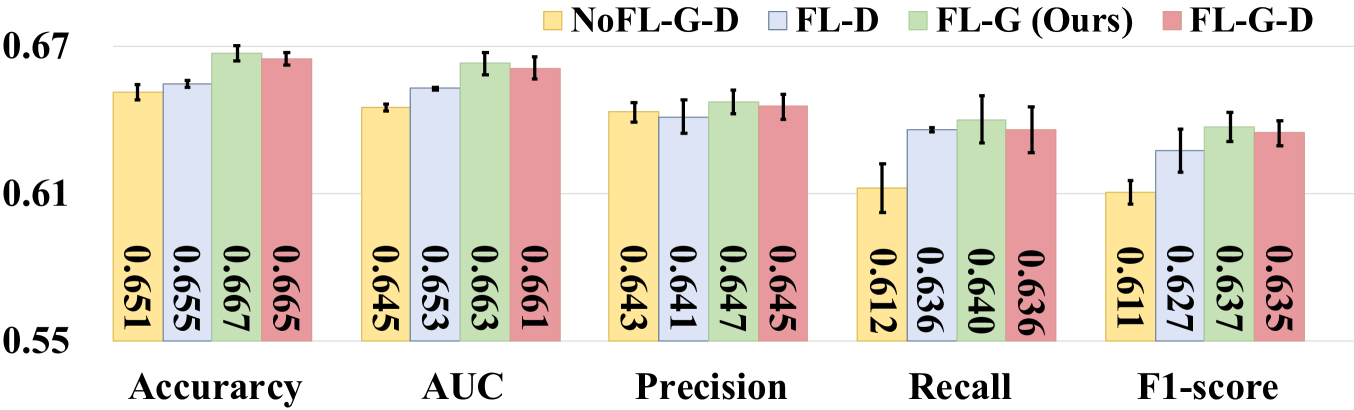
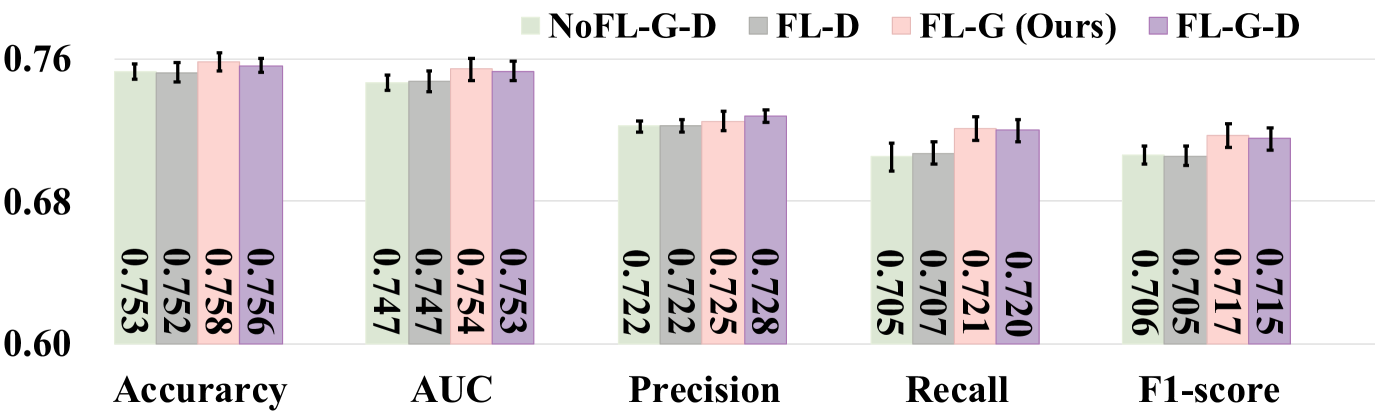
为了进一步研究在网络修复模块上应用 FL 的有效性,我们在网络修复模块上使用四种训练策略变体进行实验:(i)训练生成器模型(即 G)和非FL设置(即NoFL-D-G)下网络修复模块的判别器模型(即D); (ii) 仅FL设置下的判别器模型(即FL-D); (iii) 仅FL设置下的发电机型号(即FL-G); (iv) 在FL设置下训练生成器模型和判别器模型(即FL-D-G)。 图3显示了所提出的具有四种FL训练策略变体的网络修复模块的结果,从中我们观察到以下内容:(1)在生成器模型上应用FL(即FL-G)通常优于训练策略的其他变体(例如,NoFL-D-G 和 FL-D)。 例如,与 NoFL-D-G 和 FL-D 相比,FL-G 方法在准确度、AUC、精确度、召回率和 F1 分数方面取得了显着更好的性能(通过 t 检验得出 )。 主要原因可能是在生成器模型上应用FL可以使本地生成器模型输出与其他组织的节点特征更相似的节点特征。 (2)从FL-G与FL-G-D的比较以及NoFL-D-G与FL-D的比较可以看出,在判别器上使用FL时没有显着的改善。 原因可能是生成器可以直接影响生成的特征,而鉴别器则间接影响它。 直觉是生成器应该遵循全局人口网络的数据分布来预测丢失的节点,而局部判别器可以更好地适应局部图的异质性。 这些观察结果进一步验证了我们的网络修复策略(仅限 FL-G)的有效性。
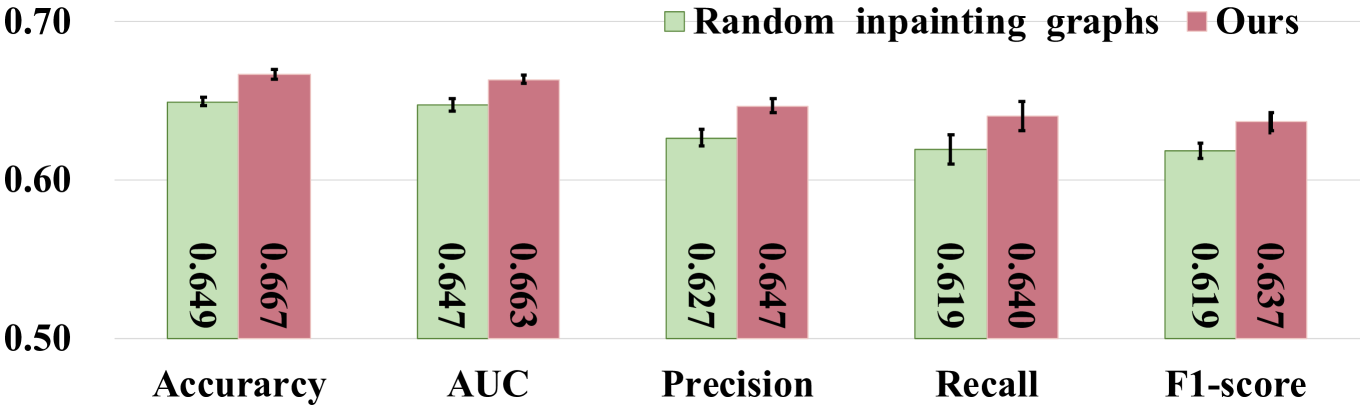
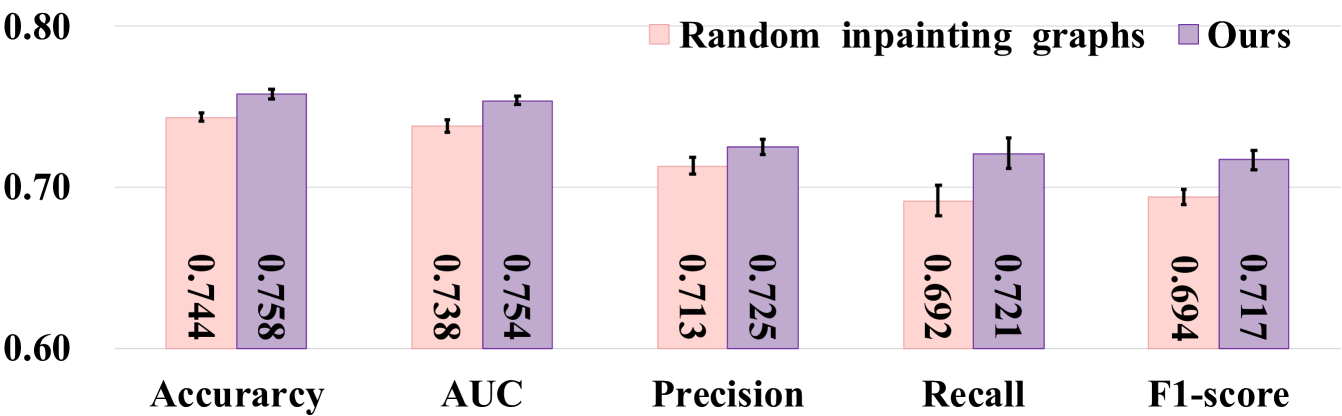
IV-C3 与随机修复的比较
IV-C4 FedNI 的可扩展性
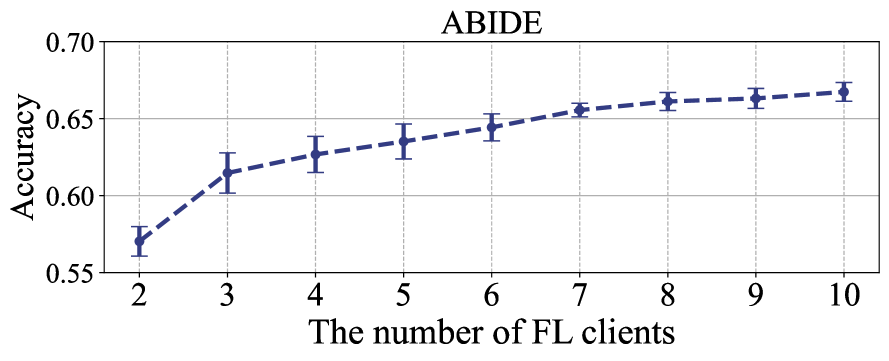
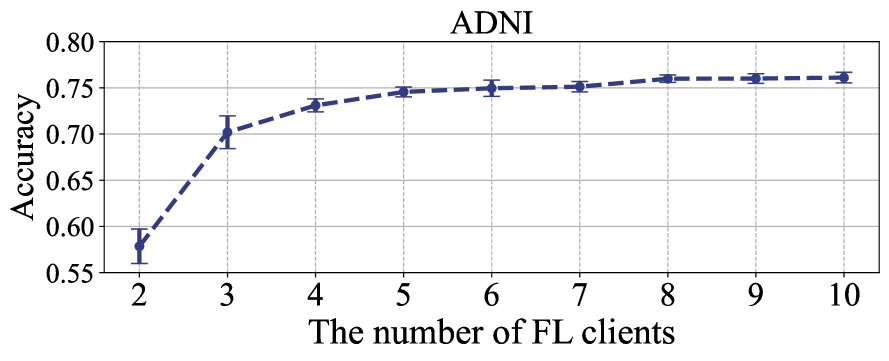
我们进行了一项实验来研究 FedNI 在 FL 客户端数量方面的可扩展性(增加 FL 客户端数量并保持本地客户端中的节点数量固定)。 这样,我们固定每个本地客户端的节点数(即数据集中节点数的10%),并增加客户端的数量(即从 2 到 10)。 客户越多,可用于全局模型学习其模式的训练样本就越多。 如图7所示,我们观察到涉及更多客户端可以提高性能并保持一致性。 根据这些结果,我们可以得出结论,FedNI 具有良好的可扩展性,随着全球范围内客户端数量的增加,从而产生更好的性能。 在这种情况下,如果我们想要在实际应用中获得更好的结果,我们可以通过让更多的客户参与来实现这一目标。 重要的是,我们在表中报告了结果的计算成本。 VI。 直观上,这对于可扩展性来说是有意义的,因为低计算成本允许涉及更多 FL 客户端以获得更好的结果。
IV-C5 计算成本
计算成本实验使用 PyTorch (vision 1.9) 框架实现,并通过四个指标进行报告,包括 FLOPs ()、Params ()、训练时间()和总时间()。 请注意,所提出的 FedNI 包括两个 FL 阶段(即联合网络修复和联合 GCN 节点分类),我们报告了以下计算成本:每个阶段以及总时间(总时间包括两个阶段的训练次数和图合并过程正如我们在第 III-C1 节中所述)。 对于联合网络修复阶段,模型的输入是客户端的一个本地图(即具有 200 个节点的图,其中每个节点包含一个 7381 维特征向量) 。 对于联合 GCN 节点分类阶段,模型的输入是客户端的一个局部融合图(即具有 300 个节点的图,其中每个节点包含 7381 维特征)向量)。 从选项卡。 VI,我们观察到FedNI的两个阶段的计算量都很低。 虽然联合网络修复阶段带来了额外的计算成本,但这是可以接受的,因为它们处于相同的计算成本水平。 结果表明FedNI具有潜在的实际应用潜力和良好的可扩展性。
|
|
|||||
| FLOPs () | 0.98 | 0.26 | ||||
| Params () | 3.1 | 0.47 | ||||
| Training time () | 66 | 11 | ||||
| Total time () | 89 | |||||
IV-D 超参数讨论
IV-D1 参数敏感性分析
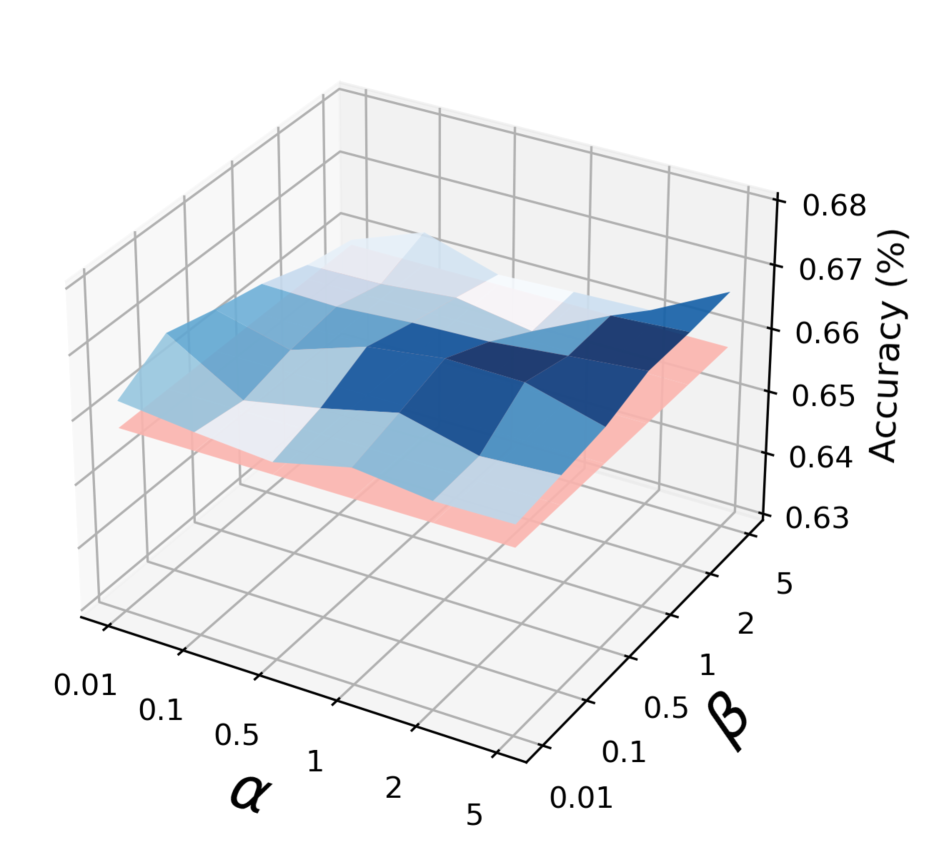
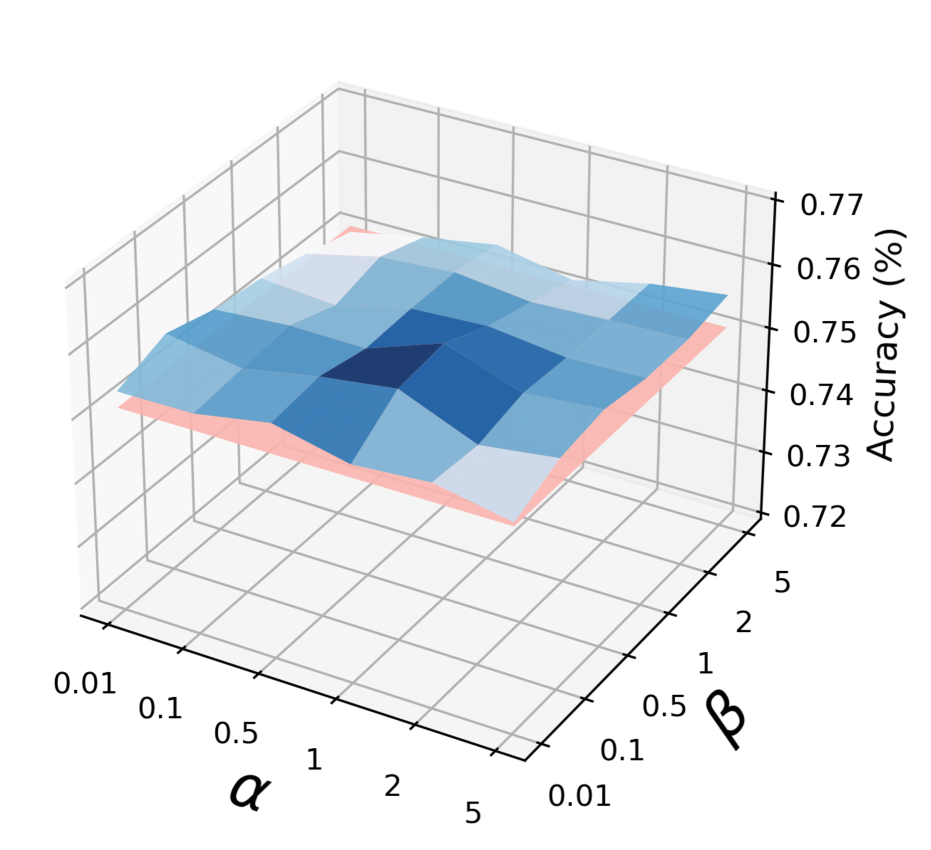
在我们的实验中,我们使用方程式中的默认非加权损失。 (10),即两个数据集的 和 。 我们研究了公式 (10) 中我们方法的加权系数(即 和 )的敏感性。 我们将 和 的值从 更改为 ,并报告 5 次独立运行内的准确度平均值。 图 6 表明我们的方法对 和 不敏感,并且始终优于 FedSage+ 的最佳性能(即 红色图6中的平面)。 这是因为我们的模型具有精心设计的特征重建框架并且非常稳健。
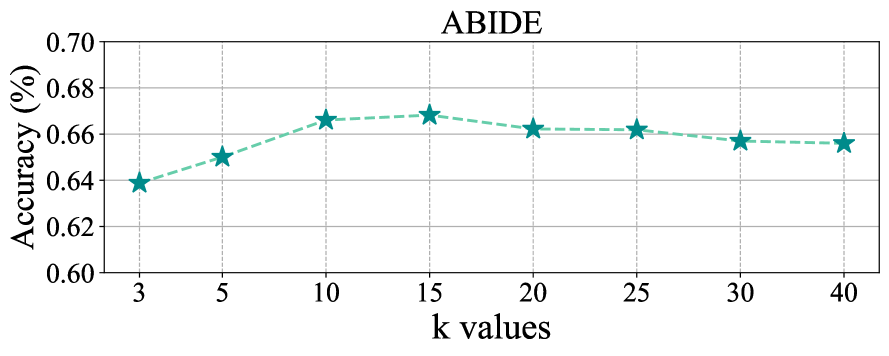
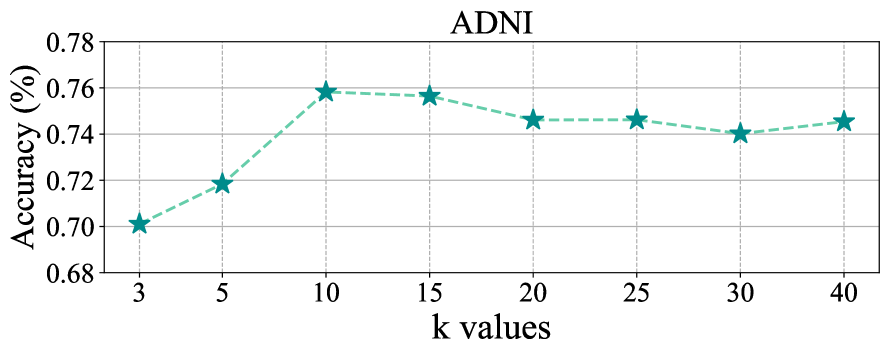
我们进一步进行了实验来研究超参数。节中的超参数。 III-A 是最近邻居的数量。 我们将的范围设置为,超参数不同值的结果如图8所示。 我们可以观察到,我们的方法的分类精度随着、的值的增加而增加,即从到,将 的值增加到超过阈值可能会轻微损害性能,即从 到 的 。 原因是较小的值无法充分发挥邻居的能力,而较大的值可能会导致GCN中出现噪声邻居和过平滑问题。 此外,我们的方法中的最佳 值可以在两个数据集上轻松找到(即 ,在 附近)。
IV-D2 本地更新纪元
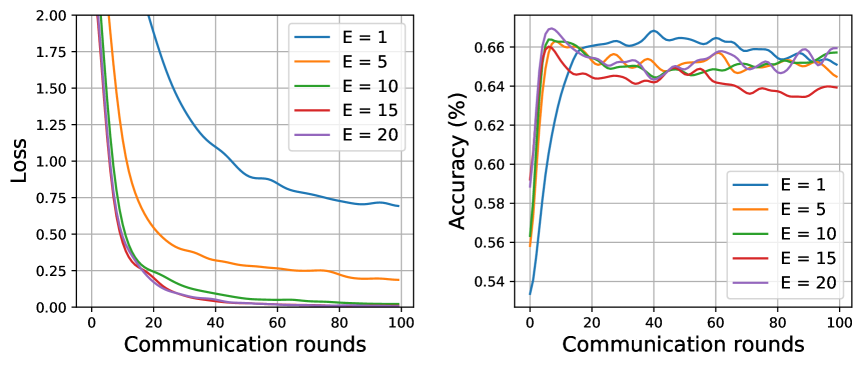
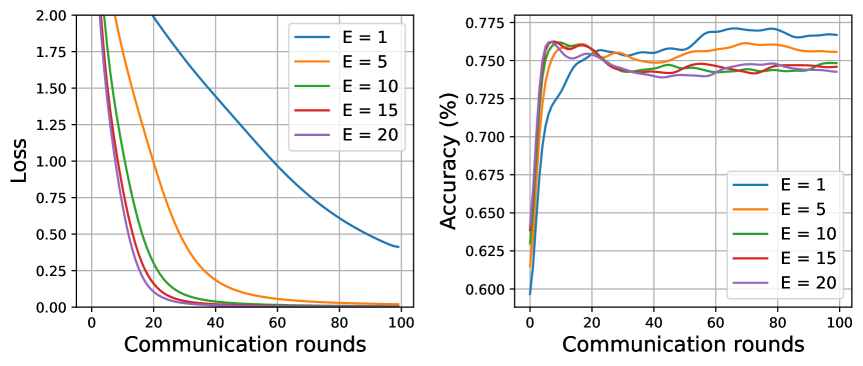
我们研究了 FedNI 中本地更新时期 的敏感性。 我们使用不同的局部更新时期 值来评估训练收敛性并测试准确性。 如图9所示,我们可以观察到随着训练过程通信轮次的增加,损失正在减小,因此我们的方法具有良好的收敛性。 此外,训练大型局部更新周期需要更少的全局通信轮次来收敛,同时导致模型性能较低,尤其是在 ADNI 数据集中。
V 结论
在这项工作中,我们提出了一个用于分布式局部人口网络分析的新 FL 框架。 为了解决本地网络中现实但被忽视的信息不完整问题,我们设计了一个联合网络修复模块,其中缺失节点生成器允许每个机构生成缺失的节点和边。 我们通过联邦训练缺失节点生成器和基于 GCN 的节点分类模型。 对公共数据集的大量实验表明,我们的方法获得了最先进的性能。 我们未来的工作将解决数据异构性问题,以进一步提高性能。
VI 致谢
该工作得到了国家自然科学基金项目(批准号:2017)的部分资助。 61876046),电子科技大学医工合作基金(编号:61876046) ZYGX2022YGRH009和ZYGX2022YGRH014)、中国广西“八桂”创新研究团队和加拿大自然科学与工程研究理事会(GECR-2022-00430)。
作者衷心感谢 NVIDIA 和 Microsoft Azure 的支持。 我们感谢斯坦福大学的赵清宇博士提供的数据收集和不列颠哥伦比亚大学的廖仁杰博士的富有洞察力的建议。
参考
- [1] S. R. Stevens and M. N. Rasband, “Ankyrins and neurological disease,” Current Opinion in Neurobiology, vol. 69, pp. 51–57, 2021.
- [2] C.-Y. Wee, P.-T. Yap, and D. Shen, “Diagnosis of autism spectrum disorders using temporally distinct resting-state functional connectivity networks,” CNS neuroscience & therapeutics, vol. 22, no. 3, pp. 212–219, 2016.
- [3] X. Song, A. Elazab, and Y. Zhang, “Classification of mild cognitive impairment based on a combined high-order network and graph convolutional network,” Ieee Access, vol. 8, pp. 42 816–42 827, 2020.
- [4] Y. Huang and A. C. Chung, “Edge-variational graph convolutional networks for uncertainty-aware disease prediction,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2020, pp. 562–572.
- [5] T.-A. Song, S. R. Chowdhury, F. Yang, H. Jacobs, G. El Fakhri, Q. Li, K. Johnson, and J. Dutta, “Graph convolutional neural networks for alzheimer’s disease classification,” in 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019). IEEE, 2019, pp. 414–417.
- [6] H. Li and Y. Fan, “Brain decoding from functional mri using long short-term memory recurrent neural networks,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2018, pp. 320–328.
- [7] S. Spasov, L. Passamonti, A. Duggento, P. Lio, N. Toschi, A. D. N. Initiative et al., “A parameter-efficient deep learning approach to predict conversion from mild cognitive impairment to alzheimer’s disease,” Neuroimage, vol. 189, pp. 276–287, 2019.
- [8] N. C. Dvornek, X. Li, J. Zhuang, and J. S. Duncan, “Jointly discriminative and generative recurrent neural networks for learning from fmri,” in International Workshop on Machine Learning in Medical Imaging. Springer, 2019, pp. 382–390.
- [9] V. P. Sudha and M. Vijaya, “Recurrrent neural network based model for autism spectrum disorder prediction using codon encoding,” Journal of The Institution of Engineers (India): Series B, pp. 1–7, 2021.
- [10] S. Parisot, S. I. Ktena, E. Ferrante, M. Lee, R. Guerrero, B. Glocker, and D. Rueckert, “Disease prediction using graph convolutional networks: application to autism spectrum disorder and alzheimer’s disease,” Medical image analysis, vol. 48, pp. 117–130, 2018.
- [11] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer International Publishing, vol. 10, p. 3152676, 2017.
- [12] A. Act, “Health insurance portability and accountability act of 1996,” Public law, vol. 104, p. 191, 1996.
- [13] X. Li, Y. Gu, N. Dvornek, L. H. Staib, P. Ventola, and J. S. Duncan, “Multi-site fmri analysis using privacy-preserving federated learning and domain adaptation: Abide results,” Medical Image Analysis, vol. 65, p. 101765, 2020.
- [14] I. Dayan, H. R. Roth, A. Zhong, A. Harouni, A. Gentili, A. Z. Abidin, A. Liu, A. B. Costa, B. J. Wood, C.-S. Tsai et al., “Federated learning for predicting clinical outcomes in patients with covid-19,” Nature medicine, vol. 27, no. 10, pp. 1735–1743, 2021.
- [15] Q. Yang, J. Zhang, W. Hao, G. Spell, and L. Carin, “Flop: Federated learning on medical datasets using partial networks,” arXiv preprint arXiv:2102.05218, 2021.
- [16] P. V. Astillo, D. G. Duguma, H. Park, J. Kim, B. Kim, and I. You, “Federated intelligence of anomaly detection agent in iotmd-enabled diabetes management control system,” Future Generation Computer Systems, 2021.
- [17] C. He, K. Balasubramanian, E. Ceyani, C. Yang, H. Xie, L. Sun, L. He, L. Yang, P. S. Yu, Y. Rong et al., “Fedgraphnn: A federated learning system and benchmark for graph neural networks,” arXiv preprint arXiv:2104.07145, 2021.
- [18] R. A. Hanneman and M. Riddle, “Introduction to social network methods,” 2005.
- [19] K. Zhang, C. Yang, X. Li, L. Sun, and S. M. Yiu, “Subgraph federated learning with missing neighbor generation,” arXiv preprint arXiv:2106.13430, 2021.
- [20] Q. Zhu, Y. Xu, H. Wang, C. Zhang, J. Han, and C. Yang, “Transfer learning of graph neural networks with ego-graph information maximization,” arXiv preprint arXiv:2009.05204, 2021.
- [21] H. Taguchi, X. Liu, and T. Murata, “Graph convolutional networks for graphs containing missing features,” Future Generation Computer Systems, vol. 117, pp. 155–168, 2021.
- [22] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics. PMLR, 2017, pp. 1273–1282.
- [23] T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, “Spectral normalization for generative adversarial networks,” arXiv preprint arXiv:1802.05957, 2018.
- [24] H. Jiang, P. Cao, M. Xu, J. Yang, and O. Zaiane, “Hi-gcn: A hierarchical graph convolution network for graph embedding learning of brain network and brain disorders prediction,” Computers in Biology and Medicine, vol. 127, p. 104096, 2020.
- [25] J. Yi, J. Lee, K. J. Kim, S. J. Hwang, and E. Yang, “Why not to use zero imputation? correcting sparsity bias in training neural networks,” arXiv preprint arXiv:1906.00150, 2019.
- [26] Y. Luo, X. Cai, Y. Zhang, J. Xu, and X. Yuan, “Multivariate time series imputation with generative adversarial networks,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, 2018, pp. 1603–1614.
- [27] A. Abraham, M. P. Milham, A. Di Martino, R. C. Craddock, D. Samaras, B. Thirion, and G. Varoquaux, “Deriving reproducible biomarkers from multi-site resting-state data: An autism-based example,” NeuroImage, vol. 147, pp. 736–745, 2017.
- [28] Y. Zhu, J. Ma, C. Yuan, and X. Zhu, “Interpretable learning based dynamic graph convolutional networks for alzheimer’s disease analysis,” Information Fusion, vol. 77, pp. 53–61, 2022.
- [29] L. Li, Y. Fan, M. Tse, and K.-Y. Lin, “A review of applications in federated learning,” Computers & Industrial Engineering, p. 106854, 2020.
- [30] W. Li, F. Milletarì, D. Xu, N. Rieke, J. Hancox, W. Zhu, M. Baust, Y. Cheng, S. Ourselin, M. J. Cardoso et al., “Privacy-preserving federated brain tumour segmentation,” in International workshop on machine learning in medical imaging. Springer, 2019, pp. 133–141.
- [31] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [32] W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in NIPS, 2017, pp. 1025–1035.
- [33] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip, “A comprehensive survey on graph neural networks,” IEEE transactions on neural networks and learning systems, vol. 32, no. 1, pp. 4–24, 2020.
- [34] S. Zhao, Z. Liu, J. Lin, J.-Y. Zhu, and S. Han, “Differentiable augmentation for data-efficient gan training,” arXiv preprint arXiv:2006.10738, 2020.
- [35] L. Zhu and S. Han, “Deep leakage from gradients,” in Federated learning. Springer, 2020, pp. 17–31.
- [36] C. Dwork, A. Roth et al., “The algorithmic foundations of differential privacy.” Found. Trends Theor. Comput. Sci., vol. 9, no. 3-4, pp. 211–407, 2014.
- [37] A. Di Martino, C.-G. Yan, Q. Li, E. Denio, F. X. Castellanos, K. Alaerts, J. S. Anderson, M. Assaf, S. Y. Bookheimer, M. Dapretto et al., “The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism,” Molecular Psychiatry, vol. 19, no. 6, pp. 659–667, 2014.
- [38] “Alzheimer’s disease neuroimaging initiative (adni),” http://adni.loni.usc.edu, 2003.
- [39] C. Yan and Y. Zang, “Dparsf: a matlab toolbox for ”pipeline” data analysis of resting-state fmri,” Frontiers in Systems Neuroscience, vol. 4, p. 13, 2010.
- [40] J. G. Sled, A. P. Zijdenbos, and A. C. Evans, “A nonparametric method for automatic correction of intensity nonuniformity in mri data,” IEEE transactions on medical imaging, vol. 17, no. 1, pp. 87–97, 1998.
- [41] B. Fischl, “Freesurfer,” Neuroimage, vol. 62, no. 2, pp. 774–781, 2012.
- [42] G. Baronzio, A. Zambelli, D. Comi, A. Barlocco, A. Baronzio, P. Marchesi, A. Gramaglia, E. Castiglioni, A. Mafezzoni, E. Beviglia et al., “Proinflammatory and regulatory cytokine levels in aids cachexia.” In vivo (Athens, Greece), vol. 13, no. 6, pp. 499–502, 1999.