0 研究 Yuyu Luo 和Guoliang Li 来自中国清华大学计算机科学系。 电子邮件:{luoyy18@mails., liguoliang@}tsinghua.edu.cn Jiawei Tang 就职于卡塔尔多哈的多哈美国学校。 电子邮件:23jtang@asd.edu.qa
学术界自然语言查询到可视化的简史。 2021 年发布 nvBench 后,开发了一些基于深度学习的模型来支持将自然语言查询转换为可视化。
nvBench:跨域
自然语言到可视化任务的大规模综合数据集
摘要
NL2VIS – 将自然语言 (NL) 查询转换为相应的可视化 (VIS) – 已吸引了商业可视化供应商和企业越来越多的关注学术研究人员。 在过去的几年里,基于深度学习的先进模型在许多自然语言处理(NLP)任务中实现了类似人类的能力,这清楚地告诉我们基于深度学习的技术是推动NL2VIS。 然而,一个很大的障碍是缺乏大量(NL,VIS)对的基准。 我们推出了 nvBench,这是第一个大规模 NL2VIS 基准测试,包含 750 个中的 25,750 个(NL、VIS)对超过 105 个域的表,由(NL、SQL)基准综合而成,以支持跨域NL2VIS 任务。 nvBench 的质量得到了 23 位专家和 300 多名众包工作者的广泛验证。 使用nvBench进行的基于深度学习的模型训练表明nvBench可以推动NL2VIS领域的发展。
介绍
通过自然语言从数据创建有意义的可视化是一种很有前途的交互范式,尤其是对于新手来说,并且是实现数据可视化民主化的重要一步[31,25,12,13,14,19]。 两个主流商业供应商(例如 Tableau 的 Ask Data [2]、Microsoft Power BI [3]、ThoughtSpot [4] 和 Amazon 的 QuickSight [1])和学术研究人员 [23, 29, 27, 8, 26, 9, 24, 17, 15, 16, 35, 11, 20 , 6] 数十年来一直在探索支持 NL2VIS 的技术。
尽管NL2VIS很重要,但NL2VIS的研究仍处于起步阶段[4]。 目前,大多数NL2VIS系统主要基于NLP统计解析器开发,仅支持简单或受限的NL查询。 尽管基于深度学习的前沿模型在许多 NLP 任务(例如文本分类、语言翻译)中具有类似人类的能力,但此类技术并不适合 NL2VIS 领域。 主要障碍是缺乏大规模、高质量的基准来支持NL2VIS任务,我们的目标是填补这一空白。
给定一个表(或数据库),NL2VIS 可以被视为翻译自然语言查询的机器翻译任务(例如,向我展示趋势中国的 COVID-19 确诊病例总数)到可视化查询(例如, 标记行数据 COVID-19 编码 x 日期 y 总和已确认转换过滤器国家/地区 = '中国'组 x),以便呈现为可视化规范(例如 Vega-Lite)。 成功的关键因素是获得足够的高质量(NL,VIS)对,因为深度学习模型需要大规模和高质量的可用性训练数据。
在本文中,我们提出了这样一个基准,即 nvBench [18],其中包含 25,750 (NL, VIS) 对来自 105 个域的 750 多个表进行配对,以支持跨域 NL2VIS 任务。 与通过手动设计和收集足够的数据和查询来构建此类基准的常见做法不同,我们通过搭载 NL2SQL 基准来综合 nvBench。 直觉基于 SQL 查询和 VIS 查询之间的语义连接:SQL 查询指定需要什么数据SQL 查询还需要指定如何 来可视化数据。 nvBench的质量已经过专家和众包工作者的验证,以及基于深度学习的模型,即ncNet [20],训练使用nvBench,也验证了nvBench的强大功能。
1 相关工作
如图nvBench: A Large-Scale Synthesized Dataset for Cross-Domain Natural Language to Visualization Task所示,已经有大量的工作致力于开发支持自然语言翻译的技术语言到可视化[29,8,26,9,17,35,23,27,20,11,6]。
基于规则的 NL2VIS 方法。 使用 NL 查询创建可视化的想法大约在二十年前就被探索过[6]。 此后,语义解析器技术(例如,Stanford Core NLP Parser[21])在NL2VIS的研究中变得越来越流行,因为这些技术可以从 NL 查询中提取有用的语义信息。 Articulate [29] 是一个 NL2VIS 系统,它通过两个步骤将用户提供的 NL 查询转换为代表性可视化。 首先,它使用斯坦福解析器将 NL 查询映射为一组显式命令,并使用监督学习方法将 NL 查询分类为一组用户任务。 其次,它部署启发式算法,根据命令和数据属性自动生成合适的可视化结果。 DataTone [8] 主要利用斯坦福核心 NLP 解析器 [21] 和一组规则将 NL 查询映射到可视化。 它还开发了一种混合主动方法来处理NL2VIS过程中的歧义。 用户可以与界面中的歧义小部件交互来处理歧义。 Eviza [26] 是一个 NL2VIS 系统,允许用户就给定的可视化进行对话。 Eviza 开发了一种基于概率语法的方法和有限状态机来管理 NL2VIS 任务的交互处理。 Eviza 还通过界面中的简单 GUI 小部件来管理语法和语义歧义,类似于 DataTone [8]。 Evizeon [9] 扩展了 Eviza 的功能并引入了额外的语用学概念,使用户能够发出独立和后续 NL 查询来指定新的可视化或与现有可视化交互。 请注意,Tableau 中的 Ask Data [2] 部分基于他们之前的研究 – Eviza [26] 和 Evizeon [9]。 DeepEye [17] 演示了一种基于规则的简单方法,用于从(受限)关键字查询生成 VIS 图表。 Flowsense [35] 使用最先进的语义解析器技术来支持数据流系统中的 NL 查询,这允许用户使用 NL 查询大多数数据流图编辑操作。 NL4DV [23] 是一个 Python 工具包,支持使用 NL 查询生成数据可视化,主要基于 NLP 解析器树技术,类似于之前的工作(例如, DataTone [8] 和 Flowsense [35])
NL2VIS 基准。 最近的一项工作[28]通过对 102 名参与者进行在线研究,收集了 3 个数据集的 893 个NL查询。 这项工作根据措辞(例如,真实用户使用的关键词类型)和所含信息(例如,聚合)来描述 NL 查询。 因此,893NL查询可用于评估现有NL2VIS系统的性能,或由开发人员用来设计他们的NL2VIS技术,特别是对于基于规则的技术。 然而,该数据集有两个局限性。 首先,数据集的大小对于训练数据密集型深度学习模型来说太小。 其次,由于该数据集是由 3 个表组成的,因此很难推广到现实世界的场景。
因此,跨域NL2VIS任务需要大规模、高质量、真实的NL2VIS数据集。
基于深度学习的 NL2VIS 方法。 上述研究主要基于基于规则的自然语言处理方法,不能很好地支持自由格式的NL输入。 一些研究人员尝试通过应用基于深度学习的 NLP 技术(例如语言表示)来支持 NL2VIS。
ADVISor [11] 是一个基于深度学习的管道,旨在创建与用户提供的 NL 查询相关的可视化。 粗略地说,ADVISor的整个流程可以分为两个步骤:(1)NL2SQL步骤,(2)基于规则的可视化生成步骤。 对于第一步 - NL2SQL,ADVISor 使用 WikiSQL [37](用于 NL2SQL 任务的大型众包数据集)作为训练数据集。 在此步骤中,ADVISor 首先将 NL 查询和表头作为 BERT 模型 [7] 的输入。 接下来,训练两个神经网络来对聚合类型以及相关属性和过滤条件进行分类。 第二步,ADVISor 设计一种基于规则的方法,根据所选的属性、过滤条件和聚合类型自动创建可视化效果。 因此,ADVISor 的神经网络组件经过训练,可以根据给定的 NL 查询生成 SQL 查询片段。 这意味着 ADVISor 的深度学习模型不会直接从给定的 NL 查询生成可视化结果。
由于 nvBench 中存在大量 (NL, VIS) 对,开发人员可以使用这些对来训练端到端神经网络用于NL2VIS任务的网络。 ncNet [20] 是一个基于 Transformer 的模型,用于将 NL 查询转换为可视化。 它以nvBench作为训练语料,以端到端的方式解决NL2VIS任务。
2 从 NL2SQL 基准综合 nvBench
广泛使用的生成基准的做法是通过耗时的手动标记,例如提供可视化并要求专家编写相应的NL查询。
上述方法的主要问题是所需的专家根本不够。 或者,我们建议从大量 NL2SQL 基准中综合 NL2VIS 基准 [18]。 因为众所周知,验证结果(即 NL 查询是否适合给定的可视化)比编写 NL 查询容易得多专家和众包工作者都可以手动提供帮助。
NL2VIS 基准可以从 NL2SQL 基准合成的合理性是因为 VIS 查询和 SQL 之间的语义联系查询:SQL查询指定需要什么数据(例如列、过滤、聚合、排序);和VIS查询指定需要什么数据以及如何可视化(例如,0>条形图或折线图) – 什么数据1>部分高度重叠。 直观上,我们可以在什么数据部分上搭载NL2SQL基准,并专注于综合NL2VIS的如何可视化。
简而言之,给定一个 (NL, SQL) 对,我们的方法将综合一组 (NL, VIS) 对。 考虑图2,输入是一对。 它输出四对 、、 和 ,其中 (分别为: )是一个饼图(分别是。 bar)图表,以及 和 (分别为。 和 )是 的 NL 查询的变体(resp. )。
从一对(NL,SQL)到多对(NL,VIS)的综合步骤总结如下(更多详情请参阅[18])。
(S1) 综合可视化。 它将SQL查询视为树结构并进行树编辑(例如,删除一些树枝并插入可视化类型),这可能会产生多棵树,每棵树对应一个可能的可视化。
(S2) 过滤“不良”可视化。 为了确保每个VIS查询都是“好”的(例如,有几百条的条形图不可读,因此被认为是坏的),我们需要过滤“坏”图表。 我们使用预先训练的机器学习模型,即 DeepEye [16] 来修剪合成的不良 VIS 查询。 DeepEye 在 2520/30892 个标记好/坏的图表上进行训练,使用的特征包括不同值的数量、元组的数量、唯一值的比率、最大值和最小值、数据类型、属性相关性和 VIS 类型。 给定 VIS 查询,DeepEye 将返回 true(即 一个好的 VIS)或 false(即,一个糟糕的VIS)。
(S3) 正在综合 NL 查询。 对于剩余的“良好”可视化,我们需要修改 SQL 的输入 NL 查询(例如, 图2)反映w.r.t.的变化 树编辑,这可能会导致多个输出 NL 查询,例如, (分别为) )是根据 之间的差异从 合成的(分别为 )。 )和。 对于删除 SQL 的 NL 查询的某些部分以生成 VIS 的 NL 查询的情况,例如,图2中的 ,我们需要与用户交互以生成VIS的NL查询。
(S4)人工验证。 我们邀请 23 名专家和 312 名众包工作者来验证合成(NL、VIS)对的质量。 专家/群众工作者认为 86.9%/88.7% 的合成(NL、VIS)对匹配良好,即得分为 4 或 范围内有 5 个,其中 1 表示不匹配,5 表示完美匹配。 根据[18]测量,我们的综合方法将从头开始开发NL2VIS基准的工时减少到5.7%。 换句话说,由人类构建 NL2VIS 基准需要我们方法的 17.5 工时。
3 nvBench:详细信息
图2概述了nvBench的统计数据,该统计数据是从跨域NL2SQL基准Spider [36]合成的。
nvBench共有153个数据库和780个表,涵盖105个领域(例如金融、大学)。 其中,68.78%的列是分类列,11.58%的列是时间列,19.64%的列是定量列。 表的最大行数为 183,978,最小行数为 1,平均为 1309.65 行。
4使用 nvBench 开发 NL2VIS 模型
考虑到如此大规模的 NL2VIS 基准测试,nvBench 的一些示例性应用包括: (1) 开发人员可以分析 25,750 个 NL 查询的特征,以导出一些常用短语或关键字来帮助NL2VIS界面的设计(例如,NL查询自动完成,NL 短语建议); (2) 开发者可以使用nvBench来训练基于深度学习的模型来完成跨域NL2VIS任务。 接下来,我们将详细介绍如何使用 nvBench 训练深度学习模型。
ncNet:基于 Transformer 的 seq2seq NL2VIS 模型。 要了解 NL 查询到 VIS 查询的转换,一种简单的解决方案是应用序列到序列 (seq2seq) 模型 [30],类似于英文翻译中文。 如图5所示,ncNet设计了一个基于Transformer的[34]seq2seq模型,该模型由两部分组成,一个编码器和一个解码器,其中每个部分都堆叠了自注意力块。 编码器的任务是理解输入序列,并生成较小的表示(即高维向量)来表示输入。 解码器的任务是以 作为输入来生成输出序列。 ncNet需要使用大量训练数据进行训练,这些数据以(输入序列,输出序列)对的形式进行。 例如,示例NL查询为:绘制折线图以显示犹他州每种病例类型的病例数趋势,及其在Vega-中的相应输出序列像 Lite 一样的语言是:
标记 行 编码 x 日期y聚合无数量0>颜色1>案例2> 3>变换4>过滤状态=5>'犹他州6>'
对于 NL2VIS,我们使用来自 nvBench< 的大量 (NL, VIS) 对来训练 ncNet /t4>,以便它学习从 NL 查询转换为 VIS 查询。
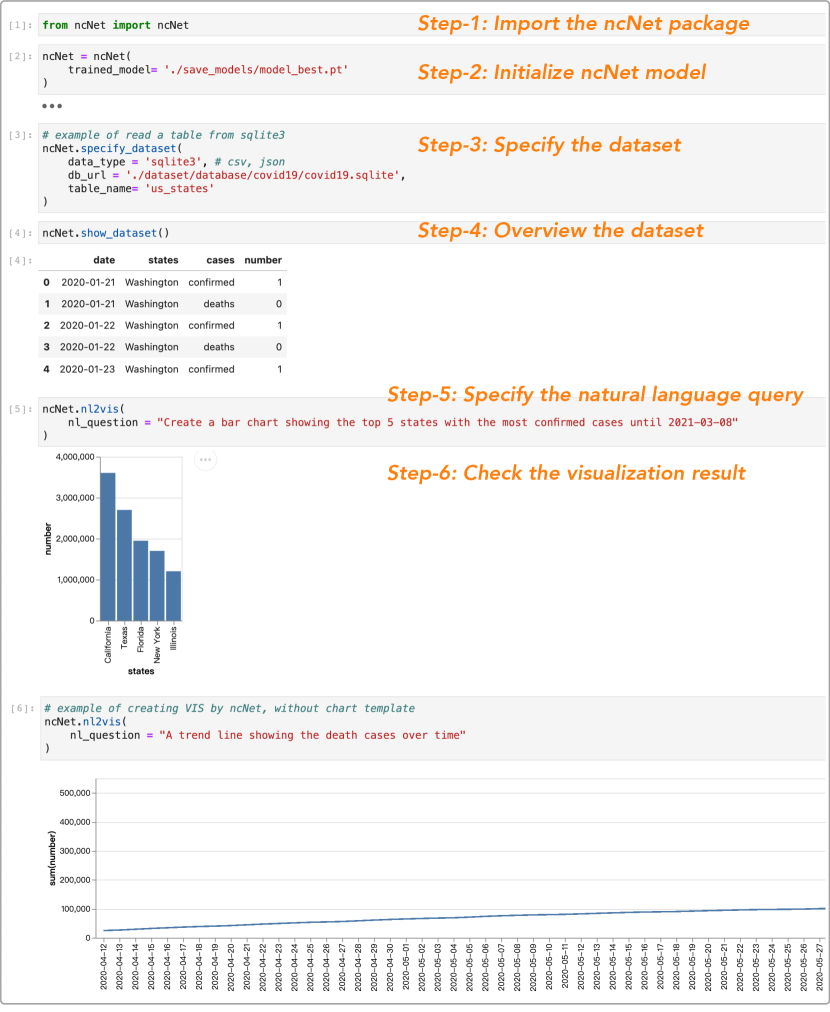
COVID-19 用例。 我们使用具有四个属性(日期、州、案例、数字)的 COVID-19 数据集来演示用户如何使用 NL 查询创建所需的可视化效果Jupyter 实验室环境。 我们邀请了数据可视化爱好者 Kevin,他在构建 COVID-19 仪表板方面拥有丰富的经验。 如图6所示,Kevin首先导入ncNet的Python包,然后通过传递模型参数来初始化ncNet。 接下来,他可以通过分别调用函数specify_dataset()、show_dataset()来指定和概述数据集。 或者,他可以使用其他软件包(例如 Pandas-profiling)探索数据集。 在NL2VIS步骤中,Kevin通过函数nl2vis(nl_question)指定NL查询,然后他可以检查ncNet。 如果他对结果不满意,他可以重新表述 NL 查询并重试。 之前,他花费数小时转换数据并编写 Vega-Lite 代码进行可视化;现在,凯文眨了眨眼,就完成了。
5 NL2VIS 基准:去哪里?
毫无疑问,NL2VIS基准测试在催生NL2VIS研究热潮中发挥了重要作用。 为了使NL2VIS的性能在实际任务和用户中更加强大和鲁棒,NL2VIS基准测试应该覆盖更多样化的任务、数据集、数据类型、的不同特征NL 查询和可视化类型。
支持对话式 NL2VIS。 在现实的可视化数据分析场景中,数据分析师通常以会话方式进行数据可视化,即会话式可视化分析。 一个会话NL查询可能由一系列独立但相关的NL查询组成。 因此,如何扩展NL2VIS基准来支持会话式视觉分析是一个有趣且有前途的方向。
支持未指定的NL查询。 在这项工作中,我们假设NL查询可以转换为有效的VIS查询,这是基于假设 已明确指定。 实际上, 可能未指定,即未提供完成的一些信息。 从 NLP 的角度来看,这与NL查询自动完成[32]问题有关。 从VIS查询角度来看,这与可视化推荐[10, 33]有关。 根据我们的建议,支持未指定的 NL 查询非常简单。 当将NL查询转换为部分VIS树时,只需完成部分VIS树即可获得许多有效的VIS 树,然后使用现有作品[22, 16]对它们进行排名。
支持更多可视化类型。 目前,nvBench 仅包含七种流行的可视化类型。 未来的研究可以收集其他流行可视化类型的(NL,VIS)对,例如热图和箱线图,以丰富 NL2VIS 基准测试涵盖更多样化的任务。 此外,如果能够涵盖某些情况,例如,在可视化中混合两个图表,以及带有高级计算的可视化,就可以完成更多实用的分析任务。
支持域指定的NL2VIS。 有些领域,如化学、生物和医疗保健,有自己的数据结构、数据格式、术语缩写和NL查询的特殊短语。 如何扩展NL2VIS基准来支持这些领域的NL2VIS任务是重要且有趣的。
收集和表征 NL 查询。 除了NL查询和NL2VIS基准中的VIS覆盖范围之外,我们还需要了解真实用户如何表达他们的NL 在不同的可视化分析任务、领域和场景中进行查询。 Srinivasan 等人[28]已经朝着这个目标迈出了第一步,但是他们收集和分析的NL查询总量仍然相对较小。 NL2VIS的研究渴望得到越来越多来自主流可视化厂商如Tableau的Ask Data[2]的真实用户生成的样本和任务。
使其完全自动化。 如第 2-(S3) 节所示,唯一不是自动的部分是编辑用于树删除的 NL 查询。 主要挑战是识别 NL 中与删除相对应的部分。 This is doable by training a deep learning model that takes tree edits as input and NL edits as output if we have enough training data, or use some powerful language models (e.g., GPT-3 [5]). 因此,如果我们使上述步骤成功,自然地,我们可以基于丰富的集合合成尽可能多的好的(NL,VIS)对NL2SQL 基准测试。
6 结束语。
在本文中,我们介绍了nvBench,这是第一个大规模NL2VIS基准测试,旨在为跨领域NL2VIS赋能基于深度学习的神经机器翻译 任务。 我们已经讨论了如何通过搭载 NL2SQL 基准来综合 nvBench。 我们提供了有关nvBench的统计信息,并在nvBench中展示了一些具体示例。 nvBench 的质量已得到专家和群众的验证。 我们还介绍了如何训练基于深度学习的模型来学习 NL2VIS 翻译。 我们的用例表明,使用 nvBench 训练的 ncNet 可以在 NL2VIS 任务中很好地工作。 我们还概述了有关 NL2VIS 基准开发的一些有趣方向,以将 NL2VIS 领域推向实际应用。
致谢。
该项目得到了国家自然科学基金(61925205、61632016)、北京信息科学技术国家研究中心(BNRist)、华为、好未来教育和之江实验室国际青年人才基金的支持。参考
- [1] Amazon’s QuickSight, https://aws.amazon.com/cn/blogs/aws/amazon-quicksight-q-to-answer-ad-hoc-business-questions/.
- [2] Ask Data. https://www.tableau.com/products/new-features/ask-data.
- [3] Microsoft Power BI Q&A. https://docs.microsoft.com/en-us/power-bi/create-reports/power-bi-tutorial-q-and-a.
- [4] SpotIQ AI-Driven Insignts (2nd Edition). https://www.thoughtspot.com/resources#white_paper.
- [5] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. Language models are few-shot learners. In NeurIPS, 2020.
- [6] K. Cox, R. E. Grinter, S. L. Hibino, L. J. Jagadeesan, and D. Mantilla. A multi-modal natural language interface to an information visualization environment. International Journal of Speech Technology, 4(3):297–314, 2001.
- [7] J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, pp. 4171–4186.
- [8] T. Gao, M. Dontcheva, and et al. Datatone: Managing ambiguity in natural language interfaces for data visualization. In UIST, 2015.
- [9] E. Hoque, V. Setlur, M. Tory, and I. Dykeman. Applying pragmatics principles for interaction with visual analytics. IEEE TVCG, 2018.
- [10] K. Z. Hu, M. A. Bakker, S. Li, and et al. Vizml: A machine learning approach to visualization recommendation. In CHI, p. 128, 2019.
- [11] C. Liu, Y. Han, R. Jiang, and X. Yuan. Advisor: Automatic visualization answer for natural-language question on tabular data. In 14th IEEE Pacific Visualization Symposium, PacificVis 2021, Tianjin, China, April 19-21, 2021, pp. 11–20. IEEE, 2021.
- [12] Y. Luo, C. Chai, X. Qin, N. Tang, and G. Li. Interactive cleaning for progressive visualization through composite questions. In 36th IEEE International Conference on Data Engineering, ICDE. IEEE, 2020.
- [13] Y. Luo, C. Chai, X. Qin, N. Tang, and G. Li. Visclean: Interactive cleaning for progressive visualization. Proc. VLDB Endow., 13(12), 2020.
- [14] Y. Luo, W. Li, T. Zhao, X. Yu, L. Zhang, G. Li, and N. Tang. Deeptrack: Monitoring and exploring spatio-temporal data - A case of tracking COVID-19 -. Proc. VLDB Endow., 13(12):2841–2844, 2020.
- [15] Y. Luo, X. Qin, C. Chai, N. Tang, G. Li, and W. Li. Steerable self-driving data visualization. IEEE Transactions on Knowledge and Data Engineering, 2020.
- [16] Y. Luo, X. Qin, N. Tang, and G. Li. Deepeye: Towards automatic data visualization. In ICDE, pp. 101–112, 2018.
- [17] Y. Luo, X. Qin, N. Tang, G. Li, and X. Wang. Deepeye: Creating good data visualizations by keyword search. In SIGMOD, 2018.
- [18] Y. Luo, N. Tang, G. Li, C. Chai, W. Li, and X. Qin. Synthesizing Natural Language to Visualization (NL2VIS) Benchmarks from NL2SQL Benchmarks. In Proceedings of the 2021 International Conference on Management of Data, SIGMOD/PODS ’21, p. 1235–1247. Available at https://sites.google.com/view/nvbench/.
- [19] Y. Luo, N. Tang, G. Li, and et al. Deepeye: A data science system for monitoring and exploring COVID-19 data. IEEE Data Eng. Bull., 2020.
- [20] Y. Luo, N. Tang, G. Li, J. Tang, C. Chai, and X. Qin. Natural language to visualization by neural machine translation. IEEE Transactions on Visualization and Computer Graphics, pp. 1–1, 2021. doi: 10 . 1109/TVCG . 2021 . 3114848
- [21] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, and D. McClosky. The stanford corenlp natural language processing toolkit. In ACL, pp. 55–60, 2014.
- [22] D. Moritz, C. Wang, G. L. Nelson, and et al. Formalizing visualization design knowledge as constraints: Actionable and extensible models in draco. IEEE Trans. Vis. Comput. Graph., 25(1):438–448.
- [23] A. Narechania, A. Srinivasan, and J. T. Stasko. NL4DV: A toolkit for generating analytic specifications for data visualization from natural language queries. In VIS, 2020.
- [24] X. Qin, Y. Luo, N. Tang, and G. Li. Deepeye: Visualizing your data by keyword search. In EDBT, pp. 441–444, 2018.
- [25] X. Qin, Y. Luo, N. Tang, and G. Li. Making data visualization more efficient and effective: a survey. VLDB J., 29(1):93–117, 2020.
- [26] V. Setlur, S. E. Battersby, and et al. Eviza: A natural language interface for visual analysis. In UIST, 2016.
- [27] A. Srinivasan, B. Lee, and J. T. Stasko. Interweaving multimodal interaction with flexible unit visualizations for data exploration. IEEE transactions on visualization and computer graphics, 2020.
- [28] A. Srinivasan, N. Nyapathy, B. Lee, S. M. Drucker, and J. Stasko. Collecting and characterizing natural language utterances for specifying data visualizations. In CHI, 2021.
- [29] Y. Sun, J. Leigh, A. Johnson, and S. Lee. Articulate: A semi-automated model for translating natural language queries into meaningful visualizations. In International Symposium on Smart Graphics, pp. 184–195. Springer, 2010.
- [30] I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. In NIPS 2014, p. 3104–3112. MIT Press, 2014.
- [31] N. Tang, E. Wu, and G. Li. Towards democratizing relational data visualization. In SIGMOD, pp. 2025–2030. ACM, 2019.
- [32] K. Trnka, D. Yarrington, and et al. The effects of word prediction on communication rate for AAC. In NAACL HLT, pp. 173–176, 2007.
- [33] M. Vartak, S. Huang, T. Siddiqui, S. Madden, and A. G. Parameswaran. Towards visualization recommendation systems. SIGMOD Rec., 2016.
- [34] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In NIPS, 2017.
- [35] B. Yu and C. T. Silva. Flowsense: A natural language interface for visual data exploration within a dataflow system. IEEE Trans. Vis. Comput. Graph., 26(1):1–11, 2020.
- [36] T. Yu and et al. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In EMNLP.
- [37] V. Zhong and et al. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103, 2017.