语义通信:原则与挑战
(特邀论文)
摘要
语义通信被认为是香农范式之外的突破,其目标是成功传输源所传达的语义信息,而不是准确接收每个单个符号或位(无论其含义如何)。 本文概述了语义通信。 在简要回顾香农信息论之后,我们讨论了深度学习支持的理论、框架和系统设计的语义通信。 与用于测量传统通信系统的符号/比特错误率不同,还讨论了语义通信的性能指标。 本文最后提出了语义通信中的几个悬而未决的问题。
索引术语:
深度学习、语义沟通、语义理论、任务导向沟通。我简介
大约70年前,韦弗[1]将通信分为三个层次:符号传输、语义交换和语义交换的效果。 第一级通信,即符号传输,已经在传统通信系统中得到了充分研究和交付,这些通信系统正在接近香农容量极限。 然而,在很多情况下,通信的最终目标是交换语义信息,例如自然语言,而通信介质,例如光纤、电磁波和电缆,只能传输物理信号。 最近,语义沟通111本文中的语义沟通指的是Level 2和Level 3,也称为面向任务/目标的沟通。 引起了工业界和学术界的广泛关注[2, 3],并被确定为第六代(6G)无线网络的核心挑战。
与香农范式相反,语义通信仅传输与接收器[1]处的特定任务相关的必要信息,这导致了真正的智能系统,并且显着减少了数据流量。 图1演示了语义通信的概念,其中传输任务是图像识别。 语义发射器不是传输代表整个图像的比特序列,而是提取与识别源中的对象(即狗)相关的特征。 不相关的信息(例如图像背景)将被省略,以最大限度地减少传输的数据,而不会降低性能。 因此,对能源和无线资源的需求将显着降低,从而形成更加可持续的通信网络。
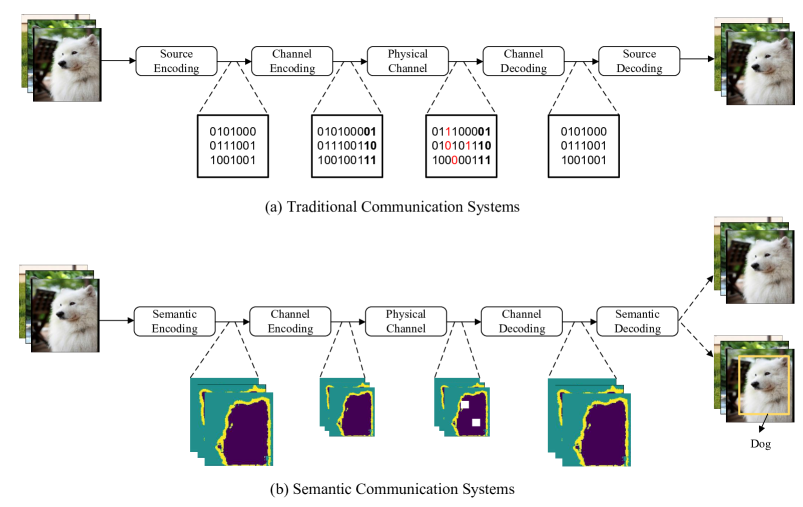
对于6G和人工智能时代的许多应用来说,智能终端、机器人、智能监控等智能体能够理解场景并自动执行指令。 因此,面向任务的语义通信的核心是深层语义级别的保真度,而不是浅层比特级别的准确性。 这种语义通信框架将广泛应用于工业互联网、智能交通、视频会议、在线教育、增强现实(AR)、虚拟现实(VR)等领域。
自从香农[1]的杰作以来,在不考虑传输符号或比特的语义的情况下理解符号传输的数学基础方面已经取得了显着的进展。 Bar-Hillel 和 Carnap [4] 重新审视了香农著作中被绕过的语义问题,并提供了语义信息的初步知识定义。 Bao等人[5]阐明了语义噪声和语义通道的概念。 提出了语义通信框架[6]来最小化语义错误。 这些开创性的工作基于逻辑概率,主要是为文本处理而设计的。 由于缺乏表示语义的通用数学模型,语义通信自提出以来已有七十年的时间,其发展仍处于起步阶段。
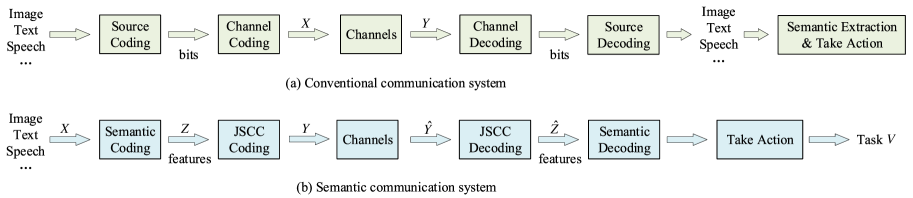
深度学习 (DL) 及其应用(例如自然语言处理 (NLP)、语音识别和计算机视觉)的最新进展为开发语义通信提供了重要见解[3, 7]。 Hwang[8]讨论了通信系统分析和设计中的情报传输。 此外,Chattopadhyay 等人 [9]量化了语义熵和语义压缩的复杂性。 联合源通道编码(JSCC)方案[10, 11]被提出来捕获和传输语义特征,其中语义接收者直接执行相应的动作而不是恢复源消息。 最近,针对多模态数据传输开发了一系列语义通信框架[12,13,14,15],引起了广泛的关注。
到目前为止,已经有一些关于语义通信的教程和调查。 Tong 等人 [3]确定了人工智能和6G面临的两个与语义通信相关的关键挑战,包括其数学基础和系统设计。 Kalfa 等人 [16]讨论了该领域流行任务的不同源的语义转换,并提出了针对不同类型源的语义通信系统设计。 Strinati 等人 [17]指出了语义通信在 6G 中的作用。 Lan 等人 [18]将语义通信分为人与人(2级)、人与机器(2级和3级)和机器- 机器(3 级)通信。 提出了语义通信的各种潜在应用。 此外,许多研究人员致力于设计新的框架[19,20,21,22],以简洁有力的杂志文章的形式进行语义交流。 通过总结高度相关的作品,它们为进入该领域提供了良好的开端。
在本文中,我们将全面概述语义通信的原理和挑战。 我们首先回顾香农信息论并总结语义理论的发展。 在澄清传统通信和语义通信之间的关键区别之后,我们介绍了语义通信的原理、框架和性能指标。 接下来,我们介绍用于多模式数据传输(包括文本、图像和音频)的深度学习语义通信的发展。 我们以研究挑战来结束本文,为语义通信铺平道路。 本教程文章试图提供有关回答以下常见问题的见解:
-
•
如何理解位序列的语义?
-
•
语义沟通的收益从何而来?
-
•
语义通信系统有理论上的限制吗?
本文将为读者呈现一幅语义通信的清晰图景。 本文其余部分的结构如下。 第二节比较了传统的和语义的通信系统和理论。 第三节介绍语义通信系统组件、语义噪声和性能指标。 第四节讨论了用于传输多模态数据的深度学习语义通信系统的最新进展。 本文最后在第五节中提出了一些悬而未决的问题。
II 从信息论到语义论
在本节中,我们首先讨论传统通信和语义通信之间的关键区别。 然后我们简要介绍了信息论和语义理论。
II-A 传统通信和语义通信之间的区别
由于语义通信的研究还处于初步知识阶段,语义通信还没有一致的定义。 在图2中,我们比较了传统通信和语义通信。 在传统的通信系统中,源被转换成比特序列来处理。 在接收器处,代表源的比特序列被准确地恢复。 在传统的通信系统中,比特/符号传输速率受到香农容量的限制。 语义通信传输源的语义含义。 关键区别之一是语义编码的引入,它根据接收者要执行的任务或操作来捕获语义特征。 仅传输那些语义特征,这显着减少了所需的通信资源。 接收器的任务可以是数据重建或一些更智能的任务,例如图像分类和语言翻译。 请注意,在语义通信中,数据不是在位级别处理的,而是在语义级别处理的。 语义通信可以用语义理论来描述。
下面首先对信息论进行简要回顾。 然后,我们介绍过去几十年发展起来的语义理论,尽管它尚未得到很好的确立。
II-B 信息论
1948年,香农提出了信息熵的概念[1],它利用不确定性来衡量以比特为单位的信息内容。
定义1
给定源 ,概率为 ,源熵测量每个符号要在没有损失的情况下重建的平均位数,定义为
| (1) |
定理1
利用信道容量,香农进一步发展了信源信道编码定理。
定理2
如果对于,满足渐近均分性质(AEP)和,则存在错误概率为 相反,如果,则错误概率为正。
传统的通信系统基于香农的分离定理,包括两个阶段:i)将源数据压缩为其最有效的形式; ii) 将信源编码序列映射到信道编码。
定理1提供了无失真传输的上限。 对于给定的失真,最小传输信息速率可以用速率失真理论来描述,也称为有损信源编码定理。
定理3
对于给定的最大平均失真,速率失真函数是传输比特率[23]的下限
| (3) |
其中 是失真, 是失真度量,如果 ,则 。 如、。
如今,信息论是一门内容丰富的学科,不可能在几页之内介绍它。 以上只是后续讨论中与语义理论高度相关的定理和定义。
II-C 语义理论
香农信息论中的熵通过信息源的不确定性来衡量信息内容。 然而,对于特定的传输任务,如何衡量语义信息量,或者信息的重要性,还有待确定。 传输任务是指传统通信中接收到源信息后在接收端执行的分类、识别、设备配置等任务。
定义2
给定传输任务,语义信息是与源中的相关的信息。
中的不确定性小于中的不确定性,这表明以下关系:
| (4) |
从中提取语义信息,可以看作是的有损压缩。 然而,从的角度来看,是的无损压缩,因为任务可以完全由它。 对于不同的任务,所需的语义表示 会有所不同,如图 1 所示。 2.(二)。
通过传输任务,可以测量信息(例如语义信息)的重要性。 例如,对于图像分类任务,接收者只对图像中的对象而不是原始图像感兴趣。 因此,这些对象被认为是必要信息,而其他对象则被认为是非必要信息。 同样,对于文本传输,接收方需要的是文本的含义,而不是无损文本恢复。
II-C1 语义熵
在过去的几十年里,研究人员遵循香农提出的信息熵的路径,努力寻找一种量化语义熵的方法。 然而,它仍然是一个活跃的研究领域,有巨大的研究空间。
基于逻辑概率,已经开发了许多不同的语义熵定义。 Carnap和Bar-Hillel[4]通过确认度来衡量语义信息,表达为
| (5) |
其中定义为假设对证据的证实程度。例如, 可以是一条新消息, 可以引用知识。 Bao 等人 [5]将消息或句子的语义熵定义为
| (6) |
其中 的逻辑概率由下式给出
| (7) |
这里,是经典源的符号集,是命题满足关系,是的模型集t3>,即 为 true 的空间。 这里,是的概率。如果没有可用背景,则。 通过扩展上述定义,也定义了具有背景知识的条件熵。
在模糊系统中,语义熵是通过引入匹配度和隶属度[24]的概念来定义的。 隶属度是模糊集理论中的一个概念,通常很难通过分析来测量。 因此,它是根据专家的直觉和经验手动定义的。 Liu 等人 [24]将定义为语义概念,可以将其视为传输任务,而 作为每个的隶属度,其中是的集合。 对于类,匹配度表征了在概念上的语义熵。 请注意,匹配度的定义与(7)中的定义相似。 根据匹配度,类的语义熵定义为
| (8) |
上的整体语义熵可以通过对所有类的语义熵求和来获得。 上述定义的语义熵的基本性质与信息熵的基本性质类似。 区别在于会员等级。 它与语义概念或传输任务相关,表征语义信息。
上述语义熵的定义假设存在一种测量语义信息的方法。 所有定理都是基于可用语义表示的假设而开发的,没有提供量化语义信息的具体方法。 一群统计学家[9]正在开展一个活跃的项目,开发一个信息理论框架,用于量化多模态数据中的语义信息内容,其中语义熵被定义为关于多模态数据的语义查询的最小数量。源,其答案足以预测传输任务。通过这样做,寻找语义熵的方法就变成了寻找服务于任务的 的最小表示,。但目前仍在研究中,如何将这样的框架应用到实际场景中还有待明确。
II-C2 语义通道
对于通过噪声信道进行的通信,接收到的消息通常会失真。 从香农定理来看,这种由失真引起的错误可以通过误码率(BER)或符号错误率(SER)来衡量,这是工程问题。 从语义的角度来看,这种错误可以通过语义不匹配来衡量。 Bao 等人 [5]从逻辑概率角度引入了两种语义错误,1)不健全性:发送的消息是真的,但接收到的消息是假的,2)不完整性:发送的消息为假,但接收到的消息为真。 然而,语义错误/噪声还没有定义,这将在第 III.A 节中进一步讨论。
II-C3 语义通道容量
定理4
离散无记忆信道的语义信道容量表示为
| (9) |
其中是源和传输任务之间的互信息。 是条件概率分布,指的是源 编码为其语义表示 和 、是任务V接收到的消息的平均逻辑信息。
请注意,较高的意味着由语义编码引起的较高语义歧义,而较高的导致接收者解释接收到的消息的能力较强。 语义信道容量可以高于或低于香农信道容量,具体取决于语义编码策略和接收器解释接收消息的能力。
这里提供两个案例以便更好地理解。 鉴于源语句“她将 Jame 的车停在大楼的底层,该大楼有 13 层,每层 120 平方米,由于创建者 William Smith 而被称为 Smith Building”。接收者想知道詹姆斯的车在哪里。
-
•
情况1:,这意味着接收者可以处理语义歧义。 源句可以压缩为“史密斯大厦的底层”。与源句相比,语义歧义更高,这意味着增加。 然而,接收者可以用接收到的句子回答问题,因此接收者可以处理语义歧义。 语义压缩可以获得更高的传输速率。 在这种情况下, 高于香农容量。
-
•
情况2:,表示接收者无法解决语义歧义。 源句子可以压缩为“她把詹姆斯的车停在大楼上”。接收者无法根据接收到的句子找到汽车,因此接收者无法处理语义歧义,其中低于香农容量。
II-C4 语义率失真和信息瓶颈
与(3)类似,语义通信系统中的速率失真可表示为[25]
| (10) |
其中 是接收器处源 和恢复信息 之间的语义失真, 是失真语义表示 和接收到的语义表示 之间。 请注意,(10) 考虑了语义压缩和通道噪声引起的失真。
信息瓶颈是寻找压缩率和准确率之间最优权衡的方法,旨在解决以下问题[26]
| (11) |
其中 V 是所需的语义表示。 作为其扩展,Sana 等人 [27]设计了一个新的损失函数为
| (12) |
其中和是调整互信息项和推理项权重的参数。 压缩项表示所需的平均位数。 推理项是编码器处的后验概率 与解码器捕获的后验概率 之间的 Kullback-Leibler (KL) 散度。 请注意 (12) 的上限是
| (13) |
这是[12]中设计的损失函数,将在第六节中详细介绍。
尽管尚不可能像香农对传统通信系统那样量化语义通信系统,但理解上述概念可以为我们提供重要的见解,特别是在支持深度学习的语义通信的损失函数设计方面。
III 组件、语义噪声和性能指标
从第二节可以看出,语义理论仍处于起步阶段。 但这并不妨碍我们开发实用的语义通信系统。 本节介绍语义通信系统的主要组件、语义噪声和性能指标。
III-A 语义通信系统组件
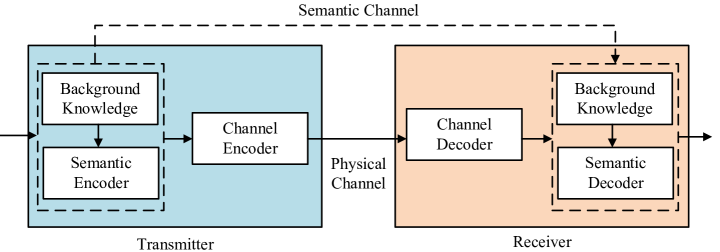
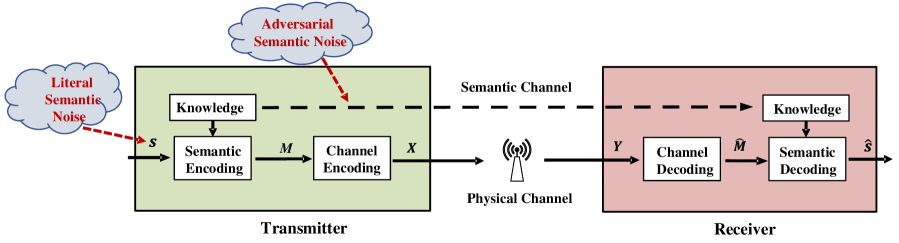
如图3所示,语义通信系统包括语义层和传输层。 语义层解决语义信息处理以获得语义表示的问题,这由语义编码器和解码器执行。 这里,语义信息是指对接收方的智能任务有用的信息。 传输级保证符号在经过传输介质后在接收器处成功接收,这通常由信道编码器和解码器进行。 语义发送器和接收器配备有一定的背景知识以方便语义特征提取,其中背景知识对于不同的应用可以是不同的。
与图3所示的总体结构类似,提出了一种面向任务的语义信号处理框架[16]。 此外,语义感知主动采样[21, 22]允许每个智能设备控制其流量,如果触发采样器来服务特定任务,则在其中生成样本。
请注意,语义通信系统中有两种类型的通道需要处理。 第一类信道是物理信道,它会给传输的符号引入信道损伤,例如噪声、衰落和符号间干扰。 过去,无线通信方面的大部分努力都是为了克服物理信道损伤。 第二种类型的通道是语义通道,它可能受到由误解、解释错误或估计信息干扰引起的语义噪声的污染。
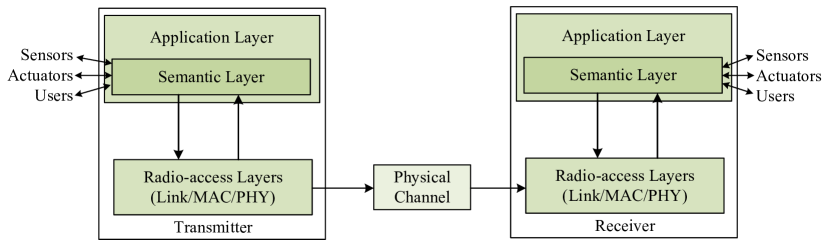
为了支持语义通信,引入了语义开放系统互连(OSI)模型[18]。 如图4所示,它允许语义层与传感器或执行器交互,并访问特定任务的算法和数据。 在语义层中,执行语义编码以将语义编码数据传输到下层。 此外,无线接入层旨在提高系统传输性能,通过控制信道将控制信号传输到语义层。 语义层利用这些控制信号来消除语义噪声以进行语义符号纠错或控制应用层的计算。 类似地,Zhang等人[20]提出了一种新的不同层次的语义系统模型作为一个综合系统来替代现有的OSI模型。
III-B 语义噪声
语义噪声是指影响消息解释的干扰,可以视为语义通信中发送者和接收者之间的语义信息不匹配。 图5说明了双方以不同方式解释“地球”一词时产生的语义噪声。

语义噪声还存在一个通用的表述。 对于语义通信,我们将其分为两种类型,如图6所示。 第一类语义噪声是指引入源的语义歧义。 例如,句子中字母或单词的微小变化,例如替换同义词或随机颠倒字母顺序,可能会使机器难以理解语义,从而导致错误的决策[28 ]。 特别是,Peng等人[29]开发了一种用于文本传输的鲁棒语义通信系统来处理此类语义噪声。
另一种类型是误导深度学习模型的对抗性语义噪声。 由于文本的离散性,不可能在不被人类注意到的情况下向文本添加扰动。 然而,对图像添加的一些修改非常微妙,以至于人类几乎无法注意到。 图7展示了图像领域对抗样本的典型例子,其中添加了对抗样本。 我们可以看到,带有对抗性噪声的图像会误导深度学习模型进行分类,但如果由人类观察,它看起来与原始图像相同。 此外,[30]中研究了样本相关和样本无关的语义噪声,这两者都会误导深度学习模型。
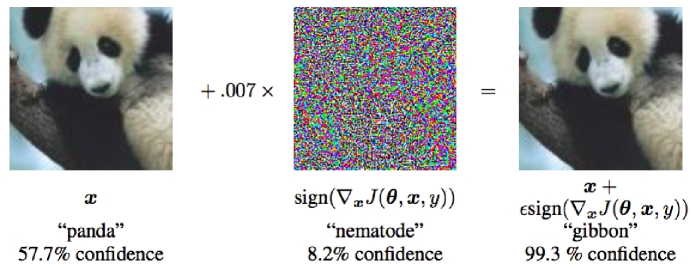
一些先前的作品研究了对抗性示例生成。 Goodfellow 等人 [31]提出了一种快速梯度符号方法,利用损失函数的梯度来生成扰动。 Miyato 等人 [32]开发了一种快速梯度方法来生成对抗性示例。 深度学习的对抗性例子有两个作用。 首先,它可以用来防止机器学习系统受到攻击。 其次,有利于提高基于DL的系统的鲁棒性。 请注意,所有上述对抗性示例都是由人类生成的。 为了调查自然界中是否存在对抗样本,使用手机摄像头拍摄对抗样本[33],这表明通过拍摄对抗样本获得的图像也会被错误分类。
III-C 性能指标
在传统的通信系统中,通常采用BER和SER作为性能指标。 然而,随着通信的重点从准确的符号传输转向有效的语义信息交换,它们不再适用于测量语义通信系统。 目前,语义通信仍然缺乏通用的度量标准。 在本节的下面,我们将讨论文献中不同来源的指标,包括文本、图像和语音。
III-C1 文本语义相似度
错误率(WER)用于衡量语义文本传输[34, 10],它不适用于语义文本传输,因为两个不同单词的句子可能具有很高的语义相似度。 双语评估学生(BLEU)分数是衡量机器翻译后文本质量的常用指标[35],已被用来衡量文本传输的语义通信系统[12 ,14]。 发送的句子 和接收的句子 之间的 BLEU 分数计算如下
| (14) |
其中和分别是和的字长,定义了权重-grams, 是 -grams 分数,定义为
| (15) |
其中 是第 语法中第 个元素的频率计数函数。 BELU分数统计两个句子之间-grams的差异,其中-grams指的是用于比较的词组中的单词数。 例如,对于句子“这是一只狗”,-gram 的词组是“this”、“is”、“a”和“dog”。 对于 -gram,词组包括“this is”、“is a”和“a dogs”。 同样的规则适用于其余部分。
BLEU 分数的范围介于 0 和 1 之间。 分数越高,两个句子之间的相似度越高。 然而,很少有人工翻译能够获得 1 分,因为不同表达或单词的句子可能指的是相同的含义。 例如,句子“我的自行车被偷了”和“我的自行车被偷了”具有相同的含义,但 BLEU 得分不是 1,因为逐字比较时它们是不同的。
为了表征这一特征,提出了句子相似度[12]作为衡量两个句子语义相似程度的新指标,其表示为
| (16) |
其中 是将句子映射到其语义向量空间的 BERT 模型 [36],这是一个包含数十亿个句子的预训练模型。 我们不是直接比较两个句子,而是比较由 BERT 模型获得的语义向量。 句子相似度范围为 0 到 1。 值越高,两个句子之间的相似度越高。
为了实现传输精度和每条消息使用的符号数量之间的权衡,度量[27]被设计为
| (17) |
其中 是每条消息的符号数, 是 和 之间的语义错误。 请注意, 可以采用各种格式,例如 BLEU 分数和均方误差 (MSE),这取决于接收器的传输任务。
此外,最近还引入了一些其他指标,即每句话的平均比特消耗从通信角度来衡量系统[34]。
III-C2 图像语义相似度
两个图像 和 的相似度测量为
| (18) |
其中 是将图像映射到欧几里德空间中的点的图像嵌入函数。 图像嵌入函数是寻找图像语义相似度的关键部分。 请注意,常用的指标,例如峰值信噪比(PSNR)和结构相似性指数(SSIM),都是浅层函数,无法计算人类感知的许多细微差别。 此外,传统的图像相似度度量建立在手工设计的特征之上,例如Gabor滤波器和尺度不变特征变换(SIFT)。 它们的性能很大程度上受到特征表示能力的限制。
图像语义相似度度量取决于高阶图像结构,通常与上下文相关。 基于深度学习的图像相似性度量可以取得有希望的结果,因为卷积神经网络 (CNN) 编码高不变性并捕获图像语义。 人们发现,在高级图像分类任务上训练的深度 CNN 通常作为表征空间非常有用。 例如,我们可以测量 VGG 特征空间中两幅图像的距离作为图像回归问题[37]的感知损失。 他们基于 VGG 网络定义了两个感知损失函数 。 特征重建损失鼓励由 计算出具有相似特征表示的两个图像。 令为第层的激活函数,其形状为。特征重建损失的计算公式为
| (19) |
风格重建损失会惩罚颜色、纹理和常见图案的差异。 它是由以下给出的两个图像的 Gram 矩阵 之间的差异
| (20) |
深度特征在相似性测量中的有效性并不限于 VGG 架构。 Richard 等人 [38]评估了不同架构和任务的深层特征,与之前的所有指标相比,显示出显着的性能提升,并且与人类的感知一致。 此外,[39]中提出的深度排序模型描述了一组三元组内的图像相似性关系:查询图像、正图像和负图像。 图像相似性关系通过三元组中的相对相似性排序来表征。 此外,还提出了包括对抗性损失[40]、初始分数(IS)和Fréchet初始距离(FID)[41]在内的指标来衡量相似性从图像分布的角度来看,生成对抗网络(GAN)生成的图像和自然图像之间的关系。
视觉语义嵌入是评估图像语义相似度的另一种方法[42]。 如前所述,可以提取和比较来自不同图像的概念。 视觉翻译嵌入(VTransE)网络[43]将对象和谓词的视觉特征映射到低维语义空间。 因此,可以测量语义相似度。 [44]中的关系检测模型学习一个模块,将视觉和语义模态的特征映射到共享空间,其中匹配的特征对应该能够区分那些不匹配的特征对,并在语义上保持紧密的距离类似的。 因此,该模型可以在关系级别很好地表示图像的语义相似性。 语义嵌入已广泛应用于场景图生成(SGG)、图像描述和图像检索。 因此,它在语义通信系统中具有巨大的开发潜力。
III-C3 语音质量测量
语义交换的传输目标可以分为全数据重构和任务执行。 为了实现语音重构,在接收器处传输并恢复全局语音语义信息,例如说话者的语音、文本信息和语音延迟。 因此,诸如语音质量感知评估(PESQ)[45]、短时客观清晰度(STOI)[46]和感知客观听力质量等指标评估(POLQA)[47],可以用来衡量语音信号的全局语义内容,对重建的语音信号进行综合评估。 在[13]中,采用PESQ作为语义通信系统中用于语音传输的性能度量。
然而,为了服务于智能任务,即语音合成,语音信号在接收器处根据文本和说话者的信息进行合成,这省略了一些语义信息内容,例如语音延迟。 因此,利用无条件Fréchet深度语音距离(FDSD)和无条件核深度语音距离(KDSD)来评估合成语音的质量,首先提取语音信号的特征并将这些特征输入到评估模型中以测量它们的相似度。
将原始语音样本和合成语音样本的提取特征分别表示为和,FDSD定义为
| (21) |
其中和分别表示和的平均值,而和 表示它们的协方差矩阵。
KDSD [48] 由下式给出
| (22) |
其中 是核函数。
综上所述,对于服务于不同任务的语义通信,性能指标在很大程度上取决于为应用程序选择的“语义语言”。 这种语义语言可以是典型的自然语言、图像处理的场景图、Carnap 等人的真值表 [4],或者定制的基于图的语言来自 Kalfa 等人 [16]。 这些指标必须适应这些语言。
IV 文本、语音和图像/视频的深度语义通信
尽管语义理论已经被研究了几十年,但缺乏通用的数学工具限制了其应用。 由于深度学习的进步,近年来语义通信领域出现了一些有趣的工作。 本节介绍文本、图像、语音和多模态数据的深度语义通信系统设计的最新工作。
IV-A 文本处理
NLP[49]的进步使得文本编码能够考虑文本的语义,这促使我们重新设计收发器以实现成功的语义信息传输。 对于图3所示的系统,神经网络用于表示支持深度学习的语义通信中的发送器和接收器。 深度学习语义通信的核心是设计语义编码,能够理解和提取语义信息。 然后压缩这些语义特征。 此外,信道解码器经过训练以对抗信道损伤。 另一个核心任务是设计适当的损失函数,以尽量减少语义错误和通道损伤。 如果系统设计用于在接收器处服务特定任务,则应相应调整损失函数以捕获与任务相关的特征。
对于擦除通道,Farsad 等人 [10]开发了一种支持长短期记忆(LSTM)的 JSCC,用于文本传输。 采用交叉熵作为损失函数,使用WER作为性能指标。 与传统通信系统相比,它显示了支持 DL 的 JSCC 的巨大潜力。 虽然[10]中没有提及语义沟通的概念,但它对后来的研究产生了很大的启发。
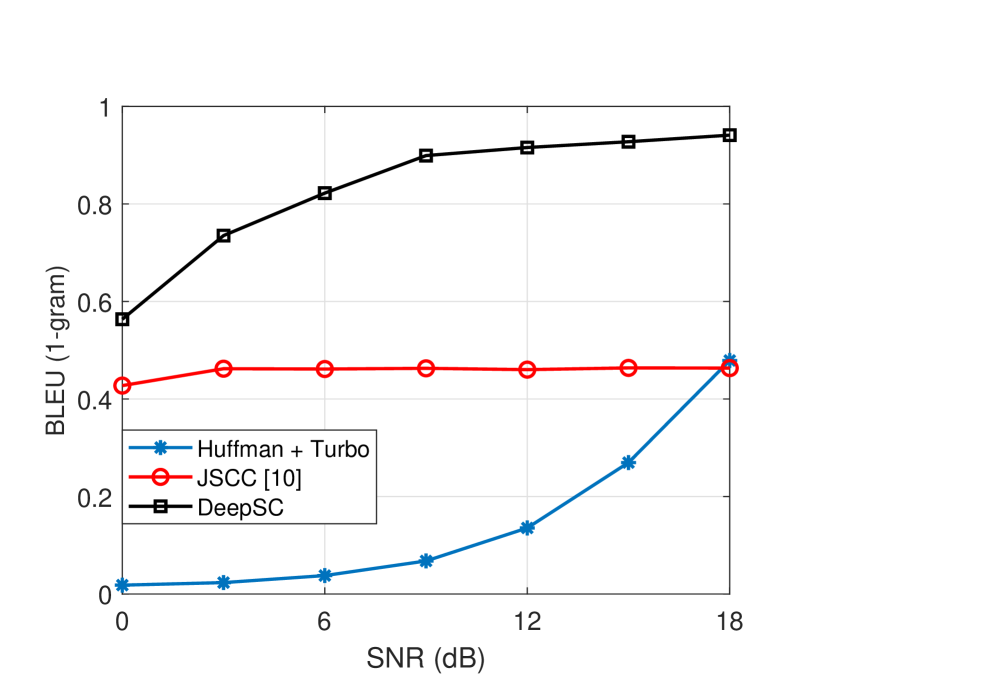
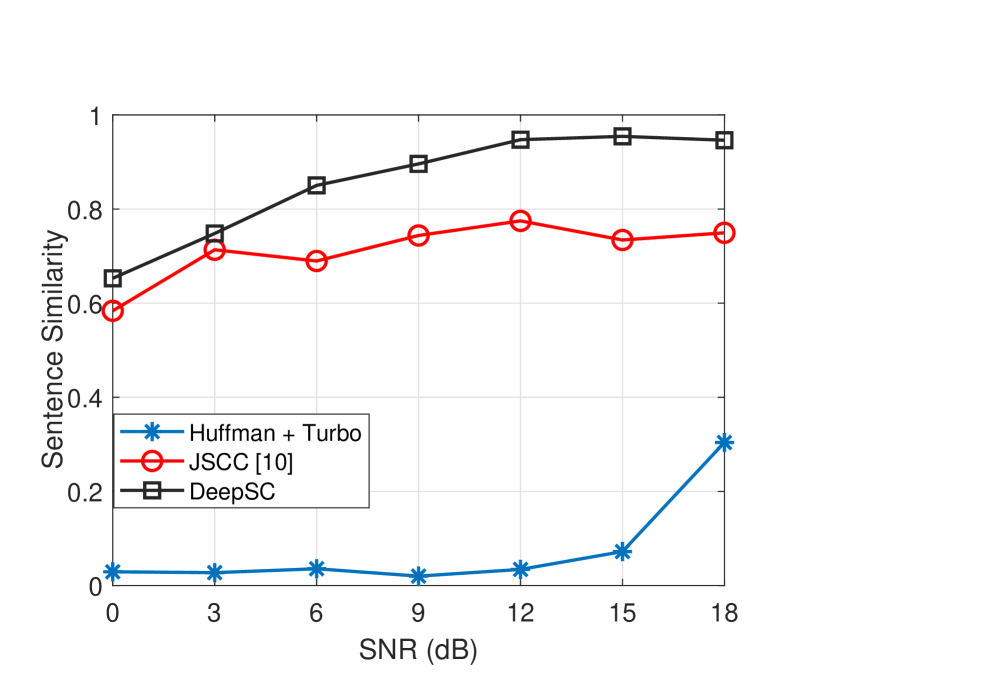
随后,Xie等人[12]开发了一种基于Transformer的联合语义信道编码的端到端语义通信系统,命名为DeepSC。 在这样的端到端系统中,传统通信系统的块结构已被合并[7]。 特别是,提供了 (13) 给出的新损失函数,它计算交叉熵以更好地理解文本,并计算互信息以获得更高的数据速率[12]。 通过设计这样的语义编码和信道编码层,DeepSC能够提取语义特征并保证其准确传输。 经验证,DeepSC 的性能显着优于典型的通信系统,尤其是在信道条件较差的情况下。 例如,当SNR = 9 dB时,图8中的BLEU得分比采用Huffman编码和Turbo码的传统方法提高了800%。 当通过(13)中定义的句子相似度来衡量时,我们还可以看到 DeepSC 与传统方法之间存在显着的性能差距。 请注意,当 SNR = 12 dB 时,BLEU 分数小于 0.2,这使得接收到的句子几乎无法被人类阅读。 这可以通过句子相似度来体现,SNR = 12 dB 时句子相似度几乎为 0。
此外,表I提供了接收到的句子经过瑞利衰落通道后的快照,其中传统方法出现了一些拼写错误。 请注意,BLEU 分数和句子相似度等性能指标不能用作 DeepSC 中的损失函数,因为它会导致收发器训练的梯度消失。
| Transmitted sentence | it is an important step towards equal rights for all passengers. |
| DeepSC | it is an important step towards equal rights for all passengers. |
| JSCC[10] | it is an essential way towards our principles for democracy. |
| Huffman + Turbo | rt is a imeomant step tomdrt equal rights for atp passurerrs. |
从那时起,DeepSC 的几个变体被开发出来。 具体来说,Jiang等人[34]将语义编码与Reed Solomon编码和混合自动重复请求相结合,以提高文本语义传输的可靠性。 提出了一种相似性检测网络来检测意义错误。 此外,Sana 等人 [27]定义了一个新的损失函数(12)来捕获语义扭曲的影响,该函数可以动态交易语义压缩对语义保真度造成损失。 请注意,(12) 的上限为 (13),但很难使用 (12) 作为神经网络的损失函数训练。 [27] 的另一个贡献是引入了用于每个单词的自适应符号数量,以根据 (17) 中定义的度量进一步提高性能。 当每个字的最大符号数很大时,性能增益变得很明显,但它也会增加要传输的数据的大小。 为了使经过训练的模型能够适用于容量有限的物联网设备,Xie 等人 [14]通过修剪和量化经过训练的 DeepSC 模型,开发了 DeepSC 的精简模型,该模型可以在不降低性能的情况下实现 40 倍的压缩比。
IV-B 图像处理
在这一部分中,我们首先介绍图像语义提取的不同方法。 然后讨论基于深度学习的图像压缩和图像传输的语义通信。
IV-B1 非结构图像语义表示
像素级图像的表示通常缺乏高级语义信息。 经典的机器学习方法利用手工制作的特征来表示图像。 后来,稀疏编码[50]被引入,将图像块表示为超完备基元素的组合,也称为码本。 然而,浅层特征的表示能力通常是有限的。
卷积神经网络(CNN)取得突破后,强大的深度特征变得可用。 在 CNN 中,每一层都会生成输入数据的连续更高级别的抽象,称为特征图,以保留重要但独特的信息。 通过采用非常深的层次结构,现代 CNN 在图像语义表示和内容理解方面实现了卓越的性能。 尽管这些方法在视觉特征提取方面取得了先进的性能,但视觉特征和语义之间仍然存在差距。
为了缩小差距,一些研究人员专注于利用上下文信息提取图像。 [51]中提出的深度语义特征匹配方法结合了卷积特征金字塔和激活引导特征选择。 在估计同一语义类别的不同实例和场景之间的对应关系方面,已经获得了有希望的结果。 Huang [52]提出了一种图像和句子匹配方法,利用图像全局上下文来学习语义概念,例如对象、属性和动作。 图像区域的描述在[53]中生成,其中视觉语义对齐模型推断句子片段与这些文本片段描述的图像区域之间的对齐。 Shi等人[54]提出了一种用于行人重识别的语义表示,其中语义属性包括衣服的颜色和类别以及身体的不同部位。
一些研究人员尝试提取图像语义的简洁表示,例如语义分割图、草图、物体骨架和面部标志。 这些语义标签描述了这些对象的布局。 例如,语义分割中的每个像素都标有其封闭对象或区域的类别。 物体骨架描述了对称轴,广泛应用于物体识别/检测。 面部标志用于定位和表示面部的显着区域,即眼睛和鼻子,这些区域应用于各种任务,例如面部对齐、头部姿势估计和面部交换等。
IV-B2 结构图像语义表示
结构图像语义表示的努力集中在使用基于图的机器学习技术来减少低级图像特征与大量人类对图像的高级感知之间的语义差距。 借助图表示的力量,解决方案空间减少,从而导致表示学习更快的优化收敛和更高的准确性。 基于图的方法已在图像分割、标注和检索方面展示了有效的性能。 通过这种方式,可以弥合图像视觉内容和语义标签之间的差距。
场景图[55]被认为是语义图的典型表示,它是描述真实场景中的对象及其关系的数据结构。 如图9所示,完整的场景图可以表示场景的详细语义,可用于将2D/3D图像/视频编码为语义特征。 场景图是场景描述的新内容,已广泛应用于推理任务,例如问答、图像检索和图像描述等。
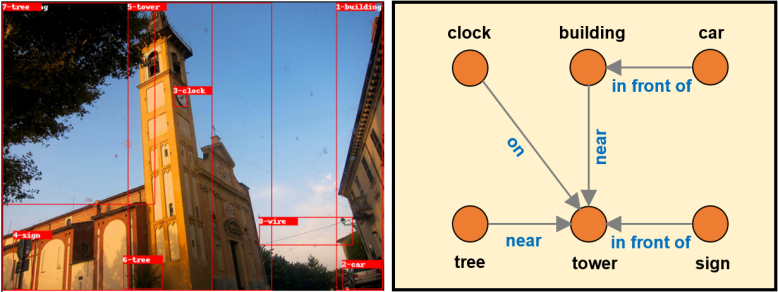
场景图生成(SGG)是为了构建更完整的场景图而开发的。 特别是,VTransE 将对象放置在低维关系空间中,其中关系可以建模为简单的平移向量 () [43]。 请注意,视觉场景的元素具有很强的结构规律性,因此可以检查场景图中的一些结构重复。 MOTIFNET [56] 将 SGG 分为预测边界框、对象标签和关系的阶段。 此外,Causal-TDE[57]基于传统似然之外的因果推断,引入了SGG因果图,以消除反事实因果关系带来的不良偏差的影响。
IV-B3 基于深度学习的图像压缩
传统的图像压缩将图像投影到其稀疏域中,并在像素级精度的指导下重建图像。 它们在低比特率下会出现块状和振铃伪影,并且重建的图像在视觉上并不令人愉悦。 基于机器学习的图像压缩方法将传统的像素重建转变为语义重建是前沿。 内容理解被认为是下一代图像编码的核心。
深度自动编码器将图像编码为低维潜在代码,从而实现高效压缩。 [58,59,60]中提出了各种基于端到端深度自动编码器的图像压缩架构。 为了处理基于非微分舍入的量化,已经提出了用于量化和熵率估计的可微替代方案。 基于图像局部信息内容在空间上变化的事实,[61]提出了一种内容感知的比特率分配方法。
此外,GAN 用于以非常低的比特率生成视觉上令人愉悦的重建。 开创性工作[62]将GAN引入压缩,提出了一种实时自适应图像压缩方法。 通过利用自动编码器特征金字塔对图像进行下采样并使用生成器进行重建,压缩器通常会生成比典型图像压缩方法(例如 JPEG)小 2.5 倍的文件。 Agustsson 等人 [63]介绍了基于GAN的极限学习图像压缩,它以极低的比特率获得视觉上令人愉悦的结果。 此外,如果语义标签图可用,则可以完全合成解码图像中的非本质区域。 Wu 等人 [64]提出了一种基于GAN的可调谐图像压缩系统,其中学习重要图来指导比特分配。
IV-B4 图像/视频语义通信
图10示出了图像语义通信的结构,其利用了前述的图像处理,但不限于此。 语义编码器以视觉语义嵌入、语义标签或语义图的形式提取低维语义信息。 采用机器学习技术来设计高效的语义编码器。 下一阶段是通道编码器,它可以与语义编码器联合训练。
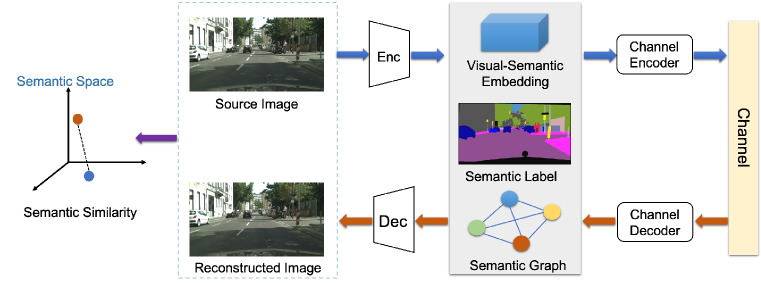
特别是,Kurka 等人提出了 DeepJSCC [65, 66] 用于图像的自适应带宽无线传输。 它利用通道输出反馈信号并优于基于分离的方案。 DeepJSCC 在低 SNR 和小带宽条件下表现良好,但略有下降。 在接收器处,语义解码器通常采用基于 GAN 的架构将语义信息映射到其视觉空间。 使用语义相似性标准来优化这种欠定图像重建训练任务。
更多的工作被设计用于服务某些视觉任务,称为面向任务的语义通信。 具体而言,Lee等人[67]设计了一种图像联合传输分类系统,其中接收器直接输出图像分类结果。 经验证,这种联合设计比单独进行图像恢复和分类获得了更高的分类精度。 Kang等人[68]提出了一种联合图像传输和场景分类的方案。 利用深度强化学习来识别服务传输任务的最本质的语义特征,从而实现分类精度和传输成本之间的最佳权衡。 Jankowski 等人 [69]将基于图像的人或汽车重识别视为传输任务,并提出了两种方案来提高检索精度。
而且,视频传输被认为是语义通信的杀手级应用,尤其是视频会议。 特别是,Wang 等人 [70]开发了一种支持强化学习的端到端框架,用于可变带宽的视频传输。 与传统方法相比,它表现出优越的性能。 Wang等人[71]设计了一种用于空中视频传输的JSCC方案,以最小化端到端传输率失真。 Jiang等人[72]提出了一种具有新颖语义错误检测器的视频会议语义传输方案。 演讲者的照片作为先验信息共享,以帮助重建演讲者面部表情的运动。 所开发的方案大大降低了对无线资源的需求。 Tai 等人 [73]开发了一种移动视频传输框架来保证体验质量(QoE)。 我们建立了一个大型数据集来寻找主观 QoE 分数与神经网络参数之间的关系,以指导语义视频传输。 此外,Fried等人[74]提出通过编辑文本来编辑头部说话视频。 后来,Tandon 等人 [75]提出只传输文本而不是视频,这大大降低了网络流量。
对于图像或视频传输,面向任务的语义通信显着降低了网络流量。 然而,由于系统是针对特定任务进行训练的,如果传输任务发生变化,则应更新甚至重新训练训练后的模型。
IV-C 语音和多模态数据处理
IV-C1 语音语义通信
语义通信系统也被设计用于语音传输[76, 77]。 Weng 等人 [13]提出了一种针对语音信号的DeepSC扩展,名为DeepSC-S。 特别是,联合语义信道编码可以处理源失真和信道效应。 在这项工作中,不涉及比特到符号的转换。 采用MSE作为损失函数,以最小化恢复的语音信号与输入信号之间的差异。 此外,采用信号失真比(SDR)和PESQ作为恢复语音信号质量的两个性能指标。 Tong 等人 [77] 将其扩展到多用户案例并实现联邦学习,以在多个本地设备和服务器上协作训练基于 CNN 的编码器和解码器。 MSE也被用作损失函数和性能度量,它很难反映接收方的语义信息量。
受到智能任务前所未有的需求的启发,DeepSC-ST[76]利用循环神经网络(RNN)从发送端的语音信号中提取与文本相关的语义信息,并在发送端恢复文本序列。语音合成的接收器。 这样,只传输文本语义信息,大大减少了所需的传输资源。 采用联结时间分类(CTC)[78]作为损失函数,其中字符错误率(CER)和WER作为两个性能指标来衡量识别文本信息的准确性。 利用前面提到的 FDSD 和 KDSD 来测量真实语音信号和合成语音信号之间的相似性。
IV-C2 多模态数据和多任务的统一语义通信
多模态数据处理被认为是一项关键任务,如图11所示。 对于 AR/VR 和人类感知护理系统等任务,生成的多模态数据在上下文中是相关的。 通过引入新的自由度,多模态数据提高了智能任务的性能[79]。
语义通信有望支持多模式数据传输。 Xie 等人 [15]开发了用于视觉问答任务的MU-DeepSC,其中关于图像的基于文本的问题由一个用户传输,查询图像从另一个用户。 采用交叉熵作为损失函数,而任务相关指标,即答案准确率,用于衡量 MU-DeepSC 的性能。 与上述所有点对点传输的工作不同,MU-DeepSC是为服务多用户传输而设计的。 作为 DeepSC 的扩展,基于 Transformer 的框架[80]已被开发为服务不同任务的独特结构。 在[80]中对各种任务进行了测试,以显示其优越性。
请注意,上述工作仍然需要对每个任务进行模型训练,这限制了应用。 一个统一的深度学习支持的语义通信系统(U-DeepSC)[81]被设计来服务于各种传输任务。 为了在一个模型中联合服务这些任务,采用域自适应来降低传输开销。 此外,由于每个任务具有不同的难度并且需要不同的层数,因此提出了多退出架构来为相对简单的任务提供早期退出结果。
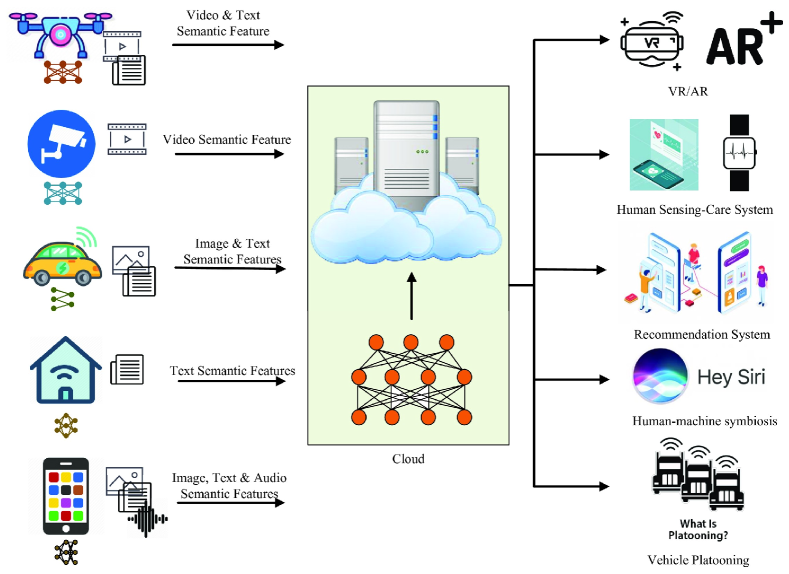
请注意,对多模式数据传输的语义交换的研究仍处于起步阶段。 但我们可以看到语义通信在支持各种应用的多模态数据传输方面的巨大潜力,特别是通过利用来自不同模态的数据之间的相关性来降低要传输的数据大小的巨大潜力。
V 研究挑战和结论
现在我们可以得出结论,语义沟通是对传统沟通的突破。 然而,其总体结构和许多相关问题尚不清楚,这促使我们在这一领域进行更多研究。 为了为语义交流铺平道路,应回答以下开放性问题:
-
1.
语义理论:虽然过去几十年来有一些研究者在研究语义理论,但大多数都是基于逻辑概率,应用场景有限,遵循传统信息论的框架。 我们是否可以遵循类似的路径,通过语义熵、语义信道容量、语义级别率失真理论以及推理精度与传输速率之间的关系来量化语义通信,这仍然是个问题。
-
2.
语义收发器:语义提供简洁有效的表示,从而使语义通信成为节省带宽和后续任务处理的高效系统。 然而,针对不同类型源的通用语义级别 JSCC 尚不可用。 此外,设计一个语义噪声稳健的通信系统,结合对抗性训练等机器学习技术是一项重大挑战。 此外,需要适当的损失函数而不导致梯度消失。
-
3.
带有推理的语义通信:受到系统 2 的进步的启发,系统 2 能够进行推理、规划和处理异常,带有推理的语义通信系统可以通过仅发送指定的最有效的语义来显着降低通信成本由 Tong 的主题演讲和 Seo 等人 [82] 提出。 然而,这方面的研究还处于起步阶段,期望更多的努力来开发更智能的推理语义通信系统。
-
4.
语义感知网络中的资源分配:在语义感知网络中,重新考虑语义干扰控制的资源分配至关重要。 与传统通信中的资源分配侧重于工程问题(即提高比特传输率)相比,语义感知资源分配旨在解决工程问题和语义问题。 语义感知资源分配的目标是提高语义领域的通信效率。 特别是,[83, 84]中提出了语义频谱效率。 但该问题仍面临以下挑战:
-
•
如何评估语义通信效率,即语义传输率或语义频谱效率?
-
•
如何为不同的面向任务的语义系统制定通用的资源分配问题,以优化资源分配策略,从而最大化语义通信效率?
-
•
-
5.
性能指标:尽管如上所述,语义通信系统中已经探索了一些新的性能指标,但为语义通信设计更合适的评估指标是非常有必要的,例如,评估语义通信量的指标已保留或丢失的语义信息。 此外,需要通用的性能指标,例如传统通信系统的SER或BER,来测量不同的语义通信系统。
-
6.
应用:除了对语义通信的广泛研究兴趣外,查杀应用程序也超出了人们的预期。 我们目睹了学术界和工业界对支持语义通信的 AR/VR 和视频会议的广泛兴趣。 我们期待在不久的将来看到语义通信的更多潜在应用。
参考
- [1] C. E. Shannon and W. Weaver, The Mathematical Theory of Communication. The University of Illinois Press, 1949.
- [2] J. Hoydis, F. A. Aoudia, A. Valcarce, and H. Viswanathan, “Toward a 6G AI-native air interface,” arXiv preprint arXiv:2012.08285, Apr. 2021.
- [3] W. Tong and G. Y. Li, “Nine challenges in artificial intelligence and wireless communications for 6G,” IEEE Wireless Commun., pp. 1–10, 2022.
- [4] R. Carnap, Y. Bar-Hillel et al., An Outline of A Theory of Semantic Information. RLE Technical Reports 247, Research Laboratory of Electronics, Massachusetts Institute of Technology., Cambridge MA, Oct. 1952.
- [5] J. Bao, P. Basu, M. Dean, C. Partridge, A. Swami, W. Leland, and J. A. Hendler, “Towards a theory of semantic communication,” in IEEE Network Science Workshop, West Point, NY, USA, Jun. 2011, pp. 110–117.
- [6] B. Guler, A. Yener, and A. Swami, “The semantic communication game,” IEEE Trans. Cogn. Commun. Netw., vol. 4, no. 4, pp. 787–802, Dec. 2018.
- [7] Z. Qin, H. Ye, G. Y. Li, and B.-H. F. Juang, “Deep learning in physical layer communications,” IEEE Wireless Commun., vol. 26, no. 2, pp. 93–99, Apr. 2019.
- [8] B. H. Juang, “Quantification and transmission of information and intelligence—history and outlook [DSP history],” IEEE Signal Process. Mag., vol. 28, no. 4, pp. 90–101, Jul. 2011.
- [9] A. Chattopadhyay, B. D. Haeffele, D. Geman, and R. Vidal, “Quantifying task complexity through generalized information measures,” https://openreview.net/pdf?id=vcKVhY7AZqK, 2021.
- [10] N. Farsad, M. Rao, and A. Goldsmith, “Deep learning for joint source-channel coding of text,” in Proc. IEEE Int. Conf. Acoustics Speech Signal Process (ICASSP), Calgary, Canada, Apr. 2018, pp. 2326–2330.
- [11] E. Bourtsoulatze, D. B. Kurka, and D. Gündüz, “Deep joint source-channel coding for wireless image transmission,” IEEE Trans. Cogn. Commun. Netw., vol. 5, no. 3, pp. 567–579, May 2019.
- [12] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, Apr. 2021.
- [13] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2434–2444, Aug. 2021.
- [14] H. Xie and Z. Qin, “A lite distributed semantic communication system for Internet of Things,” IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 142–153, Jan. 2021.
- [15] H. Xie, Z. Qin, and G. Y. Li, “Task-oriented multi-user semantic communications for VQA,” IEEE Wireless Commun. Lett., vol. 11, no. 3, pp. 553–557, Mar. 2022.
- [16] M. Kalfa, M. Gok, A. Atalik, B. Tegin, T. M. Duman, and O. Arikan, “Towards goal-oriented semantic signal processing: Applications and future challenges,” Digit. Signal Process., vol. 119, pp. 103–134, Dec. 2021.
- [17] E. C. Strinati and S. Barbarossa, “6G networks: Beyond shannon towards semantic and goal-oriented communications,” arXiv preprint arXiv:2011.14844, Feb. 2021.
- [18] Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is semantic communication? A view on conveying meaning in the era of machine intelligence,” arXiv preprint arXiv:2110.00196, Oct. 2021.
- [19] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Commun. Mag., vol. 59, no. 8, pp. 44–50, Sep. 2021.
- [20] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei, and F. Zhang, “Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks,” Engineering, pp. 1–17, Nov. 2021.
- [21] M. Kountouris and N. Pappas, “Semantics-empowered communication for networked intelligent systems,” IEEE Commun. Mag., vol. 59, no. 6, pp. 96–102, Jun. 2021.
- [22] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, T. Soleymani, B. Soret, and K. H. Johansson, “Semantic communications in networked systems,” arXiv preprint arXiv:2103.05391, Jun. 2021.
- [23] P. Blanchart, “Fast learning methods adapted to the user specificities: Application to earth observation image information mining,” PhD thesis, Sep. 2011.
- [24] X. Liu, W. Jia, W. Liu, and W. Pedrycz, “Afsse: An interpretable classifier with axiomatic fuzzy set and semantic entropy,” IEEE Trans. Fuzzy Syst., vol. 28, no. 11, pp. 2825–2840, 2020.
- [25] J. Liu, W. Zhang, and H. V. Poor, “A rate-distortion framework for characterizing semantic information,” arXiv preprint arXiv:2105.04278, May 2021.
- [26] N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,” arXiv preprint arXiv:0004057, Apr. 2000.
- [27] M. Sana and E. C. Strinati, “Learning semantics: An opportunity for effective 6G communications,” arXiv preprint arXiv:2110.08049, Oct. 2021.
- [28] W. Wang, L. Wang, R. Wang, Z. Wang, and A. Ye, “Towards a robust deep neural network in texts: A survey,” arXiv preprint arXiv:1902.07285, Feb. 2019.
- [29] X. Peng, Z. Qin, D. Huang, X. Tao, J. Lu, G. Liu, and C. Pan, “A robust deep learning enabled semantic communication system for text,” arXiv preprint arXiv:2206.02596, Jun. 2022.
- [30] Q. Hu, G. Zhang, Z. Qin, Y. Cai, G. Yu, and G. Y. Li, “Robust semantic communications with masked VQ-VAE enabled codebook,” arXiv preprint arXiv:2206.04011, Jun. 2022.
- [31] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, Dec. 2014.
- [32] T. Miyato, A. M. Dai, and I. Goodfellow, “Adversarial training methods for semi-supervised text classification,” arXiv preprint arXiv:1605.07725, May 2016.
- [33] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” Proc. Int Conf. Learning Rep. workshop, May 2017.
- [34] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Deep source-channel coding for sentence semantic transmission with HARQ,” arXiv preprint arXiv:2106.03009, Jun. 2021.
- [35] K. Papineni, S. Roukos, T. Ward, and W. Zhu, “BLEU: A method for automatic evaluation of machine translation,” in Proc. Annual Meeting Assoc. Comput. Linguistics (ACL), Philadelphia, PA, USA, Jul. 2002, pp. 311–318.
- [36] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. North American Chapter of the Assoc. for Comput. Linguistics: Human Language Tech. (NAACL-HLT), Minneapolis, MN, USA, Jun. 2019, pp. 4171–4186.
- [37] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Proc. European Conf. Comput. Vis. (ECCV). Springer, Amsterdam, The Netherlands, Mar. 2016, pp. 694–711.
- [38] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 586–595.
- [39] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu, “Learning fine-grained image similarity with deep ranking,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Columbus, OH, USA, Jun. 2014, pp. 1386–1393.
- [40] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” arXiv preprint arXiv:1406.2661, Jun. 2014.
- [41] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen, “Improved techniques for training GANs,” arXiv preprint arXiv:1606.03498, Jun. 2016.
- [42] A. Frome, G. S. Corrado, J. Shlens, S. Bengio, J. Dean, M. A. Ranzato, and T. Mikolov, “Devise: A deep visual-semantic embedding model,” in Proc. Advances Neural Inf. Processing Syst. (NIPS), vol. 26, Lake Tahoe., USA, Dec. 2013.
- [43] H. Zhang, Z. Kyaw, S.-F. Chang, and T.-S. Chua, “Visual translation embedding network for visual relation detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, Hawaii., Jun. 2017, pp. 5532–5540.
- [44] J. Zhang, Y. Kalantidis, M. Rohrbach, M. Paluri, A. Elgammal, and M. Elhoseiny, “Large-scale visual relationship understanding,” in Proc. AAAI Conf. Artif. Intell., Jan. 2019, pp. 9185–9194.
- [45] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Salt Lake City, UT, USA, May. 2001, pp. 749–752.
- [46] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,” IEEE Trans. Audio, Speech, Language Process., vol. 19, no. 7, pp. 2125–2136, Sep. 2011.
- [47] J. G. Beerends, C. Schmidmer, J. Berger, M. Obermann, R. Ullmann, J. Pomy, and M. Keyhl, “Perceptual objective listening quality assessment (POLQA), the third generation ITU-T standard for end-to-end speech quality measurement part I—temporal alignment,” J. Audio Eng. Soc., vol. 61, no. 6, pp. 366–384, Jun. 2013.
- [48] M. Bińkowski, J. Donahue, S. Dieleman, A. Clark, E. Elsen, N. Casagrande, L. C. Cobo, and K. Simonyan, “High fidelity speech synthesis with adversarial networks,” arXiv preprint arXiv:1909.11646, Sep. 2019.
- [49] D. W. Otter, J. R. Medina, and J. K. Kalita, “A survey of the usages of deep learning for natural language processing,” IEEE Trans. Neural Netw. Learning syst., vol. 32, no. 2, pp. 604–624, 2020.
- [50] H. Bristow, A. Eriksson, and S. Lucey, “Fast convolutional sparse coding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Portland, OR, USA, Jun. 2013, pp. 391–398.
- [51] N. Ufer and B. Ommer, “Deep semantic feature matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, Hawaii., Nov. 2017, pp. 6914–6923.
- [52] Y. Huang, Q. Wu, C. Song, and L. Wang, “Learning semantic concepts and order for image and sentence matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 6163–6171.
- [53] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015, pp. 3128–3137.
- [54] Z. Shi, T. M. Hospedales, and T. Xiang, “Transferring a semantic representation for person re-identification and search,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015, pp. 4184–4193.
- [55] J. Johnson, R. Krishna, M. Stark, L.-J. Li, D. Shamma, M. Bernstein, and L. Fei-Fei, “Image retrieval using scene graphs,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015, pp. 3668–3678.
- [56] R. Zellers, M. Yatskar, S. Thomson, and Y. Choi, “Neural motifs: Scene graph parsing with global context,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, Jun. 2018, pp. 5831–5840.
- [57] K. Tang, Y. Niu, J. Huang, J. Shi, and H. Zhang, “Unbiased scene graph generation from biased training,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, Jun. 2020, pp. 3716–3725.
- [58] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” arXiv preprint arXiv:1703.00395, Mar. 2017.
- [59] Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Deep convolutional autoencoder-based lossy image compression,” in IEEE Proc. Picture Coding Symposium (PCS), Sep. 2018, pp. 253–257.
- [60] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” arXiv preprint arXiv:1611.01704, Nov. 2016.
- [61] M. Li, W. Zuo, S. Gu, D. Zhao, and D. Zhang, “Learning convolutional networks for content-weighted image compression,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 3214–3223.
- [62] O. Rippel and L. Bourdev, “Real-time adaptive image compression,” in PMLR Proc. Int. Conf. Mach. Learning (ICML), Sydney, Australia, May 2017, pp. 2922–2930.
- [63] E. Agustsson, M. Tschannen, F. Mentzer, R. Timofte, and L. V. Gool, “Generative adversarial networks for extreme learned image compression,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Seoul, Korea (South), Oct. 2019, pp. 221–231.
- [64] L. Wu, K. Huang, and H. Shen, “A GAN-based tunable image compression system,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Venice, Italy, Jun. 2020, pp. 2334–2342.
- [65] D. B. Kurka and D. Gündüz, “DeepJSCC-f: Deep joint source-channel coding of images with feedback,” IEEE J. Sel. Areas Inf. Theory, May 2020.
- [66] D. B. Kurka and D. Gündüz, “Bandwidth-agile image transmission with deep joint source-channel coding,” IEEE Trans. Wireless Commun., pp. 8081–8095, Jun. 2021.
- [67] C.-H. Lee, J.-W. Lin, P.-H. Chen, and Y.-C. Chang, “Deep learning-constructed joint transmission-recognition for Internet of Things,” IEEE Access, vol. 7, pp. 76 547–76 561, Jun. 2019.
- [68] X. Kang, B. Song, J. Guo, Z. Qin, and F. R. Yu, “Task-oriented image transmission for scene classification in unmanned aerial systems,” arXiv preprint arXiv: 2112.10948, Dec. 2021.
- [69] M. Jankowski, D. Gündüz, and K. Mikolajczyk, “Wireless image retrieval at the edge,” IEEE J. Select. Areas Commun., vol. 39, no. 1, pp. 89–100, Jan. 2021.
- [70] T.-Y. Tung and D. Gündüz, “Deepwive: Deep-learning-aided wireless video transmission,” arXiv preprint arXiv:2111.13034, Nov. 2021.
- [71] S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless deep video semantic transmission,” arXiv preprint arXiv:2205.13129, 2022.
- [72] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Wireless semantic communications for video conferencing,” arXiv preprint arXiv:2204.07790, 2022.
- [73] X. Tao, Y. Duan, M. Xu, Z. Meng, and J. Lu, “Learning QoE of mobile video transmission with deep neural network: A data-driven approach,” IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1337–1348, Jun. 2019.
- [74] O. Fried, A. Tewari, M. Zollhöfer, A. Finkelstein, E. Shechtman, D. B. Goldman, K. Genova, Z. Jin, C. Theobalt, and M. Agrawala, “Text-based editing of talking-head video,” ACM Trans. Graphics (TOG), vol. 38, no. 4, pp. 1–14, 2019.
- [75] P. Tandon, S. Chandak, P. Pataranutaporn, Y. Liu, A. M. Mapuranga, P. Maes, T. Weissman, and M. Sra, “Txt2Vid: Ultra-low bitrate compression of talking-head videos via text,” arXiv preprint arXiv:2106.14014, Jun. 2022.
- [76] Z. Weng, Z. Qin, X. Tao, C. Pan, G. Liu, and G. Y. Li, “Deep learning enabled semantic communications with speech recognition and synthesis,” arXiv preprint arXiv:2205.04603, May 2022.
- [77] H. Tong, Z. Yang, S. Wang, Y. Hu, O. Semiari, W. Saad, and C. Yin, “Federated learning for audio semantic communication,” Frontiers Commun. Netw., vol. 2, p. 43, Sep. 2021.
- [78] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in PMLR Proc. Int. Conf. Mach. Learning (ICML), Pittsburgh, USA, Jun. 2006, pp. 369–376.
- [79] D. Lahat et al., “Multimodal data fusion: An overview of methods, challenges, and prospects,” Proc. IEEE, vol. 103, no. 9, pp. 1449–1477, Apr. 2015.
- [80] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-oriented multi-user semantic communications,” arXiv preprint arXiv:2112.10255, Dec. 2021.
- [81] G. Zhang, Q. Hu, Z. Qin, Y. Cai, and G. Yu, “A unified multi-task semantic communication system with domain adaptation,” arXiv preprint arXiv:2206.00254, Jun. 2022.
- [82] H. Seo, J. Park, M. Bennis, and M. Debbah, “Semantics-native communication with contextual reasoning,” arXiv preprint arXiv:2108.05681, Aug. 2021.
- [83] L. Yan, Z. Qin, R. Zhang, Y. Li, and G. Y. Li, “Resource allocation for semantic-aware networks,” arXiv preprint arXiv:2201.06023, Apr. 2022.
- [84] ——, “QoE-aware resource allocation for semantic communication networks,” arXiv preprint arXiv:2205.14530, May 2022.