Point-NeRF:基于点的神经辐射场
摘要
NeRF [35] 等体积神经渲染方法可生成高质量的视图合成结果,但针对每个场景进行优化,导致重建时间过长。 另一方面,深度多视图立体方法可以通过直接网络推理快速重建场景几何形状。 Point-NeRF 通过使用神经 3D 点云以及相关的神经特征来对辐射场进行建模,从而结合了这两种方法的优点。 Point-NeRF 可以通过在基于光线行进的渲染管道中聚合场景表面附近的神经点特征来高效渲染。 此外,Point-NeRF 可以通过预先训练的深度网络的直接推理进行初始化,生成神经点云;该点云可以进行微调,以更快的训练时间超越 NeRF 的视觉质量。 Point-NeRF 可以与其他 3D 重建方法相结合,并通过新颖的修剪和生长机制处理此类方法中的错误和异常值。 DTU [18]、NeRF Synthetics [35]、ScanNet [11] 和 Tanks and Temples 上的实验[23]数据集证明Point-NeRF可以超越现有方法并取得最先进的结果。 请访问我们的网站 https://xharlie.github.io/projects/project_sites/pointnerf 获取代码和更多结果。
1简介
根据图像数据对真实场景进行建模并渲染逼真的新颖视图是计算机视觉和图形学的核心问题。 NeRF [35] 及其扩展 [29, 32, 64] 通过对神经辐射场进行建模,在这方面取得了巨大成功。 这些方法[35,64,38]通常通过光线行进使用整个空间的全局MLP来重建辐射场。 由于每个场景的网络拟合速度慢以及对巨大的空白空间进行不必要的采样,这导致重建时间较长。
我们使用 Point-NeRF 来解决这个问题,这是一种新颖的基于点的辐射场表示,它使用 3D 神经点来建模连续体积辐射场。 与纯粹依赖于每个场景拟合的 NeRF 不同,Point-NeRF 可以通过跨场景预训练的前馈深度神经网络进行有效初始化。 此外,Point-NeRF 通过利用近似实际场景几何形状的经典点云,避免了在空场景空间中进行光线采样。 Point-NeRF 的这一优势导致比其他神经辐射场模型更高效的重建和更准确的渲染[35,8,53,63]。
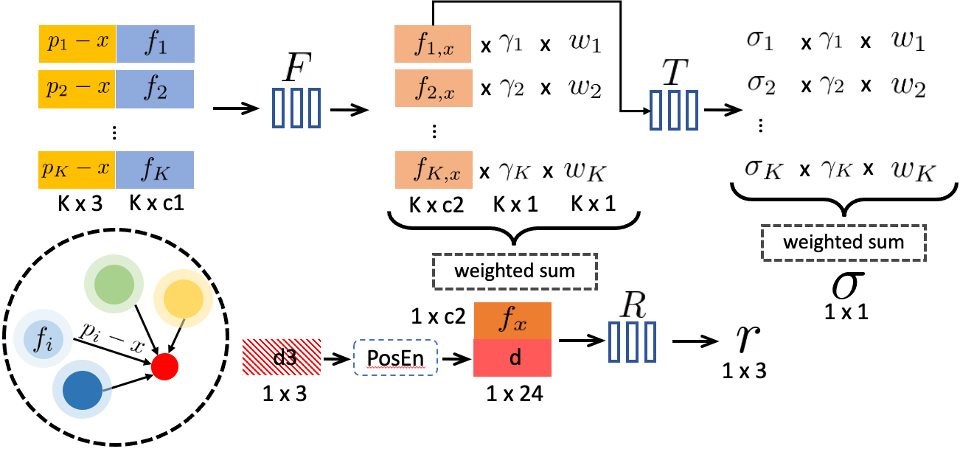
我们的 Point-NeRF 表示由具有每点神经特征的点云组成:每个神经点对其周围的局部 3D 场景几何形状和外观进行编码。 先前的基于点的渲染技术[2]使用类似的神经点云,但通过在图像空间中运行的光栅化和 2D CNN 来执行渲染。 相反,我们将这些神经点视为 3D 中的局部神经基函数,以对连续体积辐射场进行建模,从而使用可微分光线行进实现高质量渲染。 特别是,对于任何 3D 位置,我们建议使用 MLP 网络来聚合其邻域中的神经点,以回归该位置处的体积密度和与视图相关的辐射率。 这表示连续的辐射场。
我们提出了一个基于学习的框架来有效地初始化和优化基于点的辐射场。 为了生成初始场,我们利用深度多视图立体 (MVS) 技术[59],即应用基于成本体积的网络来预测深度,然后将其投影到 3D 空间。 此外,深度 CNN 经过训练,可以从输入图像中提取 2D 特征图,自然地提供每点特征。 这些来自多个视图的神经点组合成神经点云,形成场景的基于点的辐射场。 我们使用基于点的体渲染网络从头到尾训练这个点生成模块,以渲染新颖的视图图像并用地面事实对其进行监督。 这导致了一个可推广模型,可以在推理时直接预测基于点的辐射场。 一旦预测,初始的基于点的场将在短时间内针对每个场景进行进一步优化,以实现照片级真实感渲染。 如图LABEL:fig:teaser(左)所示,使用 Point-NeRF 进行 21 分钟的优化优于训练数天的 NeRF 模型。
除了使用内置点云重建外,我们的方法还具有通用性,也可以根据其他重建技术的点云生成辐射场。 然而,实际上,通过 COLMAP [44] 等技术生成的重建点云包含对最终渲染产生不利影响的空洞和异常值。 为了解决这个问题,我们引入了点增长和修剪作为优化过程的一部分。 我们在体积渲染期间利用几何推理[13],并在高体积密度区域中的点云边界附近生长点,并在低密度区域中修剪点。 该机制有效提高了我们最终的重建和渲染质量。 我们在图 LABEL:fig:teaser(右)中展示了一个示例,其中我们将 COLMAP 点转换为辐射场并成功填充大孔并生成照片级真实感渲染。
2相关工作
场景表示。 传统方法和神经方法研究了许多 3D 场景表示,包括体积 [46, 25, 19, 56, 41]、点云 [40, 1, 51]、网格[20, 52]、深度图 [28, 17] 和隐式函数 [9, 33, 37, 60],以多种形式呈现视觉和图形应用。 最近,提出了各种神经场景表示[67,47,30,4],利用体积神经辐射场(NeRF)[35] 产生高保真度结果。 NeRF 通常被重建为全局 MLP [35,64,38],对整个场景空间进行编码;在重建复杂和大规模的场景时,这可能效率低下且成本高昂。 相反,Point-NeRF 是一种局部神经表示,将体积辐射场与传统上用于近似场景几何形状的点云相结合。 我们分布细粒度的神经点来对复杂的局部场景几何和外观进行建模,从而获得比 NeRF 更好的渲染质量(见图5、6)。
具有每体素神经特征[29,8,16]的体素网格也是局部神经辐射度表示。 然而,我们基于点的表示可以更好地适应实际表面,从而获得更好的质量。 此外,我们直接预测良好的初始神经点特征,绕过大多数基于体素的方法[29, 16]所需的每个场景优化。
多视图重建和渲染。 多视图 3D 重建已得到广泛研究,并通过多种运动结构[43,50,49]和多视图立体技术[14,25,44, 59, 10]。 点云通常是 MVS 或深度传感器的直接输出,尽管它们通常会转换为网格 [31, 21] 以进行渲染和可视化。 网格划分可能会引入错误,并且可能需要基于图像的渲染[12,6,66]才能实现高质量渲染。 相反,我们直接使用深度 MVS 中的点云来实现逼真的渲染。
点云已广泛用于渲染,通常通过基于光栅化的点喷射,甚至可微分光栅化模块[55, 26]。 然而,重建的点云通常存在孔洞和异常值,导致渲染中出现伪影。 基于点的神经渲染方法通过展开神经特征并使用 2D CNN 渲染它们[2,24,34]来解决这个问题。 相比之下,我们的基于点的方法利用 3D 体积渲染,比以前的基于点的方法产生明显更好的结果。
神经辐射场。 NeRFs [35] 已经展示了新颖的视图合成的非常高质量的结果。 它们已被扩展以实现动态场景捕捉[27, 39]、重新照明[3, 5]、外观编辑[57]、快速渲染 [16, 62] 和生成模型 [7, 45, 36]。 然而,大多数方法[27,39,57,3]仍然遵循原始的NeRF框架并训练每场景MLP来表示辐射场。 我们利用场景中具有空间变化神经特征的神经点来编码其辐射场。 与网络容量有限的纯 MLP 相比,这种局部表示可以建模更复杂的场景内容。 更重要的是,我们表明,我们的基于点的神经场可以通过预先训练的深度神经网络进行有效初始化,该网络可以跨场景进行泛化并导致高效的辐射场重建。
先前的工作还提出了基于通用辐射场的方法。 PixelNeRF [63] 和 IBRNet [53] 在每个采样射线点聚合多视图 2D 图像特征,以回归辐射场渲染的体渲染属性。 相比之下,我们利用场景表面周围 3D 神经点的特征来模拟辐射场。 这避免了广阔的空白空间中的采样点,并且比 PixelNeRF 和 IBRNet 具有更高的渲染质量和更快的辐射场重建。 MVSNeRF[8]可以实现非常快速的基于体素的辐射场重建。 然而,其预测网络需要固定数量的三个小基线图像作为输入,因此只能有效地重建局部辐射场。 我们的方法可以融合任意数量视图的神经点,并实现 MVSNeRF 无法支持的完整 360 辐射场的快速重建。
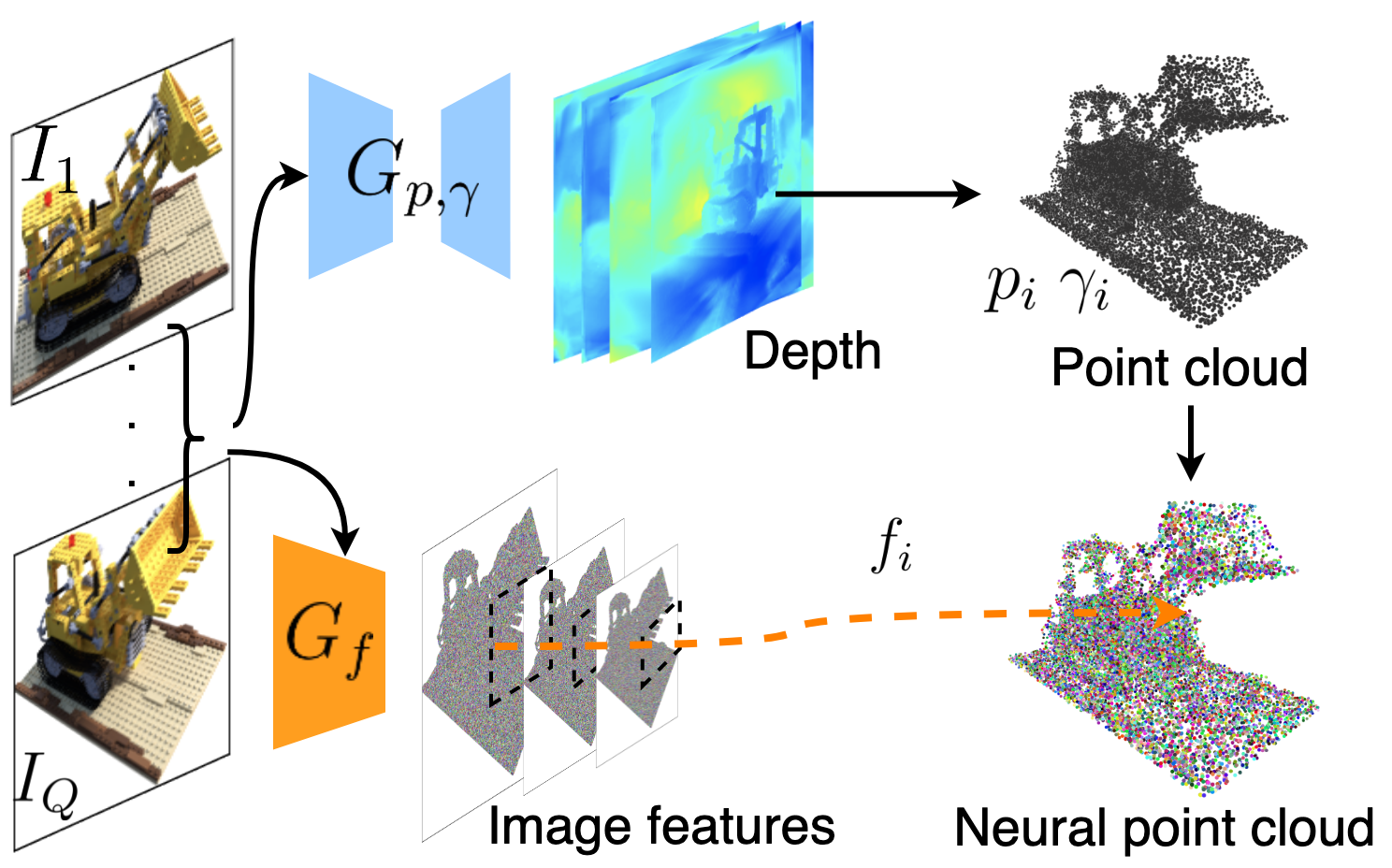
3 点-NeRF表示
我们提出了新颖的基于点的辐射场表示,专为高效重建和渲染而设计(见图1(b))。 我们从一些基本知识开始。
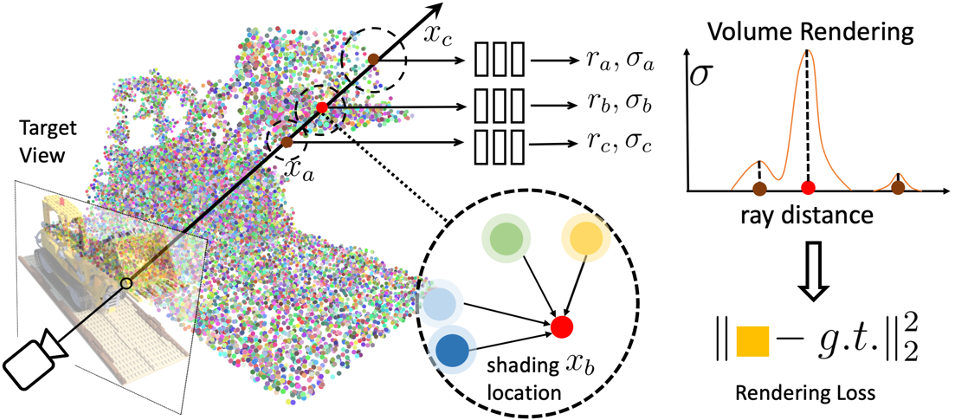
体积渲染和辐射场。 基于物理的体渲染可以通过可微的光线行进进行数值评估。 具体来说,像素的辐射率可以通过以下方式计算:使光线穿过像素,沿光线在 处采样 着色点,并使用体积密度累积辐射率,如下所示:
| (1) | ||||
其中,表示体积透过率; 和是处每个着色点的体积密度和辐射亮度,是相邻着色样本之间的距离。
辐射场表示任意 3D 位置处的体积密度 和与视图相关的辐射 。 NeRF [35]建议使用多层感知器(MLP)来回归此类辐射场。 我们提出 Point-NeRF,它利用神经点云来计算体积属性,从而实现更快、更高质量的渲染。
基于点的辐射场。 我们用表示神经点云,其中每个点位于并与神经特征向量相关联,对本地场景内容进行编码。 我们还为每个点分配一个比例置信值,表示该点位于实际场景表面附近的可能性。 我们从该点云回归辐射场。
给定任意三维位置 ,我们会查询其周围一定半径 内的相邻神经点 。我们基于点的辐射场可被摘要为一个神经模块,该模块在任何阴影位置 ,从其邻近神经点回归体积密度 和视图相关辐射度 (沿任意视图方向 ),其神经模块为:
| (2) |
我们使用类似 PointNet 的 [40] 神经网络(具有多个子 MLP)来执行此回归。 总的来说,我们首先对每个神经点进行神经处理,然后聚合多点信息以获得最终的估计。
按点处理。 我们使用 MLP 来处理每个相邻神经点,以通过以下方式预测着色位置 的新特征向量:
| (3) |
本质上,原始特征对周围的本地3D场景内容进行编码。 该 MLP 网络表达了一个局部 3D 函数,该函数在 处输出特定的神经场景描述 ,由其局部框架中的神经点建模。 相对位置 的使用使网络对于点平移具有不变性,以实现更好的泛化。
依赖于视图的辐射率回归。 我们使用标准反距离加权来聚合从这 K 个相邻点回归的神经特征 ,以获得描述 处场景外观的单个特征 :
| (4) |
然后,在给定观察方向 的情况下,MLP 会根据该特征回归与视图相关的辐射亮度:
| (5) |
反距离权重广泛应用于散乱数据插值;我们利用它来聚合神经特征,使更接近的神经点对着色计算贡献更大。 另外,我们在这个过程中使用了每点置信度;这在最终重建中进行了优化,具有稀疏性损失,使网络能够灵活地拒绝不必要的点。
密度回归。 为了计算 处的体积密度 ,我们遵循类似的多点聚合。 然而,我们首先使用 MLP 对每个点的密度 进行回归,然后进行基于反距离的加权,如下所示:
| (6) | ||||
| (7) |
因此,每个神经点直接对体积密度做出贡献,并且点置信度 与此贡献明确相关。 我们在点删除过程中利用了这一点(参见第 4.2 节)。
讨论。 与之前基于神经点的方法 [2, 34] 光栅化点特征然后使用 2D CNN 渲染它们不同,我们的表示和渲染完全是 3D 的。 通过使用近似场景几何形状的点云,我们的表示自然有效地适应场景表面,并避免在空场景空间中采样着色位置。 对于沿每条射线的着色点,我们实现了一种有效的算法来查询相邻的神经点;详细信息在补充材料中。
4点-NeRF重建
我们现在介绍用于有效重建基于点的辐射场的管道。 我们首先利用跨场景训练的深度神经网络,通过直接网络推理生成初始的基于点的字段(第 4.1 节)。 通过我们的点生长和修剪技术,这个初始场在每个场景中得到进一步优化,从而实现最终的高质量辐射场重建(第 4.2 节)。 数字。 2 显示了此工作流程以及初始预测和每个场景优化的相应梯度更新。

4.1 生成初始的基于点的辐射场
给定一组已知图像 ,..., 和点云,我们的 Point-NeRF 表示可以通过优化随机初始化的每点神经特征和 MLP 来重建具有渲染损失(类似于 NeRF)。 然而,这种纯粹的按场景优化取决于现有的点云,并且速度可能非常慢。 因此,我们提出了一个神经生成模块来通过反馈来预测所有神经点属性,包括点位置、神经特征和点置信度。用于高效重建的前向神经网络。 网络的直接推理输出良好的基于点的初始辐射场。 然后可以对初始字段进行微调以实现高质量渲染。 在很短的时间内,渲染质量更好或与 NeRF 相当,而 NeRF 需要更长的时间来优化(参见表 1)。 1 和 2)。
点位置和置信度。 我们利用深度 MVS 方法使用基于成本体积的 3D CNN [59, 10] 生成 3D 点位置。 这样的网络可以产生高质量的密集几何结构,并且可以很好地跨领域推广。 对于在视点 处具有相机参数 的每个输入图像 ,我们按照 MVSNet [17] 首先构建一个平面 -通过从相邻视点扭曲 2D 图像特征来扫描成本体积,然后使用深度 3D CNN 回归深度概率体积。 通过线性组合按概率加权的每平面深度值来计算深度图。 我们将深度图反投影到 3D 空间,以获得每个视图 的点云 。
由于深度概率描述了点位于表面上的可能性,因此我们对深度概率体积进行三线性采样以获得每个点处的点置信度。 上述过程可以表示为
| (8) |
其中 是基于 MVSNet 的网络。 是 MVS 重建中使用的附加相邻视图;在大多数情况下,我们使用两个附加视图。
点特征。 我们使用 2D CNN 从每个图像 中提取神经 2D 图像特征图。 这些特征图与 的点(深度)预测对齐,并用于直接预测每点特征 ,如下所示:
| (9) |
特别是,我们对 使用具有三个下采样层的 VGG 网络架构。 我们将不同分辨率的中间特征组合为 ,提供有意义的点描述来模拟多尺度场景外观。 (见图1(a))
端到端重建。 我们结合多个视点的点云以获得最终的神经点云。 我们训练点生成网络和表示网络,从端到端到渲染损失(见图2)。 这使得我们的生成模块能够产生合理的初始辐射场。 它还使用合理的权重初始化 Point-NeRF 表示中的 MLP,从而显着节省每个场景的拟合时间。
此外,除了使用完整的生成模块之外,我们的管道还支持使用从其他方法(如 COLMAP [44])重建的点云,其中我们的模型(不包括 MVS 网络)仍然可以提供有意义的初始神经网络每个点的特征。 详情请参阅我们的补充材料。
4.2 优化基于点的辐射场
上述管道可以为新场景输出合理的基于点的初始辐射场。 通过可微分光线行进,我们可以针对特定场景优化神经点云(点特征 和点置信度 )和表示中的 MLP,进一步改善辐射场(见图2)。
初始点云,尤其是来自外部重建方法的点云(例如图 LABEL:fig:teaser 中的 Metashape 或 COLMAP),通常可能包含孔洞和异常值,从而降低渲染质量。 在逐场景优化过程中,为了解决这个问题,我们发现直接优化现有点的位置会使训练不稳定并且无法填补大洞(参见LABEL:fig:teaser)。 相反,我们应用新颖的点修剪和生长技术来逐渐提高几何建模和渲染质量。
点修剪。 正如第 2 节中介绍的那样。 3,我们设计了点置信值来描述神经点是否靠近场景表面。 我们利用这些置信值来修剪不必要的异常点。 请注意,点置信度与体积密度回归中每点的贡献直接相关(方程: 7);因此,低置信度反映了点局部区域的低体积密度,表明该点是空的。 因此,我们每 10K 迭代修剪一次具有 的点。
点增长。 我们还提出了一种新技术来生长新点以覆盖原始点云中缺失的场景几何形状。 与直接利用现有点信息的点剪枝不同,生长点需要在不存在点的空白区域中恢复信息。 我们通过基于 Point-NeRF 表示建模的局部场景几何形状,在点云边界附近逐渐增长点来实现这一点。
5实施细节
网络详细信息。 我们对每点处理网络 的相对位置和每点特征以及网络 的观看方向应用频率位置编码。我们从网络中不同分辨率的三层中提取多尺度图像特征,得到具有56(8+16+32)通道的向量。 我们还附加了每个输入视点的相应观看方向,以处理依赖于视图的效果。 因此,我们最终的每点神经特征是一个 59 通道向量。 请参阅我们的补充材料,了解着色期间网络架构和神经点查询的详细信息。
训练和优化细节。 我们使用与 PixelNeRF 和 MVSNeRF 相同的训练和测试分割,在 DTU 数据集上训练完整的管道。 我们首先使用类似于原始 MVSNet 论文 [59] 的地面实况深度预训练基于 MVSNet 的深度生成网络。 然后,我们纯粹使用 L2 渲染损失 来训练我们从头到尾的完整管道,监督光线行进中的渲染像素(通过方程 1)。 1)与地面事实,以获得我们的Point-NeRF重建网络。 我们使用 Adam [22] 优化器训练完整的管道,初始学习率为 。 我们的前馈网络需要 从三个输入视图生成点云。
在每场景优化阶段,我们采用结合了渲染和稀疏损失的损失函数
| (12) |
我们在所有实验中都使用 。 我们每 10K 次迭代执行一次点生长和修剪,以实现最终的高质量重建。
| No Per-scene Optimization | Per-scene Optimization | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PixelNeRF[63] | MVSNeRF[8] | IBRNet [53] | Ours | Ours1K | Ours10K | MVSNeRF10K | IBRNet10K | NeRF200k | |
| PSNR | 19.31 | 26.63 | 26.04 | 23.89 | 28.43 | 30.12 | 28.50 | 31.35 | 27.01 |
| SSIM | 0.789 | 0.931 | 0.917 | 0.874 | 0.929 | 0.957 | 0.933 | 0.956 | 0.902 |
| LPIPSVgg | 0.382 | 0.168 | 0.190 | 0.203 | 0.183 | 0.117 | 0.179 | 0.131 | 0.263 |
| Time | - | - | - | - | 2min | 20min | 24min | 1h | 10h |
| NPBG[2] | NeRF [32] | IBRNet [53] | NSVF [29] | Point-NeRF | Point-NeRF20K | Point-NeRF200K | |
|---|---|---|---|---|---|---|---|
| PSNR | 24.56 | 31.01 | 28.14 | 31.75 | 31.77 | 30.71 | 33.31 |
| SSIM | 0.923 | 0.947 | 0.942 | 0.964 | 0.973 | 0.967 | 0.978 |
| LPIPSVgg | 0.109 | 0.081 | 0.072 | - | 0.062 | 0.081 | 0.049 |
| LPIPSAlex | 0.095 | - | - | 0.047 | 0.040 | 0.050 | 0.027 |
6实验
6.1DTU测试集评估。
我们在 DTU 测试集上评估我们的模型。 我们通过直接网络推理和每个场景微调优化产生新颖的视图合成,并将它们与之前最先进的方法进行比较,包括 PixelNeRF[63]、IBRNet[ 53]、MVSNeRF[8] 和 NeRF[35]。 IBRNet 和 MVSNeRF 利用类似的每场景微调;我们对所有方法进行 10k 次迭代进行比较。 此外,我们仅展示了 1k 次迭代的结果,以证明优化效率。
标签。 1展示了PSNR、SSIM、LPIPS所有方法的定量结果;定性渲染结果如图5所示。 我们可以看到,经过 10k 次迭代后,我们的微调结果实现了最佳的 SSIM 和 LPIPS[65],这是三个指标中的两个。 这些明显优于 MVSNeRF 和 NeRF。 虽然 IBRNet 产生的 PSNR 稍好一些,但我们的最终渲染实际上恢复了更准确的纹理细节和高光,如图 5 所示。 另一方面,对于相同的迭代,IBRNet 的开销也更大,需要 1 小时——比我们的长 5 倍。 这是因为 IBRNet 利用大型全局 CNN,而 Point-NeRF 利用局部点特征和更容易优化的小型 MLP。 更重要的是,我们的神经点位于实际场景表面附近,从而避免了在空白空间中采样射线点。
除了优化结果之外,我们的网络估计的初始辐射场明显优于 PixelNeRF。 在这种情况下,我们的直接推理比 IBRNet 和 MVSNet 差,主要是因为这两种方法使用更复杂的基于方差的特征提取。 我们的点特征是从简单的 VGG 网络中提取的。 PixelNeRF也采用了同样的设计;由于我们新颖的基于表面自适应点的表示,我们取得了比 PixelNeRF 更好的结果。
虽然 IBRNet 中更复杂的特征提取器可能会提高质量,但它会增加内存使用和训练效率的负担。 更重要的是,我们的生成网络已经提供了高质量的初始辐射场来支持高效的优化。 我们证明,即使对我们的方法进行 2 分钟/1K 迭代微调,也能获得与 MVSNeRF 最终 10k 迭代结果相当的非常高的视觉质量。 这清楚地表明了我们方法的高重建效率。
6.2 NeRF综合数据集的评估。
虽然我们的模型纯粹是在 DTU 数据集上训练的,但我们的网络可以很好地推广到具有完全不同相机分布的新数据集。 我们在 NeRF 合成数据集上展示了这样的结果,并与其他方法进行了比较,定性结果如图 6 所示,定量结果如图 6 所示。 2. 我们与基于点的渲染模型(NPBG)[2]、通用辐射场方法(IBRNet)[53]以及每场景辐射场重建技术进行比较(NeRF 和 NSVF)[35, 29]。
与泛化方法的比较。 我们与 IBRNet 进行比较,据我们所知,IBRNet 是之前最好的基于 NeRF 的泛化模型,可以处理任意数字的自由视点渲染。 请注意,该数据集具有 相机分布,比 DTU 数据集宽得多。 在这种情况下,无法应用 MVSNeRF 等方法,因为它从三个输入图像中恢复局部透视平截头体体积,这无法覆盖整个 观看范围。 因此,我们在本实验中与 IBRNet 进行比较,并重点关注每个场景优化后的最终结果。 我们使用他们发布的模型来产生结果。 我们的 20k 次迭代结果 (Point-NeRF20K) 已经超越了 IBRNet 的收敛结果,具有更好的 PSNR、SSIM 和 LIPIPS;我们还通过更好的几何和纹理细节实现了渲染质量,如图6所示。
与纯按场景方法的比较。 我们 20K 次迭代后的结果在数量上非常接近 NeRF 200K 次迭代训练的结果。 从视觉上看,我们的模型在 迭代中在某些情况下已经具有更好的渲染效果,例如图6中的榕树场景(第4行)。 Point-NeRF20K优化仅需40分钟,比NeRF 20多个小时的优化时间至少快。 NSVF 的 [29] 结果也是来自非常长的每个场景优化,但仅比我们的 40 分钟结果稍好一些。 将我们的模型优化 200K 直到收敛可以得到比 NeRF、NSVF 和所有其他比较方法明显更好的结果。 如图6所示,我们的200K结果包含最多的几何和纹理细节。 由于点生长技术,我们的方法是唯一能够完全恢复细节的方法,例如船舶场景(第二行)中的细绳结构。
与基于点的渲染的比较。 我们的结果明显优于以前最先进的基于点的渲染方法。 我们使用基于 MVSNet 的网络生成的相同点云运行 NPBG[2]。 然而,NPBG 的光栅化和 2D CNN 框架只能产生模糊的渲染结果。 相比之下,我们利用体积渲染技术和神经辐射场,从而获得照片般逼真的结果。
6.3 对 Tanks & Temples 和 ScanNet 数据集进行评估。
我们将 Point-NeRF 与 NSVF 在 Tanks & Temples 和 Tab. 1 中的 ScanNet 数据集上进行比较。 3. 请参阅补充材料以进行更多比较。
| Tanks & Temples[23] | ScanNet[11] | |
| NSVF[29] | 28.40 / 0.900 / 0.153 | 25.48 / 0.688 / 0.301 |
| Point-NeRF | 29.61 / 0.954 / 0.080 | 30.32 / 0.909 / 0.220 |
6.4 额外的实验。
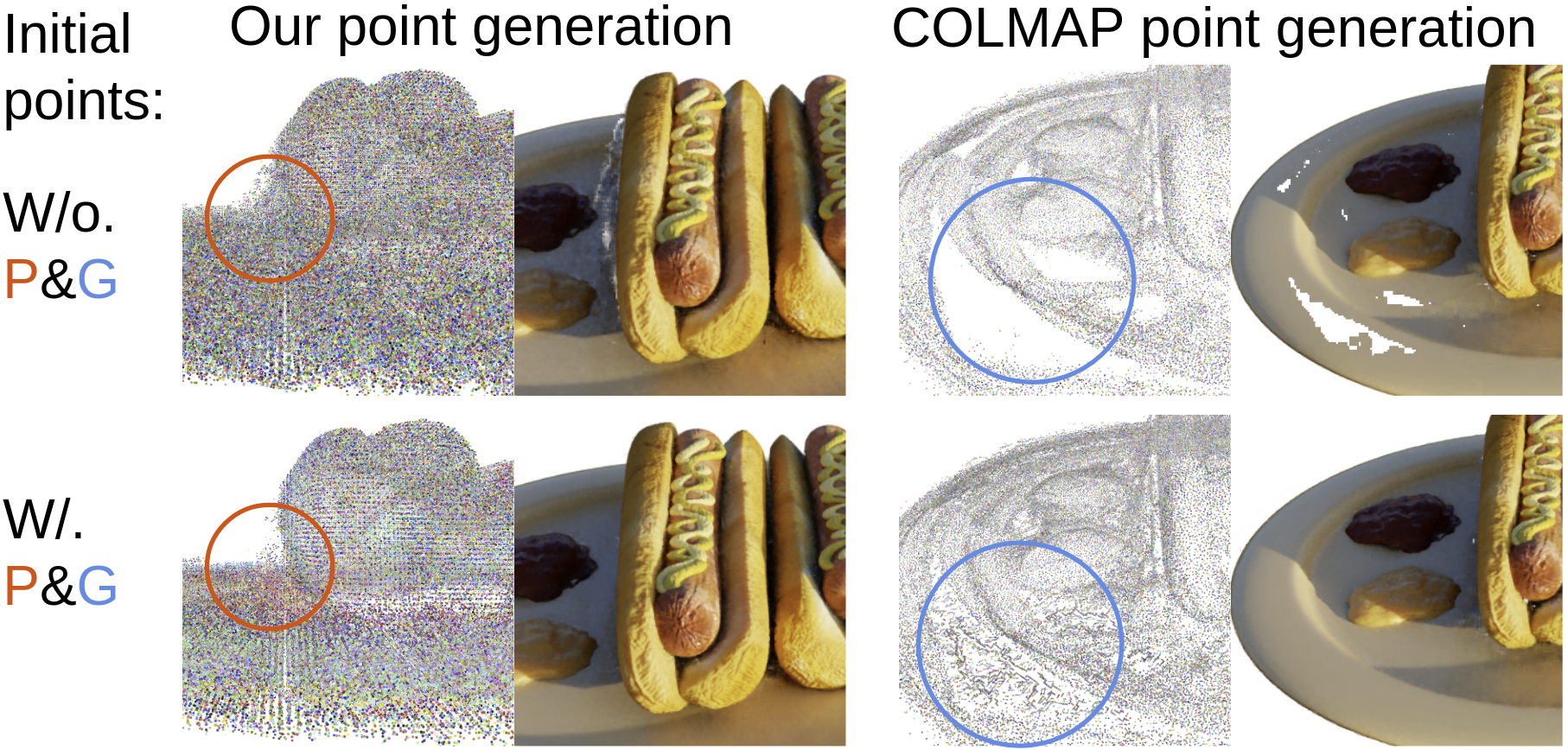
将 COLMAP 点云转换为 Point-NeRF 除了使用我们的完整流程之外,Point-NeRF 还可以用于将其他技术重建的标准点云转换为基于点的辐射场。 我们使用 COLMAP [44] 重建的点云在完整的 NeRF 合成数据集上进行实验。 定量结果如表 1 中的 Point-NeRFcol 所示。 2. 由于COLMAP点云可能包含很多空洞(如图LABEL:fig:teaser所示)和噪声,我们在初始化后对模型进行了200K的优化,以解决我们点的点云问题种植和修剪技术。 请注意,即使来自这种低质量的点云,与所有其他方法相比,我们的最终结果仍然具有非常高的质量,具有非常高的 SSIM 和 LPIPS 数量。 这表明我们的技术可以与任何现有的点云重建技术相结合,以实现逼真的渲染,同时改进点云几何形状。
点生长和修剪。 为了进一步证明我们的点生长和修剪模块的有效性,我们展示了在每个场景优化中使用和不使用点生长和修剪的消融研究结果。 我们使用我们的完整模型和带有 COLMAP 点云的模型在 Hotdog 和 Ship 场景上进行此实验。 定量结果如表 1 所示。 4;我们的点增长和修剪技术非常有效,显着改善了这两种情况的重建结果。 我们还在图 3 中展示了 Hotdog 场景的视觉结果。 我们可以清楚地看到,我们的模型能够修剪左侧的离群点,并成功填充原始 COLMAP 点云中右侧的严重漏洞。
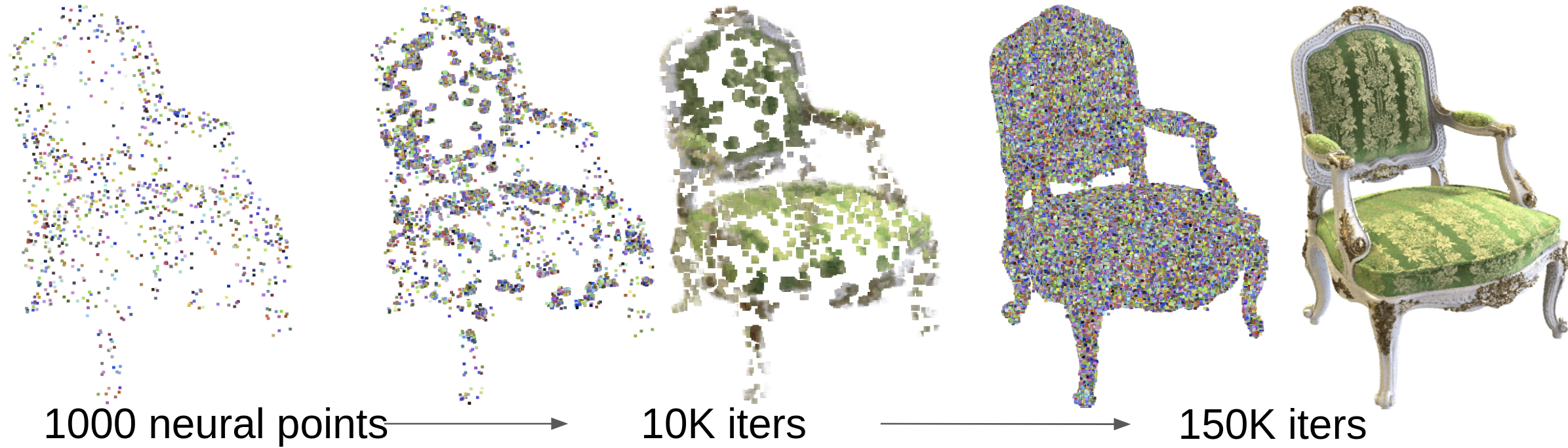
我们还手动创建了一个极端示例来展示图 4 中的点生长技术,其中我们从非常稀疏的点云开始,仅从原始点重建中采样了 1000 个点。 我们证明我们的方法可以从点云边界逐渐增长新点,直到通过迭代填充整个场景表面。 这个例子进一步证明了我们模型的有效性,该模型在使用图像数据从低质量点云中恢复准确的场景几何形状和外观方面具有很高的潜力。
请在补充材料中找到更多结果。


| Method | P&G | Ship | Hotdog |
|---|---|---|---|
| Ours | No | 25.50 / 0.878 / 0.182 | 34.91 / 0.983 / 0.067 |
| Ours | Yes | 30.97 / 0.942 / 0.124 | 37.30 / 0.991 / 0.037 |
| COLMAP | No | 19.35 / 0.905 / 0.167 | 29.91 / 0.978 / 0.061 |
| COLMAP | Yes | 30.18 / 0.941 / 0.134 | 35.49 / 0.986 / 0.061 |
7结论
在本文中,我们提出了一种用于高质量神经场景重建和渲染的新方法。 我们提出了一种新颖的神经场景表示——Point-NeRF——用神经点云对体积辐射场进行建模。 我们通过直接网络推理直接从输入图像重建 Point-NeRF 的良好初始化,并表明我们可以有效地微调场景的初始化。 这可以实现高效的 Point-NeRF 重建,每个场景优化仅需 20-40 分钟,渲染质量可与甚至超越需要更长训练时间(20 小时以上)的 NeRF。 我们还为每个场景的优化提供了新颖有效的生长和修剪技术,显着改善了我们的结果并使我们的方法在不同的点云质量下具有鲁棒性。 我们的Point-NeRF成功地结合了经典点云表示和神经辐射场表示的优点,朝着高效、真实的实用场景重建解决方案迈出了重要的一步。
参考
- [1] Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. Learning representations and generative models for 3D point clouds. In ICML, pages 40–49, 2018.
- [2] Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. Neural point-based graphics. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, pages 696–712. Springer, 2020.
- [3] Sai Bi, Zexiang Xu, Pratul Srinivasan, Ben Mildenhall, Kalyan Sunkavalli, Miloš Hašan, Yannick Hold-Geoffroy, David Kriegman, and Ravi Ramamoorthi. Neural reflectance fields for appearance acquisition. arXiv preprint arXiv:2008.03824, 2020.
- [4] Sai Bi, Zexiang Xu, Kalyan Sunkavalli, Miloš Hašan, Yannick Hold-Geoffroy, David Kriegman, and Ravi Ramamoorthi. Deep reflectance volumes: Relightable reconstructions from multi-view photometric images. In Proc. ECCV, 2020.
- [5] Mark Boss, Raphael Braun, Varun Jampani, Jonathan T Barron, Ce Liu, and Hendrik Lensch. Nerd: Neural reflectance decomposition from image collections. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12684–12694, 2021.
- [6] Chris Buehler, Michael Bosse, Leonard McMillan, Steven Gortler, and Michael Cohen. Unstructured lumigraph rendering. In Proc. SIGGRAPH, pages 425–432, 2001.
- [7] Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5799–5809, 2021.
- [8] Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. arXiv preprint arXiv:2103.15595, 2021.
- [9] Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In Proc. CVPR, 2019.
- [10] Shuo Cheng, Zexiang Xu, Shilin Zhu, Zhuwen Li, Li Erran Li, Ravi Ramamoorthi, and Hao Su. Deep stereo using adaptive thin volume representation with uncertainty awareness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2524–2534, 2020.
- [11] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017.
- [12] Paul Debevec, Yizhou Yu, and George Borshukov. Efficient view-dependent image-based rendering with projective texture-mapping. In Rendering Techniques’ 98, pages 105–116. 1998.
- [13] Robert A Drebin, Loren Carpenter, and Pat Hanrahan. Volume rendering. ACM Siggraph Computer Graphics, 22(4):65–74, 1988.
- [14] Yasutaka Furukawa and Jean Ponce. Accurate, dense, and robust multiview stereopsis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(8):1362–1376, 2009.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015.
- [16] Peter Hedman, Pratul P Srinivasan, Ben Mildenhall, Jonathan T Barron, and Paul Debevec. Baking neural radiance fields for real-time view synthesis. arXiv preprint arXiv:2103.14645, 2021.
- [17] Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. Deepmvs: Learning multi-view stereopsis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2821–2830, 2018.
- [18] Rasmus Jensen, Anders Dahl, George Vogiatzis, Engil Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. In 2014 CVPR, pages 406–413. IEEE, 2014.
- [19] Mengqi Ji, Juergen Gall, Haitian Zheng, Yebin Liu, and Lu Fang. SurfaceNet: An end-to-end 3D neural network for multiview stereopsis. In Proc. ICCV, 2017.
- [20] Angjoo Kanazawa, Shubham Tulsiani, Alexei A Efros, and Jitendra Malik. Learning category-specific mesh reconstruction from image collections. In Proc. ECCV, 2018.
- [21] Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. In Proc. Eurographics Symposium on Geometry Processing, volume 7, 2006.
- [22] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [23] Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics, 36(4), 2017.
- [24] Georgios Kopanas, Julien Philip, Thomas Leimkühler, and George Drettakis. Point-based neural rendering with per-view optimization. In Computer Graphics Forum, volume 40, pages 29–43. Wiley Online Library, 2021.
- [25] Kiriakos N Kutulakos and Steven M Seitz. A theory of shape by space carving. International Journal of Computer Vision, 38(3):199–218, 2000.
- [26] Christoph Lassner and Michael Zollhofer. Pulsar: Efficient sphere-based neural rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1440–1449, 2021.
- [27] Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6498–6508, 2021.
- [28] Fayao Liu, Chunhua Shen, Guosheng Lin, and Ian Reid. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(10):2024–2039, 2016.
- [29] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. arXiv preprint arXiv:2007.11571, 2020.
- [30] Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. Neural volumes: Learning dynamic renderable volumes from images. arXiv preprint arXiv:1906.07751, 2019.
- [31] William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. SIGGRAPH Computer Graphics, 21(4):163–169, 1987.
- [32] Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7210–7219, 2021.
- [33] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. Proc. CVPR, 2019.
- [34] Moustafa Meshry, Dan B Goldman, Sameh Khamis, Hugues Hoppe, Rohit Pandey, Noah Snavely, and Ricardo Martin-Brualla. Neural rerendering in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6878–6887, 2019.
- [35] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In European conference on computer vision, pages 405–421. Springer, 2020.
- [36] Michael Niemeyer and Andreas Geiger. Giraffe: Representing scenes as compositional generative neural feature fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11453–11464, 2021.
- [37] Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In Proc. CVPR, 2020.
- [38] Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5865–5874, 2021.
- [39] Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M Seitz. Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields. arXiv preprint arXiv:2106.13228, 2021.
- [40] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proc. CVPR, 2017.
- [41] Charles R Qi, Hao Su, Matthias Nießner, Angela Dai, Mengyuan Yan, and Leonidas J Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proc. CVPR, 2016.
- [42] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. arXiv preprint arXiv:2103.13744, 2021.
- [43] Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proc. CVPR, 2016.
- [44] Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise View Selection for Unstructured Multi-View Stereo. In European Conference on Computer Vision (ECCV), 2016.
- [45] Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis. arXiv preprint arXiv:2007.02442, 2020.
- [46] Steven M Seitz and Charles R Dyer. Photorealistic scene reconstruction by voxel coloring. International Journal of Computer Vision, 35(2):151–173, 1999.
- [47] Vincent Sitzmann, Justus Thies, Felix Heide, Matthias Nießner, Gordon Wetzstein, and Michael Zollhofer. Deepvoxels: Learning persistent 3D feature embeddings. In Proc. CVPR, 2019.
- [48] Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. Scene representation networks: Continuous 3d-structure-aware neural scene representations. arXiv preprint arXiv:1906.01618, 2019.
- [49] Chengzhou Tang and Ping Tan. BA-net: Dense bundle adjustment network. In Proc. ICLR, 2019.
- [50] Sudheendra Vijayanarasimhan, Susanna Ricco, Cordelia Schmid, Rahul Sukthankar, and Katerina Fragkiadaki. Sfm-net: Learning of structure and motion from video. arXiv preprint arXiv:1704.07804, 2017.
- [51] Jinglu Wang, Bo Sun, and Yan Lu. MVPnet: Multi-view point regression networks for 3D object reconstruction from a single image. Proc. AAAI Conference on Artificial Intelligence, 2019.
- [52] Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. Pixel2mesh: Generating 3d mesh models from single RGB images. In Proc. ECCV, 2018.
- [53] Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. In CVPR, 2021.
- [54] W Weng and X Zhu. Convolutional networks for biomedical image segmentation. IEEE Access, 2015.
- [55] Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. Synsin: End-to-end view synthesis from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7467–7477, 2020.
- [56] Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proc. CVPR, 2015.
- [57] Fanbo Xiang, Zexiang Xu, Milos Hasan, Yannick Hold-Geoffroy, Kalyan Sunkavalli, and Hao Su. Neutex: Neural texture mapping for volumetric neural rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7119–7128, 2021.
- [58] Qiangeng Xu, Xudong Sun, Cho-Ying Wu, Panqu Wang, and Ulrich Neumann. Grid-gcn for fast and scalable point cloud learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5661–5670, 2020.
- [59] Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. MVSnet: Depth inference for unstructured multi-view stereo. In Proc. ECCV, pages 767–783, 2018.
- [60] Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. Multiview neural surface reconstruction by disentangling geometry and appearance. In Proc. NeurIPS, 2020.
- [61] Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. arXiv preprint arXiv:2112.05131, 2021.
- [62] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. arXiv preprint arXiv:2103.14024, 2021.
- [63] Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In CVPR, 2021.
- [64] Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. Nerf++: Analyzing and improving neural radiance fields. arXiv preprint arXiv:2010.07492, 2020.
- [65] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.
- [66] Qian-Yi Zhou and Vladlen Koltun. Color map optimization for 3D reconstruction with consumer depth cameras. ACM Transactions on Graphics, 33(4):155, 2014.
- [67] Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images. ACM Transactions on Graphics, 37(4):1–12, 2018.
附录
附录A点特征初始化的消融研究
| Extract20k | Rand20k | Extract200k | Rand200k | |
|---|---|---|---|---|
| PSNR | 30.09 | 25.44 | 33.00 | 32.01 |
| SSIM | 0.963 | 0.932 | 0.978 | 0.972 |
我们进行实验来证明特征初始化的重要性。 我们将完整模型与未使用 NeRF 合成数据集 [35] 上提取的图像特征进行初始化的模型进行比较。 在不使用图像特征的情况下,我们使用流行的凯明初始化[15]随机初始化点特征。 如表5所示,具有图像特征的神经点不仅在次迭代收敛后获得更好的性能,而且在开始时收敛得更快。 随机初始化的神经点甚至无法像我们的完整模型一样执行,但仍然优于 NeRF 和 NSVF[29] 等最先进的方法。
附录BDTU数据集的按场景细分结果
| Scan | #1 | #8 | #21 | #103 | #114 |
|---|---|---|---|---|---|
| SSIM | |||||
| Ours1K | 0.935 | 0.906 | 0.913 | 0.944 | 0.948 |
| Ours10K | 0.962 | 0.949 | 0.954 | 0.961 | 0.960 |
| MVSNeRF10K[8] | 0.934 | 0.900 | 0.922 | 0.964 | 0.945 |
| IBRNET10K[53] | 0.955 | 0.945 | 0.947 | 0.968 | 0.964 |
| NeRF200K[35] | 0.902 | 0.876 | 0.874 | 0.944 | 0.913 |
| LPIPS | |||||
| Ours1K | 0.151 | 0.207 | 0.201 | 0.208 | 0.148 |
| Ours10K | 0.095 | 0.130 | 0.134 | 0.145 | 0.096 |
| MVSNeRF10K | 0.171 | 0.261 | 0.142 | 0.170 | 0.153 |
| IBRNET10K | 0.129 | 0.170 | 0.104 | 0.156 | 0.099 |
| NeRF200K | 0.265 | 0.321 | 0.246 | 0.256 | 0.225 |
| PSNR | |||||
| Ours1K | 28.79 | 28.39 | 24.78 | 30.36 | 29.82 |
| Ours10K | 30.85 | 30.72 | 26.22 | 32.08 | 30.75 |
| MVSNeRF10K | 28.05 | 28.88 | 24.87 | 32.23 | 28.47 |
| IBRNET10K | 31.00 | 32.46 | 27.88 | 34.40 | 31.00 |
| NeRF200K | 26.62 | 28.33 | 23.24 | 30.40 | 26.47 |
我们在表 6 中展示了 DTU[18] 数据集比较的每个场景的详细定量结果,并在我们的视频中展示了其他定性比较。 由于我们的方法还忠实地重建了场景几何形状,因此我们的方法在大多数情况下具有最佳的 SSIM 分数。 我们的模型还具有适用于大多数场景的最佳 LPIPS,因此在视觉上更加真实,如主要论文和视频的图 6 所示。 IBRNet 结合源视图中的颜色来计算着色期间的辐射颜色。 这种基于图像的方法可带来更好的 PSNR。 然而,如我们的视频所示,我们的方法在时间上更加一致,因为局部辐射率和几何形状一致地存储在每个神经点位置。
附录CNeRF合成数据集的按场景细分结果
| NeRF Synthetic | ||||||||
|---|---|---|---|---|---|---|---|---|
| Chair | Drums | Lego | Mic | Materials | Ship | Hotdog | Ficus | |
| PSNR | ||||||||
| NPBG[2] | 26.47 | 21.53 | 24.84 | 26.62 | 21.58 | 21.83 | 29.01 | 24.60 |
| NeRF[35] | 33.00 | 25.01 | 32.54 | 32.91 | 29.62 | 28.65 | 36.18 | 30.13 |
| NSVF[29] | 33.19 | 25.18 | 32.54 | 34.27 | 32.68 | 27.93 | 37.14 | 31.23 |
| Point-NeRF | 35.09 | 25.01 | 32.65 | 35.54 | 26.97 | 30.18 | 35.49 | 33.24 |
| Point-NeRF20K | 32.50 | 25.03 | 32.40 | 32.31 | 28.11 | 28.13 | 34.53 | 32.67 |
| Point-NeRF200K | 35.40 | 26.06 | 35.04 | 35.95 | 29.61 | 30.97 | 37.30 | 36.13 |
| SSIM | ||||||||
| NPBG | 0.939 | 0.904 | 0.923 | 0.959 | 0.887 | 0.866 | 0.964 | 0.940 |
| NeRF | 0.967 | 0.925 | 0.961 | 0.980 | 0.949 | 0.856 | 0.974 | 0.964 |
| NSVF | 0.968 | 0.931 | 0.960 | 0.987 | 0.973 | 0.854 | 0.980 | 0.973 |
| Point-NeRF | 0.990 | 0.944 | 0.983 | 0.993 | 0.955 | 0.941 | 0.986 | 0.989 |
| Point-NeRF20K | 0.981 | 0.944 | 0.980 | 0.986 | 0.959 | 0.916 | 0.983 | 0.986 |
| Point-NeRF200K | 0.991 | 0.954 | 0.988 | 0.994 | 0.971 | 0.942 | 0.991 | 0.993 |
| SSIM (Calibrated) | ||||||||
| Point-NeRF200K | 0.984 | 0.935 | 0.978 | 0.990 | 0.948 | 0.892 | 0.982 | 0.987 |
| LPIPS | ||||||||
| NPBG | 0.085 | 0.112 | 0.119 | 0.060 | 0.134 | 0.210 | 0.075 | 0.078 |
| NeRF | 0.046 | 0.091 | 0.050 | 0.028 | 0.063 | 0.206 | 0.121 | 0.044 |
| Point-NeRF | 0.026 | 0.099 | 0.031 | 0.019 | 0.100 | 0.134 | 0.061 | 0.028 |
| Point-NeRF20K | 0.051 | 0.103 | 0.054 | 0.039 | 0.102 | 0.181 | 0.074 | 0.043 |
| Point-NeRF200K | 0.023 | 0.078 | 0.024 | 0.014 | 0.072 | 0.124 | 0.037 | 0.022 |
| LPIPS | ||||||||
| NSVF | 0.043 | 0.069 | 0.029 | 0.010 | 0.021 | 0.162 | 0.025 | 0.017 |
| Point-NeRF | 0.013 | 0.073 | 0.016 | 0.011 | 0.076 | 0.087 | 0.032 | 0.012 |
| Point-NeRF20K | 0.027 | 0.057 | 0.022 | 0.024 | 0.076 | 0.127 | 0.044 | 0.022 |
| Point-NeRF200K | 0.010 | 0.055 | 0.011 | 0.007 | 0.041 | 0.070 | 0.016 | 0.009 |
我们在表 7 中显示了 NeRF Synthetic[35] 数据集比较的每个场景的详细定量结果,并在我们的视频中显示了其他定性比较。 Point-NeRF 在大多数场景上实现了最佳的 PSNR、SSIM 和 LPIPS,并且大幅优于最先进的方法[2,35,29,53]。 另一方面,我们用 COLMAP 点发起的方法与 NeRF 相当。 即使从不理想的初始点开始,我们仍然设法改进几何重建并通过点修剪和生长生成高质量的辐射场。 我们的模型在 次迭代中与 NeRF 在 次迭代中的结果相匹配,这一事实清楚地表明了我们快速收敛的能力。
附录D大规模3D场景评估(ScanNet)。
| Average over two scenes | Scene 101 | Scene 241 | Scene 101 | Scene 241 | ||||
|---|---|---|---|---|---|---|---|---|
| SRN [48] | NeRF [32] | NSVF [29] | Ours | Ours | Ours | |||
| PSNR | 18.25 | 22.99 | 25.48 | 30.32 | 30.13 | 30.51 | 21.98 | 29.86 |
| SSIM | 0.592 | 0.620 | 0.688 | 0.909 / 0.814 | 0.912 / 0.821 | 0.906 / 0.807 | 0.882 / 0.797 | 0.901 / 0.784 |
| RMSE | 14.764 | 0.681 | 0.079 | 0.031 | 0.032 | 0.030 | 0.091 | 0.033 |
| LPIPS | 0.586 | 0.369 | 0.301 | 0.220 | 0.203 | 0.238 | 0.283 | 0.263 |
| LPIPS | - | - | - | 0.292 | 0.286 | 0.299 | 0.345 | 0.327 |










虽然我们的模型纯粹是在对象数据集(DTU 数据集)上进行训练,但我们的网络可以很好地推广到大规模 3D 场景数据集。 在[29]之后,我们使用来自ScanNet [11]的两个3D场景,场景和场景。 我们从原始视频中提取 RGB 和深度图像,并从中采样五帧中的一帧作为训练集,并使用其余帧进行测试。 RGB 图像缩放至 640 × 480。 我们通过点修剪和增长对每个场景进行 300K 步的微调。
附录E坦克和神庙数据集
| Tanks & Tamples | ||||||
| Ignatius | Truck | Barn | Caterpillar | Family | Mean | |
| PSNR | ||||||
| NV [30] | 26.54 | 21.71 | 20.82 | 20.71 | 28.72 | 23.70 |
| NeRF [35] | 25.43 | 25.36 | 24.05 | 23.75 | 30.29 | 25.78 |
| NSVF [29] | 27.91 | 26.92 | 27.16 | 26.44 | 33.58 | 28.40 |
| Point-NeRF (Ours) | 28.43 | 28.22 | 29.15 | 27.00 | 35.27 | 29.61 |
| SSIM | ||||||
| NV [30] | 0.992 | 0.793 | 0.721 | 0.819 | 0.916 | 0.848 |
| NeRF [35] | 0.920 | 0.860 | 0.750 | 0.860 | 0.932 | 0.864 |
| NSVF [29] | 0.930 | 0.895 | 0.823 | 0.900 | 0.954 | 0.900 |
| Point-NeRF (Ours) | 0.961 | 0.950 | 0.937 | 0.934 | 0.986 | 0.954 |
| LPIPS | ||||||
| NV [30] | 0.117 | 0.312 | 0.479 | 0.280 | 0.111 | 0.260 |
| NeRF [35] | 0.111 | 0.192 | 0.395 | 0.196 | 0.098 | 0.198 |
| NSVF [29] | 0.106 | 0.148 | 0.307 | 0.141 | 0.063 | 0.153 |
| Point-NeRF (Ours) | 0.069 | 0.077 | 0.120 | 0.111 | 0.024 | 0.080 |
| LPIPS | ||||||
| Point-NeRF (Ours) | 0.079 | 0.117 | 0.180 | 0.156 | 0.046 | 0.115 |

附录F从COLMAP点初始化神经点
Point-NeRF可以使用任何外部重建方法的点。 例如,COLMAP[44] 的输出是点云。 我们一开始将设置为。 在优化过程中,有效点的置信度得分将被推至 1。 为了获取一个点的点特征,我们首先排除该点被其他点遮挡的所有视图,然后找到相机距离该点最近的视图。 然后从该视图中,我们可以将点反投影到由所选视图中的 提取的特征图上(参见主论文中的图 2(a))并获得 。
附录 G网络架构
基于体积的 CNN 成本。 我们的基于成本量的CNN采用流行的架构[59],简单高效。 它包括三层深度特征提取CNN,而后两层将空间维度下采样4并输出32通道的特征图。 然后,每个视图中的这些特征将根据相机姿势进行扭曲,并计算方差。 方差特征将经过窄U-Net [54]并输出1通道特征来计算深度概率。
图像特征提取2D CNN 。 图像特征提取网络以 RGB 图像为输入,具有三个下采样层,每个输出特征的通道为 。 我们通过将 3D 点投影到每一层并获取多尺度特征来提取点特征。
基于点的辐射场 MLP。 我们在图9中可视化点特征聚合和辐射度计算的细节。 在我们所有的实验中,我们设置了、。 MLP 分别有 2、3、2 层。 和的中间特征通道为256个,的中间特征通道为128个通道。
附录H神经点查询
为了有效地查询光线行进的神经点邻居,受[58]中引入的CAGQ点查询的启发,我们实现了一种网格查询方法。 然后我们构建网格点索引,将每个神经点注册到均匀间隔的 3D 网格。 由于这些网格在透视坐标中是立方体,因此在世界坐标中,它们具有球形体素的形状。
通过网格点索引,我们可以发现具有神经点的网格及其网格邻居。 这些网格邻居是感兴趣的区域,因为查询半径内应该存在神经点。 如果光线穿过这些区域,我们可以在里面放置着色点。 最后,我们通过根据网格点索引直接检索存储的神经点来查询神经点。
在我们所有的实验中,我们为每个着色位置查询 8 个最近的神经点邻居。 沿着每条射线,我们仅搜索神经点邻居并计算被占用的网格或附近被占用的网格中的着色位置的辐射率。 因此,与其他辐射场表示不同,我们的着色通过跳过空白空间而更加有效。 这是实现快速收敛的一项关键优势。 即使是高性能局部辐射表示 NSVF [29] 也必须在开始时探测空白空间,并沿着其过程逐渐修剪体素。
这种策略的好处有两个:首先,我们只将着色点放置在存在神经点的区域中,这样我们就可以避免在空白空间中进行辐射率计算。 其次,可以根据索引高效地检索附近的点,从而大大加快点的查询速度。
附录一限制
因为我们不关注渲染速度,也没有优化我们的实现(点查询和点特征聚合)以实现快速渲染。 尽管如此,我们的模型自然比 NeRF (3X) 更快,因为我们跳过了空白空间中的阴影。 我们相信,未来将当前论文(例如[62, 42])中引入的机制与我们基于点的辐射表示相结合的工作将进一步有利于神经渲染技术。
附录J其他讨论和需要注意的问题
处理 MVSNet 生成的点
我们收到了建设性的反馈,希望明确的是,当Point-NeRF使用MVSNet[59]重建点云时,MVSNet深度估计后的点融合将使用NeRF中的alpha通道 -合成数据集(如我们发布的代码所示)。 这是因为 MVSNet 不能很好地处理背景,并且会在背景区域创建太多异常点。 由于 Tanks and Temples 数据集中的图像 [23] 没有 Alpha 通道,因此我们过滤掉纯背景颜色区域中出现的 MVSNet 点。 在 NeRF-Synthetic 数据集上,我们与 [32, 29] 进行比较的方法使用输入:具有纯色背景知识的 RGB 图像。 因此,为了提高公平性,在 NeRF-Synthetic 数据集上,我们在使用背景颜色(不再是 alpha 通道)进行过滤时包含了 Point-NeRF 与 MVSNet 的结果。 其结果如表10所示,人们可以引用任何一个人们认为公平的设置。
请注意,在我们的实验中,COLMAP 不使用任何过滤。 因此,对 COLMAP 结果没有影响。 与 NPGB [2] 相比,我们使用相同的点云。 由于排除点云质量的影响更有意义,因此如果愿意与我们的结果进行比较,我们建议其他基于点的渲染工作使用相同的点云。 点云包含在我们在 github 存储库中发布的检查点中。
我们使用 MVSNet 的初衷是因为它的简单性以及它是早期基于深度学习的 MVS 模型之一。 因此,我们鼓励用户尝试更高级的 MVS 模型,这样就不需要过滤了。
ScanNet 和无界场景
我们还收到有关 ScanNet 实验的评论,我们想非常清楚地声明,我们使用 ScanNet 数据集中的深度图像来初始化点云。 这是因为 NSVF 是我们在此数据集上的主要基线,并且它使用此设置。 在我们原来的附录D段落中,我们提供了这些信息,我们希望这可以消除读者潜在的错误期望。
由于 Point-NeRF 是局部辐射度表示,没有附加组件,例如附加背景 NeRF(由 Plenoxel [61] 使用),因此它无法处理无界场景(也称为由内而外)中的背景场景)。 对于 ScanNet 来说,没有太多背景,因为它是一个带有噪声深度图像的室内场景,房间中的每个部分都可以被视为前景。
| Point-NeRF with MVSNet (background color filtering) on NeRF Synthetic | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Chair | Drums | Lego | Mic | Materials | Ship | Hotdog | Ficus | Mean | |
| PSNR | 35.60 | 26.04 | 35.27 | 35.91 | 29.65 | 30.61 | 37.34 | 35.61 | 33.25 |
| SSIM | 0.991 | 0.954 | 0.989 | 0.994 | 0.971 | 0.938 | 0.991 | 0.992 | 0.978 |
| LPIPS | 0.023 | 0.078 | 0.021 | 0.014 | 0.071 | 0.129 | 0.036 | 0.025 | 0.050 |
| LPIPS | 0.010 | 0.055 | 0.010 | 0.007 | 0.041 | 0.076 | 0.016 | 0.011 | 0.028 |