UniFormer:统一卷积和自注意力用于视觉识别
摘要
由于这些视觉数据中存在大量的局部冗余和复杂的全局依赖性,从图像和视频中学习判别性表示是一项具有挑战性的任务。 卷积神经网络(CNN)和视觉变换器(ViT)是过去几年的两个主要框架。 尽管 CNN 可以通过小邻域内的卷积有效地减少局部冗余,但有限的感受野使其难以捕获全局依赖性。 或者,ViT 可以通过自注意力有效捕获长程依赖,而所有 token 之间的盲目相似性比较会导致高冗余。 为了解决这些问题,我们提出了一种新颖的统一 Transformer (UniFormer),它可以以简洁的 Transformer 格式无缝地集成卷积和自注意力的优点。 与典型的 Transformer 模块不同,我们的 UniFormer 模块中的关系聚合器分别在浅层和深层配备了本地和全局词符亲和力,允许解决冗余和依赖性,从而实现高效且有效的表示学习。 最后,我们灵活地将块堆叠到一个新的强大主干中,并将其用于从图像到视频域、从分类到密集预测的各种视觉任务。 在没有任何额外训练数据的情况下,我们的 UniFormer 在 ImageNet-1K 分类任务上实现了 86.3 top-1 准确率。 仅通过 ImageNet-1K 预训练,它就可以在广泛的下游任务中轻松实现最先进的性能。 它在 Kinetics-400/600 上获得 82.9/84.8 top-1 准确度,在 Something-Something V1/V2 视频分类任务上获得 60.9/71.2 top-1 准确度,53.8 box AP 和 46.4 mask AP,ADE20K 语义分割任务上的 50.8 mIoU,以及 77.4 AP关于COCO姿势估计任务。 此外,我们构建了一个高效的UniFormer,采用词符收缩和恢复的简洁沙漏设计,与最近的轻量级模型相比,它实现了2-4更高的吞吐量。 代码可在 https://github.com/Sense-X/UniFormer 获取。
索引术语:
UniFormer、卷积神经网络、Transformer、自注意力、视觉识别。1 简介
表征学习是视觉识别的一个基础研究课题[61, 24]。 基本上,我们面临图像和视频等视觉数据中存在的两个截然不同的挑战。 一方面,局部冗余较大,例如局部区域(空间、时间或时空)的视觉内容往往相似。 这种局部性通常会带来低效的计算。 另一方面,全局依赖关系复杂,不同地区的目标之间存在动态关系。 这种远距离的互动往往会导致学习效率低下。
为了解决这些困难,研究人员在视觉识别领域提出了许多强大的模型[107,117,28,116]。 特别是,主流骨干网是卷积神经网络(CNN)[37, 40, 30]和视觉变换器(ViTs)[24, 88],其中卷积和自-attention是这两个结构中的关键操作。 不幸的是,这些操作中的每一项都主要解决上述一个挑战,而忽略了另一个挑战。 例如,卷积运算通过将每个像素与来自小邻域的上下文(例如 33 或 333)。 然而,有限的感受野使得卷积难以学习全局依赖[101, 53]。 另外,自注意力最近在 ViT 中得到了强调。 通过视觉标记之间的相似性比较,它在图像 [24, 61] 和视频 [3, 1, 62] 中表现出强大的学习全局依赖性的能力。 尽管如此,我们观察到 ViT 在浅层中编码局部特征通常效率低下。
我们以图像和视频领域著名的 ViT(即 DeiT [87] 和 TimeSformer [3])为例,并在浅层。 如图2所示,两个ViT确实捕获了浅层的详细视觉特征,而空间和时间注意力是多余的。 人们可以很容易地看出,给定一个锚词符,空间注意力主要集中在局部区域的标记上(主要是 33),并且从该图像中的其余标记中学到很少。 类似地,时间注意力主要聚合相邻帧中的标记,而忽略远处帧中的其余标记。 然而,这种局部焦点是通过所有 Token 在空间和时间上的全局比较而获得的。 显然,这种冗余的注意力方式带来了巨大且不必要的计算负担,从而恶化了 ViT 中的计算精度平衡(图1)。
基于这些讨论,我们在这项工作中提出了一种新颖的统一 Transformer (UniFormer)。 它以简洁的 Transformer 格式灵活地统一了卷积和自注意力,可以解决局部冗余和全局依赖性,从而实现有效且高效的视觉识别。 具体来说,我们的 UniFormer 模块由三个关键模块组成,即动态位置嵌入(DPE)、多头关系聚合器(MHRA)和前馈网络(FFN)。 关系聚合器的独特设计是我们的 UniFormer 与之前的 CNN 和 ViT 之间的主要区别。 在浅层中,我们的关系聚合器用一个小的可学习参数矩阵捕获局部词符亲和力,它继承了卷积风格,可以通过局部区域的上下文聚合来大大减少计算冗余。 在深层,我们的关系聚合器通过词符相似度比较来学习全局词符亲和力,它继承了自注意力风格,可以自适应地从遥远的区域或框架构建远程依赖关系。 通过以分层方式逐步堆叠本地和全局 UniFormer 块,我们可以灵活地整合它们的协作能力来促进表示学习。 最后,我们为视觉识别提供了通用且强大的支柱,并通过简单而复杂的适应成功地解决了各种下游视觉任务。 此外,我们还进一步介绍了UniFormer的轻量化设计,通过词符收缩和恢复的简洁沙漏风格,可以达到更好的整体平衡精度。
大量的实验证明了我们的 UniFormer 在广泛的视觉任务上的强大性能,包括图像分类、视频分类、对象检测、实例分割、语义分割和姿势估计。 在没有任何额外训练数据的情况下,UniFomrer-L 在 ImageNet-1K 上实现了 86.3 top-1 精度。 此外,仅通过 ImageNet-1K 预训练,UniFormer-B 在 Kinetics-400/Kinetics-600、60.9 和 上即可实现 82.9/84.8 top-1 精度Something-Something V1&V2 上的 71.2 top-1 准确度,COCO 检测任务上的 53.8 box AP 和 46.4 mask AP,50.8 ADE20K 语义分割任务上的 mIoU,COCO 姿态估计任务上的 77.4 AP。 最后,我们高效的 UniFormer 具有简洁的沙漏设计,与最近的轻量级型号相比,可实现 2-4 高吞吐量。
2 相关工作
2.1 卷积神经网络 (CNN)
过去几年,计算机视觉的发展主要由卷积神经网络(CNN)驱动。 从经典的AlexNet [49]开始,许多强大的CNN网络被提出[80,84,37,107,41,40,120,85]并取得了令人瞩目的成绩在图像理解的各种任务中的表现[22,60,121,36,6,47,104,95]。 近年来,由于视频逐渐成为许多实际应用中的主要数据资源之一,研究人员尝试将 CNN 应用于视频领域。 自然地,我们可以通过时间维度扩展[89]将2D卷积改编为3D卷积。 然而,3D CNN 经常面临困难的优化问题和巨大的计算成本。 为了解决这些问题,先前的工作尝试膨胀预训练的 2D 卷积核以实现更好的优化[11],并在不同维度分解 3D 卷积核以降低复杂性[91, 72, 90、29、30、52]。 此外,最近许多视频理解的研究[44, 59, 53, 56]侧重于采用复杂的时间建模模块来适应普通的2D CNN,例如时间平移[59, 67]、运动增强[44, 56, 63]、时空激励[53, 52]等。 不幸的是,由于接收场有限,传统的卷积很难捕获长程依赖性,即使它们堆叠得更深。
2.2 视觉转换器 (ViT)
为了捕获长期依赖关系,人们提出了 Vision Transformer (ViT)[24]。 受到 NLP 中 Transformer 架构[92]的启发,ViT 将图像视为许多视觉标记,并利用注意力对词符关系进行编码以进行表示学习。 然而,普通的 ViT 依赖于足够的训练数据和仔细的数据增强。 为了解决这些问题,人们开发了几种方法,包括改进的补丁嵌入[55]、数据高效训练[87]、高效自注意力[61、 23, 109],以及多尺度架构[99, 28, 100]。 这些工作成功提升了 ViT 在各种图像任务上的性能[8,123,106,15,46,55,110,114,38,12,57]。 最近,研究人员尝试扩展图像 ViT 以进行视频建模。 经典作品是时空注意力的TimeSformer[3]。 从这里开始,许多作品提出了时空表示学习的不同变体[3,1,28,71,5,62],随后它们适应了各种视频理解任务[98, 25、26、31、7]。 尽管这些作品展示了 ViT 学习长期词符关系的出色能力,但自注意力机制需要昂贵的 token 到 token 比较[24]。 因此,对低级特征进行编码通常效率较低,如图2所示。 尽管 Video Swin [62] 提倡使用移位窗口的局部性归纳偏差,但在编码 low-attention 时,基于窗口的自注意力仍然不如局部卷积 [37] 有效。级别特征。 此外,应仔细配置移动窗口。
2.3 CNN和ViT的结合
为了弥合 CNN 和 ViT 之间的差距,研究人员尝试利用它们来构建更强大的视觉主干以进行图像理解,通过添加卷积补丁干来实现快速收敛[111, 105],引入卷积位置嵌入[17, 23],将深度卷积插入前馈网络[111, 114],在自注意力中利用卷积投影[102],并将 MBConv [77] 与 Transformer [21] 结合起来。 对于视频理解,组合也很简单,即可以插入自注意力作为全局注意力[101],和/或使用卷积作为补丁主干[64]。 然而,所有这些方法都忽略了卷积和自注意力之间的内在关系,导致局部和/或全局词符关系学习较差。 最近的几项工作已经证明,自注意力的运作方式与卷积[75, 20]类似。 但他们建议替换卷积而不是将它们组合在一起。 不同的是,我们的 UniFormer 在 Transformer 风格中统一了卷积和自注意力,可以有效地学习局部和全局词符关系,并在从图像到视频域的所有视觉任务上实现更好的精度-计算权衡。
2.4 轻量级 CNN 和 ViT
在许多实际应用中,运行平台通常缺乏足够的计算能力。 因此,提出了一系列轻量级 CNN 来满足此类设备上的要求。 例如,经典的MobileNets [40,77,39]在组织良好的高效ResNet中采用深度可分离卷积。 ShuffleNets [120, 68] 利用通道洗牌来减少计算量。 EfficientNets [85, 86] 通过神经架构搜索在深度、宽度和分辨率上进一步扩展模型。 然而,这种轻量化设计尚未在 ViT 中得到充分研究。 最近提出的两项工作是将 Transformer 设计为卷积(即 MobielViT[69]),并引入 MobileNet 和 ViT 的并行架构(即 MobileFormer[14]) 。 但这两项工作都忽略了推理速度(例如,整个过程)。 因此,先前的高效 CNN 仍然是更好的选择。 为了弥补这一差距,我们在第 5 节中通过词符收缩和恢复构建了一个轻量级的 UniFormer。
3 方法
在本节中,我们详细介绍所提出的 UniFormer。 首先,我们描述 UniFormer 块的概述。 然后,我们解释其关键模块,例如多头关系聚合器和动态位置嵌入。 此外,我们还讨论了 UniFormer 和现有 CNN/ViT 之间的独特关系,展示了其在精度与计算平衡方面的更佳设计。
3.1 概述
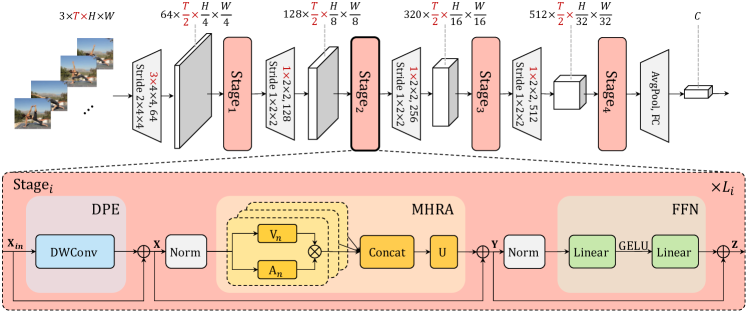
图3显示了我们的统一 Transformer (UniFormer)。 为了简单描述,我们以帧的视频为例,图像输入可以看作是单帧的视频。 因此,以红色突出显示的尺寸仅在视频输入时存在,而对于图像输入,它们全部等于 1。 我们的 UniFormer 是一种基本的 Transformer 格式,同时我们精心设计它来解决计算冗余并捕获复杂的依赖关系。
具体来说,我们的 UniFormer 模块由三个关键模块组成:动态位置嵌入 (DPE)、多头关系聚合器 (MHRA) 和前馈网络 (FFN):
| (1) | ||||
| (2) | ||||
| (3) | ||||
考虑输入词符张量(对于图像输入为),我们首先引入DPE来动态集成位置信息到所有标记中(等式1)。 它对任意输入分辨率友好,并充分利用词符顺序以实现更好的视觉识别。 然后,我们使用 MHRA 通过关系学习利用上下文标记来增强每个词符(等式2)。 通过灵活地设计浅层和深层的词符亲和力,我们的 MHRA 可以巧妙地统一卷积和自注意力,以减少局部冗余并学习全局依赖。 最后,我们添加像传统 ViTs [24] 一样的 FFN,它由两个线性层和一个非线性函数组成,即 GELU(方程 3)。 通道数先按4的比例扩大,然后恢复,这样每个词符都会单独增强。
3.2 多头关系聚合器
如前所述,传统的 CNN 和 ViT 侧重于解决局部冗余或全局依赖性,导致精度不理想或/和不必要的计算。 为了克服这些困难,我们引入了一种通用的关系聚合器(RA),它优雅地统一了词符关系学习的卷积和自注意力。 通过分别在浅层和深层设计局部词符亲和力和全局词符亲和力,可以实现高效有效的表示学习。 具体来说,MHRA 以多头方式利用词符关系:
| (4) | ||||
| (5) | ||||
给定输入张量 ,我们首先将其重塑为长度为 的词符序列 。 此外,指的是第头中的RA,是集成头的可学习参数矩阵。 每个RA由词符上下文编码和词符亲和力学习组成。 我们应用线性变换将原始标记编码为上下文标记。 随后,RA可以在词符亲和力的指导下总结上下文。 下面我们将介绍如何学习具体的。
3.2.1 本地 MHRA
如图2所示,虽然之前的ViT比较了所有token之间的相似性,但它们最终还是学习了局部表示。 这种冗余的自注意力设计在浅层带来了巨大的计算成本。 基于此,我们建议在一个小邻域中学习词符亲和力,这与卷积滤波器的设计不谋而合。 因此,我们建议将局部亲和力表示为浅层中的可学习参数矩阵。 具体来说,给定一个锚词符 ,我们的本地 RA 会学习该词符与小邻域 中其他标记之间的亲和力 ( 用于图像输入):
| (6) |
其中是可学习参数,指的是中的任何邻居词符。 表示词符和之间的相对位置。 请注意,由于标记的感受野很小,因此在浅层中相邻标记之间的视觉内容略有不同。 在这种情况下,没有必要在这些层中使词符亲和力动态化。 因此,我们使用可学习的参数矩阵来描述局部词符亲和力,它仅取决于标记之间的相对位置。
与卷积块的比较。 有趣的是,我们发现本地 MHRA 可以解释为 MobileNet 块 [77, 90, 29] 的通用扩展。 首先,等式中的线性变换。 4相当于一个逐点卷积(PWConv),其中每个头对应一个输出特征通道。 此外,我们的本地词符亲和力可以实例化为在每个输出通道(或头部)上操作的参数矩阵,因此关系聚合器可以解释为深度卷积(DWConv)。 最后,连接并融合所有头的线性矩阵也可以看作是逐点卷积。 因此,这种本地 MHRA 可以在 MobileNet 块中以 PWConv-DWConv-PWConv 的方式重新表述。 在我们的实验中,我们将本地 MHRA 实例化为通道分离卷积,以便我们的 UniFormer 可以提高视觉识别的计算效率。 此外,与 MobileNet 块不同,我们的本地 UniFormer 块被设计为通用 Transformer 格式,即除了 MHRA 之外,它还包含动态位置编码(DPE)和前馈网络(FFN)。 这种独特的集成可以有效增强词符表示,这是之前的卷积块中尚未探索过的。
3.2.2 全球 MHRA
在深层,在更广泛的词符空间中开发远程关系非常重要,这自然与自注意力的设计具有相似的见解。 因此,我们通过比较所有 token 之间的内容相似度来设计词符亲和度:
| (7) |
其中可以是全局管中任意词符,大小为( 用于图像输入),而 和
与 Transformer 块的比较。 我们的全局 MHRA (方程 7)可以实例化为时空自注意力,其中 、 和 成为 ViT 中的 Query、Key 和 Value [24]。 因此,它可以有效地学习远程依赖。 然而,我们的全局 UniFormer 块与之前的 ViT 块不同。 首先,大多数视频转换器在视频域[3,1,79]中划分空间和时间注意力,以减少词符相似度比较中的点积计算。 但这样的操作不可避免地恶化了 Token 之间的时空关系。 相比之下,我们的全局 UniFormer 块联合编码时空词符关系,以生成更具辨别力的视频表示以供识别。 由于我们本地的 UniFormer 模块很大程度上节省了浅层词符比较的计算量,因此整体模型可以实现更好的计算精度平衡。 其次,我们在 UniFormer 中采用动态位置嵌入 (DPE),而不是绝对位置嵌入 [24, 92]。 它采用卷积风格(参见下一节),可以克服排列不变性并且对视觉标记的不同输入长度友好。
| Model | Type | #Blocks | #Channels | #Param. | FLOPs |
| Small | [L, L, G, G] | [3, 4, 8, 3] | [64, 128, 320, 512] | 21.5M | 3.6G |
| Base | [L, L, G, G] | [5, 8, 20, 7] | [64, 128, 320, 512] | 50.3M | 8.3G |
| Large | [L, L, G, G] | [5, 10, 24, 7] | [128, 192, 448, 640] | 100M | 12.6G |
3.3 动态位置嵌入
位置信息是描述视觉表示的重要线索。 此前,大多数 ViT 通过绝对或相对位置嵌入 [24, 99, 61] 来编码此类信息。 然而,绝对位置嵌入必须通过微调 [87, 88] 对各种输入大小进行插值,而相对位置嵌入由于自注意力 [ 的修改而效果不佳17]。 为了提高灵活性,最近提出了卷积位置嵌入[16, 23]。 特别是,条件位置编码(CPE)[17]可以通过卷积算子隐式编码位置信息,从而解锁Transformer来处理任意输入大小并提高识别性能。 由于其即插即用的特性,我们灵活地采用它作为 UniFormer 中的动态位置嵌入 (DPE):
| (8) |
其中 指的是具有零填充的深度卷积。 我们选择这样的设计作为我们的DPE基于以下原因。 首先,深度卷积对任意输入形状都很友好,例如,可以直接使用其时空版本来编码视频中的 3D 位置信息。 其次,深度卷积是轻量级的,这是计算精度平衡的重要因素。 最后,我们添加额外的零填充,因为它可以通过逐步查询其邻居[17]来帮助标记了解其绝对位置。
4 框架
在本节中,我们主要为各种下游任务开发可视化框架。 具体来说,我们首先通过分层堆叠本地和全局 UniFormer 块并考虑计算精度平衡,开发许多用于图像分类的视觉主干。 然后,我们扩展上述主干来解决其他代表性视觉任务,包括视频分类和密集预测(即对象检测、语义分割和人体姿势估计)。 UniFormer 的这种通用性和灵活性证明了其在计算机视觉研究及其他领域的宝贵潜力。
4.1 图像分类
逐步学习视觉表示以捕获图像中的语义非常重要。 因此,我们通过四个阶段构建主干,如图 3 所示。
更具体地说,我们在前两个阶段使用本地 UniFormer 块来减少计算冗余,而在后两个阶段使用全局 UniFormer 块来学习远程词符依赖。 对于本地UniFormer块,MHRA被实例化为具有本地词符亲和力的PWConv-DWConv-PWConv(等式6),其中DWConv的空间大小设置为5 5 图像分类。 对于全局UniFormer块,MHRA被实例化为具有全局词符亲和力的多头自注意力(等式7),其中注意力头的数量设置为64。 对于局部和全局UniFormer块,DPE被实例化为DWConv,空间大小为33,FFN的扩展比率为4。
此外,正如 CNN 和 ViT 文献 [37, 24] 中所建议的,我们利用 BN [43] 进行卷积,并使用 LN [2]为了自我关注。 For feature downsampling, we use the 44 convolution with stride 44 before the first stage and the 22 convolution with stride 22 before other stages. 此外,在每个下采样卷积之后都会添加一个额外的 LN。 最后,应用全局平均池化和全连接层来输出预测。 当使用词符标签[45]训练模型时,我们添加另一个全连接层作为辅助损失。 针对不同的计算需求,我们设计了三种模型变体,如表I所示。
4.2 视频分类
鉴于我们基于图像的 2D 主干,人们可以轻松地将它们改编为视频分类的 3D 主干。 在不失一般性的情况下,我们调整时空建模的小型模型和基本模型。 具体来说,模型架构与四个阶段保持相同,我们在前两个阶段使用本地 UniFormer 块,在后两个阶段使用全局 UniFormer 块。 但不同的是,所有 2D 卷积滤波器都通过滤波器膨胀 [11] 更改为 3D 卷积滤波器。 具体来说,DPE 和本地 MHRA 中 DWConv 的内核大小分别为 333 和 555。 此外,我们在第一阶段之前对空间和时间维度进行下采样。 因此,该阶段之前的卷积滤波器变为 344,步幅为 244。 对于其他阶段,我们只是对空间维度进行下采样,以降低计算成本并保持高性能。 因此,这些阶段之前的卷积滤波器为 122 ,步幅为 122 。
请注意,我们在全局 UniFormer 块中使用时空注意力来在 3D 视图中联合学习词符关系。 值得一提的是,由于模型尺寸较大,之前的视频变换器[3, 1]通过划分空间和时间注意力来减少计算量并缓解过拟合,但这种分解操作不可避免地撕裂时空词符关系。 相反,我们的联合时空注意力可以避免这个问题。 此外,我们的本地 UniFormer 模块通过 3D DWconv 很大程度上节省了计算量。 因此,我们的模型可以实现有效且高效的视频表示学习。

4.3 密集预测
密集的预测任务对于验证我们的识别主干的通用性是必要的。 因此,我们采用 UniFormer 主干来执行许多流行的密集任务,例如对象检测、实例分割、语义分割和人体姿势估计。 然而,由于大多数密集预测任务的输入分辨率很高,因此直接使用我们的主干网是不合适的,例如,COCO 对象检测数据集中图像的大小为 1333800。 当然,将此类图像输入到我们的分类主干中将不可避免地导致大量计算,特别是在最后两个阶段操作全局 UniFormer 块的自注意力时。 以视觉标记为例,词符相似度比较(等式7)中的MatMul运算导致 复杂性,这对于大多数密集任务来说是令人望而却步的。
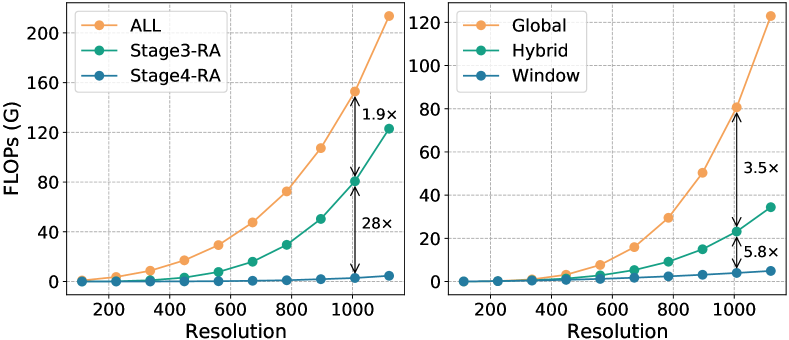
我们建议针对不同的下游任务调整全局 UniFormer 块。 首先,我们分析了 UniFormer-S 在不同输入分辨率下的 FLOP。 图4清楚地表明Stage3中的关系聚合器(RA)占用了大量的计算量。 例如,对于10081008的图像,Stage3中RA的MatMul操作甚至占据了总FLOPs的50%以上,而Stage4中的FLOPs仅为128在第三阶段。 因此,我们重点修改 Stage3 中的 RA 以减少计算量。
受 [75, 61] 的启发,我们建议在预定义窗口(例如 1414)中应用我们的全局 MHRA,而不是在具有高图像质量的整个图像中使用它。解决。 这样的操作可以有效地减少计算量,复杂度为,其中是窗口大小。 然而,由于词符交互不足,这无疑会降低模型性能。 为了弥补这一差距,我们在 Stage3 中将窗口和全局 UniFormer 块集成在一起,其中混合组由三个窗口块和一个全局块组成。 在这种情况下,我们的 UniFormer-Small/Base 主干网的 Stage3 中有 2/5 的混合组。
基于此设计,我们接下来根据训练和测试图像的输入分辨率介绍各种密集任务的具体主干设置。 对于目标检测和实例分割,输入图像通常很大(例如,1333800),因此我们在Stage3中采用混合块样式。 相比之下,姿态估计的输入相对较小,例如 384288,因此在 Stage3 中仍然应用全局块进行训练和测试。 特别是,对于语义分割,测试图像通常比训练图像大。 因此,我们利用Stage3中的全局块进行训练,同时调整Stage3中的混合块进行测试。 我们使用以下简单的设计。 测试中基于窗口的块具有与全局块相同的感受野,例如 3232。 这样的设计可以保持训练效率,并通过尽可能保持训练的一致性来提高测试性能。
5 迈向轻量级UniFormer
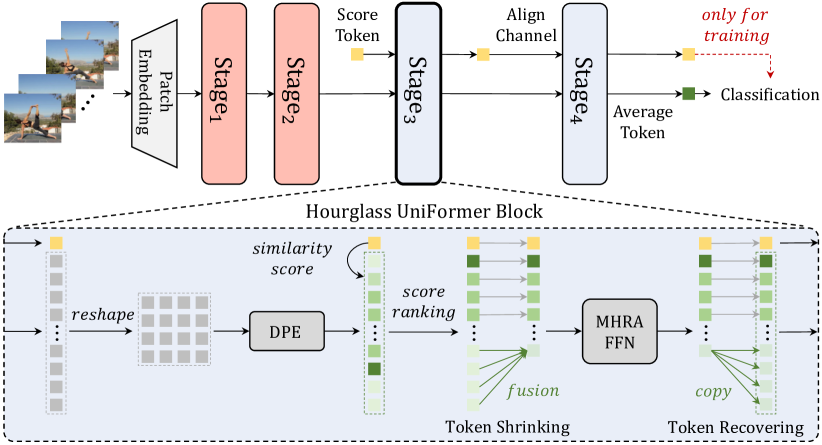
最近,研究人员尝试将 CNN 与 ViT 结合起来设计轻量级模型。 例如,MobileFormer[14]提出了MobileNet[77]和ViT[24]的并行设计,以及MobileViT[69 ] 将 Transformer 设计为卷积。 然而,这些作品的推理速度还有待进一步提高。 因此,现有的高效 CNN 仍然是更好的选择,例如用于图像任务的 EfficientNet [85] 和用于视频任务的 MoViNet[48]。 为了弥补这一差距,我们通过设计一个独特的沙漏 UniFormer 块,提出了图 6 中的轻量级 UniFormer 架构。 在这个块中,我们自适应地利用词符收缩和恢复,以实现更好的精度-吞吐量平衡。
5.1 沙漏UniFormer块
由于全局 UniFormer 块中词符相似度比较的计算量较大,因此我们提出了 Hourglass UniFormer (H-UniFormer) 块来减少全局 MHRA 中涉及的视觉标记的数量。 请注意,现有的词符剪枝方法 [76, 58, 124] 对于我们的 UniFormer 和具有卷积的 ViT [100, 111, 21] 是不可行的。 主要原因是,剪枝后,其余标记通常保持破碎的时空结构,这使得卷积不适用。 为了克服这个困难,我们提出了在 H-UniFormer 块中简洁地集成词符收缩和恢复。
词符缩小。 我们引入了一个分数词符来衡量DPE之后视觉标记的重要性。 具体来说,我们比较分数词符和视觉词符之间的相似度(使用方程7),并平均注意头,
| (9) |
其中表示视觉词符的重要性,我们使用表示所有视觉词符的重要性向量。 对于中具有高值的 Token ,我们认为它们是关键 Token 并保留它们。 对于价值较低的 Token ,我们认为它们是不重要的 Token 。 因此,我们将它们融合为一个代表性词符,其中它们的分值用作融合权重。 通过这种不重要的词符减少,我们可以将视觉标记从缩小到,其中标记的数量。 随后,减少的视觉标记被输入全局 MHRA 和 FFN,以节省计算量。 另外,我们将这个分数词符传递给Stage3和Stage4中的所有H-UniFormer块,并用它来计算训练时的分类损失。 在这种情况下,得分词符有效地受到真实标签的指导,因此对词符重要性的权重变得具有区分性。
词符正在恢复。 在学习了全球 MHRA 和 FFN 中的词符交互后,我们复制了代表性的词符来恢复不重要的 Token 。 因此,我们可以维护所有视觉标记的时空结构,以便在下一个 H-UniFormer 块中进行有效的动态位置编码(即卷积)。
| Arch. | Method | #Param | FLOPs | Train | Test | ImageNet |
| (M) | (G) | Size | Size | Top-1 | ||
| CNN | RegNetY-4G [74] | 21 | 4.0 | 224 | 224 | 80.0 |
| EffcientNet-B5 [85] | 30 | 9.9 | 456 | 456 | 83.6 | |
| EfficientNetV2-S [86] | 22 | 8.5 | 384 | 384 | 83.9 | |
| Trans | DeiT-S [87] | 22 | 4.6 | 224 | 224 | 79.9 |
| PVT-S [99] | 25 | 3.8 | 224 | 224 | 79.8 | |
| T2T-14 [112] | 22 | 5.2 | 224 | 224 | 80.7 | |
| Swin-T [61] | 29 | 4.5 | 224 | 224 | 81.3 | |
| Focal-T [109] | 29 | 4.9 | 224 | 224 | 82.2 | |
| CSwin-T [23] | 23 | 4.3 | 224 | 224 | 82.7 | |
| CSwin-T 384 [23] | 23 | 14.0 | 224 | 384 | 84.3 | |
| CNN+Trans | CvT-13 [102] | 20 | 4.5 | 224 | 224 | 81.6 |
| CvT-13 384 [102] | 20 | 16.3 | 224 | 384 | 83.0 | |
| CoAtNet-0 [21] | 25 | 4.2 | 224 | 224 | 81.6 | |
| CoAtNet-0 384 [21] | 20 | 13.4 | 224 | 384 | 83.9 | |
| Container [32] | 22 | 8.1 | 224 | 224 | 82.7 | |
| LV-ViT-S [45] | 26 | 6.6 | 224 | 224 | 83.3 | |
| LV-ViT-S 384 [45] | 26 | 22.2 | 224 | 384 | 84.4 | |
| UniFormer-S | 22 | 3.6 | 224 | 224 | 82.9 | |
| UniFormer-S⋆ | 22 | 3.6 | 224 | 224 | 83.4 | |
| UniFormer-S⋆ 384 | 22 | 11.9 | 224 | 384 | 84.6 | |
| UniFormer-S | 24 | 4.2 | 224 | 224 | 83.4 | |
| UniFormer-S | 24 | 4.2 | 224 | 224 | 83.9 | |
| UniFormer-S 384 | 24 | 13.7 | 224 | 384 | 84.9 | |
| CNN | RegNetY-8G [74] | 39 | 8.0 | 224 | 224 | 81.7 |
| EffcientNet-B7 [85] | 66 | 39.2 | 600 | 600 | 84.3 | |
| EfficientNetV2-M [86] | 54 | 25.0 | 480 | 480 | 85.1 | |
| Trans | PVT-L [99] | 61 | 9.8 | 224 | 224 | 81.7 |
| T2T-24 [112] | 64 | 13.2 | 224 | 224 | 82.2 | |
| Swin-S [61] | 50 | 8.7 | 224 | 224 | 83.0 | |
| Focal-S [109] | 51 | 9.1 | 224 | 224 | 83.5 | |
| CSwin-S [23] | 35 | 6.9 | 224 | 224 | 83.6 | |
| CSwin-S 384 [23] | 35 | 22.0 | 224 | 384 | 85.0 | |
| CNN+Trans | CvT-21 [102] | 32 | 7.1 | 224 | 224 | 82.5 |
| CoAtNet-1 [21] | 42 | 8.4 | 224 | 224 | 83.3 | |
| CoAtNet-1 384 [21] | 42 | 27.4 | 224 | 384 | 85.1 | |
| LV-ViT-M [45] | 56 | 16.0 | 224 | 224 | 84.1 | |
| LV-ViT-M 384 [45] | 56 | 42.2 | 224 | 384 | 85.4 | |
| UniFormer-B | 50 | 8.3 | 224 | 224 | 83.9 | |
| UniFormer-B⋆ | 50 | 8.3 | 224 | 224 | 85.1 | |
| UniFormer-B⋆ 384 | 50 | 27.2 | 224 | 384 | 86.0 | |
| CNN | RegNetY-16G [74] | 84 | 16.0 | 224 | 224 | 82.9 |
| EfficientNetV2-L [86] | 121 | 53 | 480 | 480 | 85.7 | |
| NFNet-F4 [4] | 316 | 215.3 | 384 | 512 | 85.9 | |
| Trans | DeiT-B [87] | 86 | 17.5 | 224 | 224 | 81.8 |
| Swin-B [61] | 88 | 15.4 | 224 | 224 | 83.3 | |
| Swin-B 384 | 88 | 47.0 | 224 | 384 | 84.2 | |
| Focal-B [61] | 90 | 16.0 | 224 | 224 | 83.8 | |
| CSwin-B [23] | 78 | 15.0 | 224 | 224 | 84.2 | |
| CSwin-B 384 [23] | 78 | 47.0 | 224 | 384 | 85.4 | |
| CaiT-S36 384 [88] | 68 | 48.0 | 224 | 384 | 85.4 | |
| CaiT-M36 448 [88] | 271 | 247.8 | 224 | 448 | 86.3 | |
| CNN+Trans | BoTNet-T7 [82] | 79 | 19.3 | 256 | 256 | 84.2 |
| CoAtNet-3 [21] | 168 | 34.7 | 224 | 224 | 84.5 | |
| CoAtNet-3 384 [21] | 168 | 107.4 | 224 | 384 | 85.8 | |
| LV-ViT-L [45] | 150 | 59.0 | 288 | 288 | 85.3 | |
| LV-ViT-L 448 [45] | 150 | 157.2 | 288 | 448 | 85.9 | |
| VOLO-D3 [113] | 86 | 20.6 | 224 | 224 | 85.4 | |
| VOLO-D3 448 [113] | 86 | 67.9 | 224 | 448 | 86.3 | |
| UniFormer-L⋆ | 100 | 12.6 | 224 | 224 | 85.6 | |
| UniFormer-L⋆ 384 | 100 | 39.2 | 224 | 384 | 86.3 | |
5.2 轻量级 UniFormer 架构
为了构建我们的轻量级UniFormer,我们遵循4.1节中的大部分架构,除了我们在Stage3和Stage4中更改为使用H-UniFormer块,并采用更小的深度、宽度或分辨率(例如,128)。 具体来说,对于 UniFomrer-XS,块号、通道号和头尺寸分别为 [3, 5, 9, 3]、[64, 128, 256, 512] 和 32。 对于 UniFomrer-XXS,块号、通道号和头尺寸为 [2, 5, 8, 2]、[56, 112, 224, 448] 和 28。
从Stage3的第二层开始,我们利用上一层中的相似度分数来指导词符收缩。 基于关键标记的位置在不同层[108]之间基本相同的现象,我们通过均值更新相似度分数,即。 因此它可以一致地关注重要的标记。 默认情况下,我们保留一半的 Token ,并将其余 Token 融合到我们的轻量级 UniFormer 中(即收缩率为 0.5)。
6 实验
为了验证我们的 UniFormer 在视觉识别方面的有效性和效率,我们在 ImageNet-1K[22] 图像分类中进行了大量实验、Kinetics-400[10]/600[9] 和 Something-Something V1&V2[34] 视频分类,COCO [60] 对象检测、实例分割和姿态估计,以及 ADE20K [121] 语义分割。 我们还进行全面的消融研究来分析 UniFormer 的每种设计。
| Method | Pretrain | #frame | FLOPs | K400 | K600 | ||
| #crop#clip | (G) | Top-1 | Top-5 | Top-1 | Top-5 | ||
| SmallBigEN[53] | IN-1K | (8+32)34 | 5700 | 78.7 | 93.7 | - | - |
| TDNEN[97] | IN-1K | (8+16)310 | 5940 | 79.4 | 94.4 | - | - |
| CT-NetEN[52] | IN-1K | (16+16)34 | 2641 | 79.8 | 94.2 | - | - |
| LGD[73] | IN-1K | 128N/A | N/A | 79.4 | 94.4 | 81.5 | 95.6 |
| SlowFast[30] | - | 8310 | 3180 | 77.9 | 93.2 | 80.4 | 94.8 |
| SlowFast+NL[30] | - | 16310 | 7020 | 79.8 | 93.9 | 81.8 | 95.1 |
| ip-CSN[90] | Sports1M | 32310 | 3270 | 79.2 | 93.8 | - | - |
| CorrNet[94] | Sports1M | 32310 | 6720 | 81.0 | - | - | - |
| X3D-M[29] | - | 16310 | 186 | 76.0 | 92.3 | 78.8 | 94.5 |
| X3D-XL[29] | - | 16310 | 1452 | 79.1 | 93.9 | 81.9 | 95.5 |
| MoViNet-A5[48] | - | 12011 | 281 | 80.9 | 94.9 | 82.7 | 95.7 |
| MoViNet-A6[48] | - | 12011 | 386 | 81.5 | 95.3 | 83.5 | 96.2 |
| ViT-B-VTN [70] | IN-21K | 25011 | 3992 | 78.6 | 93.7 | - | - |
| TimeSformer-HR[3] | IN-21K | 1631 | 5109 | 79.7 | 94.4 | 82.4 | 96.0 |
| TimeSformer-L[3] | IN-21K | 9631 | 7140 | 80.7 | 94.7 | 82.2 | 95.5 |
| STAM [79] | IN-21K | 6411 | 1040 | 79.2 | - | - | - |
| X-ViT[5] | IN-21K | 831 | 425 | 78.5 | 93.7 | 82.5 | 95.4 |
| X-ViT[5] | IN-21K | 1631 | 850 | 80.2 | 94.7 | 84.5 | 96.3 |
| Mformer-HR[71] | IN-21K | 16310 | 28764 | 81.1 | 95.2 | 82.7 | 96.1 |
| MViT-B,164[28] | - | 1615 | 353 | 78.4 | 93.5 | 82.1 | 95.7 |
| MViT-B,323[28] | - | 3215 | 850 | 80.2 | 94.4 | 83.4 | 96.3 |
| ViViT-L[1] | IN-21K | 1634 | 17352 | 80.6 | 94.7 | 82.5 | 95.6 |
| ViViT-L[1] | JFT-300M | 1634 | 17352 | 82.8 | 95.3 | 84.3 | 96.2 |
| ViViT-H[1] | JFT-300M | 1634 | 99792 | 84.8 | 95.8 | 85.8 | 96.5 |
| Swin-T[62] | IN-1K | 3234 | 1056 | 78.8 | 93.6 | - | - |
| Swin-B[62] | IN-1K | 3234 | 3384 | 80.6 | 94.6 | - | - |
| Swin-B[62] | IN-21K | 3234 | 3384 | 82.7 | 95.5 | 84.0 | 96.5 |
| Swin-L-384[62] | IN-21K | 32510 | 105350 | 84.9 | 96.7 | 86.1 | 97.3 |
| UniFormer-S | IN-1K | 1614 | 167 | 80.8 | 94.7 | 82.8 | 95.8 |
| UniFormer-B | IN-1K | 1614 | 389 | 82.0 | 95.1 | 84.0 | 96.4 |
| UniFormer-B | IN-1K | 3214 | 1036 | 82.9 | 95.4 | 84.8 | 96.7 |
| UniFormer-B | IN-1K | 3234 | 3108 | 83.0 | 95.4 | 84.9 | 96.7 |
6.1 图像分类
设置。 我们在 ImageNet-1K 数据集 [22] 上从头开始训练模型。 为了公平比较,我们默认遵循 DeiT [87] 中提出的相同训练策略,包括强大的数据增强和正则化。 此外,我们将表 I 中的 UniFormer-S/B/L 的随机深度率分别设置为 0.1/0.3/0.4。 我们通过 AdamW [65] 优化器使用余弦学习率计划 [66] 对所有模型进行 300 个时期的训练,而前 5 个时期用于线性预热 [33]。 权重衰减、学习率和批量大小分别设置为 0.05、1e-3 和 1024。 对于 UniFormer-S,我们遵循最先进的 ViT [23, 109] 来应用重叠补丁嵌入和块(3/5/9/3 块)每个阶段)进行公平比较。 对于UniFormer-B,我们使用8e-4的学习率以获得更好的收敛性。
| Method | Pretrain | #frame | FLOPs | SSV1 | SSV2 | ||
| #crop#clip | (G) | Top-1 | Top-5 | Top-1 | Top-5 | ||
| TSN[96] | IN-1K | 1611 | 66 | 19.9 | 47.3 | 30.0 | 60.5 |
| TSM[59] | IN-1K | 1611 | 66 | 47.2 | 77.1 | - | - |
| GST[67] | IN-1K | 1611 | 59 | 48.6 | 77.9 | 62.6 | 87.9 |
| TEINet[63] | IN-1K | 1611 | 66 | 49.9 | - | 62.1 | - |
| TEA[56] | IN-1K | 1611 | 70 | 51.9 | 80.3 | - | - |
| MSNet[50] | IN-1K | 1611 | 101 | 52.1 | 82.3 | 64.7 | 89.4 |
| CT-Net[52] | IN-1K | 1611 | 75 | 52.5 | 80.9 | 64.5 | 89.3 |
| CT-NetEN[52] | IN-1K | 8+12+16+24 | 280 | 56.6 | 83.9 | 67.8 | 91.1 |
| TDN[97] | IN-1K | 1611 | 72 | 53.9 | 82.1 | 65.3 | 89.5 |
| TDNEN[97] | IN-1K | 8+16 | 198 | 56.8 | 84.1 | 68.2 | 91.6 |
| TimeSformer-HR[3] | IN-21K | 1631 | 5109 | - | - | 62.5 | - |
| TimeSformer-L[3] | IN-21K | 9631 | 7140 | - | - | 62.3 | - |
| X-ViT[5] | IN-21K | 1631 | 850 | - | - | 65.2 | 90.6 |
| X-ViT[5] | IN-21K | 3231 | 1270 | - | - | 65.4 | 90.7 |
| Mformer-HR[71] | K400 | 1631 | 2876 | - | - | 67.1 | 90.6 |
| Mformer-L[71] | K400 | 3231 | 3555 | - | - | 68.1 | 91.2 |
| ViViT-L[1] | K400 | 1634 | 11892 | - | - | 65.4 | 89.8 |
| MViT-B,643[28] | K400 | 6413 | 1365 | - | - | 67.7 | 90.9 |
| MViT-B-24,323[28] | K600 | 3213 | 708 | - | - | 68.7 | 91.5 |
| Swin-B[62] | K400 | 3231 | 963 | - | - | 69.6 | 92.7 |
| UniFormer-S | K400 | 1611 | 42 | 53.8 | 81.9 | 63.5 | 88.5 |
| UniFormer-S | K600 | 1611 | 42 | 54.4 | 81.8 | 65.0 | 89.3 |
| UniFormer-S | K400 | 1631 | 125 | 57.2 | 84.9 | 67.7 | 91.4 |
| UniFormer-S | K600 | 1631 | 125 | 57.6 | 84.9 | 69.4 | 92.1 |
| UniFormer-B | K400 | 1631 | 290 | 59.1 | 86.2 | 70.4 | 92.8 |
| UniFormer-B | K600 | 1631 | 290 | 58.8 | 86.5 | 70.2 | 93.0 |
| UniFormer-B | K400 | 3231 | 777 | 60.9 | 87.3 | 71.2 | 92.8 |
| UniFormer-B | K600 | 3231 | 777 | 61.0 | 87.6 | 71.2 | 92.8 |
| UniFormer-B | K400 | 3232 | 1554 | 61.0 | 87.3 | 71.4 | 92.8 |
| UniFormer-B | K600 | 3232 | 1554 | 61.2 | 87.6 | 71.3 | 92.8 |
对于训练高性能ViT,提出了硬蒸馏[87]和词符标签[45],这两者都是对我们主干的补充。 由于词符标注效率更高,因此我们按照 LV-ViT [45] 中的设置,应用额外的全连接层和辅助损失。 与 DeiT 中的训练设置不同,MixUp [118] 和 CutMix [115] 不使用,因为它们与 MixToken [45] 冲突。 默认情况下,批量大小为 1024 时,基本学习率为 1.6e-3。 特别地,我们对 UniFormer-L 采用 1.2e-3 的基础学习率和层规模 [88] 以避免 NaN 损失。 当在更大的分辨率(即 384384)上微调我们的模型时,权重衰减、学习率、批量大小、预热时期和总时期设置为 1e-8、5e-6, 512、5 和 30。
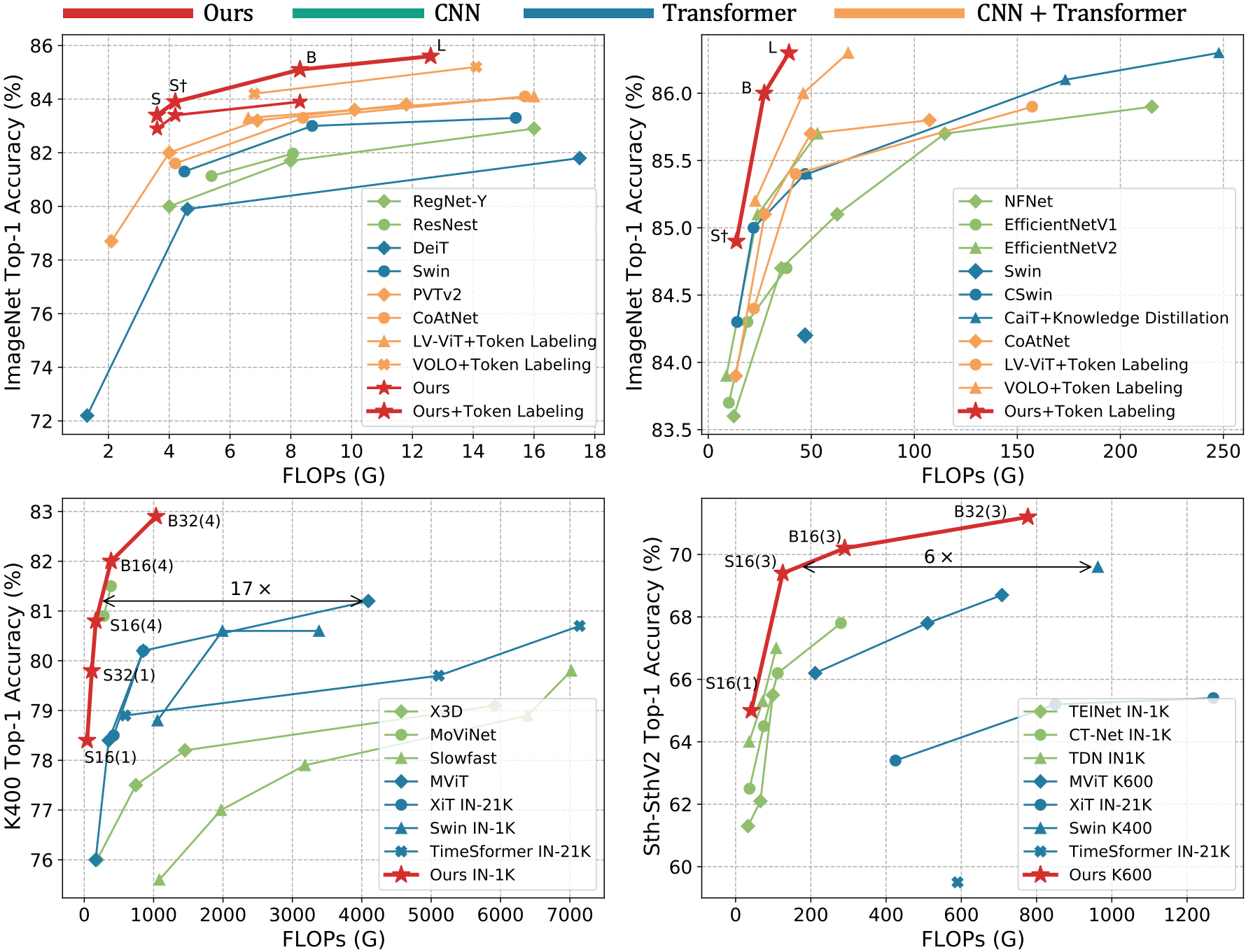
结果。 在表II中,我们将 UniFormer 与最先进的 CNN、ViT 及其组合进行了比较。 它清楚地表明我们的 UniFormer 在不同的计算限制下优于以前的模型。 例如,我们的 UniFormer-S 仅用 4.2G FLOP 就实现了 83.4% 的 top-1 准确率,超过了 RegNetY-4G [74]、Swin-T [61 ]、CSwin-T [23] 和 CoAtNet [21] 分别提高了 3.4%、2.1%、0.7% 和 1.8%。 尽管 EfficientNet [85] 来自广泛的神经架构搜索,但我们的 UniFormer 的性能优于它(83.9% vs. 83.6%),且计算成本更低( 8.3G vs。 9.9G)。 此外,我们使用词符标签[45]增强我们的模型,用“⋆”表示。 与相同设置的模型训练相比,我们的 UniFormer-L 实现了更高的准确率,但只有 LV-ViT-M[45] 的 21% FLOPs 和 VOLO-D3[ 的 61% FLOPs 113]。 此外,当对 384384 图像进行微调时,我们的 UniFormer-L 获得了 86.3% 的 top-1 准确率。 它甚至比输入更大的 EfficientNetV2-L [86] 更好,展示了我们的 UniFormer 强大的学习能力。
| Method | #Params | FLOPs | Mask R-CNN 1 schedule | Mask R-CNN 3 + MS schedule | ||||||||||
| (M) | (G) | |||||||||||||
| Res50 [37] | 44 | 260 | 38.0 | 58.6 | 41.4 | 34.4 | 55.1 | 36.7 | 41.0 | 61.7 | 44.9 | 37.1 | 58.4 | 40.1 |
| PVT-S [99] | 44 | 245 | 40.4 | 62.9 | 43.8 | 37.8 | 60.1 | 40.3 | 43.0 | 65.3 | 46.9 | 39.9 | 62.5 | 42.8 |
| TwinsP-S [16] | 44 | 245 | 42.9 | 65.8 | 47.1 | 40.0 | 62.7 | 42.9 | 46.8 | 69.3 | 51.8 | 42.6 | 66.3 | 46.0 |
| Twins-S [16] | 44 | 228 | 43.4 | 66.0 | 47.3 | 40.3 | 63.2 | 43.4 | 46.8 | 69.2 | 51.2 | 42.6 | 66.3 | 45.8 |
| Swin-T [61] | 48 | 264 | 42.2 | 64.6 | 46.2 | 39.1 | 61.6 | 42.0 | 46.0 | 68.2 | 50.2 | 41.6 | 65.1 | 44.8 |
| ViL-S [119] | 45 | 218 | 44.9 | 67.1 | 49.3 | 41.0 | 64.2 | 44.1 | 47.1 | 68.7 | 51.5 | 42.7 | 65.9 | 46.2 |
| Focal-T [109] | 49 | 291 | 44.8 | 67.7 | 49.2 | 41.0 | 64.7 | 44.2 | 47.2 | 69.4 | 51.9 | 42.7 | 66.5 | 45.9 |
| UniFormer-Sh14 | 41 | 269 | 45.6 | 68.1 | 49.7 | 41.6 | 64.8 | 45.0 | 48.2 | 70.4 | 52.5 | 43.4 | 67.1 | 47.0 |
| Res101 [37] | 63 | 336 | 40.4 | 61.1 | 44.2 | 36.4 | 57.7 | 38.8 | 42.8 | 63.2 | 47.1 | 38.5 | 60.1 | 41.3 |
| X101-32 [107] | 63 | 340 | 41.9 | 62.5 | 45.9 | 37.5 | 59.4 | 40.2 | 44.0 | 64.4 | 48.0 | 39.2 | 61.4 | 41.9 |
| PVT-M [99] | 64 | 302 | 42.0 | 64.4 | 45.6 | 39.0 | 61.6 | 42.1 | 44.2 | 66.0 | 48.2 | 40.5 | 63.1 | 43.5 |
| TwinsP-B [16] | 64 | 302 | 44.6 | 66.7 | 48.9 | 40.9 | 63.8 | 44.2 | 47.9 | 70.1 | 52.5 | 43.2 | 67.2 | 46.3 |
| Twins-B [16] | 76 | 340 | 45.2 | 67.6 | 49.3 | 41.5 | 64.5 | 44.8 | 48.0 | 69.5 | 52.7 | 43.0 | 66.8 | 46.6 |
| Swin-S [61] | 69 | 354 | 44.8 | 66.6 | 48.9 | 40.9 | 63.4 | 44.2 | 48.5 | 70.2 | 53.5 | 43.3 | 67.3 | 46.6 |
| Focal-S [109] | 71 | 401 | 47.4 | 69.8 | 51.9 | 42.8 | 66.6 | 46.1 | 48.8 | 70.5 | 53.6 | 43.8 | 67.7 | 47.2 |
| CSWin-S [23] | 54 | 342 | 47.9 | 70.1 | 52.6 | 43.2 | 67.1 | 46.2 | 50.0 | 71.3 | 54.7 | 44.5 | 68.4 | 47.7 |
| Swin-B [61] | 107 | 496 | 46.9 | - | - | 42.3 | - | - | 48.5 | 69.8 | 53.2 | 43.4 | 66.8 | 46.9 |
| Focal-B [109] | 110 | 533 | 47.8 | - | - | 43.2 | - | - | 49.0 | 70.1 | 53.6 | 43.7 | 67.6 | 47.0 |
| UniFormer-Bh14 | 69 | 399 | 47.4 | 69.7 | 52.1 | 43.1 | 66.0 | 46.5 | 50.3 | 72.7 | 55.3 | 44.8 | 69.0 | 48.3 |
| Method | Pretrain | Backbone | UCF101 | HMDB51 |
| C3D[89] | Sports-1M | ResNet18 | 85.8 | 54.9 |
| TSN[96] | IN1K+K400 | InceptionV2 | 91.1 | - |
| I3D[11] | IN1K+K400 | InceptionV2 | 95.8 | 74.8 |
| R(2+1)D[91] | K400 | ResNet34 | 96.8 | 74.5 |
| TSM[59] | IN1K+K400 | ResNet50 | 94.5 | 70.7 |
| STM[44] | IN1K+K400 | ResNet50 | 96.2 | 72.2 |
| TEA[56] | IN1K+K400 | ResNet50 | 96.9 | 73.3 |
| CT-Net[52] | IN1K+K400 | ResNet50 | 96.2 | 73.2 |
| TDN[97] | IN1K+K400 | ResNet50 | 97.4 | 76.3 |
| VidTr[54] | IN21K+K400 | ViT-B | 96.6 | 74.4 |
| UniFormer | IN1K+K400 | UniFormer-S | 98.1 | 76.9 |
6.2 视频分类
设置。 我们在流行的 Kinetics-400 [10]、Kinetics-600 [9]、UCF101 [81] 和 HMDB51 [93],我们验证了时间相关数据集 Something-Something (SthSth) V1&V2 [34] 上的迁移学习性能。 我们的代码主要依赖于 PySlowFast [27]。 对于训练,我们默认采用与 MViT [28] 相同的训练策略,但我们不对 SthSth 应用随机水平翻转。 我们利用 AdamW [65] 优化器和余弦学习率计划 [66] 来训练我们的视频骨干网。 前 5 或 10 个 epoch 用于预热[33],以克服早期优化困难。 对于 UniFormer-S,Kinetics 的预热历元、总历元、随机深度率、权重衰减分别设置为 10、110、0.1 和 0.05,SthSth 分别设置为 5、50、0.3 和 0.05,SthSth 分别设置为 5、20、0.2 和UCF101 和 HMDB51 为 0.05。 对于 UniFormer-B,所有超参数都是相同的,除非随机深度率加倍。 此外,我们根据批量大小线性缩放基础学习率,其中 Kinetics 为 1e-4,SthSth 为 2e-4,SthSth 为 1e-5 适用于 UCF101 和 HMDB51。
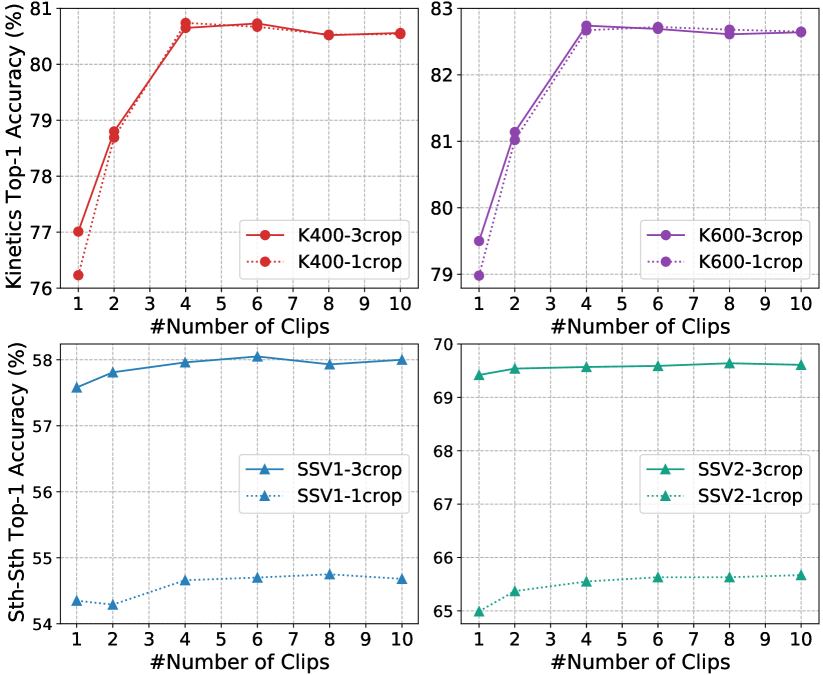
我们对 Kinetics、UCF101 和 HMDB51 使用密集采样策略 [101],对 Something-Something 使用均匀采样策略 [96]。 为了降低总训练成本,我们对在 ImageNet 上预训练的动力学 [11] 的 2D 卷积核进行了膨胀。 为了获得更好的 FLOPs-accuracy 平衡,此外,我们对 Kinetics 采用了多剪辑测试,对 Something-Something 采用了多裁剪测试。 所有分数均取平均值作为最终预测。
动力学结果。 在表 III 中,我们将 UniFormer 与 Kinetics-400 和 Kinetics-600 上最先进的方法进行了比较。 第一部分展示了使用 CNN 的先前工作。 与配备非本地块[101]的SlowFast [30]相比,我们的UniFormer-S16f需要更少的 GFLOP,但在两个数据集上都获得了 1.0% 的性能增益(80.8% vs. 79.8% 和 82.8% vs. 81.8%)。 即使与 MoViNet [48](通过广泛的神经架构搜索建立的强大的基于 CNN 的模型)相比,我们的模型也取得了稍微更好的结果(82.0% vs。 81.5%),输入帧较少( 与 )。 第二部分列出了最近基于视觉转换器的方法。 仅通过 ImageNet-1K 预训练,UniFormer-B16f 就超越了大多数现有的具有大型数据集预训练的主干网络。 例如,与根据 JFT-300M [83] 预先训练的 ViViT-L [1] 和根据 ImageNet-21K 预先训练的 Swin-B [62] 相比,UniFormer-B32f 获得了相当的性能(82.9% vs. 82.8% 和 82.7%),其中 和 在 Kinetics-400 和 Kinetics-600 上的计算量较少。 这些结果证明了我们的 UniFormer 对于视频的有效性。
某事的结果。 表IV展示了Something-Something (SthSth) V1&V2的结果。 由于这些数据集需要鲁棒的时间关系建模,基于 CNN 的方法很难捕获长期依赖性,这导致其结果更差。 相反,视频变换器擅长处理长序列数据,并表现出更好的迁移学习能力[122],因此它们实现了更高的精度,但计算成本较大。 相比之下,我们的 UniFormer-S16f 结合了卷积和自注意力的优点,在 SthSth V1/ 中获得 54.4%/65.0% V2 仅具有 42 GFLOP。 它还表明,小模型 UniFormer-S 受益于较大的数据集预训练(Kinetics-400, 53.8% vs. Kinetics-600, 54.4%),但大型模型UniFormer-B 则不然(Kinetics-400,59.1% vs。 Kinetics-600,58.8%)。 我们认为大模型更容易收敛。 此外,值得注意的是,我们从 Kinetis-600 预训练的 UniFormer 在相同设置下优于当前的所有方法。 事实上,我们的最佳模型实现了新的最先进结果:SthSth V1 上的 61.0% top-1 准确率(4.2% 高于 TDNEN) [97] 和 71.2% 在 SthSth V2 上的 top-1 准确率(1.6% 比 Swin-B [62])。 这样的结果验证了其强大的时空学习能力。
UCF101 和 HMDB51 的结果。 我们进一步验证了UCF101和HMDB51上的泛化能力。 由于这些数据集相对较小,性能已经饱和。 如表VI所示,我们的UniFormer显着优于之前的SOTA方法,揭示了其向小数据集迁移的强大泛化能力。
| Method | #Params | FLOPs | 3 + MS schedule | |||||
| (M) | (G) | |||||||
| Res50 [37] | 82 | 739 | 46.3 | 64.3 | 50.5 | 40.1 | 61.7 | 43.4 |
| DeiT [87] | 80 | 889 | 48.0 | 67.2 | 51.7 | 41.4 | 64.2 | 44.3 |
| Swin-T [61] | 86 | 745 | 50.5 | 69.3 | 54.9 | 43.7 | 66.6 | 47.1 |
| Shuffle-T [42] | 86 | 746 | 50.8 | 69.6 | 55.1 | 44.1 | 66.9 | 48.0 |
| Focal-T [109] | 87 | 770 | 51.5 | 70.6 | 55.9 | - | - | - |
| UniFormer-Sh14 | 79 | 747 | 52.1 | 71.1 | 56.6 | 45.2 | 68.3 | 48.9 |
| X101-32 [107] | 101 | 819 | 48.1 | 66.5 | 52.4 | 41.6 | 63.9 | 45.2 |
| Swin-S [61] | 107 | 838 | 51.8 | 70.4 | 56.3 | 44.7 | 67.9 | 48.5 |
| Shuffle-S [42] | 107 | 844 | 51.9 | 70.9 | 56.4 | 44.9 | 67.8 | 48.6 |
| CSWin-S [23] | 92 | 820 | 53.7 | 72.2 | 58.4 | 46.4 | 69.6 | 50.6 |
| Swin-B [61] | 145 | 972 | 51.9 | 70.9 | 57.0 | 45.3 | 68.5 | 48.9 |
| Shuffle-B [42] | 145 | 989 | 52.2 | 71.3 | 57.0 | 45.3 | 68.5 | 48.9 |
| UniFormer-Bh14 | 107 | 878 | 53.8 | 72.8 | 58.5 | 46.4 | 69.9 | 50.4 |
6.3 目标检测和实例分割
设置。 我们使用 COCO2017 [60] 对我们的模型进行对象检测和实例分割的基准测试。 使用 ImageNet-1K 预训练模型作为主干,然后配备两个代表性框架:Mask R-CNN [6] 和 Cascade Mask R-CNN [36] 。 我们的代码主要基于mmdetection [13],训练策略与Swin Transformer [61]相同。 我们采用两种训练计划:1 计划(12 个 epoch)和 3 计划(36 个 epoch)。 对于 1 计划,图像较短边的大小调整为 800,同时保持较长边不超过 1333。 对于 3 计划,我们应用多尺度训练策略在 480 到 800 之间随机调整较短边的大小。 此外,我们使用 AdamW 优化器,初始学习率为 1e-4,权重衰减为 0.05。 为了规范训练,我们将使用 Mask R-CNN 和 Cascade Mask R-CNN 的小型/基础模型的随机深度下降率设置为 0.1/0.3 和 0.2/0.4。
结果。 表V报告了Mask R-CNN框架的框mAP()和掩模mAP()。 它表明我们的 UniFormer 变体优于所有 CNN 和 Transformer 主干。 为了降低目标检测的训练成本,我们在 Stage3 中使用窗口大小为 14 的混合 UniFomer 样式(用 表示)。 具体来说,在 1 计划下,我们的 UniFormer 在可比设置下相对于 ResNet [37] 带来 7.0-7.6 点的 box mAP 和 6.7-7.2 的 mask mAP。 与流行的Swin Transformer [61]相比,我们的UniFormer实现了2.6-3.4点的box mAP和2.2-2.5点的mask mAP改进。 此外,通过 3 计划和多尺度训练,我们的模型仍然持续超越 CNN 和 Transformer 模型。 例如,我们的 UniFormer-B 的性能优于强大的 CSwin-S [23] +0.3 box mAP 和 +0.3 mask mAP,甚至比 Swin-B 和 Focal-B 等更大的主干网更好[109]。 表VII报告了Cascade Mask R-CNN框架的结果。 持续的改进证明了我们更强的上下文建模能力。
| Method | Semantic FPN 80K | ||
| #Param(M) | FLOPs(G) | mIoU(%) | |
| Res50 [37] | 29 | 183 | 36.7 |
| PVT-S [99] | 28 | 161 | 39.8 |
| TwinsP-S [16] | 28 | 162 | 44.3 |
| Twins-S [16] | 28 | 144 | 43.2 |
| Swin-T [61] | 32 | 182 | 41.5 |
| UniFormer-Sh32 | 25 | 199 | 46.2 |
| UniFormer-S | 25 | 247 | 46.6 |
| Res101 [37] | 48 | 260 | 38.8 |
| PVT-M [99] | 48 | 219 | 41.6 |
| PVT-L [99] | 65 | 283 | 42.1 |
| TwinsP-B [16] | 48 | 220 | 44.9 |
| TwinsP-L [16] | 65 | 283 | 46.4 |
| Twins-B [16] | 60 | 261 | 45.3 |
| Swin-S [61] | 53 | 274 | 45.2 |
| Twins-L [16] | 104 | 404 | 46.7 |
| Swin-B [61] | 91 | 422 | 46.0 |
| UniFormer-Bh32 | 54 | 350 | 47.7 |
| UniFormer-B | 54 | 471 | 48.0 |
| Method | Upernet 160K | |||
| #Param.(M) | FLOPs(G) | mIoU(%) | MS mIoU(%) | |
| TwinsP-S [16] | 55 | 919 | 46.2 | 47.5 |
| Twins-S [16] | 54 | 901 | 46.2 | 47.1 |
| Swin-T [61] | 60 | 945 | 44.5 | 45.8 |
| Focal-T [109] | 62 | 998 | 45.8 | 47.0 |
| Shuffle-T [42] | 60 | 949 | 46.6 | 47.8 |
| UniFormer-Sh32 | 52 | 955 | 47.0 | 48.5 |
| UniFormer-S | 52 | 1008 | 47.6 | 48.5 |
| Res101 [37] | 86 | 1029 | - | 44.9 |
| TwinsP-B [16] | 74 | 977 | 47.1 | 48.4 |
| Twins-B [16] | 89 | 1020 | 47.7 | 48.9 |
| Swin-S [61] | 81 | 1038 | 47.6 | 49.5 |
| Focal-T [109] | 85 | 1130 | 48.0 | 50.0 |
| Shuffle-S [42] | 81 | 1044 | 48.4 | 49.6 |
| Swin-B [61] | 121 | 1188 | 48.1 | 49.7 |
| Focal-B [109] | 126 | 1354 | 49.0 | 50.5 |
| Shuffle-B [42] | 121 | 1196 | 49.0 | 50.5 |
| UniFormer-Bh32 | 80 | 1106 | 49.5 | 50.7 |
| UniFormer-B | 80 | 1227 | 50.0 | 50.8 |
| Arch. | Method | Input Size | #Param(M) | FLOPs(G) | ||||||
| CNN | SimpleBaseline-R101 [103] | 256192 | 53.0 | 12.4 | 71.4 | 89.3 | 79.3 | 68.1 | 78.1 | 77.1 |
| SimpleBaseline-R152 [103] | 256192 | 68.6 | 15.7 | 72.0 | 89.3 | 79.8 | 68.7 | 78.9 | 77.8 | |
| HRNet-W [95] | 256192 | 28.5 | 7.1 | 74.4 | 90.5 | 81.9 | 70.8 | 81.0 | 78.9 | |
| HRNet-W [95] | 256192 | 63.6 | 14.6 | 75.1 | 90.6 | 82.2 | 71.5 | 81.8 | 80.4 | |
| CNN+Trans | TransPose-H-A [110] | 256192 | 17.5 | 21.8 | 75.8 | - | - | - | - | 80.8 |
| TokenPose-L/D [55] | 256192 | 27.5 | 11.0 | 75.8 | 90.3 | 82.5 | 72.3 | 82.7 | 80.9 | |
| HRFormer-S [114] | 256192 | 7.8 | 3.3 | 74.0 | 90.2 | 81.2 | 70.4 | 80.7 | 79.4 | |
| HRFormer-B [114] | 256192 | 43.2 | 14.1 | 75.6 | 90.8 | 82.8 | 71.7 | 82.6 | 80.8 | |
| UniFormer-S | 256192 | 25.2 | 4.7 | 74.0 | 90.3 | 82.2 | 66.8 | 76.7 | 79.5 | |
| UniFormer-B | 256192 | 53.5 | 9.2 | 75.0 | 90.6 | 83.0 | 67.8 | 77.7 | 80.4 | |
| CNN | SimpleBaseline-R152 [103] | 384288 | 68.6 | 35.6 | 74.3 | 89.6 | 81.1 | 70.5 | 79.7 | 79.7 |
| HRNet-W [95] | 384288 | 28.5 | 16.0 | 75.8 | 90.6 | 82.7 | 71.9 | 82.8 | 81.0 | |
| HRNet-W [95] | 384288 | 63.6 | 32.9 | 76.3 | 90.8 | 82.9 | 72.3 | 83.4 | 81.2 | |
| CNN+Trans | PRTR [51] | 384288 | 57.2 | 21.6 | 73.1 | 89.4 | 79.8 | 68.8 | 80.4 | 79.8 |
| PRTR [51] | 512384 | 57.2 | 37.8 | 73.3 | 89.2 | 79.9 | 69.0 | 80.9 | 80.2 | |
| HRFormer-S [114] | 384288 | 7.8 | 7.2 | 75.6 | 90.3 | 82.2 | 71.6 | 82.5 | 80.7 | |
| HRFormer-B [114] | 384288 | 43.2 | 30.7 | 77.2 | 91.0 | 83.6 | 73.2 | 84.2 | 82.0 | |
| UniFormer-S | 384288 | 25.2 | 11.1 | 75.9 | 90.6 | 83.4 | 68.6 | 79.0 | 81.4 | |
| UniFormer-B | 384288 | 53.5 | 22.1 | 76.7 | 90.8 | 84.0 | 69.3 | 79.7 | 81.9 | |
| UniFormer-S | 448320 | 25.2 | 14.8 | 76.2 | 90.6 | 83.2 | 68.6 | 79.4 | 81.4 | |
| UniFormer-B | 448320 | 53.5 | 29.6 | 77.4 | 91.1 | 84.4 | 70.2 | 80.6 | 82.5 | |
6.4 语义分割
设置。 我们的语义分割实验是在 ADE20k [121] 数据集上进行的,我们的代码基于 mmseg [19]。 我们采用流行的Semantic FPN [47]和Upernet [104]作为基本框架。 为了公平比较,我们遵循相同的 PVT [99] 设置到语义 FPN,使用余弦学习率计划 [66] 进行 80k 迭代。 对于Upernet,我们应用Swin Transformer [61]的设置并进行160k迭代训练。 对于具有 Semantic FPN 和 Upernet 的小型/基本变体,随机深度下降率分别设置为 0.1/0.2 和 0.25/0.4。
结果。 表VIII和表IX报告了不同框架的结果。 结果表明,利用语义 FPN 框架,我们的 UniFormer-Sh32/Bh32 比 Swin Transformer [61]< 实现了 +4.7/+2.5 更高的 mIoU /t4> 具有相似的型号尺寸。 当配备UperNet框架时,它们实现了+2.5/+1.9 mIoU和+2.7/+1.2 MS mIoU改进。 此外,当使用全局 MHRA 时,结果得到持续改进,但计算成本更大。 更多结果可见表XXII。
| Method | Size | #Param | FLOPs | Throughput | ImageNet |
| (M) | (G) | (imaegs/s) | Top-1 | ||
| UniFormer-XXS | 128 | 10.2 | 0.43 | 12886 | 76.8 |
| MobilelViT-XXS[69] | 256 | 1.3 | 0.43 | 9742 | 68.9 |
| EfficientNet-B0[85] | 224 | 5.3 | 0.42 | 9501 | 77.1 |
| UniFormer-XXS | 160 | 10.2 | 0.67 | 9382 | 79.1 |
| PVTv2-B0[100] | 224 | 3.7 | 0.57 | 8737 | 70.7 |
| EfficientNet-B1[85] | 240 | 7.8 | 0.74 | 5820 | 79.1 |
| UniFormer-XXS | 192 | 10.2 | 0.96 | 5766 | 79.9 |
| MobileFormer[14] | 224 | 14.0 | 0.51 | 4953 | 79.3 |
| MobilelViT-XS[69] | 256 | 2.3 | 1.1 | 4822 | 74.6 |
| PVTv2-B1[100] | 224 | 14.0 | 2.1 | 4812 | 78.7 |
| UniFormer-XS | 192 | 16.5 | 1.4 | 4492 | 81.5 |
| UniFormer-XXS | 224 | 10.2 | 1.3 | 4446 | 80.6 |
| EfficientNet-B2[85] | 260 | 9.1 | 1.1 | 4247 | 80.1 |
| UniFormer-XS | 224 | 16.5 | 2.0 | 3506 | 82.0 |
| MobilelViT-S[69] | 256 | 5.6 | 2.0 | 3360 | 78.3 |
| EfficientNet-B3[85] | 300 | 12.2 | 1.9 | 2568 | 81.6 |
6.5 姿势估计
设置。 我们在 COCO2017[60] 人体姿态估计基准上评估 UniFormer 的性能。 为了与以前的 SOTA 方法进行公平比较,我们在主干之后使用了一个自上而下的头。 我们遵循与 HRFormer [114] 相同的 mmpose [18] 训练和评估设置。 此外,训练期间小/基础变体的批量大小和随机深度下降率设置为 1024/256 和 0.2/0.5。
结果。 表X报告了COCO验证集上不同输入分辨率的结果。 与之前的 SOTA CNN 模型相比,我们的 UniFormer-B 在参数较少的情况下超越了 HRNet-W48 [95] 0.4% AP(53.5M vs。 63.6M) 和 FLOPs (22.1G vs. 32.9G)。 此外,我们的 UniFormer-B 的性能优于当前最佳方法 HRFormer [114] 0.2% AP,且 FLOP 更小(29.6G vs。 30.7 G)。 值得注意的是HRFormer [114]、PRTR [51]、TokenPose [55]和TransPose [110] 是为姿态估计任务而精心设计的。 相反,我们的 UniFormer 作为简单而有效的骨干网可以胜过所有这些。
| Method | #frame | Size | #Param | FLOPs | Throughput | K400 |
| (M) | (G) | (videos/s) | Top-1 | |||
| UniFormer-XXS | 4 | 128 | 10.4 | 1.0 | 1878 | 63.2 |
| UniFormer-XXS | 4 | 160 | 10.4 | 1.6 | 1384 | 65.8 |
| UniFormer-XXS | 8 | 128 | 10.4 | 2.0 | 1125 | 68.3 |
| UniFormer-XXS | 8 | 160 | 10.4 | 3.3 | 679 | 71.4 |
| UniFormer-XXS | 16 | 128 | 10.4 | 4.2 | 591 | 73.3 |
| UniFormer-XXS | 16 | 160 | 10.4 | 6.9 | 367 | 75.1 |
| MoViNet-A0[48] | 50 | 172 | 3.1 | 2.7 | 315 | 65.8 |
| MoViNet-A1[48] | 50 | 172 | 4.6 | 6.0 | 167 | 72.7 |
| UniFormer-XXS | 32 | 160 | 10.4 | 15.4 | 160 | 77.9 |
| MoViNet-A2[48] | 50 | 224 | 4.8 | 10.3 | 103 | 75.0 |
| UniFormer-XS | 32 | 192 | 16.7 | 34.2 | 75 | 78.6 |
| X3D-XS⋆[48] | 4 | 182 | 3.8 | 27.4 | 39 | 69.1 |
| MoViNet-A3[48] | 120 | 256 | 5.3 | 56.9 | 30 | 78.2 |
| X3D-S⋆[48] | 13 | 182 | 3.8 | 88.7 | 18 | 73.3 |
6.6 轻质UniFormer
设置。 对于轻量级 UniFormer,我们遵循之前的大部分设置。 不同的是,我们在 ImageNet 上训练 UniFormer-XSS 和 UniFormer-XS 600 个周期,因为轻量级模型很难收敛[35, 14]
分类结果。 表XI代表ImageNet上的结果。 我们根据FLOPs粗略地划分模型:1G和1G2G。 它清楚地表明,我们高效的 UniFormer 在类似的 FLOP 下实现了最佳的精度与吞吐量权衡。 例如,与强CNN方法EfficientNet-B3[85]相比,我们的UniFormer-XS192在相似的性能下获得了1.7更高的吞吐量。 与结合 CNN 和 ViT 的 SOTA MobileFormer[14] 相比,我们的 UniFormer-XXS192 的准确率提高了 0.6%,吞吐量提高了 16%。 我们在 Kinetics-400 上用不同的框架进一步模拟上述模型。 表XII中的结果表明,我们的高效骨干网大幅超越了SOTA轻量级视频骨干网。 与 MoViNet-A0[48] 相比,我们的 UniFormer-XXS150×16f 性能提高了 9.3%,吞吐量提高了 16%。 与 X3D-S[29] 相比,我们的 UniFormer-XS192×32f 运行速度快 4.2,精度提高 5.4%。 请注意,我们没有像最近的轻量级方法那样应用复杂的设计[14,69,48]。 我们简洁的扩展已经展现出强大的性能,这进一步展示了UniFormer的巨大潜力。
| Method | #Params | Mask R-CNN 1 + MS schedule | |||||
| (M) | |||||||
| PVTv2-B0[100] | 23.5 | 38.2 | 60.5 | 40.7 | 36.2 | 57.8 | 38.6 |
| ResNet18[37] | 31.2 | 34.0 | 54.0 | 36.7 | 31.2 | 51.0 | 32.7 |
| PVTv1-Tiny[99] | 32.9 | 36.7 | 59.2 | 39.3 | 35.1 | 56.7 | 37.3 |
| PVTv2-B1[100] | 33.7 | 41.8 | 64.3 | 45.9 | 38.8 | 61.2 | 41.6 |
| UniFormer-XXS | 29.4 | 42.8 | 65.0 | 47.0 | 39.2 | 61.7 | 42.0 |
| UniFormer-XS | 35.6 | 44.6 | 67.4 | 48.8 | 40.9 | 64.2 | 44.1 |
| Method | Semantic FPN 80K | ||
| #Param(M) | FLOPs(G) | mIoU(%) | |
| PVTv2-B0[100] | 7.6 | 25.0 | 37.2 |
| ResNet18[37] | 15.5 | 32.2 | 32.9 |
| PVTv1-Tiny[99] | 17.0 | 33.2 | 35.7 |
| PVTv2-B1[100] | 17.8 | 34.2 | 42.5 |
| UniFormer-XXS | 13.5 | 29.2 | 42.3 |
| UniFormer-XS | 19.7 | 32.9 | 44.4 |
| FFN | DPE | MHRA | ImageNet | K400 | |||
| Size | Type | #Param | Top-1 | GFLOPs | Top-1 | ||
| ✔ | ✔ | 5 | 21.5 | 82.9 | 41.8 | 79.3 | |
| ✗ | ✔ | 5 | 21.3 | 82.6 | 41.0 | 78.6 | |
| ✔ | ✗ | 5 | 21.5 | 82.4 | 41.4 | 77.6 | |
| ✔ | ✔ | 3 | 21.5 | 82.8 | 41.0 | 79.0 | |
| ✔ | ✔ | 7 | 21.6 | 82.9 | 43.5 | 79.1 | |
| ✔ | ✔ | 9 | 21.6 | 82.8 | 46.6 | 78.9 | |
| ✔ | ✔ | 5 | 23.3 | 81.9 | 31.6 | 77.2 | |
| ✔ | ✔ | 5 | 22.2 | 82.5 | 31.6 | 78.4 | |
| ✔ | ✔ | 5 | 21.6 | 82.7 | 39.0 | 79.0 | |
| ✔ | ✔ | 5 | 20.1 | 82.1 | 72.0 | 75.3 | |
| Type | Joint | GFLOPs | Pretrain | SSV1 | ||
| Dataset | Top-1 | Top-1 | Top-5 | |||
| ✔ | 26.1 | IN-1K | 81.0 | 49.2 | 77.4 | |
| K400 | 77.4 | 49.2 | 77.6 | |||
| ✗ | 36.8 | IN-1K | 82.9 | 51.9 | 80.1 | |
| K400 | 80.1 | 51.8 | 80.1 | |||
| IN-1K | 82.9 | 52.0 | 80.2 | |||
| ✔ | 41.8 | K400 | 80.8 | 53.8 | 81.9 | |
| Dataset | Pretrain | #frame | 2D | 3D | ||
| #crop#clip | Top-1 | Top-5 | Top-1 | Top-5 | ||
| K400 | IN-1K | 811 | 74.7 | 90.8 | 74.9 | 90.7 |
| 814 | 78.5 | 93.2 | 78.4 | 93.3 | ||
| SSV1 | IN-1K | 811 | 47.9 | 75.8 | 48.3 | 76.1 |
| 831 | 51.4 | 79.6 | 51.3 | 79.7 | ||
| K400 | 811 | 47.9 | 75.6 | 48.6 | 75.6 | |
| 831 | 51.3 | 79.4 | 51.5 | 79.5 | ||
6.7 消融研究
为了检查 UniFormer 作为骨干的有效性,我们取消了每个关键结构设计并评估了图像和视频分类数据集的性能。 此外,对于视频骨干网,我们探索了预训练、训练和测试的重要设计。 最后,我们展示了我们对下游任务的适应效率以及 H-UniFormer 的有效性。
6.7.1 图像和视频骨干网的模型设计
我们对表XV中的重要成分进行消融研究。
FFN。 正如 3.2 节中提到的,浅层中的 UniFormer 块被实例化为 Transformer 样式的 MobileNet 块 [90],并具有额外的 FFN,如 ViT [24 ]。 因此,我们首先通过用 MobileNet 块[77]替换浅层中的 UniFormer 块来研究其有效性。 BN和GELU与原始论文一样添加,但相似参数的扩展比率设置为3。 请注意,保留动态位置嵌入是为了公平比较。 正如预期的那样,我们的 UniFormer 在 ImageNet (+0.3%) 和 Kinetics-400 (+0.7%) 方面均优于此类 MobileNet 模块。 这表明,我们模型中的 FFN 可以进一步混合每个位置的词符上下文,以提高分类准确性。
DPE。 通过动态位置嵌入,我们的 UniFormer 在 ImageNet 上明显提高了 top-1 准确率 +0.5%,但在 Kinetics-400 上提高了 +1.7%。 它表明,通过对位置信息进行编码,我们的 DPE 可以保持空间和时间顺序,从而有助于更好的表示学习,尤其是视频。
MHRA。 在我们本地的词符亲和力(等式6)中,我们从一个小的本地管道聚合上下文。 因此,我们通过将尺寸从 3 更改为 9 来研究该管的影响。 结果表明,我们的网络对于 ImageNet 和 Kinetics-400 上的管尺寸都很稳健。 我们简单地选择内核大小 5 以获得更好的精度。 更重要的是,我们逐步研究本地和全局 UniFormer 块的配置,以验证我们网络的有效性。 如表XV中第1行7-10所示,当我们仅使用本地MHRA()时,计算成本很轻。 然而,由于缺乏学习长期依赖性的能力,准确率大幅下降(ImageNet 和 Kinetics-400 上为 -1.0% 和 -2.1%)。 当我们逐渐用全局 MHRA 替换本地 MHRA 时,准确度会如预期般变得更好。 不幸的是,当所有层都应用全局 MHRA () 时,精度会随着繁重的计算负载而急剧下降,即 Kinetics-400 上的 -4.0%。 这主要是因为,如果没有本地 MHRA,网络缺乏提取详细表示的能力,导致严重的模型过拟合,对序列视频数据产生冗余关注。
| Model | #frame | FLOPs | Sampling | K400 | K600 | ||
| #crop#clip | (G) | Stride | Top-1 | Top-5 | Top-1 | Top-5 | |
| Small | 1611 | 41.8 | 4 | 76.2 | 92.2 | 79.0 | 93.6 |
| 8 | 78.4 | 92.9 | 80.8 | 94.7 | |||
| 1614 | 167.2 | 4 | 80.8 | 94.7 | 82.8 | 95.8 | |
| 8 | 80.8 | 94.4 | 82.7 | 95.7 | |||
| Base | 1611 | 96.7 | 4 | 78.1 | 92.8 | 80.3 | 94.5 |
| 8 | 79.3 | 93.4 | 81.7 | 95.0 | |||
| 1614 | 386.8 | 4 | 82.0 | 95.1 | 84.0 | 96.4 | |
| 8 | 81.7 | 94.8 | 83.4 | 96.0 | |||
| Small | 3211 | 109.6 | 2 | 77.3 | 92.4 | - | - |
| 4 | 79.8 | 93.4 | - | - | |||
| 3214 | 438.4 | 2 | 81.2 | 94.7 | - | - | |
| 4 | 82.0 | 95.1 | - | - | |||
6.7.2 视频骨干网的预训练、训练和测试
在本节中,我们将探索更多视频主干设计。 首先,要加载 2D 预训练主干,必须确定如何继承自注意力和膨胀卷积滤波器。 因此,我们比较了不同 MHRA 配置和过滤器膨胀方法的迁移学习性能。 此外,由于我们在动力学中使用密集采样[101],因此我们应该确认适当的采样步长。 此外,当我们利用 Kinetics 预训练模型进行 SthSth 时,探索采样方法和数据集规模对预训练模型的影响是很有趣的。 最后,我们消除了不同数据集的测试策略。
迁移学习。 表XVII展示了迁移学习的结果。 所有型号共享相同的阶段编号,但阶段类型不同。 对于 Kinetics-400,它清楚地表明联合版本比单独版本更强大,验证了联合时空注意力可以学习更具辨别力的视频表示。 至于SthSth V1,当模型从ImageNet逐渐预训练到Kinetics-400时,我们的联合版本的性能变得更好。 与 ImgeNet 的预训练相比,Kinetics-400 的预训练将进一步将 top-1 准确率提高 +1.8%。 然而,在纯局部 MHRA 结构()和时空注意力分散的 UniFormer 中,没有观察到这种明显的特征。 这表明联合学习方式更适合迁移学习,因此我们默认采用它。
| Model | Train | Pre-train | 1crop1clip | 3crops1clip | ||
| #frame | #frame#stride | Top-1 | Top-5 | Top-1 | Top-5 | |
| Small | 16 | 164 | 53.8 | 81.9 | 57.2 | 84.9 |
| 168 | 53.7 | 81.3 | 57.3 | 84.6 | ||
| Base | 16 | 164 | 55.4 | 82.9 | 59.1 | 86.2 |
| 168 | 55.5 | 83.1 | 58.8 | 86.2 | ||
| Small | 32 | 164 | 55.8 | 83.6 | 58.8 | 86.4 |
| 322 | 55.6 | 83.1 | 58.6 | 85.6 | ||
| 324 | 55.9 | 82.9 | 58.9 | 86.0 | ||
充气方法。 如 I3D [11] 中所示,我们可以膨胀 2D 卷积滤波器以更容易优化。 这里我们考虑是否给过滤器充气。 请注意,补丁主干中的第一个卷积滤波器始终会因时间下采样而膨胀。 如表XVII所示,将滤波器膨胀为 3D 在 Kinetics-400 上实现了类似的结果,但在 SthSth V1 上获得了性能改进。 我们认为 Kinetics-400 是一个与场景相关的数据集,因此 2D 卷积足以识别动作。 相比之下,SthSth V1 是一个与时间相关的数据集,需要强大的时空建模。 因此,我们默认将所有卷积滤波器膨胀为 3D,以获得更好的通用性。
采样步幅。 对于密集采样策略,基本的超参数是帧的采样步长。 直观上,更大的采样步长将覆盖更长的帧范围,这对于更好地理解视频至关重要。 在表XVIII中,我们展示了不同采样步长下的更多动力学结果。 正如预期的那样,较大的采样步长(即稀疏采样)通常会获得更高的单剪辑结果。 然而,在使用多个剪辑进行测试时,帧步长为 4 的采样总是表现更好。


| Type | FLOPs | 1 + MS | 3 + MS | ||||||
| (G) | |||||||||
| W-14 | 250 | 45.0 | 67.8 | 40.8 | 64.7 | 47.5 | 69.8 | 43.0 | 66.7 |
| H-14 | 269 | 45.4 | 68.2 | 41.4 | 64.9 | 48.2 | 70.4 | 43.4 | 67.1 |
| G | 326 | 45.8 | 68.7 | 41.5 | 50.5 | 48.1 | 70.1 | 43.4 | 67.1 |
| Model | Type | Semantic FPN | UperNet | ||
| GFLOPs | mIoU(%) | GFLOPs | (MS)mIoU(%) | ||
| Small | W-32 | 183 | 45.2 | 939 | (48.4)46.6 |
| H-32 | 199 | 46.2 | 955 | (48.5)47.0 | |
| G | 247 | 46.6 | 1004 | (48.5)47.6 | |
| Base | W-32 | 310 | 47.2 | 1066 | (50.6)49.1 |
| H-32 | 350 | 47.7 | 1106 | (50.7)49.5 | |
| G | 471 | 48.0 | 1227 | (50.8)50.0 | |
| Type | Input | FLOPs | ||||||
| Size | (G) | |||||||
| W-14 | 384288 | 12.3 | 76.1 | 90.8 | 83.2 | 68.9 | 79.1 | 81.1 |
| H-14 | 384288 | 12.0 | 75.9 | 90.7 | 83.2 | 68.6 | 78.9 | 81.0 |
| G | 384288 | 11.1 | 75.9 | 90.6 | 83.4 | 68.6 | 79.0 | 81.4 |
Kinetics预训练模型的采样方法。 对于 SthSth,我们按照 [52] 中的建议对帧进行统一采样。 由于我们加载 Kinetics 预训练模型是为了快速收敛,因此有必要找出覆盖更多帧的预训练模型是否有助于微调。 表XIX显示,不同的预训练模型在微调方面取得了相似的性能。 我们应用 164 预训练以获得更好的泛化能力。
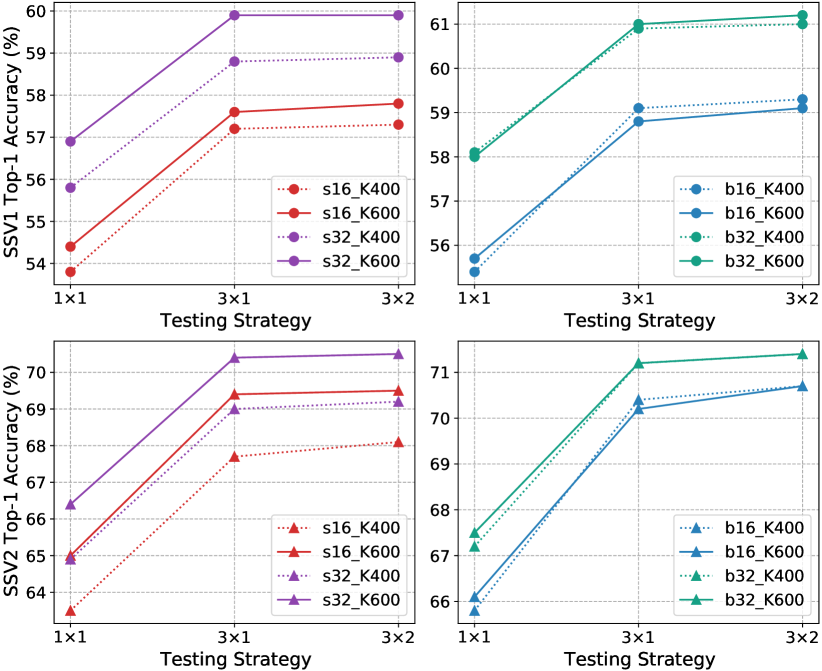
预先训练的数据集规模。 在图 8 中,我们展示了使用 Kinetics-400/600 预训练的 SthSth 的更多结果。 对于 UniFormer-S,Kinetics-600 预训练的表现始终优于 Kinetics-400 预训练,特别是对于大型基准 SthSth V2。 然而,两者在 UniFormer-B 中都取得了可比的结果。 这些结果表明,小模型更难收敛并且渴望更大的数据集预训练,但大模型则不然。
测试策略。 我们使用不同数量的剪辑和裁剪来评估我们的网络,以在不同数据集上验证视频。 如图8所示,由于Kinetics是一个与场景相关的数据集,并通过密集采样进行训练,因此多片段测试更适合覆盖更多帧以提高性能。 另外,Something-Something 是一个与时间相关的数据集,并通过均匀采样进行训练,因此多作物测试更适合捕获辨别运动以提高性能。
6.7.3 下游任务的适配设计
我们在表XXII、表XXII和表XXII中验证了我们对密集预测任务的适应的有效性。 ‘W’、‘H’和‘G’分别指Stage3中的窗口、混合和全局UniFormer样式。 请注意,预训练的全局 UniFormer 块可以看作是具有大窗口大小的窗口 UniFormer 块,因此我们实验中的最小窗口大小为 224/32=14。
表XXII显示了物体检测的结果。 尽管混合风格的性能比 1 计划的全局训练风格差,但它与 3 计划取得了相当的结果,这表明更多的 epoch 可以缩小性能差距。 我们进一步使用表XXII中的不同模型变体进行语义分割实验。 正如预期的那样,大窗口尺寸和全局 UniFormer 模块有助于提高性能,尤其是对于大型模型。 此外,在使用多尺度输入进行测试时,窗口大小为 32 的混合风格获得了与全局风格类似的结果。 对于人体姿态估计(表XXII),由于输入分辨率较小,即384288,利用窗口样式需要更多的零填充计算。 我们只需应用全局 UniFormer 块即可实现更好的计算精度平衡。
| Score | Running | Shrinking | ImageNet | ||
| Token | Mean | Ratio | GFLOPs | Throughput | Top-1 |
| ✔ | ✔ | 0.5 | 0.67 | 9382 | 79.1 |
| ✗ | ✔ | 0.5 | 0.67 | 9395(+0.1%) | 78.7(-0.4) |
| ✔ | ✗ | 0.5 | 0.67 | 9283(+0.0%) | 78.8(-0.3) |
| ✔ | ✔ | 1.0 | 0.91 | 8342(-11.1%) | 79.9(+0.8) |
| ✔ | ✔ | 0.8 | 0.82 | 8452(-9.9%) | 79.8(+0.7) |
| ✔ | ✔ | 0.6 | 0.72 | 9094(-3.1%) | 79.3(+0.2) |
| ✔ | ✔ | 0.4 | 0.62 | 9692(+3.3%) | 78.4(-0.7) |
| ✔ | ✔ | 0.25 | 0.55 | 10162(+8.3%) | 76.8(-2.3) |
6.7.4 H-UniFormer 设计
我们进一步探讨了表XXIII中基于UniFormer-XXS160的轻量化设计。 首先,我们尝试删除词符得分(即),并简单地使用全局相似度平均值来衡量词符重要性。 结果表明,可学习分数词符对于词符的选择更有帮助。 此外,相似度得分的运行平均值(即)将提高top-1的准确性,从而验证了一致的重要标记的有效性。 最后,我们消除了不同的收缩率,其中我们使用 0.5 的比率以获得更好的权衡。
6.8 可视化
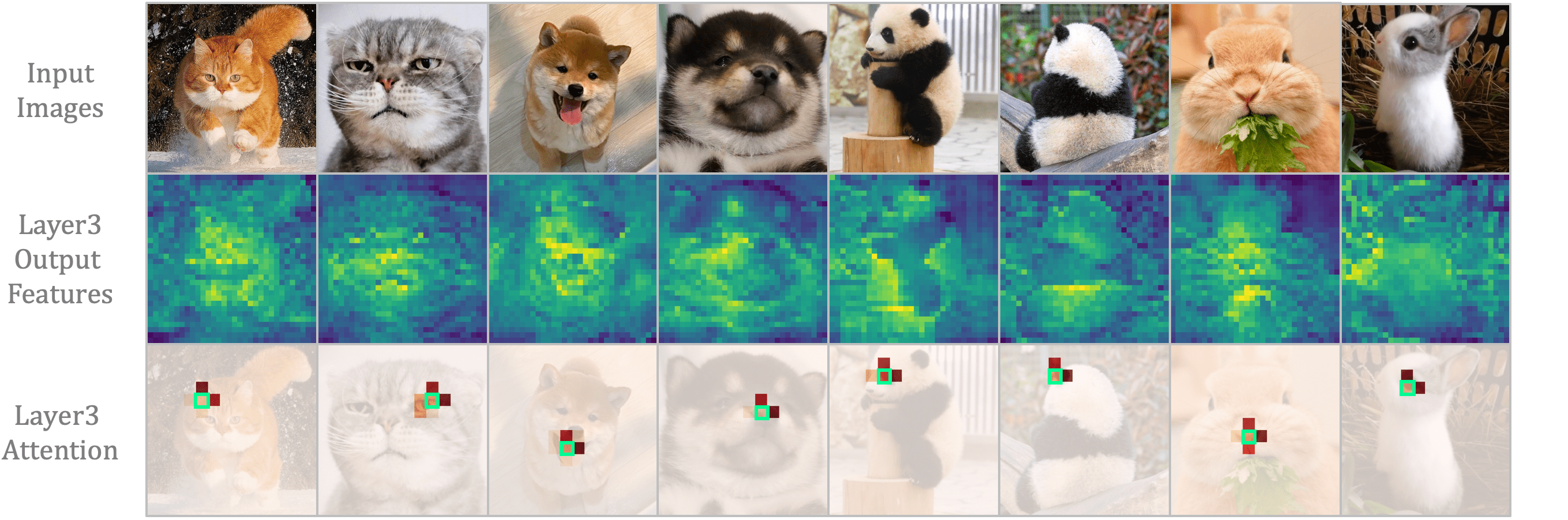
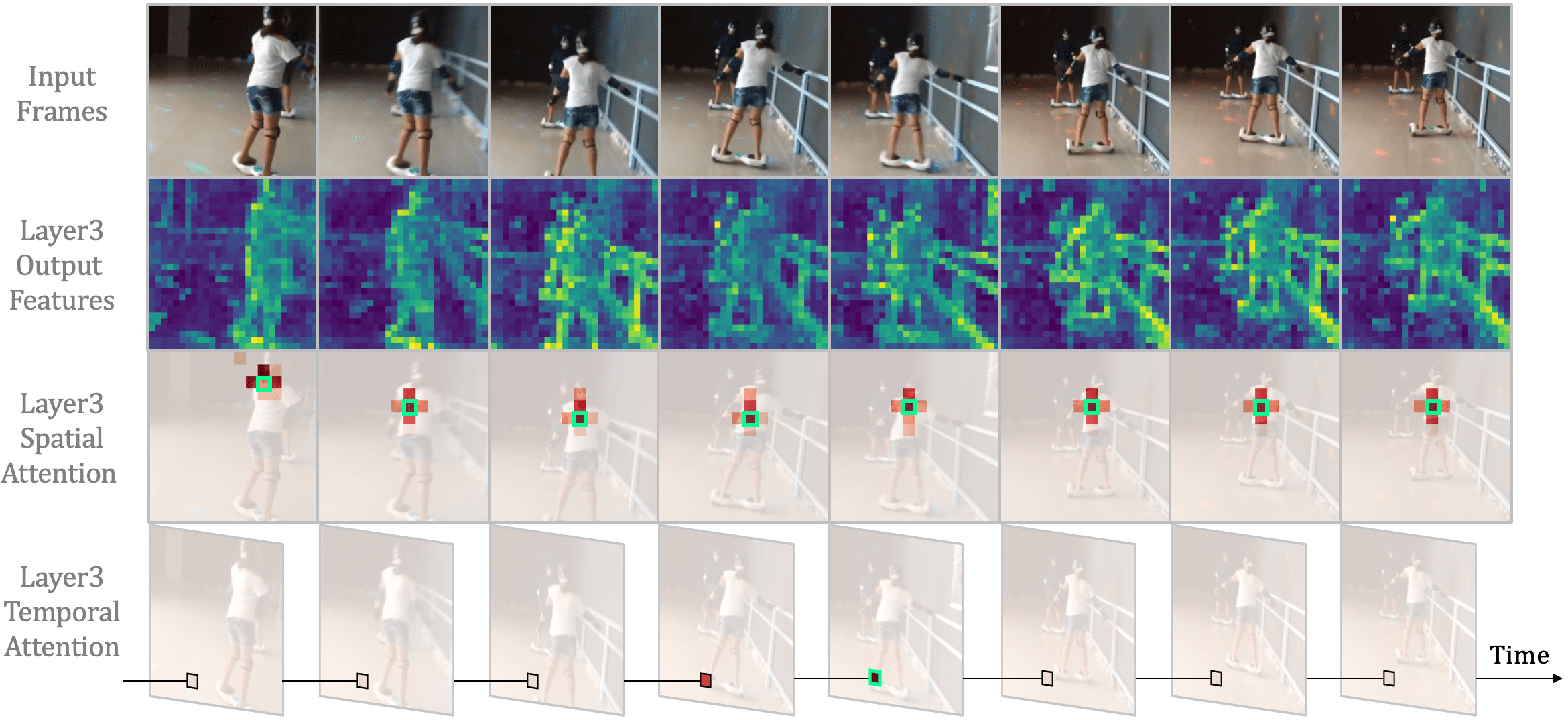
在图10中,我们应用Grad-CAM[78]来显示最后一层最受关注的区域。 图像从 ImageNet 验证集 [22] 中采样,视频从 Kintics-400 验证集 [10] 中采样。 它表明 很难专注于关键对象,即山和滑板,因为它盲目地比较所有层中所有标记的相似性。 或者,仅执行本地聚合。 因此,如果没有全局视野,它的注意力往往是粗略和不准确的。 与这两种情况不同的是,我们的 UniFormer 与 可以以联合的方式合作学习本地和全局上下文。 因此,它可以通过精确关注山体和滑板来有效捕获最具辨别力的信息。
在图10中,我们进一步对各种下游任务的验证数据集进行可视化。 如此稳健的定性结果证明了我们 UniFormer 骨干网的有效性。
7 结论
在本文中,我们提出了一种用于高效视觉识别的新颖的 UniFormer,它可以以简洁的 Transformer 格式有效地统一卷积和自注意力,以克服冗余和依赖性。 我们在浅层采用局部 MHRA 来大大减少计算负担,在深层采用全局 MHRA 来学习全局词符关系。 大量的实验证明了我们的 UniFormer 强大的建模能力。 通过简单而有效的适应,我们的 UniFormer 以更少的训练成本在广泛的视觉任务中取得了最先进的结果。
参考
- [1] A. Arnab, M. Dehghani, G. Heigold, Chen Sun, Mario Lucic, and C. Schmid. Vivit: A video vision transformer. ICCV, 2021.
- [2] Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. ArXiv, abs/1607.06450, 2016.
- [3] Gedas Bertasius, Heng Wang, and L. Torresani. Is space-time attention all you need for video understanding? ICML, 2021.
- [4] Andrew Brock, Soham De, Samuel L. Smith, and K. Simonyan. High-performance large-scale image recognition without normalization. ArXiv, abs/2102.06171, 2021.
- [5] Adrian Bulat, Juan-Manuel Pérez-Rúa, Swathikiran Sudhakaran, Brais Martínez, and Georgios Tzimiropoulos. Space-time mixing attention for video transformer. NIPS, 2021.
- [6] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: High quality object detection and instance segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
- [7] Jie Cao, Yawei Li, K. Zhang, and Luc Van Gool. Video super-resolution transformer. ArXiv, abs/2106.06847, 2021.
- [8] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. ECCV, 2020.
- [9] João Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600. ArXiv, abs/1808.01340, 2018.
- [10] João Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. CVPR, 2017.
- [11] João Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. CVPR, 2017.
- [12] Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. CVPR, 2021.
- [13] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tianheng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu, Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang, Chen Change Loy, and Dahua Lin. MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019.
- [14] Yinpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen Liu, Xiaoyi Dong, Lu Yuan, and Zicheng Liu. Mobile-former: Bridging mobilenet and transformer. CVPR, 2022.
- [15] Bowen Cheng, Alexander G. Schwing, and Alexander Kirillov. Per-pixel classification is not all you need for semantic segmentation. ArXiv, abs/2107.06278, 2021.
- [16] Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. Twins: Revisiting the design of spatial attention in vision transformers. In NIPS, 2021.
- [17] Xiangxiang Chu, Bo Zhang, Zhi Tian, Xiaolin Wei, and Huaxia Xia. Do we really need explicit position encodings for vision transformers? ArXiv, abs/2102.10882, 2021.
- [18] MMPose Contributors. Openmmlab pose estimation toolbox and benchmark. https://github.com/open-mmlab/mmpose, 2020.
- [19] MMSegmentation Contributors. MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark. https://github.com/open-mmlab/mmsegmentation, 2020.
- [20] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers. ArXiv, abs/1911.03584, 2020.
- [21] Zihang Dai, Hanxiao Liu, Quoc V. Le, and Mingxing Tan. Coatnet: Marrying convolution and attention for all data sizes. NIPS, 2021.
- [22] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- [23] Xiaoyi Dong, Jianmin Bao, Dongdong Chen, Weiming Zhang, Nenghai Yu, Lu Yuan, Dong Chen, and B. Guo. Cswin transformer: A general vision transformer backbone with cross-shaped windows. CVPR, 2022.
- [24] A. Dosovitskiy, L. Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, M. Dehghani, Matthias Minderer, G. Heigold, S. Gelly, Jakob Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- [25] Brendan Duke, Abdalla Ahmed, Christian Wolf, Parham Aarabi, and Graham W. Taylor. Sstvos: Sparse spatiotemporal transformers for video object segmentation. CVPR, 2021.
- [26] Maksim Dzabraev, Maksim Kalashnikov, Stepan Alekseevich Komkov, and Aleksandr Petiushko. Mdmmt: Multidomain multimodal transformer for video retrieval. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2021.
- [27] Haoqi Fan, Yanghao Li, Bo Xiong, Wan-Yen Lo, and Christoph Feichtenhofer. Pyslowfast. https://github.com/facebookresearch/slowfast, 2020.
- [28] Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, J. Malik, and Christoph Feichtenhofer. Multiscale vision transformers. ICCV, 2021.
- [29] Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. CVPR, 2020.
- [30] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. ICCV, 2019.
- [31] Valentin Gabeur, Chen Sun, Alahari Karteek, and Cordelia Schmid. Multi-modal transformer for video retrieval. In ECCV, 2020.
- [32] Peng Gao, Jiasen Lu, Hongsheng Li, R. Mottaghi, and Aniruddha Kembhavi. Container: Context aggregation network. NIPS, 2021.
- [33] Priya Goyal, Piotr Dollár, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. ArXiv, abs/1706.02677, 2017.
- [34] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fründ, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The “something something” video database for learning and evaluating visual common sense. ICCV, 2017.
- [35] Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Herv’e J’egou, and M. Douze. Levit: a vision transformer in convnet’s clothing for faster inference. ICCV, 2021.
- [36] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In ICCV, 2017.
- [37] Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CVPR, 2016.
- [38] Shuting He, Haowen Luo, Pichao Wang, F. Wang, Hao Li, and Wei Jiang. Transreid: Transformer-based object re-identification. ArXiv, abs/2102.04378, 2021.
- [39] Andrew G. Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, and Hartwig Adam. Searching for mobilenetv3. International Conference on Computer Vision, 2019.
- [40] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, M. Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. ArXiv, abs/1704.04861, 2017.
- [41] Gao Huang, Zhuang Liu, and Kilian Q. Weinberger. Densely connected convolutional networks. CVPR, 2017.
- [42] Zilong Huang, Youcheng Ben, Guozhong Luo, Pei Cheng, Gang Yu, and Bin Fu. Shuffle transformer: Rethinking spatial shuffle for vision transformer. ArXiv, abs/2106.03650, 2021.
- [43] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ArXiv, abs/1502.03167, 2015.
- [44] Boyuan Jiang, Mengmeng Wang, Weihao Gan, Wei Wu, and Junjie Yan. Stm: Spatiotemporal and motion encoding for action recognition. ICCV, 2019.
- [45] Zihang Jiang, Qibin Hou, Li Yuan, Daquan Zhou, Yujun Shi, Xiaojie Jin, Anran Wang, and Jiashi Feng. All tokens matter: Token labeling for training better vision transformers. NIPS, 2021.
- [46] Youngsaeng Jin, David K. Han, and Hanseok Ko. Trseg: Transformer for semantic segmentation. Pattern Recognit. Lett., 148:29–35, 2021.
- [47] Alexander Kirillov, Ross Girshick, Kaiming He, and Piotr Dollár. Panoptic feature pyramid networks. In CVPR, 2019.
- [48] D. Kondratyuk, Liangzhe Yuan, Yandong Li, Li Zhang, Mingxing Tan, Matthew A. Brown, and Boqing Gong. Movinets: Mobile video networks for efficient video recognition. ArXiv, abs/2103.11511, 2021.
- [49] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- [50] Heeseung Kwon, Manjin Kim, Suha Kwak, and Minsu Cho. Motionsqueeze: Neural motion feature learning for video understanding. In ECCV, 2020.
- [51] Ke Li, Shijie Wang, Xiang Zhang, Yifan Xu, Weijian Xu, and Zhuowen Tu. Pose recognition with cascade transformers. CVPR, 2021.
- [52] Kunchang Li, Xianhang Li, Yali Wang, Jun Wang, and Y. Qiao. Ct-net: Channel tensorization network for video classification. ICLR, 2021.
- [53] X. Li, Yali Wang, Zhipeng Zhou, and Yu Qiao. Smallbignet: Integrating core and contextual views for video classification. CVPR, 2020.
- [54] Xinyu Li, Yanyi Zhang, Chunhui Liu, Bing Shuai, Yi Zhu, Biagio Brattoli, Hao Chen, Ivan Marsic, and Joseph Tighe. Vidtr: Video transformer without convolutions. ICCV, 2021.
- [55] Yanjie Li, Shoukui Zhang, Zhicheng Wang, Sen Yang, Wankou Yang, Shutao Xia, and Erjin Zhou. Tokenpose: Learning keypoint tokens for human pose estimation. ArXiv, abs/2104.03516, 2021.
- [56] Yinong Li, Bin Ji, Xintian Shi, Jianguo Zhang, Bin Kang, and Limin Wang. Tea: Temporal excitation and aggregation for action recognition. CVPR, 2020.
- [57] Jingyun Liang, Jie Cao, Guolei Sun, K. Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 1833–1844, 2021.
- [58] Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Evit: Expediting vision transformers via token reorganizations. In International Conference on Learning Representations, 2022.
- [59] Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. ICCV, 2019.
- [60] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- [61] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. ICCV, 2021.
- [62] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, S. Lin, and Han Hu. Video swin transformer. CVPR, 2022.
- [63] Zhaoyang Liu, D. Luo, Yabiao Wang, L. Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Tong Lu. Teinet: Towards an efficient architecture for video recognition. AAAI, 2020.
- [64] Zhouyong Liu, Shun Luo, Wubin Li, Jingben Lu, Yufan Wu, Chunguo Li, and Luxi Yang. Convtransformer: A convolutional transformer network for video frame synthesis. ArXiv, abs/2011.10185, 2020.
- [65] I. Loshchilov and F. Hutter. Fixing weight decay regularization in adam. ArXiv, abs/1711.05101, 2017.
- [66] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv: Learning, 2017.
- [67] Chenxu Luo and Alan L. Yuille. Grouped spatial-temporal aggregation for efficient action recognition. ICCV, 2019.
- [68] Ningning Ma, Xiangyu Zhang, Haitao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In European Conference on Computer Vision, 2018.
- [69] Sachin Mehta and Mohammad Rastegari. Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer. In ICML, 2021.
- [70] Daniel Neimark, Omri Bar, Maya Zohar, and Dotan Asselmann. Video transformer network. ICCV, 2021.
- [71] Mandela Patrick, Dylan Campbell, Yuki M. Asano, Ishan Misra Florian Metze, Christoph Feichtenhofer, A. Vedaldi, and João F. Henriques. Keeping your eye on the ball: Trajectory attention in video transformers. NIPS, 2021.
- [72] Zhaofan Qiu, Ting Yao, and Tao Mei. Learning spatio-temporal representation with pseudo-3d residual networks. ICCV, 2017.
- [73] Zhaofan Qiu, Ting Yao, C. Ngo, Xinmei Tian, and Tao Mei. Learning spatio-temporal representation with local and global diffusion. CVPR, 2019.
- [74] Ilija Radosavovic, Raj Prateek Kosaraju, Ross B. Girshick, Kaiming He, and Piotr Dollár. Designing network design spaces. CVPR, 2020.
- [75] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. Stand-alone self-attention in vision models. In NIPS, 2019.
- [76] Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. In Neural Information Processing Systems, 2021.
- [77] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, 2018.
- [78] Ramprasaath R. Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. International Journal of Computer Vision, 2019.
- [79] Gilad Sharir, Asaf Noy, and Lihi Zelnik-Manor. An image is worth 16x16 words, what is a video worth? ICLR, 2021.
- [80] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [81] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. ArXiv, abs/1212.0402, 2012.
- [82] A. Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, P. Abbeel, and Ashish Vaswani. Bottleneck transformers for visual recognition. CVPR, 2021.
- [83] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Kumar Gupta. Revisiting unreasonable effectiveness of data in deep learning era. ICCV, pages 843–852, 2017.
- [84] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, D. Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. CVPR, 2015.
- [85] Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. ArXiv, abs/1905.11946, 2019.
- [86] Mingxing Tan and Quoc V. Le. Efficientnetv2: Smaller models and faster training. ArXiv, abs/2104.00298, 2021.
- [87] Hugo Touvron, M. Cord, M. Douze, Francisco Massa, Alexandre Sablayrolles, and Herv’e J’egou. Training data-efficient image transformers & distillation through attention. In ICML, 2021.
- [88] Hugo Touvron, M. Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herv’e J’egou. Going deeper with image transformers. ArXiv, abs/2103.17239, 2021.
- [89] Du Tran, Lubomir D. Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. ICCV, 2015.
- [90] Du Tran, Heng Wang, L. Torresani, and Matt Feiszli. Video classification with channel-separated convolutional networks. ICCV, 2019.
- [91] Du Tran, Hong xiu Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. CVPR, 2018.
- [92] Ashish Vaswani, Noam M. Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. ArXiv, abs/1706.03762, 2017.
- [93] Heng Wang and Cordelia Schmid. Action recognition with improved trajectories. 2013 IEEE International Conference on Computer Vision, pages 3551–3558, 2013.
- [94] Heng Wang, Du Tran, L. Torresani, and Matt Feiszli. Video modeling with correlation networks. CVPR), 2020.
- [95] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, D. Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deep high-resolution representation learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [96] L. Wang, Yuanjun Xiong, Zhe Wang, Y. Qiao, D. Lin, X. Tang, and L. Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV, 2016.
- [97] Limin Wang, Zhan Tong, Bin Ji, and Gangshan Wu. Tdn: Temporal difference networks for efficient action recognition. CVPR, 2021.
- [98] Ning Wang, Wen gang Zhou, Jie Wang, and Houqaing Li. Transformer meets tracker: Exploiting temporal context for robust visual tracking. CVPR, 2021.
- [99] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, P. Luo, and L. Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. ICCV, 2021.
- [100] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pvtv2: Improved baselines with pyramid vision transformer. ArXiv, abs/2106.13797, 2021.
- [101] X. Wang, Ross B. Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. CVPR, 2018.
- [102] Haiping Wu, Bin Xiao, N. Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang. Cvt: Introducing convolutions to vision transformers. ICCV, 2021.
- [103] Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselines for human pose estimation and tracking. In ECCV, 2018.
- [104] Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. In ECCV, 2018.
- [105] Tete Xiao, Mannat Singh, Eric Mintun, Trevor Darrell, Piotr Dollár, and Ross B. Girshick. Early convolutions help transformers see better. ArXiv, abs/2106.14881, 2021.
- [106] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. NIPS, 2021.
- [107] Saining Xie, Ross B. Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. CVPR, 2017.
- [108] Yifan Xu, Zhijie Zhang, Mengdan Zhang, Kekai Sheng, Ke Li, Weiming Dong, Liqing Zhang, Changsheng Xu, and Xing Sun. Evo-vit: Slow-fast token evolution for dynamic vision transformer. In AAAI, 2021.
- [109] Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Xiyang Dai, Bin Xiao, Lu Yuan, and Jianfeng Gao. Focal self-attention for local-global interactions in vision transformers. arXiv preprint arXiv:2107.00641, 2021.
- [110] Sen Yang, Zhibin Quan, Mu Nie, and Wankou Yang. Transpose: Towards explainable human pose estimation by transformer. ArXiv, abs/2012.14214, 2020.
- [111] Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou, Fengwei Yu, and Wei Wu. Incorporating convolution designs into visual transformers. ArXiv, abs/2103.11816, 2021.
- [112] Li Yuan, Y. Chen, Tao Wang, Weihao Yu, Yujun Shi, Francis E. H. Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token vit: Training vision transformers from scratch on imagenet. ArXiv, abs/2101.11986, 2021.
- [113] Li Yuan, Qibin Hou, Zihang Jiang, Jiashi Feng, and Shuicheng Yan. Volo: Vision outlooker for visual recognition. ArXiv, abs/2106.13112, 2021.
- [114] Yuhui Yuan, Rao Fu, Lang Huang, Weihong Lin, Chao Zhang, Xilin Chen, and Jingdong Wang. Hrformer: High-resolution transformer for dense prediction. NIPS, 2021.
- [115] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Young Joon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. ICCV, 2019.
- [116] David Junhao Zhang, Kunchang Li, Yunpeng Chen, Yali Wang, Shashwat Chandra, Yu Qiao, Luoqi Liu, and Mike Zheng Shou. Morphmlp: A self-attention free, mlp-like backbone for image and video. arXiv preprint arXiv:2111.12527, 2021.
- [117] Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Haibin Lin, Zhi Zhang, Yue Sun, Tong He, Jonas Mueller, R Manmatha, et al. Resnest: Split-attention networks. arXiv preprint arXiv:2004.08955, 2020.
- [118] Hongyi Zhang, Moustapha Cissé, Yann Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. ArXiv, abs/1710.09412, 2018.
- [119] Pengchuan Zhang, Xiyang Dai, Jianwei Yang, Bin Xiao, Lu Yuan, Lei Zhang, and Jianfeng Gao. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding. ArXiv, abs/2103.15358, 2021.
- [120] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. CVPR, 2018.
- [121] Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 2019.
- [122] Hong-Yu Zhou, Chixiang Lu, Sibei Yang, and Yizhou Yu. Convnets vs. transformers: Whose visual representations are more transferable? ArXiv, abs/2108.05305, 2021.
- [123] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. ICLR, 2021.
- [124] Zhuofan Zong, Kunchang Li, Guanglu Song, Yali Wang, Y. Qiao, Biao Leng, and Yu Liu. Self-slimmed vision transformer. In European Conference on Computer Vision, 2021.
![[Uncaptioned image]](kunchangli.png) |
Kunchang Li is currently a second-year Ph.D. student with Shenzhen Institutes of Advanced Technology (SIAT), Chinese Academy of Science. He received the B.Eng. degree from Beihang University, China, in 2020. His research interests focus on video understanding and efficient architecture design. |
![[Uncaptioned image]](yaliwang.png) |
Yali Wang received the Ph.D. degree in computer science from Laval University, Quebec, QC, Canada,in 2014. He is currently an Associate Professor with the Shenzhen Institutes of Advanced Technology (SIAT), Chinese Academy of Sciences. His research interests are deep learning and computer vision, machine learning, and pattern recognition. |
![[Uncaptioned image]](junhaozhang.png) |
Junhao Zhang is currently a first-year Ph.D. student with the National University of Singapore, Singapore. He received the B.Eng. degree from Shandong University, China, in 2020. He was a Research Assistant with Shenzhen Institutes of Advanced Technology, Chinese Academy of Science. His research interests are deep learning, computer vision, and robotics. |
![[Uncaptioned image]](penggao.png) |
Peng Gao received his Ph.D. degree from Chinese University of Hong Kong in 2021. Currently, he is a Young Research Scientist at Shanghai AI Lab. His research interest span from efficient neural architecture design, multimodality learning and representation learning. |
![[Uncaptioned image]](guanglusong.png) |
Guanglu Song is a senior researcher at SenseTime Research. He received a master’s degree in Computer Science and Technology from Beihang University. His current research interests lie in computer vision, efficient architecture design, and large-scale model optimization. Several papers are accepted by ECCV, CVPR, ICLR, and AAAI. He won the championships in various famous world AI competitions such as OpenImage 2019, ActivityNet 2020, and ICCV2021-MFR. |
![[Uncaptioned image]](yuliu.png) |
Yu Liu received his Ph.D. from the Multimedia Lab of CUHK and was the only awardee of the Google Ph.D. Fellowship in Greater China. He previously worked as a researcher in Microsoft Research, Google AI, and SenseTime Research. His research interests lie in large-scale machine learning and decision intelligence, where he published more than 30 papers with around 2000 citations. He won the championships in various famous world AI competitions such as ImageNet 2016, MOT 2016, OpenImage 2019, and ActivityNet 2020. |
![[Uncaptioned image]](hongshengli.png) |
Hongsheng Li received the bachelor’s degree in automation from the East China University of Science and Technology, and the master’s and doctorate degrees in computer science from Lehigh University, Pennsylvania, in 2006, 2010, and 2012, respectively. He is currently an assistant professor in the Department of Electronic Engineering at The Chinese University of Hong Kong. His research interests include computer vision, medical image analysis, and machine learning. |
![[Uncaptioned image]](yuqiao.png) |
Yu Qiao (Senior Member, IEEE) is a professor with the Shenzhen Institutes of Advanced Technology (SIAT), the Chinese Academy of Science and Shanghai AI Laboratory. His research interests include computer vision, deep learning, and bioinformation. He has published more than 240 papers in international journals and conferences, including T-PAMI, IJCV, T-IP, T-SP, CVPR, ICCV etc. His H-index is 69, with 31,000 citations in Google scholar. He is a recipient of the distinguished paper award in AAAI 2021. His group achieved the first runner-up at the ImageNet Large Scale Visual Recognition Challenge 2015 in scene recognition, and the winner at the ActivityNet Large Scale Activity Recognition Challenge 2016 in video classification. He served as the program chair of IEEE ICIST 2014. |