Transformer模型在时间序列方面的一项调查
摘要
Transformers 在自然语言处理和计算机视觉的许多任务中取得了优越的性能,这也引发了时间序列社区的极大兴趣。 在 Transformer 的众多优势中,捕获远程依赖关系和交互的能力对于时间序列建模尤其有吸引力,从而在各种时间序列应用中取得了令人兴奋的进展。 在本文中,我们系统地回顾了用于时间序列建模的 Transformer 方案,强调了它们的优点和局限性。 我们特别从两个角度审视时间序列 Transformers 的发展。 我们从网络结构的角度总结了 Transformers 为了适应时间序列分析的挑战而做出的调整和修改。 从应用的角度来看,我们根据预测、异常检测和分类等常见任务对时间序列 Transformer 进行分类。 根据经验,我们执行稳健分析、模型大小分析和季节性趋势分解分析来研究 Transformer 在时间序列中的表现。 最后,我们讨论并建议未来的方向,以提供有用的研究指导。 GitHub仓库中可以找到对应的持续更新的资源111https://github.com/qingsongedu/time-series-transformers-review。
1简介
Transformer 在深度学习方面的创新Vaswani 等人(2017)因其在自然语言处理(NLP)方面的出色表现而近期引起了极大关注Kenton 等人(2019) 、计算机视觉 (CV) Dosovitskiy 等人 (2021) 和语音处理 Dong 等人 (2018)。 在过去的几年里,人们提出了许多 Transformer 来显着提高各种任务的最先进性能。 有不少来自不同方面的文献综述,比如在 NLP 应用中Han 等人 (2021)、CV 应用中Han 等人 (2022)、高效 Transformers Tay 等人 (2022).
Transformer 对序列数据中的远程依赖和交互表现出了强大的建模能力,因此对时间序列建模很有吸引力。 为了解决时间序列建模中的特殊挑战,人们提出了 Transformer 的许多变体,并已成功应用于各种时间序列任务,例如预测Li等人(2019); Zhou 等人 (2022),异常检测 Xu 等人 (2022); Tuli 等人 (2022),以及分类 Zerveas 等人 (2021);杨等人(2021)。 具体来说,季节性或周期性是时间序列Wen 等人(2021a)的重要特征。 如何有效地模拟长期和短期时间依赖性并同时捕获季节性仍然是一个挑战 Wu 等人 (2021);文等人(2022)。 我们注意到,存在一些与时间序列深度学习相关的调查,包括预测 Lim 和 Zohren (2021);贝尼迪斯 等人 (2022); Torres 等人 (2021),分类 Ismail Fawaz 等人 (2019),异常检测 Choi 等人 (2021); Blázquez-García 等人 (2021) 和数据增强 Wen 等人 (2021b),但没有对时间序列上的tranformer模型进行全面的调查。 由于时间序列 Transformer 是深度学习中的一个新兴学科,对时间序列 Transformer 进行系统而全面的调查将极大地有益于时间序列社区。
在本文中,我们旨在通过总结时间序列 Transformer 的主要发展来填补这一空白。 我们首先简要介绍了普通 Transformer,然后从网络修改和应用领域的角度为时间序列 Transformer 提出了一种新的分类法。 对于网络修改,我们讨论了 Transformer 的低层(即模块)和高层(即架构)的改进,旨在优化时间序列建模的性能。 对于应用程序,我们分析和总结了用于流行时间序列任务的 Transformer,包括预测、异常检测和分类。 对于每个时间序列 Transformer,我们分析其见解、优势和局限性。 为了提供有关如何有效使用 Transformer 进行时间序列建模的实用指南,我们进行了广泛的实证研究,检查时间序列建模的多个方面,包括稳健性分析、模型大小分析和季节性趋势分解分析。 我们通过讨论时间序列 Transformers 未来可能的方向来结束这项工作,包括时间序列 Transformers 的归纳偏差、时间序列的 Transformers 和 GNN、时间序列的预训练 Transformers、具有架构级别变体的 Transformers 以及具有 NAS 的时间序列 Transformers 。 据我们所知,这是第一篇全面、系统地回顾 Transformers 用于建模时间序列数据的关键进展的工作。 我们希望这项调查能够激发人们对时间序列变形金刚的进一步研究兴趣。
2 Transformer 的预备知识
2.1 普通 Transformer
普通的 Transformer Vaswani 等人 (2017) 遵循最具竞争力的神经序列模型,具有编码器-解码器结构。 编码器和解码器都由多个相同的块组成。 每个编码器块由多头自注意模块和位置前馈网络组成,而每个解码器块在多头自注意模块和位置前馈网络之间插入交叉注意模型。
2.2 输入编码和位置编码
与 LSTM 或 RNN 不同,vanilla Transformer 没有递归。 相反,它利用输入嵌入中添加的位置编码来对序列信息进行建模。 我们总结了下面一些位置编码。
2.2.1 绝对位置编码
在 vanilla Transformer 中,对于每个位置索引 ,编码向量由下式给出
| (1) |
其中 是每个维度的手工频率。 另一种方法是为每个位置学习一组位置嵌入,这更加灵活 Kenton 等人 (2019); Gehring 等人 (2017).
2.2.2 相对位置编码
遵循输入元素之间的成对位置关系比元素位置更有益的直觉,已经提出了相对位置编码方法。 例如,其中一种方法是在注意力机制Shaw等人(2018)的键中添加可学习的相对位置嵌入。
除了绝对和相对位置编码之外,还有使用混合位置编码将它们组合在一起的方法 Ke 等人 (2021)。 通常,位置编码被添加到词符嵌入中并馈送到 Transformer。
2.3 多头注意力
使用查询键值(QKV)模型,Transformer 使用的缩放点积注意力由下式给出
| (2) |
其中查询 、键 、值 、 表示查询和键(或值)的长度, 表示键(或查询)和值的维度。 Transformer 使用具有 不同学习投影集的多头注意力,而不是像下面这样的单一注意力函数
|
|
其中
2.4前馈和残差网络
前馈网络是一个全连接模块
| (3) |
其中是上一层的输出,、、、是可训练参数。 在更深的模块中,每个模块周围插入一个残差连接模块,后跟一个层归一化模块。 那是,
| (4) | ||||
| (5) |
其中 表示自注意力模块, 表示层归一化操作。
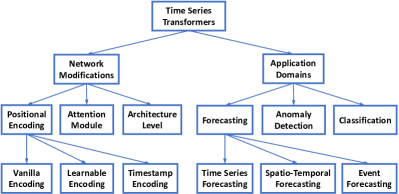
3 时间序列中 Transformer 的分类
为了总结现有的时间序列 Transformer,我们从网络修改和应用领域的角度提出了一种分类法,如图1所示。 基于分类法,我们系统地回顾了现有的时间序列 Transformers。 我们从网络修改的角度,总结了 Transformer 在模块级别和架构级别上所做的更改,以适应时间序列建模中的特殊挑战。 从应用的角度,我们根据时间序列 Transformer 的应用任务对时间序列 Transformer 进行分类,包括预测、异常检测和分类。 在接下来的两节中,我们将从这两个角度深入研究现有的时间序列 Transformer。
4 时间序列的网络修改
4.1 位置编码
由于时间序列的顺序很重要,因此将输入时间序列的位置编码到 Transformer 中非常重要。 常见的设计是首先将位置信息编码为向量,然后将它们与输入时间序列一起作为附加输入注入到模型中。 使用 Transformer 建模时间序列时如何获取这些向量可以分为三大类。
普通位置编码。 一些作品 Li 等人 (2019) 简单介绍了 Vaswani 等人 (2017) 中使用的普通位置编码(第 2.2.1 节),然后将其添加到输入时间序列嵌入中并馈送到 Transformer。 虽然这种方法可以从时间序列中提取一些位置信息,但无法充分利用时间序列数据的重要特征。
可学习的位置编码。 由于普通位置编码是手工制作的,表达能力和适应性较差,因此一些研究发现,从时间序列数据中学习适当的位置嵌入可能会更有效。 与固定的普通位置编码相比,学习嵌入更加灵活,可以适应特定任务。 Zerveas 等人 (2021) 在 Transformer 中引入了一个嵌入层,该层可以与其他模型参数联合学习每个位置索引的嵌入向量。 Lim 等人 (2021) 使用 LSTM 网络对位置嵌入进行编码,可以更好地利用时间序列中的顺序排序信息。
时间戳编码。 在现实场景中对时间序列进行建模时,通常可以访问时间戳信息,包括日历时间戳(例如秒、分、小时、周、月和年)和特殊时间戳(例如假期和事件)。 这些时间戳在实际应用程序中提供了相当丰富的信息,但在普通 Transformer 中却很难利用。 为了缓解这个问题,Informer Zhou 等人 (2021) 提出通过使用可学习的嵌入层将时间戳编码为附加位置编码。 Autoformer Wu 等人 (2021) 和 FEDformer Zhou 等人 (2022) 使用了类似的时间戳编码方案。
4.2 注意力模块
Transformer 的核心是自注意力模块。 它可以被视为一个完全连接的层,其权重是根据输入模式的成对相似性动态生成的。 因此,它与全连接层共享相同的最大路径长度,但参数数量少得多,使其适合对长期依赖关系进行建模。
正如我们在上一节中所示,普通 Transformer 中的自注意力模块的时间和内存复杂度为 ( 是输入时间序列长度),这成为计算处理长序列时出现瓶颈。 人们提出了许多高效的 Transformer 来降低二次复杂度,这些复杂度可分为两大类:(1)在注意力机制中显式引入稀疏偏差,如 LogTrans Li 等人 (2019) 和 Pyraformer 刘等人(2022a); (2)探索自注意力矩阵的低秩特性以加速计算,例如举报人 Zhou 等人 (2021) 和 FEDformer Zhou 等人 (2022)。 表 1 显示了应用于时间序列建模的流行 Transformer 的时间和内存复杂度,有关这些模型的更多详细信息将在第 5 节中讨论。
| Methods | Training | Testing | |
|---|---|---|---|
| Time | Memory | Steps | |
| Transformer Vaswani et al. (2017) | |||
| LogTrans Li et al. (2019) | 1 | ||
| Informer Zhou et al. (2021) | 1 | ||
| Autoformer Wu et al. (2021) | 1 | ||
| Pyraformer Liu et al. (2022a) | 1 | ||
| Quatformer Chen et al. (2022) | 1 | ||
| FEDformer Zhou et al. (2022) | 1 | ||
| Crossformer Zhang and Yan (2023) | 1 | ||
4.3基于架构的注意力创新
为了适应《变形金刚》中的各个模块对时间序列进行建模,许多作品 Zhou 等人 (2021);刘等人(2022a)寻求在架构层面对变形金刚进行改造。 最近的工作将分层架构引入 Transformer,以考虑时间序列的多分辨率方面。 Informer Zhou 等人 (2021) 在注意力块之间插入步长为 2 的最大池层,将序列下采样到其半切片中。 Pyraformer Liu 等人 (2022a) 设计了一种基于 -ary 树的注意力机制,其中最细尺度的节点对应于原始时间序列,而较粗尺度的节点对应于原始时间序列。比例尺代表较低分辨率的系列。 Pyraformer 开发了尺度内和尺度间注意力,以便更好地捕获不同分辨率之间的时间依赖性。 除了能够以不同的多分辨率集成信息之外,分层架构还具有高效计算的优势,特别是对于长时间序列。
5时间序列 Transformer 的应用
在本节中,我们回顾 Transformer 在重要时间序列任务中的应用,包括预测、异常检测和分类。
5.1 预测中的变形金刚
在这里,我们研究三种常见类型的预测任务,即时间序列预测、时空预测和事件预测。
5.1.1 时间序列预测
近年来,为了设计用于时间序列预测任务的新 Transformer 变体,人们做了很多工作。 模块级和架构级变体是两大类,前者包含了大多数最新作品。
模块级变体
在用于时间序列预测的模块级变体中,它们的主要架构与普通 Transformer 类似,只有细微的变化。 研究人员引入各种时间序列归纳偏差来设计新模块。 以下总结的工作包括三种不同类型:设计新的注意力模块、探索标准化时间序列数据的创新方法以及利用词符输入的偏差,如图2所示。
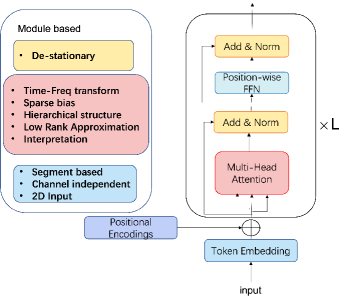
模块级 Transformer 的第一类变体是设计新的注意力模块,这是占比最大的类别。 这里先介绍六件典型作品:LogTrans 李等人 (2019)、Informer 周等人 (2021)、AST 吴等人 (2020a) t2>、Pyraformer Liu 等人 (2022a)、Quatformer Chen 等人 (2022) 和 FEDformer Zhou 等人 (2022),全部其中利用稀疏归纳偏差或低秩近似来消除噪声并实现低阶计算复杂度。 LogTrans Li 等人 (2019) 提出了卷积自注意力,通过使用因果卷积在自注意力层中生成查询和键。 它在自注意力模型中引入了稀疏偏差(Logsparse mask),可将计算复杂度从 降低到 。 Informer Zhou 等人 (2021) 没有使用显式稀疏偏差,而是根据查询和关键相似性来选择主导查询,从而在计算复杂度上实现了与 LogTrans 类似的改进。 它还设计了一种生成式解码器来直接产生长期预测,从而避免使用一次前向预测进行长期预测时出现累积误差。 AST Wu 等人 (2020a) 使用生成对抗性编码器-解码器框架来训练用于时间序列预测的稀疏 Transformer 模型。 结果表明,对抗性训练可以通过直接塑造网络的输出分布来改进时间序列预测,从而避免通过一步推理来避免错误累积。 Pyraformer Liu 等人 (2022a) 设计了一个分层金字塔注意力模块,路径上有一个二叉树,以线性时间和内存复杂度捕获不同范围的时间依赖性。 FEDformer Zhou 等人 (2022) 将注意力操作通过傅里叶变换和小波变换应用于频域。 它通过随机选择固定大小的频率子集来实现线性复杂度。 请注意,由于 Autoformer 和 FEDformer 的成功,探索频域中时间序列建模的自注意力机制引起了社区的更多关注。 Quatformer Chen 等人 (2022) 提出了基于四元数的学习旋转注意力(LRA),引入可学习的周期和相位信息来描述复杂的周期模式。 此外,它使用全局内存解耦 LRA 以实现线性复杂度。
以下三项工作专注于构建模型的显式解释能力,顺应了可解释人工智能(XAI)的趋势。 TFT Lim 等人 (2021) 设计了一种具有静态协变量编码器、门控特征选择和时间自注意力解码器的多水平预测模型。 它从各种协变量中编码并选择有用的信息来执行预测。 它还通过合并全局、时间依赖性和事件来保留可解释性。 ProTran Tang 和 Matteson (2021) 和 SSDNet Lin 等人 (2021) 将 Transformer 与状态空间模型结合起来,提供概率预测。 ProTran 设计了基于变分推理的生成建模和推理程序。 SSDNet首先使用Transformer学习时间模式并估计SSM的参数,然后应用SSM进行季节性趋势分解并保持可解释能力。
模块级 Transformer 的第二种变体是标准化时间序列数据的方法。 据我们所知,Non-stationary Transformer Liu 等人 (2022b) 是唯一主要致力于修改归一化机制的工作,如图 2 所示。 它通过相对简单的插件系列固定和去平稳模块来探索时间序列预测任务中的过度平稳化问题,以修改和提高各种注意块的性能。
模块级 Transformer 的第三种变体是利用词符输入的偏差。 Autoformer Wu 等人 (2021) 采用基于分段的表示机制。 它设计了一个简单的季节性趋势分解架构,具有作为注意模块的自相关机制。 自相关模块测量输入信号之间的时延相似性,并聚合前 k 个相似子系列以产生复杂性降低的输出。 PatchTST Nie 等人 (2023) 利用通道无关,其中每个通道包含单个单变量时间序列,在所有序列中共享相同的嵌入,以及子序列级补丁设计,将时间序列分割为子序列级补丁,用作 Transformer 的输入标记。 这种与 ViT Dosovitskiy 等人 (2021) 类似的设计大大提高了其在长时间时间序列预测任务中的数值性能。 Crossformer Zhang and Yan (2023) 提出了一种基于 Transformer 的模型,利用跨维度依赖进行多元时间序列预测。 通过新颖的维度分段嵌入将输入嵌入到二维向量数组中,以保留时间和维度信息。 然后,使用两阶段注意力层来有效捕获跨时间和跨维度的依赖性。
架构级别的变体
一些作品开始设计超出普通 Transformer 范围的新 Transformer 架构。 Triformer Cirstea 等人 (2022) 设计了一个三角形的、特定于变量的补丁注意力。 它具有三角树型结构,随着后期输入大小呈指数缩小,一组特定于变量的参数使多层 Triformer 保持轻量级和线性复杂度。 Scaleformer Shabani 等人 (2023) 提出了一个多尺度框架,可应用于基于基线 Transformer 的时间序列预测模型(FEDformerZhou 等人 (2022), Autoformer吴等人(2021)等)。 它可以通过使用共享权重在多个尺度上迭代地细化预测时间序列来提高基线模型的性能。
评论
请注意,DLinear Zeng 等人 (2023) 质疑使用 Transformer 进行长期时间序列预测的必要性,并通过实证表明,与某些 Transformer 基线相比,更简单的基于 MLP 的模型可以获得更好的结果学习。 然而,我们注意到最近的 Transformer 模型 PatchTST Nie 等人 (2023) 在长期时间序列预测方面比 DLinear 取得了更好的数值结果。 此外,深入的理论研究Yun 等人 (2020) 表明 Transformer 模型是序列到序列函数的通用逼近器。 仅根据此类方法的一些变体实例的实验结果来质疑任何类型的时间序列预测方法的潜力都是一种过分的主张,特别是对于已经在大多数基于机器学习的任务中展示了性能的 Transformer 模型。 因此,我们得出的结论是,总结最近基于 Transformer 的时间序列预测模型是必要的,并且将使整个社区受益。
5.1.2 时空预测
在时空预测中,时间序列 Transformer 中同时考虑了时间和时空依赖性,以实现准确的预测。
Traffic Transformer Cai 等人 (2020) 设计了一种编码器-解码器结构,使用自注意力模块来捕获时间依赖性,并使用图神经网络模块来捕获空间依赖性。 用于交通流预测的时空转换器 Xu 等人 (2020) 更进一步。 除了引入时间 Transformer 块来捕获时间依赖性之外,它还设计了空间 Transformer 块以及图卷积网络,以更好地捕获空间依赖性。 时空图 Transformer Yu 等人 (2020) 设计了一种基于注意力的图卷积机制,能够学习复杂的时空注意力模式,以改善行人轨迹预测。 Earthformer Gao 等人 (2022) 提出了一种用于高效时空建模的长方体注意力机制,它将数据分解为长方体并并行应用长方体级自注意力。 这表明Earthformer在天气和气候预报方面取得了卓越的表现。 最近,AirFormer Liang 等人 (2023) 设计了一个飞镖空间自注意力模块和一个因果时间自注意力模块,分别有效地捕获空间相关性和时间依赖性。 此外,它还通过潜在变量增强了 Transformer,以捕获数据不确定性并改进空气质量预测。
5.1.3事件预测
在许多现实应用中,自然会观察到具有不规则和异步时间戳的事件序列数据,这与具有相等采样间隔的规则时间序列数据形成对比。 事件预测旨在根据过去事件的历史来预测未来事件的时间和标记,通常通过时间点过程(TPP)建模 Yan 等人 (2019); Shchur 等人 (2021)。
最近,一些神经 TPP 模型结合了 Transformer,以提高事件预测的性能。 Self-attentive Hawkes process (SAHP) Zhang 等人 (2020) 和 Transformer Hawkes process (THP) Zuo 等人 (2020) 采用 Transformer 编码器架构来总结历史事件并计算事件预测的强度函数。 他们通过将时间间隔转换为正弦函数来修改位置编码,以便可以利用事件之间的间隔。 后来,提出了一种更灵活的命名的注意力神经数据记录(A-NDTT)Mei等人(2022),通过嵌入所有可能的事件和时间来扩展SAHP/THP方案。 实验表明,与现有方法相比,它可以更好地捕获复杂的事件依赖性。
5.2 Transformer 异常检测
基于 Transformer 的架构也有利于时间序列异常检测任务,能够对时间依赖性进行建模,从而带来较高的检测质量Xu 等人 (2022)。 此外,在多项研究中,包括 TranAD Tuli 等人 (2022)、MT-RVAE Wang 等人 (2022) 和 TransAnomaly Zhang 等人 (2021) ,研究人员提出将 Transformer 与神经生成模型相结合,例如 VAE Kingma and Welling (2014) 和 GAN Goodfellow 等人 (2014),以获得更好的性能在异常检测中。 我们将在下面的部分详细阐述这些模型。
TranAD Tuli 等人 (2022) 提出了一种对抗性训练程序来放大重建误差,因为简单的基于 Transformer 的网络往往会错过异常的小偏差。 GAN 风格的对抗训练过程由两个 Transformer 编码器和两个 Transformer 解码器设计,以获得稳定性。 Ablation 研究表明,如果替换基于 Transformer 的编码器-解码器,F1 分数下降近 11%,表明 Transformer 架构对时间序列异常检测的影响。
MT-RVAE Wang 等人 (2022) 和 TransAnomaly Zhang 等人 (2021) 将 VAE 与 Transformer 结合起来,但目的不同。 TransAnomaly 将 VAE 与 Transformer 结合起来,以实现更多并行化并将训练成本降低近 80%。 在 MT-RVAE 中,多尺度 Transformer 被设计用于提取和集成不同尺度的时间序列信息。 它克服了传统 Transformers 仅提取局部信息进行顺序分析的缺点。
GTA Chen 等人 (2021c) 将 Transformer 与基于图的学习架构相结合,用于多元时间序列异常检测。 请注意,MT-RVAE 也适用于多元时间序列,但维度较少或序列之间的密切关系不够,图神经网络模型效果不佳。 为了应对这样的挑战,MT-RVAE修改了位置编码模块并引入了特征学习模块。 相反,GTA 包含一个图卷积结构来模拟影响传播过程。 与 MT-RVAE 类似,GTA 也考虑“全局”信息,但通过多分支注意力机制取代普通多头注意力,即全局学习注意力、普通多头注意力和邻域卷积的组合。
AnomalyTrans Xu 等人 (2022) 将 Transformer 和高斯先验关联相结合,使异常更易于区分。 AnomalyTrans 与 TranAD 有着相似的动机,但以不同的方式实现了目标。 我们的见解是,与正常情况相比,异常情况更难与整个系列建立牢固的关联,而与相邻时间点建立牢固的关联则更容易。 在 AnomalyTrans 中,先验关联和系列关联同时建模。 除了重建损失之外,异常模型还通过极小极大策略进行优化,以约束先验关联和序列关联,以获得更可区分的关联差异。
5.3变形金刚的分类
由于其捕获长期依赖性的突出能力,Transformer 被证明在各种时间序列分类任务中都是有效的。 GTN Liu 等人 (2021) 使用两塔 Transformer,每个塔分别处理时间步进注意力和通道注意力。 为了合并两个塔的特征,使用了可学习的加权串联(也称为“门控”)。 所提出的 Transformer 扩展在 13 个多元时间序列分类上取得了最先进的结果。 Rußwurm 和 Körner (2020) 研究了用于原始光学卫星时间序列分类的基于自注意力的 Transformer,并与循环神经网络和卷积神经网络相比获得了最佳结果。 最近,TARNet Chowdhury 等人 (2022) 设计了 Transformers 来学习任务感知数据重建,从而增强分类性能,利用注意力分数进行重要时间戳屏蔽和重建,并带来卓越的性能。
预训练的 Transformer 也在分类任务中进行了研究。 Yuan and Lin (2020) 研究了用于原始光学卫星图像时间序列分类的 Transformer。 由于标记数据有限,作者使用自我监督的预训练模式。 Zerveas 等人 (2021) 引入了无监督预训练框架,模型使用按比例屏蔽的数据进行预训练。 然后,预训练的模型在分类等下游任务中进行微调。 Yang等人(2021)提出使用大规模预训练语音处理模型来解决下游时间序列分类问题,并在30个流行时间序列分类数据集上生成了19个有竞争力的结果。
6实验评估与讨论
我们对典型的挑战性基准数据集 ETTm2 Zhou 等人 (2021) 进行了预备知识实证研究,以分析 Transformers 如何处理时间序列数据。 由于经典统计 ARIMA/ETS Hyndman 和 Khandakar (2008) 模型和基本 RNN/CNN 模型在此数据集中的表现不如 Transformers,如 Zhou 等人 (2021) 所示; Wu等人(2021),我们在实验中重点关注不同配置的流行时间序列变形金刚。
6.0.1 稳健性分析
我们上面描述的许多工作都仔细设计了注意力模块以降低二次计算和内存复杂性,尽管他们实际上使用短的固定大小输入来在其报告的实验中获得最佳结果。 这让我们质疑这种高效设计的实际用途。 我们通过延长输入序列长度进行了鲁棒实验,以验证其在处理表2中的长期输入序列时的预测能力和鲁棒性。
| Model | Transformer | Autoformer | Informer | Reformer | LogFormer | |
|---|---|---|---|---|---|---|
| 96 | 0.557 | 0.239 | 0.428 | 0.615 | 0.667 | |
| 192 | 0.710 | 0.265 | 0.385 | 0.686 | 0.697 | |
| 336 | 1.078 | 0.375 | 1.078 | 1.359 | 0.937 | |
| 720 | 1.691 | 0.315 | 1.057 | 1.443 | 2.153 | |
| 1440 | 0.936 | 0.552 | 1.898 | 0.815 | 0.867 | |
如表2所示,当我们将预测结果与延长输入长度进行比较时,各种基于 Transformer 的模型恶化得很快。 这种现象使得许多精心设计的 Transformer 在长期预测任务中变得不切实际,因为它们无法有效利用长输入信息。 需要研究更多的工作和设计,以充分利用长序列输入以获得更好的性能。
| Model | Transformer | Autoformer | Informer | Reformer | LogFormer | |
|---|---|---|---|---|---|---|
| 3 | 0.557 | 0.234 | 0.428 | 0.597 | 0.667 | |
| 6 | 0.439 | 0.282 | 0.489 | 0.353 | 0.387 | |
| 12 | 0.556 | 0.238 | 0.779 | 0.481 | 0.562 | |
| 24 | 0.580 | 0.266 | 0.815 | 1.109 | 0.690 | |
| 48 | 0.461 | NaN | 1.623 | OOM | 2.992 | |
| Model | FEDformer | Autoformer | Informer | LogTrans | Reformer | Transformer | Promotion | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | Ori | Decomp | Ori | Decomp | Ori | Decomp | Ori | Decomp | Ori | Decomp | Ori | Decomp | Relative | ||
| 96 | 0.457 | 0.203 | 0.581 | 0.255 | 0.365 | 0.354 | 0.768 | 0.231 | 0.658 | 0.218 | 0.604 | 0.204 | 53% | ||
| 192 | 0.841 | 0.269 | 1.403 | 0.281 | 0.533 | 0.432 | 0.989 | 0.378 | 1.078 | 0.336 | 1.060 | 0.266 | 62% | ||
| 336 | 1.451 | 0.325 | 2.632 | 0.339 | 1.363 | 0.481 | 1.334 | 0.362 | 1.549 | 0.366 | 1.413 | 0.375 | 75% | ||
| 720 | 3.282 | 0.421 | 3.058 | 0.422 | 3.379 | 0.822 | 3.048 | 0.539 | 2.631 | 0.502 | 2.672 | 0.537 | 82% | ||
6.0.2模型大小分析
在被引入时间序列预测领域之前,Transformer 已在 NLP 和 CV 社区展现出主导性能Vaswani 等人 (2017);肯顿等人(2019);韩等人(2021, 2022)。 Transformer 在这些领域的关键优势之一是能够通过增加模型大小来提高预测能力。 通常,模型容量由Transformer的层数控制,一般设置在12到128之间。 然而,如表3的实验所示,当我们将预测结果与不同层数的Transformer模型进行比较时,3到6层的Transformer通常会取得更好的结果。 这就提出了一个问题,即如何设计合适的具有更深层次的 Transformer 架构,以提高模型的容量并实现更好的预测性能。
6.0.3 季节趋势分解分析
在最近的研究中,研究人员Wu等人(2021);周等人 (2022);林等人 (2021); Liu 等人 (2022a) 开始认识到季节趋势分解Cleveland 等人 (1990); Wen 等人 (2020) 是 Transformer 在时间序列预测方面表现的关键部分。 如表4所示的实验,我们采用Wu等人(2021)中提出的简单移动平均季节性趋势分解架构来测试各种注意力模块。 可以看出,简单的季节趋势分解模型可以使模型性能显着提升50%到80%。 它是一个独特的块,通过分解来提升性能似乎是 Transformer 应用的时间序列预测中的一致现象,值得进一步研究更先进和精心设计的时间序列分解方案。
7 未来的研究机会
在这里,我们重点介绍了未来 Transformer 时间序列研究可能有前景的几个方向。
7.1 时间序列 Transformer 的电感偏置
Vanilla Transformer 不对数据模式和特征做出任何假设。 虽然它是一个通用的、用于建模远程依赖关系的网络,但它也是有代价的,即需要大量的数据来训练 Transformer 来提高泛化能力并避免数据过拟合。 时间序列数据的关键特征之一是其季节性/周期性和趋势模式Wen 等人 (2019);克利夫兰等人(1990)。 最近的一些研究表明,将序列周期性 Wu 等人 (2021) 或频率处理 Zhou 等人 (2022) 纳入时间序列 Transformer 可以显着提高性能。 此外,有趣的是,一些研究采用了看似相反的归纳偏差,但都取得了良好的数值改进:Nie 等人(2023)通过利用通道无关的注意模块消除了跨通道依赖性,而一项有趣的工作Zhang and Yan (2023)通过利用跨维度依赖和两阶段注意机制提高了其实验性能。 显然,我们在这种跨通道学习范式中存在噪声和信号,但仍然需要一种巧妙的方法来利用这种归纳偏差来抑制噪声并提取信号。 因此,未来的一个方向是基于对时间序列数据和特定任务特征的理解,考虑更有效的方法将归纳偏差引入 Transformer 中。
7.2 时间序列的 Transformer 和 GNN
多元和时空时间序列在应用中变得越来越普遍,需要额外的技术来处理高维,特别是捕获维度之间潜在关系的能力。 引入图神经网络(GNN)是对空间依赖性或维度之间的关系进行建模的自然方法。 最近,多项研究表明,GNN 和 Transformers/attention 的结合不仅可以带来显着的性能提升,如流量预测 Cai 等人 (2020); Xu 等人 (2020) 和多模态预测 Li 等人 (2021),而且还可以更好地理解时空动态和潜在因果关系。 将 Transformer 和 GNN 结合起来进行有效的时间序列时空建模是未来的一个重要方向。
7.3 时间序列的预训练 Transformer
大规模预训练 Transformer 模型显着提升了 NLP Kenton 等人(2019)中各种任务的性能; Brown 等人 (2020) 和 CV Chen 等人 (2021a)。 然而,针对时间序列的预训练 Transformer 的工作有限,现有研究主要集中在时间序列分类Zerveas 等人 (2021);杨等人 (2021). 因此,如何针对时间序列中的不同任务开发合适的预训练 Transformer 模型仍有待未来研究。
7.4 具有架构级别变体的 Transformer
大多数开发的时间序列 Transformer 模型都保持了普通 Transformer 的架构,主要在注意力模块中进行了修改。 我们可以借鉴 NLP 和 CV 中 Transformer 变体的想法,它们也有架构级模型设计来适应不同的目的,例如轻量级 Wu 等人 (2020b); Mehta 等人 (2021),跨区块连接性 Bapna 等人 (2018),自适应计算时间 Dehghani 等人 (2019); Xin 等人 (2020),以及递归 Dai 等人 (2019)。 因此,未来的一个方向是考虑针对时间序列数据和任务专门优化的 Transformer 的更多架构级设计。
7.5 带有 NAS 的时间序列 Transformer
超参数,例如嵌入尺寸和头/层数,可以在很大程度上影响 Transformer 的性能。 手动配置这些超参数非常耗时,并且通常会导致性能不佳。 AutoML 技术,如神经架构搜索 (NAS) Elsken 等人 (2019); Wang 等人 (2020) 一直是发现有效深度神经架构的流行技术,在 NLP 和 CV 中使用 NAS 自动化 Transformer 设计可以在最近的研究中找到 So 等人 (2019);陈等人 (2021b). 对于高维和长长度的工业规模时间序列数据,自动发现内存和计算高效的 Transformer 架构具有实际意义,使其成为时间序列 Transformer 未来的重要方向。
8结论
我们提供了一项关于时间序列 Transformer 的调查。 我们将审查的方法组织在一个由网络设计和应用组成的新分类法中。 我们总结了每个类别中的代表性方法,通过实验评估讨论了它们的优点和局限性,并强调了未来的研究方向。
参考
- Bapna et al. [2018] Ankur Bapna, Mia Xu Chen, Orhan Firat, Yuan Cao, and Yonghui Wu. Training deeper neural machine translation models with transparent attention. In EMNLP, 2018.
- Benidis et al. [2022] Konstantinos Benidis, Syama Sundar Rangapuram, Valentin Flunkert, Yuyang Wang, Danielle Maddix, , et al. Deep learning for time series forecasting: Tutorial and literature survey. ACM Computing Surveys, 55(6):1–36, 2022.
- Blázquez-García et al. [2021] Ane Blázquez-García, Angel Conde, Usue Mori, et al. A review on outlier/anomaly detection in time series data. ACM Computing Surveys, 54(3):1–33, 2021.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, et al. Language models are few-shot learners. NeurIPS, 2020.
- Cai et al. [2020] Ling Cai, Krzysztof Janowicz, Gengchen Mai, Bo Yan, and Rui Zhu. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Transactions in GIS, 24(3):736–755, 2020.
- Chen et al. [2021a] Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, et al. Pre-trained image processing transformer. In CVPR, 2021.
- Chen et al. [2021b] Minghao Chen, Houwen Peng, Jianlong Fu, and Haibin Ling. AutoFormer: Searching transformers for visual recognition. In CVPR, 2021.
- Chen et al. [2021c] Zekai Chen, Dingshuo Chen, Xiao Zhang, Zixuan Yuan, and Xiuzhen Cheng. Learning graph structures with transformer for multivariate time series anomaly detection in IoT. IEEE Internet of Things Journal, 2021.
- Chen et al. [2022] Weiqi Chen, Wenwei Wang, Bingqing Peng, Qingsong Wen, Tian Zhou, and Liang Sun. Learning to rotate: Quaternion transformer for complicated periodical time series forecasting. In KDD, 2022.
- Choi et al. [2021] Kukjin Choi, Jihun Yi, Changhwa Park, and Sungroh Yoon. Deep learning for anomaly detection in time-series data: Review, analysis, and guidelines. IEEE Access, 2021.
- Chowdhury et al. [2022] Ranak Roy Chowdhury, Xiyuan Zhang, Jingbo Shang, Rajesh K Gupta, and Dezhi Hong. TARNet: Task-aware reconstruction for time-series transformer. In KDD, 2022.
- Cirstea et al. [2022] Razvan-Gabriel Cirstea, Chenjuan Guo, Bin Yang, Tung Kieu, Xuanyi Dong, and Shirui Pan. Triformer: Triangular, variable-specific attentions for long sequence multivariate time series forecasting. In IJCAI, 2022.
- Cleveland et al. [1990] Robert Cleveland, William Cleveland, Jean McRae, et al. STL: A seasonal-trend decomposition procedure based on loess. Journal of Official Statistics, 6(1):3–73, 1990.
- Dai et al. [2019] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G. Carbonell, Quoc V. Le, et al. Transformer-XL: Attentive language models beyond a fixed-length context. In ACL, 2019.
- Dehghani et al. [2019] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. In ICLR, 2019.
- Dong et al. [2018] Linhao Dong, Shuang Xu, and Bo Xu. Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition. In ICASSP, 2018.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- Elsken et al. [2019] Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research, 2019.
- Gao et al. [2022] Zhihan Gao, Xingjian Shi, Hao Wang, Yi Zhu, Bernie Wang, Mu Li, et al. Earthformer: Exploring space-time transformers for earth system forecasting. In NeurIPS, 2022.
- Gehring et al. [2017] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. Convolutional sequence to sequence learning. In ICML, 2017.
- Goodfellow et al. [2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, et al. Generative adversarial nets. NeurIPS, 2014.
- Han et al. [2021] Xu Han, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, Liang Zhang, et al. Pre-trained models: Past, present and future. AI Open, 2021.
- Han et al. [2022] Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, et al. A survey on vision transformer. IEEE TPAMI, 45(1):87–110, 2022.
- Hyndman and Khandakar [2008] Rob J Hyndman and Yeasmin Khandakar. Automatic time series forecasting: the forecast package for r. Journal of statistical software, 27:1–22, 2008.
- Ismail Fawaz et al. [2019] Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. Deep learning for time series classification: a review. Data mining and knowledge discovery, 2019.
- Ke et al. [2021] Guolin Ke, Di He, and Tie-Yan Liu. Rethinking positional encoding in language pre-training. In ICLR, 2021.
- Kenton and others [2019] Jacob Devlin Ming-Wei Chang Kenton et al. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, 2019.
- Kingma and Welling [2014] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. In ICLR, 2014.
- Li et al. [2019] Shiyang Li, Xiaoyong Jin, Yao Xuan, Xiyou Zhou, Wenhu Chen, Yu-Xiang Wang, and Xifeng Yan. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In NeurIPS, 2019.
- Li et al. [2021] Longyuan Li, Jian Yao, Li Wenliang, Tong He, Tianjun Xiao, Junchi Yan, David Wipf, and Zheng Zhang. Grin: Generative relation and intention network for multi-agent trajectory prediction. In NeurIPS, 2021.
- Liang et al. [2023] Yuxuan Liang, Yutong Xia, Songyu Ke, Yiwei Wang, Qingsong Wen, Junbo Zhang, Yu Zheng, and Roger Zimmermann. AirFormer: Predicting nationwide air quality in china with transformers. In AAAI, 2023.
- Lim and Zohren [2021] Bryan Lim and Stefan Zohren. Time-series forecasting with deep learning: a survey. Philosophical Transactions of the Royal Society, 2021.
- Lim et al. [2021] Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting, 37(4):1748–1764, 2021.
- Lin et al. [2021] Yang Lin, Irena Koprinska, and Mashud Rana. SSDNet: State space decomposition neural network for time series forecasting. In ICDM, 2021.
- Liu et al. [2021] Minghao Liu, Shengqi Ren, Siyuan Ma, Jiahui Jiao, Yizhou Chen, Zhiguang Wang, and Wei Song. Gated transformer networks for multivariate time series classification. arXiv preprint arXiv:2103.14438, 2021.
- Liu et al. [2022a] Shizhan Liu, Hang Yu, Cong Liao, Jianguo Li, Weiyao Lin, Alex X. Liu, and Schahram Dustdar. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In ICLR, 2022.
- Liu et al. [2022b] Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Non-stationary transformers: Exploring the stationarity in time series forecasting. In NeurIPS, 2022.
- Mehta et al. [2021] Sachin Mehta, Marjan Ghazvininejad, Srini Iyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Delight: Deep and light-weight transformer. In ICLR, 2021.
- Mei et al. [2022] Hongyuan Mei, Chenghao Yang, and Jason Eisner. Transformer embeddings of irregularly spaced events and their participants. In ICLR, 2022.
- Nie et al. [2023] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. In ICLR, 2023.
- Rußwurm and Körner [2020] Marc Rußwurm and Marco Körner. Self-attention for raw optical satellite time series classification. ISPRS J. Photogramm. Remote Sens., 169:421–435, 11 2020.
- Shabani et al. [2023] Amin Shabani, Amir Abdi, Lili Meng, and Tristan Sylvain. Scaleformer: iterative multi-scale refining transformers for time series forecasting. In ICLR, 2023.
- Shaw et al. [2018] Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. In NAACL, 2018.
- Shchur et al. [2021] Oleksandr Shchur, Ali Caner Türkmen, Tim Januschowski, and Stephan Günnemann. Neural temporal point processes: A review. In IJCAI, 2021.
- So et al. [2019] David So, Quoc Le, and Chen Liang. The evolved transformer. In ICML, 2019.
- Tang and Matteson [2021] Binh Tang and David Matteson. Probabilistic transformer for time series analysis. In NeurIPS, 2021.
- Tay et al. [2022] Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey. ACM Computing Surveys, 55(6):1–28, 2022.
- Torres et al. [2021] José F. Torres, Dalil Hadjout, Abderrazak Sebaa, Francisco Martínez-Álvarez, and Alicia Troncoso. Deep learning for time series forecasting: a survey. Big Data, 2021.
- Tuli et al. [2022] Shreshth Tuli, Giuliano Casale, and Nicholas R Jennings. TranAD: Deep transformer networks for anomaly detection in multivariate time series data. In VLDB, 2022.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, et al. Attention is all you need. In NeurIPS, 2017.
- Wang et al. [2020] Xiaoxing Wang, Chao Xue, Junchi Yan, Xiaokang Yang, Yonggang Hu, et al. MergeNAS: Merge operations into one for differentiable architecture search. In IJCAI, 2020.
- Wang et al. [2022] Xixuan Wang, Dechang Pi, Xiangyan Zhang, et al. Variational transformer-based anomaly detection approach for multivariate time series. Measurement, page 110791, 2022.
- Wen et al. [2019] Qingsong Wen, Jingkun Gao, Xiaomin Song, Liang Sun, Huan Xu, et al. RobustSTL: A robust seasonal-trend decomposition algorithm for long time series. In AAAI, 2019.
- Wen et al. [2020] Qingsong Wen, Zhe Zhang, Yan Li, and Liang Sun. Fast RobustSTL: Efficient and robust seasonal-trend decomposition for time series with complex patterns. In KDD, 2020.
- Wen et al. [2021a] Qingsong Wen, Kai He, Liang Sun, Yingying Zhang, Min Ke, et al. RobustPeriod: Time-frequency mining for robust multiple periodicities detection. In SIGMOD, 2021.
- Wen et al. [2021b] Qingsong Wen, Liang Sun, Fan Yang, Xiaomin Song, Jingkun Gao, Xue Wang, and Huan Xu. Time series data augmentation for deep learning: A survey. In IJCAI, 2021.
- Wen et al. [2022] Qingsong Wen, Linxiao Yang, Tian Zhou, and Liang Sun. Robust time series analysis and applications: An industrial perspective. In KDD, 2022.
- Wu et al. [2020a] Sifan Wu, Xi Xiao, Qianggang Ding, Peilin Zhao, Ying Wei, and Junzhou Huang. Adversarial sparse transformer for time series forecasting. In NeurIPS, 2020.
- Wu et al. [2020b] Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, and Song Han. Lite transformer with long-short range attention. In ICLR, 2020.
- Wu et al. [2021] Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In NeurIPS, 2021.
- Xin et al. [2020] Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy J. Lin. DeeBERT: Dynamic early exiting for accelerating bert inference. In ACL, 2020.
- Xu et al. [2020] Mingxing Xu, Wenrui Dai, Chunmiao Liu, Xing Gao, Weiyao Lin, Guo-Jun Qi, and Hongkai Xiong. Spatial-temporal transformer networks for traffic flow forecasting. arXiv preprint arXiv:2001.02908, 2020.
- Xu et al. [2022] Jiehui Xu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Anomaly Transformer: Time series anomaly detection with association discrepancy. In ICLR, 2022.
- Yan et al. [2019] Junchi Yan, Hongteng Xu, and Liangda Li. Modeling and applications for temporal point processes. In KDD, 2019.
- Yang et al. [2021] Chao-Han Huck Yang, Yun-Yun Tsai, and Pin-Yu Chen. Voice2series: Reprogramming acoustic models for time series classification. In ICML, 2021.
- Yu et al. [2020] Cunjun Yu, Xiao Ma, Jiawei Ren, Haiyu Zhao, and Shuai Yi. Spatio-temporal graph transformer networks for pedestrian trajectory prediction. In ECCV, 2020.
- Yuan and Lin [2020] Yuan Yuan and Lei Lin. Self-supervised pretraining of transformers for satellite image time series classification. IEEE J-STARS, 14:474–487, 2020.
- Yun et al. [2020] Chulhee Yun, Srinadh Bhojanapalli, Ankit Singh Rawat, Sashank J. Reddi, et al. Are transformers universal approximators of sequence-to-sequence functions? In ICLR, 2020.
- Zeng et al. [2023] Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? In AAAI, 2023.
- Zerveas et al. [2021] George Zerveas, Srideepika Jayaraman, Dhaval Patel, Anuradha Bhamidipaty, and Carsten Eickhoff. A transformer-based framework for multivariate time series representation learning. In KDD, 2021.
- Zhang and Yan [2023] Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In ICLR, 2023.
- Zhang et al. [2020] Qiang Zhang, Aldo Lipani, Omer Kirnap, and Emine Yilmaz. Self-attentive Hawkes process. In ICML, 2020.
- Zhang et al. [2021] Hongwei Zhang, Yuanqing Xia, et al. Unsupervised anomaly detection in multivariate time series through transformer-based variational autoencoder. In CCDC, 2021.
- Zhou et al. [2021] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In AAAI, 2021.
- Zhou et al. [2022] Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. In ICML, 2022.
- Zuo et al. [2020] Simiao Zuo, Haoming Jiang, Zichong Li, Tuo Zhao, and Hongyuan Zha. Transformer Hawkes process. In ICML, 2020.