DBT-Net:使用注意力中注意力 Transformer 进行双分支联合幅度和相位估计,用于单耳语音增强
摘要
解耦式概念开始在语音增强领域点燃,它将原来的复杂频谱估计任务解耦为多个更简单的子任务(即,仅幅度恢复和剩余复杂频谱估计),从而获得更好的性能和更容易的解释性。 在本文中,我们提出了一种双分支联邦幅度和相位估计框架,称为 DBT-Net,用于单声道语音增强,旨在并行恢复整个频谱的粗粒度和细粒度区域。 从互补的角度来看,幅度估计分支旨在滤除幅度域中的主要噪声分量,而复杂频谱净化分支则精心设计用于修复丢失的频谱细节并隐式估计复值频谱域中的相位信息。 为了促进每个分支之间的信息流动,引入交互模块来利用从一个分支学习到的特征,从而抑制不需要的部分并恢复另一分支丢失的组件。 我们没有采用传统的 RNN 和时间卷积网络进行序列建模,而是在每个分支中采用一种新颖的基于注意力中注意力变换器的网络,以实现更好的特征学习。 更具体地说,它由几个基于自适应谱时注意变换器的模块和一个自适应分层注意模块组成,旨在捕获长期时频依赖性并进一步聚合中间分层上下文信息。 对 WSJ0-SI84 + DNS-Challenge 和 VoiceBank + DEMAND 数据集的综合评估表明,所提出的方法始终优于以前的先进系统,并在语音质量和清晰度方面产生了最先进的性能。
索引术语:
语音增强、解耦式、幅度谱估计、复谱纯化、注意力中注意力 Transformer 。我简介
各种类型的环境干扰可能会极大地降低真实场景中的电信、自动语音识别(ASR)和助听器的性能。 在这方面,单耳语音增强(SE)通常是必要的,旨在从受噪声污染的混合物中恢复干净的语音,以提高语音质量和清晰度[1]。 随着深度神经网络 (DNN) 的复兴,人们提出了大量基于 DNN 的方法来推动 SE 算法的发展,因为它们比传统的基于统计信号处理的方法具有更强大的抑制高度非平稳噪声的能力 [2],特别是在低信噪比 (SNR) 条件下。
基于 DNN 的传统监督 SE 方法通常旨在估计掩模函数或直接预测时频 (T-F) 域中干净语音的频谱幅度 [3, 4],其中噪声相位保持不变重建时域波形时。 这是因为在很长一段时间内,相位信息对于SE任务[5]来说被认为是不重要的。 此外,由于其高度非结构性的特征,准确估计干净语音的相位分布是很困难的。 然而,最近的研究表明,未经处理的相位严重降低了语音感知质量,尤其是在低信噪比条件下[6]。 为此,人们提出了许多相位感知SE方法来解决时域或复值谱域中的相位估计问题。 对于前一类,直接使用原始波形来重新生成增强语音,而不使用任何 T-F 表示[7,8,9,10],这绕过了显式相位估计问题。 例如,SEGAN [11]提出了一种基于生成对抗网络的SE方法,其中去噪生成器通过对抗训练直接从混合原始波形映射干净语音的原始波形。 对于后一类,研究人员处理复值谱域中的相位估计[12,13,14,15],它可以分为两个主流,即基于掩蔽的和基于映射的基于。 对于第一类,人们提出了多种基于复值 DNN 的算法来估计复值比率掩模 (CRM),然后将其应用于复谱的实部和虚部 (RI) 部分,以便同时恢复幅度和相位[12,13,14]。 第二种类型利用复杂的光谱映射网络来直接预测干净的复杂光谱[15]的RI分量。 例如,在[15]中,利用实值卷积循环网络(CRN)直接映射目标语音的RI分量,其中增强的RI分量分别由两个解码器解码。 最近,一些多阶段解耦式方法在 SE 领域蓬勃发展,并被证明取得了卓越的性能[16,17,18,19]。 这些多阶段方法没有将之前单阶段范式中的映射过程仅打包到一个黑匣子中,而是将原始复杂的频谱估计解耦为逐步优化幅度和相位,并减轻了两个目标[20]。 具体而言,由于震级谱具有明显的谱规律性,第一阶段仅涉及震级估计。 随后,在第二阶段通过残差学习进行复杂的谱细化,这也可以隐式地细化相位。
在上述多阶段研究的推动下,我们并行分解了复杂的频谱估计,并提出了一种双分支框架,涉及一种新型的基于 Transformer 的网络,称为 DBT-Net。 从互补的角度来看,DBT-Net充分利用基于幅度谱和基于复杂谱的SE方法来探索整体谱估计。 具体来说,精心设计了两个并行核心分支,以促进整体频谱恢复,即M幅度E估计B牧场(MEB)和辅助C复杂谱P净化B牧场(CPB)。 由于幅度谱明显的频谱规律性,我们寻求用MEB构建滤波系统来粗略地抑制幅度域中的主要噪声分量。 同时,我们建立了一个带有 CPB 的精炼系统,以补偿复值谱域中丢失的光谱细节和相位失配效应。 通过各分支之间的信息交互,两个分支可以实现信息流动并协同促进整体频谱恢复。
一般来说,主流SE模型利用基于循环神经网络(RNN)或卷积神经网络(CNN)的编码器-解码器结构,在对语音序列建模时忽略了远程上下文信息,导致去噪性能有限。 此外,CNN需要更多的卷积层来扩大模型长期语音序列的感受野,而RNN的计算复杂度较高,无法进行并行处理。 随后,卷积循环网络(CRN)[21]和时间卷积网络(TCN)[22]被提出,用于SE领域更有效的序列建模,因为它们进一步提取高级特征和扩大感受野的能力。 然而,他们仍然缺乏足够的能力来捕获全局上下文信息[9,23,24,25]。 此外,大多数方法仅在时间轴上起作用,忽略了不同频率子带之间的相关性。 在这方面,基于 Transformer 的方法在语音序列到序列领域蓬勃发展,因为它们在捕获对自然语言处理任务的长期依赖性方面表现出色[26]。 在语音分离和增强任务中,采用基于双路径 Transformer 的网络沿时间和频率轴提取上下文信息[9,23,25]。 然而,他们在序列建模过程中忽略了远程分层上下文信息,因此中间特征图没有得到充分有效的利用。
为此,我们在每个分支内采用了一个被称为 AIAT 的注意力中注意力 Transformer 网络来引导全局序列建模过程,该网络集成了四个自适应时频注意力(ATFA) Transformer 和一个自适应分层注意力(AHA)模块来形成“注意中注意”(AIA)结构。 具体来说,ATFA Transformer 可以捕获时间和频率维度上的局部和全局上下文信息,而 AHA 模块可以通过全局注意力权重灵活地将 ATFA 模块的所有输出特征图聚合在一起。
本文的主要贡献总结如下。
-
•
我们提出了一种双分支 SE 框架,可以并行地同时恢复干净复杂频谱的幅度和相位信息,并采用基于注意力中注意力 Transformer 的网络进行序列建模。 从互补的角度来看,这两个核心分支可以协同获取干净语音的粗粒度和细粒度区域、即、频谱幅度和缺失细节。
-
•
考虑到谱幅度和复杂谱细节之间的互补关联,我们在两个分支之间引入信息交互,其中从基于幅度的分支中提取外部知识作为辅助以促进残差复杂谱估计,反之亦然。
-
•
对两个公共语料库的综合实验表明,DBT-Net 取得了显着的结果,并且始终优于最先进的基线,同时模型参数大小相对较小。
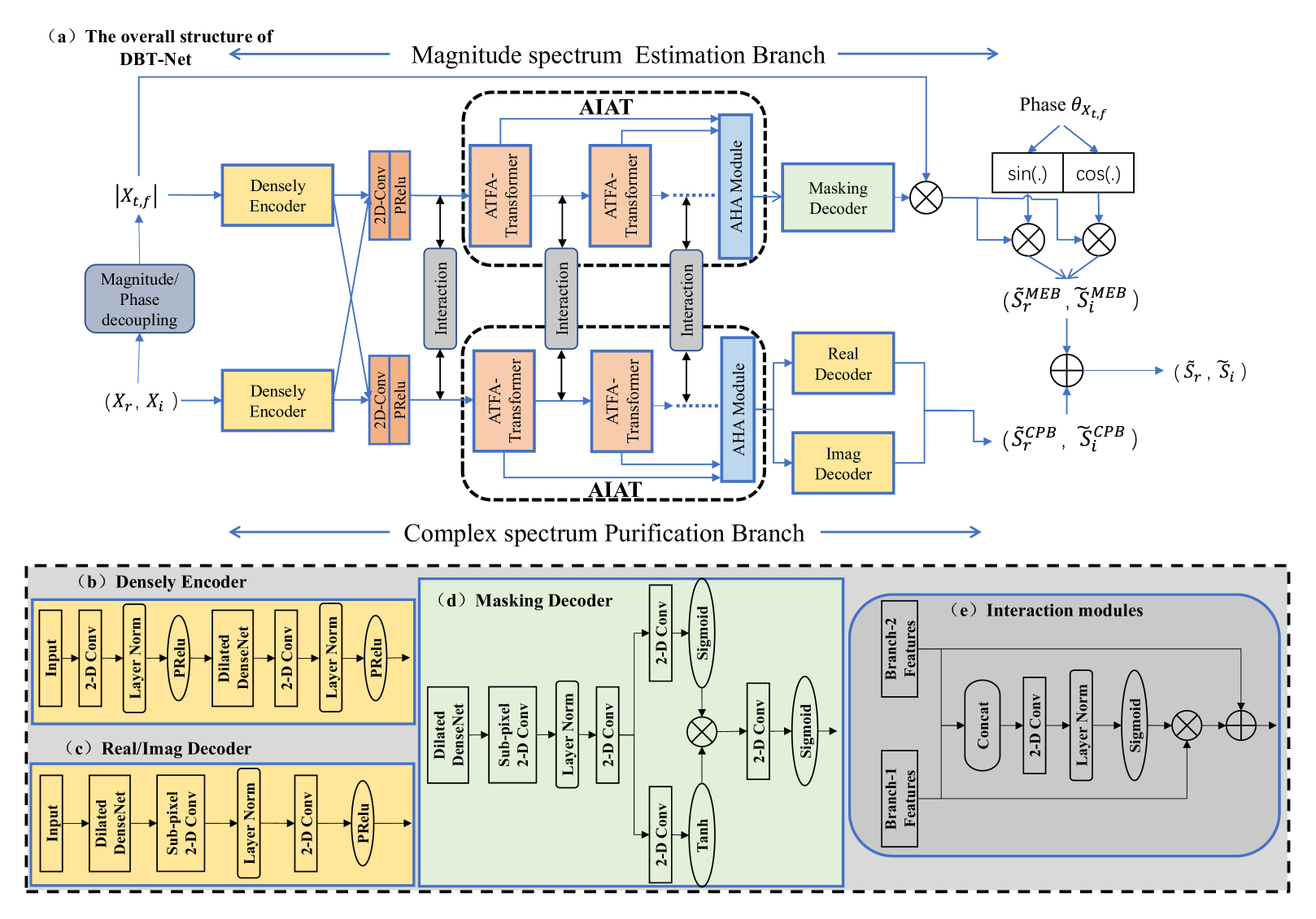
II 目标配方
II-A 信号模型
给定单声道混合,噪声信号 、干净语音 和噪声信号 可以表示为:
II-B 双分支策略
该系统的总体框图如图1所示。 它主要由两个分支组成,即幅度谱估计分支(MEB)和复杂频谱净化分支(CPB),旨在并行协作估计干净语音的幅度和相位信息。 具体来说,我们首先忽略棘手的相位估计,只关注幅度估计。 在MEB路径中,我们将噪声频谱的幅度输入网络来估计增益函数,其目的是粗略地滤除主要噪声并恢复目标的幅度语音,即、。 然后将粗略去噪的频谱幅度与相应的噪声相位耦合,以导出目标频谱的粗略估计的RI分量,即、。
作为补充,我们利用 CPB 来净化可能在 MEB 路径中丢失的细粒度光谱结构。 也就是说,CPB的目的是在解决残留噪声分量的同时恢复目标频谱的相位信息。 CPB不是明确估计整个复数频谱,而是设计用于复值频谱域中的残差映射,这可以减轻网络的整体负担。 最后,我们将粗降噪的 RI 分量和细粒度的复杂光谱细节相加,以重建目标复杂光谱。 请注意,最终输出涉及幅度估计和复杂的残差映射,这表明这两个分支共同对目标估计做出了贡献。 简而言之,整个过程可以表述为:
| (4) | |||
| (5) | |||
| (6) | |||
| (7) | |||
| (8) |
其中表示CPB的输出残余RI分量,表示干净RI分量的最终合并估计。 是逐元素乘法运算符。 MEB和CPB的输入特征分别表示为和。 这里 是帧数, 是频率仓数。
III 建议的架构
在本节中,描述了拟议框架的细节。 如图1(a)所示,MEB由三个主要组件组成,即密集卷积编码器、用于序列建模的AIAT和用于幅度谱增益估计的掩蔽解码器。 更具体地说,所提出的 AIAT 模块由四个基于自适应时频注意变换器(ATFAT)的模块和一个自适应分层注意(AHA)模块组成,如图2所示,其中 ATFAT 旨在沿着时间轴和谱轴分别捕获长程相关性,AHA 尝试在序列建模期间集成不同的中间特征图。 请注意,频谱增益的输出范围被 sigmoid 激活函数截断为 (0, 1)。
CPB的整体拓扑与MEB类似,包括一个密集卷积编码器、一个AIAT和两个密集解码器,旨在分别估计目标复谱的残差实部和虚部。 为了在序列建模过程中交互和补充信息,我们精心设计了两个分支之间的交互模块,其中MEB可以更好地利用CPB转换的信息指导特征学习过程,反之亦然。 详细的参数设置总结在表I中,而MEB和CPB除了解码器数量外共享相同的配置,其中MEB仅使用一个掩模解码器,而CPB使用两个实部和虚部解码器剩余目标复合谱的部分。
| layer name | input size | hyperparameters | output size | |
| Encoder | 2-D Conv | , , | ||
| DenseBlock_1 | , , , | |||
| DenseBlock_2 | , , , | |||
| DenseBlock_3 | , , , | |||
| DenseBlock_4 | , , , | |||
| 2-D Conv | , , | |||
| 2-D Conv (merge) | , , | |||
| ATFA Transformers ATAB | reshape | - | ||
| MHSA | - | |||
| Bi-GRU | 128 | |||
| Linear | 64 | |||
| reshape | - | |||
| AFAB | reshape | - | ||
| MHSA | - | |||
| Bi-GRU | 128 | |||
| Linear | 64 | |||
| reshape | - | |||
| 2-D Conv | , , | |||
| AHA module | - | |||
| Real/Imag Decoder | DenseBlock_1 | , , , | ||
| DenseBlock_2 | , , , | |||
| DenseBlock_3 | , , , | |||
| DenseBlock_4 | , , , | |||
| Sub-pixel Conv | , , | |||
| 2-D Conv | , , | |||
| Masking Decoder | DenseBlock_1 | , , , | ||
| DenseBlock_2 | , , , | |||
| DenseBlock_3 | , , , | |||
| DenseBlock_4 | , , , | |||
| Sub-pixel Conv | , , | |||
| 2-D Conv | , , | |||
| 2-D Conv_mask1 | , , | |||
| 2-D Conv_mask2 | , , | |||
| 2-D Conv | , , |
III-A 密集卷积编码器
如图1(b)所示,给定输入特征或,每个分支中的密集卷积编码器由两个2- D 个卷积层,然后是层归一化 (LN) 和参数化 ReLU (PReLU) 激活。 在这两个卷积层之间,采用具有四个扩张卷积层的DenseNet [27],其中扩张率为。 第一个二维卷积层的输出通道设置为64并保持不变,内核大小和步长为(1, 1),而第二个二维卷积层将频率轴的维度减半,并设置内核大小和步幅分别为 (1, 3) 和 (1, 2)。 MEB和CPB的详细参数设置如表I所示,其中CPB和MEB路径分别采用实/虚解码器和掩蔽解码器。
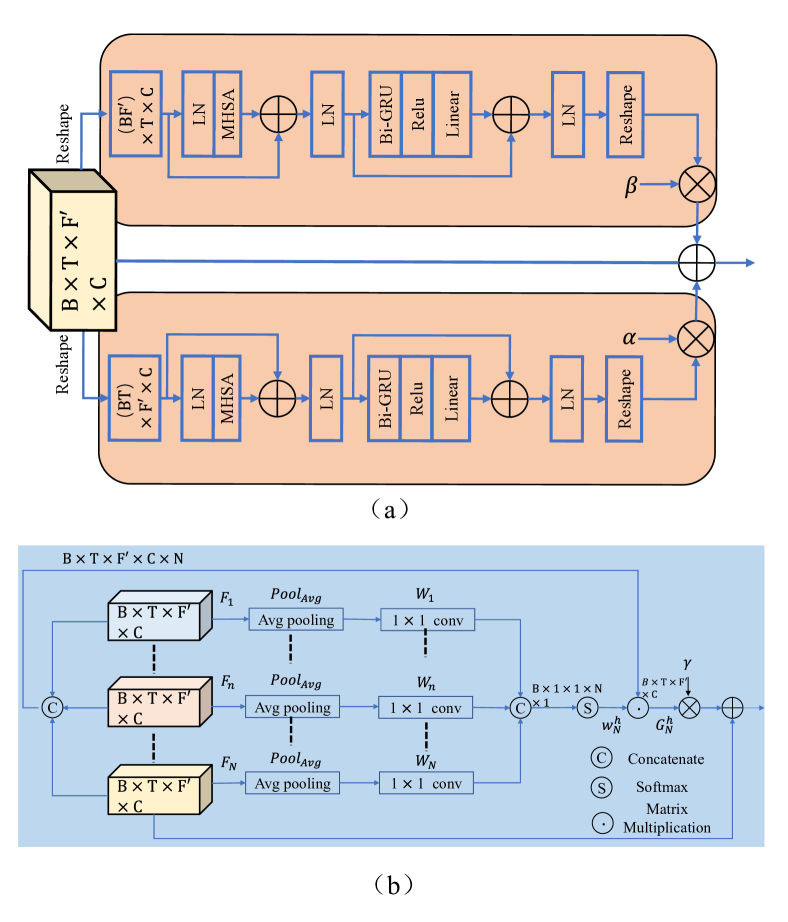
III-B 注意力中的注意力 Transformer
与循环神经网络(RNN)或卷积神经网络(CNN)相比,基于 Transformer 的神经网络可以通过直接根据上下文对语音序列进行建模来有效解决长依赖性问题,并且可以很好地并行运行,表现出了显着的性能在语音增强区域[9,23,24,25]。 在我们的注意力中注意力 Transformer (AIAT)中,我们只利用原始 Transformer [26]中的编码器部分,它由多头缩放点积自注意力和位置方向组成前馈网络类似于[9, 23]。
在将压缩特征输入每个分支的 AIAT 之前,我们将通道轴上两个分支的输出连接起来,并使用 2-D 卷积来合并信息,然后进行 PReLU 激活。 所提出的AIAT模块由四个基于自适应时频注意变换器(ATFAT)的模块和一个自适应分层注意(AHA)模块组成,如图2所示。 每个 ATFAT 都可以以相对较低的计算成本增强远程谱时依赖性,并且 AHA 模块可以聚合不同的中间特征以捕获全局多尺度上下文信息,如 [28,29,30]< 中指出的/t0>. ATFAT 和 AHA 模块协作形成“attention-in-attention”结构,这表明 ATFAT 的输出可以通过 AHA 根据自适应注意力权重进一步增强和集成。
III-B1 自适应时频注意力 Transformer
为了减轻传统自注意力的繁重计算复杂性,我们引入了自适应时频注意力(ATFA)机制作为一种轻量级解决方案来捕获时间轴和频谱轴上表现出的远程相关性,如[31]中所述。 ,28]。 如图2(a)所示,ATFAT在时间和频率轴上分为两个子分支,即自适应时间注意分支(ATAB)和自适应频率注意分支(AFAB) ),它可以与两个自适应权重 和 并行地捕获沿时间和频谱维度的全局依赖性。 在每个分支中,与普通 Transformer 不同,采用了基于 GRU 的改进 Transformer [9],它由多头自注意力(MHSA)和基于 GRU 的位置网络组成,然后是剩余连接和 LN。 多头自注意力已广泛应用于自然语言处理和语音处理领域,因为它可以利用特征图中的上下文信息[26,32,31,28]。 在 MHSA 模块中,输入特征首先使用不同的线性投影 次进行映射,以获得查询 、键 和值 表示,其中 表示 MHSA 模块中的头数。 然后,对每个头操作缩放后的点积注意力以获得值的加权和,其中权重是通过查询和相应键的注意力函数获得的。 最后,将所有头的注意力连接并线性变换以获得最终输出。 给定输入特征,ATAB中的注意力块可以写为:
| (9) |
其中表示ATAB的重塑输入,和分别是线性映射的查询、键和值。 和是线性变换矩阵。 这里,、、和分别表示批量大小、帧数、压缩频率维度和通道数, 分别。 在我们的模型中,头数 设置为 4。 随后,受到基于 GRU 的 Transformer 在语音分离和去噪任务中的有效性的启发[9, 23],我们将普通 Transformer 中前馈网络的第一个全连接层替换为双向格鲁乌。 最终输出是通过将多头注意力块的输出输入基于 GRU 的前馈网络,然后进行残差连接和层归一化来计算的:
| (10) |
其中表示基于GRU的位置前馈网络的输出,表示线性变换,表示偏差。 这里,和在此模块中设置为64。 然后,我们将 ATAB 的最终输出重塑为原始大小,即、。 类似地,我们将压缩的输入特征重塑为维度为 的 向量,并将其输入 AFAB 来计算输出,即、,沿频率轴平行。 最后,将两个分支的输出特征和原始特征再通过两个可学习的自适应权重和组合起来,得到ATFA模块的最终输出,然后是一个PReLU激活层和二维卷积层,可以表示为:
| (11) |
其中 和 初始化为 1 并自动分配给合适的值。 在每个 ATFAT 模块之后,采用 PReLU 激活和 2-D 卷积层,内核大小和步幅设置为 (1, 1)。
III-B2 自适应分层注意力模块
给定所有 ATFAT 模块的输出 ,所提出的 AHA 模块旨在根据全局上下文集成不同的中间特征图。 这里,是ATFAT的数量,论文中设置为4。 在AHA模块中,我们首先级联每个ATFAT的所有中间输出(即,)以获得全局特征图。 上标表示自适应分层注意力。 对于 ATFAT 的每个输出特征,我们采用平均池化层 和 卷积层将每个 ATFAT 的输出特征压缩为全局表示:,然后将所有池化输出级联为。 之后,我们应用softmax函数来导出分层注意力图,它可以定义为:
| (12) |
其中 表示第 个池化输出与 的注意力权重。 随后,我们通过和分层注意力权重之间的矩阵乘法来执行全局上下文信息建模,可以由下式给出:
| (13) |
其中表示ATFAT的第中间输出,表示卷积层,表示组合的全局层次结构特征。 最终的输出可以通过最后一个ATFAT模块输出和全局上下文特征图的线性组合得到,即,:
| (14) |
其中 是零初始化的可学习标量系数。 在训练过程中,这种自适应学习权重可以自动学习分配合适的值来合并更多的全局上下文信息。
III-C 交互模块
在 DBT-Net 中,MEB 和 CPB 路径被设计为分别估计光谱幅度和残留复杂光谱细节,这表明这两个分支协同促进光谱恢复。 为了更好地指导每个分支内的序列建模过程,我们进一步设计了一个交互模块来在MEB和CPB之间交换信息。 通过这种方式,可以利用来自 MEB 的外部信息作为辅助,引导 CPB 更多地关注 MEB 路径中可能丢失的光谱细节,反之亦然。
交互模块的结构如图1(e)所示。 以MEB路径的交互为例,我们首先将MEB的中间特征(即,)与CPB的中间特征(即)连接起来,)。 然后,将级联特征输入掩模模块以导出增益函数,该函数由2-D卷积、层归一化和sigmoid函数组成。 具体来说,增益函数会自动学习过滤并保留的不同区域。 然后通过将 与 元素相乘来获得过滤后的表示。 最后,我们将 MEB 路径的中间特征和 CPB 路径的过滤特征相加,得到 MEB 路径的最终交互特征,随后将其输入到 MEB 中的下一个序列建模模块中。 类似地,我们将 CPB 的中间特征(即、)与 MEB 的中间特征(即、)连接在一起,然后将其送入交互模块以获得CPB路径的交互特征。 请注意,在图1(e)中,对于MEB路径中的交互操作,“Branch-2 Features”表示来自幅度分支的压缩特征,“Branch-1 Features”表示来自复杂分支的压缩特征,反之亦然。 CPB 路径中亦然。 整个过程计算如下:
| (15) | ||||
其中 表示通道轴、卷积、层归一化和 sigmoid 操作中的串联。 表示逐元素乘法。 在我们的模型中,我们在每个 ATAFT 之间采用了四个交互模块。
III-D 掩蔽解码器
在 MEB 路径中,掩蔽解码器利用 AIAT 的输出特征来获取幅度域中的增益函数以进行噪声抑制。 请注意,预言幅度掩模的范围被认为是无界的,即,,这很难准确估计。 在这方面,我们使用sigmoid函数将光谱增益的值缩放为,并且掩模值超过1的剩余区域可以通过CPB进一步补偿。
掩蔽解码器的结构如图1(d)所示,主要由膨胀率的膨胀密集块、子像素二维卷积具有上采样因子2的层和双路径掩模模块。 利用子像素卷积对压缩特征进行上采样,在图像和语音处理领域都证明了其有效性[33]。 然后,执行双路径掩模模块,通过二维卷积和双路径 tanh/sigmoid 非线性运算获得幅度谱增益,然后进行 2-D 卷积和 sigmoid 激活。 最终的屏蔽频谱幅度是通过输入噪声频谱幅度和估计频谱增益之间的逐元素相乘获得的。 然后,MEB 中的滤波幅度与其相应的噪声相位相结合,以获得干净的复杂频谱的粗略估计。
III-E 复杂解码器
在CPB中,两个解码器被设计来并行重建残余RI分量,其目的是细化复值谱域中的谱细节。 如图1(c)所示,实部和虚部解码器均由膨胀率的膨胀密集块、子像素二维卷积、和 2-D 卷积。 复杂解码器中子像素二维卷积层的上采样因子设置为2,内核大小为(1, 3)。 然后将 CPB 路径的输出残余 RI 分量与 MEB 中的粗去噪复频谱合并,以获得最终的估计频谱。
III-F 损失函数
所提出的两分支模型的损失函数由最终估计的复谱计算,可以表示为:
| (16) | |||
| (17) | |||
| (18) |
其中和分别表示针对幅度和RI约束的损失函数。 表示均方误差 (MSE) 损失。 这里,表示估计语音频谱的RI部分,而表示干净语音频谱的RI部分。 在等式中。 (18) 中,完整的损失函数是幅度和 RI 损失函数的线性组合,据报道,这两项共同提高了语音质量[34,17,35]。 通过内部试验,我们在以下实验中凭经验设置。
IV 实验
IV-A 数据集
我们首先将所提出的模型与在 VoiceBank + DEMAND 上模拟的广泛使用的数据集上的几个最先进的基线进行比较,并进一步在 WSJ0-SI84 数据集 + DNS 挑战上评估我们的模型。
VoiceBank + DEMAND:本工作中使用的数据集是公开可用的,如[36]中提出的,它是 VoiceBank 语料库[37]中的一个选择t2> 有 28 个扬声器用于训练,另外 2 个未见过的扬声器用于测试。 训练集包含 11,572 个噪声-干净对,而测试集包含 824 对。 对于训练集,音频样本与 10 种噪声类型之一混合(包括两个人工噪声过程,即,胡言乱语和语音形状的噪声,以及从需求中获取的八个真实录音噪声过程)数据库[38])在四个SNR,即,。 测试话语是使用从需求数据库中获取的 5 个不可见噪声(SNR 为 )创建的。
WSJ0-SI84 + DNS 挑战:我们还研究了所提出的框架在 WSJ0-SI84 语料库 [39] 上的性能,该语料库由 83 个说话者的 7138 个干净话语组成( 42 名男性和 41 名女性)。 我们分别从 77 个说话者中随机选择 5,428 个训练话语和 957 个验证话语。 此外,还提供了两种类型的测试集,每种测试集包括 6 个未经训练的说话者(3 名男性和 3 名女性)说出的 150 条话语。 为了生成噪声-干净对,我们从 Interspeech 2020 DNS-Challenge [40] 中随机选择约 20,000 个环境噪声作为噪声集,其持续时间约为 55 小时。 在混合过程中,提取随机噪声削减,然后与随机采样的话语混合,信噪比从-5dB到0dB,间隔为1dB。 结果,我们总共生成了大约 150,000 和 10,000 个噪声干净对用于训练和验证。 训练总时长约为300小时。 对于模型评估,采用两个具有挑战性的未经训练的噪声过程来演示模型泛化能力,即 babble 和来自 NOISEX92 [41] 的factory1。 设置四种 SNR 情况,即、,并为每种情况生成 150 个噪声-干净对。
IV-B 实施设置
对于 VoiceBank 和 WSJ0-SI84 数据集,所有话语均以 16 kHz 重新采样,并分别分块为 3 秒和 4 秒。 选择长度为 20 ms 的汉宁窗,连续帧之间有 50% 的重叠。 利用320点STFT,可以获得161维光谱特征。 由于压缩幅度/复频谱在去混响和降噪任务[18, 42]中的功效,我们在保持相位不变的情况下对幅度进行功率压缩,并设定最佳压缩系数到 0.5,即、作为输入,作为目标。 所有模型均使用 Adam [43] 进行优化,学习率为 8e-4。 对于 VoiceBank + DEMAND 基准测试,网络训练总共进行了 80 个 epoch,而在批量大小为 4 的 WSJ0-SI84 + DNS Challenge 基准测试上进行了 40 个 epoch。 我们在线提供不同模型处理的增强语音样本,并发布源代码和预训练模型。111https://github.com/yuguochencuc/DBT-Net
IV-C 基线
在本研究中,我们首先将我们的模型与 WSJ0-SI84 + DNS 数据集上的各种先进系统进行比较。 为了公平比较,我们用非因果设置重新实现了所有基线,即 BiLSTM [44]、BiCRN [21]、GRN [45]、DCN [46]、AECNN [47]、ConvTasNet [48](非因果版本)、DPRNN [8](非因果版本)、TSTNN [9]、BiDCCRN [49]、BiGCRN [15] 和CTS-Net [17]0>(非因果版本),其中 BiLSTM、BiCRN、DPRNN(非因果版本)和 BiGCRN 分别与 LSTM、CRN、原始 DPRRN 和 GCRN 类似,并且唯一的区别是所有 LSTM 层都被其双向版本替换。 请注意,为了公平比较,所有基线都使用非因果配置重新实现。
BiLSTM和BiCRN是两种基于幅度的方法,前者引入了基于双向RNN的SE模型,后者采用了具有编码器-解码器架构的典型卷积循环网络(CRN)。 BiGCRN 是一种具有 CRN 的高级复杂频谱映射网络,其中估计 RI 分量以进行幅度和相位恢复,并且编码器和解码器中的所有常规卷积都被门控线性单元 (GLU) 取代[50]。 GRN 和 DCN 都基于全卷积网络 (FCN),其中包含扩张的 GLU [51] 和用于幅度恢复的残差连接。 AECNN 是一种先进的时域模型,其中时域样本由典型的一维 U-Net 直接估计。 DPRNN 和 TSTNN 是两种最先进的双路径时域方法,前者采用双路径递归神经网络,后者采用双路径 Transformer 对长序列进行建模。 请注意,为了进一步提高 DPRNN 的性能,我们尝试使用相位约束(PCM)损失的情况来代替原始的时域 SI-SNR 损失,这是在[52]中提出并证明的比 SI-SNR 损失更好的性能。 所有基线均使用报告文献中提到的最佳参数配置进行训练,但设置了以下几个修改。 首先,对于 BiCRN,除了 RI 损失外,我们还引入了幅度约束以获得更好的客观性能,据报道这可以减轻幅度失真[34]。 其次,对于 AECNN,输入和输出的帧大小为 16384 个样本,帧重叠率为 50%,即,每帧可以利用大约 1 秒的上下文。 此外,除了使用[47]中报告的频率损失之外,我们还添加了时域损失作为多任务学习,并且可以根据经验获得更好的性能。 最后,我们将 ConvTasNet 和 DPRNN 扩展到 16 kHz 采样率进行模型比较,而它们最初在语音分离任务中工作于 8 kHz 采样率。
为了与 VoiceBank + DEMAND 基准进行比较,我们进一步采用了几种最先进的 (SOTA) SE 基线,其中包括六种时域方法(例如、SEGAN [11] 、SERGAN [53]、MHSA-SPK [54]、TSTNN [9]、DEMUCS [7] 和 SE-Conformer [55])和十种 T-F 域方法(即、MMSEGAN [56]、MericGAN [57]、DCCRN [49]0>、CRGAN [58]1>、RDL-Net [59]2>、T-GSA [60]3>、PHASEN [61]4>、GaGNet [19]5> 和 MetricGAN+ [62]6>)。 SEGAN、SERGAN、MMSEGAN、MetricGAN、CRGAN 和 MetricGAN+ 均基于生成对抗网络 (GAN),其中生成器 () 旨在执行增强过程,鉴别器 ()旨在区分生成的语音特征和真实的干净语音特征。 请注意,MetricGAN 和 MetricGAN+ 通过预训练的与指标相关的判别器针对一个或多个评估指标(例如 PESQ 和 STOI)来优化生成器。 MHSA-SPK、T-GSA、TSTNN 和 SE-Conformer 都采用多头自注意力机制来捕获长期时间序列信息以获得更好的性能,其中后三个模型是在基于 Transformer 的网络上进行的。 RDL-Net 引入了一种新颖的残差密集网格网络,该网络并入基于 Deep Xi-MMSE-LSA 的框架[63, 64]中,以估计先验 SNR。 DEMUCS 是一种在原始波形域上工作的 SOTA 实时 SE 模型,它引入了时域 L1 损失以及频谱幅度上的多分辨率 STFT 损失。 PHASEN和GaGNet都属于先进的双分支相位感知SE方法,其中幅度和相位同时恢复。
| Metrics | id | Feat. | AIA structure | Inter. | Para. | MACs | TBT | PESQ | ESTOI(%) | SDR(dB) | ||||||||||||
| SNR(dB) | ATAB | AFAB | AHA | (M) | (G/s) | (s) | -3 | 0 | 3 | Avg. | -3 | 0 | 3 | Avg. | -3 | 0 | 3 | Avg. | ||||
| Unprocessed | - | - | - | - | - | - | - | - | - | 1.58 | 1.76 | 1.97 | 1.77 | 33.37 | 42.43 | 52.18 | 42.66 | -2.92 | 0.04 | 3.04 | 0.16 | |
| Magnitude-branch models | ||||||||||||||||||||||
| MEB-Net | 1 | Mag | ✓ | ✗ | ✗ | - | 0.64 | 8.04 | 0.60 | 2.32 | 2.48 | 2.72 | 2.51 | 60.17 | 66.32 | 72.21 | 66.23 | 4.58 | 7.12 | 9.67 | 7.12 | |
| MEB-Net | 2 | Mag | ✗ | ✓ | ✗ | - | 0.64 | 7.99 | 0.53 | 2.38 | 2.57 | 2.78 | 2.58 | 62.01 | 69.56 | 76.09 | 69.22 | 5.78 | 8.03 | 10.56 | 8.12 | |
| MEB-Net | 3 | Mag | ✓ | ✓ | ✗ | - | 0.90 | 9.71 | 1.35 | 2.47 | 2.71 | 2.92 | 2.70 | 63.91 | 72.01 | 77.89 | 71.27 | 6.42 | 8.86 | 11.02 | 8.77 | |
| MEB-Net | 4 | Mag | ✓ | ✓ | ✓ | - | 0.90 | 9.72 | 1.38 | 2.52 | 2.76 | 3.00 | 2.76 | 64.48 | 72.24 | 78.55 | 71.76 | 6.99 | 9.05 | 11.14 | 9.06 | |
| Complex-branch models | ||||||||||||||||||||||
| CPB-Net | 1 | RI | ✓ | ✗ | ✗ | - | 0.91 | 10.22 | 0.66 | 2.48 | 2.74 | 3.01 | 2.74 | 64.27 | 71.16 | 78.01 | 71.14 | 7.03 | 9.68 | 11.02 | 9.24 | |
| CPB-Net | 2 | RI | ✗ | ✓ | ✗ | - | 0.91 | 10.17 | 0.58 | 2.54 | 2.81 | 3.06 | 2.80 | 66.16 | 73.68 | 79.51 | 73.12 | 7.79 | 10.03 | 11.61 | 9.81 | |
| CPB-Net | 3 | RI | ✓ | ✓ | ✗ | - | 1.18 | 11.89 | 1.43 | 2.63 | 2.89 | 3.12 | 2.88 | 68.23 | 75.46 | 81.03 | 74.91 | 8.47 | 10.82 | 12.04 | 10.44 | |
| CPB-Net | 4 | RI | ✓ | ✓ | ✓ | - | 1.18 | 11.89 | 1.47 | 2.70 | 2.97 | 3.18 | 2.95 | 69.56 | 76.78 | 82.22 | 76.19 | 9.34 | 11.21 | 12.79 | 11.11 | |
| Dual-branch models | ||||||||||||||||||||||
| DCB-Net | 1 | RI + RI | ✓ | ✓ | ✓ | ✓ | 3.18 | 42.76 | 2.27 | 2.74 | 3.02 | 3.22 | 2.99 | 70.28 | 76.93 | 82.69 | 76.63 | 9.56 | 11.71 | 13.49 | 11.59 | |
| DBT-Net♠ | 1 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 2.91 | 40.59 | 2.20 | 2.83 | 3.06 | 3.27 | 3.05 | 72.60 | 79.43 | 84.47 | 78.83 | 9.97 | 11.99 | 13.85 | 11.94 | |
| DBT-Net (D=2) | 1 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 2.98 | 23.65 | 1.54 | 2.73 | 2.98 | 3.19 | 2.96 | 71.34 | 78.84 | 84.02 | 78.07 | 9.29 | 11.64 | 13.62 | 11.52 | |
| DBT-Net (D=3) | 2 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 3.08 | 12.48 | 0.96 | 2.65 | 2.86 | 3.12 | 2.88 | 69.01 | 75.94 | 81.51 | 76.25 | 8.59 | 10.47 | 12.71 | 10.76 | |
| DBT-Net (D=4) | 3 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 3.18 | 6.92 | 0.62 | 2.57 | 2.79 | 3.03 | 2.79 | 67.82 | 74.65 | 80.78 | 74.42 | 8.13 | 10.21 | 12.17 | 10.17 | |
| DBT-Net | 1 | Mag + RI | ✓ | ✗ | ✗ | ✗ | 2.08 | 27.67 | 1.46 | 2.62 | 2.90 | 3.09 | 2.87 | 68.28 | 76.32 | 80.99 | 75.20 | 8.62 | 10.93 | 12.19 | 10.58 | |
| DBT-Net | 2 | Mag + RI | ✗ | ✓ | ✗ | ✗ | 2.08 | 27.49 | 1.29 | 2.66 | 2.92 | 3.11 | 2.90 | 70.19 | 76.83 | 82.04 | 76.35 | 9.31 | 11.12 | 12.85 | 11.09 | |
| DBT-Net | 3 | Mag + RI | ✓ | ✓ | ✗ | ✗ | 2.80 | 40.12 | 2.06 | 2.74 | 3.01 | 3.16 | 2.97 | 71.16 | 77.69 | 83.87 | 77.57 | 9.53 | 11.65 | 13.42 | 11.53 | |
| DBT-Net | 4 | Mag + RI | ✓ | ✓ | ✓ | ✗ | 2.81 | 40.13 | 2.13 | 2.87 | 3.10 | 3.29 | 3.09 | 74.32 | 80.56 | 85.09 | 79.99 | 10.49 | 12.37 | 14.06 | 12.31 | |
| DBT-Net | 5 | Mag + RI | ✓ | ✓ | ✓ | ✓ | 2.91 | 40.59 | 2.19 | 2.89 | 3.13 | 3.32 | 3.11 | 75.07 | 81.11 | 85.55 | 80.57 | 10.60 | 12.57 | 14.36 | 12.51 | |
IV-D 评估指标
在WSJ0-SI84 + DNS基准测试中,我们使用语音质量感知评估(PESQ)[65]、扩展短时客观可懂度(ESTOI)[66]和SDR[67]作为评估不同模型增强性能的客观指标。 PESQ用于评估感知语音质量,其得分范围为至。 请注意,我们对 WSJ0-SI84 + DNS 数据集使用 ITU-T P.862.2 中推荐的窄带版本。 ESTOI是STOI的扩展版本,用于测量语音清晰度[68],其中取消了频段之间相互独立的假设。 ESTOI 分数范围为 0 到 1。 SDR广泛应用于盲语音分离,评估波形中的语音失真程度。 对于 VoiceBank + DEMAND 语料库,我们使用宽带 PESQ (WB-PESQ)、STOI 和三个 MOS 指标[69](即 CSIG、CBAK 和 COVL )来评估语音质量。 这里,CSIG、CBAK和COVL分别被设计用于测量信号失真、背景噪声质量和整体音频质量评估。 所有三个 MOS 分数范围为 1 到 5。 除了上述侵入性指标外,还采用 DNSMOS 来评估感知语音质量[70],这是一个鲁棒的非侵入性感知语音质量指标,作为主观分数的代理,范围从 1 到5. 所有上述指标的值越高表明语音质量越好。
V 结果与分析
V-A WSJ0-SI84 + DNS 挑战赛的消融研究
对于消融研究,我们在 WSJ0-SI84 + DNS Challenge 上创建了一个较小的数据集。 对于训练,我们在 的 SNR 范围内分别建立 15000、1500 个噪声-干净对,用于训练和验证。 训练总时长约为30小时。 为了进行测试,在可见和不可见的扬声器(即、上使用来自 NOISEX92 的工厂 1 噪声设置了三个 SNR 情况,并为每种情况生成 150 个噪声-干净对。 消融研究的结果如表II所示,研究了不同AIA结构、双分支策略和交互模块的影响。 具体来说,MEB-Net(1)-(4)仅估计幅度域中的频谱增益并保留不变的相位信息,而CPB-Net(1)-(4)估计干净复杂频谱的RI部分。 MEB-Net 和 CPB-Net 的配置类似于表I中的配置。 MEB-Net采用密集卷积编码器、无信息交互的AIAT和幅度掩蔽解码器。 CPB-Net 采用类似的编码器、AIAT 和两个独立的解码器来解码干净复杂频谱的 RI 分量。 通过合并 MEB-Net 和 CPB-Net,DBT-Net (1)-(5) 旨在并行估计干净复杂频谱的幅度谱增益和残余 RI 分量。 此外,还实现了另外两个双分支模型来研究单独估计光谱幅度和残留复杂光谱细节的有效性。 具体来说,我们采用双分支 CPB-Net(称为 DCB-Net)来估计 RI 分量和残余复杂光谱细节,其可以表示为:
| (19) | |||
| (20) |
其中表示DCB-Net中第一个分支估计的RI分量,表示第二个分支估计的残余RI分量。 表示DCB-Net的最终RI估计。 然后,我们实现另一个双分支网络,称为DBT-Net♠,来估计光谱幅度和干净复杂光谱的整个 RI 分量,而不是残留 RI组件并联。 在 DBT-Net♠ 中,幅度分支(即、MEB♠)旨在估计频谱幅度,而复杂分支(即,CPB♠)旨在恢复干净复频谱的整个RI分量,而不是像我们提出的重建策略中那样估计残留复频谱。 最后,我们对 MEB♠ 和 CPB♠ 估计的频谱幅度进行平均,并使用 CPB♠ 估计的相位来获得最终的 RI 分量干净的复杂光谱。 整个过程可以表述为:
| (21) | |||
| (22) | |||
| (23) | |||
| (24) |
其中 表示 CPB♠ 路径的输出 RI 分量。 和表示MEB♠和CPB♠的估计频谱幅度。 和 分别表示干净复频谱的最终输出频谱幅度和相位。
我们还研究了单分支和双分支方法中的不同注意机制。 例如,MEB-Net(1)和(2)在所提出的基于 Transformer 的网络中仅采用自适应时间注意分支(ATAB)或自适应时间注意分支(AFAB),而MEB-Net(3)利用组合ATAB 和 ATFB 作为 ATFA 模块。 然后,我们将 ATFA 模块和 AHA 模块合并为 MEB-Net 中的注意力中注意力结构(4)。 CPB-Net (1)-(4) 和 DBT-Net (1)-(4) 分别利用与 MEB-Net (1)-(4) 相同的注意机制。 最后,我们在 DBT-Net (5) 中添加交互模块来研究信息交互的影响。 此外,我们实现了另外三个类似于 DBT-Net (5) 的双分支框架,即 DBT-Net (D=2)、DBT-Net (D=3) 和 DBT-Net (D=4),以研究在我们的模型中使用更多下采样层的影响。 具体来说,DBT-Net(D=2)在编码器中使用两个2-D卷积下采样层,在解码器中使用两个对称的2-D卷积上采样层,在DBT-Net(1)-(5)中设置为1 。 也就是说,在DBT-Net中将编码特征的频率维度下采样到40(D=2)。 类似地,DBT-Net (D=3) 和 DBT-Net (D=4) 在编码器中分别采用三个和四个二维卷积下采样层。 这些值是根据可见和不可见的扬声器条件进行平均的。
V-A1 AIA结构的影响
我们首先分析序列建模网络中不同注意机制的效果。 如表II所示,以基于幅度的方法(MEB-Net)为例,增强语音的客观性能受到严重限制。 当结合 ATAB 和 AFAB 来捕获光谱时间依赖性时,MEB-Net (3) 在 PESQ、ESTOI 和 SDR 方面显着优于 MEB-Net (1) 和 MEB-Net (2)。 例如,从 MEB-Net (1) 到 MEB-Net (3),PESQ、ESTOI 和 SDR 的得分提高了约 0.19、5.04% 和 1.65dB,在可见和不可见的说话者条件下进行平均。 在复杂路径模型(CPB-Net(1)-(3))和双分支模型(DBT-Net(1)-(3))中也观察到类似的结果。 这表明了同时并行捕获谱时上下文信息的优点。 然后,通过添加自适应分层注意力(AHA)模块作为注意力中的注意力拓扑,可以在所有指标中获得一致更好的语音性能。 例如,MEB-Net (4) 比 MEB-Net (3) 平均提高 0.06 PESQ、0.49% ESTOI 和 0.29dB SDR,参数负担几乎相同。 CPB-Net 和 DBT-Net 也观察到类似的趋势。 这验证了所提出的AIA结构在提高语音质量和清晰度方面的有效性。
V-A2 双分支策略的效果
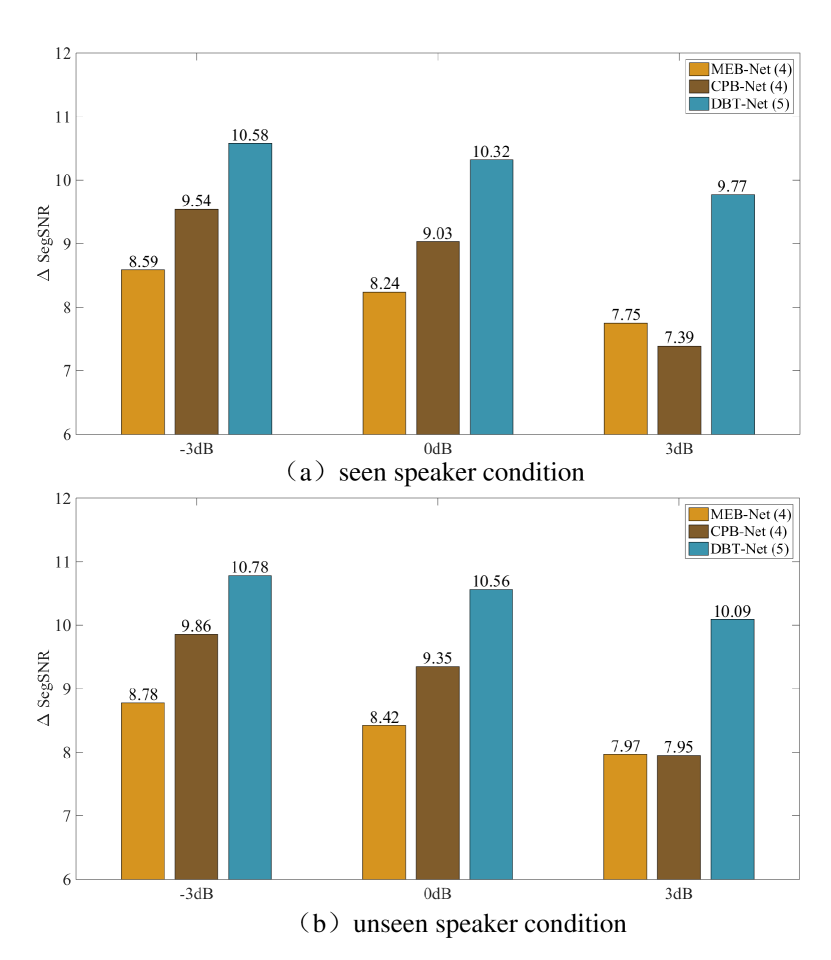
然后,我们研究了双分支策略即、幅度估算路径和复合精炼路径的影响。 首先,在使用单分支时,复合频谱映射方法(即)、CPB-Nets 始终超过幅度频谱估计方法(即 MEB-Nets)。 这表明相位恢复对于提高语音质量和清晰度的重要性。 然而,虽然涉及相位恢复,但单分支方法的性能有限。 潜在的原因是,当直接估计整个RI分量时,相位被隐式优化,并且幅度可能偏离其最优优化路径,导致次优解。 当联合合并幅度估计分支和复杂精炼分支时,DBT-Nets 的性能显着优于单分支方法。 例如,对于 PESQ、ESTOI 和 SDR,DBT-Net (4) 比 CPB-Net (4) 平均得分提高了 0.21、3.80% 和 1.87dB,在可见和不可见的说话者条件下进行平均。 随后,与其他双分支模型(即、DCB-Net和DBT-Net♠)相比,所提出的双分支模型始终获得更好的性能。 当仅直接估计干净复杂频谱的RI分量时,DCB-Net比单分支CPB-Net获得相对边际的改进,这表明在两个头中解耦幅度和相位恢复的有效性。 与此同时,DBT-Net (5) 在所有指标方面都大大超过了 DBT-Net♠,同时模型计算成本也类似。 这验证了双分支策略的优越性,即,通过两个分支消除了幅度域的主要噪声,并恢复了残余的复数细节。
此外,我们还提供了单分支(MEB-Net (4) 和 CPB-Net (4))的分段 SNR 改进(SegSNR)[71]在可见和不可见的说话人条件下,对未处理的混合物进行双分支方法(即,DBT-Net (5)),如图3(a)和(二)。 可以观察到,DBT-Net 比单分支基线产生了显着更大的 SegSNR 改进,在 -3dB、0dB、3dB SNR 情况下实现了超过平均 10dB SegSNR 改进。 这些观察结果充分强调了所提出的双分支策略在语音质量和清晰度方面的显着优越性。
V-A3 交互模块效果
最后我们研究了两个分支之间的信息交互模块的效果。 在介绍了 MEB 路径和 CPB 路径之间的信息流之后,可以观察到 DBT-Net(5)始终优于 DBT-Net(4),仅参数大小增加了一点。 例如,从 DBT-Net (4) 到 DBT-Net (5),PESQ、ESTOI 和 SDR 的得分提高了约 0.02、0.58% 和 0.20dB,在可见和不可见的说话者条件下进行平均。 这些结果表明,交互模块确实有助于同时进行幅度估计和复杂的光谱细节细化,从而实现更好的光谱恢复。
V-A4 模型复杂性讨论
在表II中,我们提供了模型之间参数数量、每秒乘法累加操作(MAC)和训练批处理时间(TBT)方面的详细模型复杂性比较。 具体来说,我们使用持续时间为一秒的话语来测量 MAC,并在具有 24 GB RAM 的 Tesla M40 上使用一秒话语和批量大小为 4 的数据来评估 TBT。 从表II可以看出,虽然所提出的DBT-Net实现了较低的可训练参数,但MAC相对较高,导致计算成本较高。 这是因为,为了通过自适应频率注意分支(AFAB)更好地建模沿不同频段的依赖性,我们仅沿频率轴采用一个下采样层,从而导致相对较高的频率维度编码特征和较大的 MAC。
然后我们研究计算成本和客观性能改进之间的权衡。 如表II所示,当编码器中使用更多下采样操作时,DBT-Net(D=2)、(D=3)和(D=4)可以有效减少MAC和TBT稍微增加参数大小。 然而,由于特征的频率维度降低导致频率轴上的序列建模不充分,DBT-Net(D=2)-(D=4)也随着下采样层数的增加而降低了语音增强性能。频率轴。 例如,DBT-Net (D=2) 使 DBT-Net (5) 的 PESQ、1.51% ETOI 和 0.99dB SDR 分数下降约 0.15,同时 MAC 下降约 16.94 G/s。 这表明,利用更多的下采样层可以降低计算成本,但会稍微增加参数负担,同时会降低语音增强性能。 在实际应用中,我们可以根据不同的设备需求,通过调整下采样层数和卷积核的数量,灵活地平衡参数数量和计算成本。 在接下来的实验中,为了以较小的模型尺寸获得最佳性能,所有模型仅在密集编码器-解码器中采用一次下采样-上采样操作,并且在序列建模期间将频率维度设置为80。 对于实际应用,通常希望减少参数负担和计算复杂度,这可以在未来的研究中进行研究。
| Metrics | Cau. | Feat. | PESQ | ESTOI(%) | SDR(dB) | |||||||||||||
| SNR(dB) | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | |||
| Babble Noise | Noisy | - | - | 1.72 | 1.88 | 2.06 | 2.25 | 1.98 | 34.76 | 43.27 | 51.95 | 61.61 | 47.90 | -2.94 | 0.04 | 3.03 | 6.03 | 1.54 |
| BiLSTM [44] | ✗ | Mag | 2.41 | 2.68 | 2.90 | 3.09 | 2.77 | 67.20 | 75.22 | 80.26 | 84.39 | 76.77 | 4.86 | 7.33 | 9.53 | 11.66 | 8.35 | |
| BiCRN [21] | ✗ | Mag | 2.38 | 2.64 | 2.84 | 3.04 | 2.73 | 66.05 | 73.67 | 79.10 | 83.63 | 75.61 | 4.90 | 7.36 | 9.52 | 11.78 | 8.39 | |
| GRN [45] | ✗ | Mag | 2.16 | 2.37 | 2.54 | 2.70 | 2.44 | 59.92 | 68.20 | 74.35 | 79.74 | 70.55 | 4.37 | 6.82 | 9.05 | 11.25 | 7.87 | |
| DCN [46] | ✗ | Mag | 2.15 | 2.41 | 2.62 | 2.82 | 2.50 | 57.38 | 66.26 | 72.99 | 78.59 | 68.81 | 4.16 | 6.75 | 9.03 | 11.21 | 7.79 | |
| AECNN [47] | ✗ | waveform | 2.30 | 2.63 | 2.90 | 3.13 | 2.74 | 64.84 | 73.49 | 79.62 | 84.14 | 75.52 | 7.16 | 9.84 | 11.96 | 13.95 | 10.73 | |
| ConvTasNet [48] | ✗ | Waveform | 2.67 | 2.96 | 3.18 | 3.35 | 3.04 | 74.97 | 81.67 | 85.81 | 88.82 | 82.82 | 9.51 | 12.21 | 14.20 | 15.98 | 12.96 | |
| DPRNN [8] | ✗ | Waveform | 2.86 | 3.14 | 3.33 | 3.47 | 3.20 | 78.09 | 81.67 | 86.25 | 88.33 | 83.59 | 10.09 | 12.21 | 14.04 | 15.98 | 13.08 | |
| TSTNN [9] | ✗ | Waveform | 2.62 | 2.92 | 3.17 | 3.38 | 3.02 | 72.23 | 74.99 | 83.62 | 88.01 | 79.71 | 9.01 | 12.18 | 13.48 | 15.21 | 12.37 | |
| BiGCRN [15] | ✗ | RI | 2.59 | 2.88 | 3.11 | 3.28 | 2.97 | 70.12 | 77.90 | 83.09 | 86.58 | 79.42 | 7.62 | 10.14 | 12.23 | 14.17 | 11.04 | |
| BiDCCRN [49] | ✗ | RI | 2.46 | 2.77 | 2.99 | 3.22 | 2.86 | 65.62 | 73.04 | 79.81 | 86.06 | 76.13 | 7.36 | 9.78 | 12.21 | 14.39 | 10.93 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.76 | 3.05 | 3.24 | 3.39 | 3.11 | 74.94 | 81.33 | 85.22 | 88.23 | 82.43 | 9.16 | 11.61 | 13.46 | 15.14 | 12.34 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.53 | 2.82 | 3.06 | 3.27 | 2.92 | 67.93 | 75.56 | 81.36 | 86.19 | 77.76 | 7.24 | 8.86 | 11.28 | 13.26 | 10.16 | |
| CPB-Net(Pro.) | ✗ | RI | 2.69 | 2.98 | 3.17 | 3.39 | 3.06 | 72.79 | 75.95 | 84.37 | 88.49 | 80.40 | 8.81 | 11.37 | 12.88 | 14.69 | 11.94 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.89 | 3.18 | 3.38 | 3.55 | 3.25 | 78.22 | 83.78 | 87.51 | 90.01 | 84.06 | 10.57 | 12.72 | 14.50 | 16.20 | 13.50 | |
| Factory1 Noise | Noisy | - | Mag | 1.60 | 1.78 | 1.99 | 2.20 | 1.89 | 34.76 | 43.73 | 54.04 | 63.90 | 49.11 | -2.92 | 0.05 | 3.04 | 6.03 | 1.55 |
| BiLSTM [44] | ✗ | Mag | 2.53 | 2.75 | 2.96 | 3.14 | 2.85 | 68.40 | 75.18 | 80.54 | 84.78 | 77.23 | 5.89 | 8.03 | 10.20 | 12.19 | 9.08 | |
| BiCRN [21] | ✗ | Mag | 2.48 | 2.70 | 2.90 | 3.07 | 2.79 | 66.10 | 73.16 | 79.12 | 83.87 | 75.56 | 5.73 | 7.96 | 10.21 | 12.31 | 9.05 | |
| GRN [45] | ✗ | Mag | 2.26 | 2.43 | 2.58 | 2.70 | 2.49 | 62.06 | 69.70 | 76.09 | 81.25 | 72.28 | 5.60 | 7.86 | 10.07 | 12.10 | 8.91 | |
| DCN [46] | ✗ | Mag | 2.32 | 2.55 | 2.74 | 2.92 | 2.63 | 59.47 | 68.05 | 74.67 | 80.18 | 70.59 | 5.60 | 7.85 | 10.02 | 12.03 | 8.88 | |
| AECNN [47] | ✗ | Waveform | 2.44 | 2.72 | 2.97 | 3.16 | 2.82 | 64.12 | 72.74 | 78.86 | 83.54 | 74.82 | 8.14 | 10.26 | 12.14 | 13.92 | 11.11 | |
| ConvTasNet [48] | ✗ | Waveform | 2.79 | 3.02 | 3.20 | 3.36 | 3.09 | 75.11 | 81.04 | 85.20 | 88.39 | 82.43 | 10.16 | 12.14 | 13.96 | 15.64 | 12.97 | |
| DPRNN [8] | ✗ | Waveform | 2.91 | 3.13 | 3.30 | 3.43 | 3.19 | 77.03 | 81.85 | 86.21 | 89.15 | 83.56 | 10.46 | 12.72 | 14.08 | 15.74 | 13.25 | |
| TSTNN [9] | ✗ | Waveform | 2.72 | 2.94 | 3.21 | 3.42 | 3.08 | 71.46 | 76.23 | 82.62 | 87.82 | 79.53 | 9.82 | 11.67 | 13.75 | 15.03 | 12.57 | |
| BiGCRN [15] | ✗ | RI | 2.69 | 2.95 | 3.16 | 3.31 | 3.02 | 69.24 | 77.11 | 82.63 | 86.45 | 78.86 | 7.78 | 10.20 | 12.21 | 14.05 | 11.06 | |
| BiDCCRN [49] | ✗ | RI | 2.49 | 2.82 | 3.07 | 3.26 | 2.91 | 65.07 | 74.37 | 81.25 | 87.02 | 76.93 | 8.01 | 10.71 | 12.43 | 14.37 | 11.38 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.80 | 3.03 | 3.21 | 3.36 | 3.10 | 73.90 | 80.02 | 84.27 | 87.60 | 81.45 | 9.60 | 11.56 | 13.33 | 14.99 | 12.37 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.63 | 2.88 | 3.11 | 3.32 | 2.98 | 67.06 | 74.82 | 80.58 | 85.76 | 77.06 | 7.31 | 9.29 | 11.36 | 13.46 | 10.35 | |
| CPB-Net(Pro.) | ✗ | RI | 2.74 | 3.00 | 3.21 | 3.41 | 3.09 | 71.86 | 76.67 | 83.54 | 88.01 | 80.02 | 9.73 | 11.64 | 13.50 | 14.99 | 12.47 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.92 | 3.15 | 3.33 | 3.49 | 3.22 | 77.11 | 82.62 | 86.48 | 89.69 | 83.98 | 10.68 | 12.57 | 14.28 | 15.99 | 13.38 | |
| Metrics | Cau. | Feat. | PESQ | ESTOI(%) | SDR(dB) | |||||||||||||
| SNR(dB) | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | -3 | 0 | 3 | 6 | Avg. | |||
| Babble Noise | Noisy | - | - | 1.64 | 1.82 | 2.01 | 2.23 | 1.93 | 31.51 | 39.66 | 48.21 | 57.74 | 44.28 | -2.93 | 0.05 | 3.03 | 6.03 | 1.55 |
| BiLSTM [44] | ✗ | Mag | 2.30 | 2.58 | 2.79 | 2.99 | 2.67 | 63.26 | 71.51 | 77.17 | 85.02 | 74.24 | 4.92 | 7.29 | 9.41 | 11.48 | 8.28 | |
| BiCRN [21] | ✗ | Mag | 2.25 | 2.55 | 2.77 | 2.97 | 2.64 | 61.51 | 70.71 | 76.73 | 81.98 | 72.73 | 4.73 | 7.42 | 9.76 | 12.08 | 8.50 | |
| GRN [45] | ✗ | Mag | 2.08 | 2.32 | 2.54 | 2.72 | 2.42 | 56.52 | 65.57 | 72.66 | 78.85 | 68.39 | 4.21 | 6.76 | 9.18 | 11.62 | 7.94 | |
| DCN [46] | ✗ | Mag | 2.03 | 2.32 | 2.57 | 2.79 | 2.43 | 53.19 | 63.17 | 70.81 | 77.49 | 66.17 | 3.92 | 6.71 | 9.14 | 11.56 | 7.83 | |
| AECNN [47] | ✗ | Waveform | 2.24 | 2.59 | 2.86 | 3.10 | 2.69 | 62.64 | 72.11 | 78.37 | 83.57 | 74.18 | 6.26 | 9.90 | 12.12 | 14.20 | 10.62 | |
| ConvTasNet [48] | ✗ | Waveform | 2.58 | 2.89 | 3.12 | 3.30 | 2.97 | 72.36 | 79.81 | 84.49 | 87.94 | 81.14 | 9.50 | 12.00 | 14.08 | 16.00 | 12.89 | |
| DPRNN [8] | ✗ | Waveform | 2.82 | 3.07 | 3.31 | 3.43 | 3.16 | 76.86 | 82.45 | 86.51 | 87.94 | 83.44 | 10.19 | 12.74 | 14.13 | 15.86 | 13.23 | |
| TSTNN [9] | ✗ | Waveform | 2.59 | 2.93 | 3.12 | 3.36 | 3.00 | 71.97 | 74.64 | 82.37 | 87.95 | 79.23 | 9.98 | 12.63 | 14.03 | 15.79 | 13.11 | |
| BiGCRN [15] | ✗ | RI | 2.55 | 2.85 | 3.08 | 3.27 | 2.94 | 68.41 | 76.68 | 82.16 | 86.38 | 78.41 | 7.77 | 10.42 | 12.55 | 14.60 | 11.34 | |
| BiDCCRN [49] | ✗ | RI | 2.41 | 2.71 | 2.96 | 3.19 | 2.82 | 63.47 | 71.94 | 77.93 | 84.92 | 74.56 | 7.31 | 9.86 | 12.37 | 14.55 | 11.02 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.68 | 3.00 | 3.22 | 3.39 | 3.07 | 73.11 | 80.10 | 84.49 | 87.76 | 81.37 | 9.34 | 11.74 | 13.70 | 15.51 | 12.57 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.50 | 2.78 | 3.02 | 3.25 | 2.89 | 66.90 | 74.42 | 80.60 | 86.37 | 77.07 | 7.31 | 9.32 | 11.42 | 13.59 | 10.41 | |
| CPB-Net(Pro.) | ✗ | RI | 2.62 | 2.97 | 3.21 | 3.41 | 3.05 | 72.47 | 75.15 | 83.85 | 88.34 | 79.95 | 9.16 | 11.83 | 13.64 | 15.24 | 12.47 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.91 | 3.18 | 3.39 | 3.57 | 3.26 | 77.74 | 83.47 | 87.37 | 90.13 | 84.68 | 11.09 | 13.23 | 15.01 | 16.81 | 14.03 | |
| Factory1 Noise | Noisy | - | - | 1.55 | 1.75 | 1.96 | 2.17 | 1.86 | 31.97 | 41.13 | 50.32 | 59.78 | 45.80 | -2.92 | 0.04 | 3.04 | 6.03 | 1.55 |
| BiLSTM [44] | ✗ | Mag | 2.43 | 2.65 | 2.86 | 3.04 | 2.75 | 64.51 | 71.81 | 77.68 | 82.01 | 74.00 | 5.96 | 8.04 | 10.03 | 11.91 | 8.99 | |
| BiCRN [21] | ✗ | Mag | 2.40 | 2.63 | 2.84 | 3.01 | 2.72 | 62.72 | 70.76 | 77.02 | 81.81 | 73.08 | 5.90 | 8.20 | 10.39 | 12.57 | 9.26 | |
| GRN [45] | ✗ | Mag | 2.24 | 2.44 | 2.61 | 2.75 | 2.51 | 59.86 | 68.38 | 74.89 | 80.01 | 70.79 | 5.78 | 8.08 | 10.31 | 12.46 | 9.16 | |
| DCN [46] | ✗ | Mag | 2.26 | 2.51 | 2.73 | 2.90 | 2.60 | 56.89 | 66.11 | 73.40 | 78.94 | 68.84 | 5.67 | 8.05 | 10.31 | 12.42 | 9.11 | |
| AECNN [47] | ✗ | Waveform | 2.40 | 2.69 | 2.94 | 3.13 | 2.79 | 62.09 | 71.23 | 78.00 | 82.54 | 73.47 | 8.30 | 10.42 | 12.35 | 14.14 | 11.30 | |
| ConvTasNet [48] | ✗ | Waveform | 2.73 | 2.98 | 3.17 | 3.33 | 3.06 | 73.12 | 79.68 | 84.39 | 87.42 | 81.15 | 10.32 | 12.31 | 14.04 | 15.72 | 13.10 | |
| DPRNN [8] | ✗ | Waveform | 2.85 | 3.11 | 3.17 | 3.38 | 3.13 | 75.92 | 81.53 | 85.63 | 88.32 | 82.85 | 10.84 | 12.89 | 14.32 | 15.85 | 13.47 | |
| TSTNN [9] | ✗ | Waveform | 2.70 | 2.94 | 3.21 | 3.40 | 3.08 | 71.01 | 76.18 | 83.05 | 87.29 | 79.38 | 10.01 | 12.07 | 13.80 | 15.27 | 12.81 | |
| BiGCRN [15] | ✗ | RI | 2.65 | 2.93 | 3.14 | 3.30 | 3.01 | 66.94 | 76.06 | 81.90 | 85.77 | 77.67 | 8.19 | 10.54 | 12.61 | 14.42 | 11.44 | |
| BiDCCRN [49] | ✗ | RI | 2.45 | 2.78 | 3.04 | 3.23 | 2.88 | 64.54 | 73.87 | 80.81 | 86.38 | 76.39 | 8.37 | 10.92 | 12.81 | 14.98 | 11.77 | |
| CTS-Net [17] | ✗ | Mag+RI | 2.78 | 3.02 | 3.22 | 3.37 | 3.09 | 72.72 | 78.33 | 83.95 | 87.07 | 80.52 | 9.92 | 11.92 | 13.68 | 15.35 | 12.72 | |
| MEB-Net(Pro.) | ✗ | Mag | 2.61 | 2.85 | 3.08 | 3.26 | 2.95 | 65.48 | 74.41 | 79.22 | 86.68 | 76.45 | 7.76 | 9.61 | 11.91 | 14.16 | 10.86 | |
| CPB-Net(Pro.) | ✗ | RI | 2.75 | 3.00 | 3.22 | 3.42 | 3.10 | 71.17 | 78.50 | 84.11 | 88.05 | 80.46 | 9.94 | 11.98 | 13.81 | 15.25 | 12.74 | |
| DBT-Net(Pro.) | ✗ | Mag+RI | 2.97 | 3.19 | 3.37 | 3.51 | 3.26 | 77.01 | 82.62 | 86.64 | 89.53 | 83.95 | 11.35 | 13.20 | 14.88 | 16.51 | 13.99 | |
V-B 使用 WSJ0-SI84 + DNS Challenge 数据集与基线进行性能比较
基于之前的消融研究,选择 DBT-Net (5) 作为所提出框架的默认配置。 此外,我们还评估了两种提出的单分支方法的最佳性能,如表II(即,MEB-Net(4)和CPB-Net(4) ))作为参考。 然后,我们在 PESQ、ESTOI 和 SDR 方面将所提出的方法与先进的非因果时间和 T-F 域基线的性能进行比较,其客观结果如表 III 和 IV 从表III和IV的结果中,我们可以得到一些观察结果。
首先,我们重点比较基于幅度的方法。 与先进的基于幅度的方法相比,我们提出的 MEB-Net 始终优于其他基线。 以所见扬声器情况下的性能为例,MEB-Net 在 Babble 噪声上比 BiCRN 提供平均 0.19 PESQ、2.15% ESTOI 和 1.77dB SDR 分数改进,而在 Babble 噪声上平均 0.21 PESQ、1.50% ESTOI 和 1.30dB SDR 分数改进根据工厂 1 噪声提供。 它充分证明了所提出的 AIA Transformer 在语音质量和清晰度方面的优越性。
其次,当关注基于复杂频谱的方法时,我们可以观察到大多数基于复杂频谱的基线始终优于基于幅度的方法。 以 BiCRN 和 BiGCRN 为例,我们发现看不见的扬声器在 babble 噪声方面平均提供了 0.30 PESQ、5.68% ESTOI 和 2.84dB SDR 分数改进。 它表明了相位恢复对于提高语音质量和清晰度的重要性。 同时,我们提出的 CPB-Net 也优于大多数基于单阶段复杂频谱的方法,这些方法都旨在优化单阶段的幅度和相位。 例如,在所见扬声器条件下,CPB-Net 在 Babble 噪声上比 BiDCCRN 提供平均 0.20 PESQ、4.27% ESTOI 和 1.01dB SDR 分数改进,而在factory1 上提供平均 0.18 PESQ、3.09% ESTOI 和 1.11dB SDR 分数改进噪音。 在看不见的扬声器案例中也观察到类似的趋势。
第三,当幅度估计和相位恢复被解耦为两个阶段时,可以获得比单阶段复杂频谱估计方法更好的性能。 例如,当所看到的说话者中出现模糊噪声时,CTS-Net 在 PESQ、ESTOI 和 SDR 方面比 BiGCRN 平均分别提高了 0.14、3.01% 和 1.30dB 的分数。 对于所见扬声器中的工厂 1 噪声,改进分别为 0.08 PESQ、2.59% ESTOI 和 1.31dB SDR。 在不可见扬声器条件下,也可以获得类似的改进。 这表明在复值谱域中基于解耦的方法相对于单级方法具有显着的优势。 然后,我们可以看到,当并行优化幅度和复杂光谱细节而不是在级联管道中优化时,DBT-Net 大大超过了 CTS-Net。 例如,对于看不见的说话者情况下的模糊噪声条件,DBT-Net 在 PESQ、ESTOI 和 SDR 方面分别比 CTS-Net 平均提高了 0.19、3.31% 和 1.46dB。 这表明了所提出的双分支管道在提高复值频谱域中的语音质量和清晰度方面的优点和有效性。
最后,我们将我们提出的方法与先进的时域系统进行比较。 从表III和IV可以发现,在可见和不可见的说话人情况下,DBT-Net在所有指标方面都大大优于AECNN,例如,大约0.49、9.67在可见和不可见的扬声器情况下,对于杂音和工厂1噪声,PESQ、ESTOI 和 SDR 均观察到 % 和 2.80dB 平均改进。 这表明我们提出的在复杂频谱域中的方法比以前的时域系统具有显着的性能优势。 此外,与其他先进的双路径时域方法相比,可以看出 DBT-Net 在所有指标方面始终取得更好的性能,表明所提出的双分支策略和注意力中注意力变换器的优越性基于网络。 例如,对于所见扬声器案例中的工厂 1 噪声,DBT-Net 在 PESQ、ESTOI 和 SDR 方面比 TSTNN 平均得分分别提高了 0.14、4.45% 和 0.82dB。
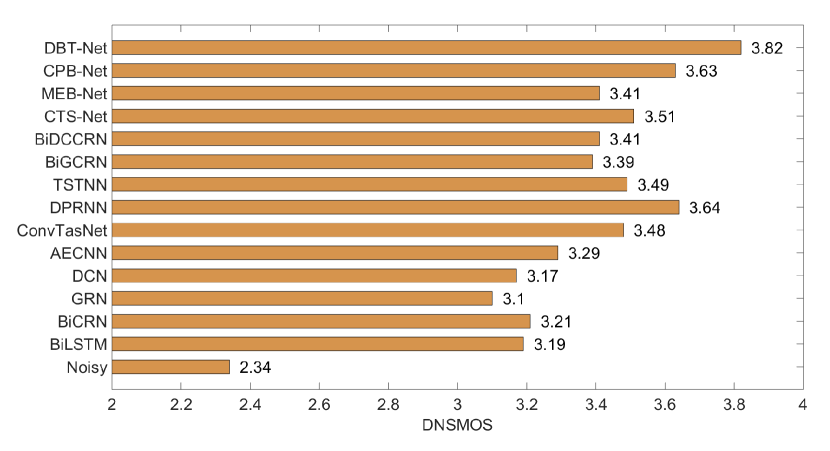
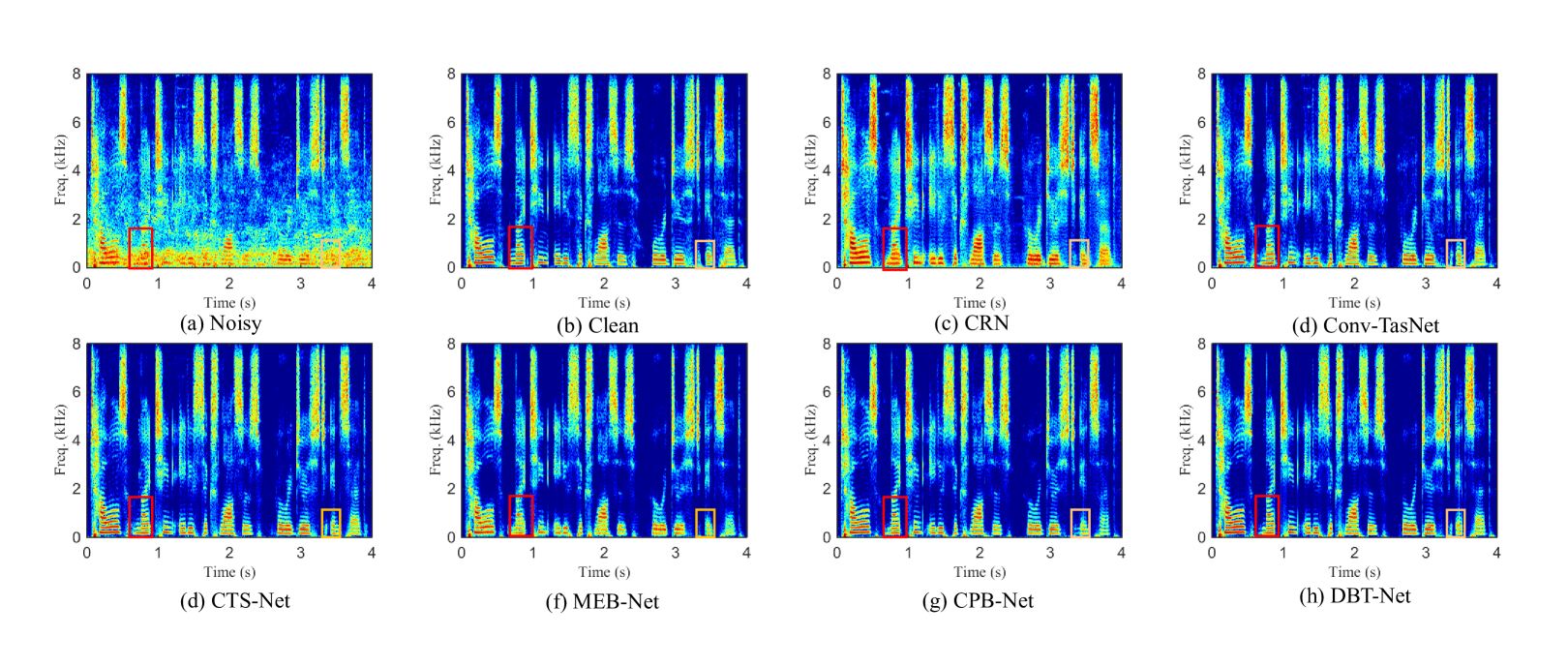
此外,图4还提供了对非侵入式感知指标DNSMOS的感知评估。 可以发现,所提出的方法明显优于所有先进基线,这也证明了 DBT-Net 在提高主观感知语音质量方面的优越性。 此外,图 5 中还展示了 CRN、ConvTasNet、CTS-Net、MEB-NET、CPB-Net 和 DBT-Net 增强话语的干净话语、嘈杂话语的频谱图示例(啊)。 很明显,DBT-NET 在恢复光谱细节和抑制背景噪声方面优于其他基线。 关注图5(f)和(g)中的红色和橙色框,可以看到MEB-Net比CPB-Net抑制了更多的背景噪声,而CPB-Net可以估计更多的损失精细获得的光谱细节。 通过合并这两个分支,DBT-Net 可以从互补的方面鼓励优点并绕过每个分支的弱点,从而产生比单分支范式更好的频谱估计,如图5所示( H)。
V-C 使用 VoiceBank + DEMAND 数据集与基线进行性能比较
| Methods | Year | Param. | PESQ | STOI(%) | CSIG | CBAK | COVL |
| Noisy | – | – | 1.97 | 92.1 | 3.35 | 2.44 | 2.63 |
| SOTA time and T-F Domain approaches | |||||||
| SEGAN [11] | 2017 | 43.2 M | 2.16 | 92.5 | 3.48 | 2.94 | 2.80 |
| MMSEGAN [56] | 2018 | – | 2.53 | 93.0 | 3.80 | 3.12 | 3.14 |
| SERGAN [53] | 2019 | 43.2 M | 2.16 | 92.5 | 3.48 | 2.94 | 2.80 |
| MetricGAN [57] | 2019 | 1.86 M | 2.86 | – | 3.99 | 3.18 | 3.42 |
| CRGAN [58] | 2020 | – | 2.92 | 94.0 | 4.16 | 3.24 | 3.54 |
| DCCRN [49] | 2020 | 3.70 M | 2.68 | 93.7 | 3.88 | 3.18 | 3.27 |
| RDL-Net [59] | 2020 | 3.91 M | 3.02 | 93.8 | 4.38 | 3.43 | 3.72 |
| PHASEN [61] | 2020 | – | 2.99 | – | 4.21 | 3.55 | 3.62 |
| MHSA-SPK [54] | 2020 | – | 2.99 | – | 4.15 | 3.42 | 3.53 |
| T-GSA [60] | 2020 | – | 3.06 | 93.7 | 4.18 | 3.59 | 3.62 |
| TSTNN [9] | 2021 | 0.92 M | 2.96 | 95.0 | 4.17 | 3.53 | 3.49 |
| DEMUCS [7] | 2021 | 128 M | 3.07 | 95.0 | 4.31 | 3.40 | 3.63 |
| CTS-Net [17] | 2021 | 4.35 M | 2.92 | – | 4.25 | 3.46 | 3.59 |
| GaGNet [19] | 2021 | 5.94 M | 2.94 | 94.7 | 4.26 | 3.45 | 3.59 |
| MetricGAN+ [62] | 2021 | – | 3.15 | – | 4.14 | 3.16 | 3.64 |
| SE-Conformer [55] | 2021 | – | 3.13 | 95 | 4.45 | 3.55 | 3.82 |
| Proposed approaches | |||||||
| MEB-Net | 2021 | 0.90 M | 3.11 | 94.9 | 4.45 | 3.60 | 3.79 |
| CPB-Net | 2021 | 1.18 M | 3.15 | 94.7 | 4.48 | 3.54 | 3.81 |
| DBT-Net | 2021 | 2.91 M | 3.30 | 95.7 | 4.59 | 3.75 | 3.92 |
除了WSJ0-SI84语料库之外,我们还在另一个公共基准即上进行了实验,即VoiceBank + DEMAND,以进一步验证所提出的方法与其他SOTA基准的优越性,其结果如表所示V。从表V的结果可以得到以下观察结果。 首先,当仅采用幅度估计分支(MEB-Net)或复杂频谱映射分支(CPB-Net)时,与幅度或复杂频谱域中大多数现有的基于单分支的先进基线相比,所提出的框架实现了有竞争力的性能。 例如,从RDL-Net到MEB-Net,在PESQ、STOI、CSIG、CBAK和COVL方面分别实现了平均0.09、1.1%、0.07、0.17和0.07的改进。 同样,与 T-GSA 相比,CPB-Net 平均提供 0.09 PESQ、1.0%STOI、0.30 CSIG 和 0.19 COVL 改进。 这验证了所提出的基于注意力中注意力变换器的网络在提高语音质量方面的有效性。 此外,当仅采用单分支拓扑时,可以观察到CPB-Net在PESQ、CSIG和COVL方面比MEB-Net产生更好的性能,而MEB-Net在CBAK方面取得了更高的分数。 这表明MEB-Net可以更好地消除噪声,而CPB-Net则可以实现更好的语音整体质量。 其次,通过同时并行采用两个分支,DBT-Net 在所有指标方面都比单分支方法有了显着的改进。 这验证了所提出的双分支方法可以从互补的角度协同促进复杂的频谱恢复。 与其他现有的单级和解耦式 SOTA 方法相比,DBT-Net 始终实现更好的语音性能。 例如,从之前的解耦式方法即GaGNet 到 DBT-Net,在 PESQ、CSIG、CBAK 和 COVL 方面分别可以观察到平均 0.36、0.33、0.30 和 0.33 的改进。 第三,与之前的 SOTA 时域基线相比,所提出的 DBT-Net 在所有客观指标上也取得了更好的性能。 例如,DBT-Net 在 PESQ、CSIG、CBAK 和 COVL 方面比 SE-Conformer 平均分别提高了 0.17、0.14、0.20 和 0.10。
此外,我们还提供了我们的方法和一些报道的 SOTA 方法之间参数数量的比较。 与最先进的时域和时频域方法相比,所提出的方法具有相对较低的参数负担,即为 2.91 M。
六结论
在本文中,我们提出了一种基于双分支 Transformer 的框架,以从互补的角度联合促进清洁频谱估计。 具体来说,幅度谱估计分支(MEB)被设计为粗略地滤除幅度域中的主要噪声分量,而残余频谱细节则由复杂频谱净化分支(CPB)并行导出。 为了利用两个分支之间的信息交换,提出了交互块,通过从另一个分支学到的信息来指导序列建模。 在每个分支中,我们在密集的编码器-解码器架构之间引入了一种新颖的基于注意力中注意力变换器(AIAT)的模块,用于上下文信息建模,其目的是加强长期光谱时间依赖性并聚合全局分层中间信息。 在两个公共数据集(即 WSJ0-SI84 + DNS Challenge 和 VoiceBank + DEMAND)上的实验结果表明,所提出的方法在各种客观和主观指标上均比以前的先进方法实现了最先进的性能。
参考
- [1] P. C. Loizou, Speech enhancement: theory and practice, CRC press, 2013.
- [2] D. L. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 26, no. 10, pp. 1702–1726, 2018.
- [3] Y. Wang, A. Narayanan, and D. L. Wang, “On training targets for supervised speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 22, no. 12, pp. 1849–1858, 2014.
- [4] Y. Xu, J. Du, L-R. Dai, and C-H. Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 23, no. 1, pp. 7–19, 2014.
- [5] D. Wang and J. Lim, “The unimportance of phase in speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 30, no. 4, pp. 679–681, 1982.
- [6] K. Paliwal, K. Wójcicki, and B. Shannon, “The importance of phase in speech enhancement,” Speech Commun., vol. 53, no. 4, pp. 465–494, 2011.
- [7] A. Defossez, G. Synnaeve, and Y. Adi, “Real time speech enhancement in the waveform domain,” in Proc. Interspeech, 2020, pp. 3291–3295.
- [8] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-Path RNN: efficient long sequence modeling for time-domain single-channel speech separation,” in Proc. ICASSP. IEEE, 2020, pp. 46–50.
- [9] K. Wang, B. He, and W. P. Zhu, “TSTNN: Two-stage transformer based neural network for speech enhancement in the time domain,” in Proc. ICASSP. IEEE, 2021, pp. 7098–7102.
- [10] K. Kinoshita, T. Ochiai, M. Delcroix, and T. Nakatani, “Improving noise robust automatic speech recognition with single-channel time-domain enhancement network,” in Proc. ICASSP. IEEE, 2020, pp. 7009–7013.
- [11] S. Pascual, A. Bonafonte, and J. Serra, “SEGAN: Speech enhancement generative adversarial network,” in Proc. Interspeech, 2017, pp. 3642–3646.
- [12] D. S. Williamson, Y. Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 24, no. 3, pp. 483–492, 2015.
- [13] H. S. Choi, J. H. Kim, J. Huh, A. Kim, J. W. Ha, and K. Lee, “Phase-aware speech enhancement with deep complex U-Net,” arXiv preprint arXiv:1903.03107, 2019.
- [14] G. Yu, Y. Wang, H. Wang, Q. Zhang, and C. Zheng, “A two-stage complex network using cycle-consistent generative adversarial networks for speech enhancement,” Speech Commun., vol. 134, pp. 42–54, 2021.
- [15] K. Tan and D. L. Wang, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 380–390, 2019.
- [16] Y. Sun, Y. Xian, W. Wang, and S. M. Naqvi, “Monaural source separation in complex domain with long short-term memory neural network,” IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 359–369, 2019.
- [17] A. Li, W. Liu, C. Zheng, C. Fan, and X. Li, “Two heads are better than one: A two-stage complex spectral mapping approach for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 29, pp. 1829–1843, 2021.
- [18] A. Li, W. Liu, X. Luo, G. Yu, C. Zheng, and X. Li, “A simultaneous denoising and dereverberation framework with target decoupling,” in Proc. Interspeech, 2021, pp. 2801–2805.
- [19] A. Li, C. Zheng, L. Zhang, and X. Li, “Glance and gaze: A collaborative learning framework for single-channel speech enhancement,” Applied Acoustics, vol. 187, pp. 108499, 2022.
- [20] Z.-Q. Wang, G. Wichern, and J. Le Roux, “On the compensation between magnitude and phase in speech separation,” IEEE Signal Processing Letters, vol. 28, pp. 2018–2022, 2021.
- [21] K. Tan and D. Wang, “A convolutional recurrent neural network for real-time speech enhancement.,” in Proc. Interspeech, 2018, pp. 3229–3233.
- [22] A. Pandey and D. Wang, “TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain,” in Proc. ICASSP. IEEE, 2019, pp. 6875–6879.
- [23] J. Chen, Q. Mao, and D. Liu, “Dual-path transformer network: Direct context-aware modeling for end-to-end monaural speech separation,” in Proc. Interspeech, 2020, pp. 2642–2646.
- [24] Y. Li, Y. Sun, and S. M. Naqvi, “U-shaped transformer with frequency-band aware attention for speech enhancement,” arXiv preprint arXiv:2112.06052, 2021.
- [25] Y. Fu, Y. Liu, J. Li, D. Luo, S. Lv, Y. Jv, and L. Xie, “Uformer: A unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation,” in Proc. ICASSP. IEEE, 2022, pp. 7417–7421.
- [26] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, p. 5998–6008.
- [27] F. Iandola, M. Moskewicz, S. Karayev, R. Girshick, T. Darrell, and K. Keutzer, “DenseNet: Implementing efficient convnet descriptor pyramids,” arXiv preprint arXiv:1404.1869, 2014.
- [28] G. Yu, Y. Wang, C. Zheng, H. Wang, and Q. Zhang, “CycleGAN-based non-parallel speech enhancement with an adaptive attention-in-attention mechanism,” in Proc. Asia-Pacific Signal Inf. Process. Assoc. (APSIPA), 2021, pp. 523–529.
- [29] G. Yu, A. Li, Y. Wang, Y. Guo, H. Wang, and C. Zheng, “Dual-branch attention-in-attention transformer for single-channel speech enhancement,” in Proc. ICASSP. IEEE, 2022, pp. 7847–7851.
- [30] G. Yu, A. Li, Y. Wang, Y. Guo, C. Zheng, and H. Wang, “Joint magnitude estimation and phase recovery using Cycle-in-Cycle GAN for non-parallel speech enhancement,” in Proc. ICASSP. IEEE, 2022, pp. 6967–6971.
- [31] C. Tang, C. Luo, Z. Zhao, W. Xie, and W. Zeng, “Joint time-frequency and time domain learning for speech enhancement,” in Proc. IJCAI, 2020, pp. 3816–3822.
- [32] M. Sperber, J. Niehues, G. Neubig, S. Stüker, and A. Waibel, “Self-attentional acoustic models,” in Proc. Interspeech, 2018, pp. 3723–3727.
- [33] W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, D. Bishop, R.and Rueckert, and Z. Wang, “Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,” in Proc. CVPR, 2016, pp. 1874–1883.
- [34] Z.-Q. Wang, P. Wang, and D. Wang, “Complex spectral mapping for single-and multi-channel speech enhancement and robust asr,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 1778–1787, 2020.
- [35] S. Wisdom, J. R. Hershey, K. Wilson, J. Thorpe, M. Chinen, B. Patton, and R. A. Saurous, “Differentiable consistency constraints for improved deep speech enhancement,” in Proc. ICASSP. IEEE, 2019, pp. 900–904.
- [36] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Investigating RNN-based speech enhancement methods for noise-robust text-to-speech,” in Proc. SSW, 2016, pp. 146–152.
- [37] C. Veaux, J. Yamagishi, and S. King, “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database,” in Proc. O-COCOSDA/CASLRE. IEEE, 2013, pp. 1–4.
- [38] J. Thiemann, N. Ito, and E. Vincent, “The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings,” JASA, vol. 133, no. 5, pp. 3591–3591, 2013.
- [39] D. Paul and J. Baker, “The design for the wall street journal-based csr corpus,” in Workshop on Speech and Natural Language, 1992, p. 357–362.
- [40] C. KA. Reddy, V. Gopal, R. Cutler, E. Beyrami, R.. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun, et al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,” in Proc. Interspeech, 2020, pp. 2492–2496.
- [41] A. Varga and H. JM. Steeneken, “Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems,” Speech Commun., vol. 12, no. 3, pp. 247–251, 1993.
- [42] A. Li, C. Zheng, R. Peng, and X. Li, “On the importance of power compression and phase estimation in monaural speech dereverberation,” JASA Express Letters, vol. 1, no. 1, pp. 014802, 2021.
- [43] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. ICLR, 2015.
- [44] J. Chen, Y. Wang, S. E. Yoho, D. Wang, and E. W. Healy, “Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises,” JASA, vol. 139, no. 5, pp. 2604–2612, 2016.
- [45] K Tan, J. Chen, and D. Wang, “Gated residual networks with dilated convolutions for monaural speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 27, no. 1, pp. 189–198, 2018.
- [46] S. Pirhosseinloo and J. S. Brumberg, “Monaural speech enhancement with dilated convolutions.,” in Proc. Interspeech, 2019, pp. 3143–3147.
- [47] A. Pandey and D. Wang, “A new framework for CNN-based speech enhancement in the time domain,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 27, no. 7, pp. 1179–1188, 2019.
- [48] Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 27, no. 8, pp. 1256–1266, 2019.
- [49] Y. Hu, Y. Liu, S. Lv, M. Xing, and L. Xie, “DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement,” in Proc. Interspeech, 2020, pp. 2472–2476.
- [50] Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional networks,” in Proc. ICML. PMLR, 2017, pp. 933–941.
- [51] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” in Proc. ICLR, 2015.
- [52] A. Pandey and D. Wang, “Dense cnn with self-attention for time-domain speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 29, pp. 1270–1279, 2021.
- [53] D. Baby and S. Verhulst, “SERGAN: Speech enhancement using relativistic generative adversarial networks with gradient penalty,” in Proc. ICASSP. IEEE, 2019, pp. 106–110.
- [54] Y. Koizumi, K. Yatabe, M. Delcroix, Y. Masuyama, and D. Takeuchi, “Speech enhancement using self-adaptation and multi-head self-attention,” in Proc. ICASSP. IEEE, 2020, pp. 181–185.
- [55] E. Kim and H. Seo, “Se-Conformer: Time-domain speech enhancement using conformer,” in Proc. Interspeech, 2021, pp. 2736–2740.
- [56] M. H. Soni, N. Shah, and H. A. Patil, “Time-frequency masking-based speech enhancement using generative adversarial network,” in Proc. ICASSP. IEEE, 2018, pp. 5039–5043.
- [57] S.-W. Fu, C.-F. Liao, Y. Tsao, and S.-D. Lin, “MetricGAN: Generative adversarial networks based black-box metric scores optimization for speech enhancement,” in Proc. ICML. PMLR, 2019, pp. 2031–2041.
- [58] Z. Zhang, C. Deng, Y. Shen, D. S. Williamson, Y. Sha, Y. Zhang, H. Song, and X. Li, “On loss functions and recurrency training for gan-based speech enhancement systems,” in Proc. Interspeech, 2020, pp. 3266–3270.
- [59] M. Nikzad, A. Nicolson, Y. Gao, J. Zhou, K. K. Paliwal, and F. Shang, “Deep residual-dense lattice network for speech enhancement,” in Proc. AAAI, 2020, vol. 34, pp. 8552–8559.
- [60] J. Kim, M. El-Khamy, and J. Lee, “T-gsa: Transformer with Gaussian-weighted self-attention for speech enhancement,” in Proc. ICASSP. IEEE, 2020, pp. 6649–6653.
- [61] D. Yin, C. Luo, Z. Xiong, and W. Zeng, “PHASEN: A phase-and-harmonics-aware speech enhancement network,” in Proc. AAAI, 2020, vol. 34, pp. 9458–9465.
- [62] S.-W. Fu, C. Yu, T.-A. Hsieh, P. Plantinga, M. Ravanelli, X. Lu, and Y. Tsao, “MetricGAN+: An improved version of MetricGAN for speech enhancement,” in Proc. Interspeech, 2021, pp. 201–205.
- [63] A. Nicolson and K. K. Paliwal, “Deep learning for minimum mean-square error approaches to speech enhancement,” Speech Commun., vol. 111, pp. 44–55, 2019.
- [64] Q. Zhang, A. Nicolson, M. Wang, K. K. Paliwal, and C. Wang, “DeepMMSE: A deep learning approach to MMSE-based noise power spectral density estimation,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 28, pp. 1404–1415, 2020.
- [65] A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. ICASSP. IEEE, 2001, vol. 2, pp. 749–752.
- [66] J. Jensen and C. H. Taal, “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 24, no. 11, pp. 2009–2022, 2016.
- [67] E. Vincent, H. Sawada, P. Bofill, S. Makino, and J. P. Rosca, “First stereo audio source separation evaluation campaign: data, algorithms and results,” in International Conference on Independent Component Analysis and Signal Separation. Springer, 2007, pp. 552–559.
- [68] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” in Proc. ICASSP. IEEE, 2010, pp. 4214–4217.
- [69] Y. Hu and P. C. Loizou, “Evaluation of objective quality measures for speech enhancement,” IEEE/ACM Trans. Audio. Speech, Lang. Process., vol. 16, no. 1, pp. 229–238, 2007.
- [70] C. K. Reddy, V. Gopal, and R. Cutler, “DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in Proc. ICASSP. IEEE, 2021, pp. 6493–6497.
- [71] P. Mermelstein, “Evaluation of a segmental snr measure as an indicator of the quality of adpcm coded speech,” JASA, vol. 66, no. 6, pp. 1664–1667, 1979.