图转换器:架构角度的概述
摘要
最近,在许多人工智能领域取得巨大成功的Transformer模型展示了其在图结构数据建模方面的巨大潜力。 到目前为止,已经提出了各种各样的 Transformer 来适应图结构数据。 然而,对这些图的 Transformer 变体的全面文献综述和系统评估仍然无法实现。 梳理现有的图 Transformer 模型并系统地研究其在各种图任务上的有效性势在必行。 在本次调查中,我们从架构设计的角度对各种 Graph Transformer 模型进行了全面的回顾。 我们首先拆解现有模型,得出将图信息合并到普通 Transformer 中的三种典型方法:1)GNN 作为辅助模块,2)改进图的位置嵌入,3)改进图的注意力矩阵。 此外,我们将代表性组件分为三组,并对各种著名的图数据基准进行全面比较,以研究每个组件的实际性能增益。 我们的实验证实了 Transformer 上当前图特定模块的优势,并揭示了它们在不同类型图任务上的优势。
1简介
图是一种数据结构,它在结构上描述了一组对象(节点)及其关系(边)。 作为一种独特的非欧几里得数据结构,图分析侧重于节点分类Yang等人(2016)、链接预测Zhang and Chen (2018)和聚类等任务阿加瓦尔(2010)。 由于深度学习模型丰富的表达能力,最近使用深度学习分析图的研究引起了越来越多的关注。 图神经网络(GNN)Kipf and Welling (2016)作为一种基于深度学习的方法,由于其令人信服的性能,最近成为广泛使用的图分析工具。 目前的 GNN 大多基于消息传递范式 Gilmer 等人 (2017),其表达能力受到 Weisfeiler-Lehamn 同构层次结构 Maron 等人 (2019) 的限制;徐等人(2018a)。 更糟糕的是,正如Kreuzer等人(2021)所指出的,GNN由于重复的局部聚合而遭受过度平滑问题,以及过度挤压 由于模型深度的增加而导致指数计算成本的问题。 多项研究Zhao 和 Akoglu (2019);荣等人 (2019); Xu等人(2018b)尝试解决此类问题。 然而,他们似乎都无法从消息传递范式中消除这些问题。
另一方面,Transformers 及其变体作为一类强大的模型,在自然语言处理(NLP)Vaswani 等人(2017)、计算机视觉(CV)等各个领域发挥着重要作用。 ) Forsyth 和 Ponce (2011)、时间序列分析 Hamilton (2020)、音频处理 Purwins 等人 (2019) 等。 此外,近年来在建模图中出现了许多成功的 Transformer 变体。 这些模型在许多应用中都取得了与 GNN 竞争甚至更优异的性能,例如量子属性预测 Hu 等人 (2021)、Catalysts Discovery Chanussot* 等人 (2021)和推荐系统Min 等人 (2022)。 然而,缺乏对这些 Transformer 变体的文献综述和系统评估。
本次调查概述了当前将 Transformer 纳入图结构数据的研究进展。 具体来说,我们从架构设计的角度对 20 多个 Graph Transformer 模型进行了全面的回顾。 我们首先拆解现有模型,总结出将图信息合并到普通 Transformer 中的三种典型方法:1)GNN 作为辅助模块,即,直接将 GNN 注入到 Transformer 架构中。 具体来说,根据 GNN 层和 Transformer 层之间的相对位置,现有的 GNN-Transformer 架构可以分为三种类型:(a)在 GNN 块之上构建 Transformer 块,(b)在每层中堆叠 GNN 块和 Transformer 块,(c) 每层中的并行 GNN 块和 Transformer 块。 2) 改进图的位置嵌入,即,将图结构压缩为位置嵌入向量,并在输入到普通 Transformer 模型之前将它们添加到输入中。 这种图位置嵌入可以从图的结构信息中导出,例如度和中心性。 3)改进图的注意力矩阵,即,通过图偏差项将图先验注入到注意力计算中,或者限制节点仅关注图中的本地邻居,这可以通过计算公式化为注意力掩蔽机制。
此外,为了研究现有模型在各种图任务中的有效性,我们将代表性组件分为三组,并对六个流行的基于图的基准进行全面的消融研究,以统一测试每个组件的实际性能增益。 我们的实验表明:1)。 当前包含图信息的模型可以提高 Transformer 在图级和节点级任务上的性能。 2)。 使用 GNN 作为辅助模块并改进图中的注意力矩阵通常比将图编码为位置嵌入能带来更多的性能提升。 3)。 图级任务的性能提升比节点级任务更显着。 4)不同类型的图任务有不同的模型组。
2 Transformer 架构
Transformer Vaswani 等人 (2017) 架构首次应用于机器翻译。 在本文中,Transformer 被介绍为一种新颖的编码器-解码器架构,采用多个自注意力块构建。 设为每个Transformer层的输入,其中为token数量,为每个词符的维度,则一个block层可以是一个函数 ,其中 定义如下:
| (1) | ||||
| (2) | ||||
| (3) | ||||
| (4) | ||||
| (5) |
其中方程1、方程2和方程3是注意力计算;而方程4和方程5是位置前馈网络(FFN)层。 这里,指的是行方向的softmax函数,指的是层归一化函数Ba等人(2016),指的是激活函数。 是层中可训练的参数。 此外,通常考虑多个注意力头将自注意力扩展到多头自注意力(MHSA)。 具体来说,被分解为头、和,以及来自注意力头的矩阵连接起来得到。 在这种情况下,方程1和方程2分别变为:
| (6) | |||
| (7) |
多头机制使模型能够隐式地从不同方面学习表示。 除了注意力机制之外,论文还使用不同频率的和函数作为位置嵌入来区分序列中每个词符的位置。
| Method | GA | PE | AT | Code |
|---|---|---|---|---|
| Zhu et al. (2019) | ✓ | ✓ | ||
| Shiv and Quirk (2019) | ✓ | |||
| Wang et al. (2019) | ✓ | ✓ | ||
| U2GNN Nguyen et al. (2019) | ✓ | ✓ | ||
| HeGT Yao et al. (2020) | ✓ | ✓ | ||
| Graformer Schmitt et al. (2020) | ✓ | ✓ | ||
| PLAN Khoo et al. (2020) | ✓ | ✓ | ||
| UniMP Shi et al. (2020) | ✓ | |||
| GTOS Cai and Lam (2020) | ✓ | ✓ | ✓ | |
| Graph Trans Dwivedi and Bresson (2020) | ✓ | ✓ | ✓ | |
| Grover Rong et al. (2020) | ✓ | ✓ | ||
| Graph-BERT Zhang et al. (2020) | ✓ | ✓ | ✓ | |
| SE(3)-Transformer Fuchs et al. (2020) | ✓ | ✓ | ||
| Mesh Graphormer Lin et al. (2021) | ✓ | ✓ | ✓ | |
| Gophormer Zhao et al. (2021) | ✓ | |||
| EGT Hussain et al. (2021) | ✓ | ✓ | ✓ | |
| SAN Kreuzer et al. (2021) | ✓ | ✓ | ✓ | |
| GraphiT Mialon et al. (2021) | ✓ | ✓ | ✓ | ✓ |
| Graphormer Ying et al. (2021) | ✓ | ✓ | ✓ | ✓ |
| Mask-transformer Min et al. (2022) | ✓ | ✓ | ||
| TorchMD-NET Thölke and de Fabritiis (2022) | ✓ | ✓ |
3 图的转换器架构
标准 Transformer 中的自注意力机制实际上将输入标记视为全连接图,这与数据之间的内在图结构无关。 使 Transformer 能够感知拓扑结构的现有方法通常分为三类:1)GNN 作为 Transformer 中的辅助模块(GA),2)改进图的位置嵌入(PE), 3) 改进了图的注意力矩阵 (AT)。 我们根据这三个维度总结了相关文献,如表1。
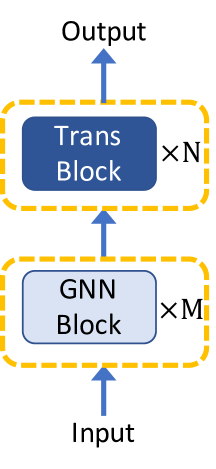
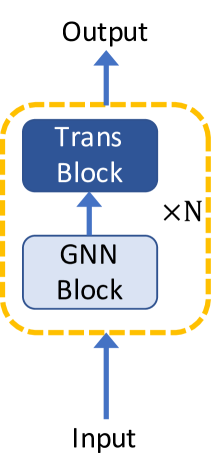
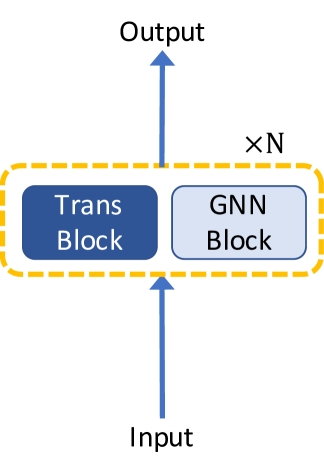
3.1 GNN 作为 Transformer 中的辅助模块
涉及结构知识以受益于自注意力的全局关系建模的最直接解决方案是将图神经网络与 Transformer 架构相结合。 一般来说,根据 GNN 层和 Transformer 层之间的相对位置,现有的带有 GNN 的 Transformer 架构分为三种类型,如图1所示:(1)在 GNN 块之上构建 Transformer 块,( 2)交替堆叠 GNN 块和 Transformer 块,(3)并行化 GNN 块和 Transformer 块。
第一种架构是这三种选项中最常采用的。 例如,GraphTrans Jain 等人 (2021) 在标准 GNN 层之上添加了一个 Transformer 子网络。 GNN 层作为一种专门的架构来学习节点直接邻域结构的局部表示,而 Transformer 子网络以与位置无关的方式计算所有成对节点交互,从而增强模型的全局推理能力。 GraphTrans 在生物学、计算机编程和化学的图分类任务上进行了评估,并在基准上取得了持续的改进。
Grover Rong 等人 (2020) 由两个 GTransformer 模块组成,分别表示节点级特征和边缘级特征。 在每个 GTransformer 中,输入首先被输入到名为 dyMPN 的定制 GNN 中,以从图的节点中提取向量作为查询、键和值,然后是标准的多头注意力块。 这种双层信息提取框架使模型能够捕获分子数据中的结构信息,并使得提取节点之间的全局关系成为可能,从而增强了 Grover 的表示能力。
GraphiT Mialon 等人 (2021) 也属于第一个架构,它采用一个图卷积核网络 (GCKN) Chen 等人 (2020) 层来产生一个结构 -感知原始特征的表示,并将它们连接起来作为 Transformer 架构的输入。 在这里,GCKN 是一个多层模型,可生成类似于 GNN 的一系列图特征图。 与 GNN 不同,GCKN 的每一层都会枚举每个节点的局部子结构,使用内核嵌入对其进行编码,并将子结构表示聚合为输出。 特征图中的这些表示比基于邻域聚合的传统 GNN 携带更多的结构信息。
Mesh Graphomer Lin 等人 (2021) 遵循第二种架构,通过在多头自注意力层上堆叠图残差块(GRB)作为 Transformer 块来建模 3D 之间的局部和全局交互网格顶点和身体关节。 具体来说,考虑到方程 3 中多头自注意力 (MHSA) 生成的上下文特征 ,Mesh Graphhormer 在每个 Transformer 块中使用图卷积来改进局部交互: :
| (8) |
其中 表示图的邻接矩阵, 表示可训练参数。 表示非线性激活函数。 Mesh Graphhormer 还实现了另外两种变体:在 MHSA 之前构建 GRB 并并行构建这两个块,但它们的性能比建议的要差。
Graph-BERT Zhang 等人 (2020) 采用第三种架构,在每个注意力层中利用图残差项,如下所示:
| (9) |
其中,符号表示Zhang和Meng(2019)中引入的图残差项,是图中所有节点的原始特征。
3.2 改进图形的位置嵌入
尽管图神经网络和 Transformer 的结合在图结构数据建模方面显示出了有效性,但整合它们的最佳架构仍然是一个问题,并且需要大量的炒作参数搜索。 因此,探索一种无需调整 Transformer 架构的图编码策略是有意义的。 与 Transformer 中对句子等顺序数据的位置编码类似,也可以将图结构压缩为位置嵌入 (PE) 向量,并在输入到实际 Transformer 模型之前将它们添加到输入中:
| (10) |
其中 是输入嵌入矩阵, 表示图嵌入向量, 是用于对齐两个向量维度的转换网络。 图位置嵌入通常是从相邻矩阵生成的。
Dwivedi 和 Bresson (2020) 采用拉普拉斯特征向量作为 Graph Transformer 中的。 对于数据集中的每个图,它们预先计算拉普拉斯特征向量 ,该特征向量由图拉普拉斯矩阵的因式分解定义:
| (11) |
其中是度矩阵,分别对应特征值和特征向量。 他们使用 最小非平凡特征值的特征向量作为位置嵌入,在本例中为 。 由于这些特征向量由于特征向量的任意符号而具有多重性,因此它们在训练期间随机翻转特征向量的符号。
Hussain 等人 (2021) 采用预先计算的相邻矩阵的 SVD 向量作为位置嵌入 。 他们使用最大的奇异值和相应的左右奇异向量来表示位置编码。
| (12) | |||
| (13) |
其中 包含与对角矩阵 顶部 奇异值相对应的 左右奇异向量, 表示沿列的连接算子。 他们还在训练期间随机翻转符号作为数据增强的一种形式,以避免过度拟合,因为与拉普拉斯特征向量类似,相应的左右奇异向量对的符号可以任意翻转。
与试图将相邻矩阵压缩为密集位置嵌入的 Eigen PE 和 SVD PE 不同,存在一些启发式方法,可以从相邻矩阵的提取中对特定结构信息进行编码。 例如,Graphormer Ying 等人 (2021) 使用度中心性作为神经网络的附加信号。 具体来说,Graphformer 根据每个节点的入度和出度为每个节点分配两个实值嵌入向量。 对于第 个节点,度感知表示表示为:
| (14) |
其中 是分别由入度 和出度 指定的可学习嵌入向量。 对于无向图,和可以统一为。 通过在输入中使用中心性编码,softmax 注意力将捕获 Transformer 的查询和键中的节点重要性信号。
Graph-BERT Zhang 等人 (2020) 引入了三种类型的 PE 来嵌入节点位置信息,即,绝对的 WL-PE,代表 Weisfeiler 标记的不同代码-雷曼算法,基于亲密性的PE和基于跳跃的PE,它们都是采样子图的变体。 Cai and Lam (2020) 将图 Transformer 应用到树形结构的抽象意义表示(AMR)图上。 它对每个节点采用距离嵌入,将距根节点的最小距离编码为相应概念在整个句子语义中的重要性的标志。 Kreuzer 等人 (2021) 提出了一种学习位置编码,可以利用完整的拉普拉斯谱来学习给定图中每个节点的位置。
3.3 改进图的注意力矩阵
尽管节点位置嵌入是将图先验注入 Transformer 架构的一种便捷做法,但将图结构压缩为固定大小向量的过程会遭受信息损失,这可能会限制其有效性。 为此,另一组工作尝试改进基于图信息的注意力矩阵计算:
| (15) |
其中 是输入特征, 是图的相邻矩阵, 是边缘特征(如果可用), 是注意参数 是额外的图编码参数。
一系列模型通过限制节点仅关注图中的本地节点邻居,将自注意力机制适应于类似 GNN 的架构,这可以在计算上表述为一种注意力屏蔽机制:
| (16) |
其中 是图的邻接矩阵。 在Dwivedi and Bresson (2020)中,如果第个节点和第个节点之间存在边。 鉴于该架构的简单性和通用性,它们在图数据集上获得了与标准 GNN 相比的竞争性能。 为了编码边缘特征,他们还将方程16扩展为:
| (17) |
其中是参数矩阵,是上一层的边缘嵌入矩阵,它是基于更新的,为了简单起见,我们不详细阐述这些细节。
这种做法的一个可能的扩展是用不同的图先验掩盖不同头的注意力矩阵。 在原始的多头自注意力块中,不同的注意力头隐式地关注来自不同节点的不同表示子空间的信息。 而在这种情况下,使用图屏蔽机制强制头显式地关注具有图先验的不同子空间,进一步提高了图数据的模型表示能力。 例如,Yao 等人 (2020) 基于扩展的 Levi 图计算注意力。 由于李维图是包含不同类型边的异构图。 他们首先将所有边类型分组为一个,以获得称为连通子图的同构子图。 连通子图实际上是一个无向图,包含了原图中完整的连通信息。 然后他们根据边类型将输入图拆分为多个子图。 除了学习直接连接的关系之外,他们还引入了全连接子图来学习间接连接的节点之间的隐式关系。 多个相邻矩阵被分配给不同的注意力头,以学习 AMR 任务的更好表示。 Min等人(2022)采用了类似的做法,精心设计了四种类型的交互图来建模CTR预测任务中的邻域关系:诱导子图、相似性图、跨邻域图和完全图。 他们使用掩蔽机制对这些图先验进行编码,以改善邻域表示。
GraphiT Mialon 等人 (2021) 将邻接矩阵扩展为核矩阵,可以更灵活地编码各种图核。 此外,他们按照Tsai等人(2019)的建议对键和查询使用相同的矩阵,以减少参数而不损害实践中的性能,并采用度矩阵来减少高度的压倒性影响。连接图组件。 更新方程可以表示为:
| (18) | ||||
其中是节点度的对角矩阵,是图上的核矩阵,用作扩散核和p步随机游走核。
另一系列模型试图将软图偏差添加到注意力分数中。 Graphormer Ying 等人 (2021) 提出了一种新颖的空间编码机制。 具体来说,他们考虑了一个距离函数,它测量图中节点和之间的空间关系。 他们选择作为和之间的最短路径距离(SPD)。 如果它们没有连接,的输出被设置为一个特殊值,即,。 他们为 的每个可行值分配一个可学习的尺度参数作为图偏差项。 所以更新规则是:
| (19) |
是偏差矩阵,其中 是由 索引的可学习标量,并在所有层之间共享。 为了处理具有边缘特征的图结构,他们还设计了边缘特征偏差项。 具体来说,对于每个有序节点对,它们搜索从到的最短路径(之一),然后计算边缘特征的点积平均值和沿路径的可学习嵌入。 结合上述空间偏差,非归一化注意力得分可以修改为:
| (20) |
其中是边缘特征偏差矩阵。 ,其中 是 中第 条边的特征 是 -th 权重嵌入, 是边缘特征的维数。
Gophormer Zhao 等人 (2021) 提出邻近增强多头注意力(PE-MHA)来编码多跳图信息。 具体来说,对于节点对,结构信息的视图被编码为邻近编码向量,表示为,以增强注意力机制。 邻近增强注意力分数定义为:
| (21) |
其中 是计算结构信息偏差的可学习参数。 邻近编码由结构编码函数计算,定义为:
| (22) |
其中每个结构编码函数对结构信息的视图进行编码。
PLAN Khoo 等人 (2020) 还提出了一种结构感知自注意力模型,对社交媒体中谣言传播的树结构进行建模。 修改后的注意力计算可以定义为:
| (23) | ||||
| (24) |
和 都是可学习的参数向量,表示推文对之间五种可能的结构关系之一(即父、子、之前、之后和自身)。
| Dataset Type | Name | #Graph | #Nodes(Avg.) | #Edges(Avg.) | Task type | Metric |
|---|---|---|---|---|---|---|
| Graph-level | ZINC | 12,000 | 23.2 | 49.8 | Regression | MAE |
| ogbg-molhiv | 41,127 | 25.5 | 27.5 | Binary cla. | ROC-AUC | |
| ogbg-molpcba | 437,929 | 26.0 | 28.1 | Binary cla. | AP | |
| Node-level | Flickr | 1 | 89,250 | 899,756 | Multi-class cla. | Accuracy |
| ogbg-arxiv | 1 | 169,343 | 1,166,243 | Multi-class cla. | Accuracy | |
| ogbg-product | 1 | 2,449,029 | 61,859,140 | Multi-class cla. | Accuracy |
| Transformer Size | |||
|---|---|---|---|
| Small | Middle | Large | |
| #Layers | 6 | 12 | 12 |
| Hidden Dimension | 80 | 80 | 512 |
| FFN Inner Hidden Dimension | 80 | 80 | 512 |
| #Attention Heads | 8 | 8 | 32 |
| Hidden Dimension of Each Head | 10 | 10 | 16 |
| graph-level tasks | node-level tasks | ||||||||||||||||||
| ZINC(MAE) | molhiv(ROC-AUC) | molpcba(AP) | Flickr(Acc) | arixv(Acc) | product(Acc) | ||||||||||||||
| Small | Middle | Large | Small | Middle | Large | Small | Middle | Large | Small | Middle | Large | Small | Middle | Large | Small | Middle | Large | ||
| TF | vanilla | 0.6689 | 0.6700 | 0.6699 | 0.7466 | 0.7230 | 0.7269 | 0.1624 | 0.1673 | 0.1676 | 0.5270 | 0.5279 | 0.5214 | 0.5539 | 0.5571 | 0.5598 | 0.7887 | 0.7887 | 0.7956 |
| GA | before | 0.4700 | 0.4809 | 0.5169 | 0.6758 | 0.7339 | 0.7182 | 0.2105 | 0.1989 | 0.2269 | 0.5352 | 0.5369 | 0.5272 | 0.5608 | 0.5590 | 0.5614 | 0.7953 | 0.7888 | 0.8012 |
| alter | 0.3771 | 0.3412 | 0.2956 | 0.7200 | 0.7086 | 0.7433 | 0.2474 | 0.2417 | 0.2244 | 0.5374 | 0.5357 | 0.5162 | 0.5599 | 0.5555 | 0.5592 | 0.7905 | 0.7915 | 0.8057 | |
| parallel | 0.3803 | 0.2749 | 0.2984 | 0.7138 | 0.7750 | 0.7603 | 0.2345 | 0.2444 | 0.2205 | 0.5370 | 0.5379 | 0.5209 | 0.5647 | 0.5600 | 0.5529 | 0.7878 | 0.7896 | 0.7999 | |
| PE | degree | 0.5364 | 0.5364 | 0.5435 | 0.7506 | 0.6818 | 0.7357 | 0.1672 | 0.1646 | 0.1650 | 0.5291 | 0.5250 | 0.5133 | 0.5551 | 0.5618 | 0.5502 | 0.7920 | 0.7913 | 0.7947 |
| eig | 0.6031 | 0.6074 | 0.6166 | 0.7407 | 0.7279 | 0.7351 | 0.2194 | 0.2087 | 0.2131 | 0.5253 | 0.5278 | 0.5257 | 0.5575 | 0.5637 | 0.5658 | 0.7893 | 0.7887 | 0.8017 | |
| svd | 0.5811 | 0.5462 | 0.5400 | 0.7350 | 0.7155 | 0.7275 | 0.1648 | 0.1663 | 0.1767 | 0.5281 | 0.5317 | 0.5203 | 0.5614 | 0.5663 | 0.5706 | 0.7856 | 0.7893 | 0.8007 | |
| AT | SPB | 0.5122 | 0.4878 | 0.6100 | 0.7065 | 0.7589 | 0.7255 | 0.2409 | 0.2524 | 0.2621 | 0.5368 | 0.5364 | 0.5234 | 0.5503 | 0.5605 | 0.5576 | 0.7921 | 0.7918 | 0.7984 |
| PMA | 0.6194 | 0.6057 | 0.5963 | 0.6902 | 0.7054 | 0.7314 | 0.2115 | 0.1956 | 0.2518 | 0.5240 | 0.5288 | 0.5204 | 0.5567 | 0.5571 | 0.5492 | 0.7877 | 0.7853 | 0.7945 | |
| Mask-1 | 0.2861 | 0.2772 | 0.2894 | 0.7610 | 0.7753 | 0.7960 | 0.2573 | 0.2662 | 0.1594 | 0.5295 | 0.5300 | 0.5236 | 0.5598 | 0.5559 | 0.5583 | 0.7923 | 0.7917 | 0.7963 | |
| Mask-n | 0.3906 | 0.3596 | 0.4765 | 0.7286 | 0.7423 | 0.7128 | 0.2619 | 0.2577 | 0.2380 | 0.5359 | 0.5349 | 0.5348 | 0.5593 | 0.5603 | 0.5576 | 0.7935 | 0.7917 | 0.8016 | |
| attention dropout | 0.1 | FFN dropout | 0.1 |
|---|---|---|---|
| maximum steps | 1e+6 | warm-up steps | 4e+4 |
| peak learning rate | 2e-4 | batch size | 256 |
| weight decay value | 1e-3 | lr decay | Linear |
| gradient clip norm | 5.0 | Adam | 1e-8, 0.9, 0.99 |
4实验评估
我们进行了广泛的评估,以研究不同方法的有效性。 在标准 Transformer 的基础上,比较了辅助 GNN 模块(GA)、位置嵌入(PE)和改进注意力(AT)三组方法。 由于大多数方法都是由多个图特定模块组成,并使用各种技巧进行训练,因此很难以公平且独立的方式评估每个模块的有效性。 在我们的实验中,我们提取现有模型的代表性模块并单独评估它们的性能。 对于 GA 方法,我们比较了 3.1 节中描述的三种架构。 在交替和并行设置中,GNN 和 Transformer 层在 FFN 层之前组合。 PE方法包括度嵌入Ying 等人(2021)、拉普拉斯特征向量Dwivedi and Bresson (2020)和SVD向量Hussain 等人(2021) 。 AT方法包含空间偏差(SPB)Ying 等人(2021),邻近增强多头注意力(PMA)Zhao 等人(2021),用1掩盖的注意力-hop 相邻矩阵 (Mask-1) Dwivedi 和 Bresson (2020)。 我们还用相邻矩阵的不同跳数来掩盖注意力,表示为(Mask-n),受到Yao等人(2020)中多头掩盖机制的启发;敏等人 (2022). 我们在小图上的图级任务和单个大图上的节点级任务上评估这些方法。 任务和数据集的详细信息列于表2中。
4.1 设置和实现细节
为了保证评估的一致性和公平性,我们将 Transformer 架构的规模固定为小型、中型和大型三个级别,其配置如表3所示。 其余超参数固定为其经验值,如表5所示。 对于大规模图中的节点级任务,我们采用影子-hop采样Zeng等人(2020)为目标节点生成子图,应用图形感知模块。 我们基于子图而不是原始图来计算所有模块所需的输入,因为它们中的大多数在计算上无法扩展到大图。 我们将最大采样跳数设置为,将每个节点的最大邻域设置为。 对于 PE 方法,我们从 中选择嵌入大小。 对于 GA 方法,我们从 GCN Kipf and Welling (2016)、GAT Velivckovic 等人 (2017) 和 GIN Xu 等人 (2018a) 中选择 GNN 类型。 我们的学习框架基于 PyTorch 1.8 和 PyTorch Geometric 2.0 构建,代码公开于 https://github.com/qwerfdsaplking/Graph-Trans。
4.2实验结果
表4报告了三个类别的十个特定于图的模块分别在图级和节点级任务的六个数据集上的性能。 我们将主要观察结果总结如下:
-
-
毫不奇怪,在大多数情况下,评估的 Transformer 特定于图的模块会带来更好的性能。 例如,在 molpcba 上,我们观察到与普通 Transformer 相比最多有 56% 的性能提升。 这一观察结果证实了图特定模块在各种图任务上的有效性。
-
-
图级任务的改进比节点级任务的改进更显着。 这可能是由于处理单个大图时的图采样过程造成的。 采样的导出子图无法保持原始图的完整性,从而在学习过程中产生方差和信息损失。
-
-
GA和AT方法比PE方法带来更多的好处。 总之,PE 的弱点是双重的。 首先,正如3.2节中介绍的,PE不包含完整的图信息。 其次,由于 PE 仅输入到网络的输入层,因此图结构信息会在模型中逐层衰减,导致性能下降。
-
-
似乎不同类型的图形任务喜欢不同的模型组。 GA 方法在超过一半的节点级任务情况(9 种情况中的 5 种)中实现了最佳性能。 更重要的是,AT 方法在几乎所有图级任务的情况下(9 种情况中的 8 种)都实现了最佳性能。 我们推测GA方法能够更好地编码节点级任务中采样的导出子图的局部信息,而AT方法适合对图级任务中单个图的全局信息进行建模。
总之,我们的实验证实了 Transformer 上现有的图特定模块的价值,并揭示了它们在各种图任务中的优势。
5 结论和未来方向
在本次调查中,我们全面回顾了 Transformer 模型在图上应用的当前进展。 基于 Transformer 中图数据和图模型的注入部分,我们将现有的图特定模块分为三个典型组:作为辅助模块的 GNN、改进的图位置嵌入和改进的图注意矩阵。 为了研究公平设置下的实际性能增益,我们实现了三组的代表性模块,并在不同任务的六个基准上对它们进行了比较。 我们希望我们的系统回顾和比较能够促进该领域的理解并激发新的想法。
尽管目前取得了成功,但我们相信未来有希望进一步研究并开始几个方向,包括:
-
-
结合图和 Transformer 的新范例。 大多数研究在修改 Transformer 模型之前都将图视为强图。 人们对开发新的范式非常感兴趣,它不仅以图为先验,而且能更好地反映图的属性。
-
-
扩展到其他类型的图。 现有的Graph Transformer模型大多关注同构图,将节点类型和边类型视为相同。 探索它们在其他形式的图(例如异构图和超图)上的潜力也很重要。
-
-
扩展到大规模图。 大多数现有方法都是针对小图设计的,这对于大图可能在计算上不可行。 正如我们的实验所示,直接将它们应用于采样的子图会损害性能。 因此,设计可销售的Graph-Transformer架构至关重要。
参考
- Aggarwal [2010] Charu C. Aggarwal. Graph Clustering, pages 459–467. Springer US, Boston, MA, 2010.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Cai and Lam [2020] Deng Cai and Wai Lam. Graph transformer for graph-to-sequence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7464–7471, 2020.
- Chanussot* et al. [2021] Lowik Chanussot*, Abhishek Das*, Siddharth Goyal*, Thibaut Lavril*, Muhammed Shuaibi*, Morgane Riviere, Kevin Tran, Javier Heras-Domingo, Caleb Ho, Weihua Hu, Aini Palizhati, Anuroop Sriram, Brandon Wood, Junwoong Yoon, Devi Parikh, C. Lawrence Zitnick, and Zachary Ulissi. Open catalyst 2020 (oc20) dataset and community challenges. ACS Catalysis, 2021.
- Chen et al. [2020] Dexiong Chen, Laurent Jacob, and Julien Mairal. Convolutional kernel networks for graph-structured data. In International Conference on Machine Learning, pages 1576–1586. PMLR, 2020.
- Dwivedi and Bresson [2020] Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs. arXiv preprint arXiv:2012.09699, 2020.
- Forsyth and Ponce [2011] David Forsyth and Jean Ponce. Computer vision: A modern approach. Prentice hall, 2011.
- Fuchs et al. [2020] Fabian Fuchs, Daniel Worrall, Volker Fischer, and Max Welling. Se (3)-transformers: 3d roto-translation equivariant attention networks. Advances in Neural Information Processing Systems, 33:1970–1981, 2020.
- Gilmer et al. [2017] Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In International conference on machine learning, pages 1263–1272. PMLR, 2017.
- Hamilton [2020] James Douglas Hamilton. Time series analysis. Princeton university press, 2020.
- Hu et al. [2021] Weihua Hu, Matthias Fey, Hongyu Ren, Maho Nakata, Yuxiao Dong, and Jure Leskovec. Ogb-lsc: A large-scale challenge for machine learning on graphs. arXiv preprint arXiv:2103.09430, 2021.
- Hussain et al. [2021] Md Shamim Hussain, Mohammed J Zaki, and Dharmashankar Subramanian. Edge-augmented graph transformers: Global self-attention is enough for graphs. arXiv preprint arXiv:2108.03348, 2021.
- Jain et al. [2021] Paras Jain, Zhanghao Wu, Matthew Wright, Azalia Mirhoseini, Joseph E Gonzalez, and Ion Stoica. Representing long-range context for graph neural networks with global attention. Advances in Neural Information Processing Systems, 34, 2021.
- Khoo et al. [2020] Ling Min Serena Khoo, Hai Leong Chieu, Zhong Qian, and Jing Jiang. Interpretable rumor detection in microblogs by attending to user interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8783–8790, 2020.
- Kipf and Welling [2016] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- Kreuzer et al. [2021] Devin Kreuzer, Dominique Beaini, William L Hamilton, Vincent Létourneau, and Prudencio Tossou. Rethinking graph transformers with spectral attention. arXiv preprint arXiv:2106.03893, 2021.
- Lin et al. [2021] Kevin Lin, Lijuan Wang, and Zicheng Liu. Mesh graphormer. arXiv preprint arXiv:2104.00272, 2021.
- Maron et al. [2019] Haggai Maron, Heli Ben-Hamu, Hadar Serviansky, and Yaron Lipman. Provably powerful graph networks. Advances in neural information processing systems, 32, 2019.
- Mialon et al. [2021] Grégoire Mialon, Dexiong Chen, Margot Selosse, and Julien Mairal. Graphit: Encoding graph structure in transformers. arXiv preprint arXiv:2106.05667, 2021.
- Min et al. [2022] Erxue Min, Yu Rong, Tingyang Xu, Yatao Bian, Peilin Zhao, Junzhou Huang, Da Luo, Kangyi Lin, and Sophia Ananiadou. Masked transformer for neighhourhood-aware click-through rate prediction. arXiv preprint arXiv:2201.13311, 2022.
- Nguyen et al. [2019] Dai Quoc Nguyen, Tu Dinh Nguyen, and Dinh Phung. Universal graph transformer self-attention networks. arXiv preprint arXiv:1909.11855, 2019.
- Purwins et al. [2019] Hendrik Purwins, Bo Li, Tuomas Virtanen, Jan Schlter, Shuo-Yiin Chang, and Tara Sainath. Deep learning for audio signal processing. IEEE Journal of Selected Topics in Signal Processing, 13(2):206–219, 2019.
- Rong et al. [2019] Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang. Dropedge: Towards deep graph convolutional networks on node classification. arXiv preprint arXiv:1907.10903, 2019.
- Rong et al. [2020] Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, and Junzhou Huang. Self-supervised graph transformer on large-scale molecular data. arXiv preprint arXiv:2007.02835, 2020.
- Schmitt et al. [2020] Martin Schmitt, Leonardo FR Ribeiro, Philipp Dufter, Iryna Gurevych, and Hinrich Schütze. Modeling graph structure via relative position for text generation from knowledge graphs. arXiv preprint arXiv:2006.09242, 2020.
- Shi et al. [2020] Yunsheng Shi, Zhengjie Huang, Shikun Feng, Hui Zhong, Wenjin Wang, and Yu Sun. Masked label prediction: Unified message passing model for semi-supervised classification. arXiv preprint arXiv:2009.03509, 2020.
- Shiv and Quirk [2019] Vighnesh Shiv and Chris Quirk. Novel positional encodings to enable tree-based transformers. Advances in Neural Information Processing Systems, 32, 2019.
- Thölke and de Fabritiis [2022] Philipp Thölke and Gianni de Fabritiis. Equivariant transformers for neural network based molecular potentials. 2022.
- Tsai et al. [2019] Yao-Hung Hubert Tsai, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, and Ruslan Salakhutdinov. Transformer dissection: A unified understanding of transformer’s attention via the lens of kernel. arXiv preprint arXiv:1908.11775, 2019.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- Velivckovic et al. [2017] Petar Velivckovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
- Wang et al. [2019] Xing Wang, Zhaopeng Tu, Longyue Wang, and Shuming Shi. Self-attention with structural position representations. arXiv preprint arXiv:1909.00383, 2019.
- Xu et al. [2018a] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018.
- Xu et al. [2018b] Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. In International Conference on Machine Learning, pages 5453–5462. PMLR, 2018.
- Yang et al. [2016] Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. In International conference on machine learning, pages 40–48. PMLR, 2016.
- Yao et al. [2020] Shaowei Yao, Tianming Wang, and Xiaojun Wan. Heterogeneous graph transformer for graph-to-sequence learning. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7145–7154, 2020.
- Ying et al. [2021] Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform bad for graph representation? arXiv preprint arXiv:2106.05234, 2021.
- Zeng et al. [2020] Hanqing Zeng, Muhan Zhang, Yinglong Xia, Ajitesh Srivastava, Andrey Malevich, Rajgopal Kannan, Viktor Prasanna, Long Jin, and Ren Chen. Deep graph neural networks with shallow subgraph samplers. arXiv preprint arXiv:2012.01380, 2020.
- Zhang and Chen [2018] Muhan Zhang and Yixin Chen. Link prediction based on graph neural networks. Advances in neural information processing systems, 31, 2018.
- Zhang and Meng [2019] Jiawei Zhang and Lin Meng. Gresnet: Graph residual network for reviving deep gnns from suspended animation. arXiv preprint arXiv:1909.05729, 2019.
- Zhang et al. [2020] Jiawei Zhang, Haopeng Zhang, Congying Xia, and Li Sun. Graph-bert: Only attention is needed for learning graph representations. arXiv preprint arXiv:2001.05140, 2020.
- Zhao and Akoglu [2019] Lingxiao Zhao and Leman Akoglu. Pairnorm: Tackling oversmoothing in gnns. arXiv preprint arXiv:1909.12223, 2019.
- Zhao et al. [2021] Jianan Zhao, Chaozhuo Li, Qianlong Wen, Yiqi Wang, Yuming Liu, Hao Sun, Xing Xie, and Yanfang Ye. Gophormer: Ego-graph transformer for node classification. arXiv preprint arXiv:2110.13094, 2021.
- Zhu et al. [2019] Jie Zhu, Junhui Li, Muhua Zhu, Longhua Qian, Min Zhang, and Guodong Zhou. Modeling graph structure in transformer for better amr-to-text generation. arXiv preprint arXiv:1909.00136, 2019.