使用深度几何描述符进行 3D 点云
异常检测
摘要
我们提出了一种新方法,用于无监督检测高分辨率 3D 点云中的几何异常。 特别是,我们建议将已建立的学生-教师异常检测框架调整为三个维度。 训练学生网络以匹配无异常点云上预训练教师网络的输出。 当应用于测试数据时,教师和学生之间的回归误差可以实现异常结构的可靠定位。 为了构建一个提取密集局部训练几何描述符的富有表现力的教师网络,我们引入了一种新颖的自监督预策略。 教师通过重建局部感受野进行训练,不需要注释。 在综合 MVTec 3D 异常检测数据集上进行的大量实验突显了我们方法的有效性,该方法大幅优于次佳方法。 消融研究表明,我们的方法满足实际应用在性能、运行时间和内存消耗方面的要求。
1简介
近年来,3D计算机视觉领域在3D分类、3D语义分割、3D物体识别等各个研究领域取得了重大进展。 许多新方法建立在 2D 领域早期成果的基础上,这些方法使用自然图像数据。 然而,从 2D 到 3D 的过渡带来了额外的挑战,例如,需要处理无序点云和传感器噪声。 这导致了针对三个维度的新网络架构和训练协议的开发。
我们考虑 3D 点云中无监督异常检测和定位的挑战性任务。 目标是检测与完全无异常样本的训练集显着偏差的数据点。 该问题在各个领域都有重要的应用,例如工业检测(Bergmann 等人, 2021, 2022; Carrera 等人, 2017; Song and Yan, 2013)、自动驾驶(Blum 等)人,2019;Hendrycks 等人,2019),以及医学影像(Bakas 等人,2017;Baur 等人,2019;Menze 等人,2015)。 它在 2D 领域受到了相当多的关注,其中模型通常使用基于卷积神经网络的已建立且经过充分研究的架构在彩色或灰度图像上进行训练。 在 3D 领域,这个问题相对来说还没有被探索过,并且只存在少量的方法。 在这项工作中,我们遵循其他计算机视觉领域的方法,从 2D 异常检测的最新进展中汲取灵感,设计出一种强大的 3D 方法。
更具体地说,我们在使用预训练神经网络的描述符进行二维无监督异常检测的成功基础上进行了构建。 已建立的协议是从在 ImageNet (Krizhevsky 等人,2012) 数据集上训练的网络中提取这些描述符作为中间特征。 基于预训练特征的模型比使用随机权重初始化训练的模型表现更好(Bergmann 等人,2020;Buurlina 等人,2019;Cohen 和 Hoshen,2020)。 特别是,它们优于基于卷积自动编码器或生成对抗网络的方法。
到目前为止,还没有建立用于 3D 点云中无监督异常检测的预训练协议。 现有工作致力于提取高度特定于任务的局部 3D 特征。 对于点云配准,特征提取器通常会对输入数据进行大量下采样或仅对少量输入点进行操作。 这使得它们不适合 3D 异常定位。 在这项工作中,我们开发了一种预训练局部几何描述符的新方法,可以很好地转移到该任务。 然后,我们使用这种预训练策略引入一种新方法,该方法在高分辨率 3D 点云中几何异常的定位方面优于现有方法。 具体来说,我们的主要贡献是:
-
我们提出了 3D 学生-教师 (3D-ST),这是第一种直接在 3D 点云上运行的无监督异常检测方法。 我们的方法仅在无异常数据上进行训练,并且通过单次前向传播来定位高分辨率测试样本中的几何异常。 我们建议采用学生-教师框架来进行三维异常检测。 训练学生网络以匹配预训练教师网络的深层局部几何描述符。 在推理过程中,异常分数是根据学生的预测与教师的目标之间的回归误差得出的。 我们的方法在最近推出的 MVTec 3D-AD 数据集上树立了新的技术水平。 它的性能明显优于使用体素网格和深度图像的现有方法。
-
我们开发了一种自我监督的训练协议,允许教师网络学习通用的局部几何描述符,这些描述符可以很好地转移到 3D 异常检测任务。 教师通过聚合有限感受野内的局部特征来提取每个输入点的几何描述符。 训练解码器网络来重建由描述符编码的局部几何形状。 我们的预训练策略提供了对感受野的明确控制以及大量输入点的密集特征提取。 这使我们能够计算高分辨率点云的异常分数,而无需中间子采样。
2相关工作
我们的工作涉及计算机视觉的几个方面,即二维和三维异常的无监督检测以及 3D 数据的深层局部几何描述符的提取。
2.1 二维异常检测
在二维(即 RGB 或灰度图像)异常的无监督检测方面有大量工作。 Ehret 等人 (2019) 和 Pang 等人 (2021) 给出了全面的概述。 一些现有方法是通过随机权重初始化从头开始训练的,特别是基于卷积自动编码器(AE)的方法(Bergmann 等人,2019;Hong 和 Choe,2020;Liu 等人,2020;Venkataramanan 等人,2020;Wang 等人,2020) 或生成对抗网络(GAN)(Carrara 等人,2021;Potter 等人,2020;Schlegl 等人,2019)。
一类不同的方法利用预训练网络中的描述符进行异常检测(Bergmann 等人,2020;Cohen 和 Hoshen,2020;Defar 等人,2021;Gudovskiy 等人,2022;Mishra 等人,2020;Reiss 等人,2021;瑞佩尔等人,2021)。 这些方法背后的关键思想是,异常区域产生的描述符与没有异常的描述符不同。 这些方法往往比从头开始训练的方法表现得更好,这促使我们将这个想法转移到 3D 领域。
Bergmann 等人 (2020) 提出了一种用于二维异常检测的学生-教师框架。 教师网络在 ImageNet 数据集上进行预训练,以输出由特征图表示的描述符。 每个描述符捕获输入图像内局部区域的内容。 对于异常检测,学生网络集合在无异常图像上进行训练,以重现预训练教师的描述符。 在推理过程中,当学生产生增加的回归误差和预测方差时,就会检测到异常。 紧密遵循这个想法,Salehi 等人 (2021) 一个学生网络来匹配单个教师的多个特征图。
2.2 3D 异常检测
迄今为止,很少有方法可以解决 3D 数据中无监督异常检测的任务。 它们都没有利用预训练网络的特征向量的描述性。
Simarro Viana 等人 (2021) 提出了 Voxel f-AnoGAN,它是 2D f-AnoGAN 模型 (Schlegl 等人, 2019) 到 3D 体素网格的扩展。 GAN 在无异常数据样本上进行训练。 然后,训练编码器来预测无异常体素网格的潜在向量,当这些向量通过生成器网络时,重建输入数据。 在推理过程中,异常分数是通过重建输入的每个体素比较得出的。 Bengs 等人 (2021) 介绍了一种基于卷积自动编码器的方法,该方法也可在 3D 体素网格上运行。 变分自动编码器经过训练以通过低维瓶颈重建输入样本。 同样,通过将输入的每个体素元素与其重建进行比较来得出异常分数。
最近,Bergmann 等人 (2022) 推出了 MVTec 3D-AD,这是一个用于评估 3D 异常检测算法的综合数据集。 到目前为止,这是唯一专门为此任务设计的公共数据集。 他们表明,现有方法在具有挑战性的高分辨率点云上表现不佳,并且需要为该任务开发新方法。
2.3 学习深度3D描述符
几何特征提取通常用于 3D 应用,例如 3D 配准或 3D 姿态估计。 社区最近从设计手工描述符(Salti 等人,2014;Tombari 等人,2010)转向基于学习的方法。
其中一项工作是学习从较大输入点云裁剪的局部 3D 块上的低维描述符。 在 3DMatch (Zeng 等人, 2017) 和 PPFNet (Deng 等人, 2018b) 中,监督度量学习用于从带注释的 3D 对应关系中学习嵌入。 PPF-FoldNet (Deng 等人, 2018a) 追求一种无监督策略,其中自动编码器根据从本地补丁中提取的点对特征进行训练。 类似地,Kehl 等人 (2016) 引入了一种自动编码器,该编码器在 RGB-D 图像块上进行训练以获得局部特征。 这些方法的缺点是需要为每个特征裁剪和处理单独的补丁。 对于大量的点来说,这很快就会变得难以计算。
为了缓解这个问题,最近的 3D 特征提取器尝试密集计算高分辨率输入的特征。 Choy 等人 (2019) 提出了 FCGF,一种用于 3D 配准的局部几何特征提取的全卷积方法。 他们设计了一个具有稀疏卷积的网络来有效处理高分辨率体素数据。 给定大量精确注释的局部对应关系,他们的方法是使用对比损失来训练的,这鼓励匹配局部几何图形以在特征空间中接近。 PointContrast (Xie 等人, 2020) 以自我监督的方式学习 3D 配准的描述符,不依赖于人类注释。 通过从单个 3D 扫描中增强一对重叠视图来自动导出对应关系。 虽然计算效率较高,但这些方法需要事先进行体素化,这可能会导致离散化不准确。 此外,所有讨论的方法都旨在生成理想情况下对输入数据的 3D 旋转不变的特征空间。 然而,在无监督异常检测中,异常可以通过局部旋转的几何结构精确地表现出来。 因此,这种差异应该反映在提取的特征向量中。 这就需要开发一种对本地轮换敏感的不同预训练策略。
3 点云中的师生异常检测
在本节中,我们将介绍 3D Student-Teacher (3D-ST),这是一种多功能框架,用于对高分辨率 3D 点云中的几何异常进行无监督检测和定位。 我们利用最近成功利用预训练网络中的局部描述符进行异常检测,并提出将 2D 学生-教师方法(Bergmann 等人,2020) 应用于 3D 数据。
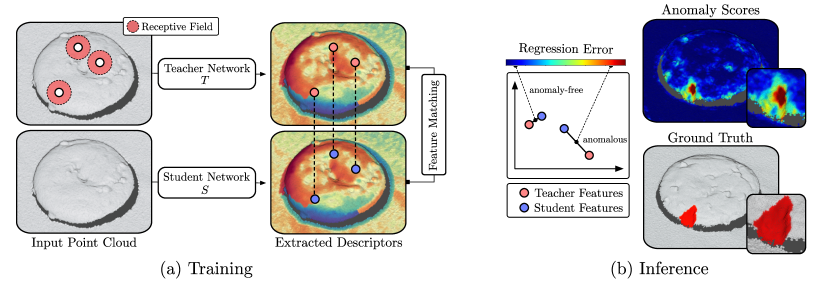
给定无异常输入点云的训练数据集,我们的目标是创建一个可以定位测试点云中的异常区域的模型,即为每个点分配实值异常分数。 为了实现这一目标,我们设计了一个密集的特征提取网络,称为教师网络,它计算任意点云的局部几何特征。 对于异常检测,学生网络根据从获得的描述符在无异常点云上进行训练。在推理过程中, 和 之间的回归误差增加表明存在异常点。 我们的方法的概述如图2所示。
对于预训练老师,我们提出了一个自我监督的协议。 它适用于任何通用辅助 3D 点云数据集,无需人工注释。
3.1密集局部几何描述符的自监督学习
我们首先描述如何构建描述性教师网络。 图3中显示了我们的预训练协议的概述。 输入点云 包含 个三维点,其目的是为每个 生成 维特征向量 。 向量描述了点周围的局部几何形状,即其感受野内的几何形状。
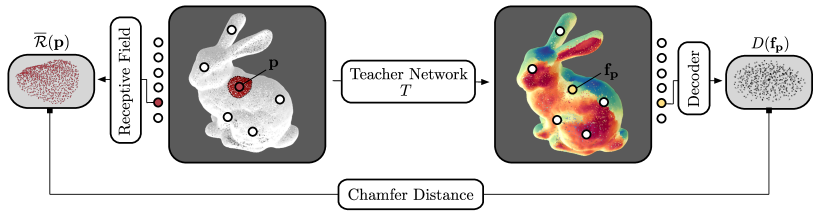
局部特征聚合。
的网络架构有两个关键要求。 首先,它应该能够通过计算每个输入点的特征向量来有效地处理高分辨率点云,而无需对输入数据进行下采样。 其次,它需要对特征向量的感受野进行显式控制。 特别是,必须能够有效地计算输出描述符的感受野内的所有点。
为了满足这些要求,我们构造输入点云的-最近邻图并初始化。 然后,我们将输入样本传递给一系列残差块,其中每个块将每个 3D 点 的特征向量从 更新到 。 这些块的灵感来自 RandLA-Net (Hu 等人, 2020, 2021),这是一种用于大规模点云语义分割的高效轻量级神经架构。 在语义分割任务中,点的绝对位置通常与其类别相关,例如在自动驾驶数据集中。 在这里,我们希望我们的模型能够生成描述对象的局部几何形状的特征,与其绝对位置无关。 因此,我们通过消除对绝对坐标的任何依赖来使残差块平移不变。 正如我们在部分 4中的实验结果所强调的那样,这显着提高了用于异常检测时的性能。
我们的残差块的架构如图图4(a)所示。 输入特征首先通过共享 MLP,然后是两个局部特征聚合 (LFA) 块。 输出特征在由额外的共享 MLP 处理后添加到输入中。 这些特征由一系列残差块和最终共享 MLP 进行转换,该共享 MLP 具有单个隐藏层,该隐藏层维护描述符的维度,即 。
LFA 块的目的是聚合每个输入点局部附近的几何信息。 为此,它计算所有 的最近邻居 以及由以下定义的每个点对的一组局部几何特征
| (1) |
运算符表示串联操作,表示范数。 由于 仅取决于相邻点之间的差异向量,因此我们的网络在设计上对于输入数据的翻译是不变的。 我们的实验表明,局部特征提取器的这种不变性对于异常检测性能至关重要。 因此,我们对 LFA 块进行了这个小但重要的更改。 图4(b)中给出了此类块的示意性描述。
对于每个 LFA 块,几何特征集 通过共享 MLP 传递,生成维度 的特征向量。 它们与输入特征集 连接起来。 LFA块的输出特征向量是通过连接特征的平均池化操作获得的,产生维度的特征向量。
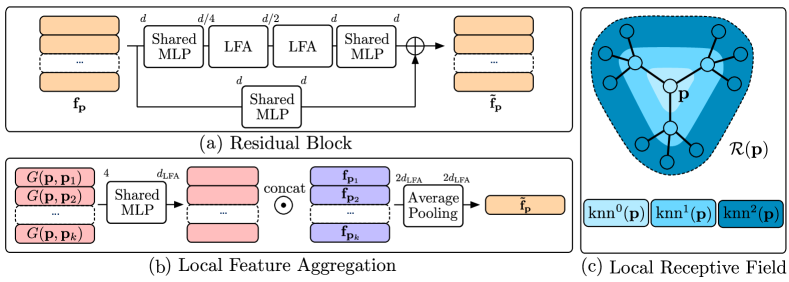
重建局部感受野。
为了以自监督的方式预训练,我们建议采用一个网络来解码特征向量的局部感受野。
我们的网络架构的设计允许有效计算点的感受野内的所有点,即影响特征向量的所有点>。 每个 LFA 块取决于周围最近邻居 的特征。 每当执行 LFA 块时, 在最近邻图中就会增长一跳。 因此,可以通过迭代遍历最近邻图来获得感受野:
| (2) |
和。 表示网络中LFA块的总数。 图 4(c) 可视化了感受野的定义。
解码器 对特征向量进行上采样,通过应用 MLP 生成 3D 点。 对于预训练,我们通过局部特征提取器从输入点云中提取描述符。 然后,我们从输入点云中随机采样一组点 。 对于每个 ,我们计算感受野 并将其各自的特征向量传递给解码器。 为了训练,我们最小化解码点和感受野之间的倒角距离(Barrow等人,1977)。 由于我们的网络架构不知道 的绝对坐标,因此我们另外计算所有 的平均值 并从每个点中减去它,得到设置。 我们的自监督训练过程的损失函数可以写为:
| (3) |
数据标准化。
为了使我们的教师网络应用于预训练数据集中未包含的任何点云,需要某种形式的数据标准化。 由于我们的网络对相邻点的距离向量进行操作,因此我们选择根据这些距离对输入数据进行归一化。 更具体地说,我们计算整个训练集中每个点与其最近邻点之间的平均距离,即
| (4) |
然后,我们将预训练数据集中每个数据样本的坐标缩放 。 这使得我们能够将教师网络应用于任意点云数据集,只要使用相同的数据归一化技术即可。
3.2匹配几何特征进行3D异常检测
最后,我们描述如何使用预训练的教师网络 来训练学生网络 进行异常检测。 给定一个无异常点云数据集,我们首先计算该数据集的缩放因子 ,如 (4) 中定义。 的权重在整个异常检测训练过程中保持恒定。 表现出与 相同的网络架构,并使用均匀分布的随机权重进行初始化。 每个训练点云都通过两个网络和传递,以计算密集特征和 分别表示所有 。 的权重经过优化,通过计算特征距离 来重现 的几何描述符:
| (5) |
我们将教师特征转换为以 为中心,单位标准差。 这需要计算整个训练集上所有教师特征的分量均值和标准差。 我们用 表示用 的条目填充的对角矩阵的逆。
在推理过程中,会为测试点云 中的每个点 得出异常分数。 它们由学生网络和教师网络各自特征之间的回归误差给出,即。 这背后的直觉是,异常几何形状会产生学生网络在训练期间未观察到的特征,因此无法重现。 大的回归误差表明几何形状异常。
4实验
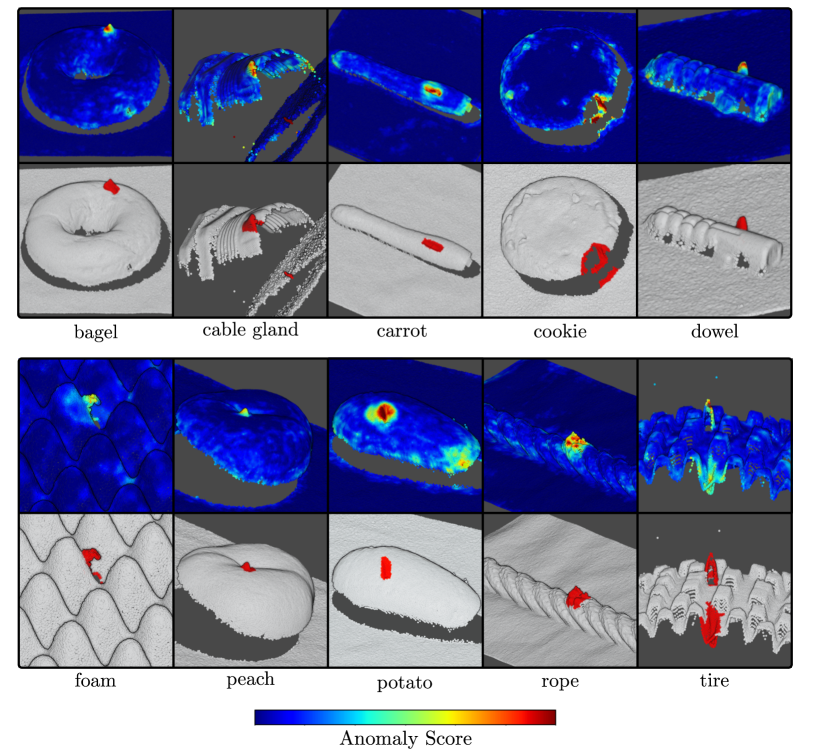
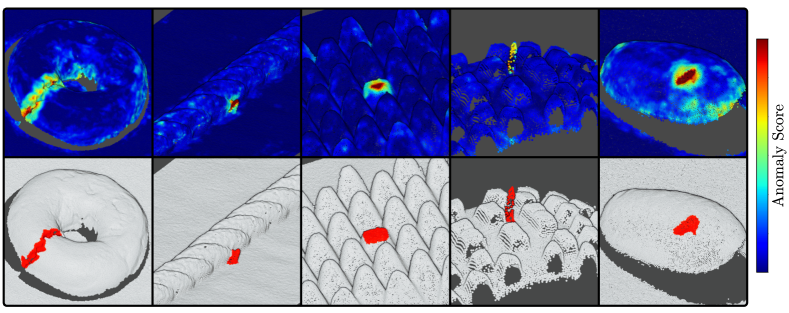
为了证明我们方法的有效性,我们对最近发布的 MVTec 3D 异常检测 (MVTec 3D-AD) 数据集(Bergmann 等人,2022) 进行了广泛的实验。 该数据集旨在评估点云数据(PCD)中几何异常的无监督检测方法。 目前,这是该任务唯一公开可用的综合数据集。 它包含工业制造产品 10 个对象类别的 4000 多个高分辨率 3D 扫描。 任务是在无异常样本上训练模型,并在推理过程中定位制造产品上作为缺陷出现的异常。
4.1 实验设置
我们将 3D-ST 方法的性能与现有的无监督 3D 异常检测方法进行了基准测试。 特别是,我们遵循 MVTec 3D-AD 的初始基准,并将 3D-ST 与 Voxel f-AnoGAN、Voxel Autoencoder 和 Voxel Variation Model 进行比较。 该基准测试还包括各自的对应版本,通过交换 3D 与 2D 卷积来处理深度图像而不是体素网格。 基于 GAN 和自动编码器的方法通过将其重建与输入样本进行逐像素或逐体素比较来得出异常分数。 变异模型是一种浅层机器学习模型,用于计算训练集的每个像素或每个体素的平均值和标准差。 在推理过程中,异常分数是通过计算从测试样本到训练分布的每像素或每体素马哈拉诺比斯距离来获得的。 我们采用与(Bergmann等人,2022)中列出的相同的训练和评估协议以及超参数设置。
老师预训练。
预训练我们方法的教师网络(参见 部分 3.1),我们使用 ModelNet10 数据集的对象生成合成 3D 场景(Wu 等人,2015) 。 它由 5000 多个 3D 模型组成,分为 10 个不同的对象类别。
我们通过从 ModelNet10 中随机选择 样本并将其边界框的最长边缩放到 来生成预训练数据集的场景。 对象围绕每个 3D 轴旋转,角度从间隔 均匀采样。 每个对象都放置在从 中均匀采样的随机位置。 点云是通过使用最远点采样(Moenning and Dodgson,2003)从场景中选择点来创建的。 训练和验证数据集分别由 和 点云组成。 我们的实验表明,使用这样的合成数据集进行预训练会产生非常适合 3D 异常检测的局部描述符。 在我们的消融研究中,我们还研究了使用来自不同领域的真实世界数据集进行预训练,即 Semantic KITTI (Behley 等人, 2019; Geiger 等人, 2012)、MVTec ITODD (Drost 等人,2017),以及 3DMatch (Zeng 等人,2017)。
教师网络由残差块组成并处理输入点。 我们使用两个不同的特征维度进行实验。 所有网络块中的共享 MLP 均使用单个密集层实现,后跟负斜率为 的 LeakyReLU 激活。 每个共享MLP的输入和输出维度在图4中给出。 对于局部特征聚合,构建具有 邻居的最近邻图。 预训练使用 Adam 优化器运行 纪元,初始学习率为 ,权重衰减为 。 在每个训练步骤中,都会通过教师网络馈送单个输入样本。 为了生成局部感受野的重建,从 的输出中随机选择的描述符 通过解码器网络 传递,该网络是作为 MLP 实现的输入维度 ,两个维度 的隐藏层,以及重建 点的输出层。 每个隐藏层后面都有一个负斜率为 的 LeakyReLU 激活。 训练结束后,我们选择验证误差最低的模型作为教师网络。
| bagel |
|
carrot | cookie | dowel | foam | peach | potato | rope | tire | mean | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voxel | GAN | 0.440 | 0.453 | 0.825 | 0.755 | 0.782 | 0.378 | 0.392 | 0.639 | 0.775 | 0.389 | 0.583 | ||
| AE | 0.260 | 0.341 | 0.581 | 0.351 | 0.502 | 0.234 | 0.351 | 0.658 | 0.015 | 0.185 | 0.348 | |||
| VM | 0.453 | 0.343 | 0.521 | 0.697 | 0.680 | 0.284 | 0.349 | 0.634 | 0.616 | 0.346 | 0.492 | |||
| Depth | GAN | 0.111 | 0.072 | 0.212 | 0.174 | 0.160 | 0.128 | 0.003 | 0.042 | 0.446 | 0.075 | 0.143 | ||
| AE | 0.147 | 0.069 | 0.293 | 0.217 | 0.207 | 0.181 | 0.164 | 0.066 | 0.545 | 0.142 | 0.203 | |||
| VM | 0.280 | 0.374 | 0.243 | 0.526 | 0.485 | 0.314 | 0.199 | 0.388 | 0.543 | 0.385 | 0.374 | |||
| PCD | 3D-ST64 | 0.939 | 0.440 | 0.984 | 0.904 | 0.876 | 0.633 | 0.937 | 0.989 | 0.967 | 0.507 | 0.818 | ||
| 3D-ST128 | 0.950 | 0.483 | 0.986 | 0.921 | 0.905 | 0.632 | 0.945 | 0.988 | 0.976 | 0.542 | 0.833 |
异常检测。
我们的 3D-ST 方法中的学生网络 具有与教师相同的网络架构。 它在 MVTec 3D-AD 数据集的无异常训练分割上训练了 个纪元。 我们以 的批量大小进行训练。 由于所使用网络的感受野有限,这相当于每次迭代处理大量局部补丁。 我们使用 Adam,初始学习率为 和权重衰减 。 使用最远点采样将每个点云缩减为 个输入点。 为了进行推理,我们选择验证误差最低的学生网络。
MVTec 3D-AD 的评估需要预测原始 图像中每个像素的异常分数。 为此,我们对未通过我们的方法分配异常分数的像素应用谐波插值(Evans,2010)。 我们遵循 MVTec 3D-AD 的标准评估协议,计算每个区域的重叠(PRO)(Bergmann 等人,2021)以及连续增加异常阈值的相应误报率。 然后,我们报告 PRO 曲线下面积 (AU-PRO) 的积分,误报率为 。 我们将结果值标准化为间隔 。
4.2实验结果
表 1显示了每种评估方法对 MVTec 3D-AD 的每个对象类别的定量结果。 前三行列出了基于体素的方法的性能。 以下三行列出了各个方法在 2D 深度图像上的性能。 底部两行显示了我们的 3D-ST 方法在 3D 点云数据上的性能,针对两个不同的描述符维度 进行了评估。 我们的方法在每个数据集类别上的表现都明显优于所有其他方法。 将描述符维度从 增加到 会产生 个百分点的轻微整体改进。 后者比之前领先的方法优于 个点。
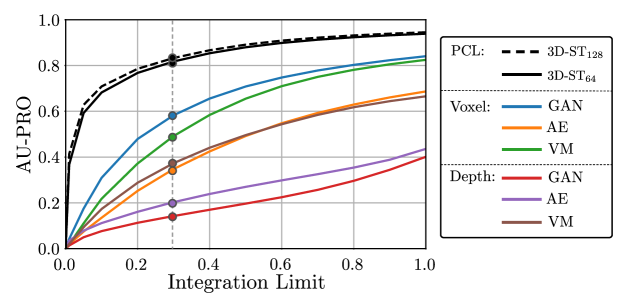
MVTec 3D-AD 论文指出,现实世界的异常检测应用需要特别低的误报率。 因此,我们在 图 5 中报告了在改变 PRO 曲线积分限制时所有评估方法的平均性能。 对于任何选定的积分限制,我们的方法都优于所有其他评估方法。 对于较低的集成限制,性能的相对差异特别大。 这使得我们的方法非常适合实际应用。 多个积分限制的确切值可以在部分A中找到。
4.3消融研究
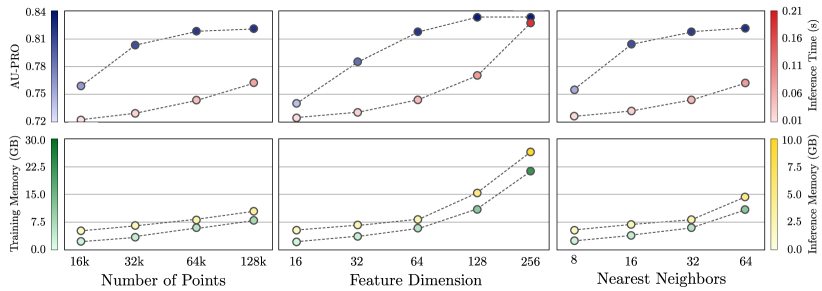
我们还针对我们提出的方法的关键超参数进行了各种消融研究。 同样,每个实验的确切值可以在部分A中找到。 图 6显示了我们方法的平均性能对输入点数、特征维度的依赖关系,或用于局部特征聚合的最近邻点的数量。 我们还可视化训练和评估期间每个模型的推理时间和内存消耗111所有模型均使用 PyTorch 库实现(Paszke 等人,2019)。 推理时间和内存消耗是在 NVIDIA Tesla V100 GPU 上测量的。. 我们发现我们的方法对每个超参数的选择不敏感。 特别是,每个评估模型的平均性能都大大优于基线实验中性能最佳的竞争模型。 我们模型的平均性能相对于每个考虑的超参数单调增长。 它最终会饱和,而推理时间和内存消耗继续超线性增加。
教师网络的特征空间。
我们在图7中描述了预训练策略的有效性。 左侧条形图显示了我们方法的训练策略变化的平均性能。 第一个条表示当我们随机初始化教师的权重并且不执行预训练时,性能如何变化。 正如预期的那样,性能显着下降。 第二个条形图显示了将每个 3D 点的绝对点坐标连接到局部特征聚合函数 时的性能,如 (Hu 等人, 2020) 中提出的。 这不再使我们的网络翻译不变并降低性能。 这表明平移不变性对于我们的网络架构确实很重要,并且我们对局部特征聚合模块的修改产生了重大影响。 第三条显示了我们的方法在尝试额外合并旋转不变性时的性能。 我们通过使用随机采样的旋转来增强训练数据来实现这一点,这样局部旋转的几何图形也被认为是无异常的。 在此设置中,性能仍然明显低于我们的方法,这表明对局部旋转的敏感性有利于 3D 异常检测。
预训练数据集。
在我们的大多数实验中,我们使用从 ModelNet10 数据集的对象创建的综合生成场景,如上所述。 我们的预训练策略不需要任何人工注释,并且可以在任意输入点云上运行。 因此,我们感兴趣的是使用不同的预训练数据集时性能是否会有所不同。 作为第一个实验,我们从 Semantic KITTI 自动驾驶数据集中随机选择 训练场景,该数据是用 LIDAR 传感器捕获的。 其次,我们对 3DMatch 的所有样本进行预训练,这是一个最初为点云配准设计的室内数据集。 最后,我们使用 MVTec ITODD 数据集的所有样本,该数据集最初是为 3D 位姿估计设计的工业数据集。 图 7中的中心条形图显示了与我们的基线模型相比,我们的方法在使用这三个数据集进行预训练时的平均性能。 我们发现,在使用 ITODD 或 3DMatch 时,我们的方法并不强烈依赖于为预训练选择的特定数据集。 我们观察到 KITTI 数据集存在轻微的性能差距,这可能是由于较大的域转移造成的。
特征提取器。
当我们的预训练教师网络被从不同特征提取器获得的描述符替换时,我们还测试了我们方法的性能。
特别是,我们与从 PPFFold-Net (Deng 等人,2018a) 和 FCGF (Choy 等人,2019) 获得的特征进行比较。 对于这两种情况,我们都使用公开的预训练模型。222https://github.com/XuyangBai/PPF-FoldNet
https://github.com/chrischoy/FCGF PPF-FoldNet 输出单个 维描述符,用于从每个输入点周围的 由于它需要基于补丁的特征提取,因此为大量输入点生成描述符变得非常慢。 因此,我们仅使用 PPF-FoldNet 提取每个点云的 描述符。
FCGF 输出 维度描述符,并通过查找 3D 配准的对应关系以监督方式在 3DMatch 数据集上进行预训练。 由于它需要对输入数据进行事先体素化,因此我们选择 mm 的体素大小并提取 点的描述符。
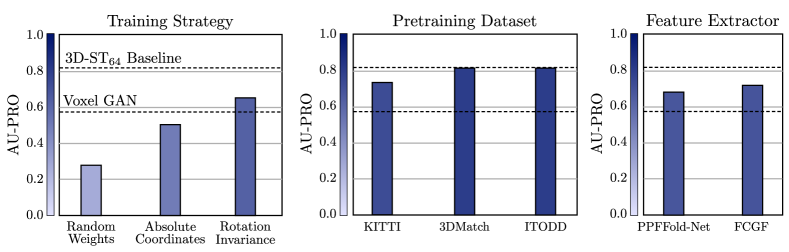
我们训练学生网络来匹配从这些预训练网络中提取的特征,而不是我们提出的教师网络。 我们的学生网络输出层的特征维度被调整以匹配描述符的特征维度。 结果显示在图7中的右侧条形图中。 传输两个网络的特征会产生比体素 GAN 更好的性能,体素 GAN 是之前从头开始训练的性能最佳的方法。 这强调了使用预训练几何描述符进行 3D 异常检测的有效性。 两个提取器都没有达到我们提出的专为异常检测问题设计的预训练策略的性能。
5结论
我们提出了 3D-ST,这是一种解决 3D 点云中无监督异常检测这一挑战性问题的新方法。 我们的方法专门针对无异常样本进行训练。 在推理过程中,它会定位与训练集中存在的几何结构不同的几何结构。 现有的方法(例如卷积自动编码器或生成对抗网络)是通过随机权重初始化进行训练的。 与此相反,我们的方法利用了从在辅助 3D 数据集上预训练的网络中提取的深层局部几何特征的描述性。 特别是,我们提出将学生-教师异常检测从 2D 调整为 3D。 为了解决 3D 异常检测预训练协议的缺乏,我们引入了一种自我监督策略。 通过这种方式,我们创建了教师网络,为任意 3D 点云生成密集的局部几何描述符。 教师网络通过重建局部感受野进行预训练。 对于异常检测,学生网络在无异常数据上匹配教师的几何描述符。 在推理过程中,通过计算相关学生和教师描述符之间的回归误差,得出每个 3D 点的异常分数。 MVTec 3D 异常检测数据集上的大量实验表明,我们的方法大幅优于所有现有方法。 我们进行了各种消融研究,进一步表明我们的方法计算效率高,并且对于所使用的超参数和预训练数据集的选择具有鲁棒性。
致谢。
我们要感谢 Bertram Drost、Carsten Steger、Markus Glitzner 以及 MVTec Software GmbH 的整个研究团队进行的宝贵讨论。
参考
- Bakas et al. (2017) S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. S. Kirby, et al. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Scientific Data, 4(1), 2017. doi: 10.1038/sdata.2017.117.
- Barrow et al. (1977) H. G. Barrow, J. M. Tenenbaum, R. C. Bolles, and H. C. Wolf. Parametric correspondence and chamfer matching: Two new techniques for image matching. In IJCAI, pages 659–663, 1977.
- Baur et al. (2019) C. Baur, B. Wiestler, S. Albarqouni, and N. Navab. Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images. In A. Crimi, S. Bakas, H. Kuijf, F. Keyvan, M. Reyes, and T. van Walsum, editors, Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pages 161–169, Cham, 2019. Springer International Publishing.
- Behley et al. (2019) J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proc. of the IEEE/CVF International Conf. on Computer Vision (ICCV), 2019.
- Bengs et al. (2021) M. Bengs, F. Behrendt, J. Krüger, R. Opfer, and A. Schlaefer. Three-dimensional deep learning with spatial erasing for unsupervised anomaly segmentation in brain MRI. International Journal of Computer Assisted Radiology and Surgery, 16, 2021. doi: 10.1007/s11548-021-02451-9.
- Bergmann et al. (2019) P. Bergmann, S. Löwe, M. Fauser, D. Sattlegger, and C. Steger. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. In A. Tremeau, G. Farinella, and J. Braz, editors, 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, volume 5: VISAPP, pages 372–380, Setúbal, 2019. Scitepress.
- Bergmann et al. (2020) P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4182–4191, 2020.
- Bergmann et al. (2021) P. Bergmann, K. Batzner, M. Fauser, D. Sattlegger, and C. Steger. The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. International Journal of Computer Vision, 129(4):1038–1059, 2021. doi: 10.1007/s11263-020-01400-4.
- Bergmann et al. (2022) P. Bergmann, X. Jin, D. Sattlegger, and C. Steger. The MVTec 3D-AD Dataset for Unsupervised 3D Anomaly Detection and Localization. In 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, volume 5: VISAPP, Setúbal, 2022. Scitepress.
- Blum et al. (2019) H. Blum, P.-E. Sarlin, J. Nieto, R. Siegwart, and C. Cadena. Fishyscapes: A Benchmark for Safe Semantic Segmentation in Autonomous Driving. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 2403–2412, 2019. doi: 10.1109/ICCVW.2019.00294.
- Burlina et al. (2019) P. Burlina, N. Joshi, and I.-J. Wang. Where’s Wally Now? Deep Generative and Discriminative Embeddings for Novelty Detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Carrara et al. (2021) F. Carrara, G. Amato, L. Brombin, F. Falchi, and C. Gennaro. Combining GANs and AutoEncoders for efficient anomaly detection. In 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021. doi: 10.1109/icpr48806.2021.9412253.
- Carrera et al. (2017) D. Carrera, F. Manganini, G. Boracchi, and E. Lanzarone. Defect Detection in SEM Images of Nanofibrous Materials. IEEE Transactions on Industrial Informatics, 13(2):551–561, 2017. doi: 10.1109/TII.2016.2641472.
- Choy et al. (2019) C. Choy, J. Park, and V. Koltun. Fully convolutional geometric features. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8957–8965, 2019. doi: 10.1109/ICCV.2019.00905.
- Cohen and Hoshen (2020) N. Cohen and Y. Hoshen. Sub-image anomaly detection with deep pyramid correspondences. arXiv preprint arXiv:2005.02357, 2020.
- Defard et al. (2021) T. Defard, A. Setkov, A. Loesch, and R. Audigier. Padim: A patch distribution modeling framework for anomaly detection and localization. In A. Del Bimbo, R. Cucchiara, S. Sclaroff, G. M. Farinella, T. Mei, M. Bertini, H. J. Escalante, and R. Vezzani, editors, Pattern Recognition. ICPR International Workshops and Challenges, pages 475–489. Springer International Publishing, 2021. ISBN 978-3-030-68799-1.
- Deng et al. (2018a) H. Deng, T. Birdal, and S. Ilic. PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors. In Proceedings of the European Conference on Computer Vision (ECCV), 2018a.
- Deng et al. (2018b) H. Deng, T. Birdal, and S. Ilic. PPFNet: Global Context Aware Local Features for Robust 3D Point Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018b.
- Drost et al. (2017) B. Drost, M. Ulrich, P. Bergmann, P. Härtinger, and C. Steger. Introducing MVTec ITODD — A Dataset for 3D Object Recognition in Industry. In IEEE International Conference on Computer Vision Workshops (ICCVW), pages 2200–2208, 2017. doi: 10.1109/ICCVW.2017.257.
- Ehret et al. (2019) T. Ehret, A. Davy, J.-M. Morel, and M. Delbracio. Image Anomalies: A Review and Synthesis of Detection Methods. Journal of Mathematical Imaging and Vision, 61(5):710–743, 2019.
- Evans (2010) L. C. Evans. Partial differential equations. American Mathematical Society, Providence, R.I., 2010. ISBN 9780821849743 0821849743.
- Geiger et al. (2012) A. Geiger, P. Lenz, and R. Urtasun. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361, 2012.
- Gudovskiy et al. (2022) D. Gudovskiy, S. Ishizaka, and K. Kozuka. CFLOW-AD: Real-Time Unsupervised Anomaly Detection With Localization via Conditional Normalizing Flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 98–107, 2022.
- Hendrycks et al. (2019) D. Hendrycks, S. Basart, M. Mazeika, M. Mostajabi, J. Steinhardt, and D. Song. A Benchmark for Anomaly Segmentation. arXiv preprint arXiv:1911.11132, 2019.
- Hong and Choe (2020) E. Hong and Y. Choe. Latent feature decentralization loss for one-class anomaly detection. IEEE Access, 8:165658–165669, 2020. doi: 10.1109/ACCESS.2020.3022646.
- Hu et al. (2020) Q. Hu, B. Yang, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, and A. Markham. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- Hu et al. (2021) Q. Hu, B. Yang, L. Xie, S. Rosa, Y. Guo, Z. Wang, N. Trigoni, and A. Markham. Learning semantic segmentation of large-scale point clouds with random sampling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- Kehl et al. (2016) W. Kehl, F. Milletari, F. Tombari, S. Ilic, and N. Navab. Deep Learning of Local RGB-D Patches for 3D Object Detection and 6D Pose Estimation. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors, Computer Vision – ECCV 2016, pages 205–220, Cham, 2016. Springer International Publishing. ISBN 978-3-319-46487-9.
- Krizhevsky et al. (2012) A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1, pages 1097–1105, 2012.
- Liu et al. (2020) W. Liu, R. Li, M. Zheng, S. Karanam, Z. Wu, B. Bhanu, R. J. Radke, and O. Camps. Towards visually explaining variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Menze et al. (2015) B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Transactions on Medical Imaging, 34(10):1993–2024, 2015. doi: 10.1109/TMI.2014.2377694.
- Mishra et al. (2020) P. Mishra, C. Piciarelli, and G. L. Foresti. A neural network for image anomaly detection with deep pyramidal representations and dynamic routing. International Journal of Neural Systems, 30(10):2050060, 2020. doi: 10.1142/S0129065720500604.
- Moenning and Dodgson (2003) C. Moenning and N. A. Dodgson. Fast Marching farthest point sampling. In Eurographics 2003 - Posters. Eurographics Association, 2003. doi: 10.2312/egp.20031024.
- Pang et al. (2021) G. Pang, C. Shen, L. Cao, and A. V. D. Hengel. Deep learning for anomaly detection: A review. ACM Comput. Surv., 54(2), 2021. ISSN 0360-0300. doi: 10.1145/3439950.
- Paszke et al. (2019) A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems, volume 32, 2019.
- Potter et al. (2020) K. M. Potter, B. Donohoe, B. Greene, A. Pribisova, and E. Donahue. Automatic detection of defects in high reliability as-built parts using x-ray CT. In Applications of Machine Learning 2020, volume 11511, pages 120 – 136. International Society for Optics and Photonics, SPIE, 2020. doi: 10.1117/12.2570459.
- Reiss et al. (2021) T. Reiss, N. Cohen, L. Bergman, and Y. Hoshen. Panda: Adapting pretrained features for anomaly detection and segmentation. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2805–2813, 2021. doi: 10.1109/CVPR46437.2021.00283.
- Rippel et al. (2021) O. Rippel, A. Chavan, C. Lei, and D. Merhof. Transfer Learning Gaussian Anomaly Detection by Fine-Tuning Representations. arXiv preprint arXiv:2108.04116, 2021.
- Salehi et al. (2021) M. Salehi, N. Sadjadi, S. Baselizadeh, M. H. Rohban, and H. R. Rabiee. Multiresolution knowledge distillation for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14902–14912, 2021.
- Salti et al. (2014) S. Salti, F. Tombari, and L. Di Stefano. SHOT: Unique signatures of histograms for surface and texture description. Computer Vision and Image Understanding, 125:251–264, 2014. ISSN 1077-3142. doi: 10.1016/j.cviu.2014.04.011.
- Schlegl et al. (2019) T. Schlegl, P. Seeböck, S. M. Waldstein, G. Langs, and U. Schmidt-Erfurth. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Medical Image Analysis, 54:30–44, 2019. doi: 10.1016/j.media.2019.01.010.
- Simarro Viana et al. (2021) J. Simarro Viana, E. de la Rosa, T. Vande Vyvere, D. Robben, D. M. Sima, and CENTER-TBI Participants and Investigators. Unsupervised 3D Brain Anomaly Detection. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, pages 133–142. Springer International Publishing, 2021. doi: 10.1007/978-3-030-72084-1.
- Song and Yan (2013) K. Song and Y. Yan. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Applied Surface Science, 285:858–864, 2013. doi: 10.1016/j.apsusc.2013.09.002.
- Tombari et al. (2010) F. Tombari, S. Salti, and L. Di Stefano. Unique signatures of histograms for local surface description. In Proceedings of the 11th European Conference on Computer Vision: Part III, page 356–369, Berlin, Heidelberg, 2010. Springer-Verlag. ISBN 364215557X.
- Venkataramanan et al. (2020) S. Venkataramanan, K.-C. Peng, R. V. Singh, and A. Mahalanobis. Attention guided anomaly localization in images. In A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, editors, Computer Vision – ECCV 2020, pages 485–503. Springer International Publishing, 2020. ISBN 978-3-030-58520-4.
- Wang et al. (2020) L. Wang, D. Zhang, J. Guo, and Y. Han. Image anomaly detection using normal data only by latent space resampling. Applied Sciences, 10(23), 2020. ISSN 2076-3417. doi: 10.3390/app10238660.
- Wu et al. (2015) Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015.
- Xie et al. (2020) S. Xie, J. Gu, D. Guo, C. Qi, L. Guibas, and O. Litany. PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding. In ECCV, 2020.
- Zeng et al. (2017) A. Zeng, S. Song, M. Nießner, M. Fisher, J. Xiao, and T. Funkhouser. 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 199–208, 2017. doi: 10.1109/CVPR.2017.29.
A 有关消融实验的其他信息
作为参考,我们提供了与我们主要手稿中的线图和条形图相对应的消融研究结果的数值。
A.1 积分下限
在我们的论文中,定量结果报告为 AU-PRO,其中 PRO 值与假阳性率 (FPR) 相结合。 在我们的大多数实验中,我们通过积分上限 来限制 FPR。 为了能够在较低积分限制下进行比较,我们在 Table 2 中列出了我们的方法在四个不同积分限制 下的性能。 前四行显示了描述符维度为 的模型的性能。 底部四行显示了特征维度 模型的相应性能。 这些值也在图5所示的线图中进行了描述。
|
bagel |
|
carrot | cookie | dowel | foam | peach | potato | rope | tire | mean | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.01 | 0.361 | 0.019 | 0.690 | 0.461 | 0.147 | 0.232 | 0.433 | 0.762 | 0.558 | 0.008 | 0.367 | |||||
| 0.05 | 0.718 | 0.095 | 0.909 | 0.699 | 0.481 | 0.428 | 0.735 | 0.934 | 0.841 | 0.083 | 0.592 | |||||
| 0.10 | 0.832 | 0.177 | 0.954 | 0.791 | 0.662 | 0.505 | 0.837 | 0.966 | 0.910 | 0.187 | 0.682 | |||||
| 0.20 | 0.910 | 0.322 | 0.977 | 0.869 | 0.815 | 0.578 | 0.909 | 0.983 | 0.952 | 0.364 | 0.768 | |||||
| 0.01 | 0.438 | 0.023 | 0.710 | 0.500 | 0.239 | 0.278 | 0.511 | 0.791 | 0.630 | 0.015 | 0.414 | |||||
| 0.05 | 0.776 | 0.114 | 0.917 | 0.741 | 0.581 | 0.456 | 0.773 | 0.933 | 0.876 | 0.113 | 0.628 | |||||
| 0.10 | 0.867 | 0.200 | 0.957 | 0.824 | 0.738 | 0.521 | 0.858 | 0.964 | 0.932 | 0.223 | 0.709 | |||||
| 0.20 | 0.927 | 0.352 | 0.979 | 0.891 | 0.858 | 0.584 | 0.920 | 0.982 | 0.965 | 0.399 | 0.786 |
A.2 改变关键模型超参数
| Performance | Number of Points | Feature Dimension | Nearest Neighbors | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | 16 | 32 | 64 | 128 | 16 | 32 | 64 | 128 | 256 | 8 | 16 | 32 | 64 | ||
|
0.759 | 0.803 | 0.818 | 0.821 | 0.740 | 0.785 | 0.818 | 0.833 | 0.833 | 0.755 | 0.804 | 0.818 | 0.821 | ||
|
0.014 | 0.026 | 0.049 | 0.080 | 0.017 | 0.028 | 0.049 | 0.093 | 0.189 | 0.020 | 0.030 | 0.049 | 0.080 | ||
|
2.29 | 3.33 | 5.89 | 7.87 | 2.06 | 3.54 | 5.89 | 10.98 | 21.13 | 2.43 | 3.98 | 5.89 | 10.86 | ||
|
1.71 | 2.15 | 2.71 | 3.47 | 1.75 | 2.24 | 2.71 | 5.14 | 8.81 | 1.79 | 2.28 | 2.71 | 4.76 | ||
A.3 修改训练策略
我们进一步尝试了应用于我们提出的方法的不同训练策略。 我们测试了随机初始化的教师网络,向模型添加绝对点坐标,并将旋转不变性纳入异常检测训练中。 然后我们研究了不同的预训练数据集和预训练的特征提取器。 这些实验的数值列于表4中。 这些值对应于图7中的条形图。
|
AU-PRO |
|
AU-PRO |
|
AU-PRO | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
0.278 | ITODD | 0.820 | FCGF | 0.719 | ||||||
|
0.505 | 3DMatch | 0.819 | PPF-FoldNet | 0.682 | ||||||
|
0.650 | KITTI | 0.735 | - | - |
B 其他定性结果
图 8 显示了我们的方法针对 MVTec 3D-AD 数据集的每个数据集类别的附加定性结果,我们的方法可以可靠地定位异常。