QaNER:用于命名实体识别的少样本提示问答模型
摘要
最近,基于提示的预训练语言模型学习通过利用提示作为任务指导来提高标签效率,在命名实体识别(NER)中取得了成功。 然而,之前基于提示的少样本NER方法存在计算复杂度较高、零样本能力差、需要手动提示工程或缺乏提示鲁棒性等局限性。 在这项工作中,我们通过提出一种新的基于提示的学习 NER 方法和问答 (QA) 来解决这些缺点,称为 QaNER。 我们的方法包括 1) 将 NER 问题转化为 QA 公式的细化策略; 2)QA模型的NER提示生成; 3)在一些带注释的 NER 示例上使用 QA 模型进行基于提示的调整; 4) 通过提示 QA 模型来零样本 NER。 与之前的方法相比,QaNER 的推理速度更快,对提示质量不敏感,对超参数具有鲁棒性,并且表现出明显更好的低资源性能和零样本能力。
1简介
命名实体识别(NER)旨在用相应的类型标记文本中的实体。 在之前的工作(Hochreiter and Schmidhuber, 1997; Tjong Kim Sang and De Meulder, 2003; Devlin 等人, 2019; Yang and Katiyar, 2020)中,NER问题通常被表述为序列标记问题(也称为序列标记或词符分类)。 通过监督学习,文本序列中的每个实体都可以分配给预定义的实体标签。 训练一个有监督的 NER 系统需要许多带标签的训练数据。 然而,标记大量的标记语料库需要深厚的领域知识,这使得创建这样的语料库既昂贵又耗时。 此外,针对不同的实际应用场景大规模构建具有丰富注释的 NER 系统是一项劳动密集型工作。 企业用例可能有数百个新领域,更不用说不同的语言了。 这些原因激发了一个实际且具有挑战性的研究问题:少样本 NER (Huang 等人, 2020)。
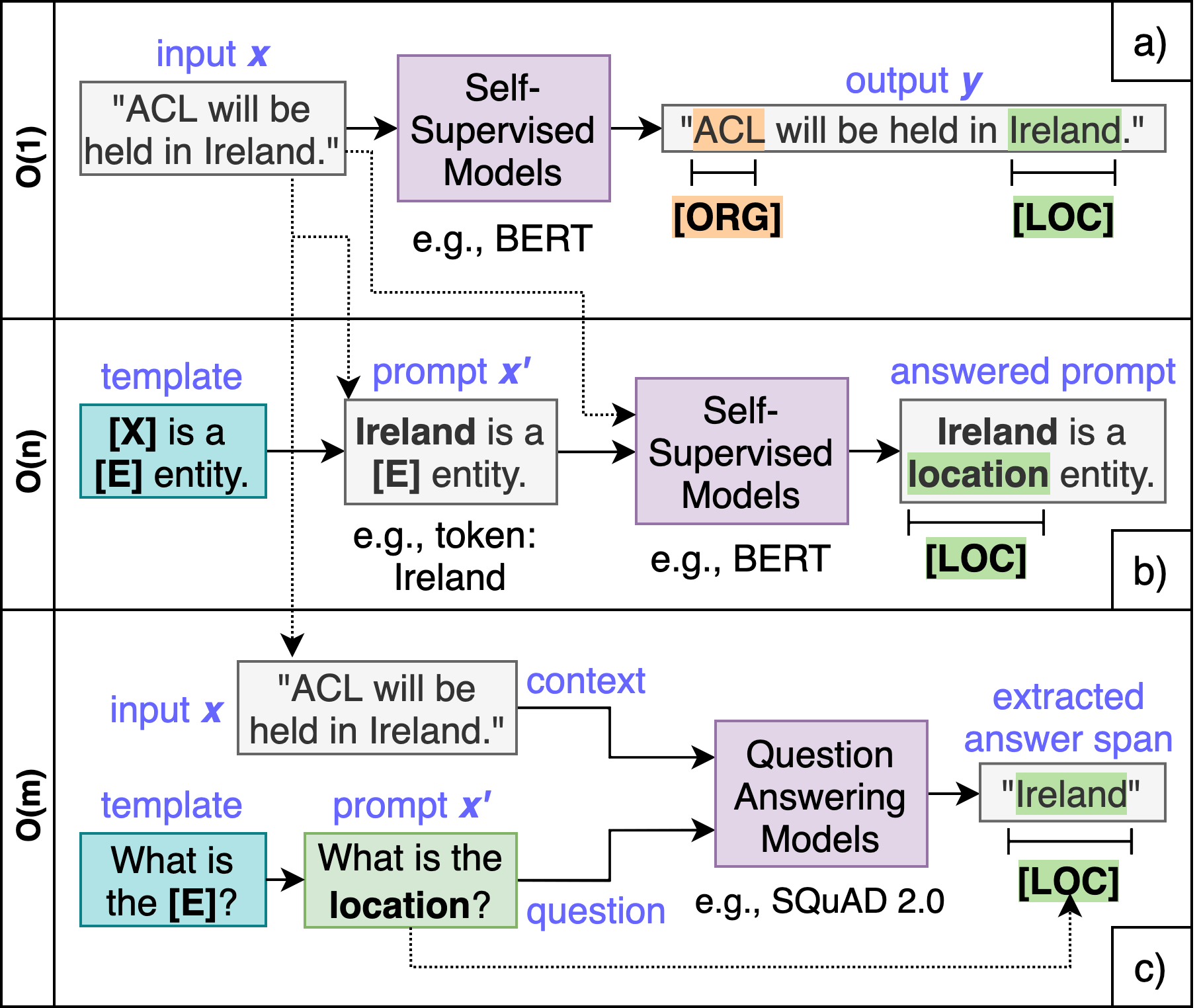
与此同时,基于提示的调优学习是自然语言处理 (NLP) 社区中的一种新范式,越来越受欢迎(Liu 等人,2021)。 基于提示的方法重新表述语言模型 (LM) 的输入,以弥合预训练和下游任务之间的差距。 之前的工作(Li等人,2020)将NER任务制定为机器阅读理解(MRC)任务。 然而,他们没有研究提示的设计(MRC 模型要回答的问题),也没有用少样本或零样本设置进行实验。 在我们的工作中,我们证明了 QA 模型可以利用从问答数据中学到的知识来提高低资源 NER 性能。 我们在少样本和零样本场景中取得了更好的结果,因为基于提示的学习可以提高标签效率(即以更少的示例适应新领域)。
之前基于提示的 NER 方法有四个限制。 首先,推理时间与序列(Chen 等人, 2021)的长度成正比,或者每个词符需要一次提示(Cui 等人, 2021) 。 因此,现有方法具有高计算复杂度。 其次,以前基于提示的方法(Cui等人,2021)需要手动提示工程来设计模板,这是一个劳动密集型的过程。 第三,基于提示的 NER (Cui 等人, 2021) 往往缺乏提示鲁棒性。 该方法对不同的提示设计很敏感,并且依赖于对大量开发集的调整,这在资源匮乏的情况下可能不可用。 最后,之前的方法(Cui等人,2021;Chen等人,2021)使用高资源NER数据集来转移知识以进行少样本学习。 由于数据集使用不同的标签集,性能会受到影响,因此这些方法灵活的可移植性较差。
为了应对这些挑战,我们建议为 NER 提供现成的问答(QA)模型。 如图 1 (c) 所示,我们的方法基于这样的想法:如果我们可以将 NER 问题表述为 QA 任务,那么 QA 模型应该回答该问题并解决原始问题。 我们在 CoNLL03 (Tjong Kim Sang 和 De Meulder,2003)、MIT Movie Review (Liu 等人,2013) 和 MIT Restaurant Review (Liu 等人,2013) 的 NER 数据集上评估了我们的方法。 t2>(刘等人,2013)。 我们的方法根据经验显示出比以前的方法明显更好的性能,特别是当标签资源较低时。 我们论文的贡献如下:
1)我们是第一个为NER(QaNER)引入提示引导问答框架的工作。 当使用完整数据集进行训练时,QaNER 在资源匮乏的情况下实现了最先进的性能和具有竞争力的结果。 这种改进很大程度上来自于 QA 模型的正确知识转移。
2)我们使用 QaNER 提高了该方法针对即时设计和开发集大小的鲁棒性。 QaNER 在各种提示(使用预先训练的 LM 提示生成)以及没有用于参数调整的开发集以进行假设(“在黑暗中拍摄”设置)时继续表现良好。 这种鲁棒性可以归因于将 NER 问题表述为 QA 的显着自然性。
3) QaNER 提高了计算复杂性并实现了更好的知识可迁移性,因为向 QA 模型提出问题是非常自然的,因为与提示其他 LM 相比,提示 QA 模型引入的不匹配更少。 QA 问题的表述使我们能够通过一个推理来识别每种类型的所有实体范围。
| Method + Model | Objective | Complexity of Model | Complexity of Method |
|---|---|---|---|
| Sequence Labeling BERT | classification | ||
| TemplateNER BART | generation | ||
| LightNER BART | generation | ||
| QaNER BERT (Ours) | extraction |
2 背景
2.1少数镜头命名实体识别
在之前的工作(Huang等人,2020;Cui等人,2021;Ziyadi等人,2020;Chen等人,2021)中,常用的方法是假设一个高资源的NER数据集,有大量训练实例的地方。 该模型首先在高资源的源数据集上进行训练,然后转移到低资源的目标 NER 数据集。 两个数据集可能具有不同的域,即高资源源数据集和低资源目标数据集之间的实体类型不同。
2.2 真正的低资源学习
在资源匮乏的 NER 研究中,一个经常被忽视的问题是假设和利用大型开发集(dev set)。 Perez 等人 2021 的工作表明,先前的工作明显高估了其模型的真实少样本能力,因为许多保留的示例用于学习的各个方面。 有几种不同的方法可以解决这个问题。
高资源开发集。 来自高资源数据集的开发集用于调整超参数并选择模板(“提示”)。 此方法假设该任务有一个大型开发集,但位于不同的域(Cui 等人,2021;Chen 等人,2021)。 小型开发集。 在Gao等人2021中,随机采样与训练集大小相同的少样本开发集,保持“少样本”设置,同时仍然能够调整超参数和选择模板。 没有开发集。 在Schick and Schütze 2021和Perez等人2021的工作中,他们选择不使用任何开发数据并采用固定的超参数,其中模型在持有时进行评估示例不可用。 这种设置也被称为“黑暗中拍摄”或“真正的少样本学习”(Perez 等人,2021)。
2.3相关工作
2.3.1 序列标记
传统上,NER 任务被视为序列标记问题。 像 BERT (Devlin 等人, 2019) 这样的预训练模型用作输入 的编码器,生成序列表示 ,其中 是输入 中的标记数量。 在编码器模型之上训练分类器,将隐藏表示映射到词符标签,如 。 在图 1 a) 中,我们说明了序列标记 NER。
2.3.2 基于提示的 NER 学习
最近,基于提示的学习已经出现,以弥补预训练和微调中不匹配的差距。 将基于提示的学习应用于NER,原始输入首先被修改为模板,这会产生一个带有一些未填充槽的新文本字符串,称为prompt。 然后使用LM填充中未填充的槽位以获得最终的字符串,最后从我们可以得出输出答案。 在图1 b)中,我们说明了先前方法的简化启发式,其方法复杂度为,其中表示输入的长度。
模板NER。 Cui 等人 2021 引入了一种基于模板的方法,其中 BART (Lewis 等人, 2020) 作为主干。 在图1 b)(简化版本)中,我们假设[E]槽只能用令牌填充。 然而,在实际情况中,[E]可以是句子中-gram的所有可能跨度的枚举。 给定长度为 的输入句子,这会导致复杂度为 。 枚举的跨度填充在手工制作的模板中,其中有对应不同实体类型的不同提示,加上用于无实体类型的附加提示,是数字数据集中的实体类型。 因此 TemplateNER 方法的复杂度为 。
LightNER。 在 Chen 等人 2021 中,NER 任务被表述为生成问题。 LightNER 还采用 BART (Lewis 等人, 2020) 作为骨干模型,生成输入中实体跨度的索引以及实体类型标签。 LightNER 方法的复杂度为 ,因为每个生成步骤的输出都是实体跨度和实体类型的预测。
2.4复杂性
为了了解每种方法的整体复杂度,这里我们介绍骨干 Transformer (Vaswani 等人, 2017) 模型的复杂度。 Transformer编码器的复杂度为 (Vaswani等人, 2017;Zhang等人, 2018),其中是模型的维度。 Transformer 解码器对编码器堆栈的输出执行 个自回归步骤的多头注意力,因此复杂度为 。 对于像 BART (Lewis 等人, 2020) 这样使用编码器和自回归解码器的模型,模型的整体复杂度为 。 我们在表1中总结了模型的复杂性和方法的复杂性(如2.3节中讨论的)。 因此,总体复杂度是“模型复杂度”和“方法复杂度”的乘积。 一般来说,比小得多,因此在大多数情况下QaNER比LightNER更快。
3方法论
3.1提取式质量检查
在各种不同的 QA 格式(Khashabi 等人,2020)中,我们考虑制定提取式 QA(基于跨度的 QA)。 提取式 QA 的选择是自然而然的,因为它完全符合 NER 识别实体跨度的目标。 在提取式 QA 中,给定问题 和可能包含答案的文本 上下文,模型需要提取相应的答案 作为子- 的字符串。因此,QA 数据集中的每个实例都是 的元组。 在 SQuAD 2.0 (Rajpurkar 等人, 2018) 等数据集中,“无法回答”可能是无法回答问题的正确答案,模型会提取特殊词符“[CLS]” t1>”。
在这项工作中,我们使用 BERT (Devlin 等人, 2019) 作为 QA 的骨干模型,将文本序列 的表示编码为 ,其中 是问题 和上下文 的串联。在 BERT 之上,QA 头将隐藏表示映射到预测范围。 QA head 本质上是一个开始和结束词符分类器,其中一个预测标记答案的开始,另一个预测标记答案的结束。 使用抽取式 QA 模型,我们将 NER 视为基于跨度的抽取问题。 每个实体类型的预测基于每个词符的开始/结束分数,这与 NER 目标本质上相同,以定位标记输入中的实体范围的开始和结束索引以及实体类型。 在这项工作中,我们采用在 SQuAD 或 SQuAD 2.0 (Rajpurkar 等人, 2016, 2018) 上微调的现成 BERT Large 模型作为我们基于提示的方案。
3.2提示QA模型
提示 QA 模型很直观。 因此,模板设计不需要花费太多精力。 使用天真的问题(模板),例如“[E]是什么?”将会简单地工作,其中 是数据集中的实体类型集。 给定一个固定的模板,我们用实体类型填充[E]槽,以创建一个名为prompt 因此,我们为 实体类型生成 提示。 我们对实体类型中的非字母字符应用一些规范化。 例如,我们通过将下划线 () 替换为空格,将 restaurant_name 转换为 restaurant name。
3.3 使用预训练的 LM 快速生成
我们探索使用 MLM(掩码语言模型)(Devlin 等人, 2019) 在生成提示时添加多种变体,以填充模板“[MASK]”中的掩码词符。 t1> 是[E]?”对 [E] 槽进行词汇化之后。 例如,我们将实体类型“location”插入到模板中以获得“[MASK]是位置?”。 然后使用 MLM 填充掩码并生成提示:“位置在哪里?”。 手工制作的提示和生成的提示之间的唯一区别是,前者提示中的[MASK]词符是由人决定的,而另一个则由传销决定。 我们使用另一个 BERT 模型来提前生成提示。 我们观察到人工填充的提示和 BERT 填充的提示之间存在一些差异。 对于同一示例,“[MASK] 是位置?”,由人工填写的手工提示将是“位置是什么?”而不是“位置在哪里?”。 前者更像是一个 QA 问题(如人类所感知的),而后者对于传销来说更自然。 我们的实验还研究了更多带有其他问题表述的模板设计,例如“是否有[E]?”。 根据经验,我们发现带有“五个 W”(谁、什么、何时何地和为什么)问题词的提示通常效果最好,因为它们与 QA 问题的表述相匹配。 考虑到对于每一种实体类型,都需要生成一个对应的提示语句,因此自动生成提示对于实体类型较多的数据集有帮助,例如Ultra-Fine数据集(Choi 等人, 2018)。
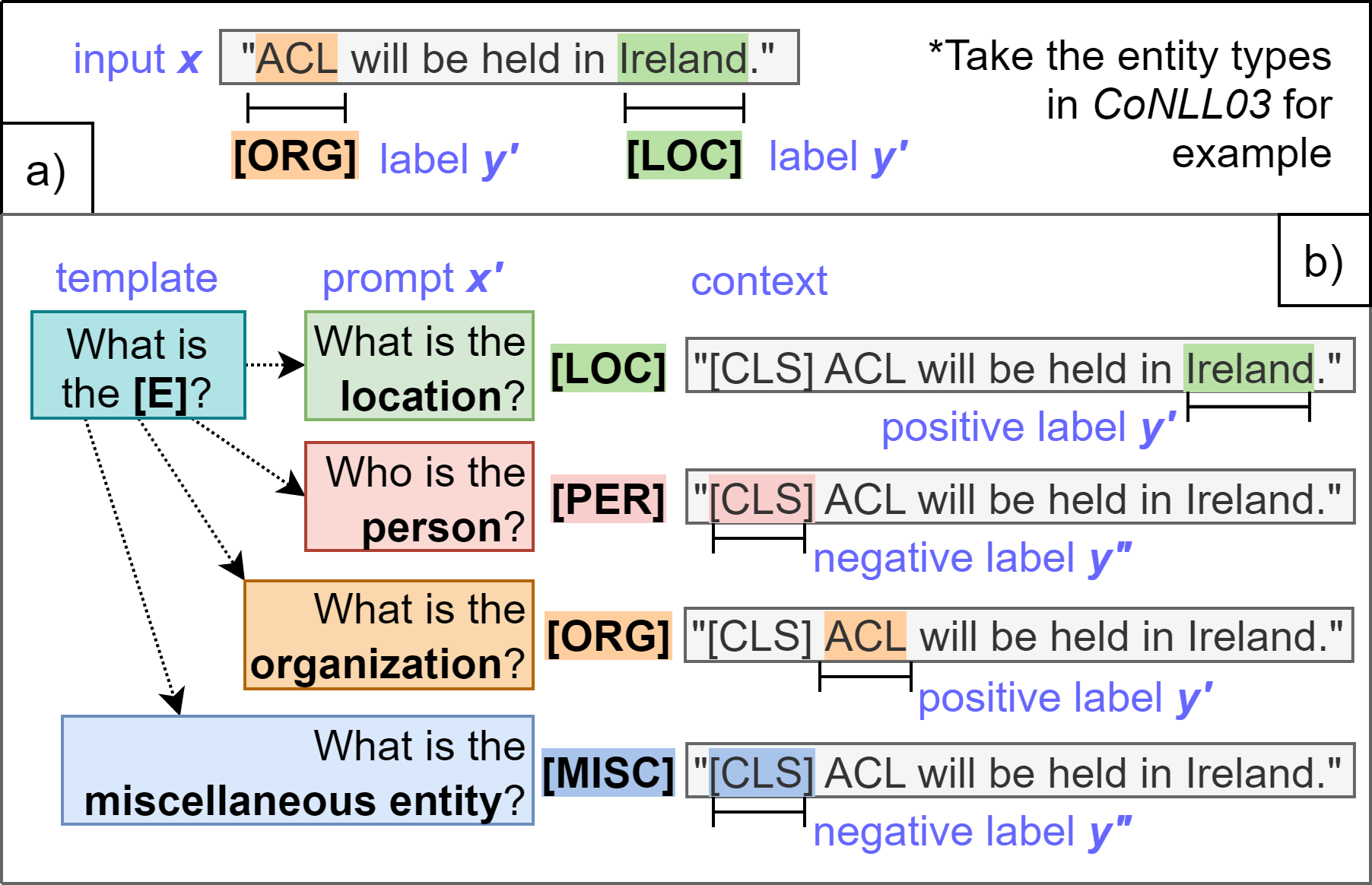
3.4 将 NER 转换为 QA
3.4.1 正反例
3.4.2 重复示例
在 NER 实例中,对于任何实体类型 , 可能会多次出现,并且出现在输入 中的不同位置。例如,一个句子中可能很容易有多个 类型。 理论上,最多可以有 个单独的实体标签,而实体数量 是固定的(其中 也是我们方法的提示数量)。 为了解决这种情况,我们允许在 NER 到 QA 转换过程中重复示例。 换句话说,对于相同的上下文和问题对 ,可能有不同的答案 ,因此 QA 实例为 ,其中 和 是特定实体类型 在 NER 示例 中重复的次数。
为了在一次传递中有效地检索相同实体类型(但在不同输入位置)的所有标记,我们首先调整 QA 模型以识别不同位置的实体类型。 然后在 QA 解码过程中,我们检索 n 个最佳候选结果(通过计算每个词符的开始/结束分数)。 这使我们能够在单个提示推理中识别与目标实体类型相对应的所有标记。 如果两个提取的跨度重叠,我们选择得分较高的跨度以避免可能的预测矛盾。
4实验设置
4.1 数据集设置
在我们的实验中,我们考虑了 NER 的三个数据集,即 MIT Movie、MIT Restaurant (Liu 等人,2013) 和 CoNLL03 (Tjong Kim Sang 和 De Meulder,2003)(Tjong Kim Sang 和 De Meulder,2003) t1> 数据集。 麻省理工学院电影数据集和麻省理工学院餐厅数据集是BIO格式的语义标记训练和测试语料库,其中包含用户对电影或餐厅信息的查询(刘等人,2013)。 由于 MIT 电影和餐厅数据集不包含开发集,因此我们随机采样并隔离 10% 的训练集作为开发集用于实验目的。 CoNLL03 数据集 是作为 CoNLL-2003 共享任务(Tjong Kim Sang 和 De Meulder,2003)的一部分发布的 NER 数据集。 该数据集包含训练集、开发集和测试集。 在本文中,我们使用取自路透社语料库的英文版本。
为了评估 NER 数据集上的少样本性能,我们采用常用的 N 每个实体类型 设置,其中 N 表示每个实体类型的 N 个实例。 我们从数据集中的每个实体类别中随机采样 N 个实例,并将 N 设置为 10、20、50、100、200 和 500,遵循之前的工作(Cui等人,2021;陈等人,2021;子亚迪等人,2020)。 我们严格限制每个实体类型最多 N 个实例。 因此,我们可能不会为所有类型提供 N。 某些类型的实例可能少于 N 个。
对于 QA 模型,我们考虑两个数据集。 SQuAD 数据集,其中每个问题的答案都是来自上下文 (Rajpurkar 等人,2016) 的一段文本(或范围)。 SQuAD 2.0 数据集结合了 SQuAD 中的 100,000 个问题以及另外 50,000 多个无法回答的问题(Rajpurkar 等人,2018)。 无法回答的问题允许我们在基于提示的 QA 微调方案中使用反例,如图 2 所示。 在我们的实验中,如果没有明确提及,所提出的方法采用在 SQuAD 2.0 上微调的 QA 模型。
4.2开发集设计
与之前的作品(Cui等人,2021;Chen等人,2021)不同,我们不依赖高资源开发集,这些开发集本质上是来自不同领域的大型NER开发集。 相反,我们设计了两个实用的开发集来公平地评估真正的低资源性能。 1) 我们使用随机采样的小型开发集,将相同大小作为最小训练集(每个实体类型 10 设置),从而使这个开发集始终保持较小。 2) 我们使用每种类型 10 个开发集,我们从整个开发集中为每个实体类别随机抽取 10 个实例。 此设置可确保每个实体类型都有足够数量的开发数据,并允许我们研究不平衡开发集的影响(通过将每个类型开发集 10 与 小型开发集进行比较设置)。
此外,我们还采用了3)no dev set设置,遵循Schick and Schütze 2021; Perez 等人 2021,我们不使用任何开发数据并采用固定的超参数。 对于此设置,我们采用 BERT 论文 (Devlin 等人,2019) 中建议的开箱即用的超参数。 具体来说,当在 无开发集 的 NER 上微调 QA 模型时,我们使用 的学习率, 的批量大小,并调整 纪元。 QA 解码过程使用 n-best 大小 ,最大答案长度达到 ,以及要求预测的开始和结束词符概率之和超过的阈值。 在我们的实验中,如果没有明确提及,所提出的方法默认采用no dev set设置。
4.3评估协议
众所周知,对少量示例进行微调可能会出现不稳定(Dodge等人,2020;Zhang等人,2021),并且对于不同的数据分割,结果可能会发生巨大变化。 为了解释这一点,在我们所有的少训练样本实验中,我们测量了五个不同的随机采样组的平均性能。 对多个随机分割进行采样可以更可靠地衡量性能和方差。
| zero-shot | full resource | Rank | |||||
|---|---|---|---|---|---|---|---|
| a) Mov | b) Rest | c) CoN | a) Mov | b) Rest | c) CoN | ||
| handcraft | 49.65 | 32.25 | 36.77 | 85.53 | 79.57 | 80.92 | 1.17 |
| [MASK] is the <e>? | 44.98 | 31.29 | 37.00 | 85.10 | 77.79 | 79.20 | 1.86 |
| What is the <e>? | 49.34 | 29.46 | 35.89 | 84.82 | 77.32 | 78.39 | 3.50 |
| The <e>? | 34.35 | 14.93 | 22.81 | 84.95 | 77.53 | 79.19 | 3.67 |
| Is there a <e>? | 31.14 | 14.55 | 20.60 | 84.01 | 76.71 | 79.71 | 4.50 |
| zero-shot | full resource | Rank | |||||
|---|---|---|---|---|---|---|---|
| a) Mov | b) Rest | c) CoN | a) Mov | b) Rest | c) CoN | ||
| all dev set | 56.20 | 31.27 | 37.80 | 85.36 | 78.86 | 89.04 | 1.17 |
| no dev set | 48.72 | 29.78 | 36.77 | 84.55 | 77.40 | 80.92 | 2.67 |
| small dev set | 41.75 | 30.87 | 37.89 | 85.14 | 76.95 | 78.26 | 2.83 |
| 10 per type | 36.15 | 29.64 | 33.72 | 84.25 | 78.44 | 84.13 | 3.33 |
5结果
5.1 最近方法的比较
我们在图 3 中比较了不同方法的性能,其中显示了使用不同数量的训练数据时的性能变化。 这里我们使用 QaNER 上手工制作的模板,以匹配其他作品的设置。 生成的模板的性能将在后面的部分中显示。 就零样本性能而言,所提出的方法显着优于以前的工作,尽管它们使用了来自高资源数据集的额外 NER 数据。 TemplateNER (Cui 等人, 2021) 和 LightNER (Chen 等人, 2021) 都声称他们的方法具有零样本能力。 我们证明所提出的方法提高了零样本性能。 就少样本性能而言,当使用的标记示例数量较低(每个实体类型 10、20、50)时,所提出的方法具有显着优势。 随着训练数据的增加,所提出的方法与其他方法之间的差距逐渐缩小。 原因是随着使用更多标记示例,利用 QA 知识的优势已被 NER 标记数据所主导。 对于更简单的 NER 数据集,差距会更快缩小。 例如,CoNLL03只有四种实体类型,使得其他方法更容易掌握。 另一方面,麻省理工学院电影和麻省理工学院餐厅的实体类型更多,学习更具挑战性。 因此,随着使用更多数据,QaNER 的性能继续领先。 此外,在上述比较中,所提出的方法采用无开发集,而TemplateNER (Cui 等人, 2021)和LightNER (Chen 等人, 2021) 在高资源开发集上调整它们的参数。 正如我们在后面的部分中所展示的,当使用开发数据进行调整时,所提出的方法的性能可以得到提高。
5.2消融研究
在本节中,我们研究所提出方法的组成部分。 在图4中,我们研究了所提出方法的各个组成部分之间的差异,没有重复示例,没有反例,并使用SQuAD代替SQuAD 2.0 用于 QA 模型的训练。 在图4中,所有消融方法均采用手工制作的模板以减少变异。 首先,我们观察到,包含重复示例略微提高了模型在 MIT 电影和餐厅数据集上的性能,而在 CoNLL03 上的性能则更为显着。 原因是 CoNLL03 数据集中有更多的重复实例。 其次,通过比较我们发现采用反例会产生很大的差异,因为反例有助于模型正确识别正例。 第三,与 w/ SQuAD 相比,我们注意到,如果不使用负 NER 示例进行微调,SQuAD 2.0 并没有什么好处。
5.3不同的提示设计
在图5中,我们研究了采用不同模板设计的效果。 这里我们尝试了多种方法来生成提示,结果相当一致,这表明了方法的稳健性(即使在样本少的情况下)。 此外,零样本和完整资源性能如表2所示。 零样本性能显示了有关 QA 模型的提示的“自然性”,完整的资源性能有助于了解每个提示的功能。 我们看到手工提示优于其他提示,然后是生成的提示(“[MASK] 是 [E]?”)。 在“What is the [E]?”中,我们将所有 “Ws” 修复为“What”,并获得比生成的提示稍低的性能。 在“The [E]?”中,我们删除了“Ws”并导致性能下降。 我们了解到,选择适当的“五个 W” 可以对 QA 模型的性能产生较小的影响。 在“Is there a [E]?”中,我们使用了不同类型的问题,没有“Ws”,并得到了平均最低的结果。 我们得出的结论是,具有“五个 W” 的提示通常效果最好,尤其是手工制作和生成的提示,因为它们与 QA 的建模相匹配。 此外,这项研究表明 QaNER 对于提示的设计是稳健的。
5.4开发集研究
在图6中,我们研究了采用不同开发集设置的效果。 此外,我们在表 3 中展示了他们的零样本和完整资源性能。 我们报告所有开发集设置作为顶线,因为假设在资源匮乏的情况下存在如此大的开发集是不现实的。 我们观察到,平均而言,使用无开发集优于其他开发集设置,特别是在 MIT 电影和餐厅数据集上。 原因是CoNLL03数据集有一个与测试集分布相匹配的标准开发集。 另一方面,麻省理工学院的数据集使用从数据中随机采样的开发训练集。 使用这些开发集可能会导致过度拟合。 请注意,之前的作品使用 CoNLL03 标准和大型开发集进行调整,而在与图 3 中的比较时,我们使用无开发集。 换句话说,我们在图 3 中报告了所提出方法的下限性能,因为 QaNER 没有在 CoNLL03 数据集上进行调整。 与 MIT 数据集上的无开发集相比,使用小型开发集和每种类型 10 个开发集的性能较差。 然而,CoNLL03 的情况并非如此。 原因与前面讨论的相同。 一般来说,假设我们不知道开发集和测试集的分布,使用无开发集会产生最稳健的性能。 总而言之,即使在“黑暗中拍摄”时,QaNER 也能很好地工作,并且针对不同的开发集设置具有鲁棒性。
6结论
在这项工作中,我们提出了 QaNER,其中我们提示 NER 任务的 QA 模型。 我们演示了如何将 NER 示例转换为 QA 示例,以及如何为 QA 模型执行提示生成。 QaNER 不仅在资源匮乏的情况下更快、更稳健,而且在少样本,尤其是零样本性能方面也很有前景,为自学习方法打开了一扇新的大门。 在未来的工作中,我们的目标是探索促进其他 NLP 任务的 QA 模型,包括句子分类和提取摘要。
参考
- Chen et al. (2021) Xiang Chen, Ningyu Zhang, Lei Li, Xin Xie, Shumin Deng, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. 2021. Lightner: A lightweight generative framework with prompt-guided attention for low-resource ner.
- Choi et al. (2018) Eunsol Choi, Omer Levy, Yejin Choi, and Luke Zettlemoyer. 2018. Ultra-fine entity typing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 87–96, Melbourne, Australia. Association for Computational Linguistics.
- Cui et al. (2021) Leyang Cui, Yu Wu, Jian Liu, Sen Yang, and Yue Zhang. 2021. Template-based named entity recognition using BART. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1835–1845, Online. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dodge et al. (2020) Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. 2020. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping.
- Gao et al. (2021) Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers).
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Computation, 9(8):1735–1780.
- Huang et al. (2020) Jiaxin Huang, Chunyuan Li, Krishan Subudhi, Damien Jose, Shobana Balakrishnan, Weizhu Chen, Baolin Peng, Jianfeng Gao, and Jiawei Han. 2020. Few-shot named entity recognition: A comprehensive study. arXiv preprint arXiv:2012.14978.
- Khashabi et al. (2020) Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. 2020. Unifiedqa: Crossing format boundaries with a single qa system. Findings of the Association for Computational Linguistics: EMNLP 2020.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
- Li et al. (2020) Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, and Jiwei Li. 2020. A unified MRC framework for named entity recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5849–5859, Online. Association for Computational Linguistics.
- Liu et al. (2013) Jingjing Liu, Panupong Pasupat, Scott Cyphers, and Jim Glass. 2013. Asgard: A portable architecture for multilingual dialogue systems. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 8386–8390.
- Liu et al. (2021) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ArXiv, abs/2107.13586.
- Perez et al. (2021) Ethan Perez, Douwe Kiela, and Kyunghyun Cho. 2021. True few-shot learning with language models. arXiv.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know what you don’t know: Unanswerable questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia. Association for Computational Linguistics.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.
- Schick and Schütze (2021) Timo Schick and Hinrich Schütze. 2021. It’s not just size that matters: Small language models are also few-shot learners. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
- Tjong Kim Sang and De Meulder (2003) Erik F. Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, pages 142–147.
- van den Oord et al. (2018) Aäron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. CoRR, abs/1807.03748.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, undefinedukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY, USA. Curran Associates Inc.
- Yang and Katiyar (2020) Yi Yang and Arzoo Katiyar. 2020. Simple and effective few-shot named entity recognition with structured nearest neighbor learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6365–6375, Online. Association for Computational Linguistics.
- Zhang et al. (2018) Biao Zhang, Deyi Xiong, and Jinsong Su. 2018. Accelerating neural transformer via an average attention network. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
- Zhang et al. (2021) Tianyi Zhang, Felix Wu, Arzoo Katiyar, Kilian Q Weinberger, and Yoav Artzi. 2021. Revisiting few-sample {bert} fine-tuning. In International Conference on Learning Representations.
- Ziyadi et al. (2020) Morteza Ziyadi, Yuting Sun, Abhishek Goswami, Jade Huang, and Weizhu Chen. 2020. Example-based named entity recognition.