回到特征:经典 3D 特征(几乎)就是 3D 异常检测所需的全部
摘要
尽管图像异常检测和分割方面取得了重大进展,但很少有方法使用 3D 信息。 我们利用最近推出的 3D 异常检测数据集来评估使用 3D 信息是否会失去机会。 首先,我们提出了一个令人惊讶的发现:标准的纯颜色方法优于所有当前明确设计用于利用 3D 信息的方法。 这是违反直觉的,因为即使对数据集进行简单的检查也表明,仅颜色方法不足以处理包含几何异常的图像。 这就引发了一个问题:异常检测方法如何有效地利用 3D 信息? 我们研究了一系列形状表示,包括手工制作和基于深度学习的形状表示;我们证明旋转不变性在性能中起着主导作用。 我们发现了一种简单的纯 3D 方法,该方法击败了所有最新方法,同时不使用深度学习、外部预训练数据集或颜色信息。 由于纯 3D 方法无法检测颜色和纹理异常,因此我们将其与基于颜色的特征相结合,显着优于以前的最先进技术。 我们的方法被称为 BTF(回到特征),在 MVTec 3D-AD 上实现了像素级 ROCAUC: 和 PRO:。
 |
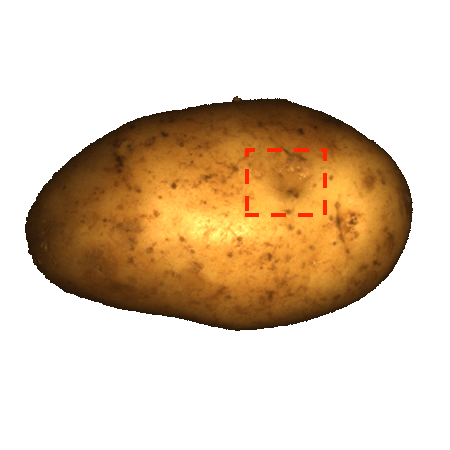 |
 |
 |
 |
 |
 |
 |
1简介
尽管 3D 理解是计算机视觉的基础,但图像异常检测和分割方法通常没有考虑它,可能是因为缺乏合适的数据集。 为了鼓励对 3D 异常检测和分割 (AD&S) 的研究,最近引入了 MVTec 3D-AD [6] 数据集以及 3D AD&S 的几种基线方法。 然而,尽管存在 3D AD&S 数据集,但与纯颜色相比,3D 信息的作用仍不清楚。 我们进行了仔细的研究,寻求以下几个问题的答案:
-
1.
当前的 3D AD&S 方法在 3D 数据上真的优于最先进的 2D 方法吗?
-
2.
3D 信息可能对 AD&S 有用吗?
-
3.
成功的 3D AD&S 表示有哪些关键属性?
-
4.
使用 3D 形状和颜色模式是否具有互补优势?
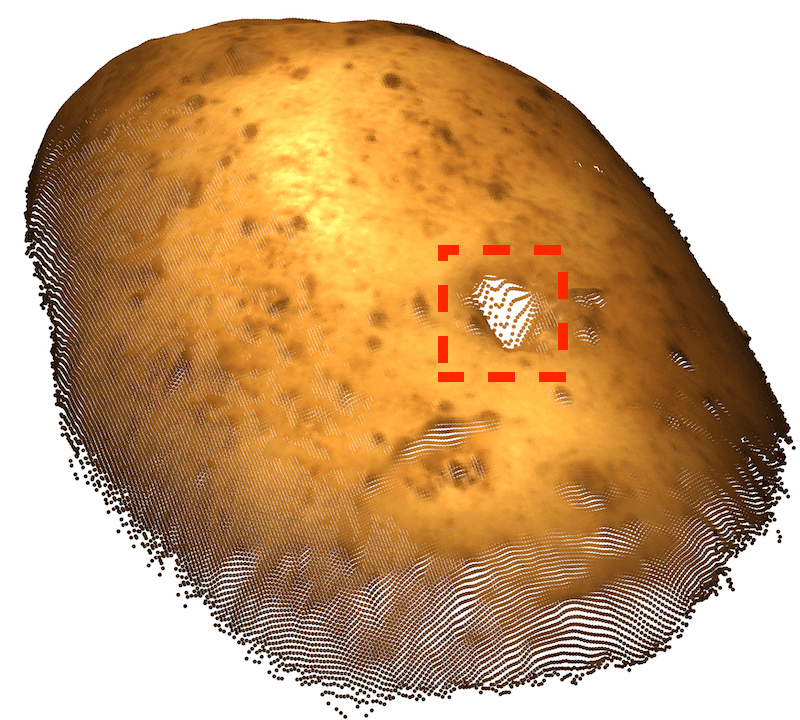
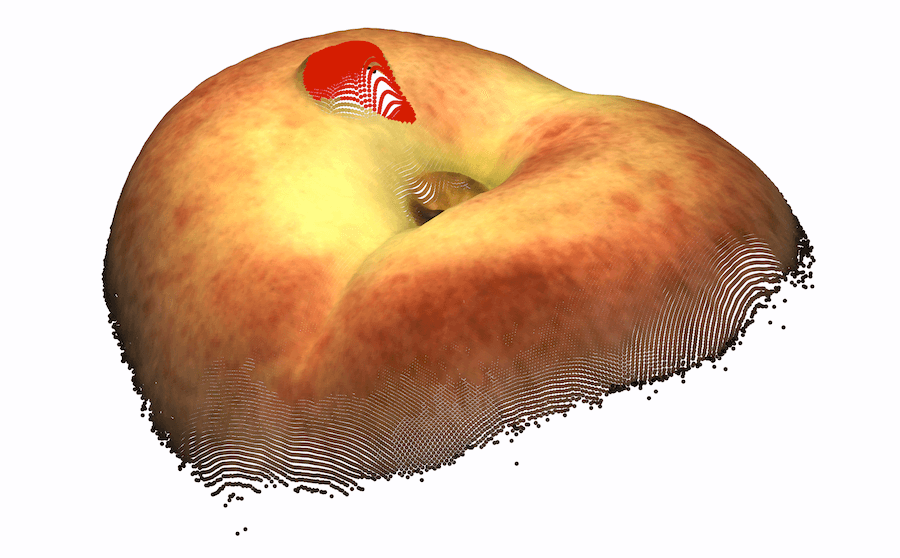
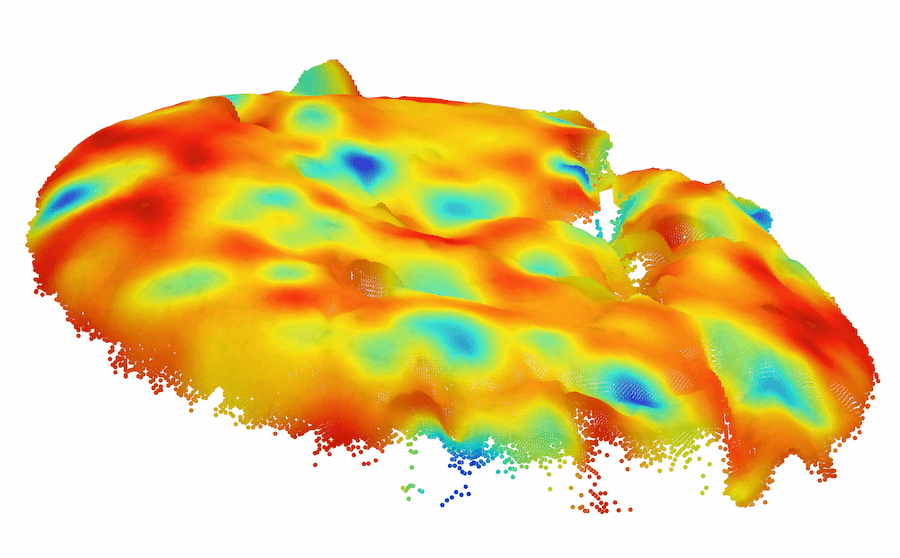
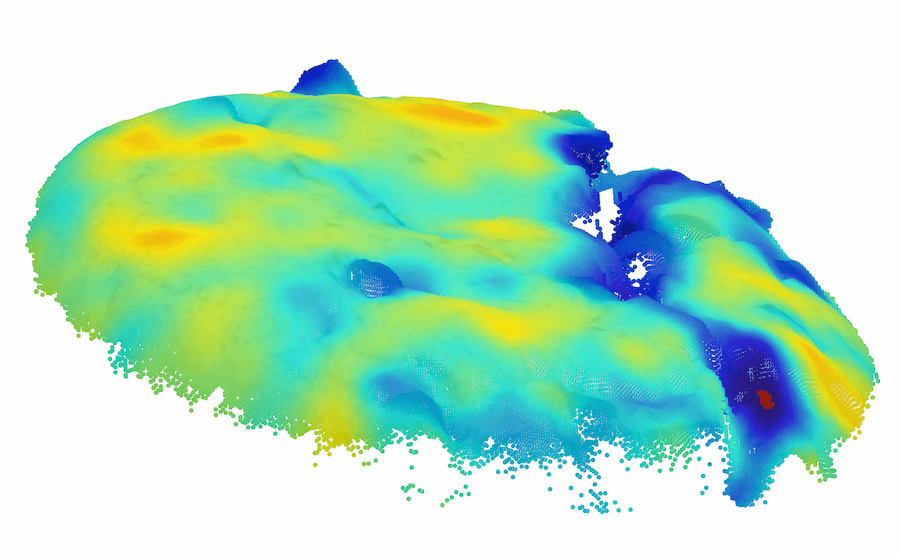
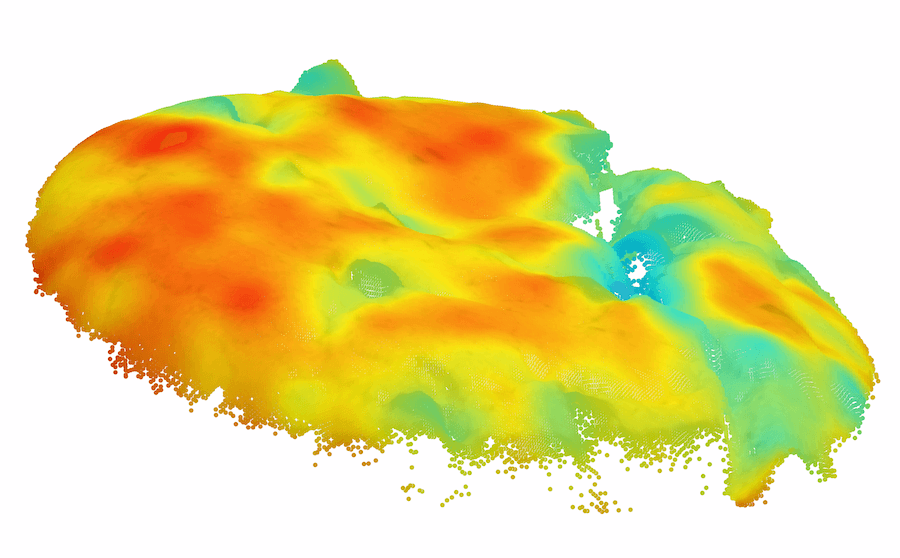
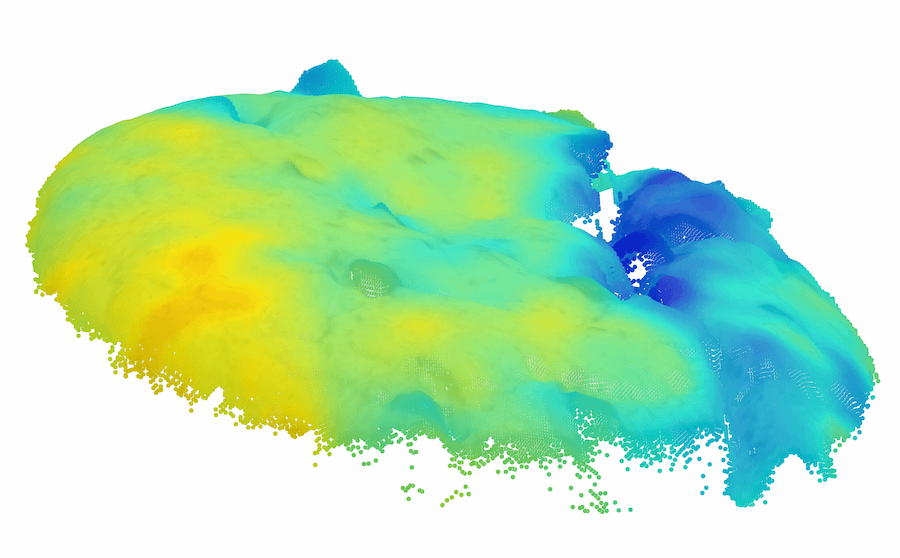
由于以前的图像 AD&S 方法很少使用 3D 信息,因此我们对 MVTec-3D 数据集上的基线方法进行了初步知识调查。 也许令人惊讶的是,纯颜色方法(例如 PatchCore [34])大幅优于当前所有 3D AD&S 方法。 接下来,我们询问 3D 信息是否对 AD&S 可能有用。 令人鼓舞的是,我们发现当使用纯颜色信息时,多种类型的异常都未被检测到(参见图1最左边的两个,顶行)。 在底行中,我们展示了使用 3D 点云渲染的相同对象的另一个视图,其中的异常现象很容易被检测到111请注意,出于可视化目的,图像的黑色背板已被删除。 在某些情况下,只有在给出 3D 信息的情况下才能实现这种去除(例如,我们无法仅通过查看彩色图像来区分孔和巧克力,需要 3D 信息)。
已经表明 AD&S 通常需要 3D 信息,我们的目标是确定 AD&S 的有效 3D 表示。 我们研究了广泛的手工制作和深度表示,发现旋转不变性是 3D AD&S 的关键。 我们的结果令人惊讶:经典的、手工制作的 3D 点云描述符优于所有其他当前方法,包括基于学习的表示。
尽管有前面的结果,颜色信息显然是有帮助的。 例如,我们提供了来自 MVTec 3D-AD 的一些示例,其中异常在颜色上比在形状上更清晰(图 1,最右边的两个示例)。 这激发了我们最终的方法,BTF(回到特征),它将 3D 和颜色结合起来,在 MVTec 3D-AD 数据集上以非常大的优势实现最佳记录结果 ( 逐像素 ROCAUC、 PRO 和 图像 ROCAUC)。
我们在本文中的主要贡献是:
-
对具有颜色和 3D 信息的图像的异常检测和分割这一重要且尚未探索的领域进行彻底分析。
-
确定当前 2D 表示在 3D 数据上的性能明显优于 3D 表示。
-
发现旋转不变表示是 3D AD&S 的关键。
-
提出 BTF,一种将手工 3D 表示 (FPFH) 与基于颜色的深度方法 (PatchCore) 相结合的方法,其性能远远优于最先进的方法。
|
Input |
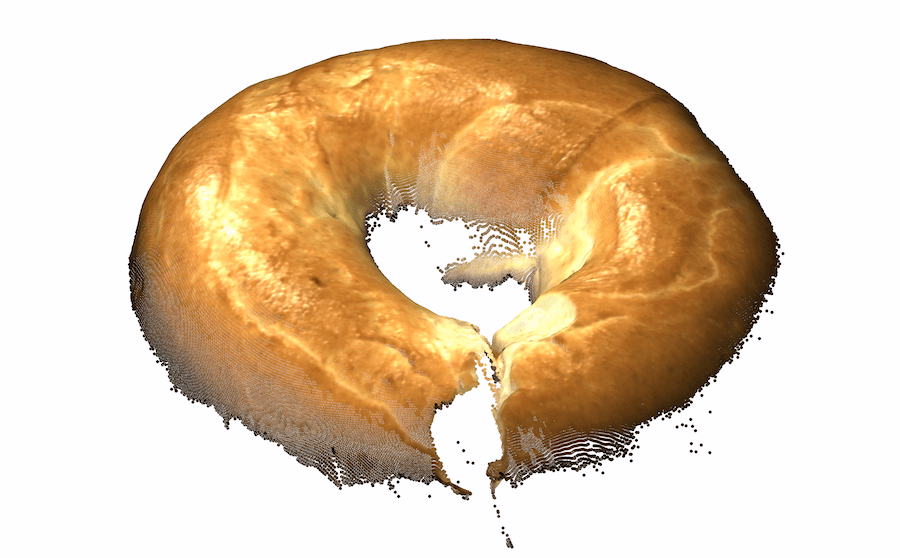 |
 |
 |
 |
|
GT |
 |
 |
 |
 |
|
Output |
 |
 |
 |
 |
2相关工作
异常检测和分割。 异常检测方法已经研究了几十年,大多数方法都基于密度估计或域外泛化思想。 经典方法包括:k-最近邻 (kNN) [15]、KDE [25]、GMM [19]、PCA [24]、一类 SVM (OCSVM) [40] 和隔离林 [27]。 随着深度学习的出现,这些方法通过深度表示进行了扩展,包括:扩展 PCA 的 DAGMM [48] 和扩展 OCSVM 的 DeepSVDD [35]。 一项新颖的工作将自监督方法扩展到异常检测,包括 Golan 和 El-Yaniv [20] 以及 Hendrycks 等人 [23],它们扩展了 RotNet [18] 和 CSI [42],扩展了对比方法[21, 22, 10]。 我们遵循另一系列工作,假设预训练表示的可用性,并将它们与 kNN 评分函数结合起来。 此类作品包括 Perera 和 Patel [29],以及 PANDA [32]。 这些工作已扩展到异常分割,包括 SPADE [11]、PADIM [13] 和 PatchCore [34]。 最近的工作在提取的表示上使用了更先进的密度估计模型,一个例子是 FastFlow [44]。 其他异常分割方法包括学生-教师自动编码器方法 [5] 以及合成异常的自监督方法,例如 CutPaste [26] 和 NSA [ 39]。
使用 3D 信息进行异常检测和分割。 与大量的 2D 异常检测方法研究相比,3D 异常检测尚未得到广泛研究。 在医学成像研究中,进行了使异常检测方法适应体素数据的工作。 Simarro 等人 [41] 将 f-Anogan [38, 37] 扩展到 3D。 Bengs 等人[3]提出了一种用于医学体素数据的 3D 自动编码器方法。 体素数据与点云 3D 数据显着不同。 Bergmann 等人[6]认识到3D点云数据中异常分割的数据集缺失,并引入了MVTec 3D-AD[6]。 我们预计这将对 3D 异常检测和分割的发展做出重要贡献。 在我们工作的同时,Bergmann 和 Sattlegger [7] 引入了一种基于 3D 点云的方法,称为 用于异常检测,我们将这项工作纳入我们的调查中。
3问题定义
3.1设置
我们假设一组输入训练样本都是正常的。 在测试时,我们会得到一个测试样本。 异常检测的目标是学习样本级评分函数,例如异常样本为,正常样本为。 异常分割的目标是学习像素级评分函数,如果样本的像素满足,则该函数满足异常,如果正常则为 。
许多当前最先进的方法(例如 SPADE [11]、PatchCore [34])遵循以下阶段:i)提取局部区域的表示 ii)估计正常局部区域的概率密度。 例如,PatchCore 和 SPADE 通过与正常训练数据集的最近邻距离来执行密度估计。
表示。 我们首先计算可能由一个或多个像素组成的每个局部区域的表示。 图像的区域的表示被表示为。 在本文中,我们重点关注表示阶段,特别是,我们的目标是找到 3D AD&S 的学习或手工表示。
异常得分。 给定每个训练图像 的每个局部区域 的表示,我们可以训练一个模型 来计算新表示 尽管一些方法针对表示的密度训练参数模型,但非参数方法要简单得多并且不需要 。 具体来说,我们使用表示 到所有训练表示 集合的 k-Nearest-Neighbor 距离。 尽管很简单,但这种方法非常准确,不需要训练,并且可以显着加快速度。
3.23D 表示
尽管 RGB 图像是默认模式,但它们缺乏明确的 3D 信息。 其他表示包含直接 3D 信息,例如深度图、有组织点云、无组织点云和体素。 有组织和无组织的点云都表示 3D 空间中点的 XYZ 位置。 然而,有组织的点云保留了空间关系,因此可以被视为图像,从而允许使用基于 RGB 的方法(例如 CNN)。 相反,无组织的点云不保留空间关系,因此需要特定的方法和模型。 最后,体素源自点云,可以被视为像素的 3D 扩展。 为了简洁起见,我们在整篇论文中使用术语“像素”,但是,根据上下文,它可能指的是上述任何表示形式。
| 3D Input | 2D View | GT | RGB iNet | Depth iNet |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Raw | HoG | SIFT | FPFH | BTF |
3.3基准
我们的调查使用最近发布的 MVTec 3D 异常检测数据集[6]。 它包含 类别工业制造产品的超过 高分辨率 3D 扫描。 每个样本都由组织点云和相应的 RGB 图像表示,点云中的像素与 RGB 图像中的像素之间具有一对一的映射。 数据集中的五个类表现出自然变化(bagel、carrot、cookie、peach 和 马铃薯)。 电缆密封套和销钉类是刚体,而泡沫、绳索和类轮胎是“人造”但可变形的。 Bergmann 等人[6]为数据集引入了三个基线:基于 GAN、基于自动编码器(AE)和变异模型(VM)——基于每像素均值和标准差的简单基线。 这些模型可以在深度图像上运行,也可以在体素空间中运行,并具有在 3D+RGB 信息上运行的其他变体。
3.4评估指标
我们使用多种评估指标。 图像级异常检测使用图像级 ROCAUC [9](表示为 I-ROC)进行测量。 两个像素级指标用于异常分割:i) 像素级 ROCAUC,像素级标准 ROCAUC 的扩展,它简单地将数据集中的每个像素视为样本,并计算数据集中所有像素的 ROCAUC(表示为P-ROC)。 ii) PRO [4]指标,定义为二元预测 与每个地面实况连接组件 的平均相对重叠度,其中 表示地面实况组件的数量。 最终指标是通过将该曲线积分到某个误报率并标准化来计算的
按照惯例,除非另有说明,否则我们使用 的积分限制。
4 3D AD&S 的实证研究
4.1 当前的 3D 方法是否优于 2D 方法?
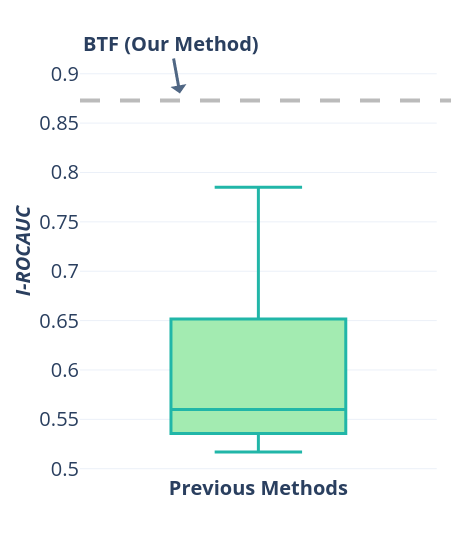
我们首先评估当前的 3D AD&S 方法在应用于 3D 数据时是否实际上优于 SoTA 2D 方法。 为了表示 3D 方法,我们测试了两种方法:i) Voxel GAN [6],一种被提议作为 3D AD&S 基线的生成方法。 虽然它有多种变体,但我们使用性能最好的变体,即“Voxel”和“Voxel + RGB”。 ii) 3D-ST [8],一种使用点云学生-教师模型来学习 3D 表示的并发方法。 我们使用 PatchCore [34] 来表示基于颜色的图像 AD&S 方法。 重要的是,PatchCore 使用在 ImageNet [14] 数据集上预先训练的特征,这已被证明对于图像 AD&S 非常有效。 相比之下,3D-ST 使用 ModelNet10 [43] 来预训练他们的教师模型。 我们在图1(a)中展示了结果。 令人惊讶的是,不使用 3D 信息的 PatchCore 的性能优于之前的所有方法。
结论。 目前,仅使用颜色信息的最先进的图像 AD&S 方法优于使用 3D 或 3D + 颜色信息的 3D AD&S 方法。
4.2 3D 信息对 AD&S 是否有潜在用途?
提供了第二节的结果。 4.1,我们面临第二个问题:“3D信息潜在对AD&S有用吗”。 下面我们将介绍 3D 信息确实对 AD&S 有用的两个案例。
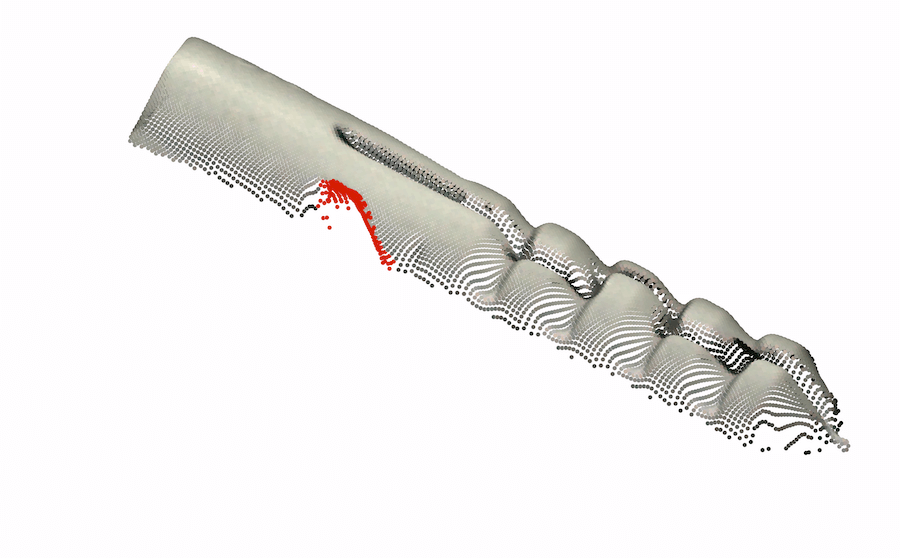
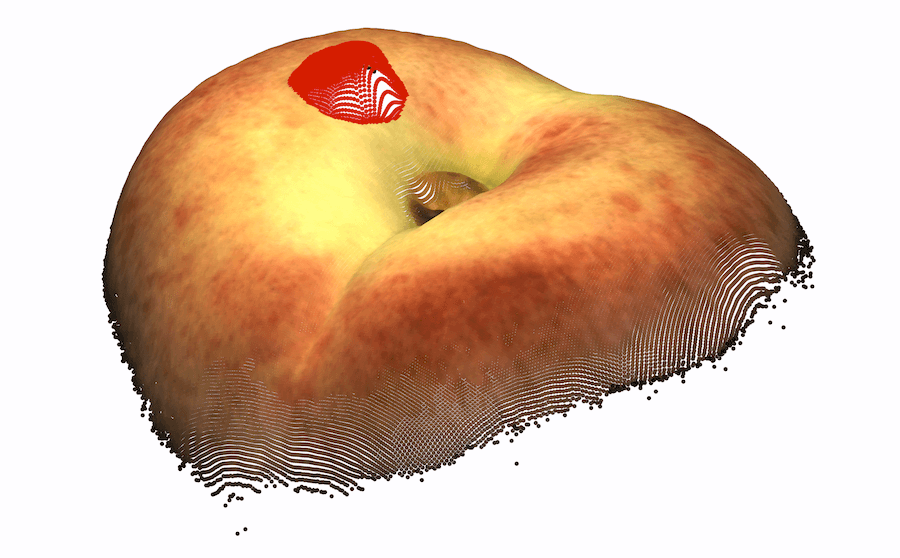
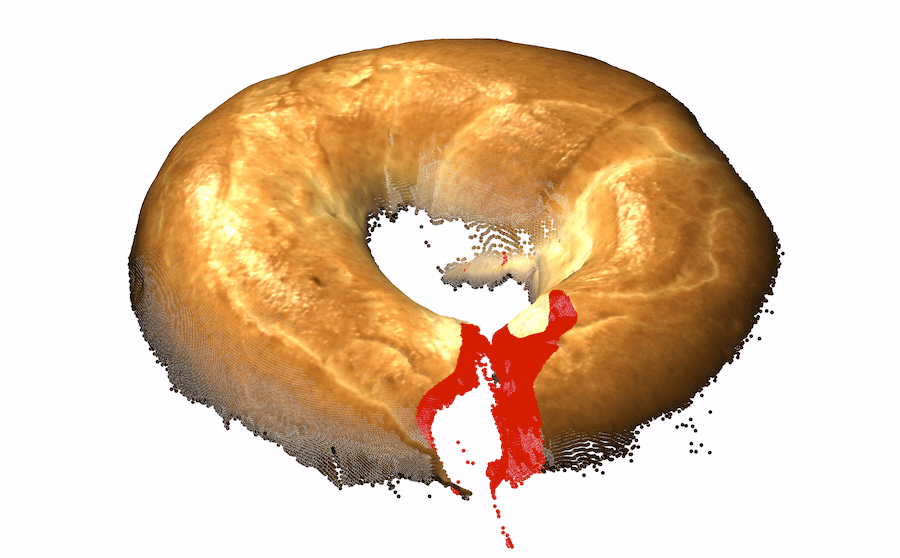
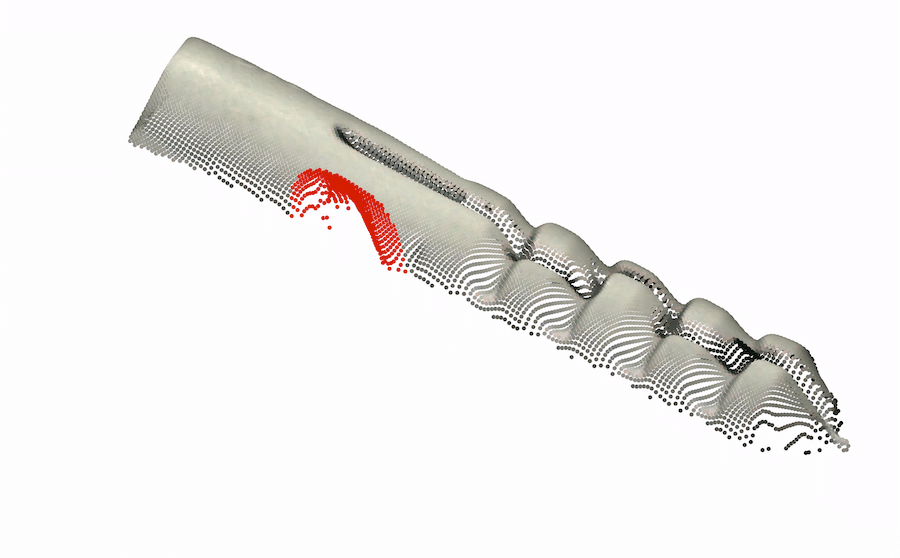
模糊的几何图形。 通常,我们无法仅通过查看对象的颜色信息来确定对象的基础几何形状。 在这种情况下,3D 信息可能会揭示真实的几何形状。 我们在图 1 的左半部分(顶行)中展示了此类情况的几个示例,仅从颜色信息无法检测到每个对象中的异常。 在底行中,我们使用 3D 信息呈现相同对象的另一个视图,其中的异常现象很容易被检测到。 对于 cookie11footnotemark: 1,查看纯彩色图像,该孔与其余巧克力片融为一体,因此很难从视觉上识别该图像是否异常。 利用 3D 信息,我们从不同角度可视化 cookie,从而轻松发现异常情况。 观察马铃薯的图像,很难从阴影和纹理推断出凹痕的几何形状。 然而,从不同角度(通过使用 3D 信息)观察马铃薯,不同的纹理会显示出凹痕。
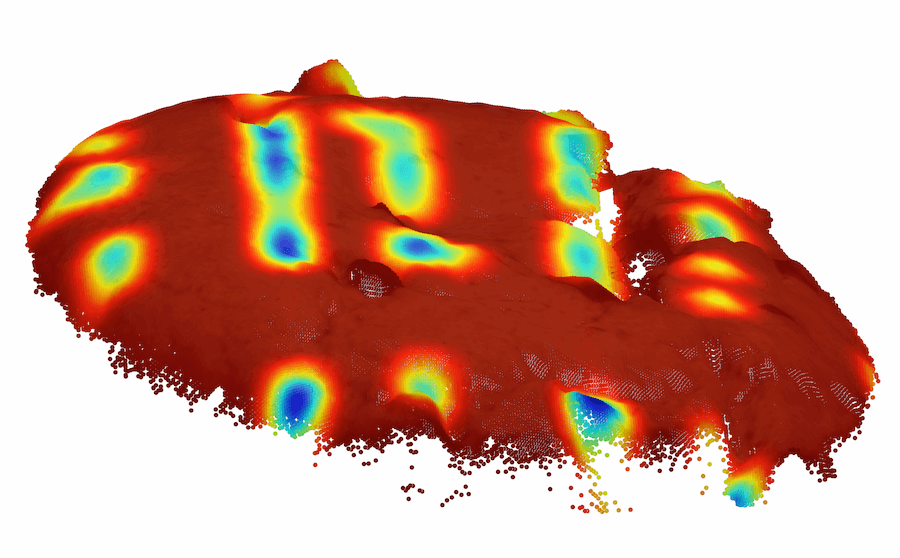
背景变化。 精心策划的数据集通常包含合成条件,例如居中的对象和干净的背景,但现实很少如此简单。 许多方法错误地将杂乱的图像背景归类为异常。 尽管背景分割并不简单,但当提供 3D 信息时,它会容易得多。 我们在 MVTec-3D 数据集中发现背景干扰伪影触发误报警报的情况。 我们在图4(a)中演示了这种情况,背景织物包含“波浪”状图案,在深色背景颜色下很难检测到。
结论。 即使有颜色可用,通常也需要 3D 信息来识别异常情况。
| Voxel | Voxel + RGB | Point Cloud | RGB | ||||
| GAN | GAN | PatchCore | |||||
| PRO | I-ROC | PRO | I-ROC | PRO | I-ROC | PRO | I-ROC |
| 0.583 | 0.537 | 0.639 | 0.517 | 0.833 | - | 0.876 | 0.785 |

3D 感知预处理(右): 织物中的令人讨厌的伪影
4.3 成功的 3D AD&S 表示有哪些关键属性?
在表明当前方法未充分利用 3D 信息,并确定了 3D 信息对于图像 AD&S 的必要性之后,我们现在寻求回答第三个问题:“成功的 3D AD&S 表示的关键属性是什么“。 我们区分几个类别。
为图像设计的基于学习的表示。 我们将两种最流行的基于学习的图像 AD&S 范式应用于 3D 数据:i) ImageNet 预训练特征 ii) 自监督方法。
仅深度 ImageNet 特征。 受 ImageNet 预训练特征在彩色图像上取得的令人印象深刻的结果(第 4.1 节)的启发,我们将 PatchCore 应用于深度图像。
美国国家安全局。 一类不同的基于学习的方法从生成的角度来处理 AD&S。 CutPaste 和 NSA [26, 39] 是最近的作品,试图通过在不同的图像位置粘贴图像补丁来模拟异常。 具体来说,NSA 使用泊松混合 [30] 使这些增强看起来更自然。
结果。 ImageNet 预训练特征在深度图像上显着优于 NSA(表 1)。 1)。 这两种方法的性能均低于应用于彩色图像的 PatchCore。
手工制作的图像表示。 深度模式通常比颜色模式简单得多。 我们假设一个简单的、手工制作的描述符就足够了。 以下深度表示不需要外部数据或训练。
原始深度值。 在这里,我们测试可能是最简单的表示,即补丁的原始深度值。
定向梯度直方图 (HoG)。 HoG [12] 考虑图像梯度并使用直方图来捕获块中梯度方向的分布。 这可能比原始值更强大,因为描述符对数据的空间结构进行编码,同时对小平移保持不变。 另一方面,HoG 对于全局旋转并不是不变的,这是 3D 表示非常需要的属性。 此外,HoG 的小上下文使其对局部几何变化具有不变性。 这与我们检测异常的目标背道而驰——通常表现为局部几何变化。
密集尺度不变特征变换(D-SIFT)。 与 HoG 相比,SIFT [28] 具有旋转、缩放和平移不变性,因为它会旋转以将最主要的方向与基本方向对齐。 这减少了旋转模糊性,允许旋转图像之间的匹配。
结果。 HoG 显着提高了像素级精度,取得了比原始特征和基于学习的特征更好的结果。 尽管 HoG 不是专门为 3D 信息设计的,但仍获得了这些强有力的结果。 最后,D-SIFT 描述符在所有三个指标上都能够超越之前所有基于深度的结果(包括基于学习的结果)。
3D 旋转不变表示。 旋转不变特征在深度图上非常有效。 我们现在问旋转不变的 3D 特征是否可以做得更好?
快速点特征直方图 (FPFH) [36]。 该方法首先计算区域中心点的 k 个最近邻点。 然后,它根据表面法线和到最近邻居的矢量距离计算基于直方图的表示。 我们选择它作为代表,是因为它久经考验的优异性能。
| Modality | RGB | Depth | Depth | Depth | Depth | Depth | PC | PC + RGB | PC | RGB + PC |
| Method | iNet | iNet | NSA | Raw | HoG | SIFT | FPFH | PointNeXt | SpinNet | BTF |
| PRO | 0.876 | 0.586 | 0.572 | 0.191 | 0.614 | 0.866 | 0.924 | 0.380 | 0.654 | 0.964 |
| I-ROC | 0.785 | 0.637 | 0.696 | 0.528 | 0.560 | 0.714 | 0.753 | 0.587 | 0.524 | 0.865 |
| P-ROC | 0.966 | 0.821 | 0.817 | 0.548 | 0.845 | 0.954 | 0.980 | 0.687 | 0.873 | 0.993 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
| Previous Methods | Voxel GAN | 0.440 | 0.453 | 0.825 | 0.755 | 0.782 | 0.378 | 0.392 | 0.639 | 0.775 | 0.389 | 0.583 | ||
| + RGB | 0.664 | 0.620 | 0.766 | 0.740 | 0.783 | 0.332 | 0.582 | 0.790 | 0.633 | 0.483 | 0.639 | |||
| Voxel AE | 0.260 | 0.341 | 0.581 | 0.351 | 0.502 | 0.234 | 0.351 | 0.658 | 0.015 | 0.185 | 0.348 | |||
| + RGB | 0.467 | 0.750 | 0.808 | 0.550 | 0.765 | 0.473 | 0.721 | 0.918 | 0.019 | 0.170 | 0.564 | |||
| Voxel VM | 0.453 | 0.343 | 0.521 | 0.697 | 0.680 | 0.284 | 0.349 | 0.634 | 0.616 | 0.346 | 0.492 | |||
| + RGB | 0.510 | 0.331 | 0.413 | 0.715 | 0.680 | 0.279 | 0.300 | 0.507 | 0.611 | 0.366 | 0.471 | |||
| Depth GAN | 0.111 | 0.072 | 0.212 | 0.174 | 0.160 | 0.128 | 0.003 | 0.042 | 0.446 | 0.075 | 0.143 | |||
| + RGB | 0.421 | 0.422 | 0.778 | 0.696 | 0.494 | 0.252 | 0.285 | 0.362 | 0.402 | 0.631 | 0.474 | |||
| Depth AE | 0.147 | 0.069 | 0.293 | 0.217 | 0.207 | 0.181 | 0.164 | 0.066 | 0.545 | 0.142 | 0.203 | |||
| + RGB | 0.432 | 0.158 | 0.808 | 0.491 | 0.841 | 0.406 | 0.262 | 0.216 | 0.716 | 0.478 | 0.481 | |||
| Depth VM | 0.280 | 0.374 | 0.243 | 0.526 | 0.485 | 0.314 | 0.199 | 0.388 | 0.543 | 0.385 | 0.374 | |||
| + RGB | 0.388 | 0.321 | 0.194 | 0.570 | 0.408 | 0.282 | 0.244 | 0.349 | 0.268 | 0.331 | 0.335 | |||
| 0.950 | 0.483 | 0.986 | 0.921 | 0.905 | 0.632 | 0.945 | 0.988 | 0.976 | 0.542 | 0.833 | ||||
| Our Findings | RGB iNet | 0.898 | 0.948 | 0.927 | 0.872 | 0.927 | 0.555 | 0.902 | 0.931 | 0.903 | 0.899 | 0.876 | ||
| Depth iNet | 0.701 | 0.544 | 0.791 | 0.835 | 0.531 | 0.100 | 0.800 | 0.549 | 0.827 | 0.185 | 0.586 | |||
| NSA | 0.724 | 0.228 | 0.716 | 0.856 | 0.320 | 0.432 | 0.712 | 0.655 | 0.818 | 0.258 | 0.572 | |||
| Raw | 0.040 | 0.047 | 0.433 | 0.080 | 0.283 | 0.099 | 0.035 | 0.168 | 0.631 | 0.093 | 0.191 | |||
| HoG | 0.518 | 0.609 | 0.857 | 0.342 | 0.667 | 0.340 | 0.476 | 0.893 | 0.700 | 0.739 | 0.614 | |||
| SIFT | 0.894 | 0.722 | 0.963 | 0.871 | 0.926 | 0.613 | 0.870 | 0.973 | 0.958 | 0.873 | 0.866 | |||
| FPFH | 0.972 | 0.849 | 0.981 | 0.939 | 0.963 | 0.693 | 0.975 | 0.981 | 0.980 | 0.949 | 0.928 | |||
| PointNext | 0.425 | 0.294 | 0.365 | 0.772 | 0.227 | 0.151 | 0.408 | 0.101 | 0.771 | 0.295 | 0.380 | |||
| SpinNet | 0.635 | 0.316 | 0.922 | 0.780 | 0.870 | 0.380 | 0.585 | 0.699 | 0.955 | 0.400 | 0.654 | |||
| BTF | 0.976 | 0.967 | 0.979 | 0.974 | 0.971 | 0.884 | 0.976 | 0.981 | 0.959 | 0.971 | 0.964 |
点云特定的基于学习的表示。
PointNeXt [31]。 一种 U-Net [33] 架构,其中编码器分层抽象点云特征,而解码器逐渐对抽象特征进行插值。
SpinNet [1]。 一种旋转不变的、基于学习的表示学习方法。 变换和体素化阶段使模型旋转不变。
结果。 与上述大多数方法相比,PointNeXt 存在不足。 SpinNet 的性能优于 PointNeXt(旋转不变性重要性的另一个指标),但未能超越所提出的旋转不变性手工方法。 参见选项卡。 2,图6(a),以及App。 C 查看结果。
结论。 FPFH 优于所有使用颜色、深度或两者的方法(表 1)。 1)。 结果表明,当 3D 信息可用时,强大的、手工制作的、旋转不变的 3D 表示对于 AD&S 非常有效。 此外,由于异常通常是局部的和“细粒度的”,因此仅使用一小部分点(根据许多基于深度学习的方法的要求)会降低性能。
4.4 同时使用 3D 和彩色模式是否有互补的好处?
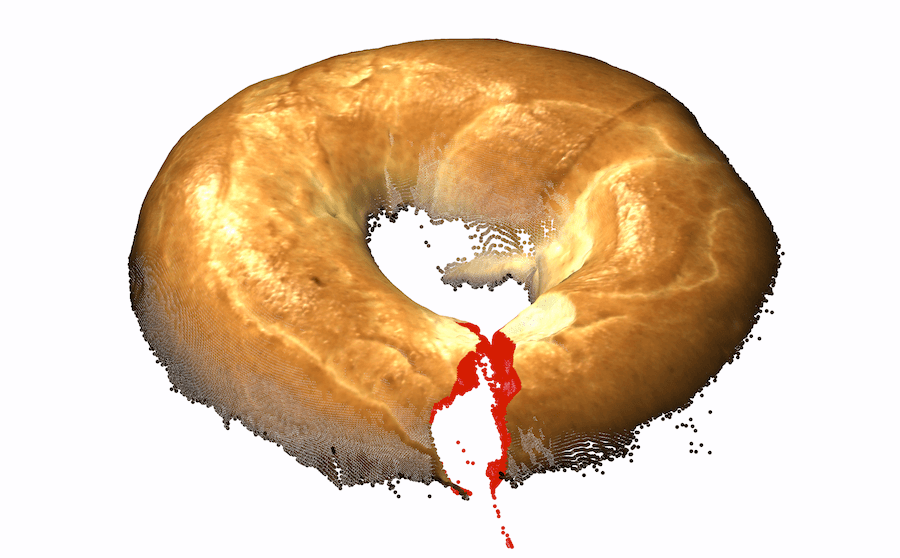
虽然最好的仅深度表示优于现有的仅颜色表示,但我们假设将它们结合起来可能会达到两全其美的效果。 在某些情况下,仅几何形状不足以检测异常。 两个例子是精细纹理和基于颜色的异常。 图1-右中的“电缆密封套”有轻微刮伤。 虽然在彩色图像中可以清楚地观察到这种异常纹理,但以当前的 3D 信息分辨率实际上不可能检测到。 这在泡沫示例中更加明显,其中异常表现为颜色的变化。 由于我们对 3D 的专注无法解决某些异常情况,因此有必要将 3D 和颜色信息结合起来。
| 3D Input | 2D View | GT | RGB iNet | Depth iNet |
 |
|
|
|
|
|
|
|
|
|
| Raw | HoG | SIFT | FPFH | BTF |
BTF - 组合颜色 + 3D 方法。 我们采用色彩+3D相结合的方法。 为此,使用第 2 节中讨论的基于 ImageNet 的方法提取颜色表示。 4.1 和 3D 表示是使用 FPFH 提取的,如第 2 节中所述。 4.3。 我们将这两个表示连接起来,形成一个颜色 + 3D 表示,我们将其称为 BTF(回到特征)。
结果。 与之前结合 3D 和 RGB 的最佳方法(“Voxel GAN + RGB”)相比,我们的 BTF 将 PRO(即异常分割)指标提高了 和 I-ROC(即异常检测)由 执行。 与仅使用 3D 信息相比,我们的 BTF 在 FPFH 上提高了 PRO 和 I-ROC. 此外,它在 P-ROC 上获得了 的分数,比 FPFH 提高了 (表 1)。 2,图6(a))。 其他颜色和 3D 组合以及扩展结果可在 App 中找到。 D 和应用程序。 A。
结论。 通过结合颜色和 3D 信息,我们的 BTF 表示利用了两种模式的互补属性,在 MVTec 3D-AD 数据集上实现了迄今为止的最佳结果。
4.5实施细节
除非另有说明,原始点云和彩色图像均被下采样至。 对于点云,我们使用最近邻插值对组织点云进行下采样(即图像下采样),使用双三次插值对彩色图像进行下采样。 对于无组织点云,我们将有组织点云从重塑为。 我们使用组织点云的通道作为我们的深度图。 我们从每个样本中提取 个补丁(特征),特征维度根据所使用的表示而变化。 当以不同的分辨率提取表示时,我们使用平均池来匹配 。 对于非方形类(即 rope 和 tire),我们用零填充颜色和 3D 图像。 对于 PointNeXt,我们使用在 S3DIS [2] 上预先训练的 PointNeXt-XL 架构,并具有分段目标。 我们报告区域 1 的结果,因为它表现最好。 欲了解更多详情,请参阅应用程序。 E。
建立基于 3D 的预处理协议。 有时需要进行预处理以消除令人讨厌的伪影。 为了处理这种情况,我们开发了一种简单的预处理方法。 我们首先通过对点云数据应用 RANSAC [17] 来删除背景平面。 删除后,我们通过应用基于连接组件的算法来丢弃离群值和远离平面的区域(有关实现细节,请参阅 App. F)。 此预处理阶段使纯颜色方法的结果基本不受影响。 更有趣的是,它极大地改善了基于深度的方法的结果,而对于基于 3D 的方法(即 FPFH),它略微降低了结果。 我们假设这是由于深度和 3D 方法处理丢失的传感器信息的方式不同造成的1113D 传感方法容易出现采样噪声和丢失信息(例如遮挡)。 在 MVTec 3D-AD 中,背景非常嘈杂是很常见的,数据集设计者将这些区域替换为零。. 对于点云,这些缺失值都位于原点(因为它们的值为 )并且很容易被忽略(因为它们不在其他点的空间上下文中)。 相反,对于深度图像,这些值位于其他点的空间上下文中,因此会被考虑在内。 删除这些平面会产生与点云类似的情况,因此有利于基于深度的方法。 当使用预处理的数据时,即使是最简单的特征(即 Raw) 优于原始基线[6],结果如图6(b)所示。
4.6限制。
我们提出的 BTF 方法有几个局限性:
特征融合。 电缆密封套和泡沫对于所有基于深度的方法都表现不佳(表 1)。 2 和应用程序。 A,应用程序。 B)。 虽然使用颜色比使用 3D 更容易检测这些类别中的异常(见图 1),但我们期望两种模式的融合能够提高性能。 不幸的是,对于这些类,融合特征的性能低于仅颜色方法。 未来的工作应该解决这个问题。
图像级精度。 虽然 BTF 在所有指标上都建立了新的最先进水平,但图像级检测精度还远未达到完美。 它的 I-ROC 为 ,与过去的方法相比有了很大的进步,但仍然是一个相对较低的分数。 由于我们使用 PatchCore 作为大多数实验的主干,因此 I-ROC 分数由距离所有训练补丁最远的图像补丁决定。 我们期望能够为 3D 数据设计更好的指标;对它们的调查留待未来的工作。
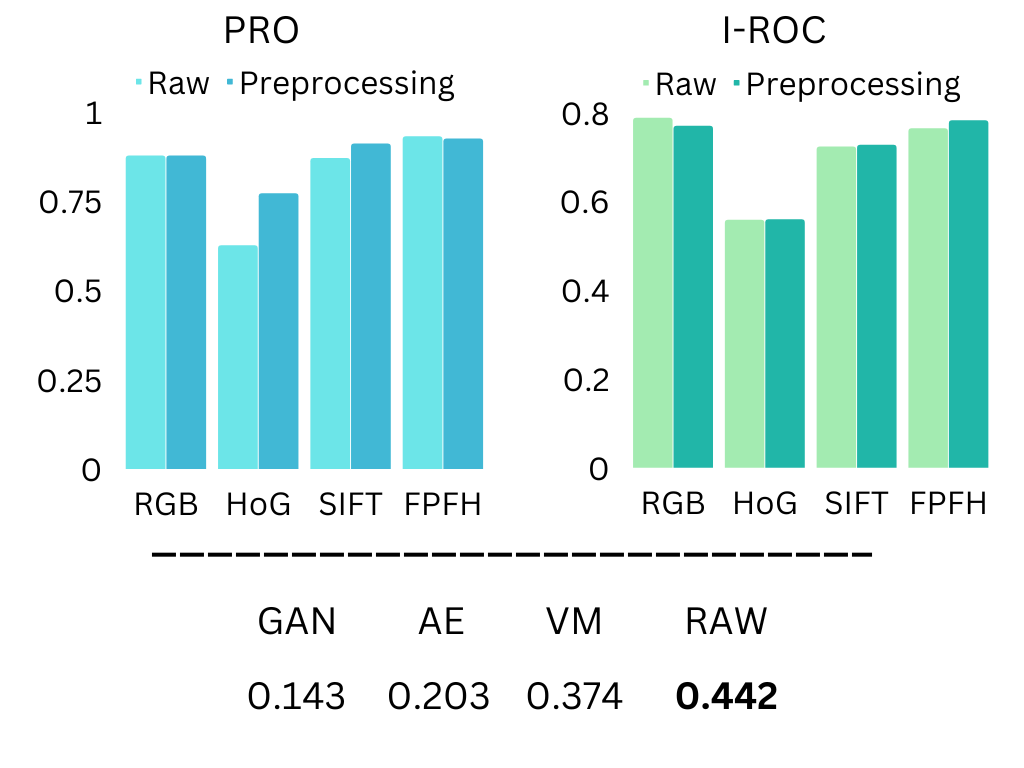
预处理(右): 顶部:比较原始数据和预处理数据。 基于深度的方法(即 HoG 和 SIFT)受益于异常分割的预处理(PRO),基于点云的方法(即 FPFH)受益于异常检测的预处理(I-ROC) 。 底部:MVTec 3D-AD 基线与预处理的 RAW 表示的 PRO 结果,预处理的 RAW 优于 MVTec 3D-AD 基线。 报告所有类别的平均指标
5结论
我们的研究动机是纯颜色方法在 MVTec 3D-AD 数据集上优于所有现有 3D 方法。 我们对 3D 表示进行了广泛的研究,发现旋转不变表示在 3D 异常检测方面实现了最佳性能。 我们提出了 BTF,它结合了 3D 和颜色特征,开创了新的最先进技术。 由于我们的方法很简单,我们希望它能够作为未来工作的强有力的基线。
6致谢
这项工作部分得到了 Oracle 研究计划提供的 Oracle 云积分和相关资源的支持。
参考
- [1] Ao, S., Hu, Q., Yang, B., Markham, A., Guo, Y.: Spinnet: Learning a general surface descriptor for 3d point cloud registration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
- [2] Armeni, I., Sener, O., Zamir, A.R., Jiang, H., Brilakis, I., Fischer, M., Savarese, S.: 3d semantic parsing of large-scale indoor spaces. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
- [3] Bengs, M., Behrendt, F., Krüger, J., Opfer, R., Schlaefer, A.: Three-dimensional deep learning with spatial erasing for unsupervised anomaly segmentation in brain mri. International journal of computer assisted radiology and surgery 16(9), 1413–1423 (2021)
- [4] Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9592–9600 (2019)
- [5] Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4183–4192 (2020)
- [6] Bergmann, P., Jin, X., Sattlegger, D., Steger, C.: The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization. arXiv preprint arXiv:2112.09045 (2021)
- [7] Bergmann, P., Sattlegger, D.: Anomaly detection in 3d point clouds using deep geometric descriptors. arXiv preprint arXiv:2202.11660 (2022)
- [8] Bergmann, P., Sattlegger, D.: Anomaly detection in 3d point clouds using deep geometric descriptors. arXiv preprint arXiv:2202.11660 (2022)
- [9] Bradley, A.P.: The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern recognition 30(7), 1145–1159 (1997)
- [10] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709 (2020)
- [11] Cohen, N., Hoshen, Y.: Sub-image anomaly detection with deep pyramid correspondences. arXiv preprint arXiv:2005.02357 (2020)
- [12] Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05). vol. 1, pp. 886–893. Ieee (2005)
- [13] Defard, T., Setkov, A., Loesch, A., Audigier, R.: Padim: a patch distribution modeling framework for anomaly detection and localization. In: International Conference on Pattern Recognition. pp. 475–489. Springer (2021)
- [14] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
- [15] Eskin, E., Arnold, A., Prerau, M., Portnoy, L., Stolfo, S.: A geometric framework for unsupervised anomaly detection. In: Applications of data mining in computer security, pp. 77–101. Springer (2002)
- [16] Ester, M., Kriegel, H.P., Sander, J., Xu, X., et al.: A density-based algorithm for discovering clusters in large spatial databases with noise. In: KDD (1996)
- [17] Fischler, M.A., Bolles, R.C.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM 24(6), 381–395 (1981)
- [18] Gidaris, S., Singh, P., Komodakis, N.: Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728 (2018)
- [19] Glodek, M., Schels, M., Schwenker, F.: Ensemble gaussian mixture models for probability density estimation. Computational Statistics 28(1), 127–138 (2013)
- [20] Golan, I., El-Yaniv, R.: Deep anomaly detection using geometric transformations. In: NeurIPS (2018)
- [21] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722 (2019)
- [22] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9729–9738 (2020)
- [23] Hendrycks, D., Mazeika, M., Kadavath, S., Song, D.: Using self-supervised learning can improve model robustness and uncertainty. In: NeurIPS (2019)
- [24] Jolliffe, I.: Principal component analysis. Springer (2011)
- [25] Latecki, L.J., Lazarevic, A., Pokrajac, D.: Outlier detection with kernel density functions. In: International Workshop on Machine Learning and Data Mining in Pattern Recognition. pp. 61–75. Springer (2007)
- [26] Li, C.L., Sohn, K., Yoon, J., Pfister, T.: Cutpaste: Self-supervised learning for anomaly detection and localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9664–9674 (2021)
- [27] Liu, F.T., Ting, K.M., Zhou, Z.H.: Isolation forest. In: 2008 Eighth IEEE International Conference on Data Mining. pp. 413–422. IEEE (2008)
- [28] Lowe, D.G.: Distinctive image features from scale-invariant keypoints. International journal of computer vision 60(2), 91–110 (2004)
- [29] Perera, P., Patel, V.M.: Learning deep features for one-class classification. IEEE Transactions on Image Processing 28(11), 5450–5463 (2019)
- [30] Pérez, P., Gangnet, M., Blake, A.: Poisson image editing. SIGGRAPH (2003)
- [31] Qian, G., Li, Y., Peng, H., Mai, J., Hammoud, H., Elhoseiny, M., Ghanem, B.: Pointnext: Revisiting pointnet++ with improved training and scaling strategies. arXiv:2206.04670 (2022)
- [32] Reiss, T., Cohen, N., Bergman, L., Hoshen, Y.: Panda: Adapting pretrained features for anomaly detection and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2806–2814 (2021)
- [33] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
- [34] Roth, K., Pemula, L., Zepeda, J., Schölkopf, B., Brox, T., Gehler, P.: Towards total recall in industrial anomaly detection. arXiv preprint arXiv:2106.08265 (2021)
- [35] Ruff, L., Gornitz, N., Deecke, L., Siddiqui, S.A., Vandermeulen, R., Binder, A., Müller, E., Kloft, M.: Deep one-class classification. In: ICML (2018)
- [36] Rusu, R.B., Blodow, N., Beetz, M.: Fast point feature histograms (fpfh) for 3d registration. In: 2009 IEEE International Conference on Robotics and Automation. pp. 3212–3217 (2009). https://doi.org/10.1109/ROBOT.2009.5152473
- [37] Schlegl, T., Seeböck, P., Waldstein, S.M., Langs, G., Schmidt-Erfurth, U.: f-anogan: Fast unsupervised anomaly detection with generative adversarial networks. Medical image analysis 54, 30–44 (2019)
- [38] Schlegl, T., Seeböck, P., Waldstein, S.M., Schmidt-Erfurth, U., Langs, G.: Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In: International Conference on Information Processing in Medical Imaging (2017)
- [39] Schlüter, H.M., Tan, J., Hou, B., Kainz, B.: Self-supervised out-of-distribution detection and localization with natural synthetic anomalies (nsa). arXiv preprint arXiv:2109.15222 (2021)
- [40] Scholkopf, B., Williamson, R.C., Smola, A.J., Shawe-Taylor, J., Platt, J.C.: Support vector method for novelty detection. In: NIPS (2000)
- [41] Simarro Viana, J., de la Rosa, E., Vande Vyvere, T., Robben, D., Sima, D.M., et al.: Unsupervised 3d brain anomaly detection. In: International MICCAI Brainlesion Workshop. pp. 133–142. Springer (2020)
- [42] Tack, J., Mo, S., Jeong, J., Shin, J.: Csi: Novelty detection via contrastive learning on distributionally shifted instances. arXiv preprint arXiv:2007.08176 (2020)
- [43] Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3d shapenets: A deep representation for volumetric shapes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1912–1920 (2015)
- [44] Yu, J., Zheng, Y., Wang, X., Li, W., Wu, Y., Zhao, R., Wu, L.: Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv preprint arXiv:2111.07677 (2021)
- [45] Zagoruyko, S., Komodakis, N.: Wide residual networks. arXiv preprint arXiv:1605.07146 (2016)
- [46] Zeng, A., Song, S., Nießner, M., Fisher, M., Xiao, J., Funkhouser, T.: 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In: CVPR (2017)
- [47] Zhou, Q.Y., Park, J., Koltun, V.: Open3D: A modern library for 3D data processing. arXiv:1801.09847 (2018)
- [48] Zong, B., Song, Q., Min, M.R., Cheng, W., Lumezanu, C., Cho, D., Chen, H.: Deep autoencoding gaussian mixture model for unsupervised anomaly detection. ICLR (2018)
附录 A 详细的 I-ROC 结果
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
| Previous Methods | Voxel GAN | 0.383 | 0.623 | 0.474 | 0.639 | 0.564 | 0.409 | 0.617 | 0.427 | 0.663 | 0.577 | 0.537 | ||
| + RGB | 0.680 | 0.324 | 0.565 | 0.399 | 0.497 | 0.482 | 0.566 | 0.579 | 0.601 | 0.482 | 0.517 | |||
| Voxel AE | 0.693 | 0.425 | 0.515 | 0.79 | 0.494 | 0.558 | 0.537 | 0.484 | 0.639 | 0.583 | 0.571 | |||
| + RGB | 0.510 | 0.540 | 0.384 | 0.693 | 0.446 | 0.632 | 0.550 | 0.494 | 0.721 | 0.413 | 0.538 | |||
| Voxel VM | 0.75 | 0.747 | 0.613 | 0.738 | 0.823 | 0.693 | 0.679 | 0.652 | 0.609 | 0.69 | 0.699 | |||
| + RGB | 0.553 | 0.772 | 0.484 | 0.701 | 0.751 | 0.578 | 0.480 | 0.466 | 0.689 | 0.611 | 0.609 | |||
| Depth GAN | 0.53 | 0.376 | 0.607 | 0.603 | 0.497 | 0.484 | 0.595 | 0.489 | 0.536 | 0.521 | 0.523 | |||
| + RGB | 0.538 | 0.372 | 0.580 | 0.603 | 0.430 | 0.534 | 0.642 | 0.601 | 0.443 | 0.577 | 0.532 | |||
| Depth AE | 0.468 | 0.731 | 0.497 | 0.673 | 0.534 | 0.417 | 0.485 | 0.549 | 0.564 | 0.546 | 0.546 | |||
| + RGB | 0.648 | 0.502 | 0.650 | 0.488 | 0.805 | 0.522 | 0.712 | 0.529 | 0.540 | 0.552 | 0.595 | |||
| Depth VM | 0.51 | 0.542 | 0.469 | 0.576 | 0.609 | 0.699 | 0.45 | 0.419 | 0.668 | 0.52 | 0.546 | |||
| + RGB | 0.513 | 0.551 | 0.477 | 0.581 | 0.617 | 0.716 | 0.450 | 0.421 | 0.598 | 0.623 | 0.555 | |||
| Our Findings | RGB iNet | 0.854 | 0.840 | 0.824 | 0.687 | 0.974 | 0.716 | 0.713 | 0.593 | 0.920 | 0.724 | 0.785 | ||
| Depth iNet | 0.624 | 0.683 | 0.676 | 0.838 | 0.608 | 0.558 | 0.567 | 0.496 | 0.699 | 0.619 | 0.637 | |||
| NSA | 0.841 | 0.494 | 0.776 | 0.913 | 0.636 | 0.616 | 0.795 | 0.597 | 0.856 | 0.438 | 0.696 | |||
| Raw | 0.578 | 0.732 | 0.444 | 0.798 | 0.579 | 0.537 | 0.347 | 0.306 | 0.439 | 0.517 | 0.528 | |||
| HoG | 0.560 | 0.615 | 0.676 | 0.491 | 0.598 | 0.489 | 0.542 | 0.553 | 0.655 | 0.423 | 0.560 | |||
| SIFT | 0.696 | 0.553 | 0.824 | 0.696 | 0.795 | 0.773 | 0.573 | 0.746 | 0.936 | 0.553 | 0.714 | |||
| FPFH | 0.820 | 0.533 | 0.877 | 0.769 | 0.718 | 0.574 | 0.774 | 0.895 | 0.990 | 0.582 | 0.753 | |||
| PointNext (area 1) | 0.499 | 0.772 | 0.498 | 0.750 | 0.589 | 0.525 | 0.545 | 0.431 | 0.805 | 0.484 | 0.587 | |||
| SpinNet | 0.535 | 0.413 | 0.568 | 0.662 | 0.472 | 0.480 | 0.367 | 0.494 | 0.722 | 0.527 | 0.524 | |||
| BTF | 0.938 | 0.765 | 0.972 | 0.888 | 0.960 | 0.664 | 0.904 | 0.929 | 0.982 | 0.726 | 0.873 |
附录 B 详细的 P-ROC 结果
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||
| RGB iNet | 0.983 | 0.984 | 0.980 | 0.974 | 0.985 | 0.836 | 0.976 | 0.982 | 0.989 | 0.975 | 0.966 | ||
| Depth iNet | 0.941 | 0.759 | 0.933 | 0.946 | 0.829 | 0.518 | 0.939 | 0.743 | 0.974 | 0.632 | 0.821 | ||
| NSA | 0.925 | 0.638 | 0.872 | 0.908 | 0.674 | 0.777 | 0.902 | 0.825 | 0.972 | 0.676 | 0.817 | ||
| Raw Depth | 0.404 | 0.306 | 0.772 | 0.457 | 0.641 | 0.478 | 0.354 | 0.602 | 0.905 | 0.558 | 0.548 | ||
| HoG | 0.782 | 0.846 | 0.965 | 0.684 | 0.848 | 0.741 | 0.779 | 0.973 | 0.926 | 0.903 | 0.845 | ||
| SIFT | 0.974 | 0.862 | 0.993 | 0.952 | 0.980 | 0.862 | 0.955 | 0.996 | 0.993 | 0.971 | 0.954 | ||
| FPFH | 0.995 | 0.955 | 0.998 | 0.971 | 0.993 | 0.911 | 0.995 | 0.999 | 0.998 | 0.988 | 0.980 | ||
| Omnivore | 0.936 | 0.840 | 0.776 | 0.901 | 0.919 | 0.850 | 0.894 | 0.911 | 0.981 | 0.958 | 0.896 | ||
| PointNext | 0.735 | 0.652 | 0.708 | 0.899 | 0.640 | 0.481 | 0.769 | 0.384 | 0.959 | 0.651 | 0.687 | ||
| SpinNet | 0.882 | 0.684 | 0.978 | 0.902 | 0.963 | 0.771 | 0.833 | 0.911 | 0.994 | 0.817 | 0.873 | ||
| BTF | 0.996 | 0.991 | 0.997 | 0.995 | 0.995 | 0.972 | 0.996 | 0.998 | 0.995 | 0.994 | 0.993 |
附录 C详细的 PointNext 结果
标签。 5、6和7包含 PointNext [31] 结果在 S3DIS [2] 数据集上的完整细分。 所有结果均基于 PointNext-XL 模型。 PointNext 为 S3DIS 中的六个区域分别训练了不同的模型。
|
Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||||
| Area1 | 0.425 | 0.294 | 0.365 | 0.772 | 0.227 | 0.151 | 0.408 | 0.101 | 0.771 | 0.295 | 0.380 | ||||
| Area2 | 0.392 | 0.261 | 0.282 | 0.549 | 0.183 | 0.166 | 0.286 | 0.168 | 0.788 | 0.293 | 0.336 | ||||
| Area3 | 0.484 | 0.299 | 0.295 | 0.671 | 0.205 | 0.161 | 0.387 | 0.173 | 0.690 | 0.313 | 0.367 | ||||
| Area4 | 0.302 | 0.309 | 0.314 | 0.554 | 0.185 | 0.158 | 0.253 | 0.164 | 0.726 | 0.343 | 0.330 | ||||
| Area5 | 0.282 | 0.315 | 0.268 | 0.649 | 0.202 | 0.173 | 0.263 | 0.116 | 0.522 | 0.312 | 0.310 | ||||
| Area6 | 0.355 | 0.305 | 0.410 | 0.633 | 0.189 | 0.147 | 0.305 | 0.157 | 0.799 | 0.262 | 0.356 |
|
Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||||
| Area1 | 0.499 | 0.772 | 0.498 | 0.750 | 0.589 | 0.525 | 0.545 | 0.431 | 0.805 | 0.484 | 0.587 | ||||
| Area2 | 0.565 | 0.600 | 0.516 | 0.486 | 0.541 | 0.379 | 0.476 | 0.308 | 0.760 | 0.432 | 0.506 | ||||
| Area3 | 0.614 | 0.697 | 0.489 | 0.588 | 0.571 | 0.446 | 0.476 | 0.318 | 0.763 | 0.516 | 0.547 | ||||
| Area4 | 0.536 | 0.698 | 0.496 | 0.491 | 0.538 | 0.459 | 0.487 | 0.275 | 0.776 | 0.501 | 0.525 | ||||
| Area5 | 0.585 | 0.641 | 0.563 | 0.831 | 0.555 | 0.412 | 0.413 | 0.342 | 0.816 | 0.459 | 0.561 | ||||
| Area6 | 0.536 | 0.674 | 0.547 | 0.620 | 0.517 | 0.406 | 0.497 | 0.319 | 0.793 | 0.493 | 0.540 |
|
Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||||
| Area1 | 0.735 | 0.652 | 0.708 | 0.899 | 0.640 | 0.481 | 0.769 | 0.384 | 0.959 | 0.651 | 0.687 | ||||
| Area2 | 0.689 | 0.650 | 0.644 | 0.780 | 0.515 | 0.425 | 0.656 | 0.478 | 0.964 | 0.643 | 0.644 | ||||
| Area3 | 0.762 | 0.660 | 0.688 | 0.845 | 0.475 | 0.505 | 0.755 | 0.469 | 0.945 | 0.654 | 0.675 | ||||
| Area4 | 0.648 | 0.643 | 0.678 | 0.807 | 0.545 | 0.512 | 0.628 | 0.437 | 0.951 | 0.715 | 0.656 | ||||
| Area5 | 0.666 | 0.681 | 0.645 | 0.837 | 0.574 | 0.507 | 0.668 | 0.385 | 0.898 | 0.661 | 0.652 | ||||
| Area6 | 0.716 | 0.577 | 0.726 | 0.837 | 0.589 | 0.512 | 0.672 | 0.425 | 0.962 | 0.632 | 0.664 |
附录 D 其他方法组合
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||
| Depth iNet+RGB | 0.877 | 0.893 | 0.908 | 0.924 | 0.877 | 0.464 | 0.927 | 0.929 | 0.911 | 0.829 | 0.853 | ||
| Raw+RGB | 0.896 | 0.948 | 0.927 | 0.874 | 0.925 | 0.549 | 0.903 | 0.932 | 0.910 | 0.887 | 0.875 | ||
| HoG+RGB | 0.898 | 0.948 | 0.927 | 0.873 | 0.927 | 0.555 | 0.902 | 0.932 | 0.911 | 0.901 | 0.877 | ||
| SIFT+RGB | 0.895 | 0.947 | 0.927 | 0.875 | 0.929 | 0.555 | 0.904 | 0.932 | 0.910 | 0.895 | 0.876 | ||
| SpinNet+RGB | 0.897 | 0.948 | 0.929 | 0.878 | 0.928 | 0.550 | 0.904 | 0.931 | 0.911 | 0.899 | 0.877 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||
| Depth iNet+RGB | 0.808 | 0.707 | 0.739 | 0.836 | 0.882 | 0.547 | 0.731 | 0.667 | 0.825 | 0.648 | 0.739 | ||
| Raw+RGB | 0.877 | 0.876 | 0.785 | 0.718 | 0.960 | 0.699 | 0.742 | 0.581 | 0.895 | 0.623 | 0.775 | ||
| HoG+RGB | 0.887 | 0.891 | 0.791 | 0.716 | 0.972 | 0.676 | 0.714 | 0.576 | 0.862 | 0.649 | 0.773 | ||
| SIFT+RGB | 0.845 | 0.882 | 0.780 | 0.727 | 0.966 | 0.671 | 0.726 | 0.619 | 0.867 | 0.681 | 0.776 | ||
| SpinNet+RGB | 0.851 | 0.841 | 0.806 | 0.682 | 0.969 | 0.753 | 0.713 | 0.627 | 0.864 | 0.679 | 0.778 |
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | ||
| Depth iNet+RGB | 0.981 | 0.966 | 0.973 | 0.983 | 0.971 | 0.777 | 0.983 | 0.979 | 0.988 | 0.954 | 0.955 | ||
| Raw+RGB | 0.983 | 0.984 | 0.980 | 0.974 | 0.985 | 0.829 | 0.976 | 0.982 | 0.987 | 0.972 | 0.965 | ||
| HoG+RGB | 0.983 | 0.984 | 0.980 | 0.974 | 0.985 | 0.832 | 0.976 | 0.982 | 0.987 | 0.976 | 0.965 | ||
| SIFT+RGB | 0.983 | 0.984 | 0.980 | 0.974 | 0.985 | 0.829 | 0.976 | 0.982 | 0.987 | 0.975 | 0.965 | ||
| SpinNet+RGB | 0.983 | 0.984 | 0.980 | 0.975 | 0.985 | 0.830 | 0.976 | 0.982 | 0.987 | 0.976 | 0.965 |
附录E方法具体实现细节
下面,我们为我们研究的每种方法提供了额外的实现细节
E.1 仅 RGB ImageNet 功能
利用 PatchCore,我们将 RGB 图像提供给 ImageNet [14] 预训练的 WideResNet50 [45] 主干网作为特征提取器。 为了实现局部分割,我们从块 和 的聚合输出中提取块级特征,从而得到 的特征维度。
E.2 仅深度 ImageNet 特征
与仅 RGB 情况一样,我们使用 PatchCore 并根据 ImageNet 统计数据标准化深度图。
E.3 原始深度值
我们将深度图像划分为 像素的块,从而产生 块。 描述符由每个补丁的 像素组成,被展平为长度为 的一维列表。
E.4美国国家安全局
我们无法找到 CutPaste [26] 的官方实现,并且公开的非官方实现落后于报告的数字最多 。 因此,我们将我们的方法与 NSA [39]进行了比较,后者是 CutPaste 的后续产品,使用泊松混合 [30] 来实现更逼真的增强。 为了在新数据集上测试 NSA,我们修改了他们的官方实现来处理深度图像。 当前的实现要求将图像表示为整数,因此深度图像被离散化为 [0, 255]。 此外,NSA 使用广泛的、依赖于类的超参数。 MVTec 3D-AD 类通过与原始类进行直观比较并分配最相似类的值来分配超参数。 我们使用深度图像来运行这些实验。 NSA 的性能可能可以通过特定的每类增强来提高,但是,这需要预先了解异常情况。
E.5HoG
我们使用深度图像作为输入。 为了与特征图分辨率保持一致,我们每个单元使用 个像素,每个块使用 个单元。 我们使用 bin 来获得 维度表示。
E.6D-SIFT
我们使用深度图像作为输入。 我们对所有像素应用 Dense SIFT,为了降低分辨率,我们应用平均池化。 遵循标准 SIFT 实践,我们使用 特征维度。
E.7FPFH
为了加快 FPFH 的计算速度,我们在运行算法之前对点云进行了下采样。 对组织好的点云进行下采样(即图像下采样);然后将其展平为无组织的点云。 使用开源库 Open3D [47] 中的实现,我们为每个点提取一个描述符。 然后,我们将这些描述符重塑回有组织的点云,并通过平均池化降低它们的分辨率。 FPFH 需要法线才能运行,我们使用 Open3D 估计法线。 FPFH 算法的半径为, 参数设置为。 生成的特征尺寸为 。
E.8PointNext
我们使用 PointNeXt-XL 变体来提取特征。 为了克服使用极少量点( 或 )的限制,我们使用 S3DIS [2] 预训练模型。 这意味着,该模型已针对 RGB+XYZ 数据的分割任务进行了预训练。 使用这些变体可以让我们为模型提供更多的点。 具体来说,样本被下采样到 ,然后将它们重塑为无组织的点云(具有相应的 RGB 值)。 对于每个点,都会返回一个 维度特征。 然后将其重新整形回有组织的特征点云。 与其他方法一样,我们将特征汇集到 像素的 块中。 我们使用官方 github 存储库中的代码。
E.9旋转网络
我们使用在 3DMatch [46] 上预训练的模型。 在将点输入网络之前,我们将采样降低到 。 然后,我们将每个样本划分为 个 像素块。 然后将这些补丁输入到输出 维度特征的模型中。 我们使用官方 github 存储库中的代码。
附录F预处理实现细节
F.1 平面移除
根据设计,数据集中的对象位于图像的中心。 因此,我们做出一个简化的假设,即图像的所有边缘都位于同一平面上。 为此,我们从组织好的点云中围绕图像边界获取 像素宽的条带。 去除所有 NaN(即噪声)后,我们使用 RANSAC [17] 来近似最能描述边界的平面。 计算点云中每个点到该平面的距离,距离内的任何点都会被删除。 实际上,我们不是删除该点,而是将该点的 XYZ 坐标和 RGB 值归零。 这可确保保留原始分辨率。 我们使用 Open3D [47] “Segment Plane” 实现来执行带有 和 的 RANSAC 步骤,对于实际的平面移除,我们使用返回的平面方程并手动将值归零。
F.2 基于聚类的异常值去除
虽然平面去除步骤可以识别并去除大部分平面,但在某些情况下,平面不是平面,见图7。 因此,这些区域中的点可能会被标记为异常。 通过将 DB-Scan [16] 作为连接组件方法运行,每个集群都被视为一个连接组件。 我们保留最大的分量并从其他分量中删除所有点(和之前一样,我们将点的 XYZ 坐标和 RGB 值归零)。 我们使用带有 和 的 Open3D [47] DB-Scan 实现。
| RGB | HoG | SIFT | FPFH | |||||
| PRO | I-ROC | PRO | I-ROC | PRO | I-ROC | PRO | I-ROC | |
| Raw | 0.876 | 0.788 | 0.625 | 0.558 | 0.869 | 0.723 | 0.930 | 0.764 |
| Pre | 0.876 | 0.770 | 0.771 | 0.559 | 0.910 | 0.727 | 0.924 | 0.782 |
