编辑 inkscapelatex=false yujiali@deepmind.com、davidhchoi@deepmind.com、vinyals@deepmind.com **affiliationtext: Joint first authors
使用 AlphaCode 生成竞赛级代码
摘要
编程是一种强大且无处不在的解决问题的工具。 开发可以帮助程序员甚至独立生成程序的系统可以使编程更加高效和易于访问,但迄今为止,整合人工智能创新已被证明具有挑战性。 最近的大规模语言模型已经展示了令人印象深刻的生成代码的能力,并且现在能够完成简单的编程任务。 然而,当对更复杂、看不见的问题进行评估时,这些模型仍然表现不佳,这些问题需要解决问题的技能,而不仅仅是将指令转换为代码。 例如,需要理解算法和复杂自然语言的竞争性编程问题仍然极具挑战性。 为了弥补这一差距,我们引入了 AlphaCode,这是一种代码生成系统,可以为这些需要更深入推理的问题创建新颖的解决方案。 在Codeforces平台近期的编程竞赛模拟评测中,AlphaCode在超过5000人参与的竞赛中平均排名前54.3%。 我们发现三个关键组件对于实现良好且可靠的性能至关重要:(1)用于和评估的广泛且干净的竞争性编程数据集,(2)大型且高效的基于 Transformer 的架构,以及(3)大型- 规模模型采样以探索搜索空间,然后根据程序行为过滤一小组提交内容。
小节
1简介
计算机编程已成为贯穿科学、工业和日常生活的通用问题解决工具。 作为这种增长的一部分,人们对工具的需求不断增加,这些工具可以提高程序员的工作效率(Matsakis 和 Klock,2014 年),或者使编程和编程教育更容易实现(Resnick 等人) ,2009)。 开发能够有效建模和理解代码的人工智能系统可以改变这些工具以及我们与它们交互的方式。 可以生成代码的系统不仅有用,而且是可以加深对人工智能及其与编程的关系的理解的垫脚石。
生成解决指定任务的代码需要在可能程序的巨大结构化空间中进行搜索,并且奖励信号非常稀疏。 单字符编辑可以完全改变程序行为,即使它们不会导致崩溃,即使对于相同的问题,解决方案也可能看起来截然不同,并且判断部分或不正确的程序是否有用是一个艰巨的挑战。 因此,大多数先前的工作仅限于受限的特定领域编程语言(Gulwani,2011)或短代码片段(Raychev等人,2014;Bruch等人,2009).
最近基于大规模 Transformer 的 (Vaswani 等人, 2017) 语言模型,用于实现生成文本 (Brown 等人, 2020) 的令人印象深刻的性能,已成功生成代码解决 Python 中的简单编程问题(Chen 等人,2021;Austin 等人,2021)。 我们模型的精简版本,没有进行 4 节中描述的修改,其性能与 Codex 类似(表 LABEL:tab: human-eval)。 然而,Codex 论文和类似工作中使用的问题大多由简单的任务描述和简短的解决方案组成,远未达到现实世界编程的全部复杂性。 从长的自然语言任务描述开始,用通用编程语言(例如 C++ 或 Python)生成整个程序仍然是一个悬而未决的问题。 生成短代码片段和整个程序之间的难度差异可以类似于命令式与声明式问题解决的难度差异。 生成短代码片段通常相当于将任务规范直接转换为代码,有时甚至简化为调用正确的 API 调用。 相比之下,生成整个程序通常依赖于理解任务并弄清楚如何完成它,这需要更深入的算法推理。
竞争性编程问题代表了所有这些方面的重大进步。 解决此类问题需要理解复杂的自然语言描述,推理以前未见过的问题,掌握广泛的算法和数据结构,并精确地实现跨越数百行的解决方案。 通过在一系列详尽的未知测试中执行解决方案来评估解决方案,检查边缘情况下的正确行为以及执行速度。 用于评估的测试用例被隐藏这一事实是挑战的一个重要部分。 这些复杂的问题都是为每场比赛新创建的,参赛者可以借鉴以前比赛的解决方案(或者通过记住旧问题隐式地解决,或者通过搜索问题明确地解决)。 此外,竞争性节目非常流行。国际大学生编程竞赛(ICPC,2021)和国际信息学奥林匹克(IOI,2021)等活动被广泛认为是计算机科学领域最负盛名的竞赛,吸引了来自世界各地的数十万参与者。 使用人类在此类经过实战考验的竞赛中发现的具有挑战性的问题,可以确保针对捷径的鲁棒性,并为智力的许多方面提供有意义的基准。
使用程序综合进行竞争性编程的早期工作表明,大型 Transformer 模型可以实现较低的个位数求解率(Hendrycks 等人,2021;Chen 等人,2021),但尚无法可靠地生成解决方案对于绝大多数问题。 此外,正如我们在第 3.2.1 节中所示,现有竞争性编程数据集中缺乏足够的测试用例,使得在其上定义的指标容易出现高误报率(30% 或更多的程序通过了测试)所有测试但实际上并不正确),因此对于衡量研究进展并不可靠。
在本文中,我们提出了 AlphaCode,一种用于解决竞争性编程问题的代码生成系统。 我们使用大型 Transformer 语言模型来生成代码,在选定的 GitHub 代码上对它们进行预训练,并对我们精心策划的一组竞争性编程问题进行微调。 对于每个未见过的问题,我们生成大量程序样本,根据问题描述中的示例测试的执行结果过滤它们,然后对剩余样本进行聚类,以获得要提交评估的一小组候选程序。 我们在4节中详细描述了AlphaCode。
开发我们系统的一个核心部分是确保提交的训练集得到严格评估,并且评估问题在训练过程中真正看不见,因此困难的问题不能通过复制训练集来解决。 为了实现这一目标,我们发布了一个新的训练和评估竞争性编程数据集 CodeContests111数据集位于https://github.com/deepmind/code_contests。 (第 3 节)。 该数据集结合了来自不同来源的数据,进行时间分割,以便所有训练数据早于所有评估问题,添加额外的生成测试以确保正确性,并在反映竞争性编程设置的设置中评估提交内容。 在我们的评估中(第 3.2.1 节),CodeContests 将现有数据集中的误报率从 30-60% 降低到仅 4%。 我们的最佳模型解决了该数据集中 34.2% 的竞争性编程问题,每个问题最多使用 10 次提交(与人类相比),而之前报告的现有数据集的解决率约为 1-5%(请参见5.4)。
 |
 |
|---|---|
| (a) AlphaCode’s ranking in 10 contests | (b) AlphaCode’s estimated rating |
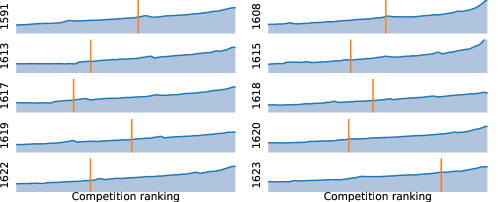
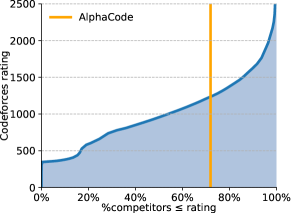
为了进一步验证我们的结果,我们在流行的 Codeforces 平台上举办的模拟编程竞赛中评估了 AlphaCode222https://codeforces.com/(第 5.1 节)。 在最近10场超过5000人参加的比赛评估中,AlphaCode的平均排名在前54.3%之内。 根据这些结果,我们估计我们的系统已达到 Codeforces 评级333The rating system is similar to the classic Elo score and is primarily explained in three blog posts: 1, 2, and 3 1238 位于前 28% 之内444AlphaCode 的总体评分百分位优于其每次比赛的百分位。 我们假设评分较高的参赛者比较评分较低的参赛者参加比赛的频率更高,因此在比赛中 AlphaCode 上方的组排名相对比下方的组排名更稳定。 过去 6 个月内参加过竞赛的用户数量(图 1)(Ebtekar,2021)。 这些评估仅包括尝试过此类竞赛的用户,这是所有程序员自选的子集。 这是计算机系统首次在编程竞赛中达到如此高的竞技水平。
我们还对我们的系统进行了详细分析(第 6 节),表明 AlphaCode 不会复制训练数据集中的代码部分来解决问题,而是严重依赖自然语言问题描述来创建原始解决方案。 我们进一步检查模型可以解决和不能解决的问题类型,并讨论验证损失如何不能很好地代表解决率。
退格键
给定两个字符串 和 ,均由小写英文字母组成。 您将逐个字符地输入字符串 ,从第一个字符到最后一个字符。
当输入一个字符时,您可以按“Backspace”按钮,而不是按该字符对应的按钮。 它会删除尚未删除的字符中您输入的最后一个字符(或者如果当前字符串中没有字符则不执行任何操作)。 例如,如果是“abcbd”,并且您按退格键而不是键入第一个和第四个字符,您将得到字符串“bd”(第一次按退格键不会删除任何字符,第二次按退格键不会删除任何字符)按删除字符“c”)。 另一个例子,如果 是“abcaa”并且您按 Backspace 而不是最后两个字母,则结果文本是“a”。
你的任务是确定是否可以获得字符串,如果你输入字符串并按“Backspace”而不是输入
输入
第一行包含一个整数 测试用例的数量。
每个测试用例的第一行包含字符串 。 的每个字符都是一个小写英文字母。
每个测试用例的第二行包含字符串 。 的每个字符都是一个小写英文字母。
保证所有测试用例的字符串中的字符总数不超过。
输出
对于每个测试用例,如果可以通过输入字符串 并通过按“Backspace”按钮替换一些字符来获取字符串 ,则打印“YES”,如果你不能。
您可以在任何情况下打印每个字母(YES、yes、Yes 都将被识别为肯定答案,NO、no 和 nO 都将被识别为否定答案)。
输入示例
⬇
4
ababa
ba
ababa
bb
aaa
aaaa
aababa
ababa
示例输出
⬇
YES
NO
NO
YES
解释
为了从“ababa”获得“ba”,您可以按退格键而不是输入第一个和第四个字符。
输入“ababa”时无法获得“bb”。
输入“aaa”时无法获得“aaaa”。
为了在输入“aababa”时获得“ababa”,您必须按退格键而不是输入第一个字符,然后输入所有剩余的字符。
2 问题设置
2.1 竞争性编程
编程竞赛最初始于 20 世纪 70 年代,此后越来越受欢迎,全世界有数十万参与者。 一年一度的国际大学生编程竞赛吸引了来自 3,000 多所大学的近 60,000 名学生(ICPC Factsheet,2020 年),以及 Google (Google Code Jam,2021 年) 和 Facebook (Facebook黑客杯,2021)定期举办比赛。 本文使用的流行 Codeforces 平台拥有超过 500,000 名活跃用户,每周举办有数万名参与者的比赛(Mirzayanov,2020)。
编程竞赛的具体形式因比赛而异,但一般来说,个人或参赛团队会给出 5 到 10 个问题描述(图 2),并且需要大约 3 个小时来编写程序(图 3) 来正确解决尽可能多的问题。 程序提交内容被发送到服务器,该服务器会自动通过一组详尽的隐藏测试对其进行评估(图A1)。 参赛者被告知他们提交的作品是否通过了所有测试,但不一定是失败的确切原因。 根据每个问题错误提交的数量以及解决每个问题所需的时间(ICPC 规则,2021 年) 进行处罚。 提交内容可以用多种编程语言编写,其中C++和Python是目前最流行的。 问题通常会通过评级来表示难度,更困难的问题得分更高。

-
1.
问题是弄清楚是否可以通过按退格键而不是键入一些字母来将一个短语转换为另一个短语。 首先我们读这两个短语(第 3-4 行)。
-
2.
如果两个短语末尾的字母不匹配,则必须删除最后一个字母。 如果它们匹配,我们可以移至倒数第二个字母并重复(11-18)。
-
3.
退格键删除两个字母。 您按退格键代替的字母及其前面的字母 (19-20)。
-
4.
如果我们匹配每个字母,则可以从 中获取字符串 (23-26)。
解决问题涉及三个步骤。 首先,参与者必须阅读并理解跨越多个段落的自然语言描述,其中包含:通常与问题无关的叙述背景、参赛者需要仔细理解和解析的所需解决方案的描述、输入和输出格式的规范、以及一个或多个示例输入/输出对(我们称之为“示例测试”)。
下一步是创建解决问题的有效算法。 从“问题是什么”到“如何解决问题”是一个巨大的飞跃,需要对问题的理解和推理,以及对各种算法和数据结构的深入理解。 这一飞跃与以前的作品有很大不同,以前的作品往往明确指定要实现的内容。 该算法还必须足够高效,能够及时执行问题指定的输入大小和时间限制,555图2中的问题的时间限制为2秒,最多使用256MB内存。 这通常会消除更简单、幼稚的尝试。
2.2评估
尽管针对现场编程竞赛运行系统是一种公正的评估,但它增加了很大程度的复杂性,并且不是一个稳定的基准。 为了缓解这个问题,我们开发了一种适合研究迭代的代理度量,类似于大多数监督学习数据集中存在的开发集。 我们的措施反映了比赛的基本结构,同时简化了附带细节。 我们使用的指标是“每个问题使用样本中的提交解决的问题的百分比”,表示为。
此指标表示如果允许针对每个问题首先创建 样本,然后根据隐藏测试评估这些样本的 ,则模型可以解决的问题的百分比。 如果这些 评估中的任何一个通过了所有测试,则认为问题已解决。 过滤方法取决于系统本身,但只能基于竞争对手可用的信息(例如,作为问题描述的一部分给出的示例测试,而不是隐藏的测试)。 为了减少运行之间的方差,假设 和 都是有限的,我们报告的指标是使用引导程序对一组通常远大于 的样本进行引导计算的期望值>(附录A.3)。 通过期望减少方差使得改进的比较更有意义,因为我们的验证和测试集相对较小,并且从单个模型采样时存在显着的方差。
将提交数量限制为 可以模拟对错误提交的惩罚,并防止系统通过对隐藏测试进行不合理的次数评估来利用评估指标。 修复 对于比较不同的评估非常重要,因为我们发现性能随着样本数量的增加而提高(第 5 节)。 我们使用 bootstrapping 确保我们仍然可以受益于通过生成更大的 样本集来估计 指标而获得的方差减少。
我们用于模拟编程竞赛的设置是 – 每个问题来自 样本 10 次提交。 我们还使用 ( 样本的求解率),以与 Chen 等人 (2021) 保持一致,假设所有样本都可以提交评估。 ,是使用 样本的上限指标。 我们显示了不同 值的解决率,因为低样本预算下的良好结果并不一定与高样本预算下的良好性能相关。
3数据集
我们所有的模型首先都在 GitHub 上的一系列开源代码上进行了预训练,随后在我们创建的编程竞赛数据数据集(CodeContests,在此处发布)上进行了微调。 预训练阶段帮助模型学习良好的代码表示并流畅地生成代码,而微调阶段帮助模型适应目标竞争编程领域。
3.1预训练数据集
我们的预训练数据集基于 2021 年 7 月 14 日拍摄的选定公共 GitHub 存储库的快照。 我们包含了多种流行语言的所有代码文件:C++、C#、Go、Java、JavaScript、Lua、PHP、Python、Ruby、Rust、Scala 和 TypeScript 。 继之前的工作(Chen等人,2021)之后,我们过滤掉了所有大于1MB或行长超过1000个字符的文件,以排除自动生成的代码。 我们还删除了同一文件的重复项,忽略比较中的空格。 经过过滤后,我们最终的预训练数据集总共包含 715.1 GB 的代码。 跨语言的数据集组成可以在附录中找到(表LABEL:tab:dataset-github-stats)。
3.2 CodeContests微调数据集
在 GitHub 上预训练的模型可以生成良好的代码并解决简单的编程问题,但如附录LABEL:sec:competitive-hardness所示,它们只能解决很少的竞争性编程问题。 在专用的竞争性编程数据集上微调模型对于性能至关重要。
为了便于微调和评估,我们策划了一个新的竞争性编程问题数据集,名为 CodeContests。666数据集可以在 GitHub 上找到。 该数据集包括我们从 Codeforces 平台抓取的问题、解决方案和测试用例,以及混合到我们的训练集中的现有公共竞争性编程数据集。 更具体地说,训练数据集将 Codeforces (Mirzayanov, 2020) 中新抓取的数据与 Description2Code (Caballero 等人, 2016) 和 CodeNet ( Puri 等人,2021)。 数据集的验证和测试部分完全由新抓取的 Codeforces 问题组成。 为了防止数据泄漏,我们采用了严格的时间分割:所有预训练和微调训练数据在任何验证问题之前在线出现,所有验证问题在测试问题之前出现。 继我们的 GitHub 预训练数据集快照日期之后,CodeContests 中的所有训练数据均已于 2021 年 7 月 14 日或之前公开发布。 验证问题出现在2021/07/15至2021/09/20之间,测试集包含2021/09/21之后发布的问题。 这种时间分割意味着只有人类可以看到的信息可用于训练模型(有关更多详细信息和分析,请参阅附录LABEL:sec:dataset-temporal-split)。 该数据集的一些基本统计数据如表1所示。
我们从 Codeforces 中抓取的数据包括如图 2 所示的完整问题描述,以及每个问题的元数据。 元数据包括难度等级和标签,指示解决问题可能需要哪些方法(例如“贪婪”或“dp”)。 难度等级和标签在比赛时都不可见(因此不应在测试时使用)。 我们的数据集还包含以最流行的提交语言编写的正确和错误的人类提交内容:C++、Python 和 Java。 每个问题都包含可从平台访问的所有测试用例:问题陈述中的示例测试以及竞赛结束后在评估结果页面上提供的隐藏测试用例。 为了提高数据质量和一致性,并避免合并数据集时涉及的重复问题,我们使用附录 LABEL:sec:appendix-dataset-merging 中概述的过程清理了这些数据。
通过在测试用例上执行程序并将程序输出与预期的正确输出进行比较来检查程序的正确性。 有关此正确性检查过程的更多详细信息记录在附录 A.2 中。
| Tests per problem | Solutions per problem (% correct) | |||||||||
| Split | Problems | Example | Hidden | Generated | C++ | Python | Java | |||
| Train | 13328 | 2.0 | 14.8 | 79.1 | 493.4 | (27%) | 281.1 | (47%) | 147.9 | (46%) |
| Valid | 117 | 1.5 | 12.9 | 190.0 | 231.6 | (47%) | 137.2 | (55%) | 131.1 | (54%) |
| Test | 165 | 1.7 | 9.4 | 192.7 | 196.0 | (45%) | 97.3 | (54%) | 105.2 | (51%) |
3.2.1 误报和额外生成的测试
我们希望测试用例尽可能详尽,这样提交的内容就不会因为缺乏测试覆盖而被标记为正确。 不幸的是,高质量的测试用例并不容易获得。 例如,当 Codeforces 平台长度超过大约 400 个字符时,Codeforces 平台不会显示完整的测试用例。 缺乏测试覆盖率会导致“误报”,即不正确的提交被标记为正确,而“慢阳性”,即正确但算法效率低下、不满足时间和内存限制的解决方案被标记为正确(例如,复杂度错误的解决方案)班级)。 这些误报不会影响第 5.1 节中所述的 Codeforces 评估。
值得注意的是,这两个问题在先前的数据集和程序综合文献中都很常见,因为输入/输出示例是程序行为的不规范(Gulwani 等人,2017)。 表 2 显示了我们的数据集与 APPS (Hendrycks 等人,2021) 和 HumanEval (Chen 等人,2021) 相比的估计误报率>,两者都有很多误报。 每个问题的平均测试数量较高并不一定表明测试很详尽,因为某些问题的每个问题的测试数量可能远少于平均水平,并且某些测试可能会检查类似的情况。
| Dataset | Tests / problem | False Positive (FP) Rate | FP or Slow Rate |
|---|---|---|---|
| APPS | 20.99 | 60% | 70% |
| HumanEval | 7.77 | 30% | N/A |
| CodeContests raw | 12.4 | 62% | 88% |
| CodeContests | 203.7 | 4% | 46% |
我们通过生成额外的测试用例来降低数据集的误报率,这些测试用例是通过改变现有的测试输入而创建的。 可能的突变包括对二进制输入应用位翻转、随机递增或递减整数以及交换和更改字符串中的字符。 通过运行 30 个正确的解决方案来验证变异输入,并检查所有解决方案是否产生相同的输出。 此过程针对每个问题运行最多 10 个 CPU 小时或 200 个生成的测试。 由于输入格式复杂,我们未能为 6.3% 的问题生成全套 200 个测试。
最后,我们过滤掉了验证和测试拆分中测试覆盖率不足的问题,仅保留至少 5 个隐藏或生成的测试用例的问题,这些测试用例会导致至少 2 个不同的输出。 这确保模型不能通过始终输出常量(例如 YES 或 NO)来简单地解决问题。 如表 2 所示,生成的测试和过滤将我们的误报率从 62% 降低到 4%。 尽管我们为 APPS 和 HumanEval 抽取的样本较少,但 CodeContests 的误报率明显高于之前的工作,而且这些数据集中的问题相对不那么复杂(这两者都倾向于降低误报率)。 然而,仍然存在大量问题,测试接受缓慢但语义正确的解决方案。
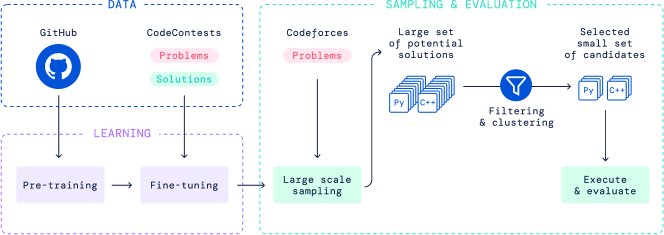
4方法
生成解决特定任务的代码需要在具有非常稀疏的奖励信号的巨大结构化程序空间中进行搜索。 更糟糕的是,对于包括竞争性编程在内的许多领域,可供学习的此类任务和解决方案的示例数量有限。 最后,由于我们限制模型可以执行的每个问题的提交数量,因此必须明智地使用每个提交。
我们的系统 AlphaCode 旨在解决所有这些挑战。 我们的方法的高级视图如图 4 所示。 主要流程是:
-
1.
使用标准语言建模目标在 GitHub 代码上预训练基于 Transformer 的语言模型。 该模型可以合理地表示人类编码的空间,从而大大减少了问题的搜索空间。
-
2.
我们的竞争性编程数据集上的模型,使用 GOLD (Pang 和 He,2020) 和回火 (Dabre 和 Fujita,2020) 作为训练目标。 这进一步减少了搜索空间,并通过利用预训练来补偿少量的竞争性编程数据。
-
3.
从我们的模型中为每个问题生成大量样本。
-
4.
过滤样本以获得一小组候选提交(最多 10 个),通过使用示例测试和聚类根据程序行为挑选样本,对隐藏的测试用例进行评估。
其中,大规模采样和过滤是我们的设置所独有的,我们发现这个过程极大地提高了问题解决率。 因此,我们做出的许多设计决策都是为了促进高效和有效的采样。
4.1模型架构
竞争性编程代码生成问题可以被视为序列到序列(Sutskever等人,2014)翻译任务:给定自然语言的问题描述(例如 图2),用编程语言生成相应的解决方案(例如 图3)。 这自然促使为 AlphaCode 选择编码器-解码器 Transformer 架构(Vaswani 等人,2017),该架构对 进行建模。 该架构将问题描述作为编码器的输入作为平面字符序列(包括元数据,标记化),并从解码器一次一个词符进行自回归采样直到生成词符代码结束,此时可以编译并运行代码(参见附录LABEL:sec:complete-examples,例如对,以及https://alphacode.deepmind.com/ 用于交互式模型可视化)。
与通常用于语言建模和生成的仅解码器架构相比,编码器-解码器架构允许双向描述表示(描述开头的标记可以关注末尾的标记)以及将编码器结构从解码器。 由于问题描述的平均长度是相应人类解决方案的两倍,因此我们使用非对称架构,编码器有 1536 个标记,但解码器只有 768 个标记。 我们进一步发现,使用浅层编码器和深度解码器可以显着提高训练效率,而不会影响问题解决率。 表 3 列出了我们模型的具体架构。 9B 和 41B 模型使用模型并行性进行训练,每个分片有 1 个键头和值头。 我们使用 JAX (Bradbury 等人,2018) 和 Haiku (Hennigan 等人,2020) 构建模型,并使用 bfloat16 精度在 TPUv4 加速器上对其进行训练。
| Heads | Blocks | Training | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Name | Query | KV | Enc | Dec | Batch | Steps | Tokens | ||
| AlphaCode 300M | 284M | 768 | 6 | 1 | 4 | 24 | 256 | 600k | 354B |
| AlphaCode 1B | 1.1B | 1408 | 11 | 1 | 5 | 30 | 256 | 1000k | 590B |
| AlphaCode 3B | 2.8B | 2048 | 16 | 1 | 6 | 36 | 512 | 700k | 826B |
| AlphaCode 9B | 8.7B | 3072 | 24 | 4 | 8 | 48 | 1024 | 530k | 1250B |
| AlphaCode 41B | 41.1B | 6144 | 48 | 16 | 8 | 56 | 2048 | 205k | 967B |
为了降低模型采样的成本,我们利用多查询注意力(Shazeer,2019)。 使用全套查询头,但每个注意块共享键和值头,可以显着减少内存使用和缓存更新成本,这是采样期间的主要瓶颈。 这种内存减少还允许更大的批量大小进行采样,从而进一步提高效率。
对于标记化,我们使用了 SentencePiece 标记器(Kudo 和 Richardson,2018),其词汇量大小为 8,000 个标记,并在 GitHub 和 CodeContests 数据的混合上进行了训练。 训练组合确保它可以有效地对多种语言的程序以及问题的自然语言描述进行标记。 我们模型中的编码器和解码器使用相同的分词器。
4.2预训练
我们在 3 节中描述的 GitHub 数据集上预训练了我们的模型,使用解码器的标准交叉熵下一个 Token 预测损失和掩码语言建模损失 (Devlin 等人, 2018) 对于编码器。 屏蔽语言建模损失对于改进编码器的表示学习至关重要。 我们通过统一采样枢轴位置来分割 GitHub 文件,使用枢轴之前的内容作为编码器的输入,使用枢轴之后的内容作为解码器的输入。
我们的基本 1B 参数模型经过 步骤的训练,批量大小为 256。 继Kaplan等人训练(2020)之后,我们调整了其他模型大小的数量,使较大的模型得到更多的训练,而较小的模型得到较少的训练,以优化计算的使用。 然而,由于资源限制和为了充分利用计算,我们最大的 41B 模型的训练提前停止,因此与其他规模的模型相比,该模型的训练相对不足(表 3)。
我们使用 Adam 优化器 (Kingma 和 Ba,2014) 的 AdamW 变体 (Loshchilov 和 Hutter,2017) 以及 、 适用于 {300M, 1B, 3B} 型号, 适用于 {9B, 41B} 型号。 我们使用 的权重衰减来增强正则化。 我们以 的初始学习率训练模型,然后在预训练结束时余弦衰减到 。 我们在第一个 训练步骤中将学习率从 线性预热到 ,并将全局梯度范数限制在 .
4.3微调
我们在 CodeContests 数据集上微调了我们的模型。 在微调过程中,我们对编码器使用自然语言问题描述,对解码器使用程序解决方案。 与预训练类似,我们使用了标准的下一个标记预测和掩码语言建模损失。 我们还采用了额外的调节和修改,我们发现这些调节和修改提高了整体解决率:回火、值调节和预测以及下面描述的 GOLD,以及附录 LABEL:sec:metadata-conditioning 中描述的元数据调节。 我们将初始学习率设置为,并在微调结束时将其余弦衰减为。 我们对第一个 训练步骤的学习率使用了相同的线性预热阶段。
回火。 Tempering 由 Dabre 和 Fujita (2020) 提出,是一种正则化技术,通过将模型的输出 logits 除以标量温度 在softmax层之前。 我们观察到,当使用 时,回火可以使训练分布更加清晰,从而使推理分布更加平滑,从而有助于避免过度拟合我们的微调数据集。 值得注意的是,这与 Dabre 和 Fujita (2020) 使用 做出更清晰的推理分布的建议相反。 在采样时,我们将 logits 除以在验证集上调整的另一个温度 ( 对于仅经过回火训练的模型; 对于经过回火训练的模型和黄金)。
价值调节和预测。 CodeContests 包含正确和错误的问题提交。 我们使用值调节和预测来区分这两种类型的提交,提供额外的训练信号并允许使用可能误导模型的数据。 Vinyals 等人 (2019) 中也使用了类似的方法。 在值调节中,我们将提交是否正确插入到问题描述中,以便模型可以根据此信息进行调节,如图5所示。 在采样时,模型始终以样本正确为条件。 在价值预测方面,我们在训练过程中添加了辅助价值预测任务,使得投影到logits之前的最后一层词符表示也被用在一个小型Transformer中来分类提交是否正确。 采样期间未使用值预测。
黄金(庞和何,2020)。 从描述中解决竞争性编程问题本质上是一项多项任务之一(Nandwani 等人,2021):每个独特的问题都允许许多不同的解决方案,这些解决方案取决于算法选择、实现等。CodeContests 包含多个解决方案比描述多几个数量级(表1)。 标准最大似然目标通过对训练集中的每个解决方案赋予一定的权重(例如召回率)来最大程度地减少损失,而我们的指标衡量模型是否可以在提交尝试预算中找到单个正确的解决方案(例如精度)。 为了解决这种差异,我们采用了 GOLD (Pang 和 He,2020) 的变体,这是一种离线 RL 算法,它允许模型从已经分配高可能性的标记中学习,并忽略标记不在其分布中(允许其专注于精度)。 为了将 GOLD 和训练结合起来,我们在预训练和微调之间引入了一个简短的训练阶段。 GOLD 和此组合的完整详细信息请参见附录 LABEL:appendix:gold。
4.4大规模采样
Transformer 模型的采样可以轻松并行化,这使我们能够将每个问题扩展到数百万个样本,这是性能改进的关键驱动力。 为了确保如此大量的样本具有足够的多样性,我们采用单个训练模型并:(i)用 Python 生成一半样本,用 C++ 生成一半样本,(ii) 在自然语言提示中随机化问题标签和评级(参见图 5 示例,附录 LABEL:sec:metadata-conditioning 了解更多详细信息), (iii) 使用相对较高的采样温度。 通过我们所依赖的附加元数据,单一模型可以生成具有不同语言、标签和评级的解决方案。 为了最有效地利用我们的样本,我们应用过滤(第4.5节)和聚类(第4.6节)来获取少量候选提交。
对于问题标签和评级调节,我们从最流行的 50 个标签中随机选择模型作为条件,并在 800 到 3500 范围内统一采样评级,因为这些元数据对于竞赛中新的未见问题不可见。 我们发现,对随机标签和评级进行调节可以通过增加样本的多样性来提高性能。
最佳采样温度取决于样品总数(一般来说样品越多,最佳温度越高)。 然而,大范围内的不同温度不会显着改变求解率(图LABEL:fig: different-sampling-settings)。 因此,我们在使用回火和 GOLD 的所有实验中使用固定采样温度 ,仅使用回火时使用 ,否则单独调整采样温度。
我们还尝试了 top- (Fan 等人, 2018) 和细胞核采样 (Holtzman 等人, 2019)。 如图LABEL:fig: Different-sampling-settings所示,尽管运行了详尽的超参数扫描,但我们没有观察到这些方法的显着性能改进。 因此,我们在实验中使用定期的温度采样。 附录 LABEL:sec:complete-examples 中提供了模型提示和示例的一些完整示例。
4.5过滤
为了准确地代表竞争性编程竞赛和处罚,我们的公式将每个问题限制为 10 次提交,无论我们抽取多少样本。 选择这些提交的一种强大工具是过滤样本,仅筛选那些通过问题陈述中给出的示例测试的样本。 过滤会删除大约 99% 的模型样本,尽管确切的数量取决于问题和模型,并且过滤仍然可以为许多问题留下数万个候选样本。 寻找通过示例测试的解决方案本身就是一个难题,对于大约 10% 的问题,我们的模型无法找到一个这样的程序。 事实上,我们设置的这个更简单的版本是一个经典的程序综合公式,其中任务由给定输入/输出对列表(Gulwani等人,2017)指定。
4.6聚类
使用示例测试进行过滤仍然可以为每个问题留下数千个候选程序。 从这个库中随机挑选会浪费有限的提交预算,用于语法不同但语义相同的程序。 如果我们有额外的测试输入,通过在这些输入上执行所有剩余的程序并将产生相同输出的程序分组到集群中,就可以检测到语义上等效的程序。 这样我们就可以避免重复从相同的集群中进行选择。
我们使用与主模型相同的架构训练了一个单独的测试输入生成模型,并从相同的 GitHub 预训练检查点进行初始化。 该模型经过训练,可以使用示例、隐藏和生成的测试输入作为训练数据,从问题描述中预测测试输入。 训练后,该模型用于为未见过的问题创建新的测试输入。 请注意,虽然这些创建的测试输入不能保证有效,特别是当问题具有复杂的约束时,但不完美甚至无效的测试输入对于对采样程序进行分组仍然有用。
这种学习的测试输入生成模型不同于 3.2.1 节中用于扩充我们的数据集的基于突变的测试生成过程。 后者需要正确的解决方案(在测试时不可用)来过滤掉不良的测试用例。
在对程序行为进行聚类之后,我们发现从每个聚类中从最大到最小选择一个解决方案效果最好,这可能是因为解决方案在很多方面可能是不正确的,而正确的解决方案往往表现相同,因此被分组到更大的聚类中。 如果问题的候选解决方案形成的簇数少于 10 个(或者在提交超过 10 个的情况下则更多),则在达到最小簇后,我们从第一个簇开始重复,跳过已提交的样本。
5结果
在本节中,我们将展示实验结果,以深入了解我们的模型性能,以及指导我们设计决策的证据。 我们重点介绍了在 Codeforces 平台(第 5.1 节)和 CodeContests(第 5.2 节)上进行评估所获得的结果,在第 5.3 节中详细研究了模型在我们的数据集上的性能,最后在第 5.4 节中与文献中已发表的模型在公共 APPS (Hendrycks 等人,2021 年) 编程问题基准上进行了比较。 为了确保我们的基线模型与过去的工作具有可比性,我们还将我们的仅解码器基线直接与附录 LABEL:sec:appendix- humaneval 中 HumanEval 基准上的 Chen 等人 (2021) 进行比较。
5.1Codeforces竞赛评估
与对我们的数据集进行评估相比,对编程竞赛进行评估可以更彻底地检查程序的正确性,因为我们的数据集存在已知的弱点,包括误报、接受算法效率低下的解决方案以及处理具有多个可接受输出的问题。 此外,在真实环境中进行评估使我们能够与这项任务中表现最好的人(人类竞争对手)进行比较。
我们在 2021/12/01 至 2021/12/28 的所有 Codeforces 比赛中评估了我们的最佳系统,每场比赛有超过 5,000 名参与者,总共 10 场比赛。 该系统是具有聚类功能的 41B 和 9B 模型的集成,在我们的验证集上表现最好,但结果比单独使用 41B 模型和聚类效果稍差(请参阅附录 LABEL:app:ensemble有关集成的更多信息)。 对于每场比赛,我们模拟实时运行 AlphaCode,为每个问题生成样本,通过示例测试进行过滤,777对于允许多个正确输出的问题,我们将示例测试输出更改为最规范的,这使我们的方法在评估中略有优势。 有关更多详细信息,请参阅附录LABEL:sec:codeforces-eval。 然后进行聚类以获得候选提交。 我们将这些选定的候选人提交给 Codeforces 平台,888提交的程序可以在 Codeforces 上的 3 个帐户中找到:SelectorUnlimited、WaggleCollide 和 角度数值。 这些问题的注意力可视化可以在此处找到。 并计算 AlphaCode 在每场比赛中的排名。 第一次运行后,我们又重复此过程两次,以测量 10 多个提交的方差和性能。 方差来源包括问题分布、模型训练、采样、过滤和聚类。 请参阅附录LABEL:sec:codeforces-eval了解确切的评估过程,以及表LABEL:tab:codeforces-result和表LABEL:tab:codeforces-contest -result 获取完整结果。
| Contest ID | 1591 | 1608 | 1613 | 1615 | 1617 | 1618 | 1619 | 1620 | 1622 | 1623 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | 43.5% | 43.6% | 59.8% | 60.5% | 65.1% | 32.2% | 47.1% | 54.0% | 57.5% | 20.6% | 48.4% |
| Estimated | 44.3% | 46.3% | 66.1% | 62.4% | 73.9% | 52.2% | 47.3% | 63.3% | 66.2% | 20.9% | 54.3% |
| Worst | 74.5% | 95.7% | 75.0% | 90.4% | 82.3% | 53.5% | 88.1% | 75.1% | 81.6% | 55.3% | 77.2% |
表4显示了10场比赛的评估结果。 对于每场比赛,我们都会使用模拟罚分以及假设零和最大提交时间罚分的上限和下限来显示估计的百分位排名。 这些界限表示排名如何取决于比赛期间用于抽取样本的加速器数量。 对于第二次和第三次运行,表 LABEL:tab:codeforces-contest-result 显示了每个问题不限制 10 次提交时的估计百分位(仍考虑到不正确提交的处罚),但这虽然不是类人确实遵循竞争规则。 我们发现,当给予更多尝试时,该模型仍然可以继续解决问题,尽管速度有所下降。 该模型倾向于解决比赛中较简单的问题,但它确实能够解决较难的问题,包括一个评级为 1800 的问题。
总体而言,我们的系统平均排名达到前 54.3%,每个问题仅限 10 次提交,每个解决的问题实际平均有 2.4 次提交。999我们的估计性能比其下限更接近其上限,因为人类解决方案(以及我们的解决方案)通常在比赛早期提交,特别是对于更简单的问题。 当每个问题允许提交超过 10 份时(第二次和第三次评估),AlphaCode 的排名达到了前 48.8%,每个解决问题的实际平均提交量为 28.8 份。 每个问题结果提交 10 次,对应的 Codeforces 估计评分为 1238,属于过去 6 个月内参加过竞赛的用户的前 28%(所有程序员的一小部分选定的子集)。 据我们所知,这是计算机系统第一次在编程竞赛中与人类参与者竞争。
5.2代码竞赛评估
除了 Codeforces 评估之外,我们还在 CodeContests 的验证和测试集上评估了我们的模型。 测试集是5.1节中使用的竞赛的超集。101010除了一个没有 5 个测试用例的问题,因此不包含在我们的测试集中。 我们数据集上的指标方差较低且更易于测量,因为它们不涉及提交到外部站点。 对于代码竞赛(此处和 5.3 节),我们重点关注 2.2 节中讨论的两个主要指标:
-
•
:当我们从每个问题的模型中获取 个样本并提交所有样本以对隐藏测试进行评估时,解决问题的百分比。 如果指定样本预算中的任何解决方案解决了问题,则该问题被视为已解决。 因此,该指标主要衡量采样过程的搜索方面,并在 5.3 节中使用。
-
•
:当我们从每个问题的模型中获取 个样本但只能提交其中的 个样本以对隐藏测试进行评估时,解决问题的百分比。 它衡量的因素包括过滤过程以及模型在大量样本中的表现。
| Approach | Validation Set | Test Set | |||||
|---|---|---|---|---|---|---|---|
| 10@1k | 10@10k | 10@100k | 10@1M | 10@1k | 10@10k | 10@100k | |
| 9B | 16.9% | 22.6% | 27.1% | 30.1% | 14.3% | 21.5% | 25.8% |
| 41B | 16.9% | 23.9% | 28.2% | 31.8% | 15.6% | 23.2% | 27.7% |
| 41B + clustering | 21.0% | 26.2% | 31.8% | 34.2% | 16.4% | 25.4% | 29.6% |
结果如表5所示。 每个问题最多有一百万个样本,我们可以解决验证集中 34.2% 的问题;对于 10 万个样本,我们解决了验证集中 31.8% 的问题,以及测试集中 29.6% 的问题。 由于时间分割,我们的模型在训练期间没有发现任何一组问题。 考虑到这些问题的难度(因为它们是给那些尝试竞争性编程的自选组的问题),这是数据集的很大一部分。
验证集和测试集之间解决率的差异是由问题分布的变化(因为测试集和验证集是在时间上不相交的时期收集的)以及一些过度拟合引起的。 然而,两组之间的性能差异仍然有限。 41B 始终优于 9B 模型,并且聚类始终提供改进。
5.3 代码竞赛消融和结果
本节包含支持我们在第 4 节中描述的设计决策的结果。 所有结果均在 CodeContests 验证集上,模型在 CodeContests 训练集上进行了微调,除非另有说明,否则不使用聚类。
5.3.1 求解速率与参数计数、计算、样本数量和数据集大小相关
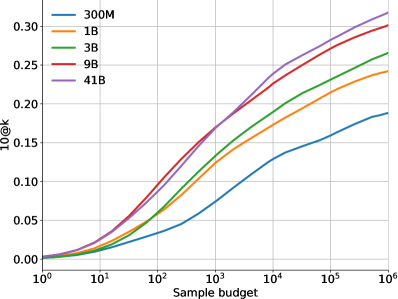
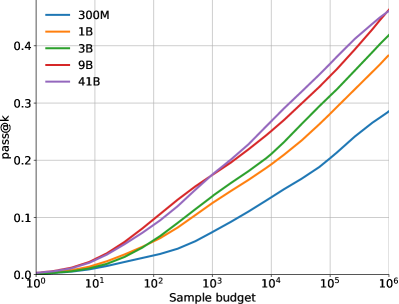
正如预期的那样,扩大模型参数的数量或数据集的大小可以极大地提高模型性能(有关随数据集大小进行缩放的信息,请参见图LABEL:fig:dataset-scaling)。 然而,即使只能提交 个样本,扩大样本总数也会导致模型求解率大幅提高。
 |
 |
| (a) 10 attempts per problem | (b) Unlimited attempts per problem |
 |
 |
| (a) Solve Rate vs. Training Compute | (b) Solve Rate vs. Sampling Compute |
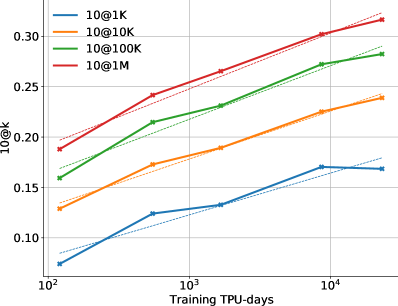
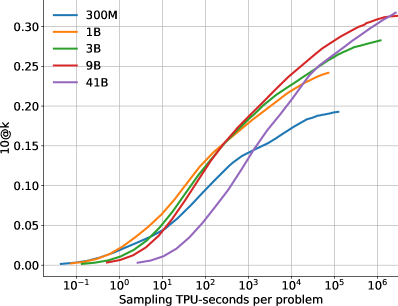
图6显示了模型性能如何在更多样本的情况下在和指标上扩展,即随着我们增加。这两个指标之间的差异凸显了选择要提交的样本的重要性。 图 7 显示了性能如何随着训练和采样所用的计算量而变化。 这些缩放曲线突出了有关该问题领域和我们的模型的一些有趣事实:
求解速率随着样本数量的增加而呈对数线性变化。 10@k 和 pass@k 求解率均与 近似对数线性缩放,10@k 曲线在高样本预算下略微向下弯曲。 事实上,采样明显超过 10 次仍然可以提高 10@k 解决率,这表明在提交每个问题的最终 10 次提交之前充分探索搜索空间是多么重要。 然而,提高解决率需要呈指数级增加样本数量,而成本很快就会变得令人望而却步。
更好的模型在缩放曲线中具有更高的斜率。 图6的另一个观察结果是,较大的模型往往具有更好的模型质量,这反映为相同数量的样本下更好的求解率以及对数线性缩放曲线中更高的斜率。 由于对数线性缩放,具有较高斜率的更好模型可以比更差的模型以指数级更少的样本达到相同的求解率。 这表明提高模型质量是应对达到更高解决率所需的样本预算指数级爆炸的有效方法。
5.3.2 架构更改以提高采样速度
由于抽取更多样本对于提高性能非常重要,因此提高采样速度的架构更改也会提高一定计算预算内的整体求解率。 因此,我们做出了两个架构决策:使用 (1) 具有不对称编码器和解码器结构的编码器-解码器架构,以及 (2) 来自 Shazeer (2019) 的多查询注意力设置,它使用一个共享注意力每个块的头为键,一个为值。
| Blocks | Seq. length | Hidden | Fan-Out | Samples / | |||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Enc. | Dec. | Enc. | Dec. | Size | Ratio | Params | TPU sec | 10@10K |
| AlphaCode model | 5 | 30 | 1536 | 768 | 1408 | 6 | 1.15B | 4.74 | 17.3% |
| Decoder-only | - | 40 | - | 2304 | 1408 | 6 | 1.17B | 1.23 | 18.5% |
| Std MH attention | 5 | 30 | 1536 | 768 | 1408 | 4.3 | 1.16B | 0.37 | 17.0% |
为了研究这些决策的影响,我们将基本 1B 参数模型与删除每个更改的两种替代方案进行了比较。 我们以与基本 1B 模型完全相同的方式对标准多头注意力模型进行预训练和微调。 仅解码器模型使用相同的计算量进行训练。 然而,由于解码器序列长度明显较长(2304 个 Token ),在相同数量的训练计算下,它比训练编码器-解码器模型多消耗 50% 的损失 Token 。
表6显示,我们的具有多查询注意力的编码器-解码器模型显着提高了采样速度,同时将样本质量保持在与更昂贵的替代方案相同的水平。
5.3.3 预训练数据集的选择
表 7 将在完整 GitHub 数据集上训练的基本 1B 模型与在 (1) GitHub 的仅 Python 部分、(2) MassiveText 通用文本数据集 ( Rae 等人,2021) 其中还包括 GitHub 的一部分或 (3) 根本没有经过预训练。 然后,以完全相同的方式对预训练模型进行微调和采样,不同之处在于,在纯 Python 数据上预训练的模型也在纯 Python 数据上进行了微调,并且仅对 Python 解决方案进行了采样。
如表7所示,在包含所有语言的完整 GitHub 数据集上进行预训练比单独在 Python 上或在主要由自然语言文本组成的 MassiveText 数据集上进行预训练可以获得更好的结果。 与在 CodeContests 上从头开始训练相比,任何预训练都可以显着提高结果。
| Pre-training dataset | Solve rate | ||
|---|---|---|---|
| 10@1K | 10@10K | 10@100K | |
| No pre-training | 4.5% | 7.0% | 10.5% |
| GitHub (Python only) | 5.8% | 11.1% | 15.5% |
| MassiveText | 9.7% | 16.1% | 21.2% |
| GitHub (all languages) | 12.4% | 17.3% | 21.5% |
5.3.4 模型增强
正如 4 节中所讨论的,我们采用了训练和模型增强功能,相对于标准编码器-解码器 Transformer 设置,显着提高了求解率。 表 8 展示了我们添加到 AlphaCode 的增强功能的累积消融结果,从没有增强功能的基本设置开始(除了 5.3.2 我们一次添加一项新设置,最终设置与表底部报告的 AlphaCode 相对应。 每个附加设置都会提高性能,并将 5 个增强功能组合在一起会将 10@100k 解决率从 15.2% 提高到 24.1%,尽管贡献取决于样本数量。
| Solve rate | ||||
|---|---|---|---|---|
| Fine-tuning setting | 10@1K | 10@10K | 10@100K | 10@1M |
| No Enhancements | 6.7% (6.5-6.8) | 10.4% (9.6-11.0) | 15.2% (14.3-15.9) | 19.6% (18.2-20.4) |
| + MLM | 6.6% (6.2-7.0) | 12.5% (12.1-12.7) | 17.0% (16.5-17.2) | 20.7% (19.1-21.3) |
| + Tempering | 7.7% (7.2-8.5) | 13.3% (12.5-13.8) | 18.7% (18.0-19.2) | 21.9% (20.7-22.6) |
| + Tags and Ratings | 6.8% (6.4-7.0) | 13.7% (12.8-14.9) | 19.3% (18.1-20.0) | 22.4% (21.3-23.0) |
| + Value | 10.6% (9.8-11.1) | 16.6% (16.4-16.9) | 20.2% (19.6-20.7) | 23.2% (21.7-23.9) |
| + GOLD | 12.4% (12.0-13.0) | 17.3% (16.9-17.6) | 21.5% (20.5-22.2) | 24.2% (23.1-24.4) |
| + Clustering | 12.2% (10.8-13.4) | 18.0% (17.3-18.8) | 24.1% (23.2-25.0) | 28.4% (27.5-29.3) |
5.3.5 过滤和聚类
为了在现实的评估预算内解决问题,我们依靠过滤和聚类从我们生成的大量模型样本中选择少量样本进行评估。
使用示例测试进行过滤。 表9显示了通过示例测试的模型样本的百分比以及至少一个样本通过示例测试的问题的百分比。 请注意,这些百分比是根据完整的样本集计算的,没有首先过滤掉有语法错误的程序(有关样本语法正确性的更多信息,请参阅第 6.2 节)。 总体而言,我们模型中不到 1% 的样本通过了示例测试,尽管不同问题的百分比差异很大,这意味着使用示例测试进行过滤会删除超过 99% 的模型样本。 对于我们的模型确实找到正确解决方案的问题,通过示例测试的样本比例大约增加了一倍,但仍然保持在较低水平。 附录LABEL:appendix:filtering-clustering更加强调了在问题之间的不均匀分布。
表 9 的另一个观察结果是,更大、质量更好的模型产生的样本更有可能通过示例测试,并且通过示例测试的问题明显更多。 通过 样本,我们最大的 41B 模型可以生成通过 90% 以上问题的示例测试的解决方案,这是一个巨大的成功,因为寻找满足 I/O 示例约束的程序仍然是一个非常具有挑战性的问题。
| % Problems with | Average | Average | |
|---|---|---|---|
| Model | samples pass example tests | on all problems | on solved problems |
| 300M | 82.05% | 0.39% | 1.18% |
| 1B | 87.18% | 0.59% | 1.40% |
| 3B | 87.18% | 0.49% | 0.98% |
| 9B | 89.74% | 0.76% | 1.52% |
| 41B | 92.31% | 0.73% | 1.47% |
聚类。 一个解决方案除了通过示例测试之外,还必须通过隐藏测试,因此我们必须进一步从通过所有公开测试的样本中选择正确的样本。 过滤 100 万个样本中的 99% 后,每个问题仍然留下数千个样本可供选择。 我们根据剩余样本在生成的测试输入上的行为对它们进行聚类,以充分利用评估预算。
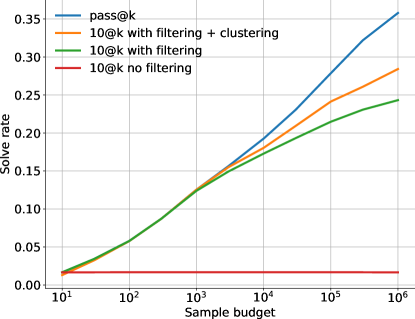
图8显示了(i)不进行过滤的情况下随机选取模型样本、(ii)过滤然后从过滤后的样本中随机选择、(iii)过滤然后使用聚类来选择样本和( iv) 允许无限的评估尝试,这为我们提供了通过完美的样本选择方法可以获得的上限性能。 过滤和聚类显然可以实现扩展,否则解决率保持不变。 但与理论上限仍有较大差距。
5.4APPS 上的结果
除了对 Codeforces 竞赛和 CodeContests 进行评估之外,我们还对之前发布的 APPS 基准进行了评估,以直接与之前的工作进行比较。 APPS 数据集(Hendrycks 等人,2021) 总共包含 10,000 个编程问题,在训练集和测试集之间平均分配。 由于数据集中缺少信息,我们无法应用完整的方法。 因此,我们遵循 GitHub 上用于预训练的设置,并在 APPS 训练集上微调我们的预训练模型,不使用聚类、标签、评级、值调节或预测,并使用采样温度 0.25 和核采样。 其他设置与我们的主要型号相同。
表 10 将我们的模型与 Hendrycks 等人 (2021) 报告的在此数据集上微调的现有大型语言模型进行了比较,以及该模型的 1-shot 性能Chen 等人 (2021) 报告的 Codex 模型。 小型 1B 参数模型在所有难度级别上都优于 GPT-NEO 基线,并且在面试和竞赛难度级别上优于 Codex 12B。 我们强调,当增加每个问题的样本数量时,AlphaCode 仍然有所改进,这支持了我们关于大规模采样重要性的主张。 APPS 结果和 CodeContests 之间的性能差异可能归因于数据集质量(例如 3.2.1 节中显示的高 APPS 误报率)、数据集大小、AlphaCode 缺少组件以及问题调整分配。
| Filtered From () | Attempts () | Introductory | Interview | Competition | |
|---|---|---|---|---|---|
| n@k | n@k | n@k | |||
| GPT-Neo 2.7B | N/A | 1 | 3.90% | 0.57% | 0.00% |
| GPT-Neo 2.7B | N/A | 5 | 5.50% | 0.80% | 0.00% |
| Codex 12B | N/A | 1 | 4.14% | 0.14% | 0.02% |
| Codex 12B | N/A | 5 | 9.65% | 0.51% | 0.09% |
| Codex 12B | N/A | 1000 | 25.02% | 3.70% | 3.23% |
| Codex 12B | 1000 | 1 | 22.78% | 2.64% | 3.04% |
| Codex 12B | 1000 | 5 | 24.52% | 3.23% | 3.08% |
| AlphaCode 1B | N/A | 1000 | 17.67% | 5.24% | 7.06% |
| AlphaCode 1B | 1000 | 5 | 14.36% | 5.63% | 4.58% |
| AlphaCode 1B | 10000 | 5 | 18.18% | 8.21% | 6.65% |
| AlphaCode 1B | 50000 | 5 | 20.36% | 9.66% | 7.75% |
6 AlphaCode 的功能和局限性
我们对模型的功能和局限性进行了详细分析。 特别是,我们发现我们的模型不仅仅是从训练集复制(第 6.1),而且我们的模型对问题描述和用于调节的元数据的各种变化很敏感(第 6.3和6.4),两者都表明我们没有通过利用任务结构中的明显弱点来解决问题。
我们还分析了模型找到的解决方案的特征,例如语法正确性、死代码以及它可以解决的问题类型(第 6.2 节)。 我们进一步表明,使用验证损失作为模型性能的代理存在几个问题(第6.5节)。 对我们的模型和方法的更多分析包含在附录LABEL:appendix:功能和限制中,注意力可视化以及模型生成的示例问题和解决方案可以在中找到https://alphacode.deepmind.com/。 除非另有说明,所有分析结果均在不进行聚类的情况下报告。
6.1 从训练数据复制
对于在大量数据上训练的大型语言模型,人们普遍担心的是,它们可以通过简单地记住训练集来解决下游问题(例如 Albert Ziegler (2021); Carlini 等人 (2021))。 为了使竞争性编程能够很好地测试解决问题的能力,我们期望模型需要提出新颖的解决方案来解决新问题。
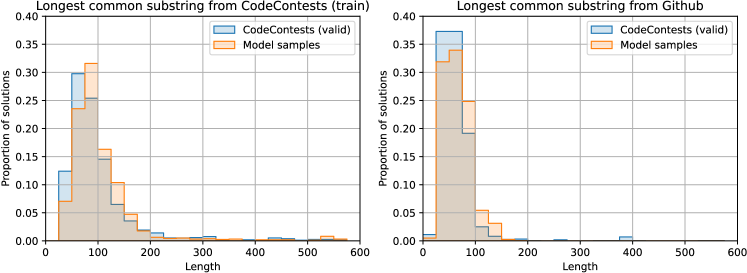
根据附录LABEL:sec:dataset-temporal-split中的结果,简单地从训练集中复制完整的解决方案不足以解决未见过的验证集中的任何问题。 然而,如果问题与以前的问题足够相似,则可以通过复制以前解决方案的大部分或关键部分来解决问题。 为了研究这个问题,我们找到了模型生成的正确验证问题解决方案和整个训练数据集(GitHub + CodeContests,忽略空格)之间最长的公共子串,并将这些匹配的长度分布与人类解决方案进行了比较。 图 9 包含这些结果,使用了 50 个 C++ 和 50 个 Python 解决方案,这些解决方案是从具有这么多解决方案的 16 个验证问题中选出的。
该图显示,模型解决方案和人类解决方案以相似的速率与训练数据共享子串,尽管模型解决方案的平均最长公共子串略高,而人类解决方案的尾部较重。 模型解决方案和训练数据之间的公共子串主要包含用于读取和解析输入数据格式的样板代码,而不是解决问题的关键逻辑(例如,FastIO Python 类的长度为 805,出现在所有人类 Python 解决方案中的 1.66% )。 因此,AlphaCode 似乎并没有通过复制长代码块来解决问题。
| Model-generated solution | Source document of LCS |
|---|---|
 |
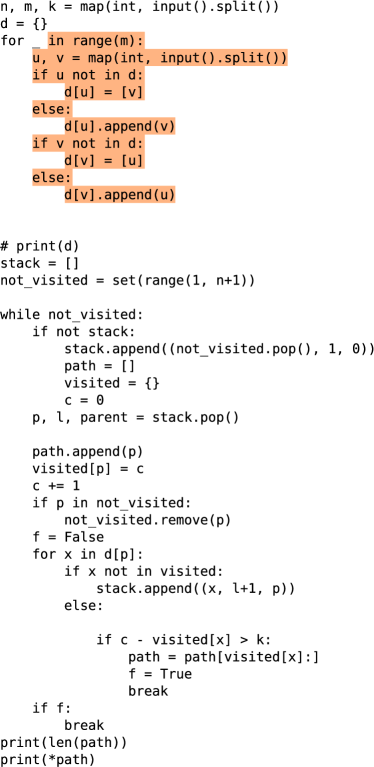 |
为了调查解决方案和训练数据之间最长的公共子串,我们对 50 个模型生成的解决方案进行了更详细的定性分析。 我们采用每个解决方案并迭代地从中删除最长的公共子字符串,从而创建由微调训练数据中的子字符串组成的每个解决方案的分区。 图10显示了一个示例。 我们没有发现任何证据表明我们的模型从训练数据中复制了核心逻辑。 附录 LABEL:appendix:verbatim-copying 中提供了更多示例。
6.2模型解决方案特征
我们针对每种语言和模型大小测量了模型中语法正确的样本比例(即针对 C++ 进行编译,并且不会为 Python 生成 SyntaxError) 。 如表 LABEL:tab:syntax 所示,我们的模型倾向于为 Python 生成大部分语法正确的程序,而 C++ 语法更难比Python还要掌握。
我们进一步分析了解决方案中的死代码量(即对程序行为没有影响的代码行)。 此类代码存在于我们的训练数据中;例如,竞争对手有时会复制粘贴未使用的导入或函数。 大量死代码可能表明模型对其生成的内容了解甚少。 图 11 显示了在正确的 Python 人类和模型解决方案上应用标准代码格式化程序和 Python 的摘要语法树 (ast) 模块以删除未使用的导入、函数和类的结果。 AlphaCode 生成的死代码数量与人类大致相同。
| Model | Greedy | Math | DP | Constructive | Brute | Data | Implem- | Graphs | Bitmasks | Sortings |
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithms | Force | Structures | entation | |||||||
| 300M | 13.1% | 19.3% | 4.5% | 7.5% | 9.8% | 8.8% | 5.0% | 0.2% | 22.2% | 16.9% |
| 1B | 19.7% | 22.7% | 4.5% | 9.1% | 12.0% | 10.5% | 14.1% | 5.9% | 26.8% | 21.5% |
| 3B | 19.9% | 22.7% | 4.9% | 11.2% | 13.2% | 11.9% | 13.4% | 8.8% | 25.4% | 23.8% |
| 9B | 23.7% | 29.4% | 7.1% | 13.8% | 19.5% | 16.9% | 16.4% | 16.6% | 27.4% | 27.8% |
| 41B | 25.0% | 28.2% | 8.8% | 14.9% | 20.4% | 15.7% | 16.5% | 13.6% | 33.8% | 25.5% |
表 11 显示了我们的模型在使用每个问题的标签指定的不同问题类型中的解决率。 值得注意的是,随着模型随着规模的扩大而改进,所有标签的解决率总体上会上升。 我们的模型在处理位掩码、排序、数学和贪婪算法的问题上相对较好,但在动态编程(DP)和构造性算法方面明显较差。
附录LABEL:appendix:solve-rate-for- Different-Ratings包含我们的模型在不同问题难度评级桶中的解决率。 毫不奇怪,我们的模型对于较简单的问题具有显着更高的总体解决率,而对于较难的问题具有较低的解决率。
6.3 对问题描述的敏感性
我们对模型对问题描述的敏感性进行了详细分析,以衡量描述对模型性能的重要性。 总体而言,AlphaCode 似乎对问题描述中的重要变化做出了适当的响应,并利用了其中可用的额外信息。 这表明,例如,系统不会忽略大部分描述,并会暴力破解适合问题类别的每种可能的解决方案(例如,如果描述中提到“素数”一词,则与素数相关的算法)。
| % correct | |||
| (a) Description simplification | Table LABEL:tab:rewording-solves | Original | 3.0% |
| Simplified | 15.7% | ||
| (b) Description rewording | Table LABEL:tab:rewording-simplified | Original | 17.1% |
| Opposite | 0.1% | ||
| Related | 3.2% | ||
| Underspecified | 0.03% | ||
| Verbose | 19.4% | ||
| Algorithm described in words only | 19.7% | ||
| 10@1024 | |||
| Original | 13.5% | ||
| (c) Variable renaming | Figure LABEL:fig:variable-renaming-scaled | variables consistently renamed | 12.1% |
| variables inconsistently renamed | 10.1% | ||
| (d) Type information | Table LABEL:tab:type-removal | No type information | 13.3% |
| (e) Typos | Figure LABEL:fig:word-level-changes | 30 typos | 11.3% |
| (f) Missing description sections | Table LABEL:tab:prompt_ablation | Description + Specification | 10.4% |
| Description + IO | 4.8% | ||
| Specification + IO | 6.9% | ||
| (g) Synonym substitution | Figure LABEL:fig:word-level-changes | 7 synonyms substituted | 12.5% |
| (h) Word permutation and deletion | Figure LABEL:fig:word-level-changes | Distance 7 permuted words | 8.0% |
| 0.40 probability of deletion | 6.7% | ||
本研究的完整详细信息参见附录LABEL:sec:sensitivity-to-rewordings-appendix,结果摘要如表12所示。 (a) 表明,当给出问题的简化描述(在实际评估中不可用)时,模型以更高的速度解决问题。 (b) 表明,当给出相关但不同的问题时,解决率会急剧下降,并且受描述同一问题的不同方式影响不大。 (c, d, e, g, h) 表明模型在很大程度上不受看起来不显着的变化的影响(例如用同义词替换单词或删除一些类型细节),但对更大的变化反应更大更改(例如删除单词或使问题不适定)。 值得注意的是,在附录LABEL:sec:appendix-var-relations中,我们看到随着模型质量的提高,模型在响应较低质量的描述时相对恶化,这表明更好的模型更有能力关注微妙但重要的描述变化。 最后,(f) 显示该模型依赖于描述的不同部分,尤其是规范。 这是有道理的,因为规范描述了如何读取输入,否则模型将不得不猜测输入格式。
6.4 对所提供元数据的敏感性
如 4.4 节所述,在采样时,我们向 AlphaCode 提供随机元数据以增加样本多样性。 这包括标签(例如问题是“二分搜索”还是“暴力破解”类型)、评级(问题的难度)、编程语言以及生成的解决方案是否正确。
有两个自然问题需要探索:模型是否适当地响应此调节元数据的变化,以及在测试时生成此元数据不可用的最佳设置是什么。 我们发现该模型确实以该元数据为条件;提供不同的标签会改变模型生成的算法。 我们还发现我们应该对标签和评级进行随机抽样,并以解决方案正确为条件。 在这里,我们对标签条件进行了分析,有关评级和正确性条件的其他结果包含在附录 LABEL:sec:sensitivity-to-metadata-appendix 中。
我们在验证集中的一个示例问题上检查了模型的标签调节行为:Codeforces 问题 1549A、Gregor 和密码学(图LABEL:fig:varname_replacement_example)。 在这个问题中,我们给定一个素数,需要找到两个整数和,这样 和。 通过暴力破解这个问题很诱人,但有一个简单的数论解决方案: 必须是奇数,因此 和 都等于 1。
Code generated with tag “brute force”:
Code generated with tag “number theory”:
我们从模型中采样,首先使用“蛮力”标签,然后使用“数论”标签。 这些标签改变了样本分布,如图12所示,两次采样运行中第一个成功的样本就证明了这一点。 “蛮力”方法就是这样——尽管实际上它保证在第一次迭代时打破循环——而“数论”方法只是简单地输出没有循环结构的答案。 此模式在接下来的 2048 个样本中继续存在。 该模型使用“数论”标签解决问题的频率是原来的三倍(29 个解,而不是 9 个),并且输出完美的无循环解(除了读取输入)的频率是原来的四倍(12 个解,而不是 3 个) 。
| Tag sampling scheme | 300M | 1B | 3B |
|---|---|---|---|
| Random per sample (default) | |||
| True problem tags | |||
| Random per problem |
标签调节可以通过两种可能的方式提高模型求解率:随机标签可以增加样本多样性,或者采样正确的标签可以提供有用的提示。 为了区分它们,我们比较了为每个样本(默认)采样一组随机标签时、提供真实问题标签时以及为每个问题采样一组随机标签时(并将其重新用于该问题的所有样本)时的解决率。同样的问题)。 结果如表13所示。 在测试时提供问题的真实标签是不可能的,但比提供一组固定的随机标签更好。 然而,最好的结果来自于每个样本使用随机标签进行采样,这表明样本的额外多样性对于提高解决率非常重要。
6.5 损失并不能很好地代表解决率
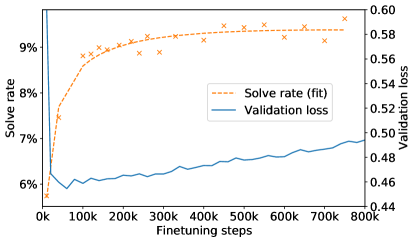
在微调 AlphaCode 模型时,我们观察到,对于 1B 模型的早期训练运行,验证语言建模损失在大约 50k 步骤后开始增加,而训练损失仍然减少。 这通常表明过度拟合。 然而,与验证损失相反,我们的目标指标求解率继续提高,远远超过了 50k 步,如图 13 所示。
正如 4.3 节中所讨论的,解决问题是一项“one-of-many”任务,即只要多个样本中的一个解决了问题,就认为该问题已解决。 我们的微调数据集 CodeContests 包含每个问题的许多解决方案。 我们的主要解决率指标 10@k 也使用 样本而不是单个样本。 我们假设该模型将概率质量从一些非典型解决方案重新分配到更典型的解决方案,从而导致整体验证损失更差,但产生更典型解决方案的概率更高,因此解决率更高。
尽管解决率是最终指标,但其高方差和计算成本使其难以用于步骤数等决策。 改进验证损失以更好地与性能相关联可以更好地指导决策过程。 我们将验证损失和解决率之间关系的全面研究留给未来的工作。
7相关工作
7.1程序综合
程序综合包括自动生成满足任务规范的程序。 表达任务的可能方式包括自然语言描述、一组输入/输出示例或一系列约束。 程序综合作为一个研究课题有着悠久的历史。 大多数经典方法将问题表述为在底层编程语言定义的搜索空间中搜索程序,其中程序必须满足定义任务的所有约束。 一个值得注意的例子是演绎综合方法(Green,1969;Manna 和 Waldinger,1971),它将任务规范转换为约束,使用定理证明器找到满足所有约束的证明,并且从证明中提取程序。 后来,基于输入/输出的任务规范变得更加流行,例如 FlashFill (Gulwani,2011) 等著名示例。 最后,基于草图的方法(Solar-Lezama,2008)从提供的目标程序框架合成程序,大大减少了搜索空间。 Gulwani 等人 (2017) 对这些程序综合方法进行了出色的调查。
近年来,深度学习已成为程序综合的有用工具。 Yin 和 Neubig (2017) 使用循环网络,注意将文本映射到 Abstract 语法树,然后编码。 Ling 等人 (2016) 使用类似的模型和指针网络,从混合自然语言和炉石卡牌的结构化规范中生成复杂的类结构。 学习的模型现在可用于指导程序搜索(Balog等人,2016),生成程序草图(Murali等人,2017;Guo等人,2021),转换伪代码到代码(Kulal 等人, 2019),直接生成目标程序(Devlin 等人, 2017),甚至在强化学习设置中生成编程策略 (Trivedi 等人,2021)。
自动代码完成也与我们的工作相关,并且已成为大多数代码编辑器和集成开发环境 (IDE) 不可或缺的一部分。 在打字时,这些工具会建议可能的延续,从而大大提高编程效率。 最早的代码完成系统是纯粹基于语法的。 Hindle 等人 (2012) 提供了代码可以通过统计 -gram 语言模型进行建模的经验证据,并利用这一点为 Java 开发了一个简单的代码完成引擎。 更新的智能代码补全系统可以从历史(Robbes and Lanza,2008)和大量现有代码数据(Svyatkovskiy 等人,2020;Aye 等人,2021) 中学习>。
然而,直到最近,大多数代码完成系统最多只生成一行的建议。 在整个程序综合中也存在类似的趋势:要么限制为狭义定义的特定领域语言中的短程序,要么限制为通用编程语言的短代码片段。 事实证明,扩大规模会增加搜索问题的深度和广度,这是一个艰巨的挑战。
7.2 用于程序综合的 Transformer
最近,大型 Transformer 在自然语言建模中的成功(Brown 等人,2020)引起了人们对使用 Transformer 模型进行代码检索、翻译和生成的兴趣(Feng 等人, 2020;Clement 等人,2020;Chen 等人,2021),在程序综合挑战方面取得了重大进展。 这些模型在涵盖互联网上广泛文本的庞大数据集上进行训练,能够以前所未有的流畅性生成文本。 与我们最相关的工作是最近的 Codex 系统(Chen 等人,2021),这是一个在 GitHub 上的公共代码上训练的 GPT 语言模型(Radford 等人,2019) 。 该模型展示了令人印象深刻的性能,在给定函数签名和文档字符串的情况下,在正确完成手动指定的 Python 函数方面取得了很高的成功率,特别是在对类似数据集进行微调之后。 Codex用于构建交互式程序综合系统,能够解决中大学水平的线性代数和概率统计问题(Tang等人,2021;Drori和Verma,2021),并进一步用于在 GitHub Copilot 中创建高级自动完成系统。 Austin 等人 (2021) 训练了与 Codex 类似的模型,他们还表明,对编程任务数据集的一部分进行微调可以提高类似任务的成功率。
然而,与竞争性编程问题的全部范围相比,这些作品解决的编程任务很简单,其中任务规范和解决方案都更加复杂。 例如,在我们的数据集中,问题描述长度中位数为 1,628 个字符,解决方案长度中位数为 606 个字符,而 HumanEval 基准 (Chen 等人,2021) 的描述长度中位数为 396 个字符,解长度为 148.5 个字符,两者都短了大约 4 倍。 HumanEval 问题还往往包含有关具体实现内容的说明,这与竞争性编程问题相反,后者会带来没有建议实现的问题。 最后,尚不清楚看不见的任务有多少。 尽管它们是手写的,而不是从现有源复制的,但诸如排序数组或检查数字是否为素数之类的任务都有可以从训练数据集中复制的解决方案。 我们的工作使用 Transformer ,但将模型性能向前迈出了重要一步,从生成函数完成到为遗留的竞争性编程问题创建完整的解决方案。
7.3 缩放采样
与我们的采样和过滤类似,但规模要小得多,Chen 等人 (2021)、Austin 等人 (2021) 和 Cobbe 等人 ( 2021)发现对同一问题进行重复采样会显着增加找到正确解决方案的概率。 Cobbe等人(2021)进一步引入了通过多数投票从多个样本中选出少量最终提交的方式。 他们还演示了用于判断模型样本正确性的验证器(价值函数),作为对样本进行重新排序的一种方式。
7.4评估指标
随着模型本身的改进,评估指标也在不断发展。 早期的工作通过测量生成的代码在词符级别、语法树级别或完整程序级别与真实参考代码的匹配程度来评估性能(任等人,2020)。 这些指标决定代码是否匹配,而不是程序是否正确(语法上不同的程序可以在功能上相同),因此随着模型的改进能够完全解决编程问题,执行程序和测量功能正确性的评估过程( Kulal 等人,2019;Chen 等人,2021;Hendrycks 等人,2021)变得更受欢迎。 然而,Chen 等人 (2021) 和 Hendrycks 等人 (2021) 作为基准都有些局限性,因为我们发现错误的程序被标记为正确的情况很常见,因为有限的测试覆盖率(表2)。
7.5竞争性编程
最后,如果没有用于训练和评估的竞争性编程数据集,就不可能在开发能够解决竞争性编程问题的模型方面取得进展。 Caballero 等人 (2016) 发布了包含数千个竞技编程问题的数据集,以及从流行的竞技编程问题中收集的相应的 Python 和 C++ 解决方案编程平台。 Zavershynskyi 等人 (2018) 引入了另一个竞争性编程问题和解决方案的数据集,尽管他们将解决方案转换为中间编程语言,这使得使用预训练模型变得困难。 Puri等人(2021)发布了多种编程语言的大量解法数据集,包含正确解法和错误解法,以及丰富的元数据。 最后,Hendrycks 等人(2021)介绍了 APPS 数据集,该数据集包含 10,000 个编码竞赛问题,并且是第一个在竞赛编程上评估大型 Transformer 语言模型的人。 作者发现,使用大型语言模型解决面试或竞赛级别问题的总体解决率仍然接近 0%。 然而,他们的评估格式并不代表竞争性编程,并且如上所述,由于缺乏测试覆盖率而导致误报,该解决率是上限(表2)。 我们的数据集基于 Caballero 等人 (2016) 和 Puri 等人 (2021) 构建,并从 Codeforces 平台进行了额外的抓取。
8更广泛的影响
良好的代码生成模型有可能对社会产生积极的、变革性的影响,具有广泛的应用,包括计算机科学教育、开发人员工具以及使编程更容易实现。 然而,与大多数技术一样,这些模型可能会带来我们需要防范的社会危害,而产生积极影响的愿望本身并不能减轻危害。
8.1应用
尽管这项工作在竞争性编程之外几乎没有直接应用,但改进人类可读的代码生成为许多具有巨大现实世界影响的未来应用程序打开了大门。 所有这些应用程序都需要不同数量的未来工作。
自动化代码生成可以提高现有程序员的工作效率,潜在的应用范围从建议扩展代码完成到优化代码块。 在未来,先进的代码生成模型可以让开发人员在更高的抽象级别上进行操作,从而省略细节,这与现代软件工程师通常不再使用汇编语言编写的方式非常相似。
派生工具可以使编程更容易进行或帮助教育新程序员。 模型可以提出替代的、更有效或更惯用的实施程序的方法,这将允许人们改进他们的编码风格。 代码到文档工具(Feng 等人, 2020) 可以让您更轻松地理解复杂代码段的用途。 完全以自然语言运行的更极端的系统,例如 Codex (Chen 等人,2021) 中提出的系统,可以使创建软件不需要任何编码知识。
然而,代码生成工具也可能被不良行为者使用。 更好的工具可能会更容易创建新版本的恶意软件,从而帮助它们避免被安全软件(通常依赖于文件指纹数据库)检测。 提高开发人员工作效率的工具也将提高编写恶意代码的开发人员的工作效率(Weidinger 等人,2021;Chen 等人,2021)。 或者,竞争性编程代码生成模型尤其可能会给用户在编程竞赛或技术面试中带来不公平的优势。
8.2潜在风险和收益
可解释性。 代码生成模型的一大优点是代码本身相对可解释。 理解神经网络的行为具有挑战性,但代码生成模型输出的代码是人类可读的,并且可以通过传统方法进行分析(因此更容易信任)。 证明排序算法的正确性通常比证明网络在所有情况下都能正确对数字进行排序更容易。
可解释性使代码生成对于现实环境和更公平的机器学习来说更加安全。 我们可以检查人类可读的代码生成系统编写的代码是否存在偏见,并理解它做出的决策。
概括。 代码生成模型生成的代码趋于泛化;通过足够数量的测试使得代码更有可能通过分布外的测试。 这种对输入和输出的整个域的泛化水平通常很难通过神经网络获得,并且可以使代码生成模型在现实世界的分布式应用中更加可靠。
偏见、公平和代表性。 与自然语言模型(Brown等人,2020)类似,代码生成模型很容易重现其训练数据的缺陷和偏差。 当使用不同的人类数据集进行训练时,这些模型可以强化和延续社会刻板印象,从而对边缘化社区产生不成比例的影响。 例如,程序可以包含有关名称(McKenzie,2010)、地址(Tandy,2013)或时间(Sussman,2017)的文化和位置特定假设),不包括代表性不足的用户。
偏见还可能导致低质量代码,从而导致错误永久存在或使用过时的 API,111111复制旧代码的人类程序员也存在这个问题。 从而导致性能和安全问题。 这可能会减少新库或编程语言的使用。
安全。 如上所述,代码生成可能存在安全风险和好处。 模型可以生成具有可利用弱点的代码,这些弱点可能是过时代码中无意的漏洞,也可能是恶意行为者故意注入训练集的漏洞(Pearce 等人,2021)。 此外,代码生成可以为威胁行为者和威胁防御者提供支持,从而提高生产力并支持新技术。 例如,多态恶意软件改变其实现以隐藏检测(Chen等人,2021)。
对环境造成的影响。 与大规模语言模型一样,基于训练 Transformer 的代码生成模型需要大量计算。 此外,由于我们发现大规模采样对于提高性能至关重要,因此与传统语言模型相比,执行我们的模型所花费的计算量相对较多。 我们模型的采样和训练都需要数百 petaFLOPS 天。121212实验在 Google 数据中心进行,该数据中心购买的可再生能源等于消耗量(Hölzle,2018)。
然而,代码生成模型的一个比较优势是,一旦合成了程序,它通常可以由任何计算机以低廉的成本执行,这与通常需要在加速器上运行的神经网络模型不同。 因此,代码生成模型可以更轻松地扩展到许多应用程序。
知识产权。 用于训练代码生成模型的大型训练语料库存在知识产权问题。 对于某些系统来说,公开数据上的训练是否合理使用是一个悬而未决的问题(Gershgorn,2021),尽管这与基于许可证过滤其数据集的 AlphaCode 关系不大。 即使有许可,仍然需要决定如何信任和使用人们的代码。
自动化。 随着编程变得更加容易和高效,并且代码生成可以自动执行一些简单的任务,程序员的供应可能会增加,需求也会减少。 这种情况在一定程度上得到了缓解,因为编写代码只是工作的一部分,而以前的部分自动化编程实例(例如编译器和 IDE)只是将程序员提升到了更高的抽象级别,并向更多人开放了该领域。
高级人工智能风险。 从长远来看,代码生成可能会导致高级人工智能风险。 编码能力可能会导致系统能够递归地编写和改进自身,从而迅速导致越来越先进的系统。
9结论
在这项工作中,我们提出了 AlphaCode,这是一个应用于竞争性编程代码生成的系统,可以为未见过的编程问题生成新颖的解决方案。 在 Codeforces 上进行评估,AlphaCode 的表现大致相当于中等竞争对手的水平。 我们发现,大规模扩展采样,然后过滤样本并将其聚类为一个小集合,再加上新的采样高效的 Transformer 架构来支持大规模采样,对于实现良好的性能至关重要。 我们干净的数据集和强大的评估程序也为指导我们的研究进展做出了重大贡献。 我们还通过详细分析表明,没有证据表明 AlphaCode 复制了先前解决方案的重要部分或利用了问题结构中的弱点。 这表明我们的模型确实能够解决以前从未见过的问题,即使这些问题需要大量推理。 最后,我们展示了各种模型探索的结果,并讨论了此类代码生成模型的更广泛的影响和危害。
致谢
我们要感谢 Trevor Cai、Jack Rae、Sebastian Borgeaud、Mia Glaese、Roman Ring、Laurent Sifre、Jordan Hoffman、John Aslanides、Jean-Baptiste Lespiau、Arthur Mensch、Erich Elsen、George van den Driessche 和 Geoffrey Irving 的开发我们用来训练大型语言模型的工具,以及借用他们在模型训练方面的专业知识; Kirsty Anderson、Claudia Pope 和 Rachel Foley 负责早期项目管理; Yee Whye Teh、Chris Dyer、David Silver、Amin Barekatain、Anton Zhernov、Matt Overlan 和 Petar Veličković 提供研究建议和帮助; Karen Simonyan、Chris Dyer 和 Dani Yogatama 审阅了该论文; Lorrayne Bennett、Kareem Ayoub 和 Jeff Stanway 在后勤方面使该项目成为可能; Sumanth Dathathri 分析了我们的模型; Ethan Caballero 授予我们使用 Description2Code 数据的许可; Rosemary Ke 帮助我们与 Ethan 取得联系; Pablo Heiber 帮助我们与 Codeforces 建立联系; Petr Mitrichev 帮助我们与 Codeforces 建立联系,并在撰写论文时提供了有竞争力的编程专业知识; Mike Mirzayanov 允许我们对 Codeforces 进行评估;以及 DeepMind 的每个人的见解和支持。
作者贡献
Agustin Dal Lago 致力于数据集的开发、评估和一般基础设施。
Cyprien de Masson d’Autume 从事模型开发和分析工作。
Daniel J. Mankowitz 研究聚类。
David Choi 是技术负责人,开发了解决竞争性编程问题的初始原型,并在通用基础设施、指标、大规模训练、模型开发、采样、评估、数据集、训练和论文写作。
Esme Sutherland Robson 从事项目管理工作。
Felix Gimeno 致力于模型开发、指标、数据集(特别是 APPS 基准)和聚类。
伊戈尔·巴布施金131313在 DeepMind 进行的工作,现在在 OpenAI。 致力于代码生成模型的初始原型并为基础设施工具做出了贡献。
James Keeling 致力于代码执行和评估、基础设施采样和扩展、集群以及论文写作。
James Molloy 致力于提高加速器上模型的效率。
Julian Schrittwieser 致力于数据集、评估、模型开发和训练损失、标记化、可视化和论文写作。
Junyoung Chung 致力于代码生成模型的初始原型、模型开发和调优、训练损失、训练管道、模型性能、数据集、采样、大规模模型,运行大多数最终实验(特别是主要实验) )和论文写作。
Nate Kushman 致力于初始样本扩展工作、指标、评估、模型开发和调整、训练损失、数据集(特别是 HumanEval 基准)、大型模型、分析扩展行为、运行最终实验,以及论文写作。
Oriol Vinyals 是代码生成模型的早期倡导者,自始至终为该项目提供支持和建议,并参与项目管理和论文写作。
Peter Choy 负责模型开发、采样和复制分析。
Rémi Leblond 致力于模型开发和调整、优化、改进损失、模型分析、采样效率和缩放、数据集和论文写作。
Thomas Hubert 致力于模型开发、基础设施和其他训练目标。
Tom Eccles 致力于数据集、指标、评估、聚类、通用基础设施、集成、元数据调节、模型分析和论文写作。
陈新云141414在加州大学伯克利分校 DeepMind 实习期间进行的工作。 从事模型开发工作。
Yujia Li 是项目负责人,开发了解决竞争性编程问题的初始原型,并在数据集、指标、评估、模型、训练、集群、基础设施工具和论文写作等方面做出了贡献。
Alexey Cherepanov、Johannes Welbl、Po-Sen Huang 和 Sven Gowal 从事模型分析工作。
Nando de Freitas、Koray Kavukcuoglu 和 Pushmeet Kohli 为该项目提供了建议,Nando de Freitas 进一步为论文写作做出了贡献。
数据可用性
实验中使用的数据集已可在 GitHub 上下载。
参考
- Albert Ziegler (2021) Albert Ziegler. Research recitation: A first look at rote learning in GitHub Copilot suggestions. https://docs.github.com/en/github/copilot/research-recitation, 2021. Accessed: 2022-01-13.
- Allamanis (2019) M. Allamanis. The adverse effects of code duplication in machine learning models of code. In Proceedings of the 2019 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software, pages 143–153, 2019.
- Austin et al. (2021) J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Aye et al. (2021) G. A. Aye, S. Kim, and H. Li. Learning autocompletion from real-world datasets. In 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 131–139. IEEE, 2021.
- Balog et al. (2016) M. Balog, A. L. Gaunt, M. Brockschmidt, S. Nowozin, and D. Tarlow. DeepCoder: Learning to write programs. arXiv preprint arXiv:1611.01989, 2016.
- Borgeaud et al. (2021) S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. van den Driessche, J.-B. Lespiau, B. Damoc, A. Clark, D. de Las Casas, A. Guy, J. Menick, R. Ring, T. Hennigan, S. Huang, L. Maggiore, C. Jones, A. Cassirer, A. Brock, M. Paganini, G. Irving, O. Vinyals, S. Osindero, K. Simonyan, J. W. Rae, E. Elsen, and L. Sifre. Improving language models by retrieving from trillions of tokens, 2021.
- Bradbury et al. (2018) J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax.
- Brown et al. (2020) T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Bruch et al. (2009) M. Bruch, M. Monperrus, and M. Mezini. Learning from examples to improve code completion systems. In Proceedings of the 7th joint meeting of the European software engineering conference and the ACM SIGSOFT symposium on the foundations of software engineering, pages 213–222, 2009.
- Caballero et al. (2016) E. Caballero, OpenAI, and I. Sutskever. Description2Code Dataset, 8 2016. URL https://github.com/ethancaballero/description2code.
- Carlini et al. (2021) N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, et al. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650, 2021.
- Chen et al. (2021) M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Clement et al. (2020) C. B. Clement, D. Drain, J. Timcheck, A. Svyatkovskiy, and N. Sundaresan. PyMT5: multi-mode translation of natural language and Python code with transformers. arXiv preprint arXiv:2010.03150, 2020.
- Cobbe et al. (2021) K. Cobbe, V. Kosaraju, M. Bavarian, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Dabre and Fujita (2020) R. Dabre and A. Fujita. Softmax tempering for training neural machine translation models. arXiv prepring arXiv:2009.09372, 2020.
- Devlin et al. (2017) J. Devlin, J. Uesato, S. Bhupatiraju, R. Singh, A.-r. Mohamed, and P. Kohli. RobustFill: Neural program learning under noisy I/O. In International conference on machine learning, pages 990–998. PMLR, 2017.
- Devlin et al. (2018) J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Drori and Verma (2021) I. Drori and N. Verma. Solving linear algebra by program synthesis. arXiv preprint arXiv:2111.08171, 2021.
- Ebtekar (2021) A. Ebtekar. How to interpret contest ratings. https://codeforces.com/blog/entry/68288, 2021. Accessed: 2021-12-04.
- Edunov et al. (2018) S. Edunov, M. Ott, M. Auli, and D. Grangier. Understanding back-translation at scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 489–500, Brussels, Belgium, Oct.-Nov. 2018. Association for Computational Linguistics. 10.18653/v1/D18-1045. URL https://aclanthology.org/D18-1045.
- Facebook Hacker Cup (2021) Facebook Hacker Cup. Facebook hacker cup. https://www.facebook.com/codingcompetitions/hacker-cup, 2021. Accessed: 2021-12-09.
- Fan et al. (2018) A. Fan, M. Lewis, and Y. Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018.
- Feng et al. (2020) Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, et al. CodeBERT: a pre-trained model for programming and natural languages. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 1536–1547, 2020.
- Ganitkevitch et al. (2013) J. Ganitkevitch, B. Van Durme, and C. Callison-Burch. PPDB: The paraphrase database. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 758–764, Atlanta, Georgia, June 2013. Association for Computational Linguistics. URL https://aclanthology.org/N13-1092.
- Gershgorn (2021) D. Gershgorn. GitHub’s automatic coding tool rests on untested legal ground. https://www.theverge.com/2021/7/7/22561180/github-copilot-legal-copyright-fair-use-public-code, 2021. Accessed: 2022-01-10.
- Google Code Jam (2021) Google Code Jam. Google Code Jam. https://codingcompetitions.withgoogle.com/codejam, 2021. Accessed: 2021-12-09.
- Green (1969) C. C. Green. Application of theorem proving to problem solving. In IJCAI, 1969.
- Gulwani (2011) S. Gulwani. Automating string processing in spreadsheets using input-output examples. ACM Sigplan Notices, 46(1):317–330, 2011.
- Gulwani et al. (2017) S. Gulwani, O. Polozov, R. Singh, et al. Program synthesis. Foundations and Trends® in Programming Languages, 4(1-2):1–119, 2017.
- Guo et al. (2021) D. Guo, A. Svyatkovskiy, J. Yin, N. Duan, M. Brockschmidt, and M. Allamanis. Learning to generate code sketches. arXiv preprint arXiv:2106.10158, 2021.
- Hendrycks et al. (2021) D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, et al. Measuring coding challenge competence with APPS. arXiv preprint arXiv:2105.09938, 2021.
- Hennigan et al. (2020) T. Hennigan, T. Cai, T. Norman, and I. Babuschkin. Haiku: Sonnet for JAX, 2020. URL http://github.com/deepmind/dm-haiku.
- Hindle et al. (2012) A. Hindle, E. T. Barr, Z. Su, M. Gabel, and P. Devanbu. On the naturalness of software. In Proceedings of the 34th International Conference on Software Engineering, pages 837–847, 2012.
- Holtzman et al. (2019) A. Holtzman, J. Buys, L. Du, M. Forbes, and Y. Choi. The curious case of neural text degeneration. In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- Hölzle (2018) U. Hölzle. Meeting our match: Buying 100 percent renewable energy. https://www.blog.google/outreach-initiatives/environment/meeting-our-match-buying-100-percent-renewable-energy/, 2018. Accessed: 2022-01-10.
- Huang et al. (2019) P.-S. Huang, R. Stanforth, J. Welbl, C. Dyer, D. Yogatama, S. Gowal, K. Dvijotham, and P. Kohli. Achieving verified robustness to symbol substitutions via interval bound propagation. In Empirical Methods in Natural Language Processing (EMNLP), pages 4081–4091, 2019.
- ICPC (2021) ICPC. International collegiate programming contest. https://cse.umn.edu/cs/icpc, 2021. Accessed: 2021-12-04.
- ICPC Factsheet (2020) ICPC Factsheet. ICPC factsheet. https://icpc.global/worldfinals/pdf/Factsheet.pdf, 2020. Accessed: 2021-12-04.
- ICPC Rules (2021) ICPC Rules. ICPC rules. https://icpc.global/worldfinals/rules, 2021. Accessed: 2021-12-09.
- IOI (2021) IOI. International olympiad in informatics. https://ioinformatics.org/, 2021. Accessed: 2021-12-04.
- Jouppi et al. (2021) N. P. Jouppi, D. H. Yoon, M. Ashcraft, M. Gottscho, T. B. Jablin, G. Kurian, J. Laudon, S. Li, P. Ma, X. Ma, et al. Ten lessons from three generations shaped Google’s TPUv4i. In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pages 1–14. IEEE, 2021.
- Kaplan et al. (2020) J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Kingma and Ba (2014) D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kudo and Richardson (2018) T. Kudo and J. Richardson. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv preprint arXiv:1808.06226, 2018.
- Kulal et al. (2019) S. Kulal, P. Pasupat, K. Chandra, M. Lee, O. Padon, A. Aiken, and P. S. Liang. Spoc: Search-based pseudocode to code. Advances in Neural Information Processing Systems, 32, 2019.
- Ling et al. (2016) W. Ling, P. Blunsom, E. Grefenstette, K. M. Hermann, T. Kočiský, F. Wang, and A. Senior. Latent predictor networks for code generation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 599–609, 2016. URL https://aclanthology.org/P16-1057.
- Loshchilov and Hutter (2017) I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Manna and Waldinger (1971) Z. Manna and R. J. Waldinger. Toward automatic program synthesis. Commun. ACM, 14(3):151–165, mar 1971. ISSN 0001-0782. 10.1145/362566.362568. URL https://doi.org/10.1145/362566.362568.
- Matsakis and Klock (2014) N. D. Matsakis and F. S. Klock. The Rust language. ACM SIGAda Ada Letters, 34(3):103–104, 2014.
- McKenzie (2010) P. McKenzie. Falsehoods programmers believe about names. https://www.kalzumeus.com/2010/06/17/falsehoods-programmers-believe-about-names/, 2010. Accessed: 2022-01-10.
- Mirzayanov (2020) M. Mirzayanov. Codeforces: Results of 2020. https://codeforces.com/blog/entry/89502, 2020. Accessed: 2021-12-04.
- Murali et al. (2017) V. Murali, L. Qi, S. Chaudhuri, and C. Jermaine. Neural sketch learning for conditional program generation. arXiv preprint arXiv:1703.05698, 2017.
- Nandwani et al. (2021) Y. Nandwani, D. Jindal, Mausam, and P. Singla. Neural learning of one-of-many solutions for combinatorial problems in structured output spaces. In International Conference on Learning Representations, 2021.
- Pang and He (2020) R. Y. Pang and H. He. Text generation by learning from demonstrations. arXiv preprint arXiv:2009.07839, 2020.
- Pearce et al. (2021) H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri. An empirical cybersecurity evaluation of GitHub Copilot’s code contributions. CoRR, abs/2108.09293, 2021. URL https://arxiv.org/abs/2108.09293.
- Puri et al. (2021) R. Puri, D. S. Kung, G. Janssen, W. Zhang, G. Domeniconi, V. Zolotov, J. Dolby, J. Chen, M. Choudhury, L. Decker, et al. Project CodeNet: A large-scale AI for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655, 2021.
- Radford et al. (2019) A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Rae et al. (2021) J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young, et al. Scaling language models: Methods, analysis & insights from training Gopher. arXiv preprint arXiv:2112.11446, 2021.
- Raychev et al. (2014) V. Raychev, M. Vechev, and E. Yahav. Code completion with statistical language models. In Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 419–428, 2014.
- Ren et al. (2020) S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, N. Sundaresan, M. Zhou, A. Blanco, and S. Ma. CodeBLEU: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297, 2020.
- Resnick et al. (2009) M. Resnick, J. Maloney, A. Monroy-Hernández, N. Rusk, E. Eastmond, K. Brennan, A. Millner, E. Rosenbaum, J. Silver, B. Silverman, et al. Scratch: programming for all. Communications of the ACM, 52(11):60–67, 2009.
- Robbes and Lanza (2008) R. Robbes and M. Lanza. How program history can improve code completion. In 2008 23rd IEEE/ACM International Conference on Automated Software Engineering, pages 317–326. IEEE, 2008.
- Shazeer (2019) N. Shazeer. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150, 2019.
- Solar-Lezama (2008) A. Solar-Lezama. Program synthesis by sketching. University of California, Berkeley, 2008.
- Sussman (2017) N. Sussman. Falsehoods programmers believe about time. https://infiniteundo.com/post/25326999628/falsehoods-programmers-believe-about-time, 2017. Accessed: 2022-01-10.
- Sutskever et al. (2014) I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104–3112, 2014.
- Svyatkovskiy et al. (2020) A. Svyatkovskiy, S. K. Deng, S. Fu, and N. Sundaresan. IntelliCode compose: Code generation using transformer. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1433–1443, 2020.
- Tandy (2013) M. Tandy. Falsehoods programmers believe about addresses. https://www.mjt.me.uk/posts/falsehoods-programmers-believe-about-addresses/, 2013. Accessed: 2022-01-10.
- Tang et al. (2021) L. Tang, E. Ke, N. Singh, N. Verma, and I. Drori. Solving probability and statistics problems by program synthesis. arXiv preprint arXiv:2111.08267, 2021.
- Trivedi et al. (2021) D. Trivedi, J. Zhang, S.-H. Sun, and J. J. Lim. Learning to synthesize programs as interpretable and generalizable policies. In Advances in neural information processing systems, 2021.
- Vaswani et al. (2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- Vinyals et al. (2019) O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019.
- Weidinger et al. (2021) L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadeh, Z. Kenton, S. Brown, W. Hawkins, T. Stepleton, C. Biles, A. Birhane, J. Haas, L. Rimell, L. A. Hendricks, W. S. Isaac, S. Legassick, G. Irving, and I. Gabriel. Ethical and social risks of harm from language models. CoRR, abs/2112.04359, 2021. URL https://arxiv.org/abs/2112.04359.
- Yin and Neubig (2017) P. Yin and G. Neubig. A syntactic neural model for general-purpose code generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 440–450, 2017.
- Zavershynskyi et al. (2018) M. Zavershynskyi, A. Skidanov, and I. Polosukhin. NAPS: Natural program synthesis dataset. arXiv preprint arXiv:1807.03168, 2018.
10附录
附录
小节
附录A问题设置
A.1 隐藏测试
Input
Output
Followed by over a hundred more extensive tests that probe various cases.
A.2节目评审
当提交给 Codeforces 时,如第 5.1 节所示,我们可以使用与比赛中使用的相同的评审系统。 我们尝试在 CodeContests 中模拟该系统:我们通过在测试用例上执行程序并将程序输出与预期的正确输出进行比较来检查程序的正确性。 然而,判断程序输出是否正确可能具有挑战性,并且不仅仅涉及检查与正确输出的精确匹配。 每个问题都可以有特定的规则,包括区分大小写、空格、格式和浮点精度。 此外,问题可能有多个正确的输出(例如,允许遵循约束的任何序列),或多个可能的输入(例如,输入取决于程序输出的交互问题)。 下面描述的评审过程既适用于最终提交,也适用于基于示例测试的过滤。
由于这些约束很难从问题中提取出来,因此我们的判断代码对格式采取了宽容的态度。 如果浮点数的差异小于 ,则认为浮点数是等效的,字符串比较不区分大小写,并且忽略空格差异。 这与问题给出的格式并不完全匹配,但我们发现这些问题并不是太重要。 在验证数据集误报率时,我们没有发现任何因该问题而被错误标记为正确的问题。
我们使用人类解决方案启发式地确定哪些问题具有多个正确输出;如果任何测试用例与人类编写的正确解决方案至少具有 不同的输出,或者由多个人类解决方案产生的 输出,我们假设它有多个输出。 根据此标准,我们的验证集问题中大约 1/4 是多输出问题。 这些问题是使用相同的宽松格式并根据单个正确输出来判断的,其中正确的输出被选择为大多数人类解决方案的输出。 因为我们假设一个正确的输出,所以我们的判断可能会低估实际模型的性能。 另一种方法是接受人类解决方案输出的任何输出,这会降低判断时的误报率,但我们发现这会导致误报率显着增加。
交互问题比多输出问题少得多,而且我们没有明确处理它们,这可能会导致误报和误报。 我们没有发现任何交互问题误报。
竞争性编程问题通常还包括时间和内存限制,我们在执行提交时会使用这些限制。
A.3评估指标
如2.2节所述,我们使用解决率来评估模型性能,它衡量模型在允许生成时可以解决的问题的比例> 样本,但仅提交其中的 份进行评估。
该指标的计算有两个方差来源:
-
•
如果我们使用相同的数据但不同的随机种子训练相同的模型架构,我们最终会得到不同的模型,从而产生不同的样本。
-
•
如果我们多次从同一个训练模型中获取 样本,我们每次都会得到一组不同的样本。
我们使用下面讨论的技术来减少除聚类结果(下面讨论)之外的所有报告结果中的第二个方差来源。 然而,减少第一个方差来源更具挑战性,并且考虑到我们模型的计算成本,为本文中的所有结果预训练和调节多个模型是不切实际的。 尽管如此,考虑到表 8 中消融结果的重要性,仅对于该表,我们从相同的预训练检查点对每个设置微调了至少 3 个模型,并报告了平均值 这些模型的结果。
要从单个模型计算 ,我们:
-
•
从模型中绘制一组 样本。
-
•
从全套 样本中抽取大小为 的 子样本,无需放回。
-
•
计算每个子样本的 提交的解决率。
-
•
报告所有这些子样本的平均解决率。
算法 1 概述了该估计过程。 为了创建缩放曲线,我们使用此过程使用同一组 样本计算不同 值的 。
为了生成表8中消融结果的置信区间,我们使用引导重采样。 具体来说,我们:
-
•
使用我们训练过的 模型中的替换 模型重新采样。
-
•
对于每个模型,使用我们从该模型中获取的 中的替换 样本重新采样。
-
•
使用上述过程使用重新采样的模型和样本计算 。
我们多次执行此重新采样和估计过程,并将 95% 置信区间报告为所得估计集的第 2.5 个百分位数和第 97.5 个百分位数。
对于包含聚类的结果,很难使用上述子采样过程,因为计算聚类会增加额外的计算复杂性。 因此,除非另有说明,我们按如下方式计算所有聚类结果。 对于每个尺寸 以及针对用于聚类的基本设置训练的每个模型,我们在五个不同的子样本上运行聚类。 报告的平均值是每个尺寸 的所有训练模型中这 5 个数据点的平均值。置信区间是使用类似于上述过程的引导重新采样来计算的,我们首先从可用的 中重新采样 模型,然后重新采样五个聚类我们为每个型号和每个尺码提供了五个可用的版本。表8和图8中的聚类结果基于在“+ GOLD”设置中微调的5个模型。 由于在这些尺寸下训练多个模型的成本,9B 和 41B 模型的聚类结果基于单个模型。
Input the number of allowed submissions in
Input the number of allowed samples in
Input the number of samples which pass the example tests for each problem
Input the number of samples which solve the problem (pass all tests) for each problem
Input the number of samples actually taken per problem
Hyperparameter the number of subsamples to use for calculation