深度批量主动学习回归的框架和基准
摘要
为监督学习获取标签可能会很昂贵。 为了提高神经网络回归的样本效率,我们研究了自适应选择批量未标记数据进行标记的主动学习方法。 我们提出了一个框架,用于根据(网络相关的)基础内核、内核转换和选择方法构建此类方法。 我们的框架包含许多基于神经网络高斯过程近似的现有贝叶斯方法以及非贝叶斯方法。 此外,我们建议用草图有限宽度神经切线内核替换常用的最后一层特征,并将它们与新颖的聚类方法相结合。 为了评估不同的方法,我们引入了一个由 15 个大型表格回归数据集组成的开源基准测试。 我们提出的方法在我们的基准测试中优于最先进的方法,可扩展到大型数据集,并且无需调整网络架构或训练代码即可开箱即用。 我们提供开源代码,其中包括所有内核、内核转换和选择方法的高效实现,可用于重现我们的结果。
关键字:批处理模式深度主动学习、回归、表格数据、神经网络、基准
1简介
虽然监督机器学习 (ML) 已成功应用于许多不同的问题,但这些成功通常依赖于解决当前问题的大型数据集的可用性。 在标记数据昂贵的情况下,减少所需的标签数量非常重要。 这种减少可以通过多种方式实现:首先,寻找样本效率更高的监督机器学习方法;其次,应用数据增强;第三,通过半监督学习利用未标记数据中的信息;第四,通过迁移学习、元学习或多任务学习利用相关问题的信息;最后,适当选择要标记的数据。 主动学习 (AL) 采用后一种方法,通过使用经过训练的模型来选择下一个数据点来标记 (settles_active_2009)。 每个新标签后都需要重新训练,这阻碍了并行标记方法的进行,并且成本可能太高,尤其是对于神经网络 (NN) 而言,其训练速度通常很慢。 这个问题可以通过批量模式主动学习(BMAL)方法来解决,该方法一次选择多个数据点进行标记。 当监督机器学习方法是深度神经网络时,这称为批处理模式深度主动学习 (BMDAL) (ren_survey_2021)。 基于池的 BMDAL 是指需要从给定的有限点集中选择用于标记的数据点的设置。
有监督和无监督的机器学习算法为给定的数据选择一个模型。 可以使用交叉验证等模型选择技术对相同数据进行比较多个模型。 这种比较会增加训练成本,但不会增加(可能更大)标记数据的成本。 与监督学习相反,AL 是选择数据本身,目标是降低标记成本。 然而,不同的 AL 算法可能会选择不同的样本,因此 AL 算法的比较可能会将标记成本增加高达 倍。因此,这种比较对于标签昂贵的应用来说是不明智的。 相反,在标签生成成本低廉或已有大量标签可用的任务上正确对 AL 方法进行基准测试更为重要。
在分类设置中,神经网络通常以通过 softmax 层获得的概率向量的形式输出不确定性,而回归神经网络通常输出没有不确定性的标量目标。 因此,许多 BMDAL 算法仅适用于两种设置之一。 对于分类,已经提出了许多 BMDAL 方法(ren_survey_2021),并且至少存在一些标准基准数据集,例如 CIFAR-10 (krizhevsky_learning_2009),通常在这些数据集上评估方法。 另一方面,回归设置的研究频率较低,据我们所知,除了药物发现的专门基准(mehrjou_genedisco_2021)之外,尚未建立通用基准。 我们预计回归设置将受到欢迎,尤其是由于人们对代理建模的神经网络越来越感兴趣(behler_perspective_2016;kutz_deep_2017;raissi_physicals-informed_2019;mehrjou_genedisco_2021;lavin_simulation_2021)。
1.1贡献
在本文中,我们研究了基于池的 BMDAL 回归方法。 我们的实验在表格数据集上使用完全连接的神经网络,但所考虑的方法可以推广到不同类型的数据和神经网络架构。 我们将我们的研究限制在不需要修改网络架构和训练的方法上,因为这些方法特别容易使用,并且很难与其他方法进行公平的比较。 我们还关注可扩展到大量(未标记)数据和大采集批量大小的方法。 我们的贡献可概括如下:
-
(1)
我们提出了一个将典型 BM(D)AL 算法分解为内核选择和选择方法的框架。 这里,可以通过一系列内核变换从基础内核构建内核。 使用内核作为基本构建块可以实现我们的框架的高效、灵活和可组合的实现,我们将其包含在我们的开源代码中。 我们还讨论了如何在此框架中表示许多流行的 BM(D)AL 算法(的回归变体)以及如何有效地实现它们。 这为我们提供了多种基础内核、内核转换和组合选择方法的选项。 我们的框架包含基于高斯过程和拉普拉斯近似的贝叶斯方法以及几何方法。
-
(2)
我们讨论了流行的 BM(D)AL 算法产生的一些替代选项:我们引入了一种称为LCMD的新颖选择方法;我们建议将有限宽度神经正切内核(NTK,jacot_neural_2018)作为基础内核与草图相结合,以实现高效计算。
-
(3)
我们引入了 BMDAL 的开源基准,涉及 15 个大型表格回归数据集。 使用此基准,我们比较不同的选择方法并评估内核、采集批量大小和目标指标的影响。
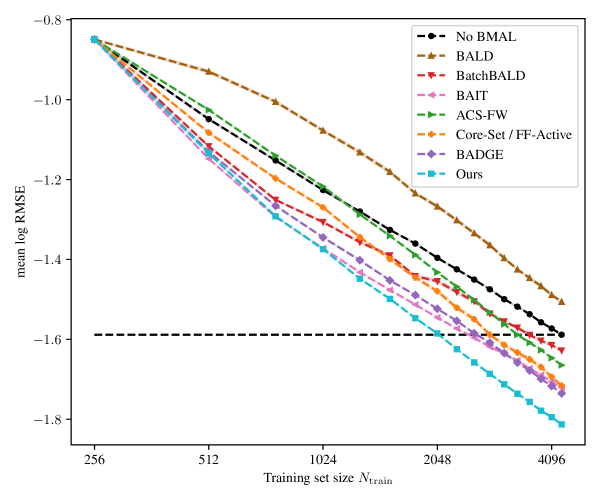
我们新提出的选择方法 LCMD 在 RMSE 和 MAE 方面提高了我们基准测试的最新水平,同时在最大误差方面仍然表现出良好的性能。 NTK 基础内核提高了所有选择方法的基准精度,并且所提出的草图方法可以保持这种精度,同时带来显着的时间增益。 图 1显示了我们的新颖 BMDAL 算法与文献中流行的 BMDAL 算法的比较,这些算法都在我们的框架中实现。 我们的框架和基准测试的代码基于 PyTorch (paszke_pytorch_2019),可在 +rCl+x* https://github.com/dholzmueller/bmdal_reg 上公开获取,将与生成的数据一起存档在https://doi.org/10.18419/darus-3394。
本文其余部分的结构如下:在部分2中,我们介绍了全连接表格回归的BMDAL基本问题设置神经网络并介绍我们构建 BMDAL 算法的框架。 我们在部分3中讨论相关工作。 然后,我们在 Section 4 中介绍从基础内核和内核转换构建内核的选项。 LABEL:sec:sel_methods 讨论各种基于迭代内核的选择方法。 我们在 LABEL:sec:bmdal:experiments 中的实验提供了对内核和选择方法的不同组合的性能的深入了解。 最后,我们在LABEL:sec:conclusion中讨论局限性和开放性问题。 附录中提供了有关所提出的方法和实验结果的更多详细信息,其结构在LABEL:sec:appendix:overview中概述。
2问题设置
在本节中,我们概述了全连接神经网络回归的 BMDAL 问题。 我们首先介绍回归目标和全连接神经网络。 随后,我们介绍了基于池的 BMDAL 的基本设置以及我们提出的框架。
2.1 全连接神经网络的回归
我们考虑多元回归,其目标是从数据 中学习函数 。 在神经网络的情况下,我们考虑参数化函数族,并尝试最小化带有样本的训练数据的均方损失:+rCl+ x* L(θ) & = 1Ntrain Σ_(x, y) ∈D _train (y - f_θ(x))^2 。 我们将 中的输入和标签分别称为 和 。 相应的数据集通常称为表格数据或结构化数据。 这与输入特征之间已知时空关系的数据(例如图像或时间序列数据)形成鲜明对比,在这些数据中,专用的神经网络架构(例如 CNN)更成功。
对于我们的推导和实验,我们考虑一个带有参数向量 和输入大小 的 层全连接神经网络 ,隐藏层大小 和输出大小 。 第 个输入 上的 NN 值 递归地定义为
| (1) |
这里,激活函数 按元素应用, 是常数因子。 在我们的实验中,权重矩阵使用独立的标准正态条目进行初始化,并将偏差初始化为零。 因子 和 源于神经切线参数化 (NTP) (jacot_neural_2018; lee_wide_2019),其理论上旨在定义神经网络也用于我们的应用程序中。 然而,我们的推导类似地适用于没有这些因素的神经网络。 当考虑不同的神经网络类型(例如 CNN)时,可以将我们的推导仅应用到神经网络的全连接部分,或者也将它们扩展到其他层。
2.2批处理模式主动学习
在单个 BMAL 步骤中,BMAL 算法选择具有给定大小 的批次 。 随后,该批次被标记并添加到训练集中。 在这里,我们考虑基于池的 BMAL,其中将从给定的有限池集 候选者中选择。 其他 AL 范例包括成员资格查询 AL(其中可以自由选择用于标记的数据点)或基于流的 AL(其中数据点按顺序到达并且必须立即标记或丢弃)。 池集可能包含有关输入空间的哪些区域比其他区域更重要的信息,特别是如果它是从与测试集相同的分布中提取的。 此外,基于池的 BMAL 可以通过为池集保留大部分数据集,从而使标记部分变得微不足道,从而可以在标记数据集上对 BMAL 方法进行有效的基准测试。
在比较和评估 BMDAL 方法时,我们主要对以下理想特性感兴趣:
-
(P1)
该方法应该提高底层神经网络的样本效率,即使对于较大的采集批量大小 和较大的池集大小 而言,对于下游应用程序来说,这可能会也可能不会涉及与训练和池数据相同的输入分布。
-
(P2)
在计算时间和内存消耗方面,该方法应该扩展到大型池集、训练集和批量大小。
-
(P3)
该方法应该适用于各种神经网络架构和训练方法,从而可以应用于不同的用例。
-
(P4)
该方法不应要求修改神经网络架构和训练方法,例如要求引入 Dropout,这样实践者就不必担心使用该方法是否会降低其训练的神经网络的准确性。
-
(P5)
该方法不应要求为单批次选择训练多个神经网络,因为这会降低其运行时效率。111从技术上讲,如果需要多个经过训练的神经网络有助于通过相应更大的 达到相同的精度,那么它不会有什么坏处。
-
(第6页)
该方法不需要在下游应用程序上调整超参数,因为这需要使用次优超参数来标记选择的样本。
属性 (P1) 对于激励使用 BMDAL 而非数据随机采样至关重要,并在 LABEL:sec:bmdal:experiments 和 LABEL:sec:appendix 中对我们的框架进行了详细评估:实验。 由于我们的基准涉及大型数据集,因此我们仅评估具有属性 (P2) 的方法。 这里考虑的所有方法在很大程度上满足(P3)。 事实上,虽然这里仅研究全连接层的高效计算,但所考虑的方法可以简单地应用于更大的神经网络的全连接部分。 所有考虑的方法都满足(P4),这也有利于基准测试中的公平比较。 尽管我们的方法可以合并神经网络的集合,但我们所有的方法都满足(P5)。 尽管一些考虑的方法具有超参数,但我们将它们固定为独立于实验中数据集的合理值,以满足(P6)。
算法 1展示了如何在带有训练和标签的循环中使用满足(P4)和(P5)的BMDAL算法。
wu_pool-based_2018制定了BMAL算法选择批量样本的三个标准,以提高学习方法的样本效率:
-
(信息)
该算法应该优先考虑对模型来说提供信息的输入。 例如,这些可能是模型对标签最不确定的输入。
-
(DIV)
该算法应确保批次包含多样化样本,即批次中的样本应彼此充分不同。
-
(代表)
该算法应确保所得训练集的代表性,即应更多地关注池数据分布密度较高的区域。
请注意,如果预计池数据和测试数据之间存在显着的分布变化,则 (REP) 可能并不理想。 尝试使非批量 AL 方法适应批量设置的一个挑战是,一些非批量 AL 方法期望立即收到每个选定样本的标签。 通常可以通过立即选择具有最大采集函数分数的 样本来规避此问题,但这不会强制执行 (DIV) 或 (REP)。
我们提出了一个用于组装 BMDAL 算法的框架,如 Algorithm 2 所示,该框架由三个部分组成:首先,需要选择一个基础内核 ,该内核应作为训练网络 的代理。 其次,可以使用各种变换来变换内核。 例如,这些转换可以使内核表示后验或提高其评估效率。 第三,调用一种选择方法,该方法使用变换后的内核作为输入之间相似性的度量。 当使用给定内核 的高斯过程回归作为监督学习方法而不是神经网络时,可以简单地将基本内核选择为 。请注意,Select 不会直接观察训练标签,但是,在 NN 设置中,这些标签可以通过依赖于训练的 NN 的内核隐式合并。
Example 1。
在算法2中,基本内核可以采用形式,其中表示训练后的神经网络没有最后一层。 当将 解释为高斯过程的内核时,TransformKernel 可以计算一个变换后的内核 ,它表示观察训练数据后的后验预测不确定性。 最后,Select 可以选择具有最大不确定性 的 点。
从贝叶斯角度来看,我们对核和核变换的选择可以对应于贝叶斯近似中的推理,正如我们在LABEL:sec:appendix:posterior中讨论的那样,而选择方法可以对应于优化一个获取函数。 不过,在我们的框架中,同样的"贝叶斯"核可以与非贝叶斯选择方法一起使用,反之亦然。
3相关工作
主动学习领域,也称为查询学习或顺序(最优)实验设计(fedorov_theory_1972;chaloner_bayesian_1995),拥有悠久的历史,至少可以追溯到 20 世纪初( smith_standard_1918)。 有关 AL 和 BMDAL 文献的概述,我们参考 settles_active_2009; kumar_active_2020; ren_survey_2021; weng_learning_2022。
我们首先回顾与框架中的内核相关的工作,然后讨论与选择方法更相关的工作,最后讨论数据集。 部分 4 和 LABEL:sec:sel_methods 中还讨论了更多与特定方法相关的文献。
3.1 不确定性度量和核近似
贝叶斯方法给出了一类流行的 BMDAL 方法,因为贝叶斯框架自然提供了可用于评估信息性的不确定性。 这些方法需要使用贝叶斯神经网络,或者换句话说,计算神经网络参数的近似后验分布。 一个简单的选择是仅在神经网络的最后一层执行贝叶斯推理(lazaro-gredilla_marginalized_2010; snoek_scalable_2015; ober_benchmarking_2019; kristiadi_being_2020)。 拉普拉斯近似(laplace_memoire_1774; mackay_bayesian_1992)可以通过二阶泰勒近似提供围绕损失景观局部最优的局部后验分布。 另一种基于 SGD 迭代的本地方法称为 SWAG (maddox_simple_2019)。 神经网络集合(hansen_neural_1990; lakshminarayanan_simple_2017)可以解释为简单的多模态后验近似,并且可以与局部近似相结合以产生拉普拉斯近似的混合(eschenhagen_mixtures_2021)或MultiSWAG (wilson_bayesian_2020)。 Monte Carlo (MC) Dropout (gal_dropout_2016) 是从单个 NN 获取整体预测的选项,尽管它需要使用 Dropout (srivastava_dropout_2014) 进行训练。 关于不确定性近似,我们考虑的算法主要与精确的最后一层方法和拉普拉斯近似有关,因为这些不需要修改训练过程。 daxberger_laplace_2021 概述了计算(近似)拉普拉斯近似的各种方法。
最近的一些方法也建立在jacot_neural_2018引入的神经切线内核(NTK)的基础上。 khan_approximate_2019 表明某些拉普拉斯近似与有限宽度 NTK 相关。 wang_deep_2022和mohamadi_making_2022提出使用有限宽度NTK进行DAL分类。 wang_neural_2021在初始化时使用有限宽度NTK对DAL的流式设置进行分类,并对所得方法进行理论分析。 aljundi_identifying_2022 使用与 DAL 的有限宽度 NTK 相关的内核。 shoham_experimental_2023、borsos_coresets_2020 和 borsos_semi-supervised_2021 使用无限宽度 NTK 进行 BMDAL 和相关任务。 han_random_2021 建议绘制无限宽度 NTK 的草图,并针对 DAL 对其进行评估。 与这些论文相反,我们建议绘制有限宽度 NTK 的草图,并允许将生成的内核与不同的选择方法相结合。
3.2选择方法
除了贝叶斯神经网络模型之外,贝叶斯 BMDAL 方法还需要指定一个获取函数来决定如何对池样本进行优先级排序。 人们提出了许多用于量化不确定性的简单采集函数(kumar_active_2020)。 选择整体最不同意的下一个样本称为委员会查询 (QbC) (seung_query_1992)。 krogh_neural_1994 采用 QbC 进行 DAL 回归。 beluch_power_2018 对 QbC 到 DAL 进行分类进行了更新的研究。 pop_deep_2018 将合奏与 MC Dropout 结合起来。 tsymbalov_dropout-based_2018使用MC Dropout for DAL得到的预测方差进行回归。 zaverkin_exploration_2021 使用 DAL 中基于最后一层的不确定性对原子数据进行回归。 与之前提到的其他方法不同,zaverkin_exploration_2021 的方法可以应用于在没有 Dropout 的情况下训练的单个神经网络。
许多基于不确定性的获取函数不区分认知不确定性(即缺乏对真实函数关系的了解)和任意不确定性(即由于标签噪声而导致的固有不确定性)。 houlsby_bayesian_2011提出BALD获取函数,其目的仅是量化认知不确定性。 gal_deep_2017 将 BALD 和其他采集函数应用于 BMDAL,以使用 MC Dropout 进行分类。 为了增强所选批次的多样性,kirsch_batchbald_2019 提出 BatchBALD 并使用 MC Dropout 对其分类问题进行评估。 ash_gone_2021提出Bait,同样通过基于最后一层特征的Fisher信息融合代表性,并在分类和回归数据集上进行评估。
BMDAL 的另一种方法是找到在几何意义上表示 的核心集。 sener_active_2018和geifman_deep_2017提出了在最后一层特征空间中用覆盖池集的算法。 ash_deep_2019 提出 BADGE,它在相似的特征空间中应用聚类,但通过 softmax 层的梯度包含不确定性以进行分类。 ACS-FW (pinsler_bayesian_2019) 可以被视为核心集和贝叶斯方法之间的混合体,尝试使用核心集来近似池集上的预期对数后验,也使用最后一层基于贝叶斯近似。 除了Bait之外,ACS-FW 是为分类和回归而设计和评估的少数方法之一。 我们新提出的选择方法 LCMD 是基于聚类的,类似于 BADGE 中使用的 k-means++ 方法,但具有确定性。
存在更多实现 BMDAL 的方法,并且它们可以与其他步骤相结合,例如预减少 (ghorbani_data_2022) 或重新加权所选实例 (farquhar_statistical_2021 )。 大多数 BMDAL 方法都面向分类,为了更广泛的概述,我们参考 ren_survey_2021。 对于(图像)回归,ranganathan_deep_2020 在池集上引入辅助损失项,用于执行 DAL。 然而,尚不清楚他们的成功在多大程度上是通过隐式执行半监督学习来解释的。
由于我们在本文中经常将高斯过程 (GP) 视为贝叶斯神经网络的近似,因此我们的工作也与 GP 的 BMAL 相关,尽管在我们的例子中 GP 仅用于选择 而不是用于选择 回归本身。 seo_gaussian_2000 和 krause_near-optimal_2008 等人建议了 GP 的流行 BMAL 方法。
3.3数据集
就用于回归的 BM(D)AL 基准数据集而言,tsymbalov_dropout-based_2018 使用七个大型表格数据集,其中一些数据集已包含在我们的基准测试中,参见。 标签:秒:附录:数据集。 pinsler_bayesian_2019 仅使用一个大型表格回归数据集。 ash_gone_2021使用一个小型表格回归数据集和三个图像回归数据集,其中两个是转换后的分类数据集。 wu_pool-based_2018 专门针对小型表格数据集进行基准测试。 zaverkin_exploration_2021 使用原子数据集,这需要专门的神经网络架构和更长的训练时间,因此不太适合大规模基准测试。 ranganathan_deep_2020 在五个图像回归数据集上使用 CNN。 最近,提出了用于药物发现的 BMDAL 基准,该基准使用四个反事实回归数据集(mehrjou_genedisco_2021)。 在本文中,我们提供了 15 个大型表格数据集的开源基准,其中包含比之前论文中的评估更多的基线和评估标准。
4 内核
在本节中,我们将讨论各种基本内核,这些内核可生成经过训练的 NN 的各种近似值,以及生成具有不同含义或只是提高效率的新内核的不同内核转换。 下面,我们考虑正半定核。 对于内核的介绍,我们参考文献(例如steinwart_support_2008)。 这里考虑的内核通常可以用有限维特征空间的特征图来表示,即和。 对于输入序列 (我们有时会通过稍微滥用符号将其视为集合 ),我们定义相应的特征矩阵
| (2) |
和核矩阵 、、。
4.1 基本内核
我们首先讨论创建基本内核的各种选项,这些选项会在 和 池输入上引入一些相似的训练概念。 这些基本内核的概述可以在表1中找到。
| Base kernel | Symbol | Feature map | Feature space dimension |
|---|---|---|---|
| Linear | |||
| NNGP | not explicitly defined | ||
| full gradient | |||
| last-layer |
4.1.1 线性核
其他基础内核的一个非常简单的基线是线性内核 ,对应于恒等特征图 +rCl+x* phi_lin(x) ≔x 。 它的评估速度通常非常快,但不能很好地代表神经网络的行为。 此外,其特征空间维度取决于输入维度,因此可能不适合依赖于数据的高维表示的选择方法。 下一个内核给出了对神经网络行为的更准确的表示:
4.1.2 全梯度内核
如果 是训练后的神经网络的参数向量,我们定义 +rCl+x* phi_grad(x) ≔∇_θ f_θ_T(x) 。 其动机如下:神经网络相对于 周围参数的线性化由一阶泰勒展开给出
| (3) |
如果我们在标记下一批 后从参数 恢复训练,则扩展数据上的训练结果可以通过函数 来近似>,其中 是使用特征图 对 的数据残差 进行线性回归的结果。
内核 也称为(经验/有限宽度)神经切线内核 (NTK)。 它取决于线性化点 ,但对于某些训练设置,当隐藏层宽度达到无穷大时,可以收敛到固定内核(jacot_neural_2018; lee_wide_2019;arora_exact_2019)。 然而,在实际设置中,据观察在训练(fort_deep_2020; long_properties_2021; shan_theory_2021; atanasov_neural_2021)期间经常“改进”,特别是在训练的开始。 这与我们在 LABEL:sec:bmdal:experiments 中的观察结果一致,并表明较短的训练可能已经产生了允许选择好的 的梯度内核。 事实上,coleman_selection_2019 发现更短的训练和更小的模型已经足以为 BMDAL 分类选择好的批次。
对于全连接层,我们现在将展示特征映射 具有附加的乘积结构,可用于减少内核评估的运行时间和内存消耗。 为了符号简单,我们重写方程。 (1) 为 +rCl+x* z_i^(l+1) & = ~W^(l+1) ~x_i^(l),
~W^(l+1) ≔ (W(l+1) b(l+1)0>) εR1>^d_l+1 ×(d_l + 1), ~x 2>_i^(l) ≔(σ3>w4>d5>l6>x7>i8>(l)9>σ0>b1>) εR2>^d_l + 1 ,带有参数 使用方程式中的符号。 (4.1.2),我们可以写
| (4) |
对于核评估,可以通过 +rCl+x* k_grad(x_i^(0), x_j^(0) 来利用权重矩阵导数的因式分解) & = Σ_l=1^L ⟨dzi(L)dzi (l) (~x_i^(l-1))^⊤, dzj0>(L)1>dz2>j3>(l)4> (~x5>_j ^(l-1))^⊤⟩_F
= Σ_l=1^L ⏟⟨~x7>_i^(l-1), ~x8> _j^(l-1)⟩_≕k^(l)_in(x9>_i^(0), x0>_j^(0)) ⋅⏟⟨dz1>i2>(L)3>dz4>i5>(l)6>, dz7>j8>(L)9>dz0>j1> (l)2>⟩_≕k^(l)_out(x3>_i^(0), x4>_j^(0)) ,自 这意味着可以分解为具有较小特征空间维度的内核的乘积之和:222对于后面定义的草图方法,我们可以利用,因此可以省略。
| (5) |
当使用方程式时。 (4.1.2),完全梯度 永远不需要显式计算或存储。 如果 和 已经计算,并且隐藏层各自包含 个神经元,则等式: (4.1.2) 将内核评估的运行时复杂性从 降低到 ,预计算功能的内存复杂性也类似。 在 LABEL:sec:kernel_transformations:rp 中,我们将了解如何使用草图进一步加速该内核计算。 novak_fast_2022 讨论了针对更一般类型的层和多个输出神经元的 的有效计算。
由于 由多个层的梯度贡献组成,因此不同层中梯度大小的平衡可能很重要。 我们至少在初始化时通过使用神经切线参数化(jacot_neural_2018)来实现这一点。 然而,对于其他神经网络架构,可能需要对不同层的梯度幅度进行重新加权,以改善使用 获得的结果。
4.1.3 最后一层内核
仅考虑最后一层参数的梯度,给出了全梯度核的简单粗略近似: +rCl+x* phi_ll(x) ≔∇_~W^(L) f_θ_T(x) 。 从方程。 (4),很明显,在我们正在考虑的单输出回归情况下, 只是最后一层的输入 神经网络。 后一种公式也可用于多输出设置,其版本(使用 而不是 )已频繁用于 BMDAL (sener_active_2018; geifman_deep_2017 ;pinsler_bayesian_2019;ash_deep_2019;ash_gone_2021;
4.1.4 无限宽度NNGP
已经表明,当隐藏 NN 层的宽度 收敛到无穷大时,初始函数 的分布收敛到均值为零且协方差核 称为神经网络高斯过程 (NNGP) 内核 (neal_priors_1994; lee_deep_2018; matthews_gaussian_2018)。 该内核取决于网络深度、使用的激活函数以及诸如初始化方差和缩放因子(如 )等细节。 在我们的实验中,我们使用与所采用的 NN 设置相对应的 NNGP 内核,其公式在 LABEL:sec:appendix:nngp 中给出。
如上所述,存在 的无限宽度限制,即所谓的神经切线内核 (jacot_neural_2018)。 在基础知识实验显示与 NNGP 类似的糟糕性能之后,我们决定从 LABEL:sec:appendix:experiments 的实验中省略它。
4.2 内核转换
部分4.1中介绍的基本内核的构造使得使用这些内核的内核回归可以充当相应神经网络回归的代理。 通过使用内核,我们可以对两个输入之间的交互 进行建模,这对于将多样性 (DIV) 纳入选择方法至关重要。 然而,这并不总是足以应用选择方法。 例如,有时我们希望内核在观察数据后表示神经网络的不确定性,或者我们希望减少特征空间维度以使选择更有效。 因此,我们在本节中介绍各种变换内核的方法。 当按此顺序将转换 应用于基本内核 时,我们用 表示转换后的内核。 当然,我们只能涵盖与我们的应用程序相关的选定转换,并且其他转换(例如核的和或乘积)也是可能的。
| Notation | Description | Configurable ? | ||
|---|---|---|---|---|
| Rescale kernel to normalize mean on | any | no | ||
| GP posterior covariance after observing | any | yes | ||
| Short for | any | yes | ||
| Sketching with features | no | |||
| Sum of kernels for ensembled networks | any | no | ||
| Gradient-based kernel from pinsler_bayesian_2019 | any | yes | ||
| Kernel from pinsler_bayesian_2019 with random features | yes | |||
| Kernel from pinsler_bayesian_2019 with random features and hyperprior on | no |
4.2.1 缩放
对于带有特征图 和缩放因子 的给定内核 ,我们可以构建带有特征图 的内核 。 如果我们随后考虑具有协方差函数 的高斯过程 (GP),则这种缩放可以产生影响。 在这种情况下,描述了函数的先验分布下和之间的协方差。由于我们使用标准化标签 进行训练,因此我们希望选择缩放因子 以便 。 因此,我们提出自动尺度归一化 +rCl+x* k_→scale(X_train)(x, ~x) ≔λ^2 k(x, ~x), λ≔(1N训练 Σ _xεX_train k(x0>, x1>))^-1/2 。
4.2.2 高斯过程后验变换
对于给定的内核和相应的特征图,我们可以考虑使用内核的高斯过程(GP),这相当于贝叶斯线性回归具有特征图 的模型:在特征空间中,我们将观察结果建模为 ,权重先验 和独立同分布。 观察噪声。 随机函数 现在具有协方差函数 。
这是众所周知的,参见例如 bishop_pattern_2006中的第2.1和2.2节,在观察输入的训练数据后,高斯过程的后验分布也是带核的高斯过程+rCl+x* & k_→post(X_train, σ^2)(x, ~x )
≔ Cov(f(x), f(~x) ∣X0>_train, Y1>_train)
= k(x3>, ~x4>) - k(x5>, X6>_train ) (k(X7>_train, X8>_train) + σ9>^2 I0>)^-1 k(X1>_train, ~x2>)
=见下文4> phi5>(x6> )^⊤(σ7>^-2 Φ8>(X9>_train)^⊤Φ0>(X1>_train) + I2>)^-1 phi3>(~x4>)
= σ6> ^2 φ7>(x8>)^⊤(φ9>(X0>_train)^⊤φ1>(X2>_train) + σ3>^2 I4>)