R3M:机器人操作的通用视觉表示
摘要
我们研究在不同的人类视频数据上预训练的视觉表示如何能够实现下游机器人操作任务的数据高效学习。 具体来说,我们使用 Ego4D 人类视频数据集,结合时间对比学习、视频语言对齐和 L1 惩罚来预训练视觉表示,以鼓励稀疏和紧凑的表示。 由此产生的表示 R3M 可用作下游策略学习的冻结感知模块。 在一组 12 个模拟机器人操作任务中,我们发现与从头开始训练相比,R3M 将任务成功率提高了 以上,与最先进的技术相比,R3M 将任务成功率提高了 以上像 CLIP 和 MoCo 这样的视觉表示。 此外,R3M 使 Franka Emika Panda 手臂只需 20 次演示,就能在真实、杂乱的公寓中学习一系列操作任务。 代码和预训练模型可在 https://tinyurl.com/robotr3m 获取。
关键字:视觉表示学习、机器人操作
1简介
我们如何训练机器人完成图像操作任务? 一种标准且广泛使用的方法是使用来自同一域[1]的数据从头开始训练端到端模型。 然而,这可能会导致数据密集度过高,并严重限制泛化。 相比之下,计算机视觉和自然语言处理 (NLP) 最近与这种“白板”范式发生了重大背离。 这些领域专注于使用多样化的大规模数据集来构建可重用的预训练表示。 这样的模型已经变得无处不在。例如,ImageNet [2] 中的视觉表示可以重复用于癌症检测 [3] 等任务,以及 BERT [4] 等预训练语言嵌入 已被用于从医学编码 [5] 到视觉问题回答 [6] 的各种领域。 相当于机器人学的 ImageNet [2] 或 BERT [4] 模型,可以轻松下载并用于任何下游模拟或现实世界的操作任务,一直难以捉摸。
为什么我们要努力构建这种通用的机器人技术表征? 我们的推测是,我们还没有集中精力使用合适的机器人数据集。 即使没有人类标注,收集与物理世界交互的机器人的大量且多样化的数据集也可能成本高昂。 最近创建此类数据集的尝试[7,8,9,10]最多由少数不同环境中的有限数量的任务组成。 缺乏多样性和规模使得学习广泛适用的表示变得困难。 与此同时,计算机视觉和 NLP 的最新发展为机器人技术提供了一条替代路线。 这些领域的最佳表示并不是来自特定于任务且精心策划的数据集,而是来自丰富的野外数据[4,11,12,13]。 类似地,对于机器人和电机控制,我们可以访问人类以语义上有趣的方式与其环境进行交互的视频[14,15,16]。 这些数据庞大且多样化,跨越全球场景,任务范围从叠衣服到做饭。 虽然该数据中存在的实施例与大多数机器人不同,但先前的工作[17, 18]发现此类人类视频数据对于学习奖励函数仍然有用。 此外,领域差距并不是在传统视觉和 NLP 任务中使用预训练表示的主要障碍。 在此背景下,我们提出一个相关问题: 在不同的人类视频上预训练的视觉表示能否实现机器人操作技能的高效下游学习?
我们假设基于视觉的机器人操作的良好表示由三个组成部分组成。 首先,它应该包含物理交互所需的信息,因此应该捕获场景的时间动态(即状态如何转换到其他状态)。 其次,它应该优先于语义相关性,并且应该关注任务相关的特征,例如对象及其关系。 最后,它应该是紧凑的,并且不包含与上述标准无关的特征(例如背景)。 为了满足这三个标准,我们研究了一种表示学习方法,该方法结合了(1)时间对比学习[19]来学习捕获时间动态的表示,(2)视频语言对齐以捕获语义相关场景的特征,以及 (3) L1 和 L2 惩罚以鼓励稀疏性。 我们在 4.4 节中的实验评估发现,所有三个组件对于训练高性能表示都很重要。
在这项工作中,我们凭经验证明,在 Ego4D [16] 等不同人类视频数据集上预训练的表示可以为机器人操作实现高效的下游策略学习。 我们的核心贡献是一个工件——预先训练的视觉模型——可以很容易地在其他工作中使用。 具体来说,我们预训练了一个用于r机器人m操纵(R3M)的r可用r表示,它可以用作模拟和真实机器人操作任务中下游策略学习的冻结感知模块。 我们通过三个现有基准模拟环境(Adroit [20]、Franka-Kitchen [21] 和 MetaWorld [22] 的大量实验结果证明了这一点。 t2>)以及在杂乱的公寓环境中进行的真实机器人实验。 R3M 特征优于多种视觉表示,例如 CLIP [12]、(监督)ImageNet [2]、MoCo [23, 24] ,在 12 个任务、9 个视点和 3 个不同的模拟环境中进行评估时,从头开始学习的速度提高了 10% 以上。 在 Franka Emika Panda 机器人上,R3M 能够学习具有挑战性的任务,例如将生菜放入锅中和折叠毛巾,在不到 10 分钟的人类演示中,平均成功率超过 50%(见图 1 ),与 CLIP 功能相比,成功率几乎提高了一倍。 总的来说,根据这些结果,我们相信 R3M 有潜力成为机器人操纵的标准视觉模型,可以简单下载并现成用于任何机器人操纵任务或环境。 请参阅 https://sites.google.com/view/.robot-r3m 了解预训练模型和代码。
2相关工作
机器人学的表征学习。 我们的工作当然不是第一个研究学习机器人一般表示问题的工作。 其中一项工作重点是从域内数据中学习表示,即使用来自目标环境和任务的数据来训练表示。 这些方法包括数据增强的对比学习 [25, 26, 27, 28]、动态预测 [29, 30]、双向模拟 [31]、时间或目标距离 [32, 33] 或领域特定信息 [34]。 然而,由于它们仅针对来自目标域和任务的数据进行训练,因此学习到的表示无法泛化,并且无法重复使用以在未见过的任务和环境中实现更快的学习。
最近,人们越来越有兴趣从大规模域外数据(例如网络图像)中学习更通用的电机控制表示。 这包括使用 CLIP、有监督的 MS-COCO、有监督的 ImageNet、MoCo ImageNet 特征或来自不同机器人的数据[35,36,37,38,23,39]。 与之前的工作相比,我们使用不同的人类视频和语言数据而不是静态帧和/或类标签来预训练表示。 此外,在我们的实验评估中,我们观察到我们的预训练表示在综合评估套件上显着优于之前的工作。 同时,Xiao 等人[40]还探索使用人类交互数据来预训练运动控制的视觉表示。 然而,他们学习到的表示仅使用这些视频中的静态帧,并不像 R3M 那样利用时间或语义信息。 此外,我们的评估侧重于数据高效的模仿学习,只需 分钟的演示数据即可在杂乱的环境中进行现实世界的学习。
利用人类视频进行机器人学习。 先前的几项工作已经探索在机器人学习中使用人类视频数据,例如获取目标[41,42,43],学习视觉动力学模型[44,45,46,47] ,或者学习表征和奖励[19,48,49,50,51,52]。 然而,这些先前的工作通常集中于与机器人环境非常相似的人类视频的小数据集。 相比之下,我们的工作利用 Ego4D [16] 等不同的人类视频数据来学习广泛推广的视觉可重用视觉表示。
自然语言和机器人操作。 先前的工作已经探索了自然语言在机器人操作中的使用,主要作为任务规范[53,54,36,55]或奖励学习[56]的手段。 相比之下,我们使用不同的人类视频数据和语言注释来学习可重用的视觉表示以进行控制。 先前的工作还发现由语言提供的视觉表示,例如 CLIP [12],对于控制 [36, 37] 是有效的。 通过实证评估,我们发现我们的 R3M 表示在机器人操作方面远远优于 CLIP。
从不同的机器人数据中学习。 对于更广泛泛化的机器人,有许多研究研究如何扩大机器人学习数据的规模和多样性。 其中许多工作侧重于收集机器人数据本身并从中学习[57,58,7,8,9,10,59]。 然而,这些作品通常最多包含几种不同的环境,使得对一系列未见过的场景进行概括变得困难。 虽然我们还旨在通过学习不同的数据来实现泛化,但我们的重点是(1)从人类视频数据中学习,从而学习更大的环境和任务分布,以及(2)预训练视觉表示,而不是政策或模式。
从视频中学习表征。 最后,有大量研究在机器人技术背景之外从视频中学习图像表示的文献[60,61,19,62,63,64]。 此外,还有许多使用语言来学习视频表示的作品[65, 66]。 重要的是,与所有这些工作不同,这项工作的主要贡献不是提出一种新颖的表示学习方法,而是研究在人类交互的不同视频和语言上训练的表示是否可以更有效地学习机器人操作。
3 R3M:R可用于R机器人M操纵的R表示
我们的目标是使用不同的人类视频数据来预训练用于运动控制(特别是机器人操作)的单个可重复使用的视觉表示,这可以在以前未见过的环境和任务中实现高效的下游学习。 在本节中,我们将介绍方法的不同组成部分,首先在 3.1 节中描述我们的问题表述,在 3.2 节中使用的数据源以及我们的训练目标在第 3.3 节中。
3.1预赛
正式地,我们假设我们可以访问 视频的数据集 ,其中每个视频由一系列 RGB 帧 组成。 此外,我们假设每个视频都与自然语言描述 配对,描述视频中正在完成的任务。 根据这些数据,我们的目标是学习单个图像编码器 ,它将图像映射到确定性的连续嵌入,即 。 经过训练后,我们希望能够重复重用 进行下游策略学习。 具体来说,下游问题将涉及代理在给定图像观察 的情况下顺序选择操作,并且代理将使用预训练的 作为状态,而不是使用原始图像作为输入表示。
3.2数据源
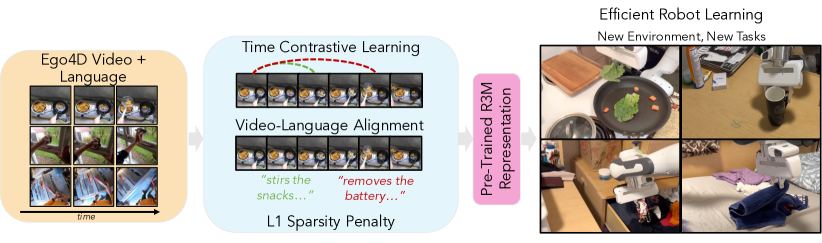
为了使我们学习到的表示 在广泛的下游任务和环境中有用,它应该(1)在足够多样化的数据上进行训练以促进泛化,并且(2)为与机器人操作相关的功能。 一种方法是使用网络上的自然图像(例如 ImageNet [2])。 虽然多种多样,但这些图像往往集中在一个特定的对象上,并且不会捕获与场景中多个对象交互的代理。 或者,人类在世界[14,65,16]中交互的数据既多种多样,又包含类似于我们希望机器人交互的场景中的有用交互。 在众多人类视频数据集中,我们利用 Ego4D 数据集 [16],因为它的多样性和大小,尽管原则上我们的方法可以用于任何合适的视频数据集。 Ego4D 包含来自全球 70 多个地点的人们从事各种任务的视频,从烹饪到社交再到组装物品,总共包含超过 3500 小时的数据。 每个视频剪辑还包含描述视频中人的行为的自然语言标注(见图2(左))。
3.3训练R3M
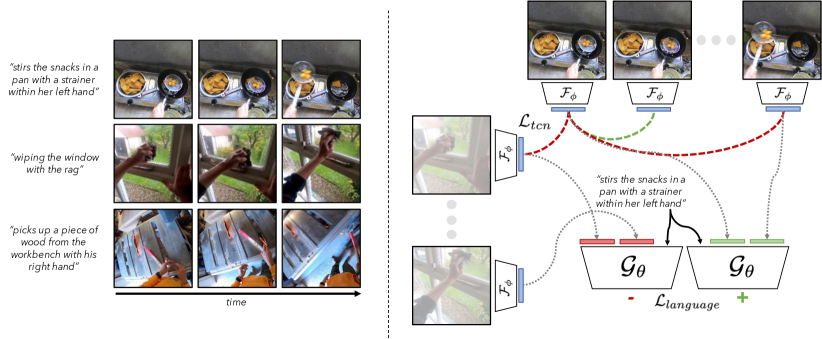
人类视频数据捕获中的机器人操作的良好表示应该是什么? 我们提出三个关键组成部分: (1) 它应该捕获时间动态,因为代理将在环境中顺序交互以完成任务,(2) 它应该捕获语义相关的特征,(3) 它应该是紧凑的。 接下来,我们将描述如何使用时间对比学习来捕捉 (1)、如何使用视频语言对齐 (2) 以及如何使用 L1 正则化来鼓励 (3)。 请参阅图 2(右),了解我们目标的概述。
时间对比学习。 为了鼓励捕获与物理交互和顺序决策相关的特征,我们目标的第一部分是时间对比损失[61]。 给定一批视频,我们训练编码器生成一种表示,使得时间上较近的图像之间的距离小于时间上较远的图像或来自不同视频的图像之间的距离。 具体来说,我们对一批帧序列 进行采样,然后最小化 InfoNCE 损失 [67]:
| (1) |
其中 和 是从批次中的不同视频采样的反例。 表示相似度的度量,在我们的例子中它被实现为负 L2 距离。
视频语言对齐。 为了鼓励 捕获语义相关的特征,我们从 输出的嵌入中训练语言预测模块。 本质上,通过捕获预测语言的特征,例如“将苹果放在盘子上”,学习到的表示应该捕获场景中语义相关的部分,例如盘子和苹果状态,这些部分可能与下游操作任务相关。 继Nair等人[56]之后,我们训练了一个模型,它接受初始图像和未来图像 ,语言 并输出与从 到 的转换完成语言 相对应的分数。我们训练模型的目标是:(1)分数应该随着视频的播放而增加,(2)正确的视频/语言配对的分数应该比不正确的配对更高。 我们再次对视频剪辑和配对语言 进行采样,然后直接针对该目标进行训练,并带来对比损失,即:
| (2) |
其中 和 是从批次中的不同视频采样的反例(与语言指令 )。
正则化。 最后,我们假设稀疏和紧凑的表示有利于控制,特别是在低数据模仿学习中。 状态分布转移是模仿学习中经过充分研究的失败模式[68],其中通过行为克隆训练的策略偏离了专家状态分布。 减少状态空间的有效维度(我们通过简单的 L1 和 L2 惩罚来实现)可以帮助缓解这个问题,正如我们在 4.4 节中演示的那样。
R3M 总结和实施。 训练 R3M 的最终目标是加权和:
| (3) |
原则上,R3M 可以在 的任何编码架构之上实现。 在我们的实验中,我们专注于 ResNet50 架构,并发布了使用 ResNet18、ResNet34 和 ResNet50 架构[69]预训练的 R3M 模型,以及随附的训练代码。 在训练期间, 和 使用 Adam 优化器进行训练,以最小化方程 3。 最后,R3M 还使用视频级别应用的随机裁剪进行训练(即,在批次内同一视频的所有帧都进行相同的裁剪)。 进一步的实施细节请参见附录。
4实验
在我们的实验中,我们的目标是研究如何将预训练的 R3M 表示重新用于多个下游机器人学习任务。 首先,我们研究与现有的视觉表示和从头开始学习相比,R3M 是否能够在未见过的环境和任务上实现更高效的数据模仿学习。 其次,同样在数据有效的模仿学习设置中,我们消除了 R3M 训练目标的不同组成部分,并观察到所有组成部分对于最终表现都很重要。 第三,我们研究 R3M 是否可以在视觉丰富的家庭环境中实现高效的真实机器人学习。 最后,在附录中,我们更深入地研究了 R3M 和现有方法在不同数据量、不同相机视点和不同任务下的任务性能。
4.1模仿学习评估框架
我们的评估方法大致受到Parisi 等人[23]的启发。 我们专注于评估视觉表示作为冻结感知模块,用于通过行为克隆进行下游策略学习。 给定预训练的视觉表示 ,我们将状态表示形成为视觉嵌入 和机器人本体感受(例如关节位置和速度)读取 的串联>。 该策略 使用标准行为克隆损失 进行训练。 我们将 参数化为两层 MLP,其前面是输入处的 BatchNorm。 我们训练代理 20,000 步,每 1000 步在环境中对其进行在线评估,并报告所达到的最佳成功率。 对于每个视觉表示和每个任务,我们运行 3 个行为克隆种子。 任务报告的最终成功率是多个种子、视点和演示数据集大小的平均值。
比较和基线。 我们将我们的 R3M 模型与已被证明对控制有效的三种现有视觉表示进行比较:CLIP [12],它训练图像表示通过对比学习与配对自然语言保持一致,并已被证明对于某些操作[36]和导航任务[37]、ImNet Supervised 使用针对 ImageNet 分类任务预训练的特征 [2],并已被证明对强化学习有效 [38] 和 MoCo (345 ) (PVR) [23],压缩并融合使用 MoCo [24] 训练的 ResNet-50 模型的第三、第四和第五卷积层> 在 ImageNet 上,并已被证明对模仿学习有效[23]1>。 我们在这里注意到,我们对 Moco (345) 模型的使用与 Parisi 等人 [23] 中的设置在本体感受特征、帧堆叠等方面有所不同。因此,数值结果不是两部作品可以直接比较。 同时,我们强调在我们的评估协议中所有视觉表示都以相同的方式使用。
4.2模拟环境

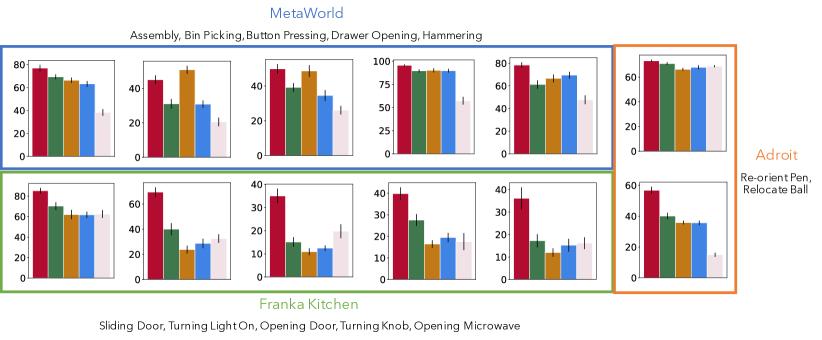
接下来,我们描述评估中使用的环境和任务。 为了进行综合评估,我们使用三个机器人操作域:MetaWorld [22]、Franka Kitchen环境[21]和Adroit [20](见图3)。 请注意,这些环境仅用于下游学习,并且在 R3M 期间从未见过这些环境和任务。 在 MetaWorld 环境中,我们考虑将环组装到钉子上、在箱子之间拾取并放置块、按下按钮、打开抽屉和钉钉子的任务。 在弗兰卡厨房,我们学习滑开右门、打开左门、打开灯、转动炉顶旋钮和打开微波炉的任务。 最后,在 Adroit 中,我们考虑将笔重新定向到指定位置,以及拾取球并将其移动到指定位置的任务。 在所有任务中,代理都会获得图像观察结果,以及与编码图像连接的机器人本体感受数据(末端执行器姿势、关节位置等)。 所有任务都涉及变化,可以通过改变 MetaWorld 中目标对象的位置、Franka Kitchen 中桌子的位置或 Adroit 中选定的目标来实现。 为了进行稳健的评估,我们考虑每个环境的多个视图(见图 3),以及 3 个数据集大小:MetaWorld 和 Franka Kitchen 中的 以及 在更具挑战性的 Adroit 环境中。 我们的比较衡量每个环境和任务的性能、视图的平均值、数据集大小以及对象或目标位置。
4.3 Exp。 1:R3M 能否实现对未见过的环境和任务的高效模仿?
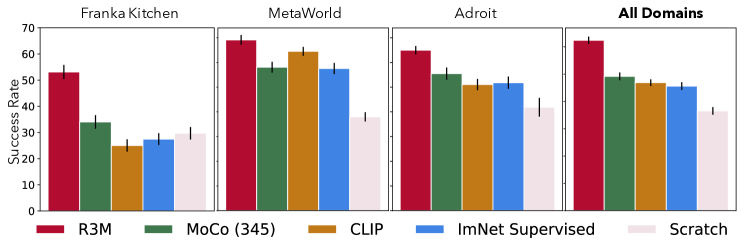
在第一个实验中,我们使用不同的视觉表示来测量下游模仿学习的成功率。 在图 4 中,我们首先注意到 R3M 总体上能够在极低的数据范围内学习这些基于视觉的操作任务,尽管从未看到任何数据,但成功率 为 62%训练表示中的目标环境,同时比从头开始学习高出 20% 以上。 此外,我们观察到 R3M 在所有 12 项任务中平均优于所有先前的表示形式 10% 以上。 通过对不同的交互式视频数据进行训练,并以捕获时间结构和语言相关性为目标,R3M 是所有 3 种环境中以及 11/12 的任务中表现最佳的方法(请参阅附录,了解按任务划分的性能细分)。 表现最好的两个比较是 CLIP 和 MoCo (345) (PVR),其中 CLIP 在 MetaWorld 上表现更好,MoCo (345) (PVR) 在 Franka Kitchen 上表现更好和熟练。 毫不奇怪,从头开始学习在我们研究的低数据环境中表现不佳。 最终,我们得出的结论是,预先训练的视觉表示对于低数据模仿学习体系中的良好性能至关重要,并且将 R3M 与不同的人类视频数据结合使用对于学习对机器人操作有用的表示特别有效。
4.4 到期。 2:R3M 的哪些组件很重要?
| Environment | Supervised | Self-Supervised | ||
|---|---|---|---|---|
| R3M | R3M(-Aug) | R3M(-L1) | R3M(-Lang) | |
| Franka Kitchen | 53.1 2.7% | 51.1 2.7% | 46.7 2.7% | 47.22.9% |
| MetaWorld | 69.2 2.0% | 68.9 2.1% | 65.0 2.4% | 67.02.0% |
| Adroit | 65.0 1.7% | 61.3 2.1% | 66.5 1.6% | 45.6 3.3% |
| All Domains | 62.4 1.3% | 60.4 1.4% | 59.4 1.5% | 53.2 1.5% |
在这个实验中,我们从目标开始,试图了解 R3M 的不同组成部分。 具体来说,我们将完整的 R3M 与 R3M(-Aug) 进行比较,后者不使用作物增强,R3M(-L1) 则使用作物增强不包括正则化和R3M(-Lang),其中不包括视频语言对齐损失。 在表 1 中,我们报告了每个环境的成功率以及所有环境的平均值。 首先,我们注意到,在三个环境中,平均而言,由于删除作物增强或删除 正则化,我们发现性能下降了 2%。 有趣的是,消除稀疏正则化的影响取决于环境。 在 Franka Kitchen 和 MetaWorld 中,稀疏性是有帮助的,而在 Adroit 中,消除稀疏性实际上对性能略有帮助。 我们怀疑这部分是由于 Adroit 环境使用了更多的演示,缓解了状态分配转移问题。
我们发现,在所有环境中,消除视频语言对齐损失对性能的负面影响最大,特别是在 Adroit 环境中。 我们假设语言对齐在更好地捕获可能预测对象并对对象操作有用的语义特征方面发挥着重要作用。 尽管如此,我们注意到,即使在完全自我监督的情况下,我们的 R3M 模型仍然优于先前最先进的视觉表示,例如 ImageNet 训练的 MoCo (345) (PVR) [23] 和 CLIP [12] 有很大差距。
| Franka | Adroit | |
|---|---|---|
| R3M | 53.1(2.7) | 65.0 (1.7) |
| MoCo-Ego4D | 42.0 (2.8) | 54.9 (2.7) |
| MVP ([70]) | 27.0 (2.6) | 51.4 (2.7) |
接下来,我们试图回答这个问题: 数据有多重要? 为此,我们进行了比较,以区分数据集和目标的训练角色。 特别是,我们在用于训练 R3M 模型的 Ego4D 数据集的完全相同的帧上训练了 MoCo 模型(参见表 2)。 此外,我们与 MVP 模型 [70] 进行比较,该模型在 Ego-soup 数据集上训练 ViT-B 掩码自动编码器,该数据集包含 Ego4D 和其他以自我为中心的视频数据集。我们评估这些比较在 Franka Kitchen 和 Adroit 环境中,发现MoCo-Ego4D 模型使用与 R3M 相同的数据和计算,在两种环境中的平均成功率% 均低于 R3M. 此外,我们发现 MVP 模型的性能比 R3M 差 %。 这表明,虽然与静态 ImageNet 图像相比,不同的人类视频数据确实有很大的好处(Franka 上为 34% → 42%),但数据并不是唯一的改进来源,而且 R3M 目标提供了额外的 % 成功率提升。
4.5 到期。 3:R3M 能否在现实环境中实现数据高效学习?

最后,我们测试 R3M 是否可以在杂乱的现实环境中实现数据高效的机器人学习。 为此,我们将 Franka Emika Panda 机器人带入真正的研究生公寓,目标是使用预先训练的 R3M 表示,从像素中学习家务任务,每个任务仅进行 20 次演示。 我们让机器人完成五个任务:(1)关闭梳妆台抽屉,(2)拿起随机放在桌子上的口罩并将其放入梳妆台抽屉中,(3)拿起随机放在切板上的生菜并放入将杯子放入烹饪锅中,(4) 将杯子推至目标位置,(5) 折叠毛巾(见图5)。 就像在我们的模拟实验中一样,我们收集了少量的演示,并使用预先训练的表示进行简单的行为克隆。
| Success out of 10 trials | R3M | CLIP |
|---|---|---|
| Closing Drawer | 80% | 70% |
| Putting Mask in Dresser | 30% | 10% |
| Putting Lettuce in Pan | 60% | 0% |
| Pushing Mug to Goal | 70% | 40% |
| Folding Towel | 40% | 0% |
| Average | 56% | 24% |
5 局限性和未来的工作
在这项工作中,我们着手研究不同人类视频的预训练视觉表示是否可以实现下游机器人操作任务的有效学习。 虽然我们对一系列广泛的模拟和真实机器人任务的强劲结果感到兴奋,但仍然存在一些重要的局限性。 我们目前的评估仅限于模仿学习,特别是行为克隆,并有少量的任务演示。 虽然我们希望看到 R3M 对强化学习等其他机器人学习设置同样有益,但情况可能是,强化学习的良好预训练表示与模仿的良好预训练表示并不相同。 研究 R3M 在 RL 设置中的表现以及可能需要进行的更改以提高其性能是令人兴奋的下一步。 当前的 R3M 模型也仅提供单帧状态表示。 原则上,人类视频的预训练应该能够超越状态表示(例如奖励学习和任务规范)。 研究 R3M 嵌入或语言基础模块是否可以提供有用的奖励信号是未来工作的一个有趣方向。
致谢
作者要感谢 Meta AI 的 Ego4D 团队在使用该数据集时提供的帮助。 我们还要感谢 Karl Pertsch、Simone Parisi、Sidd Karamcheti 以及 Meta AI 和 IRIS 实验室的众多成员进行了宝贵的讨论。 这项工作部分由 ONR 拨款 N00014-22-1-2621 支持。 最后,作者还要感谢 Evan Coleman 对机器人的帮助。
参考
- Levine et al. [2016] S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies. The Journal of Machine Learning Research, 17(1):1334–1373, 2016.
- Deng et al. [2009] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
- Mzurikwao et al. [2020] D. Mzurikwao, M. Khan, O. Samuel, J. Cinatl, M. Wass, M. Michaelis, G. Marcelli, and C. S. Ang. Towards image-based cancer cell lines authentication using deep neural networks. Scientific Reports, 10, 11 2020. doi:10.1038/s41598-020-76670-6.
- Devlin et al. [2019] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- Zhang et al. [2020] Z. Zhang, J. Liu, and N. Razavian. BERT-XML: Large scale automated ICD coding using BERT pretraining. In Proceedings of the 3rd Clinical Natural Language Processing Workshop, pages 24–34, Online, Nov. 2020. Association for Computational Linguistics. doi:10.18653/v1/2020.clinicalnlp-1.3. URL https://aclanthology.org/2020.clinicalnlp-1.3.
- Yang et al. [2020] Z. Yang, N. Garcia, C. Chu, M. Otani, Y. Nakashima, and H. Takemura. Bert representations for video question answering. In 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1545–1554, 2020. doi:10.1109/WACV45572.2020.9093596.
- Dasari et al. [2019] S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn. Robonet: Large-scale multi-robot learning. In Conference on Robot Learning, 2019.
- Mandlekar et al. [2019] A. Mandlekar, J. Booher, M. Spero, A. Tung, A. Gupta, Y. Zhu, A. Garg, S. Savarese, and L. Fei-Fei. Scaling robot supervision to hundreds of hours with roboturk: Robotic manipulation dataset through human reasoning and dexterity. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1048–1055. IEEE, 2019.
- Young et al. [2020] S. Young, D. Gandhi, S. Tulsiani, A. Gupta, P. Abbeel, and L. Pinto. Visual imitation made easy. In CoRL, 2020.
- Ebert et al. [2021] F. Ebert, Y. Yang, K. Schmeckpeper, B. Bucher, G. Georgakis, K. Daniilidis, C. Finn, and S. Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets. ArXiv, abs/2109.13396, 2021.
- Brown et al. [2020] T. B. Brown et al. Language models are few-shot learners. arXiv:2005.14165, 2020.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021.
- Goyal et al. [2022] P. Goyal, Q. Duval, I. Seessel, M. Caron, I. Misra, L. Sagun, A. Joulin, and P. Bojanowski. Vision models are more robust and fair when pretrained on uncurated images without supervision. ArXiv, abs/2202.08360, 2022.
- Goyal et al. [2017] R. Goyal, S. Ebrahimi Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, et al. The” something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, pages 5842–5850, 2017.
- Damen et al. [2018] D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray. Scaling egocentric vision: The epic-kitchens dataset. In European Conference on Computer Vision (ECCV), 2018.
- Grauman et al. [2021] K. Grauman et al. Ego4D: Around the World in 3,000 Hours of Egocentric Video, 2021.
- Shao et al. [2020] L. Shao, T. Migimatsu, Q. Zhang, K. Yang, and J. Bohg. Concept2robot: Learning manipulation concepts from instructions and human demonstrations. In Proceedings of Robotics: Science and Systems (RSS), 2020.
- Chen et al. [2021] A. S. Chen, S. Nair, and C. Finn. Learning generalizable robotic reward functions from ”in-the-wild” human videos. ArXiv, abs/2103.16817, 2021.
- Sermanet et al. [2018] P. Sermanet, C. Lynch, Y. Chebotar, J. Hsu, E. Jang, S. Schaal, and S. Levine. Time-contrastive networks: Self-supervised learning from video. Proceedings of International Conference in Robotics and Automation (ICRA), 2018.
- Rajeswaran et al. [2018] A. Rajeswaran, V. Kumar, A. Gupta, J. Schulman, E. Todorov, and S. Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. ArXiv, abs/1709.10087, 2018.
- Gupta et al. [2019] A. Gupta, V. Kumar, C. Lynch, S. Levine, and K. Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. In CoRL, 2019.
- Yu et al. [2020] T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning, 2020.
- Parisi et al. [2022] S. Parisi, A. Rajeswaran, S. Purushwalkam, and A. K. Gupta. The unsurprising effectiveness of pre-trained vision models for control. 2022.
- He et al. [2020] K. He, H. Fan, Y. Wu, S. Xie, and R. B. Girshick. Momentum contrast for unsupervised visual representation learning. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9726–9735, 2020.
- Laskin et al. [2020] M. Laskin, K. Lee, A. Stooke, L. Pinto, P. Abbeel, and A. Srinivas. Reinforcement learning with augmented data. ArXiv, abs/2004.14990, 2020.
- Srinivas et al. [2020] A. Srinivas, M. Laskin, and P. Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. In ICML, 2020.
- Kostrikov et al. [2021] I. Kostrikov, D. Yarats, and R. Fergus. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. ArXiv, abs/2004.13649, 2021.
- Pari et al. [2021] J. Pari, N. M. M. Shafiullah, S. P. Arunachalam, and L. Pinto. The surprising effectiveness of representation learning for visual imitation. ArXiv, abs/2112.01511, 2021.
- Gelada et al. [2019] C. Gelada, S. Kumar, J. Buckman, O. Nachum, and M. G. Bellemare. Deepmdp: Learning continuous latent space models for representation learning. ArXiv, abs/1906.02736, 2019.
- Hafner et al. [2020] D. Hafner, T. P. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. ArXiv, abs/1912.01603, 2020.
- Zhang et al. [2021] A. Zhang, R. McAllister, R. Calandra, Y. Gal, and S. Levine. Learning invariant representations for reinforcement learning without reconstruction. ArXiv, abs/2006.10742, 2021.
- Nair et al. [2020] S. Nair, S. Savarese, and C. Finn. Goal-aware prediction: Learning to model what matters. ArXiv, abs/2007.07170, 2020.
- Hong et al. [2022] M. Hong, K. Lee, M. Kang, W. Jung, and S. Oh. Dynamics-aware metric embedding: Metric learning in a latent space for visual planning. IEEE Robotics and Automation Letters, 2022.
- Jonschkowski and Brock [2015] R. Jonschkowski and O. Brock. Learning state representations with robotic priors. Autonomous Robots, 39:407–428, 10 2015. doi:10.1007/s10514-015-9459-7.
- Lin et al. [2020] Y.-C. Lin, A. Zeng, S. Song, P. Isola, and T.-Y. Lin. Learning to see before learning to act: Visual pre-training for manipulation. 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 7286–7293, 2020.
- Shridhar et al. [2021] M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipulation. In CoRL, 2021.
- Khandelwal et al. [2021] A. Khandelwal, L. Weihs, R. Mottaghi, and A. Kembhavi. Simple but effective: Clip embeddings for embodied ai. ArXiv, abs/2111.09888, 2021.
- Shah and Kumar [2021] R. Shah and V. Kumar. Rrl: Resnet as representation for reinforcement learning. ArXiv, abs/2107.03380, 2021.
- Seo et al. [2022] Y. Seo, K. Lee, S. James, and P. Abbeel. Reinforcement learning with action-free pre-training from videos. ArXiv, abs/2203.13880, 2022.
- Xiao et al. [2022] T. Xiao, I. Radosavovic, T. Darrell, and J. Malik. Masked visual pre-training for motor control. 2022.
- Liu et al. [2018] Y. Liu, A. Gupta, P. Abbeel, and S. Levine. Imitation from observation: Learning to imitate behaviors from raw video via context translation. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1118–1125. IEEE, 2018.
- Sharma et al. [2019] P. Sharma, D. Pathak, and A. Gupta. Third-person visual imitation learning via decoupled hierarchical controller. In NeurIPS, 2019.
- Smith et al. [2020] L. Smith, N. Dhawan, M. Zhang, P. Abbeel, and S. Levine. AVID: Learning Multi-Stage Tasks via Pixel-Level Translation of Human Videos. In Proceedings of Robotics: Science and Systems, Corvalis, Oregon, USA, July 2020.
- Yu et al. [2018] T. Yu, C. Finn, S. Dasari, A. Xie, T. Zhang, P. Abbeel, and S. Levine. One-shot imitation from observing humans via domain-adaptive meta-learning. In Proceedings of Robotics: Science and Systems, Pittsburgh, Pennsylvania, June 2018.
- Schmeckpeper et al. [2020] K. Schmeckpeper, A. Xie, O. Rybkin, S. Tian, K. Daniilidis, S. Levine, and C. Finn. Learning predictive models from observation and interaction. In ECCV, 2020.
- Edwards and Isbell [2019] A. D. Edwards and C. L. Isbell. Perceptual values from observation. arXiv preprint arXiv:1905.07861, 2019.
- Schmeckpeper et al. [2020] K. Schmeckpeper, O. Rybkin, K. Daniilidis, S. Levine, and C. Finn. Reinforcement learning with videos: Combining offline observations with interaction. In CoRL, 2020.
- Scalise et al. [2019] R. Scalise, J. Thomason, Y. Bisk, and S. Srinivasa. Improving robot success detection using static object data. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2019.
- Pirk et al. [2019] S. Pirk, M. Khansari, Y. Bai, C. Lynch, and P. Sermanet. Online object representations with contrastive learning, 2019.
- Xiong et al. [2021] H. Xiong, Q. Li, Y.-C. Chen, H. Bharadhwaj, S. Sinha, and A. Garg. Learning by watching: Physical imitation of manipulation skills from human videos, 2021.
- Das et al. [2021] N. Das, S. Bechtle, T. Davchev, D. Jayaraman, A. Rai, and F. Meier. Model-based inverse reinforcement learning from visual demonstrations, 2021.
- Zakka et al. [2021] K. Zakka, A. Zeng, P. Florence, J. Tompson, J. Bohg, and D. Dwibedi. Xirl: Cross-embodiment inverse reinforcement learning, 2021.
- Stepputtis et al. [2020] S. Stepputtis, J. Campbell, M. Phielipp, S. Lee, C. Baral, and H. B. Amor. Language-conditioned imitation learning for robot manipulation tasks. ArXiv, abs/2010.12083, 2020.
- Lynch and Sermanet [2020] C. Lynch and P. Sermanet. Grounding language in play. ArXiv, abs/2005.07648, 2020.
- Cui et al. [2022] Y. Cui, S. Niekum, A. Gupta, V. Kumar, and A. Rajeswaran. Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation? In L4DC, 2022.
- Nair et al. [2021] S. Nair, E. Mitchell, K. Chen, B. Ichter, S. Savarese, and C. Finn. Learning language-conditioned robot behavior from offline data and crowd-sourced annotation. In CoRL, 2021.
- Pinto and Gupta [2016] L. Pinto and A. Gupta. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In IEEE international conference on robotics and automation (ICRA), 2016.
- Sharma et al. [2018] P. Sharma, L. Mohan, L. Pinto, and A. K. Gupta. Multiple interactions made easy (mime): Large scale demonstrations data for imitation. In CoRL, 2018.
- Jang et al. [2022] E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. In A. Faust, D. Hsu, and G. Neumann, editors, Proceedings of the 5th Conference on Robot Learning, volume 164 of Proceedings of Machine Learning Research, pages 991–1002. PMLR, 08–11 Nov 2022. URL https://proceedings.mlr.press/v164/jang22a.html.
- Wang and Gupta [2015] X. Wang and A. K. Gupta. Unsupervised learning of visual representations using videos. 2015 IEEE International Conference on Computer Vision (ICCV), pages 2794–2802, 2015.
- Sermanet et al. [2017] P. Sermanet, K. Xu, and S. Levine. Unsupervised perceptual rewards for imitation learning. Proceedings of Robotics: Science and Systems (RSS), 2017.
- Wang et al. [2019] X. Wang, A. Jabri, and A. A. Efros. Learning correspondence from the cycle-consistency of time. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2561–2571, 2019.
- Jabri et al. [2020] A. Jabri, A. Owens, and A. A. Efros. Space-time correspondence as a contrastive random walk. ArXiv, abs/2006.14613, 2020.
- Goyal et al. [2022] M. Goyal, S. Modi, R. Goyal, and S. Gupta. Human hands as probes for interactive object understanding. In Computer Vision and Pattern Recognition (CVPR), 2022.
- Miech et al. [2019] A. Miech, D. Zhukov, J.-B. Alayrac, M. Tapaswi, I. Laptev, and J. Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2630–2640, 2019.
- Xu et al. [2021] H. Xu, G. Ghosh, P.-Y. Huang, D. Okhonko, A. Aghajanyan, and F. M. L. Z. C. Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding. ArXiv, abs/2109.14084, 2021.
- van den Oord et al. [2018] A. van den Oord, Y. Li, and O. Vinyals. Representation learning with contrastive predictive coding. ArXiv, abs/1807.03748, 2018.
- Ross et al. [2011] S. Ross, G. J. Gordon, and J. A. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In AISTATS, 2011.
- He et al. [2016] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- Radosavovic et al. [2022] I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-world robot learning with masked visual pre-training. CoRL, 2022.
- Sanh et al. [2019] V. Sanh, L. Debut, J. Chaumond, and T. Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. ArXiv, abs/1910.01108, 2019.
附录AR3M训练详情
A.1 数据预处理
Ego4D 数据集由特定场景内几个小时长的视频组成。 每个场景中都有许多子剪辑,每个子剪辑都有自然语言标注。 R3M 使用这些较短的视频剪辑和语言注释进行训练。
为了加快训练速度,R3M 将每个视频剪辑解析为帧(调整大小并裁剪为 224x224),并单独对视频剪辑中的帧进行采样。 有关视频采样实现的更多详细信息,请参阅代码库。
A.2 训练架构和超参数
原则上可以使用 的任何视觉编码架构来训练 R3M。 我们使用现成的 ResNet18、34 和 50 [69] 进行训练,由 torchvision.models 实现。
语言预测头以 5 层 MLP 的形式实现,大小为 [2*+,1024,1024,1024,1024] 并输出标量分数,其中 是 的输出维度, 是来自 HuggingFace Transformers 的 DistilBERT [71] 句子编码器(768)的输出维度。
在 R3M 的训练过程中,我们使用 16 个视频剪辑的批量大小(其中 5 帧是每个视频剪辑的样本:初始图像、最终图像和 3 帧序列)。 初始帧和最终帧是从视频剪辑的前 20% 和后 20% 中采样的。
R3M 模型在我们的实验中训练了 100 万步,在我们发布的模型中训练了 150 万步,学习率为 0.0001。
对于方程 3 中的训练目标,我们使用超参数 。
A.3其他实施细节
此外,在方程 2 的训练中,我们考虑单个批处理元素中的以下正对:初始帧和最终帧 、 和 ,分别对应否定 、 和 。 使用来自单个视频的大量正例和来自不同视频的多个负例可以稳定训练。
A.4使用示例
使用 R3M 很简单。 代码库位于https://github.com/facebookresearch/r3m。 只需克隆存储库并通过以下方式安装 pip install -e 。 然后可以通过运行以下命令来加载 R3M:
附录 B评估详细信息
B.1 模拟环境
我们专注于三个模拟环境:Franka Kitchen、MetaWorld 和 Adroit。
弗兰卡厨房。 本文使用的Franka Kitchen环境是在原有环境的基础上进行修改的;具体来说,我们向场景添加额外的随机化。 我们在剧集之间随机改变厨房的位置,使任务在感知和控制方面都更具挑战性。
弗兰卡厨房的 5 项任务包括打开左门、打开滑动门、打开灯、转动旋钮和打开微波炉。 所有 Franka 任务都包括手臂关节位置和夹具位置的本体感觉数据。 所有 Franka 任务的范围是 50 个步骤,我们的模仿实验使用 5、10 或 25 个演示。
元世界。 MetaWorld 环境是 MetaWorld [22] 中提供的标准 V2 按钮按下、箱拣选、抽屉打开、锤子和装配环境。 在所有任务中,目标对象(抽屉、钉子、木块等)的位置在情节之间是随机的。
所有 MetaWorld 任务都包括夹具末端执行器姿势和夹具打开/关闭的本体感觉数据。 所有 MetaWorld 任务的范围是 500 个步骤,我们的模仿实验使用 5、10 或 25 个演示。
熟练。 我们使用 Adroit 手动操作套件中的标准笔和重新定位任务。 笔的目标位置和球的目标位置在剧集之间随机化,并以视觉方式指定。
所有Adroit任务都包括手部关节的本体感觉数据,并且在Relocate任务中还包括手部的全局位置。 Pen 任务的范围是 100 步,Relocate 任务的范围是 200 步。 我们的模仿实验使用 25、50 或 100 个演示。
B.2 现实世界环境
我们在现实世界中的实验包括将 Franka Emika Panda 机器人带入真正的研究生公寓。 任务包括将生菜放入厨房的平底锅中、将杯子推到餐桌上的目标位置、关闭抽屉、将口罩放入抽屉中以及折叠毛巾(见图6) )。 所有任务都涉及随机化(例如毛巾/生菜/杯子/面罩位置或抽屉位置)。 每集抓取器的初始状态也是随机的。

机器人观察包括来自 USB 网络摄像头的 RGB 图像,每个任务的位置都不同(参见图 7)。 机器人末端执行器位置也与模仿学习期间的图像嵌入相连接。

B.3演示数据收集
在 Franka Kitchen 和 Adroit 任务中,专家数据是通过使用无模型 RL [20] 训练基于状态的代理来生成的。 然后,基于状态的轨迹将通过图像观察进行重放和渲染。
在 MetaWorld 环境中,使用状态信息的启发式策略用于生成专家数据,然后通过图像观察来重播和渲染专家数据。
在真实的机器人上,演示是由人类远程操作员使用 PlayStation 控制器收集的。 控制直接应用于末端执行器笛卡尔空间,演示轨迹直接通过视觉观察保存。
B.4比较
在所有实验中,所有模型都使用 ResNet50 基础架构。
CLIP:CLIP 比较使用 https://github.com/openai/CLIP 上提供的现成 CLIP RN50 型号。
ImNet Supervised:此比较使用 torchvision.models 中提供的默认 ResNet 架构以及 pretrained=True。
MoCo (345):此比较使用 Imagenet 上预训练的 MoCo 模型,该模型融合了 [23] 中提出的第三、第四和第五卷积层。
请注意,我们对 Moco (345) 模型的使用在本体感觉特征、帧堆叠等方面与 Parisi 等人 [23] 中的设置不同。因此,数值结果不能直接比较跨越两部作品。
Scratch:使用 torchvision.models 中提供的默认 ResNet 架构以及 pretrained=False。 此外,它还让行为克隆 MSE 损失的梯度传递到视觉编码器中。
MoCo-Ego4D:此比较使用预训练的 MoCo 模型,数据与 Ego4D 数据集中的 R3M 相同。
MVP:此比较使用预训练的 MVP [40, 70] 模型,该模型在 Ego-Soup 数据集上训练具有 ViT-B 架构的 MAE,该数据集由 Ego4D 组成以及其他以自我为中心的人类视频数据集。
B.5 行为克隆超参数
下游策略是一个 2 层 MLP,其隐藏大小为 [256,256],前面是 BatchNorm。 策略的输入是连接的视觉嵌入和本体感受数据,输出是动作。 该策略的训练学习率为 0.001,批量大小为 32,执行 20000 步,每 1000 步进行评估。
附录 C其他结果
C.1 性能如何随视点和演示数据集大小而变化?
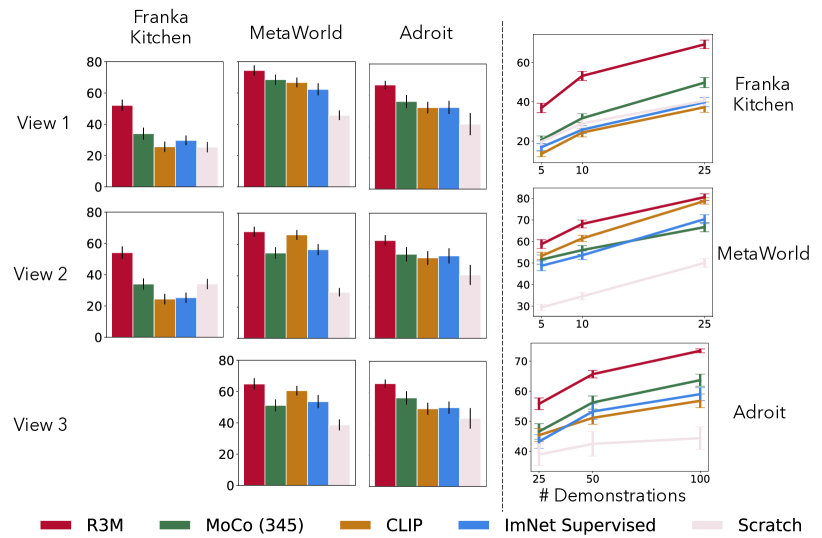
在我们的下一个实验中,我们跨视点和数据集大小仔细研究了 R3M 与先前方法的性能比较。 在图8中,我们绘制了每种方法在每个数据集大小和观点上的平均成功率。 我们观察到,R3M 的性能改进在所有观点上都是一致的,并且它是所有情况下性能最高的表示。 有趣的是,我们发现这种情况在先前的方法中并不成立,MoCo (345) 和 CLIP 之间的排名根据所选的观点而变化。
此外,我们还研究了数据集大小对模仿学习的影响。 我们再次观察到 R3M 的性能改进是一致的,在每个环境和演示数据集大小上都优于基线。 我们观察到,在 Franka Kitchen 和 Adroit 环境中,R3M 的性能增益与数据集大小的增加保持一致,即使所有方法的绝对性能都有所提高。 总的来说,我们清楚地观察到 R3M 的性能优势与特定的观点或数据集大小无关。
C.2 按任务划分的性能细分
在图 9 中,我们分别报告了每个任务的成功率。 请注意,每种方法的成功率仍然是 3 个视图、3 个演示大小和 3 个种子的平均值。 我们观察到,在 11/12 任务中,R3M 是性能最高的方法。